
Ключевые слова:Модель Gemini, Mistral AI, NVIDIA NeMo, LTX-Video, Браузер Safari, RTX 5060, AI агент, Тонкая настройка с подкреплением, Родная генерация изображений Gemini, Производительность программирования Mistral Medium 3, Модульность фреймворка NeMo 2.0, Генерация видео в реальном времени DiT, Модернизация поиска на основе ИИ
🔥 В фокусе
Обновлена встроенная функция генерации изображений Google Gemini: улучшено визуальное качество и точность рендеринга текста: Google объявила о важном обновлении встроенной функции генерации изображений в своей модели Gemini. Новая версия «gemini-2.0-flash-preview-image-generation» доступна в Google AI Studio и Vertex AI. Это обновление значительно улучшило визуальное качество изображений и точность рендеринга текста, а также снизило задержку. Новые функции включают слияние элементов изображения, редактирование в реальном времени (например, добавление объектов, изменение отдельных частей) и интеграцию с Gemini 2.0 Flash для автономной разработки концепций и генерации изображений ИИ. Пользователи могут бесплатно опробовать ее в Google AI Studio, стоимость вызова API составляет 0,039 доллара США за изображение. Несмотря на значительный прогресс, некоторые пользователи считают, что общий эффект все еще немного уступает GPT-4o. (Источник: 量子位)

Mistral AI выпустила Mistral Medium 3 с акцентом на программирование и мультимодальность, значительно снизив затраты: Французский стартап в области ИИ Mistral AI представил свою новейшую мультимодальную модель Mistral Medium 3. Модель демонстрирует выдающиеся результаты в задачах программирования и STEM, по утверждениям, достигая или превосходя 90% производительности Claude Sonnet 3.7 в различных бенчмарках при стоимости всего в 1/8 (0,4 доллара США/млн токенов на входе, 2 доллара США/млн токенов на выходе). Mistral Medium 3 обладает возможностями корпоративного уровня, такими как гибридное развертывание, кастомизированное пост-обучение и интеграция с корпоративными инструментами. Модель уже доступна на Mistral La Plateforme и Amazon Sagemaker и в будущем появится на других облачных платформах. Одновременно Mistral AI запустила сервис чат-бота для предприятий Le Chat Enterprise. (Источник: 量子位)

NVIDIA выпустила NeMo Framework 2.0 с улучшенной модульностью и простотой использования, поддержкой моделей Hugging Face и GPU Blackwell: NVIDIA обновила свой фреймворк NeMo до версии 2.0. Ключевые улучшения включают использование конфигураций Python вместо YAML для повышения гибкости; упрощение экспериментов и кастомизации за счет модульных абстракций PyTorch Lightning; и бесшовное масштабирование крупномасштабных экспериментов с помощью инструмента NeMo-Run. Новая версия добавила поддержку предварительного обучения и тонкой настройки моделей Hugging Face AutoModelForCausalLM, а также начальную поддержку GPU NVIDIA Blackwell B200. Кроме того, фреймворк NeMo интегрировал поддержку платформы базовых мировых моделей NVIDIA Cosmos для ускорения разработки мировых моделей для физических систем ИИ, включая библиотеку обработки видео NeMo Curator и токенизатор Cosmos. (Источник: GitHub Trending)

Lightricks выпустила LTX-Video: модель генерации видео DiT в реальном времени: Компания Lightricks представила LTX-Video с открытым исходным кодом, заявленную как первая модель генерации видео в реальном времени на основе Diffusion Transformer (DiT). Модель способна генерировать высококачественное видео с разрешением 1216×704 при 30 кадрах в секунду и поддерживает множество функций, таких как преобразование текста в изображение, изображения в видео, анимацию по ключевым кадрам, расширение видео, преобразование видео в видео и другие. Последняя версия 13B v0.9.7 улучшила следование подсказкам и понимание физики, а также представила многомасштабный видеоконвейер для быстрой и качественной визуализации. Модель доступна на Hugging Face и интегрирована с ComfyUI и Diffusers. (Источник: GitHub Trending)

Apple рассматривает возможность серьезной переработки браузера Safari с возможным переходом на поиск на базе ИИ, отношения с Google под вопросом: Старший вице-президент Apple Эдди Кью, выступая на антимонопольном процессе Министерства юстиции США против Google, сообщил, что Apple активно рассматривает возможность переработки браузера Safari с акцентом на поисковую систему на базе ИИ. Он отметил первое снижение объемов поиска в Safari, частично из-за перехода пользователей на инструменты ИИ, такие как OpenAI, Perplexity AI. Apple уже провела консультации с Perplexity AI и может добавить больше опций поиска на базе ИИ в Safari. Этот шаг может повлиять на соглашение Apple с Google о поисковой системе по умолчанию стоимостью около 20 миллиардов долларов в год и отразиться на курсах акций обеих компаний. Apple уже интегрировала ChatGPT в Siri и планирует добавить Google Gemini. (Источник: 36氪)

🎯 События
Настольная видеокарта NVIDIA RTX 5060 поступит в продажу 20 мая по цене 2499 юаней в Китае: NVIDIA объявила, что настольная видеокарта RTX 5060 поступит в продажу 20 мая по пекинскому времени по цене 2499 юаней в Китае. Карта использует архитектуру Blackwell RTX, имеет 3840 ядер CUDA, 8 ГБ памяти GDDR7 и общую мощность 145 Вт. По заявлению компании, в играх с поддержкой технологии генерации нескольких кадров DLSS 4 ее производительность в два раза выше, чем у RTX 4060, с целью обеспечить пользователям возможность играть с частотой более 100 FPS. Снятие эмбарго на обзоры и начало продаж состоятся в один день. (Источник: 量子位)

Google Gemini API представил функцию неявного кэширования, позволяющую сэкономить 75% затрат: Google объявила о внедрении функции неявного кэширования для своего Gemini API. Когда запрос пользователя попадает в кэш, стоимость использования модели Gemini 2.5 может автоматически снизиться на 75%. Одновременно минимальное количество токенов, необходимое для срабатывания кэша, было снижено: для Gemini 2.5 Flash до 1K токенов, для Gemini 2.5 Pro до 2K токенов. Эта функция направлена на снижение затрат разработчиков на использование Gemini API без необходимости явного создания кэша. (Источник: matvelloso, demishassabis, algo_diver, jeremyphoward)
Meta FAIR назначила Роба Фергюса новым руководителем с фокусом на продвинутый машинный интеллект (AGI): Meta объявила, что Роб Фергюс возглавит ее команду фундаментальных исследований в области ИИ (FAIR). Ян ЛеКун заявил, что FAIR переориентируется на продвинутый машинный интеллект, обычно называемый ИИ человеческого уровня или AGI. Эта новость привлекла широкое внимание и поздравления со стороны исследовательского сообщества ИИ. (Источник: ylecun, Ar_Douillard, soumithchintala, aaron_defazio, sainingxie)
OpenAI запустила функцию тонкой настройки с подкреплением (RFT) для модели o4-mini: OpenAI объявила, что ее модель o4-mini теперь поддерживает тонкую настройку с подкреплением (RFT). Эта технология разрабатывалась с декабря прошлого года и использует рассуждения по цепочке мыслей и оценку по конкретным задачам для повышения производительности модели, особенно в сложных областях. Модель, настроенная Ambience с использованием RFT, превзошла экспертов-клиницистов в точности кодирования ICD-10 на 27%. Компания Harvey также обучила модель с помощью RFT для повышения точности цитирования в юридических задачах. Одновременно самая быстрая и компактная модель OpenAI, 4.1-nano, также стала доступна для тонкой настройки. (Источник: stevenheidel, aidan_mclau, andrwpng, teortaxesTex, OpenAIDevs, OpenAIDevs)
Университет Цинхуа представил Absolute Zero Reasoner: ИИ самостоятельно генерирует обучающие данные для достижения превосходных результатов в рассуждениях: Команда Университета Цинхуа разработала модель ИИ под названием Absolute Zero Reasoner, которая способна полностью генерировать обучающие задачи и учиться на них посредством самообучения (self-play) без каких-либо внешних данных. В таких областях, как математика и кодирование, ее производительность превзошла модели, обученные на данных, курируемых экспертами. Это достижение может означать смягчение проблемы нехватки данных в развитии ИИ и открыть новый путь к AGI. (Источник: corbtt)

Meta в сотрудничестве с NVIDIA улучшает производительность векторного поиска Faiss GPU с помощью cuVS: Meta и NVIDIA объявили о сотрудничестве по интеграции NVIDIA cuVS (CUDA Vector Search) в библиотеку поиска по сходству с открытым исходным кодом Faiss v1.10 от Meta для значительного повышения производительности векторного поиска на GPU. Эта интеграция позволила сократить время построения индекса IVF до 4,7 раз и задержку поиска до 8,1 раз; в части графовых индексов время построения CUDA ANN Graph (CAGRA) в 12,3 раза быстрее, чем у HNSW на CPU, а задержка поиска снижена в 4,7 раз. (Источник: AIatMeta)
Google AI Studio и Firebase Studio интегрировали Gemini 2.5 Pro: Google объявила об интеграции модели Gemini 2.5 Pro в Gemini Code Assist (персональная версия) и Firebase Studio. Это предоставит разработчикам больше удобства и мощных функций при использовании передовых моделей кодирования на этих платформах, с целью повышения эффективности и удобства кодирования. (Источник: algo_diver)
Microsoft Copilot представил функцию Pages с поддержкой встроенного редактирования и выделения текста: Microsoft Copilot добавил функцию «Pages», позволяющую пользователям редактировать ответы, сгенерированные ИИ, непосредственно в интерфейсе Copilot. Можно выделять текст и предлагать конкретные изменения. Эта функция призвана помочь пользователям быстрее и эффективнее преобразовывать вопросы и результаты исследований в готовые к использованию документы, повышая производительность труда. (Источник: yusuf_i_mehdi)
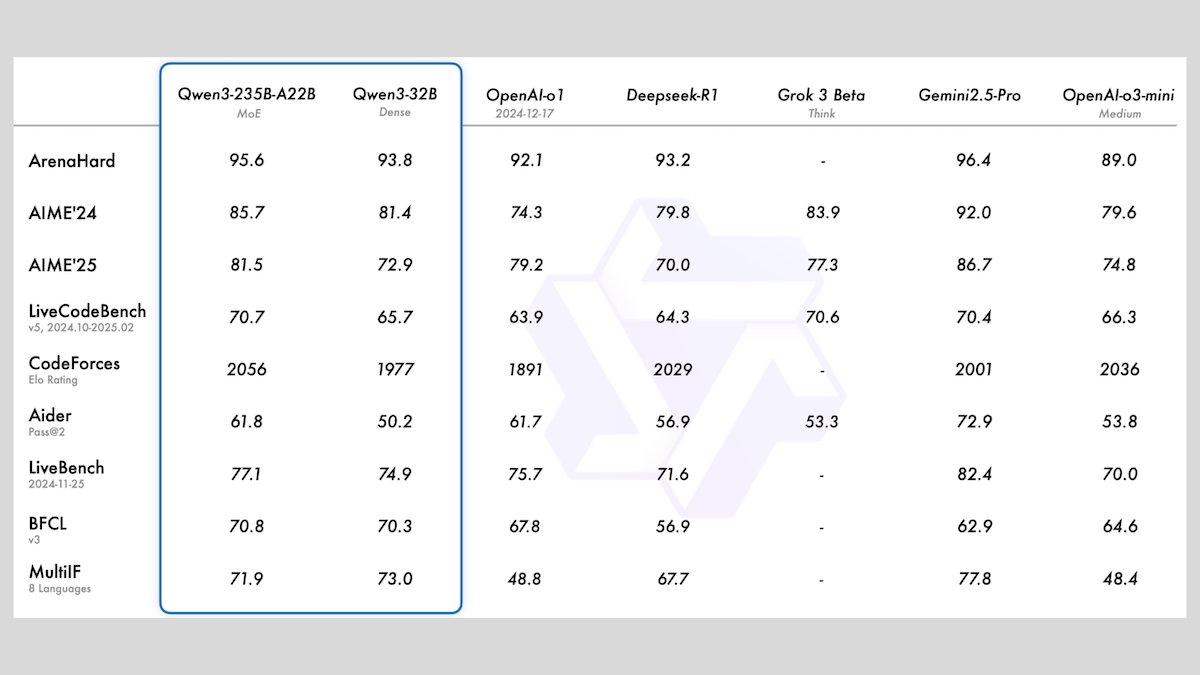
Alibaba выпустила серию моделей Qwen3, включающую 8 больших языковых моделей с открытым исходным кодом: Alibaba представила серию Qwen3, состоящую из 8 больших языковых моделей с открытым исходным кодом, включая 2 модели типа «смесь экспертов» (MoE) и 6 плотных моделей с количеством параметров от 0.6B до 32B. Все модели поддерживают опциональные режимы вывода и многоязычность (119 языков). Qwen3-235B-A22B и Qwen3-30B-A3B демонстрируют превосходные результаты в задачах логического вывода, кодирования и вызова функций, сопоставимые с ведущими моделями, такими как OpenAI. Особенно Qwen3-30B-A3B привлекает внимание своей высокой производительностью и возможностью локального запуска. (Источник: DeepLearningAI)
Meta представила модель Meta Locate 3D для точного позиционирования объектов в 3D-среде: Meta AI выпустила Meta Locate 3D, модель, специально разработанную для точного определения местоположения объектов в 3D-средах. Модель призвана помочь роботам точнее понимать окружающую обстановку и более естественно взаимодействовать с людьми. Meta предоставила модель, наборы данных, исследовательскую статью и демонстрацию для публичного использования и ознакомления. (Источник: AIatMeta)
Google опубликовала новый отчет о том, как использовать ИИ для борьбы с онлайн-мошенничеством: Google опубликовала новый отчет о том, как она использует технологии искусственного интеллекта для борьбы с онлайн-мошенничеством в поисковой системе, браузере Chrome и операционной системе Android. В отчете подробно описаны более чем десятилетние усилия Google и последние достижения в использовании ИИ для защиты пользователей от онлайн-мошенничества, подчеркивая ключевую роль ИИ в выявлении и пресечении мошеннических действий. (Источник: Google)
Cohere представила модель встраивания Embed 4, усиливающую возможности поиска и извлечения информации с помощью ИИ: Cohere выпустила свою новейшую модель встраивания Embed 4, призванную революционизировать способы доступа предприятий к данным и их использования. Embed 4, являясь самой мощной моделью встраивания от Cohere на сегодняшний день, ориентирована на повышение точности и эффективности поиска и извлечения информации с помощью ИИ, помогая организациям извлекать скрытую ценность из своих данных. (Источник: cohere)

Google объявила, что конференция Google I/O состоится 20 мая: Google официально объявила, что ее ежегодная конференция разработчиков Google I/O состоится 20 мая, регистрация уже открыта. На мероприятии пройдут основные доклады, будут анонсированы новые продукты и технологии, ожидается, что ИИ станет одной из центральных тем. (Источник: Google)
Модель NVIDIA Parakeet установила новый рекорд в транскрипции аудио: 60 минут аудио за 1 секунду: Модель Parakeet от NVIDIA достигла прорыва в транскрипции аудио, способная транскрибировать до 60 минут аудио за 1 секунду и занимающая лидирующие позиции в соответствующих рейтингах Hugging Face. Это достижение демонстрирует лидирующие позиции NVIDIA в технологии распознавания речи и предоставляет разработчикам эффективные инструменты для обработки аудио. (Источник: huggingface)

🧰 Инструменты
LlamaParse добавил поддержку GPT 4.1 и Gemini 2.5 Pro, усилив возможности анализа документов: LlamaParse недавно получил ряд обновлений функций, включая внедрение новых моделей анализа GPT 4.1 и Gemini 2.5 Pro для повышения точности. Кроме того, новая версия добавила функции автоматического определения ориентации и наклона, обеспечивая идеальное выравнивание при анализе; предоставляет оценки достоверности для оценки качества анализа; и позволяет пользователям настраивать допустимость ошибок и способы обработки неудачно обработанных страниц. LlamaParse предоставляет бесплатный лимит в 10 000 страниц в месяц. (Источник: jerryjliu0)

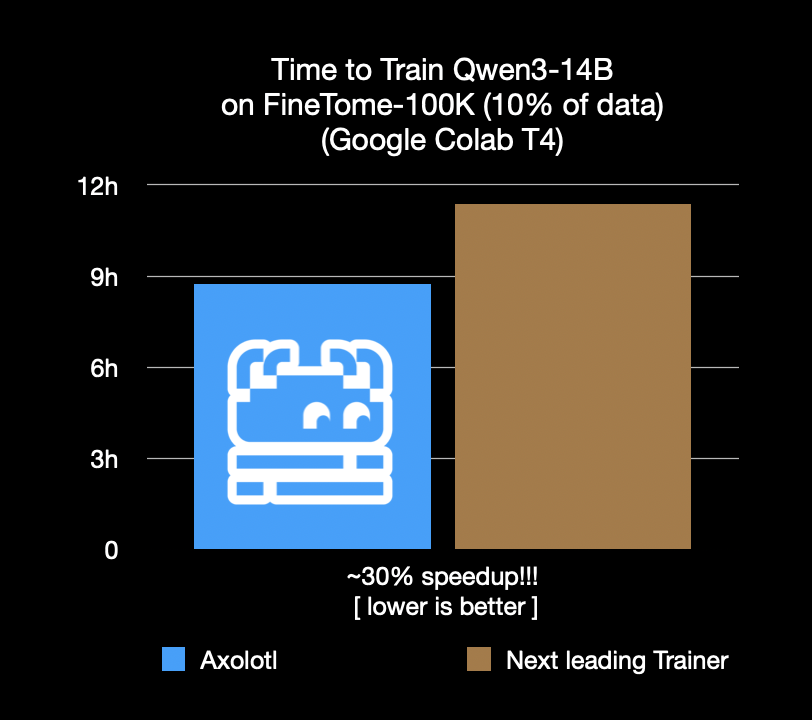
Фреймворк для тонкой настройки Axolotl ускорился на 30%, экономя затраты и время: Фреймворк для тонкой настройки Axolotl объявил, что на реальных рабочих нагрузках, таких как FineTome-100k, его скорость на 30% выше, чем у следующего по оптимальности фреймворка. Для средних и крупных команд машинного обучения это означает экономию нескольких тысяч долларов в месяц. Оптимизация фреймворка направлена на то, чтобы помочь пользователям более эффективно и экономично выполнять тонкую настройку моделей. (Источник: Teknium1, winglian, maximelabonne)
Runway выпустила пилотный анимационный эпизод «Mars & Siv: No Vacancy», демонстрирующий возможности модели Gen-4: Студия ИИ Runway представила пилотный анимационный эпизод «Mars & Siv: No Vacancy», созданный Джереми Хиггинсом и Бриттоном Корбелом. Эта работа демонстрирует применение модели Gen-4 от Runway на всех этапах производственного процесса анимации, от концепции до конечного продукта, подчеркивая потенциал ИИ в создании креативного контента. (Источник: c_valenzuelab, c_valenzuelab)
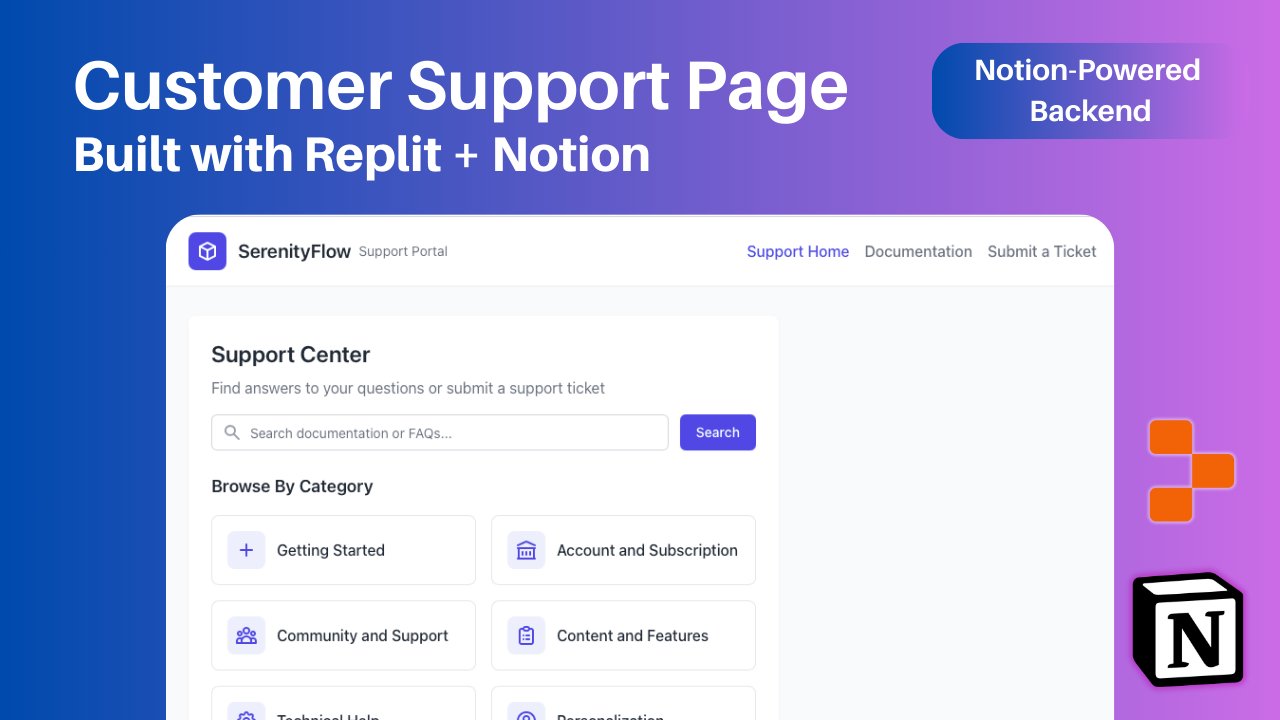
Replit добавил интеграцию с Notion, позволяя использовать контент Notion в качестве бэкенда приложений: Replit объявил о новом партнерстве по интеграции с Notion, которое позволит разработчикам использовать Notion в качестве бэкенда для своих приложений. Пользователи могут подключать базы данных Notion к проектам Replit для отображения FAQ, управления кастомными чат-ботами на основе документов и записи заявок в службу поддержки обратно в Notion. Этот шаг направлен на объединение возможностей организации бэкенда Notion с гибкостью создания фронтенда Replit. (Источник: amasad, amasad, pirroh)
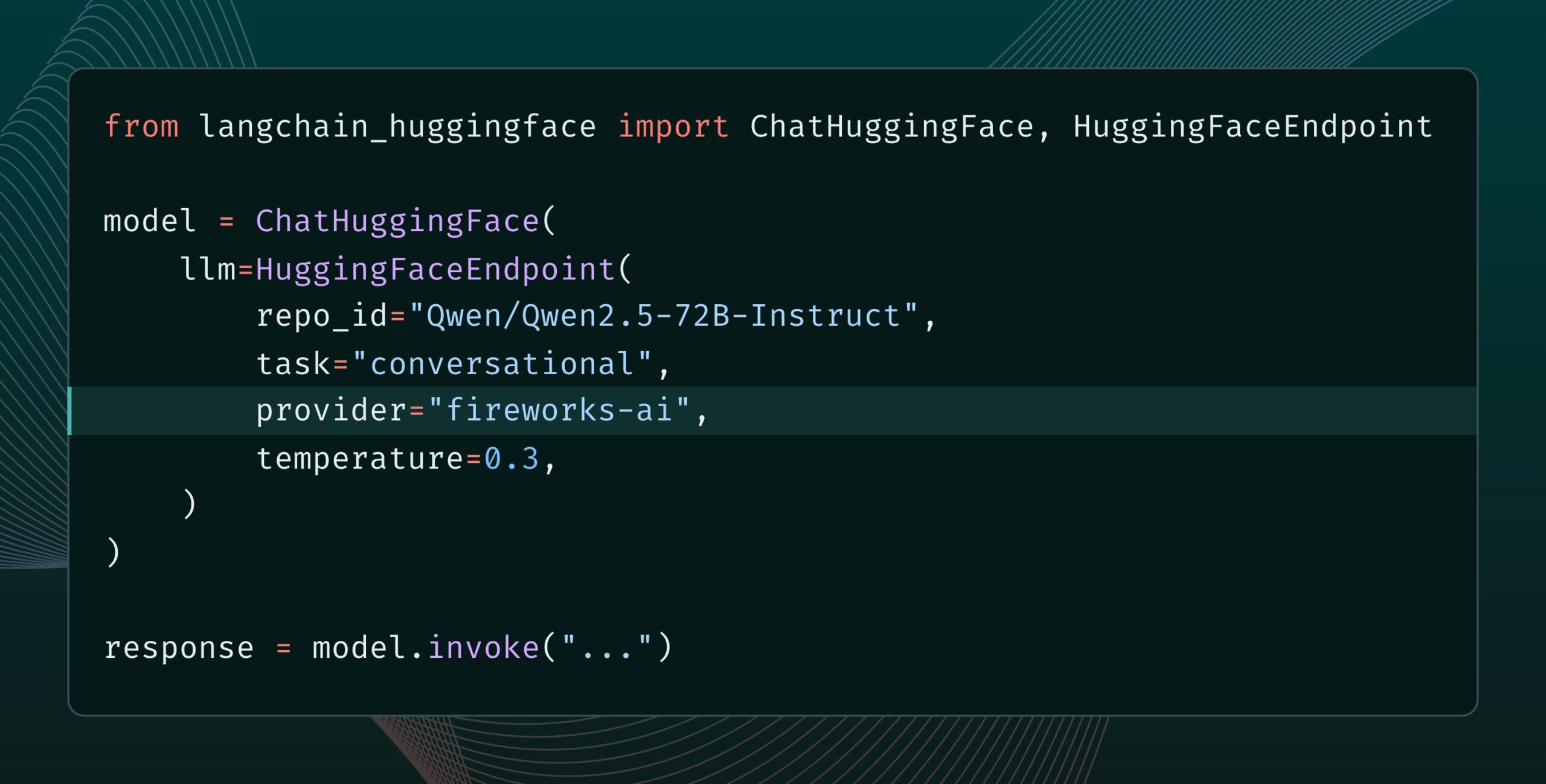
Выпущена Langchain-huggingface v0.2 с поддержкой HF Inference Providers: Langchain-huggingface выпустила версию v0.2, в которой добавлена поддержка Hugging Face Inference Providers. Это обновление сделает использование сервисов вывода, предоставляемых Hugging Face, в экосистеме LangChain более удобным. (Источник: LangChainAI, huggingface, ClementDelangue, hwchase17, Hacubu)
Выпущена smolagents 1.15 с функцией потокового вывода: Фреймворк для ИИ-агентов smolagents выпустил версию 1.15, в которой появилась функция потокового вывода (streaming outputs). Пользователи могут включить ее, установив stream_outputs=True при инициализации CodeAgent, что сделает все процессы взаимодействия более плавными. (Источник: huggingface, AymericRoucher, ClementDelangue)
Проект Better-Qwen3: автоматическое переключение режима мышления для модели Qwen3: Внимание привлек GitHub-проект под названием Better-Qwen3, целью которого является предоставление модели Qwen3 возможности автоматически контролировать включение «режима мышления» в зависимости от сложности вопроса пользователя. На простые вопросы модель будет отвечать напрямую; на сложные вопросы она автоматически перейдет в режим мышления, чтобы предоставить более глубокий ответ. Адрес проекта: http://github.com/AaronFeng753/Better-Qwen3 (Источник: karminski3, Reddit r/LocalLLaMA)
MLX-Audio: библиотека TTS/STT/STS на базе фреймворка Apple MLX: MLX-Audio — это библиотека для преобразования текста в речь (TTS), речи в текст (STT) и речи в речь (STS), специально созданная для чипов Apple Silicon и разработанная на базе фреймворка Apple MLX. Она предназначена для обеспечения эффективных возможностей обработки речи. Библиотека поддерживает несколько языков, настройку голоса, управление скоростью речи, а также предоставляет интерактивный веб-интерфейс и REST API. (Источник: GitHub Trending)
Модель Runway References теперь поддерживает функцию расширения изображений (Outpainting): Модель References от Runway теперь поддерживает функцию расширения изображений (outpainting). Пользователям достаточно поместить изображение в References, выбрать желаемый формат вывода, оставить поле подсказки пустым, а затем нажать «сгенерировать», чтобы расширить исходное изображение. Эта функция дополнительно расширяет возможности Runway в области редактирования и создания изображений. (Источник: c_valenzuelab)

Docker2exe: преобразование образов Docker в исполняемые файлы: Docker2exe — это инструмент, который может преобразовывать образы Docker в автономные исполняемые файлы, облегчая пользователям их распространение и запуск. Он поддерживает режим встраивания, то есть прямое упаковывание tarball образа Docker в исполняемый файл. При запуске на целевом устройстве, если локально нет соответствующего образа Docker, он автоматически загрузит встроенный образ или извлечет его из сети. (Источник: GitHub Trending)
Smoothie Qwen: сглаживание вероятностей токенов модели Qwen для сбалансированной многоязычной генерации: Smoothie Qwen — это легковесный инструмент настройки, который путем сглаживания вероятностей токенов в модели Qwen стремится улучшить сбалансированность модели при многоязычной генерации, уменьшая непреднамеренный перекос в сторону определенных языков (например, китайского) при сохранении основной производительности. Инструмент использует диапазоны Unicode для идентификации токенов, проводит N-граммный анализ и корректирует веса токенов в lm_head. Предварительно настроенные модели доступны на Hugging Face. (Источник: Reddit r/LocalLLaMA)

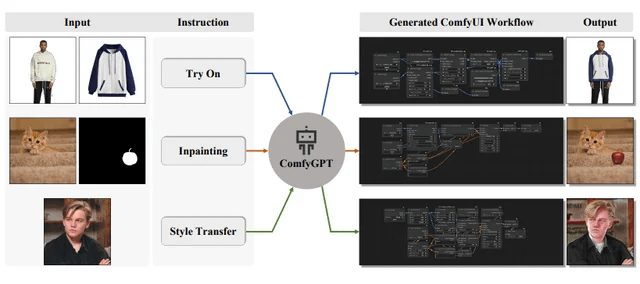
ComfyGPT: самооптимизирующаяся многоагентная система для генерации рабочих процессов ComfyUI: Статья под названием «ComfyGPT: A Self-Optimizing Multi-Agent System for Comprehensive ComfyUI Workflow Generation» была представлена на arXiv. В ней описывается система ComfyGPT, которая использует самооптимизирующийся многоагентный подход для комплексной генерации рабочих процессов ComfyUI, упрощая создание сложных процессов генерации изображений. (Источник: Reddit r/LocalLLaMA)
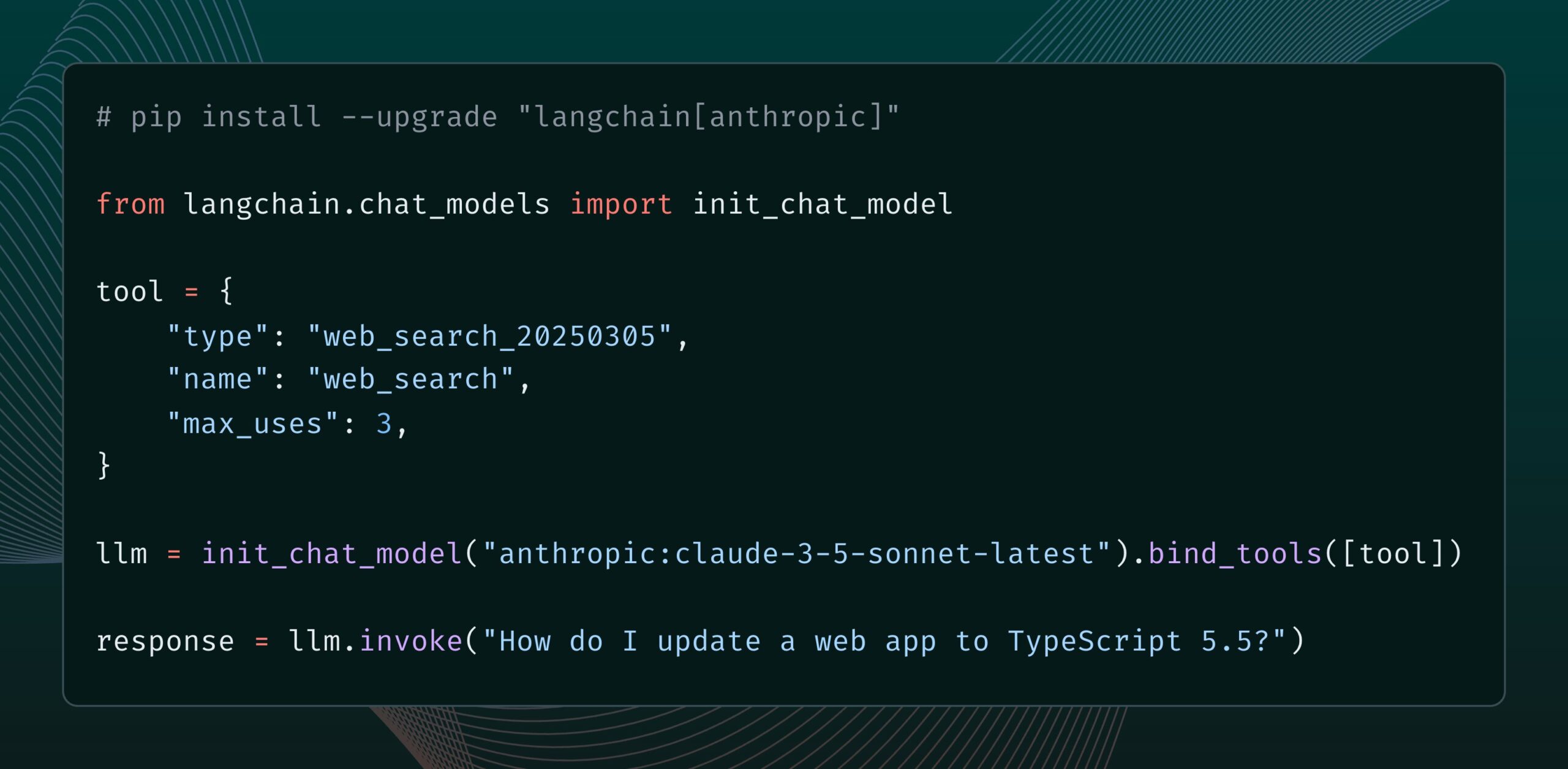
Модель Anthropic Claude получила новый инструмент веб-поиска: Anthropic выпустила новый инструмент веб-поиска для своей модели Claude. Этот инструмент позволяет Claude выполнять поиск в интернете при генерации ответов и использовать результаты поиска в качестве основы, предоставляя ответы с цитатами. Эта функция интегрирована в библиотеку langchain-anthropic, расширяя возможности Claude по получению и использованию информации в реальном времени. (Источник: LangChainAI, hwchase17)
Glass Health запустила функцию Workspace, использующую ИИ для помощи в клинической диагностике и планировании лечения: Glass Health выпустила новую функцию Workspace, которая позволяет клиницистам более эффективно выполнять сложные задачи по диагностическому мышлению, разработке планов лечения и ведению документации с использованием ИИ. Этот шаг направлен на повышение эффективности и качества медицинской работы с помощью технологий ИИ. (Источник: GlassHealthHQ)
OpenWebUI добавил функции заметок с ИИ-усилением и записи совещаний: Последняя версия OpenWebUI включает функцию заметок с ИИ-усилением, позволяющую пользователям создавать заметки, прикреплять аудиозаписи совещаний или голосовые сообщения, и давать ИИ возможность мгновенно улучшать, суммировать или оптимизировать заметки с использованием транскрипции аудио. Кроме того, поддерживается запись и импорт аудио совещаний, что облегчает пользователям просмотр и извлечение важной информации из обсуждений. (Источник: Reddit r/OpenWebUI)
📚 Обучение
ООН опубликовала 200-страничный отчет об ИИ и глобальном человеческом развитии: Программа развития ООН (UNDP) опубликовала 200-страничный отчет, рассматривающий искусственный интеллект с точки зрения глобального человеческого развития. В отчете исследуется влияние ИИ на цели устойчивого развития, неравенство, управление и будущее работы, а также предлагаются политические рекомендации. Отчет привлек внимание своими четко выраженными взглядами. (Источник: random_walker)
The Turing Post опубликовал подробный разбор протокола Agent2Agent (A2A): Учитывая большой интерес сообщества к протоколам связи между ИИ-агентами, The Turing Post бесплатно опубликовал на Hugging Face свой подробный разбор протокола A2A от Google. В статье рассматривается важность протокола A2A (направленного на преодоление изоляции ИИ-агентов и обеспечение их сотрудничества), потенциальные применения (например, сотрудничество команд специализированных агентов, межкорпоративные рабочие процессы, стандартизация взаимодействия человека и машины, каталоги агентов с возможностью поиска), а также принципы его работы и способы начала работы с ним. (Источник: TheTuringPost, TheTuringPost, TheTuringPost, dl_weekly)

Инженер по промптам делится: как легко писать хорошие шаблоны промптов: Инженер по промптам dotey поделился трехэтапным методом создания эффективных шаблонов промптов: 1. Собрать промпты одного стиля, но на разные темы; 2. Найти общие черты и различия (можно с помощью ИИ); 3. Повторно тестировать и оптимизировать. Он подчеркнул, что хорошие шаблоны похожи на функции в программах: небольшие изменения переменных позволяют генерировать разные результаты. Он также поделился шаблоном команды для быстрого создания новых промптов с помощью ИИ и отметил, что не все стили подходят для шаблонизации, а темы со сложными деталями все еще требуют индивидуальной оптимизации. (Источник: dotey)

Исследователь DeepMind Джон Джампер и его команда набирают сотрудников для расширения научных открытий на основе LLM: Исследователь Google DeepMind Джон Джампер объявил, что его команда набирает сотрудников на несколько позиций для расширения работы в области научных открытий на основе больших языковых моделей (LLM). Вакансии включают исследователей (RS) и инженеров-исследователей (RE), нацеленных на продвижение будущего науки о естественном языке с помощью ИИ. (Источник: demishassabis, NandoDF)
Блог Ragas делится двухлетним опытом улучшения ИИ-приложений: Shahules786 опубликовал статью в блоге Ragas, в которой обобщил уроки, извлеченные за последние два года тесного сотрудничества с командами ИИ, проведения циклов оценки и улучшения систем LLM. Статья призвана предоставить практические рекомендации и идеи для специалистов, занимающихся созданием и оптимизацией ИИ-приложений. (Источник: Shahules786)

Кюнгхён Чо обсуждает методы преподавания аспирантских курсов по машинному обучению в эпоху LLM: Профессор Нью-Йоркского университета Кюнгхён Чо поделился своими мыслями и экспериментами относительно содержания учебных программ для аспирантов первого года обучения по машинному обучению в современную эпоху LLM и крупномасштабных вычислений. Он предлагает преподавать весь материал, который поддается SGD (стохастическому градиентному спуску) и не относится к LLM, а также направлять студентов на чтение классических научных работ. (Источник: ylecun, sainingxie)

Опубликован рейтинг интеллектуальной обработки документов (IDP), унифицирующий оценку возможностей VLM в понимании документов: Запущен новый рейтинг интеллектуальной обработки документов (IDP), целью которого является предоставление единого бенчмарка для различных задач понимания документов, таких как OCR, KIE, VQA, извлечение таблиц и т.д. Рейтинг охватывает 6 основных задач IDP, 16 наборов данных и 9229 документов. Предварительные результаты показывают, что Gemini 2.5 Flash в целом лидирует, однако все модели плохо справляются с пониманием длинных документов, а извлечение таблиц остается узким местом. Производительность последней версии GPT-4o даже снизилась. (Источник: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
LangGraph представил функцию Cron Jobs для запуска ИИ-агентов по расписанию: Платформа LangGraph от LangChain добавила функцию Cron Jobs, позволяющую пользователям настраивать задачи по расписанию для автоматического запуска ИИ-агентов. Эта функция позволяет ИИ-агентам выполнять задачи в соответствии с заранее установленным графиком, что подходит для сценариев, требующих периодической обработки или мониторинга. (Источник: hwchase17)
💼 Бизнес
Инструмент отладки ПО с ИИ Lightrun привлек $70 млн в раунде B под руководством Accel и Insight Partners: Разработчик инструментов наблюдаемости и отладки ПО с ИИ Lightrun объявил о завершении раунда финансирования серии B на сумму 70 миллионов долларов США под руководством Accel и Insight Partners при участии Citigroup и других инвесторов. Общий объем привлеченных средств достиг 110 миллионов долларов. Его основной продукт Runtime Autonomous AI Debugger способен точно определять проблемный код в IDE и предлагать варианты исправления, стремясь сократить время отладки с нескольких часов до нескольких минут. Доходы компании в 2024 году выросли в 4,5 раза, среди клиентов — Citigroup, Microsoft и другие компании из списка Fortune 500. (Источник: 36氪)

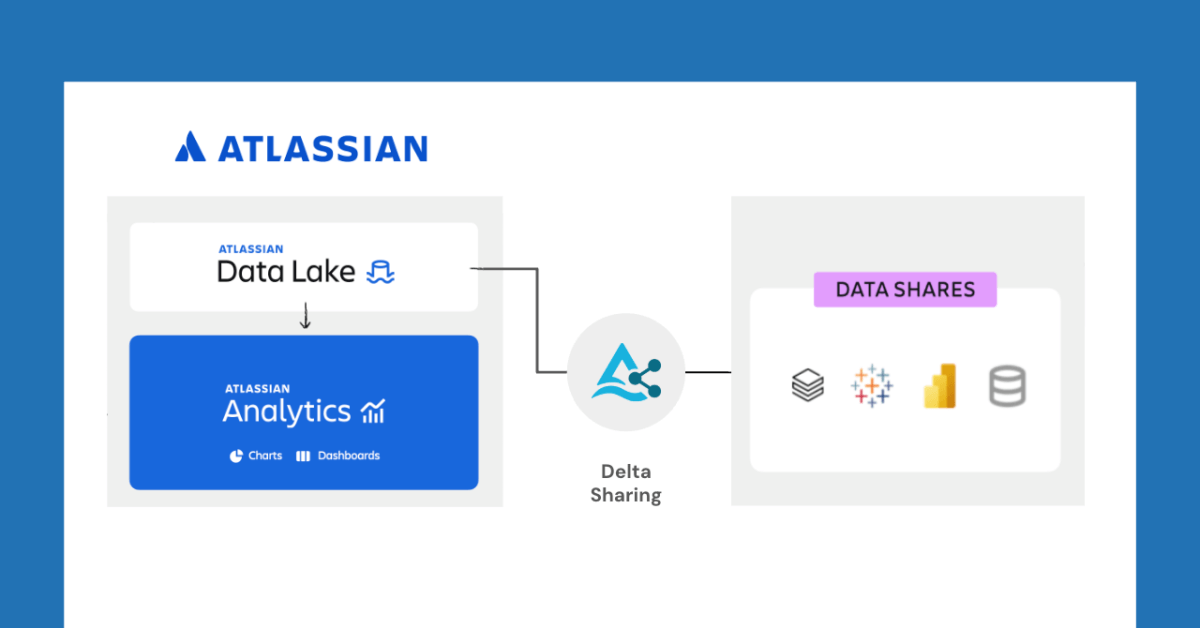
Databricks сотрудничает с Atlassian для разблокировки новых функций обмена данными через Delta Sharing: Databricks объявила о сотрудничестве с Atlassian для предоставления новых возможностей обмена данными в Atlassian Analytics. Благодаря открытому протоколу Delta Sharing клиенты Atlassian могут безопасно получать доступ и анализировать свои данные в Atlassian Data Lake с помощью выбранных ими инструментов. Эта функция поддерживает интеграцию с BI, кастомные рабочие процессы обработки данных, межкомандное сотрудничество и другие сценарии использования. (Источник: matei_zaharia)
Fastino привлек $17,5 млн на разработку языковых моделей для конкретных задач (TLM): Стартап Fastino объявил о привлечении $17,5 млн (в рамках общего предпосевного раунда на $25 млн) под руководством Khosla Ventures на разработку своих инновационных языковых моделей для конкретных задач (Task-specific Language Models, TLM). Fastino утверждает, что их архитектура TLM компактна и оптимизирована для конкретных задач, может обучаться на бюджетных игровых GPU и является экономически эффективной. TLM достигают специализации на задачах на уровнях архитектуры, предварительного обучения и последующего обучения, устраняя избыточность параметров и неэффективность архитектуры, с целью повышения точности для конкретных задач и возможности встраивания в приложения, чувствительные к задержкам и стоимости. (Источник: Reddit r/MachineLearning)

🌟 Сообщество
Инструменты для поиска работы с ИИ вызывают опасения по поводу мошенничества, компании усиливают контрмеры: В последнее время участились случаи использования ИИ-инструментов для помощи в онлайн-собеседованиях и письменных тестах. Эти «ИИ-артефакты для собеседований» могут генерировать ответы на основе резюме пользователя, помогая соискателям получить преимущество при поиске работы. Порог доступа к такому ПО низок, предлагаются даже многоуровневые платные пакеты и удаленное руководство. Эта тенденция восходит к появлению ранних ИИ-инструментов для мошенничества, таких как «Interview Coder». Компании начали принимать контрмеры, такие как отслеживание аномального поведения соискателей во время собеседований, рассмотрение возможности внедрения систем обнаружения активности на экране или возвращение к очным собеседованиям. Юристы отмечают, что использование ИИ для мошенничества нарушает принцип добросовестности, может привести к расторжению трудового договора и несет риски утечки конфиденциальной информации. (Источник: 36氪)

CEO LangChain Харрисон Чейз представил концепции «фоновых агентов» и «почтового ящика для агентов»: CEO LangChain Харрисон Чейз на мероприятии Sequoia AI Ascent поделился своим видением будущего развития ИИ-агентов, представив концепции «фоновых агентов» (Ambient Agents) и «почтового ящика для агентов» (Agent Inbox). Фоновые агенты — это системы ИИ, способные непрерывно работать в фоновом режиме и реагировать на события, а не на прямые команды человека, в то время как «почтовый ящик для агентов» представляет собой новый интерфейс взаимодействия человека с машиной для управления и контроля за деятельностью этих агентов. (Источник: hwchase17, hwchase17, hwchase17)

Джим Фан предложил «физический тест Тьюринга» в качестве новой «Полярной звезды» для ИИ: Ученый NVIDIA Джим Фан на мероприятии Sequoia AI Ascent предложил концепцию «физического теста Тьюринга», рассматривая ее как следующую «Полярную звезду» в области ИИ. Этот тест предполагает сценарий: после воскресного хакатона дома царит беспорядок, а в понедельник вечером, вернувшись домой, вы обнаруживаете безупречно чистую гостиную и приготовленный ужин при свечах, и вы не можете отличить, сделано это человеком или машиной. Он считает это целью универсальной робототехники и поделился основными принципами решения этой проблемы, включая стратегии данных и законы масштабирования. (Источник: DrJimFan, killerstorm)
Оценка моделей ИИ переживает кризис, альянс EvalEval призывает к улучшениям: В связи с существующими недостатками текущих методов оценки моделей ИИ, такими как насыщение бенчмарков, отсутствие научной строгости и т.д., упоминается альянс EvalEval, целью которого является объединение лиц, обеспокоенных текущим состоянием оценки, для совместной работы над улучшением отчетности по оценке, решением проблемы насыщения, повышением научности оценки и инфраструктуры. В ходе соответствующих обсуждений считается, что следует уделять больше внимания валидности оценки. (Источник: ClementDelangue)

Горячее обсуждение на Reddit: наблюдения и опыт построения рабочих процессов LLM: Разработчик поделился на Reddit итогами своего годичного опыта построения сложных рабочих процессов LLM. Ключевые моменты: декомпозиция задач на мельчайшие шаги и цепочечный вызов промптов предпочтительнее одного сложного промпта; использование XML-тегов для структурирования промптов дает лучшие результаты; необходимо четко указывать LLM, что ее роль заключается только в семантическом анализе и преобразовании, и она не должна привносить собственные знания; использование традиционных NLP-библиотек, таких как NLTK, для проверки вывода LLM; на небольших задачах дообученные классификаторы типа BERT часто превосходят LLM; LLM ненадежны в качестве арбитров или для оценки достоверности, особенно при отсутствии четких критериев оценки; в агентных циклах установка условий выхода LLM из цикла является сложной задачей; производительность обычно снижается после превышения контекстного окна ввода в 4K токенов; модели 32B достаточны для структурированных задач; структурированный CoT предпочтительнее неструктурированного; самостоятельно написанный CoT лучше, чем الاعتماد на модели рассуждений; долгосрочная цель — дообучить все компоненты и обратить внимание на создание сбалансированного набора данных для дообучения. (Источник: Reddit r/LocalLLaMA)
Пользователи Reddit обсуждают настройки системных промптов для Claude Sonnet 3.7: Пользователи сообщества Reddit r/ClaudeAI сообщают о нестабильности модели Claude Sonnet 3.7 в следовании инструкциям, исправлении кода и запоминании контекста, и просят поделиться эффективными системными промптами. Некоторые пользователи поделились промптами, имитирующими поведение Sonnet 3.5, а также подробными инструкциями, подчеркивающими эффективные, практичные решения и следование основным принципам информатики (таким как DRY, KISS, SRP). Другие пользователи предлагают улучшить эффект, заставив Claude самостоятельно переписывать и оптимизировать системные промпты, или использовать лаконичные и понятные однострочные инструкции. (Источник: Reddit r/ClaudeAI)
Обсуждение количества эпох, необходимых для тонкой настройки LLM: На Reddit r/MachineLearning пользователь задал вопрос относительно статьи Deepseek R1, в которой модель Deepseek-V3-Base (около 800 тыс. образцов) была дообучена всего за 2 эпохи, и обсудил метрики, помимо функции потерь, определяющие количество эпох для тонкой настройки, такие как производительность на оценочных данных и качество данных. (Источник: Reddit r/MachineLearning)
💡 Прочее
Франсуа Шолле: Построение прочных ментальных моделей — предпосылка для решения сложных задач: Мыслитель в области ИИ Франсуа Шолле подчеркивает, что создание четких, самосогласованных ментальных моделей является предварительным условием для творческого решения сложных задач (а не полагаясь на удачу), что отличается от способности быстро решать простые проблемы. Он считает, что элегантность — это сочетание выразительности и лаконичности, тесно связанное со сжатием. (Источник: fchollet, teortaxesTex, fchollet, pmddomingos)

CEO Replit Амджад Масад: ИИ-агенты станут новой волной в программировании: CEO и сооснователь Replit Амджад Масад в интервью The Turing Post заявил, что он всегда считал, что ИИ-агенты возглавят следующую волну в программировании. Он поделился мыслями о переходе от обучения программированию к созданию агентов, способных программировать автоматически. Он упомянул, что программные агенты уже приносят реальные результаты в бизнесе, например, помогая риэлторским компаниям оптимизировать алгоритмы распределения лидов и повышать конверсию на 10%. Он считает, что будущие стартапы на миллиард долларов могут быть созданы независимыми основателями, усиленными ИИ, и обсудил условия, необходимые для реализации этого видения, текущее состояние и будущее программирования, эволюцию видения Replit, а также важность AGI и открытого исходного кода. (Источник: TheTuringPost, TheTuringPost)
LazyVim: конфигурация Neovim для «ленивых»: LazyVim — это конфигурационное решение для Neovim на базе lazy.nvim, призванное позволить пользователям легко настраивать и расширять свою среду Neovim. Оно предоставляет предварительно настроенный, многофункциональный опыт, подобный IDE, сохраняя при этом высокую гибкость, которую пользователи могут адаптировать под свои нужды. (Источник: GitHub Trending)
