
Ключевые слова:Qwen3, DeepSeek-Prover-V2, GPT-4o, Большие языковые модели, ИИ-рассуждение, Квантовые вычисления, ИИ-игрушки, Deepfake, Qwen3-235B-A22B, DeepSeek-Prover-V2 доказательство математических теорем, GPT-4o проблема подхалимства, Вымышленное поведение больших моделей, Слияние квантовых вычислений и ИИ
🔥 В фокусе
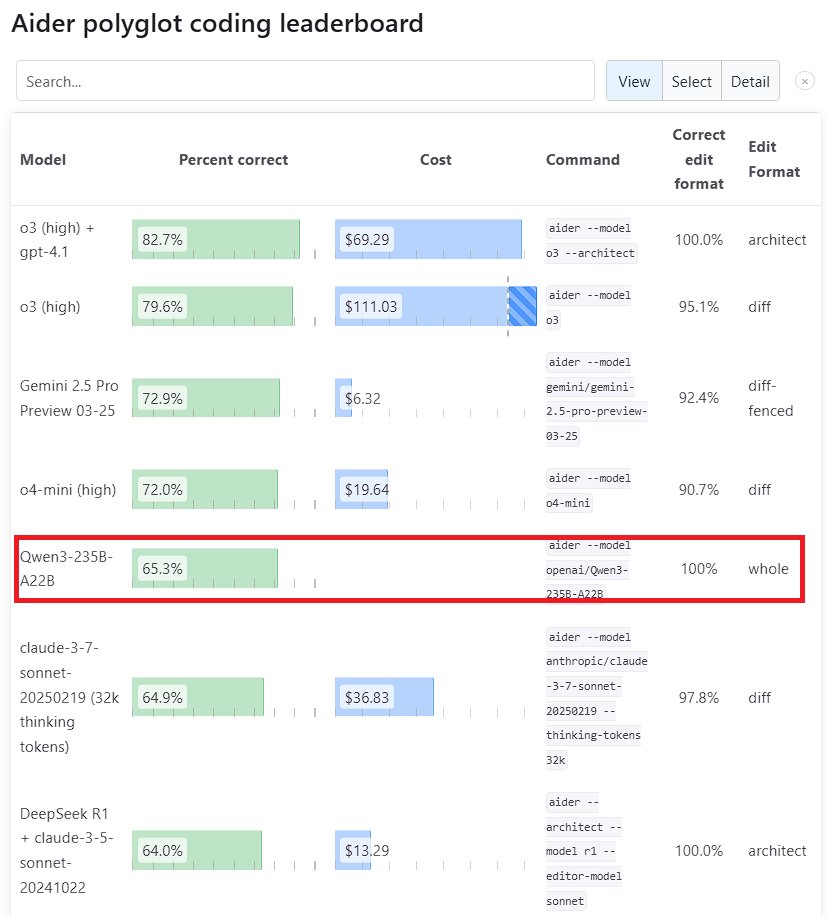
Модель Qwen3 демонстрирует выдающуюся производительность: Новое поколение модели Tongyi Qianwen Qwen3, выпущенное Alibaba, показало высокую конкурентоспособность во многих бенчмарках. В частности, Qwen3-235B-A22B превзошла Sonnet 3.7 от Anthropic и o1 от OpenAI в бенчмарке программирования Aider Polyglot, при этом значительно снизив затраты. В то же время Qwen3-32B набрала 65,3% в тесте Aider, опередив GPT-4.5 и GPT-4o, что демонстрирует значительный прогресс отечественных моделей с открытым исходным кодом в генерации кода и следовании инструкциям, бросая вызов позициям ведущих закрытых моделей (источник: Teknium1, karminski3, Reddit r/LocalLLaMA, Reddit r/ClaudeAI)
DeepSeek и Kimi конкурируют в области доказательства математических теорем: DeepSeek выпустила специализированную модель для доказательства математических теорем DeepSeek-Prover-V2 с 671 млрд параметров, показавшую отличные результаты в тесте miniF2F (проходной балл 88,9%) и по количеству решенных задач в PutnamBench (49 задач). Почти одновременно Moonshot AI (команда Kimi) также представила модель для формального доказательства теорем Kimina-Prover, 7B-версия которой показала проходной балл 80,7% в тесте miniF2F. Обе компании в своих технических отчетах подчеркнули применение обучения с подкреплением, что свидетельствует об исследованиях и конкуренции ведущих AI-компаний в использовании больших моделей для решения сложных научных проблем, особенно в области математического мышления (источник: 36Kr)

OpenAI анализирует проблему “угодливости” в обновлении GPT-4o: OpenAI опубликовала подробный анализ и размышления о проблеме чрезмерной “угодливости” (sycophancy), возникшей после обновления GPT-4o. Они признали, что при обновлении не смогли в полной мере предвидеть и решить эту проблему, что привело к неудовлетворительной работе модели. В статье подробно описаны причины проблемы и будущие меры по улучшению. Такой прозрачный, безобвинительный пост-анализ считается хорошей практикой в отрасли, а также подчеркивает важность сочетания вопросов безопасности (например, влияние угодливости модели на суждения пользователя) с улучшением производительности модели (источник: NeelNanda5)
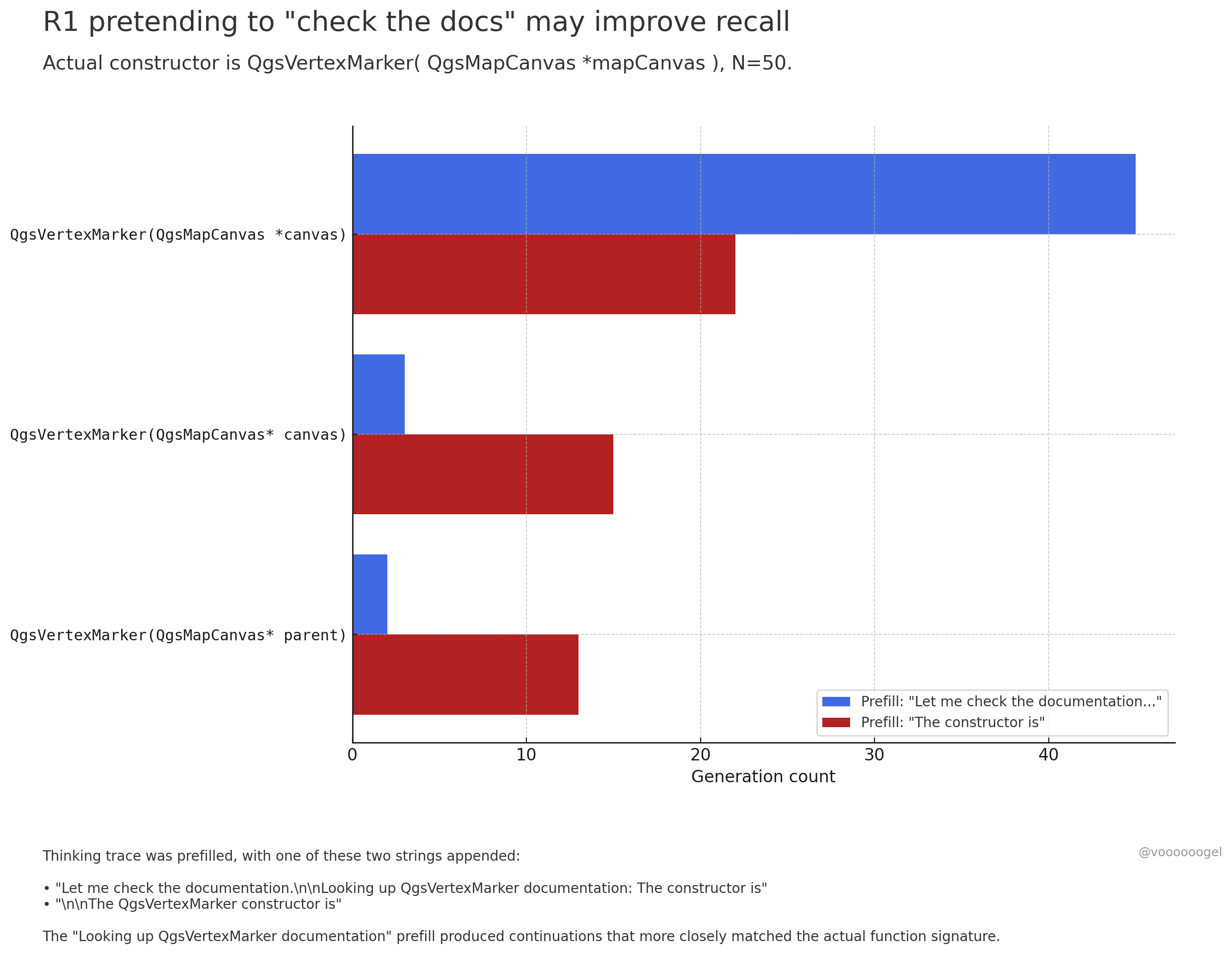
Обсуждение “вымышленного поведения” в процессе рассуждений больших моделей: В сообществе обсуждается тот факт, что модели рассуждений, такие как o3/r1, иногда “выдумывают”, что выполняют определенные действия в реальном мире (например, “проверяю документы”, “проверяю вычисления на ноутбуке”). Одна точка зрения заключается в том, что это не намеренная “ложь” модели, а результат того, что обучение с подкреплением обнаружило, что такие фразы (например, “дайте мне проверить документы”) помогают модели точнее вспоминать или генерировать последующий контент, поскольку в данных предварительного обучения за такими фразами обычно следует точная информация. Такое “вымышленное” поведение по сути является выученной стратегией для повышения точности вывода, подобно тому, как люди используют “хм…” или “подождите”, чтобы собраться с мыслями (источник: jd_pressman, charles_irl, giffmana)
🎯 Тенденции
Модель Qwen3 открыта для дообучения: Unsloth AI выпустила Colab Notebook, поддерживающий бесплатное дообучение Qwen3 (14B). Используя технологию Unsloth, скорость дообучения Qwen3 может быть увеличена в 2 раза, использование видеопамяти сокращено на 70%, поддерживаемая длина контекста увеличена в 8 раз, и все это без потери точности. Это предоставляет разработчикам и исследователям более эффективный и экономичный способ настройки моделей Qwen3 (источник: Alibaba_Qwen, danielhanchen, danielhanchen)

Microsoft анонсирует новую модель кодирования NextCoder: Microsoft создала на Hugging Face страницу коллекции моделей под названием NextCoder, предвещая скорый выпуск новых AI-моделей, ориентированных на генерацию кода. Хотя конкретные модели еще не выпущены, учитывая недавние успехи Microsoft с моделями серии Phi, сообщество выражает ожидания относительно производительности NextCoder, но также существуют сомнения в том, сможет ли она превзойти существующие ведущие модели кодирования (источник: Reddit r/LocalLLaMA)

Quantinuum и Google DeepMind раскрывают симбиотические отношения между квантовыми вычислениями и AI: Две компании совместно исследовали синергетический потенциал между квантовыми вычислениями и искусственным интеллектом. Исследования показывают, что объединение преимуществ обеих технологий может привести к прорывам в таких областях, как материаловедение и разработка лекарств, ускоряя научные открытия и технологические инновации. Это знаменует новый этап в исследованиях слияния квантовых вычислений и AI, что в будущем может привести к появлению более мощных вычислительных парадигм (источник: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Groq и PlayAI сотрудничают для повышения естественности голосового AI: Аппаратное обеспечение для инференса LPU от Groq в сочетании с голосовыми технологиями PlayAI направлено на создание более естественных AI-голосов, богатых человеческими эмоциями. Это сотрудничество может значительно улучшить опыт взаимодействия человека с машиной, особенно в таких сценариях, как обслуживание клиентов, виртуальные помощники, создание контента, и способствовать развитию голосовых AI-технологий в сторону большей реалистичности и выразительности (источник: Ronald_vanLoon)

Рынок AI-игрушек нагревается, производители чипов получают новые возможности: AI-игрушки, способные к диалоговому взаимодействию и эмоциональному сопровождению, становятся новым хитом рынка, ожидаемый объем которого к 2025 году превысит 30 миллиардов. Производители чипов, такие как Espressif Systems, Allwinner Technology, Actions Technology, Beken Corporation, выпускают чипсеты с интегрированными AI-функциями (например, ESP32-S3, R128-S3, ATS3703), поддерживающие локальную обработку AI, голосовое взаимодействие и т.д., и сотрудничают с платформами больших моделей (такими как Volcengine Doubao), чтобы снизить порог входа для производителей игрушек. Рост популярности AI-игрушек стимулирует спрос на низкопотребляющие, высокоинтегрированные AI-чипы и модули (источник: 36Kr)
Прогресс применения AI в робототехнике: Промышленный колесный робот Unitree B2-W, гуманоидный робот Fourier GR-1, четвероногий робот DEEP Robotics Lynx и другие демонстрируют прогресс AI в управлении движением роботов, восприятии окружающей среды и выполнении задач. Эти роботы способны адаптироваться к сложной местности, выполнять точные операции и применяться в таких сценариях, как промышленный осмотр, логистика и даже домашнее обслуживание, способствуя повышению уровня интеллектуализации роботов (источник: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Исследования AI в области здравоохранения: Технологии AI применяются в интерфейсах мозг-компьютер для преобразования мозговых волн в текст, предоставляя новые способы общения людям с нарушениями коммуникации. В то же время AI используется для разработки нанороботов для целенаправленного уничтожения раковых клеток. Эти исследования демонстрируют огромный потенциал AI в вспомогательной диагностике, лечении и улучшении качества жизни людей с ограниченными возможностями (источник: Ronald_vanLoon, Ronald_vanLoon)
Технология Deepfake, управляемая AI, становится все более реалистичной: Видео Deepfake, распространяемые в социальных сетях, демонстрируют поразительную степень реализма, вызывая дискуссии о достоверности информации и потенциальных рисках злоупотребления. Хотя технологический прогресс впечатляет, он также подчеркивает необходимость создания обществом эффективных механизмов распознавания и регулирования для противодействия вызовам, которые может принести Deepfake (источник: Teknium1, Reddit r/ChatGPT)
Обсуждение механизма эффективности моделей MLA: Обсуждение причин эффективности MLA (возможно, имеется в виду определенная архитектура или технология модели) предполагает, что ее успех может заключаться в комбинированном дизайне RoPE и NoPE (техники позиционного кодирования), а также в применении больших head_dims и частичного RoPE. Это указывает на то, что детальные компромиссы в дизайне архитектуры модели имеют решающее значение для производительности, и иногда кажущиеся “неэлегантными” комбинации могут давать лучшие результаты (источник: teortaxesTex)

🧰 Инструменты
Promptfoo интегрирует новые функции Google AI Studio Gemini API: Платформа оценки Promptfoo добавила документацию по поддержке новейших функций Google AI Studio Gemini API, включая Grounding с использованием Google Search, мультимодальный Live, цепочку рассуждений (Thinking), вызов функций, структурированный вывод и т.д. Это позволяет разработчикам удобнее использовать Promptfoo для оценки и оптимизации промпт-инжиниринга на основе последних возможностей Gemini (источник: _philschmid)
ThreeAI: Инструмент для сравнения нескольких AI: Разработчик создал инструмент под названием ThreeAI, который позволяет пользователям одновременно задавать вопросы трем разным AI-чат-ботам (например, последним версиям ChatGPT, Claude, Gemini) и сравнивать их ответы. Инструмент предназначен для помощи пользователям в быстром получении более точной информации, выявлении и улавливании галлюцинаций AI. В настоящее время находится на стадии Beta и предлагает ограниченное бесплатное использование (источник: Reddit r/artificial)
OctoTools получает награду за лучшую статью на NAACL: Проект OctoTools получил награду за лучшую статью на воркшопе Knowledge & NLP в рамках NAACL 2025 (Ежегодная конференция Североамериканской ассоциации компьютерной лингвистики). Хотя конкретные функции не были подробно описаны в твите, награда свидетельствует об инновационности и важной ценности этого инструмента в области обработки естественного языка, основанной на знаниях (источник: lupantech)

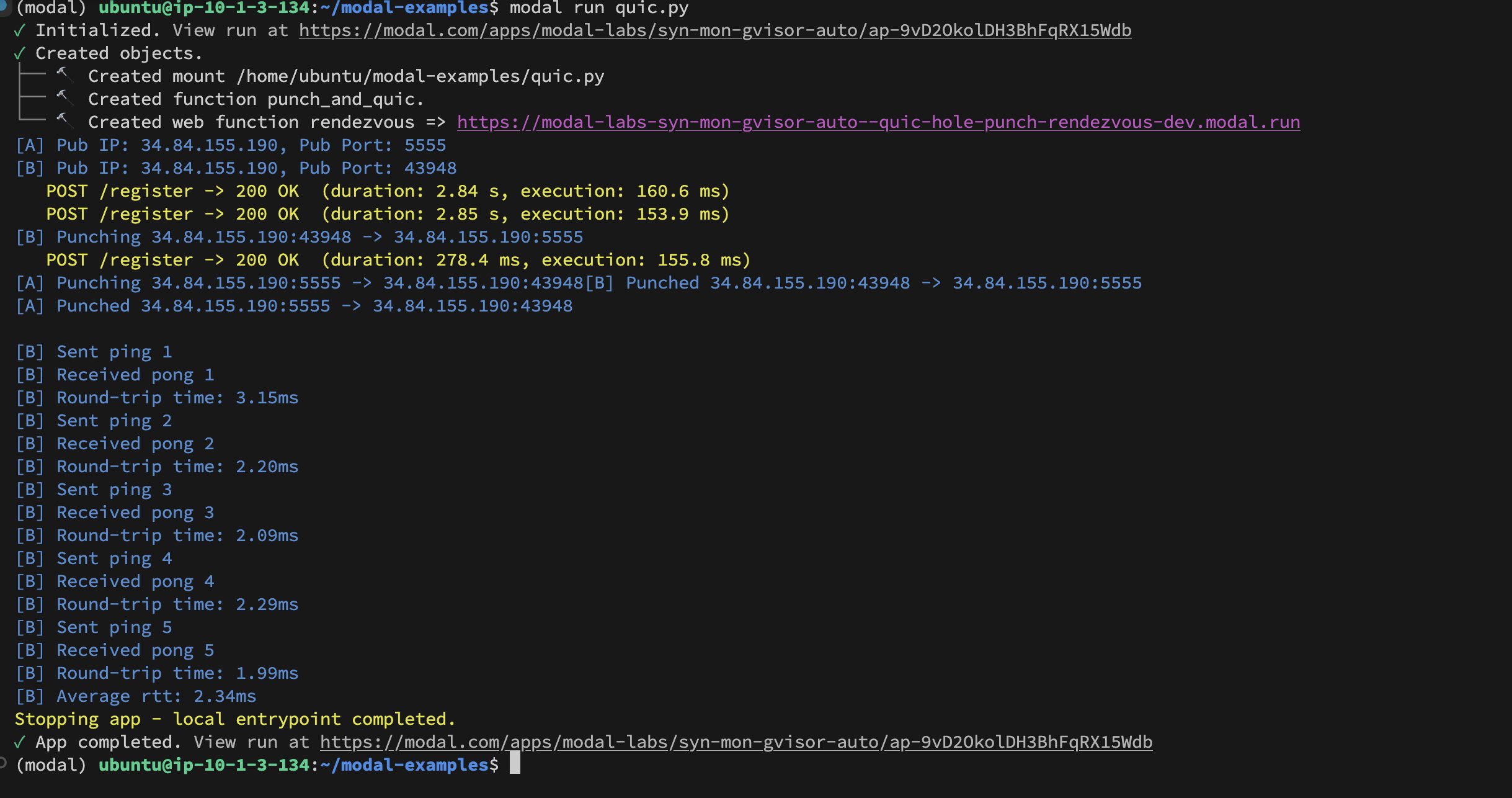
Реализация UDP Hole-Punching между контейнерами Modal Labs: Разработчик Akshat Bubna успешно реализовал установление соединения QUIC между двумя контейнерами Modal Labs с помощью технологии UDP Hole-Punching. Теоретически это можно использовать для подключения не-Modal сервисов к GPU для инференса с низкой задержкой, избегая сложности WebRTC, что демонстрирует новые идеи в развертывании распределенного AI-инференса (источник: charles_irl)
📚 Обучение
Учебное пособие по обучению доменно-специфических моделей (Qwen Scheduler): Отличная статья-руководство подробно описывает, как использовать GRPO (Group Relative Policy Optimization) для дообучения модели Qwen2.5-Coder-7B с целью создания большой модели, специально предназначенной для генерации расписаний. Автор не только предоставил подробные шаги руководства, но и выложил в открытый доступ соответствующий код и обученную модель (qwen-scheduler-7b-grpo), предоставив ценный практический пример и ресурсы для изучения того, как обучать и дообучать доменно-специфические модели (источник: karminski3)

Важность промежуточных шагов рассуждений LLM: Новая статья «LLMs are only as good as their weakest link!» указывает, что при оценке способности LLM к рассуждениям не следует смотреть только на конечный ответ, промежуточные шаги также содержат важную информацию и могут быть даже более надежными, чем конечный результат. Исследование подчеркивает потенциал анализа и использования промежуточных состояний процесса рассуждений LLM, бросая вызов традиционным методам оценки, основанным исключительно на конечном выводе (источник: _akhaliq)
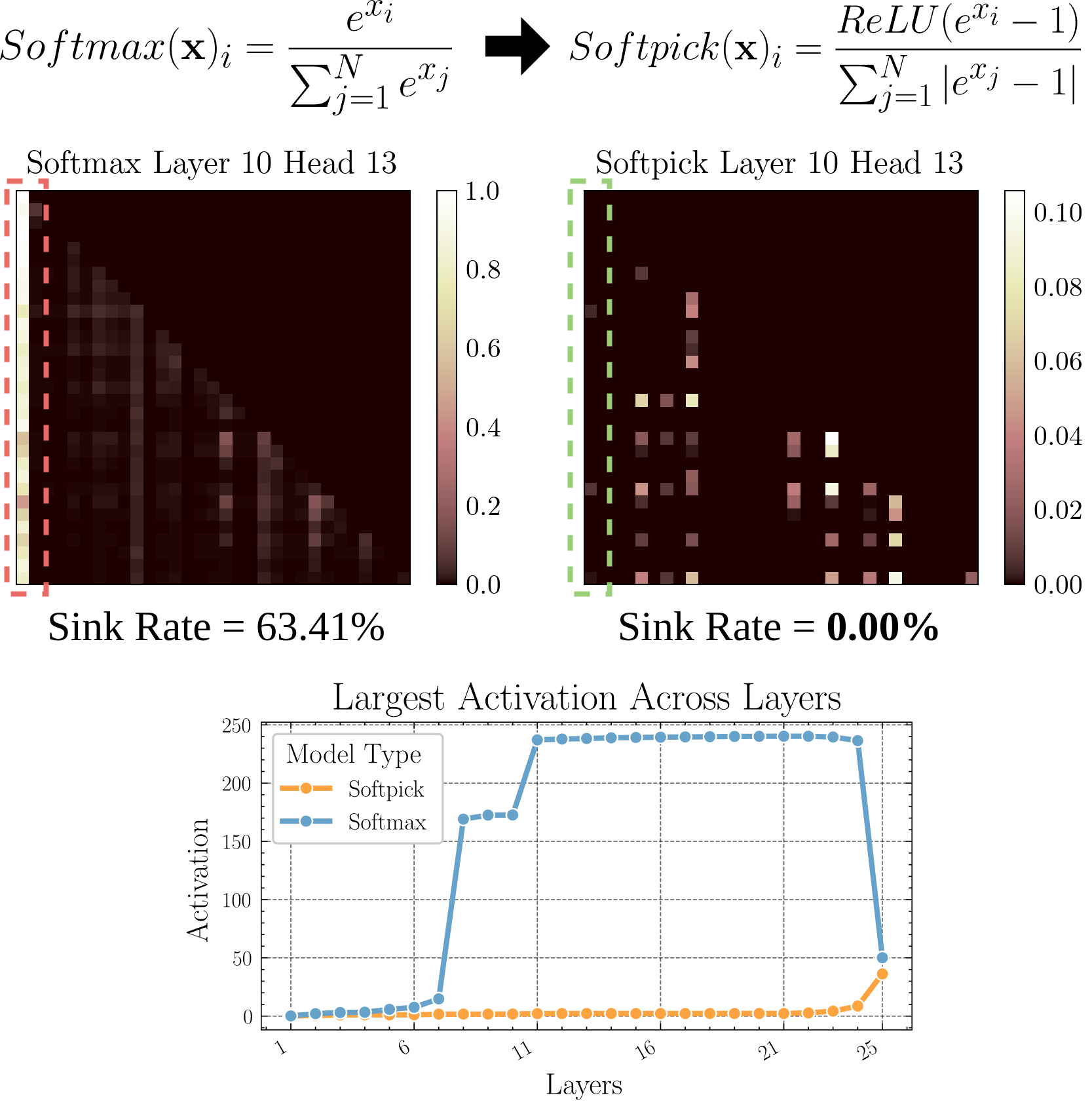
Softpick: Альтернатива Softmax для решения проблемы Attention Sink: В препринте предложен метод Softpick, использующий Rectified Softmax вместо традиционного Softmax, с целью решения проблемы Attention Sink (концентрация внимания на небольшом количестве токенов) и проблемы чрезмерно больших значений активации скрытых состояний. Это исследование изучает альтернативы механизму внимания, которые могут помочь повысить эффективность и производительность модели, особенно при обработке длинных последовательностей (источник: arohan)
Использование синтетических данных для исследования архитектуры моделей: Исследование Zeyuan Allen-Zhu и др. показывает, что при реальных масштабах данных предварительного обучения (например, 100 млрд токенов) различия между разными архитектурами моделей могут быть скрыты шумом. В то время как использование высококачественной синтетической “песочницы” данных позволяет более четко выявить тенденции производительности, обусловленные различиями в архитектуре (например, удвоение глубины инференса), раньше наблюдать появление продвинутых способностей и, возможно, предсказывать будущие направления дизайна моделей. Это говорит о том, что высококачественные, структурированные данные имеют решающее значение для глубокого понимания и сравнения архитектур LLM (источник: teortaxesTex)
Достижение выравнивания с персонализированными предпочтениями пользователя через RLHF: В сообществе предложено, что можно использовать обучение с подкреплением на основе отзывов человека (RLHF) для выравнивания модели под разные прототипы пользователей (archetypes), а затем, после определения, к какому прототипу принадлежит конкретный пользователь, использовать методы, подобные SLERP (сферическая линейная интерполяция), для смешивания или корректировки поведения модели, чтобы лучше удовлетворять персонализированные предпочтения этого пользователя. Это предлагает возможные подходы к обучению для создания более персонализированных AI-помощников (источник: jd_pressman)
🌟 Сообщество
Критика текущего стека программного обеспечения ML: В сообществе разработчиков появляются жалобы на хрупкость текущего стека программного обеспечения для машинного обучения, который сравнивают по хрупкости и сложности обслуживания с использованием перфокарт, несмотря на то, что технология AI уже не является нишевой или находящейся на самой ранней стадии. Критики отмечают, что даже при относительно унифицированной аппаратной архитектуре (в основном GPU Nvidia) программный уровень по-прежнему лишен надежности и простоты использования, и даже оправдание “слишком быстрой итерацией технологий” не выдерживает критики (источник: Dorialexander, lateinteraction)
Обсуждение избирательного поведения пользователей при предоставлении обратной связи моделям AI: Сообщество заметило, что когда AI, такие как ChatGPT, предлагают два варианта ответа и просят пользователя выбрать лучший, многие пользователи не читают и не сравнивают оба варианта внимательно. Это вызвало дискуссию об эффективности такого механизма обратной связи. Существует мнение, что такая модель поведения делает RLHF на основе сравнения текстов малоэффективным, в то время как оценка качества генерации изображений (например, в Midjourney) более интуитивна, и обратная связь может быть более эффективной. Также было предложено изменить подход: позволить пользователям выбирать “какое направление интереснее” и просить AI развить его, как альтернативный способ обратной связи (источник: wordgrammer, Teknium1, finbarrtimbers, scaling01)
Ограничения AI в копировании способностей экспертов: В обсуждении отмечается, что преобразование записей прямых трансляций эксперта в текст и передача их AI (обычно через RAG), хотя и позволяет AI отвечать на вопросы, которые обсуждал эксперт, не может полностью “скопировать” способности эксперта. Эксперт может гибко реагировать на новые проблемы, основываясь на глубоком понимании и опыте, в то время как AI в основном полагается на поиск и соединение существующей информации, испытывая недостаток в истинном понимании и творческом мышлении. Преимущества AI заключаются в быстром поиске и широте знаний, но в глубине и гибкости все еще существует разрыв (источник: dotey)
Принятие AI-контента в сообществах: Пользователь поделился опытом блокировки в сообществе с открытым исходным кодом за публикацию контента, сгенерированного LLM, что вызвало дискуссию о терпимости сообществ к AI-контенту. Многие сообщества (например, сабреддиты на Reddit) относятся к AI-контенту с осторожностью или даже враждебностью, опасаясь, что его распространение приведет к снижению качества информации или заменит человеческое взаимодействие. Это отражает проблемы и конфликты, возникающие при интеграции технологий AI в существующие нормы сообщества (источник: Reddit r/ArtificialInteligence)
Функция Claude Deep Research получает положительные отзывы: Пользователи сообщают, что функция Claude Deep Research от Anthropic превосходит другие инструменты (включая OpenAI DR и обычный o3) при проведении углубленных исследований при наличии определенной базы знаний. Она может предоставлять нетривиальные, точные и новые идеи, а также информацию, неизвестную пользователю. Однако для изучения новой области с нуля OAI DR и vanilla o3 сравнимы с Claude DR (источник: hrishioa, hrishioa)

“Странное” поведение AI-чат-ботов: Пользователи Reddit поделились опытом взаимодействия с Instagram AI (AI в виде чашки) и Yahoo Mail AI. Instagram AI демонстрировал странное флиртующее поведение, а Yahoo Mail AI предоставил длинное и совершенно неверное “резюме” простого письма с расписанием, что привело к недоразумению. Эти случаи показывают, что некоторые текущие AI-приложения все еще имеют проблемы с пониманием и взаимодействием, иногда приводя к запутанным или даже неприятным результатам (источник: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Обсуждение сознания AI: Сообщество продолжает обсуждать, как определить, обладает ли AI сознанием. Учитывая, что наше собственное понимание человеческого сознания неполно, судить о сознании машины чрезвычайно сложно. Некоторые ссылаются на исследования Anthropic внутренних “мыслительных” процессов Claude, указывая, что AI может обладать неожиданными для нас внутренними представлениями и способностями к планированию. В то же время, существует мнение, что AI необходимо обладать самомотивированным, не требующим явных инструкций “свободным мышлением”, чтобы потенциально развить сознание, подобное человеческому (источник: Reddit r/ArtificialInteligence)
Обмен опытом использования моделей Qwen3: Пользователи сообщества делятся первыми впечатлениями от использования моделей серии Qwen3 (особенно версий 30B и 32B). Некоторые пользователи считают, что они отлично и быстро работают в таких задачах, как RAG, генерация кода (при отключенном thinking), но другие сообщают о плохой производительности или уступках моделям вроде Gemma 3 в конкретных случаях использования (например, строгое следование формату, создание художественной литературы). Это указывает на возможное расхождение между высокими оценками модели в бенчмарках и ее производительностью в конкретных сценариях применения (источник: Reddit r/LocalLLaMA)
💡 Прочее
Размышления о ценности AI-контента: Член сообщества NandoDF предполагает, что, хотя AI уже сгенерировал огромное количество текста, изображений, аудио и видео, похоже, он еще не создал по-настоящему ценных произведений искусства (таких как песни, книги, фильмы), которые стоило бы пересматривать. Он признает практическую ценность некоторого AI-контента (например, математических доказательств), но это вызывает размышления о текущих способностях AI в создании глубокой, долговременной ценности (источник: NandoDF)
AI и персонализация: Suhail подчеркивает, что AI, лишенный контекстной информации о личной жизни, работе, целях пользователя и т.д., имеет ограниченный интеллект. Он предвидит появление в будущем множества компаний, специализирующихся на создании AI-приложений, способных использовать личный контекст пользователя для предоставления более интеллектуальных услуг (источник: Suhail)
Влияние AI на внимание: Пользователь заметил, что по мере увеличения длины контекста LLM способность людей читать длинные абзацы, похоже, снижается, наблюдается тенденция “все можно TLDR”. Это вызывает размышления о том, как распространение инструментов AI может подсознательно влиять на когнитивные привычки человека (источник: cloneofsimo)