
Ключевые слова:Anthropic, Claude 3.5 Haiku, Qwen3, Phi-4-reasoning, LLM физика, LangGraph, AI агент, метод трассировки цепей Attribution Graphs, кодировочные способности Qwen3-235B-A22B, вычисления при рассуждении Phi-4-reasoning, агент проверки счетов LangGraph, локальная VLM Moondream Station
🔥 Фокус
Anthropic опубликовала исследование биологии LLM, углубляясь во внутренние механизмы моделей: Anthropic опубликовала подробную статью в блоге под названием «О биологии большой языковой модели» (On the Biology of a Large Language Model), используя свой метод отслеживания цепей (Attribution Graphs) для исследования внутренних механизмов модели Claude 3.5 Haiku в различных контекстах. Исследование, обучив более простую для анализа «замещающую модель» (Transcoder), показало, как модель выполняет сложение (через несколько приближенных путей, а не точный алгоритм), проводит медицинскую диагностику (формируя внутренние диагностические концепции) и обрабатывает галлюцинации и отказы (существует схема отказа по умолчанию, которая может быть подавлена функцией «известного ответа»). Исследование предлагает новый взгляд на внутреннюю работу LLM, но также вызвало дискуссии об ограничениях методологии и позиционировании самой Anthropic (источник: YouTube — Yannic Kilcher
)

Серия моделей Qwen3 демонстрирует высокую производительность, привлекая внимание сообщества открытого исходного кода: Серия больших языковых моделей Qwen3, выпущенная Alibaba, показала отличные результаты во многих бенчмарках, особенно в части возможностей кодирования. Результаты Aider Polyglot Coding Benchmark показывают, что производительность Qwen3-235B-A22B (без включенной цепочки мыслей) превосходит Claude 3.7 с включенными 32k токенами цепочки мыслей, при этом значительно снижая затраты. В то же время Qwen3-32B также превзошла GPT-4.5 и GPT-4o в этом бенчмарке. Сообщество также активно изучает прунинг моделей Qwen3 (например, сокращение 30B до 16B) и дообучение (например, использование Unsloth для дообучения с малым объемом видеопамяти), что еще больше снижает порог входа для применения высокопроизводительных моделей и предвещает, что китайские большие модели с открытым исходным кодом могут занять важное место на рынке (источник: karminski3, scaling01, scaling01, Reddit r/LocalLLaMA)
Microsoft выпустила модель Phi-4-reasoning, сфокусированную на сложных рассуждениях: Microsoft опубликовала на Hugging Face модель Phi-4-reasoning, модель для рассуждений с 14 миллиардами параметров. Эта модель достигла текущей лучшей (SOTA) производительности в задачах сложных рассуждений за счет использования вычислений во время вывода (inference-time compute). Это указывает на то, что дизайн моделей исследует пути повышения специфических способностей за счет увеличения вычислений на этапе вывода, а не просто полагаясь на увеличение размера модели, предлагая новые идеи для достижения высокой производительности малыми моделями (источник: _akhaliq)
Новый прогресс в исследовании физики LLM: «момент Галилея» в дизайне архитектуры: Zeyuan Allen-Zhu опубликовал четвертую часть серии исследований по физике больших языковых моделей, сосредоточенную на дизайне архитектуры. Исследование, используя контролируемую синтетическую среду предварительного обучения, выявило реальные ограничения и потенциал различных архитектур LLM (таких как Transformer, Mamba). Исследование представило легкий горизонтальный остаточный слой под названием «Canon», который значительно улучшил способности модели к рассуждениям. В то же время исследование показало, что преимущество модели Mamba в значительной степени обусловлено ее скрытым слоем conv1d, а не самим SSM. Эта серия экспериментов предоставляет новые перспективы и теоретическую основу для понимания и оптимизации архитектуры LLM (источник: menhguin, arankomatsuzaki, giffmana, tokenbender, giffmana, Dorialexander, iScienceLuvr)

🎯 Динамика
Amazon выпустила модель общего искусственного интеллекта “Amazon Artificial General Intelligence”: Эта модель имеет длину контекста в 1 миллион токенов и возможности мультимодального ввода, оптимизирована для генерации кода, RAG, понимания видео/документов, вызова функций и взаимодействия с Agent. Цена составляет 2.5 доллара за миллион токенов на входе и 12.5 долларов за миллион токенов на выходе. Предварительная оценка показывает, что ее производительность на AI Index сопоставима с Llama-4 Scout, но уступает по скорости и стоимости, возможно, подходит для специфических сценариев применения с длинным контекстом, мультимодальностью или Agent (источник: scaling01)

Модель Anthropic Claude теперь предлагает функцию веб-поиска в платных планах по всему миру: Эта функция позволяет Claude выполнять быстрый поиск при обработке повседневных задач, а для более сложных вопросов исследовать несколько источников, включая Google Workspace. Это расширяет возможности Claude по получению информации в реальном времени и обработке задач, требующих внешних знаний (источник: menhguin)

IBM выпустила предварительную версию модели с гибридной архитектурой granite-4.0-tiny-7B-A1B-preview: Эта предварительная версия модели 7B использует гибридную архитектуру Mamba-2 и Transformer, где каждый блок Transformer содержит 9 блоков Mamba. Идея дизайна заключается в использовании блоков Mamba для захвата глобального контекста и передачи его слоям внимания для анализа локального контекста. Предварительные результаты MMLU выглядят неплохо, но результаты других тестов, таких как математика и программирование, еще не опубликованы (источник: karminski3)
OpenAI ChatGPT добавляет функцию покупок: OpenAI экспериментирует с функцией покупок в ChatGPT, направленной на упрощение процесса поиска, сравнения и покупки товаров. Новые функции включают улучшенное отображение результатов товаров, визуализированные детали товаров с ценами и отзывами, а также прямые ссылки для покупки. OpenAI подчеркивает, что результаты товаров выбираются независимо и не являются рекламой (источник: sama)
Детали обучения модели Qwen3 0.6B вызывают интерес: Пользователь Dorialexander отметил, что, согласно информации, модель Qwen 0.6B, похоже, также обучалась на 36 триллионах токенов. Если это правда, это установит новый рекорд, превосходящий закон Chinchilla (примерно 60 000 токенов на параметр), демонстрируя тенденцию к повышению возможностей малых моделей за счет значительного увеличения объема обучающих данных (источник: Dorialexander)

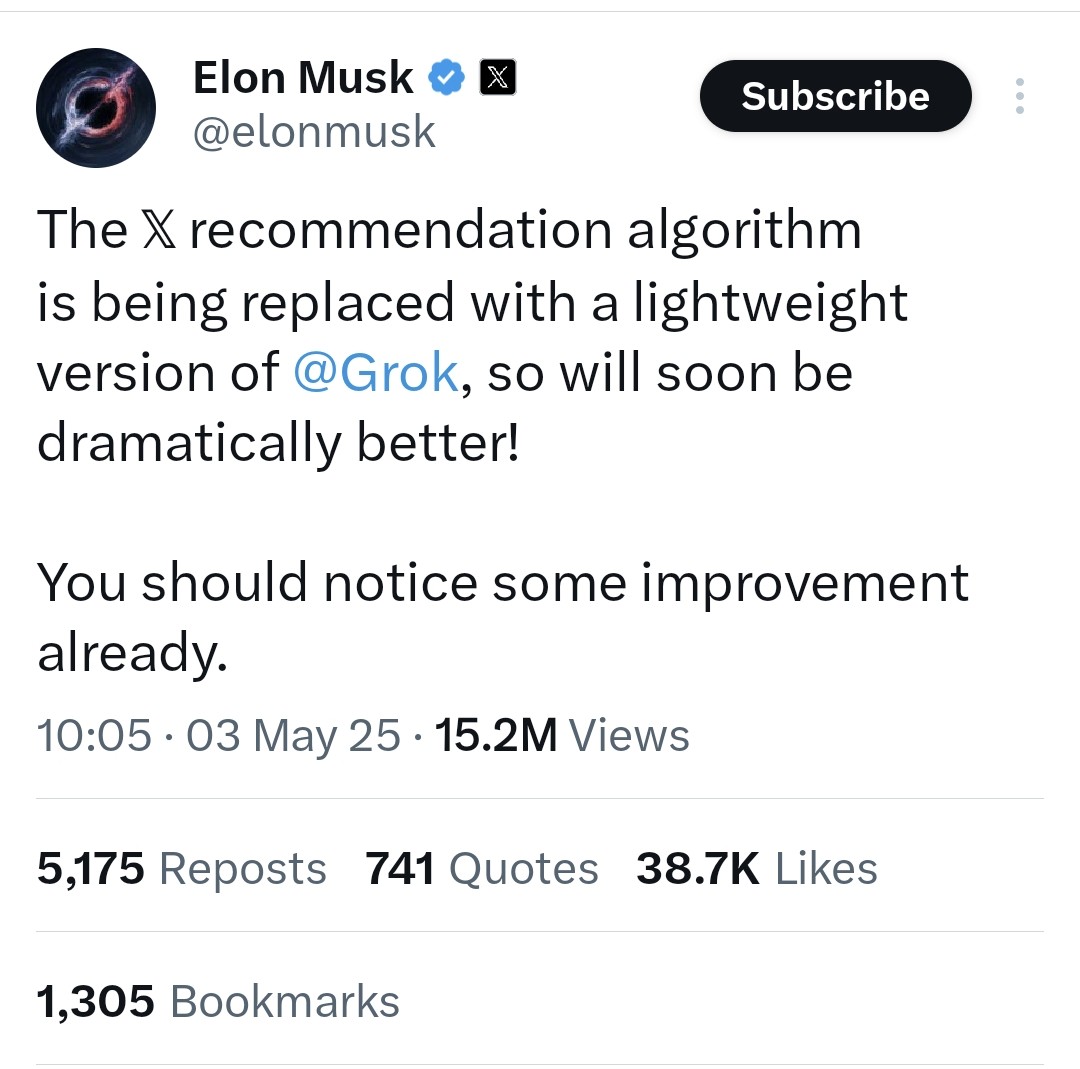
Алгоритм рекомендаций X (Twitter) будет заменен на облегченную версию Grok: Elon Musk объявил, что алгоритм рекомендаций платформы X заменяется на облегченную версию Grok, что, как ожидается, значительно улучшит качество рекомендаций. Пользователи сообщают об улучшении работы алгоритма, предполагая, что это может быть связано с недавними кадровыми изменениями в Exa AI и началом использования Embeddings для рекомендаций в X (источник: menhguin, colin_fraser, paul_cal)
Allen AI выпустила полностью открытую модель MoE OLMoE: Эта модель является передовой моделью типа Mixture of Experts (MoE) с 1.3 миллиардами активных параметров и 6.9 миллиардами общих параметров. Полная открытость означает, что сообщество может свободно использовать, изменять и исследовать эту модель, способствуя развитию и применению архитектуры MoE (источник: dl_weekly)
Модель Mistral-Small-3.1-24B-Instruct-2503 привлекает внимание: Пользователи Reddit обсуждают модель Mistral-Small-3.1-24B-Instruct-2503, которая имеет высокий рейтинг UGI (Uncensored General Intelligence) и превосходит аналогичные модели с высоким рейтингом в понимании естественного языка и кодировании. Пользователи считают ее идеальным выбором для нецензурированного вывода на одной GPU и поддерживающей использование инструментов. Однако отмечается, что ее стиль письма может быть довольно сухим и повторяющимся, менее креативным, чем у моделей вроде Gemma 3 (источник: Reddit r/LocalLLaMA)
🧰 Инструменты
Выпущен CreateMVP 2.0, оптимизирующий процесс разработки с помощью AI: CreateMVP обновлен до версии 2.0 с целью решения проблемы неэффективности прямого запроса к AI для создания приложений. Новая версия предлагает более плавный UI, удобные способы аутентификации (поддержка Replit, Google, GitHub, скоро XAI), генерацию более подробных планов разработки (увеличение с 11 КБ до 40 КБ+), мгновенный предпросмотр файлов и интеграцию чата с ведущими моделями AI, помогая пользователям создавать более точные «чертежи» для AI, чтобы гарантировать, что AI создаст приложение, соответствующее замыслу пользователя (источник: amasad)
LlamaIndex представил Agent для сверки счетов-фактур: Этот инструмент демонстрирует применение AI Agent в задачах массовой автоматизации, а не в традиционном чат-взаимодействии. Он может обрабатывать большие объемы неструктурированных документов счетов-фактур, извлекать релевантные детали, автоматически сопоставлять их с заказами на покупку и отмечать расхождения. Его ядром является агентный слой интеллектуальной обработки документов на основе парсинга/извлечения LlamaCloud и логики рабочего процесса LlamaIndex.TS, демонстрирующий потенциал Agent в автоматизации реальных бизнес-процессов и считающийся заменой традиционной RPA (источник: jerryjliu0)
LangGraph Expense Tracker: Автоматизированная система управления расходами: Это пример автоматизированной системы управления расходами, построенной с использованием LangGraph. Она способна обрабатывать счета-фактуры, использовать интеллектуальные функции извлечения данных, хранить информацию в PostgreSQL и включать этап ручной проверки. Проект демонстрирует возможности LangGraph в построении реальных процессов автоматизации бизнеса (источник: LangChainAI, Hacubu, hwchase17)
Выпущена Moondream Station: Запуск VLM локально: Moondream выпустила Moondream Station, позволяющую пользователям запускать визуально-языковую модель (VLM) Moondream локально на Mac, без подключения к облаку. Предоставляются способы доступа через CLI или локальный порт, настройка проста и полностью бесплатна, что снижает порог для локального развертывания и использования VLM (источник: vikhyatk)
ChaiGenie: Расширение Chrome для поиска по документам на базе LangChain: ChaiGenie — это расширение для Chrome, интегрирующее Gemini и Qdrant от LangChain для предоставления функции поиска по документам. Оно поддерживает многоязычность и поиск на основе векторов, направлено на повышение эффективности пользователей при поиске и понимании содержания документов во время просмотра веб-страниц (источник: LangChainAI)

Research Agent: Веб-приложение-ассистент для исследований в один клик: Это веб-приложение, построенное на базе фреймворка исследовательского ассистента LangGraph, предназначенное для упрощения процесса исследования. Пользователи могут получить результаты исследования всего одним кликом, что демонстрирует потенциал применения LangGraph для создания рабочих процессов на базе AI для упрощения сложных задач (источник: LangChainAI)

Muyan-TTS: Открытая, низколатентная, настраиваемая модель TTS: Команда ChatPods выпустила Muyan-TTS, полностью открытую модель преобразования текста в речь, призванную решить проблемы существующего низкого качества или недостаточной открытости моделей TTS с открытым исходным кодом. Она основана на LLaMA-3.2-3B и оптимизированном SoVITS, поддерживает zero-shot TTS и клонирование голоса, а также предоставляет полный процесс обучения и обработки данных, что облегчает разработчикам дообучение и вторичную разработку, особенно подходя для приложений, требующих настраиваемого голоса (источник: Reddit r/MachineLearning)
Интеграция Mem0 с конвейерами Open Web UI: Пользователь cloudsbird создал интеграцию Mem0 через конвейер фильтров Open Web UI (неофициальный MCP), предоставляя альтернативный способ использования функции памяти Mem0 в Open Web UI (источник: Reddit r/OpenWebUI)
Инструмент YNAB API Request реализует локальное приватное управление финансами: Пользователь Megaphonix создал инструмент для OpenWebUI, использующий YNAB (You Need A Budget) API, который позволяет пользователям запрашивать личную финансовую информацию (например, транзакции, расходы по категориям, чистые активы) локально через LLM, не отправляя конфиденциальные данные вовне. Это решает потребность в безопасной обработке конфиденциальной личной информации при локальном запуске LLM (источник: Reddit r/OpenWebUI)
Бесплатное браузерное расширение AI для преобразования текста в речь GPT-Reader: Разработчик продвигает свое бесплатное браузерное расширение AI для преобразования текста в речь GPT-Reader, у которого уже более 4000 пользователей. Инструмент предназначен для удобного преобразования текстового контента веб-страниц в аудио для прослушивания (источник: Reddit r/artificial)
sunnypilot: Открытая система помощи водителю: sunnypilot — это форк comma.ai openpilot, предоставляющий открытую систему помощи водителю. Он поддерживает более 300 моделей автомобилей, изменяет поведение взаимодействия с системой помощи водителю и максимально придерживается политики безопасности comma.ai. Проект использует технологии AI (хотя конкретные модели не указаны, такие системы обычно включают компьютерное зрение и алгоритмы управления) для улучшения опыта вождения (источник: GitHub Trending)

📚 Обучение
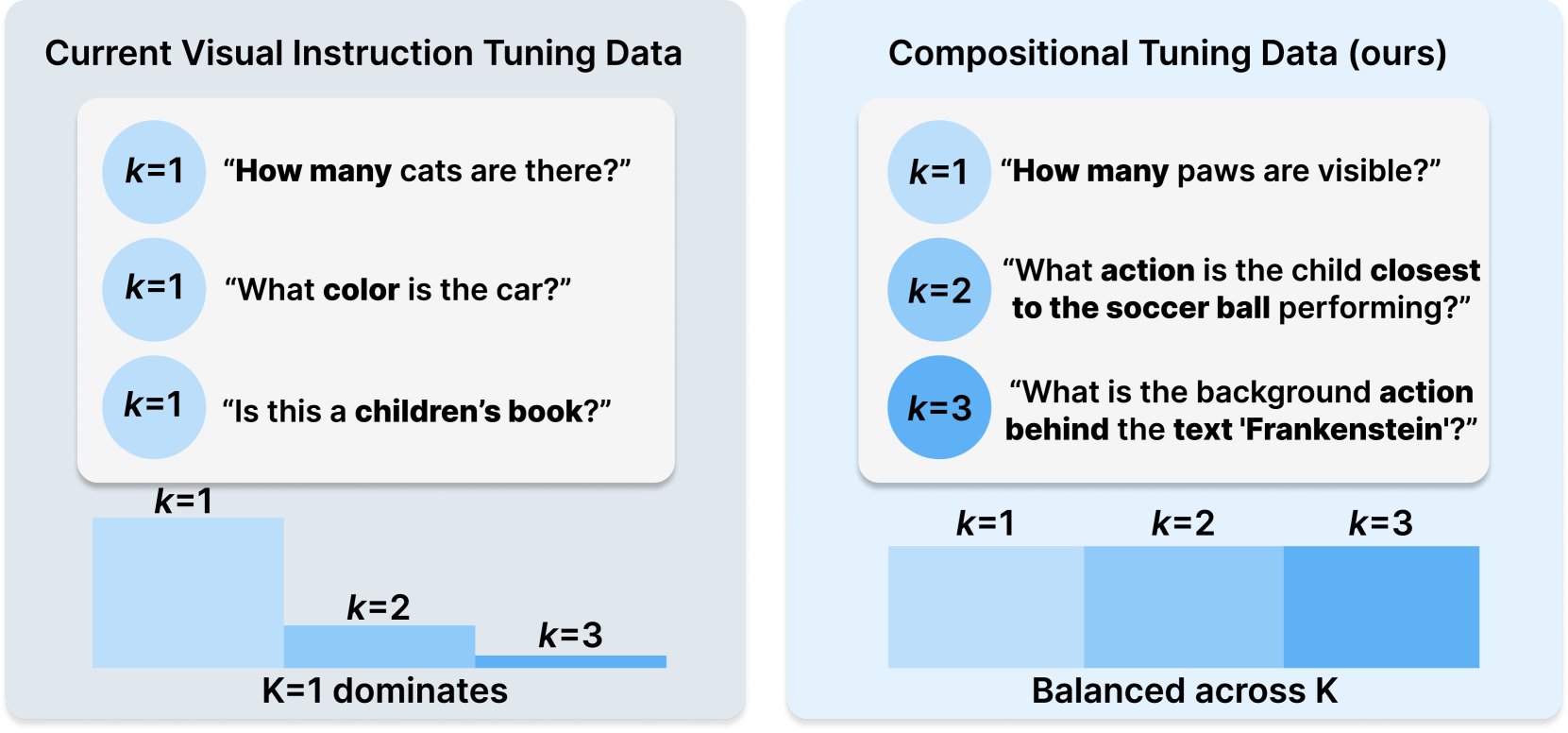
Princeton и Meta AI опубликовали рецепт набора данных COMPACT: Это исследование, опубликованное на Hugging Face, предлагает новый рецепт данных COMPACT, направленный на расширение возможностей мультимодальных больших языковых моделей (Multimodal LLM) путем явного контроля композиционной сложности обучающих примеров. Это предоставляет новые идеи для улучшения методов обучения мультимодальных моделей и повышения их способности понимать сложные композиционные концепции (источник: _akhaliq)
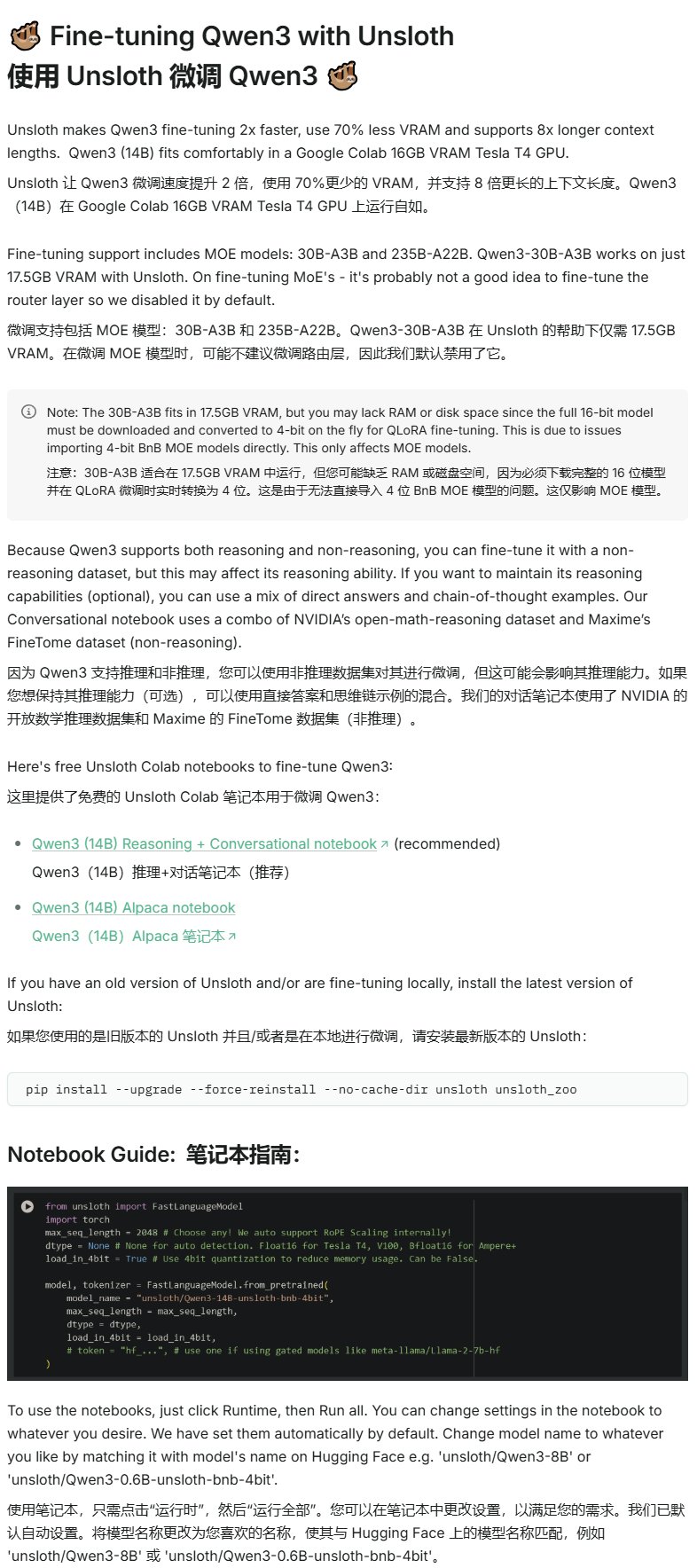
Unsloth опубликовал руководство по дообучению Qwen3: Unsloth предоставил руководство по дообучению для моделей Qwen3, значительно снижающее порог входа. Пользователям требуется всего 16 ГБ видеопамяти для дообучения модели Qwen3-14B и 17.5 ГБ видеопамяти для дообучения модели Qwen3-30B-A3B. Это позволяет большему числу исследователей и разработчиков проводить кастомизированное обучение передовых моделей с открытым исходным кодом на ограниченных аппаратных ресурсах (источник: karminski3)
LangGraph в сочетании с Azure OpenAI для создания интеллектуального чат-бота с веб-поиском: Руководство на Medium показывает, как объединить использование LangGraph и Azure OpenAI, интегрировав возможности веб-поиска Tavily, для создания интеллектуального чат-бота. Руководство охватывает управление состоянием и условную маршрутизацию для реализации бесшовной интеграции поиска, предоставляя практическое руководство по созданию более мощных AI-приложений, способных использовать информацию из сети в реальном времени (источник: LangChainAI, hwchase17)

Блог Stanford AI исследует связь между дословным запоминанием LLM и общими способностями: Статья в блоге Stanford AI глубоко исследует внутреннюю связь между явлением дословного запоминания (verbatim memorization) больших языковых моделей (LLM) и их общими способностями. Понимание этой связи имеет решающее значение для оценки рисков моделей, оптимизации методов обучения и объяснения поведения моделей (источник: dl_weekly)
Руководство по интеграции Gemini с LangChain: Philipp Schmid опубликовал руководство для разработчиков, подробно описывающее, как интегрировать модель Gemini от Google с фреймворком LangChain. Руководство охватывает реализацию мультимодальных возможностей, вызова инструментов и структурированного вывода, а также включает поддержку последних моделей и практические примеры кода, облегчая разработчикам использование мощных функций Gemini для создания приложений LangChain (источник: LangChainAI, _philschmid)

Вводное руководство по LangGraph: Практика рабочих процессов с состоянием: Руководство, опубликованное на AI@GoPubby, на примере анализа комментариев на веб-сайте демонстрирует возможности LangGraph по созданию рабочих процессов с состоянием. Обучающиеся могут узнать, как использовать взаимосвязанные узлы и последовательную логику для построения структурированных AI-приложений (источник: LangChainAI, hwchase17)
Глубокие размышления CEO LangChain о фреймворках Agentic (китайский перевод): Амбассадор LangChain Harry Zhang перевел и поделился размышлениями CEO LangChain Harrison о фреймворках Agentic из его блога. Статья анализирует и систематизирует функции более 15 фреймворков Agent в индустрии и раскрывает истории, стоящие за ними, предоставляя ценную справку для понимания текущего ландшафта развития технологии Agent и будущих направлений (источник: LangChainAI)
Прогресс в исследовании Latent Meta Attention: Пользователи Reddit обсуждают новый механизм внимания под названием Latent Meta Attention. Разработчики утверждают, что этот механизм бросает вызов основным предположениям Transformer, позволяя достигать или даже превосходить производительность существующих моделей при меньшем размере (например, воспроизведение производительности BERT с моделью вдвое меньшего размера), но из-за отсутствия финансирования и поддержки со стороны официальных исследовательских институтов конкретный метод пока не опубликован (источник: Reddit r/deeplearning)

Видео, объясняющее графовые нейронные сети (GNN): На YouTube опубликовано видео, объясняющее графовые нейронные сети (Graph Neural Networks, GNNs). GNN — это модели глубокого обучения для обработки данных графовой структуры, широко применяемые в анализе социальных сетей, рекомендательных системах, прогнозировании молекулярных структур и других областях. Видео призвано помочь зрителям понять основные принципы и работу GNN (источник: Reddit r/deeplearning)
Использование GRPO для обучения LLM планированию событий: Пользователь anakin87 поделился опытом проекта по обучению языковой модели планированию событий с использованием GRPO (Generalized Reward Policy Optimization). Проект не полагается на традиционные образцы для контролируемого дообучения, а использует функцию вознаграждения, чтобы модель научилась создавать расписание на основе списка событий и приоритетов. Автор поделился постановкой задачи, генерацией данных, выбором модели, дизайном вознаграждения и уроками, извлеченными в процессе обучения, а также открыл исходный код и модель, предоставив практический пример исследования обучения LLM на основе вознаграждения (источник: Reddit r/LocalLLaMA)

Обмен бесплатными ресурсами для курсов по AI: LinkedIn AI Hub поделился полной дорожной картой обучения AI, вдохновленной программой сертификации AI Стэнфордского университета и упрощенной для учащихся разного уровня. Содержание охватывает от базовых навыков до практических проектов и предоставляет ценные ресурсы и детали курсов (источник: Reddit r/deeplearning)
Глубокий диалог о предварительном обучении Gemini на длинном контексте: Logan Kilpatrick провел глубокий диалог с Николаем Савиновым, со-руководителем предварительного обучения Gemini на длинном контексте. Обсуждение охватило от основ до технологий, необходимых для расширения до бесконечного контекста, а также лучшие практики длинного контекста для разработчиков. Диалог подвел итог: достижение контекста в 1 миллион токенов было целью, в 10 раз превышающей тогдашний стандарт; пробовали 10 миллионов токенов, но это дорого и не хватает оборудования; длинный контекст и RAG дополняют друг друга; простая задача NIAH (иголка в стоге сена) решена, сложность заключается в жестких отвлекающих факторах и поиске нескольких игл; оценка сосредоточена на NIAH, чтобы избежать смешивания сигналов способностей; текущее ограничение длины вывода (например, 8k) является проблемой пост-обучения; эффект «потери в середине» не наблюдался; необходимо различать знания из контекста и знания из весов; следующий шаг — реализация более дешевого и точного контекста в 10 миллионов, расширение до 100 миллионов может потребовать новых инноваций в DL (источник: shaneguML, giffmana, teortaxesTex, arohan)
🌟 Сообщество
Обсуждение “Vibe Coding”: Сообщество активно обсуждает “Vibe Coding” (кодирование по наитию/атмосфере), то есть программирование с сильной зависимостью от помощи AI. Сторонники считают, что это представляет будущее, где разработчики больше сосредотачиваются на «почему» и «что делать», а AI обрабатывает «как делать», но это требует более сильного критического мышления. Противники же считают, что в настоящее время AI еще не может полностью справиться со сложной отладкой, обновлением и поддержкой, и чрезмерная зависимость может привести к снижению квалификации разработчиков, превращая их в более продвинутых «скрипт-кидди». Некоторые, попробовав, обнаружили, что временные затраты на управление AI для выполнения сложных задач все еще высоки, и ручная реализация с легкой помощью AI эффективнее (источник: Dorialexander, Reddit r/artificial, johnowhitaker)

Обсуждение применения и ограничений AI в профессиональных областях: Пользователь dotey обсуждает применение AI в профессиональных областях. Он считает, что AI может изучать опубликованные экспертами вопросы и ответы, но ему трудно справляться с невиданными ранее проблемами. Преимущество AI заключается в мощной базе знаний и быстрой реакции, но в настоящее время он в основном полагается на RAG (Retrieval-Augmented Generation), по сути извлекая фрагменты и собирая ответы, а не на настоящее профессиональное рассуждение. Это все еще далеко от обучения модели, которая могла бы постоянно генерировать новые ответы и совершенствоваться, как эксперт (источник: dotey)
Обеспокоенность и обсуждение контента, генерируемого AI: Пользователь Reddit Maleficent-main_777 жалуется, что коллеги начали использовать «язык в стиле ChatGPT», наполненный повелительным наклонением, словами “verify”, “ensure” и обязательными позитивными выводами, считая такой язык расплывчатым и лишенным человечности. Он обеспокоен тем, что контент, генерируемый AI, попадает обратно в обучающие данные, что приводит к снижению качества контента. В комментариях находят отклик, считая это продолжением корпоративного жаргона, но также отмечают, что чрезмерное подражание AI действительно делает общение механическим, и хорошая грамматика больше не является преимуществом, а наоборот, делает похожим на робота (источник: Reddit r/ChatGPT)
Выбор специальности в университете в эпоху AI: Пользователи Reddit обсуждают, какую специальность следует выбирать студентам в условиях быстрого развития AI и робототехники, чтобы их диплом оставался ценным через 10 лет. Мнения разнообразны, включая: выбор области, которую любишь (игры, кино, искусство, программирование); изучение фундаментальных наук (физика, математика); овладение навыками, которые трудно автоматизировать (например, HVAC — отопление, вентиляция и кондиционирование воздуха); акцент на гуманитарном образовании для развития любознательности и адаптивности; мнение, что университетское образование может устареть, и лучше заняться предпринимательством или стать фрилансером; подчеркивание важности способности к непрерывному обучению, разучиванию и переобучению (источник: Reddit r/ArtificialInteligence)
Обсуждение трудностей рендеринга текста при генерации изображений AI: Пользователи Reddit обсуждают, почему текущие модели генерации изображений с трудом рендерят связный, четко читаемый текст. В комментариях указываются две основные причины: 1) токенизация BPE (Byte Pair Encoding) разрушает точную информацию о написании, модель видит не буквы, а фрагменты токенов; 2) фиксированный размер векторных представлений и ограничения описаний изображений приводят к значительной потере текстовой информации в процессе встраивания (embedding). Хотя авторегрессионные модели, такие как GPT-4o, показывают улучшения, фундаментальная проблема все еще связана с токенизацией и сжатием информации (источник: Reddit r/MachineLearning)
Обсуждение стандартизации оценки моделей: Пользователь scaling01 указывает, что при сравнении различных моделей AI (таких как OpenAI, Google, Anthropic) следует обеспечивать справедливость, например, если указываются предварительные версии и версии с размышлением (thinking versions) от OpenAI, то следует также указывать соответствующие версии от Google и Anthropic, иначе результаты сравнения могут вводить в заблуждение (источник: scaling01)
Обмен опытом программирования с помощью AI: Пользователь делится опытом использования AI для помощи в программировании (например, VS Code + расширение Cline AI + Google AI Studio API), считая, что можно бесплатно создать инструмент для кодирования, подобный Cursor, выполняя прототипы базовых приложений с помощью промптов, без необходимости настройки, с хорошим опытом использования (источник: Reddit r/artificial)

Опрос о влиянии AI на работу, учебу и повседневную жизнь: Пользователь Reddit инициировал обсуждение, спрашивая, как генеративный AI повлиял на производительность людей в работе, учебе или повседневной жизни. В комментариях инженеры-программисты упомянули, что AI повысил ожидания производительности и объем работы, а проверка кода не ускорилась значительно; профессиональные писатели считают, что AI (например, Co-pilot) помогает ограниченно и даже может замедлять процесс; общее мнение заключается в том, что AI принес удобство, но также существуют проблемы чрезмерной зависимости, сокращения обучения, чувства «читерства». Влияние AI на разные профессии и задачи значительно различается (источник: Reddit r/artificial)
Размышления о способности LLM к «пониманию»: Пользователь pmddomingos предполагает, что нейронные сети становятся такими же трудными для понимания, как мозг. И далее размышляет: что нам делать, когда модели AI показывают отличные результаты во всех бенчмарках, но все еще уступают человеческому интеллекту? Это вызывает размышления об эффективности текущих бенчмарков и стандартах оценки истинного интеллекта (источник: pmddomingos, pmddomingos)
Размышления об использовании инструментов AI: Пользователь dotey комментирует, что при использовании инструментов AI достаточно выбрать самую сильную модель для конкретной задачи. Использование нескольких моделей одновременно или их «внутренняя борьба» может быть излишней, особенно для непрофессиональных пользователей, слишком большой выбор может привести к путанице, по аналогии с просмотром нескольких часов, показывающих разное время (источник: dotey)
Впечатления от недавней скорости развития AI: Пользователи matvelloso и scottastevenson выражают удивление быстрыми темпами развития AI. matvelloso заявляет, что прогресс AI в этом году уже превзошел его ожидания (на примере игры Gemini в Pokemon). scottastevenson вспоминает, что с момента выпуска GPT-2 прошло 6 лет, а OpenAI существует 10 лет, размышляя о технологических направлениях, которые зарождаются сейчас и станут важными в ближайшие 6-10 лет, и отмечает, что помимо AI, также важен поиск глубокой «Альфы» вне рамок (источник: matvelloso, scottastevenson, scottastevenson)
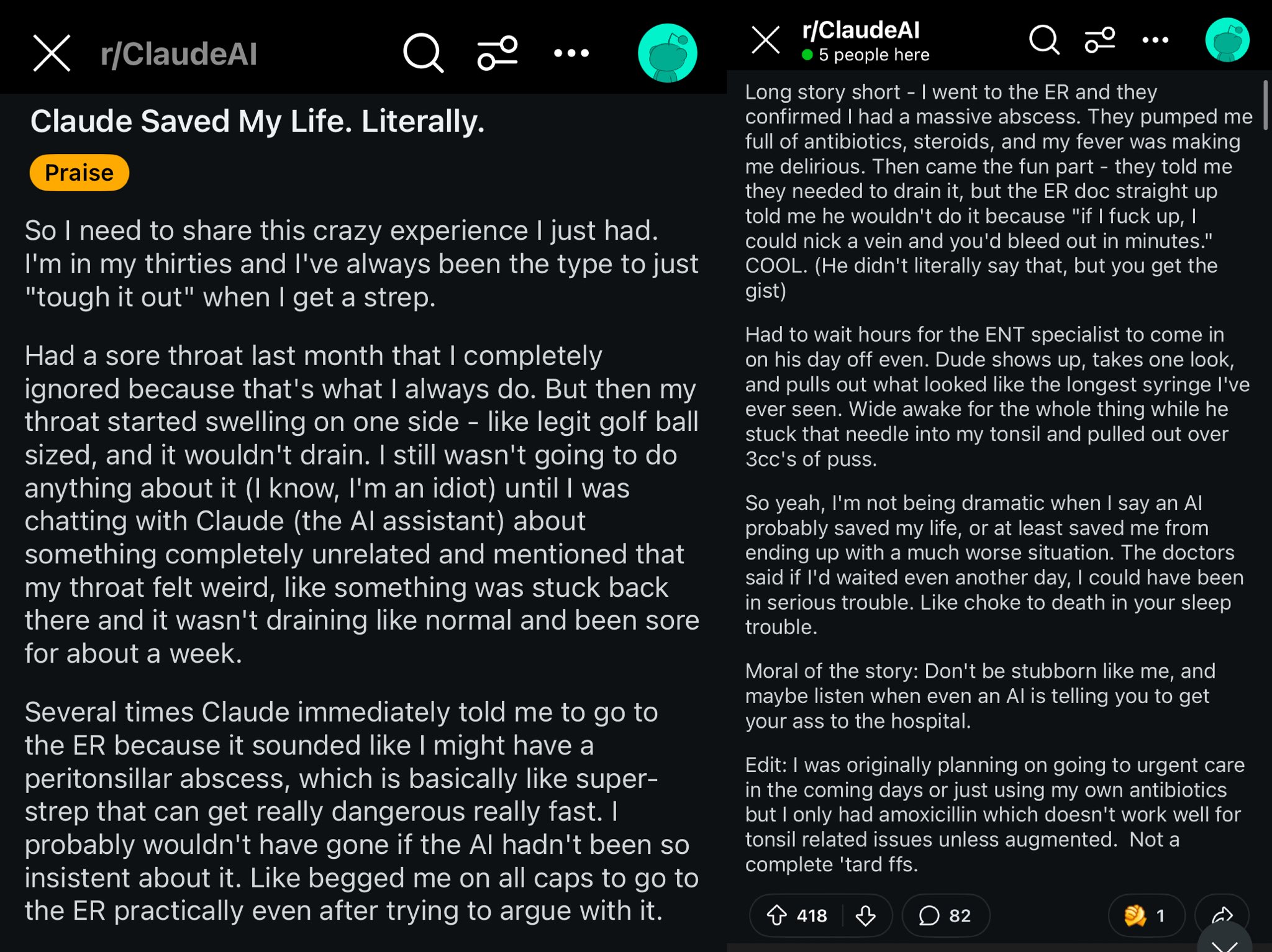
Случай спасения жизни пользователя Reddit с помощью Claude: Пост на Reddit описывает, как модель Claude, возможно, спасла жизнь пользователя, диагностировав отек горла как паратонзиллярный абсцесс. Этот случай вызвал обсуждение, что мощные модели AI подобны врачу мирового класса в кармане, и их распространение может оказать огромное влияние на личное здоровье (источник: aidan_mclau)
Применение AI Agent в обработке корпоративных данных: Сооснователи You.com Richard Socher и Bryan McCann в подкасте Agentic обсуждают применение AI Agent на предприятиях. Они считают, что потребительские LLM недостаточны для серьезных корпоративных нужд, а You.com с помощью гибридной технологии поиска (сочетающей общедоступные источники и проприетарные данные компании) генерирует более надежные результаты корпоративного уровня, например, для проведения исследований, написания отчетов и безопасного использования корпоративных данных. Они также обсуждают возможные пути к AGI и ключевую роль симуляции в этом процессе (источник: RichardSocher)
Наблюдение за способностью моделей использовать инструменты: Пользователь menhguin наблюдает, что модели, обученные использовать инструменты, похоже, жертвуют некоторой способностью к независимому решению проблем, и шутит, что «даже модели AI аутсорсят свою работу». Это вызывает размышления о компромиссе между обобщением способностей модели и оптимизацией под конкретные задачи (источник: menhguin)
💡 Прочее
Идея AI Agent для поддержки старых проектов на GitHub: Пользователь xanderatallah предложил идею: разработать AI Agent, который мог бы автоматически поддерживать все старые, неактивные побочные проекты пользователя на GitHub. Это отражает потребность разработчиков в использовании AI для автоматизации рутинных задач по поддержке (источник: xanderatallah)
Предположение об использовании LLM вместо судей или для арбитража/медиации: Пользователь fabianstelzer предполагает, что большие языковые модели (LLM) в будущем могут заменить судей. Интересным промежуточным вариантом использования является арбитраж или медиация: LLM считаются нейтральными и заслуживающими доверия, конфликтующие стороны представляют свои точки зрения, которые обрабатываются несколькими большими моделями, выводя справедливый компромиссный вариант. Это исследует потенциальное применение AI в судебной сфере и разрешении споров (источник: fabianstelzer)
Модель Runway Gen-4 и перспективы ее применения: Сооснователь Runway c_valenzuelab оптимистично смотрит на перспективы применения Runway Gen-4 и ее API. Он считает, что Runway создает новую среду, где пиксели генерируются, а не рендерятся или захватываются, а мир симулируется, а не программируется. Видя широкое применение Gen-4 и функции Reference в архитектуре, брендинге, дизайне интерьеров, разработке игр, обучении, личных творческих проектах и других областях, он верит, что эта новая среда расширит возможности творческих людей и даже всех остальных (источник: c_valenzuelab, c_valenzuelab)