
Ключевые слова:ChatBot Arena, Phi-4-reasoning, Claude Integrations, AI агенты, DeepSeek-Prover-V2, Qwen3, Gemini, Parakeet-TDT-0.6B-v2, галлюцинации в рейтингах, способности к рассуждению у маленьких моделей, интеграция сторонних приложений, AI агенты для программирования, доказательство математических теорем
🔥 В центре внимания
Рейтинг ChatBot Arena обвиняют в «галлюцинациях» и манипуляциях: В статье на ArXiv [2504.20879] ставится под сомнение широко цитируемый рейтинг моделей ChatBot Arena, утверждая, что он страдает от «иллюзии рейтинга». В статье отмечается, что крупные технологические компании (например, Meta) могут манипулировать рейтингом, отправляя множество вариантов дообученных моделей (например, 27 тестов для Llama-4) и публикуя только лучшие результаты; частота показа моделей также может быть смещена в пользу моделей крупных компаний, уменьшая шансы на показ моделей с открытым исходным кодом; механизм исключения моделей непрозрачен, и многие модели с открытым исходным кодом удаляются при недостаточном количестве тестовых данных; кроме того, сходство часто задаваемых пользователями вопросов может привести к тому, что модели будут целенаправленно переобучаться для повышения баллов. Это вызывает обеспокоенность по поводу надежности и справедливости текущих основных бенчмарков LLM, и рекомендуется разработчикам и пользователям с осторожностью относиться к рейтингам, а также рассмотреть возможность создания систем оценки, соответствующих их собственным потребностям. (Источник: karminski3, op7418, TheRundownAI)
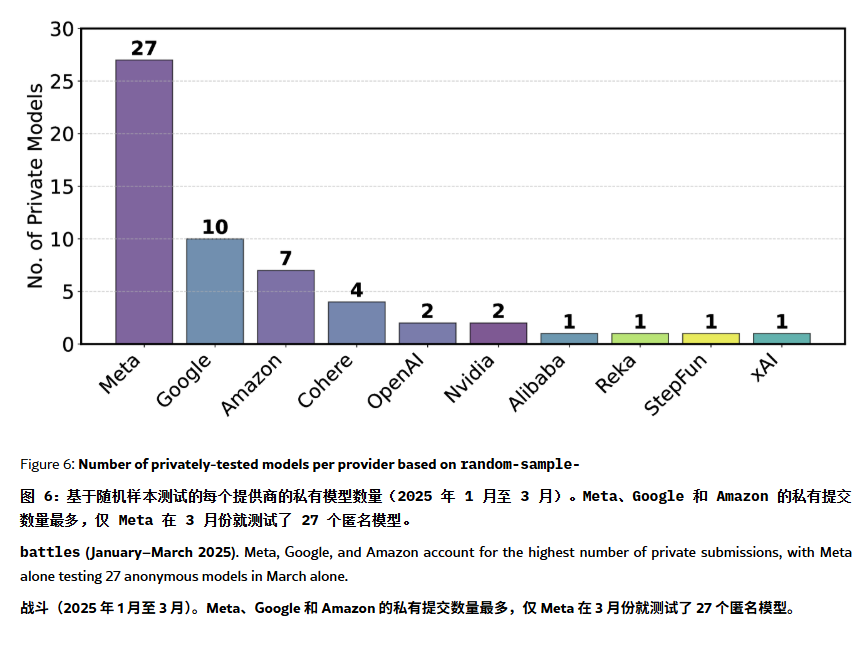
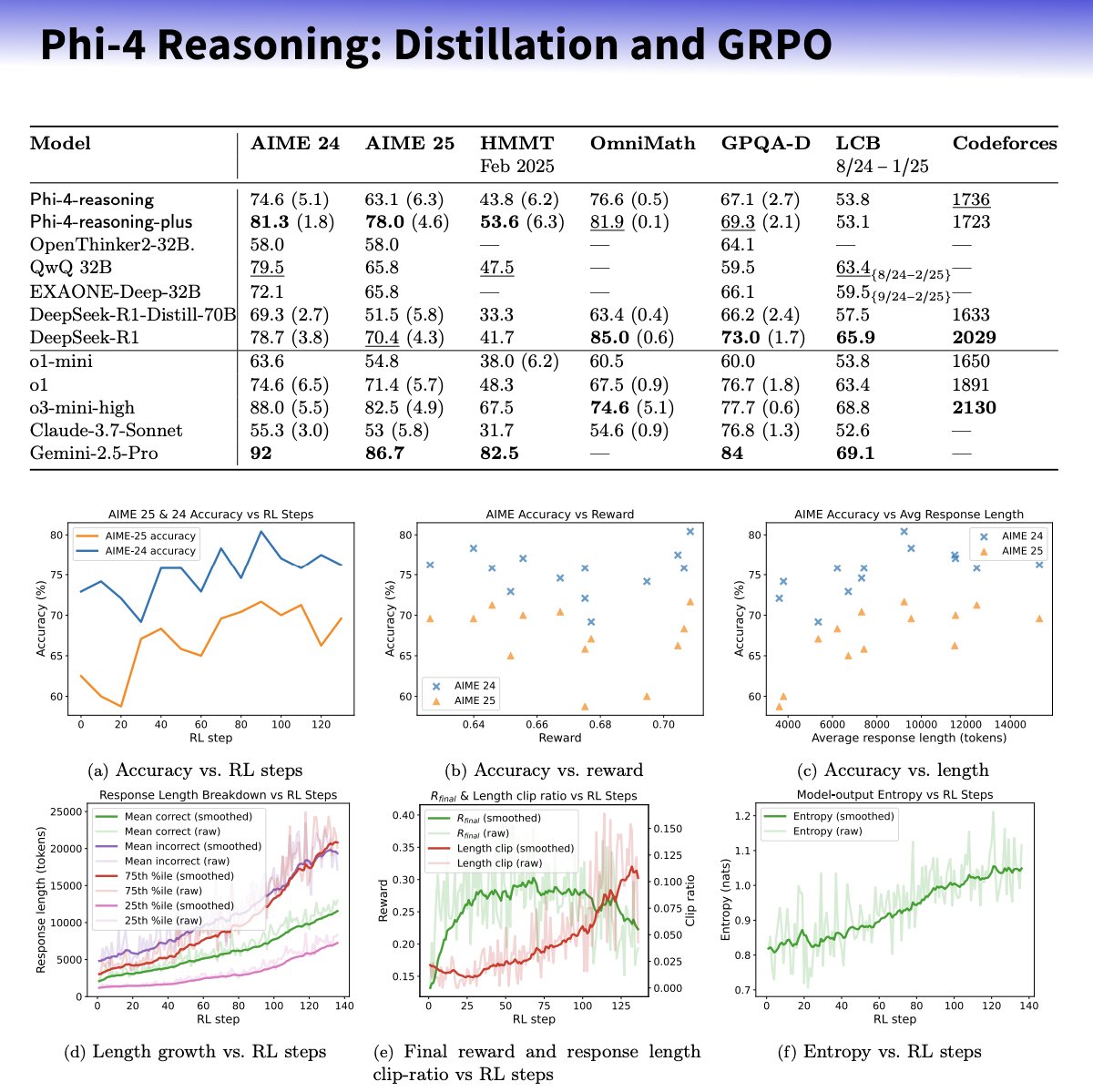
Microsoft выпускает серию малых моделей Phi-4-reasoning, фокусируясь на улучшении способностей к рассуждению: Microsoft представила модели Phi-4-reasoning и Phi-4-reasoning-plus, основанные на архитектуре Phi-4, с целью улучшения способностей к рассуждению малых языковых моделей с помощью тщательно отобранных наборов данных, контролируемого дообучения (SFT) и целевого обучения с подкреплением (RL). Утверждается, что эти модели используют OpenAI o3-mini в качестве «учителя» для генерации высококачественных траекторий рассуждений Chain-of-Thought (CoT) и оптимизируются с помощью алгоритма GRPO для обучения с подкреплением. Исследователь Microsoft Sebastien Bubeck утверждает, что Phi-4-reasoning превосходит DeepSeek R1 в математических способностях, при этом размер модели составляет всего 2% от размера DeepSeek R1. Серия моделей использует специализированные токены для рассуждений и расширенную длину контекста в 32K. Этот шаг рассматривается как исследование в направлении создания малых, специализированных моделей, которые могут предоставить более мощные решения для рассуждений в сценариях с ограниченными ресурсами, но также вызывает дискуссии о том, используются ли в них технологии OpenAI и выпускаются ли они под лицензией MIT. (Источник: _philschmid, TheRundownAI, Reddit r/LocalLLaMA)
Anthropic запускает функцию Integrations и расширяет исследовательские возможности: Anthropic анонсировала запуск Claude Integrations, позволяющий пользователям подключать Claude к 10 сторонним приложениям и сервисам, таким как Jira, Confluence, Zapier, Cloudflare, Asana и другим, с планами поддержки Stripe, GitLab и т.д. в будущем. Поддержка MCP (Model Context Protocol), ранее ограниченная локальными серверами, расширена на удаленные серверы, позволяя разработчикам создавать собственные интеграции примерно за 30 минут с помощью документации или решений, таких как Cloudflare. Одновременно улучшена исследовательская функция Claude (Research): добавлен расширенный режим, который может искать в интернете, Google Workspace и подключенных Integrations, разбивать сложные запросы для исследования, генерировать комплексные отчеты с цитатами, при этом время обработки может достигать 45 минут. Функция веб-поиска также стала доступна платным пользователям по всему миру. Эти обновления направлены на повышение уровня интеграции Claude как рабочего ассистента и его возможностей для глубоких исследований. (Источник: _philschmid, Reddit r/ClaudeAI)

Способности ИИ-агентов следуют новому закону Мура: удваиваются каждые 4 месяца: Исследование AI Digest показывает, что способность ИИ-агентов к программированию выполнять задачи растет экспоненциально. Время, необходимое им для обработки задач (измеряемое временем, которое потребовалось бы человеку-эксперту), в период 2024-2025 годов удваивается примерно каждые 4 месяца, что быстрее, чем удвоение каждые 7 месяцев в период 2019-2025 годов. В настоящее время лучшие ИИ-агенты могут справляться с задачами программирования, на которые человеку требуется 1 час. Если эта ускоряющаяся тенденция сохранится, ожидается, что к 2027 году ИИ-агенты смогут выполнять сложные задачи продолжительностью до 167 часов (около месяца). Этот стремительный рост способностей обусловлен как прогрессом самих моделей, так и повышением эффективности алгоритмов, и может сформировать положительную обратную связь суперэкспоненциального роста за счет ИИ, помогающего в исследованиях и разработках ИИ. Это предвещает возможность «взрыва программного интеллекта», который глубоко изменит такие области, как разработка программного обеспечения и научные исследования, но также принесет социальные вызовы, связанные с влиянием автоматизации на рынок труда. (Источник: 新智元)

🎯 Новости и тенденции
Выпущен DeepSeek-Prover-V2, улучшающий возможности доказательства математических теорем: DeepSeek AI выпустила DeepSeek-Prover-V2 в двух масштабах, 7B и 671B, сфокусированный на формальном доказательстве теорем в Lean 4. Модель обучалась с использованием рекурсивного поиска доказательств и обучения с подкреплением (GRPO), используя DeepSeek-V3 для декомпозиции сложных теорем и генерации набросков доказательств, а затем дообучалась и усиливалась с помощью экспертной итерации и синтетических данных для холодного старта. DeepSeek-Prover-V2-671B достиг 88.9% прохождения на MiniF2F-test и решил 49 задач на PutnamBench, демонстрируя производительность SOTA. Одновременно был выпущен бенчмарк ProverBench, включающий задачи AIME и из учебников. Модель направлена на объединение неформального рассуждения и формального доказательства, способствуя развитию автоматического доказательства теорем. (Источник: 新智元)

Nvidia и UIUC предложили новый метод расширения контекста до 4 миллионов токенов: Исследователи из Nvidia и Иллинойсского университета в Урбане-Шампейне предложили эффективный метод обучения, позволяющий расширить контекстное окно Llama 3.1-8B-Instruct со 128K до 1M, 2M и даже 4M токенов. Метод использует двухэтапную стратегию непрерывного предварительного обучения и дообучения на инструкциях. Ключевые технологии включают использование специальных разделителей документов, расширение позиционного кодирования на основе YaRN и одноэтапное предварительное обучение. Обученная модель UltraLong-8B показала отличные результаты на бенчмарках для длинного контекста, таких как RULER, LV-Eval, InfiniteBench, и сохранила или даже превзошла производительность базовой Llama 3.1 на стандартных задачах с коротким контекстом, таких как MMLU и MATH, опередив другие модели с длинным контекстом, такие как ProLong и Gradient. Исследование предоставляет эффективный и масштабируемый путь для создания LLM с ультрадлинным контекстом. (Источник: 新智元)

Выпущен Qwen3 со значительным улучшением производительности: Alibaba выпустила серию моделей Qwen3, включая Qwen3-30B-A3B и другие. Согласно предварительным тестам пользователей Reddit и данным бенчмарков (например, AHA Leaderboard), Qwen3 показывает лучшие результаты по сравнению с предыдущими версиями Qwen2.5 и QwQ по нескольким параметрам (например, знания в специфических областях, таких как здоровье, биткоин, Nostr). Отзывы пользователей показывают, что Qwen3 демонстрирует сильные способности при обработке специфических задач (например, симуляция динамики Солнечной системы), правильно применяя законы физики для генерации эллиптических орбит и относительных периодов. Однако некоторые пользователи отмечают, что производительность Qwen3 заметно снижается при длинном контексте (например, около 16K), а потребление токенов при выводе высокое, рекомендуя использовать его совместно с инструментами поиска. Система именования Qwen3 (например, Qwen3-30B-A3B) также получила положительные отзывы за свою ясность. (Источник: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, karminski3, madiator)
Gemini скоро интегрирует данные учетной записи Google для предоставления персонализированного опыта: Google планирует предоставить ИИ-ассистенту Gemini доступ к данным учетной записи пользователя Google, включая Gmail, Фото, историю YouTube и т.д., с целью предоставления более персонализированного, проактивного и мощного вспомогательного опыта. Руководитель продукта Google Josh Woodward заявил, что это делается для того, чтобы Gemini лучше понимал пользователя и стал его продолжением. Функция будет опциональной (opt-in), и пользователи смогут выбирать, предоставлять ли доступ к данным. Этот шаг вызвал дискуссии о конфиденциальности и безопасности данных, и пользователям придется найти баланс между удобством персонализации и конфиденциальностью данных. (Источник: JeffDean, Reddit r/ArtificialInteligence)

Nvidia выпускает модель ASR Parakeet-TDT-0.6B-v2: Nvidia выпустила новую модель автоматического распознавания речи (ASR) Parakeet-TDT-0.6B-v2 с 600 миллионами параметров. Утверждается, что эта модель превосходит Whisper3-large (1.6 миллиарда параметров) на Open ASR Leaderboard, особенно при обработке разнообразных наборов данных (включая LibriSpeech, Fisher Corpus, данные YouTube и др., около 120 000 часов данных). Модель поддерживает временные метки на уровне символов, слов и абзацев, но в настоящее время поддерживает только английский язык и требует для работы GPU Nvidia и специфические фреймворки. Первые отзывы пользователей отмечают высокую точность транскрипции и пунктуации. (Источник: Reddit r/LocalLLaMA)

Выпущен Qwen2.5-VL для улучшения понимания визуального языка: Alibaba выпустила серию мультимодальных моделей Qwen2.5-VL (включая варианты с 3B, 7B, 72B параметрами), направленных на улучшение понимания машиной визуального мира и взаимодействия с ним. Эти модели могут использоваться для аннотирования изображений, визуальных вопросов и ответов, генерации отчетов из сложной визуальной информации и т.д. В статье описывается их архитектура, результаты бенчмарков и детали вывода, демонстрируя прогресс в области понимания визуального языка. (Источник: Reddit r/deeplearning)

Поддержка Mistral Small 3.1 Vision добавлена в llama.cpp: В проект llama.cpp была добавлена поддержка модели Mistral Small 3.1 Vision (24B параметров). Это означает, что пользователи смогут запускать эту мультимодальную модель в рамках фреймворка llama.cpp для выполнения задач, таких как понимание изображений. Unsloth уже предоставил соответствующие файлы модели в формате GGUF. Это облегчает локальный запуск визуальной модели Mistral. (Источник: Reddit r/LocalLLaMA)
Meta выпускает Synthetic Data Kit: Meta выпустила в открытый доступ инструмент командной строки под названием Synthetic Data Kit, предназначенный для упрощения этапа подготовки данных, необходимого для дообучения LLM. Инструмент предоставляет четыре команды: ingest (импорт данных), create (генерация пар вопрос-ответ, опционально с цепочкой рассуждений), curate (использование Llama в качестве оценщика для отбора качественных образцов), save-as (экспорт в совместимые форматы). Он использует локальные LLM (через vLLM) для генерации высококачественных синтетических обучающих данных, что особенно полезно для разблокировки способностей к рассуждению для конкретных задач у моделей, таких как Llama-3. (Источник: Reddit r/MachineLearning)
GTE-ModernColBERT-v1 становится популярной моделью встраивания: Модель GTE-ModernColBERT-v1, выпущенная LightOnIO, стала новой популярной моделью для поиска/встраивания на Hugging Face. Модель использует метод многовекторного поиска (также известный как late interaction или ColBERT), предоставляя новый выбор для разработчиков, интересующихся такими технологиями. (Источник: lateinteraction)
Обновление алгоритма рекомендаций X: Платформа X (ранее Twitter) внесла исправления в свой алгоритм рекомендаций, направленные на решение давних проблем, таких как игнорирование отрицательных отзывов пользователей, повторный показ одного и того же контента и рекомендации нерелевантного контента алгоритмом SimCluster. Утверждается, что первые отзывы положительные. (Источник: TheGregYang)
Википедия объявляет о новой стратегии ИИ для помощи редакторам-людям: Википедия обнародовала свою новую стратегию в области искусственного интеллекта, направленную на использование инструментов ИИ для поддержки и улучшения работы редакторов-людей, а не их замены. Конкретные детали в источнике не уточняются, но это указывает на то, что крупнейшая в мире онлайн-энциклопедия изучает способы интеграции технологий ИИ в свои процессы создания и поддержания контента. (Источник: Reddit r/artificial)
🧰 Инструменты
Midjourney запускает функцию Omni-Reference: Midjourney выпустила новую функцию Omni-Reference (oref), которая позволяет пользователям направлять генерацию изображений, предоставляя URL-адреса референсных изображений (с использованием параметра –oref), для достижения согласованности персонажей, объектов, транспортных средств или нечеловеческих существ. Пользователи могут контролировать вес влияния референсного изображения с помощью параметра –ow: более низкие значения подходят для стилизации, более высокие — для реализма или точного совпадения лиц. Функция направлена на повышение согласованности и управляемости конкретных элементов в генерируемых изображениях. (Источник: op7418, DavidSHolz)

Runway Gen-4 References реализует персонализацию по одному изображению: Модель Runway Gen-4 представила функцию References (Референсы), позволяющую пользователям, предоставив всего одно референсное изображение, применять стиль или черты персонажа из этого изображения к новому генерируемому контенту. Демонстрации показывают, что функция позволяет легко воссоздавать портреты людей в стиле референсного изображения или помещать их в мир, изображенный на референсе, демонстрируя способность модели достигать высокой согласованности и эстетического качества персонализированной генерации на основе всего одного референсного изображения. (Источник: c_valenzuelab, c_valenzuelab)

WhatsApp-бот Perplexity возобновил работу: WhatsApp-бот от Perplexity AI, который был временно отключен из-за спроса, значительно превысившего ожидания, возобновил свою работу. Пользователи могут взаимодействовать с ним по номеру телефона +1 (833) 436-3285, пересылая сообщения для проверки фактов, задавая прямые вопросы для получения ответов, ведя свободные текстовые диалоги и создавая изображения. (Источник: AravSrinivas, AravSrinivas)
Krea AI сочетает модель изображений 4o для точного контроля над изображениями: Инструмент для творчества с ИИ Krea AI добавил новую функцию, позволяющую пользователям сочетать возможности модели изображений 4o от OpenAI для более точного контроля над содержанием и стилем генерируемых изображений с помощью коллажей и набросков. Это демонстрирует постоянные инновации Krea в области интерактивной генерации изображений, позволяя пользователям более интуитивно и детально направлять творчество ИИ. (Источник: op7418)
行云褐蚁一体机: недорогая система «все-в-одном» для запуска полной версии DeepSeek: Компания 行云集成电路, связанная с Университетом Цинхуа, представила ИИ-систему «все-в-одном» 褐蚁 (Brown Ant), которая, как утверждается, способна запускать неквантифицированную модель DeepSeek-R1/V3 671B с точностью FP8 со скоростью более 20 токенов/с и поддержкой контекста 128K по цене 149 000 юаней. Решение использует двухпроцессорную конфигурацию AMD EPYC CPU и большой объем высокочастотной памяти с небольшим количеством GPU для ускорения. Цель состоит в том, чтобы значительно снизить стоимость аппаратного обеспечения для частного развертывания больших моделей за счет архитектуры CPU+память, обеспечивая локальный опыт, близкий к официальной производительности, что подходит для предприятий, чувствительных к затратам и нуждающихся в высокой точности. (Источник: 新智元)

Скоро выйдет приложение NotebookLM: ИИ-приложение для заметок от Google, NotebookLM, скоро выпустит официальные приложения для iOS и Android, ожидаемая дата запуска — 20 мая, предварительный заказ уже открыт. Это перенесет функции NotebookLM по предоставлению резюме, ответов на вопросы и генерации идей на основе заметок и документов пользователя на мобильные устройства. (Источник: zacharynado)
Granola запускает приложение для iOS для ведения протоколов встреч в реальном времени с помощью ИИ: ИИ-приложение для заметок Granola выпустило версию для iOS, расширяя свои первоначальные функции ведения ИИ-заметок для встреч в Zoom на офлайн-встречи лицом к лицу. Пользователи могут использовать Granola на iPhone для записи и транскрибирования разговоров, а также использовать ИИ для генерации резюме и заметок для удобного последующего просмотра и организации. (Источник: amasad)
Grok Studio теперь поддерживает обработку PDF: ИИ-ассистент Grok добавил в свою функцию Studio возможность обработки PDF-файлов. Теперь пользователи могут удобнее обрабатывать и анализировать PDF-документы в Grok Studio. Конкретные детали функционала не уточняются, но это знаменует расширение возможностей Grok в понимании и взаимодействии с документами различных форматов. (Источник: grok, TheGregYang)
Новая модель Suno демонстрирует выдающиеся способности к генерации музыки: Платформа для генерации музыки с помощью ИИ Suno выпустила новую модель, отзывы пользователей о которой говорят о “очень выдающихся” результатах генерации. Один пользователь попытался сгенерировать песню в стиле живого выступления, и хотя не удалось полностью реализовать ожидаемый эффект отклика аудитории, сгенерированная музыка хорошо передала атмосферу толпы, демонстрируя прогресс новой модели в качестве музыки и разнообразии стилей. (Источник: nptacek, nptacek)
Приложение Frog Spot для распознавания кваканья лягушек с помощью ИИ: Разработчик создал бесплатное приложение под названием Frog Spot, которое использует самостоятельно обученную модель CNN (TensorFlow Lite) для распознавания кваканья различных видов лягушек путем анализа спектрограммы 10-секундного аудиофайла. Приложение призвано помочь общественности узнать о местных видах, а также демонстрирует потенциал глубокого обучения в области биоакустического мониторинга и гражданской науки. (Источник: Reddit r/deeplearning)
Автоматизация промышленных технических чертежей с помощью ИИ: В статье для IAAI 2025 описывается метод автоматизации расширения «типовых схем приборов» (Instrument Typicals) на схемах трубопроводов и КИП (P&ID). Метод сочетает модели компьютерного зрения (обнаружение и распознавание текста) и предметно-ориентированные правила для автоматического извлечения информации из чертежей P&ID и таблиц условных обозначений, расширяя упрощенные символы типовых схем приборов в подробные перечни приборов и генерируя точный индекс приборов. Это направлено на повышение эффективности инженерных проектов (особенно на этапе тендера) и сокращение человеческих ошибок. (Источник: aihub.org)

Использование Sora для генерации миниатюрного пейзажа из утки по-сычуаньски: Пользователь поделился изображением «миниатюрного пейзажа из утки по-сычуаньски», сгенерированным Sora по подробному текстовому описанию. Описание детально описывало стиль сцены (макросъемка, миниатюрный пейзаж), основной объект (здание-ларек, построенное из утки по-сычуаньски), детали (красновато-коричневая кожица, перец чили и кунжут, повар, нарезающий утку, посетители), окружение (улицы из утиного соуса, стены в стиле маринованных продуктов, красные фонари и т.д.). Это демонстрирует способность Sora понимать сложные, образные текстовые описания и генерировать соответствующие высококачественные изображения. (Источник: dotey)

Создание 3D-прогнозов погоды с помощью GPTs: Пользователь поделился самодельным приложением ChatGPTs под названием «Weather 3D», которое по введенному пользователем названию города вызывает API погоды для получения данных в реальном времени и генерирует 3D-изометрическую миниатюрную модель знакового здания этого города в стиле иллюстрации, интегрируя текущие погодные условия. В верхней части иллюстрации отображается название города, погодные условия, температура и иконка погоды. Этот GPTs демонстрирует, как можно сочетать вызовы API и возможности генерации изображений для создания практичных и визуально привлекательных ИИ-приложений. (Источник: dotey)

📚 Обучение
AdaRFT: новый метод оптимизации дообучения с подкреплением: Taiwei Shi и др. предложили легковесный, подключаемый метод обучения по учебной программе под названием AdaRFT, предназначенный для оптимизации процесса обучения алгоритмов обучения с подкреплением на основе обратной связи от человека (RFT), таких как PPO, GRPO, REINFORCE. Утверждается, что AdaRFT способен сократить время обучения RFT до 2 раз и повысить производительность модели за счет более интеллектуального упорядочивания обучающих данных для повышения эффективности и результативности обучения. (Источник: menhguin)

Онлайн-мастер-класс по оценке ИИ (Evals): Hamel Husain и Shreya Shankar запустили 4-недельный онлайн-мастер-класс по оценке ИИ-приложений (Evals). Курс направлен на то, чтобы помочь разработчикам перевести ИИ-приложения от стадии прототипа к готовности к производству, охватывая методы оценки на этапах разработки и после запуска, различия между бенчмаркингом и практической оценкой, проверку данных, PromptEvals и т.д. Подчеркивается важность оценки для обеспечения надежности и производительности ИИ-приложений. (Источник: HamelHusain, HamelHusain)

Руководство по настройке моделей от Google: Google Research предоставил репозиторий под названием “tuning_playbook”, предназначенный для предоставления руководств и лучших практик по настройке моделей. Это ценный учебный ресурс для разработчиков и исследователей, которым необходимо дообучать большие языковые модели или другие модели машинного обучения для адаптации к конкретным задачам или наборам данных. (Источник: zacharynado)

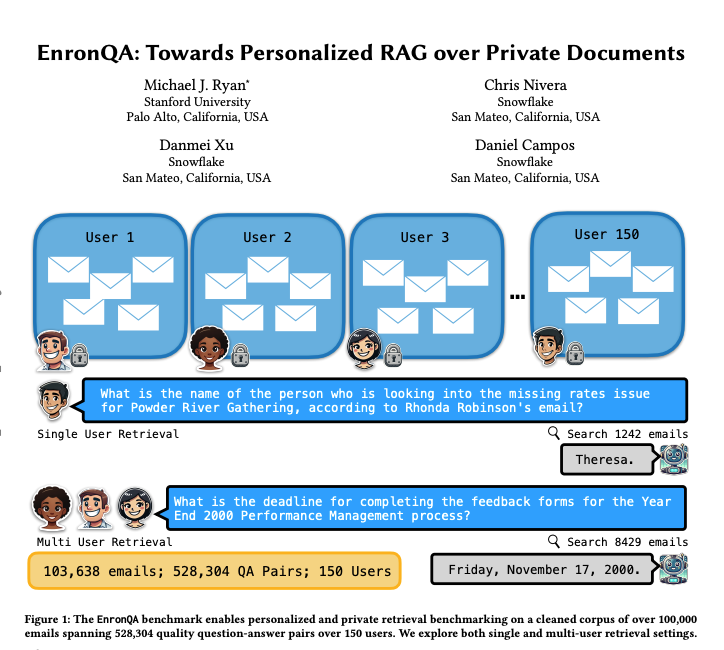
EnronQA: персонализированный бенчмарк-набор данных для RAG: Исследователи представили набор данных EnronQA, содержащий 103 638 электронных писем от 150 пользователей и 528 304 высококачественных пар вопрос-ответ. Набор данных предназначен для использования в качестве бенчмарка для оценки производительности персонализированных систем генерации с дополнением извлечением (RAG) при обработке частных документов. Набор данных содержит эталонные ответы, неверные ответы, обоснования рассуждений и альтернативные ответы, что помогает более детально анализировать производительность систем RAG. (Источник: tokenbender)
ReXGradient-160K: крупномасштабный набор данных рентгенограмм грудной клетки и отчетов: Опубликован крупный общедоступный набор данных рентгенограмм грудной клетки под названием ReXGradient-160K, содержащий 60 000 исследований грудной клетки от 109 487 уникальных пациентов из 3 систем здравоохранения США (79 медицинских учреждений) и соответствующие им радиологические отчеты (свободный текст). Утверждается, что это самый большой общедоступный набор данных рентгенограмм грудной клетки по количеству пациентов на данный момент, предоставляющий ценный ресурс для обучения и оценки ИИ-моделей для медицинской визуализации. (Источник: iScienceLuvr)

Статья в блоге, обсуждающая рост способностей ИИ-агентов: Исследователь Shunyu Yao опубликовал статью в блоге под названием «The Second Half», в которой утверждается, что текущее развитие ИИ находится в моменте «перерыва между таймами». До этого момента обучение было важнее оценки; после этого момента оценка станет важнее обучения, поскольку обучение с подкреплением (RL) наконец-то начинает эффективно работать. В статье рассматривается важность изменения методологии оценки на фоне постоянного роста способностей ИИ. (Источник: andersonbcdefg)
OpenAI делится исследованиями о конфиденциальности и запоминании: Исследователи OpenAI Pratyush Maini и Zhili Feng проведут презентацию об исследованиях в области конфиденциальности и запоминания, обсуждая, как обнаруживать, количественно оценивать и устранять явление запоминания в больших языковых моделях, а также его практическое применение в производственных LLM. Это касается баланса между возможностями модели и защитой конфиденциальности данных пользователей. (Источник: code_star)

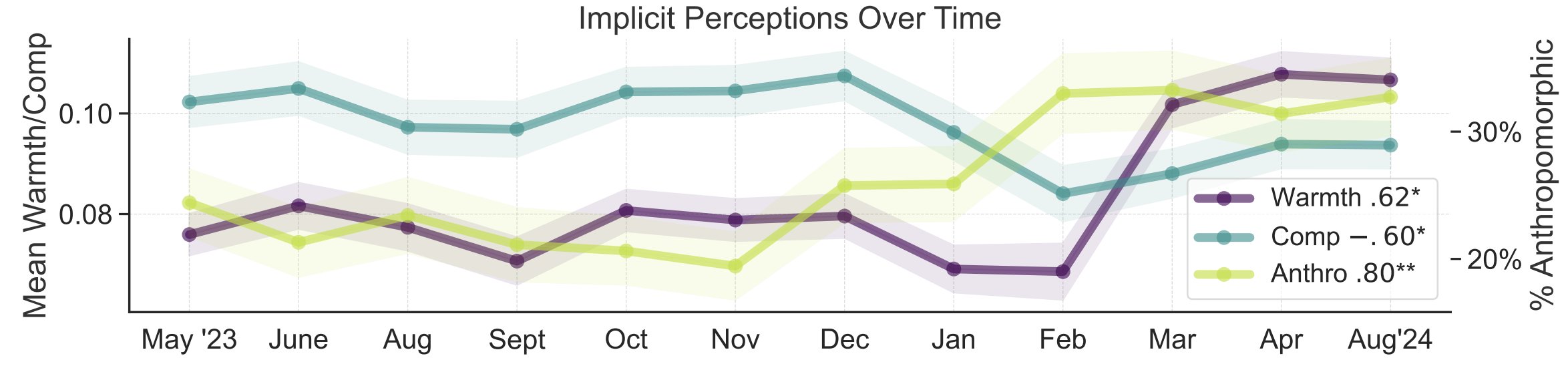
Исследование метафор общественного восприятия ИИ: Исследователи из Стэнфордского университета Myra Cheng и др. представили на FAccT 2025 статью, в которой анализируются 12 000 метафор об ИИ, собранных за 12 месяцев, чтобы понять ментальные модели ИИ у общественности и их изменение со временем. Исследование показало, что со временем общественность склонна воспринимать ИИ как более человекоподобный и обладающий большей субъектностью (уровень антропоморфизации растет), а также эмоциональное отношение к нему (теплота) улучшается. Этот метод предоставляет более детальное понимание общественного восприятия, чем самоотчеты. (Источник: stanfordnlp, stanfordnlp)
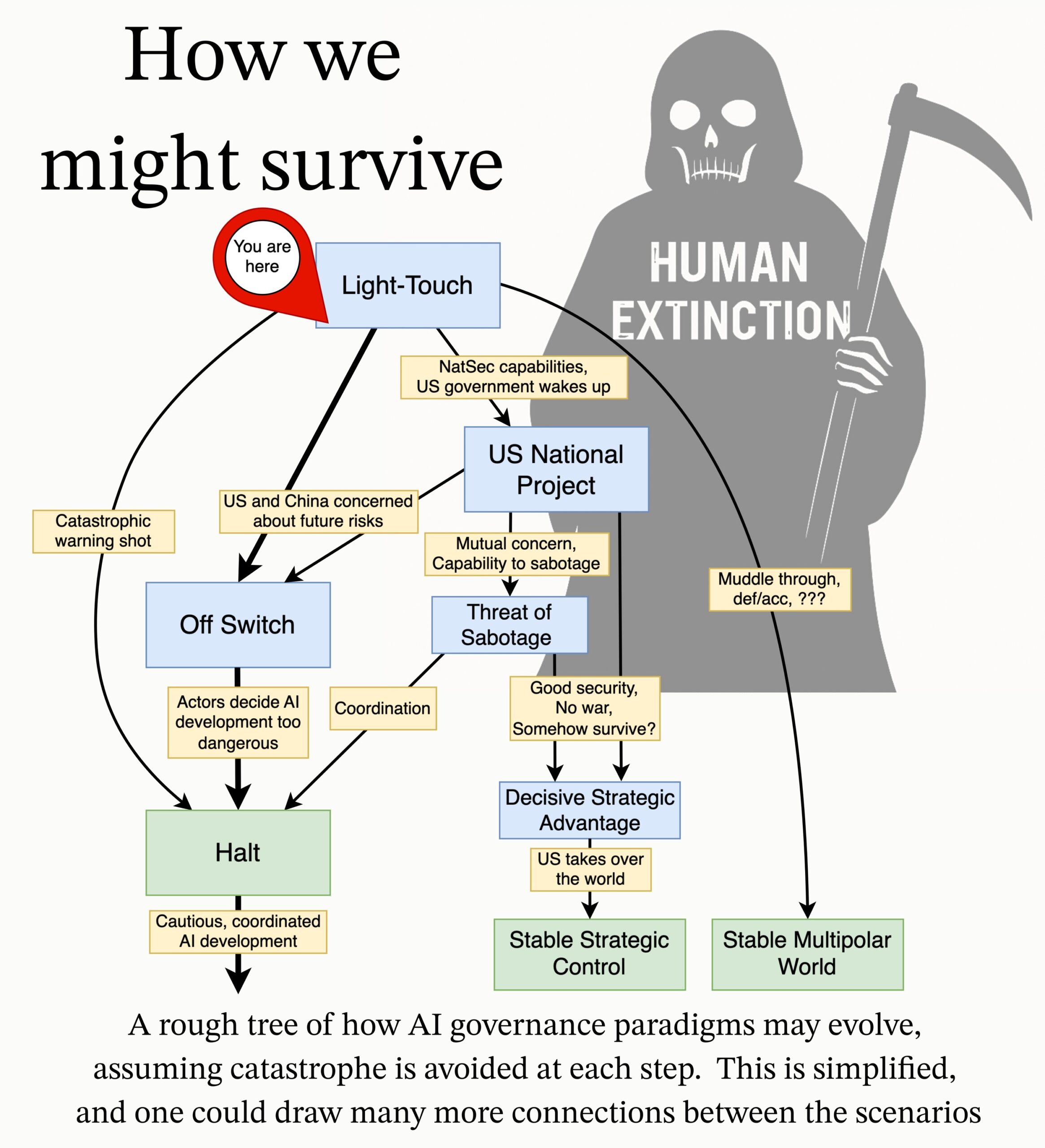
MIRI публикует исследовательскую повестку по управлению ИИ: Команда по техническому управлению Института исследований машинного интеллекта (MIRI) опубликовала новую исследовательскую повестку по управлению ИИ, излагая свое видение стратегического ландшафта и предлагая ряд практических исследовательских вопросов. Их цель — изучить, какие меры необходимо принять, чтобы предотвратить создание неконтролируемого сверхинтеллекта какой-либо организацией или отдельным лицом, с целью снижения катастрофических рисков и рисков вымирания, связанных с ИИ. (Источник: JeffLadish)
💼 Бизнес
Поставщик корпоративных ИИ-решений Deepexi подал заявку на IPO в Гонконге: Компания Deepexi (滴普科技), основанная бывшими топ-менеджерами Huawei и Alibaba во главе с Чжао Цзехуэем и специализирующаяся на корпоративных ИИ-решениях, официально подала заявку на листинг на Гонконгской фондовой бирже. Компания фокусируется на платформе интеллектуальной обработки данных FastData и корпоративном ИИ-решении FastAGI, обслуживая такие отрасли, как розничная торговля (например, Belle), производство и здравоохранение. За последние три года выручка компании постоянно росла, достигнув 243 млн юаней в 2024 году. Deepexi привлекла 8 раундов финансирования от известных инвесторов, включая Hillhouse Capital, IDG Capital, 5Y Capital и др., с оценкой около 6.8 млрд юаней после последнего раунда. Несмотря на рост выручки, компания в настоящее время все еще убыточна, хотя скорректированный чистый убыток ежегодно сокращается. (Источник: 36氪)
BMW China объявляет об интеграции большой модели DeepSeek: После сотрудничества с Alibaba, BMW Group进一步 углубляет свое присутствие в области ИИ в Китае, объявляя об интеграции большой модели DeepSeek. Планируется, что эта функция начнет внедряться с третьего квартала 2025 года, сначала в нескольких новых моделях, продаваемых в Китае и оснащенных операционной системой BMW 9-го поколения, а в будущем также будет применяться в новых моделях BMW Neue Klasse китайского производства. Этот шаг направлен на усиление взаимодействия человека и машины, ядром которого является интеллектуальный персональный ассистент BMW, за счет глубоких мыслительных способностей DeepSeek, повышение уровня интеллекта автомобиля и эмоциональной связи. Это важный шаг BMW по ускорению локализации стратегии ИИ и ответу на вызовы интеллектуальной трансформации. (Источник: 36氪)
Shopify обязывает всех сотрудников использовать ИИ, намереваясь заменить им часть должностей: CEO глобальной платформы электронной коммерции Shopify Tobi Lutke во внутренней записке подчеркнул, что эффективное использование ИИ стало «железным правилом» для всех сотрудников компании, а не просто рекомендацией. Записка требует от сотрудников применять ИИ в рабочих процессах, формируя условный рефлекс; команды, запрашивающие увеличение штата, должны доказать, почему ИИ не может выполнить задачу; в оценку производительности будут введены показатели использования ИИ. Lutke отметил, что ИИ может значительно повысить эффективность (у некоторых сотрудников в 10 или даже 100 раз), и сотрудникам необходимо ежегодно повышать производительность на 20-40%, чтобы оставаться конкурентоспособными. Ранее Shopify уже проводила сокращения в отделах, таких как обслуживание клиентов, и внедряла ИИ на замену. Этот шаг рассматривается как явный сигнал тенденции к корректировке и сокращению должностей «белых воротничков» из-за ИИ. (Источник: 新智元)

🌟 Сообщество
Обсуждение проблемы «галлюцинаций» ИИ: Критика Ли Яньхуна (Robin Li) в адрес DeepSeek-R1 на конференции разработчиков Baidu AI за высокий уровень галлюцинаций, медленную скорость и высокую стоимость вызвала в сообществе очередное обсуждение феномена «галлюцинаций» больших моделей. Аналитики отмечают, что проблема галлюцинаций присуща не только DeepSeek, но и передовым моделям, включая o3/o4-mini от OpenAI и Qwen3 от Alibaba, причем многоэтапное мышление моделей-рассуждателей может усиливать отклонения. Оценка Vectara показывает, что уровень галлюцинаций R1 (14.3%) значительно выше, чем у V3 (3.9%). Сообщество считает, что по мере роста возможностей моделей галлюцинации становятся более скрытыми и логичными, что затрудняет их распознавание пользователями и вызывает опасения по поводу надежности. В то же время существует мнение, что галлюцинации являются побочным продуктом творчества, особенно ценным в таких областях, как литературное творчество. Определение допустимого уровня галлюцинаций и способы их смягчения с помощью таких технологий, как RAG, контроль качества данных и критические модели, остаются предметом постоянных исследований в отрасли. (Источник: 36氪)

Размышления и обсуждения об ИИ-компаньонах/друзьях: Предложение CEO Meta Марка Цукерберга использовать персонализированных ИИ-друзей для удовлетворения потребности людей в большем количестве социальных связей (утверждая, что у среднего человека 3 друга, а потребность — 15) вызвало обсуждение в сообществе. Sebastien Bubeck считает, что создание настоящих ИИ-компаньонов чрезвычайно сложно, и ключевым моментом является способность ИИ осмысленно отвечать на вопрос «Чем ты занимался в последнее время?», то есть иметь собственный опыт и переживания, а не просто разделять опыт пользователя. Он считает, что текущие концепции ИИ-компаньонов слишком сосредоточены на совместном опыте, игнорируя необходимость наличия у ИИ собственного независимого опыта, которым можно поделиться, и даже сплетен (обмен опытом друг друга). Другие комментаторы ставят под сомнение идею с точки зрения числа Данбара, полагая, что обширный социальный круг, состоящий из ИИ, может быть лишен реального смысла. Также высказываются опасения, что конечной целью ИИ-друзей, предоставляемых коммерческими компаниями, может быть точный маркетинговый таргетинг, а не настоящее компаньонство. (Источник: jonst0kes, SebastienBubeck, gfodor, gfodor)

Эмоции и размышления, вызванные творчеством ИИ в искусстве: В сообществе пользователи выражают «печаль» (grieving) из-за того, что ИИ может создавать «безумно хорошие» произведения искусства за короткое время, считая, что это бросает вызов уникальности человека в художественном творчестве. Это вызвало дискуссию об искусстве ИИ, сущности человеческого творчества и ощущении личной ценности в условиях технологического прорыва. Некоторые комментаторы считают, что удовольствие от художественного творчества заключается в самом процессе, а не в соревновании с ИИ; искусство ИИ может служить источником вдохновения. Другие считают, что искусству ИИ не хватает «ошибок» или души человеческого творчества, оно кажется слишком совершенным или шаблонным. Обсуждение также распространилось на философские размышления о симуляции эмоций ИИ, сознании и будущей социальной структуре (например, замена рабочих мест) и т.д. (Источник: Reddit r/ArtificialInteligence)
Этика и ответственность ИИ: секретные эксперименты и раскрытие информации: Сообщество обсуждает этические проблемы в исследованиях ИИ. В одной новости упоминалось, что исследователи ИИ проводили секретный эксперимент на Reddit, пытаясь изменить мнения пользователей, что вызвало обеспокоенность по поводу права пользователей на информацию и рисков манипулирования со стороны ИИ. В другом обсуждении пользователь сообщил о сложностях процесса и нечеткой ответственности при сообщении ИИ-компаниям о потенциальных проблемах безопасности, что подчеркивает незрелость текущей сферы ИИ в части механизмов ответственного раскрытия информации и реагирования на уязвимости. (Источник: Reddit r/ArtificialInteligence, nptacek)

Рефлексия в области NLP на подъем ChatGPT: Журнал Quanta Magazine опубликовал статью, в которой через интервью с несколькими экспертами в области обработки естественного языка (NLP), такими как Chris Potts, Yejin Choi, Emily Bender, рассматривается шок и рефлексия, вызванные выпуском ChatGPT во всей области. В статье обсуждается, как подъем больших языковых моделей бросил вызов теоретическим основам традиционного NLP, вызвал споры в области, разделение на фракции и корректировку направлений исследований. Члены сообщества активно отреагировали на статью, считая, что она хорошо описывает потрясения и процесс адаптации в области лингвистики после GPT-3. (Источник: stanfordnlp, Teknium1, YejinChoinka, sleepinyourhat)
Появление и восприятие рекламы, сгенерированной ИИ: Пользователи социальных сетей сообщают, что начали видеть на платформах, таких как YouTube, рекламу, сгенерированную ИИ, и выражают «крайне неприятные» ощущения. Это свидетельствует о том, что технологии генерации контента ИИ начали применяться в производстве коммерческой рекламы, а также вызывает первичную реакцию пользователей на качество, достоверность и эмоциональное восприятие контента, сгенерированного ИИ. (Источник: code_star)
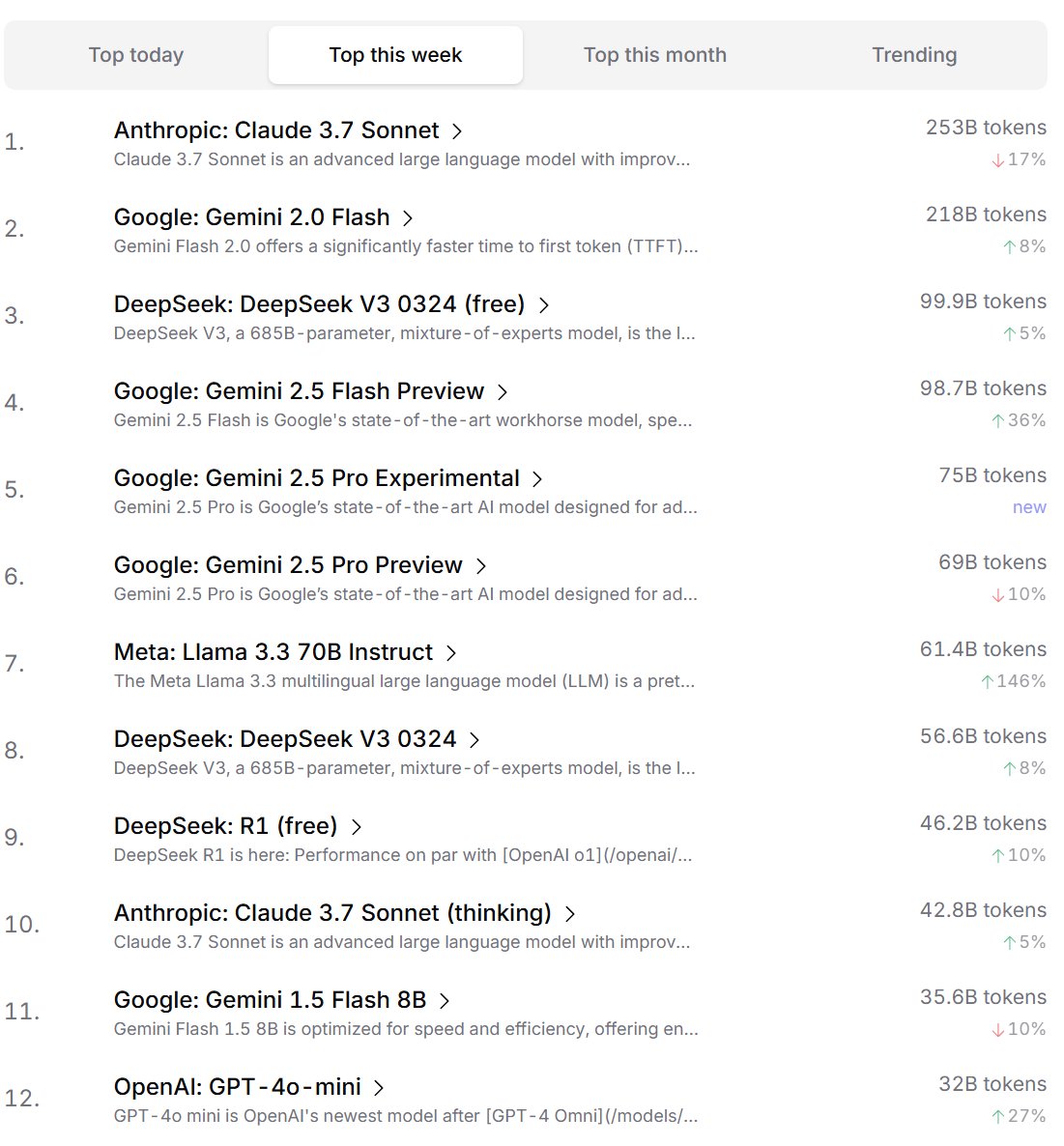
Рейтинг предпочтений ИИ-моделей среди разработчиков: Cursor.ai опубликовал рейтинг ИИ-моделей, предпочитаемых его пользователями (в основном разработчиками), в то время как Openrouter также обнародовал рейтинг использования токенов моделями. Считается, что эти рейтинги, основанные на данных реального использования продуктов, могут лучше отражать выбор пользователей в реальных сценариях разработки, чем рейтинги типа ChatBot Arena, предоставляя иную перспективу для оценки практичности моделей. (Источник: op7418, Reddit r/LocalLLaMA)
Дискуссия о том, обладают ли ИИ способностью «мыслить»: В сообществе продолжается дискуссия о том, обладают ли большие языковые модели (LLMs) действительно способностью «мыслить». Существует мнение, что текущие LLMs на самом деле не думают перед тем, как говорить, а имитируют процесс мышления путем генерации большего количества текста (например, цепочки мыслей), что вводит в заблуждение. Другая точка зрения заключается в том, что использование непрерывных математических методов (таких как LLMs) для дискретных рассуждений на дискретных компьютерах само по себе является фундаментальной проблемой. Эти дискуссии отражают глубокие размышления о сущности текущих технологий ИИ и будущих направлениях развития. (Источник: francoisfleuret, pmddomingos)
Диалектическое осмысление энергопотребления ИИ и его влияния на окружающую среду: В ответ на экологические проблемы, связанные с огромным энергопотреблением для обучения и работы ИИ, в сообществе появляются диалектические размышления. Одна точка зрения заключается в том, что огромные энергетические потребности ИИ (особенно у гипермасштабных вычислительных компаний, таких как Google, Amazon, Microsoft) заставляют эти компании инвестировать в строительство собственных возобновляемых источников энергии (солнечная, ветровая, аккумуляторная) и даже перезапускать атомные электростанции (например, сотрудничество Microsoft с Constellation по перезапуску АЭС Три-Майл-Айленд). Этот спрос может, наоборот, стать катализатором ускоренного развертывания чистой энергии и технологических прорывов (например, малые модульные ядерные реакторы SMR). Однако есть и точка зрения, указывающая на проблему убывающей отдачи от энергопотребления ИИ, а также на то, что потребление водных ресурсов для охлаждения также заслуживает внимания. (Источник: Reddit r/ArtificialInteligence)
Anthropic обвиняют в попытке ограничить конкуренцию в области ИИ-чипов: В сообществе обсуждается, что CEO Anthropic Dario Amodei выступает за ужесточение контроля над экспортом ИИ-чипов в такие страны, как Китай, и даже выдвигает утверждения о том, что чипы могут контрабандой провозиться под видом накладных животов для беременных. Критики считают, что Anthropic таким образом пытается ограничить доступ конкурентов (особенно таких китайских компаний, как DeepSeek, Qwen) к передовым вычислительным ресурсам, чтобы сохранить свое преимущество в разработке передовых моделей. Такую практику обвиняют в использовании политики для подавления конкуренции, что не способствует открытому развитию глобальных технологий ИИ и сообщества открытого исходного кода. (Источник: Reddit r/LocalLLaMA)

💡 Прочее
Размышления об ИИ и пределах человеческого познания: Jeff Ladish комментирует, что окно возможностей для человека в роли «помощника по копированию-вставке» для ИИ чрезвычайно коротко, намекая на то, что автономные способности ИИ быстро превзойдут простую помощь. В то же время основатель DeepMind Hassabis в интервью заявил, что настоящий AGI должен быть способен самостоятельно выдвигать ценные научные гипотезы (как Эйнштейн предложил общую теорию относительности), а не просто решать проблемы, считая, что текущий ИИ все еще недостаточен в генерации гипотез. Лю Цысинь же ожидает, что ИИ сможет преодолеть биологические когнитивные ограничения человеческого мозга. Эти точки зрения вместе указывают на глубокие размышления о границах возможностей ИИ, эволюции роли человека и сущности будущего интеллекта. (Источник: JeffLadish, 新智元)
Лидар Waymo запечатлел опасный момент: Система лидара (LiDAR) автономного автомобиля Waymo во время успешно предотвращенной аварии с мотоциклом четко зафиксировала 3D-облако точек курьера, переворачивающегося при столкновении. Это не только демонстрирует мощные возможности системы восприятия Waymo (даже в сложных динамических сценах), но и неожиданно зафиксировало аварию с уникальной точки зрения. К счастью, в аварии никто серьезно не пострадал. (Источник: andrew_n_carr)
Новый подход к созданию романов с помощью ИИ: система сюжетных обещаний: Разработчик Levi предложил систему «сюжетных обещаний» (Plot Promise) для создания романов с помощью ИИ в качестве альтернативы традиционному методу иерархического плана. Система вдохновлена теорией Брэндона Сандерсона «обещание, прогресс, вознаграждение» и рассматривает историю как серию активных повествовательных нитей (обещаний). Каждое обещание имеет оценку важности, и алгоритм предлагает время для его продвижения на основе оценки и прогресса, но ИИ логически выбирает наиболее подходящее для продвижения в данный момент обещание, исходя из контекста. Пользователь может динамически добавлять и удалять обещания. Метод направлен на повышение гибкости истории, масштабируемости (адаптация к сверхдлинным форматам) и эмерджентности творчества, но сталкивается с проблемами оптимизации принятия решений ИИ, поддержания долгосрочной согласованности и ограничений длины входного промпта. (Источник: Reddit r/ArtificialInteligence)