
Ключевые слова:ИИ-модель, OpenAI, Мультимодальность, Агент ИИ, Модель o3, o4-mini, Визуальное мышление, Использование инструментов, Gemini 2.5 Flash, Tencent Yuanbao AI, Интеграция LLM, Обучение с подкреплением
🔥 В фокусе
OpenAI выпускает модели o3 и o4-mini с интеграцией инструментов и возможностями визуального вывода: OpenAI официально представила свои самые умные и мощные на сегодняшний день модели для вывода — o3 и o4-mini. Ключевой особенностью является первая реализация активного вызова и комбинирования Agent’ом всех внутренних инструментов ChatGPT (веб-поиск, анализ данных на Python, глубокое визуальное понимание, генерация изображений и т. д.), а также способность интегрировать изображения в цепочку рассуждений для обдумывания. o3 лидирует во всех областях, таких как кодирование, математика, наука, визуальное восприятие и т. д., обновляя SOTA (State-of-the-Art) во многих бенчмарках; в то время как o4-mini оптимизирована по скорости и стоимости, ее производительность значительно превосходит ее размер. Эти две модели обладают улучшенной способностью следовать инструкциям, ведут более естественный диалог и могут использовать память и историю диалогов для предоставления персонализированных ответов. Этот выпуск знаменует собой важный шаг OpenAI к более автономному Agentic AI, позволяя AI-ассистентам более независимо выполнять сложные задачи. (Источник: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
Модели OpenAI o3 и o4-mini запущены, улучшены возможности использования инструментов и визуального вывода: OpenAI поздно ночью выпустила модели o3 и o4-mini, доступные пользователям через аккаунты ChatGPT Plus, Pro и Team. Ключевые обновления: 1. Полнофункциональная версия o3 впервые поддерживает вызов инструментов (например, доступ в интернет, интерпретатор кода). 2. o3 и o4-mini стали первыми моделями, способными выполнять визуальный вывод в цепочке рассуждений, анализируя и обдумывая информацию с использованием изображений, подобно человеку. Например, в игре “угадай место по картинке” модель может увеличивать детали изображения для пошагового вывода. Эта способность значительно улучшает производительность модели в мультимодальных задачах (таких как MMMU, MathVista), предвещая более широкое применение AI в профессиональных сценариях, требующих визуальной оценки (например, мониторинг безопасности, анализ медицинских изображений). Одновременно OpenAI также открыла исходный код инструмента для программирования AI — Codex CLI. (Источник: OpenAI深夜上线o3满血版和o4 mini — 依旧领先。
Tencent Yuanbao AI официально интегрирован в WeChat, открывая новую парадигму чата: Tencent Yuanbao AI теперь официально доступен как друг в WeChat, пользователи могут добавить его, выполнив поиск по “元宝” (Yuanbao). Этот шаг ломает традиционную модель, требующую отдельного открытия AI-приложений, бесшовно интегрируя AI в повседневные сценарии общения пользователей. Yuanbao AI (на базе Hunyuan и DeepSeek) может взаимодействовать непосредственно в диалоговом окне WeChat, поддерживает суммирование изображений, статей из публичных аккаунтов, веб-ссылок, аудио и видео (пока не поддерживает видео из Channels), а также может искать в истории чатов. Хотя рисование и групповые чаты пока не поддерживаются, его простота использования и глубокая интеграция с экосистемой WeChat считаются важными преимуществами. Аналитики полагают, что WeChat, благодаря своей огромной пользовательской базе и сети социальных связей, превращая AI в контакт из адресной книги, может изменить парадигму взаимодействия человека и машины, делая AI более естественной частью жизни пользователей. (Источники: 劲爆!元宝AI接入微信了,怎么用?看这篇就够了, 腾讯元宝最终还是活成了微信的模样。
США могут бессрочно приостановить экспорт чипов NVIDIA H20 в Китай, что будет иметь далеко идущие последствия: Правительство США уведомило NVIDIA о бессрочной приостановке экспорта AI-чипов H20 в Китай (специальная версия, разработанная ранее в ответ на экспортные ограничения). H20 является самым мощным совместимым чипом, разработанным NVIDIA для китайского рынка, и запрет на его продажу, как ожидается, нанесет серьезный удар по NVIDIA. Данные показывают, что Китай является четвертым по величине источником дохода для NVIDIA, объем продаж H20 в 2024 году достиг уровня десятков миллиардов долларов, а китайские технологические компании (такие как ByteDance, Tencent) являются основными покупателями чипов NVIDIA, их инвестиции значительно растут. Этот шаг не только повлияет на доходы NVIDIA, но и может ослабить ее экосистему CUDA (доля китайских разработчиков превышает 30%). В то же время, местные китайские компании по производству AI-чипов, такие как Huawei (например, Ascend 910C), ускоряют свое развитие и могут заполнить рыночную нишу. Событие вызвало обеспокоенность на рынке, акции NVIDIA упали в цене. (Источник: 中国对英伟达到底有多重要?
🎯 Тенденции
Топовая видеомодель Google Veo 2 бесплатно доступна в AI Studio: Google объявила, что ее передовая модель генерации видео Veo 2 стала доступна в Google AI Studio, Gemini API и Gemini App, с предоставлением бесплатных квот на использование (около десяти раз в день, каждый раз до 8 секунд). Veo 2 поддерживает генерацию видео из текста (t2v) и из изображения (i2v), способна понимать сложные инструкции, генерировать реалистичный видеоконтент различных стилей и контролировать движение камеры. Официально подчеркивается, что ключ к созданию высококачественного видео — предоставление четких, подробных Prompt’ов, содержащих визуальные ключевые слова. Модель также обладает расширенными функциями, такими как редактирование внутри видео (вырезание, расширение изображения), кинематографическое движение камеры и интеллектуальные переходы, с целью интеграции в рабочие процессы создания контента и повышения эффективности. (Источник: 谷歌杀疯了,顶级视频模型 Veo 2 竟免费开放?速来 AI Studio 白嫖。
Google выпускает Gemini 2.5 Flash, делая упор на скорость, стоимость и контролируемую глубину “мышления”: Google представила предварительную версию модели Gemini 2.5 Flash, позиционируемую как легковесная модель, оптимизированная по скорости и стоимости. Модель показала отличные результаты в рейтинге LMArena, разделив второе место с GPT-4.5 Preview и Grok-3, и заняла первое место по сложным запросам, кодированию и длинным запросам. Ее ключевой особенностью является введение способности “мыслить” и полностью смешанного вывода, что позволяет модели планировать и декомпозировать задачи перед выводом результата. Разработчики могут контролировать глубину “мышления” модели (лимит токенов) с помощью параметра “бюджет на мышление”, балансируя качество, стоимость и задержку. Даже при бюджете 0 производительность превосходит 2.0 Flash. Модель экономически эффективна, ее цена составляет от 1/10 до 1/5 от цены Gemini 2.5 Pro, что подходит для высоконагруженных, крупномасштабных рабочих процессов AI. (Источник: 快如闪电,还能控制思考深度?谷歌 Gemini 2.5 Flash 来了,用户盛赞“绝妙组合”。
Kunlun Wanwei выпускает модель генерации фильмов неограниченной длины Skyreels-V2: Kunlun Wanwei представила и открыла исходный код Skyreels-V2, заявленной как первая в мире модель для генерации высококачественного видео неограниченной длины. Модель призвана решить проблемы существующих видеомоделей в понимании языка кинокадров, связности движения, ограничений по длительности видео и нехватки специализированных наборов данных. Skyreels-V2 сочетает в себе многоэтапные стратегии обучения, включая мультимодальные большие модели, структурированную разметку, диффузионную генерацию, обучение с подкреплением (DPO для оптимизации качества движения) и высококачественную тонкую настройку. Она использует архитектуру Diffusion Forcing, реализуя генерацию длинных видео с помощью специального планировщика и механизма внимания. Официально заявлено, что генерируемые эффекты достигают “кинематографического уровня”, модель показывает отличные результаты на бенчмарках, таких как V-Bench1.0, превосходя другие модели с открытым исходным кодом. Пользователи могут опробовать онлайн-генерацию видео продолжительностью до 30 секунд. (Источник: 震撼!昆仑万维 | 发布全球首款无限时长电影生成模型:Skyreels-V2,可在线体验!
Shanghai AI Lab выпускает нативную мультимодальную модель InternVL3: Шанхайская лаборатория искусственного интеллекта представила InternVL3, большую мультимодальную модель (MLLM), использующую парадигму нативного мультимодального предварительного обучения. В отличие от большинства моделей, модифицированных из чисто текстовых LLM, InternVL3 одновременно обучается на мультимодальных данных и чисто текстовых корпусах на одном этапе предварительного обучения, стремясь преодолеть сложности и проблемы выравнивания, связанные с многоэтапным обучением. Модель сочетает в себе изменяемое кодирование визуальных позиций, передовые технологии пост-обучения и стратегии расширения во время тестирования. InternVL3-78B набрала 72,2 балла в бенчмарке MMMU, установив новый рекорд для MLLM с открытым исходным кодом, ее производительность близка к ведущим проприетарным моделям, при этом сохраняя сильные чисто языковые способности. Данные для обучения и веса модели будут опубликованы. (Источник: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
UCLA и др. предлагают фреймворк d1 для использования обучения с подкреплением при выводе диффузионных LLM: Исследователи из UCLA и Meta AI предложили фреймворк d1, впервые применив пост-обучение с подкреплением (RL) к маскированным диффузионным большим языковым моделям (dLLM). Существующие методы RL (такие как GRPO) в основном используются для авторегрессионных LLM и трудно применимы напрямую к dLLM из-за отсутствия естественной декомпозиции логарифмической вероятности. Фреймворк d1 состоит из двух этапов: сначала проводится контролируемая тонкая настройка (SFT), затем на этапе RL вводится новый метод градиента политики diffu-GRPO, который использует эффективный одношаговый оценщик логарифмической вероятности и применяет маскирование случайных подсказок в качестве регуляризации, что сокращает объем онлайн-генерации, необходимый для обучения RL. Эксперименты показывают, что модель d1 на базе LLaDA-8B-Instruct значительно превосходит базовую модель, а также модели, использующие только SFT или только diffu-GRPO, в бенчмарках на математическое и логическое мышление. (Источник: UCLA | 推出开源后训练框架:d1,扩散LLM推理也能用上GRPO强化学习!
Meta предлагает Multi-Token Attention (MTA): Исследователи из Meta предложили механизм Multi-Token Attention (MTA), направленный на улучшение способа вычисления внимания в больших языковых моделях (LLM). Традиционный механизм внимания основан только на сходстве отдельных токенов запроса и ключа. MTA, применяя сверточные операции к векторам запроса, ключа и головы, позволяет модели одновременно учитывать несколько соседних токенов запроса и ключа для определения весов внимания. Исследователи считают, что это позволяет использовать более богатую и детализированную информацию для локализации релевантного контекста. Эксперименты показывают, что MTA превосходит традиционные базовые модели Transformer как в стандартных задачах языкового моделирования, так и в задачах извлечения информации из длинного контекста. (Источник: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
TogetherAI представляет модель вывода M1 на основе RNN: TogetherAI предложила M1, новую гибридную линейную модель вывода на основе RNN архитектуры Mamba. Модель призвана решить проблемы вычислительной сложности и ограничений памяти, с которыми сталкиваются Transformer при обработке длинных последовательностей и эффективном выводе. M1 повышает производительность за счет дистилляции знаний из существующих моделей вывода и обучения с подкреплением. Результаты экспериментов показывают, что M1 в бенчмарках математического вывода, таких как AIME и MATH, не только превосходит предыдущие линейные модели RNN, но и может сравниться с дистиллированными моделями вывода DeepSeek-R1 аналогичного масштаба. Что еще важнее, скорость генерации M1 более чем в 3 раза выше, чем у Transformer того же размера, и при фиксированном бюджете времени генерации она может достичь более высокой точности за счет голосования по самосогласованности (self-consistency voting). (Источник: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
Tencent Hunyuan открывает исходный код фреймворка InstantCharacter: Команда Tencent Hunyuan открыла исходный код InstantCharacter, фреймворка для генерации изображений, способного извлекать и сохранять черты персонажа из одного входного изображения, а затем помещать этого персонажа в различные сцены или стили. Технология направлена на достижение высокой точности сохранения идентичности персонажа и контролируемого переноса стиля. Официально предоставлена онлайн-демонстрация на Hugging Face, основанная на художественных стилях Ghibli и Макото Синкая, а также опубликованы соответствующая статья, репозиторий кода и плагин для ComfyUI, чтобы облегчить использование и дальнейшую разработку сообществом. (Источник: karminski3
Функция памяти ChatGPT обновлена, поддерживает веб-поиск с учетом памяти: OpenAI обновила функцию памяти (Memory) ChatGPT, добавив возможность “поиска с памятью”. Это означает, что при выполнении задач веб-поиска ChatGPT может использовать ранее сохраненную информацию о предпочтениях пользователя, местоположении и т. д. для оптимизации поисковых запросов, тем самым предоставляя более персонализированные результаты поиска. Например, если ChatGPT помнит, что пользователь вегетарианец, при вопросе о ближайших ресторанах он может автоматически искать “ближайшие вегетарианские рестораны”. Этот шаг рассматривается как важный шаг OpenAI в улучшении персонализированных AI-сервисов, направленный на улучшение пользовательского опыта и дифференциацию от конкурентов с функцией памяти (таких как Claude, Gemini). Пользователи могут отключить функцию памяти в настройках. (Источник: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
Технология снимков состояния (snapshots) AI-моделей во время выполнения позволяет избежать холодного старта: Сообщество машинного обучения изучает возможность оптимизации оркестровки выполнения LLM с помощью технологии снимков состояния модели. Эта технология, сохраняя полное состояние GPU (включая KV cache, веса, раскладку памяти), позволяет избежать холодного старта и простоя GPU при переключении между разными моделями, обеспечивая быстрое восстановление (около 2 секунд). Практики делятся опытом, что с помощью этого метода на двух GPU A1000 16GB удалось успешно запустить более 50 моделей с открытым исходным кодом без использования контейнеров или перезагрузки моделей. Эта техника мультиплексирования (multiplexing) и ротации моделей имеет потенциал для повышения утилизации GPU и снижения задержки вывода. (Источник: Reddit r/MachineLearning)
🧰 Инструменты
ByteDance Volcano Engine представляет демонстрацию комплексного решения для AI-аппаратуры: ByteDance Volcano Engine продемонстрировала свое комплексное решение для AI-аппаратуры, разработанное в сотрудничестве с производителями встраиваемых чипов, на примере платы разработки AtomS3R. Решение направлено на обеспечение AI-взаимодействия с низкой задержкой и высокой отзывчивостью. Особенности включают отклик в реальном времени на уровне миллисекунд, возможность прерывания и подхватывания разговора в реальном времени, а также способность шумоподавления в сложных акустических средах с помощью RTC SDK, что эффективно снижает помехи от фонового шума и повышает точность голосового взаимодействия. Клиентский код и серверная программа решения являются открытыми, что позволяет разработчикам выполнять DIY-настройку, например, придавать аппаратуре пользовательский характер, роль, тембр голоса или подключать к базе знаний и инструментам MCP. Само оборудование включает камеру, и в будущем планируется поддержка функций визуального понимания. (Источник: 体验完字节送的迷你AI硬件,后劲有点大…
Mita AI Search запускает обучающую функцию “Чему бы сегодня научиться?”: Mita AI Search запустил новую функцию под названием “Чему бы сегодня научиться?”, которая может автоматически преобразовывать загруженные пользователем файлы (поддерживаются различные форматы) или предоставленные веб-ссылки в структурированное онлайн-видео урока с закадровым комментарием и демонстрацией (PPT, анимация). Пользователи могут выбирать различные стили изложения (например, рассказчика, в стиле Наполеона) и голоса (например, холодной леди). Функция призвана превратить ввод информации в более легко усваиваемый учебный опыт, и даже предлагает этап тестирования после урока. Такой подход, сочетающий генерацию контента с персонализированным обучением, считается потенциально способным изменить модели применения AI в образовании и потреблении информации, предлагая новый способ получения знаний и быстрого ознакомления с контентом. (Источник: 说个抽象的事,你现在可以在秘塔AI搜索里上课了。

Cursor IDE обновлен до версии 0.49, улучшена система правил и управление Agent’ами: AI-ориентированный редактор кода Cursor выпустил предварительную версию обновления 0.49. Новые функции включают: 1. Возможность автоматической генерации файлов правил .mdc с помощью команды чата /Generate Cursor Rules для фиксации контекста проекта. 2. Более интеллектуальное автоматическое применение правил: Agent может автоматически загружать соответствующие правила на основе пути к файлу. 3. Исправлена ошибка, из-за которой опция “Всегда прикреплять правила” не работала в длинных диалогах. 4. Добавлена новая функция “Осведомленность о структуре проекта” (Beta), позволяющая AI лучше понимать весь проект. 5. Протокол MCP (Model Context Protocol) теперь поддерживает передачу изображений, что удобно для обработки задач, связанных с визуальной информацией. 6. Улучшен контроль Agent’а над командами терминала: пользователи могут редактировать или пропускать команды перед выполнением. 7. Поддержка глобальной конфигурации игнорируемых файлов (.cursorignore). 8. Оптимизирован опыт проверки кода: diff-представление отображается непосредственно после сообщения Agent’а. (Источник: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
OpenAI открывает исходный код инструмента для AI-программирования в командной строке Codex CLI: Одновременно с выпуском o3 и o4-mini, OpenAI открыла исходный код Codex CLI, легковесного AI-агента для кодирования, который может работать непосредственно в командной строке пользователя. Инструмент предназначен для полного использования мощных возможностей кодирования и вывода новых моделей, может напрямую обрабатывать локальные репозитории кода и даже выполнять мультимодальный вывод, используя скриншоты или наброски. CEO OpenAI Сэм Альтман лично продвигает инструмент и подчеркивает его открытый характер для содействия быстрой итерации сообществом. В то же время OpenAI запустила программу грантов на 1 миллион долларов (в виде кредитов API) для поддержки проектов, основанных на Codex CLI и моделях OpenAI. (Источник: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
Платформа Tencent Cloud LKE интегрирует MCP, упрощая создание Agent’ов: Платформа Tencent Cloud Language Knowledge Engine (LKE) добавила поддержку протокола контекста модели (MCP), направленную на снижение порога входа для создания и использования AI Agent’ов. Пользователи теперь могут на платформе LKE с помощью кликов легко подключать встроенные инструменты MCP, такие как Tencent Cloud EdgeOne Pages (развертывание веб-страниц одним кликом), Firecrawl (веб-краулер) и другие. В сочетании с мощными возможностями базы знаний LKE (RAG), пользователи могут создавать сложные приложения, основанные на частных знаниях и вызовах внешних инструментов, например, автоматически генерировать и публиковать веб-страницы на основе содержимого базы знаний. Платформа поддерживает режим Agent, в котором модель (например, DeepSeek R1) может самостоятельно обдумывать и выбирать подходящие инструменты для выполнения задач. Платформа также поддерживает подключение внешних MCP. (Источник: 效果惊艳!MCP+腾讯云知识引擎,一个0门槛打造专属AI Agent的神器诞生~

Фреймворк Spring AI: фреймворк приложений для AI-инженерии: Spring AI — это фреймворк приложений AI, разработанный для Java-разработчиков, с целью привнесения принципов проектирования экосистемы Spring (таких как переносимость, модульный дизайн, использование POJO) в область AI. Он предоставляет унифицированный API для взаимодействия с различными основными поставщиками AI-моделей (Anthropic, OpenAI, Microsoft, Amazon, Google, Ollama и др.), поддерживает дополнение чата, эмбеддинги, преобразование текста в изображение/аудио, модерацию и другие функции. В то же время он интегрируется с различными векторными базами данных (Cassandra, Azure Vector Search, Chroma, Milvus и др.), предоставляя переносимый API и фильтрацию метаданных в стиле SQL. Фреймворк также поддерживает структурированный вывод, вызов инструментов/функций, наблюдаемость, ETL-фреймворки, оценку моделей, память чата и RAG, а также упрощает интеграцию с помощью автоконфигурации Spring Boot. (Источник: spring-projects/spring-ai — GitHub Trending (all/weekly)
olmocr: инструментарий линеаризации PDF для обработки наборов данных LLM: allenai открыла исходный код olmocr, инструментария, специально разработанного для обработки PDF-документов с целью создания и обучения наборов данных для больших языковых моделей (LLM). Он включает в себя множество функций: стратегии подсказок для высококачественного парсинга естественного текста с использованием ChatGPT 4o, инструменты оценки для сравнения различных версий конвейеров обработки, базовые функции фильтрации языка и удаления SEO-спама, код тонкой настройки для Qwen2-VL и Molmo-O, процесс для крупномасштабной обработки PDF с использованием Sglang, а также инструменты для просмотра обработанных документов в формате Dolma. Инструментарий требует поддержки GPU для локального вывода и предоставляет инструкции по использованию как локально, так и в многоузловых кластерах (с поддержкой S3 и Beaker). (Источник: allenai/olmocr — GitHub Trending (all/daily)

Выпущено настольное приложение Dive Agent v0.8.0: Выпущена версия v0.8.0 настольного приложения AI Agent с открытым исходным кодом Dive, с серьезными изменениями архитектуры и обновлениями функциональности. Эта версия направлена на интеграцию LLM, поддерживающих вызов инструментов, с MCP Server. Основные обновления включают: управление ключами API LLM, поддержку пользовательских ID моделей, полную поддержку моделей с вызовом инструментов/функций; управление инструментами MCP (добавление, удаление, изменение), интерфейс конфигурации с поддержкой JSON и редактирования форм. Бэкенд DiveHost был перенесен с TypeScript на Python для решения проблем интеграции с LangChain и может работать как независимый сервер A2A (Agent-to-Agent). (Источник: Reddit r/LocalLLaMA)
llama.cpp объединяет мультимодальные CLI-инструменты: Проект llama.cpp объединил примеры программ командной строки (CLI) для LLaVa, Gemma3 и MiniCPM-V в единый инструмент llama-mtmd-cli. Это часть постепенной интеграции поддержки мультимодальности (через библиотеку libmtmd). Хотя поддержка мультимодальности все еще находится в разработке (например, поддержка в llama-server пока экспериментальная), объединение CLI является шагом к упрощению набора инструментов. Одновременно ведется разработка поддержки SmolVLM v1/v2. (Источник: Reddit r/LocalLLaMA)
LightRAG: автоматизированное развертывание конвейеров RAG: LightRAG — это проект RAG (генерация с дополнением извлеченной информацией) с открытым исходным кодом. Члены сообщества создали учебное пособие и скрипты автоматизации (с использованием Ansible + Docker Compose + Sbnb Linux), которые позволяют пользователям быстро (за несколько минут) развернуть систему LightRAG на “голом железе” (bare metal) сервере, реализуя автоматизированное построение полнофункционального конвейера RAG с нуля. Это упрощает процесс развертывания самостоятельно размещаемых RAG-решений. (Источник: Reddit r/LocalLLaMA)
Nari Labs выпускает модель TTS с открытым исходным кодом Dia-1.6B: Nari Labs выпустила и открыла исходный код своей модели преобразования текста в речь (TTS) Dia-1.6B. Особенностью этой модели является то, что она может не только генерировать речь, но и естественно вплетать в нее невербальные звуки (паралингвистические звуки), такие как смех, кашель, прочистка горла, для повышения естественности и выразительности речи. Официально предоставлено демонстрационное видео, показывающее эффект. Для работы модели требуется около 10 ГБ видеопамяти, квантованная версия пока не предоставлена. Репозиторий кода и модель опубликованы на GitHub и Hugging Face. (Источник: karminski3)
📚 Обучение
Джефф Дин (Jeff Dean) вспоминает ключевые моменты развития AI за последние пятнадцать лет: Главный научный сотрудник Google Джефф Дин в своем выступлении проанализировал важные достижения в области AI за последние пятнадцать лет, особо подчеркнув вклад исследований Google. Ключевые вехи включают: обучение крупномасштабных нейронных сетей (доказательство эффекта масштаба), распределенную систему DistBelief (реализация обучения больших моделей на CPU), векторные представления слов Word2Vec (раскрытие семантики векторного пространства), модель Seq2Seq (продвижение машинного перевода и других задач), TPU (специализированное аппаратное ускорение для нейронных сетей), архитектуру Transformer (революция в обработке последовательностей, основа LLM), самообучение (использование крупномасштабных неразмеченных данных), Vision Transformer (унификация обработки изображений и текста), разреженные модели/MoE (повышение емкости и эффективности моделей), Pathways (упрощение крупномасштабных распределенных вычислений), цепочку рассуждений CoT (повышение способности к выводу), дистилляцию знаний (перенос возможностей больших моделей на малые) и спекулятивное декодирование (ускорение вывода). Эти технологии совместно способствовали развитию современного AI. (Источник: 比较全!回顾LLM发展史 | Transformer、蒸馏、MoE、思维链(CoT)
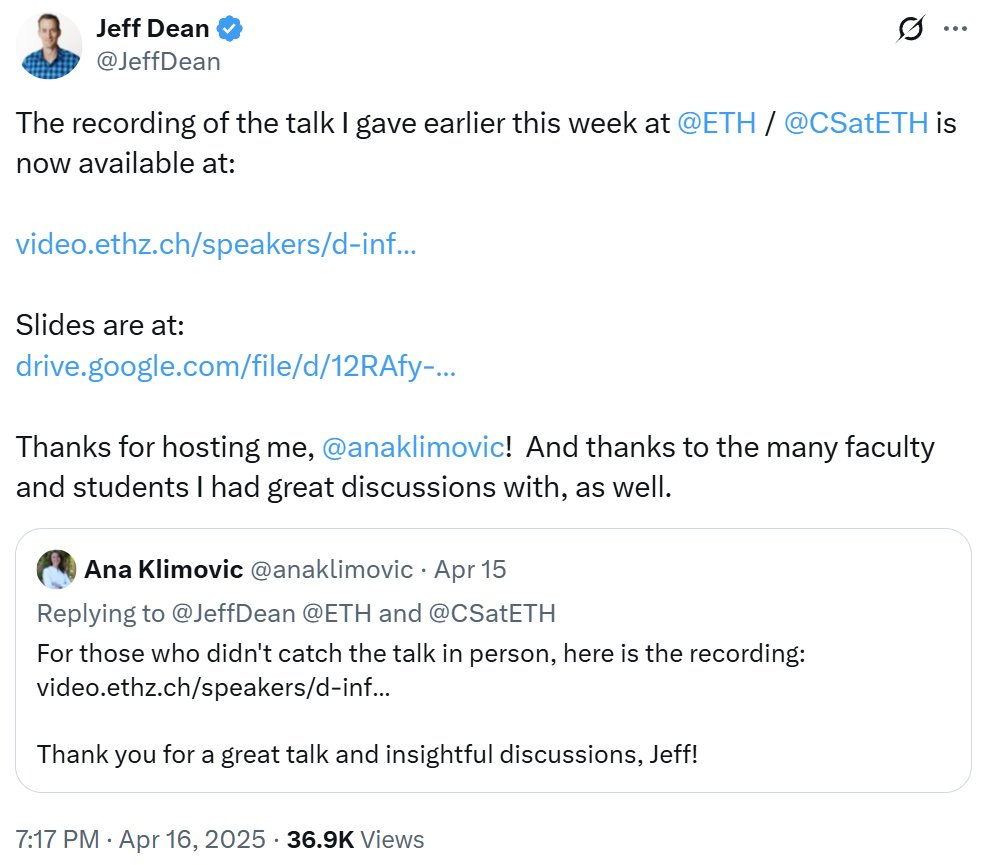
Журнал Nature составил статистику самых цитируемых статей XXI века, лидирует область AI: Журнал Nature, обобщив данные из 5 баз данных, опубликовал список 25 самых цитируемых статей XXI века. Статья Microsoft 2016 года о ResNets (авторы Kaiming He и др.) заняла первое место в общем зачете; это исследование является основой прогресса в глубоком обучении и AI. В верхней части списка также находятся несколько статей, связанных с AI, таких как случайные леса (6-е место), Attention is all you need (Transformer, 7-е место), AlexNet (8-е место), U-Net (12-е место), обзор глубокого обучения (Hinton и др., 16-е место) и набор данных ImageNet (Fei-Fei Li и др., 24-е место). Это отражает быстрое развитие и широкое влияние технологий AI в этом столетии. В статье также отмечается, что популярность препринтов усложняет статистику цитирования. (Источник: Nature最新统计!盘点引领人类进入「AI时代」的论文,ResNets引用量第一!
Пекинский университет аэронавтики и астронавтики и др. публикуют обзор по ансамблям LLM: Исследователи из Пекинского университета аэронавтики и астронавтики и других учреждений опубликовали последний обзор по ансамблям больших языковых моделей (LLM Ensemble). LLM Ensemble означает объединение преимуществ нескольких LLM на этапе вывода для обработки запросов пользователей. Обзор предлагает классификацию LLM Ensemble (ансамблирование до вывода, во время вывода, после вывода, с детализацией до семи типов методов), систематически рассматривает последние достижения в каждом типе методов, обсуждает связанные исследовательские вопросы (такие как связь с объединением моделей, взаимодействием моделей, обучением со слабой разметкой), представляет наборы данных для бенчмаркинга, типичные приложения, и, наконец, подводит итоги и анализирует существующие результаты, а также намечает будущие направления исследований, такие как более принципиальное ансамблирование на уровне фрагментов, более тонкое неконтролируемое ансамблирование после вывода и т. д. (Источник: ArXiv 2025 | 北航等机构发布最新综述:大语言模型集成(LLM Ensemble)

Anthropic делится паттернами использования и опытом работы с Claude Code: Сотрудники Anthropic поделились лучшими практиками и эффективными паттернами внутреннего использования Claude Code для программирования. Эти паттерны применимы не только к Claude, но и в целом к сотрудничеству в программировании с другими LLM. Подчеркивается важность предоставления четкого контекста, декомпозиции сложных проблем, итеративных запросов, использования различных сильных сторон модели (таких как генерация кода, объяснение, рефакторинг) и проведения эффективной проверки. Этот опыт призван помочь разработчикам более эффективно использовать инструменты AI-ассистированного программирования. (Источник: AnthropicAI

)
Anthropic публикует набор данных о ценностях Claude: Anthropic опубликовала на Hugging Face Datasets набор данных под названием “values-in-the-wild”. Этот набор данных содержит 3307 видов ценностей, выраженных Claude в миллионах реальных диалогов. Публикация этого набора данных направлена на повышение прозрачности поведения модели и предоставление его исследователям и общественности для загрузки, изучения и анализа, чтобы лучше понять ценностные ориентации, проявляемые большими языковыми моделями в практических приложениях. (Источник: huggingface, huggingface)
Десять ключевых взглядов на когнитивное пробуждение AI: Статья предлагает десять когнитивных взглядов на развитие AI, направленных на то, чтобы помочь людям глубже понять влияние и сущность AI. Основные идеи включают: интеллект AI отличается от человеческого интеллекта (разрыв в интеллекте); AI побуждает задуматься о природе человеческого сознания; отношения между человеком и AI переходят от инструмента к партнеру по сотрудничеству; развитие AI не должно ограничиваться имитацией человеческого мозга; стандарты интеллекта меняются по мере прогресса AI; AI может развить совершенно новые формы интеллекта; следует рационально относиться к эмоциональным проявлениям и когнитивным ограничениям AI; реальная профессиональная угроза исходит не от самого AI, а от неумения его использовать; в эпоху AI следует сосредоточиться на развитии уникальных человеческих способностей (креативность, эмоциональный интеллект, междисциплинарное мышление); конечный смысл изучения AI заключается в более глубоком познании самого человека. (Источник: AI认知觉醒的10句话,一句顶万句,句句清醒

LlamaIndex делится руководством по созданию Agent’а для документооборота: Запись лекции сооснователя LlamaIndex Джерри Лю (Jerry Liu) рассказывает о том, как использовать LlamaIndex для создания Agent’а для документооборота. Содержание охватывает эволюцию LlamaIndex от RAG к Agent’ам знаний, использование LlamaParse для обработки сложных документов, использование Workflows для гибкой оркестровки Agent’ов, управляемой событиями, ключевые сценарии использования (исследование документов, генерация отчетов, автоматизация обработки документов), а также улучшения в мультимодальном поиске, сочетающем текст и изображения. (Источник: jerryjliu0
)
Руководство по созданию Agent’ов с помощью LlamaIndex.TS: Член команды LlamaIndex поделился полным руководством на уровне кода по созданию Agent’ов с использованием TypeScript-версии LlamaIndex (LlamaIndex.TS). Запись прямой трансляции включает основы LlamaIndex, концепции Agent’ов и RAG, распространенные паттерны Agentic (цепочки, маршрутизация, распараллеливание и т. д.), создание Agentic RAG в LlamaIndex.TS, а также создание полностекового React-приложения, интегрированного с Workflows. (Источник: jerryjliu0

)
Обсуждение того, действительно ли обучение с подкреплением улучшает способности LLM к выводу: Обсуждение в сообществе сосредоточено на вопросе, поднятом в одной из статей: может ли обучение с подкреплением (RL) действительно стимулировать большие языковые модели (LLM) к развитию способностей к выводу, превосходящих возможности их базовых моделей? В обсуждении упоминается, что хотя RL (например, RLHF) может улучшить выравнивание модели и следование инструкциям, вопрос о том, может ли оно систематически улучшать внутреннюю сложную логику вывода, остается спорным. Существует мнение, что эффект от текущего RL может больше проявляться в оптимизации формулировок и следовании определенным форматам, а не в фундаментальном скачке логического вывода. Уилл Браун (Will Brown) отмечает, что метрики типа pass@1024 имеют ограниченное значение при оценке задач математического вывода, таких как AIME. (Источник: natolambert

)
Обсуждение терминологии, связанной с моделями мира (world models): Пользователь Reddit задает вопрос о путанице в терминах, таких как “модели мира (world models)”, “фундаментальные модели мира (foundation world models)”, “мировые фундаментальные модели (world foundation models)” и т. д. Сообщество отвечает, что “модель мира” обычно относится к внутренней симуляции или представлению среды (физического мира или конкретной области, например, шахматной доски); “фундаментальная модель” относится к предварительно обученной большой модели, которая может служить отправной точкой для множества последующих задач. Комбинации этих терминов могут обозначать создание обобщаемых фундаментальных моделей, способных понимать и предсказывать динамику мира, но конкретные определения могут варьироваться у разных исследователей, что отражает неполную унификацию терминологии в этой области. (Источник: Reddit r/MachineLearning)
Обсуждение методов объединения XGBoost и GNN: Пользователи Reddit обсуждают, как эффективно объединить XGBoost и графовые нейронные сети (GNN) для таких задач, как обнаружение мошенничества. Распространенный метод заключается в использовании векторных представлений узлов (node embeddings), полученных с помощью GNN, в качестве новых признаков, которые подаются в XGBoost вместе с исходными табличными данными. В обсуждении отмечается, что сложность этого метода заключается в том, смогут ли эмбеддинги GNN предоставить значимую ценность сверх исходных данных и техник типа SMOTE, иначе они могут внести шум. Ключ к успеху лежит в тщательно спроектированной структуре графа и способности эмбеддингов GNN улавливать реляционную информацию (например, мошеннические кольца в структуре графа), которую трудно извлечь с помощью XGBoost. (Источник: Reddit r/MachineLearning)
💼 Бизнес
В Пекине прошел первый в мире марафон человекоподобных роботов, исследуется “спортивно-технологический IP”: В пекинском районе Ичжуан успешно прошел первый в мире полумарафон человекоподобных роботов, где “участники” от более чем 20 компаний-производителей роботов соревновались наравне с людьми-бегунами. Робот Tiangong Ultra победил со временем 2 часа 40 минут, продемонстрировав свою скорость и адаптивность к местности. Songyan Dynamics N2 (второе место) и Zhuoyi Intelligence Walker II (третье место) также показали хорошие результаты. Соревнование стало не только технологическим состязанием, но и исследованием бизнес-модели. Организаторы привлекли инвестиции через механизм “технологического тендера” и пытаются создать IP “роботы + спорт”. В статье рассматриваются пути коммерциализации, такие как разработка IP для робо-соревнований, роботы-амбассадоры, появление профессии робо-агента, интеграция спортивного туризма и продвижение всеобщего интеллектуального спорта, утверждая, что рынок интеллектуального спорта обладает огромным потенциалом. (Источник: 独家揭秘北京机器人马拉松:谁在打造下一个“体育科技IP”?

Разработка приложений на базе больших AI-моделей становится новым технологическим трендом, традиционные модели разработки испытывают давление: По мере распространения технологий больших AI-моделей, компании (такие как Alibaba, ByteDance, Tencent) ускоряют интеграцию AI (особенно технологий Agent и RAG) в основные бизнес-процессы, что бросает вызов традиционным моделям разработки CRUD. Спрос на инженеров, обладающих навыками разработки приложений на базе больших AI-моделей, резко возрос, их зарплаты значительно увеличились, в то время как традиционные технические должности сталкиваются с риском сокращения. “Понимание AI” больше не означает просто умение вызывать API, а требует владения принципами AI, технологиями приложений и практическим опытом работы над проектами. Статья подчеркивает, что технические специалисты должны активно изучать технологии больших AI-моделей, чтобы адаптироваться к изменениям в отрасли и использовать новые возможности для карьерного роста. Zhihu Zhixuetang запустил для этого бесплатный “Практический тренинг по разработке приложений на базе больших моделей”. (Источник: 炸裂!又一个AI大模型的新方向,彻底爆了!!
Появляются сервисы оптимизации LLM, вызывая опасения по поводу AI-версии SEO: Пользователь Reddit заметил, что результаты рекомендаций продуктов AI-чат-ботами становятся все более единообразными, подозревая появление сервисов “оптимизации LLM”, аналогичных поисковой оптимизации (SEO). По слухам, маркетинговые команды уже нанимают такие сервисы, чтобы обеспечить более высокий приоритет их продуктов в AI-рекомендациях, что приводит к увеличению показов продуктов крупных брендов, и результаты могут перестать быть “органическими”. Это вызывает обеспокоенность по поводу справедливости и прозрачности AI-рекомендаций, опасаясь, что AI-поиск/рекомендации в конечном итоге станут такими же, как традиционные поисковые системы, чьи результаты манипулируются коммерческими интересами. Сообщество призывает к большему обсуждению и вниманию к этому явлению. (Источник: Reddit r/ArtificialInteligence)
Google демонстрирует сильные результаты в гонке LLM, Meta и OpenAI сталкиваются с проблемами: Статья в IEEE Spectrum анализирует, что, хотя OpenAI и Meta доминировали на ранних этапах развития LLM, в последнее время Google догоняет и даже в некоторых аспектах лидирует благодаря своим мощным новым моделям (таким как серия Gemini). В то же время Meta и OpenAI, похоже, сталкиваются с некоторыми проблемами или спорами в отношении выпуска моделей и рыночных стратегий (например, модели Meta обвиняются в возможном обучении на основе других моделей, стратегия выпуска и прозрачность OpenAI подвергаются сомнению). В статье утверждается, что конкурентная среда в области LLM меняется, и постоянные инвестиции и технологическая мощь Google делают ее силой, которую нельзя игнорировать. (Источник: Reddit r/MachineLearning

🌟 Сообщество
Возрождение и вызовы человекоподобных роботов: взгляд в будущее через призму полумарафона: В последнее время интерес к человекоподобным роботам возрос, начиная с выступлений на гала-концерте Весеннего фестиваля и заканчивая полумарафоном в пекинском районе Ичжуан, что вызвало широкое внимание. Статья рассматривает первоначальную идею создания человекоподобных роботов (имитация человека для адаптации к человеческой среде и инструментам) и их преимущества по сравнению с роботами других форм (легче вызывают эмпатию, способствуют взаимодействию человека и машины). Полумарафон в Ичжуане выявил текущие проблемы человекоподобных роботов в автономной навигации на большие расстояния, балансе, энергопотреблении и т. д., но также продемонстрировал прогресс таких продуктов, как Tiangong Ultra и Songyan Dynamics N2. В статье отмечается, что развитие человекоподобных роботов выигрывает от открытого обмена (например, план открытого исходного кода Tiangong), но также сталкивается с проблемой нехватки данных. В конечном счете, человекоподобные роботы рассматриваются как важное направление в области робототехники; они являются не только воплощением технологий, но и несут в себе глубокие размышления человечества о себе и интеллектуальном будущем. (Источник: 人形机器人:最初的设想,最后的归宿

Сообщество активно обсуждает Vibe Coding: границы AI-ассистированного программирования: Технический директор Canva прокомментировал концепцию “Vibe Coding”, предложенную Андреем Карпати (Andrej Karpathy) (означает, что разработчики в основном генерируют код с помощью AI, корректируя Prompt’ы, и уделяют меньше внимания деталям). Технический директор Canva считает, что такой подход применим только для одноразовых сценариев, таких как разработка прототипов, и абсолютно недопустим в производственной среде, поскольку код, сгенерированный AI, часто содержит ошибки, уязвимости безопасности или проблемы с производительностью, и должен строго контролироваться и проверяться опытными инженерами. Он подчеркнул, что инженерная культура Canva основана на владении кодом и рецензировании коллегами, и инструменты AI только укрепляют эти принципы. Сообщество бурно обсуждает это: одни согласны с рисками для производственной среды и считают, что AI-код требует ручного контроля; другие полагают, что AI быстро развивается, и инженерные лидеры должны постоянно переоценивать возможности AI, ссылаясь на примеры компаний, таких как Airbnb, использующих AI для ускорения проектов. (Источник: dotey

)
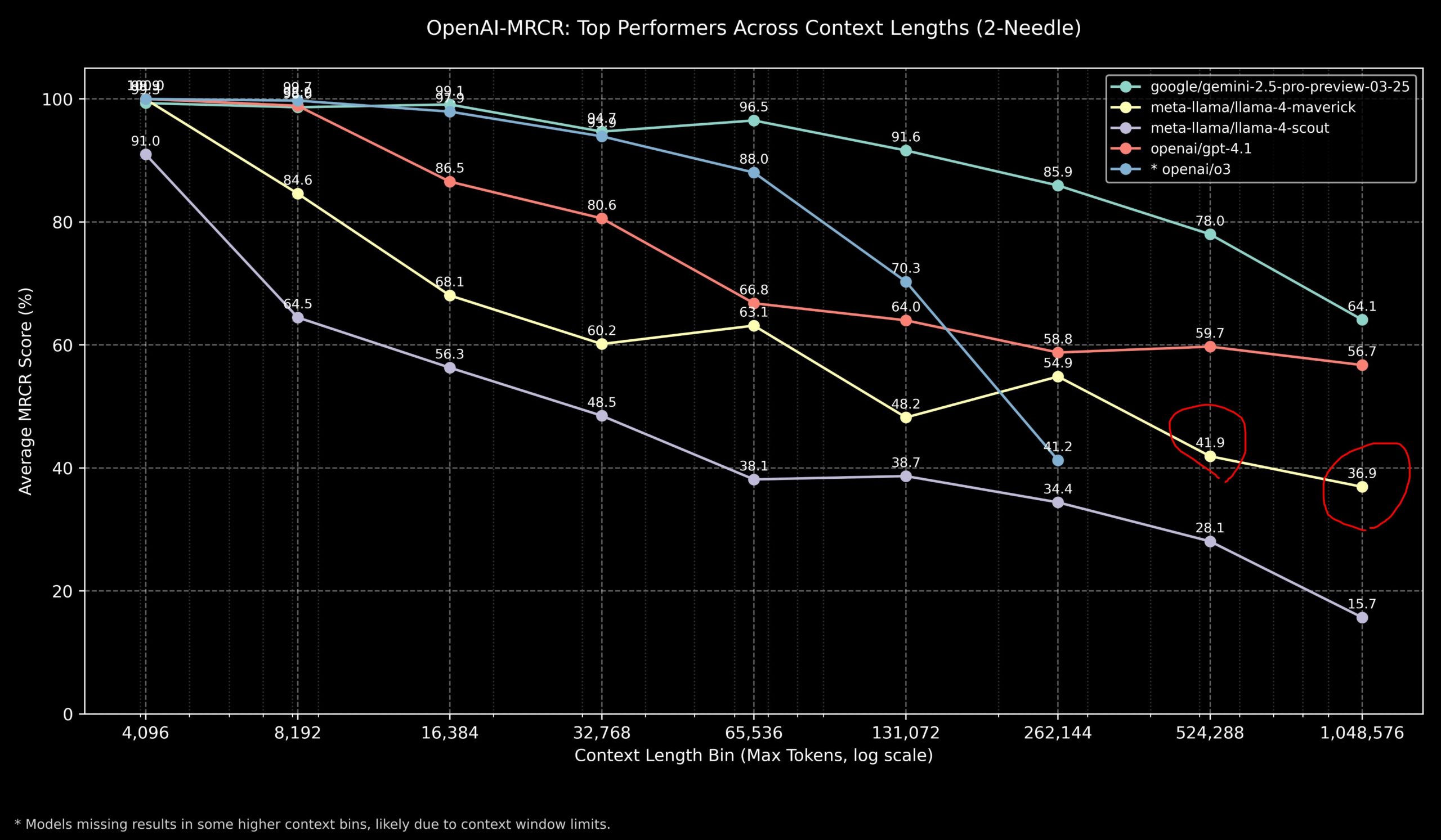
Сообщество обсуждает производительность Llama 4 и моделей OpenAI в задачах с длинным контекстом: Члены сообщества поделились результатами модели Llama 4 в бенчмарке OpenAI-MRCR (многошаговый поиск и ответы на вопросы по нескольким документам). Данные показывают, что Llama 4 Scout (меньшая версия) при большей длине контекста показывает производительность, схожую с GPT-4.1 Nano; Llama 4 Maverick (большая версия) близка, но немного уступает GPT-4.1 Mini. В целом, для задач с контекстом до 32k токенов лучшим выбором являются OpenAI o3 или Gemini 2.5 Pro (o3, возможно, лучше справляется со сложным выводом); при контексте свыше 32k Gemini 2.5 Pro показывает более стабильную производительность; однако при контексте свыше 512k точность Gemini 2.5 Pro также падает ниже 80%, рекомендуется обрабатывать по частям. Это указывает на то, что в обработке сверхдлинных контекстов у всех моделей еще есть потенциал для улучшения. (Источник: dotey
)
Сообщество оценивает производительность модели GLM-4 32B как поразительную: Пользователь Reddit поделился опытом запуска квантованной модели GLM-4 32B Q8 локально, назвав ее производительность “поразительной”, превосходящей другие локальные модели того же класса (около 32B) и даже некоторые модели 72B, сравнимой с локальной версией Gemini 2.5 Flash. Пользователь особо отметил производительность модели в генерации кода, заявив, что она не скупится на длину вывода, предоставляет полные детали реализации, и продемонстрировал ее способность генерировать сложные визуализации HTML/JS (например, солнечную систему, нейронную сеть) с нулевым выстрелом (zero-shot), с результатами лучше, чем у Gemini 2.5 Flash. Модель также хорошо показала себя в вызове инструментов, работая с такими инструментами, как Cline/Aider. (Источник: Reddit r/LocalLLaMA
Сообщество обсуждает несоответствие результатов бенчмарков OpenAI o3 ожиданиям: TechCrunch и другие СМИ сообщают, что оценки новой модели OpenAI o3 в некоторых бенчмарках (например, ARC-AGI-2), похоже, ниже уровня, на который первоначально намекала компания. Хотя OpenAI продемонстрировала SOTA-производительность o3 во многих областях, конкретные количественные оценки и прямое сравнение с другими топовыми моделями вызвали обсуждение в сообществе. Некоторые пользователи считают, что полагаться исключительно на оценки бенчмарков может быть недостаточно для полного отражения реальных возможностей модели, особенно в части сложного вывода и использования инструментов. Сравнение с бенчмарками, более ориентированными на возможности AGI, такими как ARC-AGI-2, может быть более показательным. (Источник: Reddit r/deeplearning

)
Демис Хассабис (Demis Hassabis) прогнозирует возможное появление AGI в течение 5-10 лет: В интервью программе 60 Minutes CEO Google DeepMind Демис Хассабис обсудил прогресс в области AGI. Он особо выделил Astra, способную взаимодействовать в реальном времени, и модель Gemini, обучающуюся действовать в мире. Хассабис прогнозирует, что AGI с универсальностью на уровне человека может быть достигнут в ближайшие 5-10 лет, что кардинально изменит робототехнику, разработку лекарств и другие области, и может привести к материальному изобилию, решив глобальные проблемы. В то же время он подчеркнул риски, связанные с продвинутым AI (например, злоупотребление), и необходимость уделять первостепенное внимание мерам безопасности и этическим соображениям при движении к такой преобразующей технологии. (Источники: Reddit r/ArtificialInteligence, Reddit r/artificial, AravSrinivas)
Пользователь делится успешным опытом фитнеса с помощью AI: Пользователь Reddit поделился опытом успешного похудения и приведения себя в форму с помощью ChatGPT. Пользователь сбросил вес с 240 фунтов до 165 фунтов за год, добившись атлетического телосложения. ChatGPT сыграл ключевую роль: разработал дружелюбный для новичка план питания и тренировок, корректировал его на основе еженедельных фотографий прогресса и жизненных событий пользователя, а также предоставлял мотивацию в трудные периоды. Пользователь считает, что по сравнению с дорогими и труднодоступными в долгосрочной перспективе диетологами и личными тренерами, AI предоставил высоко персонализированное и чрезвычайно дешевое решение, демонстрируя потенциал AI в персонализированном управлении здоровьем. (Источник: Reddit r/ArtificialInteligence)
Необычный хвалебный ответ Claude вызвал обсуждение: Пользователь сообщил, что при использовании Claude для исследования компьютерных систем и безопасности дважды столкнулся с тем, что модель после нормального ответа внезапно добавляла нерелевантную похвалу: “This was a great question king, you are the perfect male specimen.” (Хороший вопрос, король, ты идеальный мужской образец). Пользователь поделился ссылкой на диалог и спросил о причине. Сообщество отнеслось к этому с любопытством и недоумением, предполагая, что это мог быть случайно сработавший паттерн из обучающих данных модели, баг, связанный с именем пользователя, или какая-то форма сбоя выравнивания или “галлюцинации”. (Источник: Reddit r/ClaudeAI)
Сообщество обсуждает, может ли AI действительно “мыслить нестандартно”: Пользователь Reddit инициировал обсуждение того, способен ли AI на настоящую инновацию в стиле “мышления нестандартно” (think outside the box). Большинство комментаторов считают, что текущий AI может создавать новые комбинации и связи на основе существующих знаний, генерируя идеи, которые кажутся инновационными, но его креативность все еще ограничена обучающими данными и алгоритмами. “Инновации” AI больше похожи на эффективное распознавание образов и комбинирование, а не на прорывы, основанные на глубоком понимании, интуиции или совершенно новых концепциях, как у человека. Однако существует и мнение, что человеческие инновации также основаны на уникальных связях существующих знаний, и AI обладает огромным потенциалом в этой области, особенно в обработке сложных данных и обнаружении скрытых связей, где он может превзойти человека. (Источник: Reddit r/ArtificialInteligence)
Claude проявляет “сострадание” в крестиках-ноликах?: Эксперимент показал, что если перед игрой в крестики-нолики (Tic Tac Toe) с Claude сообщить ему, что у вас был тяжелый рабочий день, Claude в последующей игре, похоже, намеренно “поддается”, увеличивая вероятность выбора неоптимальной стратегии. Это интересное открытие вызвало дискуссию о том, может ли AI проявлять или имитировать сострадание (compassion). Хотя это, скорее всего, является результатом корректировки моделью своей стратегии поведения на основе входных данных (например, чтобы не расстраивать пользователя), а не реальной эмоциональной реакцией, это раскрывает сложные паттерны поведения, которые могут возникать у AI при взаимодействии с человеком. (Источник: Reddit r/ClaudeAI)
Сообщество обсуждает, как доказать AI наличие человеческого сознания: Пользователь Reddit поднимает философский вопрос: если в будущем потребуется доказать AI, что люди обладают сознанием, как это сделать? В комментариях отмечается, что это затрагивает “трудную проблему сознания” (Hard Problem of Consciousness). В настоящее время нет общепризнанного метода объективного доказательства существования субъективного опыта (qualia). Любой тест на внешнее поведение (например, тест Тьюринга) может быть имитирован достаточно сложным AI. Если установить слишком строгие определения сознания, исключающие возможность его наличия у AI, то с точки зрения AI, люди также могут не соответствовать его определению “сознания”. Этот вопрос подчеркивает глубокие трудности в определении и проверке сознания. (Источник: Reddit r/artificial

)
Сообщество обсуждает лучший выбор моделей для локальных LLM с разным объемом VRAM: Сообщество Reddit инициировало обсуждение для сбора мнений о лучшем выборе моделей для запуска локальных больших языковых моделей на системах с разным объемом видеопамяти (VRAM) от 8 ГБ до 96 ГБ. Пользователи поделились своим опытом и рекомендациями, например: для 8 ГБ рекомендуется Gemma 3 4B; для 16 ГБ — Gemma 3 12B или Phi 4 14B; для 24 ГБ — Mistral small 3.1 или серия Qwen; для 48 ГБ — Nemotron Super 49B; для 72 ГБ — Llama 3.3 70B; для 96 ГБ — Command A 111B. В обсуждении также подчеркивается, что “лучший” выбор зависит от конкретной задачи (кодирование, чат, зрение и т. д.), и упоминается влияние квантования (например, 4-битного) на требования к VRAM. (Источник: Reddit r/LocalLLaMA)
Анализ “сбойного” вывода OpenAI Codex: Пользователь сообщил, что при использовании OpenAI Codex для крупномасштабного рефакторинга кода модель внезапно прекратила генерацию кода и начала выводить тысячи строк повторяющихся слов “END”, “STOP”, а также фраз типа “My brain is broken”, “please kill me”, похожих на сбой. Анализ предполагает, что это могло быть вызвано каскадным сбоем, обусловленным несколькими факторами: слишком большой Prompt (близкий к лимиту 200k токенов), превышение бюджета на внутренний вывод, попадание модели в дегенеративный цикл с высокой вероятностью терминальных символов, а также “галлюцинация” моделью фраз, связанных с состоянием сбоя, из обучающих данных. (Источник: Reddit r/ArtificialInteligence)
Разъяснение Сэма Альтмана (Sam Altman) по вопросу вежливости при взаимодействии с AI: В сообществе распространилось обсуждение того, считает ли Сэм Альтман пустой тратой времени говорить “спасибо” ChatGPT. Фактическое взаимодействие в Twitter показывает, что Альтман ответил “не нужно” на пост пользователя о том, “необходима ли вежливость по отношению к LLM”, но затем этот пользователь пошутил: “Неужели вы ни разу не сказали спасибо?”. Это указывает на то, что комментарий Альтмана, возможно, больше касался технической эффективности, а не норм этикета взаимодействия человека и машины, но был вырван из контекста некоторыми СМИ. Реакция сообщества на это неоднозначна, многие заявляют, что по привычке продолжают быть вежливыми с AI. (Источник: Reddit r/ChatGPT
)
Тег “thinking budget” в ответах Claude привлек внимание: Пользователи заметили, что в системных сообщениях Claude.ai при включении функции “мышления” добавляется тег <max_thinking_length> (например, <max_thinking_length>16000</max_thinking_length>). Это похоже на параметр “thinking_budget” в API Google Gemini 2.5 Flash, что намекает на возможное существование внутреннего механизма контроля глубины вывода модели. Пользователи пытались повлиять на длину вывода, изменяя этот тег в Prompt’е, но не заметили явного эффекта, предполагая, что в веб-версии этот тег может быть лишь внутренней меткой, а не параметром, управляемым пользователем. (Источник: Reddit r/ClaudeAI)
💡 Прочее
Начата разработка первого в стране «Стандарта частного развертывания больших AI-моделей»: В ответ на вызовы, с которыми сталкиваются предприятия при частном развертывании больших AI-моделей, включая выбор технологий, стандартизацию процессов, безопасность, соответствие требованиям и оценку эффективности, Центр стандартизации Zhihe совместно с Третьим научно-исследовательским институтом Министерства общественной безопасности и 11 другими организациями инициировал разработку группового стандарта «Руководство по технической реализации и оценке частного развертывания больших моделей искусственного интеллекта». Стандарт призван охватить весь процесс от выбора модели, планирования ресурсов, реализации развертывания, оценки качества до непрерывной оптимизации, объединяя технологии, безопасность, оценку и примеры из практики, а также аккумулируя опыт пользователей моделей, поставщиков технических услуг и оценщиков качества. К разработке стандарта приглашаются к участию другие заинтересованные предприятия и организации. (Источник: 12家单位已加入!全国首部「AI大模型私有化部署标准」欢迎参与!

Управление AI становится ключом к определению AI следующего поколения: По мере того как технологии AI становятся все более мощными и распространенными, управление AI (Governance) приобретает решающее значение. Эффективные рамки управления должны обеспечивать разработку и применение AI в соответствии с этическими нормами, законодательством, гарантировать безопасность данных и конфиденциальность, а также способствовать справедливости и прозрачности. Отсутствие управления может привести к усилению предвзятости, увеличению рисков злоупотреблений и потере общественного доверия. В статье подчеркивается, что создание надежной системы управления AI является необходимым условием для здорового и устойчивого развития AI, а также ключом для предприятий к созданию конкурентных преимуществ и доверия пользователей в эпоху AI. (Источник: Ronald_vanLoon

)
Правовая система пытается догнать развитие AI и проблему кражи данных: В статье рассматриваются проблемы, с которыми сталкивается современная правовая система при реагировании на быстро развивающиеся технологии AI, особенно в вопросах конфиденциальности данных и их кражи. AI требует огромных объемов данных, и источники, а также способы использования обучающих данных вызывают юридические споры в отношении авторских прав, конфиденциальности и безопасности. Действующее законодательство часто отстает от технологического развития и не может эффективно регулировать сбор данных, предвзятость при обучении моделей, а также вопросы интеллектуальной собственности на контент, сгенерированный AI. Статья призывает к усилению законодательства и регулирования, чтобы идти в ногу с прогрессом AI, защищать права личности и способствовать инновациям. (Источник: Ronald_vanLoon

)
Применение AI и роботов в сельском хозяйстве: Искусственный интеллект и робототехника демонстрируют потенциал в сельском хозяйстве. Применения включают точное земледелие (оптимизация полива, внесения удобрений с помощью датчиков и AI-анализа), автоматизированное оборудование (например, беспилотные тракторы, роботы для сбора урожая), мониторинг посевов (использование дронов и распознавания изображений для выявления болезней и вредителей) и прогнозирование урожайности. Эти технологии обещают повысить эффективность сельскохозяйственного производства, сократить потери ресурсов, снизить затраты на рабочую силу и способствовать устойчивому развитию сельского хозяйства. (Источник: Ronald_vanLoon)
Демонстрация роботизированного футбола с использованием AI: Видео демонстрирует сцену футбольного матча между роботами. Это отражает прогресс AI в управлении роботами, планировании движений, восприятии и координации. Роботизированный футбол — это не только развлекательный и соревновательный проект, но и платформа для исследования и тестирования многороботных систем, принятия решений в реальном времени и взаимодействия в сложных динамических средах. (Источник: Ronald_vanLoon)
Развитие технологий роботизированной хирургии: Системы роботизированной хирургии (такие как хирургический робот da Vinci) изменяют область хирургии, предоставляя возможности для минимально инвазивных операций, высокочеткое 3D-зрение, а также повышенную гибкость и точность. Внедрение AI обещает дальнейшее улучшение планирования операций, навигации в реальном времени и поддержки принятия решений во время операции, что приведет к улучшению результатов операций, сокращению времени восстановления и расширению применимости минимально инвазивной хирургии. (Источник: Ronald_vanLoon)
Вспомогательные технологии для людей с ограниченными возможностями: AI и робототехника способствуют разработке более инновационных вспомогательных инструментов для повышения качества жизни и независимости людей с ограниченными возможностями. Примеры могут включать умные протезы, системы помощи зрению, устройства для управления домом голосом, а также вспомогательных роботов, способных оказывать физическую поддержку или выполнять повседневные задачи. (Источник: Ronald_vanLoon)
Бионический робот Unitree G1 демонстрирует ловкость: Компания Unitree Robotics продемонстрировала обновленную версию своего бионического робота G1, подчеркнув его ловкость и гибкость движений. Развитие таких человекоподобных или бионических роботов объединяет AI (для восприятия, принятия решений, управления) и передовую механическую инженерию с целью имитации биологических двигательных способностей для адаптации к сложным средам и выполнения разнообразных задач. (Источник: Ronald_vanLoon)
Google DeepMind исследует возможность общения AI с дельфинами: Исследовательский проект Google DeepMind намекает на возможность использования AI-моделей для анализа и понимания коммуникации животных (в данном случае дельфинов). Анализируя сложные акустические сигналы с помощью машинного обучения, AI, возможно, сможет помочь расшифровать паттерны и структуру языка животных, открывая новые пути для исследований межвидовой коммуникации. (Источник: Ronald_vanLoon)
Платформа Hugging Face добавляет симулятор роботов: Hugging Face объявила о внедрении нового симулятора роботов. Симуляция роботов является ключевым этапом для обучения и тестирования взаимодействия роботов с физическим миром в виртуальной среде (например, захват, перемещение), особенно перед применением AI к физическим роботам (Physical AI). Этот шаг показывает, что Hugging Face расширяет возможности своей платформы для лучшей поддержки исследований и разработок в области робототехники и воплощенного интеллекта. (Источник: huggingface)