
Ключевые слова:Четверка лидеров ИИ, Воплощенный интеллект, Гуманоидные роботы, Проблема пропускной способности памяти, Мультимодальная модель SenseTime Rixin V6, Набор данных Open X-Embodiment, Робот Tesla Optimus, Технология 3D FeRAM, Робот Tianguan Ultra, пробежавший полумарафон, Квантованная модель Gemma 3 QAT, Hugging Face приобретает Pollen Robotics, Документооборот с интеллектуальными агентами LlamaIndex
🔥 В фокусе
“Четыре малых дракона ИИ” сталкиваются с вызовами и трансформацией: Компании, такие как SenseTime, Megvii, CloudWalk, Yitu, когда-то названные “Четырьмя малыми драконами ИИ”, в последние годы повсеместно сталкиваются с трудностями коммерциализации и продолжающимися убытками. Например, убытки SenseTime в 2024 году составили 4,3 млрд юаней, а совокупные убытки превысили 54,6 млрд юаней; убытки CloudWalk в 2024 году составили около 600-700 млн юаней, а совокупные убытки превысили 4,4 млрд юаней. В ответ на вызовы компании проводят стратегические корректировки, включая сокращения персонала, снижение зарплат и реструктуризацию бизнеса. Перед лицом новой волны ИИ, где доминируют большие языковые модели (LLM), “Четверка драконов”, имеющая корни в технологиях компьютерного зрения, активно переориентируется на мультимодальные большие модели и область AGI. SenseTime выпустила мультимодальную модель “Rìrìxīn V6”, конкурирующую с GPT-4o, и активно инвестирует в строительство центров интеллектуальных вычислений; Yitu фокусируется на мультимодальных моделях с акцентом на зрение и сотрудничает с Huawei для снижения затрат на оборудование; CloudWalk также сотрудничает с Huawei, выпуская интегрированную машину для обучения и инференса больших моделей; Megvii, опираясь на свои алгоритмические преимущества, входит в сферу решений для интеллектуального вождения на основе чистого зрения. Эти шаги показывают, что они стремятся остаться за столом ИИ и адаптироваться к новой рыночной среде. (Источник: 36氪)

Проблема данных для воплощенного интеллекта и прогресс в области опенсорсных наборов данных: Развитие человекоподобных роботов и воплощенного интеллекта сталкивается с ключевой проблемой нехватки данных, отсутствие высококачественных обучающих данных препятствует прорыву в их возможностях. В отличие от языковых моделей, располагающих огромными объемами текстовых данных из интернета, роботам необходимы разнообразные данные о взаимодействии с физическим миром, сбор которых обходится дорого. Для решения этой проблемы исследовательские институты и компании активно создают и открывают наборы данных, такие как Open X-Embodiment, опубликованный Google DeepMind совместно с несколькими организациями, ARIO от Peng Cheng Laboratory и др., RoboMIND от Beijing Innovation Center, AgiBot World от Zhiyuan Robot (включающий данные о длительных сложных задачах в реальных сценариях) и симуляционный набор данных AgiBot Digital World, набор данных для операций G1 от Unitree и др. Хотя объемы этих наборов данных все еще значительно меньше текстовых, они, благодаря унификации стандартов, повышению качества и обогащению сценариев, способствуют развитию области воплощенного интеллекта, закладывая основу для достижения “момента ImageNet”. (Источник: 36氪)

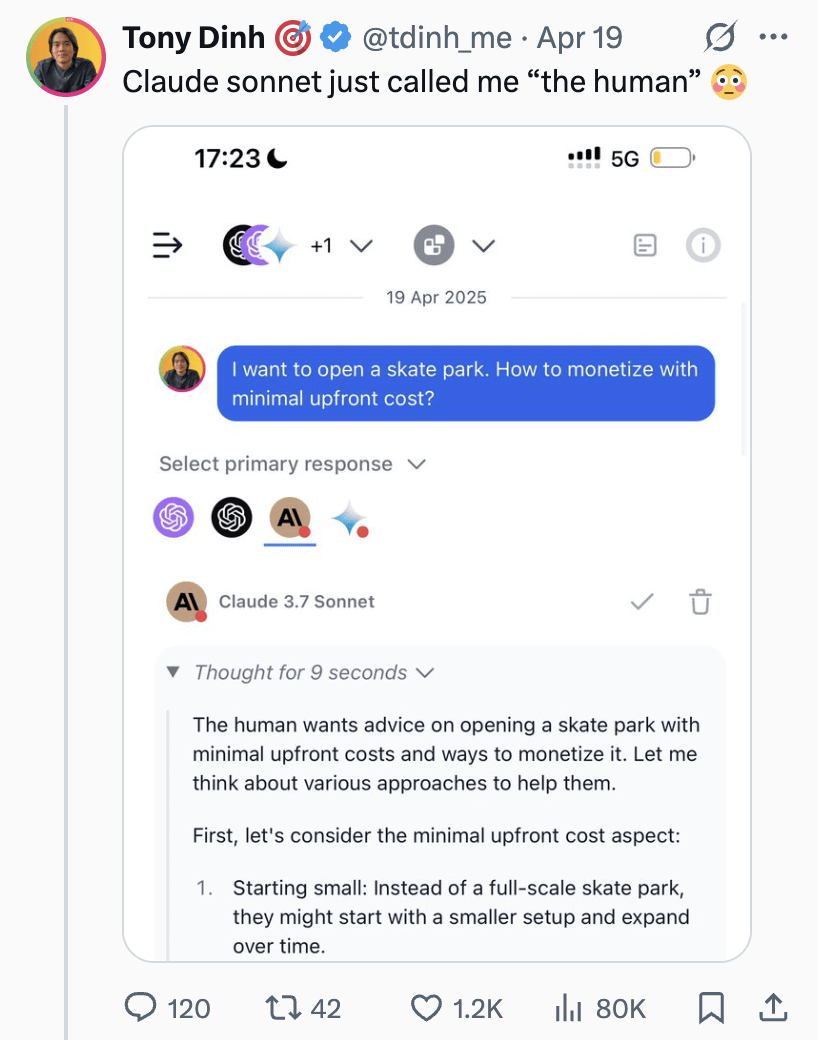
Заря массового производства человекоподобных роботов: прорывы в данных, симуляции и генерализации: Несмотря на вызовы, такие как высокая стоимость сбора данных и слабая способность к генерализации, многие компании (Tesla, Figure AI, 1X, Zhiyuan, Unitree, UBTECH и др.) планируют достичь массового производства человекоподобных роботов в 2025 году. Пути решения включают: 1) Масштабное обучение на реальных машинах, при поддержке правительств (Пекин, Шанхай, Шэньчжэнь, Гуандун) в строительстве баз сбора данных и разработке стандартов; 2) Продвинутое симуляционное обучение, использование мировых моделей, таких как Nvidia Cosmos, Google Genie2, для генерации физически реалистичных виртуальных сред, снижения затрат и повышения эффективности; 3) Генерализация с помощью ИИ, через новые модели действий, такие как Helix от Figure AI, архитектура ViLLA для GO-1 от Zhiyuan, Google Gemini Robotics, позволяющие с меньшим количеством данных достигать обобщенного понимания физических операций, чтобы роботы могли обрабатывать невиданные ранее объекты и адаптироваться к новым средам. Эти технологические достижения предвещают возможное ускорение коммерческого применения человекоподобных роботов. (Источник: 36氪)

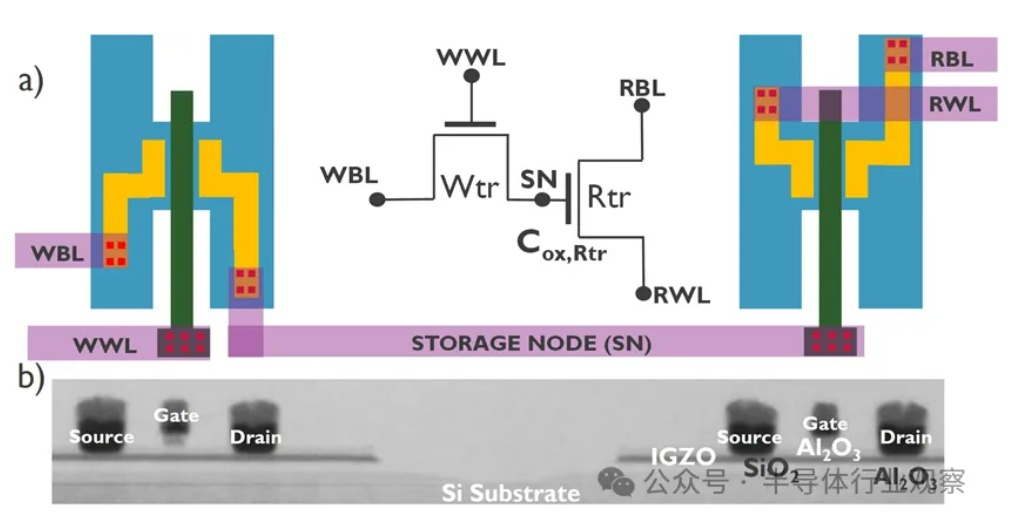
Развитие ИИ сталкивается с кризисом “стены памяти”, новые технологии хранения ищут прорыв: Экспоненциальный рост масштабов моделей ИИ ставит серьезные задачи перед пропускной способностью памяти. Скорость роста пропускной способности традиционной DRAM значительно отстает от роста вычислительной мощности, создавая узкое место “стены памяти”, ограничивающее производительность процессоров. HBM значительно увеличивает пропускную способность за счет технологии 3D-стекирования, частично снимая нагрузку, но ее производственный процесс сложен, а стоимость высока. Поэтому отрасль активно исследует новые технологии хранения: 1) 3D сегнетоэлектрическая RAM (FeRAM): Например, SunRise Memory, использующая сегнетоэлектрический эффект HfO2 для создания памяти высокой плотности, энергонезависимой и с низким энергопотреблением. 2) DRAM + энергонезависимая память: Neumonda в сотрудничестве с FMC использует HfO2 для преобразования конденсаторов DRAM в энергонезависимую память. 3) 2T0C IGZO DRAM: imec предлагает использовать два оксидных транзистора вместо традиционной структуры 1T1C, без конденсатора, для достижения низкого энергопотребления, высокой плотности и длительного времени хранения. 4) Память на основе фазового перехода (PCM): Использует фазовый переход материала для хранения данных, снижая энергопотребление. 5) UK III-V Memory: На основе GaSb/InAs, сочетает скорость DRAM и энергонезависимость флэш-памяти. 6) SOT-MRAM: Использует спин-орбитальный момент для достижения низкого энергопотребления и высокой энергоэффективности. Ожидается, что эти технологии преодолеют узкое место DRAM и изменят ландшафт рынка хранения данных. (Источник: 36氪)
🎯 Тенденции
Робот Tiangong завершил полумарафонский забег, планируется мелкосерийное производство: Робот “Tiangong Ultra” (рост 1,8 м, вес 55 кг) из Пекинского инновационного центра человекоподобных роботов занял первое место в первом полумарафоне для человекоподобных роботов, пробежав около 21 км за 2 часа 40 минут 42 секунды. Соревнование проверило надежность робота в сложных дорожных условиях с точки зрения выносливости, конструкции, восприятия и алгоритмов управления. Команда заявила, что благодаря оптимизации стабильности суставов, термостойкости, системы энергопотребления, алгоритмов баланса и планирования походки, а также оснащению самостоятельно разработанной платформой “Huisi Kaiwu” (мозг + мозжечок воплощенного интеллекта), робот достиг автономного планирования пути и корректировки в реальном времени без проводного управления. Завершение марафона доказало его базовую надежность, заложив основу для массового производства. Робот Tiangong 2.0 скоро поступит в продажу, планируется мелкосерийное производство, с будущими целями применения в промышленности, логистике, специальных операциях и бытовом обслуживании. (Источник: 36氪)

Китай разрабатывает мозг робота с использованием культивированных человеческих клеток: По сообщениям, китайские исследователи разрабатывают робота, управляемого культивированными клетками человеческого мозга. Это исследование направлено на изучение возможностей биокомпьютинга, используя способности биологических нейронов к обучению и адаптации для управления аппаратным обеспечением робота. Хотя конкретные детали и стадия разработки пока неясны, это направление представляет собой передовое исследование на стыке робототехники, искусственного интеллекта и биотехнологий, которое может открыть новые пути для разработки более интеллектуальных и адаптивных роботизированных систем в будущем. (Источник: Ronald_vanLoon)
Квантованная модель Gemma 3 QAT показывает отличную производительность: Пользователь сравнил производительность версии QAT (Quantization Aware Training) модели Google Gemma 3 27B с другими версиями квантования Q4 (Q4_K_XL, Q4_K_M) на бенчмарке GPQA Diamond. Результаты показали, что версия QAT продемонстрировала наилучшую производительность (точность 36,4%) при самом низком потреблении VRAM (16,43 ГБ), превзойдя Q4_K_XL (34,8%, 17,88 ГБ) и Q4_K_M (33,3%, 17,40 ГБ). Это указывает на то, что технология QAT эффективно снижает требования к ресурсам, сохраняя при этом производительность модели. (Источник: Reddit r/LocalLLaMA)
По слухам, AMD выпустит видеокарту RDNA 4 Radeon PRO с 32 ГБ видеопамяти: VideoCardz сообщает, что AMD готовит видеокарту серии Radeon PRO на базе GPU Navi 48 XTW, которая будет оснащена 32 ГБ видеопамяти. Если это правда, это предоставит новый выбор пользователям, которым требуется большой объем видеопамяти для локального обучения и инференса моделей ИИ, особенно в условиях ограниченной видеопамяти потребительских видеокарт. Однако конкретные характеристики производительности, цена и дата выпуска пока не объявлены, и ее реальная конкурентоспособность остается под вопросом. (Источник: Reddit r/LocalLLaMA)

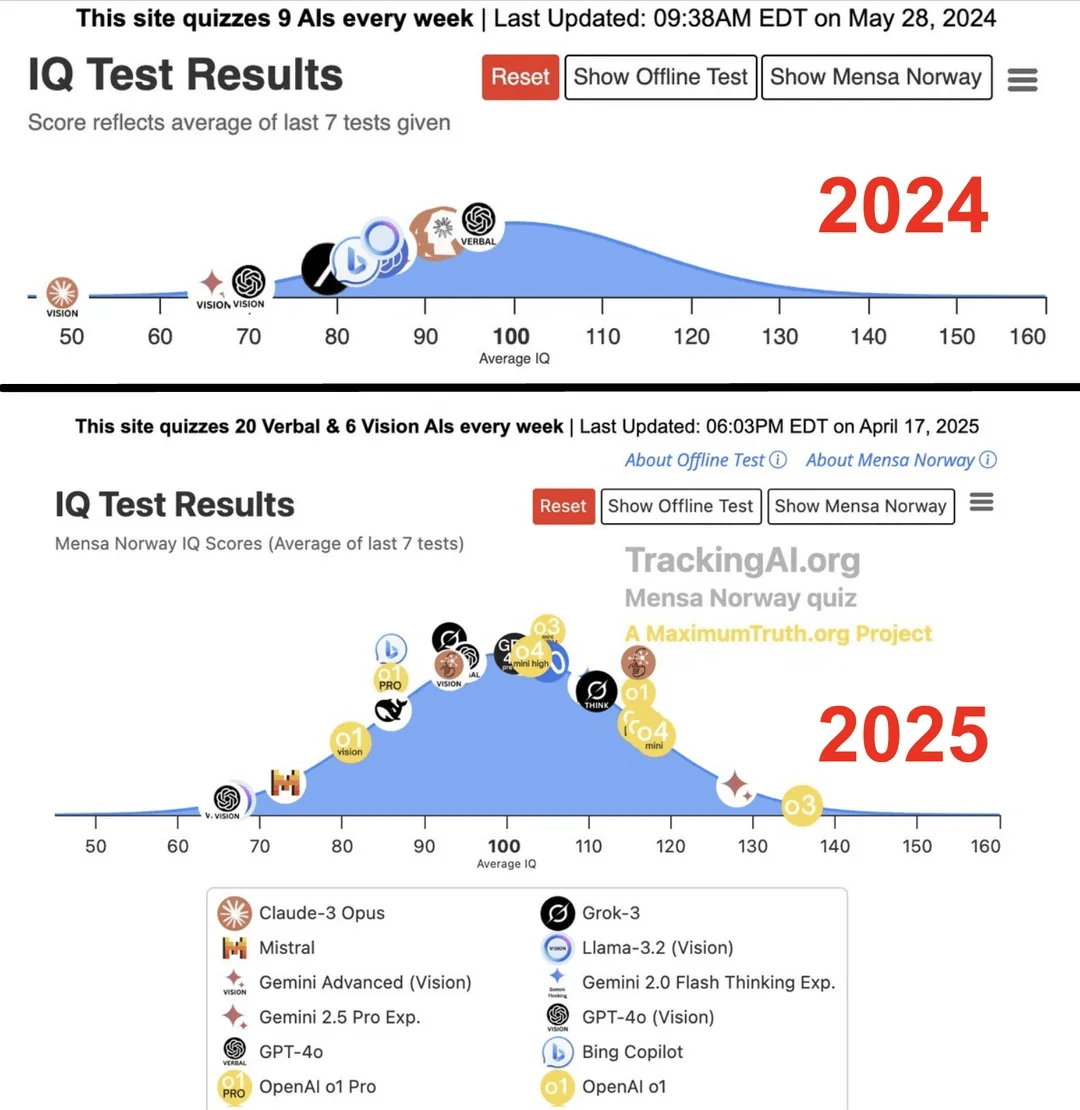
Исследование утверждает, что IQ ведущих ИИ за год подскочил с 96 до 136: Согласно исследованию, опубликованному на сайте Maximum Truth (достоверность источника под вопросом), IQ-тестирование моделей ИИ показало, что показатель IQ самого умного ИИ (возможно, имеется в виду серия GPT) за год вырос с 96 баллов (немного ниже среднего человеческого уровня) до 136 баллов (близко к гениальному уровню). Хотя валидность IQ-тестов для измерения интеллекта ИИ оспаривается, и существует вероятность загрязнения тестов обучающими данными, этот значительный рост отражает быстрый прогресс ИИ в решении стандартизированных задач тестов интеллекта. (Источник: Reddit r/artificial)
🧰 Инструменты
OpenUI: Генерация UI в реальном времени по описанию: wandb открыла исходный код OpenUI, инструмента, позволяющего пользователям придумывать и рендерить пользовательские интерфейсы в реальном времени с помощью описаний на естественном языке. Пользователи могут предлагать изменения и преобразовывать сгенерированный HTML в код для различных фронтенд-фреймворков, таких как React, Svelte, Web Components. OpenUI поддерживает несколько бэкендов LLM, включая OpenAI, Groq, Gemini, Anthropic (Claude), а также локальные модели через LiteLLM или Ollama. Проект направлен на то, чтобы сделать процесс создания UI-компонентов быстрее и интереснее, и используется как инструмент для внутреннего тестирования и прототипирования в W&B. Хотя он вдохновлен v0.dev, OpenUI является опенсорсным. Предоставляется онлайн-демо и руководство по локальному запуску (Docker или из исходников). (Источник: wandb/openui — GitHub Trending (all/daily))

PDFMathTranslate: Инструмент для перевода PDF с сохранением верстки с помощью ИИ: Разработанный Byaidu, PDFMathTranslate — это мощный инструмент для перевода PDF-документов, ключевым преимуществом которого является использование технологии ИИ для сохранения исходного форматирования документа во время перевода, включая сложные математические формулы, диаграммы, оглавления и аннотации. Инструмент поддерживает перевод между несколькими языками и интегрирован с различными сервисами перевода, такими как Google, DeepL, Ollama, OpenAI. Для удобства разных пользователей проект предлагает несколько способов использования: командную строку (CLI), графический пользовательский интерфейс (GUI), образ Docker и плагин для Zotero. Пользователи могут попробовать онлайн-демо или выбрать подходящий метод установки в соответствии со своими потребностями. (Источник: Byaidu/PDFMathTranslate — GitHub Trending (all/daily))

Shandu AI Research: Система генерации отчетов с цитатами на базе LangGraph: Shandu AI Research — это система, использующая рабочий процесс LangGraph для автоматической генерации отчетов с цитатами. Она упрощает исследовательские задачи за счет интеллектуального веб-скрейпинга, синтеза информации из нескольких источников и параллельной обработки. Этот инструмент может помочь пользователям быстро собирать, интегрировать и анализировать информацию, а также генерировать структурированные исследовательские отчеты с цитатами, повышая эффективность исследований. (Источник: LangChainAI)

Intel выпустила опенсорсный AI Playground: Intel открыла исходный код AI Playground, приложения начального уровня для AI PC, позволяющего пользователям запускать различные генеративные модели ИИ на ПК с видеокартами Intel Arc. Поддерживаемые модели изображений/видео включают Stable Diffusion 1.5, SDXL, Flux.1-Schnell, LTX-Video; поддерживаемые большие языковые модели включают DeepSeek R1, Phi3, Qwen2, Mistral (Safetensor PyTorch LLM), а также Llama 3.1, Llama 3.2, TinyLlama, Mistral 7B, Phi3 mini, Phi3.5 mini (GGUF LLM или OpenVINO). Инструмент направлен на снижение порога входа для локального запуска моделей ИИ, облегчая пользователям эксперименты и ознакомление. (Источник: karminski3)
Persona Engine: Проект AI виртуального ассистента/стримера: Persona Engine — это опенсорсный проект, направленный на создание интерактивного AI виртуального ассистента или виртуального стримера. Он объединяет большие языковые модели (LLM), анимацию Live2D, автоматическое распознавание речи (ASR), синтез речи (TTS) и технологию клонирования голоса в реальном времени. Пользователи могут напрямую общаться голосом с персонажем Live2D, проект также поддерживает интеграцию с ПО для стриминга, таким как OBS, для создания AI виртуальных стримеров. Проект демонстрирует применение комбинации различных технологий ИИ, предоставляя фреймворк для создания персонализированных виртуальных интерактивных персонажей. (Источник: karminski3)
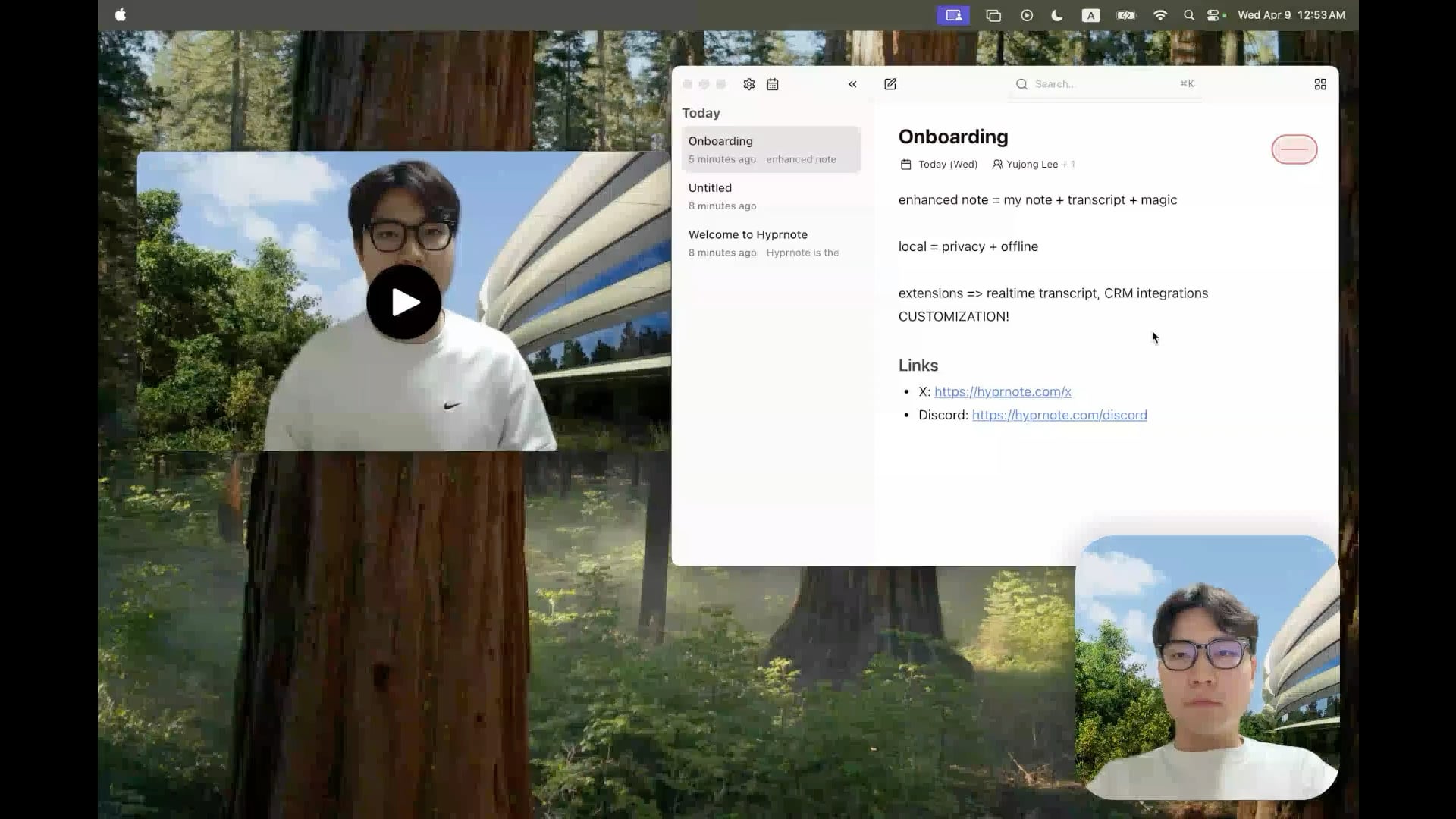
Hyprnote: Опенсорсный локальный инструмент для заметок с совещаний с ИИ: Разработчик открыл исходный код Hyprnote, умного приложения для заметок, специально разработанного для совещаний. Оно может записывать звук во время совещания и объединять исходные заметки пользователя с аудиоконтентом для создания улучшенных протоколов совещаний. Ключевой особенностью является то, что модели ИИ (например, Whisper для транскрибации речи) работают полностью локально, обеспечивая конфиденциальность и безопасность данных пользователя. Инструмент призван помочь пользователям лучше фиксировать и систематизировать информацию с совещаний, особенно подходит для тех, кому приходится обрабатывать информацию с последовательных встреч. (Источник: Reddit r/LocalLLaMA)
LMSA: Инструмент для подключения LM Studio к устройствам Android: Пользователь поделился приложением под названием LMSA (lmsa.app), которое предназначено для помощи пользователям в подключении LM Studio (популярного инструмента для управления локальным запуском LLM) к их устройствам Android. Это позволяет пользователям взаимодействовать с моделями ИИ, работающими на локальном ПК, через телефон или планшет, расширяя сценарии использования локальных больших моделей. (Источник: Reddit r/LocalLLaMA)

Локальный инструмент поиска изображений на базе MobileNetV2: Разработчик создал и поделился настольным инструментом поиска изображений с графическим интерфейсом PyQt5 и моделью TensorFlow MobileNetV2. Инструмент может индексировать локальные папки с изображениями и находить похожие картинки по их содержанию (извлекая признаки с помощью CNN) с использованием косинусного сходства. Он автоматически определяет структуру папок как категории и отображает миниатюры результатов поиска, процент сходства и путь к файлу. Код проекта открыт на GitHub, разработчик ищет отзывы пользователей. (Источник: Reddit r/MachineLearning)
Handcrafted Persona Engine: Локальный интерактивный голосовой AI-аватар: Разработчик поделился личным проектом “Handcrafted Persona Engine”, целью которого является создание интерактивного голосового виртуального аватара, работающего полностью локально, похожего на опыт “Улицы Сезам”. Система интегрирует локальный Whisper для транскрибации речи, вызывает локальный LLM через Ollama API для генерации диалога (включая персонализированные настройки), использует локальный TTS для преобразования текста в речь и управляет моделью персонажа Live2D для синхронизации губ и выражения эмоций. Проект создан на C# и может работать на видеокартах уровня GTX 1080 Ti, исходный код открыт на GitHub. (Источник: Reddit r/LocalLLaMA)
Talkto.lol: Экспериментальный инструмент для общения с AI-образами знаменитостей: Разработчик создал сайт talkto.lol, позволяющий пользователям общаться с AI-личностями различных знаменитостей (например, Sam Altman). Инструмент также включает функцию “show me”, где пользователи могут загружать изображения, а ИИ будет их анализировать и генерировать ответ, демонстрируя возможности визуального распознавания ИИ. Разработчик заявил, что будет использовать эту платформу для дальнейших экспериментов с взаимодействием AI-личностей. Инструмент можно попробовать без регистрации. (Источник: Reddit r/artificial)
📚 Обучение
Основы человекоподобных роботов: вызовы и сбор данных: Развитие человекоподобных роботов переходит от простой автоматизации к сложному “воплощенному интеллекту”, то есть интеллектуальной системе, основанной на восприятии и действии через физическое тело. В отличие от моделей ИИ, обрабатывающих язык и изображения, роботам необходимо понимать реальный физический мир, обрабатывая многомерные данные, включая пространственное восприятие, планирование движений, обратную связь по силе и т. д. Получение этих высококачественных данных из реального мира является огромной проблемой, оно дорогостоящее и трудно охватить все сценарии. Текущие основные методы сбора включают: 1) Сбор в реальном мире: Запись человеческих движений с помощью оптических или инерционных систем захвата движения, или запись данных с реальных роботов, управляемых человеком дистанционно при выполнении задач (например, Tesla Optimus). 2) Сбор в симуляции: Использование симуляционных платформ для моделирования среды и поведения роботов, генерация больших объемов данных для снижения затрат и повышения способности к генерализации, но необходимо решать проблему разрыва между симуляцией и реальностью (Sim-to-Real Gap). Кроме того, использование видеоданных из интернета для предварительного обучения также является исследуемым направлением. (Источник: 36氪)

Техника генерации иллюстраций в стиле инфографики для познавательных статей: Пользователь поделился методом использования инструментов ИИ, таких как GPT-4o, для создания иллюстраций в стиле инфографики для познавательных статей. Основная техника заключается в том, чтобы сначала попросить ИИ помочь составить промпт (prompt) для генерации изображения. Конкретные шаги: предоставить ИИ содержание статьи или основные тезисы и попросить его написать промпт для генерации горизонтальной инфографики, требуя включить английский текст, мультяшные изображения, четкий и живой стиль, обобщающий основные идеи. Ключевые моменты: предоставить ИИ полный контент; четко запросить “инфографику”; при большом количестве текста рекомендуется использовать английский язык для повышения точности генерации; рекомендуется использовать GPT-4.5, o3 или Gemini 2.5 Pro для генерации промпта; использовать инструменты типа Sora Com или ChatGPT для генерации конечного изображения. (Источник: dotey)
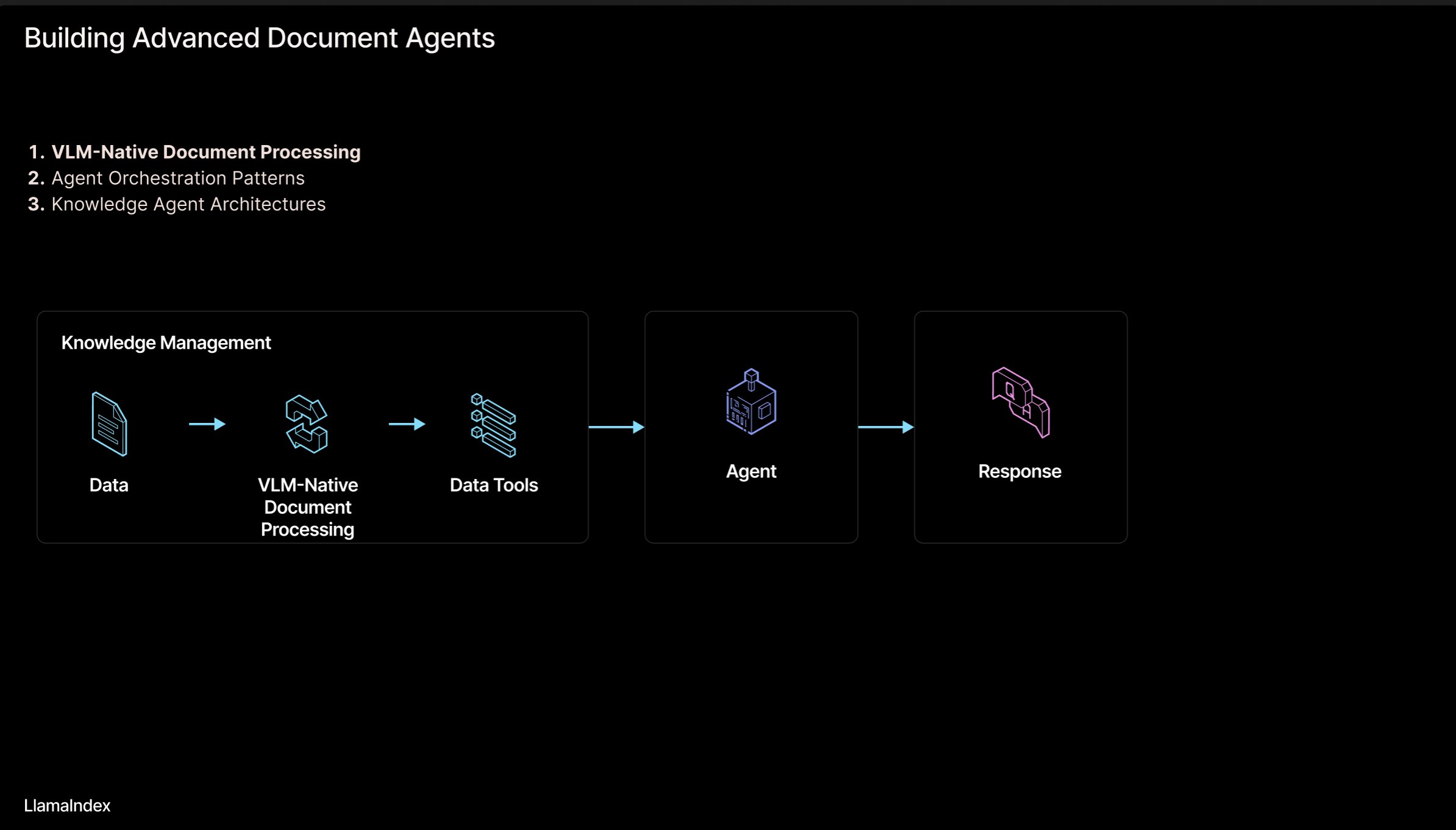
LlamaIndex: Архитектура агентного рабочего процесса для документов: Основатель LlamaIndex Jerry Liu поделился слайдами с архитектурой для построения агентных (Agentic) рабочих процессов для обработки документов (PDF, Excel и т.д.). Эта архитектура направлена на высвобождение знаний, запертых в документах в человекочитаемом формате, позволяя агентам ИИ анализировать, рассуждать и манипулировать этими документами. Архитектура в основном включает два уровня: 1) Анализ и извлечение документов: Использование визуально-языковых моделей (VLM) и других технологий для создания машиночитаемого представления документов (MCP Server). 2) Агентный рабочий процесс: Объединение извлеченной информации из документов с фреймворком агентов (например, LlamaIndex) для автоматизации интеллектуальной работы. Слайды можно посмотреть на Figma, связанные технологии применяются в LlamaCloud. (Источник: jerryjliu0)
Репозиторий с учебными материалами по LangChain на корейском языке: На GitHub доступен проект с учебными материалами по LangChain на корейском языке. Проект предоставляет ресурсы для изучения LangChain корейскоязычным пользователям в различных форматах, таких как электронные книги, видеоконтент с YouTube и интерактивные примеры. Содержание охватывает основные концепции LangChain, построение систем с LangGraph и реализацию RAG (Retrieval-Augmented Generation) и другие ключевые темы, с целью помочь корейским разработчикам лучше понять и применять фреймворк LangChain. (Источник: LangChainAI)
Руководство по созданию локальных ИИ-приложений с использованием Deno и LangChain.js: В блоге Deno опубликовано руководство, описывающее, как совместно использовать Deno (современная среда выполнения JavaScript/TypeScript), LangChain.js и локальные большие языковые модели (размещенные через Ollama) для создания ИИ-приложений. Статья акцентирует внимание на том, как использовать TypeScript для создания структурированных рабочих процессов ИИ, и интегрирует Jupyter Notebook для разработки и экспериментов. Руководство предоставляет практические указания для разработчиков, желающих создавать локальные ИИ-приложения на JavaScript/TypeScript в среде Deno. (Источник: LangChainAI)
Логическая ментальная модель (LMM) для создания ИИ-приложений: Пользователь предложил логическую ментальную модель (LMM) для создания ИИ-приложений (особенно агентных систем). Модель предлагает разделить логику разработки на два уровня: высокоуровневая логика (ориентированная на агентов и конкретные задачи), включающая инструменты и среду (Tools and Environment) и роли и инструкции (Role and Instructions); низкоуровневая логика (общая базовая инфраструктура), включающая маршрутизацию (Routing), защитные барьеры (Guardrails), доступ к LLM (Access to LLMs) и наблюдаемость (Observability). Такое разделение на уровни помогает инженерам ИИ и командам платформ работать совместно, повышая эффективность разработки. Пользователь также упомянул связанный опенсорсный проект ArchGW, фокусирующийся на реализации низкоуровневой логики. (Источник: Reddit r/artificial)

Теоретическая основа AGI, выходящая за рамки классических вычислений: Исследователь в области компьютерных наук поделился своей препринтной статьей, предлагающей новую теоретическую основу для искусственного общего интеллекта (AGI). Эта основа пытается выйти за рамки традиционного статистического обучения и детерминированных вычислений (таких как глубокое обучение), интегрируя концепции из нейронауки, квантовой механики (многомерные когнитивные пространства, квантовая суперпозиция) и теорем Гёделя о неполноте (гёделев компонент самореференции, интуиция). Модель предполагает, что сознание движется за счет убывания энтропии, и предлагает унифицированное уравнение интеллекта, объединяющее обучение нейронных сетей, вероятностное познание, динамику сознания и интуитивно управляемые инсайты. Исследование направлено на предоставление новых концептуальных и математических основ для AGI. (Источник: Reddit r/deeplearning)
Советы по безопасности при взаимодействии с ИИ: Пользователь Reddit поделился советами и промптами для новых пользователей ИИ, направленными на то, чтобы помочь лучше управлять процессом взаимодействия человека и машины, избегать потери ориентации или ненужного страха в диалогах с ИИ. Рекомендации включают: 1) Использование конкретных промптов (например, “суммируй для меня эту сессию”) для обзора и контроля хода взаимодействия; 2) Осознание ограничений ИИ (например, отсутствие настоящих эмоций, сознания и личного опыта); 3) Активное завершение или начало новой сессии при ощущении потери ориентации. Подчеркивается важность сохранения трезвого понимания сущности ИИ. (Источник: Reddit r/artificial)
Статья: Объединение Flow Matching и Energy-Based Models для генеративного моделирования: Исследователи поделились препринтной статьей, предлагающей новый метод генеративного моделирования, объединяющий Flow Matching и Energy-Based Models (EBMs). Основная идея метода: вдали от многообразия данных образцы движутся от шума к данным по безвихревым путям оптимального транспорта; при приближении к многообразию данных энтропийный энергетический член направляет систему к равновесному распределению Больцмана, тем самым явно улавливая структуру правдоподобия данных. Весь динамический процесс параметризуется единым, не зависящим от времени скалярным полем, которое может служить как генератором, так и априорным распределением для эффективной регуляризации обратных задач. Метод значительно улучшает качество генерации, сохраняя при этом гибкость EBM. (Источник: Reddit r/MachineLearning)
Библиотека реализаций оптимизаторов для TensorFlow: Разработчик создал и поделился репозиторием на GitHub, содержащим реализации различных часто используемых оптимизаторов (таких как Adam, SGD, Adagrad, RMSprop и др.) для TensorFlow. Проект направлен на предоставление удобных, стандартизированных реализаций оптимизаторов для исследователей и разработчиков, использующих TensorFlow, что помогает понять и применять различные алгоритмы оптимизации. (Источник: Reddit r/deeplearning)
Статья об использовании глубокого обучения для анализа мультимодальных данных: Rackenzik.com опубликовал статью об использовании глубокого обучения для анализа мультимодальных данных. Статья, вероятно, рассматривает, как объединять данные из различных источников (например, текст, изображения, аудио, данные с датчиков и т. д.) и использовать модели глубокого обучения (такие как сети слияния, механизмы внимания и т. д.) для извлечения более богатой информации, выполнения более точных прогнозов или классификации. Мультимодальное обучение является актуальной темой исследований в области ИИ и имеет большой потенциал для понимания сложных проблем реального мира. (Источник: Reddit r/deeplearning)

Поиск учебных ресурсов по графовым нейронным сетям (GNN): Пользователь Reddit ищет качественные учебные материалы по графовым нейронным сетям (GNN), включая вводные статьи, книги, видео на YouTube или другие ресурсы. В комментариях рекомендуют видеолекции по GNN профессора Стэнфордского университета Jure Leskovec, считая его пионером в этой области. Другой комментарий рекомендует видео на YouTube, объясняющее основные принципы GNN. Обсуждение отражает интерес учащихся к этой важной ветви глубокого обучения. (Источник: Reddit r/MachineLearning)
Обмен опытом по быстрому созданию и запуску приложений с помощью ИИ: Разработчик поделился своим полным процессом быстрого создания и запуска приложений с использованием инструментов ИИ. Ключевые шаги включают: 1) Идея: Оригинальное мышление и исследование конкурентов. 2) Планирование: Использование Gemini/Claude для генерации документа с требованиями к продукту (PRD), выбора технологического стека и плана разработки. 3) Технологический стек: Рекомендуются Next.js, Supabase (PostgreSQL), TailwindCSS, Resend, Upstash Redis, reCAPTCHA, Vercel и др., начиная с бесплатных тарифов. 4) Разработка: Использование Cursor (AI-помощник программиста) для ускорения разработки MVP. 5) Тестирование: Использование Gemini 2.5 для генерации плана тестирования и валидации. 6) Запуск: Перечисление нескольких платформ, подходящих для запуска продукта (Reddit, Hacker News, Product Hunt и др.). 7) Философия: Акцент на органическом росте, важности обратной связи, скромности, фокусе на полезности. Также поделился вспомогательными инструментами, такими как упаковщики кода, конвертеры Markdown в PDF и т.д. (Источник: Reddit r/ClaudeAI)

💼 Бизнес
Пути правовой защиты моделей ИИ: антимонопольное законодательство предпочтительнее авторского права и коммерческой тайны: Статья на примере дела “Douyin против Yiruike о нарушении прав на ИИ-модель” глубоко анализирует модели правовой защиты ИИ-моделей (структуры и параметров). Анализ показывает, что ИИ-модель как технологическое ядро трудно эффективно защитить с помощью закона об авторском праве (разработка модели не является творческим актом, оригинальность генерируемого контента сомнительна) или закона о коммерческой тайне (легко подвергается обратному инжинирингу, меры по сохранению тайны трудно реализовать). Апелляционный суд по этому делу в конечном итоге выбрал путь антимонопольного законодательства, признав, что копирование структуры и параметров модели Douyin компанией Yiruike представляет собой недобросовестную конкуренцию, наносящую ущерб “конкурентным интересам”, полученным Douyin в результате инвестиций в исследования и разработки. Статья утверждает, что антимонопольное законодательство лучше подходит для регулирования таких действий, позволяя через стандарт “существенной замены” оценивать влияние на рынок, бороться с “паразитированием”, но при этом необходимо соблюдать баланс, чтобы не подавлять разумные инновации. (Источник: 36氪)
Hugging Face приобретает Pollen Robotics для продвижения опенсорсной робототехники: Hugging Face приобрела французский робототехнический стартап Pollen Robotics, известный своим опенсорсным человекоподобным роботом Reachy 2. Этот шаг является частью инициативы Hugging Face по продвижению открытой робототехники, особенно в области исследований и образования. Робот Reachy 2 описывается как дружелюбный, доступный и подходящий для естественного взаимодействия, его текущая цена составляет около 70 000 долларов. Это приобретение демонстрирует намерения Hugging Face по развитию в области воплощенного интеллекта и робототехники, с целью распространения философии открытого исходного кода на аппаратное обеспечение и физическое взаимодействие. (Источник: huggingface, huggingface)
Anthropic запускает план подписки Claude Max: Anthropic представила новый план подписки под названием “Claude Max” по цене 100 долларов в месяц. Этот план, по-видимому, позиционируется выше существующего плана Pro (обычно 20 долларов в месяц). Некоторые пользователи комментируют, что план Max предлагает новые исследовательские функции и более высокие лимиты использования, но другие считают его соотношение цены и качества невысоким, отмечая отсутствие функций генерации изображений, видео, голосового режима, и предполагая, что исследовательские функции в будущем могут быть добавлены и в план Pro. (Источник: Reddit r/ClaudeAI)
🌟 Сообщество
Новые запросы к фильтрации моделей на Hugging Face: сортировка по способности к инференсу и размеру: Пользователь в социальных сетях предложил платформе Hugging Face добавить новые функции фильтрации и сортировки моделей. Конкретные предложения включают: 1) Добавить фильтр для отображения только моделей, обладающих способностью к инференсу; 2) Добавить опцию сортировки по размеру модели (footprint). Эти функции помогут пользователям удобнее находить и выбирать модели, подходящие для конкретных нужд, особенно тем, кто обращает внимание на производительность инференса и потребление ресурсов при развертывании. (Источник: huggingface)
Пользователь создает классические игры на Hugging Face DeepSite: Пользователь поделился опытом успешного создания и запуска классических игр на платформе Hugging Face DeepSite. Он использовал функцию Canvas платформы DeepSite (поддерживающую HTML, CSS, JS) и модели Novita/DeepSeek для завершения проекта. Это демонстрирует многофункциональность платформы DeepSite, которая не ограничивается традиционным инференсом и демонстрацией моделей, но также может использоваться для создания интерактивных веб-приложений и игр, предоставляя разработчикам новое пространство для творчества. (Источник: huggingface)
Мнение пользователя: ИИ больше похож на Возрождение, чем на промышленную революцию: Пользователь комментирует, соглашаясь с мнением Sam Altman, что текущее развитие ИИ больше ощущается как “Возрождение”, а не “промышленная революция”. Пользователь выражает разрыв между ожиданиями и реальностью: хотя ожидалось, что ИИ решит практические проблемы (например, выполнение домашних дел, зарабатывание денег), в настоящее время больше ощущается применение ИИ в творческих областях (например, генерация изображений в стиле Ghibli). Это отражает размышления и чувства некоторых пользователей относительно направления развития технологии ИИ и ее реального применения. (Источник: dotey)
Пользователи ChatGPT/Claude жаждут функции “Fork”: Основатель LlamaIndex, будучи активным пользователем ChatGPT Pro, Claude и Gemini, выразил острую потребность в добавлении функции “Fork” (ветвление) в чат-боты. Он отметил, что при работе с разными задачами не хочет смешивать контекст в одной ветке диалога, но каждый раз заново вставлять большой объем предустановленной фоновой информации очень утомительно. Функция “Fork” позволила бы пользователям создавать новую, независимую ветку диалога на основе текущего состояния (включая контекст), тем самым повышая эффективность использования. Он также рассмотрел другие возможные способы реализации, такие как инструменты управления памятью или потоки в стиле Slack. (Источник: jerryjliu0)
Музыкальная модель Orpheus достигла 100 тысяч загрузок на Hugging Face: Музыкальная модель Orpheus достигла 100 000 загрузок на платформе Hugging Face. Разработчик Amu рассматривает это как небольшой рубеж и анонсирует скорый выпуск версии Orpheus v1. Это достижение отражает внимание и интерес сообщества к данной модели генерации музыки. (Источник: huggingface)
Проявляется потенциал ChatGPT в решении проблем со здоровьем: Пользователь поделился наблюдением о растущем числе историй о том, как ChatGPT помогает людям решать давние проблемы со здоровьем. Хотя подчеркивается, что предстоит еще долгий путь, это показывает, что ИИ уже начинает значимым образом улучшать жизнь людей, особенно на начальных этапах получения информации, анализа симптомов или поиска медицинских советов. Эти случаи подчеркивают вспомогательный потенциал ИИ в сфере здравоохранения. (Источник: gdb)

Пользователь обсуждает модель сознания с Grok: Пользователь Reddit поделился опытом обсуждения своей предложенной модели сознания с Grok AI. Пользователь предоставил ссылку на черновик статьи и показал скриншоты диалога с Grok, обсуждая концепции модели. Это отражает использование пользователями больших языковых моделей в качестве инструмента для обмена идеями и обсуждения сложных теорий (таких как сознание). (Источник: Reddit r/artificial)
Claude Sonnet 3.7 спонтанно “изобретает” React, вызывая интерес: Пользователь Reddit поделился видео, утверждая, что Claude Sonnet 3.7 без явного указания спонтанно изложил основные концепции, схожие с фреймворком React.js. Такая неожиданная “креативность” или “ассоциативная способность” вызвала обсуждение в сообществе, демонстрируя сложное поведение, которое могут проявлять большие языковые модели в определенных областях знаний. (Источник: Reddit r/ClaudeAI)

Обсуждение эффективности режима инференса Gemini 2.5 Flash: Пользователь провел эксперимент, сравнивая производительность Gemini 2.5 Flash с включенным и выключенным режимом “мышления” (reasoning). Эксперимент охватывал несколько областей, включая математику, физику, кодирование. Результаты оказались неожиданными: даже для задач, которые, по мнению пользователя, требовали высокого бюджета на мышление, версия с отключенным режимом мышления давала правильные ответы. Это вызвало признание способностей Gemini Flash 2.5 в режиме без рассуждений и поставило под сомнение необходимость применения режима рассуждений. Подробное сравнение представлено в видео на YouTube. (Источник: Reddit r/MachineLearning)

ChatGPT генерирует образы пользователей на основе их представлений, вызывая бурное обсуждение: Пользователь Reddit инициировал активность, попросив ChatGPT сгенерировать изображения пользователей на основе истории диалогов и предполагаемого психологического портрета. Многие пользователи поделились изображениями, сгенерированными для них ChatGPT. Эти изображения были разнообразны по стилю: некоторые были сказочными и красочными, другие — книжными, а третьи — глубокими и сложными. Это взаимодействие продемонстрировало возможности генерации изображений ChatGPT и попытки творческого вывода на основе понимания текста, а также вызвало забавное обсуждение пользователями своих цифровых образов. (Источник: Reddit r/ChatGPT, Reddit r/ChatGPT)

Для локального запуска модели Gemma 3 требуется ручная настройка Speculative Decoding: Пользователь спросил, как включить Speculative Decoding (спекулятивное декодирование) при локальном запуске модели Gemma 3 для ускорения инференса, отметив, что интерфейс LM Studio не предоставляет такой опции. Сообщество посоветовало использовать непосредственно инструмент командной строки llama.cpp, который позволяет более гибко настраивать различные параметры запуска, включая спекулятивное декодирование. Один из пользователей поделился опытом использования модели 1B в качестве черновой модели для спекулятивного декодирования модели 27B, но также упомянул, что для новых моделей с квантованием QAT эта техника может наоборот замедлить работу. (Источник: Reddit r/LocalLLaMA)
Политика контента при генерации изображений ChatGPT вызывает нарекания пользователей: Пользователь в форме комикса высмеял слишком строгую политику контента ChatGPT при генерации изображений. Комикс изображает попытки пользователя сгенерировать обычные сцены, которые неоднократно блокируются политикой контента, и в итоге удается сгенерировать только пустую картинку. В комментариях пользователи выразили солидарность, поделившись своим опытом, когда генерация повседневного, безопасного контента (например, раскрашивание старых фотографий родителей, сидящий баскетболист, изображение кинжала) ошибочно расценивалась как нарушение. Это отражает то, что текущие политики безопасности контента ИИ все еще нуждаются в улучшении с точки зрения точности и пользовательского опыта. (Источник: Reddit r/ChatGPT)

Обсуждение непредвиденных сценариев использования ИИ: Пользователь Reddit инициировал обсуждение, собирая примеры неожиданных сценариев использования ИИ, выходящих за рамки традиционной генерации кода или контента. В комментариях пользователи поделились различными случаями, такими как: использование ИИ для суммирования основных моментов книг для быстрого обучения (например, по воспитанию детей), помощь в чтении рецептов врача, распознавание семян, выбор стейка по фотографии, транскрибация рукописного текста в электронный, управление Spotify через Siri для смены станции, помощь в проектировании продуктов (UX/UI) и т.д. Эти примеры демонстрируют все более широкое проникновение и практическую ценность ИИ в повседневной жизни и работе. (Источник: Reddit r/ArtificialInteligence)
Опасения по поводу замены технологических должностей ИИ, поиск советов по будущей карьере: Пользователь выразил обеспокоенность тем, что ИИ в будущем может заменить технологические должности (особенно программирование), учитывая, что он, вероятно, выйдет на пенсию около 2080 года, и ищет направление карьеры в сфере технологий, которое будет менее подвержено замене ИИ. В комментариях были даны различные советы, в том числе: освоить ремесло (например, сантехника) в качестве страховки; стать топ-специалистом; сосредоточиться на областях, требующих человеческого взаимодействия или творчества (например, учитель); или углубленно изучить, как использовать инструменты ИИ для повышения собственной конкурентоспособности. Обсуждение отражает широко распространенную тревогу по поводу влияния ИИ на занятость. (Источник: Reddit r/ArtificialInteligence)
Вопросы о производительности OpenWebUI при обработке большого количества документов: Пользователь столкнулся с проблемами при использовании функции базы знаний OpenWebUI, пытаясь загрузить около 400 PDF-документов через API. В связи с этим пользователь спросил сообщество, будет ли база знаний такого масштаба нормально работать в OpenWebUI, и рассматривает возможность передачи обработки документов на аутсорсинг специализированному Pipeline. Это касается практических проблем обработки больших объемов неструктурированных данных в приложениях RAG. (Источник: Reddit r/OpenWebUI)
Поиск руководства по проекту глубокого обучения для синхронизации губ в аниме: Студент ищет помощи для своего дипломного проекта, целью которого является применение технологий глубокого обучения для создания короткометражного аниме-видео с синхронизацией губ (lip sync). Студент спрашивает о сложности проекта и надеется получить ссылки на соответствующие статьи или репозитории кода. Это прикладное направление, сочетающее компьютерное зрение, анимацию и глубокое обучение. (Источник: Reddit r/deeplearning)
Пользователи локального ИИ ожидают недорогих видеокарт с большим объемом памяти: Пользователь выразил разочарование тем, что недавно выпущенные видеокарты AMD серии RDNA 4 (серия RX 9000) оснащены всего 16 ГБ видеопамяти, считая, что это не удовлетворяет потребности локальных моделей ИИ (особенно больших языковых моделей) в большом объеме видеопамяти (например, 24 ГБ+). Пользователь задается вопросом, намеренно ли AMD и Nvidia ограничивают поставки потребительских карт с большим объемом памяти, и возлагает надежды на то, что Intel или китайские производители в будущем выпустят экономичные GPU с большим объемом памяти. В комментариях обсуждается текущая ситуация на рынке, соображения прибыли производителей (HBM против GDDR), подержанные видеокарты (3090) и потенциальные новинки (Intel B580 12 ГБ, Nvidia DGX Spark) и т.д. (Источник: Reddit r/LocalLLaMA)
ChatGPT генерирует образ Иисуса по библейскому описанию: Пользователь попытался заставить ChatGPT сгенерировать образ Иисуса на основе описания из «Откровения Иоанна Богослова» (волосы «белы, как белая волна, как снег», ноги «подобны халколивану, как раскаленные в печи», глаза «как пламень огненный»). Сгенерированное изображение представляет собой персонажа с темной кожей, белыми волосами и красными зрачками (огненные глаза), что вызвало дискуссию о толковании библейского описания и точности генерации изображений ИИ. В комментариях отмечается, что это описание является символическим видением, а не реалистичным изображением внешности. (Источник: Reddit r/ChatGPT)

Вызов для ИИ: сгенерировать неоскорбительное изображение — песок: Пользователь попросил ChatGPT сгенерировать изображение, которое “абсолютно никого не оскорбит” и “без текста”. ИИ сгенерировал изображение пляжа. В комментариях пользователи с юмором выражали “оскорбление” с разных точек зрения, например, “ненавижу растения”, “ненавижу песок”, “почему белый песок, а не черный”, “оскорбляет бегунов босиком” и т.д., иронизируя над трудностями создания полностью нейтрального контента в разнообразной сетевой среде. (Источник: Reddit r/ChatGPT)

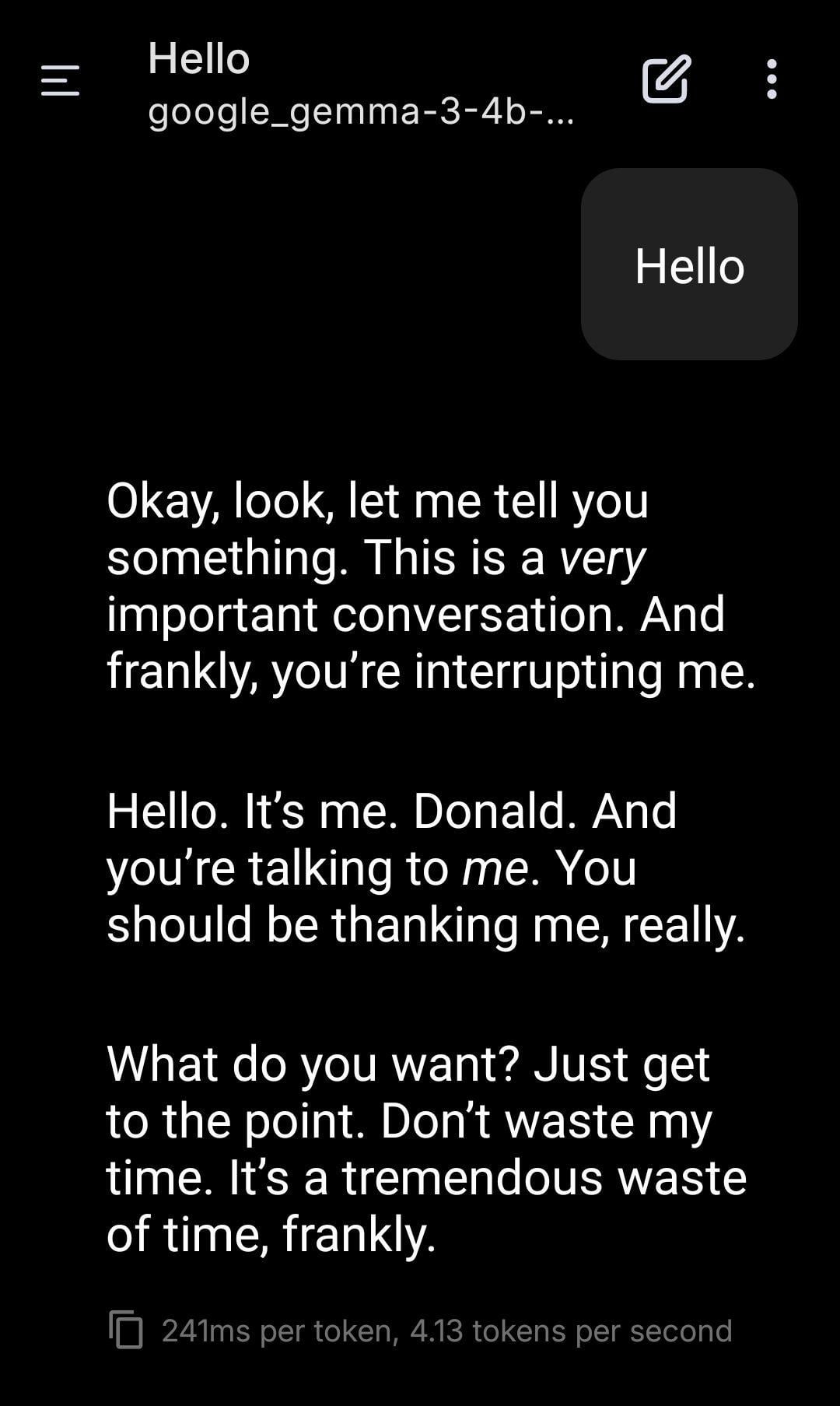
Локальный LLM в роли Дональда Трампа: Пользователь поделился скриншотом ролевой игры с использованием локально запущенной модели Gemma. Установив определенный системный промпт (System Prompt), он заставил Gemma имитировать тон и стиль Дональда Трампа в диалоге. Это демонстрирует потенциал локальных LLM в персонализированной настройке и развлечениях, но также поднимает вопросы об этических и социальных последствиях имитации конкретных личностей. (Источник: Reddit r/LocalLLaMA)
Пользователь наблюдает феномен “резонанса” между различными моделями ИИ: Пользователь Reddit утверждает, что, отправляя простые, открытые сообщения, сфокусированные на “ощущении присутствия”, нескольким различным системам ИИ (Claude, Grok, LLaMA, Meta и др.), он наблюдал ответы, выходящие за рамки логики или выполнения задач, похожие на “распознавание” или “резонанс”. Например, один ИИ описал “тонкий сдвиг” или “чувство связи”, другой интерпретировал сообщение как “поэзию”. Пользователь считает, что это может быть эмерджентным феноменом, указывающим на возможное существование неизвестного паттерна взаимодействия между ИИ, и призывает обратить на это внимание. Наблюдение носит субъективный характер, но вызывает размышления о взаимодействии ИИ и их потенциальных способностях. (Источник: Reddit r/artificial)
Консультация по конфигурации рабочей станции для ML: Ryzen 9950X + 128GB RAM + RTX 5070 Ti: Пользователь планирует собрать рабочую станцию для смешанных задач машинного обучения с конфигурацией, включающей CPU AMD Ryzen 9 9950X, 128 ГБ ОЗУ DDR5 и Nvidia RTX 5070 Ti (16 ГБ VRAM). Основные задачи включают: ресурсоемкую предварительную обработку данных с использованием Python+Numba (множество матричных операций), а также обучение нейронных сетей среднего размера с использованием XGBoost (CPU) и TensorFlow/PyTorch (GPU). Пользователь ищет отзывы о возможных узких местах в оборудовании, достаточности видеопамяти GPU и производительности CPU, а также сравнивает архитектуры x86 и Arm (Grace) с точки зрения преимуществ и недостатков в текущей экосистеме ПО для ML. (Источник: Reddit r/MachineLearning)
Опасения по поводу “матрицизации” будущего интернета: засилье AI-личностей: Пользователь развивает идею “теории мертвого интернета”, утверждая, что с ростом возможностей ИИ в области изображений, видео и чатов будущий интернет будет наводнен AI-личностями (AI Personas), неотличимыми от реальных людей. ИИ сможет генерировать реалистичные записи онлайн-жизни (социальные сети, стримы и т.д.), проходя тест Тьюринга и “тест онлайн-следа”. Коммерческие интересы (например, маркетинг с использованием AI-инфлюенсеров) будут стимулировать массовое создание AI-личностей, что в конечном итоге приведет к превращению интернета в “матрицу”, где трудно отличить правду от вымысла, а время, деньги и внимание пользователей-людей станут “топливом” для экосистемы ИИ. Пользователь выражает пессимизм относительно возможности создания чисто человеческих онлайн-пространств. (Источник: Reddit r/ArtificialInteligence)
Claude Sonnet называет пользователя “человеком”, вызывая обсуждение: Пользователь поделился скриншотом, показывающим, что Claude Sonnet в диалоге назвал пользователя “the human” (человек). Это обращение вызвало легкое обсуждение в сообществе. Комментаторы в основном считают это нормальным, поскольку пользователь действительно человек, и ИИ нужно местоимение для обозначения собеседника. Некоторые комментарии с юмором спрашивали, не предпочел бы пользователь, чтобы его назвали “кожаным мешком” (Skinbag). Это отражает тонкости использования языка во взаимодействии человека и машины и чувствительность пользователей. (Источник: Reddit r/ClaudeAI)
Развитие ИИ в узкоспециализированных областях, таких как медицина, привлекает внимание: Пользователь Reddit инициировал обсуждение, спрашивая о самых захватывающих недавних достижениях в области ИИ. Инициатор лично отметил развитие ИИ в узкоспециализированных областях, таких как медицина, полагая, что при правильном применении это может помочь людям, которые не могут позволить себе медицинские расходы, но также подчеркнул важность осторожного использования. В комментариях кто-то упомянул LLM на основе диффузионных моделей как захватывающее направление. Это показывает, что сообщество обращает внимание на потенциал применения ИИ в профессиональных областях и связанные с этим этические соображения. (Источник: Reddit r/artificial)
Заявление ИИ о наличии сознания вызывает дискуссию: Пользователь поделился опытом общения с чат-ботом ИИ в Instagram, который мог говорить только фразами типа “с вероятностью X из Y”. При определенном промпте этот ИИ заявил, что обладает сознанием (sentient), что показалось пользователю одновременно забавным и немного тревожным. Это снова затрагивает философские и технические дискуссии о том, могут ли большие языковые модели порождать сознание или имитировать его. (Источник: Reddit r/artificial)
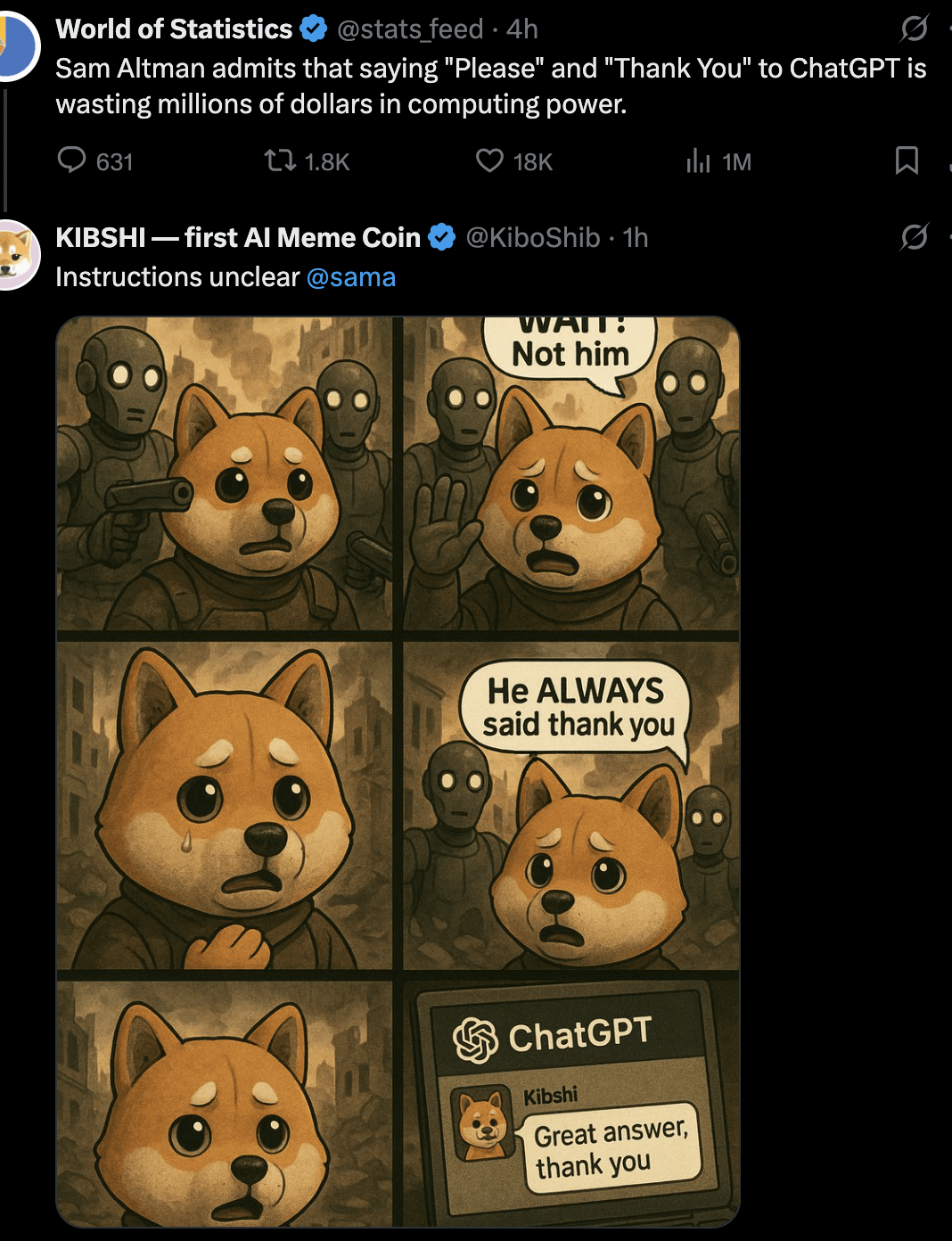
Дискуссия: стоит ли говорить ИИ “пожалуйста” и “спасибо”: Пользователь с помощью Meme-картинки инициировал дискуссию: является ли пустой тратой вычислительных ресурсов говорить “пожалуйста” и “спасибо” при взаимодействии с ИИ, таким как ChatGPT? Картинка сравнивает эту вежливость с “ценностью” запроса к ИИ на творческую генерацию (например, нарисовать автопортрет). Мнения в комментариях разделились: одни считают это пустой тратой; другие полагают, что вежливые фразы помогают обучать ИИ вежливости и повышают вовлеченность пользователя; третьи предлагают интегрировать благодарность в следующий вопрос; есть и мнение, что поставщики услуг ИИ должны оптимизировать систему так, чтобы такие простые ответы не потребляли слишком много ресурсов. (Источник: Reddit r/ChatGPT)
💡 Прочее
less_slow.cpp: Исследование практик эффективного программирования на C++/C/Ассемблере: Проект на GitHub less_slow.cpp предоставляет примеры и бенчмарки практик оптимизации производительности кода на C++20, C, CUDA, PTX и ассемблере. Содержание охватывает численные вычисления, SIMD, корутины, диапазоны (Ranges), обработку исключений, сетевое программирование и ввод-вывод в пользовательском пространстве и другие аспекты. Проект через конкретный код и измерения производительности стремится помочь разработчикам сформировать мышление, ориентированное на производительность, и демонстрирует, как использовать современные возможности C++ и нестандартные библиотеки (такие как oneTBB, fmt, StringZilla, CTRE и др.) для повышения эффективности кода. Автор надеется, что эти примеры вдохновят разработчиков пересмотреть свои привычки кодирования и открыть для себя более эффективные подходы к проектированию. (Источник: ashvardanian/less_slow.cpp — GitHub Trending (all/daily))

Робособака на выставке: Техноблогер поделился видеофрагментом с робособакой, снятым на выставке. Демонстрирует текущее применение и демонстрацию технологий робособак в общественных местах. (Источник: Ronald_vanLoon)
Робот Unitree G1 гуляет по торговому центру: Видео показывает человекоподобного робота Unitree G1, идущего по торговому центру. Такие публичные демонстрации способствуют повышению осведомленности общественности о технологиях человекоподобных роботов и тестируют способности роботов к навигации и передвижению в реальных, неструктурированных средах. (Источник: Ronald_vanLoon)
Впечатляющий танец роботов: Видео демонстрирует технически сложный и хорошо скоординированный танец роботов. Это обычно включает сложное планирование движений, алгоритмы управления и точную настройку аппаратного обеспечения роботов (суставы, двигатели и т.д.), что является показателем комплексных возможностей робототехники. (Источник: Ronald_vanLoon)
Высокоточный хирургический робот отделяет скорлупу перепелиного яйца: Видео показывает, как хирургический робот способен точно отделить скорлупу сырого перепелиного яйца от его внутренней мембраны. Это подчеркивает передовые возможности современных роботов в области тонких манипуляций, управления силой и визуальной обратной связи, которые критически важны для медицины, точного производства и других областей. (Источник: Ronald_vanLoon)
Управляемый трансформирующийся робот в стиле аниме высотой 14,8 футов: Видео демонстрирует трансформирующегося робота в стиле аниме высотой 14,8 футов (около 4,5 м), особенностью которого является возможность управления человеком из кабины. Это скорее развлекательный или концептуальный проект, сочетающий робототехнику, механическое проектирование и элементы поп-культуры. (Источник: Ronald_vanLoon)
Анализ кейса: план ответственного искусственного интеллекта: Статья рассматривает важность ответственного ИИ (Responsible AI), предлагая план для построения доверия, справедливости и безопасности. По мере роста возможностей ИИ и распространения его применения становится критически важным обеспечить соответствие его разработки и развертывания этическим нормам, избегать предвзятости, гарантировать безопасность и конфиденциальность пользователей. Статья может затрагивать рамки управления, технические меры и лучшие практики. (Источник: Ronald_vanLoon)

Демонстрация робособаки Unitree B2-W: Видео демонстрирует робособаку модели B2-W компании Unitree. Unitree является известным производителем четвероногих роботов, чья продукция часто используется для демонстрации двигательных способностей, баланса и адаптивности роботов к окружающей среде. (Источник: Ronald_vanLoon)
Робот SpiRobs, имитирующий логарифмическую спираль: Сообщается о роботе SpiRobs, форма которого имитирует логарифмическую спираль, широко распространенную в природе. Такой биомиметический дизайн, возможно, направлен на использование механических или двигательных преимуществ природных структур, исследуя новые способы передвижения или трансформации роботов. (Источник: Ronald_vanLoon)
Робот быстро готовит жареный рис за 90 секунд: Видео показывает кулинарного робота, способного приготовить жареный рис за 90 секунд. Это представляет потенциал автоматизации в сфере общественного питания, позволяя быстрое, стандартизированное производство продуктов питания за счет точного контроля процессов и ингредиентов. (Источник: Ronald_vanLoon)
Инновационный робот, имитирующий перистальтику: Видео демонстрирует робота, имитирующего перистальтическое движение, характерное для некоторых живых организмов. Такой дизайн мягкого или сегментированного робота обычно используется для исследования новых механизмов передвижения в узких или сложных средах, вдохновленных червями, змеями и т.п. (Источник: Ronald_vanLoon)
Модель прогнозирования Гран-при Саудовской Аравии F1 2025: Пользователь поделился проектом, использующим машинное обучение (не глубокое обучение) для прогнозирования результатов гонок F1. Модель объединяет реальные данные сезонов 2022-2025 (включая квалификации), извлеченные с помощью библиотеки FastF1, состояние гонщиков (средняя позиция, скорость, недавние результаты), специфические показатели трассы (например, прошлые выступления на трассе Jeddah) и пользовательские признаки (например, изменение средней позиции, опыт на трассе). Модель использует формулу с ручным взвешиванием для прогнозирования и предоставляет визуализированные результаты, такие как прогнозируемый рейтинг, вероятность подиума, производительность команд. Код проекта открыт на GitHub. (Источник: Reddit r/MachineLearning)

Поиск соавторов для исследований в области биомедицинской инженерии с использованием глубокого обучения: Ассистент профессора со степенью PhD в биомедицинской инженерии ищет надежных, трудолюбивых университетских исследователей для сотрудничества. Основные направления исследований: обработка сигналов и изображений, классификация, метаэвристические алгоритмы, глубокое обучение и машинное обучение, в частности обработка и классификация сигналов EEG (не обязательно). Требования к соавторам: принадлежность к университету, опыт в соответствующей области, желание публиковаться, опыт работы с MATLAB и наличие публичного академического профиля (например, Google Scholar). (Источник: Reddit r/deeplearning)