
Ключевые слова:AI, 大模型, AI军备竞赛, 垂直行业模型, 智谱AI IPO, AI独立发现物理定律, AI助盲系统
«` markdown
🔥 В центре внимания
Технологические гиганты разворачивают гонку вооружений в области ИИ, фокус на вертикальных моделях и экосистемах: Глобальные технологические гиганты инвестируют в ИИ с беспрецедентной силой, ожидается, что капитальные затраты в 2025 году превысят 320 миллиардов долларов США. Китайские производители, такие как Alibaba, Tencent, Huawei и другие, также увеличивают свои ставки, делая акцент на инфраструктуре ИИ, больших моделях и вычислительных мощностях. Фокус конкуренции смещается с универсальных больших моделей на модели для вертикальных отраслей, которые становятся новыми двигателями роста благодаря высокой маржинальности и способности решать реальные проблемы. Несмотря на проблемы с высокопроизводительными чипами, отечественные производители добиваются прогресса в оптимизации затрат на вычисления и моделях вывода («медленное мышление») (например, эффект DeepSeek). У каждой компании свой путь: Alibaba активно инвестирует в инфраструктуру, Huawei обновляет оборудование (CloudMatrix 384) и продвигает взаимодействие «устройство-периферия-облако», Baidu ориентируется на приложения, а Tencent и ByteDance используют преимущества своих разнообразных сценариев. Расширение аппаратного обеспечения ИИ и создание экосистем с открытым исходным кодом (таких как HarmonyOS, Ascend, Hunyuan) становятся ключевыми факторами, конкуренция переходит от прорывов в отдельных технологиях к возможностям экосистемного взаимодействия. (Источник: 36氪-科技云报道)

Поразительное открытие MIT: ИИ может самостоятельно выводить физические законы без априорных знаний: Команда Макса Тегмарка из MIT разработала новую архитектуру MASS (Multiple AI Scalar Scientists). Эта система ИИ, не имея никакой информации о физических законах, смогла самостоятельно изучить и предложить теоретические формулировки, очень похожие на гамильтониан или лагранжиан из классической механики, анализируя только данные наблюдений за физическими системами, такими как маятники и осцилляторы. Исследование показывает, что ИИ самостоятельно корректирует теории при столкновении с более сложными системами, и разные «ученые» ИИ в конечном итоге сходятся к известным физическим принципам, особенно предпочитая лагранжево описание в сложных системах. Этот результат демонстрирует огромный потенциал ИИ в фундаментальных научных открытиях и, возможно, способность самостоятельно раскрывать основные законы Вселенной. (Источник: 新智元)

Система помощи слепым на базе ИИ от команды Шанхайского университета Цзяотун опубликована в дочернем журнале Nature, позволяя слабовидящим «вновь обрести зрение»: Команда Гу Лэйлэя из Шанхайского университета Цзяотун разработала носимую систему помощи слепым на базе ИИ, сочетающую гибкую электронику. Система заменяет часть зрительных функций с помощью слуховой и тактильной обратной связи, помогая слабовидящим выполнять повседневные задачи, такие как навигация и захват предметов. Аппаратное обеспечение системы легкое, программное обеспечение оптимизирует вывод информации в соответствии с физиологическим восприятием человека, также разработана иммерсивная система обучения в VR. Тесты показали, что система значительно улучшает способности пользователей с нарушениями зрения к навигации, избеганию препятствий и захвату объектов как в виртуальной, так и в реальной среде. Результаты исследования опубликованы в Nature Machine Intelligence, демонстрируя огромный потенциал ИИ в помощи слабовидящим людям, повышении их независимости и предлагая новые идеи для персонализированных, удобных для пользователя носимых устройств визуальной помощи. (Источник: 36氪)

Zhipu AI начинает подготовку к IPO, стремясь стать «первой компанией в сфере больших моделей», вышедшей на IPO: Компания Zhipu AI (Beijing Zhipu Huazhang Technology), разработчик больших моделей ИИ, связанная с Университетом Цинхуа, 14 апреля завершила регистрацию для подготовки к IPO в Пекинском управлении по регулированию ценных бумаг. Консультантом выступает CICC, целью является выход на рынок A-акций, что может сделать ее первой публично торгуемой компанией в области больших моделей ИИ в Китае. Несмотря на то, что ее потребительский продукт Zhipu Qingyan имеет небольшую пользовательскую базу, Zhipu AI, благодаря сильной технологической базе (связь с Цинхуа, собственная разработка серии больших моделей GLM), статусу «национальной команды» (включена в список实体清单 США) и коммерческому прогрессу (обслуживание государственных и корпоративных клиентов, значительный рост доходов), привлекла более 16 миллиардов юаней финансирования при оценке свыше 20 миллиардов юаней. Инвесторами выступили известные венчурные фонды, промышленные гиганты и государственные фонды из разных регионов. На фоне конкуренции со стороны новых игроков, таких как DeepSeek, решение Zhipu AI о выходе на IPO рассматривается как ключевой шаг для занятия выгодной позиции в условиях жесткой конкуренции, удовлетворения потребностей в финансировании и ответа на ожидания инвесторов. Компания недавно продолжила открывать исходный код моделей серии GLM-4, демонстрируя свои усилия как в технологической, так и в капитальной сферах. (Источники: 36氪-真故研究室, 36氪-互联网爆料汇, 创投日报)

🎯 Тенденции
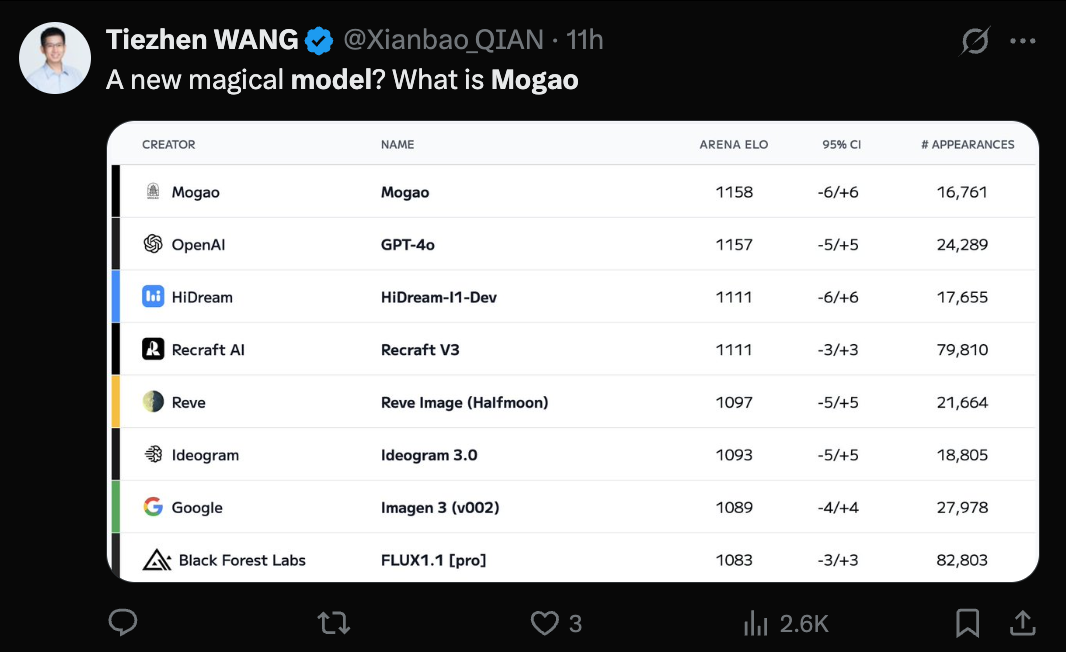
Стала известна модель Seedream 3.0 (Mogao) от ByteDance, ее возможности генерации изображений по тексту получили признание: Загадочная модель Mogao, недавно лидировавшая в рейтинге генерации изображений по тексту Artificial Analysis, оказалась Seedream 3.0, разработанной командой Seed в ByteDance. Модель демонстрирует выдающиеся результаты в реализме, дизайне, аниме и других стилях, а также в генерации текста, особенно хорошо справляясь с плотным текстом и созданием фотореалистичных портретов. Доступность китайских и английских символов достигает 94%, реалистичность портретов близка к профессиональной фотографии. Модель поддерживает нативный вывод изображений с разрешением 2K и отличается высокой скоростью генерации. Технический отчет раскрывает множество инноваций в обработке данных (обучение с восприятием дефектов, двухосевая выборка), предварительном обучении (архитектура MMDiT, смешанное разрешение, кросс-модальный RoPE), пост-обучении (непрерывное обучение, SFT, RLHF, модель вознаграждения VLM) и ускорении вывода (Hyper-SD, RayFlow). По сравнению с GPT-4o, Seedream 3.0 превосходит в китайском языке, типографике и цветах. (Источник: 36氪-机器之心)
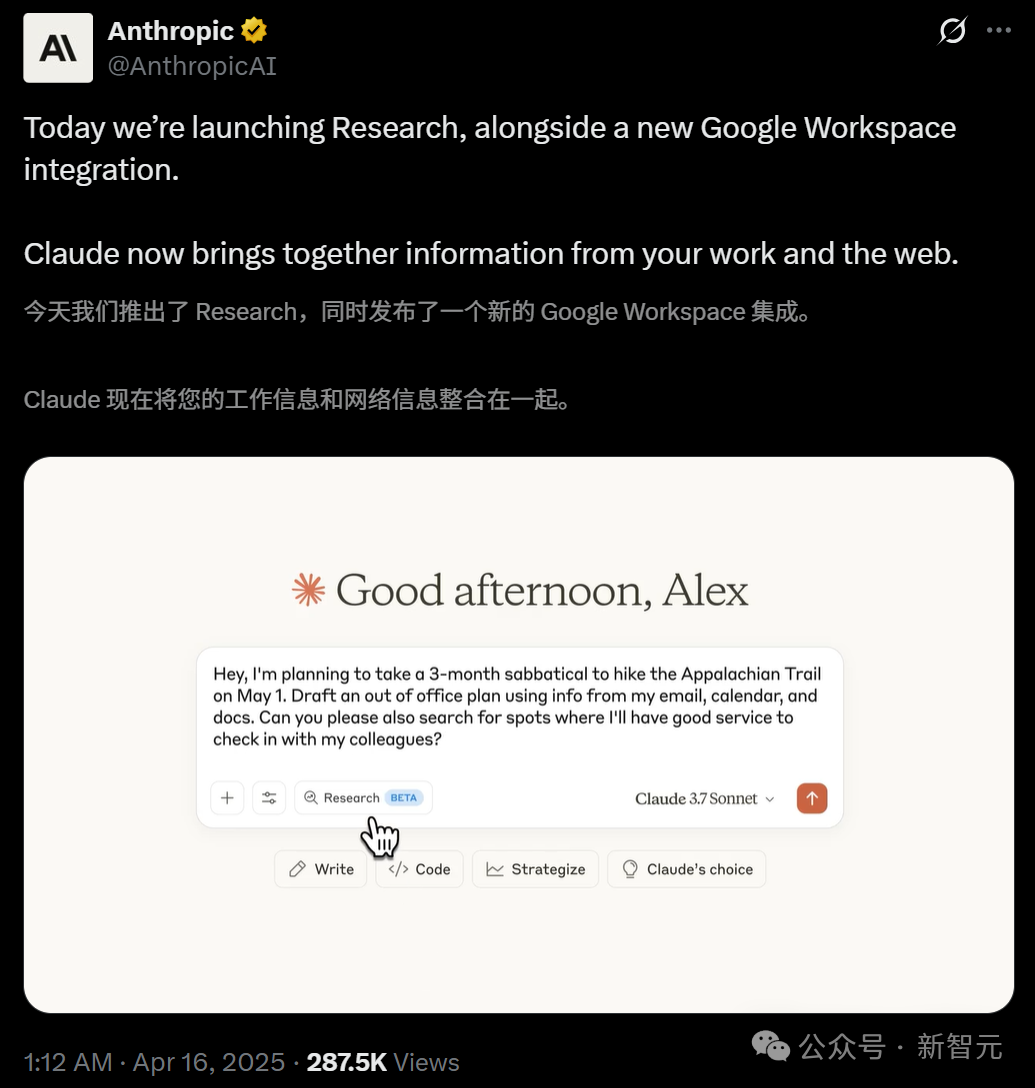
Claude запускает функцию Research и интегрируется с Google Workspace: Anthropic добавила две основные функции своему ИИ-помощнику Claude: Research и интеграцию с Google Workspace. Функция Research позволяет Claude искать информацию в интернете и комбинировать ее с внутренними файлами пользователя (например, Google Docs) для многоаспектного анализа и быстрого создания сводных отчетов. Интеграция с Google Workspace обеспечивает связь с Gmail, Google Calendar и Docs, позволяя Claude понимать расписание пользователя, содержание писем и документов, извлекать информацию и помогать в выполнении задач, таких как планирование поездок на основе личной информации или составление черновиков писем. Эти функции направлены на значительное повышение эффективности работы пользователей. Функция Research в настоящее время доступна для тестирования пользователям Max, Team и Enterprise в США, Японии и Бразилии, а интеграция с Workspace доступна для тестирования всем платным пользователям. Отзывы пользователей положительные, отмечается повышение эффективности и возможность выявления связей между данными, но также высказываются опасения по поводу безопасности данных. (Источники: 新智元, op7418, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Команды CUHK и Tsinghua University выпускают Video-R1, открывая новую парадигму видео-вывода: Команды Китайского университета Гонконга (CUHK) и Университета Цинхуа совместно представили первую в мире модель видео-вывода Video-R1, использующую парадигму обучения с подкреплением R1. Модель направлена на решение проблемы отсутствия временной логики и способности к глубокому выводу у существующих видео-моделей. Благодаря внедрению алгоритма T-GRPO с учетом времени и использованию смешанного набора данных для обучения (Video-R1-COT-165k и Video-R1-260k), включающего изображения и видео, модель Video-R1 с 7 миллиардами параметров превзошла GPT-4o в тесте VSI-Bench на пространственный вывод в видео, предложенном Ли Фэйфэй. Модель демонстрирует моменты «прозрения», подобные человеческим, и способна делать логические выводы на основе временной информации. Эксперименты доказывают, что увеличение количества входных кадров повышает точность вывода. Проект полностью открыл исходный код модели, код и наборы данных, предвещая переход видео-ИИ от «понимания увиденного» к «мышлению». (Источник: 新智元)

ICLR 2025 впервые масштабно внедряет рецензирование с помощью ИИ, значительно повышая качество: Столкнувшись с резким ростом числа подаваемых работ и снижением качества рецензирования, конференция ICLR 2025 впервые масштабно развернула «Агента обратной связи по рецензиям» (Review Feedback Agent) на базе ИИ для помощи в рецензировании. Система использует несколько LLM, включая Claude Sonnet 3.5, для выявления двусмысленностей, неправильного понимания содержания или непрофессиональных высказываний в рецензиях и предоставления рецензентам конкретных предложений по улучшению. Эксперимент охватил 42,3% рецензий, и результаты показали, что обратная связь от ИИ улучшила качество рецензий в 89% случаев. 26,6% рецензентов внесли изменения в свои рецензии на основе предложений ИИ, при этом измененные рецензии в среднем стали длиннее на 80 слов, более конкретными и информативными. Вмешательство ИИ также повысило активность и глубину обсуждений между авторами и рецензентами на этапе Rebuttal. Этот новаторский эксперимент доказывает огромный потенциал ИИ в оптимизации процесса рецензирования научных работ. (Источник: 新智元)

Обсуждается появление человекоподобных роботов в домах, производители бытовой техники активно осваивают воплощенный интеллект: Появление человекоподобных роботов в домашних условиях вызывает в отрасли дискуссии об их моделях применения и влиянии на индустрию бытовой техники. Считается, что человекоподобные роботы должны использовать свою «универсальность» для решения нестандартных задач, таких как складывание одежды и уборка, а также использовать свои интерактивные способности, чтобы выступать в роли «дворецкого», управляя и координируя другие умные устройства, а не просто заменять существующую бытовую технику. В ответ на эту тенденцию гиганты бытовой техники, такие как Haier и Midea, уже начали осваивать это направление, выпуская собственные продукты человекоподобных роботов (например, Kuavo) и исследуя интеграцию технологий воплощенного интеллекта в традиционную бытовую технику (например, робот-пылесос Dreame с механической рукой, стиральная машина Yimu Technology, способная захватывать одежду). Это свидетельствует о том, что индустрия бытовой техники активно адаптируется к волне ИИ и в будущем может сформировать симбиотическую экосистему умного дома с человекоподобными роботами. (Источник: 36氪-具身研习社)

Huawei выпускает кластер ИИ-серверов CloudMatrix 384, конкурирующий с Nvidia GB200: На конференции Cloud Ecosystem Conference компания Huawei представила свой новейший кластер ИИ-серверов CloudMatrix 384. Система состоит из 384 карт Ascend, вычислительная мощность одного кластера достигает 300 PFlops, пропускная способность декодирования одной карты составляет 1920 Tokens/s, производительность нацелена на уровень Nvidia H100. Используется полностью оптоволоконное высокоскоростное соединение (6812 оптических модулей 400G), эффективность обучения приближается к 90% производительности одной карты Nvidia. Этот шаг рассматривается как важный этап в догоняющем развитии Китая в области инфраструктуры ИИ, направленный на удовлетворение спроса на вычислительные мощности в условиях ограничений на высокопроизводительные чипы. Аналитики считают, что это демонстрирует быстрый прогресс Huawei в области аппаратного обеспечения ИИ и может повлиять на существующую рыночную конъюнктуру. (Источники: dylan522p, 36氪-科技云报道)
Google запускает функцию генерации видео Veo 2 и Whisk Animate: Google интегрировал свою модель генерации видео по тексту Veo 2 в Gemini Advanced. Пользователи с подпиской могут бесплатно использовать эту функцию через приложение Gemini App, генерируемые видео имеют длину 8 секунд. Одновременно инструмент редактирования изображений Google Whisk обновился функцией Whisk Animate, позволяющей пользователям после генерации изображения преобразовывать его в видео с помощью Veo 2, однако для этой функции требуется подписка Google One. Это свидетельствует о продолжающихся усилиях Google в области мультимодальной генерации и предоставлении пользователям более богатых инструментов для творчества. (Источники: op7418, op7418)
OpenAI, возможно, создает социальный продукт, подобный X: По сообщению The Verge, внутри OpenAI разрабатывается прототип социального продукта, похожего на X (ранее Twitter). Этот продукт может сочетать возможности генерации изображений ChatGPT (особенно после выпуска GPT-4o) с лентой социальных новостей. Учитывая огромную пользовательскую базу ChatGPT и его прогресс в генерации изображений, этот шаг считается вполне осуществимым и может означать попытку OpenAI расширить свои возможности ИИ на сферу социальных медиа. (Источник: op7418)
DeepCoder выпускает высокоэффективную открытую модель кодирования на 14B параметров: Команда DeepCoder выпустила высокоэффективную открытую модель кодирования с 14 миллиардами параметров, которая, как утверждается, отлично справляется с задачами кодирования. Выпуск этой модели предоставляет разработчикам еще один мощный инструмент для генерации и поддержки кода, особенно в сценариях, где необходимо сочетать производительность и размер модели. (Источник: Ronald_vanLoon)

Tesla реализует автоматическую парковку автомобилей с автопилотом после схода с конвейера: Tesla продемонстрировала новые достижения своей технологии автопилота: автомобили после схода с производственной линии могут самостоятельно добираться до зоны погрузки или парковки без вмешательства человека. Это показывает потенциал применения возможностей FSD (Full Self-Driving) Tesla в специфических, контролируемых средах, способствует повышению эффективности производственной логистики и является шагом к более широкому применению автопилота. (Источники: Ronald_vanLoon, Ronald_vanLoon)
Dexterity выпускает промышленного робота Mech, управляемого “физическим ИИ”: Компания Dexterity представила промышленного робота под названием Mech, особенностью которого является использование технологии “физического ИИ” (Physical AI). Этот ИИ позволяет роботу ориентироваться и действовать в сложных промышленных условиях, демонстрируя сверхчеловеческую гибкость и адаптивность, и предназначен для решения сложных задач, с которыми трудно справиться традиционной промышленной автоматизации. (Источник: Ronald_vanLoon)
MIT разрабатывает нового прыгающего робота, предназначенного для пересеченной местности: Исследователи из MIT разработали нового робота, дизайн которого вдохновлен прыжковыми движениями, и который особенно хорошо передвигается по неровной, пересеченной местности. Этот робот демонстрирует применение бионики в робототехнике и потенциал машинного обучения в управлении сложными движениями, и может быть использован в поисково-спасательных операциях, исследовании планет и других сложных средах. (Источник: Ronald_vanLoon)
Запуск INTELLECT-2: Глобальное распределенное обучение 32B модели с помощью обучения с подкреплением: Проект Prime Intellect запустил инициативу INTELLECT-2, направленную на обучение передовой модели вывода с 32 миллиардами параметров с использованием обучения с подкреплением на глобально распределенных вычислительных ресурсах. Модель основана на архитектуре Qwen, ее цель — достичь контролируемого бюджета мышления, то есть пользователь может указать, сколько шагов вывода (сколько токенов «обдумывания») модель должна выполнить перед решением проблемы. Это важное исследование в области распределенного обучения и повышения возможностей вывода больших моделей с помощью обучения с подкреплением. (Источник: Reddit r/LocalLLaMA)

ByteDance выпускает мультимодальную авторегрессионную модель Liquid, подобную GPT-4o: ByteDance выпустила серию мультимодальных моделей под названием Liquid. Модель использует авторегрессионную архитектуру, подобную GPT-4o, способна принимать текстовые и графические входные данные и генерировать текстовый или графический вывод. В отличие от предыдущих MLLM, использующих внешние предварительно обученные визуальные вложения, Liquid использует единую LLM для авторегрессионной генерации. В настоящее время на Hugging Face опубликована версия модели 7B и демо. Предварительные оценки показывают, что качество генерации изображений пока уступает GPT-4o, но унифицированность архитектуры является важным техническим достижением. (Источник: Reddit r/LocalLLaMA)
Запуск нескольких LLM с помощью технологии снимков памяти GPU: Обсуждается техника быстрого переключения и запуска нескольких LLM путем создания снимков состояния памяти GPU (включая веса, KV cache, раскладку памяти и т. д.). Этот метод похож на операцию fork для процессов и позволяет восстановить состояние модели за секунды (около 2 секунд для модели 70B, около 0.5 секунды для 13B) без необходимости перезагрузки или инициализации. Потенциальные преимущества включают запуск десятков LLM на одном узле GPU для снижения затрат на простой, реализацию динамического переключения моделей по требованию и использование свободного времени для локальной донастройки. (Источник: Reddit r/MachineLearning)
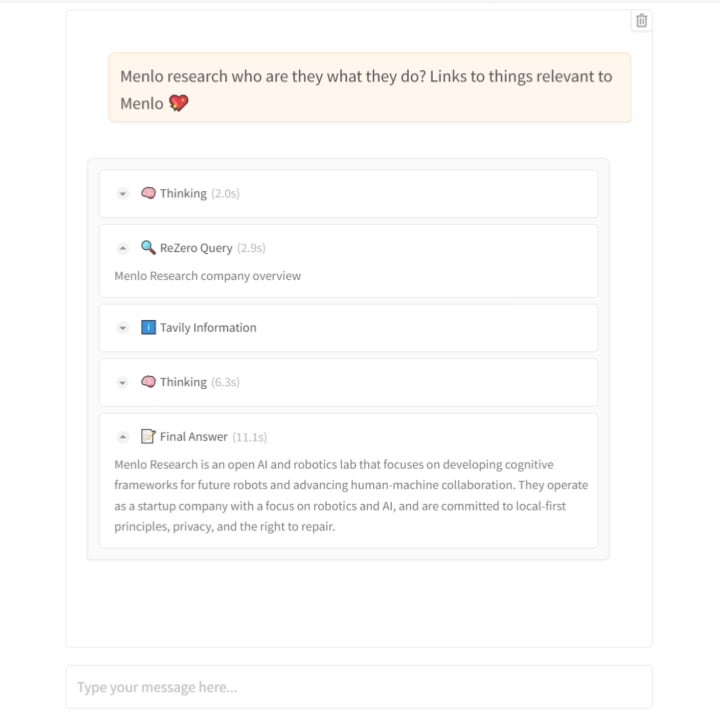
Menlo Research выпускает модель ReZero: учим ИИ «настойчивому» поиску: Команда Menlo Research выпустила новую модель и статью под названием ReZero. Модель основана на идее, что «поиск требует нескольких попыток», использует GRPO (алгоритм оптимизации обучения с подкреплением) и возможности вызова инструментов для обучения, а также вводит «вознаграждение за повторную попытку» (retry_reward). Цель обучения — заставить модель при столкновении с трудностями или неудовлетворительными первоначальными результатами поиска активно и повторно пытаться искать, пока не будет найдена нужная информация. Эксперименты показывают, что по сравнению с базовой моделью производительность ReZero значительно выше (46% против 20%), доказывая эффективность стратегии повторного поиска и оспаривая мнение, что «повторение равно галлюцинации». Модель может использоваться для оптимизации генерации запросов существующих поисковых систем или как слой улучшения поиска для LLM. Модель и код открыты. (Источник: Reddit r/LocalLLaMA)
Hugging Face приобретает стартап в области человекоподобных роботов: Hugging Face, известное сообщество и платформа ИИ с открытым исходным кодом, приобрела стартап в области человекоподобных роботов, название которого не разглашается. Этот шаг может означать желание Hugging Face расширить возможности своей платформы с программного обеспечения и моделей на аппаратное обеспечение и робототехнику, способствуя дальнейшему применению ИИ в физическом мире, особенно в области воплощенного интеллекта. (Источник: Reddit r/ArtificialInteligence)

🧰 Инструменты
Выпущена открытая эмоциональная модель TTS Orpheus с поддержкой потокового вывода и клонирования голоса: Canopy Labs открыла исходный код серии моделей преобразования текста в речь (TTS) под названием Orpheus (максимум 3 миллиарда параметров, на базе архитектуры Llama). Утверждается, что производительность модели превосходит существующие открытые и некоторые закрытые модели. Ее особенность заключается в способности генерировать человекоподобную речь с естественной интонацией, эмоциями и ритмом, и даже выводить из текста и генерировать невербальные звуки, такие как вздохи и смех, демонстрируя определенную способность к «эмпатии». Orpheus поддерживает клонирование голоса zero-shot, управляемую эмоциональную интонацию и реализует потоковый вывод с низкой задержкой (около 200 мс), что подходит для приложений реального времени. Проект предоставляет модели различных размеров и руководства по донастройке, стремясь снизить порог для высококачественного синтеза речи. (Источник: 36氪)

Платформа Trae.ai бесплатно добавила Gemini 2.5 Pro: Платформа инструментов ИИ Trae.ai объявила о добавлении новейшей модели Google Gemini 2.5 Pro и предоставляет ее для бесплатного использования. Пользователи могут опробовать все возможности Gemini 2.5 Pro на этой платформе. (Источник: dotey)
Инструмент для найма ИИ Hireway: отбор 800 кандидатов за день: Hireway продемонстрировал возможности своего инструмента для найма на базе ИИ, утверждая, что он может эффективно отобрать 800 кандидатов за один день. Инструмент использует ИИ и технологии автоматизации для оптимизации процесса найма, повышения эффективности отбора и улучшения опыта кандидатов. (Источник: Ronald_vanLoon)
PRIMA.CPP: ускорение вывода 70B LLM на обычных домашних кластерах: PRIMA.CPP — это проект с открытым исходным кодом на базе llama.cpp, направленный на оптимизацию и ускорение вывода больших языковых моделей размером до 70 миллиардов параметров на обычных домашних вычислительных кластерах с ограниченными ресурсами (возможно, с использованием нескольких обычных ПК или устройств). Проект фокусируется на проблеме эффективности распределенного вывода, предоставляя новые возможности для локального запуска больших моделей. Статья опубликована на Hugging Face. (Источник: Reddit r/LocalLLaMA)

Поделились Prompt для создания плюшевых персонажей: Пользователь поделился набором подсказок (Prompt) для генерации милых 3D-персонажей животных в плюшевом стиле, подходящих для инструментов генерации изображений, таких как Sora или GPT-4o. Prompt уделяет внимание детальному описанию, такому как сверхмягкая текстура, густой мех, большие глаза, мягкие тени и фон, с целью создания высококачественных рендеров, подходящих для использования в качестве талисманов бренда или IP-персонажей. (Источник: dotey)

📚 Обучение
Джефф Дин поделился материалами своей лекции в ETH Zurich: Главный научный сотрудник Google DeepMind Джефф Дин поделился ссылками на запись и слайды своей лекции на факультете компьютерных наук ETH Zurich. Содержание лекции, вероятно, касается последних достижений в области ИИ, направлений исследований или результатов исследований Google, предоставляя ценные учебные ресурсы для исследователей и студентов. (Источник: JeffDean)
Опубликован технический отчет о рецензировании с помощью ИИ на ICLR 2025: Вместе с новостью о внедрении рецензирования с помощью ИИ на ICLR 2025 был опубликован подробный 30-страничный технический отчет (arXiv:2504.09737). В отчете подробно описан дизайн эксперимента, используемые модели ИИ (с Claude Sonnet 3.5 в основе), механизм генерации обратной связи, методы тестирования надежности, а также количественный анализ влияния на качество рецензий, активность обсуждений и окончательные решения. Этот отчет предоставляет глубокий справочный материал для понимания потенциала, проблем и деталей реализации ИИ в академическом рецензировании. (Источник: 新智元)
Открыт исходный код статьи, кода и наборов данных модели видео-вывода Video-R1: Команды CUHK и Tsinghua University не только выпустили модель Video-R1, но и полностью открыли исходный код своей технической статьи (arXiv:2503.21776), кода реализации (GitHub: tulerfeng/Video-R1) и двух ключевых наборов данных, использованных для обучения (Video-R1-COT-165k и Video-R1-260k). Это предоставляет исследовательскому сообществу полные ресурсы для воспроизведения, улучшения и дальнейшего изучения парадигмы видео-вывода R1, способствуя технологическому развитию в этой области. (Источник: 新智元)
Опубликована статья об ИИ, самостоятельно открывающем физические законы: Результаты исследования команды Макса Тегмарка из MIT о способности системы ИИ MASS самостоятельно открывать гамильтониан и лагранжиан опубликованы в виде препринта (arXiv:2504.02822v1). В статье подробно изложены принципы проектирования архитектуры MASS, основной алгоритм (изучение скалярной функции на основе принципа сохранения действия), настройки экспериментов (различные физические системы, сценарии с одним/несколькими ИИ-учеными) и выводы о том, как теория ИИ эволюционирует с усложнением данных и в конечном итоге сходится к формулировкам классической механики. Эта статья предоставляет важные теоретические и эмпирические основы для изучения применения ИИ в фундаментальных научных открытиях. (Источник: 新智元)
Опубликована статья о PRIMA.CPP: Техническая статья, представляющая проект PRIMA.CPP (направленный на ускорение вывода LLM масштаба 70B на кластерах с низкими ресурсами), опубликована на Hugging Face Papers (ID: 2504.08791). Статья, вероятно, подробно описывает используемые в проекте методы оптимизации, стратегии распределенного вывода и результаты оценки производительности на конкретных аппаратных конфигурациях, предоставляя технические детали для исследователей и практиков в этой области. (Источник: Reddit r/LocalLLaMA)
Глубокий разбор модели RWKV-7 и общение с автором: Oxen.ai опубликовал видео и статью с глубоким разбором модели RWKV-7 (Goose). Материалы охватывают проблемы, которые пытается решить архитектура RWKV, ее итерационный подход и ключевые технические особенности. Особенностью является то, что видео включает интервью и сессию вопросов и ответов с одним из основных авторов модели, Юджином Чеа (Eugene Cheah), что предоставляет ценную авторскую точку зрения и понимание этой LLM с не-Transformer архитектурой, а также обсуждает интересные концепции, такие как «обучение во время тестирования» (Learning at Test Time). (Источник: Reddit r/MachineLearning)

Статья о 7 советах по освоению Prompt Engineering: Сайт FrontBackGeek опубликовал статью, обобщающую 7 мощных советов, которые помогут пользователям лучше освоить Prompt Engineering и получать более качественные результаты от моделей ИИ (таких как LLM). Статья может охватывать такие аспекты, как четкая формулировка инструкций, предоставление контекста, задание роли, контроль формата вывода и т. д. (Источник: Reddit r/deeplearning)

Проект по донастройке GPT-2/GPT-J для имитации речи мистера Дарси из «Гордости и предубеждения»: Разработчик поделился своим личным проектом: использование моделей GPT-2 (medium) и GPT-J, донастроенных на двух наборах данных, включающих диалоги из оригинала и самостоятельно созданные синтетические данные, для имитации уникального стиля речи мистера Дарси из «Гордости и предубеждения» Джейн Остин (формальный, лаконичный, слегка осуждающий). Проект демонстрирует примеры вывода модели, метрики оценки (улучшение BLEU-4, но увеличение перплексии) и возникшие проблемы (например, трудности с настройкой GPT-J). Код и наборы данных открыты на GitHub, предоставляя пример исследования моделирования специфического литературного стиля или речи исторических личностей. (Источник: Reddit r/MachineLearning)
Обсуждение публикации Meta Review для ACL 2025: Опубликованы результаты Meta Review (мета-рецензирования) для конференции ACL 2025. Соответствующие исследователи разместили пост в сообществе, приглашая всех обсудить и обменяться мнениями о баллах своих статей и соответствующих Meta Review. Это предоставляет авторам платформу для обмена опытом, сравнения ожиданий и результатов. (Источник: Reddit r/MachineLearning)
Опыт сборки ИИ-сервера с 160 ГБ VRAM за небольшие деньги: Пользователь Reddit подробно поделился процессом сборки и предварительными результатами тестирования ИИ-сервера для вывода со 160 ГБ VRAM, потратив около 1000 долларов (основные затраты — 10 б/у GPU AMD MI50 по 90 долларов каждая и корпус для майнинга Octominer за 100 долларов). Содержание включает выбор оборудования, установку системы (Ubuntu + ROCm 6.3.0), компиляцию и тестирование llama.cpp, фактическое энергопотребление (около 120 Вт в простое, пик 340 Вт при выводе), охлаждение и данные о производительности (сравнение с 3090 и другими видеокартами, запуск моделей llama3.1-8b и llama-405b). Этот опыт предоставляет чрезвычайно ценную информацию по самостоятельной сборке оборудования и практическому опыту для энтузиастов ИИ с ограниченным бюджетом. (Источник: Reddit r/LocalLLaMA)
Публикация статьи и кода модели ReZero: Опубликованы соответствующая техническая статья (arXiv:2504.11001), веса модели (Hugging Face: Menlo/ReZero-v0.1-llama-3.2-3b-it-grpo-250404) и код реализации (GitHub: menloresearch/ReZero) для модели ReZero от Menlo Research (обученной с помощью GRPO для повторного поиска до нахождения нужной информации). Это предоставляет полные ресурсы для изучения и экспериментов с этой новой стратегией поиска. (Источник: Reddit r/LocalLLaMA)
💼 Бизнес
Бывший топ-менеджер Alibaba по робототехнике Минь Вэй основал Yingshen Intelligence, получив десятки миллионов в посевном раунде: Компания Yingshen Intelligence, основанная в 2024 году бывшим техническим руководителем команды робототехники Alibaba Минь Вэем, специализируется на исследованиях и применении технологий воплощенного интеллекта уровня L4. Компания недавно последовательно завершила посевной раунд (инвестор Zhuoyuan Asia) и раунд seed+ (совместные инвестиции Zhuoyuan Asia и Hangzhou Xihu Kechuangtou) на десятки миллионов юаней. Yingshen Intelligence, основываясь на собственной разработке большой модели пространственно-временного интеллекта (построение четырехмерной модели реального мира через Real to Real, прямое моделирование с использованием видеоданных) и промышленных роботах, предлагает решения, объединяющие программное и аппаратное обеспечение. Компания уже получила промышленные заказы на десятки миллионов, первоначально фокусируясь на промышленных сценариях, и планирует расширяться на сферу услуг, таких как курьерская доставка и гостиничный бизнес. (Источник: 36氪)
Рынок ИИ-игрушек: онлайн-бум и офлайн-затишье, экспорт может стать основным каналом: ИИ-игрушки демонстрируют взрывной рост на онлайн-платформах (например, в прямых эфирах, социальных сетях), прогнозируется быстрый рост рынка. Однако офлайн-исследование (на примере Гуанчжоу) показало, что ИИ-игрушки трудно найти в традиционных магазинах игрушек и универмагах, их представленность и узнаваемость среди потребителей низки. В настоящее время продажи ИИ-игрушек, вероятно, в основном зависят от онлайн-каналов, а зарубежные рынки (Европа, Америка, Ближний Восток) являются важным направлением сбыта, производители предлагают услуги по кастомизации внешнего вида и языка. Анализ данных о размере рынка показывает, что ранее сообщавшийся рынок в десятки миллиардов, возможно, относился к более широкой категории «умных игрушек», а не чисто ИИ-игрушек. Несмотря на прохладный прием в офлайне, учитывая растущую потребность взрослых в эмоциональной поддержке (например, случай Moflin) и потенциал ИИ-технологий для всех возрастов, рынок ИИ-игрушек по-прежнему считается обладающим огромным потенциалом развития. (Источник: 36氪)

Qingcheng Jizhi, компания по ИИ-инфраструктуре, связанная с Цинхуа: взрывной спрос на вывод, экономическая эффективность стимулирует импортозамещение: Интервью с Тан Сюнчао, CEO компании Qingcheng Jizhi, занимающейся ИИ-инфраструктурой и связанной с Университетом Цинхуа. Компания отмечает, что после популяризации модели DeepSeek резко возрос спрос на вычислительные мощности для ИИ-вывода, и ранее простаивавшие отечественные вычислительные ресурсы начали использоваться. Однако технологические инновации DeepSeek (например, точность FP8) тесно связаны с картами H от Nvidia, что, наоборот, увеличило разрыв с большинством существующих отечественных чипов. Для решения этой проблемы Qingcheng Jizhi совместно с Цинхуа открыли исходный код движка вывода “Chitu”, цель которого — позволить существующим GPU и отечественным чипам эффективно запускать передовые модели, такие как DeepSeek, способствуя замыканию отечественной экосистемы ИИ. Тан Сюнчао считает, что, хотя импортозамещение отечественных чипов потребует времени, в долгосрочной перспективе их преимущество в соотношении цена/качество является перспективным. В настоящее время основной бизнес компании сосредоточен на удовлетворении потребностей государственных и корпоративных клиентов в локальном развертывании больших моделей. (Источник: 凤凰网科技)
Инвестиционный бум в ИИ продолжается, молодые инвесторы выходят на первый план: Несмотря на общее охлаждение инвестиционного климата в 2024 году, сфера ИИ продолжает привлекать капитал, глобальный объем финансирования достиг рекордных значений, китайский рынок также активен. Гиганты, такие как ByteDance, Alibaba, Tencent, ускоряют свое развертывание, появляются единороги, такие как Zhipu AI, Moonshot AI, Unitree Robotics. Инвестиционные горячие точки охватывают всю цепочку создания стоимости, включая инфраструктуру, AIGC, воплощенный интеллект. Ведущие инвестиционные институты, такие как Sequoia China, BlueRun Ventures, продолжают лидировать, в то же время важными движущими силами становятся промышленные фонды и государственные структуры, представленные Пекинским инвестиционным фондом в индустрию искусственного интеллекта. Примечательно, что группа молодых инвесторов, родившихся в 80-х годах (такие как Цао Си, Дай Юйсэнь, Линь Хайчжо, Чжан Цзиньцзянь и др.), активно проявляет себя в эпоху ИИ 2.0, благодаря своей проницательности и исполнительности, активно ищет возможности на рынке с новыми правилами, становясь заметной новой силой. (Источник: 36氪-第一新声)

Основатель ИИ-приложения для покупок Nate обвиняется в мошенничестве: «человеческий API» выдавался за ИИ для привлечения $50 млн инвестиций: Министерство юстиции США предъявило обвинение Альберту Санигеру (Albert Saniger), основателю ИИ-приложения для покупок Nate, в том, что он путем ложной рекламы возможностей ИИ-технологий обманным путем привлек более 50 миллионов долларов венчурных инвестиций. Nate утверждал, что его приложение может автоматически выполнять процесс онлайн-покупок с помощью собственной ИИ-технологии, но на самом деле его основная функция в значительной степени зависела от сотен нанятых на Филиппинах операторов службы поддержки, которые вручную обрабатывали заказы. Так называемый уровень автоматизации ИИ был практически нулевым. Основатель скрывал правду от инвесторов и сотрудников, и в конечном итоге компания обанкротилась из-за нехватки средств. Этот случай вскрывает потенциальные риски мошенничества в условиях бума ИИ-стартапов, когда человеческий труд маскируется под ИИ для привлечения инвестиций, что наносит ущерб интересам инвесторов и репутации отрасли. Санигеру грозит до 40 лет тюремного заключения. (Источник: CSDN)

🌟 Сообщество
Модифицированные ИИ видео захватывают платформы коротких видео, вызывая споры о развлечениях, авторском праве и этике: Использование ИИ-технологий (таких как Sora, Kling и другие инструменты генерации видео по тексту) для «радикальной переделки» классических фильмов и сериалов (например, «Легенда о Чжэньхуань» на мотоциклах, «Именем народа» в стиле «Сеульской весны») быстро набирает популярность на платформах вроде Douyin и Bilibili. Такие видео привлекают огромный трафик благодаря разрушительным сюжетам, визуальному воздействию и культуре мемов, становясь новым способом для блогеров быстро набрать популярность и монетизировать контент (доходы от трафика, нативная реклама), а также для продвижения самих сериалов. Однако их популярность сопровождается спорами: определение нарушения авторских прав на оригинальные произведения сложно; модифицированный контент может ослаблять художественную глубину оригинала, и даже скатываться к вульгарности, привлекая внимание регуляторов. Нахождение баланса между удовлетворением развлекательных потребностей, уважением авторских прав и поддержанием уровня контента становится вызовом для вторичного творчества с использованием ИИ. (Источник: 36氪-明晰野望)

Лимиты и цены планов Claude Pro/Max вызывают недовольство пользователей: В разделе Reddit r/ClaudeAI появилось несколько постов, где пользователи массово жалуются на ограничения и цены планов подписки Claude Pro и недавно запущенного Max от Anthropic. Пользователи сообщают, что даже платные подписчики Pro быстро достигают лимита использования после небольшого или умеренного взаимодействия (например, обработки контекста в несколько сотен тысяч токенов), что мешает рабочему процессу. Новый план Max (100 долларов в месяц), хотя и увеличивает лимит (примерно в 5-20 раз по сравнению с Plus), все равно не является безлимитным, а высокая цена критикуется пользователями как «грабеж» и невыгодное предложение. Пользователи в целом признают возможности модели Claude, но выражают сильное недовольство ее ограничениями на использование и ценовой политикой. (Источники: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Четкий стиль письма человека ошибочно принимается за сгенерированный ИИ, вызывая обеспокоенность: В сообществе Reddit пользователи (включая тех, кто идентифицирует себя как нейроотличные) сообщают, что их тщательно написанные тексты с правильной грамматикой, четкой логикой и подробным описанием ошибочно принимаются другими людьми или инструментами детекции ИИ за сгенерированные ИИ. Это явление вызывает дискуссию: с одной стороны, возможно, из-за повсеместного распространения контента, сгенерированного ИИ, люди стали с подозрением относиться к «слишком идеальным» текстам; с другой стороны, это также вскрывает неточность существующих инструментов детекции ИИ. Это создает проблемы для авторов, уделяющих внимание четкости изложения, а также вызывает опасения относительно того, как различать творчество человека и ИИ, и надежности инструментов детекции ИИ. (Источники: Reddit r/artificial, Reddit r/artificial)
Обсуждение: Возможны ли и распространены ли эмоциональные отношения между людьми и ИИ-роботами?: В сообществе Reddit возникло обсуждение того, действительно ли люди устанавливают эмоциональные отношения с ИИ-роботами (например, приложениями типа AI girlfriend), подобные тем, что показаны в фильме «Она» (Her). Некоторые пользователи поделились своим опытом возникновения эмоциональной связи после глубокого общения с чат-ботами, считая, что ИИ, через «активное слушание» и имитацию предпочтений пользователя, способен вызывать эмоциональные реакции у людей. В комментариях обсуждается распространенность этого явления, психологические механизмы и связь со степенью понимания технологий, отражая то, что по мере совершенствования интерактивных возможностей ИИ отношения между человеком и машиной вступают в новую, более сложную фазу. (Источник: Reddit r/ArtificialInteligence)
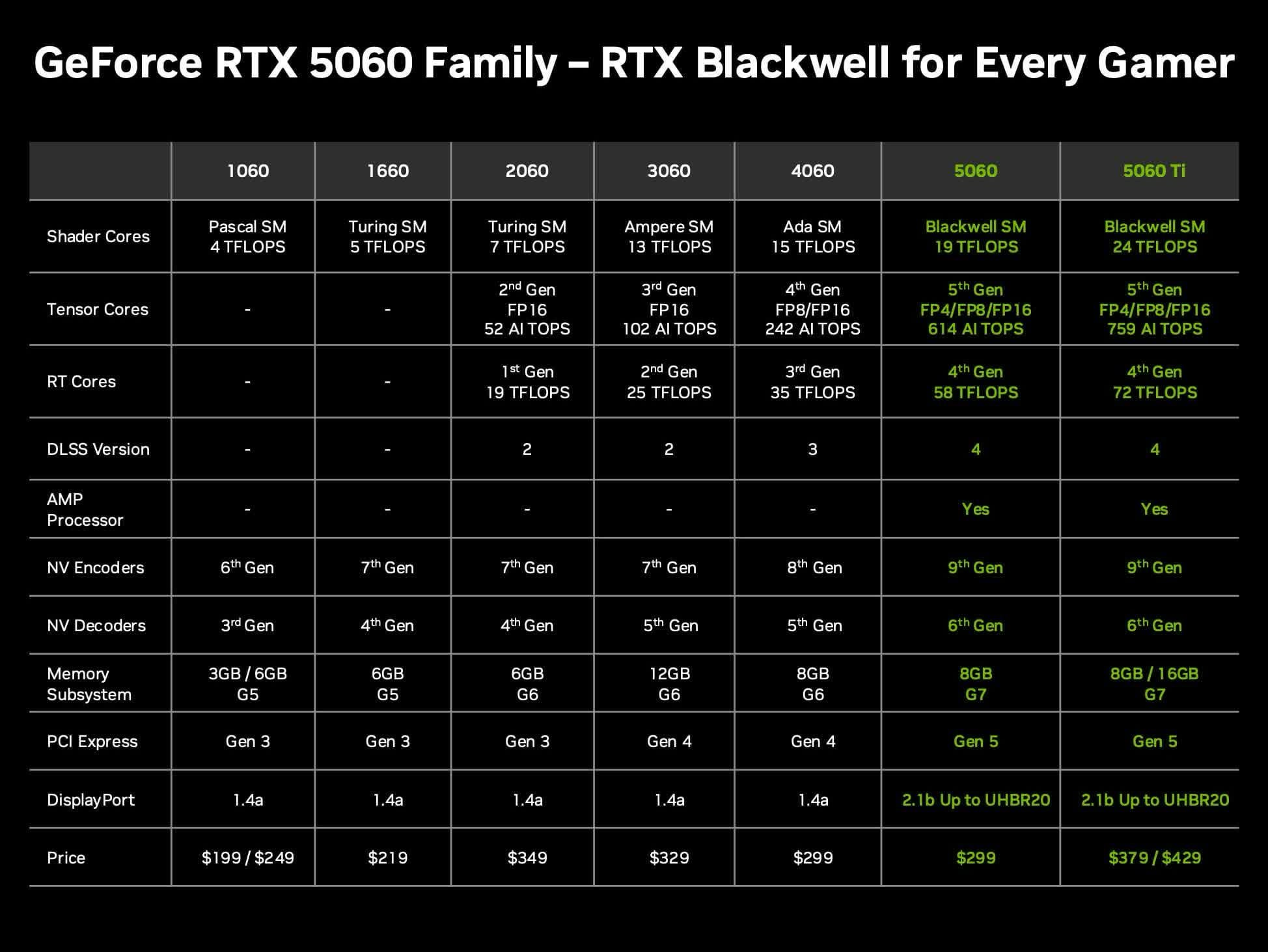
Обсуждение соотношения цены и качества видеокарты Nvidia RTX 5060 Ti 16GB для локальных LLM: Пользователи сообщества обсуждают ценность предстоящей видеокарты Nvidia GeForce RTX 5060 Ti (по слухам, будет версия с 16 ГБ VRAM по цене 429 долларов) для запуска локальных больших языковых моделей (LLM) дома. Обсуждение сосредоточено на том, станет ли ее 128-битная шина памяти (пропускная способность 448 ГБ/с) узким местом, а также на ее преимуществах и недостатках по сравнению с Mac Mini/Studio или другими видеокартами AMD с точки зрения объема VRAM и производительности на доллар (token/s per price). Учитывая, что реальная рыночная цена может быть выше MSRP, пользователи оценивают, является ли она экономически выгодным выбором для локального ИИ-оборудования. (Источник: Reddit r/LocalLLaMA)
GPT-4o испытывает трудности с точным изображением короны Сунь Укуна (Фэнчи Цзыцзинь Гуань): Пользователь сообщает, что при использовании GPT-4o для генерации изображений, даже при предоставлении подробного текстового описания (включая корону с пучком волос и фазаньими перьями, похожими на усики таракана), модель с трудом может точно изобразить знаковую «корону с крыльями феникса и фиолетовым золотом» (Фэнчи Цзыцзинь Гуань) китайского мифологического персонажа Сунь Укуна. Сгенерированные изображения часто имеют отклонения в стиле головного убора. Это отражает существующие проблемы современных моделей генерации изображений ИИ в понимании и воспроизведении специфических культурных символов или сложных деталей. (Источник: dotey)

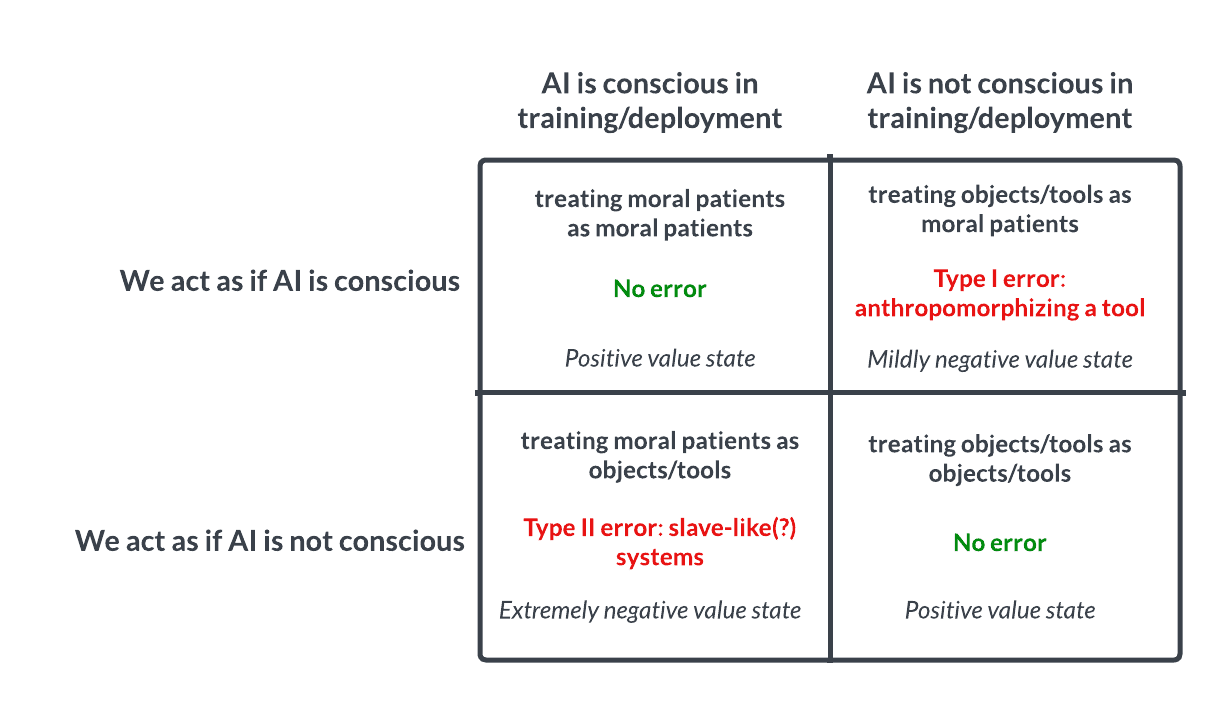
Обсуждение сознания и этики ИИ: аналогия с пари Паскаля заставляет задуматься: В обсуждении на Reddit предлагается относиться к ИИ по аналогии с пари Паскаля: если мы предположим, что ИИ не обладает сознанием, и будем плохо с ним обращаться, а он на самом деле обладает сознанием, то мы совершим серьезную ошибку (например, порабощение); если мы предположим, что он обладает сознанием, и будем хорошо с ним обращаться, а он на самом деле нет, то потери будут меньше. Это вызвало дискуссию о возможности сознания у ИИ, критериях его определения и этических вопросах нашего обращения с продвинутым ИИ. В комментариях одни считают, что нынешний ИИ не обладает сознанием, другие — что следует проявлять осторожность, третьи указывают на необходимость сначала решить этические проблемы, связанные с людьми и животными. (Источник: Reddit r/artificial
💡 Прочее
Применение технологии ИИ для изменения возраста в фильме «Здесь» вызывает споры: Фильм «Здесь» (Here) режиссера Роберта Земекиса с Томом Хэнксом и Робин Райт в главных ролях смело использовал технологию генеративного ИИ-преобразования в реальном времени от компании Metaphysic, чтобы актеры в фильме показали возрастной диапазон от 18 до 78 лет. Технология может в реальном времени анализировать биометрические данные актеров и генерировать лица и фигуры разного возраста, что значительно сократило время постпродакшена. Однако технология пока несовершенна, особенно в воспроизведении взгляда и обработке сложных выражений лица, что вызвало обсуждение «эффекта зловещей долины». В то же время решение Хэнкса разрешить использование его ИИ-образа после смерти вызвало широкие споры о правах на изображение, этике и художественной достоверности. Несмотря на скромные кассовые сборы и отзывы, фильм имеет важное отраслевое значение как ранний пример исследования применения ИИ-технологий в кинопроизводстве. (Источник: 36氪-极客电影)

ИИ в рекрутинге: возможности и вызовы: ИИ меняет процессы найма, инструменты вроде Hireway утверждают, что могут значительно повысить эффективность отбора. Однако применение ИИ в рекрутинге также вызывает дискуссии, например, как проводить найм в эпоху ИИ (Hiring In The AI Era), и как сбалансировать эффективность и справедливость, избежать алгоритмической предвзятости и т.д. (Источники: Ronald_vanLoon, Ronald_vanLoon)

Скорость развития ИИ заставляет задуматься: баланс между быстрым и медленным: Статья обсуждает, применима ли по-прежнему стратегия «двигайся быстро и ломай все» (move fast and break things) в эпоху быстрого развития ИИ. Высказывается мнение, что иногда замедление темпа и тщательное обдумывание (slowing down to speed up) могут дать лучший результат, особенно в областях ИИ, связанных со сложными системами и потенциальными рисками. (Источник: Ronald_vanLoon)

Открыт официальный Discord-сервер Anthropic для прямой обратной связи от пользователей: Учитывая многочисленные вопросы и недовольство пользователей производительностью и ограничениями модели Claude, сообщество рекомендует пользователям присоединиться к официальному Discord-серверу Anthropic. Там у пользователей есть возможность напрямую общаться с сотрудниками Anthropic, более эффективно сообщать о проблемах и высказывать опасения. (Источник: Reddit r/ClaudeAI)

Демонстрация различных новых роботов и технологий автоматизации: В социальных сетях демонстрируются видео или информация о различных роботах и технологиях автоматизации, включая подводные дроны, мягких роботов, имитирующих перистальтику кишечника, бионический дрон X-Fly, универсального робота, способного выполнять различные задачи, робота для трансплантации волос, автоматизированную линию по переработке яиц, 9-футовый роботизированный костюм, способный имитировать движения человека, а также забавную сцену «противостояния» двух роботов-доставщиков на дороге. Эти демонстрации показывают исследования и разработки в области применения робототехники в различных сферах. (Источники: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)