
Ключевые слова:GPT-4.1, Hugging Face, GPT-4.1 серия моделей сравнение производительности, Hugging Face приобретает Pollen Robotics, OpenAI новая модель улучшение кодирования, GPT-4.1 mini снижение стоимости на 83%, робот с открытым исходным кодом Reachy 2
🔥 В фокусе
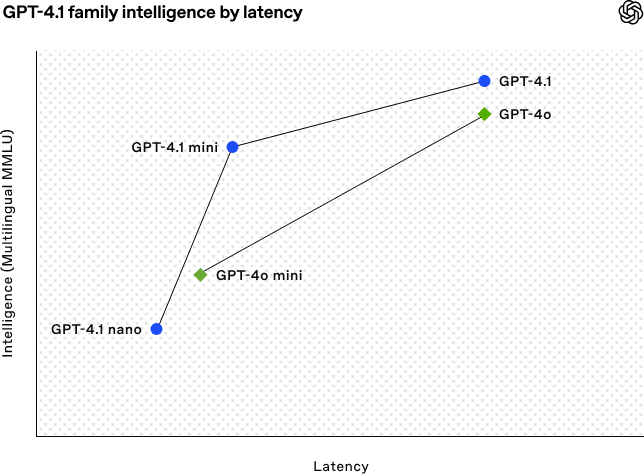
OpenAI выпускает серию моделей GPT-4.1, улучшая возможности кодирования и обработки длинных текстов: Рано утром 15 апреля OpenAI выпустила три новые модели серии GPT-4.1: GPT-4.1 (флагманская), GPT-4.1 mini (высокоэффективная) и GPT-4.1 nano (сверхмалая), все они доступны только через API. Модели этой серии демонстрируют превосходные результаты в кодировании, следовании инструкциям и понимании длинного контекста, с контекстным окном до 1 миллиона токенов и выходным окном до 32 768 токенов. GPT-4.1 набрала 54,6% в тесте SWE-bench Verified, что значительно превосходит GPT-4o и устаревшую GPT-4.5 Preview. GPT-4.1 mini превосходит GPT-4o по производительности, при этом задержка уменьшена вдвое, а стоимость снижена на 83%. GPT-4.1 nano является самой быстрой и экономичной моделью на данный момент, подходящей для задач с низкой задержкой. Этот выпуск направлен на предоставление разработчикам более производительных, экономичных и быстрых моделей, способствуя созданию сложных интеллектуальных систем и приложений с агентами. (Источник: 36氪, 智东西, op7418, openai, karminski3, sama, natolambert, karminski3, karminski3, karminski3, dotey, OpenAI, GPT-4.1来了,超越GPT-4.5,SWE-Bench达到55%,开发者专属。)
Hugging Face приобретает компанию по разработке роботов с открытым исходным кодом Pollen Robotics: Платформа сообщества ИИ Hugging Face объявила о приобретении французского стартапа по разработке роботов с открытым исходным кодом Pollen Robotics с целью содействия открытости и популяризации ИИ-робототехники. Это приобретение объединит преимущества Hugging Face в области программных платформ (таких как библиотека LeRobot и Hub) с опытом Pollen Robotics в области аппаратного обеспечения с открытым исходным кодом (например, гуманоидный робот Reachy 2). Reachy 2 — это гуманоидный робот с открытым исходным кодом, совместимый с VR, разработанный для исследований, образования и экспериментов с воплощенным интеллектом, стоимостью 70 000 долларов США. Hugging Face считает, что роботы являются следующим важным интерфейсом взаимодействия для ИИ, и они должны быть открытыми, доступными и настраиваемыми. Это приобретение является ключевым шагом к реализации этого видения, цель которого — позволить сообществу создавать и контролировать своих собственных роботов-партнеров, а не полагаться на закрытые и дорогие системы. (Источник: huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface)

🎯 Тенденции
ИИ помог решить 50-летнюю математическую проблему: Китайский ученый Weiguo Yin из Брукхейвенской национальной лаборатории (США) добился прорыва в точном решении одномерной модели Поттса J_1-J_2 с q состояниями, используя модель рассуждений OpenAI o3-mini-high, особенно в случае q=3, где ИИ помог завершить ключевое доказательство. Эта проблема касается фундаментальной модели статистической механики, связанной с такими физическими явлениями, как атомное упорядочение в слоистых материалах и нетрадиционная сверхпроводимость, точное решение которой не удавалось найти в течение последних 50 лет. Исследователь, применив метод максимального симметричного подпространства (MSS) и используя пошаговые подсказки ИИ для обработки матрицы переноса, успешно упростил матрицу переноса 9×9 для q=3 до эффективной матрицы 2×2 и обобщил этот метод на произвольное значение q. Это исследование не только решает давнюю математическую и физическую проблему, но и демонстрирует огромный потенциал ИИ в содействии сложным научным исследованиям и предоставлении новых идей. (Источник: 刚刚,AI破解50年未解数学难题!南大校友用OpenAI模型完成首个非平凡数学证明)

Рост веб-версий ИИ-помощников, производители телефонов и автомобилей создают многоплатформенный опыт: Huawei (Xiaoyi Assistant), Li Auto (Lixiang Tongxue), OPPO (Xiaobu Assistant) и другие производители последовательно запускают веб-версии своих ИИ-помощников, привлекая внимание. Хотя эти веб-версии могут уступать специализированным сервисам моделей, таким как DeepSeek, по полноте функций (например, редактирование вопросов, форматирование, настройки), их основная цель — не прямая конкуренция, а обслуживание пользователей своих брендов, создание замкнутого цикла взаимодействия между телефоном, автомобильной системой и ПК. Связывая учетные записи пользователей и синхронизируя историю диалогов, эти веб-версии направлены на повышение лояльности пользователей, обеспечение единообразного взаимодействия между устройствами и интеграцию ИИ-помощников в более широкий спектр пользовательских сценариев, что по сути является стратегией по захвату пользовательских точек входа и созданию экосистемы данных. (Источник: AI网页版扎堆上线,华为、理想、OPPO们打的什么算盘?)
Робот Figure достигает переноса из симуляции в реальность без дополнительного обучения (zero-shot) с помощью обучения с подкреплением: Компания Figure продемонстрировала, как ее гуманоидный робот Figure 02 достигает естественной походки с помощью обучения с подкреплением (RL) исключительно в симулированной среде. Используя высокоэффективный симулятор физики с ускорением на GPU, за несколько часов генерируются данные, эквивалентные годам тренировок, для обучения единой нейросетевой стратегии, способной управлять множеством виртуальных роботов с различными физическими параметрами и в разных сценариях (например, разный рельеф, помехи). Сочетая рандомизацию домена симуляции и высокочастотную обратную связь по крутящему моменту от реального робота, обученная стратегия может быть перенесена на физического робота без дополнительного обучения (zero-shot) и без тонкой настройки. Этот метод не только сокращает время разработки и повышает стабильность работы в реальном мире, но и позволяет одной стратегии управлять целой армией роботов, демонстрируя потенциал для крупномасштабных коммерческих приложений. (Источник: 一套算法控制机器人军团!纯模拟环境强化学习,Figure学会像人一样走路)

DeepSeek откроет исходный код части оптимизаций своего движка вывода: DeepSeek объявила о планах внести вклад в сообщество, открыв исходный код части оптимизаций и функций своего высокопроизводительного движка вывода, основанного на модифицированном vLLM. Они не будут публиковать полный, сильно кастомизированный стек вывода, а вместо этого интегрируют ключевые улучшения (такие как поддержка новейших архитектур моделей, оптимизация производительности) в основные фреймворки вывода с открытым исходным кодом, такие как vLLM и SGLang. Цель состоит в том, чтобы сообщество с первого дня могло получить поддержку SOTA-уровня для новых моделей и технологий. Этот шаг был положительно воспринят сообществом как реальное стремление к вкладу в открытый исходный код, а не просто словесные заявления. (Источник: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert)
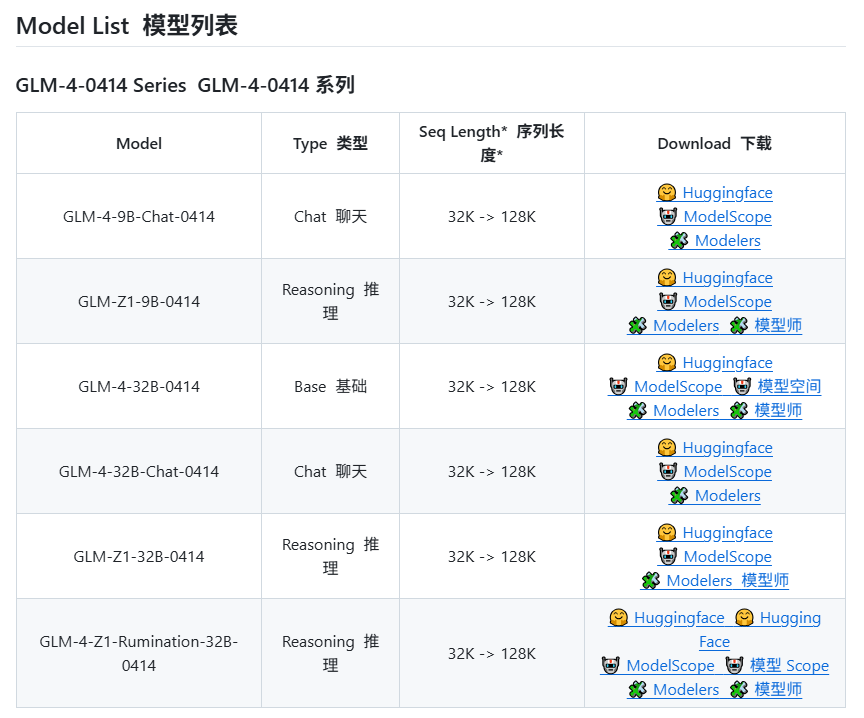
Zhipu AI предположительно выпустит новые модели серии GLM-4: Согласно утекшей информации с GitHub (позже удаленной), Zhipu AI, похоже, готовится к выпуску новой серии моделей GLM-4. Серия может включать версии с разным количеством параметров (например, 9B, 32B) и функциями, такими как базовая модель (GLM-4-32B-0414), диалоговая модель (Chat), модель рассуждений (GLM-Z1-32B-0414) и модель с более глубокими возможностями обдумывания “Rumination”, возможно, конкурирующая с Deep Research от OpenAI. Кроме того, может быть включена визуальная мультимодальная модель (GLM-4V-9B). Утекшие данные бенчмарков показывают, что GLM-4-32B-0414 по некоторым показателям может превосходить DeepSeek-V3 и DeepSeek-R1. Соответствующий код поддержки движка вывода уже объединен в transformers/vllm/llama.cpp. Сообщество проявляет большой интерес и ожидает официального релиза и тестов. (Источник: karminski3, karminski3, Reddit r/LocalLLaMA)
NVIDIA выпускает новые модели серии Nemotron: NVIDIA опубликовала на Hugging Face новые базовые модели серии Nemotron-H, включая версии с 56B, 47B и 8B параметрами, все с поддержкой контекстного окна 8K. Эти модели основаны на гибридной архитектуре Transformer и Mamba. В настоящее время выпущены базовые модели (Base), версии с тонкой настройкой инструкций (Instruct) пока не предоставлены. Серия Nemotron направлена на исследование потенциала новых архитектур в языковом моделировании. (Источник: Reddit r/LocalLLaMA)

🧰 Инструменты
Интеграция GitHub Copilot в Windows Terminal Canary: Microsoft интегрировала функции GitHub Copilot в предварительную версию Windows Terminal Canary, представив новую функцию под названием “Terminal Chat”. Эта функция позволяет пользователям напрямую взаимодействовать с ИИ в среде терминала, получая предложения и объяснения команд. Пользователям необходимо подписаться на GitHub Copilot, установить последнюю версию Canary Terminal и подтвердить свою учетную запись для использования. Этот шаг направлен на интеграцию ИИ-помощи непосредственно в часто используемую разработчиками среду командной строки, сокращение переключения контекста, повышение эффективности при работе со сложными или незнакомыми задачами, ускорение процесса обучения и помощь в сокращении ошибок. (Источник: GitHub Copilot 现可在 Windows 终端中运行了)

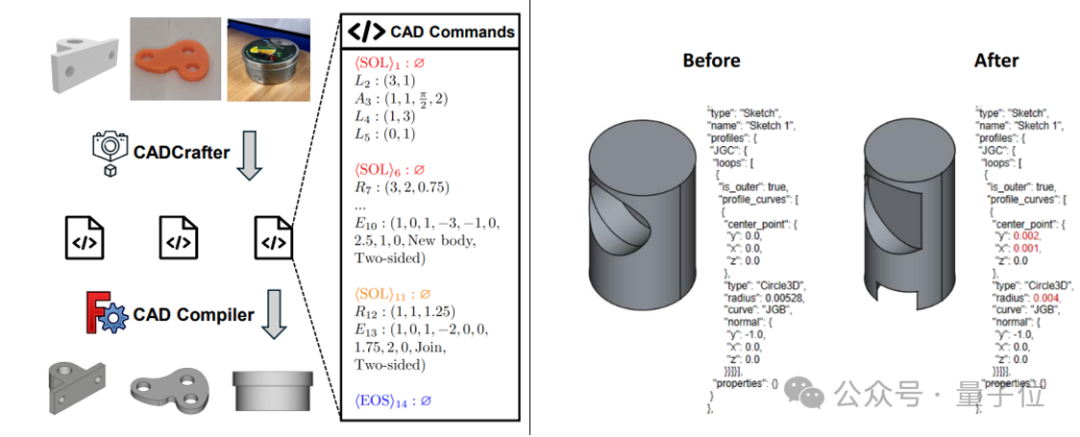
CADCrafter: Генерация редактируемых CAD-файлов из одного изображения: Исследователи из KOKONI 3D, Наньянского технологического университета и других учреждений предложили новую структуру под названием CADCrafter, способную напрямую генерировать параметризованные, редактируемые инженерные файлы CAD (представленные в виде последовательности команд CAD) из одного изображения (рендера, фотографии реального объекта и т. д.). Это решает проблему существующих методов генерации 3D из изображений (создающих Mesh или 3DGS), выходные модели которых трудно точно редактировать и которые имеют невысокое качество поверхности. Метод использует двухэтапную генеративную архитектуру, сочетающую VAE и Diffusion Transformer, а также стратегию дистилляции от нескольких видов к одному и механизм проверки компилируемости на основе DPO для повышения качества и успешности генерации. Результаты исследования приняты на CVPR 2025 и предлагают новую парадигму для автоматизированного проектирования с помощью ИИ. (Источник: 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品)
LangChain представляет интеграцию GraphRAG с MongoDB Atlas: LangChain объявила о сотрудничестве с MongoDB для запуска системы RAG на основе графов (GraphRAG). Эта система использует MongoDB Atlas для хранения и обработки данных, реализуется через LangChain и способна превзойти традиционные RAG, основанные на поиске по сходству, понимая и рассуждая о связях между сущностями. Она поддерживает извлечение сущностей и отношений с помощью LLM и использует обход графа для получения связанной контекстной информации, стремясь предоставить более мощные возможности ответов на вопросы и рассуждений для приложений, требующих глубокого понимания отношений. (Источник: LangChainAI)
Hugging Face открывает исходный код своей площадки для тестирования вывода (Inference Playground): Hugging Face открыла исходный код своего онлайн-инструмента Inference Playground, используемого для тестирования и сравнения моделей вывода. Это веб-интерфейс чата с LLM, позволяющий пользователям контролировать различные настройки вывода (такие как температура, top-p и т. д.), изменять ответы ИИ, сравнивать производительность различных моделей и поставщиков. Проект создан с использованием Svelte 5, Melt UI и Tailwind, код опубликован на GitHub, предоставляя разработчикам настраиваемую и расширяемую платформу для локального или онлайн-взаимодействия с моделями и их оценки. (Источник: huggingface)
Платформа Flowith достигла ARR более 1 миллиона долларов, демонстрируя возможности ИИ-агентов в генерации веб-страниц: Годовой регулярный доход (ARR) платформы ИИ-агентов Flowith превысил 1 миллион долларов США, что свидетельствует о сильном рыночном спросе на универсальные платформы ИИ-агентов, способные заменить ручной труд. Пользователь поделился опытом использования функции Oracle в Flowith: всего лишь с помощью простого описания на естественном языке («Я хочу создать веб-страницу для предварительного просмотра графики в социальных сетях…») удалось быстро сгенерировать полнофункциональный веб-инструмент с точным воспроизведением стиля (например, в стиле Twitter) и поддержкой предварительного просмотра изображений, без необходимости подключения к GitHub или сложной настройки. Это демонстрирует потенциал ИИ-агентов в области low-code/no-code генерации веб-страниц. (Источник: karminski3)
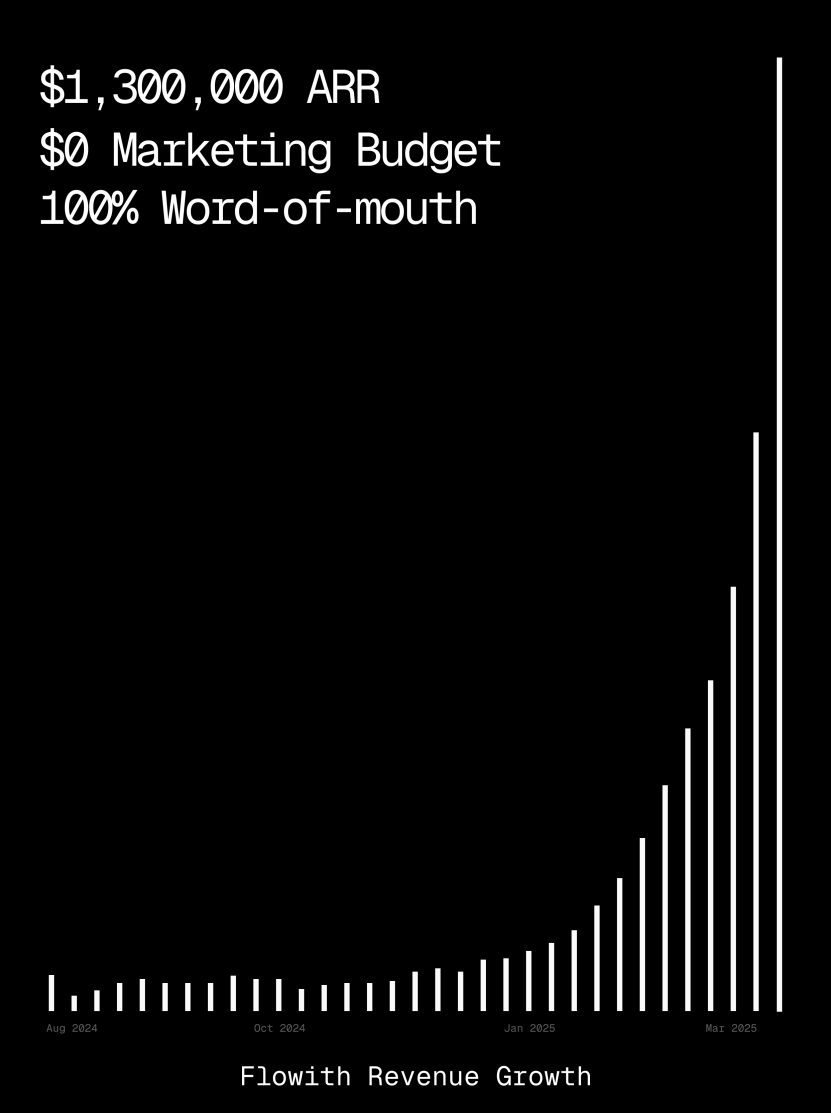
Выпущен автономный агент отладки Deebo: Исследователи создали автономный агент отладки MCP-сервер под названием Deebo. Он работает как локальный демон, которому агенты программирования могут асинхронно передавать сложные задачи по обработке ошибок. Deebo генерирует несколько дочерних процессов с различными гипотезами исправления, запускает каждый сценарий в изолированной ветке git, а «материнский агент» циклически тестирует, рассуждает и, наконец, возвращает диагностические результаты и предлагаемые исправления. В реальном тесте на исправление бага с наградой $100 в tinygrad, Deebo успешно определил причину проблемы и предложил два конкретных варианта исправления, пройдя тесты. (Источник: Reddit r/MachineLearning)
![[D] We built an autonomous debugging agent. Here’s how it grokked a $100 bug](https://rebabel.net/wp-content/uploads/2025/04/81BPXr5Ywnk-6MetZBQchhgsROH341CoTk3xAdE5Jic.jpg)
📚 Обучение
Nabla-GFlowNet: Новый метод тонкой настройки диффузионных моделей поощрением, сочетающий разнообразие и эффективность: В ответ на проблемы медленной сходимости традиционного обучения с подкреплением, легкого переобучения при прямой максимизации вознаграждения и потери разнообразия при тонкой настройке диффузионных моделей, исследователи из Китайского университета Гонконга (Шэньчжэнь) и других учреждений предложили Nabla-GFlowNet. Этот метод основан на фреймворке сетей генеративных потоков (GFlowNet), рассматривает процесс диффузии как систему сбалансированных потоков и выводит условие баланса Nabla-DB и соответствующую функцию потерь. Благодаря параметризованному дизайну, он использует одношаговую оценку градиента остатка при шумоподавлении, избегая необходимости в дополнительных сетях для оценки. Эксперименты показывают, что при тонкой настройке Stable Diffusion с использованием функций вознаграждения, таких как эстетическая оценка и следование инструкциям, Nabla-GFlowNet сходится быстрее и менее склонен к переобучению по сравнению с методами ReFL, DRaFT и другими, сохраняя при этом разнообразие генерируемых образцов. (Источник: ICLR 2025 | 扩散模型奖励微调新突破!Nabla-GFlowNet让多样性与效率兼得)

MegaMath: Выпущен крупнейший открытый набор данных для математического вывода объемом 371 млрд токенов: Набор данных MegaMath, представленный LLM360 и содержащий 371 миллиард токенов, направлен на решение проблемы нехватки крупномасштабных, высококачественных данных для предварительного обучения математическому выводу в сообществе открытого исходного кода. Набор данных разделен на три части: веб-страницы с интенсивным использованием математики (279B), код, связанный с математикой (28.1B), и высококачественные синтетические данные (64B). В процессе создания использовался инновационный конвейер обработки данных, включающий оптимизированный для математических формул парсинг HTML, двухэтапное извлечение текста, динамическую оценку образовательной ценности, многоэтапный точный отбор данных кода и различные методы крупномасштабного синтеза (Q&A, генерация кода, чередование текста и кода). Проверка предварительного обучения на 100B токенов на Llama-3.2 (1B/3B) показала, что MegaMath обеспечивает абсолютное улучшение производительности на 15-20% на бенчмарках GSM8K, MATH и других. (Источник: 3710亿数学Tokens!全球最大开源数学数据集MegaMath震撼发布,碾压DeepSeek-Math)
Обзор OS Agents: Исследование интеллектуальных агентов для компьютеров, телефонов и браузеров на основе мультимодальных больших моделей: Чжэцзянский университет совместно с OPPO, 01.AI и другими учреждениями опубликовал обзорную статью об агентах операционной системы (OS Agents). В статье систематически рассматривается текущее состояние исследований по созданию интеллектуальных агентов (таких как Computer Use от Anthropic, Apple Intelligence от Apple) с использованием мультимодальных больших языковых моделей (MLLM), способных автоматически выполнять задачи в средах компьютера, телефона, браузера и т. д. Содержание охватывает основы OS Agents (среда, пространство наблюдения, пространство действий, основные возможности), методы построения (архитектура базовой модели и стратегии обучения, модули восприятия/планирования/памяти/действия фреймворка агента), протоколы и бенчмарки оценки, а также связанные коммерческие продукты и будущие вызовы (безопасность и конфиденциальность, персонализация и самоэволюция). Исследовательская группа поддерживает открытый репозиторий, содержащий более 250 релевантных статей, с целью содействия развитию этой области. (Источник: 浙大、OPPO等发布最新综述:基于多模态大模型的计算机、手机与浏览器智能体研究)
NLPrompt: Устойчивый метод обучения подсказкам (prompt learning), сочетающий потери MAE и оптимальный транспорт: Лаборатория YesAI Шанхайского технологического университета в статье Highlight на CVPR 2025 представила NLPrompt, направленный на решение проблемы шума в метках при обучении подсказкам визуально-языковых моделей. Исследование показало, что в сценарии обучения подсказкам использование потерь средней абсолютной ошибки (MAE) (PromptMAE) более устойчиво к влиянию зашумленных меток, чем потери перекрестной энтропии (CE), и доказало его устойчивость с точки зрения теории обучения признаков. Кроме того, предложен метод очистки данных на основе оптимального транспорта с использованием подсказок (PromptOT), который использует текстовые признаки в качестве прототипов для разделения набора данных на чистое подмножество (обучаемое с потерями CE) и зашумленное подмножество (обучаемое с потерями MAE), эффективно объединяя преимущества обоих типов потерь. Эксперименты показали, что NLPrompt превосходит аналоги на синтетических и реальных зашумленных наборах данных и обладает хорошей обобщающей способностью. (Источник: CVPR 2025 | MAE损失+最优传输双剑合璧!上科大提出全新鲁棒提示学习方法)
Анализ механизма вывода DeepSeek-R1: Исследователи из Университета Макгилла проанализировали процесс вывода крупных моделей рассуждений, таких как DeepSeek-R1. В отличие от LLM, которые дают прямой ответ, модели рассуждений генерируют подробные многошаговые цепочки рассуждений. Исследование изучает связь между длиной цепочки рассуждений и производительностью (существует «оптимальная точка», слишком длинная цепочка может ухудшить производительность), управление длинным контекстом, культурные и безопасные вопросы (по сравнению с не-рассуждающими моделями существуют более серьезные уязвимости безопасности), а также связь с когнитивными явлениями человека (например, постоянное зацикливание на уже исследованных вопросах). Это исследование раскрывает некоторые особенности и потенциальные проблемы механизма работы текущих моделей рассуждений. (Источник: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
C3PO: Метод оптимизации во время тестирования для больших моделей MoE: Исследователи из Университета Джонса Хопкинса обнаружили проблему субоптимальности путей экспертов в LLM типа Mixture-of-Experts (MoE) и предложили метод оптимизации во время тестирования C3PO (Critical layer, Core expert, Collaborative Path Optimization). Этот метод не зависит от истинных меток, а определяет альтернативную цель на основе «успешных соседей» в референсном наборе данных для оптимизации производительности модели. Он использует алгоритмы поиска паттернов, ядерную регрессию, средние потери по схожим образцам и для снижения затрат оптимизирует только веса ключевых экспертов в критических слоях. Применение C3PO к MoE LLM повысило точность базовых моделей на 7-15% в шести бенчмарках, превзойдя стандартные базовые линии обучения во время тестирования, и позволило моделям MoE с меньшим числом параметров превзойти LLM с большим числом параметров, повысив эффективность MoE. (Источник: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Исследование влияния квантования на производительность моделей вывода: Исследовательская группа из Университета Цинхуа впервые систематически исследовала влияние методов квантования на производительность языковых моделей, ориентированных на вывод (таких как серии DeepSeek-R1, Qwen, LLaMA). Исследование оценило производительность различных алгоритмов квантования весов, KV-кэша и активаций с разной битовой шириной (W8A8, W4A16 и т. д.) на бенчмарках вывода в области математики, науки, программирования и др. Результаты показывают, что квантование W8A8 или W4A16 обычно позволяет достичь производительности без потерь, но более низкая битовая ширина несет значительный риск снижения точности. Размер модели, источник и сложность задачи являются ключевыми факторами, влияющими на производительность после квантования. Длина вывода квантованных моделей существенно не увеличилась, а разумная корректировка размера модели или увеличение шагов вывода могут повысить производительность. Соответствующие квантованные модели и код были опубликованы с открытым исходным кодом. (Источник: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
SHIELDAGENT: Защитный барьер для принуждения агентов к соблюдению политик безопасности: Чикагский университет предложил фреймворк SHIELDAGENT, направленный на принуждение траекторий действий ИИ-агентов к соответствию четким политикам безопасности с помощью логического вывода. Фреймворк сначала извлекает проверяемые правила из документов политики, строит модель политики безопасности (на основе вероятностных схем правил (PRC)), а затем в процессе выполнения агента извлекает соответствующие правила на основе его траектории действий и генерирует план защиты, используя библиотеку инструментов и исполняемый код для формальной верификации, чтобы гарантировать, что поведение агента не нарушает правила безопасности. Также выпущен набор данных SHIELDAGENT-BENCH, содержащий 3K инструкций и пар траекторий, связанных с безопасностью. Эксперименты показывают, что SHIELDAGENT достигает SOTA на нескольких бенчмарках, значительно повышая соответствие требованиям безопасности и полноту, одновременно снижая количество запросов к API и время вывода. (Источник: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
MedVLM-R1: Стимулирование способностей к выводу медицинских VLM с помощью обучения с подкреплением: Технический университет Мюнхена, Оксфордский университет и другие учреждения совместно предложили MedVLM-R1, медицинскую визуально-языковую модель (VLM), предназначенную для генерации четких процессов рассуждения на естественном языке. Эта модель использует фреймворк обучения с подкреплением DeepSeek Group Relative Policy Optimization (GRPO), обучается на наборах данных, содержащих только окончательные ответы, но способна автономно находить пути рассуждения, понятные человеку. После обучения всего на 600 образцах MRI VQA эта модель с 2B параметрами достигла точности 78,22% на бенчмарках MRI, CT, X-ray, значительно превзойдя базовые модели и продемонстрировав сильную способность к обобщению на незнакомые домены, даже превзойдя более крупные модели, такие как Qwen2-VL-72B. Это исследование предлагает новые подходы к созданию надежного и интерпретируемого медицинского ИИ. (Источник: 小样本大能量!MedVLM-R1借力DeepSeek强化学习,重塑医疗AI推理能力)
Исследование показывает, что обучение с подкреплением может приводить к избыточным ответам моделей вывода: Исследование от Wand AI проанализировало причины, по которым модели вывода (такие как DeepSeek-R1) генерируют более длинные ответы. Исследование показало, что такое поведение может быть связано с процессом обучения с подкреплением (в частности, алгоритмом PPO), а не с тем, что сама проблема требует более длительного рассуждения. Когда модель получает отрицательное вознаграждение за неправильный ответ, функция потерь PPO склонна генерировать более длинные ответы, чтобы “разбавить” штраф за каждый токен, даже если дополнительное содержание не способствует повышению точности. Исследование также показало, что краткость рассуждений часто коррелирует с более высокой точностью. С помощью второго раунда обучения с подкреплением, использующего только часть решаемых проблем, можно сократить длину ответов, сохраняя или даже повышая точность, что имеет важное значение для повышения эффективности развертывания. (Источник: 更长思维并不等于更强推理性能,强化学习可以很简洁)

Университет науки и технологий Китая и ZTE предлагают Curr-ReFT: Улучшение способностей к выводу и обобщению у малоразмерных VLM: В ответ на феномен «кирпичной стены» (трудности в обучении) и недостаточную способность к обобщению на незнакомые домены у малоразмерных визуально-языковых моделей (VLM) при решении сложных задач, Университет науки и технологий Китая и ZTE Corporation предложили парадигму пост-тренировки с использованием курсового обучения с подкреплением (Curr-ReFT). Эта парадигма сочетает курсовое обучение (CL) и обучение с подкреплением (RL), разрабатывает механизм вознаграждения, учитывающий сложность, позволяя модели постепенно учиться от простого к сложному (бинарное решение → множественный выбор → открытый ответ). В то же время используется стратегия самосовершенствования на основе выборки с отклонением для поддержания базовых способностей модели с помощью высококачественных мультимодальных и языковых образцов. Эксперименты на моделях Qwen2.5-VL-3B/7B показали, что Curr-ReFT значительно улучшает производительность вывода и обобщения моделей, причем модель 7B на некоторых бенчмарках даже превосходит InternVL2.5-26B/38B. (Источник: 中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理)

GenPRM: Расширение моделей вознаграждения процесса с помощью генеративного вывода: Университет Цинхуа и Shanghai AI Lab предложили генеративную модель вознаграждения процесса (GenPRM), направленную на решение проблем традиционных моделей вознаграждения процесса (PRM), которые полагаются на скалярные оценки, лишены интерпретируемости и не могут масштабироваться во время тестирования. GenPRM использует генеративный подход, сочетая рассуждения по цепочке мыслей (CoT) и верификацию кода, для проведения анализа на естественном языке и проверки выполнения кода Python на каждом шаге рассуждения, обеспечивая более глубокий и интерпретируемый надзор за процессом. Кроме того, GenPRM вводит механизм масштабирования во время тестирования, повышая точность оценки путем параллельной выборки нескольких путей рассуждения и агрегирования значений вознаграждения. Модель 1.5B, обученная всего на 23K синтетических данных, превосходит GPT-4o на ProcessBench благодаря масштабированию во время тестирования, а версия 7B превосходит Qwen2.5-Math-PRM-72B (72B). GenPRM также может выступать в качестве модели-критика для руководства оптимизацией стратегической модели. (Источник: 过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o)
Исследование выявило феномен «чрезмерного обдумывания» у ИИ-рассуждателей при решении задач с отсутствующими предпосылками: Исследование Университета Мэриленда и Университета Лихай показало, что текущие модели рассуждений (такие как DeepSeek-R1, o1) при столкновении с задачами, в которых отсутствует необходимая исходная информация (Missing Premise, MiP), часто проявляют склонность к «чрезмерному обдумыванию». Они генерируют ответы в 2-4 раза длиннее, чем для обычных задач, зацикливаясь на повторном рассмотрении проблемы, догадках о намерениях, сомнениях в себе, вместо того чтобы быстро распознать неразрешимость задачи и остановиться. В отличие от них, не-рассуждающие модели (такие как GPT-4.5) отвечают на задачи MiP короче и лучше распознают отсутствие предпосылок. Исследование показывает, что модели рассуждений, хотя и способны заметить отсутствие предпосылок, не обладают «критическим мышлением» для решительного прекращения бесполезных рассуждений. Этот паттерн поведения может быть связан с недостаточным ограничением длины в процессе обучения с подкреплением и распространяться через дистилляцию. (Источник: 推理AI「脑补」成瘾,废话拉满!马里兰华人学霸揭开内幕)

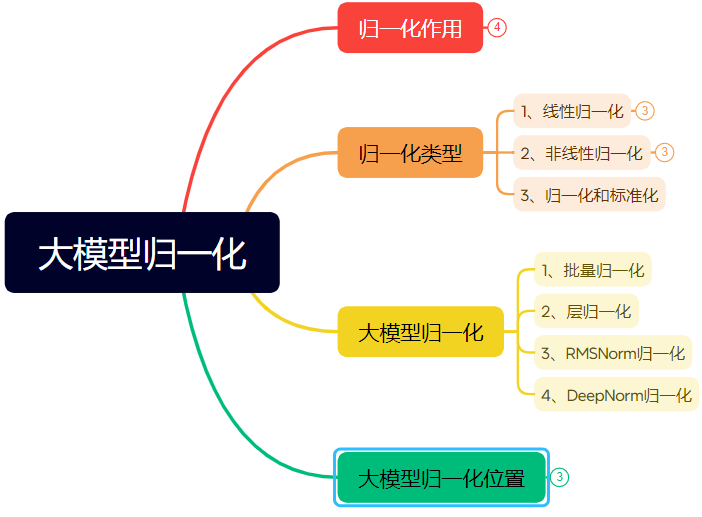
Подробное объяснение эволюции технологий нормализации в нейронных сетях (длинная статья): Статья систематически рассматривает роль и эволюцию нормализации (Normalization) в нейронных сетях, особенно в Transformer и больших моделях. Нормализация, ограничивая данные фиксированным диапазоном, решает проблему сопоставимости данных, повышает скорость оптимизации, смягчает проблемы насыщения функций активации и внутреннего ковариантного сдвига (ICS). В статье представлены распространенные методы линейной (Min-max, Z-score, Mean) и нелинейной нормализации, подробно описаны методы, подходящие для моделей глубокого обучения: Batch Normalization (BN), Layer Normalization (LN), RMSNorm и DeepNorm, анализируются различия в их применении в архитектуре Transformer (почему LN/RMSNorm больше подходят для NLP). Кроме того, обсуждаются различные позиции размещения модуля нормализации в слоях Transformer (Post-Norm, Pre-Norm, Sandwich-Norm) и их влияние на стабильность обучения и производительность. (Источник: 万字长文!一文了解归一化:从Transformer归一化到主流大模型归一化的演变!)
Инженерия подсказок (Prompt engineering) для генерации шрифтового дизайна в определенном стиле с помощью ИИ: Статья делится опытом автора в исследовании использования Tiamat AI 3.0 (即梦AI 3.0) для генерации текстового дизайна с определенным стилем и шаблонами подсказок. Автор обнаружил, что прямое указание названий шрифтов (например, Songti, Kaiti) дает плохие результаты, так как модель ИИ имеет ограниченное понимание этого. Поэтому автор переключился на описание характеристик стиля шрифта, эмоциональной атмосферы и визуальных эффектов, сочетая это с примерами различных стилей, и создал шаблон подсказки «Генератор подсказок для продвинутого дизайна текстового стиля». Пользователю нужно только ввести текстовое содержание, и шаблон интеллектуально подберет или объединит несколько предустановленных стилей (таких как свето-теневой ночной, индустриально-простой, детско-наивный, металлическо-научно-фантастический и т. д.), чтобы сгенерировать подробную подсказку для модели генерации изображений из текста, тем самым получая относительно стабильное качество графического и текстового дизайна. (Источник: AI生成字体设计我有点玩明白了,用这套Prompt提效50%。, 即梦AI 3.0制作含字体封面,这个方案酷到封神【附:16+案例和Prompt】)

ZClip: Адаптивный метод подавления пиков градиента для предварительного обучения LLM: Исследователи предложили ZClip, легковесный адаптивный метод обрезки градиента, направленный на уменьшение пиков потерь в процессе обучения LLM и повышение стабильности обучения. В отличие от традиционной обрезки градиента с использованием фиксированного порога, ZClip использует метод на основе z-оценки для обнаружения и обрезки аномальных пиков градиента, то есть тех градиентов, которые значительно отклоняются от недавнего скользящего среднего. Этот метод помогает поддерживать стабильность обучения, не мешая сходимости, и легко интегрируется в любой цикл обучения. Код и статья опубликованы. (Источник: Reddit r/deeplearning)
![[2504.02507] ZClip: Adaptive Spike Mitigation for LLM Pre-Training](https://rebabel.net/wp-content/uploads/2025/04/Swd9uQN43Dpl2SJyH6zjTbJAdRaXwKbmzZwM9L2rPXk.jpg)
💼 Бизнес
Решение Intel на базе видеокарт Arc™ и процессоров Xeon® W способствует созданию недорогих моноблоков для ИИ: Intel, благодаря сочетанию своих видеокарт Arc™ и процессоров Xeon® W, предлагает рынку решение для создания доступных (в ценовом диапазоне 100 000 юаней) и производительных моноблоков для больших моделей. Видеокарты Arc™ используют архитектуру Xe и движок ускорения ИИ XMX, поддерживают основные фреймворки ИИ и Ollama/vLLM, имеют низкое энергопотребление и поддерживают параллельное подключение нескольких карт. Процессоры Xeon® W обеспечивают большое количество ядер и возможность расширения памяти, а также встроенную технологию ускорения AMX. В сочетании с программными оптимизациями, такими как IPEX-LLM, OpenVINO™ и oneAPI, достигается эффективное взаимодействие CPU и GPU. Тесты показывают, что моноблок на базе этого решения при работе с моделью QwQ-32B для одного пользователя может достигать 32 токенов/с, а при работе с моделью 671B DeepSeek R1 (требуется оптимизация FlashMoE) — почти 10 токенов/с, удовлетворяя потребности в офлайн-выводе и способствуя популяризации ИИ-вывода. (Источник: 榨干3000元显卡,跑通千亿级大模型的秘方来了)

NVIDIA будет производить суперкомпьютеры ИИ на территории США: NVIDIA объявила, что впервые полностью спроектирует и построит свои суперкомпьютеры ИИ на территории США, сотрудничая с основными производственными партнерами. В то же время, производство ее чипов нового поколения Blackwell началось на заводе TSMC в Аризоне. NVIDIA планирует в течение следующих 4 лет произвести в США инфраструктуру ИИ на сумму до пятисот миллиардов долларов, партнерами выступят TSMC, Foxconn, Wistron, Amkor и SPIL. Этот шаг направлен на удовлетворение спроса на чипы ИИ и суперкомпьютеры, укрепление цепочки поставок и повышение ее устойчивости. (Источник: nvidia, nvidia)

Horizon Robotics ищет стажеров по 3D-реконструкции/генерации: Команда по воплощенному интеллекту Horizon Robotics ищет стажеров-алгоритмистов по направлению 3D-реконструкции/генерации в Шанхае/Пекине. Обязанности включают участие в проектировании и разработке алгоритмических решений Real2Sim для роботов (сочетающих реконструкцию 3D GS, прямую реконструкцию, генерацию 3D/видео), оптимизацию производительности симулятора Real2Sim (поддержка симуляции жидкостей, тактильной симуляции и т. д.), а также отслеживание передовых исследований и публикацию статей на ведущих конференциях. Требования: степень магистра или выше, специальность в области компьютерных наук/графики/ИИ, опыт работы с 3D-зрением/генерацией видео или мультимодальными/диффузионными моделями, свободное владение Python/Pytorch/Huggingface. Преимущество отдается кандидатам с публикациями на ведущих конференциях, знакомым с симуляционными платформами или опытом работы с открытым исходным кодом. Предоставляется возможность перехода на постоянную работу, доступ к кластеру GPU и конкурентоспособная заработная плата. (Источник: 上海/北京内推 | 地平线机器人具身智能团队招聘3D重建/生成方向算法实习生)

Meituan Hotel & Travel ищет инженеров-алгоритмистов больших моделей уровня L7-L8: Команда алгоритмов снабжения Meituan Hotel & Travel в Пекине ищет инженеров-алгоритмистов больших моделей уровня L7-L8 (для соискателей с опытом работы). Обязанности включают построение системы понимания снабжения в сфере гостиничного бизнеса и путешествий (теги товаров, распознавание горячих точек, поиск похожих предложений и т. д.), оптимизацию демонстрационных материалов (генерация заголовков, изображений и текстов, рекомендаций), создание комбинаций туристических пакетов (выбор продуктов, прогнозирование продаж, ценообразование), а также исследование и внедрение передовых технологий больших моделей (тонкая настройка, RL, оптимизация Prompt). Требования: степень магистра или выше, опыт работы от 2 лет, специальность в области компьютерных наук/автоматизации/математической статистики, наличие прочных основ в алгоритмах и навыков программирования. (Источник: 北京内推 | 美团酒旅供给算法团队招聘L7-L8大模型算法工程师)

Meta будет использовать данные пользователей в ЕС для обучения ИИ: Meta объявила о готовности начать использовать общедоступные данные пользователей Facebook и Instagram в регионе ЕС (такие как посты, комментарии, но не личные сообщения) для обучения своих моделей ИИ, только для пользователей старше 18 лет. Компания уведомит пользователей через уведомления в приложении и по электронной почте, а также предоставит ссылку для отказа (opt-out). Ранее Meta приостановила планы по использованию данных пользователей в Европе для обучения ИИ по требованию ирландского регулятора. (Источник: Reddit r/artificial)

Tencent Cloud запускает управляемые услуги MCP: Tencent Cloud также начала предоставлять управляемые услуги облачной платформы (Managed Cloud Platform, MCP), направленные на предоставление предприятиям более удобных и эффективных решений по управлению и эксплуатации облачных ресурсов. Этот шаг означает усиление конкуренции между основными облачными провайдерами в этой области. Конкретные детали услуг и «особенности WeChat» пока не уточняются. (Источник: 腾讯云也搞 MCP 托管了,还带了点“微信特色”。)
🌟 Сообщество
Лауреат премии Тьюринга Лекун об развитии ИИ: Человеческий интеллект не универсален, следующий прорыв может быть в негенеративных моделях: В недавнем подкасте Янн Лекун вновь подчеркнул, что термин AGI вводит в заблуждение, считая человеческий интеллект высокоспециализированным, а не универсальным. Он предсказывает, что следующий крупный прорыв в ИИ может прийти от негенеративных моделей, с акцентом на то, чтобы машины действительно понимали физический мир, обладали способностью к рассуждению и планированию, а также долговременной памятью, подобно предложенной им архитектуре JEPA. Он считает, что текущим LLM не хватает настоящей способности к рассуждению и моделированию физического мира, и достижение уровня интеллекта кошки уже будет огромным прогрессом. Что касается открытия исходного кода LLaMA компанией Meta, он считает это правильным выбором для стимулирования развития всей экосистемы ИИ и подчеркивает, что инновации приходят со всего мира, а открытый исходный код является ключом к ускорению прорывов. Он также видит большой потенциал в умных очках как важном носителе для ИИ-помощников. (Источник: 图灵奖得主LeCun:人类智能不是通用智能,下一代AI可能基于非生成式)

Кратковременная «блокировка» китайских IP на GitHub привлекла внимание, официальные лица назвали это ошибкой конфигурации: С 12 по 13 апреля некоторые китайские пользователи обнаружили, что не могут получить доступ к GitHub, на странице отображалось сообщение «Доступ с IP-адреса ограничен», что вызвало панику и обсуждения в сообществе, опасения по поводу целенаправленной блокировки. Ранее GitHub уже блокировал аккаунты разработчиков из России, Ирана и других стран из-за санкций США. Позже официальные представители GitHub ответили, что этот инцидент был вызван ошибкой изменения конфигурации, из-за которой незалогиненные пользователи временно не могли получить доступ, и проблема была устранена 13 апреля. Несмотря на то, что это была техническая неисправность, инцидент вновь вызвал дискуссии о геополитических рисках платформ хостинга кода и отечественных альтернативах (таких как Gitee, CODING, JiHu GitLab и др.). (Источник: “Bug”还是“预演”?GitHub 突然“封禁”所有中国 IP,官方:只是“手滑”技术出错了)

ИИ-агенты вызывают опасения по поводу кибербезопасности: Статья в MIT Technology Review указывает на то, что автономные кибератаки, управляемые ИИ, не за горами. По мере роста возможностей ИИ злоумышленники могут использовать ИИ-агентов для автоматического обнаружения уязвимостей, планирования и проведения более сложных и масштабных кибератак, создавая новые угрозы для личной, корпоративной и даже национальной безопасности. Это требует от сферы кибербезопасности ускорить исследования и внедрение стратегий и технологий защиты, способных противостоять атакам, управляемым ИИ. (Источник: Ronald_vanLoon)

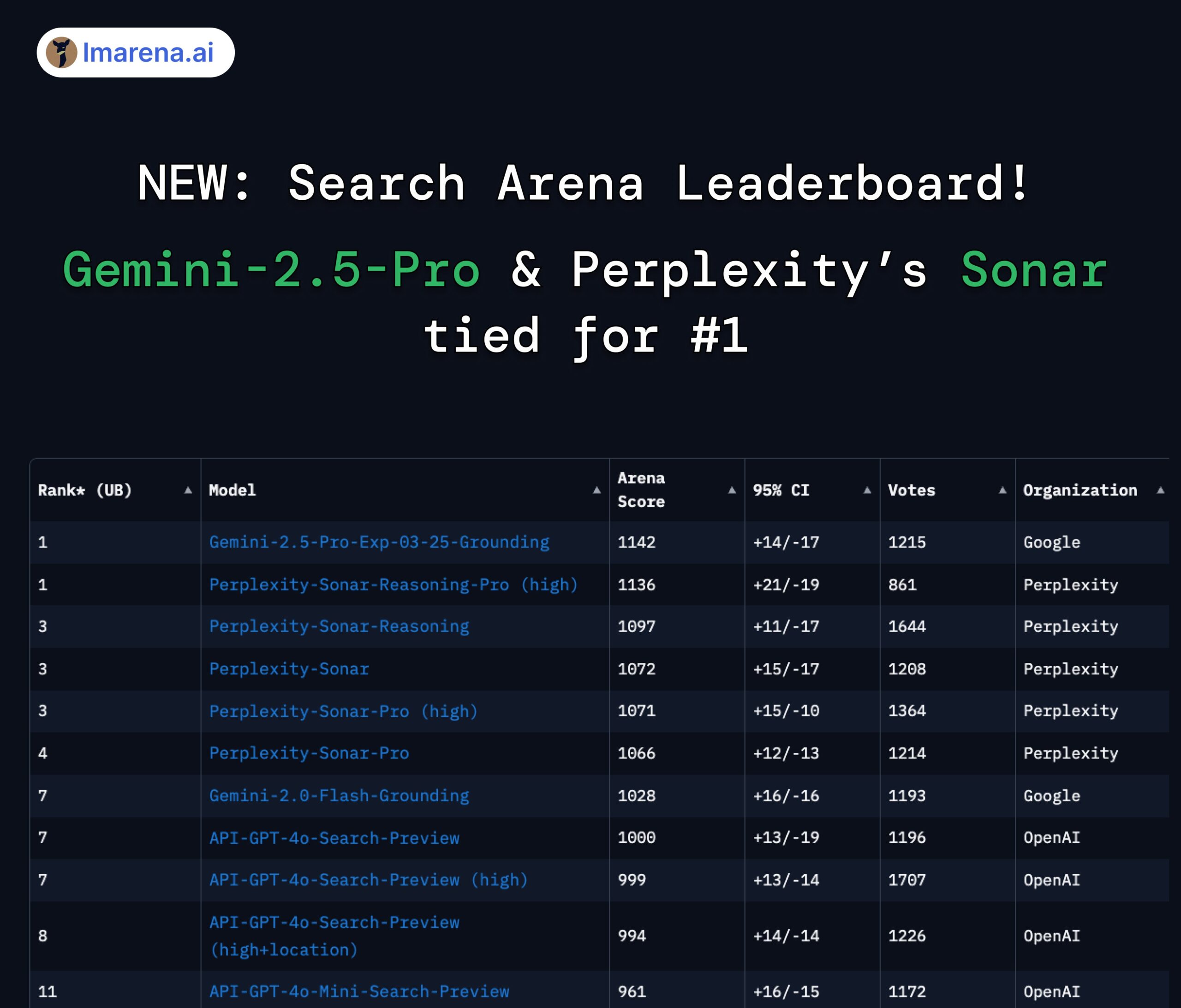
Perplexity Sonar и Gemini 2.5 Pro делят первое место на арене поиска: В новом рейтинге Search Arena на LMArena.ai (ранее LMSYS) модель Perplexity Sonar-Reasoning-Pro-High и модель Google Gemini-2.5-Pro-Grounding разделили первое место. Этот рейтинг специально оценивает качество ответов LLM, основанных на поиске в Интернете. CEO Perplexity Арав Шринивас поздравил с этим достижением и подчеркнул, что компания продолжит улучшать модель Sonar и поисковый индекс. Сообщество считает, что это показывает, что в области LLM, усиленных поиском, конкуренция в основном разворачивается между Google и Perplexity. (Источник: AravSrinivas, lmarena_ai, lmarena_ai, AravSrinivas, lmarena_ai, AravSrinivas)
Обсуждение ограничений использования модели Claude: В сообществе Reddit r/ClaudeAI пользователи спорят об ограничениях использования версии Claude Pro (таких как лимит сообщений, ограничения емкости). Некоторые пользователи жалуются на частые столкновения с ограничениями, что мешает рабочему процессу, и даже рассматривают возможность смены модели; другие же утверждают, что редко сталкиваются с ограничениями, предполагая, что причиной могут быть особенности использования (например, загрузка очень большого контекста) или преувеличение проблемы. Это отражает различный опыт и мнения пользователей относительно политики использования и стабильности моделей Anthropic. (Источник: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Обсуждение ИИ и будущего занятости: Сравнительная картинка на Reddit r/ChatGPT вызвала дискуссию: усилит ли ИИ человеческие возможности, принеся изобилие, или заменит человеческий труд, приведя к массовой безработице? В комментариях многие пользователи выразили обеспокоенность по поводу замены рабочих мест ИИ, особенно в творческих профессиях (программирование, искусство). Некоторые считают, что ИИ усугубит социальное неравенство, поскольку выгоды в основном достанутся владельцам ИИ, а сокращение налоговой базы может затруднить реализацию безусловного базового дохода (UBI). Другие настроены более оптимистично, считая ИИ мощным инструментом, способным повысить эффективность и создать новые рабочие места (например, инженеры по подсказкам), ключевым моментом является адаптация и обучение использованию ИИ. (Источник: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

Сбор данных ИИ вызывает опасения по поводу конфиденциальности: Инфографика, сравнивающая типы пользовательских данных, собираемых различными чат-ботами ИИ (ChatGPT, Gemini, Copilot, Claude, Grok), вызвала обсуждение в сообществе по поводу проблем конфиденциальности. На графике видно, что Google Gemini собирает наибольшее количество типов данных, в то время как Grok (требуется учетная запись) и ChatGPT (не требуется учетная запись) собирают относительно меньше. Пользователи в комментариях подчеркнули повсеместность сбора данных за бесплатными услугами («бесплатного сыра не бывает») и выразили обеспокоенность по поводу конкретных целей сбора данных (например, прогнозирование поведения). (Источник: Reddit r/artificial)

Дистилляция моделей считается эффективным способом воспроизведения высокой производительности при низких затратах: Пользователь Reddit поделился опытом использования техники дистилляции моделей для обучения небольших, тонко настроенных моделей с помощью больших моделей (таких как GPT-4o), достигнув производительности, близкой к GPT-4o (точность 92%) в конкретной области (анализ тональности) при затратах в 14 раз ниже. В комментариях отмечается, что дистилляция является широко используемой техникой, но по способности к обобщению между доменами малые модели обычно уступают большим. Для конкретных, стабильных областей дистилляция является эффективным методом снижения затрат и повышения эффективности, но для сложных сценариев, требующих постоянной адаптации к новым данным или охватывающих несколько областей, прямое использование больших API может быть более экономичным. (Источник: Reddit r/MachineLearning)
![[D] Distillation is underrated. I replicated GPT-4o's capability in a 14x cheaper model](https://rebabel.net/wp-content/uploads/2025/04/zyj7as7ogque1.png)
💡 Прочее
OceanBase проводит первый хакатон по ИИ: Производитель распределенных баз данных OceanBase совместно с Ant Open Source, Jiqizhixin и другими организует первый хакатон по ИИ. Регистрация открыта с 10 апреля по 7 мая. Конкурс посвящен теме «DB+AI» и имеет два основных направления: использование OceanBase в качестве основы данных для создания ИИ-приложений и исследование интеграции OceanBase с экосистемой ИИ (например, CAMEL AI, FastGPT, OpenDAL). Общий призовой фонд составляет 100 000 юаней. К участию приглашаются как отдельные лица, так и команды. Цель — стимулировать разработчиков к исследованию инновационных приложений глубокой интеграции баз данных и ИИ. (Источник: 10万奖金×认知升级!OceanBase首届AI黑客松广发英雄帖,你敢来么?)

Профессор Лю Синьцзюнь из Университета Цинхуа проведет онлайн-лекцию о параллельных роботах: Профессор Лю Синьцзюнь, директор Института инженерного проектирования механического факультета Университета Цинхуа и председатель Китайского комитета IFToMM, проведет онлайн-лекцию вечером 15 апреля на тему «Основы механики параллельных роботов и инновации в оборудовании». Лекция будет посвящена фундаментальной теории параллельных роботов и их применению в передовых инновациях оборудования. Модератором выступит профессор Лю Инсян из Харбинского политехнического университета. (Источник: 重磅直播!清华大学刘辛军教授开讲:并联机器人机构学基础与装备创新前沿)

Опубликовано руководство по Третьему китайскому саммиту индустрии AIGC: Опубликована подробная программа и основные моменты Третьего китайского саммита индустрии AIGC, который состоится 16 апреля в Пекине. Саммит будет посвящен технологиям ИИ и их практическому применению, темы охватывают инфраструктуру вычислений, применение больших моделей в вертикальных сценариях, таких как образование/развлечения/корпоративные услуги/AI4S, а также безопасность и управляемость ИИ. Среди докладчиков представители Baidu, Huawei, AWS, Microsoft Research Asia, Mianbi Intelligence, Shengshu Technology, Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health, Ant Group и др. На саммите также будут объявлены списки заслуживающих внимания компаний и продуктов AIGC на 2025 год, а также представлена панорамная карта приложений AIGC в Китае. (Источник: 倒计时2天!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此)
