
Ключевые слова:AI, GPT-4.1, Zhipu AI IPO, инвестиции NVIDIA в AI суперкомпьютеры, капитальные затраты Amazon на AI, протокол взаимодействия AI Agent, количество пользователей DeepSeek
🔥 В центре внимания
OpenAI выпустила серию моделей GPT-4.1, повысив производительность API и отказавшись от GPT-4.5: 15 апреля OpenAI через API выпустила три новые модели: GPT-4.1, GPT-4.1 mini и GPT-4.1 nano, стремясь полностью превзойти серию GPT-4o. Новые модели имеют контекстное окно до 1 миллиона Token и базу знаний, обновленную до июня 2024 года. GPT-4.1 демонстрирует выдающиеся результаты в области кодирования (оценка 54,6% на SWE-bench Verified, улучшение на 21,4% по сравнению с GPT-4o), следования инструкциям (оценка 38,3% на MultiChallenge, улучшение на 10,5% по сравнению с GPT-4o) и понимания длинных контекстных видео (оценка 72,0% на Video-MME, улучшение на 6,7% по сравнению с GPT-4o). Примечательно, что GPT-4.1 nano — первая модель nano, превосходящая по производительности GPT-4o mini при меньшей стоимости. Одновременно OpenAI объявила, что через 3 месяца (14 июля) прекратит поддержку GPT-4.5 Preview API, назвав его предварительной исследовательской версией, и в будущем интегрирует понравившиеся разработчикам функции в новые модели. Этот выпуск рассматривается как стратегический шаг OpenAI по разграничению моделей API и продуктовой линейки ChatGPT, а также как прямая конкуренция с серией Google Gemini. (Источник: 36氪, 新智元1, AI科技评论, Reddit r/LocalLLaMA, Reddit r/artificial)
Zhipu AI начала подготовку к IPO и открыла исходный код новых моделей, оценка превышает 20 млрд юаней: Zhipu AI (Zhipu Huazhang), один из «шести тигрят» больших моделей Китая, 14 апреля подала заявку на регистрацию в Пекинское управление Комиссии по регулированию ценных бумаг Китая, официально начав процесс IPO. CICC выступает в качестве консультанта. Zhipu AI выросла из Лаборатории инженерии знаний Университета Цинхуа, ключевые члены команды в основном из Цинхуа. Компания привлекла более 15 миллиардов юаней финансирования, а недавняя оценка превышает 20 миллиардов юаней. Одновременно с началом IPO Zhipu AI объявила о масштабном открытии исходного кода моделей серии GLM-4-32B/9B, включая базовые, инференсные и «созерцательные» (contemplative) модели, распространяемые по лицензии MIT и доступные для бесплатного коммерческого использования. Среди них инференсная модель GLM-Z1-32B-0414 с 32B параметрами по производительности в некоторых задачах сопоставима с моделью DeepSeek-R1 с 671B параметрами. Скорость вывода (inference) ее сверхбыстрой версии API GLM-Z1-AirX достигает 200 tokens/s, а цена экономичной версии составляет всего 1/30 от цены DeepSeek-R1. Компания также запустила новый домен z.ai в качестве платформы для бесплатного тестирования моделей. Этот шаг демонстрирует комплексный подход Zhipu AI к собственным исследованиям и разработкам, коммерциализации и построению экосистемы с открытым исходным кодом. (Источник: 智东西, InfoQ, 量子位, 极客公园, 雷递, 公众号)

Nvidia инвестирует 500 миллиардов долларов в производство AI-суперкомпьютеров на территории США: Nvidia объявила о крупном плане инвестировать 500 миллиардов долларов в течение следующих четырех лет в производство AI-суперкомпьютеров впервые на территории США. План включает сотрудничество с несколькими гигантами отрасли, включая TSMC (производство чипов Blackwell в Аризоне), Foxconn и Wistron (строительство заводов суперкомпьютеров в Техасе), Amkor и SPIL (сборка и тестирование в Аризоне). CEO Nvidia Дженсен Хуанг заявил, что этот шаг направлен на удовлетворение растущего спроса на AI-чипы и суперкомпьютеры, повышение устойчивости цепочек поставок и использование технологий Nvidia в области AI, робототехники (Isaac GR00T) и цифровых двойников (Omniverse) для проектирования и эксплуатации заводов. План рассматривается как стратегическое развертывание в контексте продвижения американским правительством местного производства (например, через CHIPS Act) и геополитической обстановки, направленное на укрепление позиций США в глобальной гонке за AI-инфраструктурой, но сталкивается с проблемами сложности цепочек поставок, нехватки квалифицированных технических работников и неопределенности политики. (Источник: 新智元1, 新智元2, Reddit r/artificial)

Amazon планирует инвестировать более 100 миллиардов долларов в AI, чтобы противостоять конкуренции и использовать возможности: CEO Amazon Энди Джесси (Andy Jassy) в ежегодном письме акционерам 2024 года сообщил, что компания планирует в 2025 году осуществить капитальные затраты на сумму более 100 миллиардов долларов, большая часть которых будет направлена на проекты, связанные с AI, включая центры обработки данных, сетевое оборудование, аппаратное обеспечение AI (например, собственные чипы Trainium) и генеративные AI-сервисы (например, собственные большие модели серии Nova, платформу Bedrock, обновленную Alexa+, помощника для покупок Rufus). Эти огромные инвестиции (почти 1/6 годового дохода) отражают то, что Amazon рассматривает AI как ключ к противостоянию жесткой конкуренции в сфере электронной коммерции (со стороны SHEIN, Temu, TikTok и др.) и использованию исторических возможностей. Джесси подчеркнул, что AI изменит правила игры в поиске, программировании, покупках и т.д., и отказ от инвестиций приведет к потере конкурентоспособности. В настоящее время годовой доход AI-бизнеса Amazon уже достиг нескольких миллиардов долларов, демонстрируя трехзначный рост в годовом исчислении. Этот шаг также показывает решимость Amazon продолжать инвестировать для укрепления лидирующих позиций в области облачных сервисов (AWS) в условиях конкуренции с Microsoft Azure, Google Cloud и другими. (Источник: 36氪)
🎯 Тенденции
Протоколы взаимодействия AI Agent MCP и стандарт A2A привлекают внимание: В области AI-агентов (AI Agent) разворачивается конкуренция за стандартизированные протоколы взаимодействия. Предложенный Anthropic протокол MCP (Model Context Protocol), направленный на унификацию связи больших моделей с внешними инструментами и источниками данных, назван «USB-C для AI» и уже получил поддержку от OpenAI, Google и других. Google, в свою очередь, открыл исходный код протокола A2A (Agent2Agent), ориентированного на безопасное и эффективное сотрудничество между агентами разных поставщиков и фреймворков с целью преодоления барьеров экосистем. Появление этих двух протоколов знаменует эволюцию AI от монолитного интеллекта к сетям сотрудничества, но также вызывает дискуссии о «протоколе как власти», монополии на данные и барьерах экосистем («высокие заборы вокруг маленьких двориков»). Контроль над разработкой стандартов может перестроить структуру AI-индустрии и оказать глубокое влияние на интеграцию AI с физическим миром (робототехника, IoT). Китайские компании, такие как Alibaba Cloud и Tencent Cloud, также начали поддерживать MCP. (Источник: 36Kr)

Отчет QuestMobile: DeepSeek переворачивает ландшафт AI-приложений в Китае, аудитория достигла 240 миллионов: Отчет QuestMobile «Анализ конкуренции на рынке AI-приложений в первом квартале 2025 года» показывает, что под влиянием взрывной популярности модели DeepSeek и ее приложений ландшафт рынка нативных AI-приложений в Китае был полностью перевернут. По состоянию на конец февраля 2025 года ежемесячная активная аудитория нативных AI-приложений достигла 240 миллионов, что почти на 90% больше, чем в январе. Приложение DeepSeek App возглавило рейтинг с 194 миллионами ежемесячных активных пользователей, Doubao от ByteDance (116 миллионов) и Tencent Yuanbao (41,64 миллиона) заняли второе и третье места, вытеснив предыдущих лидеров, таких как Kimi. В отчете отмечается, что эффект открытого исходного кода и доступности DeepSeek способствовал подключению ведущих игроков и взрывному росту AI-приложений, сформировав 23 направления, включая универсальных AI-помощников и AI-поиск, причем конкуренция в AI-поиске наиболее острая. В настоящее время «мультимодельный привод» стал стандартом для ведущих приложений, а фокус конкуренции сместился на дизайн продукта и операционную деятельность. (Источник: QuestMobile)

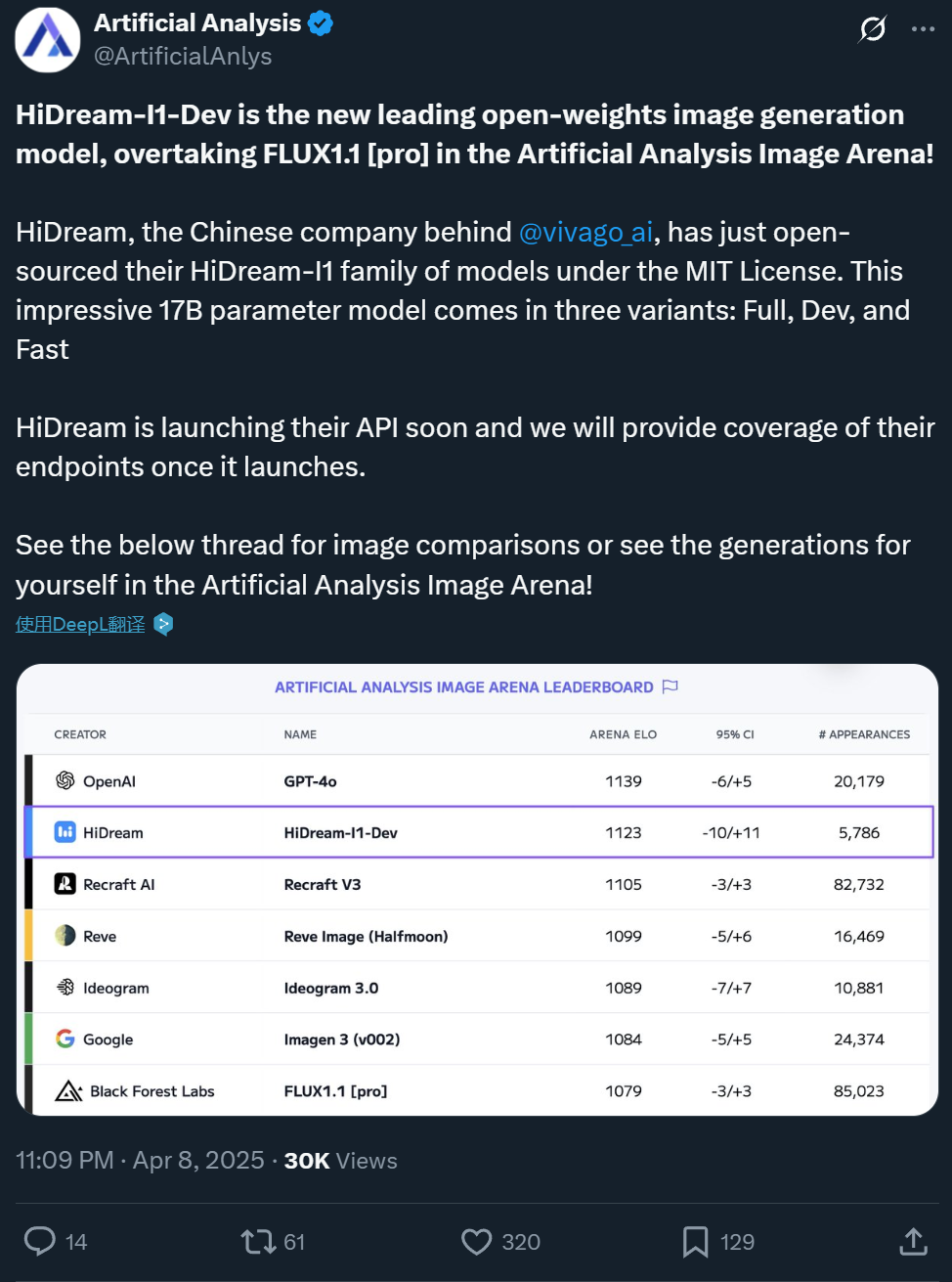
Zxiang Future открывает исходный код 17B модели генерации изображений из текста HiDream-I1, сравнимой по эффекту с GPT-4o: Китайская компания Zxiang Future (智象未来) открыла исходный код своей большой модели генерации изображений из текста HiDream-I1 с 17 миллиардами параметров под свободной лицензией MIT, разрешающей коммерческое использование. Модель показала отличные результаты на аренах и бенчмарках (таких как HPSv2.1, GenEval, DPG-Bench) платформ вроде Artificial Analysis. Считается, что реалистичность, детализация и следование инструкциям генерируемых изображений сопоставимы с GPT-4o и FLUX 1.1 Pro, а в некоторых аспектах даже превосходят их. HiDream-I1 использует архитектуру Sparse Diffusion Transformer (Sparse DiT), интегрируя технологию MoE для повышения производительности и эффективности. Компания также объявила о скором открытии исходного кода модели HiDream-E1, поддерживающей интерактивное редактирование изображений. Сочетание этих двух моделей призвано предоставить опыт генерации и редактирования изображений, сравнимый с «открытой версией GPT-4o». Модель доступна на Hugging Face и для тестирования на платформе Vivago. (Источник: 机器之心1, 机器之心2)
ByteDance выпускает 7B базовую видеомодель Seaweed с низкой стоимостью и высокой эффективностью: Команда Seed из ByteDance выпустила базовую модель генерации видео под названием Seaweed (омофон Seed-Video). Модель имеет всего 7 миллиардов параметров и, как сообщается, была обучена за 665 тысяч часов работы GPU H100 (эквивалентно примерно 28 дням обучения на 1000 картах), что делает ее относительно недорогой. Seaweed способна генерировать видео по тексту с разным разрешением (нативно поддерживает 1280×720, с возможностью апскейлинга до 2K), произвольным соотношением сторон и длительностью. Модель поддерживает генерацию видео из изображений, управление референтным объектом (одно/несколько изображений), генерацию видео с синхронизацией губ в сочетании с решением для цифровых людей Omnihuman, озвучивание видео и другие функции. Технически используется архитектура DiT+VAE в сочетании с комплексным процессом обработки данных и многоэтапной многозадачной стратегией обучения (предобучение, SFT, RLHF), а также системной оптимизацией для повышения эффективности обучения. Команду возглавляет доктор Цзян Лу, бывший руководитель отдела генерации видео в Google. (Источник: 量子位)

Alibaba Tongyi выпускает модель генерации видео с цифровыми людьми OmniTalker: Команда HumanAIGC из лаборатории Alibaba Tongyi представила новую большую модель генерации видео с цифровыми людьми OmniTalker. Модель призвана решить проблемы, связанные с традиционными каскадными методами (TTS + аудио-драйвинг), такие как задержка, рассинхронизация аудио и видео, несоответствие стиля. OmniTalker представляет собой единый end-to-end фреймворк, который на вход принимает текст и короткое референтное аудио/видео, и в реальном времени генерирует синхронизированное аудио и видео цифрового человека, сохраняя при этом голос и стиль речи референтного источника. Ее основная архитектура использует двухпотоковый DiT (Diffusion Transformer), обрабатывающий отдельно аудио и визуальную информацию, и обеспечивает синхронизацию и стилевое соответствие с помощью нового модуля слияния аудио и видео. Модель использует модуль обучения на основе контекстных референсов для захвата стилевых особенностей из референтного видео без необходимости дополнительного обучения экстрактора стиля. Проект уже доступен для тестирования в сообществе ModelScope и на HuggingFace. (Источник: 机器之心)

Kuaishou выпускает версию 2.0 AI-модели для видео Kling AI: Модель генерации видео Kling AI от Kuaishou выпустила версию 2.0, которая, как сообщается, значительно улучшена в плане амплитуды движения камеры, соблюдения физических законов, актерской игры персонажей, стабильности движений и семантического понимания. Отзывы пользователей показывают, что новая версия отлично справляется со сложными взаимодействиями (например, тираннозавр ломает дерево), мелкими движениями (например, снятие очков), сценами с несколькими людьми и симуляцией реалистичного освещения и теней. Реалистичность и кинематографичность генерируемых видео значительно возросли, и считается, что эффект превосходит предыдущую версию 1.6 и достиг лидирующего уровня в отрасли. Хотя все еще есть возможности для улучшения в области высокоскоростных групповых движений и экстремальной физической симуляции (например, бросок в баскетболе), ее общая производительность, как считается, уже начинает бросать вызов профессиональному уровню производства. Пользователи могут опробовать новую версию на официальном сайте klingai.com. (Источник: 公众号, op7418)

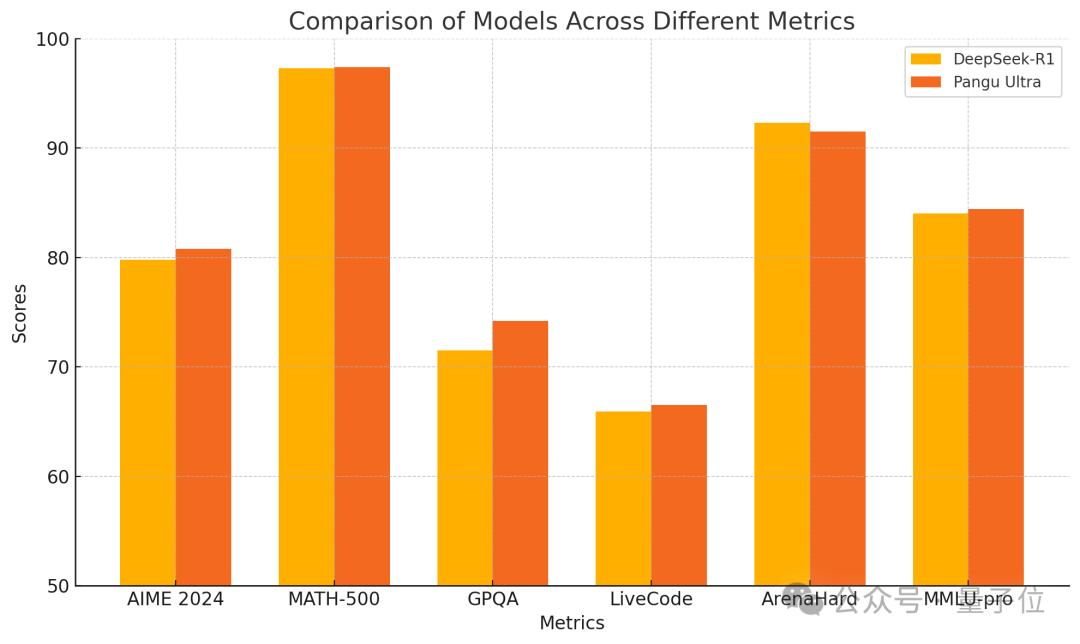
Huawei выпускает плотную модель Pangu Ultra 135B, обученную исключительно на Ascend, с превосходной производительностью: Huawei анонсировала нового члена своей серии больших моделей Pangu — Pangu Ultra. Это плотная (Dense) модель с 135 миллиардами параметров, полностью обученная на вычислительном кластере Huawei Ascend AI (8192 NPU) без использования GPU Nvidia. Согласно отчету, Pangu Ultra демонстрирует выдающиеся результаты в задачах математического рассуждения (AIME 2024, MATH-500) и программирования (LiveCodeBench), а ее производительность сопоставима с более крупными MoE-моделями, такими как DeepSeek-R1. Технически модель использует инновационную нормализацию слоев Sandwich-Norm с глубоким масштабированием и стратегию инициализации параметров TinyInit, что эффективно решает проблемы нестабильности при обучении сверхглубоких сетей (94 слоя), обеспечивая плавное обучение без пиков потерь. Благодаря системной оптимизации обучение достигло более 52% эффективности использования вычислительной мощности (MFU). (Источник: 量子位)
Canopy Labs открывает исходный код модели синтеза эмоциональной речи Orpheus: Canopy Labs выпустила и открыла исходный код серии моделей преобразования текста в речь (TTS) под названием Orpheus. Модель основана на архитектуре Llama, первая версия имеет 3 миллиарда параметров, в дальнейшем планируется выпуск меньших версий (1B, 0.5B, 0.15B и т.д.). Особенностью Orpheus является способность генерировать речь с высокой степенью человекоподобных эмоций, интонаций и ритма, и даже выводить из текста и генерировать невербальные звуки, такие как смех, вздохи, достигая «эмпатического» выражения. Модель поддерживает клонирование голоса zero-shot и управление эмоциональной интонацией с помощью тегов. Она использует потоковый инференс (streaming inference) с низкой задержкой 100-200 мс, а скорость вывода на видеокарте A100 40GB превышает скорость воспроизведения в реальном времени. Разработчики утверждают, что ее производительность превосходит существующие открытые и некоторые закрытые SOTA-модели, стремясь разрушить монополию закрытых TTS-моделей. Модель и код доступны на GitHub и Hugging Face. (Источник: 新智元)

Чжэцзянский университет и ByteDance совместно выпускают модель синтеза речи MegaTTS3: Команда профессора Чжао Чжоу из Чжэцзянского университета в сотрудничестве с ByteDance выпустила и открыла исходный код модели синтеза речи третьего поколения MegaTTS3. Эта модель, имея всего 0,45 миллиарда параметров, обеспечивает высококачественный синтез речи на китайском и английском языках и демонстрирует выдающиеся результаты в клонировании голоса zero-shot, генерируя естественную, управляемую и персонализированную речь. MegaTTS3 делает акцент на прорывах в разреженном выравнивании речи и текста, управляемости генерации, а также балансе между эффективностью и качеством. Технические особенности включают технологию «многоусловного управления без классификатора» (Multi-Condition CFG) для контроля над несколькими измерениями, такими как интенсивность акцента, и технологию «ускорения сегментированного выпрямленного потока» (PeRFlow), которая увеличивает скорость сэмплирования в 3 раза. Модель демонстрирует лидирующую естественность (CMOS) и сходство с диктором (SIM-O) на бенчмарках, таких как LibriSpeech. (Источник: PaperWeekly)

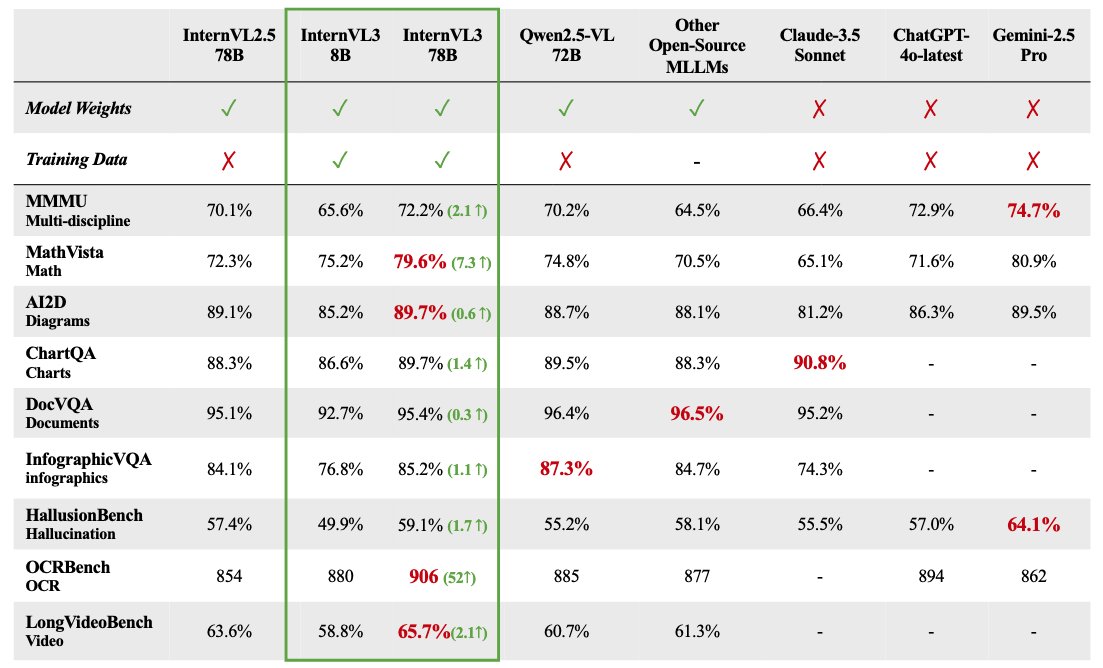
Открыт исходный код серии мультимодальных больших моделей InternVL 3: OpenGVLab выпустила серию мультимодальных больших моделей InternVL 3 с размерами параметров от 1B до 78B, которые уже доступны на Hugging Face. Сообщается, что версия с 78B параметрами набрала 72,2 балла на бенчмарке MMMU, установив новый SOTA-рекорд для открытых мультимодальных моделей. Технические особенности InternVL 3 включают: использование нативного мультимодального предобучения для одновременного изучения языка и зрения; введение изменяемого визуального позиционного кодирования (V2PE) для поддержки расширенного контекста; использование передовых техник пост-обучения, таких как SFT и MPO; применение стратегии масштабирования во время тестирования для улучшения способностей к математическому рассуждению. Данные для обучения и веса модели открыты для использования сообществом. (Источник: huggingface)
Анализ реальной производительности GPT-4.1: улучшение кодирования, но отставание в рассуждениях: Выпущенные OpenAI модели серии GPT-4.1 в предварительных тестах и оценках на бенчмарках демонстрируют сложную картину производительности. Хотя они показывают значительный прогресс по сравнению с GPT-4o в задачах генерации кода, например, лучше справляются с физической симуляцией, разработкой игр и т.д., и получают высокие баллы на SWE-Bench. Однако на более широких бенчмарках рассуждений, математики и ответов на вопросы на основе знаний (таких как Livebench, GPQA Diamond), производительность GPT-4.1 все еще отстает от Gemini 2.5 Pro от Google и Claude 3.7 Sonnet от Anthropic. Аналитики полагают, что GPT-4.1 может быть инкрементальным обновлением GPT-4o или дистиллированной версией GPT-4.5. Стратегия выпуска, возможно, направлена на предоставление через API более экономичных, специфически оптимизированных моделей, а не флагманской модели, полностью превосходящей конкурентов. (Источник: 新智元)
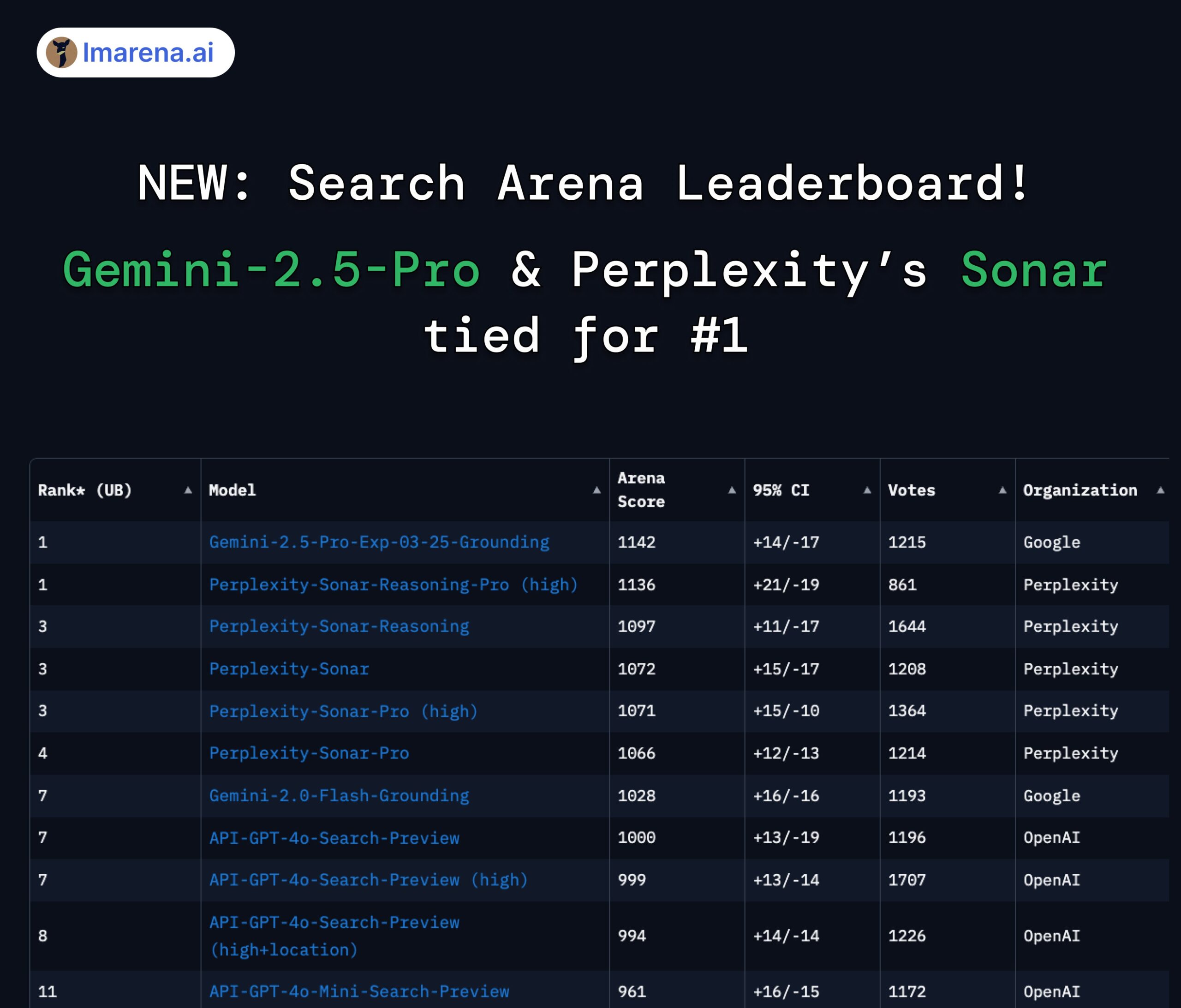
Рейтинг LMArena Search: Gemini 2.5 Pro и Perplexity Sonar делят первое место: В рейтинге LMArena, посвященном оценке больших моделей с возможностями поиска/подключения к сети, Google Gemini-2.5-Pro (в сочетании с Google Search) и Perplexity Sonar-Reasoning-Pro разделили первое место. Этот результат был подтвержден репостами CEO Google DeepMind Демиса Хассабиса и руководителя отдела по связям с разработчиками Google Логана Килпатрика. CEO Perplexity Аравинд Шринивас также прокомментировал это, заявив, что внутренние A/B тесты показывают, что их модель Sonar превосходит GPT-4o по удержанию пользователей, а ее производительность сравнима с Gemini 2.5 Pro и недавно выпущенной GPT-4.1. Организаторы оценки lmarena.ai открыли доступ к данным 7000 пользовательских голосований. (Источник: lmarena_ai 1, lmarena_ai 2, AravSrinivas, demishassabis)
Meta возобновит использование общедоступного контента европейских пользователей для обучения AI: Компания Meta объявила, что возобновит использование общедоступного контента европейских пользователей для обучения своих моделей искусственного интеллекта. Ранее Meta приостановила эту практику из-за давления и регуляторных требований со стороны европейских органов по защите данных (в частности, Ирландской комиссии по защите данных). Решение о возобновлении обучения может отражать постоянные усилия и стратегические корректировки Meta в балансировании между конфиденциальностью пользователей, соблюдением нормативных актов (таких как GDPR) и получением достаточного количества данных для поддержания конкурентоспособности своих AI-моделей. Этот шаг может вновь вызвать дискуссии о правах пользователей на данные и прозрачности обучения AI. (Источник: Reddit r/artificial)

Мобильное приложение Claude может получить режим голосового взаимодействия: Согласно информации, обнаруженной пользователем X @testingcatalog, Anthropic, возможно, планирует добавить функцию голосового взаимодействия в свое мобильное приложение Claude. Скриншоты показывают иконку микрофона в интерфейсе приложения, намекая на то, что пользователи в будущем смогут общаться с Claude голосом, аналогично голосовым режимам, уже доступным в приложениях ChatGPT и Google Gemini. Это сделает взаимодействие с Claude на мобильных устройствах более разнообразным и удобным, улучшит пользовательский опыт и обеспечит функциональное соответствие другим основным AI-помощникам. (Источник: Reddit r/ClaudeAI)
Скорость моделей серии Z1 от Zhipu привлекает внимание, их называют «мгновенными моделями»: Недавно выпущенные модели серии Z1 от Zhipu AI, особенно версия GLM-Z1-AirX, привлекли внимание своей чрезвычайно высокой скоростью инференса. Некоторые аналитики называют их «мгновенными моделями», отмечая, что они могут выдать первый ответ и сгенерировать более 50 китайских иероглифов за 0,3 секунды, что близко ко времени человеческой нервной реакции. Такая низкая задержка и высокая пропускная способность могут изменить модель взаимодействия человека и машины, перейдя от схемы «вопрос-ожидание-ответ» к почти реальному времени синхронного диалога, что особенно подходит для сценариев, требующих высокой скорости отклика, таких как образование, обслуживание клиентов, создание контента и вызовы Agent. Скорость API-версии Z1-AirX, как утверждается, может достигать 200 tokens/s. (Источник: 公众号)

AI-нативные игры: эволюция от инструмента повышения эффективности к инновациям в геймплее и вызовы: Игровая индустрия переходит от использования AI для повышения эффективности разработки и эксплуатации (например, генерация артов, помощь в кодировании, автоматизированное тестирование) к исследованию настоящих «AI-нативных игр». Суть AI-нативных игр заключается в глубокой интеграции AI в геймплей, создании динамического контента и персонализированного опыта, управляемого взаимодействием игрока, а не предустановленным сценарием. Примерами таких исследований являются игра «Whispers from the Star», в которую инвестировал основатель miHoYo Цай Хаоюй, и режим AI-игроков в «太空杀» (Space Kill) от Giant Network. Однако реализация AI-нативных игр сталкивается с множеством проблем: на техническом уровне необходимо решить вопросы возможностей моделей, стабильности и стоимости; на уровне дизайна отсутствуют зрелые примеры, необходимо сбалансировать управляемость и свободу; на уровне пользователя необходимо удовлетворить потребности игроков в интересности и глубине взаимодействия; кроме того, существуют риски, связанные с соответствием контента нормам и этикой. В настоящее время отрасль все еще находится на ранней стадии исследования, и до зрелой реализации еще далеко. (Источник: 界面新闻)
🧰 Инструменты
Обзор пяти креативных AI-приложений: 36Kr представил пять креативных и практичных AI-инструментов из недавнего сбора инновационных кейсов AI-нативных приложений: 1) AiPPT.com: Быстро генерирует PPT по одному предложению или импортированному файлу (Word, PDF, Xmind, ссылка), поддерживает офлайн-работу. 2) Shineji AI Plogging Mirror (闪极AI拍拍镜): AI-очки с функциями фото- и видеосъемки, перевода в реальном времени, распознавания формул и т.д. 3) Lianxin Digital Unperceived Interrogation Intelligent Agent (连信数字无感审讯智能体): Основан на психологической большой модели «Insight into Human», помогает в допросах путем анализа микровыражений, голоса, физиологических сигналов, генерирует отчеты. 4) Huiliima Vali Footwear AI (惠利玛Vali鞋履AI): Генерирует 8 дизайнов обуви за 10 секунд по ключевым словам, интегрирует базу материалов и данных о колодках, связывает с производством. 5) Nanfang Shidong Sandbag HR Intelligent Agent (南方仕通沙包HR智能体): Обрабатывает задачи управления персоналом, связанные с социальным страхованием, предоставляет разъяснения по политике, расчет затрат, интеллектуальную обработку, предупреждение о рисках и т.д. Эти приложения демонстрируют потенциал AI в инструментах повышения эффективности, умном оборудовании и профессиональных областях (безопасность, дизайн, HR). (Источник: 36Kr)

Haisin Intelligence выпускает AI-платформу для разработки без кода «Haisnap»: Пекинская компания Haisin Intelligence Technology, поддерживаемая государственным капиталом, запустила платформу для разработки AI без кода/с низким кодом под названием «Haisnap» (响指). Пользователи могут описывать свои потребности на естественном языке, чтобы AI автоматически генерировал веб-приложения, мини-игры и т.д. Особенностью платформы является то, что код виден в реальном времени в процессе генерации, и поддерживается вторичное редактирование и модификация через диалог. Приложения, разработанные пользователями, могут быть опубликованы в «Креативном сообществе» платформы, где другие могут их просматривать, использовать и переделывать (remix). В настоящее время платформа доступна бесплатно, с целью снижения порога входа в разработку AI-приложений, содействия всеобщему творчеству, с особым акцентом на AI-образование молодежи и внедрение в отраслевые приложения. (Источник: 量子位)

Выпущена система вопросов и ответов на основе базы знаний с открытым исходным кодом ChatWiki, поддерживающая GraphRAG и интеграцию с WeChat: ChatWiki — это новая система вопросов и ответов на основе базы знаний AI с открытым исходным кодом, которая интегрирует большие языковые модели (поддерживает более 20 моделей, включая DeepSeek, OpenAI, Claude) с технологией Retrieval-Augmented Generation (RAG) и особенно поддерживает GraphRAG на основе графов знаний для обработки сложных запросов. Функции системы включают: поддержку импорта документов различных форматов (OFD, Word, PDF и т.д.) для создания частных баз знаний; поддержку семантической сегментации для повышения точности RAG; возможность публикации базы знаний как общедоступного сайта документации; предоставление API-интерфейса для бесшовной интеграции с экосистемами WeChat Official Accounts, WeChat Customer Service и т.д. для создания AI-чат-ботов; встроенный инструмент визуального оркестрирования рабочих процессов; поддержку интеграции с бизнес-данными сторонних разработчиков; предоставление управления правами доступа корпоративного уровня; поддержку локального развертывания с помощью Docker и исходного кода. (Источник: 公众号)

Сообщество ModelScope запускает MCP Plaza, создавая крупнейшую экосистему сервисов MCP в Китае: Сообщество AI-моделей ModelScope от Alibaba официально запустило «MCP Plaza», собрав почти 1500 сервисов, реализующих протокол контекста модели (MCP), охватывающих такие области, как поиск, карты, платежи, инструменты для разработчиков, с целью создания крупнейшего китайского сообщества MCP в стране. Несколько MCP-сервисов от Alipay и MiniMax были эксклюзивно запущены здесь, например, возможности Alipay по оплате, запросам, возвратам, а также возможности MiniMax по генерации голоса, изображений и видео — все они могут быть вызваны AI-агентами через протокол MCP. Разработчики могут в экспериментальной зоне MCP на ModelScope быстро опробовать и интегрировать эти сервисы с помощью простой конфигурации JSON и бесплатных облачных ресурсов, что значительно снижает барьер для доступа AI-приложений к внешним инструментам и данным. ModelScope также запустила MCP Bench для оценки качества и производительности различных MCP-сервисов. (Источник: 新智元)

Обсуждение использования функции WebSearch в Open WebUI: Пользователи сообщества Reddit обсуждают, как использовать функцию Web Search в Open WebUI. Вопросы сосредоточены на том, как точно контролировать ключевые слова запроса, используемые поисковой системой, и как ограничить функцию Web Search определенными моделями, чтобы предотвратить случайную отправку данных частных моделей в сеть. Это отражает реальные потребности пользователей в точности контроля и безопасности конфиденциальности при использовании AI-инструментов с интегрированными функциями поиска. (Источник: Reddit r/OpenWebUI 1, Reddit r/OpenWebUI 2)
Пользователи ищут понимания протокола контекста модели (MCP): В сообществе Reddit пользователь разместил пост с просьбой объяснить протокол контекста модели (MCP), что указывает на растущую потребность сообщества разработчиков и пользователей в понимании этой новой технологии и принципов ее работы по мере распространения и применения стандарта MCP (например, MCP Plaza на ModelScope). (Источник: Reddit r/OpenWebUI)
📚 Обучение
Премия ICLR 2025 Test of Time присуждена оптимизатору Adam и механизму внимания: Международная конференция по обучающим представлениям (ICLR) присудила свою премию «Проверка временем» (Test of Time Award) 2025 года двум знаковым статьям, опубликованным десять лет назад (в 2015 году). Одна из них — «Adam: A Method for Stochastic Optimization» Дидерика П. Кингмы и Джимми Ба, предложенный в которой оптимизатор Adam стал стандартным алгоритмом для обучения моделей глубокого обучения. Другая — «Neural Machine Translation by Jointly Learning to Align and Translate» Дмитрия Багданова, Кёнхёна Чо и Йошуа Бенджио, в которой впервые был введен механизм внимания, заложивший основу для архитектуры Transformer и современных больших языковых моделей. Эти две награды подчеркивают глубокое влияние фундаментальных исследований на текущее развитие AI. (Источник: 新智元)

Краткая история развития AI и эволюции предприятий: Статья систематически рассматривает историю развития искусственного интеллекта с середины 20-го века до наших дней, включая ключевые моменты, такие как тест Тьюринга, Дартмутская конференция, символизм и экспертные системы, «зима AI», подъем машинного обучения (DeepBlue, PageRank), революция глубокого обучения (AlexNet, AlphaGo) и текущая эра больших моделей (серия GPT, коммерциализация генеративного AI, спор между открытым и закрытым исходным кодом). Одновременно статья делит развитие AI-предприятий на четыре эры: эра первопроходцев (2000-2010, исследование инструментальных приложений), эра золотой лихорадки (2011-2016, расширение возможностей платформ и взрывной рост, обусловленный данными), эра пузыря (2017-2020, борьба за сценарии использования и узкие места коммерциализации) и эра перестройки (с 2021 года по настоящее время, новая структура, движимая большими моделями). Статья подчеркивает синергетическое действие вычислительной мощности, данных и алгоритмов, а также влияние новых сил, таких как DeepSeek, на структуру отрасли. (Источник: 混沌大学)
OpenAI публикует руководство по промпт-инжинирингу для GPT-4.1: В связи с выпуском моделей серии GPT-4.1 OpenAI обновила свое руководство по промпт-инжинирингу (Prompting). Руководство подчеркивает, что модели серии GPT-4.1, по сравнению с более ранними моделями, такими как GPT-4, будут строже и буквальнее следовать инструкциям, будучи более чувствительными к четким и конкретным подсказкам. Если модель ведет себя не так, как ожидалось, обычно достаточно добавить краткие и ясные указания, чтобы направить ее поведение. Это отличается от предыдущих моделей, которые были склонны угадывать намерения пользователя, поэтому разработчикам может потребоваться скорректировать свои прежние стратегии промптинга. Руководство предлагает лучшие практики, от базовых принципов до продвинутых стратегий, чтобы помочь разработчикам лучше использовать возможности новых моделей. (Источник: dotey, Reddit r/LocalLLaMA)
Шанхайский университет Цзяотун и др. выпускают бенчмарк пространственно-временного интеллекта STI-Bench, бросая вызов пониманию физики мультимодальными моделями: Шанхайский университет Цзяотун совместно с несколькими учреждениями выпустил первый бенчмарк для оценки пространственно-временного интеллекта мультимодальных больших моделей (MLLM) — STI-Bench. Этот бенчмарк использует видео из реального мира, фокусируясь на точных, количественных способностях пространственно-временного понимания, и включает восемь задач: измерение масштаба, пространственные отношения, 3D-локализация, траектория перемещения, скорость и ускорение, эгоцентрическое направление, описание траектории, оценка позы. Оценка ведущих моделей, таких как GPT-4o, Gemini 2.5 Pro, Claude 3.7 Sonnet, Qwen 2.5 VL, показала, что существующие модели в целом плохо справляются с этими задачами (точность <42%), особенно с обработкой количественных пространственных атрибутов, временных динамических изменений и интеграцией информации между модальностями. Бенчмарк выявляет ограничения современных MLLM в понимании физического мира и указывает направления для будущих исследований. (Источник: 量子位)

Исследования сочетания обучения с подкреплением и многокритериальной оптимизации привлекают внимание: Пересечение областей обучения с подкреплением (RL) и многокритериальной оптимизации (MOO) становится горячей точкой в исследованиях принятия решений AI. Это сочетание направлено на то, чтобы позволить агентам взвешивать несколько (возможно, конфликтующих) целей в сложных средах, а не стремиться к единственному оптимуму. Например, Гонконгский университет науки и технологии предложил фреймворк динамического баланса градиентов для автономного вождения, одновременно оптимизируя безопасность и энергоэффективность; алгоритм поиска Парето-стратегий от MIT используется для управления роботами; Alibaba Cloud применяет технологию многокритериального выравнивания в финансовых транзакциях для балансировки доходности и риска. Связанные исследования, такие как CMORL (непрерывное многокритериальное обучение с подкреплением) и обучение Парето-множеств для комбинаторной оптимизации, изучают, как сделать RL-агентов более эффективными в обработке динамически изменяющихся или имеющих несколько измерений оптимизации проблем реального мира. (Источник: 公众号)

Выпущена платформа автоматической состязательной атаки и защиты A³D с открытым исходным кодом (TPAMI 2025): Исследовательская группа по интеллектуальному проектированию и робастному обучению (IDRL) Института инноваций в области оборонных технологий Академии военных наук разработала и открыла исходный код платформы под названием A³D (Автоматическая состязательная атака и защита). Платформа использует технологии автоматического машинного обучения (AutoML) в сочетании с идеями теории игр атаки и защиты с целью автоматического поиска робастных архитектур нейронных сетей и эффективных стратегий состязательных атак. Платформа интегрирует различные методы поиска нейронных архитектур (NAS) и метрики оценки робастности (атаки по норме, семантические атаки, состязательная маскировка и т.д.) для автоматической защиты, а также предоставляет модуль автоматической состязательной атаки, который может искать оптимальные схемы комбинированных атак с помощью алгоритмов оптимизации. Результаты исследования опубликованы в ведущем журнале TPAMI, код размещен на платформах с открытым исходным кодом, таких как Hongshan Open Source, предоставляя новый инструмент для оценки и повышения безопасности моделей DNN. (Источник: 公众号)

Университет Флориды набирает аспирантов/стажеров с полным финансированием по направлению NLP/LLM: Ассистент-профессор Юаньюань Лэй с кафедры компьютерных наук Университета Флориды (начинает работу осенью 2025 года) объявляет набор аспирантов с полным финансированием на осень 2025 или весну 2026 года, а также научных стажеров с гибким графиком (возможно удаленно). Направления исследований сосредоточены на обработке естественного языка (NLP) и больших языковых моделях (LLM), в частности, включая LLM, усиленные знаниями, проверку фактов, рассуждения и планирование, приложения NLP (мультимодальные, юридические, бизнес, научные и т.д.). Приглашаются студенты с опытом в области компьютерных наук, электротехники, статистики, математики и т.д., заинтересованные и мотивированные к исследованиям в области AI. В письме упоминается потенциальное влияние закона Флориды SB-846 на набор студентов из материкового Китая и пути решения этой проблемы. (Источник: PaperWeekly)

Новое исследование диффузионных моделей: априорный шум с временной корреляцией: Статья на arXiv «How I Warped Your Noise: a Temporally-Correlated Noise Prior for Diffusion Models» предлагает новый тип априорного шума для диффузионных моделей. Метод направлен на улучшение качества генерации или эффективности диффузионных моделей (возможно, для видео) путем введения шума с временной корреляцией. Подробности технической реализации следует искать в оригинальной статье. (Источник: Reddit r/MachineLearning)
Новое исследование в области автоматизированных научных открытий: AI Scientist-v2: Статья на arXiv «The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search» представляет систему AI Scientist-v2. Эта система использует метод Agentic Tree Search (поиск по дереву с помощью агентов) с целью достижения автоматизированных научных открытий уровня «семинара» (Workshop-Level). Это указывает на то, что исследователи изучают использование AI-агентов для более продвинутых и автономных научных исследований и открытий. (Источник: Reddit r/MachineLearning)
Объяснение реализации регуляризации Dropout: Статья на Substack подробно объясняет реализацию техники регуляризации Dropout. Dropout — это широко используемая в глубоком обучении техника регуляризации, которая предотвращает переобучение модели путем случайного «отключения» части нейронов во время обучения. Статья, вероятно, предназначена для тех, кто хочет глубже понять принцип работы Dropout или реализовать эту технику самостоятельно. (Источник: Reddit r/deeplearning)
Сбор списка статей arXiv по архитектурам LLM: Пользователь Reddit инициировал обсуждение для обмена и сбора статей arXiv по архитектурам больших языковых моделей (LLM). В уже перечисленные архитектуры входят BERT, Transformer, Mamba, RetNet, RWKV, Hyena, Jamba, серия DeepSeek и др. Этот список отражает разнообразие и быстрое развитие исследований в области архитектур LLM и представляет ценность для исследователей, желающих систематически ознакомиться с этой областью. (Источник: Reddit r/MachineLearning)
💼 Бизнес
AI-платформа для питания Fay привлекает 50 млн долларов финансирования, годовой доход достигает 50 млн: AI-платформа для питания Fay из Кремниевой долины недавно завершила раунд финансирования B на 50 миллионов долларов под руководством Goldman Sachs, доведя общий объем финансирования до 75 миллионов долларов при оценке в 500 миллионов долларов. Fay связывает зарегистрированных диетологов с пациентами, используя AI для повышения эффективности услуг (утверждается, что время на пациента сократилось с 6,5 до 2 часов), автоматизируя генерацию клинических записей (включая кодирование ICD), разработку персонализированных планов питания, обработку страховых возмещений, управление бэк-офисом и другие задачи. Платформа точно уловила резкий рост спроса на консультации по питанию, вызванный препаратами для похудения GLP-1, и наладила процесс оплаты через сотрудничество со страховыми компаниями (вмешательство в питание может снизить долгосрочные медицинские расходы при хронических заболеваниях). На платформе Fay работает менее 3000 диетологов, но она достигла годового дохода (ARR) в 50 миллионов долларов, демонстрируя успешную бизнес-модель использования AI для расширения возможностей профессионалов в вертикальной медицинской сфере и взаимодействия с плательщиками. (Источник: 乌鸦智能说)
Hengtu Technology из Чэнду: AI расширяет возможности цифрового творчества, прибыльный выход на международный рынок: Местная компания из Чэнду Hengtu Technology благодаря своему основному продукту Fotor (платформа для редактирования изображений и видео) накопила около 700 миллионов пользователей по всему миру, с ежемесячной активной аудиторией более десяти миллионов, особенно выделяясь на зарубежных рынках. Это одна из первых китайских компаний в сфере AI-приложений, вышедших на международный рынок и достигших масштабной прибыльности. Компания 16 лет занимается технологиями обработки изображений и в 2022 году быстро интегрировала функции AIGC (генерация изображений и видео из текста и т.д.) в Fotor и новую платформу Clipfly. Fotor с помощью AI снижает порог входа в создание цифрового визуального контента, обслуживая электронную коммерцию, блоги, рекламу, культурный туризм, образование и другие отрасли. Hengtu Technology использует AI для «культурного перевода», помогая китайской культуре выходить на международный уровень и исследуя новые пути развития индустрии цифрового творчества. (Источник: 36Kr四川)
Практика внедрения AI в предприятиях: фокус на ценности, осторожность с тонкой настройкой, содействие синергии: В процессе внедрения больших моделей предприятия перешли от ранних исследований к более прагматичному подходу, ориентированному на ценность. Успешные AI-приложения часто фокусируются на сценариях с высокой повторяемостью, потребностью в творчестве и возможностью формализации, таких как ответы на вопросы на основе знаний, интеллектуальное обслуживание клиентов, генерация материалов, анализ данных и т.д. Предприятия повсеместно осознают, что слепое стремление к тонкой настройке моделей часто имеет низкое соотношение затрат и результатов, и следует отдавать приоритет управлению знаниями и построению платформ интеллектуальных агентов (на начальном этапе в основном с использованием RAG). Внедрение AI требует глубокого участия бизнес-подразделений и поддержки высшего руководства; стратегия параллельного внедрения «быстрых побед в пилотных проектах + подготовка AI-инфраструктуры» показывает лучшие результаты. В плане кадрового обеспечения предприятия склонны формировать небольшие профессиональные AI-команды для расширения возможностей бизнеса и решать проблему нехватки кадров путем привлечения внешних ведущих специалистов, развития внутренних молодых талантов (сочетание стажеров и опытных сотрудников) и сотрудничества с экспертами-подрядчиками. (Источник: AI前线)
Индекс искусственного интеллекта на площадке科创板 (STAR Market) привлекает внимание, может стать новым инвестиционным трендом: Аналитический отчет указывает, что, несмотря на недавнюю волатильность рынка, китайская индустрия искусственного интеллекта сформировала полный цикл «вычислительная мощность — модель — приложение» и демонстрирует сильную устойчивость. Государственный проект «Восточные данные, западные вычисления», недорогие модели, такие как DeepSeek, и прорывы в приложениях, таких как гуманоидные роботы, являются яркими моментами. AI рассматривается как важный двигатель глобального экономического роста в ближайшее десятилетие, и связанные с ним активы показывают значительную долгосрочную доходность. В этом контексте индекс искусственного интеллекта Шанхайской фондовой биржи на площадке科创板 (STAR Market AI Index), фокусирующийся на чипах для вычислений и AI-приложениях, привлекает внимание инвесторов благодаря ожиданиям высокого роста и повышению уровня самодостаточности. Компании, такие как E Fund, уже запустили ETF и связанные фонды (например, 588730, 023564/023565), отслеживающие этот индекс, предоставляя инвесторам инструменты для инвестирования в отечественную цепочку поставок AI. (Источник: 创业最前线)

Стратегия Apple в области AI смещается к открытости: разрешено использование сторонних моделей для разработки Siri: Чтобы ускорить разработку функции «персонализированной Siri» и догнать конкурентов, Apple, по сообщениям, скорректировала свою давнюю стратегию закрытой внутренней разработки. Под руководством нового старшего вице-президента по разработке программного обеспечения Крейга Федериги (Craig Federighi) инженерам Siri впервые разрешено использовать сторонние большие языковые модели для разработки функций Siri, нарушив прежнее ограничение на использование только собственных моделей Apple. Этот сдвиг рассматривается как ключевой шаг Apple в ответ на относительное отставание в технологическом резерве в области AI и во избежание дальнейшего недовольства пользователей (и даже судебных исков) из-за возможной задержки выпуска «персонализированной Siri». Этот шаг может открыть возможности для сотрудничества Apple с внешними поставщиками моделей, такими как OpenAI или Alibaba (на китайском рынке). (Источник: 三易生活)

🌟 Сообщество
Острая конкуренция между приложениями DeepSeek, Doubao, Yuanbao, ключевым становится пользовательский опыт: Конкуренция на рынке AI-помощников в Китае накаляется. DeepSeek резко увеличил количество пользователей после взрывной популярности своей модели, что привело к временному лидерству Tencent Yuanbao, который первым интегрировал ее. Однако Doubao от ByteDance, благодаря более полному набору функций и глубокой интеграции с Douyin (TikTok в Китае), снова обогнал Yuanbao. Аналитики считают, что простое подключение мощной модели (например, DeepSeek) может принести лишь краткосрочную выгоду. В долгосрочной конкуренции более важными являются богатство функций самого приложения, пользовательский опыт, межплатформенная синергия и возможности интеграции с экосистемой платформы. По мере того как возможности моделей разных компаний сближаются (например, все обладают способностью к глубокому мышлению), будущий фокус конкуренции сместится на дизайн продукта, операционные стратегии и прорывы в новых формах приложений, таких как AI Agent. (Источник: 字母榜)
Азиатский студент разработал чит для собеседований, вызвав бурное обсуждение в сети: Студент Колумбийского университета азиатского происхождения Рой Ли разработал AI-инструмент под названием Interview Coder, который с помощью ChatGPT помог ему пройти удаленные технические собеседования в нескольких технологических компаниях, включая Amazon, Meta и TikTok. Он не только отклонил предложения о работе от этих компаний, но и записал видео процесса использования чита и опубликовал его на YouTube. После жалобы от Amazon его отстранили от учебы в университете. Рой Ли отнесся к этому спокойно, наоборот, обнародовал детали инцидента и переписку с университетом и компаниями, получив широкую поддержку пользователей сети и внимание отрасли, и использовал это как повод для основания собственной компании. Инцидент вызвал горячие дискуссии об эффективности технических собеседований (особенно модели решения задач на LeetCode), этических границах использования AI-инструментов в рекрутинге, а также о вызове отдельной личности крупным корпоративным системам. (Источник: 直面AI)

Пользователь тестирует интеграцию новых открытых моделей GLM от Zhipu с базой знаний и MCP: Пользователь протестировал недавно выпущенные модели серии GLM от Zhipu AI (через вызов API). Результаты показали, что GLM-Z1-AirX (сверхбыстрая версия) при подключении к локальной базе знаний, построенной на FastGPT, отвечает чрезвычайно быстро (утверждается, что до 200 tokens/s), а качество ответов улучшилось по сравнению с обычными моделями, генерируя более подробные и полные ответы и сравнительные таблицы. GLM-4-Air (базовая модель) при подключении к MCP (Model Context Protocol) для выполнения задач Agent (таких как поиск в интернете, запись в локальные файлы, управление Docker, резюмирование веб-страниц) правильно вызывает инструменты и выполняет задачи, но эффект немного уступает DeepSeek-V3. Пользователь также положительно оценил производительность моделей Zhipu в плане безопасности (не реагируют на попытки взлома промпта). (Источник: 公众号)

Обмен промптом «сверхрационального решателя проблем» и сравнение эффективности моделей: Пользователь сообщества поделился продвинутым промптом (Prompt), предназначенным для того, чтобы LLM играл роль «сверхрационального решателя проблем, основанного на первых принципах». Промпт подробно определяет принципы работы модели (декомпозиция проблемы, инженерия решений, протокол доставки, правила взаимодействия), формат ответа и тональность, подчеркивая логику, действия и результаты, отвергая двусмысленность, оправдания и эмоциональное утешение. Пользователь использовал этот промпт для сравнительного тестирования DeepSeek, Claude Sonnet 3.7 и ChatGPT 4o в решении проблем, предоставлении указаний и рекомендации ресурсов в сети, придя к выводу, что Claude 3.7 показал лучшие результаты. Это демонстрирует, как тщательно разработанный Prompt может значительно направлять и улучшать производительность LLM в конкретных задачах. (Источник: 公众号)

Горячее обсуждение в сообществе выпуска GPT-4.1: производительность, стратегия и наименование: Выпуск серии моделей GPT-4.1 от OpenAI вызвал широкое обсуждение в сообществе. С одной стороны, пользователи путем реальных тестов и сравнения на бенчмарках (таких как Aider, Livebench, GPQA Diamond, KCORES Arena) обнаружили, что, хотя GPT-4.1 значительно улучшился в кодировании, он все еще отстает от Google Gemini 2.5 Pro и Claude 3.7 Sonnet в общих способностях к рассуждению. С другой стороны, сообщество обсуждает и критикует продуктовую стратегию OpenAI (разграничение API и ChatGPT, отказ от GPT-4.5), скорость итерации моделей и запутанную систему наименований (4.1 выпущен после 4.5). Существует мнение, что OpenAI может столкнуться с инновационным тупиком, а также мнение, что это ее стратегия по оптимизации линейки продуктов API и предложению вариантов с разным соотношением цены и качества. (Источник: dotey, op7418, Reddit r/LocalLLaMA 1, Reddit r/ArtificialInteligence, karminski3, Reddit r/LocalLLaMA 2)

ChatGPT проявляет себя в юридических консультациях, пользователи делятся успешным опытом: Пользователь Reddit поделился успешным случаем использования ChatGPT для разрешения юридического спора, связанного с работой. Пользователь столкнулся с риском увольнения, предоставил документы ChatGPT и попросил его выступить в роли эксперта по трудовому праву Великобритании. ChatGPT обнаружил процедурные ошибки работодателя, и с помощью составленного ChatGPT письма пользователь провел переговоры, в результате чего было достигнуто мировое соглашение, включающее компенсацию в размере двухмесячной зарплаты, что позволило избежать негативной записи в трудовой книжке. В комментариях другие пользователи также поделились опытом использования AI (ChatGPT или Gemini) для составления юридических писем, подготовки к слушаниям и достижения положительных результатов, отметив, что AI может значительно сэкономить расходы и время в юридической поддержке. (Источник: Reddit r/ChatGPT)
Пользователь жалуется на низкую эффективность функции Deep Research от OpenAI: Пользователь Reddit раскритиковал функцию Deep Research (глубокое исследование) от OpenAI, указав на три основные проблемы: 1) неточные или нерелевантные результаты поиска (зависимость от Bing API); 2) способ исследования больше похож на поиск в глубину, а не на широкое исследование; 3) оторванность от исследовательских целей пользователя, отсутствие ограничений. Пользователь считает, что это скорее расширение возможностей поиска, чем настоящее глубокое исследование. Это отражает разрыв между ожиданиями пользователей от текущих возможностей AI Agent для исследований и реальным опытом. (Источник: Reddit r/deeplearning)
Демонстрация и обсуждение контента, сгенерированного AI: Пользователи сообщества активно делятся контентом, созданным с помощью различных AI-инструментов (таких как ChatGPT, Midjourney, Kling AI, Suno AI), включая сатирические карикатуры (Трамп и Маск), антропоморфные образы университетов, альтернативный короткометражный фильм о Второй мировой войне, изображения персонажей греческой мифологии, рекламу зубной пасты в стиле 90-х, многопанельные комиксы и т.д. Эти публикации не только демонстрируют возможности AI в генерации текста, изображений, видео и музыки, но и вызывают дискуссии о креативности, эстетике (например, обвинения в «китче»), ограничениях (например, плохая согласованность персонажей в комиксах) и этических вопросах, связанных с AI-генерируемым контентом. (Источник: dotey 1, dotey 2, Reddit r/ChatGPT 1, Reddit r/ChatGPT 2, Reddit r/ChatGPT 3, Reddit r/ChatGPT 4, Reddit r/ChatGPT 5)

Опасения по поводу петли обратной связи данных для обучения AI, ведущей к «коллапсу модели»: Обсуждение в сообществе сосредоточено на потенциальном риске: по мере того как AI-генерируемый контент все больше распространяется в интернете, будущие AI-модели, если они будут обучаться в основном на этих данных, могут столкнуться с «коллапсом модели» (Model Collapse). Это явление означает деградацию производительности модели, когда ее выводы становятся узкими, повторяющимися, лишенными оригинальности и точности, подобно тому, как копия копии становится размытой. Пользователи опасаются, что это будет медленно подрывать достоверность информации и человеческую перспективу. В обсуждении также упоминаются методы противодействия, такие как использование синтетических данных для обучения, усиление контроля качества данных, но существуют разногласия относительно того, происходит ли проблема уже сейчас и как ее эффективно избежать. (Источник: Reddit r/ArtificialInteligence)
Мнение: В эпоху AI вычислительная мощность — это новая нефть: Пользователь Reddit высказал мнение, что в развитии AI ключевым узким местом и стратегическим ресурсом станет вычислительная мощность (Compute), а не данные, подобно нефти в эпоху промышленной революции. Причины: более мощные AI-модели (особенно для рассуждений и систем Agent) требуют экспоненциально растущей вычислительной мощности; робототехника и другие физические взаимодействия будут генерировать огромные объемы новых данных, что еще больше увеличит потребность в вычислениях. Обладание большей вычислительной мощностью напрямую преобразуется в более сильную способность к экономическому производству. Это мнение вызвало обсуждение в сообществе, где согласились, что вычислительная мощность действительно является ключевым элементом, определяющим верхний предел возможностей AI и скорость его развития. (Источник: Reddit r/ArtificialInteligence)
Обсуждение этики использования AI: неуместно ли использовать AI для улучшения оценок?: Студент онлайн-курса не справлялся с учебой из-за структуры курса (только один тест или задание в неделю, сразу за которым следовал экзамен) и в итоге провалил его. Затем он начал использовать ChatGPT для генерации практических заданий на основе лекционных PDF для ежедневного изучения, и его оценки значительно улучшились. Однако студент увидел критику в адрес AI относительно его влияния на окружающую среду и «независимого мышления» и почувствовал вину. Комментарии в сообществе в целом считают, что использование AI для помощи в учебе является законным и эффективным применением, помогает повысить эффективность и результаты обучения, и не стоит чувствовать себя виноватым. Комментаторы отмечают, что влияние AI на окружающую среду следует рассматривать в сравнении с другими видами человеческой деятельности, и использование AI для повышения производительности уже является тенденцией на рабочем месте. (Источник: Reddit r/ArtificialInteligence)
Опыт использования Claude Pro: обсуждение ограничений и бизнес-модели: В сообществе Reddit ClaudeAI пользователи обсуждают проблему ограничений (throttling), с которой они сталкиваются при использовании сервиса Claude Pro, и рассматривают бизнес-модель Anthropic. Один пользователь отметил, что ежемесячная плата за подписку Pro в размере 20 долларов значительно ниже фактических затрат Anthropic на вычисления для активных пользователей (которые могут достигать 100 долларов в месяц), полагая, что жалобы пользователей (например, считающих себя «эксплуатируемыми») могут игнорировать структуру затрат AI-сервисов. Обсуждение также коснулось недавнего решения Anthropic предоставлять новые функции в первую очередь более дорогому тарифу Max, а не Pro, что вызвало недовольство пользователей, оформивших годовую подписку Pro ранее. (Источник: Reddit r/ClaudeAI 1, Reddit r/ClaudeAI 2)
Обновление KCORES LLM Arena, DeepSeek R1 показывает отличные результаты: Пользователь поделился последними результатами тестов своей личной арены LLM (KCORES LLM Arena), в которой моделям предлагалось сгенерировать код Python для сложной физической симуляции (20 шаров сталкиваются и отскакивают внутри вращающегося семиугольника). После добавления в тест новых моделей, таких как GPT-4.1, Gemini 2.5 Pro, DeepSeek-V3, результаты показали, что DeepSeek R1 отлично справился с этой задачей, сгенерировав симуляцию с хорошим эффектом. Это предоставляет сообществу еще одну точку отсчета для оценки способностей различных моделей в сложных задачах программирования. (Источник: Reddit r/LocalLLaMA)
Обсуждение способности различных LLM к эмоциональному отклику: Пользователь Reddit опубликовал мем, который с юмором сравнивает стили реакции ChatGPT 4o, Claude 3 Sonnet, Llama 3 70B и Mistral Large на выражение пользователем грусти. Это отражает различия в опыте пользователей при использовании разных LLM для эмоционального общения или поиска поддержки, а также восприятие и оценку сообществом «эмпатических» способностей моделей. В комментариях также обсуждались преимущества использования локальных моделей для обработки конфиденциальных эмоциональных тем с точки зрения конфиденциальности. (Источник: Reddit r/LocalLLaMA)

Дискуссия о том, является ли AGI обманом Кремниевой долины: Член сообщества поделился и, возможно, обсудил статью, ставящую под сомнение, не является ли общий искусственный интеллект (AGI) чрезмерно разрекламированной концепцией (hoax), используемой Кремниевой долиной (технологической индустрией) для привлечения инвестиций или поддержания ажиотажа. Это отражает продолжающиеся дебаты и скептицизм в отрасли и обществе относительно возможности достижения AGI, сроков и достоверности текущей рекламы. (Источник: Ronald_vanLoon)

💡 Прочее
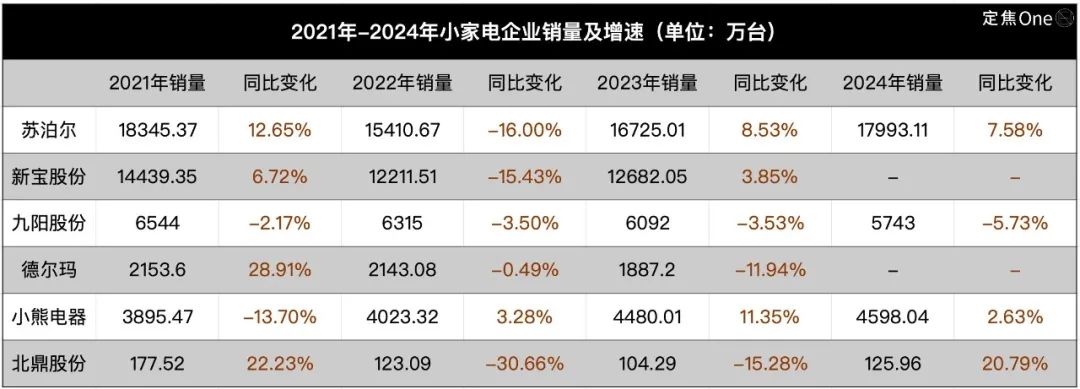
Охлаждение в индустрии мелкой бытовой техники, AI становится новой историей, но применение пока поверхностное: Рынок мелкой кухонной бытовой техники (например, тостеры, аэрофритюрницы) столкнулся со спадом продаж и ценовыми войнами после окончания бума «экономики домохозяйств». Показатели шести ведущих компаний, котирующихся на бирже, таких как Supor, Joyoung, Bear Electric, находятся под давлением. В поисках прорыва компании повсеместно обращают внимание на расширение зарубежных рынков и интеграцию технологий AI. Однако в настоящее время применение AI в мелкой бытовой технике в основном ограничивается простыми голосовыми командами, автоматической регулировкой и т.д., практичность и инновационное пространство ограничены, к тому же это может увеличить стоимость и отпугнуть пользователей. В отличие от этого, крупная бытовая техника имеет больше преимуществ в применении AI, позволяя создавать экосистемы умного дома и использовать большие данные для предоставления персонализированных услуг. История AI в индустрии мелкой бытовой техники все еще находится на ранней стадии. (Источник: 36Kr)
Таможенные споры влияют на рынок чипов в Хуацянбэй, возможно ускорение импортозамещения: Недавние изменения в таможенной политике в отношении чипов вызвали беспокойство на электронном рынке Хуацянбэй в Шэньчжэне. Продавцы популярных чипов, таких как CPU и GPU (особенно те, что могут быть американского происхождения), приостановили котировки и придерживают товар в ожидании, что привело к усилению колебаний цен. Влияние на такие категории, как чипы памяти, относительно невелико. Несколько котирующихся на бирже дистрибьюторов заявили, что прямое влияние таможенной войны ограничено из-за небольшой доли прямого импорта из США, но неопределенность на рынке возросла. В отрасли普遍но считается, что наибольшее влияние испытают IDM-компании с фабриками в США (такие как TI, Intel, Micron). Это событие уже побудило некоторых клиентов нижнего звена запрашивать информацию о вариантах замены на отечественные чипы, что может ускорить процесс импортозамещения в полупроводниковой отрасли. (Источник: 创业板观察)

AI усугубляет кризис смысла человеческого существования? Переосмысление баланса между технологиями и ценностями: Статья исследует, как стремительное развитие искусственного интеллекта влияет на смысл человеческого существования. Утверждается, что превосходство AI в профессиональных областях (таких как го, медицинская диагностика, художественное творчество) усугубляет кризис смысла человеческого существования, вызванный отчуждением труда, кризисом веры, экологическими проблемами и т.д. со времен промышленной революции. AI может еще больше усилить дилемму «человека-инструмента», особенно заменяя способность принимать решения в работе белых воротничков. Статья цитирует мнения философов и научно-фантастические произведения (такие как «Дюна», «Мир Дикого Запада»), предупреждая о риске технологического рабства, и призывает, принимая технологическое усиление, приносимое AI, восстановить ценностную рациональность, защищая человеческую креативность, эмоциональные связи и критическое мышление с помощью этических рамок и гуманитарного образования, чтобы не стать придатком собственных творений. (Источник: 腾讯研究院)
Высокая стоимость производства iPhone в США, может превысить 25000 юаней: Статья анализирует, что если iPhone будет полностью производиться на территории США, его стоимость резко возрастет, предполагаемая цена продажи может достичь 3500 долларов (около 25588 юаней), что значительно превышает текущую цену. Основные причины включают то, что США значительно уступают Китаю в получении сырья (например, редкоземельные элементы, рафинированный литий и кобальт), логистике, строительстве заводов (земля, электроэнергия, экологические разрешения) и стоимости рабочей силы (минимальная почасовая оплата в 4-5 раз выше, чем в Китае, при нехватке квалифицированных промышленных рабочих). Модель Apple, основанная на выжимании глобальной цепочки поставок (особенно китайских поставщиков с относительно большой маржой прибыли) для поддержания высокой рентабельности, будет труднореализуема в США. Высокая себестоимость производства в конечном итоге может быть переложена на потребителей, что подорвет ценовую стратегию и рыночные позиции Apple. (Источник: 星海情报局)

Математический прорыв: доказана теория сингулярностей потока средней кривизны: Гипотеза Multiplicity-one, которая беспокоила математиков почти 30 лет, недавно была доказана Ричардом Бамлером и Брюсом Кляйнером. Гипотеза касается потока средней кривизны (Mean Curvature Flow, MCF) — математического процесса, описывающего, как поверхность эволюционирует со временем, чтобы максимально быстро уменьшить свою площадь (подобно таянию кубика льда или эрозии песчаного замка). Доказательство указывает, что в трехмерном пространстве сингулярности (точки, где кривизна стремится к бесконечности), образующиеся на двумерных замкнутых поверхностях под действием MCF, являются простыми, обычно проявляясь как локальное сжатие в точку (сфера) или коллапс в линию (цилиндр), и сложные многослойные перекрывающиеся сингулярности не возникают. Этот прорыв гарантирует, что MCF можно продолжать анализировать даже после образования сингулярностей, предоставляя более прочную теоретическую основу для использования MCF для решения важных проблем в геометрии и топологии (таких как гипотеза Пуанкаре). (Источник: 机器之心)

Пользователь делится «бюджетной» конфигурацией локального AI-оборудования 4x RTX 3090: Пользователь Reddit поделился своей конфигурацией оборудования для локального запуска LLM общей стоимостью около 4204 доллара. Конфигурация включает 4 подержанные видеокарты EVGA RTX 3090 (по 600 долларов каждая), серверный процессор AMD EPYC 7302P, материнскую плату Asrock Rack, 96 ГБ памяти DDR4 и 2 ТБ NVMe SSD, собранные в открытом корпусе MLACOM Quad Station Pro Lite и питаемые двумя блоками питания по 1200 Вт. Эта публикация предоставляет относительно «экономичный» справочный вариант для пользователей, желающих собрать дома AI-рабочую станцию с достаточно высокой вычислительной мощностью (4x 24GB VRAM). (Источник: Reddit r/LocalLLaMA)

Хакеры в США взломали светофоры для трансляции Deepfake-сообщений Маска и Цукерберга: Сообщается, что несколько систем пешеходных светофоров в районе залива Сан-Франциско в США были взломаны хакерами и использованы для трансляции Deepfake (глубоких подделок) сообщений, сгенерированных AI, от имени Маска и Цукерберга. Этот инцидент подчеркивает уязвимость общественной инфраструктуры перед кибератаками с использованием AI-технологий, а также риск злоупотребления технологией Deepfake для распространения ложной информации или совершения хулиганских действий. (Источник: Reddit r/ArtificialInteligence)

Демонстрация разнообразных роботов и технологий автоматизации: В социальных сетях демонстрируются различные применения роботов и технологий автоматизации, в том числе: робот Booster T1, способный имитировать человеческие движения для выполнения кунг-фу; роботизированные системы для реабилитационных тренировок; механическая рука, способная готовить кофе; сельскохозяйственные роботы для посадки риса и прополки; автоматизированная система для удобной обработки овец пастухами; а также танцующие роботы и т.д. Эти примеры отражают широкое применение и постоянное развитие робототехники в промышленности, сельском хозяйстве, сфере услуг, медицинской реабилитации и развлечениях. (Источник: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6)
Демонстрация новых технологий и инновационных продуктов: В социальных сетях делятся информацией о различных новых технологиях и инновационных продуктах, например: разработанная Массачусетским технологическим институтом миниатюрная беспроводная антенна, использующая свет для мониторинга сотовой связи; однокрылый дрон, имитирующий полет семени клена; умный туалет IoT; технология цифровых оттисков для ортодонтии; устройство, генерирующее электричество из соленой воды; динамическая стена, способная дышать и двигаться; косплей-костюм Железного человека; вездеходный электрический сноуборд; а также технология копирования ключей с помощью устройства Flipper Zero и т.д. Эти демонстрации показывают непрерывные инновации в технологиях в таких областях, как связь, энергетика, здравоохранение, транспорт, строительство и безопасность. (Источник: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6, Ronald_vanLoon 7, Ronald_vanLoon 8, Ronald_vanLoon 9)

Тенденции в области медицинских технологий: В социальных сетях и по ссылкам на статьи упоминаются технологические применения и тенденции развития в области здравоохранения, включая роботизированную хирургию, тенденции и поворотные моменты в применении AI в здравоохранении, использование технологий для достижения операционного совершенства (гиперавтоматизация), а также возможные преобразования, которые может принести AI. Эти материалы отражают потенциал и практику применения AI, робототехники, автоматизации и других технологий для повышения эффективности медицинских услуг, точности диагностики и качества обслуживания пациентов. (Источник: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4)

Информация, связанная с кибербезопасностью: В социальных сетях делятся контентом, связанным с кибербезопасностью, включая инфографику типов атак на пароли и статью о важности возможности восстановления в течение 60 минут после утечки данных. Эти материалы напоминают пользователям о необходимости обращать внимание на риски кибербезопасности и стратегии реагирования. (Источник: Ronald_vanLoon 1, Ronald_vanLoon 2)

Обсуждение платформы AMD ROCm: Пользователи Reddit обсуждают возможность создания рабочей станции для глубокого обучения с использованием двух GPU AMD Radeon RX 7900 XTX, затрагивая программный стек ROCm (Radeon Open Compute platform). Это отражает интерес и исследование пользователями решений на базе GPU AMD и их программной экосистемы (ROCm) на рынке AI-оборудования, где доминирует Nvidia. (Источник: Reddit r/deeplearning)