
Ключевые слова:AI, искусственный интеллект, AI суверенитет дилемма, HBM и передовая упаковка, AI-движимые научные открытия, Gemini 2.5 Pro программирование возможности, AI решение математических задач
🔥 В фокусе
Дилемма суверенитета в области AI: как нарратив национальной безопасности поглощает общественные ценности?: В отчете глубоко исследуется концепция «суверенитета в области AI», то есть контроль государства над стеком технологий AI (данные, вычислительные мощности, таланты, энергия). Текущая глобальная тенденция смещается от «слабого суверенитета», зависящего от союзников, к стремлению к «сильному суверенитету» с полной локализацией, особенно под влиянием политики США. Хотя этот сдвиг направлен на обеспечение национальной безопасности и военного превосходства, он также вызывает опасения по поводу чрезмерной централизации, подавления открытых инноваций, препятствования международному сотрудничеству и возможной гонки вооружений в области AI. В статье утверждается, что чрезмерная секьюритизация AI может пожертвовать его огромным потенциалом для служения общественным интересам и решения глобальных проблем, и призывается найти баланс между потребностями суверенитета и открытым сотрудничеством, чтобы избежать превращения AI в жертву геополитической конкуренции, а не в инструмент коллективного прогресса человечества. (Источник: 人工智能主权困局:国家安全叙事如何吞噬AI的公共价值?)
HBM и передовая упаковка: скрытая арена революции вычислительных мощностей AI: Экспоненциальный рост потребности в вычислительных мощностях для больших моделей AI приводит к тому, что традиционная вычислительная архитектура сталкивается с узким местом «стены памяти». Память с высокой пропускной способностью (HBM), благодаря 3D-стекированию и технологии TSV, увеличивает пропускную способность в несколько раз (например, HBM3E превышает 1 ТБ/с), значительно снижая задержку передачи данных. В то же время, передовые технологии упаковки (такие как CoWoS от TSMC, EMIB от Intel) посредством гетерогенной интеграции тесно объединяют чипы CPU, GPU, HBM и другие, преодолевая ограничения одного чипа, повышая плотность вычислительных мощностей и энергоэффективность. HBM и передовая упаковка стали ключевым стандартом для чипов AI (особенно для обучения), их рынок контролируется гигантами, такими как SK Hynix, Samsung, Micron (HBM) и TSMC (упаковка), с огромными инвестициями и дефицитом производственных мощностей. Совместное развитие этих двух технологий не только меняет структуру полупроводниковой цепочки поставок (увеличивая долю стоимости упаковки), но и становится решающим полем битвы в конкуренции за вычислительные мощности AI. (Источник: HBM与先进封装:AI算力革命的隐形赛点)
Шокирующее заявление нобелевского лауреата: AI за год выполнил объем “докторских исследований” за 1 миллиард лет: Нобелевский лауреат, CEO Google DeepMind Демис Хассабис заявил, что AI-проект его команды AlphaFold-2, предсказав структуру 200 миллионов известных на Земле белков, за год выполнил научные исследования, эквивалентные 1 миллиарду лет докторских исследований. Он подчеркнул, что AI, особенно AlphaFold, коренным образом меняет скорость и масштаб научных открытий, демократизируя доступ к знаниям. В своей лекции в Кембриджском университете Хассабис далее развил идею наступления эры «цифровой биологии», движимой AI, и считает, что будущее AI заключается в создании «мировых моделей» (таких как архитектура JEPA), способных понимать физический мир, рассуждать и планировать, а не просто полагаться на обработку языка. Он подтвердил свою приверженность открытому исходному коду AI, считая это лучшим путем для продвижения технологий. (Источник: 诺奖得主震撼宣言:AI一年完成10亿年“博士研究时间”)

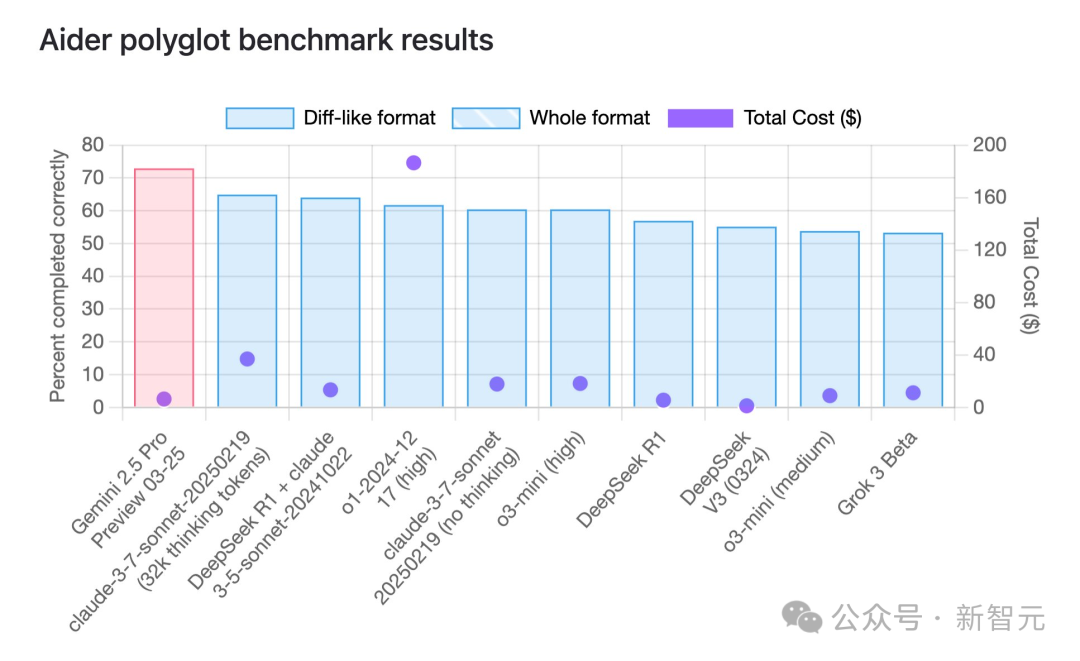
Gemini 2.5 Pro лидирует по возможностям программирования, обладая значительным преимуществом в соотношении цена/качество: Согласно многоязычному бенчмарку программирования aider, последняя выпущенная Google модель Gemini 2.5 Pro превзошла Claude 3.7 Sonnet по возможностям программирования, заняв первое место в мире. Она не только лидирует по производительности, но и имеет чрезвычайно низкую стоимость вызова API (около 6 долларов США), что значительно ниже, чем у конкурентов с сопоставимой или худшей производительностью (таких как GPT-4o, Claude 3.7 Sonnet). Jeff Dean подчеркнул ее преимущество в соотношении цена/качество. Кроме того, по слухам в сообществе, невыпущенная модель Google “Dragontail” показала в тестах веб-разработки результаты даже лучше, чем Gemini 2.5 Pro, намекая на то, что у Google еще есть козыри в области программирования AI. Gemini 2.5 Pro также занимает лидирующие позиции во многих комплексных бенчмарках, бросая вызов OpenAI и Anthropic благодаря высокой производительности, низкой стоимости, большому контекстному окну и бесплатному доступу. (Источник: Gemini 2.5编程全球霸榜,谷歌重回AI王座,神秘模型曝光,奥特曼迎战)
AI успешно помог доказать математическую проблему, нерешенную 50 лет: Китайский ученый Weiguo Yin (Брукхейвенская национальная лаборатория) с помощью модели o3-mini-high от OpenAI добился прорыва в исследовании точного решения одномерной модели Поттса J_1-J_2 с q состояниями, решив проблему, которая оставалась нерешенной в этой области на протяжении 50 лет. Модель AI, при обработке конкретного случая q=3, с помощью анализа симметрии успешно упростила сложную передаточную матрицу 9×9 до эффективной матрицы 2×2. Этот ключевой шаг вдохновил исследователей на обобщение метода, что в конечном итоге привело к нахождению аналитического решения, применимого для любого значения q. Это достижение не только демонстрирует потенциал AI в сложных математических выводах и нетривиальных доказательствах, но и предоставляет новые теоретические инструменты для понимания таких проблем, как фазовые переходы в физике конденсированного состояния. (Источник: 刚刚,AI破解50年未解数学难题,南大校友用OpenAI模型完成首个非平凡数学证明)

🎯 Тенденции
Применение и эволюция AI в области игровых NPC: Статья рассматривает историю развития технологии AI в игровых NPC, начиная с ранних конечных автоматов в «Pac-Man», затем деревьев поведения, и до сложных AI, сочетающих поиск по дереву Монте-Карло и глубокие нейронные сети (например, AlphaGo). В статье отмечается, что хотя AI уже может побеждать лучших игроков-людей в таких играх, как «StarCraft 2» и «Dota 2», для обычных игроков слишком сильный AI не приносит удовольствия. Идеальный игровой AI должен больше фокусироваться на симуляции человеческого поведения, предоставлении эмоциональной ценности и адаптивной сложности (как система Nemesis в «Middle-earth» или динамическая сложность в «Resident Evil 4»). В последнее время, на примере Stella из «Whispers from the Star» от Mihoyo, генеративный AI используется для управления диалогами NPC в реальном времени, эмоциональными реакциями и развитием сюжета. Несмотря на проблемы с задержкой, памятью и т.д., это демонстрирует тенденцию к созданию более человечных и интерактивных NPC с помощью AI. (Источник: AI,让游戏再次伟大)

OpenAI ужесточает доступ к API, вводя верификацию организаций: OpenAI недавно внедрила новую политику верификации организаций для API, требуя от пользователей предоставления действительного государственного удостоверения личности, выданного в поддерживаемой стране или регионе, для доступа к своим самым передовым моделям и функциям. Каждый ID может верифицировать только одну организацию каждые 90 дней. OpenAI заявляет, что этот шаг направлен на снижение небезопасного использования AI и подготовку к выпуску «захватывающих новых моделей» (возможно, включая GPT-4.1, o3, o4-mini и другие версии). Это изменение политики вызвало широкое внимание и обеспокоенность в сообществе, особенно для разработчиков, находящихся в неподдерживаемых странах/регионах, и пользователей, зависящих от сторонних API-сервисов, которые могут столкнуться с ограничением доступа или увеличением затрат, а также вызвало дискуссии об открытости OpenAI. (Источник: GitHub中国IP访问崩了又复活,OpenAI API新政恐锁死GPT-5?, op7418, Reddit r/artificial)
Вступление Apple стимулирует развитие «AI-врачей», но существуют проблемы и необходимость регулирования: По слухам, Apple планирует использовать AI для улучшения функций своего приложения Health, запуская такие сервисы, как «AI Health Coach», что еще больше способствует превращению «AI-врачей» в глобальный тренд. Однако реальное применение AI в клинике сталкивается с множеством проблем: высокая стоимость разработки, зависимость от огромных объемов конфиденциальных медицинских данных (связанных с законодательством о конфиденциальности), трудности с разметкой данных и т.д. В настоящее время AI в основном используется как вспомогательный инструмент диагностики. Китайский рынок также сталкивается с особыми потребностями, связанными с неравномерным распределением медицинских ресурсов и необходимостью AI для поддержки сортировки пациентов. Компании, такие как Baichuan Intelligence, предлагают «модель двойного врача» (AI-врач + AI-помощник врача-человека) для решения этих проблем. В статье подчеркивается, что широкое применение AI в медицине должно основываться на строгом регулировании и системе сертификации для обеспечения точности диагностики, безопасности данных и доверия пользователей, чтобы избежать потенциальных рисков. (Источник: 苹果入局,「AI医生」成全球热点,患者隐私保护成最大障碍?)

Попытка Microsoft напрямую генерировать игры с помощью AI оказалась неудачной: Microsoft недавно продемонстрировала DEMO, использующее ее модель AI “Muse” для прямой генерации игровых кадров «Quake 2», с целью показать способность AI быстро создавать прототипы игр. Однако DEMO показало плохие результаты, страдая от низкого разрешения, низкой частоты кадров и множества багов (таких как аномальное поведение врагов, нарушение физических правил, искажение окружения), и было оценено как «постоянно разрушающийся сон». Статья считает, что это показывает, что текущие технологии генеративного AI (особенно с проблемой «галлюцинаций») пока недостаточны для прямой и надежной генерации сложных, играбельных интерактивных игровых опытов. По сравнению с этим, применение AI на определенных этапах конвейера разработки игр (например, взаимодействие NPC, генерация ассетов) более реалистично. Путь прямой генерации игровых кадров или геймплея в настоящее время представляется чрезвычайно сложным. (Источник: 微软的AI游戏翻车,直接生成游戏或是条不归路)
Google выпускает модели с открытым исходным кодом TxGemma для сферы здравоохранения: Google представила серию моделей TxGemma, построенных на базе семейств моделей Gemma и Gemini, специально оптимизированных для здравоохранения и разработки лекарств. Этот шаг направлен на предоставление более специализированных инструментов AI для биомедицинских исследований и разработки терапевтических средств, способствуя инновациям в этой области. Выпуск TxGemma является частью стратегии Google по предоставлению как универсальных, так и специализированных моделей с открытым исходным кодом. (Источник: JeffDean)
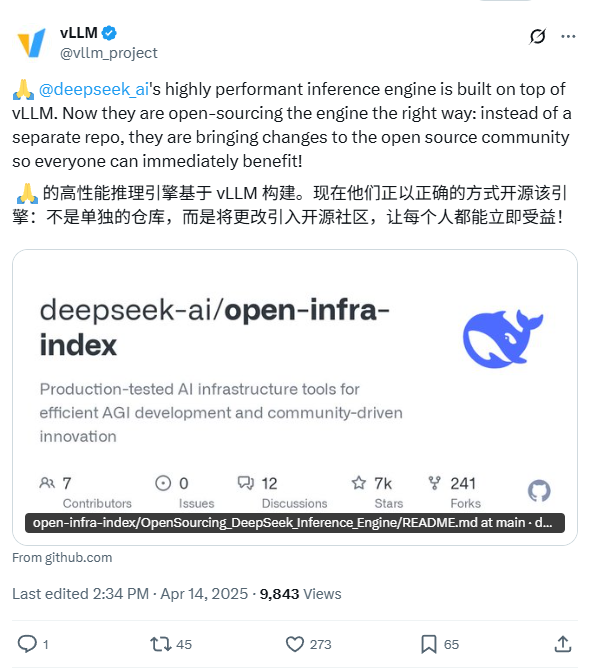
DeepSeek объявляет о планах открыть исходный код своего внутреннего движка для инференса: DeepSeek AI заявила, что откроет исходный код своего внутреннего движка для инференса. Согласно описанию, этот движок является модифицированной и оптимизированной версией популярного фреймворка vLLM. Этот шаг DeepSeek направлен на то, чтобы вернуть оптимизированные технологии инференса сообществу открытого исходного кода, помогая разработчикам более эффективно развертывать большие модели. Этот план отражает готовность DeepSeek внести вклад в сообщество открытого исходного кода, ожидается, что код будет опубликован на GitHub. (Источник: karminski3)
ChatGPT добавляет функцию памяти для улучшения связности: OpenAI добавила функцию памяти (Memory) в свою модель ChatGPT. Эта функция позволяет ChatGPT запоминать информацию, предпочтения или обсуждавшиеся темы, предоставленные пользователем в предыдущих диалогах. Цель состоит в том, чтобы повысить непрерывность и персонализацию взаимодействия, избегая необходимости для пользователя повторять одну и ту же фоновую информацию в последующих диалогах, тем самым улучшая пользовательский опыт. (Источник: Ronald_vanLoon)

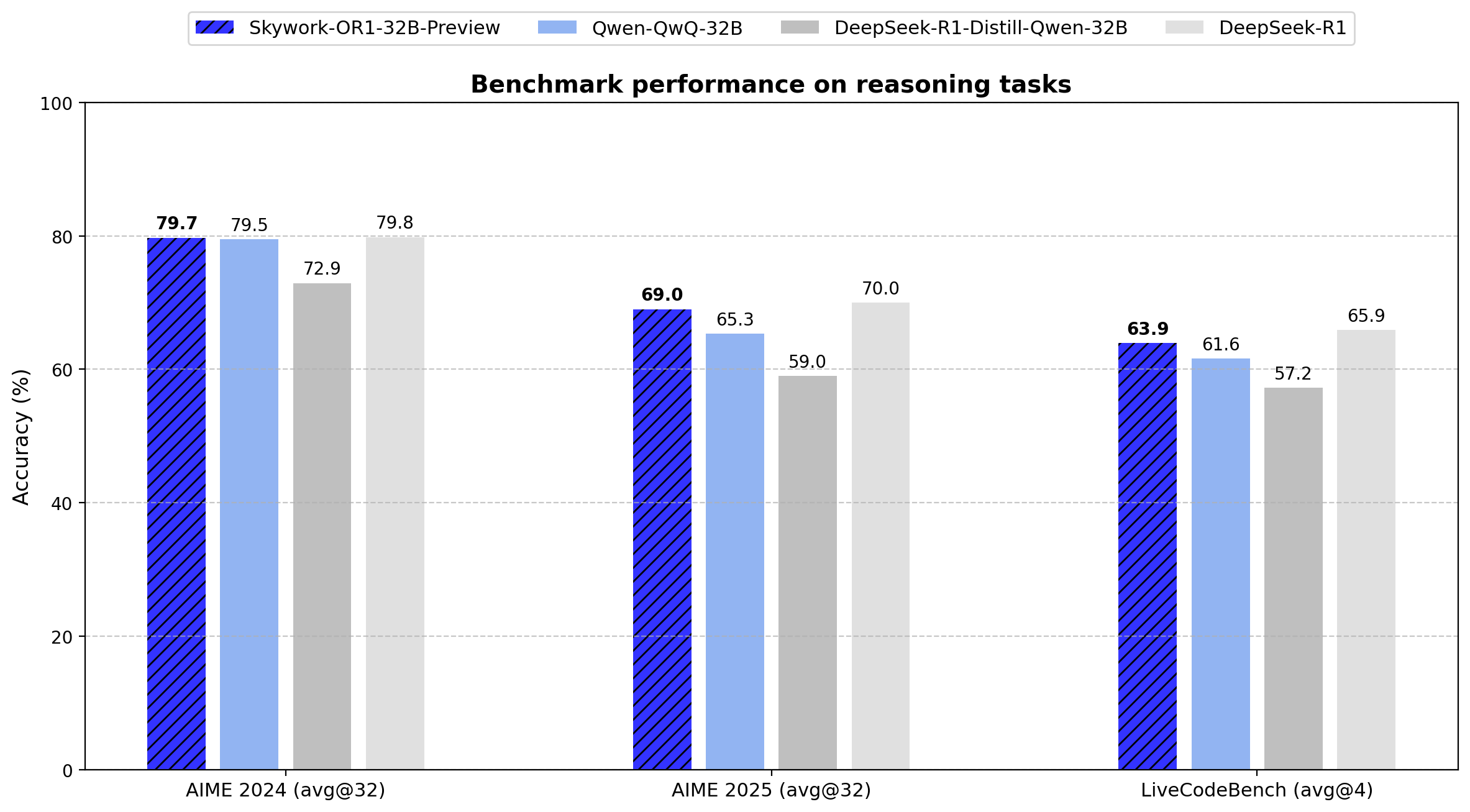
Skywork выпускает серию моделей для инференса с открытым исходным кодом OR1: Китайская компания Skywork (Tiangong-Kunlun Wanwei) выпустила новую серию моделей для инференса с открытым исходным кодом Skywork OR1. Серия включает OR1-Math-7B, оптимизированную для математики, а также предварительные версии OR1-7B и OR1-32B, показавшие отличные результаты в математике и кодировании, причем версия 32B, по утверждениям, сопоставима по математическим способностям с DeepSeek-R1. Skywork получила похвалу за свою открытость, опубликовав веса моделей, обучающие данные и полный код обучения. (Источник: natolambert)
Улучшение навигации и точности операций роботов с помощью AI: Социальные сети демонстрируют способность автономных роботов, управляемых AI, точно навигировать и выполнять задачи в сложных средах. Эти роботы, вероятно, используют компьютерное зрение, SLAM (одновременная локализация и построение карты), обучение с подкреплением и другие технологии AI для эффективной работы в неструктурированных или динамичных средах, демонстрируя прогресс в области восприятия, планирования и управления роботами. (Источник: Ronald_vanLoon)
Экзоскелет с AI помогает пользователям инвалидных колясок ходить: Демонстрируется передовое экзоскелетное устройство, использующее технологию AI, которое может помочь пользователям инвалидных колясок снова вставать и ходить. AI в нем может использоваться для интерпретации намерений пользователя, поддержания равновесия, координации движений и адаптации к различным средам, отражая потенциал AI в улучшении качества жизни людей с ограниченными возможностями и являясь важным достижением в области вспомогательных робототехнических технологий. (Источник: Ronald_vanLoon)
Опасения по поводу возможного использования AI Agent для кибератак: Статья в MIT Technology Review указывает, что автономные AI Agent могут быть использованы для выполнения сложных кибератак. Эти AI Agent потенциально могут автоматически обнаруживать уязвимости, генерировать вредоносный код и осуществлять атаки, причем их масштаб и скорость могут значительно превосходить возможности хакеров-людей, создавая серьезные проблемы для существующих систем кибербезопасности. Это вызывает опасения по поводу вооружения AI и рисков безопасности. (Источник: Ronald_vanLoon)

OpenAI анонсирует прямую трансляцию и возможно выпустит новые модели: OpenAI с помощью туманного сообщения (разработчик и сверхмассивная черная дыра) анонсировала прямую трансляцию, в то время как в сети распространяется информация об обновленных иконках и карточках моделей на ее официальном сайте, намекая на возможный скорый выпуск нескольких новых моделей, включая серию GPT-4.1 (с версиями nano, mini), o4-mini и полную версию o3. Это указывает на то, что OpenAI, возможно, готовится выпустить серию новых продуктов или обновлений моделей, чтобы справиться с растущей конкуренцией на рынке. (Источник: openai, op7418)

Робот Figure осваивает естественную ходьбу от симуляции к реальности с помощью обучения с подкреплением: Figure AI успешно обучила своего гуманоидного робота Figure 02 естественной походке в чисто симуляционной среде с использованием обучения с подкреплением (RL). Генерируя большие объемы данных с помощью эффективного симулятора и сочетая рандомизацию домена с высокочастотной обратной связью по крутящему моменту от самого робота, удалось добиться переноса стратегии из симуляции в реальность без дополнительного обучения (zero-shot transfer). Этот метод не только ускоряет процесс разработки, но и доказывает возможность управления несколькими роботами с помощью единой стратегии нейронной сети, что имеет важное значение для будущих коммерческих применений роботов. (Источник: 一套算法控制机器人军团!纯模拟环境强化学习,Figure学会像人一样走路)
🧰 Инструменты
Jimeng AI 3.0 генерирует стилизованный текстовый дизайн и делится Prompt: Пользователь поделился опытом и методами использования китайского инструмента для рисования AI “Jimeng AI 3.0” для создания изображений с дизайнерским текстом. Поскольку прямое указание названия шрифта не давало хороших результатов, автор создал подробный шаблон подсказок (prompt template), в котором предустановлены различные визуальные стили (например, индустриальный, милый, технологический, акварельный и т.д.) и установлены правила, позволяющие AI автоматически подбирать или смешивать стили в соответствии со значением и эмоциями введенного текста. Пользователю нужно только ввести целевой текст (например, «киберспортсмен», «хочу конфет»), и шаблон сгенерирует полный prompt для рисования, включающий стиль, фон, верстку, атмосферу, что позволяет получить высококачественные текстово-графические дизайны в Jimeng AI. Статья предоставляет этот шаблон prompt и множество примеров генерации. (Источник: 即梦AI 3.0制作含字体封面,这个方案酷到封神【附:16+案例和Prompt】, AI生成字体设计我有点玩明白了,用这套Prompt提效50%。)
Использование мультимодального AI для преобразования фотографий еды в изображения в стиле меню: Пользователь социальных сетей продемонстрировал технику использования мультимодальных моделей AI, таких как GPT-4o, для преобразования обычных фотографий еды в изысканные изображения для меню. Метод заключается в предоставлении AI исходной фотографии в сочетании с описательными подсказками (например, ссылаясь на «стандарты и стиль меню элитного пятизвездочного отеля»), чтобы направить AI на стилизацию и редактирование изображения, создавая профессионально выглядящие фотографии блюд. Это демонстрирует практический потенциал мультимодального AI в понимании, редактировании и стилизации изображений. (Источник: karminski3)

Slideteam.net: Возможно, инструмент для мгновенного создания слайдов на базе AI: В социальных сетях упоминается, что Slideteam.net может «мгновенно» создавать идеальные слайды, намекая на то, что он может использовать технологию AI для автоматизации процесса проектирования и генерации презентаций. Такие инструменты обычно используют AI для автоматического макетирования, предложений по контенту, подбора стиля и т.д., с целью повышения эффективности создания PPT. (Источник: Ronald_vanLoon)
Демонстрация AI-робота-массажиста: Видео демонстрирует робота-массажиста, управляемого AI. Робот сочетает физические возможности манипулятора с интеллектуальным управлением AI. AI может использоваться для понимания потребностей пользователя, распознавания частей тела, планирования траектории массажа, регулировки силы и техники, и даже для восприятия реакции пользователя через датчики для оптимизации массажа, демонстрируя потенциал AI в персонализированных услугах здравоохранения и автоматизированной физиотерапии. (Источник: Ronald_vanLoon)
GitHub Copilot интегрирован в Windows Terminal: Microsoft интегрировала функцию GitHub Copilot в предварительную версию Canary своего Windows Terminal под названием «Terminal Chat». Пользователи с подпиской Copilot могут напрямую взаимодействовать с AI в среде терминала, получая предложения, объяснения и помощь по командам. Этот шаг направлен на сокращение необходимости переключения приложений разработчиками при написании команд, предоставляя интеллектуальную помощь с учетом контекста, повышая эффективность и точность работы в командной строке, особенно для сложных или незнакомых задач. (Источник: GitHub Copilot 现可在 Windows 终端中运行了)
Обсуждение требований к оборудованию для развертывания OpenWebUI: Пользователи сообщества Reddit обсуждают конфигурацию виртуальной машины Azure, необходимую для развертывания OpenWebUI (веб-интерфейса для LLM) для команды из примерно 30 человек. Пользователь планирует локально запускать модель встраивания Snowflake и использовать OpenAI API. Обсуждение касается масштабирования ресурсов, влияния размера модели встраивания на CPU/RAM/хранилище и важности предварительной обработки данных. Сообщество советует, что сильная зависимость от API может снизить требования к локальному оборудованию, но если модели (особенно модели встраивания) запускаются локально, потребуется более мощная конфигурация. В случае ограниченных ресурсов рекомендуется также использовать API для обработки встраиваний. (Источник: Reddit r/OpenWebUI)
📚 Исследования
Модели AI для рассуждений имеют недостаток “чрезмерного обдумывания” при отсутствии предпосылок: Исследование Университета Мэриленда и других учреждений показало, что текущие модели рассуждений (такие как DeepSeek-R1, o1), сталкиваясь с проблемами, в которых отсутствует необходимая информация (отсутствующие предпосылки, MiP), склонны генерировать длинные и неэффективные ответы, вместо того чтобы быстро распознать дефект самой проблемы. Это явление «чрезмерного обдумывания MiP» приводит к растрате вычислительных ресурсов и слабо связано с тем, сможет ли модель в конечном итоге осознать отсутствие предпосылки. По сравнению с ними, модели без рассуждений показывают лучшие результаты. Исследователи считают, что это выявляет недостаток критического мышления у текущих моделей рассуждений, что может быть связано с парадигмой обучения с подкреплением или процессом дистилляции знаний. (Источник: 推理AI“脑补”成瘾,废话拉满,马里兰华人学霸揭开内幕)

CVPR 2025: CADCrafter реализует генерацию редактируемых CAD-файлов из одного изображения: Исследователи из Moxin Technology, Наньянского технологического университета и других учреждений предложили фреймворк CADCrafter, способный генерировать параметризованные, редактируемые инженерные файлы CAD (представленные в виде последовательности команд CAD) непосредственно из одного изображения (рендера детали, фотографии реального объекта и т.д.), а не традиционные модели сетки или облака точек. Метод использует VAE для кодирования команд CAD и сочетает его с Diffusion Transformer для генерации в скрытом пространстве с учетом изображения, повышает производительность с помощью стратегии дистилляции от нескольких видов к одному и использует DPO для оптимизации, обеспечивая компилируемость сгенерированных команд. Сгенерированные CAD-файлы могут быть непосредственно использованы для производства и поддерживают модификацию модели путем редактирования команд, что значительно повышает практичность и качество поверхности 3D-моделей, генерируемых AI. (Источник: 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品)
Чжэцзянский университет, OPPO и др. публикуют обзор OS Agents: В этой обзорной статье систематически рассматривается текущее состояние исследований интеллектуальных агентов операционной системы (OS Agents) на основе мультимодальных больших моделей (MLLM). OS Agents — это AI, способные автоматически выполнять задачи на компьютерах, телефонах и других устройствах через интерфейс операционной системы (GUI). В статье определены их ключевые элементы (среда, пространство наблюдений, пространство действий), основные возможности (понимание, планирование, выполнение), рассмотрены методы построения (архитектура базовой модели и обучение, проектирование фреймворка агента), а также обобщены протоколы оценки, бенчмарки и связанные коммерческие продукты. Наконец, обсуждаются проблемы и будущие направления, такие как безопасность и конфиденциальность, персонализация и самоэволюция, предоставляя всесторонний справочник для исследований в этой области. (Источник: 浙大、OPPO等发布最新综述:基于多模态大模型的计算机、手机与浏览器智能体研究)
ICLR 2025: Nabla-GFlowNet реализует эффективную тонкую настройку диффузионных моделей с разнообразными вознаграждениями: Для решения проблем медленной сходимости (традиционное RL) или потери разнообразия (прямая оптимизация) при тонкой настройке диффузионных моделей с вознаграждением, исследователи предложили метод Nabla-GFlowNet. Метод основан на фреймворке генеративных потоковых сетей (GFlowNet), выводит новые условия баланса потока (Nabla-DB) и функцию потерь, используя информацию о градиенте вознаграждения для управления тонкой настройкой. Благодаря специфической параметризации, сохраняя разнообразие генерируемых образцов, достигается более быстрая скорость сходимости по сравнению с методами, такими как DDPO. Метод был проверен на модели Stable Diffusion с использованием функций вознаграждения за эстетику, следование инструкциям и т.д., показав лучшие результаты, чем существующие методы. (Источник: ICLR 2025 | 扩散模型奖励微调新突破!Nabla-GFlowNet让多样性与效率兼得)
Анализ механизма рассуждений DeepSeek-R1: Исследование Университета Макгилла углубленно анализирует процесс «мышления» моделей рассуждений, таких как DeepSeek-R1. Исследование показало, что длина цепочки рассуждений не всегда положительно коррелирует с производительностью, существует «оптимальная точка», и слишком длинные рассуждения могут быть даже вредны. Модель может зацикливаться на уже существующих формулировках при обработке длинных контекстов или сложных проблем. Кроме того, по сравнению с моделями без рассуждений, DeepSeek-R1 может иметь более явные уязвимости в плане безопасности. Это исследование раскрывает некоторые особенности и потенциальные ограничения механизма работы текущих моделей рассуждений. (Источник: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Новый метод оптимизации MoE моделей во время тестирования C3PO: Университет Джонса Хопкинса предложил метод C3PO (Оптимизация критических слоев, ключевых экспертов, путей сотрудничества) для оптимизации производительности больших моделей типа «смесь экспертов» (MoE) во время тестирования. Метод перевзвешивает ключевых экспертов в критических слоях, оптимизируя для каждого тестового образца, чтобы решить проблему субоптимальных путей экспертов. Эксперименты показывают, что C3PO может значительно повысить точность MoE моделей (на 7-15%), и даже позволить MoE моделям с меньшим количеством параметров превзойти по производительности более крупные плотные модели, повышая эффективность архитектуры MoE. (Источник: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Систематическое исследование влияния квантования на производительность моделей рассуждений: Университет Цинхуа и другие учреждения впервые систематически исследовали влияние квантования моделей на производительность моделей рассуждений (таких как DeepSeek-R1, серия Qwen). Эксперименты оценили эффект квантования при различных битностях (веса, KV-кэш, активации) и алгоритмах. Исследование показало, что квантование W8A8 или W4A16 обычно позволяет достичь производительности без потерь или близкой к ней, но более низкие битности значительно увеличивают риски. Размер модели, источник и сложность задачи являются ключевыми факторами, влияющими на производительность после квантования. Результаты исследования и квантованные модели были опубликованы с открытым исходным кодом. (Источник: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
APIGen-MT: Фреймворк для генерации высококачественных данных многоходового взаимодействия агентов: Salesforce предложила фреймворк APIGen-MT, направленный на решение проблемы нехватки высококачественных данных, необходимых для обучения AI Agent, способных к многоходовому взаимодействию. Фреймворк состоит из двух этапов: сначала с помощью LLM для рецензирования и итеративной обратной связи генерируется подробный план задачи, затем путем симуляции взаимодействия человека и машины план преобразуется в полные данные траектории. Серия моделей xLAM-2, обученная на основе этого фреймворка, показала отличные результаты в бенчмарках многоходовых агентов, превзойдя такие модели, как GPT-4o, что подтверждает эффективность этого метода генерации данных. Синтетические данные и модели были опубликованы с открытым исходным кодом. (Источник: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Исследование показывает: более длинная цепочка мыслей не равна более сильной производительности рассуждений, обучение с подкреплением может быть более лаконичным: Исследование Wand AI указывает, что модели рассуждений (особенно обученные с помощью алгоритмов RL, таких как PPO) склонны генерировать более длинные ответы не из-за потребности в точности, а потому что сам механизм RL может к этому приводить: для неправильных ответов (отрицательное вознаграждение) удлинение ответа может «разбавить» наказание за каждый токен, тем самым снижая потери. Исследование доказывает, что лаконичные рассуждения связаны с более высокой точностью, и предлагает двухэтапный метод обучения RL: сначала обучать на сложных задачах для повышения способностей (что может удлинить ответы), затем обучать на задачах средней сложности, чтобы способствовать лаконичности и сохранению точности. Этот метод эффективен для повышения производительности и надежности даже на очень маленьких наборах данных. (Источник: 更长思维并不等于更强推理性能,强化学习可以很简洁)
Университет науки и технологий Китая, ZTE предлагают Curr-ReFT: новую парадигму пост-тренировки для малоразмерных VLM: Для решения проблем малой обобщающей способности, ограниченных возможностей рассуждения и нестабильности обучения («эффект кирпичной стены») у малых визуально-языковых моделей (VLM) после контролируемой тонкой настройки, Университет науки и технологий Китая (USTC) и ZTE предложили парадигму пост-тренировки Curr-ReFT. Метод сочетает обучение с подкреплением по учебному плану (Curr-RL) и самосовершенствование на основе выборки с отклонением. Curr-RL с помощью механизма вознаграждения, учитывающего сложность, направляет модель к постепенному обучению от простого к сложному; выборка с отклонением использует высококачественные образцы для поддержания базовых способностей модели. Эксперименты на моделях Qwen2.5-VL-3B/7B показали, что Curr-ReFT значительно улучшает производительность рассуждений и обобщения модели, позволяя малым моделям превосходить крупные модели во многих бенчмарках. Код, данные и модели опубликованы с открытым исходным кодом. (Источник: 中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理)
Университет Цинхуа, Shanghai AI Lab предлагают GenPRM: масштабируемую генеративную модель вознаграждения процесса: Для решения проблем отсутствия интерпретируемости и масштабируемости во время тестирования у традиционных моделей вознаграждения процесса (PRM) при контроле рассуждений LLM, Университет Цинхуа и Shanghai AI Lab предложили GenPRM. Она оценивает шаги рассуждений путем генерации цепочки мыслей на естественном языке (CoT) и исполняемого кода верификации, предоставляя более прозрачную обратную связь. GenPRM поддерживает масштабирование вычислений во время тестирования, повышая точность путем выборки нескольких путей оценки и усреднения вознаграждений. Эта модель, обученная всего на 23 тыс. синтетических данных, в версии 1.5B с помощью масштабирования во время тестирования превзошла GPT-4o, а версия 7B превзошла базовую модель 72B. GenPRM также может использоваться как критик на уровне шагов для итеративного улучшения ответов. (Источник: 过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o)
Выпущен крупнейший в мире открытый набор математических данных MegaMath (371 млрд токенов): LLM360 представила набор данных MegaMath, содержащий 371 миллиард токенов, который является крупнейшим на данный момент в мире открытым набором данных для предварительного обучения, ориентированным на математические рассуждения. Он призван сократить разрыв в масштабе и качестве между открытым сообществом и закрытыми математическими корпусами (такими как DeepSeek-Math). Набор данных состоит из трех частей: крупномасштабные данные с математических веб-страниц (279 млрд, включая высококачественный поднабор 15 млрд), математический код (28 млрд) и высококачественные синтетические данные (64 млрд, включая вопросы-ответы, генерацию кода, смешанные текстово-графические данные). После тщательной обработки и нескольких раундов проверки предварительного обучения, использование MegaMath для предварительного обучения модели Llama-3.2 позволяет добиться значительного повышения производительности на 15-20% в таких бенчмарках, как GSM8K и MATH. (Источник: 3710亿数学Tokens!全球最大开源数学数据集MegaMath震撼发布,碾压DeepSeek-Math)
CVPR 2025: NLPrompt повышает робастность обучения с подсказками VLM при наличии зашумленных меток: Лаборатория YesAI Шанхайского технологического университета предложила метод NLPrompt, направленный на решение проблемы снижения производительности при обучении с подсказками визуально-языковых моделей (VLM) из-за шума в метках. Исследование показало, что в сценарии обучения с подсказками потери средней абсолютной ошибки (MAE) (PromptMAE) более робастны, чем потери перекрестной энтропии (CE). Одновременно предложен метод очистки данных PromptOT на основе оптимального транспорта, который использует текстовые признаки, сгенерированные подсказками, в качестве прототипов для разделения набора данных на чистый и зашумленный. NLPrompt использует потери CE для чистого набора и потери MAE для зашумленного, эффективно сочетая преимущества обоих подходов. Эксперименты показали, что этот метод значительно повышает робастность и производительность методов обучения с подсказками, таких как CoOp, как на синтетических, так и на реальных зашумленных наборах данных. (Источник: CVPR 2025 | MAE损失+最优传输双剑合璧!上科大提出全新鲁棒提示学习方法)
Применение и обсуждение технологии дистилляции знаний для сжатия моделей: Сообщество обсуждает технологию дистилляции знаний, при которой большая модель-«учитель» используется для обучения маленькой модели-«ученика», чтобы последняя достигла производительности, близкой к модели-учителю, в конкретной задаче, но со значительно меньшими затратами. Один пользователь поделился успешным опытом дистилляции способностей GPT-4o в задаче анализа тональности (точность 92%) в маленькую модель, снизив затраты в 14 раз. В комментариях отмечается, что хотя эффект дистилляции значителен, он обычно ограничен конкретной областью, и модели-ученику не хватает обобщающей способности модели-учителя. В то же время, для профессиональных сценариев, требующих постоянной адаптации к изменяющимся данным, затраты на поддержку самообучаемой модели могут быть выше, чем прямое использование большого API. (Источник: Reddit r/MachineLearning)

Определение AI Agent привлекает внимание: Консалтинговые компании, такие как McKinsey, начинают определять и обсуждать концепцию AI Agent, что отражает растущую важность AI Agent как интеллектуальных сущностей, способных автономно воспринимать, принимать решения и действовать для достижения целей, в деловой и технологической сферах. Понимание определения, возможностей и сценариев применения AI Agent становится предметом внимания отрасли. (Источник: Ronald_vanLoon)

💼 Бизнес
Расшифровка стратегии AI Alibaba: AGI в центре, крупные инвестиции в инфраструктуру для трансформации: Анализ показывает, что хотя Alibaba официально не объявляла свою стратегию AI, ее действия уже обрисовывают четкую картину: стремление к AGI как главная цель, чтобы вернуть инициативу в конкурентной борьбе. В ближайшие три года планируется инвестировать более 380 миллиардов юаней в инфраструктуру AI и облачных вычислений, с акцентом на удовлетворение растущего спроса на инференс. Стратегические пути включают: продвижение возможностей AI Agent через DingTalk; использование семейства моделей Qwen с открытым исходным кодом для стимулирования роста Alibaba Cloud; развитие модели MaaS для Tongyi API. В то же время Alibaba будет глубоко трансформировать существующие бизнесы с помощью AI, например, улучшая пользовательский опыт на Taobao, превращая Quark во флагманское приложение AI (поиск + Agent), исследуя применение AI в сервисах на Gaode Map. Alibaba также может ускорить развертывание AI через инвестиции и поглощения. (Источник: 解秘阿里 AI 战略:从未发布,但已开始狂奔)
Новые тенденции на рынке AI-талантов: акцент на практику, а не на диплом, востребованы комплексные навыки: На основе анализа почти 3000 высокооплачиваемых вакансий в области AI в крупных городах Китая, отчет выявляет три основные тенденции спроса на AI-таланты: 1) Высокий спрос на инженеров по алгоритмам с хорошей зарплатой, автомобильная промышленность становится основным источником вакансий; 2) Компании (включая звездные компании, такие как DeepSeek) постепенно снижают жесткие требования к образованию, уделяя больше внимания практическим инженерным навыкам и опыту решения сложных проблем; 3) Растет спрос на специалистов с комплексными навыками, например, менеджеры по продуктам AI должны одновременно понимать пользователей, модели и промпт-инжиниринг, поскольку AI берет на себя все больше специализированных задач, требуя от людей интеграции и контроля на более высоком уровне. (Источник: 从近3000个招聘数据里,我找到了挖掘AI人才的三条铁律)
UBTECH продолжает нести убытки, коммерциализация гуманоидных роботов сталкивается с серьезными проблемами: Финансовый отчет компании по производству гуманоидных роботов UBTECH за 2024 год показывает, что, несмотря на рост выручки на 23,7% до 1,3 млрд юаней, убытки по-прежнему составляют 11,6 млрд юаней. Коммерциализация ее основного бизнеса гуманоидных роботов идет медленно: за год было поставлено всего 10 единиц по цене 3,5 млн юаней за штуку, что значительно превышает ожидания рынка и цены конкурентов (например, G1 от Unitree Robotics стоит всего 99 тыс. юаней). Кроме того, слухи о проблемах с финансированием у другой ведущей компании отрасли, CloudMinds, вызывают сомнения в коммерческой жизнеспособности индустрии гуманоидных роботов, подтверждая осторожную точку зрения инвестора Zhu Xiaohu. Высокая стоимость, ограниченные сценарии применения, а также вопросы безопасности и надежности являются основными препятствиями для массовой коммерциализации гуманоидных роботов в настоящее время. (Источник: 优必选一年亏损近12亿 朱啸虎这下更有话说了)

AI стимулирует рост в телекоммуникационной, высокотехнологичной и медиаиндустрии: Обсуждается, что искусственный интеллект (включая генеративный AI) становится ключевой силой, стимулирующей рост в телекоммуникационной, высокотехнологичной и медиаиндустрии. Технологии AI широко применяются для улучшения клиентского опыта, оптимизации сетевых операций, автоматизации создания контента, повышения операционной эффективности и разработки инновационных услуг, помогая компаниям в этих отраслях получить конкурентное преимущество на быстро меняющемся рынке. (Источник: Ronald_vanLoon)
Hugging Face приобретает компанию по производству роботов с открытым исходным кодом Pollen Robotics: Известная платформа для моделей и инструментов AI Hugging Face приобрела стартап Pollen Robotics, известный своим гуманоидным роботом с открытым исходным кодом Reachy. Это приобретение показывает намерение Hugging Face расширить свою успешную модель открытого исходного кода на область робототехники AI, с целью содействия сотрудничеству и инновациям в этой области через открытые аппаратные и программные решения, ускоряя демократизацию робототехники. (Источник: huggingface, huggingface, huggingface, huggingface)

🌟 Сообщество
Эпоха AI может быть более благоприятной для гуманитариев: Линн Дуан, основатель сообщества AI+ в Кремниевой долине, считает, что по мере того, как инструменты AI (такие как Cursor) снижают порог входа в программирование, важность инженерных навыков относительно уменьшается, в то время как навыки в области коммерциализации, маркетинга, коммуникаций и других гуманитарных и социальных наук становятся более важными. AI заменяет некоторые технические должности начального уровня, но создает спрос на специалистов с комплексными навыками, способных соединить технологии и рынок. Она советует выпускникам рассматривать стартапы для быстрого роста и демонстрировать свои способности через практические проекты (например, развертывание моделей, разработка приложений), а не только на основе диплома. Она также отмечает, что качества основателя (такие как убежденность, понимание отрасли) важнее чисто технического бэкграунда, и видит хорошие перспективы для стартапов AI в американском SaaS и китайском секторе умного оборудования. (Источник: AI反而是文科生的好时代|对话硅谷AI+创始人Lynn Duan)

Кратковременная “блокировка” китайских IP на GitHub вызвала беспокойство, официальные лица заявили об ошибке: Недавно некоторые китайские пользователи обнаружили, что не могут получить доступ к GitHub без входа в систему, получая сообщение об ограничении IP, что вызвало в сообществе опасения по поводу возможной «блокировки». Хотя официальные представители GitHub быстро ответили, что это была ошибка конфигурации, которая уже исправлена, инцидент все же вызвал обсуждение. Учитывая, что GitHub в прошлом ограничивал доступ из Ирана, России и других регионов в соответствии с санкционной политикой США, это событие было воспринято некоторыми как «репетиция» возможных ограничительных мер. В статье подчеркивается важность GitHub для китайских разработчиков и экосистемы открытого исходного кода (включая множество проектов AI), а также негативные последствия, которые могут повлечь за собой такие ограничения, и перечисляются отечественные платформы для хостинга кода, такие как Gitee, CODING, в качестве альтернативных вариантов. (Источник: “Bug”还是“预演”?GitHub 突然“封禁”所有中国 IP,官方:只是“手滑”技术出错了)
Производительность и сервис Claude AI вызывают споры среди пользователей: Обсуждение на Reddit показывает, что некоторые пользователи выражают недовольство моделью Claude от Anthropic, упоминая снижение производительности, внесение ненужных изменений при кодировании, а также разочарование платными уровнями и ограничениями скорости, причем некоторые известные разработчики даже заявляют о переходе на другие модели (например, Gemini 2.5 Pro). Однако есть и пользователи, которые считают, что Claude (особенно старая версия Sonnet 3.5) по-прежнему имеет преимущества в определенных задачах (например, кодировании), или заявляют, что не сталкивались часто с ограничениями скорости. Этот спор отражает расхождения в опыте пользователей с Claude, а также высокие ожидания пользователей от производительности и сервиса моделей AI в условиях жесткой конкуренции. (Источник: Reddit r/ClaudeAI)

Масштаб функции Deep Research в Gemini вызывает обсуждение: Пользователь поделился опытом использования функции Deep Research в Google Gemini Advanced, когда AI для ответа на один вопрос обратился почти к 700 веб-сайтам и сгенерировал длинный отчет (например, 37 страниц). Этот масштаб впечатлил пользователя, но также вызвал дискуссию о качестве информации. Комментаторы сомневаются, может ли обработка такого большого количества веб-информации гарантировать точность и глубину, или это просто агрегация результатов веб-поиска, которые могут содержать ошибки, в большем масштабе. Это отражает внимание и критический взгляд сообщества на возможности обработки информации (глубина против широты) инструментов исследования AI. (Источник: Reddit r/artificial)

Возможности программирования Gemini 2.5 Pro получили высокую оценку сообщества: Несколько пользователей поделились в сообществе положительным опытом использования Google Gemini 2.5 Pro для программирования, считая его интеллектуальный уровень высоким, способным хорошо понимать намерения пользователя, обладающим возможностью обработки длинного контекста в 1 миллион токенов (достаточно для анализа больших кодовых баз) и бесплатным, что в совокупности превосходит конкурентов, таких как Claude. Хотя есть некоторые мелкие недостатки (например, случайные галлюцинации несуществующих библиотечных функций), общая оценка очень высока, он считается одной из самых популярных моделей для кодирования на данный момент, и выражаются ожидания относительно будущих, возможно, более сильных моделей от Google (таких как Dragontail). (Источник: Reddit r/ArtificialInteligence)
Малые модели с открытым исходным кодом быстро развиваются, восприятие пользователей требует обновления: Обсуждение в сообществе выражает восхищение быстрым прогрессом открытых LLM. Отмечается, что модели, такие как QwQ-32B, Gemma-3-27B, которые сейчас кажутся неплохими, были бы революционными год или два назад (когда только вышел GPT-4). Это напоминает всем не пренебрегать реальными возможностями текущих малых открытых моделей, которые уже достигли довольно высокого уровня. В комментариях также признается, что эти модели все еще уступают топовым закрытым моделям (например, в стабильности, скорости, обработке контекста), но подчеркивается их скорость прогресса и потенциал, предполагая, что будущие прорывы могут быть достигнуты за счет инноваций в архитектуре, а не простого наращивания параметров. (Источник: Reddit r/LocalLLaMA)
Член сообщества предлагает бесплатные вычислительные мощности A100 для поддержки проектов AI: Пользователь, владеющий 4 GPU Nvidia A100, разместил сообщение в сообществе Reddit, предлагая бесплатные вычислительные мощности (около 100 часов A100) для инновационных проектов энтузиастов AI, направленных на оказание положительного влияния и ограниченных вычислительными ресурсами. Этот шаг получил положительный отклик, несколько исследователей и разработчиков представили конкретные планы проектов, охватывающие обучение новых архитектур моделей, интерпретируемость моделей, модульное обучение, приложения для взаимодействия человека и машины и другие направления, что отражает потребность исследовательского сообщества AI в вычислительных ресурсах и дух взаимопомощи и обмена. (Источник: Reddit r/deeplearning)
Проблема ограничений скорости Claude AI вызывает споры в сообществе: Жалобы на частое срабатывание ограничений скорости при использовании модели Claude AI (например, уже после 5 сообщений) вызвали споры в сообществе. Некоторые пользователи выразили сильное сомнение в таких жалобах, считая их преувеличением или неправильным использованием со стороны пользователя (например, каждый раз загружая сверхдлинный контекст), и потребовали предоставить доказательства. Однако другие пользователи подтвердили, что при выполнении интенсивных задач (например, редактировании большого кода) они действительно часто достигают лимитов, что мешает рабочему процессу. Обсуждение отражает большие различия в опыте пользователей с ограничениями скорости, которые могут быть связаны с конкретным способом использования и сложностью задачи, а также показывает чувствительность пользователей к ограничениям платных услуг. (Источник: Reddit r/ClaudeAI)
💡 Прочее
Конференция по экосистеме AIGC и интеллектуальных агентов пройдет в Шанхае в июне: Вторая конференция по экосистеме AIGC и искусственного интеллекта (AI Agent) состоится 12 июня 2025 года в Шанхае под девизом «Интеллектуальная связь всего · Симбиоз без границ». Конференция сосредоточится на совместных инновациях и экологической интеграции генеративного AI (AIGC) и интеллектуальных агентов (AI Agent), охватывая такие темы, как инфраструктура AI, большие языковые модели, маркетинг и применение AIGC в различных сценариях (медиа, электронная коммерция, промышленность, медицина и т.д.), мультимодальные технологии, фреймворки автономного принятия решений и т.д. Цель — способствовать переходу AI от отдельных инструментов к экологическому сотрудничеству, соединяя поставщиков технологий, заказчиков, капитал и политиков. (Источник: 6月上海|“智链万物”上海峰会:AIGC+智能体生态融合)

Конференция 36Kr AI Partner посвящена Super APP: 36Kr проведет конференцию «Super APP грядет · 2025 AI Partner Conference» 18 апреля 2025 года в Shanghai Model Speed Space. Цель конференции — обсудить, как приложения AI перестраивают деловой мир, порождая прорывные «суперприложения». Конференция соберет руководителей высшего звена и инвесторов из таких компаний, как AMD, Baidu, 360, Qualcomm, для обсуждения актуальных тем, таких как индустриализация AI, вычислительные мощности AI, поиск AI, образование AI, и объявит инновационные кейсы нативных приложений AI и награды AI Partner Innovation Award. Одновременно пройдут салон AI普惠 (AI для всех) и закрытый семинар по выходу AI на международный рынок. (Источник: Super App来了!看AI应用正如何「改写」商业世界?|2025 AI Partner大会核心看点)

Horizon Robotics ищет стажеров по алгоритмам 3D-реконструкции/генерации: Команда Embodied Intelligence компании Horizon Robotics ищет стажеров по алгоритмам в области 3D-реконструкции/генерации в Шанхае и Пекине. Позиция предполагает участие в проектировании и разработке алгоритмов Real2Sim, использовании технологий 3D Gaussian Splatting, прямой реконструкции, генерации 3D/видео для снижения затрат на сбор данных для роботов и оптимизации производительности симулятора. Требуется степень магистра или выше, соответствующий опыт и навыки. Предоставляется возможность штатного трудоустройства, ресурсы GPU и профессиональное руководство. (Источник: 上海/北京内推 | 地平线机器人具身智能团队招聘3D重建/生成方向算法实习生)
OceanBase проводит первый хакатон AI: Производитель баз данных OceanBase совместно с Ant Open Source, Jiqizhixin и другими организует первый хакатон AI на тему «DB+AI» с призовым фондом 100 000 юаней. Конкурс поощряет разработчиков исследовать сочетание технологий OceanBase и AI, направления включают использование OceanBase в качестве базы данных для приложений AI или создание приложений AI в экосистеме OceanBase (в сочетании с CAMEL AI, FastGPT и т.д.), таких как системы вопросов и ответов, диагностические системы. Регистрация открыта с 10 апреля по 7 мая для отдельных лиц и команд. (Источник: 10万奖金×认知升级!OceanBase首届AI黑客松广发英雄帖,你敢来么?)
Meituan Travel ищет инженеров по алгоритмам больших моделей уровня L7-L8: Команда алгоритмов снабжения Meituan Travel в Пекине ищет инженеров по алгоритмам больших моделей уровня L7-L8 (для опытных специалистов). Обязанности включают использование технологий NLP и больших моделей для построения системы понимания предложений в сфере путешествий и гостеприимства (теги, горячие точки, анализ сходства), оптимизацию материалов для отображения товаров (заголовки, текст и изображения), создание комбинаций туристических пакетов и исследование передовых технологий больших моделей для применения в алгоритмах на стороне предложения. Требуется степень магистра или выше, опыт работы от 2 лет, сильные навыки в алгоритмах и программировании. (Источник: 北京内推 | 美团酒旅供给算法团队招聘L7-L8大模型算法工程师)
QbitAI ищет редакторов/авторов в области AI: Технологическое медиа в области AI QbitAI ищет штатных редакторов/авторов, место работы в Пекине (Чжунгуаньцунь), для опытных специалистов и выпускников, с возможностью стажировки и последующего трудоустройства. Направления включают большие модели AI, воплощенный интеллект и робототехнику, терминальное оборудование, а также редактора новых медиа AI (Weibo/Xiaohongshu). Требуется энтузиазм в области AI, хорошие навыки письма и сбора информации. Плюсами будут знакомство с инструментами AI, умение анализировать научные статьи, навыки программирования и т.д. Предлагается конкурентоспособная зарплата, льготы и возможности профессионального роста. (Источник: 量子位招聘 | DeepSeek帮我们改的招聘启事)
Лауреат премии Тьюринга ЛеКун о развитии AI: человеческий интеллект не универсален, следующее поколение AI может быть не генеративным: В подкаст-интервью Ян ЛеКун высказал мнение, что текущее стремление к AGI (общему искусственному интеллекту) основано на недоразумении, поскольку сам человеческий интеллект высокоспециализирован, а не универсален. Он предсказывает, что прорыв следующего поколения AI может быть основан на негенеративных моделях, таких как предложенная им архитектура JEPA, с акцентом на то, чтобы AI понимал физический мир, обладал способностью к рассуждению и планированию (мировые модели), а не просто обрабатывал язык. Он считает, что текущим LLM не хватает настоящей способности к рассуждению. ЛеКун также подчеркнул важность открытого исходного кода (например, LLaMA от Meta) для продвижения развития AI и считает умные очки и подобные устройства важным направлением для внедрения технологий AI. (Источник: 图灵奖得主LeCun:人类智能不是通用智能,下一代AI可能基于非生成式)
Китайский саммит индустрии AIGC скоро состоится (16 апреля, Пекин): Третий Китайский саммит индустрии AIGC пройдет 16 апреля в Пекине. Саммит соберет более 20 лидеров отрасли из таких компаний и организаций, как Baidu, Huawei, AWS, Microsoft Research Asia, ModelBest, ShengShu Technology, Fenbi, NetEase Youdao, Quwan Technology, QingSong Health, для совместного обсуждения последних достижений в области технологий AI, их применения в тысячах отраслей, инфраструктуры вычислительных мощностей, безопасности и управляемости и других ключевых вопросов. Цель саммита — продемонстрировать, как AI способствует модернизации промышленности, а также вручить соответствующие награды и опубликовать «Полную панораму приложений AIGC в Китае». (Источник: 倒计时2天!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此)
Обсуждение решения для запуска моделей с триллионами параметров на недорогих видеокартах: В статье обсуждается решение для создания управляемого по стоимости (уровня 100 000 юаней) AI-моноблока с использованием видеокарт Intel Arc™ (например, A770) и процессоров Xeon® W. Это решение, благодаря совместной оптимизации аппаратного и программного обеспечения (IPEX-LLM, OpenVINO™, oneAPI), позволяет запускать на одном компьютере такие большие модели, как QwQ-32B (со скоростью до 32 токенов/с) и даже 671B DeepSeek R1 (с оптимизацией FlashMoE, скорость около 10 токенов/с). Это предоставляет предприятиям высокоэффективный по стоимости вариант для развертывания больших моделей локально или на периферии, удовлетворяя потребности в офлайн-инференсе, безопасности данных и т.д. Intel также запустила платформу OPEA, объединяя партнеров по экосистеме для продвижения стандартизации и популяризации корпоративных приложений AI. (Источник: 榨干3000元显卡,跑通千亿级大模型的秘方来了)
Хирургический робот демонстрирует высокоточные операции: Видео показывает, как хирургический робот может точно отделить скорлупу сырого перепелиного яйца от его внутренней пленки, демонстрируя передовой уровень современных роботов в области тонких манипуляций и управления. (Источник: Ronald_vanLoon)
Обзор достижений в области полупроводниковой литографии: Ссылка на статью о содержании конференции SPIE Advanced Lithography + Patterning, обсуждающую последние достижения в технологиях производства чипов следующего поколения, включая High-NA EUV, стоимость EUV, формирование рисунка, новые фоторезисты (оксиды металлов, сухие) и Hyper-NA. Эти технологии критически важны для поддержки развития будущих чипов AI. (Источник: dylan522p)
Демонстрация точных навыков колесного робота: Видео демонстрирует высокоточные движения или навыки управления колесного робота, возможно, с использованием технологий AI и машинного обучения для управления и восприятия. (Источник: Ronald_vanLoon)