
Ключевые слова:AI, LLM, AI清洗, LLM推理模型, Gemini自托管, vLLM推理引擎, Suno AI音乐生成
🔥 В фокусе
Приложение для покупок «AI» оказалось управляемым вручную: Стартап Fintech и его основатель обвиняются в мошенничестве. Их приложение для покупок, заявленное как работающее на AI, на самом деле в значительной степени полагалось на команду операторов на Филиппинах для обработки транзакций. Этот инцидент вновь привлек внимание к явлению «AI Washing» (AI-отмывание), когда компании преувеличивают или ложно заявляют о своих возможностях AI для привлечения инвестиций или пользователей. Случай подчеркивает сложности в распознавании подлинных AI-технологий в условиях текущего ажиотажа вокруг AI, а также важность проведения должной проверки (due diligence) стартапов (Источник: Reddit r/ArtificialInteligence)

Новый бенчмарк выявляет недостаточную способность AI-моделей к обобщению логических рассуждений: Новый бенчмарк под названием LLM-Benchmark (https://llm-benchmark.github.io/) показывает, что даже новейшие AI-модели для логических рассуждений испытывают трудности при решении логических головоломок вне распределения (OOD — out-of-distribution). Исследование показало, что по сравнению с результатами моделей на бенчмарках вроде математических олимпиад, их оценки на этих новых логических головоломках значительно ниже ожидаемых (примерно в 50 раз ниже). Это выявляет ограничения текущих моделей в способности к настоящим логическим рассуждениям и обобщению за пределами распределения данных, на которых они обучались (Источник: Reddit r/ArtificialInteligence)
Google разрешает компаниям самостоятельно размещать модели Gemini, отвечая на опасения по поводу конфиденциальности данных: Google объявила, что позволит корпоративным клиентам запускать AI-модели Gemini в своих собственных центрах обработки данных, начиная с Gemini 2.5 Pro. Этот шаг направлен на удовлетворение строгих требований предприятий к конфиденциальности и безопасности данных, позволяя им использовать передовые AI-технологии Google без отправки конфиденциальных данных в облако. Эта стратегия схожа с Mistral AI, но контрастирует с OpenAI и Anthropic, которые в основном предоставляют услуги через облачные API или партнеров, что может изменить конкурентную среду на рынке корпоративного AI (Источник: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

🎯 Тенденции
VSCode нативно поддерживает llama.cpp, расширяя возможности локального Copilot: Недавнее обновление Visual Studio Code добавило поддержку локальных AI-моделей. Вслед за поддержкой Ollama, теперь, с небольшими изменениями, обеспечена совместимость с llama.cpp. Это означает, что разработчики могут напрямую использовать локальные большие языковые модели (LLM), запущенные через llama.cpp, в VSCode в качестве альтернативы или дополнения к GitHub Copilot. Это еще больше упрощает использование LLM для помощи в написании кода в локальной среде, повышая гибкость разработки и конфиденциальность данных. Пользователям необходимо выбрать Ollama в качестве прокси в настройках (хотя фактически используется llama.cpp), чтобы включить эту функцию (Источник: Reddit r/LocalLLaMA)

Yandex и другие организации выпустили HIGGS: новый метод сжатия LLM: Исследователи из Yandex Research, НИУ ВШЭ, MIT и других институтов разработали новую технологию квантования и сжатия LLM под названием HIGGS. Метод направлен на значительное уменьшение размера модели, чтобы ее можно было запускать на менее производительных устройствах, минимизируя при этом потерю качества модели. Утверждается, что метод успешно применен для сжатия модели DeepSeek R1 с 671 млрд параметров, и результаты впечатляют. HIGGS призван снизить барьер для использования LLM, делая большие модели более доступными для небольших компаний, исследовательских институтов и индивидуальных разработчиков. Соответствующий код опубликован на GitHub и Hugging Face (Источник: Reddit r/LocalLLaMA)
Google исправила проблемы квантования в модели QAT 2.7: Google обновила версию 2.7 своей квантованной модели QAT (Quantization Aware Training) (возможно, имеется в виду Gemma 2 7B или аналогичная модель), исправив некоторые ошибки с управляющими токенами (control tokens), присутствовавшие в предыдущей версии. Ранее модель могла генерировать неверные маркеры, такие как <end_of_turn>, в конце вывода. Вновь загруженные квантованные модели решили эти проблемы, и пользователи могут скачать обновленную версию для корректного поведения модели (Источник: Reddit r/LocalLLaMA)
CEO DeepMind об успехах AlphaFold: CEO DeepMind Демис Хассабис (Demis Hassabis) в интервью подчеркнул огромное влияние AlphaFold, образно сравнив его достижения с «миллиардом лет исследований на уровне PhD» за один год. Он отметил, что раньше на расшифровку структуры одного белка обычно уходил весь период аспирантуры (4-5 лет), тогда как AlphaFold за год предсказал структуры всех (известных на тот момент) 200 миллионов белков. Эти слова подчеркивают революционный потенциал AI в ускорении научных открытий (Источник: Reddit r/artificial)

🧰 Инструменты
MinIO: Высокопроизводительное объектное хранилище для AI: MinIO — это высокопроизводительная, S3-совместимая система объектного хранения с открытым исходным кодом, распространяемая по лицензии GNU AGPLv3. Особо подчеркивается ее способность создавать высокопроизводительную инфраструктуру для машинного обучения, аналитики и рабочих нагрузок с данными приложений, а также предоставляется специальная документация по хранилищу для AI. Пользователи могут установить MinIO через контейнеры (Podman/Docker), Homebrew (macOS), бинарные файлы (Linux/macOS/Windows) или из исходного кода. MinIO поддерживает создание распределенных, высокодоступных кластеров хранения с кодированием стирания (erasure coding), подходящих для сценариев AI-приложений, требующих обработки больших объемов данных (Источник: minio/minio — GitHub Trending (all/daily))

IntentKit: Фреймворк для создания AI-агентов с навыками: IntentKit — это фреймворк для автономных агентов с открытым исходным кодом, предназначенный для того, чтобы разработчики могли создавать и управлять AI-агентами с различными возможностями, включая взаимодействие с блокчейном (приоритет у EVM-сетей), управление социальными сетями (Twitter, Telegram и др.), а также интеграцию пользовательских навыков. Фреймворк поддерживает управление несколькими агентами и автономную работу, планируется выпуск расширяемой системы плагинов. Проект в настоящее время находится на стадии Alpha, предоставляет обзор архитектуры и руководство по разработке, поощряет вклад сообщества в виде навыков (Источник: crestalnetwork/intentkit — GitHub Trending (all/daily))

vLLM: Высокопроизводительный движок для инференса и обслуживания LLM: vLLM — это библиотека с высокой пропускной способностью и эффективным использованием памяти, ориентированная на инференс и обслуживание LLM. Ее основные преимущества включают эффективное управление памятью ключей и значений внимания с помощью технологии PagedAttention, поддержку непрерывной пакетной обработки (Continuous Batching), оптимизацию графов CUDA/HIP, различные методы квантования (GPTQ, AWQ, FP8 и др.), интеграцию с FlashAttention/FlashInfer, а также спекулятивное декодирование (Speculative Decoding). vLLM поддерживает модели Hugging Face, предоставляет OpenAI-совместимый API, может работать на различном оборудовании, включая NVIDIA и AMD, и подходит для сценариев, требующих крупномасштабного развертывания сервисов LLM (Источник: vllm-project/vllm — GitHub Trending (all/daily))
tfrecords-reader: Читатель TFRecords с произвольным доступом и поиском: Это инструмент Python для работы с наборами данных TFRecords, специально разработанный для проверки и анализа данных. Он позволяет пользователям создавать индексы для файлов TFRecords, реализуя произвольный доступ и поиск по содержимому (с использованием запросов Polars SQL), решая проблему нативного последовательного чтения TFRecords. Инструмент не зависит от пакетов TensorFlow и protobuf, поддерживает прямое чтение из Google Storage, быстро индексирует и облегчает разработчикам исследование и поиск образцов в крупномасштабных наборах данных TFRecords вне процесса обучения модели (Источник: Reddit r/MachineLearning)
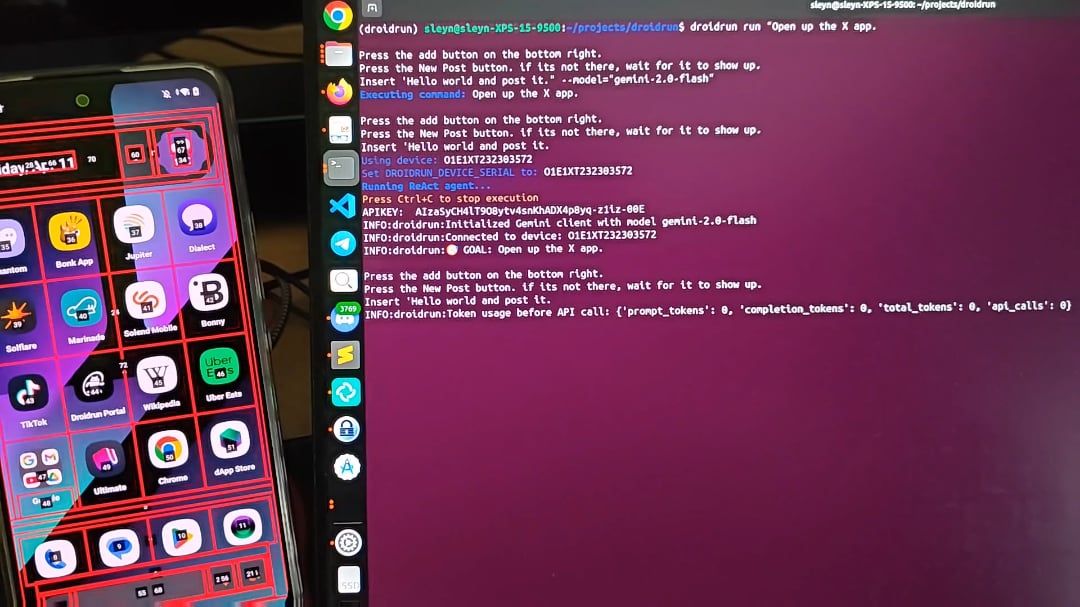
DroidRun: Позволяет AI Agent управлять телефоном Android: DroidRun — это проект, позволяющий AI Agent управлять устройством Android так же, как человек. Подключив любую LLM, он может обеспечить интерактивное управление пользовательским интерфейсом телефона для выполнения различных задач. Проект демонстрирует свой потенциал, нацеленный на автоматизацию операций на телефоне, таких как автоматическая публикация контента, управление приложениями и т. д. Разработчики приглашают сообщество делиться отзывами и идеями для изучения большего количества сценариев автоматизации (Источник: Reddit r/LocalLLaMA)
📚 Обучение
Cell Patterns публикует масштабный обзор многоязычных больших моделей (MLLM): В этом обзоре систематически анализируется текущее состояние исследований многоязычных больших моделей на основе 473 публикаций. Содержание включает ресурсы наборов данных и методы их создания для многоязычного предварительного обучения, тонкой настройки по инструкциям и RLHF; стратегии межъязыкового выравнивания, разделенные на выравнивание с настройкой параметров (например, предварительное обучение, тонкая настройка по инструкциям, RLHF, тонкая настройка для последующих задач) и выравнивание с замороженными параметрами (например, прямое промптирование, переключение кода, выравнивание через перевод, дополненная генерация с извлечением); метрики и бенчмарки для многоязычной оценки (задачи NLU и NLG); а также обсуждаются будущие направления исследований и проблемы, такие как галлюцинации, редактирование знаний, безопасность, справедливость, расширение языков/модальностей, интерпретируемость, эффективность развертывания и согласованность обновлений. Представлена всеобъемлющая карта исследований MLLM (Источник: Cell Patterns重磅综述!473篇文献全面解析多语言大模型最新研究进展)

AAAI 2025 | Команда из Бэйханского университета предлагает TRACK: совместное обучение динамической дорожной сети и представлений траекторий: Команда из Бэйханского университета (Beihang University) предложила модель TRACK, направленную на решение проблемы существующих методов, не учитывающих пространственно-временную динамику трафика. Эта модель впервые совместно моделирует состояние трафика (макроскопические групповые характеристики) и данные траекторий (микроскопические индивидуальные характеристики), полагая, что они взаимно влияют друг на друга. TRACK изучает динамические представления дорожной сети и траекторий с помощью графовых сетей внимания (GAT), Transformer, а также инновационных GAT, учитывающих переходы траекторий, и механизма совместного внимания. Модель использует совместную предварительную подготовку, включающую самообучающиеся задачи, такие как предсказание маскированных траекторий, контрастное обучение траекторий, предсказание маскированного состояния, предсказание следующего состояния и сопоставление траектории и состояния трафика. Модель показывает превосходные результаты в задачах прогнозирования состояния трафика и оценки времени в пути (Источник: AAAI 2025 | 告别静态建模!北航团队提出动态路网与轨迹表示的协同学习范式)

Профессор Ян Линьи из Южного научно-технологического университета (SUSTech) набирает аспирантов/RA/стажеров по направлению больших моделей: Профессор Ян Линьи (Yang Linyi) с факультета статистики и наук о данных Южного научно-технологического университета (скоро приступит к работе, независимый PI) создает лабораторию генеративного искусственного интеллекта (GenAI Lab) и набирает аспирантов и магистрантов на 2025/2026 учебный год, а также постдоков, научных ассистентов (RA) и стажеров. Направления исследований включают причинно-следственный анализ рассуждений больших моделей, обобщаемые методы больших моделей на основе обучения с подкреплением, создание надежных не-агентных систем для предотвращения потери контроля над AI. Профессор Ян имеет множество публикаций на ведущих конференциях, обширные связи с университетами и исследовательскими институтами в Китае и за рубежом, поощряет совместное научное руководство. Требования к кандидатам: сильная мотивация, солидная математическая подготовка и навыки программирования (Источник: 博士申请 | 南方科技大学杨林易老师招收大模型方向全奖博士/RA/访问学生)

Личный проект: Создание большой языковой модели с нуля: Разработчик поделился своим личным проектом по созданию Causal Language Model (аналогичной GPT) с нуля. Проект использует Python и PyTorch, основная архитектура включает многоголовое самовнимание с Causal Mask, полносвязные сети, стеки блоков декодера (нормализация слоев, остаточные связи). Модель использует предварительно обученные вложения слов и позиционные вложения GPT-2, выходной слой отображает логиты на словарь. Для авторегрессионной генерации текста используется Top-k сэмплирование, а обучение проводится на наборе данных WikiText с использованием оптимизатора AdamW и функции потерь CrossEntropyLoss. Код проекта открыт на GitHub и демонстрирует базовый процесс создания LLM (Источник: Reddit r/MachineLearning)
Разбор статьи: d1 — Расширение возможностей рассуждения диффузионных больших языковых моделей (dLLM) с помощью обучения с подкреплением: В этом исследовании предлагается фреймворк d1, направленный на применение предварительно обученных диффузионных LLM (dLLM) для задач рассуждения. dLLM генерируют текст методом «от грубого к точному», в отличие от авторегрессионных (AR) моделей. Фреймворк d1 сочетает в себе контролируемую тонкую настройку (SFT) и обучение с подкреплением (RL), в частности: использование Masked SFT для дистилляции знаний и управляемого самосовершенствования; предложение нового алгоритма RL на основе градиента политики без критика diffu-GRPO. Эксперименты показывают, что d1 значительно улучшает производительность SOTA dLLM на бенчмарках математических и логических рассуждений, доказывая потенциал dLLM в задачах рассуждения (Источник: Reddit r/MachineLearning)
💼 Бизнес
Лаборатория Alibaba Tongyi ищет экспертов-алгоритмистов по направлению универсального RAG/AI-поиска (Пекин/Ханчжоу): Команда AI-поиска лаборатории Alibaba Tongyi набирает экспертов-алгоритмистов, ответственных за продвижение исследований и оптимизацию основных модулей поиска и RAG (Retrieval-Augmented Generation), таких как Embedding, ReRank модели, для улучшения их эффективности и достижения лидирующих позиций в отрасли. Обязанности также включают оптимизацию всего конвейера для последующих приложений (вопросно-ответные системы, обслуживание клиентов, мультимодальная память), повышение точности, эффективности и масштабируемости, а также сотрудничество с командой для внедрения в бизнес. Требуется степень магистра или выше по соответствующей специальности, знание технологий поиска/NLP/больших моделей, опыт работы над соответствующими проектами (Источник: 北京/杭州内推 | 阿里通义实验室招聘通用RAG/AI搜索方向算法专家)

AI-стартап в сфере рекрутинга OpportuNext ищет CTO (удаленно/доля в компании): OpportuNext — это стартап на ранней стадии, целью которого является улучшение процесса найма с помощью AI-технологий, предлагая интеллектуальный подбор вакансий, анализ резюме и инструменты карьерного планирования. Основатель ищет технического партнера (CTO), который возглавит разработку AI-функций, построит масштабируемую бэкенд-систему и будет продвигать инновации продукта. Требуется опыт в AI/ML, Python и масштабируемых системах, энтузиазм в решении реальных проблем, готовность присоединиться к стартапу на ранней стадии (удаленная позиция с оплатой долей в компании) (Источник: Reddit r/deeplearning)
🌟 Сообщество
Обсуждение: Суть больших моделей — «языковой фокус»: В статье для глубокого размышления утверждается, что большие модели (такие как ChatGPT) на самом деле не понимают информацию, а имитируют и предсказывают формы выражения, обучаясь на огромных объемах языковых данных. Роль промпта — задать контекст и направить внимание модели, а не общаться с сознательной сущностью. Ответы модели основаны на воспроизведении паттернов, которые она «видела достаточно много раз», кажутся интеллектуальными, но лишены истинного понимания и склонны к «галлюцинациям» — «уверенной чепухе». Взаимодействие человека и машины больше похоже на то, что пользователь думает за модель, а вывод модели может незаметно изменять привычки мышления и суждения пользователя, а также отражать и усиливать существующие в реальности предубеждения (Источник: 我所理解的大模型:语言的幻术)
Дискуссия: Энергопотребление AI и различия в стратегиях разработки моделей в США и Китае: Пользователи Reddit обсуждают заявление Трампа о включении угля в список ключевых минералов для развития AI, что вызывает обеспокоенность по поводу энергопотребления AI. В комментариях отмечается, что большие модели становятся все более энергозатратными, в то время как китайские компании, похоже, склоняются к созданию более компактных и эффективных моделей. Это отражает компромисс между производительностью и энергоэффективностью в развитии AI, а также возможные различия в технологических путях, выбираемых разными регионами (Источник: Reddit r/artificial)

Вопрос: Поиск фреймворка для глубокого обучения с подкреплением, аналогичного PyTorch Lightning: Пользователь Reddit спрашивает, существуют ли фреймворки, аналогичные PyTorch Lightning (PL), специально предназначенные для глубокого обучения с подкреплением (DRL). Пользователь считает, что хотя PL можно использовать для DRL, его дизайн больше ориентирован на обучение с учителем на основе наборов данных, а не на DRL, управляемое взаимодействием со средой. В посте ищут рекомендации сообщества по фреймворкам, подходящим для DRL (например, DQN, PPO) и хорошо интегрирующимся со средами типа Gymnasium, или просят поделиться лучшими практиками использования PL для DRL (Источник: Reddit r/deeplearning)
Сообщество: Запуск Discord-сообщества MetaMinds для виртуальных музыкантов: Создано новое Discord-сообщество под названием MetaMinds, предназначенное для общения, сотрудничества и обмена опытом между виртуальными артистами, использующими AI-инструменты (такие как Suno) для создания музыки. Сообщество уже запустило свой первый конкурс по написанию песен под названием «A Personal Song» и планирует в будущем проводить конкурсы более высокого уровня, возможно, даже с денежными призами. Это отражает формирование новой экосистемы сообществ в области создания музыки с помощью AI (Источник: Reddit r/SunoAI)
Обсуждение: Как назвать коллекцию наборов данных, включающую обучающие наборы?: Пользователь Reddit спрашивает, как называется коллекция наборов данных, предназначенная для обучения и оценки одной и той же модели, в отличие от «бенчмарка (Benchmark)», который используется для оценки производительности модели на нескольких задачах. Этот вопрос затрагивает детали классификации наборов данных и использования терминологии в области машинного обучения (Источник: Reddit r/MachineLearning)
Помощь: Реализация функции преобразования речи в текст в OpenWebUI: Пользователь ищет наилучшее решение и рекомендуемые модели для реализации функции преобразования речи в текст (пользователь написал TTS, но описание касается транскрибации видео с YouTube/аудиофайлов, что должно быть ASR/STT) в среде OpenWebUI+Ollama, развернутой в Docker, с использованием GPU H100. Это отражает потребность пользователей в интеграции большего количества модальных возможностей обработки в локальные интерфейсы взаимодействия с LLM (Источник: Reddit r/OpenWebUI)
Обсуждение: Мнения о годовой подписке на Claude и изменениях ограничений: Пользователь Reddit рад, что не купил годовую подписку на Claude, так как в последнее время многие пользователи жалуются на ужесточение ограничений использования. Пользователь считает, что Anthropic, возможно, изменила стратегию для экономии затрат после привлечения большого числа платных пользователей. В то же время пользователь упоминает высокую производительность бесплатного Gemini 2.5 Pro и выражает обеспокоенность и надежды относительно будущего развития Claude. Обсуждение отражает чувствительность пользователей к ценообразованию, ограничениям использования и соотношению цены и качества LLM-сервисов (Источник: Reddit r/ClaudeAI)
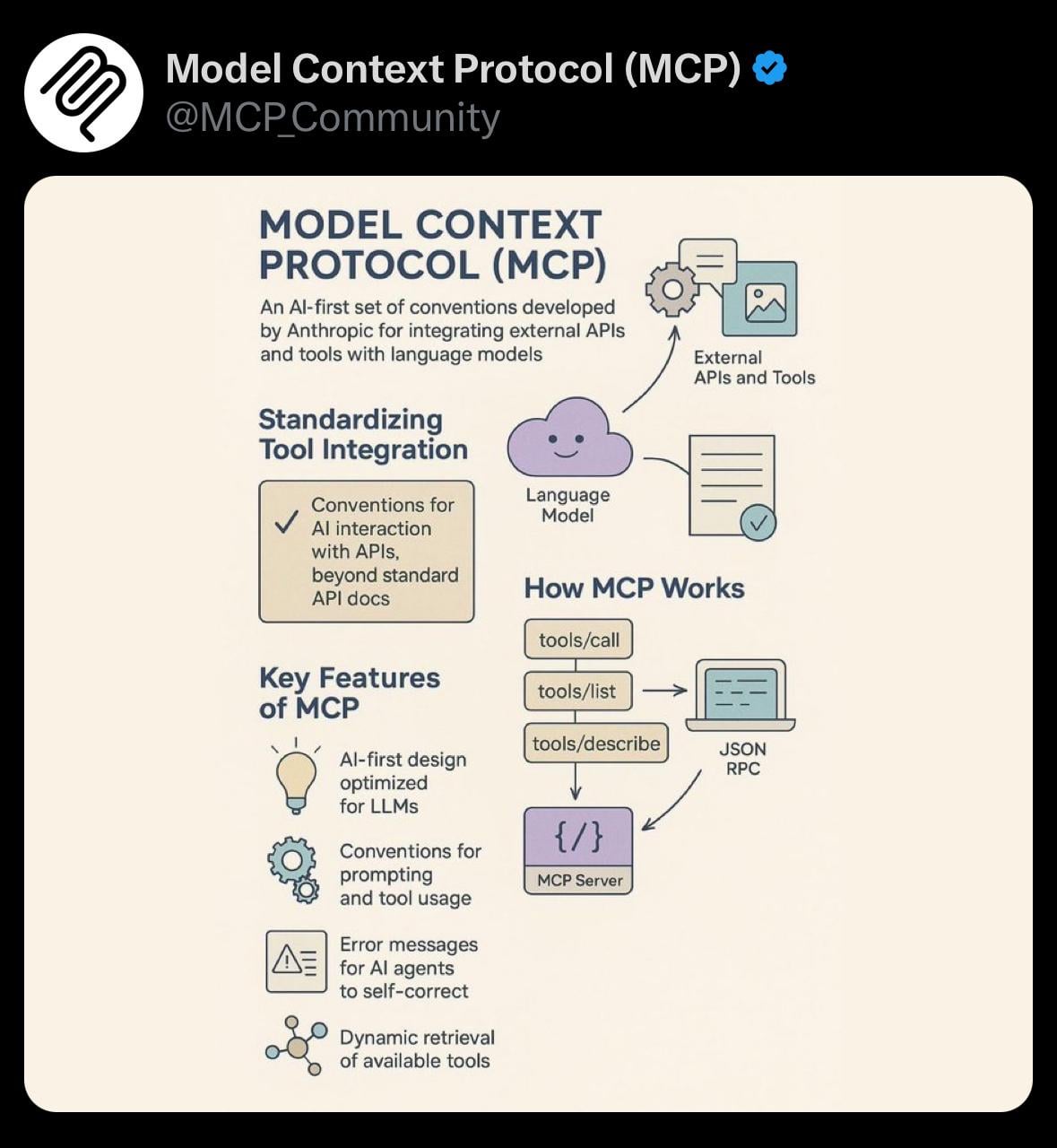
Шеринг: Простая визуализация Протокола Контекста Модели (MCP): Пользователь поделился простой визуализацией Протокола Контекста Модели (Model Context Protocol, MCP). MCP, возможно, является технической концепцией, связанной с моделью Anthropic Claude, направленной на оптимизацию или управление тем, как модель обрабатывает длинные контексты. Этот шеринг предоставляет сообществу визуальную помощь для понимания соответствующих технических концепций (Источник: Reddit r/ClaudeAI)
Помощь: Добавление пользовательских команд в чат OpenWebUI: Пользователь спрашивает о технической сложности добавления пользовательских команд (например, в формате @tag с меню автодополнения) в интерфейс чата OpenWebUI для удобства выполнения настраиваемых RAG-запросов (например, фильтрации по типу документа). Пользователь также рассматривает выпадающее меню как альтернативный вариант. Это отражает желание пользователей расширить возможности фронтенд-взаимодействия для более гибкого управления бэкенд-функциями AI (Источник: Reddit r/OpenWebUI)
Обсуждение: Генерация красивых и функциональных AI QR-кодов: Пользователь пытался использовать ChatGPT/DALL-E для генерации QR-кодов, сочетающих художественный стиль и возможность сканирования, но результаты были неудовлетворительными, отмечая, что методы вроде ControlNet более эффективны. Это вызвало дискуссию об ограничениях текущих основных моделей генерации текста в изображение при создании изображений, требующих точной структуры и функциональности (например, сканируемости) (Источник: Reddit r/ChatGPT)

Поиск партнеров для изучения AI/ML: Студент 3-го курса бакалавриата по компьютерным наукам (специализация AI/ML) ищет 4-5 единомышленников для создания группы по углубленному изучению AI/ML, совместной разработке проектов и практике структур данных и алгоритмов (DSA/CP). Инициатор перечислил свой технический стек и интересующие направления, надеясь создать группу для взаимной мотивации и совместного обучения (Источник: Reddit r/deeplearning)
Обсуждение: Усугубят ли AI Agent проблему спама?: Пользователь Reddit выражает обеспокоенность тем, что широкое использование AI Agent для автоматизации задач (таких как поиск лидов и отправка сообщений) может привести к засилью спама. Когда все будут использовать подобные инструменты, целевые получатели будут завалены большим количеством персонализированных автоматических сообщений, что снизит эффективность коммуникации и обесценит инструменты Agent. Обсуждение затрагивает размышления о возможных негативных внешних эффектах масштабного применения AI-инструментов (Источник: Reddit r/ArtificialInteligence)
Обсуждение: Недавние проблемы с качеством Suno AI: Пользователь поделился музыкальным фрагментом, сгенерированным с помощью Suno AI, отметив, что, несмотря на недавние обсуждения в сообществе о снижении качества вывода Suno, лично ему этот результат кажется неплохим. Это отражает восприятие сообществом колебаний производительности инструментов генерации AI и субъективные различия в оценках (Источник: Reddit r/SunoAI)

Обсуждение: RTX 4090 против RTX 5090 для обучения глубоких нейронных сетей: Пользователь консультируется, стоит ли при сборке персональной рабочей станции с одним GPU для глубокого обучения (в основном не LLM) выбирать текущую RTX 4090 или дождаться скорого выпуска RTX 5090. В посте ищут советы сообщества по выбору оборудования и спрашивают, как при покупке отличить игровую карту от профессиональной (хотя это потребительские карты). Отражает соображения AI-разработчиков при выборе аппаратного обеспечения (Источник: Reddit r/deeplearning)
Обсуждение: Разрушит ли AI капитализм?: Пользователь считает, что из-за стремления компаний к максимизации прибыли AI в конечном итоге может заменить большинство рабочих мест. В существующей капиталистической системе это приведет к массовой безработице и потере источников дохода. Пользователь предполагает, что универсальный базовый доход (UBI), финансируемый за счет дополнительных налогов на компании, получающие прибыль от AI, может стать необходимым решением. Обсуждение затрагивает глубокое влияние AI на будущую экономическую структуру и социальные модели (Источник: Reddit r/ArtificialInteligence)
Помощь: Воспроизведение результатов статьи Anthropic «Reasoning Models Don’t Always Say What They Think»: Пользователь ищет помощи сообщества в поиске промптов или связанных идей, которые позволили бы воспроизвести результаты статьи Anthropic о том, что «модели рассуждений не всегда говорят то, что думают». Статья исследует возможное несоответствие между внутренним процессом рассуждения больших языковых моделей и их конечным выводом. Это свидетельствует об интересе членов сообщества к пониманию и проверке передовых результатов исследований в области AI (Источник: Reddit r/MachineLearning)
Помощь: Конфигурация и опыт использования RAG в OpenWebUI: Пользователь спрашивает о лучших практиках использования RAG (Retrieval-Augmented Generation) в OpenWebUI, включая рекомендуемые настройки, параметры, которых следует избегать, и предпочтительные модели встраивания (embedding). Пользователь также столкнулся с проблемами аномального поведения модели (например, Mistral Small выводит пустой список) и спрашивает о приоритете личных настроек пользователя по сравнению с настройками модели администратора. Это отражает проблемы, с которыми сталкиваются пользователи при реальном развертывании и оптимизации RAG-приложений, и их потребность в обмене опытом (Источник: Reddit r/OpenWebUI)
Обсуждение: Улучшит ли отток пользователей Claude качество сервиса?: Пользователь выдвигает гипотезу, что недавний отток части пользователей Claude («Genesis Exodus») из-за ограничений и проблем с производительностью может, наоборот, высвободить вычислительные ресурсы, что приведет к возвращению качества обслуживания (например, производительности, ограничений) к более желаемому состоянию. Пользователь выражает свою привязанность к Claude и надеется на улучшение сервиса. Обсуждение отражает наблюдения и размышления пользователей о взаимосвязи спроса и предложения на AI-сервисы, распределении ресурсов и динамике качества обслуживания (Источник: Reddit r/ClaudeAI)

Обсуждение: Как определить «AI-искусство»?: Пользователь инициирует обсуждение, спрашивая членов сообщества, как они определяют «AI-искусство», и задает сопутствующие вопросы: является ли человек, использующий AI-инструменты (например, ChatGPT) для генерации изображений, создателем? Обладает ли он правами собственности? Какую роль играют поставщики LLM-сервисов в творчестве, и следует ли их считать соавторами? Эта дискуссия направлена на прояснение основных понятий, связанных с авторством и правами на контент, сгенерированный AI (Источник: Reddit r/ArtificialInteligence)
Обсуждение: Угрожает ли AI-музыка «общественному характеру» музыки?: Пользователь задает вопрос, ослабляют ли AI-инструменты, такие как Suno, способные легко генерировать сверхперсонализированную музыку, «общественный характер» музыки как общего опыта? Опасения включают: музыка может стать персонализированным зеркалом, а не маяком, объединяющим сообщество; коллективные музыкальные мероприятия, такие как концерты, могут пострадать; пользователи могут стать восприимчивыми только к кастомизированному контенту, снижая открытость к разнообразной или сложной музыке. Обсуждение фокусируется на потенциальном влиянии AI на музыкальную культуру и социальные функции музыки (Источник: Reddit r/SunoAI)
Вопрос: Насколько точно Suno AI генерирует песни на хинди?: Пользователь, не говорящий на хинди, спрашивает о точности и естественности исполнения на хинди, генерируемого Suno AI. Ищет информацию о производительности инструмента на конкретном неанглийском языке (Источник: Reddit r/SunoAI)
💡 Прочее
Шеринг работы Suno AI: Nightingale’s Melody (Альтернативный/инди-рок): Пользователь поделился песней в стиле альтернативного/инди-рока «Nightingale’s Melody», созданной с помощью Suno AI, и приложил ссылку на YouTube (Источник: Reddit r/SunoAI)

Шеринг работы Suno AI: The Art of Abundance (Psytrance): Пользователь поделился AI-сгенерированной музыкой, сочетающей высокоэнергетический Psytrance и элементы спиритической техно. Текст написан ChatGPT, музыка и вокал сгенерированы Suno AI, визуальные эффекты созданы MidJourney и PhotoMosh Pro. Работа исследует концепцию изобилия в цифровую эпоху, выходя за рамки материализма, затрагивая творчество, сознание AI и человеческие желания (Источник: Reddit r/SunoAI)

Шеринг работы Suno AI: Do your Job (Кантри): Пользователь поделился песней в стиле кантри, созданной с помощью Suno AI. Текст песни основан на реальном нераскрытом деле (исчезновение Колтона Росса Барреры) и выражает разочарование семьи и призыв к справедливости (Источник: Reddit r/SunoAI)

Шеринг работы Suno AI: Toxic Friends (Электро-поп): Пользователь поделился своей работой в стиле электро-поп «Toxic Friends», представленной на апрельский конкурс Suno AI (Источник: Reddit r/SunoAI)

Шеринг работы Suno AI: Starlight Visitor (Поп-кавер в стиле 80-х): Пользователь поделился кавер-версией существующей песни в стиле поп-музыки 80-х, созданной с помощью Suno AI, и предоставил ссылку на YouTube (Источник: Reddit r/SunoAI)

Креативное применение ChatGPT: Расширение мема о яичных продуктах: Пользователь, вдохновленный мемом о яйцах, использовал ChatGPT для генерации серии юмористических, концептуальных изображений и описаний продуктов, связанных с яйцами, таких как «Precracked Life» (Предварительно треснутая жизнь), «Internet of Eggs» (Интернет яиц) и т. д. Демонстрирует возможность использования AI для творческого брейншторминга и создания юмористического контента (Источник: Reddit r/ChatGPT)
Шеринг работы Suno AI: Tom and Jerry / Crambone (Блюз-рок кавер): Пользователь поделился кавер-версией песни «Tom and Jerry / Crambone» в стиле блюз-рок, созданной с помощью Suno AI, и предоставил ссылку на YouTube (Источник: Reddit r/SunoAI)

AI-сгенерированные изображения: Воплощение семи смертных грехов: Пользователь поделился видео, демонстрирующим воплощенные, антропоморфные изображения семи смертных грехов (таких как жадность, лень, зависть и т. д.), сгенерированные с помощью AI (возможно, ChatGPT/DALL-E) (Источник: Reddit r/ChatGPT)
