
Ключевые слова:GPT-4.5, 大 модель, GPT-4.5 детали обучения, производительность Huawei PanGu Ultra, влияние RLHF на способность к рассуждению, исследование предела обучения человека 4GB, открытый математический датасет MegaMath
🔥 В фокусе
OpenAI раскрывает детали обучения и проблемы GPT-4.5: CEO OpenAI Сэм Альтман и ключевая техническая команда GPT-4.5 обсудили детали разработки модели. Проект стартовал два года назад, задействовал почти весь персонал и занял больше времени, чем ожидалось. Во время обучения столкнулись с «катастрофическими проблемами», такими как сбой кластера из 100 000 карт и скрытые ошибки, что выявило узкие места в инфраструктуре, но также способствовало обновлению технологического стека. Теперь для воспроизведения модели уровня GPT-4 требуется всего 5-10 человек. Команда считает, что ключом к будущему повышению производительности является эффективность данных, а не вычислительная мощность, и необходимо разрабатывать новые алгоритмы, чтобы извлекать больше знаний из того же объема данных. Архитектура системы переходит к мультикластерной, и в будущем может потребоваться сотрудничество десятков миллионов GPU, что предъявляет более высокие требования к отказоустойчивости. В беседе также затрагивались Scaling Law, машинное обучение и совместное проектирование систем, сущность обучения без учителя, демонстрируя размышления и практику OpenAI в продвижении передовых исследований больших моделей (Источник: 36Kr)

Huawei выпустила плотную большую модель Pangu Ultra на 135B параметров на базе Ascend: Команда Huawei Pangu выпустила универсальную языковую модель Pangu Ultra с 135B плотных параметров, обученную на отечественных NPU Ascend. Модель использует 94-слойную структуру Transformer и внедряет технологии Depth-scaled sandwich-norm (DSSN) и TinyInit для решения проблем стабильности обучения сверхглубоких моделей, достигнув стабильного обучения без скачков потерь (loss) на 13,2 ТБ высококачественных данных. На системном уровне, благодаря оптимизациям, таким как гибридный параллелизм, слияние операторов и разделение подпоследовательностей, коэффициент использования вычислительной мощности (MFU) на кластере из 8192 карт Ascend был повышен до более чем 50%. Оценка показывает, что Pangu Ultra превосходит плотные модели, такие как Llama 405B и Mistral Large 2, на нескольких бенчмарках и может конкурировать с более крупными моделями MoE, такими как DeepSeek-R1, доказывая возможность разработки передовых больших моделей на базе отечественных вычислительных мощностей (Источник: Jiqizhixin)

Исследование ставит под сомнение значимость обучения с подкреплением (RL) для улучшения способности LLM к рассуждению: Исследователи из Тюбингенского и Кембриджского университетов ставят под сомнение недавние заявления о том, что обучение с подкреплением (RL) может значительно улучшить способность языковых моделей к рассуждению. Путем тщательного исследования распространенных бенчмарков для оценки рассуждений (например, AIME24) исследователи обнаружили, что результаты крайне нестабильны, и простое изменение случайного начального числа (seed) может привести к значительным колебаниям оценок. При стандартизированной оценке прирост производительности от RL значительно меньше, чем сообщалось изначально, часто не является статистически значимым и даже уступает эффекту контролируемой донастройки (SFT), а способность к обобщению также ниже. Исследование указывает, что различия в выборке, конфигурации декодирования, системы оценки и гетерогенность оборудования являются основными причинами нестабильности, и призывает к использованию более строгих и воспроизводимых стандартов оценки для трезвой оценки и измерения реального прогресса в способностях моделей к рассуждению (Источник: Jiqizhixin)

Выступление Альтмана на TED: OpenAI выпустит мощную модель с открытым исходным кодом, считает ChatGPT не AGI: CEO OpenAI Сэм Альтман заявил на конференции TED, что компания разрабатывает мощную модель с открытым исходным кодом, производительность которой превзойдет все существующие модели с открытым исходным кодом, прямо отвечая конкурентам, таким как DeepSeek. Он подчеркнул, что количество пользователей ChatGPT продолжает стремительно расти, а новая функция памяти улучшит персонализированный опыт. Он считает, что в области научных открытий и разработке ПО (огромный прирост эффективности) ожидаются прорывы, но текущие модели, такие как ChatGPT, пока не обладают способностью к самообучению и обобщению на разные области и не являются AGI. Он также обсудил вопросы авторского права и «права на стиль», вызванные творческими возможностями GPT-4o, и подтвердил уверенность OpenAI в безопасности моделей и механизмах контроля рисков (Источник: Xinzhiyuan)

Исследование утверждает, что предел обучения человека за всю жизнь составляет около 4 ГБ, что вызвало бурное обсуждение интерфейсов мозг-компьютер и развития ИИ: Журнал Neuron, входящий в группу Cell, опубликовал исследование Калифорнийского технологического института (Caltech), которое оценивает скорость обработки информации человеческим мозгом примерно в 10 бит в секунду, что значительно ниже скорости сбора данных сенсорными системами (1 миллиард бит в секунду). Исходя из этого, исследователи делают вывод, что предел накопления знаний человеком за всю жизнь (предполагая 100 лет непрерывного обучения без забывания) составляет около 4 ГБ, что значительно меньше способности больших моделей хранить параметры (например, модель 7B может хранить 14 миллиардов бит). Исследование считает, что это узкое место связано с механизмом последовательной обработки центральной нервной системы, и прогнозирует, что превосходство машинного интеллекта над человеческим — лишь вопрос времени. Это исследование также ставит под сомнение проект Neuralink Маска, утверждая, что он не сможет преодолеть фундаментальные структурные ограничения мозга и что лучше оптимизировать существующие способы коммуникации. Это исследование вызвало широкое обсуждение пределов человеческого познания, потенциала развития ИИ и направлений развития интерфейсов мозг-компьютер (Источник: QubitAI)

🎯 Тенденции
GPT-4 скоро будет выведен из эксплуатации, возможно появление GPT-4.1 и загадочных новых моделей: OpenAI объявила, что с 30 апреля в ChatGPT модель GPT-4o полностью заменит выпущенную два года назад GPT-4, которая по-прежнему будет доступна через API. В то же время утечки в сообществе и коде указывают на то, что OpenAI, возможно, скоро выпустит серию новых моделей, включая GPT-4.1 (и ее версии mini/nano), полнофункциональную модель вывода o3, а также новую серию o4 (например, o4-mini). Загадочная модель под названием Optimus Alpha уже появилась на OpenRouter, демонстрирует отличную производительность (особенно в программировании), поддерживает контекст в миллион токенов, и широко предполагается, что это одна из новых моделей, которые OpenAI скоро выпустит (возможно, GPT-4.1 или o4-mini). Она имеет множество сходств с моделями OpenAI (например, специфические ошибки). Это предвещает ускорение итераций моделей OpenAI и укрепляет ее технологическое лидерство (Источник: source, source)

Большая модель Alibaba Qwen3 готовится к выпуску: Сообщается, что Alibaba планирует выпустить большую модель Qwen3 в ближайшее время. Команда разработчиков подтвердила, что модель вошла в финальную стадию подготовки, но конкретная дата выпуска не определена. Известно, что Qwen3 является важным модельным продуктом Alibaba на первую половину 2025 года, ее разработка началась после Qwen2.5. Под влиянием конкурирующих моделей, таких как DeepSeek-R1, команда базовых моделей Alibaba Cloud еще больше сместила стратегический фокус на улучшение способности модели к рассуждению, демонстрируя стратегическую фокусировку на конкретных возможностях в условиях конкуренции больших моделей (Источник: InfoQ)

Kimi снижает цены на открытой платформе и открывает исходный код легковесной визуальной модели: Открытая платформа Kimi от Moonshot AI объявила о снижении цен на услуги вывода моделей и кэширование контекста с целью снижения затрат пользователей за счет технической оптимизации. Одновременно Kimi открыла исходный код двух легковесных визуально-языковых моделей на базе архитектуры MoE: Kimi-VL и Kimi-VL-Thinking, поддерживающих контекст 128K и активируя всего около 3 миллиардов параметров. Утверждается, что они значительно превосходят большие модели с в 10 раз большим количеством параметров в задачах мультимодального рассуждения, с целью содействия разработке и применению небольших эффективных мультимодальных моделей (Источник: InfoQ)
Google выпустила протокол взаимодействия агентов A2A и несколько новых ИИ-продуктов: На конференции Google Cloud Next ’25 Google совместно с более чем 50 партнерами представила открытый протокол Agent2Agent (A2A), направленный на обеспечение взаимодействия и сотрудничества между ИИ-агентами, разработанными разными компаниями и платформами. Одновременно были анонсированы Gemini 2.5 Flash (эффективная версия флагманской модели), Lyria (генерация музыки из текста), Veo 2 (создание видео), Imagen 3 (генерация изображений), Chirp 3 (настраиваемый голос) и другие ИИ-модели и приложения, а также представлен чип TPU седьмого поколения Ironwood, оптимизированный специально для вывода (inference). Эта серия анонсов отражает комплексный подход Google и открытую стратегию в области ИИ-инфраструктуры, моделей, платформ и агентов (Источник: InfoQ)
ByteDance выпустила модель вывода Seed-Thinking-v1.5 с 200B параметров: Команда Doubao из ByteDance опубликовала технический отчет, представляющий их модель вывода MoE Seed-Thinking-v1.5 с общим числом параметров 200B. Модель, активирующая 20B параметров при каждом вызове, показала отличные результаты на нескольких бенчмарках. Утверждается, что она превосходит DeepSeek-R1, имеющий 671B общих параметров. Сообщество предполагает, что это может быть модель, используемая в режиме «глубокого мышления» текущего приложения Doubao от ByteDance, демонстрируя прогресс ByteDance в разработке эффективных моделей для вывода (Источник: InfoQ)
Midjourney выпустила модель V7, улучшающую качество изображений и эффективность генерации: Инструмент генерации изображений ИИ Midjourney выпустил новую модель V7 (альфа-версия). Новая версия улучшает согласованность и последовательность генерируемых изображений, особенно в отображении рук, частей тела и деталей объектов, и генерирует более реалистичные и насыщенные текстуры. V7 представляет режим Draft Mode, позволяющий в десять раз ускорить рендеринг за половину стоимости, подходящий для быстрой итеративной разведки. Также предлагаются режимы turbo (быстрее, но дороже) и relax (медленнее, но дешевле) для удовлетворения различных потребностей пользователей (Источник: InfoQ)
Amazon представила модель ИИ для обработки речи Nova Sonic: Amazon выпустила генеративную модель ИИ нового поколения Nova Sonic, нативно обрабатывающую речь. Утверждается, что эта модель по ключевым показателям, таким как скорость, распознавание речи и качество диалога, сопоставима с лучшими речевыми моделями OpenAI и Google. Nova Sonic доступна через платформу для разработчиков Amazon Bedrock, использует новый двунаправленный потоковый API, и ее цена примерно на 80% ниже, чем у GPT-4o, с целью предоставления экономически эффективных возможностей естественного речевого взаимодействия для корпоративных ИИ-приложений (Источник: InfoQ)
ИИ-функции для китайской версии iPhone от Apple могут появиться в середине года, интегрируя технологии Baidu и Alibaba: Сообщается, что Apple планирует внедрить сервис Apple Intelligence для iPhone на китайском рынке до середины 2025 года (возможно, в iOS 18.5). Эта функция будет использовать большую модель Baidu Ernie для предоставления интеллектуальных возможностей и интегрировать механизм цензуры Alibaba для соответствия требованиям по контролю контента. Apple не подписывала эксклюзивных соглашений с Baidu или Alibaba, что свидетельствует о применении стратегии локализованного сотрудничества на ключевых рынках для быстрого развертывания ИИ-функций (Источник: InfoQ)
🧰 Инструменты
Volcano Engine выпустила корпоративный агент данных Data Agent: Volcano Engine представила корпоративный агент данных Data Agent. Этот инструмент использует возможности больших моделей по рассуждению, анализу и вызову инструментов с целью глубокого понимания бизнес-потребностей предприятия, автоматизации выполнения сложных задач анализа данных и их применения, таких как составление подробных исследовательских отчетов, разработка маркетинговых кампаний, повышения эффективности использования данных и уровня принятия решений в компании (Источник: InfoQ)
Новые стили генерации изображений GPT-4o привлекают внимание: Пользователи социальных сетей демонстрируют новые стили, созданные с помощью функции генерации изображений GPT-4o, например, сочетание элементов ретро-интерфейса Windows 2000 с изображениями персонажей для создания уникальных коллажей. Пользователи делятся техниками составления запросов (prompts), например, использование изображений-основ для направления генерации, сочетание описаний стиля и содержания, что вызвало интерес сообщества к исследованию творческого потенциала GPT-4o (Источник: source, source)

📚 Обучение
Выпущен MegaMath — крупнейший открытый датасет для предварительного обучения математическому мышлению: LLM360 представил MegaMath, открытый датасет для предварительного обучения математическому мышлению, содержащий 371 миллиард токенов, превосходящий по размеру DeepSeek-Math Corpus. Датасет охватывает веб-страницы с математическим содержанием (279B), код, связанный с математикой (28B), и высококачественные синтетические данные (64B). Команда использовала тщательно проработанный процесс обработки данных, включая оптимизацию структуры HTML, двухэтапное извлечение, фильтрацию и уточнение с помощью LLM, обеспечивая масштаб, качество и разнообразие данных. Проверка предварительного обучения на модели Llama-3.2 показывает, что использование MegaMath обеспечивает абсолютное улучшение на 15-20% в бенчмарках GSM8K, MATH, предоставляя сообществу открытого исходного кода мощную основу для обучения моделей математическому мышлению (Источник: Jiqizhixin)

Nabla-GFlowNet: Баланс между разнообразием и эффективностью при донастройке диффузионных моделей: Исследователи из CUHK (Шэньчжэнь) и других институтов предложили Nabla-GFlowNet, новый метод донастройки диффузионных моделей на основе вознаграждения, использующий генеративные потоковые сети (GFlowNet). Метод направлен на решение проблем медленной сходимости традиционной донастройки с помощью RL и склонности к переобучению и потере разнообразия при прямой оптимизации по вознаграждению. Путем вывода нового условия баланса потока (Nabla-DB) и разработки специальной функции потерь и параметризации градиента логарифмического потока, Nabla-GFlowNet позволяет эффективно выравнивать модель по функции вознаграждения (например, эстетическая оценка, следование инструкциям), сохраняя при этом разнообразие генерируемых образцов. Эксперименты на Stable Diffusion подтвердили его преимущества по сравнению с методами DDPO, ReFL, DRaFT (Источник: Jiqizhixin)
Llama.cpp исправляет проблемы, связанные с Llama 4: Проект llama.cpp объединил два исправления для модели Llama 4, касающиеся RoPE (вращающиеся позиционные эмбеддинги) и неверного расчета норм (norms). Эти исправления направлены на улучшение качества вывода модели, но пользователям может потребоваться повторно загрузить файлы модели GGUF, сгенерированные с помощью исправленных инструментов преобразования, чтобы изменения вступили в силу (Источник: source)
💼 Бизнес
Nvidia завершила приобретение Lepton AI: По сообщениям, Nvidia приобрела Lepton AI, стартап в области ИИ-инфраструктуры, основанный бывшим вице-президентом Alibaba Цзя Янцзином. Стоимость сделки может достигать сотен миллионов долларов. Основной бизнес Lepton AI — аренда серверов Nvidia GPU и предоставление ПО для помощи компаниям в создании и управлении ИИ-приложениями. Цзя Янцзин, его сооснователь Бай Цзюньцзе и около 20 сотрудников присоединились к Nvidia. Этот шаг рассматривается как стратегическое развертывание Nvidia для расширения рынка облачных услуг и корпоративного ПО в ответ на конкуренцию со стороны AWS, Google Cloud и других компаний, разрабатывающих собственные чипы (Источник: InfoQ)
В технологической отрасли США растет тревога из-за влияния ИИ на рынок труда: Отмечается, что технологическая отрасль США переживает сокращение рабочих мест, снижение зарплат и удлинение циклов поиска работы. Массовые увольнения, использование ИИ компаниями (такими как Salesforce, Meta, Google) для замены сотрудников или приостановка найма (особенно инженеров и младших специалистов) усугубляют карьерную тревогу работников отрасли. Данные показывают, что растет доля людей, сообщающих о снижении зарплаты и переходящих с руководящих должностей на позиции индивидуальных исполнителей. ИИ перестраивает рынок труда, вынуждая соискателей расширять горизонты за пределы технологической отрасли или переходить к предпринимательству. Эксперты советуют обращать внимание на возможности трудоустройства за пределами «Большой семерки» и осваивать инструменты ИИ для повышения конкурентоспособности (Источник: InfoQ)

Слух: OpenAI планирует приобрести компанию по производству ИИ-устройств io Products, основанную Альтманом и Джони Айвом: Сообщается, что OpenAI обсуждает приобретение компании io Products за сумму не менее 500 миллионов долларов. Компания основана CEO OpenAI Сэмом Альтманом совместно с бывшим главным дизайнером Apple Джони Айвом и нацелена на разработку персональных устройств на базе ИИ, возможные форматы включают «телефон» без экрана или домашнее устройство. Команда инженеров создает устройство, OpenAI предоставляет технологии, студия Айва отвечает за дизайн, Альтман активно участвует. В случае завершения сделки, команда разработчиков оборудования будет интегрирована в OpenAI, ускоряя ее продвижение в области аппаратного обеспечения для ИИ (Источник: InfoQ)
Стартап бывшего CTO OpenAI Миры Мурати снова переманивает сотрудников из OpenAI: ИИ-компания «Лаборатория мыслящих машин», основанная бывшим CTO OpenAI Мирой Мурати, привлекла двух ключевых бывших сотрудников OpenAI в качестве консультантов: бывшего главного научного сотрудника Боба МакГрю и бывшего исследователя Алека Рэдфорда. Рэдфорд является ведущим автором ключевых технических статей по серии GPT. Этот найм еще больше укрепляет технический потенциал стартапа и отражает острую конкуренцию за таланты в области ИИ (Источник: InfoQ)
Baichuan Intelligent корректирует фокус бизнеса, концентрируясь на медицине: Основатель Baichuan Intelligent Ван Сяочуань в письме ко всем сотрудникам по случаю двухлетия компании подтвердил, что компания сосредоточится на сфере здравоохранения, развивая такие сервисы, как Baixiaoying, ИИ-педиатрия, ИИ-терапия и прецизионная медицина. Он подчеркнул необходимость сокращения избыточных действий и перехода к более плоской организационной структуре. Ранее сообщалось о сокращении B2B-подразделения компании в финансовом секторе, уходе бизнес-партнера Дэн Цзяна, а также об уходе или скором уходе нескольких сооснователей, что свидетельствует о стратегической переориентации и организационной перестройке в компании (Источник: InfoQ)
Alibaba Cloud запускает партнерскую программу для ИИ-экосистемы «Пышный цвет» (繁花): Alibaba Cloud объявила о запуске программы «Пышный цвет», направленной на поддержку партнеров в области ИИ. Программа будет предоставлять облачные ресурсы, поддержку вычислительными мощностями, пакетирование продуктов, планирование коммерциализации и услуги полного жизненного цикла в зависимости от зрелости продуктов партнеров. Также Alibaba Cloud запускает рынок ИИ-приложений и услуг с целью создания процветающей ИИ-экосистемы и ускорения внедрения ИИ-технологий и приложений (Источник: InfoQ)
Kugou Music и DeepSeek заключили соглашение о глубоком сотрудничестве: Kugou Music объявила о сотрудничестве с ИИ-компанией DeepSeek и представит ряд инновационных функций на базе ИИ. Включая генерацию персонализированных отчетов о прослушивании с использованием мультимодального анализа, ежедневные ИИ-рекомендации, умный поиск, управление плейлистами с помощью ИИ, генерацию динамических обложек ИИ, а также «ИИ-комментаторов» с заданными ролями. Цель — улучшить пользовательский опыт прослушивания музыки и взаимодействие в сообществе с помощью технологий ИИ (Источник: InfoQ)
Слух: Google использует «агрессивные» соглашения о неконкуренции для удержания ИИ-талантов: Сообщается, что DeepMind, подразделение Google, ввела для некоторых сотрудников в Великобритании годичные соглашения о неконкуренции, чтобы предотвратить их переход к конкурентам. В течение этого периода сотрудники не обязаны работать, но продолжают получать зарплату (оплачиваемый отпуск), однако это заставляет некоторых исследователей чувствовать себя изолированными и неспособными участвовать в быстро развивающихся процессах отрасли. Такой шаг может быть запрещен FTC в США, но применим в лондонской штаб-квартире, что вызвало дискуссии о конкуренции за таланты и ограничении инноваций (Источник: InfoQ)
Бывшие сотрудники OpenAI подали юридические документы в поддержку иска Маска против OpenAI: 12 бывших сотрудников OpenAI подали юридические документы в поддержку иска Илона Маска против OpenAI. Они считают, что план реструктуризации OpenAI (переход к коммерческой структуре) может коренным образом нарушать первоначальную некоммерческую миссию компании, которая была ключевым фактором, привлекшим их в компанию. OpenAI ответила, что ее миссия не изменится, несмотря на структурные изменения (Источник: InfoQ)
🌟 Сообщество
Исследование Anthropic раскрывает модели использования и проблемы ИИ в высшем образовании: Anthropic проанализировала миллионы анонимных диалогов студентов на платформе Claude.ai и обнаружила, что студенты технических специальностей (особенно информатики) являются ранними пользователями ИИ. Модели взаимодействия студентов с ИИ включают четыре типа (прямое решение задач, прямая генерация контента, совместное решение задач и совместная генерация контента) с примерно равным распределением. ИИ в основном используется для когнитивных задач высокого порядка, таких как создание (например, программирование, написание упражнений) и анализ (например, объяснение концепций). Исследование также выявило потенциальные случаи академической недобросовестности (например, получение ответов, обход систем обнаружения плагиата), что вызывает обеспокоенность по поводу академической честности, развития критического мышления и методов оценки (Источник: Xinzhiyuan)

Генерация изображений GPT-4o задает новые тренды: от стиля Ghibli до карточек ИИ-знаменитостей: Мощные возможности генерации изображений GPT-4o продолжают вызывать творческий ажиотаж в социальных сетях. После вирусного успеха «семейных портретов в стиле Ghibli» (ключевой фигурой за этим был бывший инженер Amazon Грант Слэттон), пользователи начали создавать карточки знаменитостей из мира ИИ в стиле «Magic: The Gathering» (например, Альтман представлен как «Повелитель AGI»), а также персонализированные карты Таро. Эти примеры демонстрируют потенциал ИИ в имитации художественных стилей и генерации креативного контента, но также вызывают дискуссии об оригинальности, авторском праве, эстетической ценности и влиянии ИИ на профессию дизайнера (Источник: Xinzhiyuan)

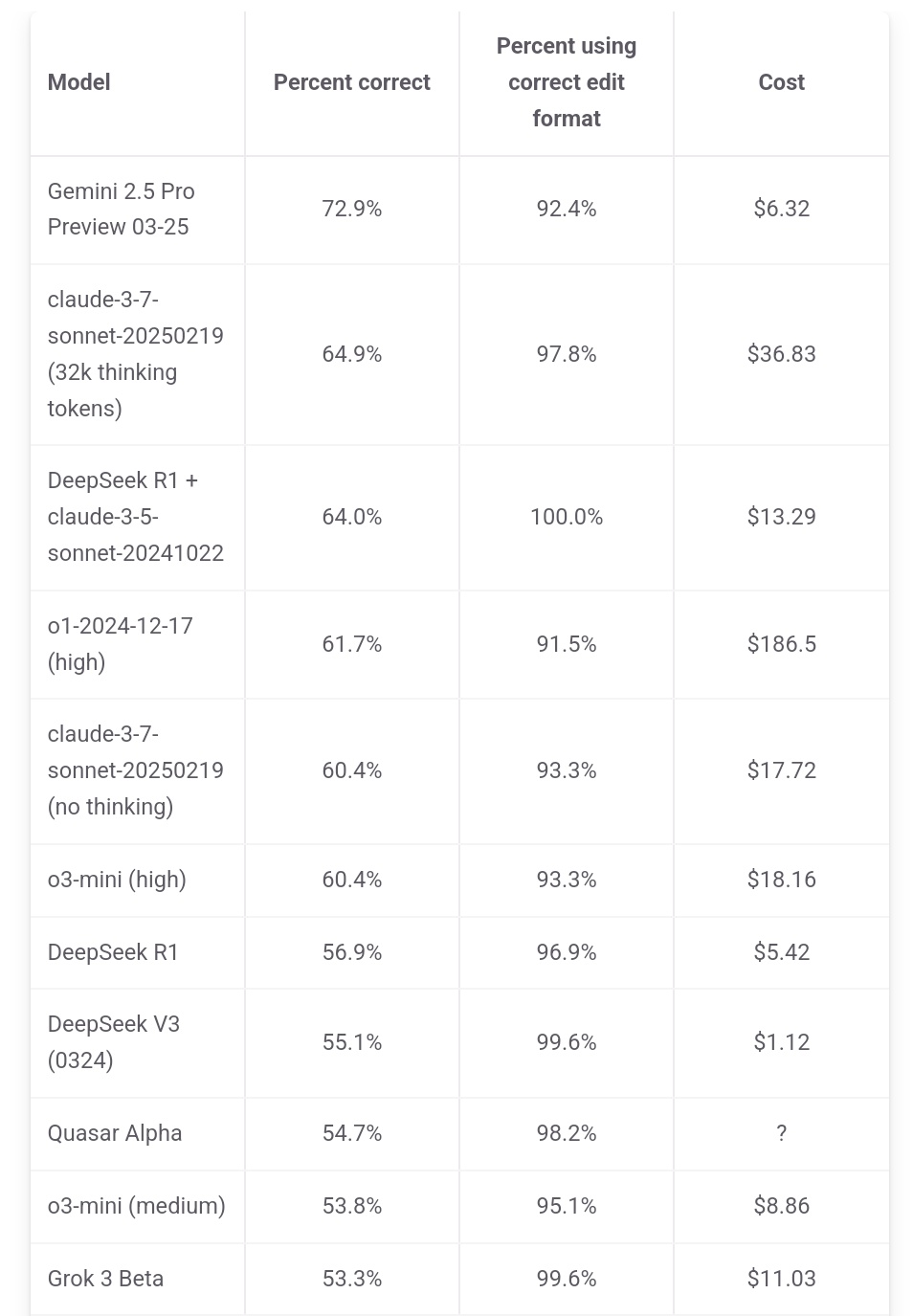
Джефф Дин подчеркивает ценовое преимущество Gemini 2.5 Pro: Глава Google AI Джефф Дин поделился данными рейтинга с aider.chat и отметил, что Gemini 2.5 Pro не только лидирует по производительности в бенчмарке программирования Polyglot, но и его стоимость (6 долларов) значительно ниже, чем у других моделей из топ-10, за исключением DeepSeek, подчеркнув его преимущество в соотношении цена/качество. Стоимость некоторых конкурирующих моделей в 2, 3 и даже 30 раз выше, чем у Gemini 2.5 Pro (Источник: JeffDean)
Горячее обсуждение на Reddit: Влияние ИИ на рынок труда, особенно на начальные позиции: Пост на форуме Reddit вызвал бурное обсуждение. Автор поста (студент магистратуры CIS) выразил глубокую обеспокоенность тем, что ИИ заменит нефизическую работу начального уровня (особенно в разработке ПО, анализе данных, ИТ-поддержке), считая, что утверждение «ИИ не отнимет работу» игнорирует трудности недавних выпускников. Он отметил, что крупные компании уже сокращают набор выпускников, и будущий рынок труда может быть суровым. В комментариях мнения разделились: одни соглашались с кризисом, другие считали это нормой технологических изменений, требующей адаптации к новым ролям (например, управление командами ИИ), третьи ставили под сомнение утверждение о «исчезновении 90% рабочих мест», указывая на экономические циклы, различия между странами и ограниченные текущие возможности ИИ (Источник: source)
Пользователи Claude жалуются на снижение производительности и ужесточение ограничений: В разделе Reddit r/ClaudeAI возникло активное обсуждение: многие пользователи (включая Pro-пользователей) сообщают, что недавно столкнулись с более строгими ограничениями на использование (quota), даже при обычном использовании часто достигается лимит. Некоторые пользователи считают, что Anthropic тайно ужесточает лимиты, и выражают недовольство, полагая, что это вынудит пользователей перейти к конкурентам. Кроме того, пользователи отмечают, что «личность» Claude, похоже, изменилась, стала более «холодной», «механической», утратив философский и поэтический оттенок ранних версий, что привело к отмене подписки некоторыми пользователями (Источник: source, source, source, source)
Генерация изображений ChatGPT вызывает интерес и обсуждения: Пользователи Reddit делятся различными попытками и результатами использования ChatGPT для генерации изображений. Один пользователь попросил «превратить» собаку в человека, в результате чего были сгенерированы изображения, похожие на «орков/фурри», что вызвало дискуссии о понимании запросов и потенциальных предвзятостях. Другой пользователь попросил изобразить себя в виде витража из мультивселенной, результат получился впечатляющим. Другие пользователи просили сгенерировать метафорические изображения об ИИ или спрашивали ИИ о его «кошмарах», демонстрируя возможности и ограничения генерации изображений ИИ в творческом самовыражении и визуализации абстрактных концепций (Источник: source, source, source, source, source)

Обсуждение в сообществе: Выбор и стратегии использования LLM моделей: В разделе Reddit r/LocalLLaMA пользователь предложил проводить ежемесячное обсуждение используемых моделей, делиться лучшими моделями (открытыми и закрытыми), которые они используют в различных сценариях (кодирование, письмо, исследования и т.д.), и причинами выбора. В комментариях пользователи поделились своими текущими комбинациями моделей, таких как Deepseek V3.1, Gemini 2.5 Pro, 4o, R1, Qwen 2.5 Max, Sonnet 3.7, Gemma 3, Claude 3.7, Mistral Nemo и др., упоминая конкретные цели использования (например, вызов инструментов, классификация, ролевые игры), что отражает практическую тенденцию пользователей выбирать и комбинировать различные модели в зависимости от потребностей задачи (Источник: source)
💡 Прочее
Скоро состоится саммит индустрии AIGC Китая: Третий саммит индустрии AIGC Китая пройдет 16 апреля в Пекине. Саммит соберет более 20 лидеров отрасли из таких компаний, как Baidu, Huawei, Microsoft Research Asia, Amazon Web Services, Mianbi Intelligence, Shengshu Technology, для обсуждения прорывов в технологиях ИИ (вычислительные мощности, большие модели), отраслевых применений (образование, развлечения, наука, корпоративные услуги), построения экосистемы (безопасность, контроль, проблемы внедрения) и других вопросов. На саммите также будут представлены рейтинги компаний/продуктов AIGC и панорамная карта приложений AIGC в Китае (Источник: QubitAI)

Отчет Стэнфорда: Разрыв в производительности между ведущими ИИ-моделями США и Китая сократился до 0,3%: Отчет AI Index 2025, опубликованный Стэнфордским университетом, показывает, что разрыв в производительности между ведущими ИИ-моделями США и Китая значительно сократился с 20% в 2023 году до 0,3%. Хотя США по-прежнему лидируют по количеству известных моделей (40 против 15) и доминирующим компаниям в отрасли, китайские модели быстро догоняют. В отчете также отмечается, что разрыв в производительности между ведущими моделями также сокращается (с 12% в 2024 году до 5%), наблюдается явное явление конвергенции (Источник: InfoQ)