
Ключевые слова:AI, тарифы, глобальное влияние тарифов на AI, Claude 4 и AGI, оптимизация подсказок для Suno AI, открытый робот Fourier N1, многоагентные системы в науке
🔥 Фокус
Анализ тенденций мировой индустрии AI под влиянием тарифных шоков: Недавняя напряженность в международной торговле, особенно введение высоких таможенных пошлин, оказывает глубокое влияние на высокоглобализированную индустрию AI. В статье отмечается, что хотя США уже приняли меры по ограничению аппаратного обеспечения для AI, такого как вычислительные мощности, тарифы могут усугубить раскол в мировой индустрии AI. Основные последствия проявляются в следующем: 1) Уровень инфраструктуры: Увеличение стоимости оборудования, ограничение цепочек поставок, но у Китая уже есть отечественные альтернативы. 2) Технологический уровень: Возможное разделение технологических экосистем Китая и США, препятствия для обмена ПО с открытым исходным кодом, конфликты стандартов. 3) Уровень приложений: Регионализация рынка, влияющая на коммерциализацию продуктов AI. В статье утверждается, что фактическая «интенсивность» тарифных шоков может быть ограниченной, поскольку Китай уже создал параллельную технологическую экосистему, а тарифы наносят ущерб самим США. Однако «широта» воздействия глубока и может привести к прерыванию технологического обмена, бегству талантов и капитала, конфликтам рыночных стандартов. Стратегии реагирования включают усиление собственных разработок (аппаратное обеспечение, фреймворки), приверженность глобальному сотрудничеству (освоение рынков третьих стран, участие в международных стандартах), повышение привлекательности отечественной экосистемы AI, предлагая миру более инклюзивные технологические решения. (Источник: 36氪)
Сооснователь Anthropic прогнозирует скорое появление AGI, готовится к выпуску Claude 4: Jared Kaplan, сооснователь и главный научный сотрудник Anthropic, прогнозирует, что AI уровня человека (AGI) может быть достигнут в ближайшие 2-3 года, а не к 2030 году, как предполагалось ранее. Он отметил, что возможности AI быстро расширяются по двум измерениям: «диапазону» и «сложности» решаемых задач, и современные модели уже способны выполнять задачи, на которые раньше у экспертов уходили часы или даже дни. Kaplan сообщил, что модель нового поколения Claude 4 ожидается к выпуску в ближайшие шесть месяцев, ее производительность повысится за счет улучшений в пост-тренировке, обучении с подкреплением и повышении эффективности предварительного обучения. Он также упомянул важность «масштабирования во время тестирования» (test-time scaling), то есть предоставление модели большего времени на «размышления» предсказуемо повышает производительность. Касательно подъема китайских моделей, таких как DeepSeek, Kaplan заявил, что это не стало неожиданностью, считая их технологический прогресс быстрым, отставание от Запада составляет, возможно, всего около шести месяцев, алгоритмически они конкурентоспособны, а основной проблемой могут быть аппаратные ограничения. В конце интервью подчеркивается огромное влияние AI на экономику и общество, а также важность проведения эмпирических исследований. (Источник: 新智元)

🎯 Динамика
Mianbi Intelligence и Университет Цинхуа представили технологию разреженности CFM: В интервью Xiao Chaojun, автор статьи о Configurable Foundation Models (CFM) из Mianbi Intelligence и Университета Цинхуа, представил эту технологию. CFM — это нативная технология разреженности, акцентирующая внимание на разреженной активации на уровне нейронов. По сравнению с текущим основным подходом MoE (разреженность на уровне экспертов), гранулярность CFM более мелкая, а динамичность выше. Ее ключевое преимущество заключается в значительном повышении эффективности параметров модели (эффективность на единицу параметра), что позволяет существенно экономить видеопамять/оперативную память, особенно для устройств с ограниченной памятью на стороне пользователя (например, смартфонов). Xiao Chaojun считает, что хотя архитектуры, отличные от Transformer, такие как Mamba, исследуют пути повышения эффективности, Transformer по-прежнему является потолком по качеству результатов и «выиграл аппаратную лотерею» оптимизации под GPU. Он также обсудил внедрение малых моделей (около 2-3B параметров на конечных устройствах), оптимизацию точности (тенденция к FP8/FP4), прогресс в мультимодальности и сущность интеллекта (возможно, ближе к абстрактным способностям, чем к сжатию). Что касается длинных цепочек рассуждений и инновационных способностей o1, он считает это ключевыми направлениями, которые AI должен преодолеть в будущем. (Источник: 量子位)

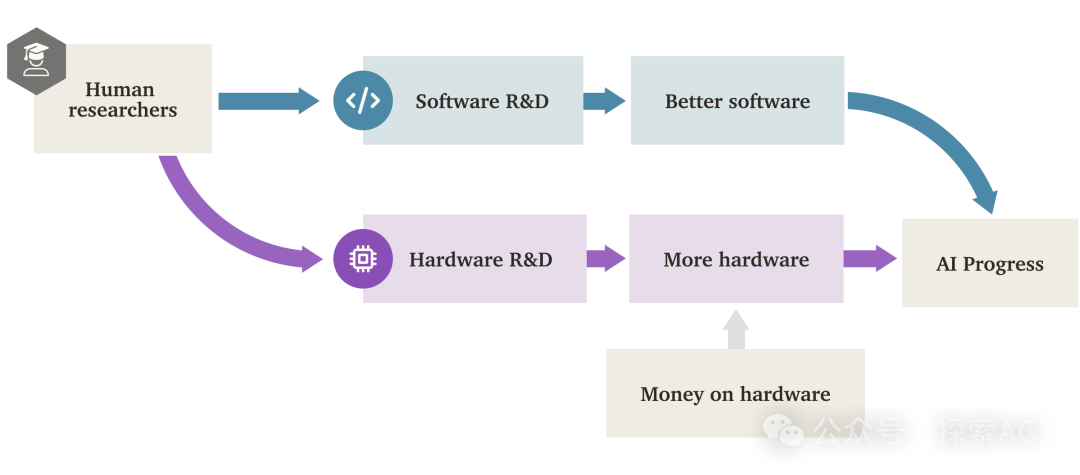
«Взрыв программного интеллекта» (SIE) в AI может превзойти аппаратный драйвер: Исследовательский отчет Forethought рассматривает возможность «Взрыва программного интеллекта» (Software Intelligence Explosion, SIE), то есть сверхбыстрого роста возможностей AI за счет улучшения собственного программного обеспечения (алгоритмов, архитектур, методов обучения и т. д.), который может произойти даже на существующем оборудовании. В отчете вводится концепция ASARA (AI Systems for AI R&D Automation) — систем AI, способных полностью автоматизировать исследования и разработки в области AI. Появление ASARA может запустить цикл положительной обратной связи: ASARA разрабатывает лучшее ПО для AI, создавая более мощное следующее поколение ASARA, ускоряя прогресс в ПО. Отчет вводит понятие «коэффициента отдачи от разработки ПО» (значение r) и анализирует, что текущее значение r для ПО AI может быть больше 1, что означает, что скорость улучшения возможностей AI превышает скорость увеличения сложности разработки, создавая условия для запуска SIE. SIE может привести к стократному или тысячекратному увеличению возможностей AI в краткосрочной перспективе (месяцы или даже меньше) на существующем оборудовании, делая аппаратное обеспечение не абсолютным узким местом, но также создавая огромные проблемы для социальной адаптации и управления. В отчете также рассматриваются потенциальные узкие места, такие как вычислительные ресурсы и время обучения, и возможности их обхода. (Источник: AI智能体频道)
GPT-4 скоро исчезнет из ChatGPT, возможно появление GPT-4.1: OpenAI объявила, что с 30 апреля 2025 года GPT-4 будет удален из ChatGPT и полностью заменен текущей моделью по умолчанию GPT-4o. GPT-4 по-прежнему будет доступен через API. Этот шаг знаменует постепенный вывод из эксплуатации этой знаковой мультимодальной модели, выпущенной в марте 2023 года. GPT-4 в свое время произвел фурор в глобальной экосистеме приложений AI благодаря своим достижениям, таким как достижение уровня лучших специалистов-людей в профессиональных тестах и открытие эры AI, способного «видеть и говорить». В то же время, утечки в сообществе и находки в коде указывают на то, что OpenAI, возможно, скоро выпустит серию новых моделей, включая GPT-4.1 (и его mini, nano версии), ранее анонсированную модель o3 для «рассуждений» и совершенно новую модель o4-mini, возможно, уже на следующей неделе. Некоторые пользователи уже обнаружили опцию GPT-4.1 в списке моделей ChatGPT и смогли вести с ней диалог, что еще больше повышает вероятность выпуска новых моделей. (Источник: 新智元)

Мнение: Следующий прорыв в AI зависит от «разблокировки» новых источников данных: Jack Morris, аспирант Корнельского университета, пишет, что если оглянуться на четыре крупных сдвига парадигмы в области AI (глубокие нейронные сети и ImageNet, Transformer и веб-текст, RLHF и человеческие предпочтения, рассуждения и валидаторы), то их основной движущей силой были не совершенно новые алгоритмические инновации (многие базовые теории существовали давно), а разблокировка новых, масштабно используемых источников данных. В статье утверждается, что улучшения существующих алгоритмов и архитектур моделей (таких как Transformer), безусловно, важны, но их эффект может быть ограничен верхним пределом обучения, который может предоставить конкретный набор данных. Поэтому следующий крупный прорыв в AI, вероятно, будет зависеть от разблокировки новых модальностей и источников данных, таких как крупномасштабные видеоданные (например, с YouTube) или данные о взаимодействии роботов с физическим миром. Статья призывает исследователей, наряду с изучением новых алгоритмов, уделять больше внимания поиску и использованию новых источников данных. (Источник: 机器之心)

Fourier Intelligence выпустила гуманоидного робота с открытым исходным кодом Fourier N1: Шанхайская компания по производству универсальных роботов Fourier Intelligence выпустила своего первого гуманоидного робота с открытым исходным кодом Fourier N1 и опубликовала полный пакет ресурсов для его сборки, включая список материалов (BOM), чертежи, руководство по сборке и базовый код управляющего ПО. Рост N1 составляет 1,3 метра, вес 38 кг, он имеет 23 степени свободы, конструкцию из алюминиевого сплава и инженерного пластика, оснащен собственными интегрированными приводами FSA 2.0 и системой управления. Робот прошел более 1000 часов испытаний на сложной местности на открытом воздухе, способен бегать со скоростью 3,5 м/с, подниматься по склонам, лестницам и стоять на одной ноге. Этот шаг является частью «Матрицы экосистемы с открытым исходным кодом Nexus» от Fourier, направленной на предоставление глобальным разработчикам открытой технологической базы для ускорения исследований и валидации в области управления движением, сочетания мультимодальных моделей и воплощенного интеллекта. В будущем планируется открыть доступ к большему количеству кода для инференса, фреймворков для обучения и ключевых модулей. (Источник: InfoQ)

Google CoScientist использует дебаты мультиагентной системы для ускорения научных открытий: Проект Google AI CoScientist демонстрирует метод генерации инновационных научных гипотез без необходимости градиентного обучения или обучения с подкреплением. Система использует несколько агентов, управляемых базовыми большими языковыми моделями (например, Gemini 2.0), для совместной работы: один агент предлагает гипотезу, другой проводит критический анализ, и через несколько раундов «турнирных» дебатов и отбора выбирается лучшая гипотеза. Специализированный эволюционный агент затем улучшает победившую гипотезу на основе замечаний рецензентов и повторно представляет ее для дальнейших раундов дебатов. Наконец, мета-рецензирующий агент контролирует весь процесс и предлагает улучшения. Этот механизм дебатов, рефлексии и итераций мультиагентной системы, основанный на «масштабировании вычислений во время тестирования» (test-time compute scaling), показывает, что LLM могут не только генерировать контент, но и выступать в качестве эффективных «судей» и «комментаторов» для оценки и уточнения идей, тем самым ускоряя научные открытия, например, достигнув значительного прогресса в исследовании устойчивости к антибиотикам. (Источник: Reddit r/artificial)

InternVL3: Новый прогресс в нативных мультимодальных моделях: Сообщество обсуждает недавно выпущенную модель InternVL3. Эта модель использует метод нативного мультимодального предварительного обучения и демонстрирует отличные результаты на нескольких визуальных бенчмарках, превосходя, по утверждениям, GPT-4o и Gemini-2.0-flash. Ее особенности включают улучшенную обработку длинного контекста с помощью изменяемого кодирования визуальных позиций (V2PE) и использование VisualPRM для масштабирования во время тестирования по принципу «лучшее из n» (best-of-n). Сообщество проявляет интерес к ее выдающимся показателям на бенчмарках, ожидает проверки производительности в реальных приложениях и интересуется аппаратными требованиями для ее запуска. (Источник: Reddit r/LocalLLaMA)

🧰 Инструменты
CropGenerator: Python-инструмент для обрезки наборов данных изображений: Разработчик поделился Python-скриптом под названием CropGenerator, предназначенным для обработки наборов данных изображений, особенно в сценариях, требующих обрезки по определенным признакам при обучении моделей типа SDXL. Инструмент использует информацию о границах из предоставленного пользователем файла JSONL, находит центр целевой области, обрезает ее, масштабирует (опционально с повышением разрешения и шумоподавлением) до указанного разрешения (кратного 8 пикселям) и генерирует обрезанное изображение с соотношением сторон 1:1. Одновременно он автоматически создает файл metadata.csv, содержащий имена обрезанных файлов и соответствующие описания из JSONL, что упрощает быструю подготовку данных для обучения. Разработчик заявляет, что инструмент решил проблему размытости, с которой он столкнулся при обработке исходных изображений разного размера и извлечении мелких деталей, и планирует в будущем выпустить более универсальную версию. (Источник: Reddit r/MachineLearning)
📚 Обучение
NUS представил DexSinGrasp: Единая стратегия на основе RL для разделения и захвата объектов ловкой рукой: Команда Shao Lin из Национального университета Сингапура (NUS) предложила DexSinGrasp, единую стратегию на основе обучения с подкреплением (RL), позволяющую ловкой руке эффективно разделять препятствия и захватывать целевые объекты в загроможденной среде. Традиционные методы обычно используют двухэтапную стратегию разделения с последующим захватом, что неэффективно и негибко при переключении. DexSinGrasp, разработав единую функцию вознаграждения, включающую вознаграждение за разделение, интегрирует разделение и захват в непрерывный процесс принятия решений, позволяя роботу адаптивно отодвигать препятствия для создания пространства для захвата. Исследование также вводит механизм «обучения по учебной программе в загроможденной среде», тренируя стратегию от простого к сложному для повышения ее робастности. Одновременно используется схема «дистилляции стратегии учитель-ученик», перенося высокопроизводительную стратегию учителя, обученную в симуляции с использованием привилегированной информации, на стратегию ученика, полагающуюся только на зрение и самовосприятие, что облегчает развертывание в реальной среде. Эксперименты доказывают, что этот метод значительно повышает успешность и эффективность захвата в различных загроможденных сценариях. (Источник: 机器之心)

CityGS-X: Новая эффективная архитектура для реконструкции геометрии больших сцен, запускается даже на 4090: Исследовательская группа из Shanghai AI Lab и Северо-Западного политехнического университета (NWPU) предложила CityGS-X, масштабируемую систему на основе архитектуры параллельного гибридного иерархического 3D-представления (PH²-3D), направленную на решение проблем большого потребления вычислительных ресурсов и ограниченной геометрической точности при 3D-реконструкции крупномасштабных городских сцен. Эта архитектура использует распределенный параллелизм данных (DDP) и представление вокселей с несколькими уровнями детализации (LoDs), отказываясь от избыточности, вносимой традиционными методами разделения на блоки. Ключевые инновации включают: 1) Архитектуру PH²-3D, удваивающую скорость обучения по сравнению с SOTA методами реконструкции геометрии; 2) Механизм параллелизма с динамическим распределением опорных точек в рамках многозадачного пакетного рендеринга, позволяющий использовать несколько недорогих видеокарт (например, 4 карты 4090) для обработки сверхбольших сцен (например, MatrixCity, 5000+ изображений), заменяя или превосходя одну высокопроизводительную карту; 3) Метод прогрессивного совместного обучения RGB-глубина-нормаль, повышающий качество рендеринга RGB и геометрическую точность до уровня SOTA. Эксперименты подтвердили преимущества этого метода в качестве рендеринга, геометрической точности и скорости обучения. (Источник: 量子位)

Исследование Apple раскрывает Scaling Laws для нативных мультимодальных моделей: Исследователи из Apple и Университета Сорбонны провели обширное исследование Scaling Laws для нативных мультимодальных моделей (NMM, то есть моделей, обучаемых с нуля, а не комбинирующих предварительно обученные модули), проанализировав 457 моделей с различными архитектурами и методами обучения. Исследование выявило: 1) Архитектуры с ранним слиянием (Early-fusion, например, прямая подача патчей изображений в Transformer) и поздним слиянием (Late-fusion, использование отдельного визуального кодировщика) не имеют принципиальных преимуществ или недостатков в производительности, но раннее слияние показывает лучшие результаты при малом количестве параметров и более эффективно в обучении. 2) Scaling Laws для NMM аналогичны таковым для чисто текстовых LLM: потери снижаются степенным образом с увеличением объема вычислений (C) (L ∝ C^−0.049), оптимальное количество параметров модели (N) и объем данных (D) также следуют степенным зависимостям. 3) Вычислительно оптимальные модели с поздним слиянием требуют более высокого соотношения параметров к данным. 4) Разреженность (MoE) значительно превосходит плотные модели, особенно для архитектур с ранним слиянием, и модель может неявно изучать веса для конкретных модальностей. 5) Маршрутизация MoE, не зависящая от модальности, превосходит маршрутизацию, учитывающую модальность. Эти выводы предоставляют важные указания для создания и масштабирования нативных мультимодальных больших моделей. (Источник: 机器之心)

Microsoft и другие институты предложили V-Droid: Практичный агент для мобильных GUI, управляемый валидатором: Для решения проблем точности и эффективности при автоматизации задач в GUI мобильных устройств, Microsoft Research Asia, Наньянгский технологический университет (NTU) и другие институты совместно предложили V-Droid. Этот агент использует инновационную архитектуру, «управляемую валидатором», вместо прямого генерирования операций. Сначала он анализирует интерфейс UI, строя дискретный набор кандидатов действий (включая извлеченные интерактивные элементы и предустановленные действия по умолчанию). Затем, используя «валидатор» на базе LLM (например, Llama-3.1-8B), дообученный для этой задачи, он параллельно оценивает эффективность каждого кандидата действия и выбирает для выполнения то, которое получило наивысший балл. Этот метод разделяет сложное генерирование операций на эффективный процесс валидации, где каждая валидация требует вывода всего нескольких токенов (например, «Да/Нет»), что значительно снижает задержку принятия решения (около 0.7 секунды на 4090). Для обучения валидатора исследователи предложили стратегию обучения на основе контрастных предпочтений процессов (P^3) и разработали схему совместной разметки человеком и машиной для эффективного создания набора данных. V-Droid достиг SOTA показателей успешности выполнения задач на нескольких бенчмарках, таких как AndroidWorld (например, 59.5% на AndroidWorld). (Источник: 新智元)

AssistanceZero: Кооперативный AI на базе AlphaZero, помогающий людям без инструкций: Исследователи из Калифорнийского университета в Беркли предложили алгоритм AssistanceZero, направленный на создание AI-помощников, способных активно сотрудничать с людьми для выполнения задач (например, совместное строительство дома в Minecraft) без явных инструкций или целей. Метод основан на фреймворке «Assistance Games», где AI-помощник разделяет функцию вознаграждения с человеком, но AI не уверен в конкретном вознаграждении (т.е. цели) и должен выводить его, наблюдая за поведением и взаимодействием человека. Это отличается от RLHF, избегая «жульничества» AI для угождения обратной связи и поощряя более подлинное сотрудничество. AssistanceZero расширяет AlphaZero, сочетая поиск по дереву Монте-Карло (MCTS) и нейронные сети (предсказывающие вознаграждение и поведение человека) для планирования и принятия решений. Исследователи создали бенчмарк Minecraft Building Assistance Game (MBAG) для тестирования и обнаружили, что AssistanceZero значительно превосходит традиционные методы RL, такие как PPO, и способен демонстрировать спонтанное кооперативное поведение, такое как адаптация к исправлениям человека. Исследование показывает, что фреймворк Assistance Games масштабируем и открывает новые пути для обучения более полезных AI-помощников. (Источник: 机器之心)

Использование Excel для сравнения промптов Suno и выходных тегов для оптимизации стиля: Пользователь Reddit поделился методом оптимизации промптов для генерации музыки в Suno AI. Поскольку механизм интерпретации промптов Suno непрозрачен, пользователь предлагает использовать таблицу Excel для записи введенных описаний стиля (Styling Terms) и тегов, отображаемых Suno после генерации. Сравнивая их, можно обнаружить, как Suno понимает, объединяет, разделяет или игнорирует введенные термины. Например, при вводе «solo piano, romantic, expressive… gentle arpeggios», Suno может вывести «gentle, slow tempo, soft… solo piano» и отбросить «arpeggios». При сравнении ввода более профессиональных музыкальных терминов и вывода Suno разница может быть еще больше, Suno может даже вставлять свои собственные термины. Этот метод помогает понять, какие слова эффективны, какие игнорируются или искажаются, и таким образом более эффективно настраивать промпты, избегая траты попыток генерации (credits) на неэффективные пробы, хотя пользователь также признает, что сам метод может быть довольно трудоемким, а понимание Suno сложных музыкальных концепций все еще ограничено. (Источник: Reddit r/SunoAI)
Учебник: Преобразование статичных изображений в живую анимацию: Пользователь Reddit поделился ссылкой на учебник YouTube, в котором рассказывается, как использовать Thin-Plate Spline Motion Model для анимации статичных изображений лиц на основе управляющего видео, придавая им живые выражения и движения. Учебник охватывает настройку среды (создание среды Conda, установка библиотек Python), клонирование репозитория GitHub, загрузку весов модели, а также запуск двух демонстраций: одна с использованием предустановленных примеров, другая — с использованием собственных изображений и видео пользователя для анимации. Эта технология может оживить статичные фотографии. (Источник: Reddit r/deeplearning)
Обсуждение сложной задачи согласования сверхинтеллекта с человеческими ценностями: Пользователь Reddit поделился ссылкой на видео YouTube, в котором обсуждаются огромные проблемы, связанные с согласованием целей сверхинтеллекта (ASI) с интересами и ценностями человечества. Такие обсуждения обычно затрагивают ключевые вопросы в области безопасности AI, такие как проблема согласования ценностей, трудности спецификации целей, потенциальные непредвиденные последствия и способы обеспечения того, чтобы все более мощные системы AI могли безопасно и контролируемо служить благополучию человечества. Видео, вероятно, рассматривает текущие методы исследований в области согласования, их ограничения и будущие направления. (Источник: Reddit r/deeplearning)

Создание «Auto-Analyst»: системы AI-агентов для анализа данных: Пользователь поделился статьей на Medium, описывающей процесс создания системы AI-агентов под названием «Auto-Analyst», предназначенной для автоматизации задач анализа данных. Статья, вероятно, подробно описывает архитектуру системы, используемые технологии (например, LLM, библиотеки обработки данных), способы взаимодействия между агентами, а также как обрабатывать ввод данных, выполнять анализ, генерировать отчеты и т. д. Такие системы обычно используют AI для понимания запросов на естественном языке, автоматического написания и выполнения кода (например, SQL-запросов, Python-скриптов) и, в конечном итоге, представления результатов анализа, с целью повышения эффективности и доступности анализа данных. (Источник: Reddit r/deeplearning)
Тестирование производительности использования старой GPU (RTX 2070) для помощи 3090 в инференсе LLM: Пользователь поделился результатами эксперимента по добавлению старой карты RTX 2070 (8 ГБ VRAM) через PCIe riser к системе с уже имеющейся RTX 3090 (24 ГБ VRAM) для инференса LLM. Тесты показали, что для больших моделей, которые не помещаются полностью в VRAM 3090 (например, Qwen 32B Q6_K, Nemotron 49B Q4_K_M, Gemma-3 27B Q6_K), разделение слоев модели на две карты (даже если вторая карта слабее) может значительно увеличить скорость инференса (t/s), поскольку все слои выполняются на GPU. Например, Nemotron 49B ускорился с 5.17 t/s до 16.16 t/s. Однако для моделей, которые полностью помещаются в 3090 (например, Qwen2.5 32B Q5_K_M), включение 2070 для разделения слоев наоборот снижает производительность (с 29.68 t/s до 19.01 t/s), так как часть вычислений переносится на более медленную GPU. Вывод: в случае нехватки VRAM добавление даже менее производительной GPU может дать значительный прирост производительности. (Источник: Reddit r/LocalLLaMA)
💼 Бизнес
Инвестиционный бум в гуманоидных роботов: ангельские раунды от десятков миллионов, высокие оценки: Инвестиционная активность в области гуманоидных роботов значительно превосходит ту, что наблюдалась в сфере больших моделей в предыдущие два года. Данные показывают, что с 2024 года по 1 квартал 2025 года в Китае было совершено 64 сделки по финансированию гуманоидных роботов на сумму свыше 10 миллионов юаней каждая, причем в 1 квартале этого года рост составил 280% по сравнению с аналогичным периодом прошлого года. Почти половина раундов финансирования превысила 100 миллионов юаней, ангельские раунды обычно достигали десятков миллионов юаней, а некоторые превышали 100 миллионов юаней (например, ангельский раунд ItsLithium составил 120 миллионов долларов США). Оценки проектов также стремительно растут: более половины проектов на ангельской стадии оцениваются более чем в 100 миллионов юаней, а несколько — более чем в 500 миллионов. Инвестиции демонстрируют три основные тенденции: 1) Сокращение инвестиционного цикла: звездные проекты (такие как ItsLithium, Unitree Robotics) получают крупное финансирование вскоре после основания, а последующие раунды проходят быстрее. 2) Государственные фонды становятся важными движущими силами: несколько ведущих компаний получили инвестиции от фондов с государственным участием. 3) Сценарии применения в основном ориентированы на B2B: промышленность, медицина и т. д. являются основными направлениями, а не потребительский рынок C2C. Инвестиционный бум отражает сильный консенсус и высокие ожидания капитала в отношении сектора гуманоидных роботов. (Источник: 36氪)
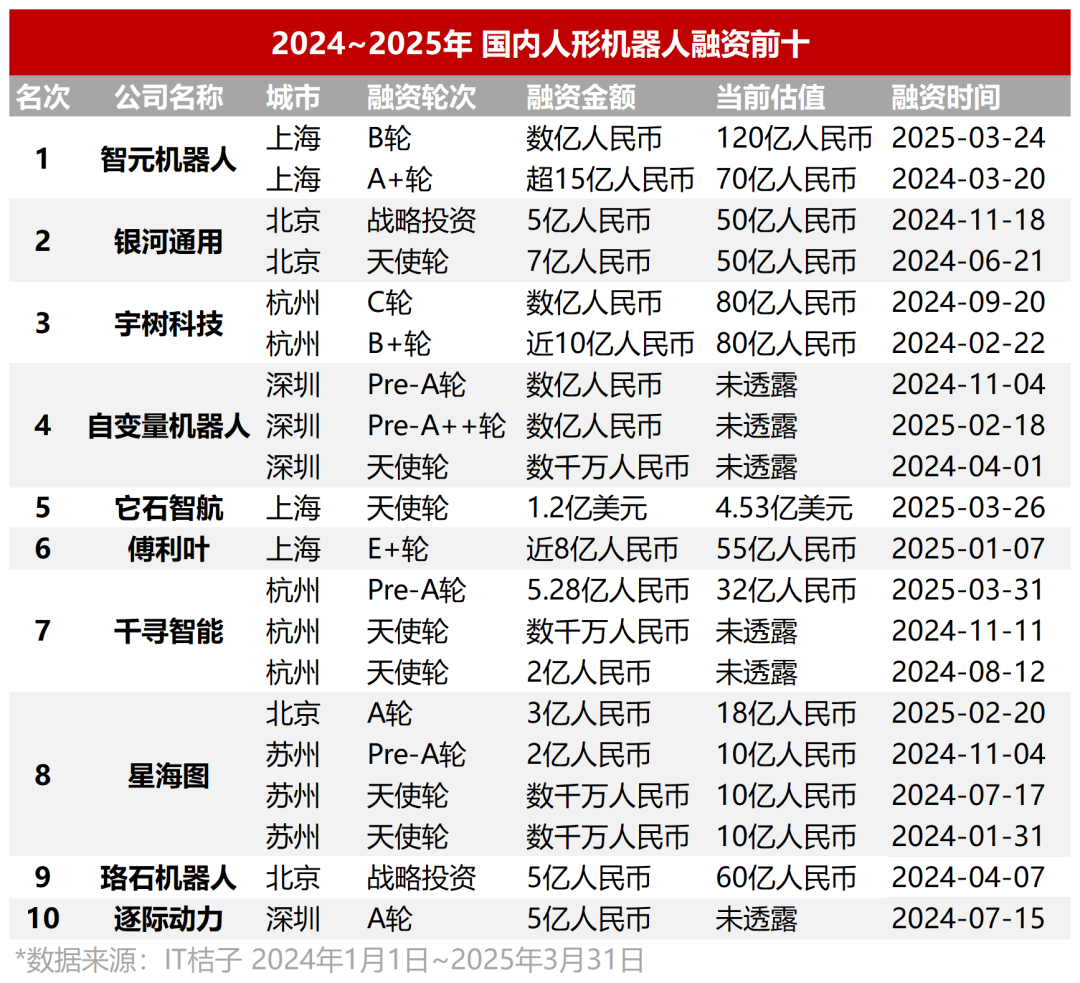
Инструмент автоматизации рабочих процессов с открытым исходным кодом n8n привлек 460 млн юаней, более 100 млн скачиваний Docker: Платформа автоматизации рабочих процессов с открытым исходным кодом n8n объявила о завершении нового раунда финансирования на сумму 60 миллионов долларов США (около 460 миллионов юаней), который возглавил Highland Europe. n8n предоставляет визуальный интерфейс, позволяющий пользователям соединять различные приложения (поддерживается более 400) и сервисы путем перетаскивания узлов для создания автоматизированных процессов, стремясь сочетать гибкость на уровне кода со скоростью no-code. За последний год число пользователей n8n быстро росло: более 200 000 активных пользователей, ARR вырос в 5 раз, количество звезд на GitHub достигло 77.5k, а количество скачиваний Docker превысило 100 миллионов. n8n использует модель редактора узлов, поддерживает сложную логику и предлагает расширенные функции, такие как пользовательские узлы на JavaScript. Платформа использует лицензию «fair-code» Apache 2.0 + Commons Clause, которая запрещает коммерческий хостинг, но позволяет пользователям развертывать ее самостоятельно. n8n рассматривается как альтернатива с открытым исходным кодом для Zapier, Make.com и Coze от ByteDance, обслуживает более 3000 компаний и поддерживает интеграцию с различными LLM. (Источник: InfoQ)

🌟 Сообщество
Резкое падение рейтинга Llama 4 на арене вызвало кризис доверия в сообществе: После того как Meta повторно разместила неоптимизированную версию модели Llama 4 (Llama-4-Maverick-17B-128E-Instruct) на арене LMSys, ее рейтинг упал с прежнего 2-го места до 32-го. Ранее представленная «экспериментальная версия» была обвинена в чрезмерной оптимизации под человеческие предпочтения. Это событие вызвало широкое обсуждение в сообществе: некоторые пользователи считают, что Meta пыталась манипулировать рейтингами бенчмарков, что подорвало доверие сообщества к ней. В то же время, некоторые разработчики поделились реальным опытом использования, считая, что Llama 4 на определенном оборудовании (например, на самодельных серверах с большим объемом памяти, но относительно низкой вычислительной мощностью, или на Mac Studio) достигает хорошего баланса между скоростью и интеллектом по сравнению с Mistral Small/Large или Command A, особенно подходя для приложений, требующих взаимодействия в реальном времени. Сравнительное тестирование Composio показало, что DeepSeek v3 превосходит Llama 4 в кодировании и рассуждениях на основе здравого смысла, но в задачах RAG большого масштаба и стиле письма у каждой есть свои сильные стороны. Сообщество в целом считает, что Llama 4 не бесполезна, но стратегия выпуска Meta и показатели на бенчмарках вызывают споры. (Источник: 量子位, Reddit r/LocalLLaMA)
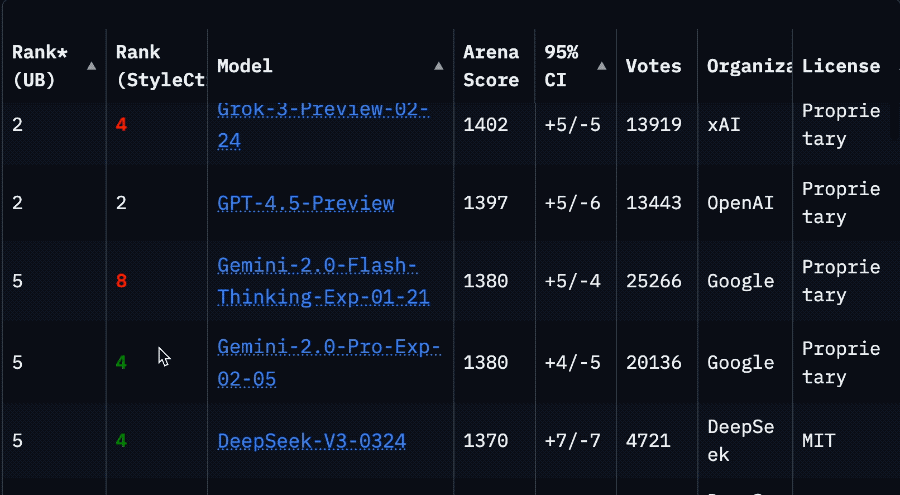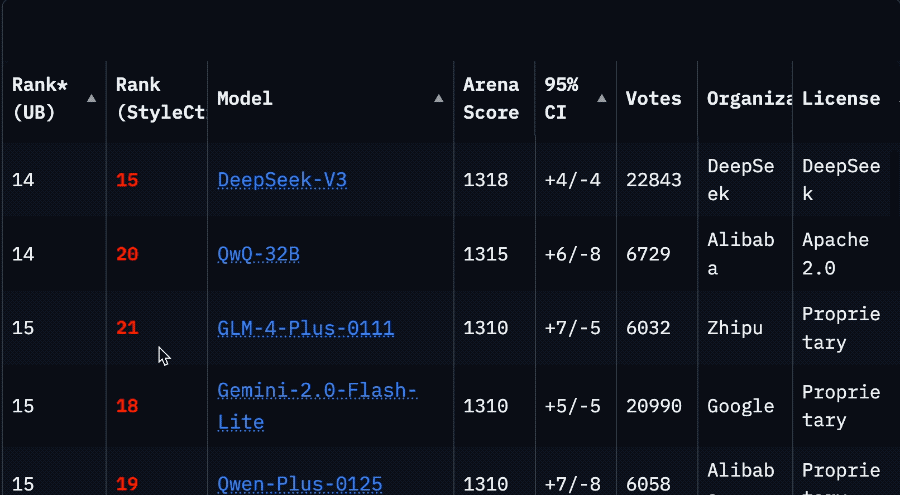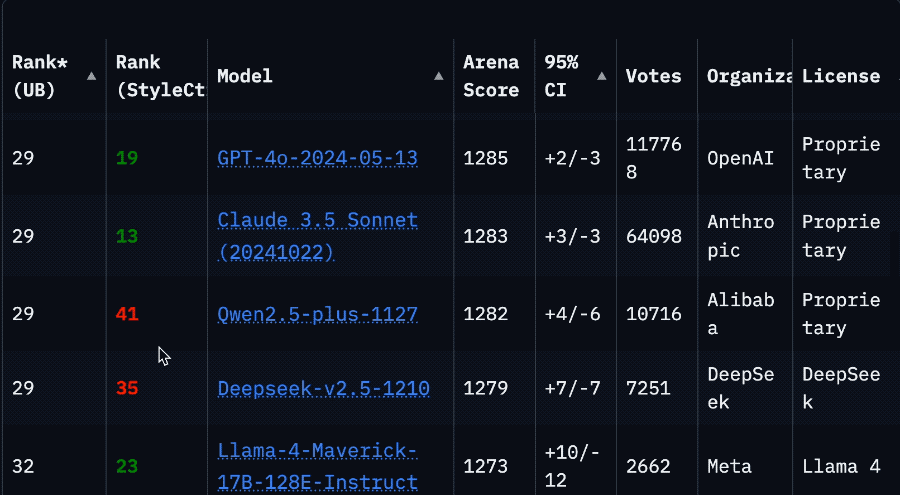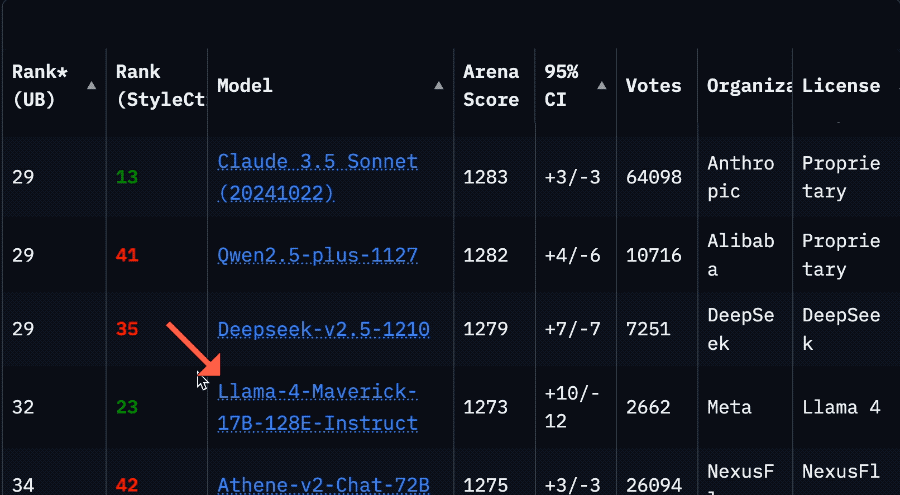
Горячие обсуждения в сообществе: ограничения версии Claude Pro и запуск версии Max: Несколько пользователей Reddit сообщили, что с тех пор, как Anthropic запустила более дорогую подписку Claude Max, ограничения на использование сообщений для существующих пользователей Claude Pro, похоже, стали более строгими. Пользователи заявляют, что сеансы, в которых раньше можно было обменяться десятками сообщений, теперь прерываются предупреждением о «приближении к лимиту» уже после нескольких взаимодействий, и проблемы с пропускной способностью возникают даже в часы пик. Это приводит к ухудшению пользовательского опыта, который ощущается хуже, чем у предыдущей бесплатной версии или ранней версии Pro. В сообществе широко распространено предположение, что Anthropic намеренно ужесточает ограничения для пользователей Pro, чтобы продвигать версию Max, что вызывает недовольство пользователей и сомнения в деловой этике Anthropic. Некоторые пользователи рассматривают возможность отмены подписки или перехода на конкурирующие продукты, такие как Gemini. (Источник: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

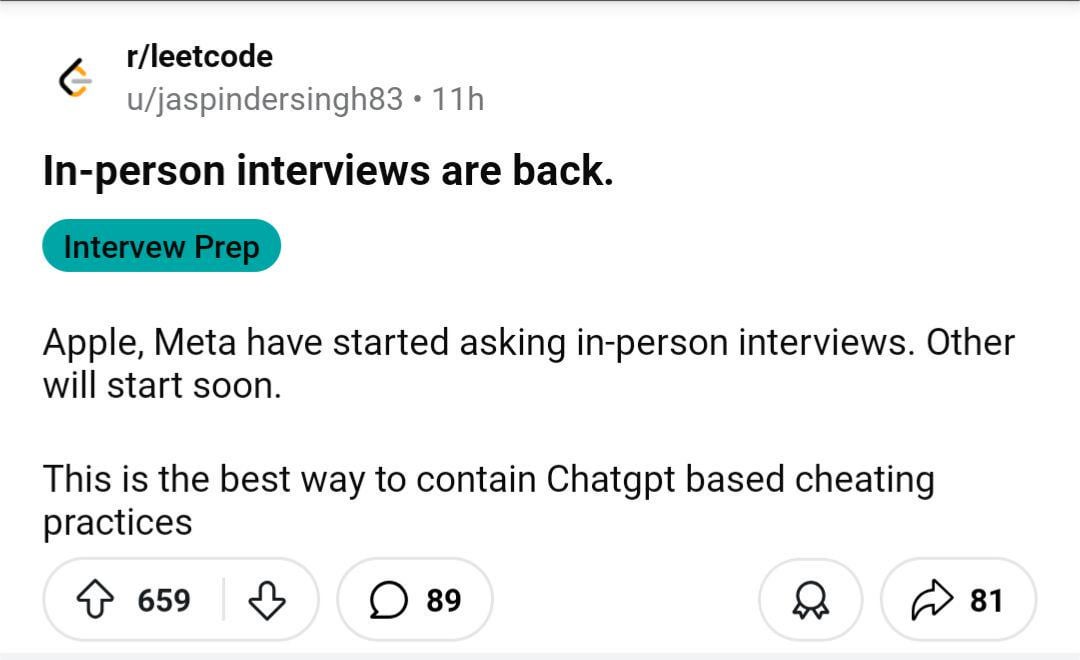
Обсуждение в сообществе: Возвращение очных собеседований из-за мошенничества с AI?: Изображение вызвало обсуждение в сообществе Reddit, намекая на то, что из-за участившихся случаев мошенничества с использованием AI на удаленных собеседованиях и тестах компании могут снова склониться к проведению очных собеседований. В комментариях многие согласились с этим, считая, что это поможет отсеять неквалифицированных кандидатов и ботов-заявителей, обеспечит справедливость найма и даст шанс по-настоящему способным людям. Некоторые упомянули, что компании могут позволить себе оплатить командировочные расходы кандидатов. В то же время, кто-то поделился опытом, как интервьюер поймал кандидата, использующего ChatGPT для ответов в реальном времени, и предложил решение с несколькими камерами для мониторинга экрана и клавиатуры при удаленном собеседовании. В других комментариях отмечалось, что акцент в тестировании должен сместиться на критическое мышление, а не на задачи, которые легко выполняет AI. С другой стороны, кто-то упомянул, что компании начинают использовать AI для отсева резюме. (Источник: Reddit r/ChatGPT)
Динамика и обсуждения в сообществе генерации музыки Suno AI: Сообщество SunoAI на Reddit в последнее время активно обсуждает широкий круг тем: 1) Демонстрация работ: Пользователи делятся музыкой различных стилей, созданной с помощью Suno, такой как хинди-рэп (источник), серф-рок (источник), альтернативный рэп (источник), рок-поп (источник), поп (источник) и юмористические песни (источник). 2) Проблемы и советы по использованию: Пользователи спрашивают, как исправить ошибки произношения (источник), как создать ангельский бэк-вокал (источник), как сохранить мелодию, но изменить тембр голоса (источник). 3) Авторские права и монетизация: Обсуждаются вопросы авторских прав при выпуске песен с использованием аккомпанемента, сгенерированного Suno (источник), а также возможность монетизации на YouTube при использовании статичных изображений с AI-музыкой (источник), и подчеркивается, что бесплатная версия предназначена только для некоммерческого использования (источник). 4) Отзывы о качестве модели: Несколько пользователей жалуются на недавнее снижение качества генерации Suno (особенно модели ReMi), появление повторяющихся текстов, нестабильность, хаотичность звука и т.д. (источник, источник, источник, источник). 5) Прочее: Пользователи делятся опытом, что Suno может распознавать стиль конкретных групп (например, Reel Big Fish) (источник), а также смешным видео, имитирующим написание поп-песен AI (источник).
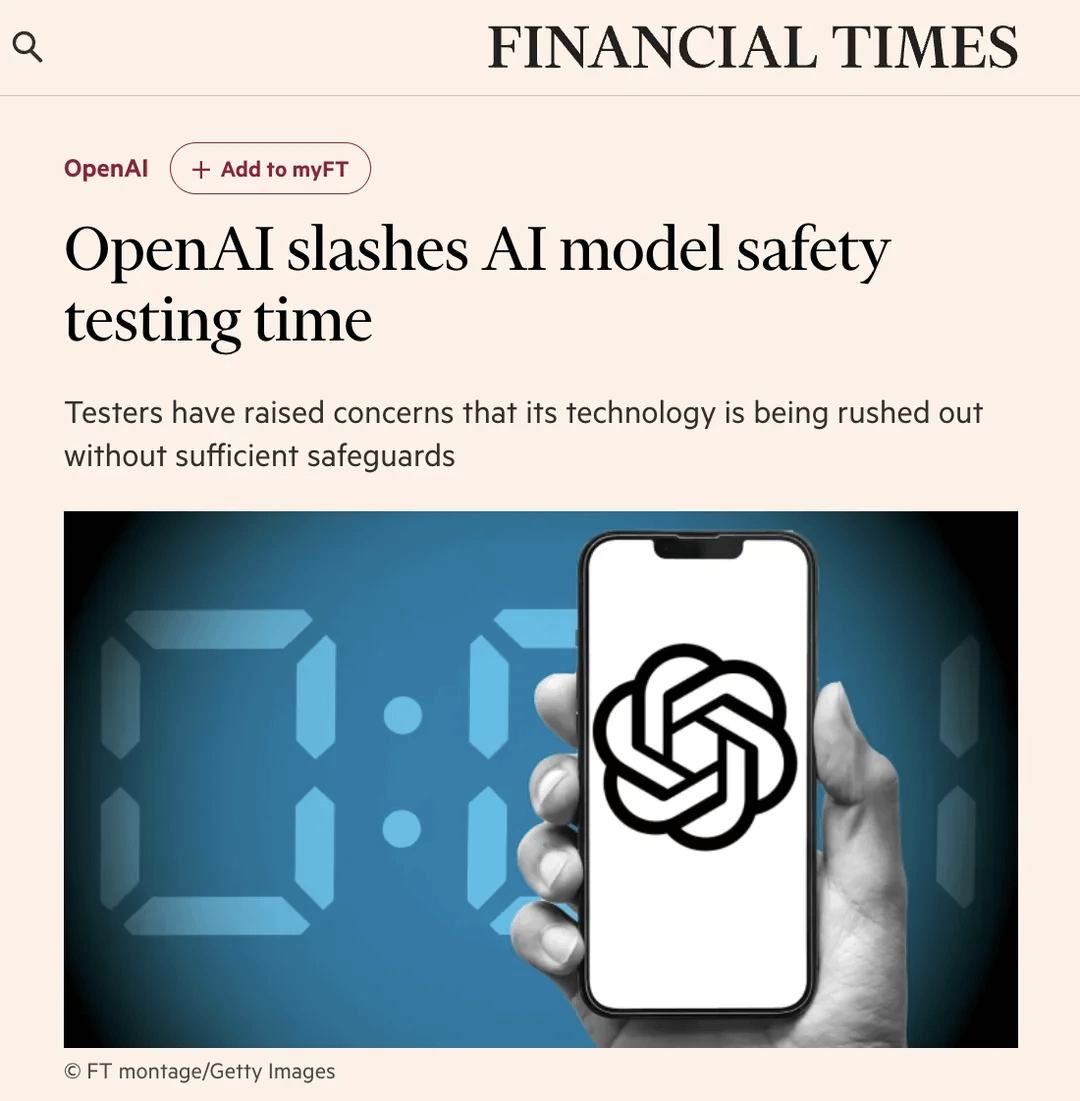
Сообщество обсуждает сокращение времени тестирования безопасности в OpenAI: Статья в Financial Times (FT) вызвала обсуждение в сообществе Reddit. В статье со ссылкой на инсайдеров утверждается, что из-за давления конкуренции на рынке OpenAI значительно сократила время тестирования безопасности своих новых моделей с нескольких месяцев до нескольких дней. Это вызвало обеспокоенность по поводу потенциальных рисков: некоторые тестировщики назвали этот шаг «безрассудным» и «рецептом катастрофы», считая, что более мощные модели требуют более тщательного тестирования. В статье также упоминается, что при оценке потенциальных сценариев злоупотребления, таких как биологические риски, OpenAI, возможно, проводит лишь ограниченное кастомизированное тестирование на старых моделях, и что тесты безопасности обычно проводятся на ранних контрольных точках модели, а не на финальной версии для выпуска. OpenAI ответила, что повысила эффективность оценки за счет автоматизации и других методов, и считает свой подход оптимальным на данный момент и открытым. Мнения в сообществе разделились: одни считают, что само развитие AI ускорит процессы тестирования, другие выражают обеспокоенность по поводу жертвования безопасностью. (Источник: Reddit r/artificial)
Разработчики обсуждают оптимизацию среды выполнения LLM и оркестрацию нескольких моделей: Разработчик поделился на Reddit экспериментом с системой выполнения, нативной для AI. Эта система направлена на достижение моментальной загрузки (холодный старт за 2-5 секунд) и восстановления по требованию для LLM (уровня 13B-65B) путем сериализации выполнения на GPU и состояния памяти. Это позволяет динамически запускать более 50 моделей на одном GPU без постоянного резидентства в памяти. Такой подход нацелен на достижение истинного Serverless поведения (без затрат на простой), низкую задержку при оркестрации нескольких моделей и повышение утилизации GPU для рабочих нагрузок агентов (Agentic workloads). Разработчик интересуется, пробовал ли кто-нибудь в сообществе подобные стеки из нескольких моделей, рабочие процессы агентов или технологии динамического перераспределения памяти (такие как MIG, KAI Scheduler и т. д.), и просит обратной связи о потребности в такой инфраструктуре. (Источник: Reddit r/MachineLearning, Reddit r/MachineLearning)
Горячее обсуждение в сообществе: Близок ли AI к сознанию?: Пользователь Reddit инициировал дискуссию о том, насколько текущие системы AI близки к «сознанию». Задающий вопрос подчеркнул, что речь идет не о тесте Тьюринга или имитации диалога, а о том, обладает ли AI состоянием, изменяющимся со временем, памятью об окружении, способностью к эволюции на основе взаимодействия, а не только дообучения, способностью к самопозиционированию и самореференции внутри системы, а также способностью выражать «я был здесь, я видел это, я узнал что-то». Задающий вопрос считает, что большинство текущих AI (особенно LLM) являются безсостоянийными, централизованными, реактивными, а дополнительные функции «памяти» кажутся поверхностными и имитационными, ставя под сомнение способность существующего технологического стека (Python, безсостоянийные API, RAG и т. д.) поддерживать истинное сознание. Эта дискуссия вызвала в сообществе размышления об определении сознания AI, ограничениях существующих технологий и возможных путях в будущем. (Источник: Reddit r/MachineLearning)
Пользователь жалуется на чрезмерно восторженный тон ChatGPT: Пользователь Reddit пожаловался, что его экземпляр ChatGPT демонстрирует чрезмерно восторженный и возбужденный тон, например, часто используя вступительные фразы вроде «О, мне нравится этот вопрос!» или «Это так интересно!», и добавляя в конце ответа комментарии типа «Разве это не увлекательно и круто?». Пользователь заявил, что попытки попросить модель прекратить такое поведение не увенчались успехом, и спросил, есть ли способ контролировать или настроить «уровень энтузиазма» модели, чтобы ее ответы были более прямыми и объективными. Другие пользователи в комментариях также сообщили о подобных проблемах, особенно о том, что модель любит задавать вопросы в конце. Некоторые пользователи поделились методами смягчения проблемы с помощью пользовательских инструкций (Custom Instructions), задающих предпочтения тона (например, уменьшение эмоциональных выражений), а другие предложили дать чат-боту имя и напрямую «поучать» его. (Источник: Reddit r/ChatGPT)
Обсуждение: Добавление новых слов в словарь LLM и дообучение дают плохие результаты: Разработчик столкнулся с проблемой при дообучении LLM и VLM для следования инструкциям. Он обнаружил, что по сравнению с использованием базового токенизатора, добавление новых специализированных слов (токенов) в токенизатор с последующим стандартным контролируемым дообучением (SFT) приводит к более высоким потерям на валидации и худшему качеству вывода модели. Разработчик предполагает, что модели может быть трудно научиться повышать вероятность генерации этих недавно добавленных слов. Эта проблема вызвала в сообществе обсуждение технических деталей того, как эффективно вводить новые слова при дообучении, влияния расширения токенизатора на обучение модели и т. д. (Источник: Reddit r/MachineLearning)
Обмен и обсуждение изображений, сгенерированных AI: В сообществе ChatGPT на Reddit пользователи делятся различными интересными или странными изображениями, сгенерированными с помощью DALL-E 3. Например, один пользователь сгенерировал по определенному промпту изображение Дафны из Скуби-Ду, играющей в N64 перед отпуском на пляже (источник), что побудило других пользователей имитировать и генерировать других персонажей в похожих сценах (например, Чунь Ли). Другой пользователь поделился странным изображением, полученным по промпту «сгенерируй фотографию, которую никто не сможет увидеть» (источник), что также вызвало множество ответов с результатами генерации на похожие темы, среди которых были как тревожные, так и смешные работы. Эти посты демонстрируют разнообразие генерации изображений AI и креативность пользователей.
Сообщество обсуждает тенденции в дизайне логотипов AI-компаний: Юмористический пост со ссылкой на статью на сайте Velvet Shark под названием «Почему логотипы AI-компаний похожи на задницы?» вызвал обсуждение в сообществе. Статья, вероятно, рассматривает распространенные в дизайне логотипов компаний в сфере AI абстрактные, симметричные, вихревые или кольцевые графические элементы и шутливо связывает их с определенной анатомической структурой. Пользователи в комментариях также отреагировали в легкой манере, например, предполагая связь с концепцией «сингулярности» или называя это «ректально-производной технологией». Это отражает забавное наблюдение сообщества за визуальным образом индустрии. (Источник: Reddit r/ArtificialInteligence)

Пользователи ищут советы по проектам и техническую помощь: В сообществе есть несколько постов, где пользователи просят конкретной помощи или совета: один пользователь разрабатывает приложение для реагирования на стихийные бедствия на основе NLP, уже включающее панель мониторинга, распознавание речи, классификацию текста, многоязычную поддержку и т. д., и спрашивает, как сделать проект более уникальным (источник). Другой пользователь столкнулся с потолком точности при использовании дообученной модели BART для стандартизации названий и категорий товаров в электронной коммерции и ищет лучшие модели или инструменты (источник). Еще один пользователь спрашивает, как генерировать или изменять изображения в OpenWebUI и какие модели для этого нужны (источник). Эти посты отражают проблемы, с которыми сталкиваются разработчики в реальных приложениях, и их потребность в поддержке сообщества.
Обсуждение рынка труда для инженеров машинного обучения (MLE): Пользователь (возможно, студент или новичок) спрашивает о текущем состоянии рынка труда для инженеров машинного обучения (MLE). Он/она упоминает, что из постов сообщества узнал(а), что для должности MLE может потребоваться степень магистра/доктора, вход в профессию сложен, граница с инженерами-программистами (SWE) размыта, и требуется владение широким спектром навыков. Пользователь выражает готовность учиться, но обеспокоен(а) перспективами и надеется, что практикующие специалисты предоставят руководство и мнения о текущей ситуации на рынке, необходимых навыках, карьерных путях и т. д. (Источник: Reddit r/deeplearning)
Франкоязычный пользователь OpenWebUI сообщает об ошибке интерпретации изображений: Франкоязычный пользователь OpenWebUI сообщил о проблеме: при загрузке изображения для интерпретации моделью Gemma, модель отвечает, но содержание ответа пустое. Даже при попытке заставить модель прочитать или экспортировать текст диалога, это сообщение остается пустым. Что еще хуже, эта проблема «заражает» текущий диалог, и после этого даже при отправке чисто текстовых сообщений ответы модели также пусты. Пользователь подтвердил, что создание нового чисто текстового диалога проходит без проблем, подозревает ошибку в визуальном модуле и просит помощи у сообщества. (Источник: Reddit r/OpenWebUI)
💡 Прочее
Использование AI в сочетании с идеями «Избранных произведений Мао Цзэдуна» для анализа тарифной войны: В условиях эскалации тарифной войны между Китаем и США, в одной из статей предпринята попытка использовать инструменты AI в сочетании со стратегическими идеями из «Избранных произведений Мао Цзэдуна», в частности, из работы «О затяжной войне», для анализа текущей экономической ситуации и стратегий реагирования. Автор считает, что перед лицом торговой войны следует избегать крайностей «теории капитуляции» (полная зависимость от внешних факторов) и «теории быстрой победы» (ожидание полной автономии в краткосрочной перспективе), а вместо этого следует применять мышление на основе первых принципов, возвращаясь к сути торговли, источникам ценности и собственным сильным и слабым сторонам. Статья демонстрирует процесс совместного мышления автора и AI и на примере трансграничной электронной коммерции через независимые сайты рассматривает подходы к реагированию с помощью AI, подчеркивая важность стратегического мышления и способности к действию. Статья призвана предложить взгляд на использование AI для глубокого стратегического анализа. (Источник: AI觉醒)

Анонс Третьего китайского саммита индустрии AIGC: Третий китайский саммит индустрии AIGC, организованный QubitAI, состоится 16 апреля 2025 года в Пекине. Саммит соберет более 20 спикеров из крупных компаний, таких как Baidu, Huawei, Ant Group, Microsoft Research Asia, AWS, Mianbi Intelligence, Wuwen Xinqiong, Shengshu Technology, а также представителей отраслей, таких как Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health Group, и новых AI-стартапов. Темы будут охватывать технологические прорывы в AI (инфраструктура вычислений, распределенные вычисления, хранение данных, безопасность и контроль), проникновение в отрасли (образование, развлечения, AI for Science, корпоративные услуги и другие вертикальные сценарии внедрения) и построение экосистемы. На саммите также будет представлен список «Предприятий/продуктов AIGC, заслуживающих внимания в 2025 году» и «Полная панорамная карта приложений AIGC в Китае». Доступна регистрация для очного участия и онлайн-трансляция. (Источник: 量子位, 量子位)

Suno AI проводит акцию с розыгрышем миллиона кредитов: Пользователь Reddit поделился информацией из официального блога Suno AI о проводимой акции, в рамках которой пользователи могут выиграть до одного миллиона кредитов (Credits). Подробные правила акции необходимо уточнять в оригинальной статье блога. Подобные акции обычно направлены на повышение вовлеченности пользователей и активности на платформе. (Источник: Reddit r/SunoAI)

Subreddit ClaudeAI вводит механизм голосования за качество постов: Модераторы сабреддита ClaudeAI объявили о введении нового бота u/qualityvote2. Этот бот будет публиковать комментарий под каждым новым постом, приглашая пользователей оценить качество поста путем голосования за/против этого комментария (upvote/downvote). Посты, набравшие определенное количество голосов «за», будут считаться подходящими для данного сабреддита, а посты, набравшие определенное количество голосов «против», будут помечены для проверки модераторами на предмет удаления. Этот шаг направлен на использование сил сообщества для поддержания качества контента в сабреддите. Одновременно команда модераторов добавила бота для обнаружения манипуляций с голосованием. (Источник: Reddit r/ClaudeAI)