
Ключевые слова:AI, TPU, Google A2A протокол, TPU v7 характеристики, AI Agent взаимодействие, Gemini 2.5 Flash, модели MoE архитектура
🔥 В фокусе
Google представила протокол A2A и TPU седьмого поколения, ускоряя эру AI Agent и инференса: Google выпустила открытый протокол Agent2Agent (A2A), предназначенный для обеспечения безопасной связи и сотрудничества между AI Agent от разных поставщиков и фреймворков, дополняя, а не заменяя протокол MCP (MCP соединяет Agent с инструментами, A2A соединяет Agent с Agent). A2A следует принципам обнаружения возможностей, управления задачами, сотрудничества и согласования пользовательского опыта, и уже получил поддержку более 50 партнеров. Одновременно Google выпустила TPU седьмого поколения (Ironwood/TPU v7), оптимизированный для AI-инференса, с производительностью FP8 4614 TFlops, 192 ГБ HBM на чип, пропускной способностью 7,2 ТБ/с и в 2 раза большей энергоэффективностью по сравнению с предыдущим поколением. Кластер максимальной конфигурации (9216 чипов) достигает производительности 42,5 ExaFlops и предназначен для поддержки «мыслящих» моделей, таких как Gemini, и приложений AI Agent следующего поколения, что знаменует переход ИИ от реактивного к проактивному генерированию инсайтов. (Источник: 36氪, 36氪, 微信公众号, 微信公众号, 微信公众号, 微信公众号)

MCP становится центром экосистемы AI Agent, Alibaba и Tencent полностью его принимают: Протокол контекста модели (MCP) быстро становится стандартным интерфейсом для соединения AI Agent с внешними инструментами и источниками данных, его называют «USB» экосистемы ИИ. Alibaba Cloud Baichuan запустил первый в отрасли сервис MCP полного жизненного цикла, интегрирующий Function Compute, более 200 больших моделей и более 50 сервисов MCP, позволяя быстро создавать Agent за 5 минут. Tencent Cloud также выпустил «AI Development Kit», поддерживающий хостинг плагинов MCP. MCP снижает затраты на повторную разработку за счет разделения хоста, сервера и клиента, улучшает возможности взаимодействия инструментов ИИ и имеет решающее значение для реализации сложного сотрудничества Agent. Несмотря на ранние проблемы, такие как незрелая экосистема и неполная цепочка инструментов, с поддержкой OpenAI, Google, Microsoft, Amazon и крупных китайских компаний, MCP, как ожидается, ускорит взрывной рост приложений ИИ и развитие отрасли. (Источник: 36氪)
ИИ добился прорывного прогресса на Математической олимпиаде: Результаты второй Математической олимпиады ИИ (AI Mathematical Olympiad — Progress Prize 2) показывают значительный прогресс ИИ в решении сложных математических задач. Лучшая модель набрала 34/50 баллов в тесте, состоящем из совершенно новых задач, с ограниченными вычислительными ресурсами (стоимость решения каждой задачи менее 1 доллара) и требующем точных целочисленных ответов (0-999). Это значительно превосходит предыдущие оценки людей, согласно которым LLM могли достичь уровня около 5%. Даже относительно базовая модель, производная от DeepSeek R1, набрала 28/50 баллов. Этот результат показывает, что математические способности ИИ к рассуждению, особенно в задачах олимпиадного уровня, требующих творческого подхода, быстро растут и не являются простым распознаванием образов или запоминанием данных. (Источник: Reddit r/MachineLearning)
SenseTime выпустила SenseNova V6, мультимодальную модель MoE с 600 миллиардами параметров: SenseTime представила большую модель шестого поколения SenseNova V6, использующую архитектуру «смесь экспертов» (MoE) с 600 миллиардами параметров, которая нативно поддерживает ввод и обработку текста, изображений, видео и других модальностей. Модель показала отличные результаты во многих бенчмарках для чисто текстовых и мультимодальных задач, превзойдя GPT-4.5 и Gemini 2.0 Pro. Ее основные возможности включают сильное логическое мышление (мультимодальное и языковое глубокое мышление превосходит o1, Gemini 2.0 flash-thinking), сильное взаимодействие (понимание аудио и видео в реальном времени, выражение эмоций) и долговременную память (поддержка анализа длинных видео, например, прямое логическое заключение по содержанию видео длительностью несколько минут). Ключевые технологии включают нативное мультимодальное совместное обучение, синтез мультимодальных длинных цепочек мыслей (поддержка 64K токенов), мультимодальное смешанное обучение с подкреплением (RLHF+RFT), а также унифицированное представление и динамическое сжатие длинных видео. SenseTime подчеркивает, что ИИ должен служить повседневным приложениям и способствовать внедрению ИИ в различных отраслях. (Источник: 微信公众号)
🎯 Тенденции
Скоро выйдет Google Gemini 2.5 Flash, ориентированный на эффективный инференс: На конференции Cloud Next ’25 Google анонсировала модель Gemini 2.5 Flash. Как облегченная версия флагманской модели Gemini 2.5 Pro, Flash будет сосредоточена на обеспечении быстрого и недорогого инференса. Ее особенность заключается в способности динамически регулировать глубину инференса в зависимости от сложности запроса, избегая избыточных вычислений для простых задач. Разработчики смогут настраивать глубину инференса для контроля затрат. Ожидается, что модель скоро станет доступна на Vertex AI и будет предназначена для повседневных приложений, чувствительных к скорости отклика. (Источник: 微信公众号, X)

ByteDance опубликовала технический отчет о Seed-Thinking-v1.5 с сильными способностями к рассуждению: ByteDance раскрыла технические детали своей модели рассуждения Seed-Thinking-v1.5, обученной с использованием обучения с подкреплением. Отчет показывает, что модель отлично проявила себя в нескольких бенчмарках, превзойдя DeepSeek-R1 и приблизившись к уровню Gemini-2.5-Pro и O3-mini-high, набрав 40% в тесте ARC-AGI. Модель имеет 200 миллиардов общих параметров и 20 миллиардов активных параметров. Веса модели пока не опубликованы, но ее выдающиеся способности к рассуждению и относительно небольшое количество активных параметров привлекли внимание сообщества. (Источник: X)

ChatGPT улучшает функцию памяти, может ссылаться на все предыдущие диалоги: OpenAI объявила об обновлении функции памяти ChatGPT, позволяя модели ссылаться на всю историю чатов пользователя для предоставления более персонализированных ответов. Это улучшение направлено на использование предпочтений и интересов пользователя для повышения эффективности помощи в написании текстов, предоставлении советов, обучении и т. д. При начале нового диалога ChatGPT будет естественным образом использовать эту память. Пользователи по-прежнему полностью контролируют эту функцию и могут отключить ссылку на историю в настройках, полностью отключить память или использовать режим временного чата. Функция уже начала распространяться среди пользователей Plus и Pro (за исключением некоторых регионов) и скоро охватит пользователей Team, Enterprise и Education. (Источник: X, X)
OpenAI выпустила подкаст о разработке GPT-4.5: Sam Altman и ключевые члены команды OpenAI Alex Paino, Dan Selsam, Amin Tootoonchian записали подкаст, в котором обсуждается процесс разработки GPT-4.5 и будущие направления. Команда сообщила, что разработка GPT-4.5 знаменует собой переход от оптимизации вычислительной эффективности к оптимизации эффективности данных с целью достижения интеллекта, в десять раз превышающего GPT-4. В подкасте обсуждалась важность механизма «сжатия» в неконтролируемом обучении (приближение к индукции Соломонова), подчеркивалась необходимость точной оценки производительности модели и предотвращения механического запоминания, а также рассказывалось об опыте преодоления технических трудностей и важности командного духа. (Источник: X, X)
Perplexity интегрирует Gemini 2.5 Pro, планирует подключить Grok 3 и WhatsApp: Поисковая система с ИИ Perplexity объявила об интеграции новейшей модели Google Gemini 2.5 Pro для пользователей Pro и пригласила их сравнить ее с моделями Sonar, GPT-4o, Claude 3.7 Sonnet, DeepSeek R1 и O3. Кроме того, CEO Perplexity Aravind Srinivas подтвердил, что после получения большого количества положительных отзывов пользователей начнется разработка интеграции Perplexity с WhatsApp. В то же время планируется, что модель Grok 3 скоро будет поддерживаться на платформе Perplexity. (Источник: X, X, X)

Модели серии Qwen3 от Alibaba готовятся к выпуску, но потребуется время: Сообщество с нетерпением ожидает следующего поколения моделей серии Qwen3 от Alibaba, включая не-open-source версии, Qwen3-8B и Qwen3-MoE-15B-A2B. Однако, согласно ответам разработчиков Qwen в социальных сетях, выпуск Qwen3 произойдет не «в течение нескольких часов», и для подготовки потребуется больше времени. Это указывает на то, что Alibaba активно разрабатывает модели нового поколения, но конкретный график выпуска еще не определен. (Источник: X, Reddit r/LocalLLaMA)

На LM Arena появились загадочные высокопроизводительные модели «Dragontail» и «Quasar Alpha», вызывая предположения: На платформе LMSYS Chatbot Arena (LM Arena) появились анонимные модели под названием «Dragontail» и «Quasar Alpha», которые во взаимодействии с пользователями демонстрируют производительность, сравнимую или даже превосходящую топовые модели (такие как o3-mini-high, Claude 3.7 Sonnet) в некоторых математических задачах. Сообщество предполагает, что «Dragontail» может быть вариантом готовящейся к выпуску Qwen3 или Gemini 2.5 Flash, в то время как «Quasar Alpha» некоторые пользователи считают моделью из серии o4-mini от OpenAI. Появление этих анонимных моделей отражает роль арены моделей как платформы для тестирования и оценки производительности передовых моделей. (Источник: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Демо-версия модели Kimi-VL-A3B-Thinking от Moonshot AI доступна на Hugging Face: Moonshot AI (月之暗面) разместила интерактивную демонстрацию (Demo) своей мультимодальной модели Kimi-VL-A3B-Thinking на Hugging Face Spaces. Теперь пользователи могут публично опробовать эту модель. Предварительные тесты показывают, что модель обладает возможностями онлайн OCR и распознавания изображений, но может иметь ограниченную производительность в задачах, требующих обширных знаний (например, понимание юмора конкретного мема), что может быть связано с размером модели. (Источник: X, X)

AMD проведет мероприятие по ИИ, представит новые GPU для дата-центров: AMD планирует провести мероприятие под названием “Advancing AI 2025”, на котором будут представлены новые GPU для дата-центров. Презентация будет сосредоточена на приложениях ИИ, а не на игровых видеокартах. Этот шаг свидетельствует о продолжающихся инвестициях AMD в рынок аппаратного обеспечения для ИИ с целью конкуренции в области ИИ-ускорителей, где доминирует Nvidia. (Источник: Reddit r/artificial)
🧰 Инструменты
Firecrawl: Open-source инструмент для преобразования веб-сайтов в данные, готовые для LLM: Firecrawl от Mendable AI — это мощный open-source инструмент (написанный на TypeScript), предназначенный для сканирования, обхода и преобразования целых веб-сайтов в готовый для LLM Markdown или структурированные данные через единый API. Он справляется с прокси, механизмами защиты от ботов, рендерингом динамического контента и другими сложностями, а также поддерживает настраиваемое сканирование (например, исключение тегов, аутентифицированное сканирование), разбор медиафайлов (PDF, DOCX) и взаимодействие со страницей (клики, прокрутка, ввод). Предоставляет API, SDK для Python/Node/Go/Rust и уже интегрирован во многие фреймворки LLM (Langchain, Llama Index, Crew.ai) и low-code платформы (Dify, Langflow, Flowise). Firecrawl предлагает хостинговый API-сервис и open-source версию для локального запуска. (Источник: GitHub)
KrillinAI: Инструмент для перевода и озвучивания видео на основе больших моделей: KrillinAI — это open-source проект, написанный на Go, использующий большие языковые модели (LLM) для предоставления профессиональных услуг по переводу и озвучиванию видео. Он поддерживает развертывание всего процесса одним щелчком мыши и может обрабатывать полный рабочий цикл: от загрузки видео (поддержка yt-dlp и локальной загрузки), генерации высокоточных субтитров (Whisper), интеллектуального разделения и выравнивания субтитров (LLM), многоязычного перевода, замены терминологии, ИИ-озвучивания и клонирования голоса (CosyVoice) до синтеза видео (автоматическая адаптация к горизонтальному/вертикальному формату). Предназначен для создания контента, адаптированного для платформ YouTube, TikTok, Bilibili и др. Проект предлагает десктопные версии для Win/Mac и не-десктопную версию (Web UI), а также поддерживает развертывание через Docker. (Источник: GitHub)
Second Me: Создание локализованного, персонализированного «ИИ-я»: Second Me — это open-source проект, целью которого является создание «цифрового двойника» или «ИИ-я» пользователя с использованием локально работающих моделей ИИ. Он подчеркивает конфиденциальность (полностью локальное выполнение) и персонализацию, моделируя личность, память, ценности и способ рассуждения пользователя с помощью иерархического моделирования памяти (HMM) и структуры «Me-alignment». Проект поддерживает развертывание через Docker (macOS, Windows, Linux) и OpenAI-совместимый API-интерфейс, а также изучает поддержку обучения MLX. Сообщество активно, уже внесло вклад в интеграцию с ботом WeChat, поддержку нескольких языков и т. д. Его видение состоит в том, чтобы ИИ стал продолжением возможностей пользователя, а не дополнением к платформе. (Источник: Reddit r/LocalLLaMA)

EasyControl: Внедрение условий в стиле LoRA для Diffusion моделей на архитектуре DiT: EasyControl — это недавно выпущенный open-source фреймворк, предназначенный для решения проблемы отсутствия зрелых плагинов (таких как LoRA) для новых Diffusion моделей на основе архитектуры DiT (Diffusion Transformer). Он предоставляет легковесный модуль внедрения условий, позволяющий пользователям легко добавлять возможности управления, подобные LoRA, к моделям DiT для выполнения таких задач, как перенос стиля. Проект демонстрирует результаты модели, обученной на 100 изображениях азиатских лиц и соответствующих им изображений в стиле Ghibli (сгенерированных GPT-4o), и уже поддерживает интеграцию с ComfyUI. (Источник: X)

XplainMD: Конвейер интерпретируемого ИИ для биомедицины, объединяющий GNN и LLM: XplainMD — это open-source end-to-end конвейер ИИ, разработанный специально для биомедицинских графов знаний. Он сочетает графовые нейронные сети (R-GCN) для предсказания мультиреляционных связей (например, лекарство-болезнь, ген-фенотип), использует GNNExplainer для интерпретируемости модели, визуализирует предсказанные подграфы с помощью PyVis и использует модель LLaMA 3.1 8B Instruct для объяснения предсказаний на естественном языке и проверки их обоснованности. Весь процесс развернут в интерактивном приложении Gradio, целью которого является предоставление предсказаний вместе с объяснением «почему», повышая доверие и удобство использования ИИ в таких чувствительных областях, как прецизионная медицина. (Источник: Reddit r/deeplearning, Reddit r/MachineLearning)
LaMPlace: Новый метод оптимизации размещения макроблоков на чипе с помощью ИИ: Исследователи из Научно-технического университета Китая, Лаборатории Ноева Ковчега Huawei и Тяньцзиньского университета предложили LaMPlace, метод оптимизации размещения макроблоков на чипе на основе ИИ. Метод использует структурированный предиктор метрик (используя полиномы Лорана для моделирования влияния расстояния между макроблоками на межэтапные метрики, такие как WNS/TNS) и механизм генерации обучаемой маски для направления решений по размещению на ранних этапах компоновки с целью оптимизации конечной производительности чипа (PPA). LaMPlace направлен на перенос цели оптимизации с легко вычисляемых промежуточных метрик (таких как длина проводников, плотность) на конечные цели проектирования, реализуя «оптимизацию со сдвигом влево» и повышая эффективность проектирования. Метод был принят для устного доклада на ICLR 2025. (Источник: 微信公众号)
Google выпускает Agent Development Kit (ADK) и Firebase Studio: В рамках продвижения экосистемы AI Agent Google выпустила Agent Development Kit (ADK), фреймворк для создания мультиагентных систем. ADK поддерживает различных поставщиков моделей (Gemini, GPT-4o, Claude, Llama и др.), предоставляет инструменты CLI, управление артефактами, AgentTool (вызовы между Agent) и поддерживает развертывание в Agent Engine или Cloud Run. Одновременно Google также запустила Firebase Studio, облачный инструмент программирования с ИИ, интегрированный с моделью Gemini, поддерживающий полный цикл разработки приложений: от кодирования с помощью ИИ, компиляции и сборки до развертывания в облачных сервисах. (Источник: 微信公众号, Reddit r/LocalLLaMA)
OpenFOAMGPT: Снижение затрат на CFD-симуляции с использованием китайских больших моделей: Команда из Эксетерского университета (Великобритания) и Пекинского университета аэронавтики и астронавтики обновила проект OpenFOAMGPT, который позволяет пользователям управлять симуляциями вычислительной гидродинамики (CFD) с помощью естественного языка. Новая версия успешно интегрировала китайские большие модели DeepSeek V3 и Qwen 2.5-Max, сохраняя производительность, близкую к GPT-4o/o1, при этом снижая затраты до 100 раз. Кроме того, команда реализовала локальное развертывание (в среде с одним GPU) с использованием модели QwQ-32B, предоставляя китайским исследователям и малым/средним предприятиям более экономичное и удобное решение для CFD с поддержкой ИИ, снижая порог входа для специалистов. (Источник: 微信公众号)
Slop Forensics Toolkit: Инструмент для анализа повторяющегося контента в выводах LLM: Выпущен новый open-source инструментарий для анализа «slop» — чрезмерно повторяющихся слов и фраз — в выводах больших языковых моделей (LLM). Инструмент использует стилометрический анализ для выявления слов и n-грамм, которые встречаются чаще, чем в текстах, написанных человеком, создавая «slop profile» модели. Он также заимствует методы из биоинформатики, рассматривая лексические особенности как «мутации», чтобы вывести дерево сходства между различными моделями. Инструмент предназначен для помощи исследователям в понимании и сравнении генеративных характеристик различных LLM и потенциального загрязнения данных или смещений при обучении. (Источник: Reddit r/MachineLearning)
Фреймворк для инференса vLLM добавил поддержку Google TPU: Популярный open-source фреймворк для инференса и обслуживания больших моделей vLLM объявил о добавлении поддержки Google TPU. В сочетании с недавно выпущенным Google TPU седьмого поколения (Ironwood), это обновление означает, что разработчики могут использовать vLLM для эффективного инференса и развертывания моделей на высокопроизводительном оборудовании Google для ИИ. Это способствует расширению программной экосистемы TPU, предоставляя пользователям больше выбора аппаратного обеспечения. (Источник: X)

📚 Обучение
CUHK, Tsinghua и др. предложили фреймворк SICOG, исследуя новый путь самоэволюции больших моделей: В ответ на зависимость больших моделей от высококачественных данных для предварительного обучения и проблему истощения ресурсов данных, Гонконгский китайский университет (CUHK), Университет Цинхуа и другие учреждения предложили фреймворк SICOG (Self-Improving Systematic Cognition). Этот фреймворк строит триединый механизм самоэволюции «усиление после обучения — оптимизация инференса — повторное предварительное обучение», улучшая структурированное визуальное восприятие с помощью «цепочки описаний» (CoD), усиливая мультимодальное рассуждение с помощью «структурированной цепочки мыслей» (CoT), и используя замкнутый цикл самогенерации данных и фильтрацию по согласованности для непрерывного повышения когнитивных способностей модели без ручной разметки. Эксперименты доказывают, что SICOG может значительно улучшить производительность модели в нескольких задачах, уменьшить галлюцинации и демонстрирует хорошую масштабируемость, предлагая новые идеи для решения проблемы узких мест предварительного обучения и продвижения к самообучающемуся ИИ. (Источник: 微信公众号)
OpenAI открыла исходный код бенчмарка BrowseComp для оценки способностей AI Agent к веб-браузингу: OpenAI выпустила и открыла исходный код бенчмарка BrowseComp (Browsing Competition). Этот бенчмарк предназначен для оценки способности AI Agent просматривать интернет в поисках труднодоступной информации, подобно онлайн-игре «охота за сокровищами» для Agent. OpenAI считает, что такие тесты могут уловить ключевые способности агентов к глубокому исследовательскому браузингу, что крайне важно для оценки уровня интеллекта продвинутых Agent для веб-браузинга. (Источник: X, X)
Исследование показало, что модели с рассуждением лучше обобщают на OOD задачах кодирования: Новое исследование (arXiv:2504.05518v1) сравнило способности к обобщению моделей с рассуждением и без него на задачах кодирования. Результаты показали, что производительность моделей с рассуждением не снижается при переходе от задач внутри распределения (in-distribution) к задачам вне распределения (out-of-distribution, OOD); в то время как модели без рассуждения демонстрировали падение производительности. Это говорит о том, что модели с рассуждением — это не просто распознаватели образов; они способны учиться и обобщать на задачи за пределами обучающего распределения, обладая более сильными способностями к абстракции и применению знаний. (Источник: Reddit r/ArtificialInteligence)
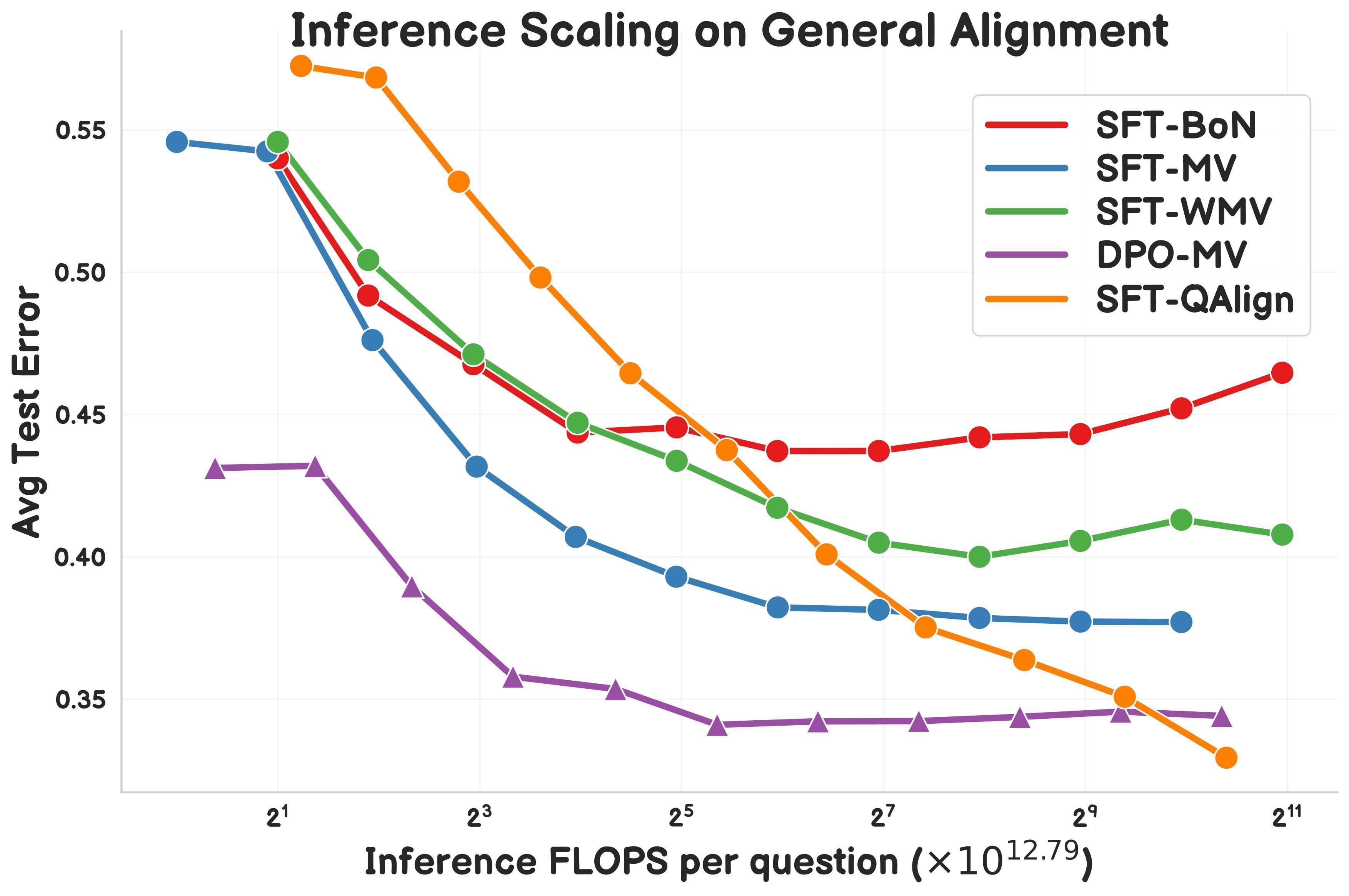
Исследование предлагает QAlign: метод выравнивания во время тестирования на основе MCMC: Gonçalo Faria и др. предложили QAlign, новый метод выравнивания во время тестирования (test-time alignment), использующий метод Монте-Карло по схеме Марковских цепей (MCMC) для повышения производительности языковых моделей без их переобучения. Исследование показывает, что QAlign превосходит по производительности модели, настроенные с помощью DPO (Direct Preference Optimization) (при одинаковых вычислительных затратах на инференс), и может преодолеть ограничения традиционного сэмплирования Best-of-N (склонного к переоптимизации модели вознаграждения) и голосования большинством (неспособного обнаружить уникальные ответы), и потенциально может использоваться для генерации высококачественных данных и в других сценариях. (Источник: X)
Yann LeCun вновь подчеркивает ограничения авторегрессионных LLM: В недавнем выступлении главный научный сотрудник Meta по ИИ Yann LeCun подтвердил свою точку зрения об ограничениях текущих основных авторегрессионных (Auto-Regressive) архитектур больших языковых моделей, считая их подход «обреченным на провал» (doomed). Он полагает, что этот способ предсказания слово за словом ограничивает способность модели к настоящему планированию и глубокому рассуждению. Хотя авторегрессионные модели в настоящее время все еще являются state-of-the-art, LeCun и другие исследователи активно изучают альтернативные подходы, такие как архитектуры совместного предсказания вложений (JEPA), в надежде создать системы ИИ, более близкие к человеческому интеллекту. (Источник: Reddit r/MachineLearning)
LlamaIndex демонстрирует создание Agent для генерации отчетов в связке с Google Cloud: Основатель LlamaIndex Jerry Liu на Google Cloud Next ’25 продемонстрировал, как объединить рабочие процессы LlamaIndex и базы данных Google Cloud (такие как BigQuery, AlloyDB) для создания Agent, генерирующего отчеты. Этот Agent способен анализировать документы SOP (используя LlamaParse), базы данных учебных пособий, юридические данные и т. д., чтобы генерировать персонализированные руководства для новых сотрудников. Это демонстрирует, что архитектура Agent, основанных на знаниях, требует мощных возможностей доступа к данным и их обработки, а также показывает роль LlamaIndex в создании таких приложений Agent. (Источник: X)

Исследователь делится движком Symbolic Compression и форматом файлов .sym: Независимый исследователь открыл исходный код движка под названием Symbolic Compression и соответствующего формата файлов .sym. Проект утверждает, что способен выполнять сжатие путем извлечения рекурсивных правил и структурной логики, лежащих в основе последовательностей (таких как простые числа, числа Фибоначчи) (на основе предложенного им закона Миллера: κ(x) = ((ψ(x) — x)/x)²), а не просто сжимать исходные данные. Он предназначен для хранения и предсказания появления самой структуры, предоставляя формат, похожий на JSON, но для рекурсивной логики. Проект включает инструменты CLI и функцию многорегионального сжатия. (Источник: Reddit r/MachineLearning)

💼 Бизнес
Объявлены цены на API Grok-3, минимум 0,3 доллара за миллион токенов: xAI официально открыла доступ к API серии Grok 3 для широкой публики, используя многоуровневую ценовую стратегию. Grok 3 (Beta), ориентированный на корпоративные приложения, стоит 3 доллара за миллион входных токенов и 15 долларов за миллион выходных токенов; облегченный Grok 3 Mini (Beta) стоит 0,3 доллара за миллион входных токенов и 0,5 доллара за миллион выходных токенов. Обе модели также предлагают версии с быстрым откликом (fast-beta) по более высокой цене. Эта ценовая стратегия ставит его в конкуренцию по стоимости с такими моделями, как Google Gemini 2.5 Pro, тарифный план Anthropic Claude Max (минимум 100 долларов) и Meta Llama 4 Maverick (около 0,36 доллара за миллион токенов). (Источник: 微信公众号)
Отчет Стэнфорда по ИИ: Alibaba занимает третье место в мире по силе ИИ, разрыв между Китаем и США сокращается: Последний отчет Стэнфордского университета «Индекс искусственного интеллекта 2025» показывает, что в глобальном вкладе в важные большие модели Google и OpenAI делят первое место с 7 моделями каждая, а Alibaba занимает третье место в мире и первое в Китае с 6 моделями (серия Qwen). В отчете отмечается, что разрыв в производительности моделей между Китаем и США значительно сократился: с 17,5 процентных пунктов (бенчмарк MMLU) в конце 2023 года до 0,3 процентных пункта в конце 2024 года. Семейство моделей Alibaba Qwen (более 200 моделей с открытым исходным кодом) стало крупнейшей в мире серией моделей с открытым исходным кодом, с более чем 100 000 производных моделей. В отчете также упоминается, что ведущие китайские модели (такие как Qwen2.5, DeepSeek-V3) обычно требуют меньше вычислительных мощностей для обучения, чем аналогичные американские модели, демонстрируя более высокую эффективность. (Источник: 微信公众号)
Китайские компании в области медицинского ИИ ищут пути прорыва в условиях таможенных и технологических барьеров: Столкнувшись с давлением из-за повышения американских тарифов и технологической монополии (например, гиганты GPS контролируют интерфейсы данных изображений), китайские медицинские технологические компании ускоряют импортозамещение и интеллектуальную трансформацию. United Imaging Healthcare настаивает на собственной разработке ключевых технологий, выпуская высококлассное оборудование, такое как МРТ 5.0T, и развивая медицинские большие модели и интеллектуальных агентов. Mindray Medical через стратегию «оборудование + ИТ + ИИ» строит цифровизованную экосистему (например, платформа Ruiying Cloud++, интегрирующая DeepSeek) и активно осваивает международные рынки. Dinfectome Bio использует большую модель медицинских изображений iMedImage® для входа в сферу прецизионной медицины, участвует в разработке отраслевых стандартов и достигает дифференцированной конкуренции. Эти компании, движимые ИИ, стремятся прорваться в области ключевых технологий, цепочек поставок и клинического признания, чтобы переформатировать рынок. (Источник: 微信公众号)
🌟 Сообщество
Применение ИИ в образовании вызывает дискуссии: В сообществе обсуждается, как искусственный интеллект (ИИ) может изменить образование с помощью индивидуальных учебных планов. ИИ обладает потенциалом для адаптации учебного контента и методов к индивидуальным потребностям, темпу обучения и стилю учащихся, реализуя персонализированное образование и повышая эффективность и результативность обучения. (Источник: X)

Сложная инженерия за редактором Cursor привлекает внимание: В сообществе упоминается, что реализация ИИ-редактора кода Cursor — непростая задача. Его основная цель — избавить пользователей от ручного копирования и вставки кода, для чего было проведено множество оптимизаций пользовательского опыта и инженерных инноваций, включая изобретение новых парадигм редактирования кода, разработку собственных моделей быстрого применения правок FastApply и предсказания автодополнения кода Fusion, реализацию двухуровневого RAG на локальном и серверном уровнях для оптимизации обработки контекста и т. д. Эти усилия показывают техническую глубину, необходимую для создания плавного опыта программирования с ИИ. (Источник: X)
Инструменты для мошенничества с ИИ вызывают дискуссии об этике и системах найма: Студент Колумбийского университета Рой Ли разработал ИИ-инструмент «Interview Coder» для мошенничества на собеседованиях по программированию, получил предложения от нескольких ведущих компаний, был отчислен из университета, а затем заработал 2,2 миллиона долларов за 50 дней, продавая этот инструмент. Инструмент может работать незаметно, генерируя ответы, имитирующие стиль кодирования человека. Инцидент вызвал широкое обсуждение: с одной стороны, многие разработчики недовольны жесткими, оторванными от реальности собеседованиями по программированию (например, решение задач на LeetCode); с другой стороны, резкий рост мошенничества с использованием ИИ (по некоторым данным, доля выросла с 2% до 10%) ставит под сомнение эффективность существующих технических собеседований, может заставить компании пересмотреть системы найма и поднимает вопросы об этических границах того, что считать «мошенничеством» в эпоху ИИ. (Источник: 36氪)
Появляются инновационные приложения универсальных Agent: На недавних хакатонах по Agent (таких как flowith, openmanus) появилось множество инновационных приложений. Категория разработки и дизайна: Agent может автоматически генерировать полный проект с кодом фронтенда, бэкенда и структурой базы данных на основе эскиза UI (maxcode), или самостоятельно собирать информацию, определять стиль и генерировать персональный веб-сайт. Категория анализа и принятия решений: Agent может рассчитать лучшее место в самолете для наблюдения за полярным сиянием, или выполнять самоитеративную оптимизацию стратегии количественной торговли (一鹿向北). Категория персонализированных услуг: Agent может интеллектуально рекомендовать места для встреч (Jarvis-CafeMeet), анализировать данные с Douban для создания «отчета о вкусах», или обслуживать пожилых пользователей через голосовое взаимодействие (老奶奶教你用OpenManus). Категория художественного творчества: Agent может генерировать цифровое искусство в определенном стиле, генерировать танец на основе музыки, настраивать кисти для рисования, генерировать программируемую музыку в реальном времени (strudel-manus) и т. д. Эти примеры демонстрируют огромный потенциал Agent в различных областях. (Источник: 微信公众号)
Andrew Ng комментирует влияние американских тарифов на развитие ИИ: Эндрю Ын (Andrew Ng) выразил обеспокоенность по поводу широкомасштабного введения высоких тарифов США, считая, что это нанесет ущерб отношениям с союзниками, затормозит мировую экономику, вызовет инфляцию и окажет негативное влияние на развитие ИИ. Он отметил, что хотя свободное перемещение идей и программного обеспечения (особенно open-source) может не сильно пострадать, тарифы ограничат доступ к аппаратному обеспечению для ИИ (такому как серверы, охлаждение, сетевое оборудование), увеличат стоимость строительства дата-центров и косвенно повлияют на поставки вычислительных мощностей через влияние на импорт энергетического оборудования. Хотя тарифы могут незначительно стимулировать внутренний спрос на роботов и автоматизацию, это вряд ли компенсирует недостатки в производственном секторе. Он призвал сообщество ИИ поддерживать международное сотрудничество и обмен. (Источник: X)
Сообщество активно обсуждает применение ИИ для поддержки психического здоровья: Все больше пользователей делятся опытом использования инструментов ИИ, таких как ChatGPT, для психологического консультирования и эмоциональной поддержки. Многие отмечают, что ИИ предоставляет безопасное, безоценочное пространство для высказываний, позволяет получать немедленную обратную связь и полезные советы, и даже в некоторых случаях помогает почувствовать себя услышанным и понятым лучше, чем человеческие терапевты, что приводит к положительному эмоциональному катарсису. Хотя пользователи в целом согласны, что ИИ не может полностью заменить профессиональных лицензированных терапевтов, особенно при работе с серьезными психологическими проблемами, он демонстрирует огромный потенциал в предоставлении базовой поддержки, справлении с повседневным стрессом и первоначальном исследовании личных проблем, а также пользуется популярностью благодаря своей доступности и низкой стоимости. (Источник: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
Определение статуса контента, переведенного ИИ, вызывает дискуссии: В сообществе обсуждался вопрос: если для перевода истории, написанной человеком, используется ИИ (например, ChatGPT), следует ли считать ее содержание созданным человеком или ИИ? Существует точка зрения, что если ИИ используется только как инструмент перевода и не изменяет идеи, структуру и тон оригинала, то содержание по сути остается человеческим творением. Однако детекторы ИИ-текстов могут пометить его как сгенерированный ИИ из-за анализа текстовых паттернов. Это поднимает вопросы об определении роли ИИ в творческом процессе, ограничениях детекторов ИИ и о том, как сохранить стиль оригинала при переводе. (Источник: Reddit r/ArtificialInteligence)
Пользователи сообщают о проблемах с обработкой длинного контекста в Gemini 2.5 Pro: Пользователь Nathan Lambert при тестировании Gemini 2.5 Pro обнаружил, что при обработке запросов с очень длинным входным контекстом модель сталкивается с ошибками соединения. Наблюдаемое явление заключается в том, что модель в процессе инференса, похоже, регенерирует почти все входные токены, что приводит к чрезвычайно высокой стоимости инференса и в конечном итоге к сбою. Кроме того, он отметил невозможность поделиться историей чата Gemini при возникновении ошибки. Эти отзывы указывают на возможные проблемы со стабильностью и эффективностью текущей модели при обработке сверхдлинных контекстов. (Источник: X)

Реакция сообщества на выпуск Llama 4 неоднозначна, ставятся под сомнение производительность и открытость: Выпущенная Meta серия моделей Llama 4 вызвала широкое обсуждение и негативные отзывы в сообществе. Пользователи в целом считают, что, хотя модель Maverick имеет контекстное окно до 10 миллионов токенов и показывает приемлемую производительность при вызове функций, ее общее количество параметров в 400B (17B активных параметров) не привело к ожидаемому повышению производительности рассуждений, уступая даже таким моделям, как QwQ 32B. Кроме того, ее ограничительная лицензия, отсутствие технической документации и системной карты, а также обвинения в «накрутке» результатов на бенчмарках, таких как LMSYS, подорвали репутацию Meta в open-source сообществе. Сообщество выражает разочарование тем, что Meta не смогла сохранить открытость и лидирующие позиции Llama 3. (Источник: Reddit r/LocalLLaMA)

План Claude Pro обвиняют в скрытом ухудшении, пользователи жалуются на возросшие ограничения: После того как Anthropic представила более дорогой тариф Max (утверждая, что он предлагает в 5 или 20 раз больший объем использования, чем план Pro), многие пользователи Claude Pro в сообществе сообщили, что ощущают ужесточение ограничений на использование самого плана Pro, и лимиты достигаются легче. Пользователи предполагают, что Anthropic могла снизить фактический доступный лимит для плана Pro, чтобы побудить пользователей перейти на план Max. Эта непрозрачная корректировка и ощущаемое ухудшение сервиса вызвали недовольство пользователей, особенно учитывая, что сама модель Claude все еще имеет проблемы с памятью в контекстном окне. (Источник: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Сообщество OpenWebUI обсуждает функции и проблемы: Пользователи OpenWebUI в сообществе обсуждают функциональность инструмента и возникающие проблемы. Один пользователь спрашивает, возможно ли интегрировать Nextcloud в качестве дополнительного облачного хранилища. Другой пользователь сообщает о проблеме с функцией базы знаний: при загрузке нескольких документов LLM, похоже, ссылается только на первый документ. Еще один пользователь столкнулся с ошибкой тайм-аута при попытке подключения к Gemini-совместимой конечной точке OpenAI API. Эти обсуждения отражают потребности и опасения пользователей относительно расширяемости и стабильности инструмента. (Источник: Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Сообщество Suno AI обменивается советами и проблемами: Сообщество пользователей Suno AI активно, обсуждения включают: как исключить определенные инструменты (например, барабаны, клавишные) при использовании функции Cover для выделения сольных инструментов; поиск советов по генерации музыки в определенном стиле (например, Trip Hop); сообщения о проблемах с функцией приглашения друзей, которая не дает кредитов; обсуждение вопросов авторского права на тексты песен, например, вызывают ли определенные фразы (например, «You’re Dead») ограничения по авторскому праву; а также обмен примерами творческого использования Suno, например, создание фоновой музыки для персонажей D&D. (Источник: Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI)
💡 Прочее
Исследование генерации «случайных фотографий» с помощью ИИ: Пользователи сообщества пробуют использовать ИИ для генерации изображений, которые выглядят как случайно снятые, с произвольной композицией, возможно, слегка размытые или переэкспонированные «случайные фотографии». Это исследование бросает вызов тенденции ИИ генерировать идеальные изображения, имитируя случайность и несовершенство человеческой фотографии, и демонстрирует способность ИИ понимать и имитировать определенные фотографические стили (включая стиль «плохих» фотографий). (Источник: Reddit r/ChatGPT)

Потенциал ИИ в управлении цепочками поставок: Обсуждение подчеркивает потенциал искусственного интеллекта (ИИ) в повышении отслеживаемости и прозрачности цепочек поставок. Используя машинное обучение и анализ данных, ИИ может помочь компаниям лучше отслеживать потоки товаров, прогнозировать риски сбоев, оптимизировать управление запасами и предоставлять потребителям более надежную информацию о происхождении продукции. (Источник: X)

Исследование применения ИИ в управлении персоналом: В сообществе обсуждается возможность использования виртуальных аватаров ИИ (Avatars) для управления персоналом. Это может включать использование ИИ для первичного отбора кандидатов на собеседовании, обучения сотрудников, ответов на вопросы по политикам компании и даже эмоциональной поддержки, с целью повышения эффективности HR-процессов и улучшения опыта сотрудников. (Источник: X)

Банк Англии предупреждает, что ИИ может спровоцировать рыночный кризис: Банк Англии выпустил предупреждение о том, что программное обеспечение с искусственным интеллектом может быть использовано для манипулирования рынками и даже для преднамеренного создания рыночного кризиса с целью получения прибыли. Это вызвало обеспокоенность по поводу регулирования и контроля рисков применения ИИ в финансовой сфере. (Источник: Reddit r/artificial)

Новый метод генерации реалистичных 3D-форм с помощью ИИ: Исследователи из MIT разработали новый генеративный метод ИИ, способный создавать более реалистичные трехмерные формы. Это имеет важное значение для таких областей, как дизайн продуктов, виртуальная реальность, разработка игр и 3D-печать, способствуя прогрессу в технологиях генерации сложных 3D-моделей из 2D-изображений или текстовых описаний. (Источник: X)

Энергопотребление и стоимость ИИ-инференса значительно снизились: Сообщается, что новые технологические достижения позволили снизить энергопотребление задач ИИ-инференса (измеряемое энергопотреблением на MAC) в 100 раз, а стоимость — в 20 раз. Такое повышение эффективности имеет решающее значение для осуществимости и экономической целесообразности развертывания моделей ИИ на периферийных устройствах, мобильных платформах и в крупномасштабных облачных средах. (Источник: X)

Обсуждение влияния ИИ на когнитивные способности человека: В сообществе обсуждается влияние чрезмерной зависимости от ИИ на человеческий мозг, при этом некоторые ссылаются на заголовок статьи, утверждающий, что это может привести к тому, что мозг станет «атрофированным и неподготовленным» (Atrophied And Unprepared). Это отражает опасения по поводу возможной деградации основных когнитивных функций человека, таких как критическое мышление, память, способность решать проблемы, после повсеместного распространения инструментов ИИ. (Источник: X)

Перспективы и опасения относительно будущих моделей работы, управляемых ИИ: В сообществе цитируется мнение из статьи, предсказывающее, что к 2025 году ИИ перепишет правила работы, и текущие модели работы могут прекратить свое существование. Это вызывает дискуссии и опасения по поводу влияния автоматизации ИИ на рынок труда, изменения требуемых навыков, а также новых моделей сотрудничества человека и машины. (Источник: X)
