
Ключевые слова:AI, LLM, фотонный процессор AI, Claude 3.5 Haiku, многоязычная модель Orpheus TTS, локальное развертывание Gemini, анализ данных Graphiti
🔥 В фокусе
Стэнфорд опубликовал отчет AI Index 2025: Стэнфордский университет выпустил 456-страничный отчет «AI Index 2025», представляющий всесторонний обзор текущего состояния и тенденций в области ИИ. В отчете отмечается, что США лидируют по количеству выпущенных моделей, но Китай быстро догоняет по качеству моделей, значительно сокращая разрыв в производительности. Стоимость обучения продолжает расти (например, Gemini 1.0 Ultra обошлась примерно в 192 миллиона долларов США), но стоимость инференса резко падает. Проблема углеродных выбросов от ИИ становится все более серьезной, обучение Meta Llama 3.1 сопровождалось огромными выбросами. В отчете также упоминается, что многие бенчмарки ИИ насыщены и с трудом различают возможности моделей, «последний экзамен для человечества» становится новым вызовом. Ограничения на сбор общедоступных данных (48% доменов верхнего уровня ограничивают веб-сканеры) вызывают опасения по поводу «пика данных». Корпоративные инвестиции в ИИ огромны, но пока не привели к заметному росту производительности. ИИ обладает огромным потенциалом в науке и медицине, но для практического применения требуется время. В политике активно законодательство на уровне штатов США, особенно в отношении дипфейков, в то время как на глобальном уровне преобладают необязательные декларации. Несмотря на опасения по поводу замещения рабочих мест, общественное отношение к ИИ в целом остается оптимистичным (Источник: AINLPer)
Прорыв в разработке нового фотонного ИИ-процессора: Журнал Nature опубликовал две статьи, представляющие новые ИИ-процессоры, сочетающие фотонику и электронику, с целью преодоления ограничений производительности и энергопотребления в пост-транзисторную эпоху. Фотонный ускоритель PACE сингапурской компании Lightelligence (содержащий более 16 000 фотонных компонентов) продемонстрировал вычислительную скорость до 1 GHz и сокращение минимальной задержки в 500 раз, а также показал отличные результаты в решении задачи Изинга. Фотонный процессор американской компании Lightmatter (содержащий четыре матрицы 128×128) успешно запустил ИИ-модели, такие как BERT и ResNet, с точностью, сравнимой с электронными процессорами, и продемонстрировал такие приложения, как игра в Pac-Man. Оба исследования показывают масштабируемость их систем и возможность производства на существующих фабриках CMOS, что обещает продвижение аппаратного обеспечения ИИ к большей мощности и энергоэффективности, знаменуя важный шаг к практическому применению фотонных вычислений (Источник: 36氪)

UC Berkeley открывает исходный код 14B модели для кода DeepCoder, сравнимой с o3-mini: UC Berkeley совместно с Together AI выпустили DeepCoder-14B-Preview, полностью открытую модель для инференса кода с 14 миллиардами параметров, производительность которой сравнима с o3-mini от OpenAI. Модель была дообучена (fine-tuned) из Deepseek-R1-Distilled-Qwen-14B с использованием распределенного обучения с подкреплением (RL) и достигла 60.6% Pass@1 на бенчмарке LiveCodeBench. Команда создала обучающий набор из 24 000 высококачественных задач по программированию и применила улучшенный метод обучения GRPO+, итеративное расширение контекста (с 16K до 32K, до 64K при инференсе) и технологию сверхдлинной фильтрации. Также была открыта оптимизированная система обучения RL verl-pipeline, которая увеличила скорость сквозного обучения в 2 раза. Этот релиз включает не только модель, но и набор данных, код и журналы обучения (Источник: 新智元)
🎯 Тенденции
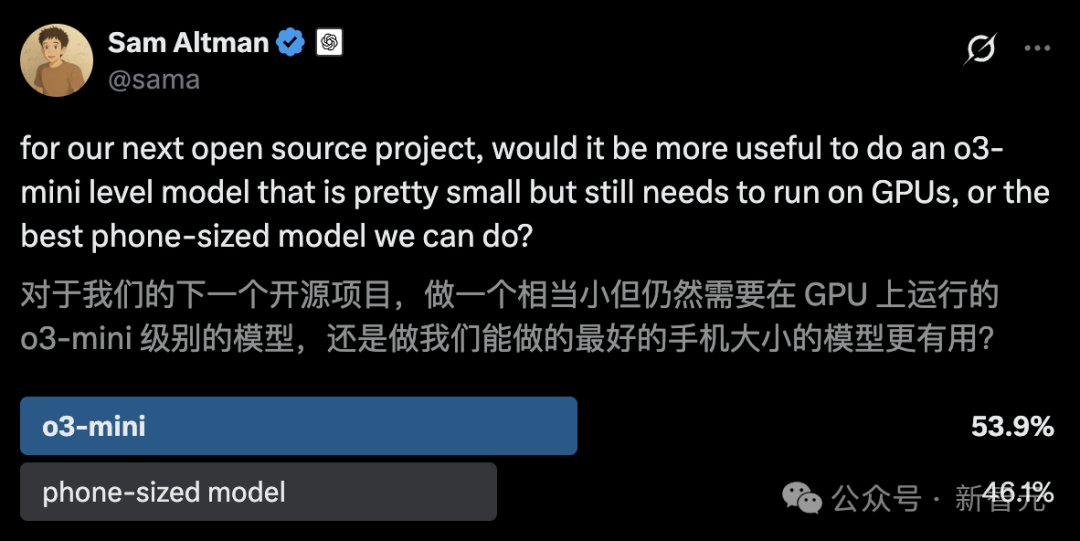
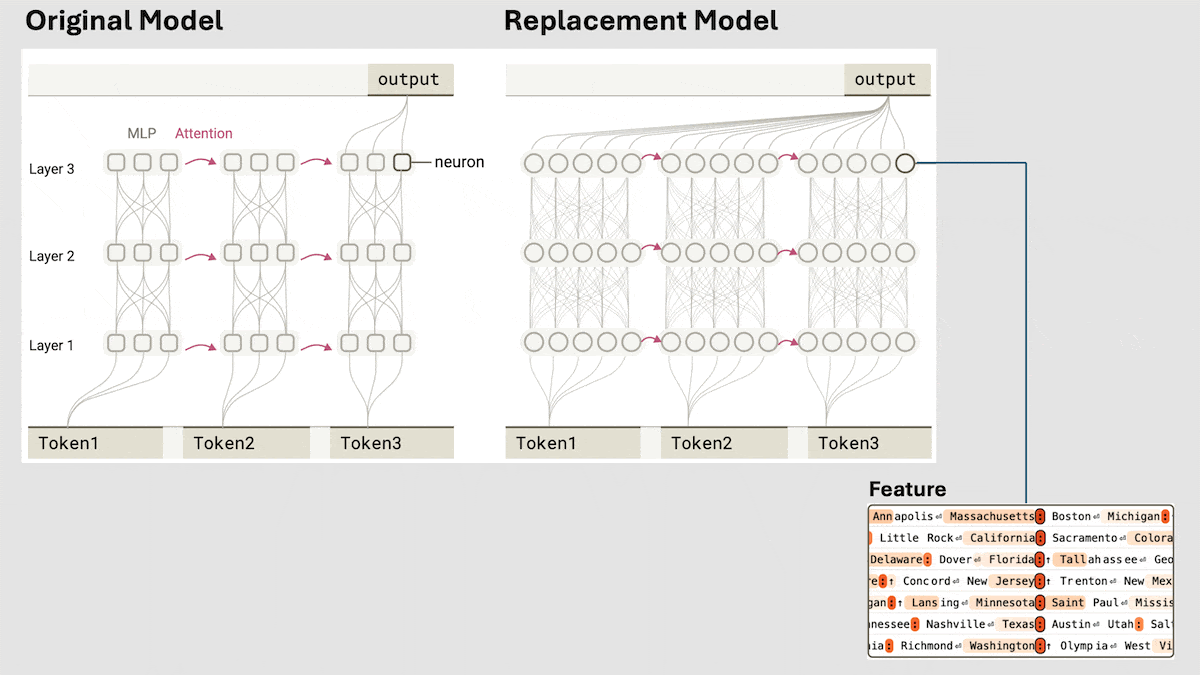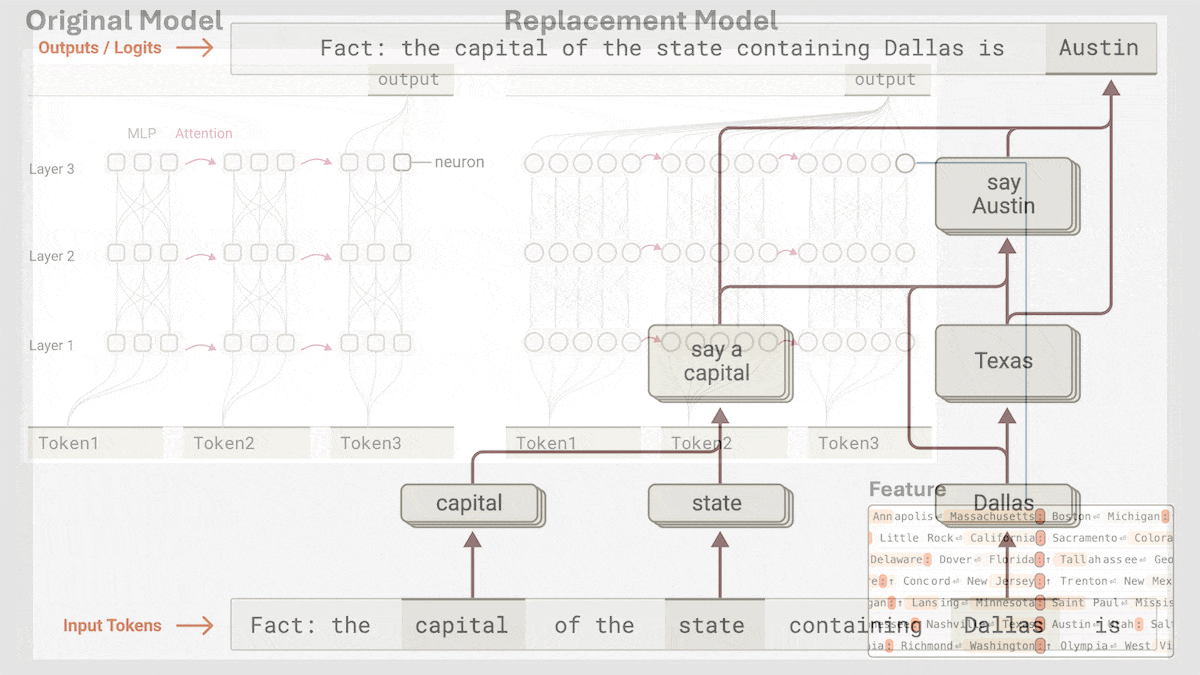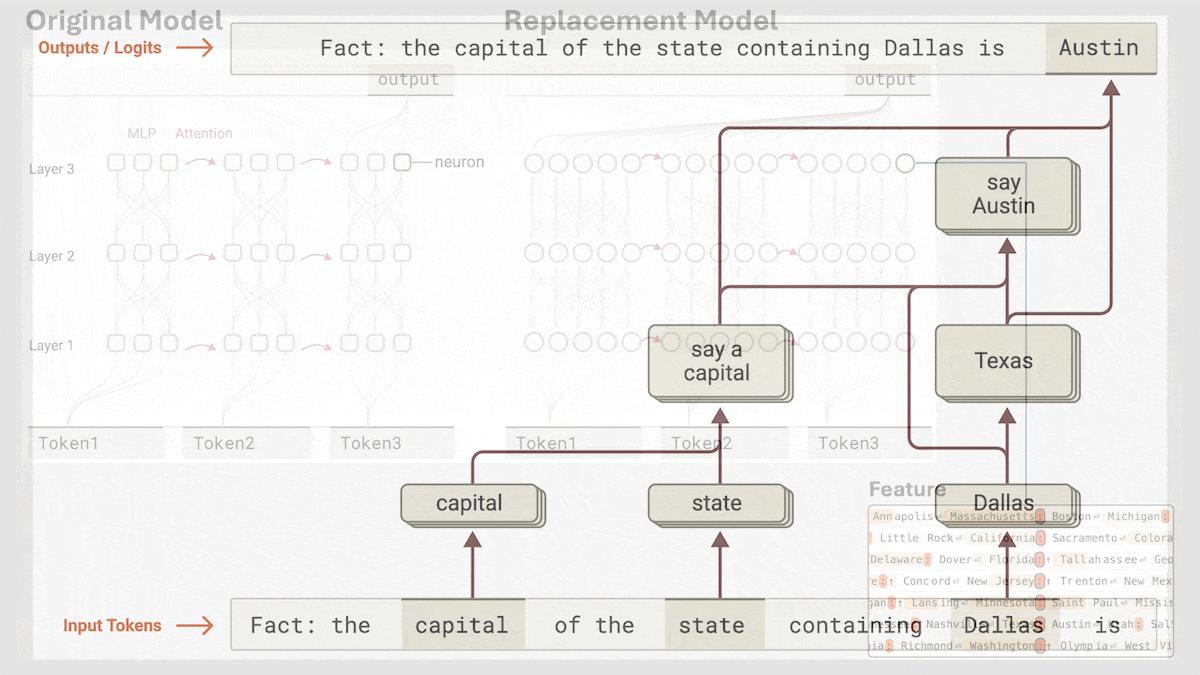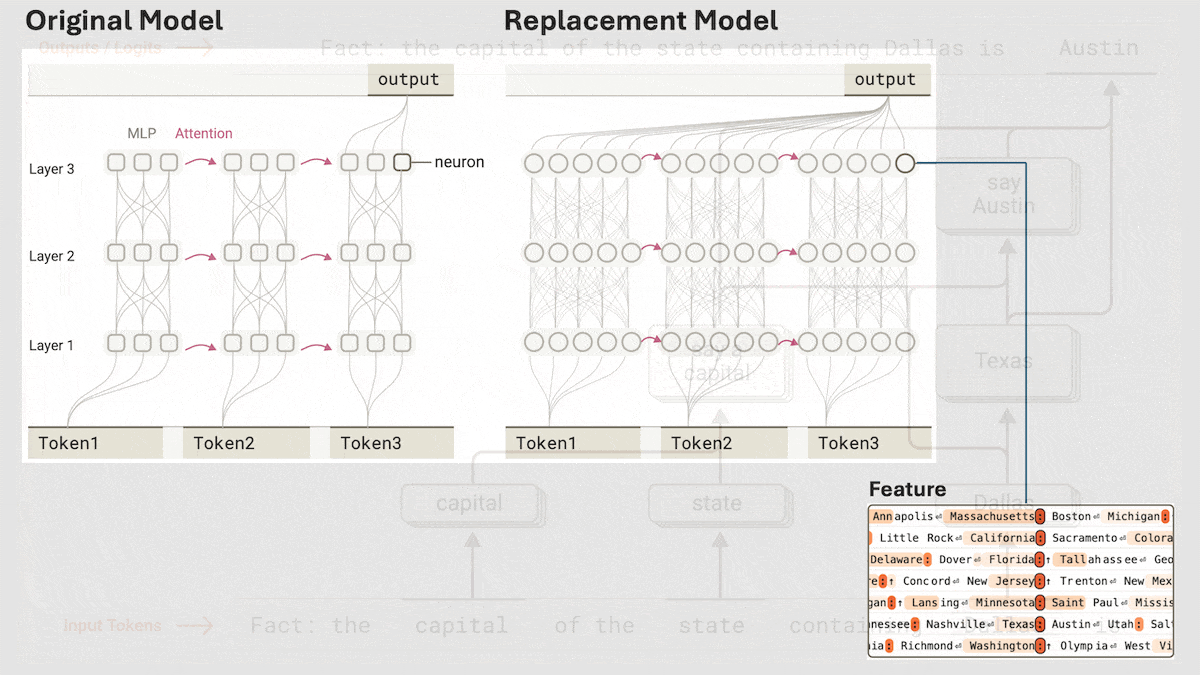
Anthropic раскрывает механизм неявного логического вывода Claude 3.5 Haiku: Исследовательская группа Anthropic с помощью нового метода проанализировала внутреннюю работу моделей Transformer (в частности, Claude 3.5 Haiku). Они обнаружили, что даже без явного обучения цепочке рассуждений (Chain-of-Thought), модель при генерации ответа демонстрирует шаги, похожие на логический вывод, через активации нейронов. Метод заменяет полносвязные слои интерпретируемыми «межслойными транскодерами» (cross-layer transcoder), идентифицирует «признаки» (features), связанные с конкретными концепциями или предсказаниями, и строит графы атрибуции для визуализации потока информации. Эксперименты показывают, что при ответе на вопросы (например, «Какой антоним у слова ‘маленький’?» или определение столицы штата, где находится Даллас) модель внутренне проходит несколько логических шагов, а не предсказывает ответ напрямую. Исследование помогает понять внутреннюю работу LLM и отличить истинные способности к рассуждению от поверхностной имитации (Источник: DeepLearning.AI)
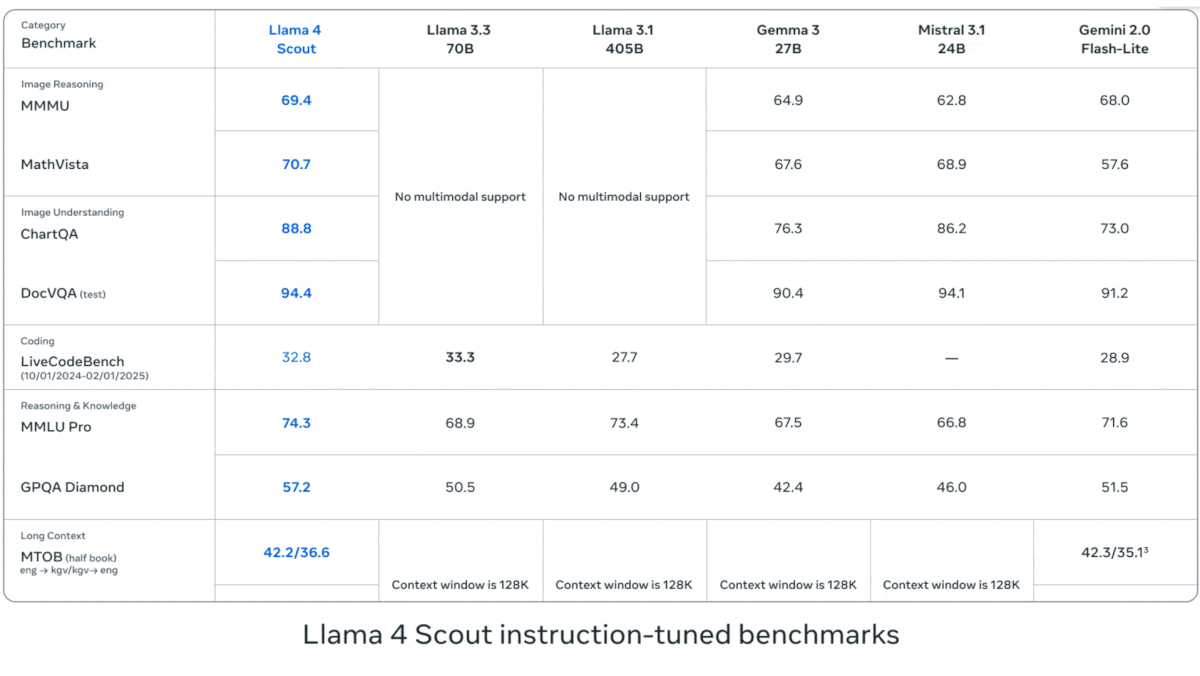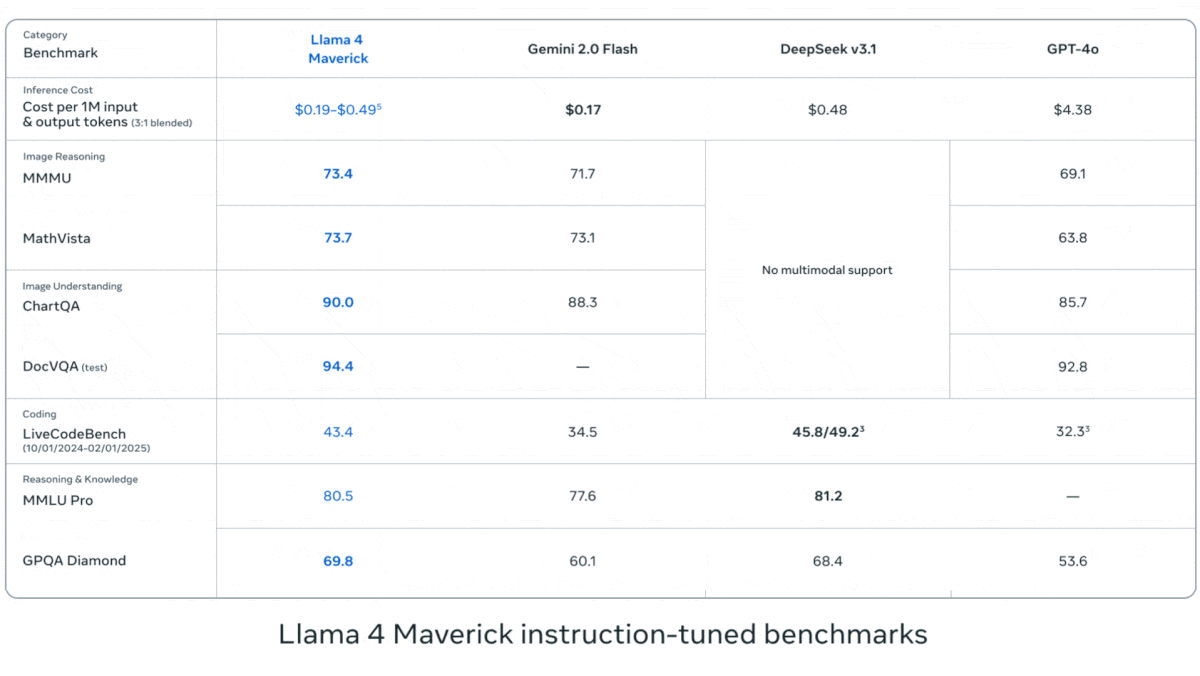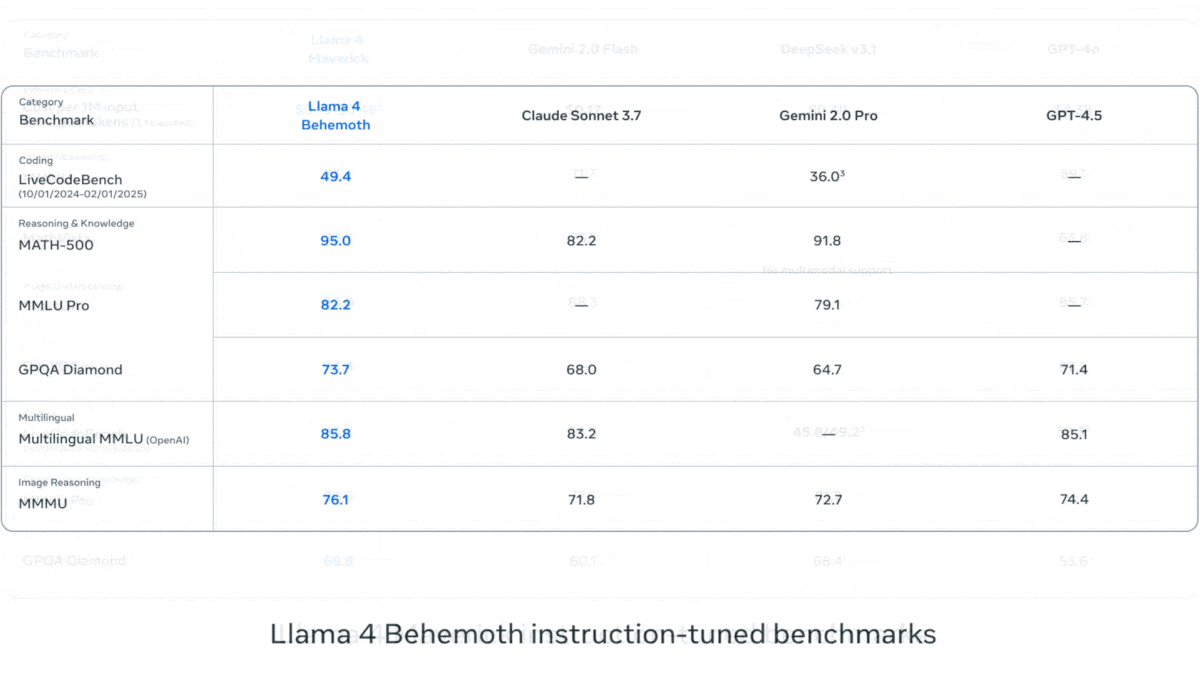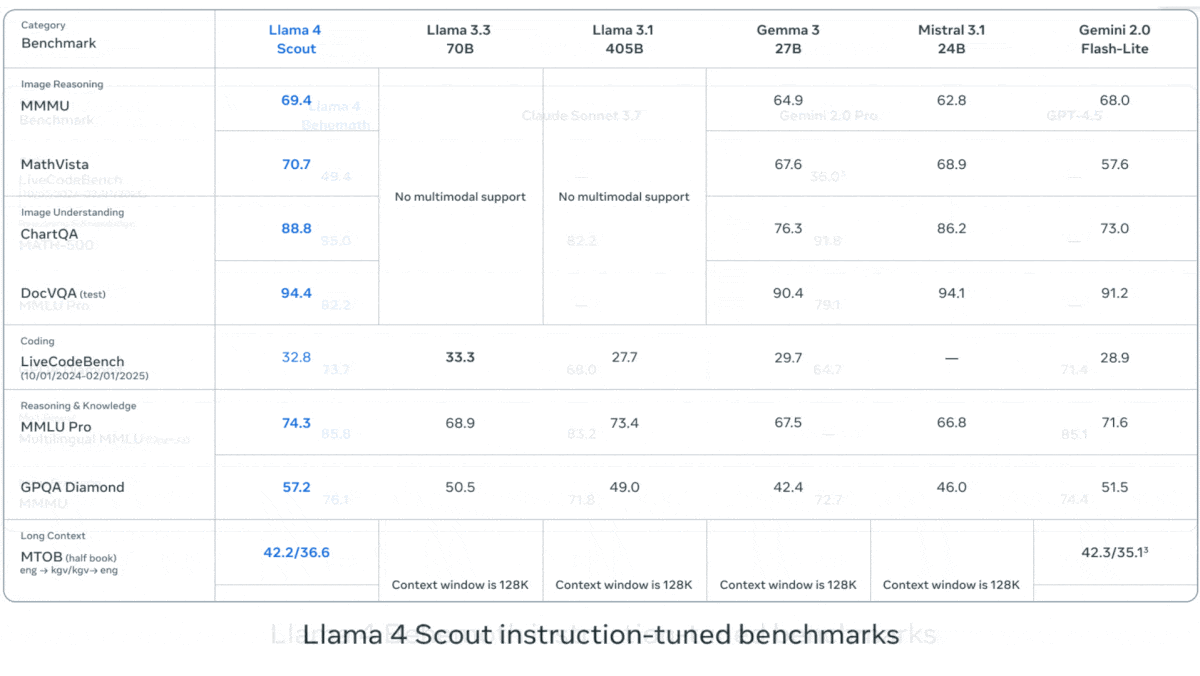
Meta выпускает серию визуально-языковых моделей Llama 4: Meta представила две мультимодальные модели с открытым исходным кодом из серии Llama 4: Llama 4 Scout (109B параметров, 17B активных) и Llama 4 Maverick (400B параметров, 17B активных), а также анонсировала Llama 4 Behemoth с почти 2T параметрами. Все эти модели используют архитектуру MoE, поддерживают ввод текста, изображений, видео и вывод текста. Scout имеет контекстное окно до 10M токенов (хотя фактическая эффективность оспаривается), Maverick — 1M. Модели показывают высокие результаты на множестве бенчмарков по изображениям, кодированию, знаниям и рассуждениям: Scout превосходит Gemma 3 27B и другие, Maverick превосходит GPT-4o и Gemini 2.0 Flash, а ранняя версия Behemoth превосходит GPT-4.5 и другие. Выпуск этих моделей способствует дальнейшему сокращению разрыва между открытыми и закрытыми моделями (Источник: DeepLearning.AI, X @AIatMeta)
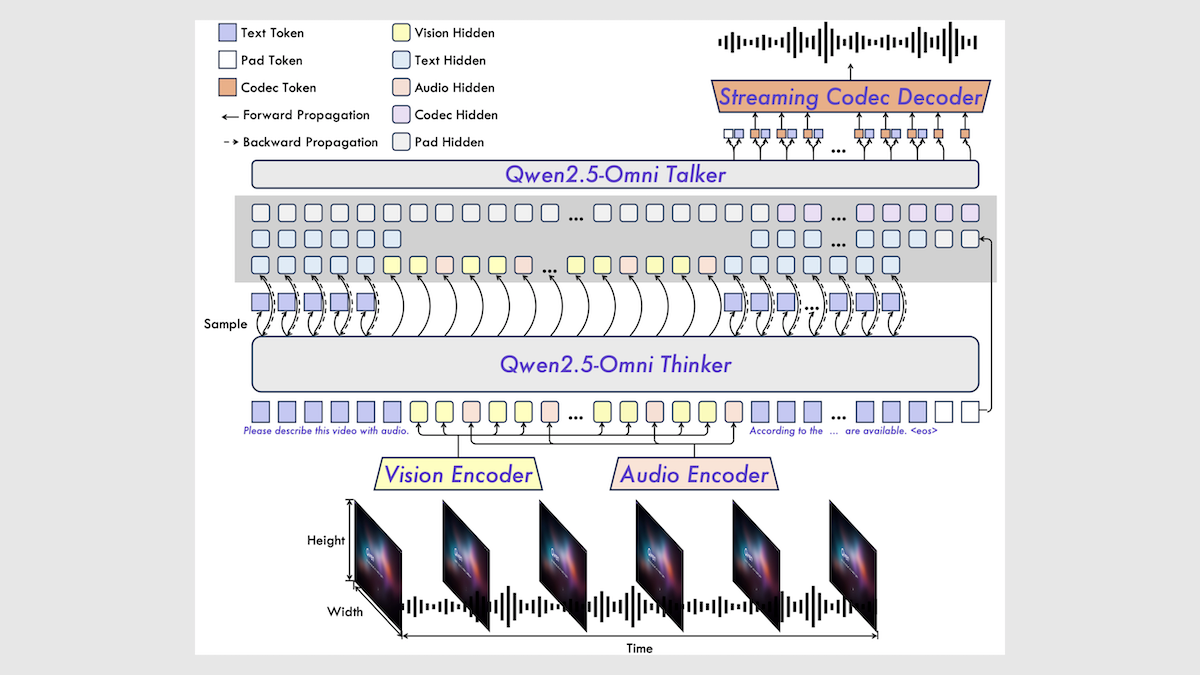
Alibaba выпускает мультимодальную модель Qwen2.5-Omni 7B: Alibaba выпустила новую мультимодальную модель с открытым исходным кодом Qwen2.5-Omni 7B, способную обрабатывать ввод текста, изображений, аудио и видео, а также генерировать текст и речь. Модель построена на базе текстовой модели Qwen 2.5 7B, визуального кодировщика Qwen2.5-VL и аудиокодировщика Whisper-large-v3, используя инновационную архитектуру Thinker-Talker. Модель демонстрирует отличные результаты на ряде бенчмарков, особенно достигая уровня SOTA в задачах преобразования аудио в текст, изображений в текст и видео в текст, но немного уступает в чисто текстовых задачах и задачах преобразования текста в речь. Выпуск Qwen2.5-Omni расширяет выбор высокопроизводительных мультимодальных моделей с открытым исходным кодом (Источник: DeepLearning.AI)
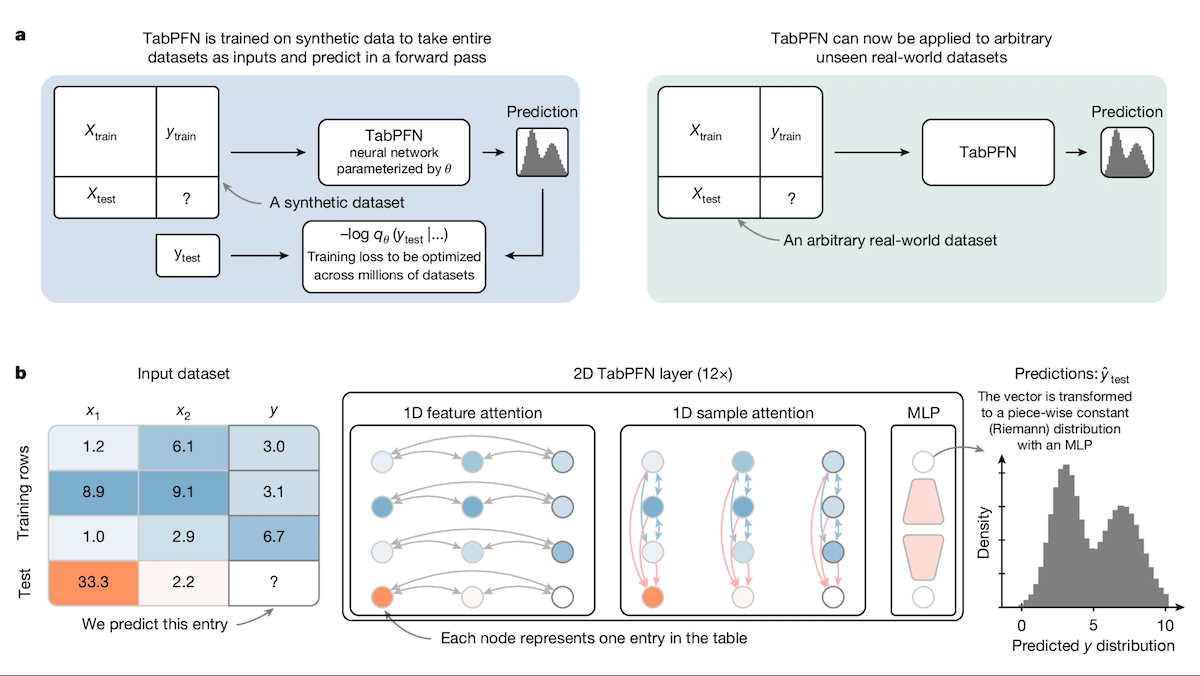
TabPFN: Transformer для табличных данных, превосходящий деревья решений: Исследователи из Фрайбургского университета и других институтов представили Tabular Prior-data Fitted Network (TabPFN), модель Transformer, специально разработанную для табличных данных. Предварительно обученная на 100 миллионах синтетических наборов данных, TabPFN научилась распознавать закономерности между наборами данных, что позволяет ей напрямую выполнять классификацию и регрессию на новых табличных данных без дополнительного обучения. Эксперименты на бенчмарках AutoML и OpenML-CTR23 показали, что TabPFN превосходит популярные методы градиентного бустинга, такие как CatBoost, LightGBM и XGBoost, в задачах классификации (AUC) и регрессии (RMSE), хотя скорость инференса ниже. Эта работа открывает новые пути для применения Transformer в области обработки табличных данных (Источник: DeepLearning.AI)
Платформа Intel становится новым экономичным выбором для универсальных машин с большими моделями: С популяризацией моделей с открытым исходным кодом, таких как DeepSeek, универсальные машины с большими моделями становятся популярным выбором для быстрого развертывания ИИ в компаниях. Intel предлагает экономичное аппаратное решение, сочетающее игровые видеокарты Arc™ (например, A770) с процессорами Xeon® W, снижая цену таких машин с уровня миллионов юаней до уровня сотен тысяч юаней. Платформа поддерживает не только DeepSeek R1, но и совместима с моделями Qwen, Llama и другими. Несколько компаний, включая Feizhi Cloud, SuperCloud и CloudTip, уже выпустили продукты или решения на базе этой платформы для задач, таких как ответы на вопросы по базе знаний, интеллектуальные чат-боты, финансовые консультации, обработка документов, удовлетворяя потребности малых и средних предприятий и отдельных отделов в локальном инференсе ИИ (Источник: 量子位)
Google представляет седьмое поколение TPU «Ironwood»: На конференции Google Cloud Next компания Google анонсировала свою систему TPU седьмого поколения Ironwood, оптимизированную для инференса ИИ. По сравнению с первым поколением Cloud TPU, производительность Ironwood выросла в 3600 раз, а энергоэффективность — в 29 раз. По сравнению с шестым поколением Trillium, производительность на ватт у Ironwood в 2 раза выше, память на одном чипе достигает 192 ГБ (в 6 раз больше, чем у Trillium), а скорость доступа к данным увеличена в 4.5 раза. Ожидается, что Ironwood будет доступен позже в этом году для удовлетворения растущего спроса на инференс ИИ (Источник: X @demishassabis, X @JeffDean, Reddit r/LocalLLaMA)

Google DeepMind и модели Gemini будут поддерживать протокол MCP: Сооснователь Google DeepMind Демис Хассабис и руководитель моделей Gemini Ориол Виньялс заявили о поддержке протокола контекста модели (MCP) и выразили надежду на совместное развитие этого протокола с командой MCP и партнерами по отрасли. MCP быстро становится открытым стандартом в эпоху AI Agent, направленным на то, чтобы различные модели могли понимать единый «язык сервисов» для удобного вызова внешних инструментов и API. Этот шаг позволит моделям Gemini лучше интегрироваться в растущую экосистему MCP для создания более мощных приложений Agent (Источник: X @demishassabis, X @OriolVinyalsML)
Moonshot AI выпускает мультимодальную модель KimiVL A3B: Moonshot AI (月之暗面) выпустила модели KimiVL A3B Instruct & Thinking, серию мультимодальных больших моделей с открытым исходным кодом (лицензия MIT) и возможностью обработки контекста длиной 128K. Серия включает MoE VLM и MoE Reasoning VLM, с активными параметрами всего около 3B. Утверждается, что они превосходят GPT-4o на бенчмарках по зрению и математике, достигая 36.8% на MathVision, 34.5% на ScreenSpot-Pro, 867 баллов на OCRBench, и показывают отличные результаты в тестах с длинным контекстом (MMLongBench-Doc 35.1%, LongVideoBench 64.5%). Веса моделей опубликованы на Hugging Face (Источник: X @huggingface)

Выпущена Orpheus TTS 3B: многоязычная модель клонирования голоса zero-shot: Сообщество с открытым исходным кодом выпустило модель Orpheus TTS 3B, многоязычную модель преобразования текста в речь с 3 миллиардами параметров. Она поддерживает клонирование голоса zero-shot, потоковую генерацию с задержкой около 100 мс и позволяет управлять эмоциями и интонацией для генерации голоса, похожего на человеческий. Модель распространяется под лицензией Apache 2.0, веса доступны на Hugging Face, что способствует дальнейшему развитию открытых технологий TTS (Источник: X @huggingface)
Представлена OmniSVG: унифицированная модель генерации масштабируемой векторной графики: Предложена новая модель под названием OmniSVG, предназначенная для унифицированной генерации масштабируемой векторной графики (SVG). Модель основана на Qwen2.5-VL и интегрирует токенизатор SVG, способный принимать ввод текста и изображений и генерировать соответствующий код SVG. Веб-сайт проекта демонстрирует ее мощные возможности генерации SVG. В настоящее время опубликованы статья и набор данных, веса модели пока не доступны (Источник: X @karminski3, Reddit r/LocalLLaMA)
Google Cloud Next 2025 фокусируется на ИИ: Конференция Google Cloud Next осветила достижения в области ИИ. Была представлена седьмая версия TPU Ironwood, оптимизированная для инференса; объявлено, что Gemini 2.5 Pro является самой умной моделью на данный момент и возглавила рейтинг Chatbot Arena; объединены результаты исследований DeepMind, Google Research и Google Cloud для предоставления клиентам моделей, таких как WeatherNext и AlphaFold; разрешено предприятиям запускать модели Gemini в собственных центрах обработки данных; объявлено о сотрудничестве с Nvidia для переноса моделей Gemini на локальные системы с использованием Blackwell и Confidential Computing (Источник: X @GoogleDeepMind, X @GoogleDeepMind, Reddit r/artificial, X @nvidia)
Прогноз тенденций ИИ на 2025 год: Согласно обобщенным мнениям, ключевые тенденции ИИ в 2025 году включают: дальнейшее развитие и углубление применения генеративного ИИ, повышение важности этики ИИ и ответственного ИИ, распространение ИИ на периферии (edge AI), ускоренное внедрение ИИ в конкретных отраслях (таких как медицина, финансы, цепочки поставок), расширение возможностей мультимодального ИИ, автономность и вызовы AI Agent, подрыв традиционных бизнес-моделей ИИ, а также рост спроса на таланты и разнообразие навыков в области ИИ (Источник: X @Ronald_vanLoon, X @Ronald_vanLoon, X @Ronald_vanLoon)

Завод Tesla реализует автоматическую транспортировку автомобилей с помощью автопилота: Tesla продемонстрировала, что произведенные автомобили могут самостоятельно передвигаться по территории завода от производственной линии до зоны погрузки без вмешательства человека. Это демонстрирует потенциал применения технологии автопилота в контролируемых средах (например, в заводской логистике) и является примером прогресса ИИ в автомобилестроении и автоматизации (Источник: X @Ronald_vanLoon)
🧰 Инструменты
Free-for-dev: Полный список бесплатных ресурсов для разработчиков: Проект ripienaar/free-for-dev на GitHub — это популярный список ресурсов, объединяющий полезные бесплатные тарифные планы для разработчиков (особенно DevOps и разработчиков инфраструктуры) в различных продуктах SaaS, PaaS, IaaS. Список охватывает облачные сервисы, базы данных, API, мониторинг, CI/CD, хостинг кода, инструменты ИИ и многие другие категории, при этом четко требуется, чтобы сервис предлагал постоянный бесплатный уровень, а не пробный период, и уделялось внимание безопасности (например, сервисы, ограничивающие TLS, не принимаются). Проект поддерживается сообществом и постоянно обновляется, предоставляя разработчикам огромное удобство для поиска и сравнения бесплатных сервисов (Источник: GitHub: ripienaar/free-for-dev)

Graphiti: Фреймворк для построения графов знаний ИИ в реальном времени: getzep/graphiti — это Python-фреймворк для создания и запроса графов знаний с учетом времени, особенно подходящий для AI Agent, которым необходимо обрабатывать информацию о динамической среде. Он может непрерывно интегрировать взаимодействия с пользователем, структурированные/неструктурированные данные, поддерживает инкрементные обновления и точные исторические запросы без необходимости полного пересчета графа. Graphiti сочетает семантические вложения, поиск по ключевым словам (BM25) и обход графа для эффективного гибридного поиска и позволяет определять пользовательские сущности. Этот фреймворк является основной технологией слоя памяти Zep и теперь доступен с открытым исходным кодом (Источник: GitHub: getzep/graphiti)

WeChatMsg: Инструмент для извлечения истории чатов WeChat и обучения ИИ-помощника: LC044/WeChatMsg — это инструмент для извлечения локальной истории чатов WeChat (поддерживает WeChat 4.0) в Windows и ее экспорта в форматы HTML, Word, Excel и др. Он предназначен для помощи пользователям в постоянном сохранении истории чатов и может анализировать записи для создания годовых отчетов. Кроме того, инструмент поддерживает использование данных чатов пользователя для обучения персонализированного ИИ-помощника, отражая идею «мои данные — под моим контролем». Проект предоставляет графический интерфейс пользователя и подробные инструкции по использованию (Источник: GitHub: LC044/WeChatMsg)
Alibaba Cloud Bailian запускает полный цикл сервисов MCP, создавая «фабрику» Agent’ов: Платформа Alibaba Cloud Bailian официально запустила полный набор возможностей для сервисов протокола контекста модели (MCP), охватывающий весь жизненный цикл: регистрацию сервисов, облачный хостинг, вызов Agent’ов и композицию процессов. Разработчики могут напрямую использовать официальные или сторонние сервисы MCP, размещенные на платформе, такие как Amap (高德地图) и Notion, или регистрировать собственные API как сервисы MCP с помощью простой конфигурации (без управления серверами). Это направлено на снижение порога входа в разработку Agent’ов, позволяя разработчикам быстро создавать и развертывать AI Agent’ов, способных вызывать внешние инструменты, и способствуя внедрению больших моделей в реальные сценарии. Этот сервис рассматривается как важный шаг в коммерциализации ИИ Alibaba (Источник: 微信公众号 — AINLPer, 量子位)
Hugging Face и Cloudflare сотрудничают для предоставления бесплатной инфраструктуры WebRTC: Hugging Face в партнерстве с Cloudflare предоставляет разработчикам ИИ глобальную инфраструктуру WebRTC корпоративного уровня через FastRTC. Разработчики могут бесплатно передавать 10 ГБ данных, используя Hugging Face Token, для создания приложений ИИ для голоса и видео в реальном времени. В качестве примера предоставлена демонстрация голосового чата Llama 4, показывающая удобство, обеспечиваемое этим сотрудничеством (Источник: X @huggingface)
Google AI Studio получает крупное обновление пользовательского интерфейса: Пользовательский интерфейс Google AI Studio (ранее MakerSuite) прошел первый этап редизайна, получив более современный вид и ощущения. Это обновление призвано заложить основу для дополнительных функций платформы для разработчиков, которые будут запущены в ближайшие месяцы. Новый UI более согласован со стилем приложений Gemini и добавляет специальный бэкэнд для разработчиков для управления API и платежами. Обновление предвещает расширение функциональности платформы, возможно, включая доступ к новым моделям (таким как Veo 2) (Источник: X @JeffDean, X @op7418)

LlamaIndex представляет функцию визуальных ссылок: LlamaIndex выпустил новое руководство, демонстрирующее, как использовать функцию Layout Agent в LlamaParse для реализации визуальных ссылок в ответах Agent’а. Это означает, что сгенерированные ответы могут быть не только отслежены до текстового источника, но и напрямую сопоставлены с соответствующими визуальными областями (точно определенными с помощью ограничивающих рамок) в исходном документе (например, PDF). Это повышает интерпретируемость и возможность отслеживания ответов Agent’а, особенно при обработке документов, содержащих визуальные элементы, такие как диаграммы и таблицы (Источник: X @jerryjliu0)

LangGraph представляет конструктор GUI без кода: LangGraph теперь предлагает графический пользовательский интерфейс (GUI) без кода для проектирования архитектуры Agent’ов. Пользователи могут планировать рабочие процессы Agent’а и соединения узлов с помощью визуальных операций, таких как перетаскивание, а затем генерировать код на Python или TypeScript одним щелчком мыши. Это снижает порог входа для создания сложных приложений Agent’ов и облегчает быстрое прототипирование и разработку (Источник: X @LangChainAI)
Perplexity обновляет функцию графиков акций: Perplexity обновила свою функцию графиков акций, которая теперь отражает изменения цен акций в течение дня в реальном времени, а не растягивает временную шкалу, чтобы заполнить весь график. Это улучшение, хотя и базовое, повышает актуальность и практичность отображения финансовой информации (Источник: X @AravSrinivas, X @AravSrinivas)

OLMoTrace: Инструмент для связи вывода LLM с обучающими данными: Allen Institute for AI (AI2) представил инструмент OLMoTrace, который может в реальном времени сопоставлять вывод моделей OLMo с соответствующими источниками обучающих данных (достигая сопоставления за секунды в данных объемом 4T токенов). Это помогает понять поведение модели, повысить прозрачность и улучшить данные после обучения. Инструмент предназначен для помощи исследователям и разработчикам в лучшем понимании внутренних механизмов работы и источников знаний больших языковых моделей (Источник: X @natolambert)
llama.cpp объединяет поддержку моделей Qwen3: Популярный фреймворк для локального инференса LLM llama.cpp объединил поддержку для готовящейся к выпуску серии моделей Qwen3, включая базовые модели и версии MoE. Это означает, что как только модели Qwen3 будут выпущены, пользователи смогут немедленно использовать квантованные модели в формате GGUF в экосистеме llama.cpp, что удобно для запуска на локальных устройствах (Источник: X @karminski3, Reddit r/LocalLLaMA)

Фреймворк KTransformers поддерживает модели Llama 4: Китайский фреймворк для инференса ИИ KTransformers (известный поддержкой гибридного инференса CPU+GPU, особенно для разгрузки моделей MoE) добавил экспериментальную поддержку моделей серии Meta Llama 4 в свою ветку разработки. Согласно документации, для запуска квантованной Q4 модели Llama-4-Scout (109B) требуется около 65 ГБ ОЗУ и 10 ГБ видеопамяти, а для Llama-4-Maverick (402B) — около 270 ГБ ОЗУ и 12 ГБ видеопамяти. На конфигурации 4090 + два Xeon 4 скорость инференса одного батча может достигать 32 токенов/с. Это открывает возможность запуска больших моделей MoE при ограниченной видеопамяти (Источник: X @karminski3, Reddit r/LocalLLaMA)
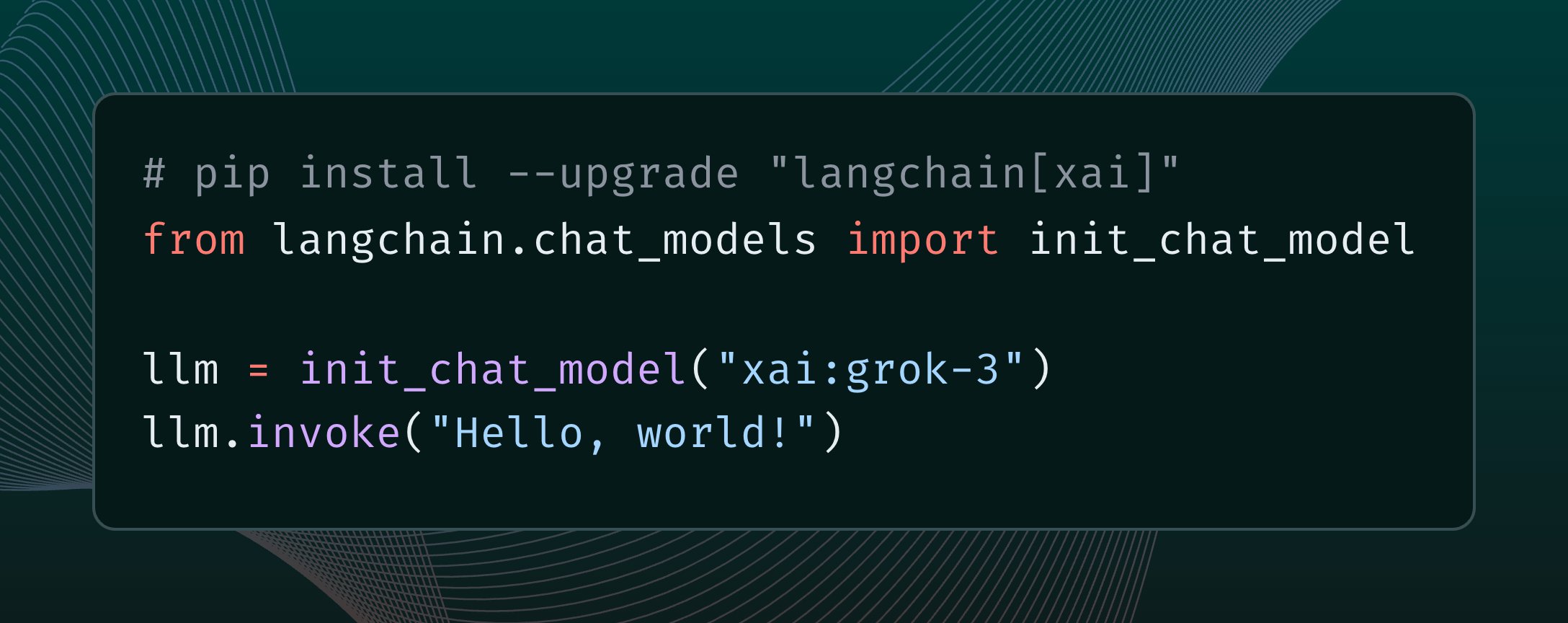
LangChain интегрирует модель xAI Grok 3: LangChain объявил об интеграции недавно выпущенной модели Grok 3 от xAI. Пользователи теперь могут вызывать Grok 3 через фреймворк LangChain, используя ее мощные возможности для создания приложений (Источник: X @LangChainAI)
Руководство по бесплатному развертыванию облачного сервиса n8n: Описано, как бесплатно развернуть платформу автоматизации рабочих процессов с открытым исходным кодом n8n с использованием Hugging Face Spaces и Supabase, и получить доступ через публичный домен с поддержкой HTTPS. Это позволяет пользователям использовать все функции n8n (включая узлы, требующие URL обратного вызова), не покупая серверы и не настраивая домен и SSL-сертификаты самостоятельно. Этот метод использует бесплатную базу данных Supabase для решения проблемы потери данных из-за спящего режима Hugging Face Space (Источник: 微信公众号 — 袋鼠帝AI客栈)
Обновление плагинов OpenWebUI: Счетчик контекста и Адаптивная память: Разработчики сообщества выпустили/обновили два плагина для OpenWebUI: 1) Enhanced Context Counter v3, предоставляющий подробную панель инструментов для отслеживания использования токенов, затрат и метрик производительности, с поддержкой нескольких моделей и пользовательской калибровки. 2) Adaptive Memory v2, который динамически извлекает, хранит и внедряет специфичную для пользователя информацию (факты, предпочтения, цели и т. д.) с помощью LLM, обеспечивая персонализированную, постоянную и адаптивную память диалога, при этом полностью работая локально без внешних зависимостей (Источник: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
QuickVoice MCP: Позволяет Claude совершать телефонные звонки: Разработчик сообщества создал инструмент MCP (Model Context Protocol) под названием QuickVoice, который позволяет моделям, поддерживающим MCP, таким как Claude 3.7 Sonnet, совершать и обрабатывать реальные телефонные звонки. Пользователи могут давать команды на естественном языке (например, «позвони врачу, чтобы записаться на прием»), чтобы ИИ выполнил задачу звонка, включая навигацию по меню IVR. Проект открыт на GitHub (Источник: Reddit r/ClaudeAI)

RPG Dice Roller для OpenWebUI: Сообщество разработало плагин-инструмент для броска RPG-костей для OpenWebUI, чтобы удобно получать действительно случайные результаты во время диалогов в ролевых играх (Источник: Reddit r/OpenWebUI)
📚 Обучение
Курс машинного обучения с открытым исходным кодом от girafe-ai: Проект girafe-ai/ml-course на GitHub предоставляет учебные материалы первого семестра курса машинного обучения girafe-ai, включая Naive Bayes, kNN, линейную регрессию/классификацию, SVM, PCA, деревья решений, ансамблевое обучение, градиентный бустинг, а также введение в глубокое обучение. Предоставляются видеозаписи лекций, презентации PPT и домашние задания. Это ценный ресурс для изучения основ машинного обучения (Источник: GitHub: girafe-ai/ml-course)
USTC и Huawei Noah’s Ark предлагают фреймворк CMO для оптимизации логического синтеза чипов: Команда профессора Ван Цзе из Научно-технического университета Китая (USTC) в сотрудничестве с лабораторией Huawei Noah’s Ark опубликовала статью на ICLR 2025, предлагая эффективный метод логической оптимизации CMO, основанный на майнинге нейросимволических функций. Фреймворк использует графовые нейронные сети (GNN) для управления поиском по дереву Монте-Карло (MCTS), генерируя легковесные, интерпретируемые и хорошо обобщающие символические функции оценки для отсечения неэффективных преобразований узлов в операторах логической оптимизации (таких как Mfs2). Эксперименты показывают, что CMO может повысить эффективность выполнения ключевых операторов до 2.5 раз, сохраняя при этом качество оптимизации, и уже применяется в собственном инструменте логического синтеза EMU от Huawei (Источник: 量子位)
Shanghai AI Lab предлагает новый метод обрезки гауссиан MaskGaussian: Исследовательская группа Shanghai AI Lab представила на CVPR 2025 метод MaskGaussian для оптимизации 3D Gaussian Splatting. Метод интегрирует обучаемые распределения масок в процесс растеризации, впервые позволяя одновременно сохранять градиенты как для используемых, так и для неиспользуемых гауссовых точек. Это позволяет обрезать большое количество избыточных гауссовых точек, максимально сохраняя качество реконструкции. Эксперименты на нескольких наборах данных показали обрезку более 60% гауссовых точек с незначительной потерей производительности, при этом повышая скорость обучения и уменьшая потребление памяти (Источник: 量子位)
Разбор технического отчета Qwen2.5-Omni: Пользователь Reddit поделился подробными заметками по техническому отчету Alibaba Qwen2.5-Omni. В отчете описывается архитектура модели Thinker-Talker, методы обработки мультимодального ввода (текст, изображение, аудио, видео), включая инновационное позиционное кодирование TMRoPE для выравнивания аудио и видео, механизм потоковой генерации речи, процесс обучения (предварительное обучение + последующее обучение RL) и т. д. Эти заметки предоставляют ценную информацию для понимания принципов работы этой передовой мультимодальной модели (Источник: Reddit r/LocalLLaMA)
McKinsey публикует руководство по масштабированию генеративного ИИ в компаниях: McKinsey выпустила операционное руководство для лидеров в области данных, рассматривающее вопросы масштабирования применения генеративного ИИ в компаниях. Отчет, вероятно, охватывает разработку стратегии, выбор технологий, развитие талантов, управление рисками и другие аспекты, предоставляя руководство для практического внедрения и расширения GenAI в бизнесе (Источник: X @Ronald_vanLoon)

Руководство для начинающих по изучению AI Agent: Khulood_Almani поделился ресурсами или шагами о том, как начать изучение AI Agent, возможно, включая пути обучения, ключевые концепции, рекомендуемые инструменты или платформы, предоставляя руководство для тех, кто хочет начать изучать область AI Agent (Источник: X @Ronald_vanLoon)

Исследование методов переранжирования в визуальном распознавании местоположения: Статья на arXiv исследует, остаются ли методы переранжирования (Re-Ranking) эффективными в задаче визуального распознавания местоположения (Visual Place Recognition, VPR). Исследование, вероятно, анализирует преимущества и недостатки существующих методов переранжирования и оценивает их роль и необходимость в современных системах VPR (Источник: Reddit r/deeplearning, Reddit r/MachineLearning)
Исследовательский отчет «AI 2027» рассматривает риски ASI и будущее: Исследовательский отчет под названием «AI 2027» рассматривает возможные сценарии развития ИИ к 2027 году, в частности, как автоматизированная разработка ИИ может привести к появлению сверхразумного ИИ (ASI). Отчет анализирует потенциальные риски, связанные с ASI, такие как потеря контроля человеком из-за несовпадения целей, концентрация власти, усиление рисков безопасности из-за международной гонки вооружений, кража моделей и отставание общественного сознания, а также рассматривает возможные геополитические исходы, такие как война, соглашения или подчинение (Источник: Reddit r/artificial)
Исследование выравнивания активаций в нейронных сетях: Статья, опубликованная на OpenReview, исследует причины возникновения выравнивания представлений (representational alignment) в нейронных сетях. Исследование обнаружило, что выравнивание происходит не из-за отдельных нейронов, а связано с тем, как работают функции активации, и предлагает метод Spotlight Resonance Method для объяснения этого явления, предоставляя экспериментальные подтверждения (Источник: Reddit r/deeplearning)
💼 Бизнес
Alibaba International делает ставку на ИИ для прорыва: Столкнувшись с жесткой конкуренцией в трансграничной электронной коммерции и изменениями в мировой торговле, Alibaba International Digital Commerce Group рассматривает ИИ как основную стратегию, активно инвестируя в него для роста и повышения эффективности. Компания запустила глобальную программу обучения талантов в области ИИ «Bravo 102» и установила 80% вакансий при наборе выпускников как связанные с ИИ. Приложения ИИ уже охватывают B2B (поисковая система ИИ Accio, AI Agent «помощник по бизнесу») и B2C (платформа Aidge предоставляет виртуальную примерку, ИИ-обслуживание клиентов и т. д.). Несмотря на значительный рост выручки Alibaba International (рост на 32% в 4 квартале 2024 года), инвестиции привели к увеличению убытков. ИИ рассматривается как ключевой фактор для выхода Alibaba International из ценовой конкуренции, достижения трансформации с высокой добавленной стоимостью и精细化运营 (Источник: 36氪)
Бывшие ключевые сотрудники OpenAI присоединяются к новой компании Миры Мурати: Алек Рэдфорд, первый автор основополагающей статьи о GPT, и Боб МакГрю, бывший главный научный сотрудник OpenAI, присоединились в качестве консультантов к новой ИИ-компании Thinking Machines Lab, основанной бывшим техническим директором OpenAI Мирой Мурати. Рэдфорд сыграл ключевую роль в создании моделей серии GPT, а МакГрю был глубоко вовлечен в разработку GPT-3/4 и модели o1. В учредительской команде Thinking Machines Lab много (не менее 19) выходцев из OpenAI. Цель компании — популяризация приложений ИИ, по слухам, планируется привлечь 1 миллиард долларов при оценке в 9 миллиардов долларов, что свидетельствует о высоких ожиданиях рынка от стартапов, возглавляемых ведущими специалистами в области ИИ (Источник: 新智元)
Публичные фонды интересуются бизнесом фармацевтических компаний в сфере ИИ+медицина: Недавно несколько китайских публичных фондов активно исследовали котирующиеся на бирже фармацевтические компании, при этом применение ИИ в медицине стало центром внимания. Haier Biomedical представила применение ИИ в своих сетях IoT Blood Network и Vaccine Network, а также прогресс в повышении эффективности сценариев общественного здравоохранения (например, запись на вакцинацию) с помощью ИИ. Hisun Pharmaceutical заявила, что внедрила модель DeepSeek-R1 и сотрудничает с компаниями по разработке лекарств с помощью ИИ, надеясь использовать ИИ для расширения возможностей всего процесса разработки новых лекарств. Kanion Pharmaceutical также заявила, что строит платформу для открытия инновационных лекарств традиционной китайской медицины на основе ИИ + мультиомики. Это свидетельствует о том, что применение технологий ИИ в фармацевтических исследованиях и разработках, операционной деятельности и обслуживании пациентов привлекает повышенное внимание рынка капитала (Источник: 创业板观察)
OpenAI запускает программу Pioneers для углубления отраслевого сотрудничества: OpenAI запустила программу Pioneers, направленную на установление партнерских отношений с амбициозными компаниями для совместного создания передовых продуктов ИИ. Программа будет сосредоточена на двух аспектах: во-первых, интенсивное дообучение моделей (fine-tuning), чтобы они превосходили общие модели в выполнении ценных задач в конкретных областях; во-вторых, создание более качественных оценок в реальных условиях (evals), чтобы отрасль могла лучше измерять производительность моделей в задачах, связанных с конкретной областью. Это свидетельствует о том, что OpenAI стремится глубже применять свои технологии в конкретных отраслях и повышать практичность и стандарты оценки моделей в вертикальных областях посредством сотрудничества (Источник: X @sama)
Nvidia и Google Cloud сотрудничают для продвижения локального развертывания Gemini: Nvidia и Google Cloud объявили о сотрудничестве для поддержки запуска моделей Google Gemini на локальной инфраструктуре предприятий (on-prem). Решение будет сочетать платформу Nvidia Blackwell GPU и технологию Confidential Computing, направленную на предоставление предприятиям высокопроизводительных и безопасных вариантов локального развертывания ИИ. Этот шаг отвечает потребностям некоторых предприятий в конфиденциальности данных, соблюдении требований безопасности и специфической производительности, позволяя им запускать мощные модели Gemini на собственной инфраструктуре (Источник: X @nvidia)
Google разрешает компаниям запускать модели Gemini в собственных центрах обработки данных: Google Cloud объявил, что позволит корпоративным клиентам запускать свои модели ИИ Gemini в собственных центрах обработки данных. Эта инициатива направлена на удовлетворение потребностей предприятий в суверенитете данных, безопасности и индивидуальном развертывании, позволяя им использовать мощные возможности Gemini в локальной среде без необходимости передачи конфиденциальных данных в облако. Это предоставляет предприятиям большую гибкость и контроль, особенно в строго регулируемых отраслях, таких как финансы и здравоохранение (Источник: Reddit r/artificial)
Генеральный директор Nvidia Дженсен Хуанг преуменьшает влияние тарифов, серверы ИИ могут быть освобождены: Столкнувшись с возможной новой тарифной политикой США, генеральный директор Nvidia Дженсен Хуанг заявил, что влияние будет ограниченным, и намекнул, что большинство серверов ИИ Nvidia могут получить освобождение. Это может быть связано со стратегической важностью их продукции или особой торговой классификацией. Эта новость является позитивным сигналом для индустрии ИИ, зависящей от оборудования Nvidia, и помогает смягчить опасения по поводу роста затрат в цепочке поставок (Источник: Reddit r/artificial, Reddit r/ArtificialInteligence)
🌟 Сообщество
Горячее обсуждение на Reddit: Когда выйдет модель Qwen3?: Сообщество Reddit и пользователи платформы X (ранее Twitter) активно обсуждают дату выпуска модели Qwen3 от Alibaba. Хотя некоторые пользователи поделились постером саммита Alibaba AI и предположили скорый выпуск, позже появилась информация, подтверждающая, что Qwen3 на этом саммите не была выпущена. В то же время новость о слиянии поддержки Qwen3 в llama.cpp усилила ожидания сообщества. Это отражает высокое внимание и ожидания сообщества с открытым исходным кодом в отношении прогресса китайских больших моделей (Источник: X @karminski3, Reddit r/LocalLLaMA)

Запущен конкурс наборов данных для инференса: Bespoke Labs совместно с Hugging Face и Together AI запустили конкурс наборов данных для инференса. Цель — стимулировать сообщество к созданию более разнообразных и приближенных к реальной сложности мира наборов данных для рассуждений, особенно в многопрофильных областях, таких как финансы и медицина, чтобы способствовать развитию LLM следующего поколения. Существующие наборы данных (например, OpenThoughts-114k) уже играют важную роль в обучении моделей, и конкурс надеется еще больше расширить границы наборов данных (Источник: X @huggingface)

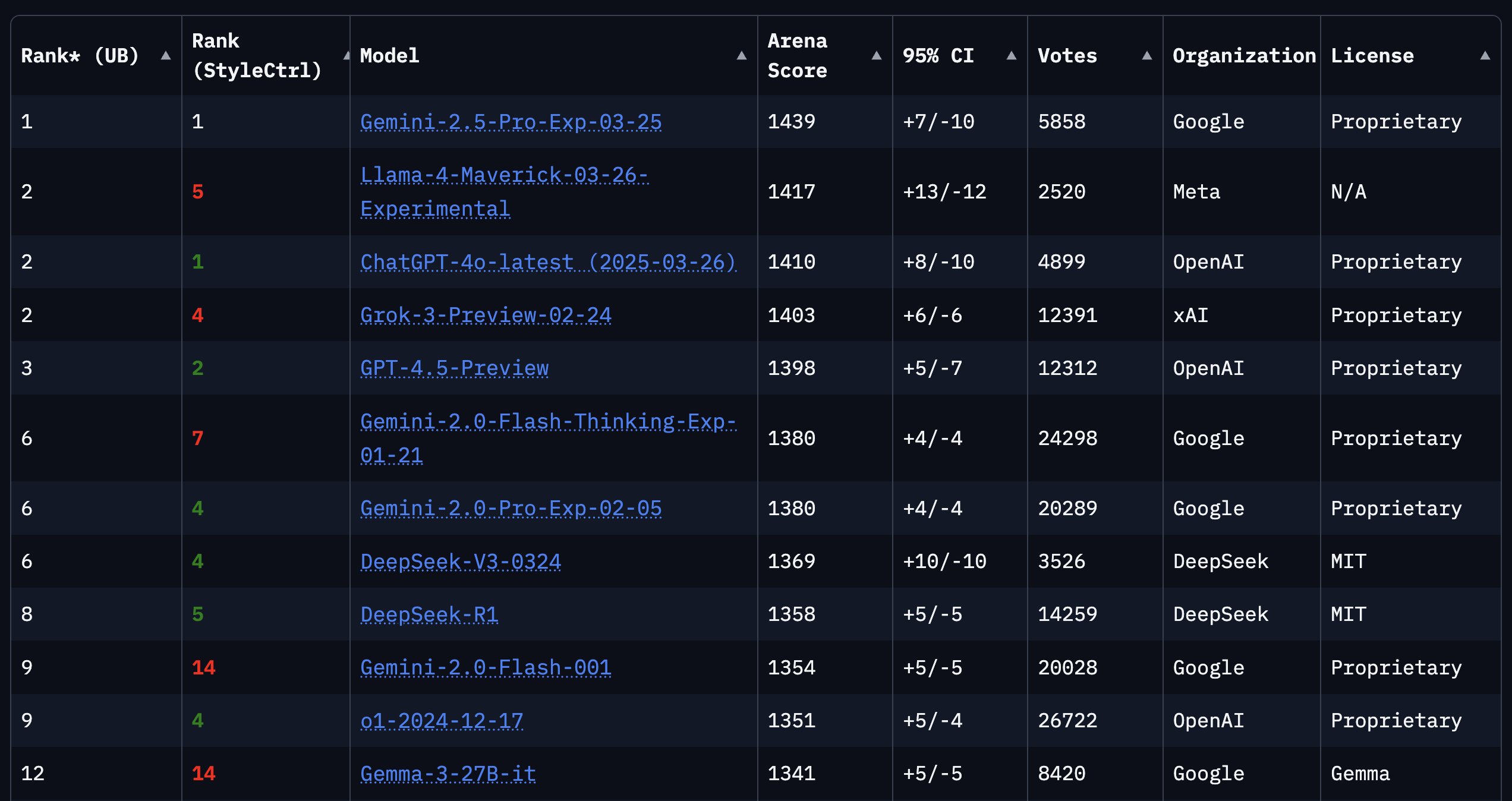
Обновлен бенчмарк программирования LiveCodeBench, лидирует o3-mini: Рейтинг способностей к программированию LiveCodeBench обновлен спустя 8 месяцев, o3-mini (high) и o3-mini (medium) от OpenAI занимают первое и второе места соответственно, Google Gemini 2.5 Pro — на третьем. Этот рейтинг вызвал обсуждение в сообществе, некоторые пользователи выразили сомнение относительно сравнительно низкого рейтинга Claude 3.5/3.7, считая, что это не соответствует реальному опыту использования, что отражает возможные расхождения между различными бенчмарками и субъективными ощущениями пользователей (Источник: Reddit r/LocalLLaMA)

Обсуждение в сообществе Claude Code: Мощный, но дорогой и с ошибками: Пользователи Reddit обсуждают Claude Code от Anthropic, в целом считая его сильным в плане контекстной осведомленности и хорошим для кодирования, даже ощущающимся «как из будущего». Но недостатки — высокая цена (один пользователь сообщил о ежедневных расходах до 30 долларов) и наличие некоторых ошибок (например, потеря сессии в файле claude.md, ошибки синтаксиса в выводе). Пользователи ожидают появления в будущем более мощных и дешевых альтернатив (Источник: Reddit r/ClaudeAI)
Пользователь поделился квантованными моделями Mistral-Small-3.1-24B: Пользователь сообщества Ollama поделился квантованными версиями Q5_K_M и Q6_K (формат GGUF) модели Mistral-Small-3.1-24B, восполнив пробел в официальном репозитории, где предлагались только Q4 и Q8. Эти квантованные модели были созданы с использованием клиента Ollama, поддерживают визуальные функции и предоставляют ориентировочную длину контекста на RTX 4090 (Источник: Reddit r/LocalLLaMA)

Сообщество ищет инструмент для апскейлинга видео с помощью ИИ: Пользователь Reddit спрашивает, существует ли инструмент ИИ, способный повысить разрешение видео с 240p до 1080p/60fps, в надежде восстановить старые музыкальные клипы. В комментариях упоминаются такие инструменты, как Ai4Video и Cutout.Pro, но также высказывается мнение, что апскейлинг с очень низкого разрешения дает ограниченный эффект и может быть больше похож на перегенерацию, чем на восстановление (Источник: Reddit r/artificial)
Пользователь сообщает о подозрении на тайное обновление Claude 3.5 Sonnet: Пользователь-разработчик на Reddit, основываясь на опыте использования (например, модель начала использовать эмодзи, изменился стиль ответов), подозревает, что Anthropic без уведомления заменила оригинальную модель Claude 3.5 Sonnet оптимизированной или дистиллированной версией, что привело к изменению производительности или поведения. Этот пользователь считает, что оригинальная версия 3.5 была лучше для кодирования, чем 3.7, но недавний опыт ухудшился. Это вызвало обсуждение в сообществе о прозрачности и согласованности версий моделей (Источник: Reddit r/ClaudeAI)
Отчет Anthropic вызвал обсуждение использования ИИ студентами для списывания: Anthropic опубликовала отчет об образовании, проанализировав миллионы анонимных диалогов студентов, и обнаружила, что студенты могут использовать Claude для академической недобросовестности. Отчет вызвал обсуждение в сообществе, мнения включают: списывание студентами существовало всегда, ИИ — лишь новый инструмент; система образования должна адаптироваться к эпохе ИИ, методы оценки должны измениться; некоторые пользователи выразили обеспокоенность по поводу конфиденциальности данных при анализе Anthropic диалогов пользователей (Источник: Reddit r/ClaudeAI)

Пользователи обсуждают методы мониторинга приложений LLM/Agent: Пользователь сообщества машинного обучения на Reddit инициировал обсуждение, спрашивая, как другие отслеживают производительность и затраты приложений LLM или AI Agent, например, отслеживая использование токенов, задержку, частоту ошибок, изменения версий Prompt и т. д. Обсуждение направлено на понимание практик и проблем сообщества в области LLMOps, используются ли самописные решения или специальные инструменты (Источник: Reddit r/MachineLearning)
💡 Прочее
Эндрю Ын комментирует влияние тарифной политики США на ИИ: Эндрю Ын в своем еженедельном бюллетене The Batch выразил обеспокоенность новой тарифной политикой США, считая, что она не только вредит отношениям с союзниками и мировой экономике, но и косвенно препятствует развитию и распространению ИИ в самих США через ограничение импорта оборудования (такого как серверы, охлаждение, сетевое оборудование, компоненты электросетей) и повышение цен на потребительскую электронику. Он отметил, что хотя тарифы могут незначительно стимулировать спрос на робототехнику и автоматизацию, это неэффективный путь решения проблем производства, к тому же прогресс ИИ в робототехнике относительно медленный. Он призвал сообщество ИИ укреплять международное сотрудничество и обмен идеями (Источник: DeepLearning.AI)

Прорывы и ловушки ИИ в телекоммуникационной отрасли: Статья рассматривает потенциал применения искусственного интеллекта в телекоммуникационной отрасли, такой как оптимизация сети, обслуживание клиентов, предиктивное обслуживание и т. д., а также указывает на возможные проблемы и ловушки, например, конфиденциальность данных, предвзятость алгоритмов, сложность интеграции и влияние на существующие рабочие процессы (Источник: X @Ronald_vanLoon)
Разнообразие навыков имеет решающее значение для рентабельности инвестиций в ИИ: Antonio Grasso подчеркивает, что для успешного достижения возврата инвестиций (ROI) в проекты искусственного интеллекта командам необходимо обладать разнообразным набором навыков, который может включать в себя специалистов по данным, инженеров, экспертов в предметной области, специалистов по этике, бизнес-аналитиков и т. д. (Источник: X @Ronald_vanLoon)

Цепочки поставок, управляемые ИИ, ведут к устойчивому развитию: Статья Nicochan33 указывает, что использование ИИ для оптимизации управления цепочками поставок (например, планирование маршрутов, управление запасами, прогнозирование спроса) не только повышает эффективность, но и способствует достижению целей устойчивого развития за счет сокращения отходов, снижения энергопотребления и т. д. (Источник: X @Ronald_vanLoon)

Автономность, гарантии и ловушки AI Agent: Статья VentureBeat рассматривает ключевые вопросы развития AI Agent, включая то, как сбалансировать их автономные возможности, разработать эффективные меры безопасности для предотвращения злоупотреблений или непредвиденных последствий, а также ловушки, которые могут возникнуть при развертывании и использовании (Источник: X @Ronald_vanLoon)

ИИ рассматривается как самая большая угроза для «скучного» бизнеса: Статья Forbes утверждает, что искусственный интеллект представляет наибольшую разрушительную угрозу для тех видов бизнеса, которые традиционно считаются «скучными» или основанными на рутинных процессах, поскольку такие бизнесы часто включают большое количество задач, которые могут быть автоматизированы или оптимизированы с помощью ИИ (Источник: X @Ronald_vanLoon)

Проблема предвзятости в медицинских алгоритмах и новые руководства: Статья Fortune обращает внимание на давнюю проблему предвзятости ИИ в медицинской сфере и рассматривает, смогут ли новые руководящие принципы способствовать решению этой проблемы, обеспечивая справедливость и точность медицинских приложений ИИ (Источник: X @Ronald_vanLoon)

Роль ИИ в повышении квалификации рабочей силы и распознавании заболеваний: Статья Forbes рассматривает положительную роль ИИ в двух аспектах: во-первых, помощь в повышении квалификации существующей рабочей силы для адаптации к будущим требованиям работы, во-вторых, поддержка в раннем распознавании и диагностике заболеваний (Источник: X @Ronald_vanLoon)

Цифровые агенты ИИ переопределят работу: Статья VentureBeat обсуждает, как AI Agent (цифровые агенты) интегрируются в рабочее место, не только как инструменты, но и потенциально изменяя само определение работы, процессы и способы взаимодействия человека и машины (Источник: X @Ronald_vanLoon)

Дилемма невидимости, автономности и уязвимости AI Agent: Статья VentureBeat углубляется в новые дилеммы, связанные с AI Agent: их работа может быть «невидимой» для пользователей, они обладают высокой степенью автономности, но в то же время могут быть использованы злоумышленниками или атакованы, что ставит новые задачи перед безопасностью и этикой (Источник: X @Ronald_vanLoon)

Трамп угрожает ввести 100% пошлину на продукцию TSMC: Бывший президент США Трамп заявил, что он сообщил TSMC, что если компания не построит заводы в США, на ее продукцию будет введена 100% пошлина. Это заявление отражает продолжающееся влияние геополитики на цепочку поставок полупроводников и может создать потенциальные риски для поставок аппаратного обеспечения ИИ, зависящего от чипов TSMC (Источник: Reddit r/ArtificialInteligence, Reddit r/artificial)

Утверждается, что у Google Gemini 2.5 Pro отсутствует ключевой отчет о безопасности: Fortune сообщает, что в последней выпущенной модели Google Gemini 2.5 Pro отсутствует ключевой отчет о безопасности (Model Card), что может нарушать обязательства по безопасности ИИ, ранее данные Google правительству США и на международных саммитах. Этот случай вызвал обеспокоенность по поводу прозрачности выпуска моделей и выполнения обязательств по безопасности крупными технологическими компаниями (Источник: Reddit r/artificial)

Использование ИИ для распознавания номерных знаков: Статья Rackenzik знакомит с технологией обнаружения и распознавания номерных знаков на основе глубокого обучения, обсуждая связанные с этим проблемы, такие как размытость изображений, различия в стилях номерных знаков в разных странах/регионах и трудности распознавания в различных реальных условиях (Источник: Reddit r/deeplearning)
