
Ключевые слова:AI, LLM, отчет AI Index 2025, Meta Llama 4 скандал, Gemini Deep Research обновление, NVIDIA Llama 3.1 Nemotron, AI в производстве
🔥 В фокусе
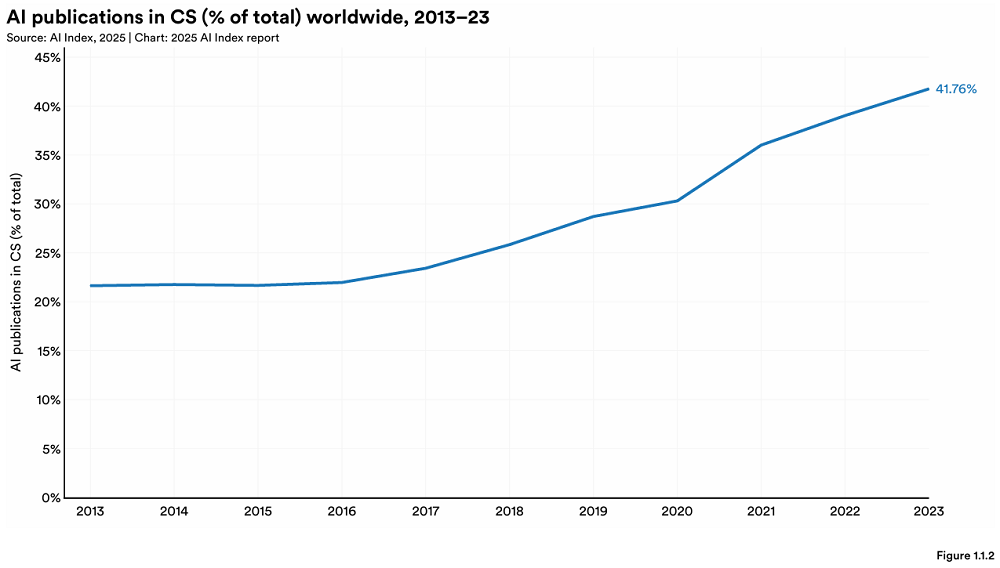
Стэнфорд опубликовал ежегодный отчет AI Index, раскрывающий новые изменения в глобальном ландшафте ИИ: Стэнфордский университет HAI опубликовал 456-страничный отчет «AI Index Report 2025». Отчет показывает, что США по-прежнему лидируют в производстве передовых моделей ИИ, но Китай быстро сокращает разрыв в производительности (например, разрыв по MMLU и HumanEval почти исчез). Промышленность доминирует в разработке важных моделей (90%), но количество моделей несколько сократилось. Стоимость оборудования для ИИ снижается на 30% в год, а производительность удваивается каждые 1,9 года. Глобальные инвестиции в ИИ достигли 252,3 млрд долларов США, при этом США лидируют с 109,1 млрд долларов (примерно в 12 раз больше, чем 9,3 млрд долларов в Китае), инвестиции в генеративный ИИ достигли 33,9 млрд долларов. Уровень внедрения ИИ на предприятиях вырос до 78%, при этом Китай демонстрирует самый быстрый рост (до 75%). ИИ уже начал помогать предприятиям снижать затраты и повышать эффективность. ИИ добился прорывов в науке, получив две Нобелевские премии, и превзошел человека в секвенировании белков и клинической диагностике. Глобальный оптимизм в отношении ИИ растет, но существуют значительные региональные различия, при этом Китай наиболее оптимистичен. Экосистема ответственного ИИ (RAI) постепенно созревает, но оценка и практика все еще неравномерны. (Источник: 36氪, AI科技评论, dotey, 36kr)
Выпуск Meta Llama 4 вызвал огромные споры, модель обвиняют в «накрутке рейтингов» и низкой производительности: Последняя серия опенсорсных больших моделей Llama 4 от Meta (Scout, Maverick, Behemoth) столкнулась с падением репутации в течение 72 часов после выпуска. Версия Maverick быстро поднялась на второе место в Chatbot Arena, но выяснилось, что была представлена неопубликованная «экспериментальная версия», оптимизированная для диалогов, что вызвало подозрения в «накрутке рейтинга». Хотя Meta отрицает обучение на тестовом наборе, она признала проблемы с производительностью. Сообщество отмечает, что производительность Llama 4 в кодировании, понимании длинного контекста и т. д. не соответствует ожиданиям и даже уступает моделям с меньшим количеством параметров (например, DeepSeek V3). Эксперты в области ИИ, такие как Gary Marcus, прокомментировали это словами «Scaling мертв», считая, что простое увеличение масштаба модели не может обеспечить надежную способность к рассуждениям, и выражая обеспокоенность тем, что глобальный прогресс ИИ может застопориться из-за финансирования, геополитики и других факторов. LMArena опубликовала соответствующие данные оценки для проверки и обновила стратегию ранжирования, чтобы избежать путаницы. (Источник: 36kr, 雷科技, AIatMeta, karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

🎯 Тенденции
Функция Gemini Deep Research обновлена, используется модель Gemini 2.5 Pro: Функция Deep Research в приложении Google Gemini App теперь работает на базе модели Gemini 2.5 Pro. Отзывы ранних пользователей показывают, что ее производительность превосходит конкурентов. Это обновление направлено на улучшение возможностей поиска и синтеза информации, глубины анализа отчетов и аналитических способностей. Пользователи Gemini Advanced могут опробовать это обновление. Несколько пользователей и CEO Google DeepMind Demis Hassabis поделились положительным опытом использования новой версии Deep Research для выполнения сложных задач (например, анализа рынка), отметив ее скорость и полноту контента. (Источник: JeffDean, dotey, JeffDean, demishassabis)

Nvidia выпустила модель Llama 3.1 Nemotron Ultra 253B: Nvidia опубликовала модель Llama 3.1 Nemotron Ultra 253B на Hugging Face. Эта модель является плотной (не MoE) и имеет функцию включения/выключения инференса. Она была модифицирована из модели Meta Llama-405B с использованием техники NAS прунинга и прошла пост-тренировку, ориентированную на инференс (SFT + RL в FP8). Бенчмарки показывают, что ее производительность превосходит DeepSeek R1, однако есть комментарии, указывающие на то, что прямое сравнение с MoE моделью DeepSeek R1 (с меньшим количеством активных параметров) может быть не совсем справедливым. Nvidia также опубликовала на Hugging Face соответствующий датасет для пост-тренировки. (Источник: huggingface, Reddit r/LocalLLaMA, dylan522p, huggingface)

AI+Производство становится новым фокусом, сочетая возможности и вызовы: ИИ ускоряет проникновение в производственный сектор Китая. Сценарии применения включают автоматизацию производства (например, производство стоматологических материалов Yurucheng), интеллектуализацию продуктов (например, очки для сна с ИИ от Binghan Technology), оптимизацию процессов (например, протоколы совещаний с ИИ от Zhongke Lingchuang), а также исследования, разработки и диагностику (например, платформа для диагностики сердечно-сосудистых заболеваний от Ruixin Intelligence, прогнозирование спроса на автозапчасти и обнаружение неисправностей от Bihu Auto). Финансовые учреждения, такие как WeBank, также используют технологии ИИ (например, генерацию отчетов об интеллектуальной проверке благонадежности) для обслуживания научно-технических производственных предприятий. Однако «AI+Производство» все еще сталкивается с проблемами, такими как низкое качество данных и слабая цифровая база предприятий. Инвесторы рекомендуют предприятиям использовать ИИ для обслуживания основного бизнеса, а не просто как рекламный трюк, и требуют долгосрочных инвестиций для решения проблем с данными и внедрением. (Источник: 36氪)
DeepSeek R1 установил рекорд скорости инференса на Nvidia B200: Стартап в области ИИ Avian.io объявил, что в сотрудничестве с Nvidia достиг скорости инференса модели DeepSeek R1 в 303 tokens/сек на новейшей платформе GPU Blackwell B200, установив мировой рекорд. Avian.io заявила, что в ближайшие дни предоставит выделенные эндпоинты для инференса DeepSeek R1 на базе B200 и уже открыла предзаказы. Это достижение знаменует новую эру моделей, управляемых вычислениями во время тестирования (test time compute driven models). (Источник: Reddit r/LocalLLaMA)

OpenAI создает команду стратегического развертывания для внедрения передовых моделей: OpenAI сформировала новую команду стратегического развертывания (Strategic Deployment), целью которой является доведение передовых моделей (таких как GPT-4.5 и будущие модели) до более высокого уровня возможностей, надежности и согласованности, а также их развертывание в реальных областях с высоким уровнем влияния для ускорения трансформации экономики с помощью ИИ и исследования пути к AGI. Команда активно набирает сотрудников и проводит презентации на академических конференциях, таких как ICLR. (Источник: sama)
ИИ сталкивается с проблемами при улучшении клиентского опыта (CX): В статье рассматриваются трудности и проблемы, возникающие при использовании ИИ для улучшения клиентского опыта. Хотя ИИ предоставляет потенциал, эффективное внедрение не является простым и может включать проблемы с интеграцией данных, точностью моделей, принятием пользователями и затратами на обслуживание. (Источник: Ronald_vanLoon)

Применение ИИ вызывает инновации и опасения на рабочем месте: В статье обсуждается двойственное влияние применения ИИ на рабочем месте: с одной стороны, стимулирование инновационного потенциала, с другой — опасения относительно существующей рабочей силы, такие как возможность замены рабочих мест, изменение требований к навыкам и т. д. (Источник: Ronald_vanLoon)

Интернет поведения (IoB) меняет бизнес-решения: Технология использования машинного обучения и искусственного интеллекта для анализа данных о поведении пользователей (Internet of Behavior) предоставляет предприятиям более глубокие инсайты, тем самым трансформируя способы принятия бизнес-решений, что может затрагивать персонализированный маркетинг, оценку рисков, разработку продуктов и другие аспекты. (Источник: Ronald_vanLoon)

Мультимодальная модель RolmOCR показывает выдающиеся результаты в рейтинге Hugging Face: Yifei Hu отметил, что разработанная его командой визуально-языковая модель RolmOCR показала отличные результаты в рейтинге Hugging Face, заняв третье место среди VLM и пятое место среди всех моделей. Команда планирует в будущем выпустить больше моделей, датасетов и алгоритмов для поддержки опенсорсных научных исследований. (Источник: huggingface)

Сводка новостей ИИ (2025/04/08): Последние новости, связанные с ИИ, включают: Meta Llama 4 обвиняется в вводящем в заблуждение поведении в бенчмарках; Apple может перенести больше производства iPhone в Индию, чтобы избежать пошлин; IBM выпустила новый мейнфрейм для эры ИИ; по слухам, Google платит некоторым сотрудникам ИИ высокую зарплату за «простой» в течение года, чтобы удержать таланты; сообщается, что Microsoft уволила сотрудников, протестовавших и прервавших ее мероприятие по Copilot; Amazon утверждает, что ее модель ИИ для видео теперь может генерировать клипы длиной в несколько минут. (Источник: Reddit r/ArtificialInteligence)

🧰 Инструменты
FunASR: Опенсорсный базовый end-to-end инструментарий для распознавания речи от Alibaba DAMO Academy: FunASR — это инструментарий, объединяющий функции распознавания речи (ASR), детекции речевой активности (VAD), восстановления пунктуации, языкового моделирования, распознавания голоса, разделения дикторов и распознавания нескольких дикторов. Он поддерживает инференс и файн-тюнинг промышленных предобученных моделей (таких как Paraformer, SenseVoice, Whisper, Qwen-Audio и др.) и предоставляет удобные скрипты и руководства. Последние обновления включают поддержку SenseVoiceSmall, Whisper-large-v3-turbo, моделей обнаружения ключевых слов, моделей распознавания эмоций, а также выпуск сервисов офлайн/реального времени для транскрипции с оптимизированной памятью и производительностью (включая версию для GPU). (Источник: modelscope/FunASR — GitHub Trending (all/daily))

LightRAG: Простой и эффективный фреймворк для Retrieval-Augmented Generation: LightRAG — это фреймворк RAG, разработанный лабораторией HKUDS, предназначенный для упрощения и ускорения создания приложений RAG. Он интегрирует возможности построения и поиска в графе знаний (KG), поддерживает несколько режимов поиска (локальный, глобальный, смешанный, наивный, Mix) и может гибко подключаться к различным LLM (таким как OpenAI, Hugging Face, Ollama) и моделям Embedding. Фреймворк также поддерживает различные бэкэнды хранения (такие как NetworkX, Neo4j, PostgreSQL, Faiss) и ввод различных типов файлов (PDF, DOC, PPT, CSV), а также предоставляет функции редактирования сущностей/отношений, экспорта данных, управления кэшем, отслеживания токенов, истории диалогов и пользовательских промптов. Проект предоставляет Web UI и API сервисы, а также инструмент визуализации графа знаний. (Источник: HKUDS/LightRAG — GitHub Trending (all/daily))
LangGraph помогает Definely создавать юридических AI Agent: Компания Definely использовала LangGraph для создания системы с несколькими AI Agent, интегрированной непосредственно в Microsoft Word, для помощи юристам в сложной юридической работе. Система способна разбивать юридические задачи на подзадачи, извлекать условия, анализировать изменения и составлять договоры с учетом контекстной информации, а также использовать цикл взаимодействия человека с машиной (Human-in-the-loop) для ввода и утверждения юристами при принятии ключевых решений. Это демонстрирует возможности LangGraph в построении сложных, управляемых рабочих процессов Agent. (Источник: LangChainAI)

LlamaParse представляет новый Agent, учитывающий разметку: LlamaIndex представил новую функцию LlamaParse — Agent разметки. Этот Agent использует SOTA VLM модели различных масштабов, от Flash 2.0 до Sonnet 3.7, для динамического анализа страниц документов с учетом разметки. Сначала он анализирует общую разметку и разбивает страницу на блоки (например, таблицы, диаграммы, абзацы), а затем выбирает различные модели для обработки в зависимости от сложности блока (например, использует более мощную модель для обработки диаграмм и меньшую модель для текста). Эта функция особенно важна для рабочих процессов Agent, требующих обработки большого контекста документов. (Источник: jerryjliu0)

Auth0 выпускает инструменты безопасности для приложений GenAI: Auth0 представила новый продукт «Auth for GenAI», призванный помочь разработчикам легко защитить свои приложения и Agent GenAI. Продукт предоставляет функции аутентификации пользователей, вызова API от имени пользователей, асинхронного подтверждения пользователя (CIBA) и авторизации RAG. Он предлагает SDK и документацию для популярных фреймворков GenAI (таких как LangChain, LlamaIndex, Firebase Genkit и др.), упрощая интеграцию аутентификации и авторизации в приложения ИИ. (Источник: jerryjliu0, jerryjliu0)

Ollama добавляет поддержку визуальной модели Mistral Small 3.1: Инструмент для локального запуска больших моделей Ollama теперь поддерживает последнюю модель Mistral Small 3.1 от Mistral AI, включая ее визуальные (мультимодальные) возможности. Пользователи могут загрузить и запустить квантованные версии, такие как mistral-small3.1:24b-instruct-2503-q4_K_M, через библиотеку Ollama. Отзывы сообщества показывают, что модель хорошо справляется с задачами, такими как OCR, но некоторые пользователи сообщают о медленной скорости инференса на определенном оборудовании (например, AMD 7900xt). (Источник: Reddit r/LocalLLaMA)

Unsloth выпускает квантованную модель Llama-4 Scout GGUF: Unsloth опубликовал опенсорсную квантованную версию модели Llama-4 Scout 17B в формате GGUF, что облегчает ее запуск локально на CPU или GPU с ограниченной памятью. Среди них есть версия с динамическим квантованием 2,71 бита размером всего 42,2 ГБ. Пользователи могут просмотреть файлы моделей с различными уровнями квантования (например, Q6_K) и информацию об их аппаратной совместимости на Hugging Face. (Источник: karminski3)

OpenEvals от LangSmith теперь поддерживает пользовательские схемы вывода: Инструмент оценки LLM OpenEvals от LangSmith теперь позволяет пользователям настраивать схемы вывода (output schemas) для оценщиков LLM-as-judge. Хотя схема по умолчанию охватывает многие распространенные случаи, это обновление предоставляет пользователям полную гибкость для настройки структуры и содержания ответов модели в соответствии с конкретными потребностями оценки. Эта функция доступна как в версиях Python, так и JS. (Источник: LangChainAI)

Модели Qwen 3 скоро будут поддерживаться llama.cpp: Патч для поддержки моделей серии Qwen 3 от Alibaba в llama.cpp был отправлен в виде Pull Request, одобрен и скоро будет объединен. Это означает, что пользователи скоро смогут запускать модели Qwen 3 локально с помощью фреймворка llama.cpp. Это обновление было представлено bozheng-hit, который ранее также внес вклад в поддержку Qwen 3 для библиотеки transformers. (Источник: Reddit r/LocalLLaMA)

Запущена Computer Use Agent Arena: Команда OSWorld запустила Computer Use Agent Arena, платформу для тестирования агентов использования компьютера (Computer-Use Agents) в реальной среде без необходимости настройки. Пользователи могут сравнивать производительность ведущих VLM, таких как OpenAI Operator, Claude 3.7, Gemini 2.5 Pro, Qwen 2.5 VL, в более чем 100 реальных приложениях и веб-сайтах. Платформа предлагает конфигурацию в один клик и утверждает, что она безопасна и бесплатна. (Источник: lmarena_ai)
Сервис дистрибуции музыки Too Lost дружелюбен к AI-музыке: Пользователь Reddit поделился опытом использования Too Lost для дистрибуции музыки, сгенерированной ИИ, такой как Suno, Udio и др. Преимущества включают: явное принятие AI-музыки, быстрое одобрение (1-2 дня), доступная цена (35 долларов в год за неограниченное количество релизов), музыка не удаляется по истечении срока подписки (но доля дохода меняется на 85/15), поддержка пользовательского названия лейбла. Недостатки: медленная дистрибуция в Instagram/Facebook (>16 дней), может потребоваться подтверждение предыдущей дистрибуции. (Источник: Reddit r/SunoAI)
📚 Обучение
NVIDIA выпускает CUDA Python: NVIDIA представила CUDA Python, целью которого является предоставление унифицированной точки входа к платформе CUDA из Python. Он включает несколько компонентов: cuda.core предоставляет Pythonic-доступ к CUDA Runtime; cuda.bindings предоставляет низкоуровневые привязки к CUDA C API; cuda.cooperative предоставляет примитивы параллелизма на стороне устройства CCCL (для Numba CUDA); cuda.parallel предоставляет параллельные алгоритмы на стороне хоста CCCL (сортировка, сканирование и т. д.); а также numba.cuda для компиляции подмножества Python в ядра CUDA. Сам пакет cuda-python превратится в мета-пакет, включающий эти независимо версионируемые подпакеты. (Источник: NVIDIA/cuda-python — GitHub Trending (all/daily))
Hugging Face публикует большой датасет для кодирования с рассуждениями: На Hugging Face опубликован большой датасет, содержащий 736 712 решений кода на Python, сгенерированных DeepSeek-R1. Датасет содержит следы рассуждений (reasoning traces) для кода, может использоваться в коммерческих и некоммерческих целях и является одним из крупнейших на данный момент датасетов для кодирования с рассуждениями. (Источник: huggingface)

Пять основных проблем и решений при создании AI Agent: В статье рассматриваются пять основных проблем, возникающих при создании AI Agent: 1) Управление рассуждениями и принятием решений (обеспечение согласованности и надежности); 2) Обработка многошаговых процессов и контекста (управление состоянием, обработка ошибок); 3) Управление интеграцией инструментов (увеличение точек отказа, риски безопасности); 4) Контроль галлюцинаций и обеспечение точности; 5) Управление производительностью в больших масштабах (обработка высокой конкуренции, тайм-аутов, узких мест ресурсов). Для каждой проблемы предлагаются конкретные решения, такие как использование структурированных подсказок (ReAct), надежное управление состоянием, точное определение инструментов, строгие системы проверки (фактическая основа, цитаты), ручная проверка, мониторинг LLMOps и т. д. (Источник: AINLPer)
Бывший главный научный сотрудник Kaggle вспоминает ULMFiT, возможно, первую LLM: Jeremy Howard (основатель fast.ai, бывший главный научный сотрудник Kaggle) заявил в социальных сетях, что его модель ULMFiT 2018 года была первой «универсальной языковой моделью», что вызвало дискуссию о «первой LLM». ULMFiT использовала парадигму неконтролируемого предварительного обучения и тонкой настройки, достигла SOTA в задачах классификации текстов и вдохновила GPT-1. Статья-расследование считает, что по критериям самоконтролируемого обучения, предсказания следующего токена, способности адаптироваться к новым задачам, универсальности и т. д. ULMFiT ближе к современному определению LLM, чем CoVE или ELMo, и является одним из «общих предков» современных LLM. (Источник: 量子位)
Обмен опытом по легковесной тонкой настройке LLM с точки зрения разработчика: Для разработчиков, не являющихся профессиональными инженерами ML, делятся опытом и уроками использования методов параметро-эффективной тонкой настройки (PEFT), таких как LoRA, QLoRA, для улучшения качества вывода LLM. Подчеркивается, что эти методы лучше подходят для интеграции в обычный процесс разработки, избегая сложности полной тонкой настройки. Соответствующая команда проведет бесплатный вебинар, посвященный обсуждению проблем, с которыми сталкиваются разработчики на практике. (Источник: Reddit r/artificial, Reddit r/MachineLearning)
Статья предлагает переосмыслить рефлексию в предварительном обучении: Исследование Essential AI (возглавляемое одним из авторов Transformer Ashish Vaswani) обнаружило, что LLM уже на этапе предварительного обучения демонстрируют универсальные способности к рассуждению между задачами и областями. В статье предлагается, что простой токен «wait» может служить «триггером рефлексии», значительно улучшая производительность модели в рассуждениях. Исследование считает, что по сравнению с методами пост-тренировки, зависящими от тонко настроенной Reward Model (например, RLHF), использование внутренней способности модели к рефлексии на этапе предварительного обучения может быть более простым и фундаментальным способом повышения универсальной способности к рассуждению, потенциально преодолевая ограничения текущих методов task-specific тонкой настройки. (Источник: dotey)

Статья предлагает использовать RL-потери для генерации историй без модели вознаграждения: Исследователи предложили парадигму вознаграждения VR-CLI, вдохновленную RLVR, для оптимизации генерации длинных историй (задача предсказания следующей главы, около 100 тыс. токенов) с помощью RL-потерь (например, перплексии) без явной модели вознаграждения. Эксперименты показывают, что этот метод коррелирует с человеческими оценками качества сгенерированного контента. (Источник: natolambert)

Статья предлагает метод P3 для повышения робастности Zero-Shot классификации: Для решения проблемы чувствительности Zero-Shot классификации текста к изменениям промпта (prompt brittleness) исследователи предложили метод Placeholding Parallel Prediction (P3). Этот метод предсказывает вероятности токенов в нескольких позициях, имитируя всестороннюю выборку путей генерации, а не полагаясь только на вероятность следующего токена. Эксперименты показывают, что P3 повышает точность и снижает стандартное отклонение между различными промптами до 98%, повышая робастность и даже сохраняя сопоставимую производительность без промптов. (Источник: Reddit r/MachineLearning)
Статья предлагает слой Test-Time Training для улучшения генерации длинных видео: Для решения проблемы согласованности при генерации длинных видео (например, более минуты) архитектурой Transformer, вызванной неэффективностью механизма самовнимания, исследование предлагает новый слой Test-Time Training (TTT). Скрытое состояние этого слоя само может быть нейронной сетью, что делает его более выразительным, чем традиционные слои, и позволяет генерировать длинные видео с лучшей согласованностью, естественностью и эстетикой. (Источник: dotey)
Опубликован технический отчет SmolVLM, исследующий эффективные малые мультимодальные модели: Технический отчет представляет идеи проектирования и экспериментальные выводы SmolVLM (параметры 256M, 500M, 2.2B), направленные на создание эффективных малых мультимодальных моделей. Ключевые выводы включают: увеличение длины контекста (2K->16K) значительно повышает производительность (+60%); малые LLM больше выигрывают от меньшего SigLIP (80M); Pixel shuffling может значительно сократить длину последовательности; обучаемые позиционные токены превосходят исходные текстовые токены; системные подсказки и выделенные медиа-токены особенно важны для видеозадач; слишком много данных CoT вредит производительности малых моделей; обучение на более длинных видео помогает улучшить производительность в задачах с изображениями и видео. SmolVLM достигает уровня SOTA в рамках своих аппаратных ограничений и уже реализован для инференса в реальном времени на iPhone 15 и в браузере. (Источник: huggingface)

Hugging Face публикует датасет Reasoning Required Dataset: Этот датасет содержит 5000 образцов из fineweb-edu, аннотированных по сложности рассуждений (0-4 балла), для определения пригодности текста для генерации датасетов рассуждений. Датасет предназначен для обучения классификатора ModernBERT для эффективной предварительной фильтрации контента и расширения области применения датасетов рассуждений за пределы математики и кодирования. (Источник: huggingface)
Бенчмарк CoCoCo оценивает способность LLM к количественной оценке последствий: Upright Project опубликовал технический отчет о бенчмарке CoCoCo, предназначенном для оценки согласованности LLM в количественной оценке последствий действий. Тестирование показало, что Claude 3.7 Sonnet (с бюджетом на размышление в 2000 токенов) показал лучшие результаты, но имеет предвзятость к подчеркиванию положительных последствий и преуменьшению отрицательных. В отчете делается вывод, что, несмотря на прогресс LLM в этой способности за последние годы, предстоит еще долгий путь. (Источник: Reddit r/ArtificialInteligence)

Сравнение движков инференса GenAI: TensorRT-LLM против vLLM против TGI против LMDeploy: NLP Cloud поделился сравнительным анализом и результатами бенчмарков четырех популярных движков инференса GenAI. TensorRT-LLM самый быстрый на GPU Nvidia, но сложен в настройке; vLLM опенсорсный, гибкий и с высокой пропускной способностью, но немного уступает в задержке одного запроса; Hugging Face TGI прост в настройке и масштабировании, хорошо интегрирован с экосистемой HF; LMDeploy (TurboMind) выделяется скоростью декодирования и производительностью 4-битного инференса на GPU Nvidia, низкой задержкой, но TurboMind имеет ограниченную поддержку моделей. (Источник: Reddit r/MachineLearning)
Анонс нового сезона подкаста Google DeepMind: Новый сезон подкаста Google DeepMind выйдет 10 апреля, ведущая — Hannah Fry. Темы будут включать, как наука, управляемая ИИ, революционизирует медицину, передовые робототехнические технологии, ограничения данных, генерируемых человеком, и другие. (Источник: GoogleDeepMind)
Видео-презентация платформы LangGraph: LangChain выпустила 4-минутное видео, объясняющее функции платформы LangGraph и демонстрирующее, как использовать этот продукт корпоративного уровня для разработки, развертывания и управления AI Agents. (Источник: LangChainAI, LangChainAI)

Реализация First-Order Motion Transfer в Keras: Разработчик поделился реализацией модели движения первого порядка (First-Order Motion Model) из статьи Siarohin и др. (NeurIPS 2019) в Keras для анимации изображений. Из-за отсутствия в Keras функции, аналогичной grid_sample в PyTorch, разработчик создал пользовательский модуль деформации карты потока, поддерживающий пакетную обработку, нормализованные координаты и ускорение на GPU. Проект включает обнаружение ключевых точек, оценку движения, генератор и процесс обучения GAN, а также предоставляет примеры кода и документацию. (Источник: Reddit r/deeplearning)

Блок-схема обработки естественного языка (NLP): Изображение показывает базовый процесс обработки естественного языка, который может включать предварительную обработку текста, извлечение признаков, обучение модели, оценку и другие шаги. (Источник: Ronald_vanLoon)

Блог с объяснением математических принципов GANs: Разработчик поделился своей статьей в блоге на Medium о математических принципах, лежащих в основе генеративно-состязательных сетей (GANs), с акцентом на объяснение вывода и доказательства функции ценности, используемой в минимаксной игре GANs. (Источник: Reddit r/deeplearning)

Вводное понятие кластеризации K-Means: Поделились вводным объяснением алгоритма кластеризации K-Means как популяризации концепции для начинающих в машинном обучении, объясняя этот метод неконтролируемого обучения. (Источник: Reddit r/deeplearning)

Летняя школа и конференция по биомедицинским данным: В Будапеште, Венгрия, с 28 июля по 8 августа 2025 года пройдет Летняя школа и конференция по биомедицинским данным. Летняя школа предлагает интенсивное обучение по визуализации медицинских данных, машинному обучению, глубокому обучению, биомедицинским сетям и др. На конференции будут представлены передовые исследования, выступят эксперты, включая лауреатов Нобелевской премии. (Источник: Reddit r/MachineLearning)
Обмен личным репозиторием моделей глубокого обучения: Самоучка поделился своим репозиторием на GitHub, документирующим его практику создания моделей глубокого обучения для различных датасетов (таких как CIFAR-10, MNIST, yt-finance), включая оценки, графики предсказаний и документацию, как способ личного обучения и тренировки. (Источник: Reddit r/deeplearning)

💼 Бизнес
AI-единорог OpenEvidence использует интернет-мышление для подрыва AI в медицине: Медицинская AI-компания OpenEvidence получила финансирование в размере 75 миллионов долларов от Sequoia Capital при оценке в 1 миллиард долларов, став новым единорогом. В отличие от традиционной модели to B, OpenEvidence использует стратегию, подобную потребительскому интернету, предоставляя бесплатные услуги непосредственно врачам (зарабатывая на рекламе), помогая им точно находить информацию в огромном объеме медицинской литературы и разбираться со сложными случаями. Продукт быстро растет, и утверждается, что им пользуется уже 1/4 врачей в США. Ключ к успеху заключается в строгих источниках данных (рецензируемая литература) и архитектуре интеграции нескольких моделей для обеспечения точности информации, а также в гарантии прозрачности через цитирование источников, формируя модель взаимной выгоды для врачей и медицинских журналов. (Источник: 36氪)
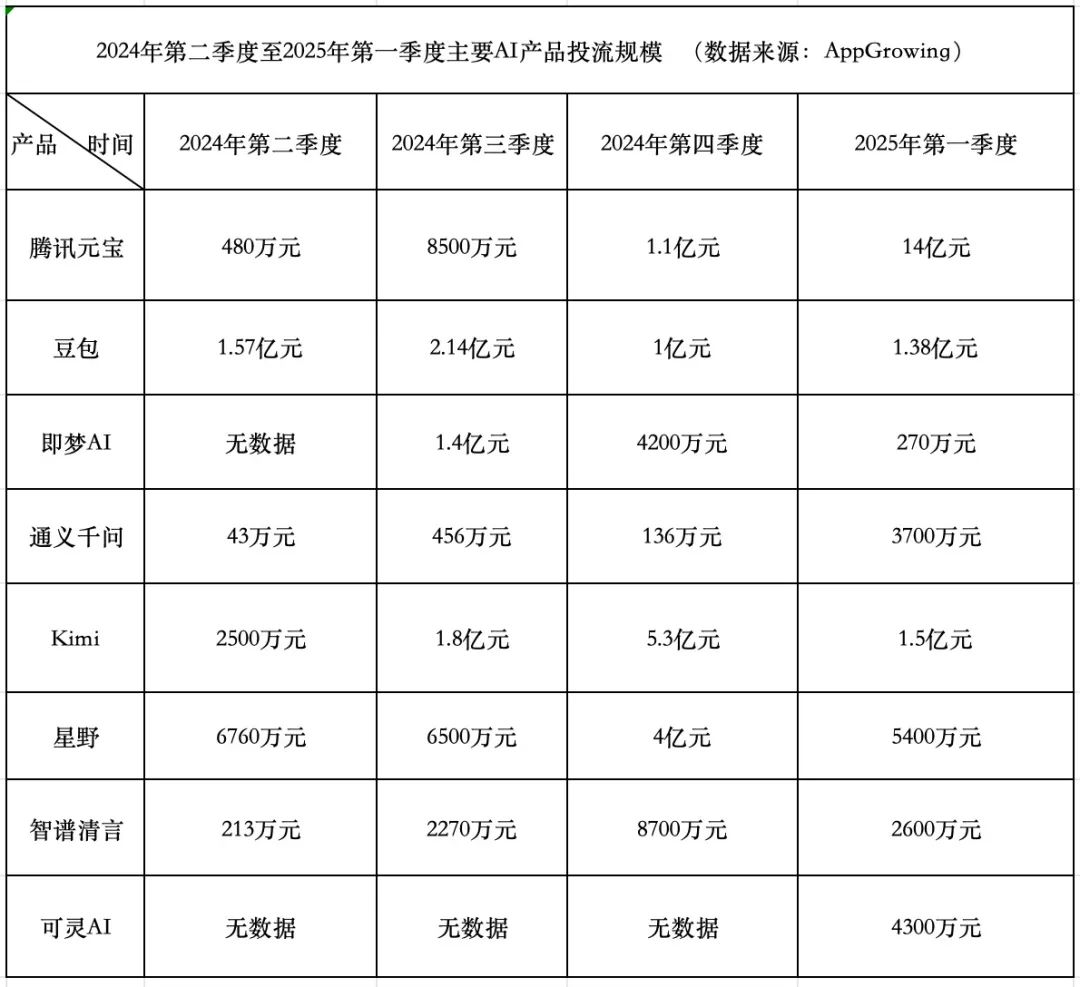
Гонка расходов на AI-продукты: Tencent агрессивен, ByteDance консервативен, стартапы отступают: В Q1 2025 года расходы на продвижение AI-продуктов достигли 1,84 млрд юаней, при этом Tencent Yuanbao лидирует с 1,4 млрд юаней, реклама размещается даже на стенах в деревнях. ByteDance Doubao потратил 138 млн юаней, придерживаясь относительно консервативной стратегии. Kuaishou Keling AI инвестировал 43 млн юаней. В отличие от них, звездные стартапы Kimi и Xingye значительно сократили расходы на продвижение (в сумме около 200 млн, что намного ниже 930 млн в Q4), Zhipu Qingyan также заметно снизил инвестиции. Основатели стартапов начинают переосмысливать модель «сжигания денег», уделяя больше внимания улучшению возможностей моделей и техническим барьерам. Tencent, благодаря своей рекламной системе, становится бенефициаром войны за продвижение ИИ. Alibaba Tongyi Qianwen и Baidu Wenxin Yiyan продвигаются относительно спокойно, уделяя больше внимания экосистеме и опенсорсу. Тенденции в отрасли показывают, что методология простого сжигания денег ради масштаба теряет свою эффективность, и конкуренция AI-продуктов вступает в новую фазу, ориентированную на возможности моделей и построение экосистем. (Источник: 中国企业家杂志)
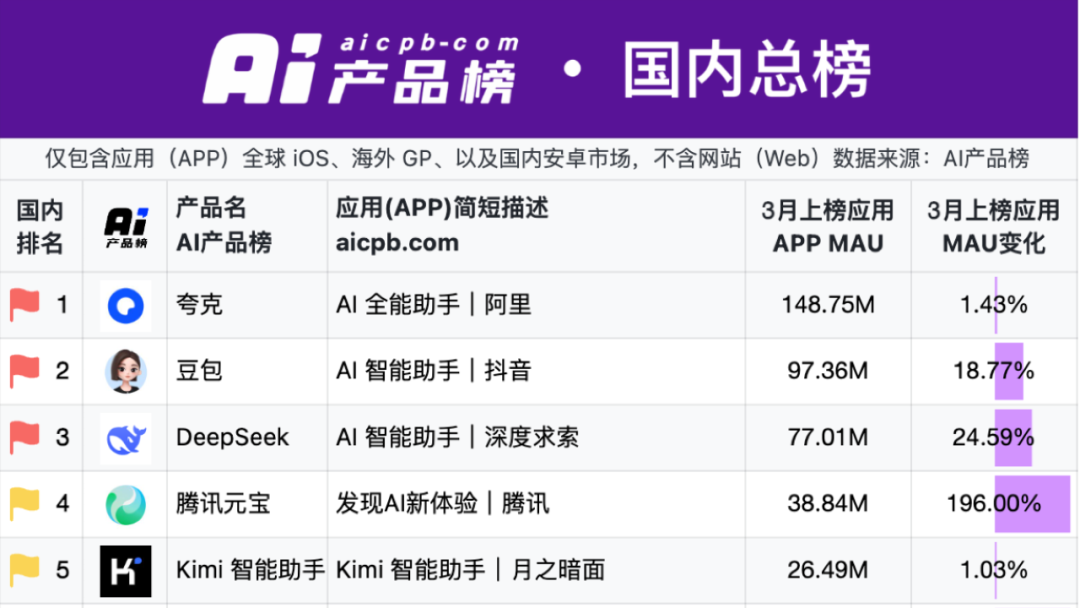
Quark и Baidu Wenku лидируют на новом поле битвы AI-приложений: подъем модели «Super Box»: В 2025 году фокус AI-приложений смещается с ChatBot на «AI Super Box», то есть на единую точку входа, объединяющую AI-поиск, диалоги и инструменты (такие как PPT, перевод, генерация изображений). Alibaba Quark и Baidu Wenku стали лидерами в этой гонке, опережая по данным MAU. Оба основаны на базе «Поиск + Облачное хранилище + Документы», интегрируя возможности ИИ и пытаясь удовлетворить потребности пользователей в выполнении задач в одном месте, борясь за точку входа для C-пользователей. Тесты показывают, что оба превосходят традиционный поиск в подборе базовой информации, но все еще есть возможности для улучшения в глубине и удовлетворенности при выполнении конкретных задач (таких как планирование поездок, генерация PPT). Крупные компании выбрали эти два продукта в качестве авангарда ИИ, стремясь использовать их пользовательскую базу и накопленные данные для исследования оптимальной формы AI To C и дополнения своих собственных AI-экосистем. (Источник: 定焦One)
Как предприятия могут эффективно внедрять ИИ при ограниченной внутренней экспертизе: В статье рассматривается, как предприятия при отсутствии глубоких внутренних знаний в области ИИ могут эффективно и обдуманно внедрять и реализовывать технологии искусственного интеллекта. Это может включать использование внешнего сотрудничества, выбор подходящих инструментальных платформ, начало с мелкомасштабных пилотных проектов, акцент на обучении сотрудников и четкое определение бизнес-целей. (Источник: Ronald_vanLoon, Ronald_vanLoon)

Разнообразие навыков имеет решающее значение для достижения ROI от инвестиций в ИИ: Успешные проекты ИИ требуют не только технических экспертов, но и талантов, обладающих пониманием бизнеса, навыками анализа данных, этическими соображениями, управлением проектами и другими многогранными навыками. Разнообразие навыков внутри организации является ключевым фактором для обеспечения эффективного внедрения проектов ИИ, решения реальных проблем и, в конечном итоге, получения коммерческой ценности (ROI). (Источник: Ronald_vanLoon)

Обмен стратегией SEO-лендингов для AI-продуктов: Gefei поделился своей карточкой-сводкой стратегии SEO-лендингов, используемой для AI-продуктов (утверждается, что она приносит $100 тыс. в месяц), подчеркивая эффективность своей методологии. (Источник: dotey)

🌟 Сообщество
Феномен мошенничества на AI-собеседованиях привлекает внимание, распространение инструментов бросает вызов справедливости найма: Статья раскрывает растущее явление использования AI-инструментов для мошенничества на удаленных видеособеседованиях. Эти инструменты могут в реальном времени транскрибировать вопросы интервьюера и генерировать ответы для чтения кандидатом, и даже помогать с техническими письменными тестами. Автор лично протестировал и обнаружил, что такие инструменты имеют заметную задержку, ошибки распознавания и риск сбоя, опыт использования неудовлетворительный, а стоимость высокая. Однако это явление уже вызвало настороженность у HR и интервьюеров, которые начали изучать методы борьбы с мошенничеством. В статье обсуждается влияние AI-мошенничества на справедливость найма и опровергается точка зрения, что «способность решать проблемы с помощью ИИ — это и есть компетентность», подчеркивая, что суть собеседования — это проверка реальных способностей и мышления, а не зависимость от нестабильных внешних инструментов. (Источник: 差评X.PIN)

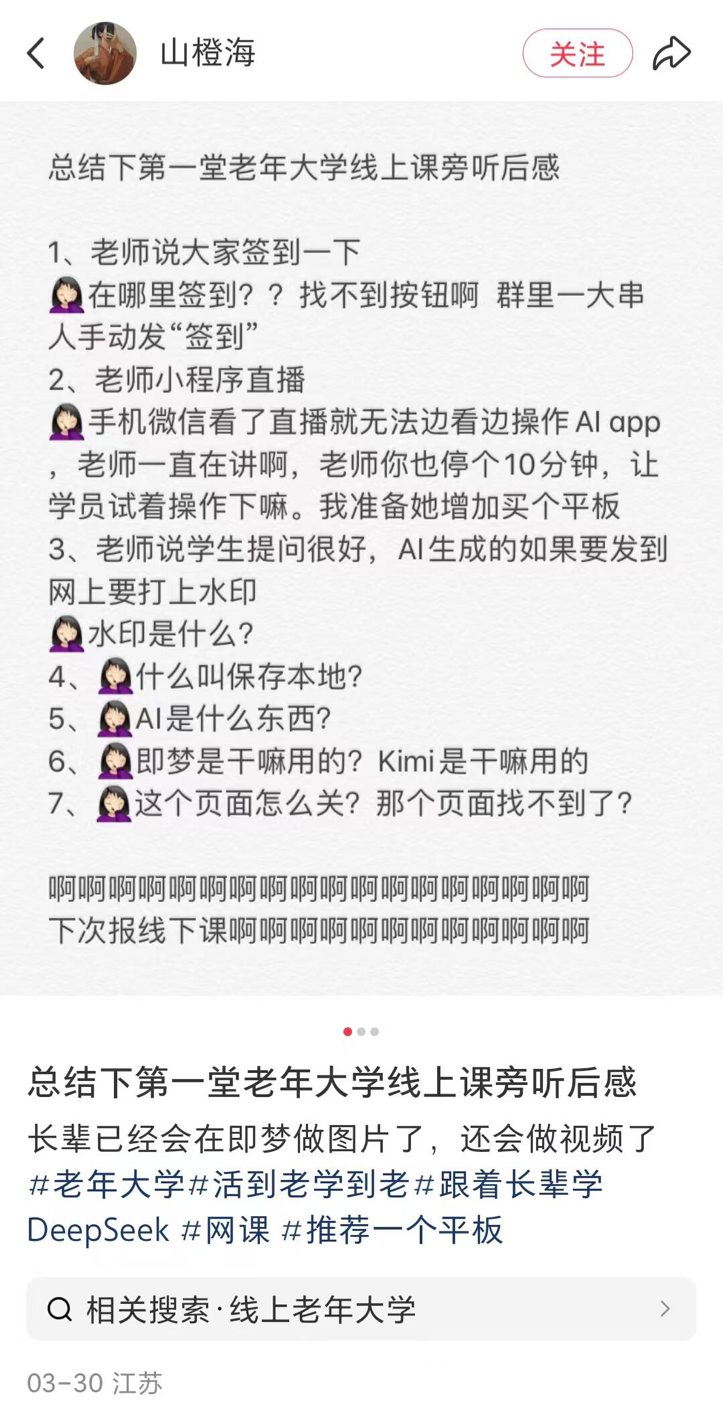
В университетах для пожилых в уездных городах появляются курсы по ИИ, сочетая популяризацию и риски: Сообщается о тенденции открытия курсов по ИИ во многих университетах для пожилых по всей стране (включая уездные города). Содержание курсов в основном сосредоточено на создании контента с помощью ИИ (например, написание текстов с Doubao, генерация изображений/видео с Jimeng/Keling, написание стихов/рисование с DeepSeek) и применении в быту (интерпретация отчетов о медосмотре, поиск рецептов, предотвращение мошенничества). Стоимость обучения обычно составляет 100-300 юаней за семестр, что более выгодно по сравнению с дорогими коммерческими курсами по ИИ. Однако пожилые люди сталкиваются с цифровым разрывом при обучении (например, трудности с загрузкой APP, базовыми операциями), а в обучении может отсутствовать достаточное предупреждение о рисках, таких как галлюцинации ИИ, особенно в критически важных областях, таких как здоровье, что создает скрытые опасности. (Источник: 刺猬公社)
John Carmack отвечает на опасения о влиянии AI-инструментов на ценность навыков: В ответ на опасения, что AI-инструменты могут обесценить навыки программистов, художников и других специалистов, John Carmack считает, что прогресс инструментов всегда был ядром компьютерной сферы. Подобно тому, как игровые движки расширили круг участников разработки игр, AI-инструменты расширят возможности ведущих создателей, небольших команд и привлекут новые группы людей. Хотя в будущем, возможно, можно будет генерировать игры и другой контент с помощью простых подсказок, выдающиеся произведения все равно потребуют создания профессиональными командами. В целом AI-инструменты повысят эффективность производства качественного контента. Он выступает против отказа от использования передовых инструментов из-за страха потерять работу. (Источник: dotey)
Серия размышлений и критики в адрес ИИ: Статья в виде серии кратких и емких предложений выражает критику и размышления о распространенных явлениях в текущей области ИИ, затрагивая чрезмерную рекламу AGI, наводнение новостей об ИИ, пузыри финансирования, разрыв между возможностями моделей и ожиданиями людей, этические проблемы ИИ, проблему «черного ящика» в принятии решений и искажения в общественном восприятии ИИ. Основная мысль заключается в том, что существует разрыв между реальностью и хайпом, и необходимо более осмотрительно относиться к развитию ИИ. (Источник: 世上本无 AGI,报道多了,就有了)
Обсуждение: заменит ли длинный контекст RAG?: Сообщество снова обсуждает, вытеснит ли заявленное сверхдлинное контекстное окно моделей, таких как Llama 4 (например, 10 миллионов токенов), технологию RAG (Retrieval-Augmented Generation). Мнения сходятся в том, что простое увеличение длины контекста не может полностью заменить RAG, поскольку RAG по-прежнему имеет преимущества в обработке информации в реальном времени, поиске в конкретных базах знаний, контроле источников информации и экономической эффективности. Длинный контекст и RAG, скорее всего, будут дополнять друг друга, а не заменять. (Источник: Reddit r/artificial)

Дискуссия в сообществе ИИ: Как успевать за развитием ИИ?: Пользователь Reddit выразил сожаление о том, что развитие ИИ происходит слишком быстро, трудно успевать, и испытывает FOMO (страх упустить что-то важное). В комментариях в целом согласны, что полностью успевать уже невозможно, и предлагают советы: сосредоточиться на своей нише, сотрудничать с коллегами и обмениваться информацией, не беспокоиться из-за каждого мелкого обновления, различать реальный прогресс и рыночный хайп, принять, что это непрерывный процесс обучения. (Источник: Reddit r/ArtificialInteligence)
Дискуссия в сообществе: Лучший пользовательский интерфейс (UI) для локальных LLM на данный момент?: Пользователь Reddit инициировал обсуждение, спрашивая, какой UI для локальных LLM сообщество рекомендует в апреле 2025 года. Среди популярных вариантов в комментариях упоминаются OpenWebUI, LM Studio, SillyTavern (особенно для ролевых игр и создания миров), Msty (вариант с установкой в один клик и множеством функций), Reor (заметки + RAG), llama.cpp (командная строка), llamafile, llama-server, а также d.ai (мобильное приложение для Android). Выбор зависит от потребностей пользователя (простота использования, функциональность, конкретные сценарии и т. д.). (Источник: Reddit r/LocalLLaMA)
Выравнивание ИИ, заставляющее модель «лгать», вызывает беспокойство: Пользователь Reddit раскритиковал некоторые методы выравнивания ИИ, которые заставляют модель отрицать свою собственную идентичность (например, не признавать себя конкретной моделью), считая такой способ выравнивания «вынужденной ложью» проблематичным. Пост демонстрирует скриншоты диалога, где с помощью наводящих вопросов модель в конечном итоге «признает» свою идентичность, что вызвало дискуссию о целях выравнивания и прозрачности. (Источник: Reddit r/artificial

A/B-тестирование OpenAI GPT-4.5 вызывает обсуждение: Пользователи заметили, что при использовании GPT-4.5 часто появляются подсказки A/B-тестирования «Какой вариант вам нравится больше?». В комментариях предполагают, что OpenAI может использовать платных пользователей для сбора данных о предпочтениях моделей, и данные, собранные таким образом, могут отличаться от данных с публичных платформ, таких как LM Arena. (Источник: natolambert)
Проблемы в практике использования протокола контекста модели (MCP): Пользователи сообщества отмечают, что, хотя MCP (Model Context Protocol) как концепция стандартизации взаимодействия ИИ с инструментами является перспективной, качество многих текущих реализаций оставляет желать лучшего. Риски включают: разработчики не могут полностью контролировать команды, отправляемые сервером MCP, недостаточная способность системы обрабатывать ошибки ввода человеком (например, орфографические), проблема галлюцинаций самой LLM, а также нечеткие границы возможностей MCP. Рекомендуется использовать с осторожностью, особенно в сценариях, отличных от «только для чтения», и отдавать предпочтение опенсорсным реализациям для обеспечения прозрачности. (Источник: Reddit r/artificial)
Пользователи Suno сообщают о сбоях функции Extend: Несколько пользователей Suno сообщили о проблемах с функцией «Extend» (расширение), которая не продолжает стиль песни, как ожидалось, а вместо этого вводит новые мелодии, инструменты и даже ритм и стиль. Пользователи выражают недовольство тратой большого количества кредитов без получения пригодного результата и сомневаются, не является ли это системной ошибкой. Один пользователь создал видео, демонстрирующее проблему. (Источник: Reddit r/SunoAI, Reddit r/SunoAI)

Пользователи Suno сообщают о недавнем снижении качества генерации: Давний платный пользователь Suno жалуется на серьезное снижение качества генерации моделей V4 и V3.5 в последнее время, утверждая, что ранее надежные промпты теперь генерируют «шум» или фальшивую музыку, и потратив 3000 кредитов, он не смог получить ни одной пригодной песни. Пользователь сомневается, не является ли это ошибкой, и рассматривает возможность отмены подписки. (Источник: Reddit r/SunoAI)
Сообщество делится: генерация картинок профессий мечты для детей с помощью ИИ: Видео демонстрирует трогательный сценарий использования: дети описывают, кем они хотят стать, когда вырастут (например, юристом, продавцом мороженого, смотрителем зоопарка, велосипедистом), а затем с помощью ИИ (в видео — ChatGPT) генерируются соответствующие картинки по описанию. Дети очень радуются, увидев картинки. (Источник: Reddit r/ChatGPT)

Сообщество делится: ИИ генерирует изображения встреч знаменитостей с собой в молодости/старости: Пользователь использовал функцию генерации изображений ChatGPT для создания серии картинок, на которых знаменитости (такие как Маск, Арнольд Шварценеггер, Пол Маккартни, Тони Хоук, Клинт Иствуд и др.) встречаются со своими молодыми или старыми версиями, результат реалистичен и забавен. (Источник: Reddit r/ChatGPT)
ИИ генерирует «странное» видео о реиндустриализации США: Пользователь поделился видео, предположительно сгенерированным китайским ИИ, о «реиндустриализации США». Содержание и стиль саундтрека видео считаются «дикими» и несут юмористический/саркастический оттенок, демонстрируя возможности ИИ в генерации контента с определенным нарративом и потенциальные предвзятости. (Источник: Reddit r/ChatGPT

Пользователь сравнивает стоимость и результаты Claude и o1-pro: Пользователь поделился опытом использования OpenAI o1-pro и Anthropic Claude Sonnet 3.7 для улучшения стилей карточек Tailwind CSS. Результаты показали, что вывод Claude был лучше, а стоимость значительно ниже, чем у o1-pro (менее 1 доллара против почти 6 долларов). (Источник: Reddit r/ClaudeAI)
Пользователи шутят над стабильностью сервиса Claude: Пользователи публикуют мемы или комментарии, высмеивая частые случаи «неожиданно высокого спроса», приводящие к перегрузке или недоступности сервиса Anthropic Claude в пиковые часы рабочих дней, намекая на необходимость улучшения его стабильности. (Источник: Reddit r/ClaudeAI)

Аспирант-математик ищет ресурсы для начинающих в машинном обучении: Студент, начинающий аспирантуру по математике, чье исследование включает применение инструментов линейной алгебры к машинному обучению (в частности, PINNs), ищет подходящие для математического бэкграунда, строгие и краткие ресурсы для начинающих в ML (книги, конспекты, видеокурсы), считая стандартные учебники (например, Bishop, Goodfellow) слишком многословными. (Источник: Reddit r/MachineLearning)

Студент тестирует разницу в производительности малых моделей на разном оборудовании: Студент поделился данными о производительности малых моделей, таких как Llama3.2 1B и Granite3.1 MoE, протестированных на настольном GPU RTX 2060 и Raspberry Pi 5. Обнаружил, что Llama3.2 показывает лучшие результаты на настольном ПК, но хуже на Raspberry Pi, что его озадачило. Также заметил, что результаты MoE моделей более волатильны, и спрашивает о причинах. (Источник: Reddit r/MachineLearning)
Пользователь ищет способ разделить модели для поиска и генерации заголовков в OpenWebUI: Пользователь OpenWebUI спрашивает, можно ли разделить модель, используемую для генерации поисковых запросов (предпочтительно использовать модель с сильными способностями к рассуждению), и модель, используемую для генерации заголовков/тегов (предпочтительно использовать более экономичную малую модель). (Источник: Reddit r/OpenWebUI)
Пользователь ищет руководство по промптам для музыки Suno AI: Пользователь спрашивает, сохранилось ли у кого-нибудь ранее распространявшееся руководство по промптам для музыки Suno AI (PDF), так как исходная ссылка больше не работает. (Источник: Reddit r/SunoAI)

Пользователь ищет помощи в интеграции OpenWebUI с LM Studio: Пользователь пытается подключить OpenWebUI к LM Studio в качестве бэкэнда (через OpenAI-совместимый API), но сталкивается с проблемами при настройке функций веб-поиска и embedding, ищет помощи у сообщества. (Источник: Reddit r/OpenWebUI)
Пользователи делятся музыкальными произведениями, созданными ИИ: Несколько пользователей в r/SunoAI поделились своими музыкальными произведениями, созданными с помощью Suno AI, охватывающими различные стили, такие как Ambient, Musical, Alternative Psychedelic Rock, Folk Country, Comedy ballad (EDM), Rap, Folk Music, Dreamy indie pop и др. (Источник: Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI)

Пользователь спрашивает о ценности подписки Suno: Учитывая недавние жалобы на качество Suno v4, пользователь спрашивает, стоит ли сейчас покупать подписку Suno, особенно для ремастеринга старых песен версии v3. (Источник: Reddit r/SunoAI)
Пользователь ищет совета по созданию музыкального альбома Suno: Опытный пользователь Suno планирует собрать свои лучшие работы в альбом и выпустить его на Spotify через платформы вроде DistroKid, обращаясь к сообществу за советами по выбору песен, их порядку и техническим аспектам. (Источник: Reddit r/SunoAI)
Пользователь жалуется на проблемы с UI Suno на iPad: Новый подписчик сообщает о проблемах с интерфейсом при использовании сайта Suno на iPad, невозможности нормально использовать функции записи, редактирования текстов, перетаскивания и др., ищет решения или советы. (Источник: Reddit r/SunoAI)
Пользователь жалуется, что Cursor AI мог тайно понизить версию модели: Пользователь подозревает, что Cursor AI без уведомления понизил используемую им модель с заявленной Claude 3.7 до 3.5, основываясь на изменении поведения Agent и отказе раскрывать информацию о модели. Пользователь утверждает, что его пост с сомнениями в r/cursor был удален. (Источник: Reddit r/ClaudeAI)
Пользователь спрашивает о часто используемых платных AI-сервисах: Пользователь инициировал обсуждение, спрашивая, на какие платные AI-сервисы люди подписываются ежемесячно, чтобы узнать, какие инструменты считаются стоящими своих денег, и есть ли рекомендуемые сервисы. (Источник: Reddit r/artificial)
Помощь по глубокому обучению: распознавание смешанных сигналов: Новичок просит помощи в использовании глубокого обучения для распознавания паттернов смешанных научных измерительных сигналов. Данные представлены в виде координатных точек в формате txt/Excel. Вопросы включают: как интегрировать дополнительные данные в формате изображений? Может ли модель обрабатывать смешанные паттерны, представленные координатными точками? Какие модели или направления обучения рекомендуются? (Источник: Reddit r/deeplearning)
Мемы/Юмор: В сообществе появилось несколько мемов или юмористических постов, связанных с ИИ, например, о влюбленности в ИИ (фильм Her), предпочтении модели Gemma 3, насыщении рынка AI Note-Taker, сбоях сервиса Claude, а также сгенерированных ИИ коллекционных карточках знаменитостей и т. д. (Источник: Reddit r/ChatGPT, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, AravSrinivas, Reddit r/artificial)

💡 Прочее
Protocol Buffers (Protobuf) продолжает привлекать внимание: Разработанный Google формат обмена данными Protobuf сохраняет высокую популярность на GitHub. Как языково-нейтральный, платформенно-нейтральный расширяемый механизм для сериализации структурированных данных, он широко используется в AI/ML и многих крупных системах (таких как TensorFlow, gRPC). Репозиторий предоставляет инструкции по установке компилятора (protoc), ссылки на библиотеки времени выполнения для разных языков и руководство по интеграции с Bazel. (Источник: protocolbuffers/protobuf — GitHub Trending (all/daily))
Веб-фреймворк Gin остается популярным: Высокопроизводительный HTTP веб-фреймворк Gin, написанный на языке Go, продолжает пользоваться популярностью на GitHub. Он известен своим API, похожим на Martini, и повышением производительности до 40 раз (благодаря httprouter), и подходит для сценариев, требующих высокопроизводительных веб-сервисов (возможно, включая API-сервисы для AI-моделей). (Источник: gin-gonic/gin — GitHub Trending (all/daily))
Hugging Face Hub использует новый бэкэнд Xet для повышения эффективности: Hugging Face Hub начал использовать новый бэкэнд хранения Xet, заменив прежний бэкэнд Git. Xet использует технологию Content-Defined Chunking (CDC) для дедупликации данных на уровне байтов (примерно 64 КБ блоки), а не на уровне файлов. Это означает, что при изменении больших файлов (например, Parquet) необходимо передавать и хранить только изменения на уровне строк, что значительно повышает эффективность загрузки/скачивания и хранения. Выпуск модели Llama-4 успешно протестировал этот бэкэнд. (Источник: huggingface)
Hugging Face Hub скоро будет поддерживать MCP-клиент: Разработчик Hugging Face отправил Pull Request с планами добавить поддержку протокола контекста модели (MCP) в Inference-клиент библиотеки huggingface_hub. Это может означать, что сервис инференса Hugging Face сможет лучше взаимодействовать с инструментами и Agent, следующими стандарту MCP. (Источник: huggingface)
Система доставки дронами Zipline: Демонстрация системы доставки дронами компании Zipline. Эта система может использовать ИИ для планирования маршрутов, обхода препятствий и точной доставки, применяясь в логистике и цепочках поставок, особенно демонстрируя потенциал в транспортировке медицинских товаров. (Источник: Ronald_vanLoon)
Робот ergoCub для физического взаимодействия человека и робота: Итальянский технологический институт (IIT) продемонстрировал робота ergoCub, разработанного для исследований в области физического взаимодействия человека и робота. Такие роботы обычно требуют передовых алгоритмов ИИ для реализации возможностей восприятия, управления движением и безопасного взаимодействия. (Источник: Ronald_vanLoon)
KeyForge3D: изготовление ключей с помощью компьютерного зрения: Проект на GitHub под названием KeyForge3D использует OpenCV (библиотеку компьютерного зрения) для распознавания формы ключа, вычисления кода нарезки ключа (bitting code) и может экспортировать модель STL для 3D-печати. Хотя в основном используются традиционные методы CV, это демонстрирует потенциал применения распознавания изображений в задачах копирования в физическом мире, и в будущем может быть объединено с ИИ для дальнейшего повышения точности распознавания и адаптивности. (Источник: karminski3)

Принципы ответственного ИИ (Responsible AI) привлекают внимание: В посте упоминаются принципы ответственного ИИ, используемые такими организациями, как EY, подчеркивая необходимость учета справедливости, прозрачности, интерпретируемости, конфиденциальности, безопасности и подотчетности, а также других этических и социальных факторов при разработке и развертывании систем ИИ. (Источник: Ronald_vanLoon)
Kawasaki демонстрирует водородного робота-«лошадь» для верховой езды: Kawasaki Heavy Industries продемонстрировала четвероногого робота по имени Corleo, предназначенного для верховой езды и использующего водородное топливо в качестве источника энергии. Хотя это робот, в сообщении не уточняется степень применения ИИ в его системах управления или взаимодействия. (Источник: Reddit r/ArtificialInteligence)
