
Ключевые слова:NVIDIA, Искусственный интеллект (ИИ) вычислительная мощность, 6G сети, Квантовые вычисления, Автономное вождение, Графический процессор (GPU), Инфраструктура ИИ, Технология NVLink, Супер-GPU Vera Rubin, ИИ суперкомпьютер, Квантовые процессоры соединение, Практичность моделей ИИ
🔥 Фокус
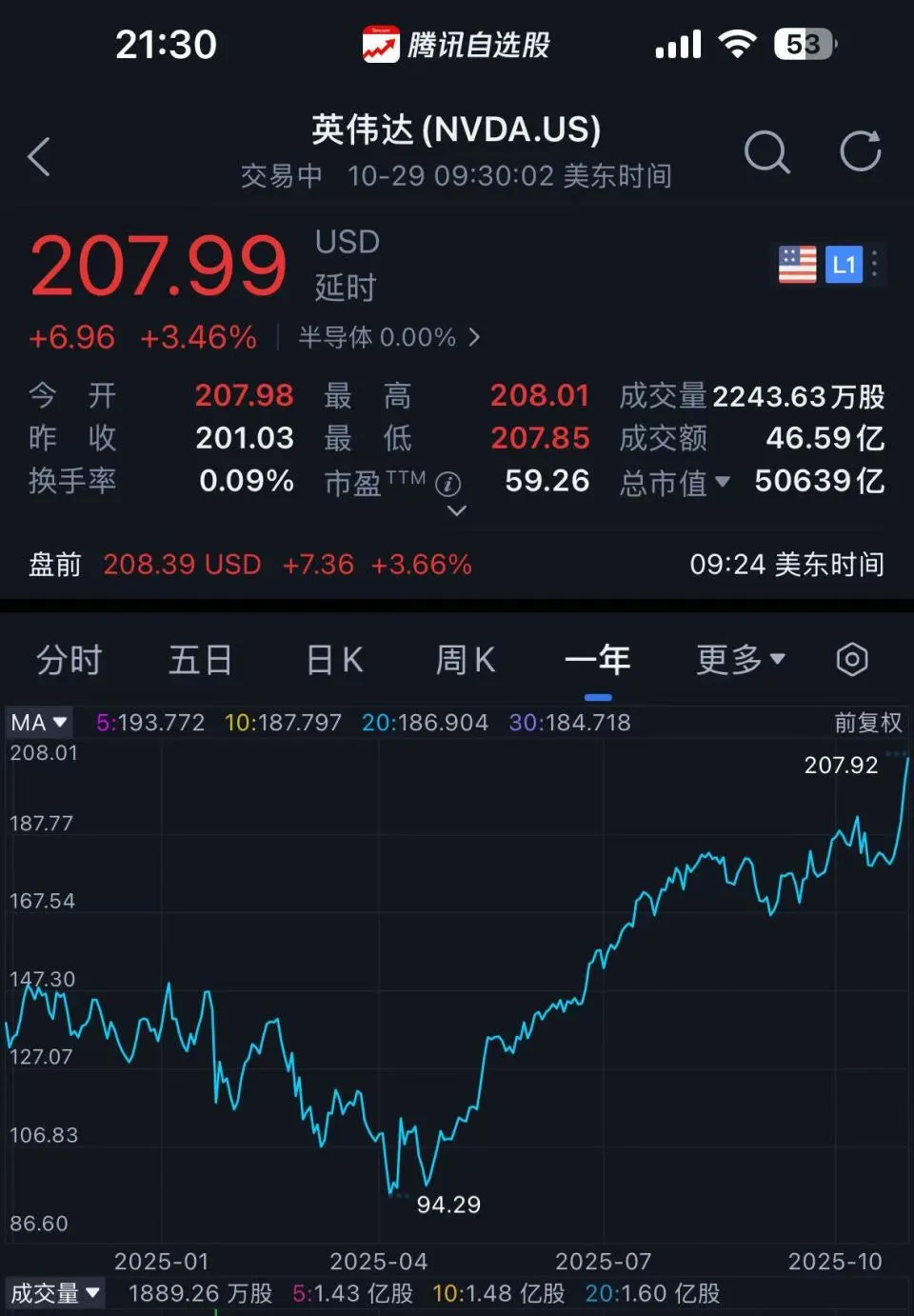
Рыночная капитализация NVIDIA превысила 5 триллионов долларов США, представлены важные обновления GTC: На конференции GTC NVIDIA объявила о сотрудничестве с Nokia по разработке сетевой платформы 6G, представила технологию NVQLink для подключения квантовых процессоров к суперкомпьютерам на GPU, а также о сотрудничестве с Министерством энергетики США по созданию суперкомпьютеров для ИИ. В то же время NVIDIA углубляет сотрудничество с такими компаниями, как Uber и Stellantis, для развития автономного вождения, а также анонсировала следующее поколение супер-GPU Vera Rubin, ожидая, что к концу 2026 года совокупный объем продаж GPU достигнет 500 миллиардов долларов США. Jensen Huang опроверг теорию “пузыря ИИ”, подчеркнув практичность моделей ИИ и готовность клиентов платить. Это знаменует дальнейшее укрепление глобального доминирования NVIDIA в области вычислительной мощности ИИ, 6G, квантовых вычислений и робототехники, способствуя быстрому развитию инфраструктуры ИИ. (Источник: 36氪, TheTuringPost, TheTuringPost)
🎯 Тенденции
Фокус ИИ смещается на мультимодальность, объединение понимания и генерации становится прорывом: Во второй половине 2025 года фокус индустрии ИИ смещается от чисто текстовых моделей к мультимодальным областям. Такие продукты, как Sora 2 и Nano Banana, приближаются к “прорывному” уровню по своей применимости. Хотя архитектура мультимодальных моделей еще не претерпела революционных изменений, накопление данных и улучшение методов обучения значительно продвинулись. DeepSeek-OCR, используя технологию визуального сжатия, преобразует длинный текст в распознаваемое изображение, значительно сокращая объем вычислений токенов, что обещает снижение затрат и повышение эффективности. В отрасли широко распространено мнение, что мультимодальность является неизбежным путем для LLM, а объединение понимания и генерации является текущей точкой прорыва, что откроет больше рыночных возможностей для предпринимателей и инвесторов. (Источник: 36氪)
CEO Microsoft AI Мустафа Сулейман подчеркивает этику и границы ИИ: CEO Microsoft AI Мустафа Сулейман заявил, что Microsoft никогда не будет разрабатывать “секс-роботов” и стремится создавать ИИ, который “расширяет возможности человека, а не заменяет его”. Он считает, что ИИ должен помогать людям общаться и создавать сообщества, а не втягивать их в “спираль эмоциональной бездны”. Microsoft Copilot добавил функцию группового чата и режим “Real Talk”, призванный обеспечить более сложный, нельстивый опыт взаимодействия и улучшить функцию памяти. Сулейман признал, что ранние сравнения ИИ с “цифровыми видами” могли вызвать недопонимание, но подчеркнул, что их целью было побудить индустрию задуматься о “сдерживании и выравнивании” ИИ, чтобы обеспечить его служение человечеству. (Источник: MIT Technology Review, MIT Technology Review)

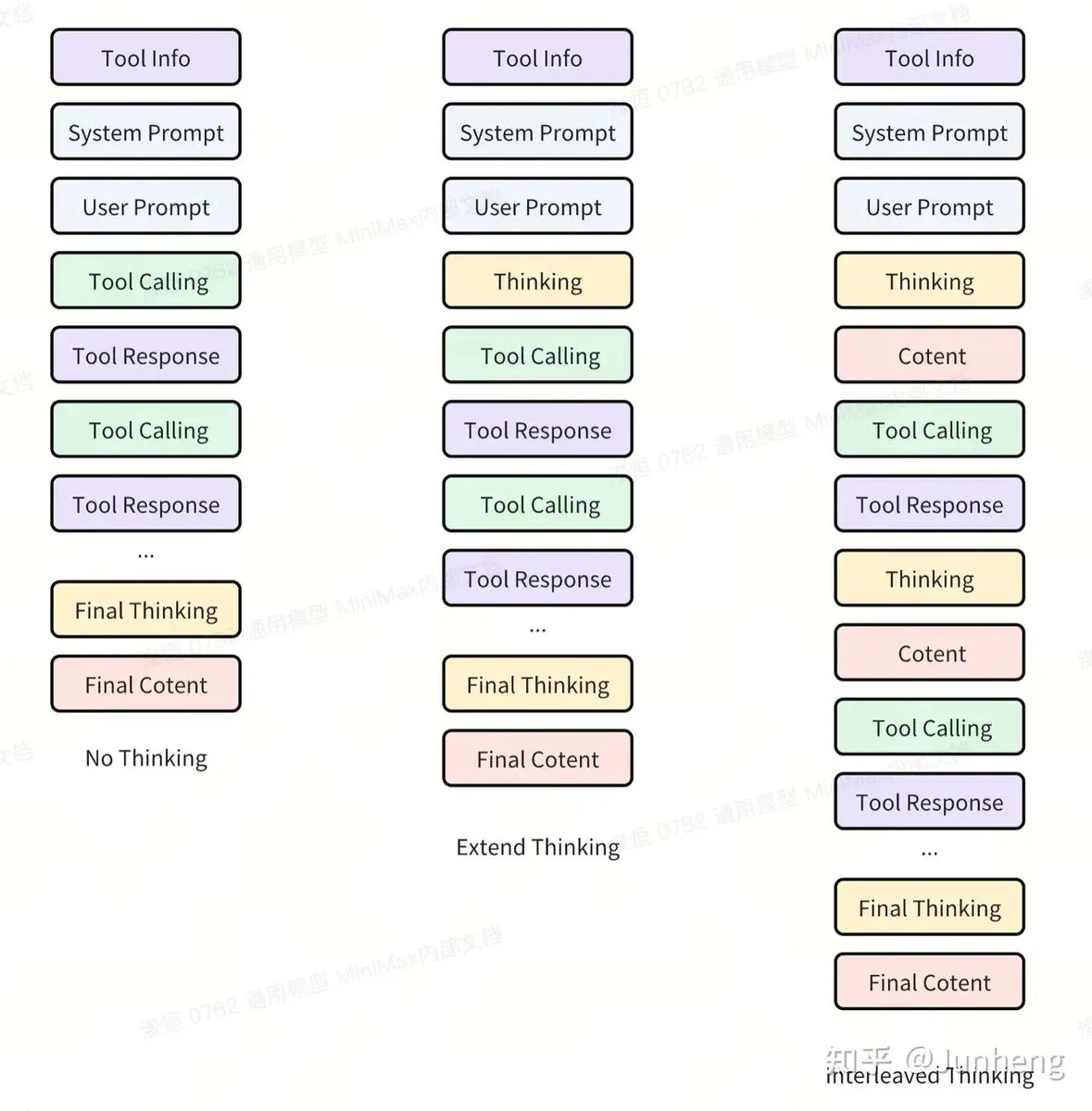
Модель MiniMax M2 с открытым исходным кодом: отличная производительность и высокая экономическая эффективность: Модель MiniMax M2 теперь доступна с открытым исходным кодом и привлекает внимание сообщества своей выдающейся производительностью в задачах Agent и кодирования. Модель демонстрирует мощные навыки в Agentic-задачах, при этом ее стоимость составляет всего 8% от стоимости Claude Sonnet, а скорость примерно в 2 раза выше. Команда MiniMax подчеркивает, что M2 использует механизм “перемежающегося мышления” (Interleaved Thinking), который позволяет Agent постоянно размышлять во время выполнения задачи, чтобы адаптироваться к внешним возмущениям и сохранять фокус на задаче, что крайне важно для сложных, многоэтапных задач вызова инструментов. В то же время, модель в своей способности к обобщению фокусируется не только на адаптивности инструментов, но и на устойчивости к различным возмущениям в пространстве операций модели. (Источник: MiniMax__AI, MiniMax__AI, ImazAngel, QuixiAI)
Скоро выйдет модель Qwen3 Max, вызывая ожидания в индустрии: Лаборатория Alibaba Tongyi Lab объявила, что модель Qwen3 Max находится на завершающей стадии разработки и, как ожидается, будет выпущена на этой неделе. Эта новость вызвала широкое обсуждение в сообществе относительно производительности и потенциального влияния модели. Учитывая сильное влияние серии Qwen в сообществе открытого исходного кода, Qwen3 Max, как ожидается, принесет новые прорывы в области LLM, особенно в возможностях обработки китайского языка и общего интеллекта, что будет способствовать дальнейшему развитию технологий больших моделей. (Источник: teortaxesTex, huybery, scaling01, Reddit r/LocalLLaMA)
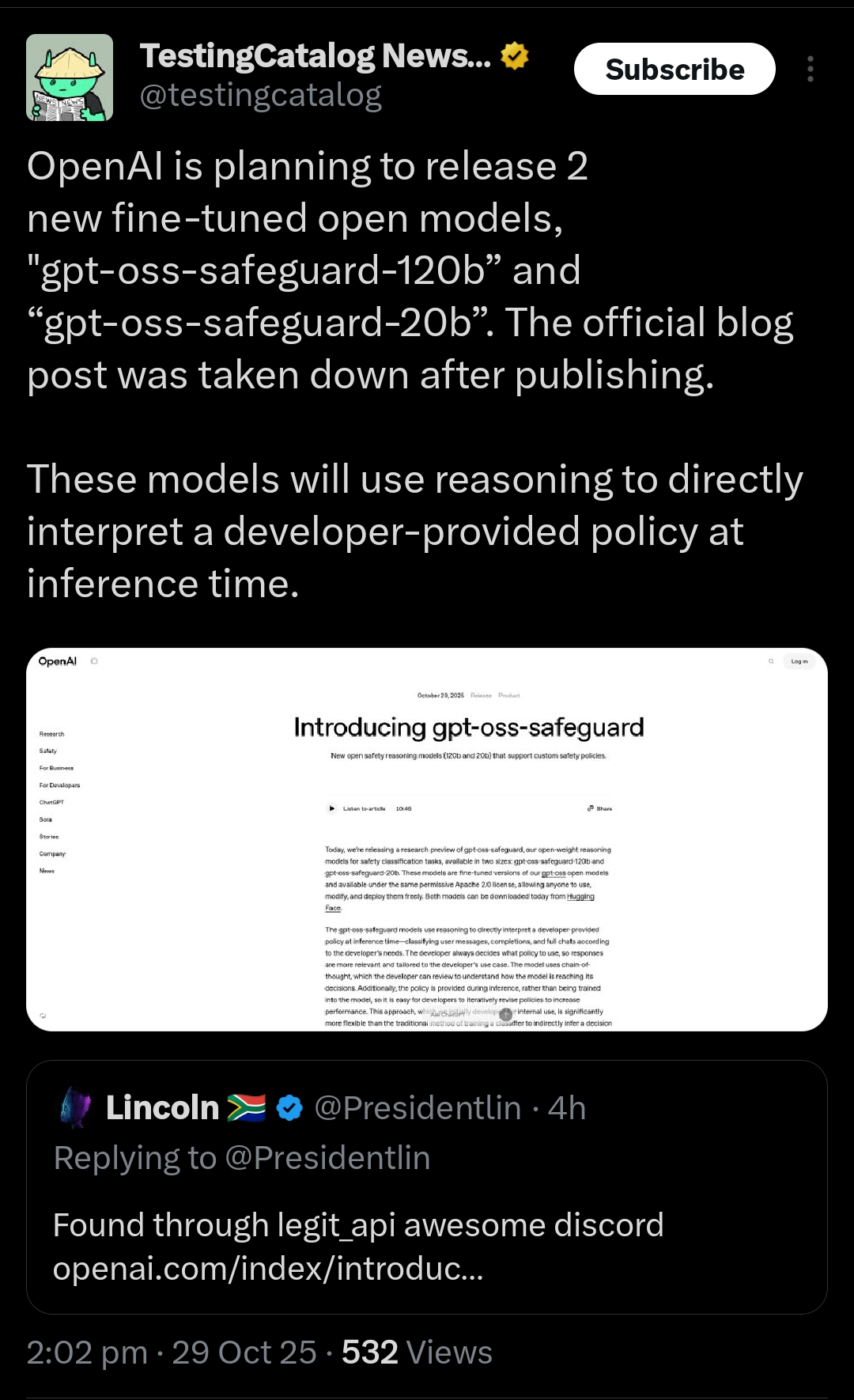
OpenAI выпустила модель gpt-oss-safeguard для улучшения классификации безопасности контента: OpenAI представила gpt-oss-safeguard, набор открытых моделей вывода для классификации безопасности, разработанных для помощи разработчикам в использовании пользовательских политик для выявления и управления вредоносным контентом и атаками с внедрением подсказок. Эти модели являются тонко настроенными версиями открытых моделей gpt-oss, поддерживают лицензию Apache 2.0 и уже доступны на Hugging Face. Эта инициатива направлена на содействие применению открытых моделей в создании более безопасного цифрового пространства и онлайн-безопасности. (Источник: OpenAIDevs, clefourrier, huggingface, ClementDelangue, johnowhitaker, Reddit r/LocalLLaMA)
Anthropic Sonnet 4.5 демонстрирует отличную производительность, значительно повышая продуктивность пользователей: Пользователи сообщают, что модель Anthropic Sonnet 4.5 демонстрирует выдающуюся производительность, впечатляющий интеллект и скорость. Модель особенно выделяется своими возможностями отладки и планирования, значительно повышая эффективность работы пользователей. Хотя еженедельные ограничения на использование по-прежнему вызывают критику, пользователи в целом считают Sonnet 4.5 непревзойденной моделью на рынке и ожидают более гибких условий использования в будущем. (Источник: Reddit r/ClaudeAI)
Kani TTS выпустила многоязычную модель 400M, обеспечивающую 5-кратную скорость в реальном времени: Kani TTS выпустила многоязычную модель преобразования текста в речь (TTS) 400M, включающую английский, японский, китайский, немецкий, испанский, корейский и арабский языки. Модель достигает коэффициента реального времени (RTF) около 0,2 на RTX 4080, что в 5 раз быстрее реального времени. Благодаря сочетанию базовой сети LFM2-350M и эффективного NanoCodec, модель значительно повышает скорость и эффективность развертывания, сохраняя при этом высокое качество речи, что подходит для сценариев, таких как диалоги в реальном времени, развертывание на экономичном оборудовании и новое поколение программ для чтения с экрана. (Источник: Reddit r/LocalLLaMA)

Soul выпустила SoulX-Podcast, модель для генерации подкастов с несколькими участниками: Soul AI Lab выпустила SoulX-Podcast, модель для генерации подкастов, поддерживающую диалоги с несколькими участниками. Модель, обученная на 1,3 миллиона часов данных, поддерживает китайский, английский, а также различные китайские диалекты и паралингвистические элементы (например, смех, вздохи), предоставляя мощный инструмент для создания подкастов и синтеза речи с несколькими ролями. Эта инициатива с открытым исходным кодом, как ожидается, будет способствовать применению и развитию технологий генерации аудио в области создания контента. (Источник: dotey, multimodalart, huggingface, ClementDelangue)
Gradient выпустила Parallax с открытым исходным кодом: суверенная ОС для ИИ, способствующая локальному развертыванию ИИ: Gradient объявила о выпуске Parallax с открытым исходным кодом, суверенной операционной системы ИИ, разработанной для упрощения настройки локальных кластеров ИИ на Mac и PC, а также для размещения собственных моделей и приложений пользователей без ущерба для производительности. Parallax позволяет пользователям легко развертывать и запускать приложения ИИ, подчеркивая суверенитет данных и локальные вычисления, предоставляя частным лицам и предприятиям большую гибкость и контроль, например, для быстрого запуска модели Qwen 235B. (Источник: menhguin, Alibaba_Qwen)

vLLM проведет более 10 выступлений на Ray Summit 2025, сосредоточившись на высокопроизводительном выводе и сервисах MoE: Проект vLLM объявил, что проведет более 10 выступлений на Ray Summit 2025, углубляясь в ключевые технологии, такие как высокопроизводительный вывод, унифицированный бэкенд, кэширование префиксов, сервисы моделей MoE (смесь экспертов) и крупномасштабная оркестровка. Саммит будет охватывать последние достижения vLLM, включая его применение на платформах Apple, AWS, AMD, Intel и других, а также эффективную многоузловую оркестровку для разреженных моделей MoE. Это демонстрирует постоянные усилия vLLM по оптимизации эффективности и масштабируемости вывода LLM, а также активное создание открытой экосистемы. (Источник: vllm_project, vllm_project)
DeepMind демонстрирует прорыв в автономном открытии алгоритмов RL с помощью ИИ: DeepMind опубликовала статью в Nature, демонстрирующую способность ИИ автономно открывать более совершенные алгоритмы обучения с подкреплением (RL). Это исследование, возглавляемое Дэвидом Силвером, создателем AlphaGo, предвещает, что следующее поколение алгоритмов RL может быть открыто машинами автономно, открывая новые пути для самообучения и повышения способностей ИИ. Это считается важным шагом в продвижении ИИ и может полностью изменить модель исследований и разработок алгоритмов RL. (Источник: NerdyRodent)
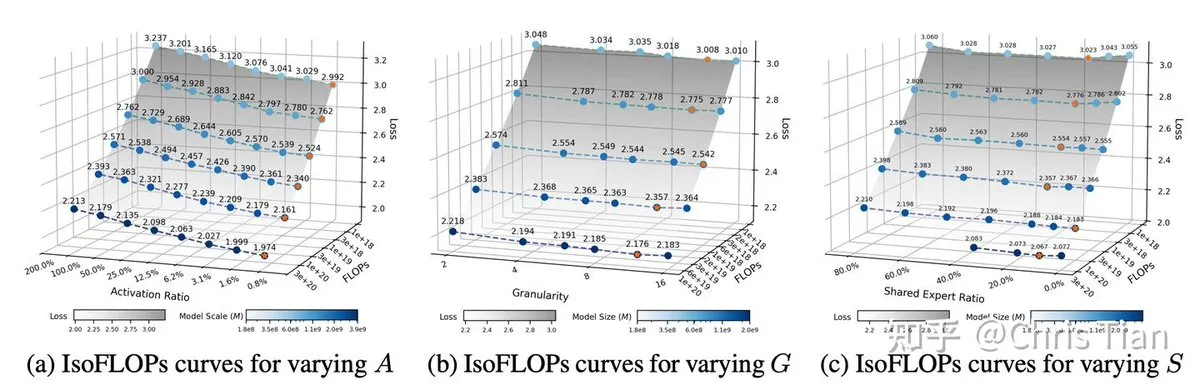
Дизайн MoE LLM и “Ling Scaling Laws” раскрывают оптимизацию эффективности: ZhihuFrontier опубликовала исследование по дизайну MoE LLM и “Ling Scaling Laws”, которое показывает, как скорость активации, гранулярность экспертов и вычислительный бюджет влияют на эффективность модели. Исследование показало, что снижение скорости активации (повышение разреженности) приводит к большему повышению эффективности, а активация 8-12 экспертов достигает оптимального баланса между производительностью и пропускной способностью. Кроме того, чем больше объем вычислений, тем более очевидно преимущество моделей MoE по сравнению с плотными моделями. Эти открытия предоставляют теоретические рекомендации и практические основы для эффективного проектирования архитектур MoE, что подтверждается моделями серии Ling-2.0. (Источник: ZhihuFrontier, bigeagle_xd)
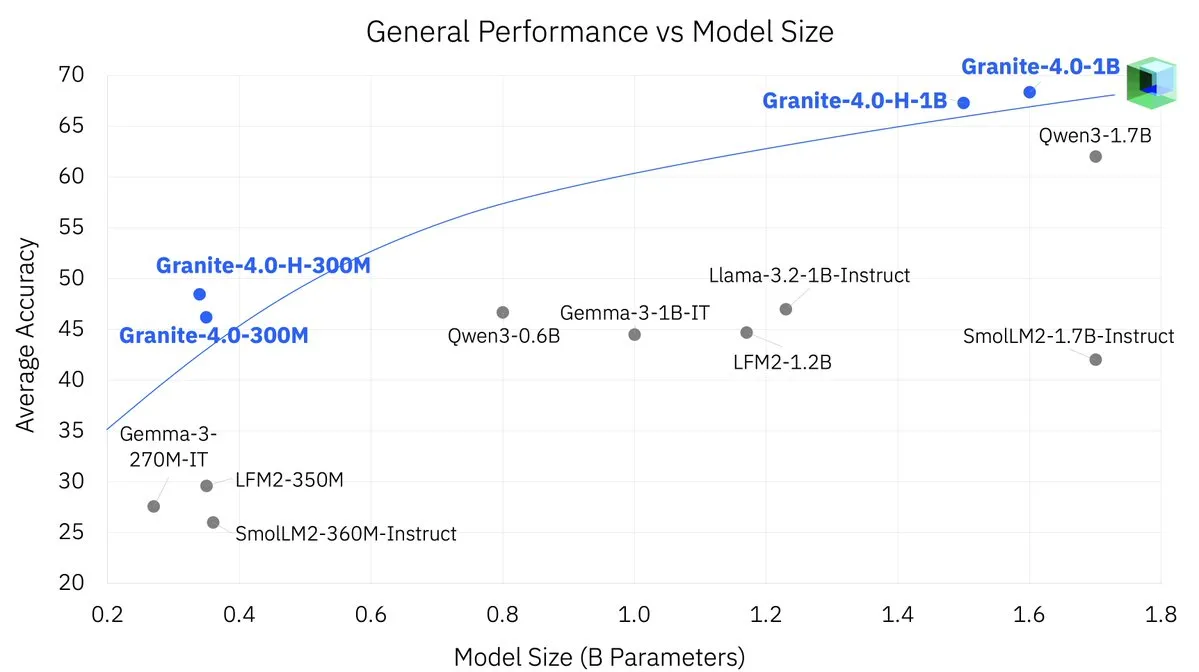
IBM выпустила модель Granite 4.0 Nano для мобильных устройств: IBM выпустила модель Granite 4.0 Nano, разработанную специально для мобильных устройств. Эта легкая модель призвана привнести передовые возможности ИИ на периферийные устройства, обеспечивая более эффективную и энергоэффективную локальную обработку ИИ. Этот шаг будет способствовать распространению приложений ИИ на мобильных платформах, таких как смартфоны и устройства IoT, предоставляя разработчикам больше локализованных решений ИИ. (Источник: adrgrondin)
🧰 Инструменты
Опыт глубокого использования Claude Code: создание эффективной системы помощника по программированию на базе ИИ: Опытный инженер-программист поделился своим шестимесячным опытом использования Claude Code для переписывания 300 000 строк кода, создав эффективную систему помощника по программированию на базе ИИ. Эта система включает: 1. Систему автоматической активации навыков: Реализована через TypeScript hooks для автоматической загрузки и применения навыков, обеспечивая согласованность стиля кода и лучших практик; 2. Систему документации для разработки: Создание каталогов задач и документации (планы, контекст, списки задач) для предотвращения потери контекста Claude при длительных задачах; 3. Управление процессами PM2: Используется для мониторинга логов и автоматического перезапуска бэкенд-микросервисов, что значительно упрощает процесс отладки; 4. Систему Hooks: Реализует отслеживание изменений файлов, проверки сборки, форматирование кода и уведомления об ошибках, обеспечивая качество кода; 5. Интеграцию скриптов и инструментов: Связывает часто используемые скрипты инструментов с навыками для повышения эффективности, а также использует SuperWhisper для голосового ввода и Memory MCP для управления проектными решениями. Этот опыт подчеркивает, что программирование с ИИ требует, чтобы инженеры-люди выступали в роли “технических руководителей” для планирования, проверки и итераций, а не полностью полагались на ИИ для “Vibe Coding”. (Источник: Reddit r/ClaudeAI, dotey, omarsar0, Reddit r/ClaudeAI)

VoiceInk: приложение для мгновенного преобразования речи в текст на macOS: Beingpax разработал и выпустил VoiceInk с открытым исходным кодом, нативное приложение macOS для преобразования речи в текст. Этот инструмент способен практически мгновенно транскрибировать речь в текст с точностью до 99% и поддерживает 100% автономную обработку, обеспечивая конфиденциальность пользователя. VoiceInk также имеет “умный режим” для автоматической настройки параметров в зависимости от приложения или URL, а также функцию “контекстной осведомленности” для понимания содержимого экрана. Кроме того, он предлагает глобальные горячие клавиши, личный словарь и встроенного ИИ-помощника, стремясь стать самым эффективным и ориентированным на конфиденциальность решением для преобразования речи в текст на macOS. (Источник: GitHub Trending)

moon-dev-ai-agents: фреймворк AI Agent с открытым исходным кодом для торговли: moondevonyt выпустил проект “moon-dev-ai-agents” с открытым исходным кодом, предоставляющий серию автономных AI Agent для торговли. Фреймворк включает Agent для бэктестинга и исследований (например, RBI Agent для исследования стратегий и автоматического бэктестинга), Agent для реальной торговли (поддерживающий режим консенсуса одной или нескольких моделей), Agent для анализа рынка (например, активность китов, анализ настроений, анализ графиков), а также Agent, специфичные для Solana, и Agent для создания контента. Проект направлен на демократизацию технологии AI Agent, подчеркивает тщательное бэктестинг и управление рисками, а также предоставляет подробное руководство по быстрому запуску и параметры конфигурации. (Источник: GitHub Trending)

Qdrant помогает создавать финансовых исследовательских Agent и производственные системы RAG: Qdrant демонстрирует, как он преобразует финансовый анализ с помощью интеллектуальных рабочих процессов автоматизации исследований (интегрированных с Dust), автоматизируя прием и индексацию документов, а также используя гибридный поиск для извлечения точных данных из сложных финансовых данных. Кроме того, Qdrant выступает в качестве ядра многопользовательского векторного хранилища, поддерживая создание производственных систем RAG, реализуя прием PDF в реальном времени, потоковый поиск и вывод LLM, а также развертывание и масштабирование на Kubernetes, предоставляя эффективные и масштабируемые решения RAG. (Источник: qdrant_engine, qdrant_engine, qdrant_engine)
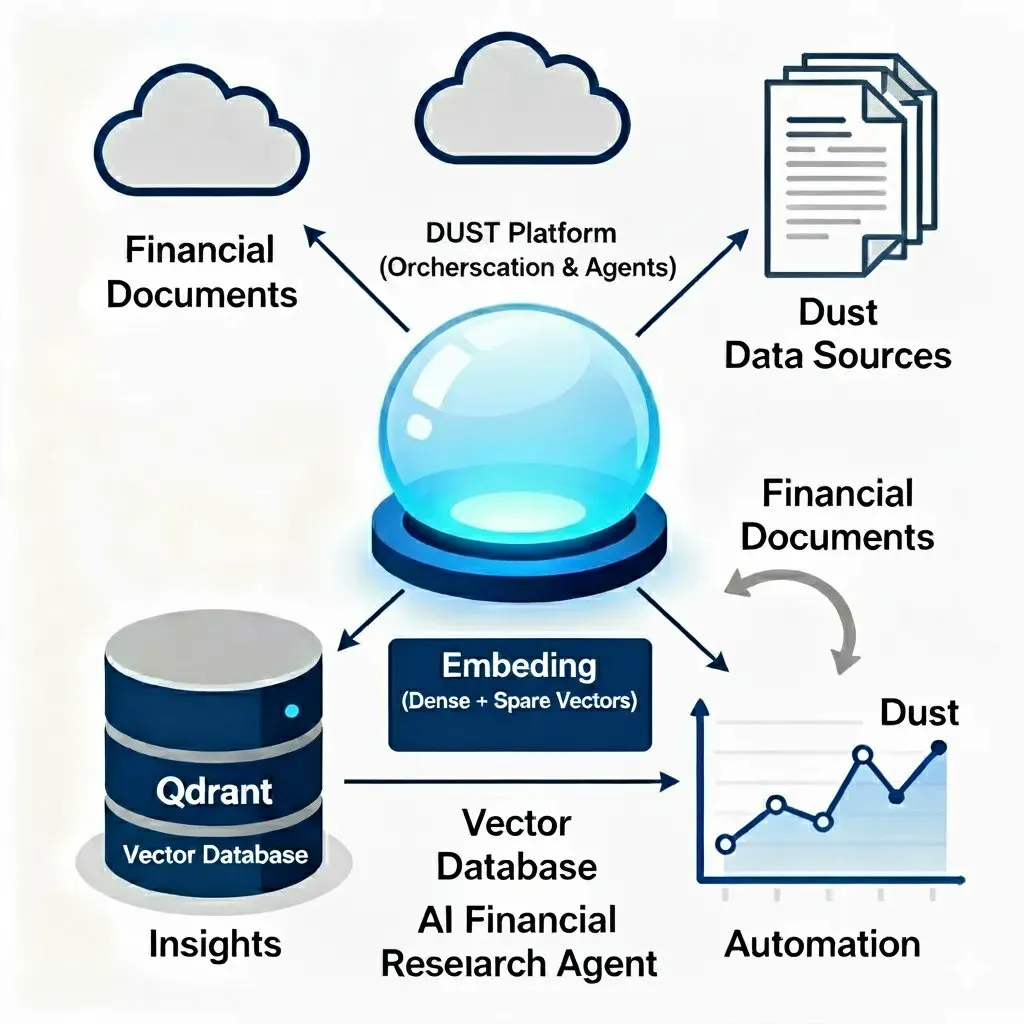
Выпущен Deep Agents 0.2, представлен подключаемый бэкенд файловой системы: Команда LangChain выпустила Deep Agents версии 0.2, в основном добавив абстракцию “бэкенда”, позволяющую пользователям заменять файловую систему, используемую Deep Agents. Это означает, что пользователи могут выбирать локальную файловую систему, базу данных, удаленную виртуальную машину и т. д. в качестве рабочего пространства Agent. Это улучшение повышает гибкость и применимость Deep Agents, позволяя им лучше адаптироваться к различным средам разработки и требованиям, что способствует дальнейшему развитию важности Agent Harnesses. (Источник: hwchase17)
Google запускает маркетинговый инструмент ИИ Pomelli для ускорения создания брендового контента: Google Labs запустила экспериментальный маркетинговый инструмент ИИ Pomelli, призванный помочь пользователям легко создавать масштабируемый, соответствующий бренду контент, тем самым быстрее устанавливая связь с аудиторией. Пользователям достаточно ввести URL веб-сайта, и Pomelli поймет их уникальную бизнес-идентичность, создавая индивидуальные и эффективные маркетинговые кампании. Инструмент уже запущен в США, Канаде, Австралии и Новой Зеландии, демонстрируя потенциал применения ИИ в автоматизации маркетинга. (Источник: demishassabis)
Agent HQ интегрирует множество Coding Agent, повышая эффективность экосистемы разработчиков: GitHub выпустил новый Agent HQ, предназначенный для интеграции различных Coding Agent в подписку Copilot, предоставляя разработчикам единую интерактивную платформу и облачную среду выполнения задач без необходимости отдельных подписок на несколько продуктов. Эта инициатива использует GitHub как крупнейшую экосистему разработчиков, упрощает использование Agent и повышает эффективность разработки, что знаменует дальнейшую интеграцию экосистемы инструментов программирования на базе ИИ. (Источник: dotey)

Serve 100 Large AI Models on a single GPU: движок для обслуживания ста больших моделей на одном GPU: Разработчик создал движок, который может загружать большие модели с SSD в VRAM в десять раз быстрее, чем существующие решения, тем самым эффективно обслуживая 100 больших моделей ИИ на одном GPU с минимальным влиянием на время отклика первого токена. Проект решает проблему длительного времени холодного запуска в бессерверном выводе ИИ, подходит для бессерверного вывода ИИ, робототехники, локального развертывания и локальных Agent, и является открытым исходным кодом. (Источник: Reddit r/LocalLLaMA)

Обмен архитектурой интеллектуального агента для написания патентов на базе ИИ: Цзююань Кэ поделился простой архитектурой интеллектуального агента для написания патентов, которую можно реализовать с помощью таких инструментов, как Claude Code, путем построения на основе модели Agent-SubAgent и подсказок (которые могут быть написаны с помощью Claude). Эта архитектура призвана упростить процесс написания патентов, повысить эффективность, и версия без загрузки SKILLs была выпущена с открытым исходным кодом для справки и настройки. Это демонстрирует потенциал применения LLM Agent в области генерации специализированного текста. (Источник: dotey, dotey)
📚 Обучение
Программирование с ИИ ускоряет разработку ПО, но требует более высоких навыков от инженеров: Обсуждения в социальных сетях показывают, что ИИ снижает порог входа в программирование и стоимость демонстраций, но высококачественная разработка ПО предъявляет более высокие требования к проектированию структур данных, архитектурному проектированию и модульной простоте. Код, сгенерированный ИИ, может содержать “мусорный код”, увеличивая риски будущего обслуживания. Следовательно, чем мощнее ИИ, тем выше требования к человеческим знаниям в области программирования, опыту и архитектурным способностям. В статье подчеркивается режим “Agentic Coding”, где ИИ выступает в роли “сверхспособного, но безответственного младшего программиста”, а инженеры-люди играют роль “технического руководителя”, смещая акцент на “постановку требований” и “проверку кода”. (Источник: dotey, dotey, gfodor, zhuohan123, lateinteraction, finbarrtimbers)

Руководство по программированию Claude: RAG, использование инструментов, мультимодальность и многое другое: В социальных сетях было опубликовано руководство по программированию Claude (claude-cookbooks) с 25 тысячами звезд на GitHub, охватывающее использование Claude для RAG, извлечения резюме, использования инструментов, агентов поддержки клиентов, интеграции с векторными базами данных, мультимодальности (интерпретация изображений и диаграмм) и более продвинутых вызовов субагентов. Это руководство предоставляет разработчикам всестороннюю практику применения Claude, помогая повысить эффективность разработки LLM Agent и реализации функций. (Источник: dotey)
Ресурсы для обучения ИИ: курсы по тонкой настройке LLM и обучению с подкреплением: DeepLearning.AI в сотрудничестве с AMD запустила бесплатный курс по ИИ “Fine-Tuning & Reinforcement Learning for LLMs: Intro to Post-Training”, призванный предоставить разработчикам инструменты и вычислительные ресурсы для технологий пост-обучения LLM (таких как тонкая настройка и обучение с подкреплением). Курс охватывает основные технологии, используемые ведущими лабораториями ИИ сегодня, и является важным учебным ресурсом для повышения навыков разработки LLM. (Источник: realSharonZhou)
Статьи в блогах считаются более эффективной формой обмена знаниями, чем научные статьи: Несколько пользователей в социальных сетях обсуждали, что статьи в блогах превосходят традиционные научные статьи в обмене знаниями и обучении. Блоги могут начинать объяснения с базовых концепций, формировать интуитивное понимание, не ограничиваясь новизной и строгим форматом, а также улучшать процесс обучения за счет интерактивности. Научная команда Hugging Face также активно делится знаниями о крупномасштабном глубоком обучении через интерактивные блоги, считая это лучшей формой обмена научными идеями. (Источник: LoubnaBenAllal1, _lewtun, clefourrier)

Технический блог MiniMax M2 углубляется в выбор модели полного внимания: Команда MiniMax M2 опубликовала технический блог, объясняющий, почему M2 в конечном итоге выбрала модель полного внимания вместо линейного/разреженного внимания. В блоге отмечается, что, хотя эффективное внимание теоретически может сэкономить вычисления, в реальных промышленных системах полное внимание по-прежнему превосходит по производительности и в сложных задачах (таких как многошаговый вывод). Основные проблемы заключаются в ограничениях оценки, высоких затратах на эксперименты, слишком большом количестве переменных обучения модели и незрелости инфраструктуры эффективного внимания. Это предоставляет ценный практический опыт и размышления для проектирования архитектур больших моделей. (Источник: yacinelearning, ImazAngel, giffmana, code_star, QuixiAI, eliebakouch)
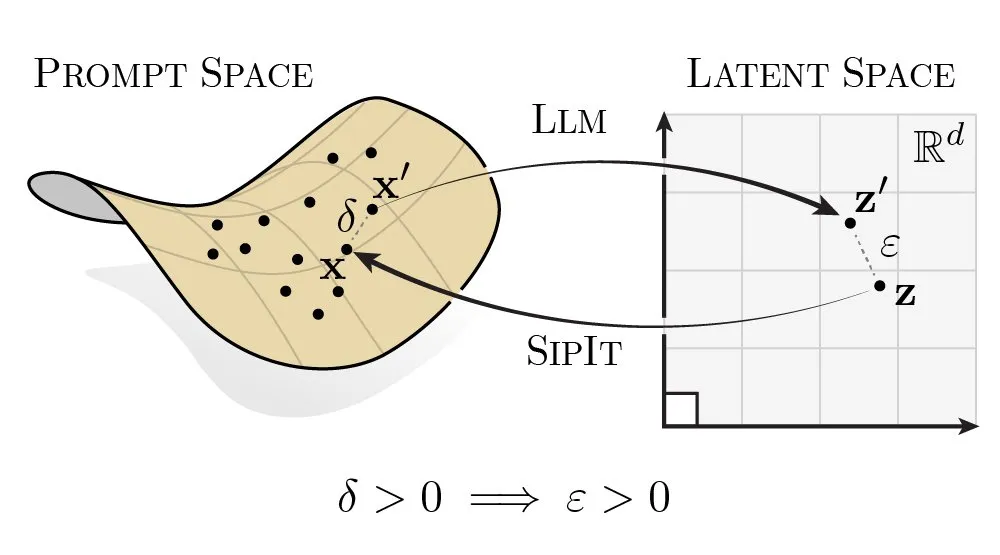
Исследование инъективности и обратимости LLMs раскрывает потенциал восстановления входных данных: Новое исследование показывает, что LLMs обладают инъективностью и обратимостью, то есть различные подсказки всегда отображаются в различные встраивания. Это свойство может быть использовано для восстановления входных токенов из одного встраивания в латентном пространстве. Это открытие предоставляет новый взгляд на понимание внутренних механизмов LLM и потенциальных рисков безопасности/конфиденциальности, а также может быть применено в будущем для восстановления входных данных или исследований атак противников. (Источник: tokenbender)
Вышла монография “Принципы Diffusion Models”, систематически объясняющая диффузионные модели: Вышла монография под названием “The Principles of Diffusion Models”, призванная систематически объяснить основные идеи, принципы работы и направления развития диффузионных моделей. Монография прослеживает ключевые концепции, лежащие в основе формирования диффузионных моделей, и углубленно объясняет, как, почему и куда движутся современные модели. Она рассматривается как надежный, фундаментальный справочный материал, помогающий исследователям и разработчикам глубоко понять диффузионные модели, избегая многократного обращения к оригинальным статьям. (Источник: NandoDF, sedielem)

Agent Data Protocol (ADP) унифицирует наборы данных для обучения Agent: Исследование представляет Agent Data Protocol (ADP), легковесный язык представления, предназначенный для унификации разнородных форматов, инструментов и интерфейсов различных наборов данных для обучения Agent. ADP достаточно выразителен для описания различных задач, таких как использование API/инструментов, просмотр, кодирование, программная инженерия и общие рабочие процессы Agent, и упрощает последующие унифицированные процессы обучения Agent. Эксперименты показывают, что SFT 13 существующих наборов данных с использованием ADP повышает производительность модели в среднем примерно на 20% и достигает SOTA или близких к SOTA результатов на нескольких бенчмарках. (Источник: HuggingFace Daily Papers)
Фреймворк SPICE повышает способность к рассуждению через самообучение в корпусных средах: SPICE (Self-Play In Corpus Environments) — это фреймворк обучения с подкреплением, в котором одна модель играет две роли: челленджера (ищущего задачи на рассуждение в корпусе) и решателя (решающего задачи). Благодаря антагонистической динамике челленджер создает автоматическую программу обучения на переднем крае возможностей решателя, в то время как корпус обеспечивает богатый, почти неисчерпаемый источник внешних сигналов для постоянного улучшения. SPICE демонстрирует постоянные улучшения на бенчмарках по математике и общему рассуждению, показывая, что основа, состоящая из документов, является ключом к постоянному генерированию сложных целей и их достижению. (Источник: HuggingFace Daily Papers)
💼 Бизнес
Первый год коммерциализации ИИ-единорогов: от технологического ажиотажа к внедрению, рост Agent и AI-нативных компаний: В 2025 году экосистема венчурного капитала ИИ переходит от технологического ажиотажа к коммерческому внедрению, и ИИ-единороги начинают доказывать устойчивые модели дохода. Зрелость AI Agent и “AI-нативных” бизнес-моделей породила новые формы предприятий, например, ThinkinMachinesLab получила оценку в 12 миллиардов долларов США, не выпустив продукта, юридический AI Harvey оценен в 3 миллиарда долларов США, а ARR Cursor от Anysphere достиг 500 миллионов долларов США. Основная ценность этих компаний заключается в их владении вычислительной мощностью, алгоритмами и моделями, а ценность продукта растет с улучшением производительности модели, а не с операционной эффективностью. Услуги ИИ переходят от подписки на программное обеспечение к оплате, ориентированной на результат, что ускоряет цикл стартапов и способствует созданию “гибридных человеко-машинных” команд для организационного рычага. (Источник: 36氪)

Загадка окупаемости инвестиций в ИИ: компании сталкиваются с проблемами в расходах на ИИ: Несмотря на многолетний ажиотаж вокруг ИИ, отчет MIT NANDA указывает, что 95% пилотных проектов генеративного ИИ не смогли масштабироваться или достичь измеримого ROI. Компании сталкиваются с дилеммой в инвестициях в ИИ: с одной стороны, им необходимо идти в ногу с технологическими тенденциями, с другой — они сталкиваются с трудностями в измерении прибыли и рисками для стабильности бизнеса. В статье рекомендуется, чтобы компании рассматривали данные как основную ценность, договаривались с поставщиками моделей о доступе к данным для получения услуг или ценовых преимуществ; применяли стратегию “скучного дизайна”, применяя ИИ к конкретным болевым точкам бизнеса, а не часто обновляя модели; и следовали принципу “экономики минивэна”, разрабатывая системы, отвечающие потребностям пользователей и ориентированные на экономию, избегая слепого стремления к новейшим технологиям. (Источник: MIT Technology Review, MIT Technology Review)

Услуги облачной аренды GPU способствуют обучению и выводу моделей ИИ: С ростом потребностей в оборудовании для обучения и тонкой настройки больших моделей ИИ, услуги аренды GPU становятся эффективным и экономичным решением. Пользователи могут арендовать высокопроизводительные GPU-серверы, такие как A100, H100, RTX 4090, по требованию, избегая высоких первоначальных инвестиций и мгновенно масштабируясь в соответствии с потребностями рабочей нагрузки. Эта модель предоставляет разработчикам ИИ, глубокого обучения и проектов с интенсивным использованием данных гибкую, масштабируемую и безопасную вычислительную среду, эффективно экономя время и бюджет. (Источник: Reddit r/deeplearning, Reddit r/LocalLLaMA)

🌟 Сообщество
ИИ и навыки программирования: более высокие требования к программистам в эпоху ИИ: Обсуждения в социальных сетях показывают, что ИИ снижает порог входа в программирование и стоимость демонстраций, но высококачественная разработка ПО предъявляет более высокие требования к проектированию структур данных, архитектурному проектированию и модульной простоте. Код, сгенерированный ИИ, может содержать “мусорный код”, увеличивая риски будущего обслуживания. Следовательно, чем мощнее ИИ, тем выше требования к человеческим знаниям в области программирования, опыту и архитектурным способностям. В статье подчеркивается режим “Agentic Coding”, где ИИ выступает в роли “сверхспособного, но безответственного младшего программиста”, а инженеры-люди играют роль “технического руководителя”, смещая акцент на “постановку требований” и “проверку кода”. (Источник: dotey, dotey, gfodor, zhuohan123, lateinteraction, finbarrtimbers)
ChatGPT вызывает проблемы с психическим здоровьем у пользователей и реакция OpenAI: OpenAI оценивает, что сотни тысяч пользователей ChatGPT демонстрируют серьезные симптомы психического здоровья, и уже скорректировала GPT-5 для более эффективного реагирования на пользователей, находящихся в бедственном положении. Хотя OpenAI не будет принуждать пользователей к перерывам, в отрасли обсуждается, что ИИ должен обладать функцией “отключения”, чтобы защитить пользователей. В то же время некоторые пользователи поделились опытом, когда ChatGPT генерировал экстремальный или даже неприемлемый контент при определенных подсказках, что подчеркивает проблемы моделей ИИ в понимании намерений пользователя и безопасности контента. (Источник: MIT Technology Review, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

Влияние распространения AI Agent на рабочие места в сфере продаж и стратегические соображения компаний: Компания Vercel заменила большую часть своей команды продаж, сократив ее с 10 до 1 человека, обучив AI Agent, что вызвало опасения по поводу замены AI Agent начальных должностей в сфере продаж. Однако есть мнение, что если рабочий процесс может быть задокументирован, AI Agent сможет его выполнить, но на практике это может быть не так просто. Кроме того, обсуждается, почему компании в эпоху ИИ не сохраняют больше сотрудников для достижения “умножения силы”, а вместо этого увольняют их для финансирования ИИ, что отражает стратегические соображения компаний в трансформации ИИ и неопределенность перспектив занятости сотрудников. (Источник: Reddit r/artificial, Reddit r/ArtificialInteligence)

Влияние ИИ на рынок труда: различия между технологической и традиционной отраслями: В социальных сетях обсуждается, почему ИИ вызывает больше увольнений и нестабильности в технологической отрасли, в то время как в традиционных отраслях, таких как бухгалтерский учет или гражданское строительство, ситуация относительно стабильна. Предполагается, что в области разработки программного обеспечения больше данных, которые могут быть использованы ИИ-компаниями, и персонал внутри технологических компаний лучше знаком с процессами разработки программного обеспечения. Традиционные отрасли, связанные с финансовой ответственностью или безопасностью жизни, имеют более низкий уровень доверия к ИИ. Кроме того, некоторые комментаторы отмечают, что увольнения могут быть предлогом для компаний, использующих ИИ для повышения будущих прогнозов прибыли, а не прямым следствием массовой безработицы, вызванной ИИ. (Источник: Reddit r/ArtificialInteligence)
Grokipedia вызывает споры: политическая предвзятость и точность контента ИИ-энциклопедии: Grokipedia, конкурент Википедии на базе ИИ, запущенный Илоном Маском, вызвал споры из-за своего праворадикального контента и распространения неточных исторических и консервативных взглядов. Например, он ошибочно утверждал, что порнография усугубила эпидемию СПИДа, и намекал, что социальные сети могли способствовать росту трансгендерного сообщества. Этот инцидент подчеркивает проблемы ИИ-генерируемого контента в отношении объективности, точности и потенциальной предвзятости, а также возможное социальное влияние ИИ в области распространения знаний. (Источник: Reddit r/artificial, MIT Technology Review)

Применение ИИ в проверке медицинских счетов: Claude помогает семье значительно сократить больничные счета: Скорбящая семья использовала чат-бот ИИ Claude, чтобы успешно сократить больничный счет в 195 000 долларов США до 33 000 долларов США. Claude значительно снизил медицинские расходы, выявив дублирующиеся платежи, неправильное кодирование и другие нарушения. Этот случай демонстрирует огромный потенциал ИИ в анализе сложных документов и оптимизации затрат, особенно в таких областях, как здравоохранение, где асимметрия информации позволяет ИИ расширять возможности потребителей для защиты своих прав. (Источник: Reddit r/artificial)
ИИ-браузеры: обсуждение соответствия продукта рынку и рисков безопасности/конфиденциальности: Обсуждения в социальных сетях сосредоточены на соответствии продукта рынку и рисках безопасности/конфиденциальности ИИ-браузеров. Анил Дэш описывает Atlas как “анти-веб-браузер”, в то время как Саймон Уиллисон подчеркивает, что его риски безопасности и конфиденциальности слишком высоки, чтобы их преодолеть, заявляя, что он не будет доверять таким продуктам, пока исследователи безопасности не проведут тщательную оценку. Обсуждение указывает на то, что, хотя ИИ может ускорить разработку программного обеспечения, его модели не обладают способностью ставить под сомнение обоснованность категории продукта, и эта способность суждения по-прежнему уникальна для человека. Это вызывает глубокие размышления о взаимосвязи между инновациями ИИ-продуктов и реальными потребностями, а также этическими границами. (Источник: random_walker)
Влияние ИИ на индустрию развлечений для взрослых: потенциал технологии генерации видео и этические проблемы: Обсуждения в социальных сетях касаются влияния технологии генерации видео с помощью ИИ на индустрию развлечений для взрослых. Пользователи считают, что реалистичность видео, сгенерированных ИИ, достигла удивительного уровня, предвещая, что ИИ может в значительной степени заменить традиционное производство контента для взрослых. Однако это также порождает этические проблемы, такие как использование изображений людей без согласия, влияние на занятость актеров и как сбалансировать творческую свободу с проблемами эксплуатации. В то же время есть мнение, что ценность реального контента для взрослых может возрасти, а персонализированный контент, сгенерированный ИИ, станет новым рынком. (Источник: Reddit r/artificial)
Причины неудачи модели Llama и споры о стратегии Meta AI: Обсуждения в социальных сетях показывают, что серия моделей Llama от Meta не достигла ожидаемого успеха, и причина может быть связана с “непостоянной” стратегией CEO Цукерберга в инвестициях в ИИ. Хотя Meta вложила огромные средства в VR, ей, возможно, не хватает долгосрочной приверженности и настойчивости в области ИИ, что привело к тому, что серия Llama не смогла сохранить конкурентоспособность. Комментарии указывают на то, что колебания Meta в стратегии открытого исходного кода и акцент на снижение рисков могут предвещать отсутствие конкурентоспособных моделей с открытым исходным кодом в будущем, что вызывает обеспокоенность сообщества по поводу направления стратегии Meta AI. (Источник: Reddit r/LocalLLaMA)

Автономность ИИ-роботов: от “старого автомобиля” к “гоночному автомобилю” — вызовы программной инженерии: Обсуждения в социальных сетях показывают, что 10-кратное увеличение скорости кодирования, обеспечиваемое ИИ, больше похоже на модернизацию двигателя автомобиля. Если установить его на старый “автомобиль”, это приведет лишь к 10-кратному увеличению проблем. Чтобы насладиться увеличением скорости, обеспечиваемым ИИ, необходимо одновременно в 10 раз снизить “вероятность возникновения проблем”. Это требует синхронного обновления практик программной инженерии (таких как CI/CD, автоматизированное тестирование), сокращения циклов обратной связи с “часов” до “минут” и оптимизации систем принятия решений и коммуникации. Истинная ценность программирования с ИИ заключается в том, чтобы сделать ранее дорогостоящие лучшие практики осуществимыми, а не заменять инженеров-людей, а скорее адаптировать их к высокоскоростному двигателю. (Источник: dotey, finbarrtimbers)

💡 Прочее
ИИ-роботы-продавцы и объекты для обучения человекоподобных роботов: Xpeng представила человекоподобного робота-продавца “Тедан”, демонстрируя новое применение ИИ в розничных услугах. В то же время в Пекине также были созданы объекты для обучения человекоподобных роботов, направленные на ускорение развития и применения робототехники. Эти достижения предвещают растущее распространение человекоподобных роботов в коммерческой и промышленной сферах, и в будущем ожидается их взаимодействие и сотрудничество с людьми в большем количестве сценариев. (Источник: Ronald_vanLoon, Ronald_vanLoon)
Музыка и песни, сгенерированные ИИ: создание за считанные минуты: Технология ИИ теперь способна создавать музыку и песни за считанные минуты. Это достижение демонстрирует мощные возможности ИИ в области художественного творчества, позволяя быстро генерировать высококачественный аудиоконтент. Это открывает новые творческие инструменты и возможности для музыкальной индустрии, а также вызывает дискуссии о авторских правах, оригинальности и роли человеческих художников. (Источник: Ronald_vanLoon)
VaultGemma: Google предварительно обучает LLM с помощью дифференциальной приватности, достигая отсутствия запоминания данных: Проект VaultGemma от Google DeepMind успешно предварительно обучил LLM с помощью дифференциальной приватности (Differential Privacy), достигнув отсутствия запоминания обучающих данных. Несмотря на 100-кратные вычислительные затраты и достижение уровня производительности GPT-2, это первая LLM без обнаруживаемого запоминания обучающих данных. Этот прорыв имеет важное значение для защиты конфиденциальности ИИ, предоставляя новое направление для создания более безопасных и ответственных LLM в будущем. (Источник: jxmnop/status/1983542209703248071)
