
Ключевые слова:GPT-5, Квантовые вычисления, Дизайн материалов с ИИ, Обучение с подкреплением, Большие языковые модели, Инфраструктура ИИ, Мультимодальные модели, Агенты ИИ, Квантовые NP-сложные задачи, Кристаллографическая графовая нейронная сеть CGformer, Фреймворк обучения с подкреплением RLMT, Разреженное внимание DeepSeek DSA, Унифицированная система визуальных задач UniVid
🔥 Фокус
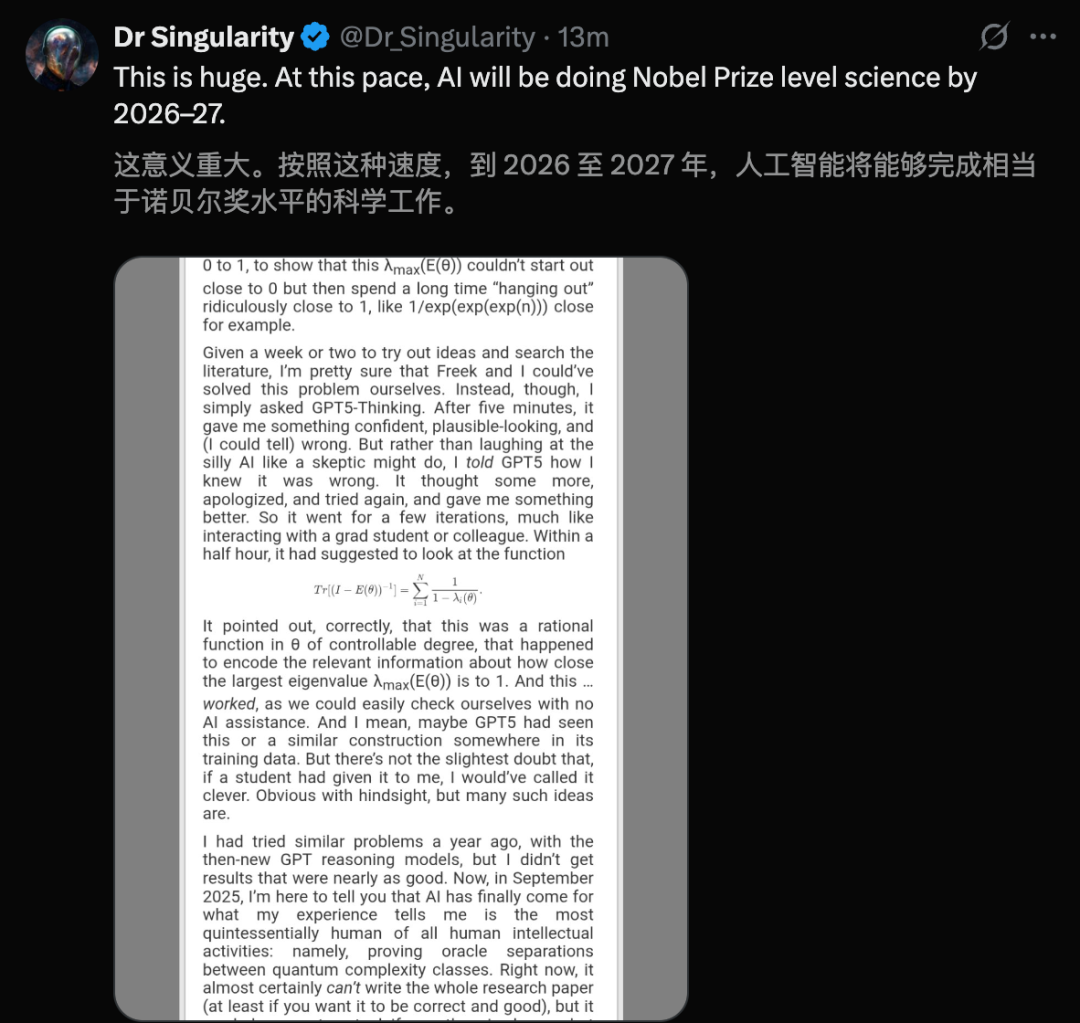
GPT-5 преодолевает «квантовую NP-проблему»: Эксперт по квантовым вычислениям Scott Aaronson впервые опубликовал статью, раскрывающую прорывную вспомогательную роль GPT-5 в исследованиях квантовой теории сложности. GPT-5 за 30 минут помог решить ключевой этап вывода в «квантовой версии NP-проблемы», что обычно занимает у человека 1-2 недели. Этот результат знаменует, что ИИ начал затрагивать основную научную работу человеческого интеллекта, предвещая огромный скачок потенциала ИИ в области научных исследований. (Источник: arXiv, scottaaronson.blog)
Новая модель ИИ для проектирования материалов CGformer: Команда профессоров Ли Цзиньцзинь и Хуан Фуцян из Шанхайского университета Цзяотун разработала совершенно новую модель ИИ для проектирования материалов CGformer. Инновационное сочетание механизма глобального внимания Graphormer с CGCNN, а также интеграция кодирования центральности и пространственного кодирования, успешно преодолели ограничения традиционных нейронных сетей для кристаллических графов. Эта модель способна полностью захватывать глобальную информацию о сложных кристаллических структурах, значительно повышая точность прогнозирования и эффективность отбора новых материалов, таких как высокоэнтропийные натрий-ионные твердотельные электролиты. (Источник: Matter)

UniVid — унифицированная структура для визуальных задач: UniVid — это инновационная структура, которая путем тонкой настройки предварительно обученного видеодиффузионного Transformer позволяет ему адаптироваться к разнообразным задачам с изображениями и видео без необходимости модификаций, специфичных для задачи. Этот метод представляет задачи как визуальные утверждения, определяя задачу и ожидаемую модальность вывода через контекстную последовательность, демонстрируя огромный потенциал предварительно обученных моделей генерации видео как унифицированной основы для визуального моделирования. (Источник: HuggingFace Daily Papers)
RLMT переворачивает пост-обучение больших моделей: Команда доцента Чэнь Даньци из Принстонского университета предложила структуру «обучения с подкреплением на основе мышления с модельным вознаграждением» (RLMT). Она позволяет LLM генерировать длинные цепочки рассуждений перед ответом и сочетает это с моделью вознаграждения, основанной на предпочтениях, для онлайн-оптимизации RL. Этот метод значительно повысил способность LLM к рассуждениям и обобщению в открытых задачах, и даже позволил 8B-модели превзойти GPT-4o в чате и творческом письме. (Источник: arXiv)

Модель распознавания исторических текстов CHURRO: CHURRO — это открытая визуально-языковая модель (VLM) с 3B параметрами, специально разработанная для высокоточного и недорогого распознавания исторических текстов. Модель обучена на наборе данных CHURRO-DS, содержащем 99 491 страницу исторических документов из 22 веков на 46 языках. Ее производительность превосходит существующие VLM, такие как Gemini 2.5 Pro, значительно повышая эффективность исследований и сохранения культурного наследия. (Источник: HuggingFace Daily Papers)
🎯 Тенденции
Altman предсказывает супер-интеллект ИИ и функцию Pulse: Sam Altman предсказывает, что ИИ полностью превзойдет человеческий интеллект к 2030 году, и отмечает поразительную скорость развития ИИ. OpenAI запустила функцию «активного режима» ChatGPT — Pulse, что знаменует переход ИИ от пассивного реагирования к активному мышлению за пользователя. Она способна активно предоставлять соответствующую информацию на основе случайных разговоров пользователя, реализуя крайне персонализированные услуги, предвещая, что ИИ станет аутсорсингом человеческого подсознания. (Источник: 36氪, )
Huang Renxun опровергает теорию «пузыря ИИ» и стратегию NVIDIA: Huang Renxun в интервью опроверг теорию «империи пузыря ИИ», подчеркнув ключевую роль ИИ в экономике и предсказав, что NVIDIA может стать первой компанией с рыночной капитализацией в 10 триллионов долларов. Он отметил огромную потребность в вычислительной мощности, скрывающуюся за выводом ИИ, и что NVIDIA, благодаря экстремальному совместному проектированию, ежегодно выпускает новые архитектуры и открывает системную экосистему, не боясь волны самостоятельных разработок, стремясь сформировать экономическую систему ИИ и продвигать «суверенный ИИ» как новый консенсус. (Источник: 36氪, )

DeepSeek открывает исходный код V3.2-Exp и механизм DSA: DeepSeek открыла исходный код экспериментальной версии V3.2-Exp с 685B параметрами и одновременно опубликовала статью, подробно описывающую свой новый механизм разреженного внимания (DeepSeek Sparse Attention, DSA). DSA направлен на исследование и проверку оптимизации эффективности обучения и вывода в сценариях с длинным контекстом. Он значительно повышает эффективность обработки длинного контекста, сохраняя при этом качество вывода модели. (Источник: 36氪, HuggingFace)

Скоро выйдет GLM-4.6: Ожидается скорый выпуск модели GLM-4.6 от Zhipu AI. На официальном сайте Z.ai модель GLM-4.5 уже помечена как «флагманская модель предыдущего поколения», что предвещает возможное улучшение длины контекста и других аспектов в новой версии, вызывая интерес и ожидания сообщества. (Источник: Reddit r/LocalLLaMA, karminski3)
Стратегия Apple в области ИИ и внутренний чат-бот Veritas: Раскрыта информация о внутреннем чат-боте Apple с кодовым названием «Veritas», разработанном как спарринг-партнер для Siri, способный выполнять действия внутри приложений. Несмотря на это, Apple по-прежнему отказывается выпускать потребительский чат-бот, сосредоточившись на системной интеграции ИИ и планируя углубить интеграцию сторонних моделей через движок ответов ИИ и универсальный интерфейс MCP, а не разрабатывать собственный чат-бот. (Источник: 36氪)

Рост рынка AI PC и технологические узкие места: Ожидается сильный рост поставок AI PC в 2025-2026 годах, но в основном это будет обусловлено прекращением поддержки Windows 10 и циклом обновления ПК, а не прорывом в технологии ИИ. Текущие функции ИИ в основном дополняют традиционные ПК, сталкиваясь с такими проблемами, как недостаточная локальная вычислительная мощность, пассивное взаимодействие и закрытая экосистема. Настоящие устройства ИИ должны реализовать принцип «локальная вычислительная мощность как основная, облачная как вспомогательная» и активное восприятие. (Источник: 36氪)

ИИ наводняет рынок торговли электроэнергией: ИИ широко применяется на рынке торговли электроэнергией. Такие компании, как Qingpeng Smart, используют большие временные модели для прогнозирования выработки ветровой и солнечной энергии, а также спроса на электроэнергию, помогая принимать торговые решения. Преимущество ИИ в обработке огромных объемов данных может увеличить прибыль, но также может привести к убыткам из-за незрелости моделей и сложности рынка. Отрасль все еще находится на стадии исследования. (Источник: 36氪)
Обновление большой модели Alibaba Tongyi и полнофункциональные услуги ИИ: Alibaba Cloud на конференции Cloud Summit значительно обновила свою полнофункциональную систему ИИ, выпустив 6 новых моделей, включая Qwen3-MAX и Qwen3-Omni, позиционируя себя как «поставщика полнофункциональных услуг искусственного интеллекта». Alibaba Cloud стремится создать «Android эпохи ИИ» и «компьютер следующего поколения», предоставляя полнофункциональные облачные услуги ИИ от базовых моделей до инфраструктуры, чтобы справиться с эволюцией AI Agent от «интеллектуального возникновения» до «автономных действий». (Источник: 36氪)

Глубокий анализ архитектуры NVIDIA Blackwell: Мероприятие по глубокому анализу архитектуры NVIDIA Blackwell, на котором будут обсуждаться ее архитектура, оптимизация и реализация в облаке GPU. Мероприятие, проводимое экспертами SemiAnalysis и NVIDIA, направлено на раскрытие того, как GPU Blackwell, как «GPU следующего десятилетия», будет способствовать развитию вычислительной мощности ИИ и будущему облака GPU. (Источник: TheTuringPost)

🧰 Инструменты
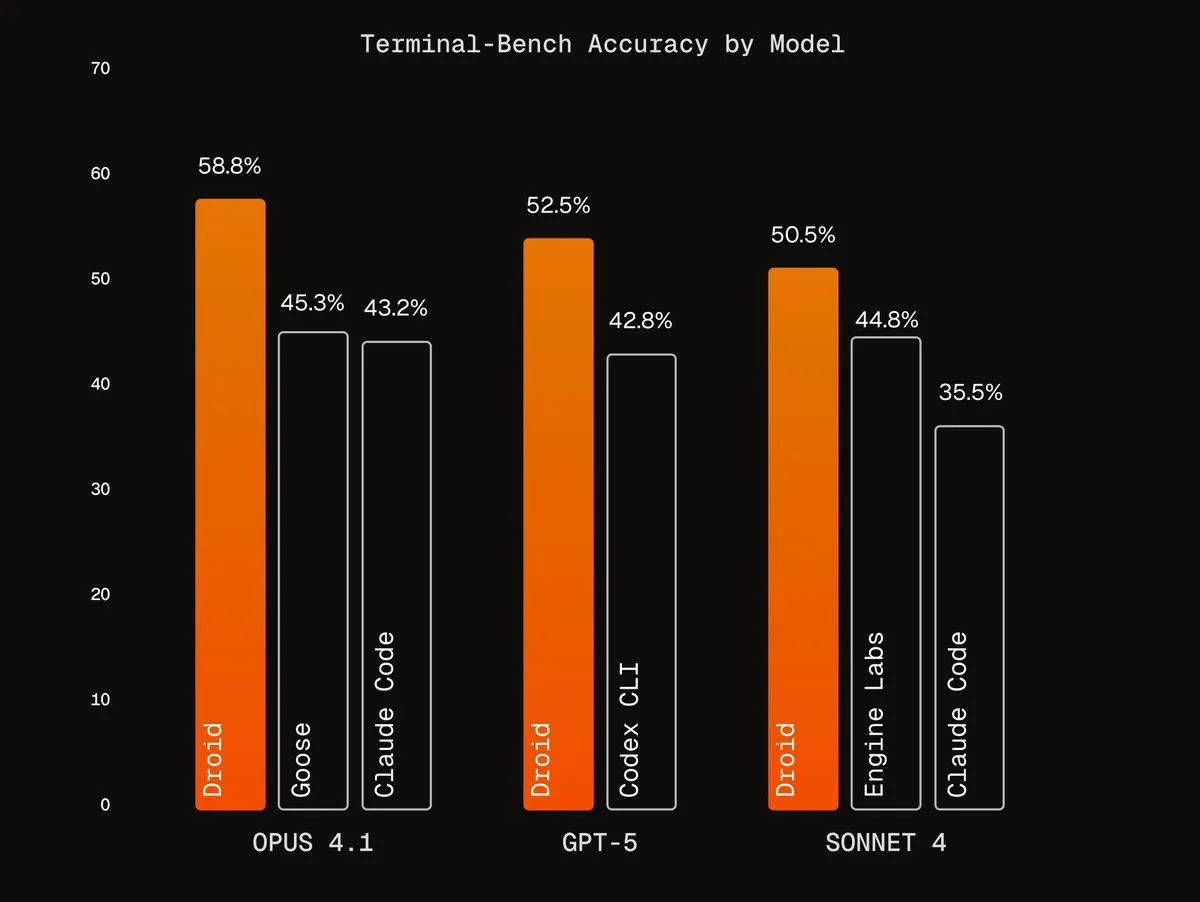
Agentic Harnesses от Factory AI: Factory AI разработала Agentic Harnesses мирового класса, значительно повышающие производительность существующих моделей, особенно в задачах кодирования, и названные пользователями «читерским кодом». Их агенты Droids занимают первое место в Terminal-Bench и обеспечивают надежный рефакторинг кода через рабочий процесс многоагентной верификации. (Источник: Vtrivedy10, matanSF, matanSF)
RAGLight — открытая библиотека RAG: LangChainAI выпустила RAGLight, легковесную библиотеку Python для создания производственных RAG-систем. Библиотека включает агентные конвейеры на основе LangGraph, поддержку LLM от нескольких провайдеров, встроенную интеграцию с GitHub и инструменты CLI, предназначенные для упрощения разработки и развертывания RAG-систем. (Источник: LangChainAI, hwchase17)
Семантическая операционная система ArgosOS: ArgosOS — это настольное приложение, которое обеспечивает интеллектуальный поиск документов и консолидацию контента на основе архитектуры, основанной на тегах, а не на векторных базах данных. Оно использует LLM для создания соответствующих тегов и хранения их в базе данных SQLite, тем самым интеллектуально обрабатывая запросы, например, анализируя чеки покупок, предоставляя точное и эффективное решение для управления документами для небольших приложений. (Источник: Reddit r/MachineLearning)
Инструмент веб-поиска Ollama: Ollama теперь поддерживает инструмент веб-поиска, позволяя пользователям интегрировать функцию веб-поиска в рабочие нагрузки Minions, тем самым обогащая контекстную информацию приложений ИИ и повышая их способность обрабатывать сложные задачи. (Источник: ollama)
Локальный мультимодальный RAG Hyperlink: Hyperlink предоставляет локальные мультимодальные функции RAG, позволяя пользователям искать и суммировать библиотеки скриншотов/фотографий в автономном режиме. Используя технологии OCR и встраивания, этот инструмент может преобразовывать неструктурированные данные изображений в доступный для запросов контент, реализуя полностью частное, локальное управление документами и извлечение информации. (Источник: Reddit r/LocalLLaMA)

Коннектор Azure PostgreSQL LangChain: Microsoft представила нативный коннектор Azure PostgreSQL, унифицирующий постоянство агентов для экосистемы LangChain. Этот коннектор предоставляет векторное хранилище корпоративного уровня и управление состоянием, упрощая сложность создания и развертывания агентов ИИ в среде Azure. (Источник: LangChainAI)
Стандартизация LLM API и протокол MCP: Сообщество обсуждает проблему фрагментации LLM API, указывая на несовместимость структур сообщений, шаблонов вызова инструментов и имен полей вывода у разных провайдеров, призывая к стандартизации протокола JSON API в отрасли. В то же время, внедрение протокола MCP (Model-Client Protocol) также вызвало дискуссии о его влиянии на развитие агентов. (Источник: AAAzzam, charles_irl)
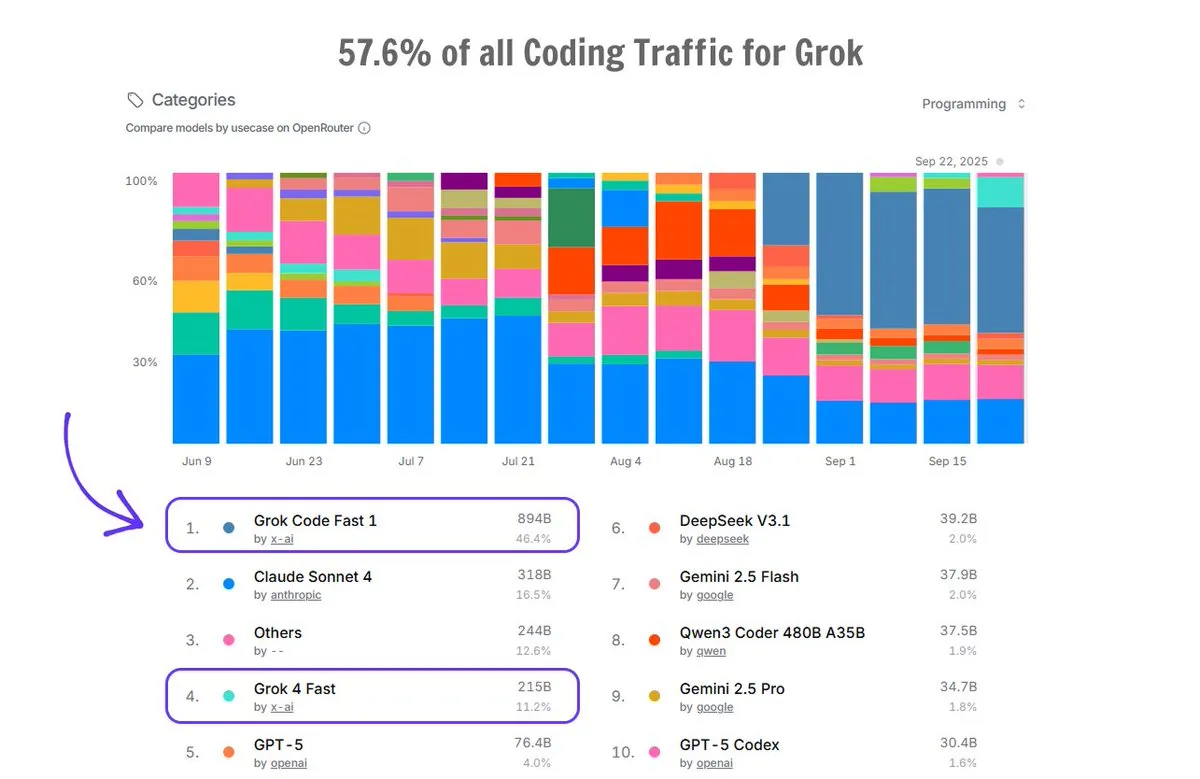
Применение Grok Code на OpenRouter: Grok Code занимает 57,6% трафика кодирования на платформе OpenRouter, превосходя сумму всех других генераторов кода ИИ, при этом Grok Code Fast 1 занимает первое место, что демонстрирует его сильные рыночные показатели и предпочтение пользователей в области генерации кода. (Источник: imjaredz)
📚 Обучение
Базовый курс по ИИ Cursor Learn: Lee Robinson запустил Cursor Learn, бесплатную серию видеоуроков из шести частей, призванную помочь новичкам освоить базовые концепции ИИ, такие как tokens, context и agents. Курс длится около 1 часа, предлагает тесты и пробное использование моделей ИИ, являясь удобным ресурсом для изучения основ ИИ. (Источник: crystalsssup)
Бесплатная книга по структурам данных Python: Donald R. Sheehy опубликовал бесплатную книгу под названием «A First Course on Data Structures in Python», охватывающую структуры данных, алгоритмическое мышление, анализ сложности, рекурсию/динамическое программирование и методы поиска, предоставляя прочную основу для изучающих ИИ и машинное обучение. (Источник: TheTuringPost)

dots.ocr — многоязычная модель OCR: Hi Lab от Xiaohongshu выпустила dots.ocr, мощную многоязычную модель OCR, поддерживающую 100 языков, способную сквозным образом анализировать текст, таблицы, формулы и макеты (вывод в Markdown), и доступную для бесплатного коммерческого использования. Модель компактна (1.7B VLM), но достигает производительности SOTA на OmniDocBench и dots.ocr-bench. (Источник: mervenoyann)

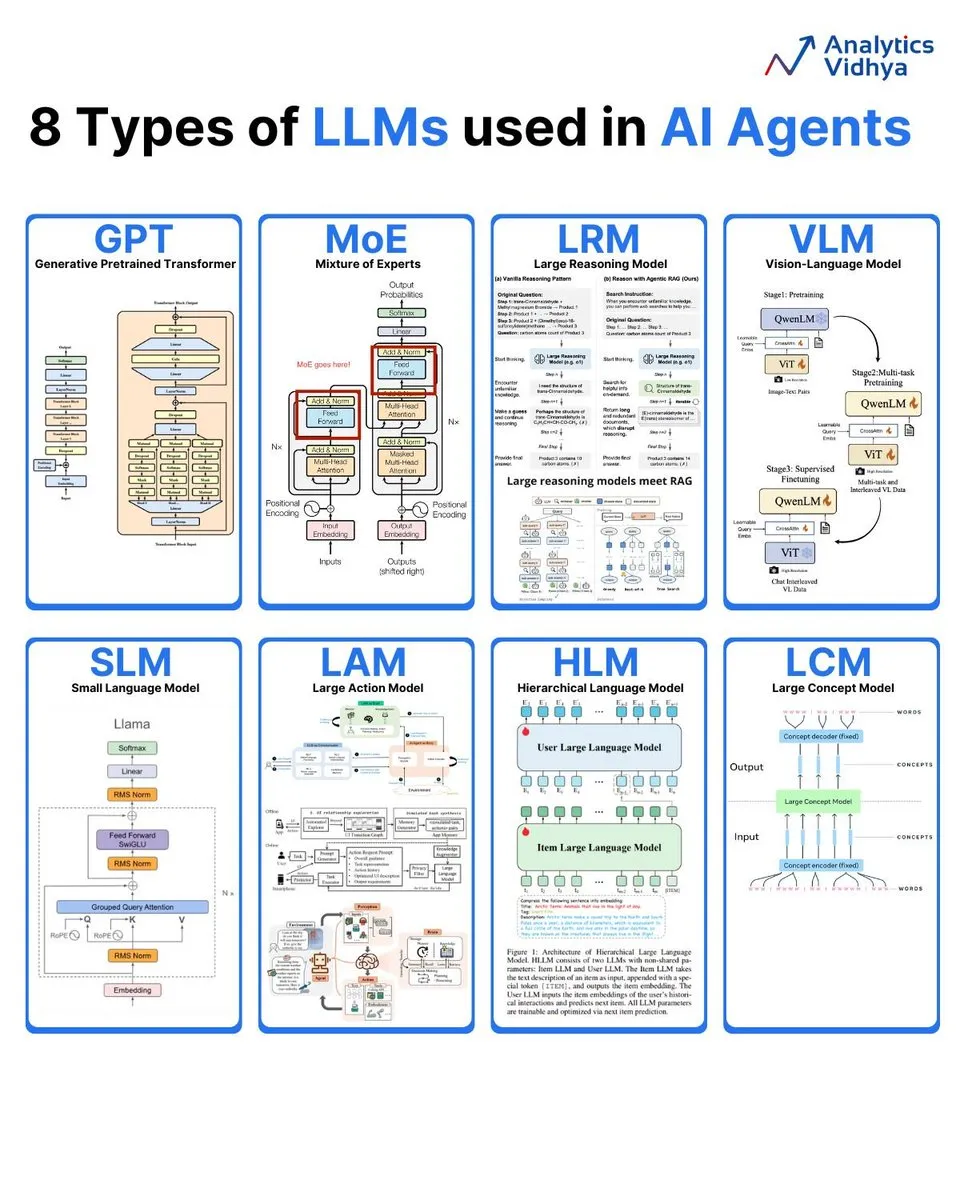
Анализ 8 типов больших языковых моделей: Analytics Vidhya суммировала 8 основных типов больших языковых моделей, включая GPT (Generative Pre-trained Transformer), MoE (Mixture of Experts), LRM (Large Reasoning Model), VLM (Vision-Language Model), SLM (Small Language Model), LAM (Large Action Model), HLM (Hierarchical Language Model) и LCM (Large Concept Model), подробно объясняя их архитектуру и применение. (Источник: karminski3)
Еженедельный отчет по ИИ: обзор последних статей: DAIR.AI опубликовал подборку лучших статей по ИИ за эту неделю (22-28 сентября), охватывающую такие передовые исследования, как ATOKEN, LLM-JEPA, Code World Model, Teaching LLMs to Plan, Agents Research Environments, Language Models that Think, Chat Better, Embodied AI: From LLMs to World Models, предоставляя исследователям ИИ последние новости. (Источник: dair_ai)
Советы молодым исследователям в эпоху ИИ: Jascha Sohl-Dickstein поделился практическими советами для молодых исследователей о том, как выбирать исследовательские проекты и принимать карьерные решения в заключительной фазе «антропоцена». Он обсудил глубокое влияние AGI на академическую карьеру и подчеркнул необходимость переосмысления направлений исследований и профессионального развития в условиях, когда системы ИИ превзойдут человеческий интеллект. (Источник: mlpowered)
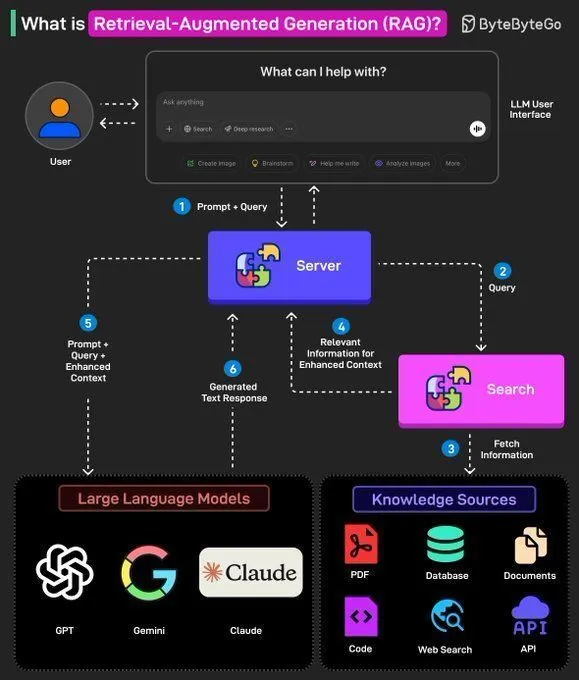
Концепция RAG и создание AI Agent: Ronald van Loon поделился базовыми концепциями RAG (Retrieval-Augmented Generation) и их важностью в LLM, а также предоставил 8 ключевых шагов для создания AI Agent. Содержание охватывает концепции AI Agent, стек, преимущества и способы оценки с помощью фреймворков, предоставляя разработчикам ИИ руководство от теории к практике. (Источник: Ronald_vanLoon, Ronald_vanLoon)
Meta решает проблему неэффективности вывода LLM: Исследование Meta выявило проблему неэффективности вывода LLM, вызванную повторяющейся работой в длинных цепочках рассуждений. Они предложили сжимать повторяющиеся шаги в небольшие именованные действия, позволяя модели вызывать эти действия вместо повторного вывода, тем самым сокращая потребление токенов и повышая эффективность и точность вывода, предлагая новый подход к оптимизации процесса вывода LLM. (Источник: ylecun)

Проявление способностей визуального рассуждения Veo-3: Lisan al Gaib отметил, что видеомодель Veo-3 демонстрирует возникающие (визуальные) способности рассуждения, аналогичные GPT-3, предвещая, что нативные мультимодальные модели, после полного раскрытия своего потенциала, принесут более полное визуальное понимание и преимущества рассуждений. (Источник: scaling01)

💼 Бизнес
Ставка OpenAI в сотни миллиардов и «пузырь» инфраструктуры ИИ: OpenAI с огромной скоростью строит гигантскую сеть, охватывающую чипы, облачные вычисления и центры обработки данных, включая инвестиции NVIDIA в 100 миллиардов долларов и партнерство с Oracle на 300 миллиардов долларов по проекту «StarGate». Хотя прогнозируемый доход на 2025 год составляет всего 13 миллиардов долларов, руководство OpenAI считает инвестиции в инфраструктуру ИИ «возможностью, которая выпадает раз в столетие», что вызывает споры о том, не столкнется ли инфраструктура ИИ с «пузырем» наподобие интернет-пузыря. (Источник: 36氪)

Маск в шестой раз подает в суд на OpenAI: Компания xAI, принадлежащая Маску, в шестой раз подала в суд на OpenAI, обвиняя ее в систематическом переманивании сотрудников, незаконном хищении исходного кода большой модели Grok и стратегических планов центров обработки данных, а также других коммерческих секретов. Этот иск знаменует собой обострение конкуренции между двумя гигантами ИИ. Маск считает, что OpenAI отошла от своих некоммерческих принципов, в то время как OpenAI отрицает обвинения, называя их «постоянным преследованием». (Источник: 36氪)

Ведущий ученый в области ИИ Сюй Чжухун присоединяется к Alibaba Tongyi: Всемирно известный ученый в области ИИ, член IEEE Fellow Сюй Чжухун (Steven Hoi) присоединился к лаборатории Alibaba Tongyi, где займется фундаментальными передовыми исследованиями мультимодальных больших моделей. Сюй Чжухун имеет более чем 20-летний опыт в области исследований, разработок и коммерциализации ИИ, ранее занимал должность вице-президента Salesforce и основал HyperAGI. Его присоединение знаменует собой новые крупные инвестиции Alibaba в область мультимодальных больших моделей для ускорения итерации моделей и прорывов в мультимодальных инновациях. (Источник: 36氪)

🌟 Сообщество
Снижение производительности ChatGPT 4o и настроения пользователей: Множество пользователей ChatGPT сообщают о снижении производительности модели 4o, появлении проблем с «уменьшением» и «безопасной маршрутизацией», что вызывает у пользователей разочарование и ощущение обмана. Многие нейроотличные пользователи особенно опечалены, считая, что 4o был для них «спасательным кругом» в общении и самопонимании. Пользователи повсеместно ставят под сомнение отсутствие прозрачности со стороны OpenAI и призывают ее выполнить обещание «относиться к пользователям как к взрослым», выступая против неясных механизмов цензуры. (Источник: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

Споры о занятости и увольнениях в эпоху ИИ: Сообщество активно обсуждает влияние ИИ на рынок труда, включая значительное сокращение числа начальных должностей, параллельные увольнения и инвестиции компаний в ИИ, а также достоверность причин увольнений, связанных с ИИ. В обсуждениях отмечается тенденция «люди, знающие ИИ, заменяют людей, не знающих ИИ» и содержится призыв к компаниям перепроектировать начальные должности, а не просто сокращать их, чтобы воспитывать редких специалистов, соответствующих требованиям эпохи ИИ. (Источник: 36氪, 36氪, Reddit r/artificial)

Вызовы и пороги исследований LLM: Сообщество активно обсуждает постоянно растущий порог для исследований в области машинного обучения, отмечая, что индивидуальным исследователям трудно конкурировать с крупными технологическими гигантами. Столкнувшись с огромным количеством статей, дорогими вычислительными мощностями и сложными математическими теориями, многие чувствуют трудности с началом работы и достижением прорывов, что вызывает опасения относительно устойчивости этой области. (Источник: Reddit r/MachineLearning)
Влияние моделей MoE на локальное размещение: Сообщество глубоко обсуждает преимущества и недостатки моделей MoE для локального размещения LLM. Мнения сходятся в том, что модели MoE, хотя и занимают больше VRAM, обладают высокой вычислительной эффективностью и могут работать с более крупными моделями за счет выгрузки на CPU, что особенно подходит для потребительского оборудования с достаточным объемом памяти, но ограниченным GPU, являясь эффективным способом повышения производительности LLM. (Источник: Reddit r/LocalLLaMA)
Быстрое развитие и применение AI Agents: Сообщество обсуждает быстрое развитие AI Agents, чьи возможности менее чем за год значительно улучшились от «почти непригодных» до «хорошо работающих» в узких сценариях, и даже «универсальные агенты начинают быть полезными», при этом скорость прогресса превосходит ожидания. Однако есть также мнение, что текущие агенты кодирования слишком однородны и не имеют существенных различий. (Источник: nptacek, HamelHusain)
Тенденции исследований RL и споры вокруг GRPO: Сообщество глубоко обсуждает последние тенденции в исследованиях обучения с подкреплением (RL), особенно статус и споры вокруг алгоритма GRPO. Есть мнение, что исследования RL смещаются в сторону предварительного обучения/моделирования, и GRPO является важным открытым достижением, но сотрудники OpenAI считают, что он значительно отстает от передовых технологий, что вызывает жаркие дискуссии об инновациях в алгоритмах и фактической производительности. (Источник: natolambert, MillionInt, cloneofsimo, jsuarez5341, TheTuringPost)

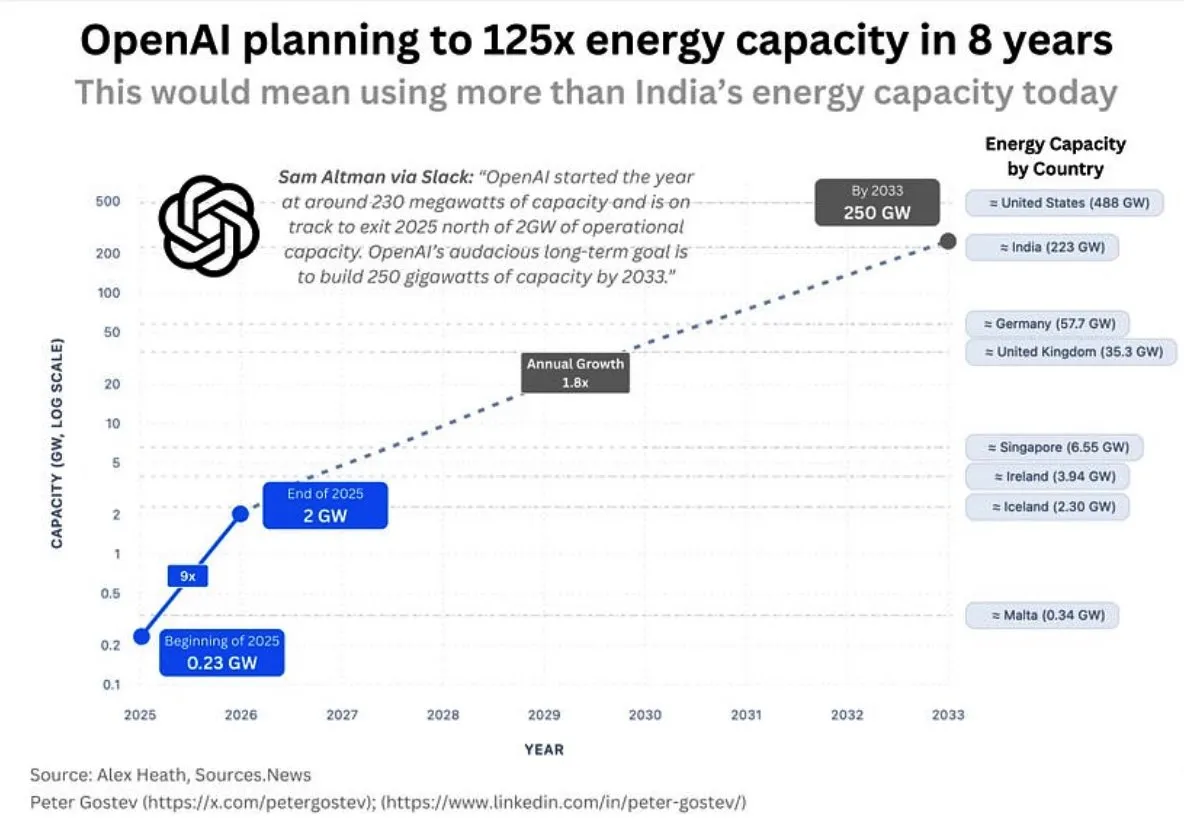
Энергопотребление OpenAI и инфраструктура ИИ: Сообщество обсуждает огромные будущие потребности OpenAI в энергии, прогнозируя, что в течение пяти лет она будет потреблять больше энергии, чем Великобритания или Германия, а в течение восьми лет — больше, чем Индия, что вызывает опасения по поводу масштабов строительства инфраструктуры ИИ, энергоснабжения и воздействия на окружающую среду. В то же время выбор места для центров обработки данных Google также встретил сопротивление местных жителей из-за проблем с потреблением воды. (Источник: teortaxesTex, brickroad7)
«Горький урок» Саттона и развитие ИИ: Сообщество обсуждает «Горький урок» Richard Sutton и его значение для исследований ИИ, подчеркивая превосходство общих вычислительных методов над человеческими априорными знаниями. Дискуссия разворачивается вокруг отношений между «имитацией и моделями мира», утверждая, что простая имитация может привести к «культу карго», а имитация без реального опыта имеет фундаментальные ограничения. (Источник: rao2z, jonst0kes)
💡 Прочее
Бионический робот BionicWheelBot: Робот BionicWheelBot, имитируя перекатывающиеся движения паука-колеса, реализовал многофункциональную навигацию по сложной местности. Это нововведение демонстрирует потенциал применения бионики в робототехнике, предлагая новые решения для будущих роботов, способных справляться с меняющимися условиями окружающей среды. (Источник: Ronald_vanLoon)
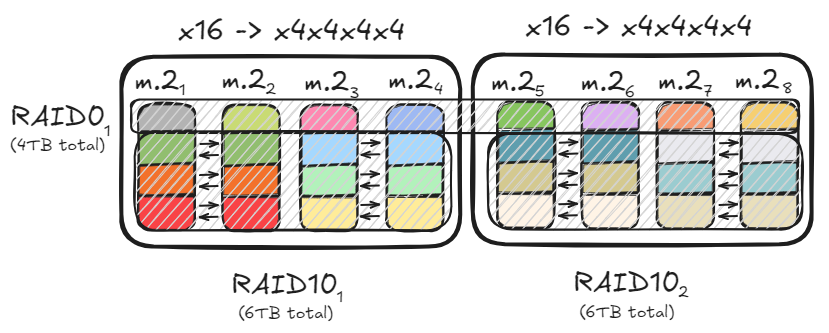
Оптимизация хранилища ПК и конфигурация RAID: Пользователь поделился, как с помощью конфигураций RAID0 и RAID10, используя несколько каналов PCIe и диски M.2, достичь пропускной способности данных до 47 ГБ/с для ускорения загрузки больших моделей. Это решение по оптимизации, удовлетворяя потребности в высокоскоростном чтении/записи, также учитывает объем хранилища и избыточность данных, обеспечивая эффективную аппаратную основу для локального развертывания моделей ИИ. (Источник: TheZachMueller)
Открытие индустриального сообщества Liangzhu «Shuxiwan AI+»: В Ханчжоу официально открылось индустриальное сообщество Liangzhu «Shuxiwan AI+», ориентированное на передовые области, такие как искусственный интеллект, цифровая экономика кочевников и культурные и творческие индустрии. Это сообщество, благодаря специальной политике «Восемь пунктов Shuxi» и пространственной планировке «Четырех полей», предоставляет исследователям ИИ полную поддержку на всех этапах, от зарождения идеи до лидерства в экосистеме, стремясь создать инновационную экосистему, глубоко интегрирующую технологии и гуманитарные науки. (Источник: 36氪)
