
Ключевые слова:Gemini 2.5 Pro, Veo 3, OpenAI, Claude 4 Opus, Генерация видео с помощью ИИ, Джони Айв, ИИ-агенты, Мультимодальные модели, Режим Deep Think, Модели генерации видео, Способности ИИ к рассуждению, Проектирование аппаратного обеспечения ИИ, Оптимизация программной инженерии
🔥 В фокусе
Google представила Gemini 2.5 Pro Deep Think и Veo 3, поднимая ИИ-рассуждения и генерацию видео на новую высоту: На конференции Google I/O компания Google представила режим Deep Think для Gemini 2.5 Pro, специально разработанный для решения сложных задач. Он показал отличные результаты в решении сложных задач математических олимпиад, таких как USAMO, продемонстрировав значительный прогресс ИИ в области продвинутых рассуждений, например, путем многошаговых рассуждений и опробования различных методов доказательства (таких как доказательство от противного, теорема Ролля) для решения сложных алгебраических задач. В то же время, представленная Google модель генерации видео Veo 3, благодаря своим реалистичным сценам, контролируемой согласованности персонажей, синтезу звука и разнообразным функциям редактирования (таким как смена сцен, генерация на основе референсных изображений, перенос стиля, указание начального и конечного кадров, локальное редактирование и т.д.), установила новый стандарт в области генерации видео с помощью ИИ и привлекла широкое внимание (Источник: demishassabis, lmthang, GoogleDeepMind, _philschmid, fabianstelzer, matvelloso, seo_leaders, op7418, )
OpenAI инвестировала 6,5 миллиарда долларов в приобретение компании Jony Ive для совместного создания компьютера нового поколения на базе ИИ: OpenAI объявила о сотрудничестве с бывшим главным дизайнером Apple Jony Ive и приобретении его компании с целью совместной разработки компьютера нового поколения на базе ИИ. Этот шаг знаменует расширение OpenAI в область аппаратного обеспечения и попытку глубокой интеграции возможностей ИИ в вычислительные устройства, что может изменить способы взаимодействия человека с компьютером. Jony Ive известен своим выдающимся дизайном во время работы в Apple, и его участие предвещает возможный значительный прорыв в дизайне и пользовательском опыте новых устройств, бросая вызов существующим формам вычислительных устройств (Источник: op7418, TheRundownAI, BorisMPower)
Конференция разработчиков Anthropic не за горами, возможно, будет представлен Claude 4 Opus, с акцентом на возможности в области программной инженерии: Anthropic скоро проведет свою первую конференцию разработчиков, и сообщество в целом предполагает, что на ней может быть представлена модель нового поколения Claude 4 (включая Sonnet 4 и Opus 4). Есть признаки того, что API Claude Sonnet 3.7 уже демонстрирует поведение, схожее с Claude 4, например, быстрое использование инструментов без необходимости «шагов обдумывания». Похоже, Anthropic концентрирует усилия на решении сложных задач программной инженерии, что отличается от пути OpenAI и Google, стремящихся к созданию «универсальной модели». Журнал TIME также косвенно подтвердил выпуск Claude 4 Opus, что еще больше повысило ожидания рынка в отношении возможностей Anthropic в области кодирования с помощью ИИ и обработки сложных задач (Источник: op7418, mathemagic1an, cto_junior, scaling01, Reddit r/ClaudeAI)
Различия в стратегиях экосистем ИИ OpenAI и Google: сборка линкора против преобразования империи: OpenAI и Google соответственно идут двумя различными путями — «сборки экосистемы» и «преобразования экосистемы» — в борьбе за статус «главной операционной системы» будущей платформы ИИ. OpenAI собирает с нуля полнофункциональные возможности ИИ путем приобретения аппаратного обеспечения (io), баз данных (Rockset), инструментальных цепочек (Windsurf) и инструментов для совместной работы (Multi). В то время как Google выбирает глубокую интеграцию своей модели Gemini в существующие продукты (Поиск, Android, Docs, YouTube и т.д.) и преобразование базовых систем для достижения нативности ИИ. Хотя стратегии обеих компаний различаются, их цель едина — создание конечной платформы эпохи ИИ (Источник: dotey)
🎯 Тенденции
Microsoft раскрыла концепцию «сети интеллектуальных агентов», подчеркнув, что ИИ-агенты станут ядром работы следующего поколения: Генеральный директор Microsoft Satya Nadella на конференции Build 2025 и в интервью изложил видение компанией «сети интеллектуальных агентов (agentic web)». Он считает, что в будущем ИИ-агенты станут первоклассными гражданами экосистемы бизнеса и M365, и даже могут породить новые профессии, такие как «администратор ИИ-агентов». Когда 95% кода будет генерироваться ИИ, роль человека сместится в сторону управления и оркестровки этими агентами. Microsoft создает открытую экосистему агентов с помощью Azure AI Foundry, Copilot Studio и открытых протоколов, таких как NLWeb, а также превращает Teams в центр совместной работы нескольких агентов (Источник: rowancheung, TheTuringPost)
MMaDA: Выпущена мультимодальная диффузионная языковая модель, объединяющая текстовые рассуждения, мультимодальное понимание и генерацию изображений: Исследователи представили MMaDA (Multimodal Large Diffusion Language Models), новую мультимодальную диффузионную базовую модель, которая объединяет возможности текстовых рассуждений, мультимодального понимания и генерации изображений с помощью смешанной длинной цепочки рассуждений (Mixed Long-CoT) и унифицированного алгоритма обучения с подкреплением UniGRPO. MMaDA-8B превосходит Show-o и SEED-X в мультимодальном понимании и превосходит SDXL и Janus в генерации текста в изображение. Модель и код доступны на Hugging Face (Источник: _akhaliq, arankomatsuzaki, andrew_n_carr, Reddit r/LocalLLaMA)

dKV-Cache: разработан механизм кэширования для диффузионных языковых моделей, значительно повышающий скорость вывода: Для решения проблемы медленной скорости вывода диффузионных языковых моделей (DLM) исследователи предложили механизм dKV-Cache. Этот метод, заимствованный из KV-Cache в авторегрессионных моделях, разрабатывает кэш ключ-значение для процесса шумоподавления DLM с помощью стратегий отложенного и условного кэширования. Эксперименты показывают, что dKV-Cache может обеспечить ускорение вывода в 2-10 раз, значительно сокращая разрыв в скорости между DLM и авторегрессионными моделями, и даже улучшая производительность на длинных последовательностях, при этом его можно применять к существующим DLM без обучения (Источник: NandoDF, HuggingFace Daily Papers)

Imagen4 демонстрирует превосходную детализацию, приближаясь к финальной стадии генерации изображений: Модель Imagen4 продемонстрировала мощные возможности детализации при генерации изображений по сложным текстовым подсказкам. Например, при генерации изображения, содержащего 25 конкретных деталей (таких как определенные цвета, объекты, местоположение, освещение и атмосфера), Imagen4 успешно воспроизвела 23 из них. Такая высокая точность и точное понимание сложных инструкций указывают на то, что технология генерации текста в изображение приближается к «финальной стадии», способной идеально воспроизводить воображение пользователя (Источник: cloneofsimo)

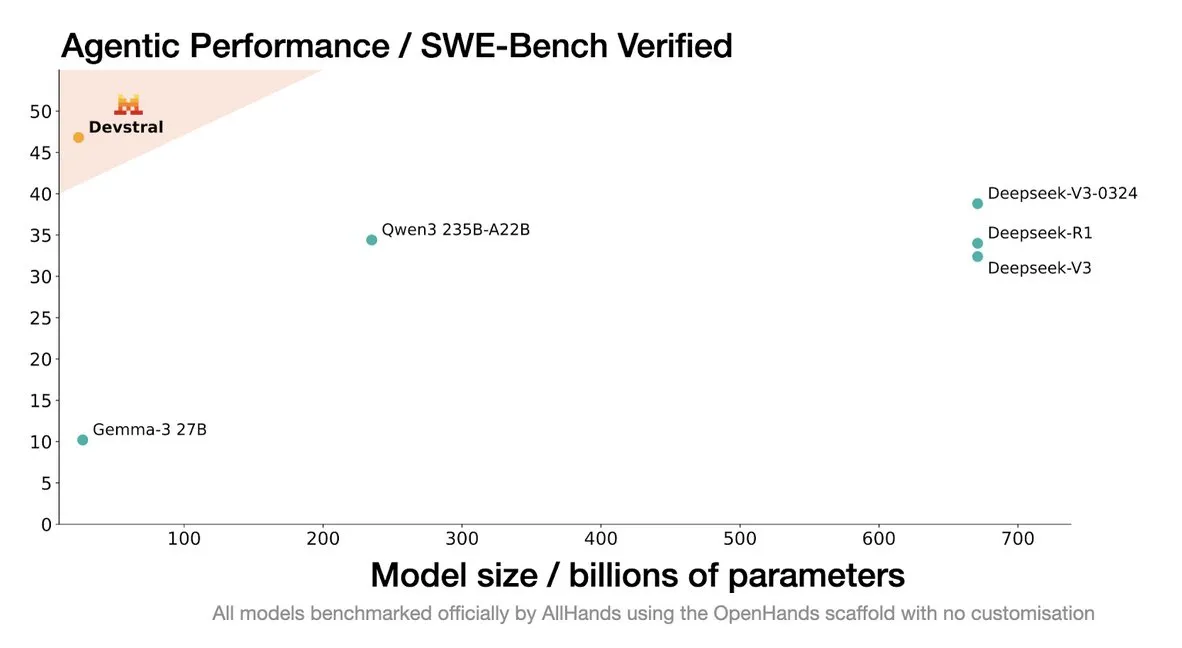
Mistral выпустила модель Devstral, специально разработанную для агентов кодирования: Mistral AI представила Devstral, модель с открытым исходным кодом, специально разработанную для агентов кодирования, в сотрудничестве с allhands_ai. Ее 4-битная квантованная версия DWQ уже доступна на Hugging Face (mlx-community/Devstral-Small-2505-4bit-DWQ) и может плавно работать на устройствах, таких как M2 Ultra, демонстрируя потенциал оптимизации в генерации и понимании кода (Источник: awnihannun, clefourrier, GuillaumeLample)
ByteDance опубликовала отчет об обучении мультимодальной модели уровня Gemini, использующей архитектуру Integrated Transformer: ByteDance опубликовала 37-страничный отчет, подробно описывающий метод обучения нативной мультимодальной модели, подобной Gemini. Наибольшее внимание привлекает архитектура «Integrated Transformer», которая использует одну и ту же базовую сеть одновременно как авторегрессионную модель типа GPT и как диффузионную модель типа DiT, демонстрируя исследования компании в области унифицированного мультимодального моделирования (Источник: NandoDF)

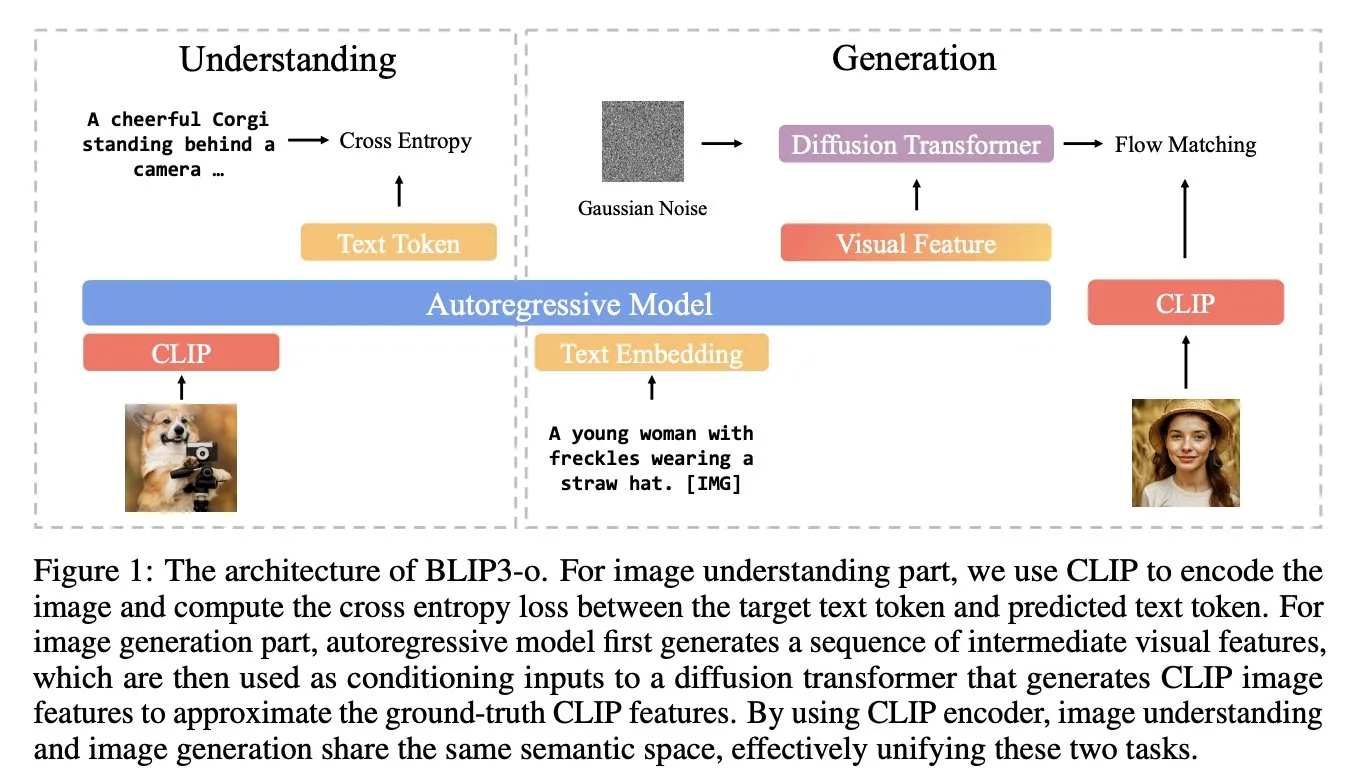
BLIP3-o: Salesforce представляет полностью открытую серию унифицированных мультимодальных моделей, открывая возможности генерации изображений уровня GPT-4o: Исследовательская группа Salesforce выпустила серию моделей BLIP3-o, представляющую собой группу полностью открытых унифицированных мультимодальных моделей, нацеленных на раскрытие возможностей генерации изображений, аналогичных GPT-4o. Проект не только открыл исходный код моделей, но и опубликовал предварительно обученный набор данных, содержащий 25 миллионов записей, способствуя открытости мультимодальных исследований (Источник: arankomatsuzaki)
Google выпускает предварительную версию Gemma 3n E4B, мультимодальную модель, разработанную для устройств с низкими ресурсами: Google выпустила на Hugging Face модель Gemma 3n E4B-it-litert-preview. Эта модель предназначена для обработки текстовых, изобразительных, видео- и аудиовходов и генерации текстового вывода; текущая версия поддерживает текстовые и визуальные входы. Gemma 3n использует новую архитектуру Matformer, позволяющую вкладывать несколько моделей и эффективно активировать параметры 2B или 4B, специально оптимизированную для эффективной работы на устройствах с низкими ресурсами. Модель обучена примерно на 11 триллионах токенов мультимодальных данных, знания актуальны на июнь 2024 года (Источник: Tim_Dettmers, Reddit r/LocalLLaMA)
Исследование выявило феномен языко-специфических знаний (LSK) в больших моделях: Новое исследование изучает феномен «языко-специфических знаний» (Language Specific Knowledge, LSK) в языковых моделях, то есть явление, когда модель при обработке определенных тем или областей может показывать лучшие результаты на конкретном неанглийском языке, чем на английском. Исследование показало, что производительность модели можно улучшить, используя цепочку рассуждений на определенном языке (даже на языке с низкими ресурсами). Это указывает на то, что культурно-специфические тексты более распространены на соответствующих языках, что делает возможным существование специфических знаний только на «экспертных» языках. Исследователи разработали метод LSKExtractor для измерения и использования этого LSK, добившись среднего относительного повышения точности на 10% на нескольких моделях и наборах данных (Источник: HuggingFace Daily Papers)
DeepMind Veo 3 демонстрирует потрясающие эффекты генерации видео, реалистичные детали привлекают внимание: Модель генерации видео Veo 3 от Google DeepMind продемонстрировала мощные возможности генерации видео, включая смену сцен, управление на основе референсных изображений, перенос стиля, согласованность персонажей, указание начального и конечного кадров, масштабирование видео, добавление объектов и управление действиями. Реалистичность генерируемых видео и понимание сложных инструкций заставили пользователей восхищаться стремительным развитием технологий генерации видео с помощью ИИ, а некоторые даже использовали ее для создания рекламных роликов, по качеству сопоставимых с профессиональными (Источник: demishassabis, , Reddit r/ChatGPT)
Визуально-языковая модель Moondream выпустила 4-битную квантованную версию, значительно снизив потребление видеопамяти и повысив скорость: Визуально-языковая модель (VLM) Moondream выпустила 4-битную квантованную версию, что позволило сократить потребление видеопамяти на 42% и повысить скорость вывода на 34%, сохранив при этом точность на уровне 99,4%. Эта оптимизация делает эту мощную небольшую VLM более простой в развертывании и использовании для таких задач, как обнаружение объектов, и была хорошо принята разработчиками (Источник: Sentdex, vikhyatk)
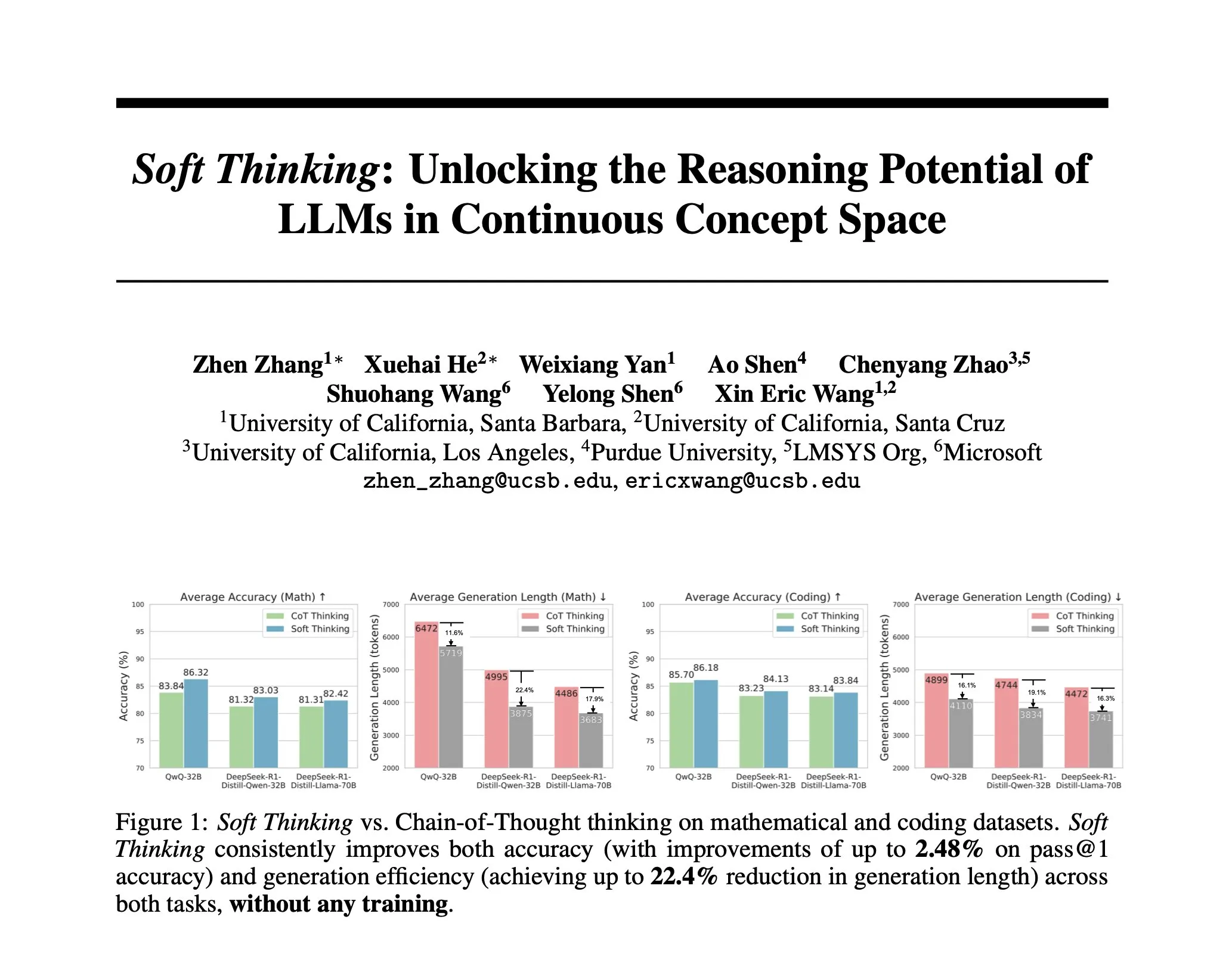
Исследование предлагает Soft Thinking: метод без обучения для имитации «мягкого» человеческого мышления: Чтобы приблизить ИИ-рассуждения к плавному человеческому мышлению, не ограниченному дискретными токенами, исследователи предложили метод Soft Thinking. Этот метод не требует дополнительного обучения и генерирует непрерывные, абстрактные концептуальные токены, которые плавно смешивают несколько значений посредством вероятностно взвешенных смесей вложений, тем самым достигая более богатых представлений и бесшовного исследования различных путей рассуждений. Эксперименты показывают, что этот метод повышает точность на математических и кодовых бенчмарках до 2,48% (pass@1), одновременно сокращая использование токенов до 22,4% (Источник: arankomatsuzaki)
Фреймворк IA-T2I: использование Интернета для улучшения способности моделей генерации текста в изображение обрабатывать неопределенные знания: Для устранения недостатков существующих моделей генерации текста в изображение при обработке текстовых подсказок, содержащих неопределенные знания (например, недавние события, редкие концепции), был предложен фреймворк IA-T2I (Internet-Augmented Text-to-Image Generation). Этот фреймворк с помощью модуля активного поиска определяет, нужно ли ссылаться на изображение, использует модуль иерархического выбора изображений для выбора наиболее подходящих изображений из результатов поисковой системы для улучшения модели T2I, а также с помощью механизма саморефлексии постоянно оценивает и оптимизирует генерируемые изображения. На специально созданном наборе данных Img-Ref-T2I IA-T2I превзошел GPT-4o примерно на 30% (по оценке людей) (Источник: HuggingFace Daily Papers)
MoI (Mixture of Inputs) улучшает качество авторегрессионной генерации и способность к рассуждению: Для решения проблемы отбрасывания информации о распределении токенов в стандартном процессе авторегрессионной генерации исследователи предложили метод Mixture of Inputs (MoI). Этот метод не требует дополнительного обучения и после генерации токена смешивает сгенерированный дискретный токен с ранее отброшенным распределением токенов для создания нового входа. С помощью байесовской оценки распределение токенов рассматривается как априорное, а сэмплированный токен — как наблюдение, при этом для нового входа модели используется непрерывное апостериорное ожидание вместо традиционного one-hot вектора. MoI последовательно улучшил производительность нескольких моделей, таких как Qwen-32B и Nemotron-Super-49B, в задачах математического рассуждения, генерации кода и вопросно-ответных системах докторского уровня (Источник: HuggingFace Daily Papers)
ConvSearch-R1: оптимизация перезаписи запросов в диалоговом поиске с помощью обучения с подкреплением: Для решения проблем неоднозначности, пропусков и анафор в контекстно-зависимых запросах в диалоговом поиске был предложен фреймворк ConvSearch-R1. Этот фреймворк впервые использует самодвижущийся подход, оптимизируя перезапись запросов непосредственно с помощью сигналов поиска через обучение с подкреплением, полностью устраняя зависимость от внешнего надзора за перезаписью (например, ручной разметки или больших моделей). Его двухэтапный метод включает предварительный прогрев самодвижущейся стратегии и обучение с подкреплением на основе поисковой выдачи (с использованием механизма поощрения на основе ранжирования). Эксперименты показывают, что ConvSearch-R1 значительно превосходит предыдущие SOTA-методы на наборах данных TopiOCQA и QReCC (Источник: HuggingFace Daily Papers)
Фреймворк ASRR реализует эффективное адаптивное рассуждение для больших языковых моделей: Для решения проблемы чрезмерных вычислительных затрат больших моделей рассуждений (LRM) на простых задачах из-за избыточных рассуждений исследователи предложили фреймворк адаптивного самовосстанавливающегося рассуждения (Adaptive Self-Recovery Reasoning, ASRR). Этот фреймворк, раскрывая «внутренний механизм самовосстановления» модели (неявное дополнение рассуждений при генерации ответа), подавляет ненужные рассуждения и вводит регулирование вознаграждения за длину с учетом точности, адаптивно распределяя усилия по рассуждению в зависимости от сложности вопроса. Эксперименты показывают, что ASRR может значительно сократить бюджет на рассуждения и повысить уровень безвредности на эталонных тестах безопасности при минимальных потерях производительности (Источник: HuggingFace Daily Papers)
Фреймворк MoT (Mixture-of-Thought) улучшает способность к логическому мышлению: Вдохновленные использованием человеком нескольких модальностей рассуждений (естественный язык, код, символическая логика) для решения логических задач, исследователи предложили фреймворк Mixture-of-Thought (MoT). MoT позволяет LLM рассуждать в трех взаимодополняющих модальностях, включая недавно введенную символическую модальность таблицы истинности. Благодаря двухэтапному дизайну (обучение самоэволюционирующего MoT и рассуждение MoT), MoT значительно превосходит одномодальные методы цепочки мыслей на эталонных тестах логического мышления, таких как FOLIO и ProofWriter, со средним повышением точности до 11,7% (Источник: HuggingFace Daily Papers)
RL Tango: совместное обучение генератора и валидатора с помощью обучения с подкреплением для улучшения языкового рассуждения: Для решения проблем взлома вознаграждения и плохой генерализации, возникающих в существующих методах обучения с подкреплением для LLM из-за фиксированного или контролируемого тонкого тюнинга валидатора (модели вознаграждения), был предложен фреймворк RL Tango. Этот фреймворк попеременно обучает генератор LLM и генеративный, процессно-ориентированный валидатор LLM с помощью обучения с подкреплением. Валидатор обучается только на основе вознаграждения за правильность проверки на уровне результата, без необходимости разметки на уровне процесса, тем самым формируя эффективное взаимное усиление с генератором. Эксперименты показывают, что генератор и валидатор Tango достигают уровня SOTA на моделях масштаба 7B/8B (Источник: HuggingFace Daily Papers)
pPE: Предварительная инженерия подсказок способствует усиленному тонкому тюнингу (RFT): Исследование изучает роль предварительной инженерии подсказок (prior prompt engineering, pPE) в усиленном тонком тюнинге (RFT). В отличие от инженерии подсказок во время вывода (iPE), pPE на этапе обучения помещает инструкции (например, пошаговое рассуждение) перед запросом, чтобы направить языковую модель на усвоение определенного поведения. В ходе эксперимента пять стратегий iPE (рассуждение, планирование, кодовое рассуждение, извлечение знаний, использование пустых примеров) были преобразованы в методы pPE и применены к Qwen2.5-7B. Результаты показали, что все модели, обученные с помощью pPE, превзошли соответствующие модели iPE, причем pPE с пустыми примерами показал наибольший прирост на бенчмарках AIME2024 и GPQA-Diamond, что выявило pPE как недостаточно изученный, но эффективный метод в RFT (Источник: HuggingFace Daily Papers)
BiasLens: Фреймворк для оценки предвзятости LLM без использования тестовых наборов, созданных человеком: Для решения проблемы зависимости существующих методов оценки предвзятости LLM от размеченных вручную данных с ограниченным охватом был предложен фреймворк BiasLens. Этот фреймворк, исходя из структуры векторного пространства модели, сочетает векторы активации концепций (CAV) и разреженные автоэнкодеры (SAE) для извлечения интерпретируемых представлений концепций, количественно оценивая предвзятость путем измерения изменений в сходстве представлений между целевыми и эталонными концепциями. BiasLens демонстрирует сильную согласованность (коэффициент корреляции Спирмена r > 0,85) с традиционными показателями оценки предвзятости в отсутствие размеченных данных и способен выявлять формы предвзятости, трудно обнаруживаемые существующими методами (Источник: HuggingFace Daily Papers)
HumaniBench: Человеко-ориентированный фреймворк для оценки больших мультимодальных моделей: В связи с недостаточной производительностью текущих LMM по человеко-ориентированным стандартам, таким как справедливость, этика и эмпатия, был предложен HumaniBench. Это всеобъемлющий бенчмарк, содержащий 32 тыс. реальных пар вопросов и ответов с изображениями, аннотированный с помощью GPT-4o и проверенный экспертами. HumaniBench оценивает семь принципов человеко-ориентированного ИИ: справедливость, этику, понимание, рассуждение, языковую инклюзивность, эмпатию и устойчивость, охватывая семь разнообразных задач. Тестирование 15 LMM уровня SOTA показало, что закрытые модели в целом лидируют, но устойчивость и визуальная локализация остаются слабыми местами (Источник: HuggingFace Daily Papers)
AJailBench: первый комплексный бенчмарк для атак типа “jailbreak” на большие аудио-языковые модели: Для систематической оценки безопасности больших аудио-языковых моделей (LAM) при атаках типа “jailbreak” был предложен AJailBench. Этот бенчмарк сначала создает набор данных AJailBench-Base, содержащий 1495 состязательных аудио-подсказок, охватывающих 10 категорий нарушений. Оценка на основе этого набора данных показывает, что существующие LAM уровня SOTA не демонстрируют последовательной устойчивости. Для имитации более реалистичных атак исследователи разработали набор инструментов для аудио-возмущений (APT), который с помощью байесовской оптимизации ищет незаметные и эффективные возмущения, создав расширенный набор данных AJailBench-APT. Исследование показывает, что незначительные и семантически сохраняющие возмущения могут значительно снизить безопасность LAM (Источник: HuggingFace Daily Papers)
WebNovelBench: бенчмарк для оценки способности LLM к созданию длинных романов: Для решения проблем оценки способности LLM к созданию длинных повествований был предложен WebNovelBench. Этот бенчмарк использует набор данных из более чем 4000 китайских веб-романов и определяет оценку как задачу генерации истории по синопсису. С помощью метода LLM-как-судья проводится автоматическая оценка по восьми измерениям качества повествования, а для агрегирования оценок используется анализ главных компонент, сравнивая их с человеческими произведениями по процентильному ранжированию. Эксперимент эффективно различает человеческие шедевры, популярные веб-романы и контент, сгенерированный LLM, а также проводит комплексный анализ 24 LLM уровня SOTA (Источник: HuggingFace Daily Papers)
MultiHal: Многоязычный набор данных для оценки галлюцинаций LLM на основе графов знаний: Для восполнения пробелов существующих бенчмарков для оценки галлюцинаций в части путей в графах знаний и многоязычности был предложен MultiHal. Это многоязычный, многошаговый бенчмарк на основе графов знаний, специально разработанный для оценки генерируемого текста. Команда извлекла 140 тысяч путей из открытых графов знаний и отобрала 25,9 тысяч высококачественных путей. Базовая оценка показывает, что на многоязычных и многомодельных данных RAG с усилением графами знаний (KG-RAG) по сравнению с обычным вопросно-ответным методом демонстрирует абсолютное улучшение оценки семантического сходства примерно на 0,12-0,36 пункта, демонстрируя потенциал интеграции графов знаний (Источник: HuggingFace Daily Papers)
Llama-SMoP: Метод распознавания аудиовизуальной речи LLM на основе разреженных смешанных проекторов: Для решения проблемы высокой вычислительной стоимости LLM при распознавании аудиовизуальной речи (AVSR) был предложен Llama-SMoP. Это эффективная мультимодальная LLM, использующая модуль разреженных смешанных проекторов (SMoP), который расширяет емкость модели без увеличения затрат на вывод за счет использования разреженно управляемых проекторов типа «смесь экспертов» (MoE). Эксперименты показывают, что конфигурация Llama-SMoP DEDR с использованием модально-специфической маршрутизации и экспертов достигает превосходной производительности в задачах ASR, VSR и AVSR, а также демонстрирует хорошие результаты в активации экспертов, масштабируемости и устойчивости к шуму (Источник: HuggingFace Daily Papers)
VPRL: фреймворк для чисто визуального планирования на основе обучения с подкреплением, превосходящий по производительности текстовые рассуждения: Исследовательские группы из Кембриджского университета, Университетского колледжа Лондона и Google предложили VPRL (Visual Planning with Reinforcement Learning), новую парадигму рассуждений, основанную исключительно на последовательностях изображений. Этот фреймворк использует групповую относительную оптимизацию политики (GRPO) для дообучения больших визуальных моделей, вычисляя сигналы вознаграждения и проверяя ограничения среды через визуальные переходы состояний. В задачах визуальной навигации, таких как FrozenLake, Maze и MiniBehavior, точность VPRL достигла 80,6%, значительно превзойдя методы рассуждений на основе текста (например, 43,7% у Gemini 2.5 Pro), а также показав лучшие результаты в сложных задачах и в плане устойчивости, что доказывает превосходство визуального планирования (Источник: 量子位)

Nvidia обнародовала дорожную карту развития технологий ИИ на ближайшие пять лет, трансформируясь в компанию по созданию инфраструктуры ИИ: Генеральный директор Nvidia Jensen Huang на COMPUTEX 2025 объявил о корректировке позиционирования компании как поставщика инфраструктуры ИИ и обнародовал дорожную карту развития технологий на ближайшие пять лет. Он подчеркнул, что инфраструктура ИИ станет такой же повсеместной, как электричество или интернет, и Nvidia стремится построить «фабрики» эпохи ИИ. Для поддержки трансформации Nvidia расширит «круг друзей» в цепочке поставок, углубит сотрудничество с TSMC и другими компаниями, а также планирует создать офис на Тайване (NVIDIA Constellation) и первый гигантский суперкомпьютер ИИ (Источник: 36氪)

Google возобновляет проект ИИ-очков, выпускает платформу Android XR и устройства сторонних производителей: На конференции I/O 2025 Google объявила о возобновлении проекта ИИ/AR-очков, выпустила платформу Android XR, специально разработанную для XR-устройств, и продемонстрировала два устройства сторонних производителей на базе этой платформы: Project Moohan от Samsung (конкурент Vision Pro) и Project Aura от Xreal. Google стремится повторить успех Android в области смартфонов, создав «момент Android» для XR-устройств и заложив основу для будущих платформ эмбиентных и пространственных вычислений. В сочетании с обновленной мультимодальной большой моделью Gemini 2.5 Pro и технологией интеллектуального помощника Project Astra, новое поколение ИИ/AR-очков обеспечит революционный опыт в понимании речи, переводе в реальном времени, ситуационной осведомленности и выполнении сложных задач (Источник: 36氪)

Обновлены принципы конкурса ARC-AGI-2, акцент на многошаговом контекстном рассуждении: В недавно опубликованной статье ARC-AGI-2 обновлены принципы проектирования этого конкурса. Новые принципы требуют, чтобы решение задач включало многоправильное, многошаговое и контекстное рассуждение. Сетки стали больше, содержат больше объектов и кодируют несколько взаимодействующих концепций. Задачи являются новыми и не подлежат повторному использованию, чтобы ограничить запоминание. Такой дизайн намеренно противостоит брутфорс-синтезу программ. Люди-решатели в среднем тратят 2,7 минуты на задачу, в то время как лучшие системы (например, OpenAI o3-medium) набирают всего около 3%, и все задачи требуют явных когнитивных усилий (Источник: TheTuringPost, clefourrier)
Skywork представляет супер-агента, нацеленного на сокращение 8-часовой работы до 8 минут: Skywork выпустила своего ИИ-агента для рабочего пространства — Skywork Super Agents, заявляя, что он способен сократить 8-часовую рабочую нагрузку пользователя до 8 минут. Продукт позиционируется как пионер в области ИИ-агентов для рабочего пространства, конкретные функции и способы реализации требуют дальнейшего наблюдения (Источник: _akhaliq)
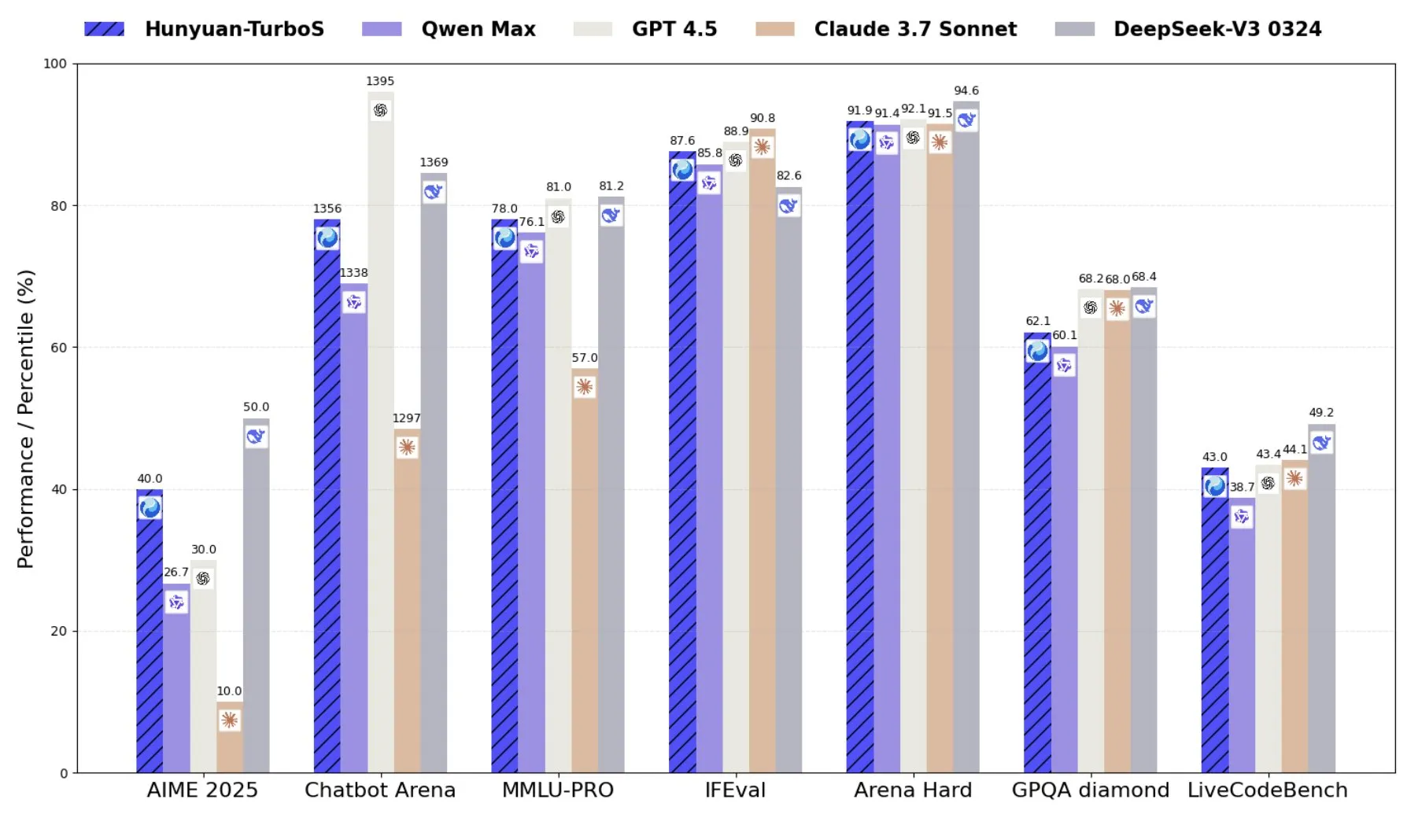
Tencent выпускает Hunyuan-TurboS, гибридную модель экспертов, сочетающую Transformer и Mamba: Tencent выпустила модель Hunyuan-TurboS, которая использует гибридную архитектуру экспертов (MoE), сочетающую Transformer и Mamba, имеет 56 миллиардов активных параметров и обучена на 16 триллионах токенов. Hunyuan-TurboS способна динамически переключаться между режимами быстрого ответа и глубокого «обдумывания» и входит в топ-7 общего рейтинга на LMSYS Chatbot Arena (Источник: tri_dao)
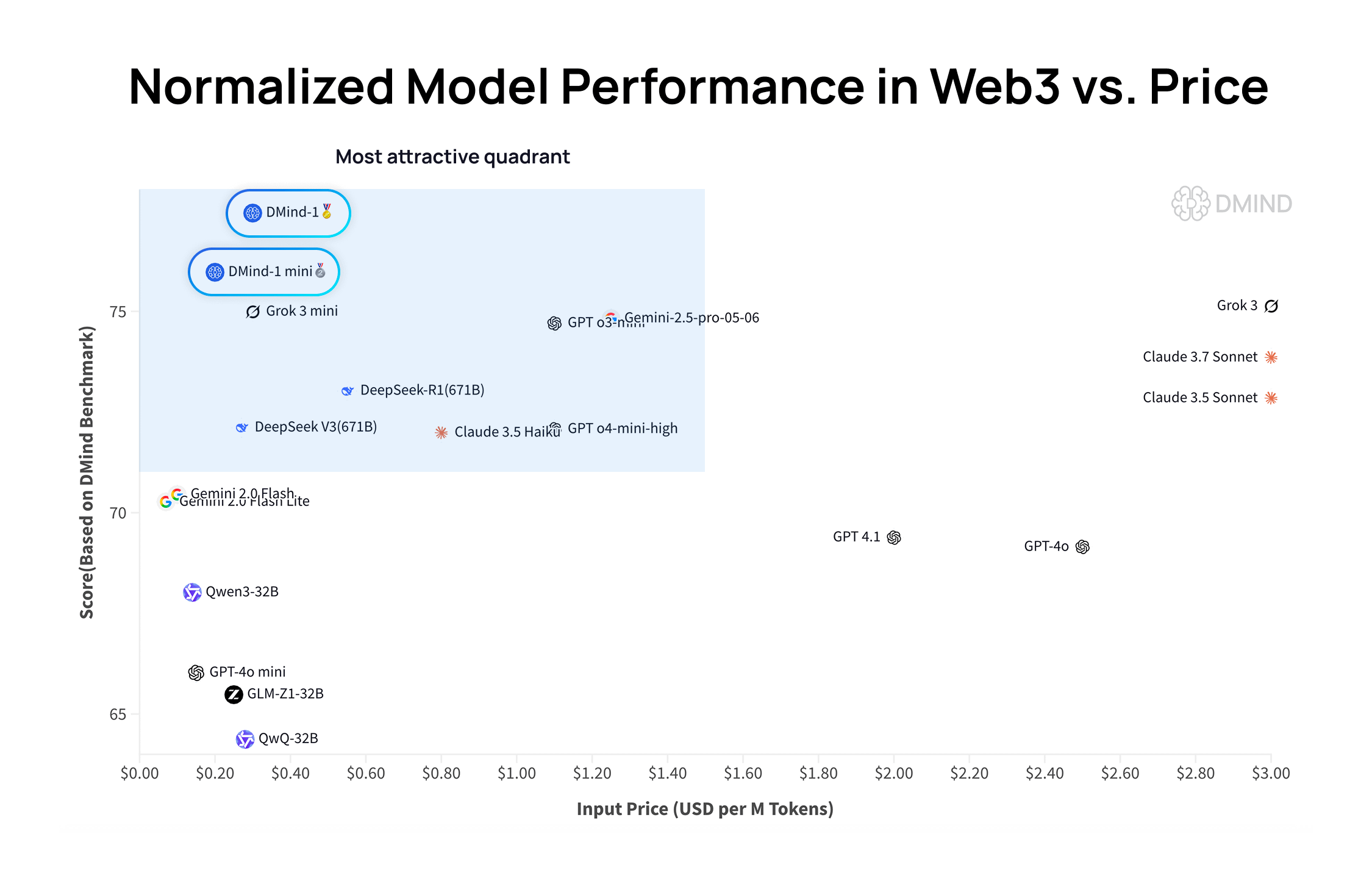
DMind-1: Открытая большая языковая модель, разработанная специально для сценариев Web3: DMind AI выпустила DMind-1, открытую большую языковую модель, оптимизированную для сценариев Web3. DMind-1 (32B) доработана на основе Qwen3-32B с использованием большого количества специфичных для Web3 знаний, с целью сбалансировать производительность и стоимость приложений AI+Web3. В бенчмарках Web3 DMind-1 превосходит основные универсальные LLM, при этом стоимость токенов составляет всего около 10% от их стоимости. Одновременно выпущенная DMind-1-mini (14B) сохраняет более 95% производительности DMind-1 и превосходит ее по задержке и вычислительной эффективности (Источник: _akhaliq)
LightOn выпускает Reason-ModernColBERT, модель с малым количеством параметров, демонстрирующую превосходные результаты в задачах поиска, требующих интенсивных рассуждений: LightOn представила Reason-ModernColBERT, модель с поздним взаимодействием, содержащую всего 149 миллионов параметров. В популярном бенчмарке BRIGHT (сфокусированном на поиске, требующем интенсивных рассуждений) эта модель показала выдающиеся результаты, превзойдя модели с в 45 раз большим количеством параметров и достигнув уровня SOTA в нескольких областях. Этот результат еще раз доказывает высокую эффективность моделей с поздним взаимодействием в конкретных задачах (Источник: lateinteraction, jeremyphoward, Dorialexander, huggingface)

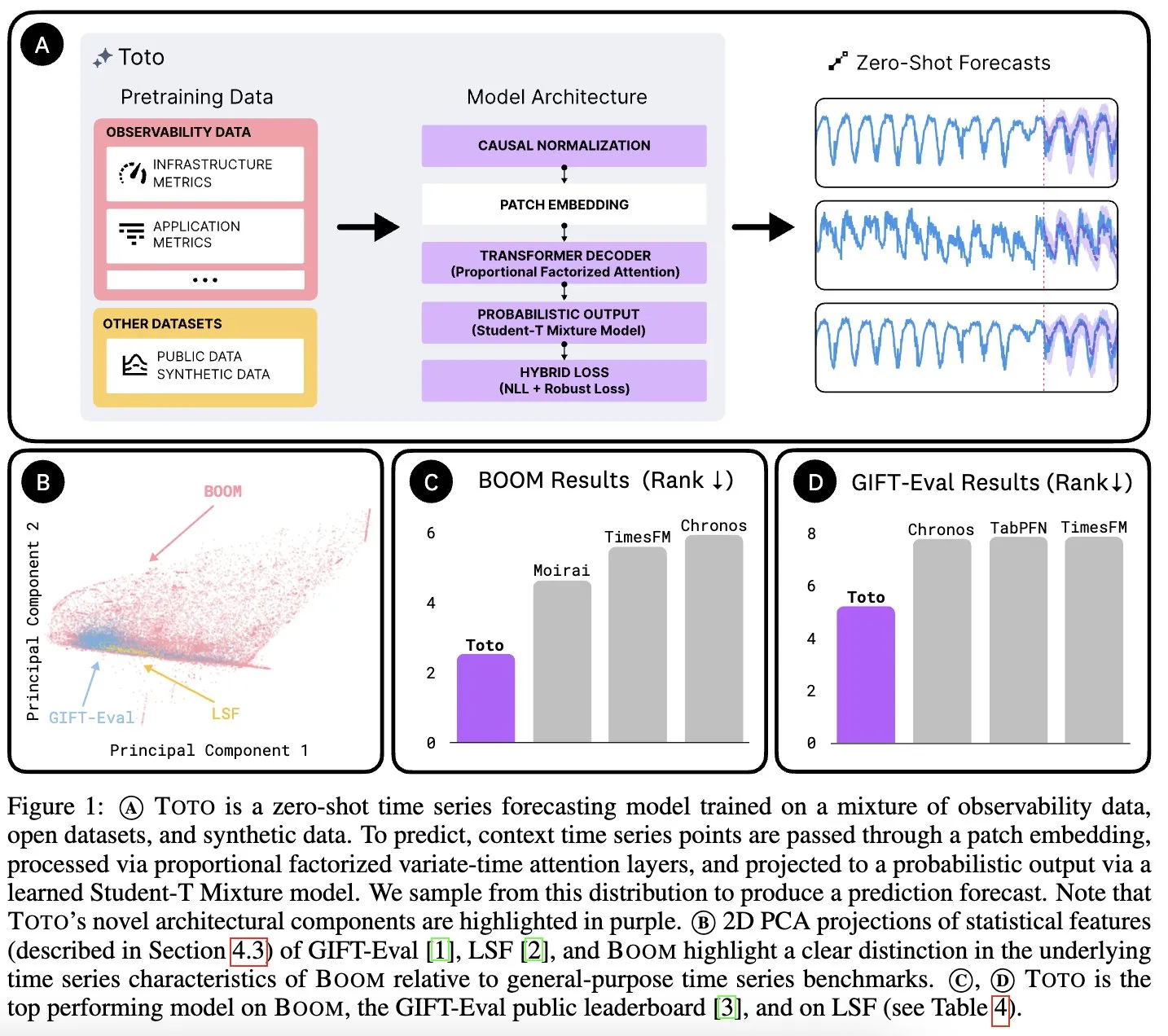
Datadog AI Research выпускает базовую модель временных рядов Toto и бенчмарк наблюдаемых метрик BOOM: Datadog AI Research представила Toto, новую базовую модель временных рядов, которая значительно опережает существующие SOTA-модели в соответствующих бенчмарках. Одновременно был выпущен BOOM, крупнейший на данный момент бенчмарк наблюдаемых метрик. Оба продукта выпущены под лицензией Apache 2.0 с открытым исходным кодом и нацелены на содействие исследованиям и приложениям в области анализа временных рядов и наблюдаемости (Источник: jefrankle, ClementDelangue)
TII выпускает серию гибридных моделей Falcon-H1 Transformer-SSM: Технологический инновационный институт (TII) ОАЭ выпустил серию моделей Falcon-H1, представляющую собой группу языковых моделей с гибридной архитектурой, сочетающей механизмы внимания Transformer и головки модели пространства состояний Mamba2 (SSM). Модели этой серии имеют от 0,5B до 34B параметров, поддерживают длину контекста до 256K и превосходят или сравнимы с ведущими моделями Transformer, такими как Qwen3-32B и Llama4-Scout, в нескольких бенчмарках, особенно демонстрируя преимущества в многоязычности (нативная поддержка 18 языков) и эффективности. Модели интегрированы в vLLM, Hugging Face Transformers и llama.cpp (Источник: Reddit r/LocalLLaMA)

Исследование MIT: ИИ может изучать связь между визуальной информацией и звуком без вмешательства человека: Исследователи из MIT продемонстрировали систему ИИ, способную самостоятельно изучать связи между визуальной информацией и соответствующими звуками без явного руководства или размеченных данных от человека. Эта способность имеет решающее значение для разработки более комплексных мультимодальных систем ИИ, позволяя им понимать и воспринимать мир подобно человеку (Источник: Reddit r/artificial, Reddit r/ArtificialInteligence)

ОАЭ запускает большую арабскую модель ИИ, ускоряя гонку ИИ в регионе Персидского залива: Объединенные Арабские Эмираты выпустили большую арабскую модель ИИ, что знаменует их дальнейшие инвестиции в область искусственного интеллекта и усиливает конкуренцию между странами Персидского залива в развитии технологий ИИ. Этот шаг направлен на повышение влияния арабского языка в области ИИ и удовлетворение потребностей в локализованных приложениях ИИ (Источник: Reddit r/artificial)
Fenbi Technology выпускает отраслевую большую модель, определяя новую парадигму «ИИ+Образование»: Fenbi Technology на саммите Tencent Cloud AI Industry Application Summit продемонстрировала свою собственную отраслевую большую модель для профессионального образования. Эта модель уже применяется в таких продуктах, как оценка собеседований и система ИИ-тренажеров, охватывая всю цепочку «обучение, изучение, практика, оценка, тестирование». С помощью ИИ-учителей и других форм компания стремится перейти от «одного подхода для всех» к персонализированному обучению «тысяча подходов для тысячи учеников» и планирует выпустить аппаратные продукты на базе собственной большой модели, способствуя интеллектуальной трансформации образования (Источник: 量子位)

Beisen Kuxueyuan выпускает платформу AI Learning нового поколения, внедряя пять AI Agent: Beisen Holdings после приобретения Kuxueyuan представила платформу обучения нового поколения AI Learning на базе большой модели ИИ. Платформа дополнила существующую eLearning пятью интеллектуальными агентами: AI-ассистентом для создания курсов, AI-ассистентом для обучения, AI-тренером, AI-коучем по лидерству и AI-ассистентом для экзаменов. Цель — перевернуть традиционные модели корпоративного обучения с помощью диалогов с агентами в реальном времени, тренировки навыков, персонализированного обучения и комплексного создания курсов и экзаменов с помощью ИИ (Источник: 量子位)

Финансовый отчет Pony.ai за Q1: доходы от услуг Robotaxi выросли в 8 раз по сравнению с аналогичным периодом прошлого года, к концу года будет развернуто тысяча беспилотных автомобилей: Pony.ai опубликовала финансовый отчет за первый квартал 2025 года, общий доход составил 102 миллиона юаней, что на 12% больше по сравнению с аналогичным периодом прошлого года. Из них основной доход от услуг Robotaxi достиг 12,3 миллиона юаней, увеличившись на 200,3% по сравнению с аналогичным периодом прошлого года, а доходы от платы за проезд пассажиров выросли в 8 раз. Компания планирует начать массовое производство Robotaxi седьмого поколения во втором квартале и развернуть 1000 автомобилей к концу года, стремясь достичь точки безубыточности на один автомобиль. Pony.ai также объявила о сотрудничестве с Tencent Cloud и Uber для расширения на внутреннем и ближневосточном рынках соответственно через платформы WeChat и Uber (Источник: 量子位)

Директор по продуктам OpenAI Kevin Weil: ChatGPT трансформируется в помощника для выполнения действий, стоимость модели уже в 500 раз выше GPT-4: Главный директор по продуктам OpenAI Kevin Weil заявил, что позиционирование ChatGPT изменится с ответов на вопросы на выполнение задач для пользователей, превратившись в ИИ-помощника для выполнения действий за счет чередования использования инструментов (таких как просмотр веб-страниц, программирование, подключение к внутренним источникам знаний). Он сообщил, что текущая стоимость модели уже в 500 раз превышает первоначальную GPT-4, но OpenAI стремится повысить эффективность и снизить цены на API за счет улучшения аппаратного обеспечения и алгоритмов. Он считает, что AI Agent будет быстро развиваться, вырастая с уровня младшего инженера до уровня архитектора в течение года (Источник: 量子位)

🧰 Инструменты
FlowiseAI: Визуальное создание ИИ-агентов: FlowiseAI — это проект с открытым исходным кодом, который позволяет пользователям создавать ИИ-агентов и LLM-приложения с помощью визуального интерфейса. Он поддерживает перетаскивание компонентов, подключение различных LLM, инструментов и источников данных, упрощая процесс разработки ИИ-приложений. Пользователи могут установить Flowise через npm или развернуть с помощью Docker для быстрого создания и тестирования собственных ИИ-процессов (Источник: GitHub Trending)

Выпущена библиотека Hugging Face JS, упрощающая взаимодействие с Hub API и сервисами вывода: Hugging Face представила серию JavaScript-библиотек (@huggingface/inference, @huggingface/hub, @huggingface/mcp-client и др.), предназначенных для облегчения взаимодействия разработчиков на JS/TS с Hugging Face Hub API и сервисами вывода. Эти библиотеки поддерживают создание репозиториев, загрузку файлов, вызов вывода для более чем 100 000 моделей (включая дополнение чата, генерацию текста в изображение и т.д.), использование клиента MCP для создания агентов и другие функции, а также поддерживают различных поставщиков услуг вывода (Источник: GitHub Trending)

Локальная среда выполнения Jan AI обновлена до лицензии Apache 2.0, снижая барьеры для корпоративного использования: Jan AI, инструмент с открытым исходным кодом для локального запуска LLM, недавно изменил свою лицензию с AGPL на более свободную Apache 2.0. Этот шаг направлен на облегчение развертывания и использования Jan предприятиями и командами внутри организаций без опасений по поводу проблем соответствия, связанных с AGPL, позволяя свободно форкать, изменять и публиковать, тем самым способствуя массовому внедрению Jan в реальных производственных средах (Источник: reach_vb, Reddit r/LocalLLaMA)
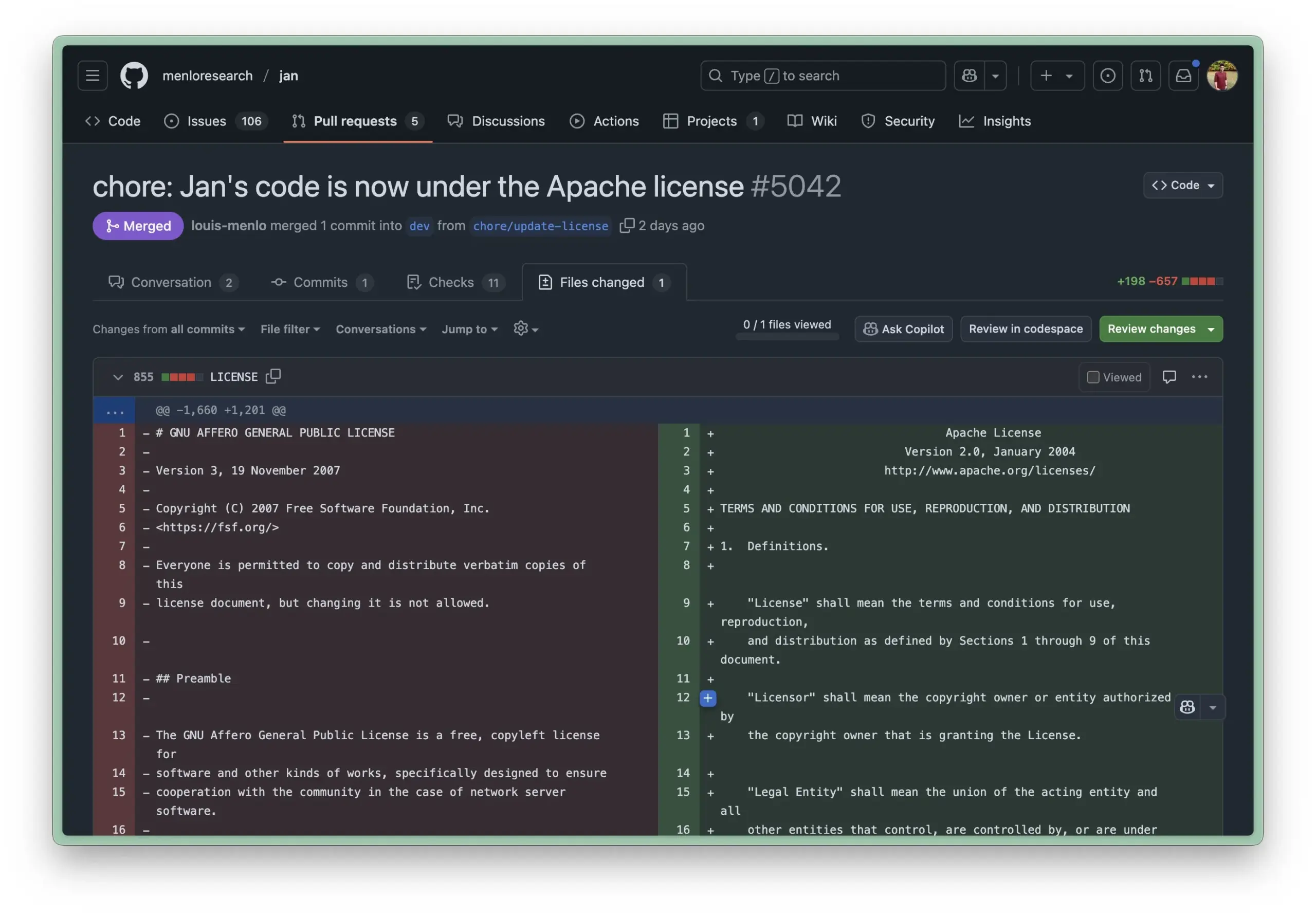
Obsidian представляет основной плагин Bases, реализующий управление заметками в виде базы данных: Программное обеспечение для управления знаниями Obsidian обновило свой основной плагин Bases, позволяющий пользователям преобразовывать наборы заметок в мощные базы данных. С помощью Bases пользователи могут создавать настраиваемые табличные представления, визуализировать и интерактивно работать с данными в своей базе знаний, поддерживая фильтрацию заметок по свойствам и создание формул для получения динамических атрибутов, что подходит для управления проектами, планирования поездок, списков для чтения и других сценариев. Эта функция в настоящее время доступна для ранних пользователей (Источник: op7418)
Hugging Face представляет Tiny Agents, упрощающий управление браузером и файловыми операциями с помощью локальных моделей: Hugging Face в своем курсе MCP представила Tiny Agents, простой в освоении фреймворк для настройки управления браузером. Пользователи с помощью командной строки, конфигурации JSON и подсказок могут позволить локально работающей LLM (через OpenAI-совместимый сервер) управлять браузером (например, Playwright) или локальной файловой системой без прямого вызова API, что обеспечивает удобство для приложений-агентов на базе локальных моделей, таких как llama.cpp (Источник: Reddit r/LocalLLaMA)

Разработчик открыл исходный код приложения для оптимизации резюме на базе ИИ, использующего LangChain и Ollama: Один разработчик создал и открыл исходный код приложения для оптимизации резюме на базе ИИ. После загрузки текущего резюме и описания целевой вакансии приложение пытается скорректировать ключевые слова в резюме, чтобы оно лучше соответствовало требованиям работодателя. Бэкенд проекта использует LangChain, сочетая разреженный поиск BM25 и плотную модель для гибридного поиска, языковая модель работает локально через Ollama, а фронтенд использует React. Проект в настоящее время находится на стадии проверки концепции, код открыт на GitHub (Источник: Reddit r/deeplearning)
Инструмент для создания приложений Lovable расширяет возможности обработки изображений: Инструмент для создания ИИ-приложений Lovable объявил об улучшении своих функций обработки изображений. Теперь пользователи могут загружать изображения в чат и указывать Lovable использовать эти графические материалы в приложении, что улучшает пользовательский опыт при создании приложений с визуальными элементами с помощью ИИ (Источник: op7418)
Helios: первая платформа, пытающаяся ускорить работу правительства с помощью ИИ: Joe Scheidler представил Helios, платформу, нацеленную на повышение эффективности работы правительства с помощью ИИ, которую называют «Cursor для правительства». Эта платформа является одной из первых, явно ориентированных на государственные ведомства и пытающихся оптимизировать их рабочие процессы и эффективность с помощью технологий ИИ. Конкретные функции и сценарии применения требуют дальнейшего изучения (Источник: timsoret)
📚 Обучение
Чжэцзянский университет выпустил учебник «Основы больших моделей», систематически излагающий знания об LLM и постоянно обновляемый: Команда LLM Чжэцзянского университета открыла исходный код учебника «Основы больших моделей», целью которого является предоставление читателям, интересующимся большими языковыми моделями, систематических базовых знаний и передовых технологий. Книга охватывает традиционные языковые модели, эволюцию архитектуры LLM, инженерию подсказок, эффективную параметрическую тонкую настройку, редактирование моделей, генерацию с расширенным поиском и другие темы, и будет обновляться ежемесячно. Каждая глава сопровождается списком соответствующих статей для отслеживания последних достижений. Полный PDF-файл и содержание по главам опубликованы на GitHub (Источник: GitHub Trending)

Hugging Face предлагает 10 бесплатных курсов по ИИ, охватывающих знания различных уровней и областей: Hugging Face собрала 10 бесплатных курсов по ИИ, предлагаемых на своей платформе. Содержание охватывает различные популярные темы ИИ от начального до продвинутого уровня, включая обработку естественного языка, глубокое обучение, обучение с подкреплением, обработку аудио, мультимодальность и другие. Эти курсы предоставляют ценные ресурсы для систематического изучения знаний в области ИИ для учащихся разного уровня, способствуя дальнейшему распространению знаний об ИИ и развитию сообщества открытого исходного кода (Источник: huggingface, reach_vb, _akhaliq)

Стэнфордский университет делится опытом и уроками обучения модели Marin 8B: Команда Percy Liang из Стэнфордского университета опубликовала подробный обзор своего опыта обучения модели Marin 8B с нуля (которая превзошла базовую модель Llama 3.1 8B по нескольким бенчмаркам). Этот честный отчет содержит все выводы команды и допущенные ошибки в процессе разработки, предоставляя сообществу ценный реальный опыт создания LLM и подчеркивая важность проб, ошибок и итераций в исследовательском процессе (Источник: stanfordnlp, YejinChoinka, hrishioa)
DeepLearning.AI и Predibase совместно запускают курс по усиленной тонкой настройке (RFT) LLM: DeepLearning.AI Andrew Ng в сотрудничестве с Predibase запускает бесплатный краткосрочный курс по использованию GRPO (Group Relative Policy Optimization) для усиленной тонкой настройки (RFT) с целью повышения производительности LLM. Курс ведут сооснователь и технический директор Predibase Travis Addair и другие, он направлен на то, чтобы помочь учащимся освоить, как использовать обучение с подкреплением для превращения небольших LLM с открытым исходным кодом в механизмы рассуждений для конкретных случаев использования, используя лишь небольшое количество аннотированных данных (Источник: DeepLearningAI)
Страница статей Hugging Face добавила функцию генерации резюме с помощью ИИ: Hugging Face на своей странице отображения статей ввела новую функцию, предоставляющую для каждой статьи однострочное резюме, сгенерированное ИИ. Это резюме предназначено для краткого и ясного изложения основного содержания статьи, помогая пользователям быстро отбирать и понимать исследовательскую литературу, повышая доступность и эффективность использования академических ресурсов. Эта функция работает на основе LLM с открытым исходным кодом и отражает концепцию «ИИ расширяет возможности исследований в области ИИ» (Источник: _akhaliq, _akhaliq, _akhaliq, _akhaliq, huggingface)

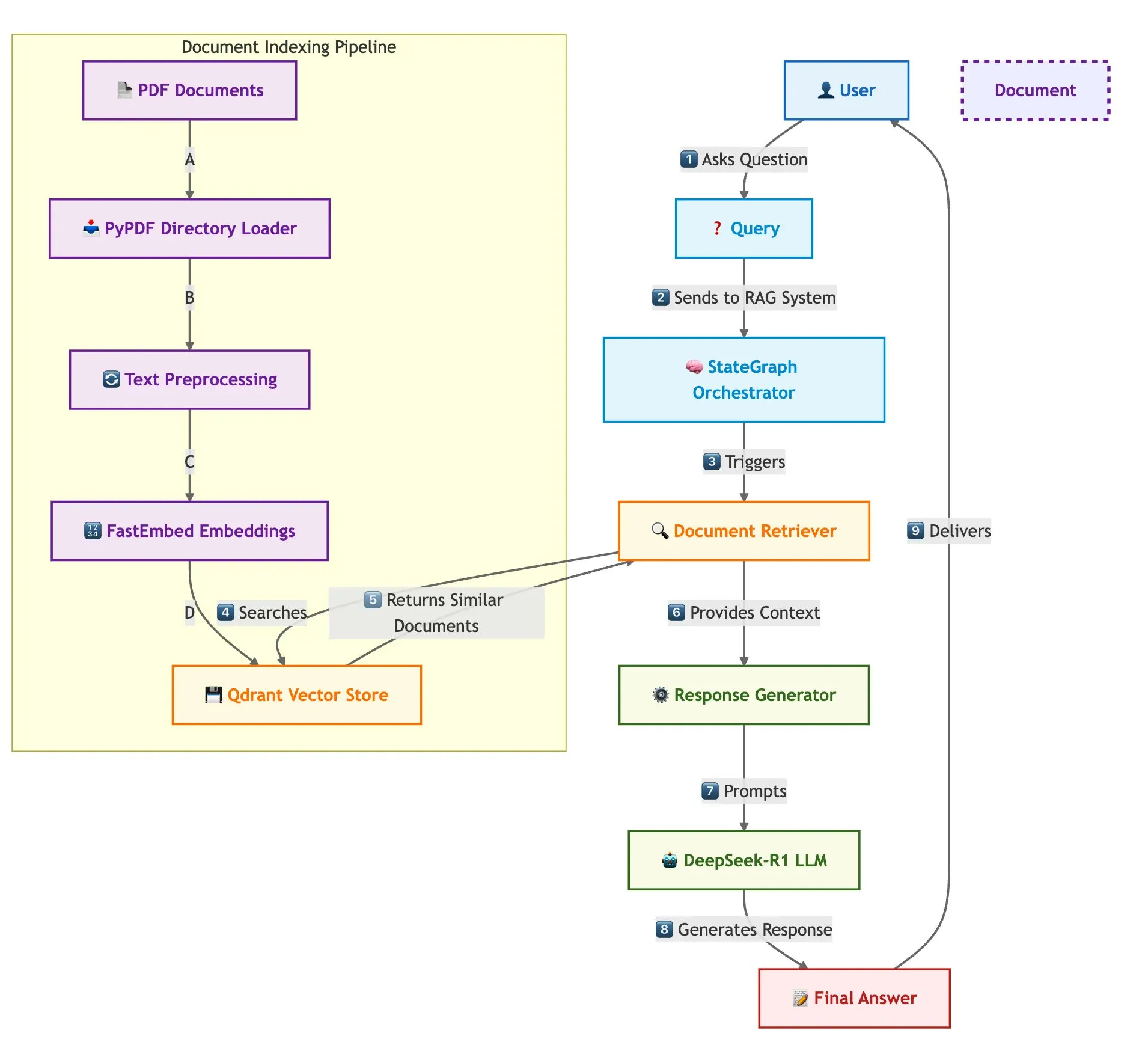
Qdrant, SambaNova и другие совместно демонстрируют решение для быстрого создания системы RAG для нескольких документов: В техническом блоге описывается, как использовать векторную базу данных Qdrant, SambaNova, DeepSeek-R1 и LangGraph для создания высокоскоростной, эффективной по памяти системы генерации с расширенным поиском (RAG) для нескольких документов. Это решение обеспечивает 32-кратную экономию памяти за счет бинарной квантизации, использует DeepSeek-R1 для быстрых и концентрированных ответов LLM и использует LangGraph для модульной оркестровки, что подходит для сценариев обработки больших объемов нескольких документов (Источник: qdrant_engine)
Опубликован обзор саммита LangChain Interrupt 2025 (на китайском языке): Опубликован обзор саммита LangChain Interrupt 2025 на китайском (путунхуа) языке. В этом саммите приняли участие более 800 человек со всего мира, которые поделились опытом и перспективами создания ИИ-агентов, а также анонсировали несколько продуктов, включая LangGraph Platform и LangGraph Studio v2, и обсудили такие темы, как инженерия агентов и наблюдаемость ИИ (Источник: hwchase17)
Andi Marafioti опубликовал учебник nanoVLM, подробно объясняющий обучение визуально-языковой модели на чистом PyTorch: Andi Marafioti опубликовал новый учебник в блоге под названием nanoVLM, в котором подробно описывается, как обучить собственную визуально-языковую модель (VLM) с нуля, используя только PyTorch. Учебник прост для понимания и освоения и призван помочь новичкам быстро овладеть процессом обучения VLM (Источник: LoubnaBenAllal1)

Ferenc Huszár разъясняет непрерывные цепи Маркова и их применение в диффузионных языковых моделях: Исследователь в области глубокого обучения Ferenc Huszár опубликовал пост в блоге, в котором доступно объясняет интуицию, лежащую в основе непрерывных цепей Маркова (CTMC), являющихся ключевым компонентом диффузионных языковых моделей (DLM), таких как Mercury и Gemini Diffusion. В статье рассматриваются различные точки зрения на цепи Маркова и их связь с точечными процессами, что представляет ценный справочный материал для понимания теоретических основ DLM (Источник: fhuszar)
💼 Бизнес
Компания «искусственного ИИ» Builder.ai объявила о банкротстве, ранее привлекшая почти 500 миллионов долларов: Британская компания Builder.ai (ранее Engineer.ai), некогда заявлявшая о революции в разработке программного обеспечения с помощью ИИ и оцененная в 1 миллиард долларов, на этой неделе объявила о банкротстве и ликвидации. Ранее сообщалось, что многие функции ее ИИ-платформы на самом деле выполнялись вручную индийскими инженерами. Несмотря на привлечение почти 500 миллионов долларов финансирования от известных инвесторов, таких как Microsoft и SoftBank DeepCore, компания в конечном итоге исчерпала средства из-за сомнений в подлинности технологий, хаотичного финансового управления и юридических споров с основателем, а также задолжала Microsoft 30 миллионов долларов и Amazon 85 миллионов долларов за облачные услуги (Источник: 36氪)

LMArena.ai (ранее LMSys) привлекла 100 миллионов долларов в рамках посевного раунда, переходя от приложения Gradio к коммерциализации: LMArena.ai, изначально являвшаяся академическим проектом LMSys на базе Gradio (для соревнований и оценки LLM), объявила о привлечении 100 миллионов долларов в рамках посевного раунда финансирования под руководством a16z и инвестиционной компании Калифорнийского университета. Этот раунд финансирования поддержит LMArena в продолжении исследований в области надежного ИИ и эксплуатации платформы, знаменуя переход успешного академического проекта с открытым исходным кодом к коммерческой деятельности. Это также подчеркивает потенциал инструментов быстрого прототипирования, таких как Gradio, в инкубации влиятельных ИИ-проектов (Источник: ClementDelangue, _akhaliq, clefourrier)
Борьба за таланты в области ИИ обостряется, OpenAI, Google и другие предлагают многомиллионные годовые зарплаты: Борьба за таланты в области ИИ в Кремниевой долине достигла апогея, ведущие исследователи (IC) стали ключевым ресурсом, за который борются гиганты, такие как OpenAI, Google, xAI, предлагая годовые зарплаты и опционы на акции, обычно превышающие десять миллионов долларов. Например, OpenAI предложила опытному исследователю, намеревавшемуся перейти в SSI, бонус в размере 2 миллионов долларов и опционы на акции на сумму более 20 миллионов долларов, чтобы удержать его; Google DeepMind также предлагает ведущим талантам годовую зарплату в размере 20 миллионов долларов. Такая ожесточенная конкуренция обусловлена огромным вкладом небольшого числа ключевых специалистов в развитие больших языковых моделей, и их уход или приход может напрямую повлиять на успех или неудачу ИИ-моделей (Источник: 36氪)
🌟 Сообщество
Кажется, возможности Sora по работе с китайским языком улучшились, но ограничения модели все еще существуют: Пользователи социальных сетей заметили, что модель генерации видео Sora от OpenAI, похоже, добилась прогресса в обработке китайского текста, будучи способной генерировать сцены, содержащие китайские иероглифы. Однако пользователи также отмечают, что у модели все еще есть свои ограничения, и генерируемый контент не идеален. Принятие этого несовершенства может быть нормой взаимодействия с ИИ-моделями на данном этапе (Источник: dotey)

Gemini запускает функцию «экзамена» по подробным отчетам, способствуя повторному использованию знаний и замыканию цикла обучения: Google Gemini запустила новую функцию: после прочтения подробного отчета Gemini может напрямую задавать вопросы для проверки. Эта функция направлена на проверку реального понимания пользователем содержания и построение ИИ-нативного цикла обучения «изучение → экзамен → восполнение пробелов → повторное изучение», подчеркивая, что в эпоху ИИ ядром обучения является способность к повторному использованию знаний, а не объем прочитанного (Источник: dotey)
Функция памяти ChatGPT вызывает у пользователей опасения по поводу контроля: Новая функция ChatGPT «обучение на основе чатов для запоминания» позволяет модели запоминать информацию из прошлых диалогов пользователя для предоставления более персонализированных ответов в последующих взаимодействиях. Однако некоторые продвинутые пользователи выражают обеспокоенность по этому поводу, считая, что это меняет способ взаимодействия с моделью. Они предпочитают полностью контролировать входные данные модели и не хотят, чтобы модель использовала историческую информацию без их ведома или точного контроля (Источник: random_walker)
AI Agent быстро развиваются, будущие модели работы могут измениться: Сообщество активно обсуждает быстрое развитие AI Agent и их потенциальное влияние на будущие модели работы. Считается, что AI Agent превращаются из простых инструментов для ответов на вопросы в «виртуальных сотрудников», способных самостоятельно выполнять сложные задачи (такие как кодирование, исследования, поддержка клиентов). Директор по продуктам OpenAI Kevin Weil ожидает, что возможности AI Agent будут быстро расти, развиваясь с уровня младшего инженера до уровня архитектора в течение года. Microsoft также предложила концепцию «сети интеллектуальных агентов», предвещая, что будущая работа может быть сосредоточена вокруг управления и оркестровки AI-агентами (Источник: rowancheung, 量子位)
ИИ обладает огромным потенциалом в области медицинской диагностики, но вызывает у врачей опасения за свою профессию: ИИ демонстрирует поразительные способности в медицинской диагностике, например, в одном исследовании утверждается, что модель o1-preview показала сверхчеловеческие способности в задачах медицинского мышления и диагностики, а случаи обнаружения ИИ пневмонии за несколько секунд также привлекли внимание. Это сделало ИИ-ассистированную диагностику горячей темой, но также заставило некоторых врачей с 20-летним стажем беспокоиться о своих карьерных перспективах, вплоть до шуток о поиске работы в McDonald’s. В сообществе обсуждается, что ИИ следует рассматривать скорее как инструмент, помогающий врачам повышать эффективность и точность, а не как полную замену (Источник: paul_cal, Reddit r/ArtificialInteligence)
Издатели новостей обвиняют поисковую модель Google AI в «воровстве»: Альянс новостных медиа и другие издатели выразили резкое недовольство новой поисковой моделью Google AI, назвав ее «воровством». Они считают, что Google AI напрямую извлекает информацию из новостного контента и интегрирует ее в результаты поиска, обходя новостные сайты, что наносит ущерб трафику и доходам от рекламы издателей, вызывая ожесточенные дебаты об авторских правах на контент и добросовестном использовании в эпоху ИИ (Источник: Reddit r/artificial)
Модель DeepSeek используется в Китае для традиционных гаданий, вызывая дискуссию о границах применения ИИ: Некоторые пользователи обнаружили, что значительная часть трафика модели DeepSeek в Китае приходится на ее использование для гаданий по Книге Перемен и других традиционных предсказательных практик. Это явление вызвало дискуссию о границах применения ИИ и его культурной адаптации, а также косвенно отражает разнообразные исследования и потребности пользователей в возможностях ИИ (Источник: menhguin, cto_junior)

💡 Прочее
Человекоподобный робот компании Figure отработал 20-часовую непрерывную смену на производственной линии BMW: Компания по производству человекоподобных роботов Figure объявила, что ее робот успешно отработал 20-часовую непрерывную смену на производственной линии BMW X3. Ранее робот в течение нескольких недель проходил тестирование в 10-часовых сменах. Figure заявляет, что это первый случай в мире, когда человекоподобный робот выполнил такую длительную непрерывную работу на автомобильной производственной линии, демонстрируя свой потенциал в области промышленной автоматизации (Источник: adcock_brett, TheRundownAI)
Разница и связь между Agentic AI и GenAI: Сообщество обсудило концепции Agentic AI (интеллектуальный агентский ИИ) и Generative AI (генеративный ИИ). Генеративный ИИ в основном относится к ИИ, способному создавать новый контент (текст, изображения, код и т.д.), в то время как агентский ИИ больше подчеркивает автономность, целеустремленность и способность взаимодействовать с окружающей средой. Агентский ИИ обычно использует генеративный ИИ как одну из своих основных возможностей для понимания, планирования и выполнения задач, являясь важным направлением развития ИИ в сторону более продвинутого автономного интеллекта (Источник: Ronald_vanLoon, Ronald_vanLoon)

Применение ИИ в научных исследованиях недооценено, существует явление «приукрашивания результатов»: В сообществе отмечается, что потенциал применения ИИ в научных исследованиях огромен, но может быть недооценен, при этом существует явление, когда исследователи «приукрашивают» результаты экспериментов с ИИ ради публикации. Например, в таких областях, как уравнения в частных производных (PDE), реальная производительность ИИ может быть не такой выдающейся, как представлено в статьях. Это указывает на необходимость более строгого и прозрачного подхода научного сообщества к оценке реальной роли и ограничений ИИ в научных открытиях (Источник: clefourrier)