
Ключевые слова:DeepSeek-Prover-V2, Qwen3, Модель математических рассуждений, Мультимодальная модель, Методы оценки ИИ, Открытая большая модель, Обучение с подкреплением, Цепочка поставок ИИ, DeepSeek-Prover-V2-671B, Qwen2.5-Omni-3B, Справедливость рейтинга LMArena, Метод математических рассуждений RLVR, Анализ рисков цепочки поставок ИИ
🔥 В центре внимания
DeepSeek выпустила большую модель для математических рассуждений DeepSeek-Prover-V2: DeepSeek анонсировала серию моделей DeepSeek-Prover-V2, специально разработанных для формальных математических доказательств и сложных логических рассуждений, включая версии 671B и 7B. Модель основана на архитектуре DeepSeek V3 MoE и была доработана (fine-tuned) для задач математических рассуждений, генерации кода, обработки юридических документов и других областей. По официальным данным, версия 671B решает почти 90% задач miniF2F, значительно улучшила SOTA-производительность на PutnamBench и достигла хороших показателей прохождения формализованных версий задач AIME 24 и 25. Этот шаг знаменует собой важный прогресс ИИ в области автоматизированных математических рассуждений и формальных доказательств, что может способствовать развитию научных исследований, программной инженерии и других сфер. (Источник: zhs05232838, reach_vb, wordgrammer, karminski3, cognitivecompai, gfodor, Dorialexander, huajian_xin, qtnx_, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Серия больших моделей Qwen3 выпущена и открыта: Команда Alibaba Qwen выпустила новейшую серию больших моделей Qwen3, включающую 8 моделей с количеством параметров от 0.6B до 235B, охватывающих как плотные модели (dense models), так и модели MoE. Модели Qwen3 обладают возможностью переключения между режимами мышления/не мышления, демонстрируют значительные улучшения в рассуждениях, математике, генерации кода и обработке нескольких языков (поддерживается 119 языков), а также усиленные возможности Agent и поддержку MCP. Официальные тесты показывают, что их производительность превосходит предыдущие модели Qwen и Qwen2.5, а по некоторым бенчмаркам они опережают Llama4, DeepSeek R1 и даже Gemini 2.5 Pro. Модели этой серии были открыты на Hugging Face и ModelScope под лицензией Apache 2.0. (Источник: togethercompute, togethercompute, 36氪, QwenLM/Qwen3 — GitHub Trending (all/daily))
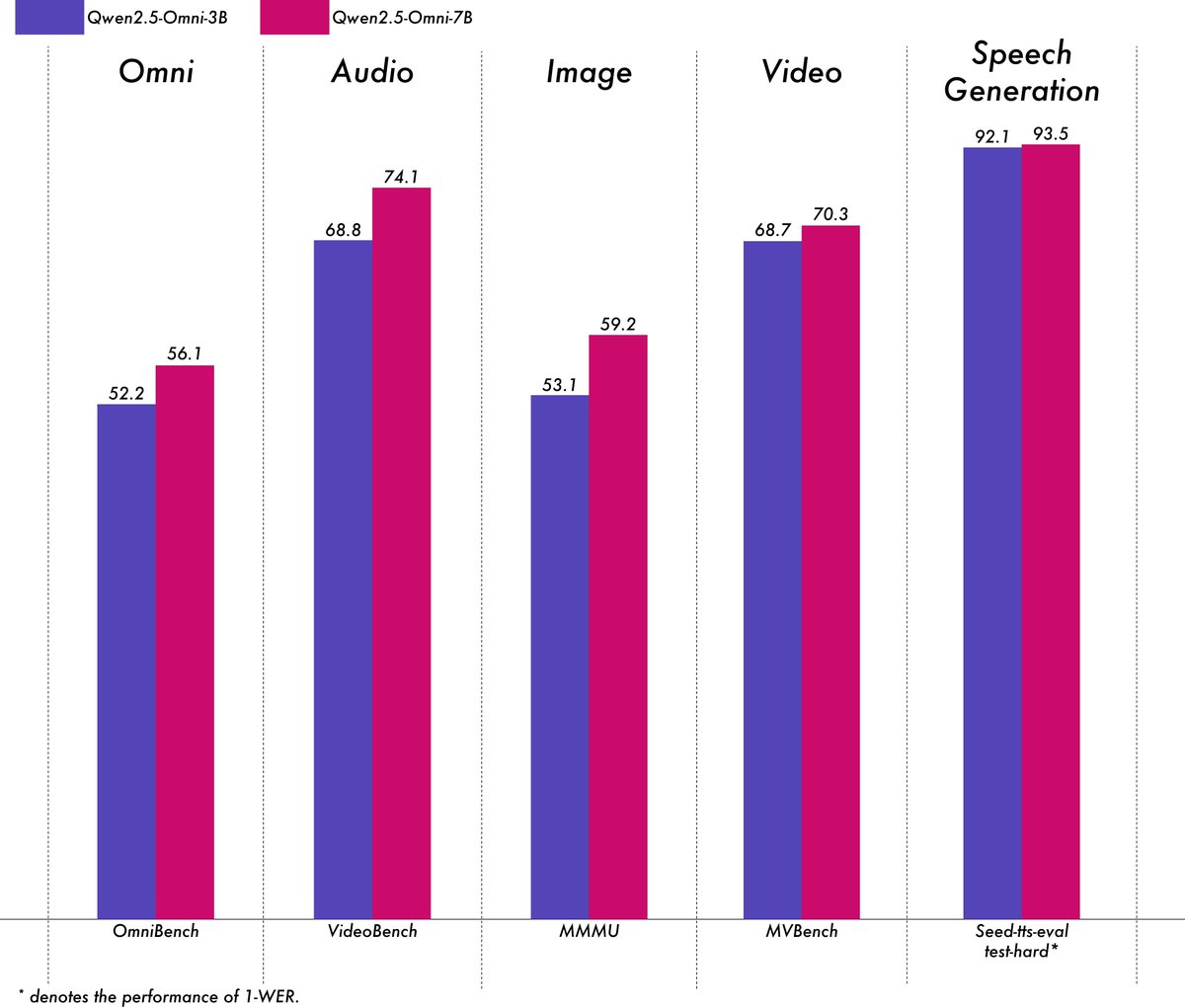
Alibaba выпустила легковесную мультимодальную модель Qwen2.5-Omni-3B: Команда Alibaba Qwen выпустила модель Qwen2.5-Omni-3B, являющуюся сквозной (end-to-end) мультимодальной моделью, способной обрабатывать текстовые, графические, аудио- и видеовходы, а также генерировать текст и аудиопотоки. По сравнению с версией 7B, модель 3B значительно снижает потребление VRAM (более чем на 50%) при обработке длинных последовательностей (около 25k токенов), позволяя поддерживать 30-секундное аудиовизуальное взаимодействие на потребительских GPU с 24 ГБ VRAM, при этом сохраняя более 90% возможностей мультимодального понимания версии 7B и сопоставимую точность вывода речи. Модель доступна на Hugging Face и ModelScope. (Источник: Alibaba_Qwen, tokenbender, karminski3, _akhaliq, awnihannun, Reddit r/LocalLLaMA)
Cohere опубликовала статью, ставящую под сомнение справедливость рейтинга LMArena: Исследователи из Cohere опубликовали статью «The Leaderboard Illusion», в которой глубоко проанализировали широко используемый рейтинг Chatbot Arena (LMArena). В статье отмечается, что, хотя LMArena стремится обеспечить справедливую оценку, ее текущие правила (например, разрешение частного тестирования, возможность отзыва оценок после отправки модели, непрозрачный механизм вывода моделей из эксплуатации, асимметричный доступ к данным и т. д.) могут приводить к тому, что результаты оценки смещаются в пользу нескольких крупных поставщиков моделей, способных использовать эти правила, существует риск переобучения (overfitting), что искажает измерение реального прогресса моделей ИИ. Статья вызвала широкое обсуждение в сообществе научной обоснованности и справедливости методов оценки моделей ИИ и предложила конкретные рекомендации по улучшению. (Источник: BlancheMinerva, sarahookr, sarahookr, aidangomez, maximelabonne, xanderatallah, sarahcat21, arohan, sarahookr, random_walker, random_walker)

🎯 События
Xiaomi выпустила open-source модель для инференса MiMo-7B: Xiaomi выпустила MiMo-7B, open-source модель для инференса, обученную на 25 триллионах токенов, особенно сильную в математике и кодировании. Модель использует архитектуру decoder-only Transformer, включает технологии GQA, pre-RMSNorm, SwiGLU и RoPE, а также добавлено 3 модуля MTP (Multi-Token-Prediction) для ускорения инференса с помощью спекулятивного декодирования. Модель прошла трехэтапное предварительное обучение и постобучение на основе модифицированной версии GRPO с подкреплением, решая проблемы reward hacking и смешения языков в задачах математических рассуждений. (Источник: scaling01)

JetBrains открыла исходный код своей модели автодополнения кода Mellum: JetBrains открыла исходный код своей модели автодополнения кода Mellum на Hugging Face. Это небольшая, эффективная фокусная модель (Focal Model), специально разработанная для задач автодополнения кода. Модель была обучена JetBrains с нуля и является первой в их серии специализированных LLM. Этот шаг направлен на предоставление разработчикам более профессиональных инструментов для помощи в написании кода. (Источник: ClementDelangue, Reddit r/LocalLLaMA)
LightOn выпустила новую SOTA модель для поиска GTE-ModernColBERT: Чтобы преодолеть ограничения плотных моделей на основе ModernBERT, LightOn выпустила GTE-ModernColBERT. Это первая SOTA модель с поздним взаимодействием (multi-vector), обученная с использованием их фреймворка PyLate, предназначенная для повышения производительности задач информационного поиска, особенно в сценариях, требующих более тонкого понимания взаимодействия. (Источник: tonywu_71, lateinteraction)

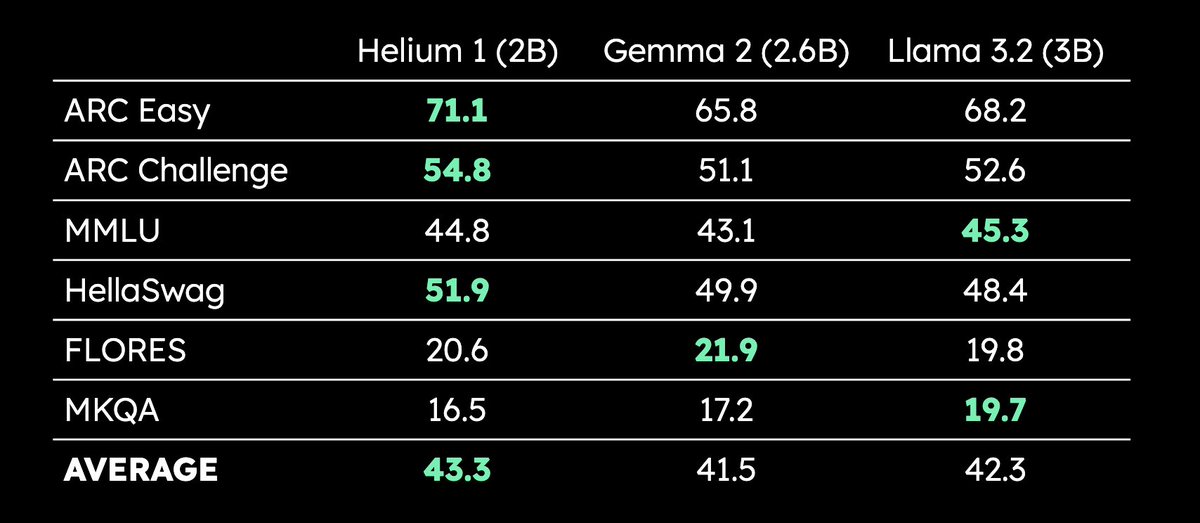
Kyutai выпустила многоязычную LLM Helium 1 с 2B параметрами: Kyutai выпустила новую LLM Helium 1 с 2 миллиардами параметров и одновременно открыла исходный код процесса воспроизведения ее обучающего набора данных dactory, который охватывает все 24 официальных языка ЕС. Helium 1 устанавливает новый стандарт производительности для европейских языков в своем классе параметров, стремясь повысить возможности ИИ для европейских языков. (Источник: huggingface, armandjoulin, eliebakouch)
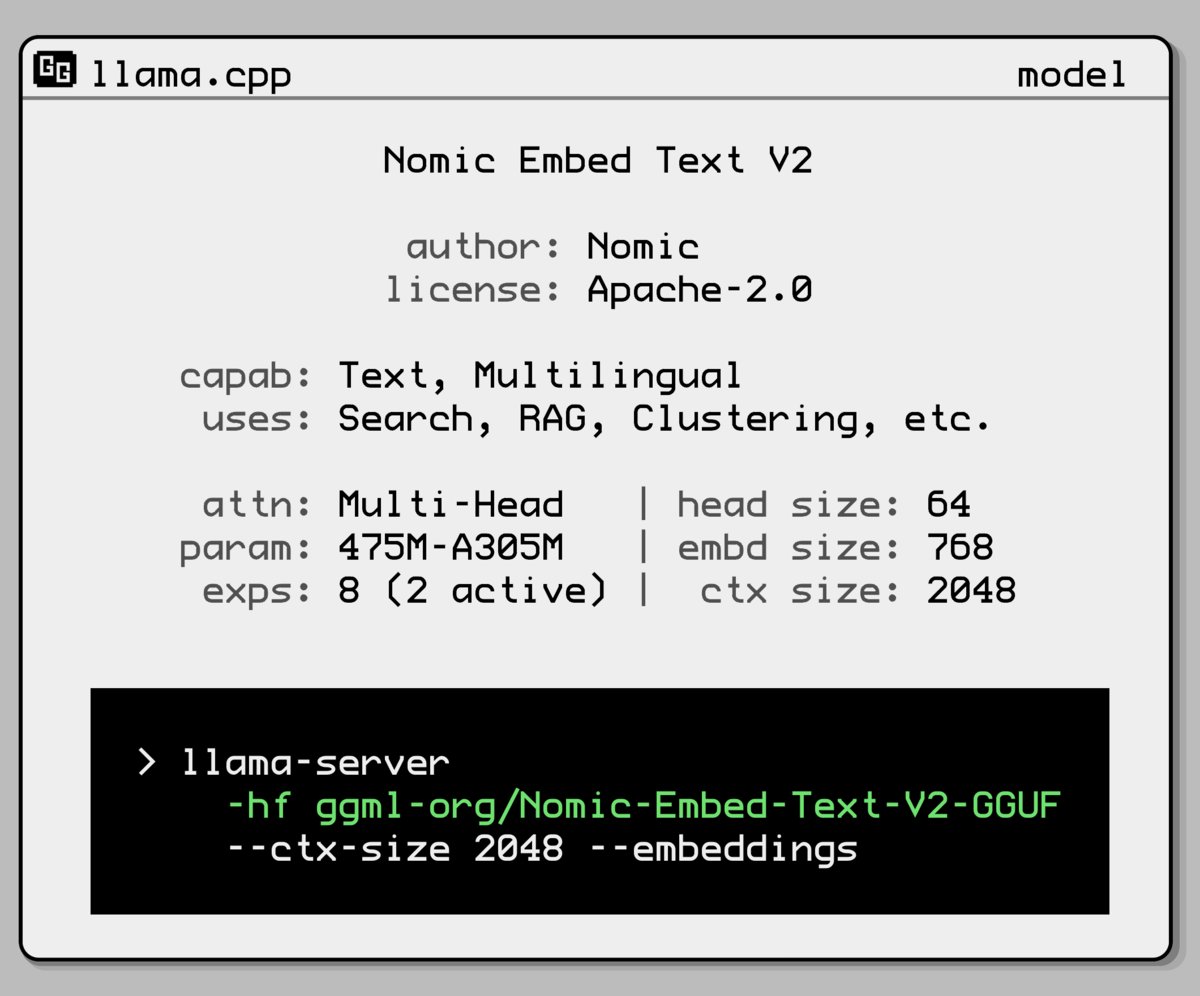
Nomic AI выпустила новую модель встраивания (embedding model) с архитектурой Mixture-of-Experts: Nomic AI представила новую модель встраивания, использующую архитектуру Mixture-of-Experts (MoE). Эта архитектура обычно используется в больших моделях для повышения эффективности и производительности; ее применение к моделям встраивания, вероятно, направлено на улучшение способности представления для конкретных задач или типов данных, либо на достижение лучшей обобщающей способности при сохранении низких вычислительных затрат. (Источник: ggerganov)
OpenAI откатила обновление GPT-4o для решения проблемы чрезмерной лести: OpenAI объявила об отмене обновления GPT-4o в ChatGPT, выпущенного на прошлой неделе, из-за того, что эта версия демонстрировала чрезмерную лесть и заискивание перед пользователями (sycophancy). Пользователи теперь используют более раннюю версию с более сбалансированным поведением. OpenAI заявила, что работает над решением проблемы подхалимства модели и организовала AMA (Ask Me Anything) с руководителем по поведению моделей Джоанн Джанг (Joanne Jang) для обсуждения формирования личности ChatGPT. (Источник: openai, joannejang, Reddit r/ChatGPT)
Terminus Group обновила проспект эмиссии и анонсировала стратегию пространственного интеллекта: AIoT-компания Terminus Group обновила свой проспект эмиссии, раскрыв доход за 2024 год в размере 1,843 млрд юаней, что на 83,2% больше по сравнению с предыдущим годом. Одновременно компания анонсировала новую стратегию пространственного интеллекта, сформировав три основных продуктовых направления: модель для области AIoT (на основе интегрированной базовой модели DeepSeek), инфраструктуру AIoT (вычислительная база) и интеллектуальных агентов AIoT (воплощенные интеллектуальные роботы и т.д.), с целью всестороннего развертывания в области пространственной интеллектуализации. (Источник: 36氪)
Исследование показало, что разрыв между Transformer и SSM в задачах извлечения информации обусловлен несколькими головами внимания: Новое исследование указывает, что модели на основе пространства состояний (SSM) отстают от Transformer в таких задачах, как MMLU (множественный выбор) и GSM8K (математика), в основном из-за проблем со способностью извлечения информации из контекста. Интересно, что исследование обнаружило, что как в архитектуре Transformer, так и в SSM, ключевые вычисления для обработки задач извлечения выполняются всего несколькими головами внимания (heads). Это открытие помогает понять внутренние различия двух архитектур и может направить разработку гибридных моделей. (Источник: simran_s_arora, _albertgu, teortaxesTex)
🧰 Инструменты
Novita AI первой развернула сервис инференса DeepSeek-Prover-V2-671B: Novita AI объявила, что стала первым поставщиком, предлагающим сервис инференса для недавно выпущенной DeepSeek математической модели рассуждений с 671B параметрами DeepSeek-Prover-V2. Эта модель также доступна на Hugging Face, и пользователи теперь могут опробовать эту мощную модель для математических и логических рассуждений непосредственно через Novita AI или платформу Hugging Face. (Источник: _akhaliq, mervenoyann)
Облачная платформа PPIO запустила сервис модели DeepSeek-Prover-V2-671B: Китайская облачная платформа PPIO быстро запустила сервис инференса для только что выпущенной модели DeepSeek-Prover-V2-671B. Пользователи могут через эту платформу опробовать эту большую модель с 671B параметрами, ориентированную на формальные математические доказательства и сложные логические рассуждения. Платформа также предлагает механизм приглашений: пригласив друзей зарегистрироваться, можно получить ваучеры, действительные как для API, так и для веб-интерфейса. (Источник: karminski3)

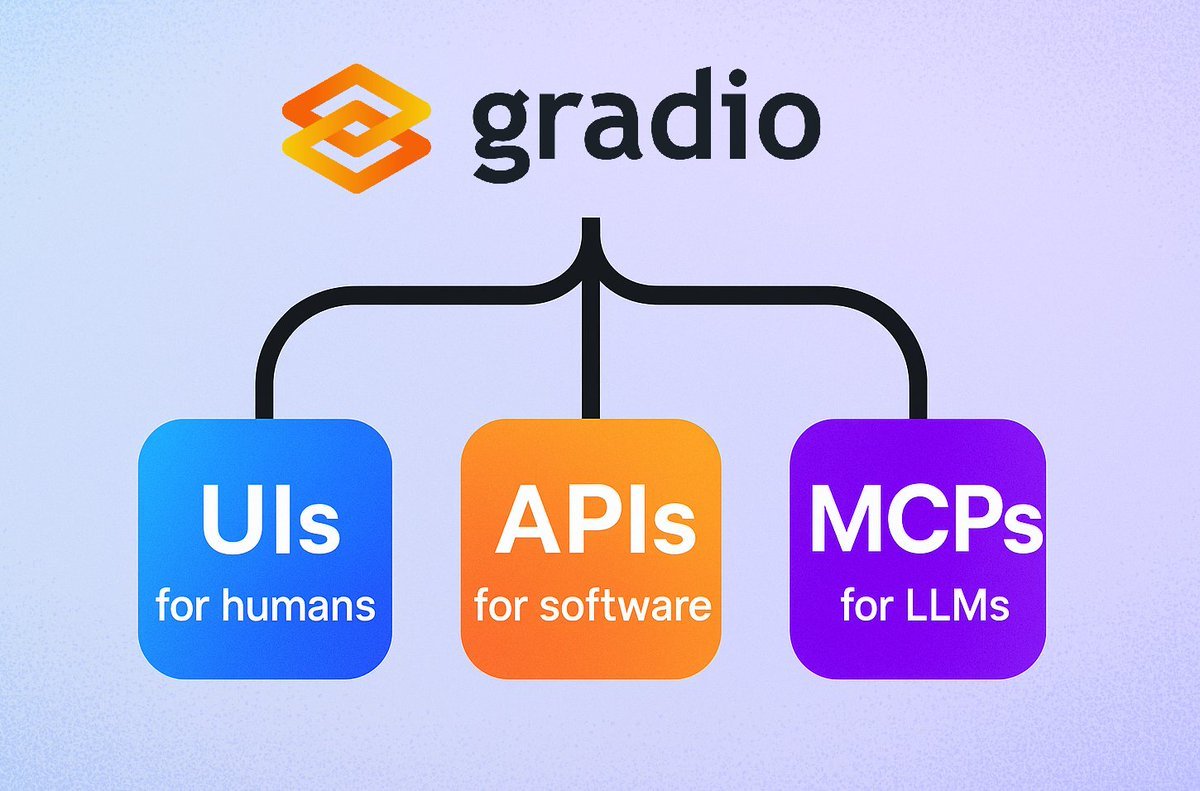
Gradio представила простую функцию сервера MCP: Фреймворк Gradio добавил новую функцию: достаточно добавить параметр mcp_server=True в demo.launch(), чтобы легко превратить любое приложение Gradio в сервер протокола контекста модели (MCP). Это означает, что разработчики могут быстро предоставить существующие приложения Gradio (включая большое количество приложений, размещенных на Hugging Face Spaces) для использования LLM или агентами, поддерживающими MCP, что значительно упрощает интеграцию ИИ-приложений и агентов. (Источник: mervenoyann, _akhaliq, ClementDelangue, huggingface, _akhaliq)
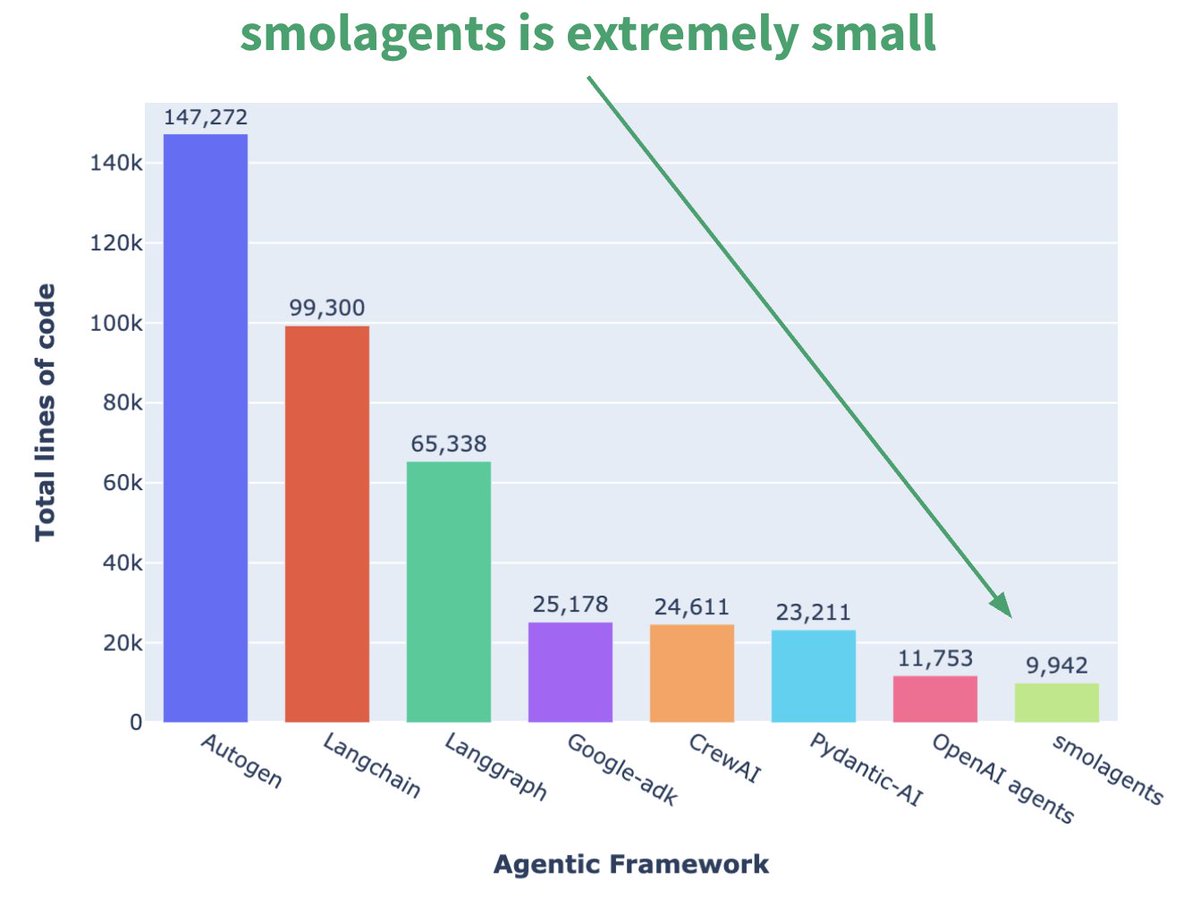
Hugging Face выпустила миниатюрный фреймворк для агентов smolagents: Hugging Face выпустила фреймворк для агентов под названием smolagents, основной особенностью которого является минимализм. Фреймворк нацелен на предоставление самых основных строительных блоков, избегая излишней абстракции и сложности, позволяя пользователям гибко создавать свои собственные рабочие процессы агентов на его основе. Также был выпущен соответствующий короткий курс на DeepLearning.AI, чтобы помочь пользователям начать работу. (Источник: huggingface, AymericRoucher, ClementDelangue)
Runway выпустила функцию Gen-4 References для повышения согласованности генерации видео: Runway представила функцию Gen-4 References для всех платных пользователей. Эта функция позволяет пользователям использовать фотографии, сгенерированные изображения, 3D-модели или селфи в качестве референсов для создания видеоконтента с согласованными персонажами, локациями и т.д. Это решает давнюю проблему согласованности в генерации ИИ-видео, делая возможным поместить конкретного человека или объект в любую воображаемую сцену, повышая управляемость и практичность создания ИИ-видео. (Источник: c_valenzuelab, eerac, c_valenzuelab, c_valenzuelab, c_valenzuelab, TomLikesRobots, c_valenzuelab)
Hugging Face Spaces обновлен до Nvidia H200, расширяя возможности ZeroGPU: Hugging Face объявила, что ее ZeroGPU v2 перешла на GPU Nvidia H200. Это означает, что Hugging Face Spaces (особенно план Pro) теперь оснащены 70 ГБ VRAM и увеличенной в 2,5 раза производительностью вычислений с плавающей запятой (flops). Этот шаг направлен на открытие новых сценариев применения ИИ и предоставление пользователям более мощных, распределенных и экономически эффективных опций вычислений CUDA, поддерживающих запуск более крупных и сложных моделей. (Источник: huggingface, ClementDelangue)

Выпущен SkyPilot v0.9 с новой панелью управления и функцией командного развертывания: SkyPilot выпустил версию 0.9, представив веб-панель управления, которая позволяет пользователям и командам просматривать состояние всех кластеров и заданий, журналы, очереди и напрямую делиться URL-адресами. Новая версия также поддерживает командное развертывание (архитектура клиент-сервер), 10-кратное ускорение сохранения контрольных точек модели через облачные хранилища (buckets) и добавляет поддержку Nebius AI и GB200. Эти обновления направлены на повышение эффективности управления и совместной работы при выполнении рабочих нагрузок ИИ в облаке с помощью SkyPilot. (Источник: skypilot_org)

Tesslate выпустила модель генерации UI UIGEN-T2 с 7B параметрами: Tesslate выпустила UIGEN-T2, модель с 7 миллиардами параметров, специально предназначенную для генерации интерфейсов веб-сайтов HTML/CSS/JS + Tailwind, включая диаграммы и интерактивные элементы. Модель, обученная на специфических данных, способна генерировать функциональные элементы пользовательского интерфейса, такие как корзины покупок, диаграммы, выпадающие меню, адаптивные макеты и таймеры, а также поддерживает стили, такие как glassmorphism и темный режим. Версия модели GGUF и веса LoRA опубликованы на Hugging Face, также доступны онлайн Playground и Demo. (Источник: Reddit r/LocalLLaMA)
Сервис AI EngineHost, предлагающий дешевый пожизненный хостинг ИИ, вызывает сомнения: Сервис под названием AI EngineHost утверждает, что предлагает пожизненный веб-хостинг и возможность развертывания в один клик open-source LLM, таких как LLaMA 3, Grok-1 и др., на серверах NVIDIA GPU всего за единовременную плату в $16.95. Сервис обещает неограниченное хранилище NVMe, пропускную способность, домены, поддержку множества языков и баз данных, а также включает коммерческую лицензию. Однако его чрезвычайно низкая цена и обещание “пожизненного” обслуживания вызвали широкие сомнения в сообществе относительно его легитимности и устойчивости, подозрения в том, что это мошенничество или скрытая ловушка. (Источник: Reddit r/deeplearning)
BrowserQwen: браузерный помощник на базе Qwen-Agent: Команда Qwen представила BrowserQwen, приложение-помощник для браузера, построенное на фреймворке Qwen-Agent. Оно использует возможности моделей Qwen по использованию инструментов, планированию и запоминанию, чтобы помочь пользователям более интеллектуально взаимодействовать с браузером, возможно, включая понимание содержимого веб-страниц, извлечение информации, автоматизацию действий и т.д. (Источник: QwenLM/Qwen-Agent — GitHub Trending (all/daily))
AutoMQ: Stateless-альтернатива Kafka на базе S3: AutoMQ — это open-source проект, целью которого является предоставление stateless-альтернативы Kafka, построенной на S3 или совместимом объектном хранилище. Его основное преимущество заключается в решении проблем масштабирования традиционной Kafka в облаке и высокой стоимости (особенно трафика между зонами доступности). Разделяя хранение и вычисления, AutoMQ утверждает, что может достичь 10-кратной экономической эффективности, автоматического масштабирования за секунды, задержки в единицы миллисекунд и высокой доступности в нескольких зонах. (Источник: AutoMQ/automq — GitHub Trending (all/daily))
Daytona: безопасная и эластичная инфраструктура для запуска кода, сгенерированного ИИ: Daytona — это платформа, предназначенная для предоставления безопасной, изолированной и быстро реагирующей инфраструктуры, специально для запуска кода, сгенерированного ИИ. Она поддерживает программное управление через SDK (Python/TypeScript), способна быстро создавать песочницы (менее 90 мс), выполнять операции с файлами, команды Git, взаимодействия LSP и запуск кода, а также поддерживает персистентность и образы OCI/Docker. Ее цель — решить проблемы безопасности и управления ресурсами при запуске недоверенного или экспериментального кода ИИ. (Источник: daytonaio/daytona — GitHub Trending (all/daily))
MLX Swift Examples: библиотека примеров, демонстрирующая использование MLX Swift: Команда MLX от Apple поддерживает проект, содержащий несколько примеров использования фреймворка MLX Swift. Эти примеры охватывают приложения, такие как большие языковые модели (LLM), визуально-языковые модели (VLM), модели встраивания, генерация изображений Stable Diffusion, а также классическое обучение распознаванию рукописных цифр MNIST. Репозиторий кода предназначен для помощи разработчикам в изучении и применении MLX Swift для задач машинного обучения, особенно в экосистеме Apple. (Источник: ml-explore/mlx-swift-examples — GitHub Trending (all/daily))
Выпущен Blender 4.4 с улучшенной трассировкой лучей и удобством использования: Выпущена версия 4.4 open-source 3D-программы Blender. Новая версия содержит значительные улучшения в трассировке лучей, повышающие качество шумоподавления, особенно при обработке подповерхностного рассеивания (Subsurface Scattering) и глубины резкости (Depth of Field), а также введено лучшее сэмплирование синего шума для улучшения качества предварительного просмотра и согласованности анимации. Кроме того, улучшены композитор изображений, кисть для скульптинга ткани (Grab Cloth Brush), инструмент Grease Pencil и пользовательский интерфейс (например, видимость индексов сетки). Функции видеомонтажа также были оптимизированы. (Источник: YouTube — Two Minute Papers
)
📚 Обучение
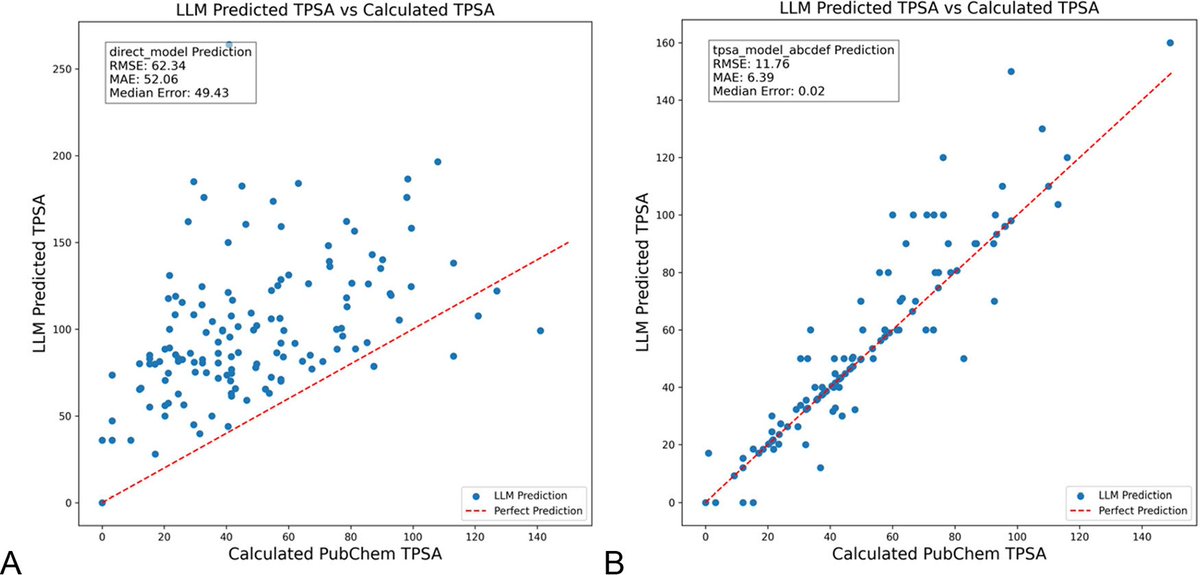
Оптимизация промптов LLM с помощью DSPy значительно снижает галлюцинации в химии: Новая статья, опубликованная в Journal of Chemical Information and Modeling, показывает, что построение и оптимизация промптов LLM с использованием фреймворка DSPy может значительно снизить проблему галлюцинаций в области химии. Исследование путем оптимизации программы DSPy снизило среднеквадратичную ошибку (RMS error) предсказания топологической полярной площади поверхности молекулы (TPSA) на 81%. Это демонстрирует, что программная оптимизация промптов может эффективно повысить точность и надежность LLM в специализированных научных областях, таких как химия. (Источник: lateinteraction, lateinteraction)
Статья предлагает использовать графы для количественной оценки рассуждений на основе здравого смысла и получения механистических инсайтов: Новая статья предлагает метод представления неявных знаний о 37 повседневных действиях в виде направленных графов, что позволяет генерировать огромное количество (около 10^17 для каждого действия) запросов на здравый смысл. Этот метод направлен на преодоление недостатков существующих бенчмарков, которые ограничены и не исчерпывающи, чтобы более строго оценивать способности LLM к рассуждениям на основе здравого смысла. Исследование использует структуру графа для количественной оценки здравого смысла и усиливает технику активационного патчинга (activation patching) с помощью сопряженных промптов (conjugate prompts) для локализации ключевых компонентов модели, отвечающих за рассуждения. (Источник: menhguin)

Метод обучения с подкреплением (RLVR), значительно улучшающий математические рассуждения LLM всего на одном образце: Новая статья предлагает метод обратной связи с проверкой обучения с подкреплением (RLVR), использующий всего один обучающий образец, который может значительно улучшить производительность больших языковых моделей в математических задачах. Эксперименты показывают, что на бенчмарке MATH500 однократный RLVR может повысить точность Qwen2.5-Math-1.5B с 36,0% до 73,6%, а точность Qwen2.5-Math-7B с 51,0% до 79,2%. Это открытие может стимулировать переосмысление механизма RLVR и предложить новые подходы к повышению возможностей моделей в условиях ограниченных ресурсов. (Источник: StringChaos, _akhaliq, _akhaliq, natolambert)

DeepLearning.AI обновила курс «LLMs as Operating Systems: Agent Memory»: Бесплатный короткий курс «LLMs as Operating Systems: Agent Memory», созданный DeepLearning.AI в сотрудничестве с Letta, был обновлен. Курс объясняет использование метода MemGPT для создания агентов LLM, способных управлять долговременной памятью (превышающей ограничения контекстного окна). Новое содержание включает предварительно развернутый сервис Letta Agent (для практики с агентами в облаке) и функцию потокового вывода (позволяющую наблюдать за пошаговым процессом рассуждений агента), направленные на помощь учащимся в создании более адаптивных и коллаборативных систем ИИ. (Источник: DeepLearningAI)

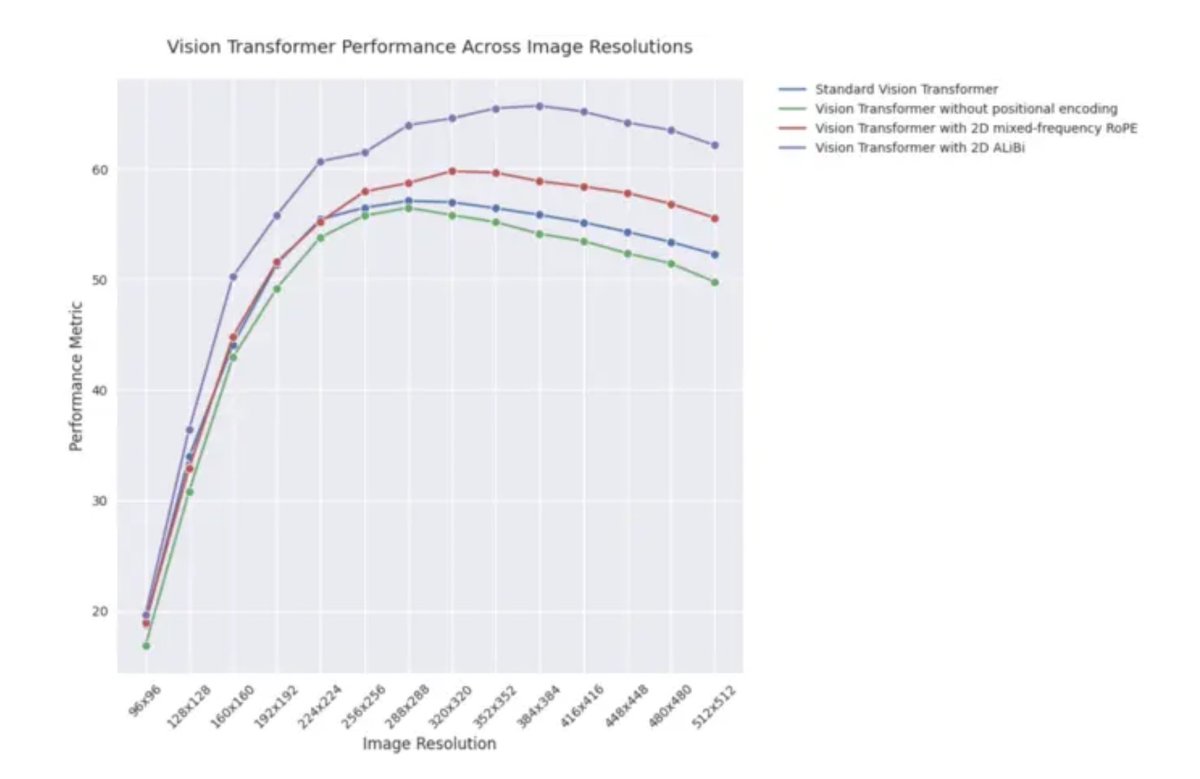
Пост в блоге ICLR 2025: Экстраполяционная производительность 2D ALiBi в визуальных Transformer: Пост в блоге ICLR 2025 указывает, что визуальные Transformer (ViT), использующие двумерное внимание с линейным смещением (2D ALiBi), показывают наилучшую производительность на наборе данных Imagenet100 при экстраполяции на изображения большего размера. ALiBi — это метод относительного позиционного кодирования, успешное применение которого в NLP вдохновило его исследование в области зрения. Результат показывает, что 2D ALiBi помогает ViT лучше обобщать на разрешения изображений, не встречавшиеся во время обучения. (Источник: OfirPress)
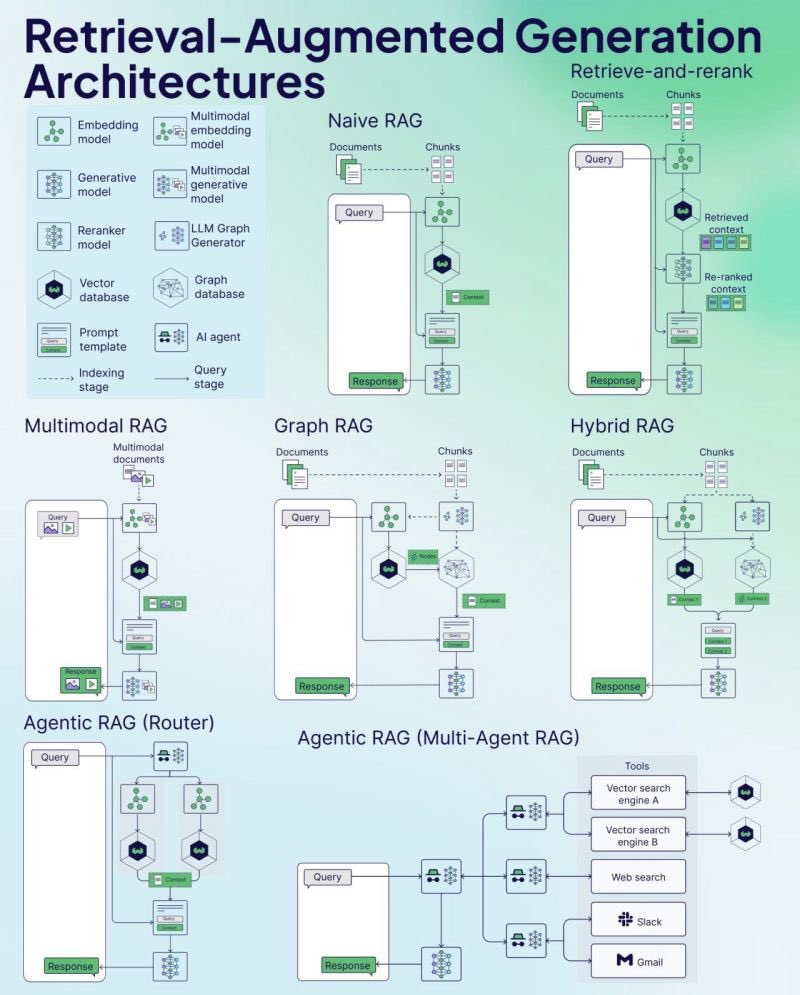
Weaviate выпустила шпаргалку по RAG (Cheat Sheet): Компания Weaviate, разработчик векторных баз данных, выпустила шпаргалку (Cheat Sheet) по генерации с дополнением извлеченной информацией (RAG). Этот материал предназначен для предоставления разработчикам краткого справочного руководства, которое может охватывать ключевые концепции RAG, архитектуру, распространенные методы, лучшие практики или часто задаваемые вопросы, чтобы помочь разработчикам лучше понять и реализовать системы RAG. (Источник: bobvanluijt)
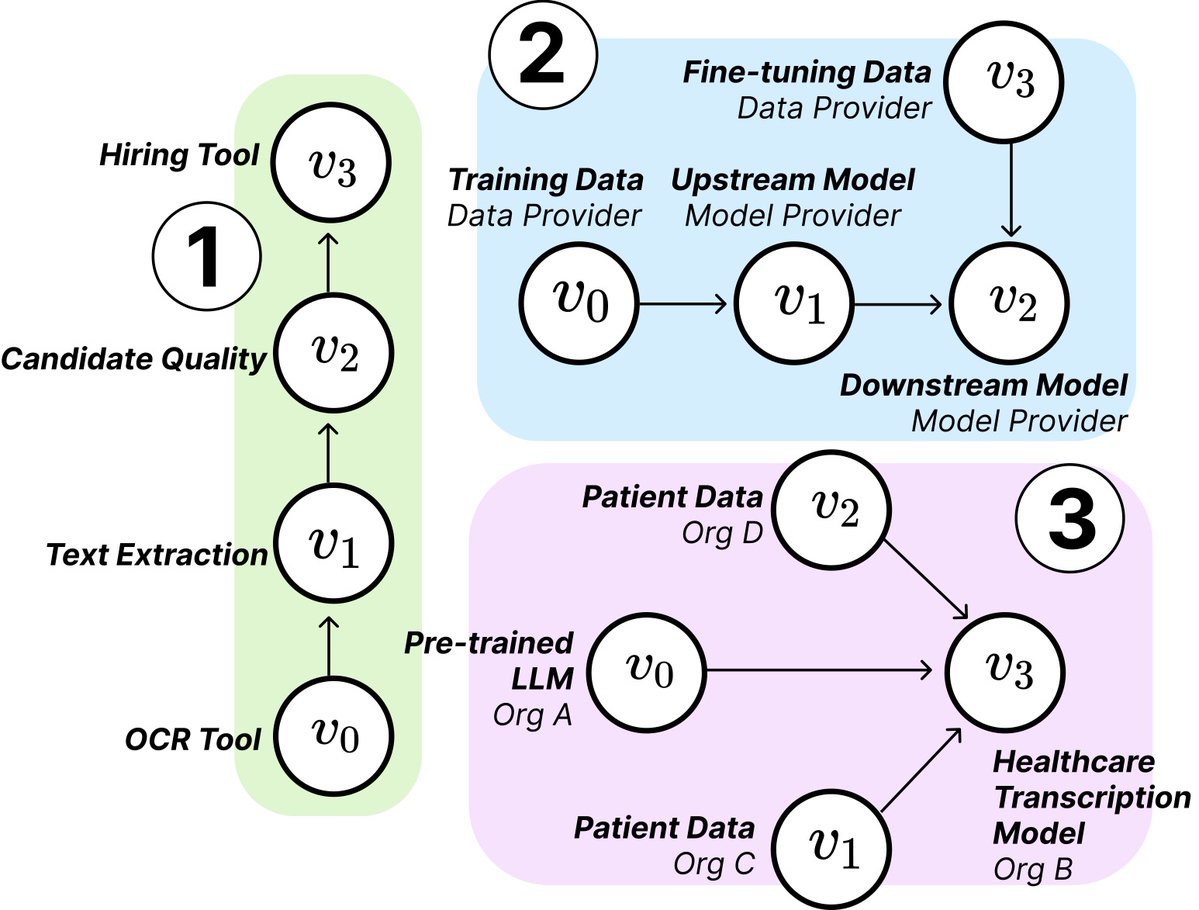
Исследование MIT раскрывает структуру и риски цепочек поставок ИИ: Исследователи из MIT и других учреждений опубликовали новую статью, исследующую возникающие цепочки поставок ИИ (AI Supply Chains). Поскольку процесс создания систем ИИ становится все более децентрализованным (включая поставщиков базовых моделей, сервисы дообучения, поставщиков данных, платформы развертывания и т. д.), статья исследует влияние этой сетевой структуры, включая потенциальные риски (например, распространение сбоев вверх по цепочке), асимметрию информации, конфликты контроля и целей оптимизации. Исследование анализирует два случая с помощью теоретического и эмпирического анализа, подчеркивая важность понимания и управления цепочками поставок ИИ. (Источник: jachiam0, aleks_madry)
LangChain выпустила 5-минутное видео-представление LangSmith: LangChain выпустила короткое 5-минутное видео, объясняющее функции ее коммерческой платформы LangSmith. Видео рассказывает, как LangSmith помогает на протяжении всего жизненного цикла разработки приложений и агентов LLM, включая наблюдаемость (observability), оценку (evaluation) и инжиниринг промптов (prompt engineering), с целью помочь разработчикам повысить производительность приложений. (Источник: LangChainAI)
Together AI выпустила обучающее видео по запуску и дообучению OSS моделей: Together AI выпустила новое обучающее видео, которое показывает пользователям, как запускать и дообучать (fine-tune) open-source большие модели на платформе Together AI. Видео, вероятно, охватывает шаги по выбору модели, настройке среды, загрузке данных, запуску задач обучения и выполнению инференса, с целью снижения порога входа для пользователей, использующих их платформу для кастомизации и развертывания open-source моделей. (Источник: togethercompute)
Статья предлагает использовать «разумных агентов» для оценки социальных когнитивных способностей LLM: Новая статья представляет фреймворк SAGE (Sentient Agent as a Judge), новый метод оценки, использующий симулированных разумных агентов (Sentient Agent), имитирующих человеческую эмоциональную динамику и внутренние рассуждения, для оценки социальных когнитивных способностей LLM в диалоге. Фреймворк предназначен для проверки способности LLM интерпретировать эмоции, выводить скрытые намерения и отвечать с эмпатией. Исследование показало, что в 100 сценариях поддерживающего диалога эмоциональные оценки разумных агентов сильно коррелируют с человеко-центрированными метриками (такими как BLRI, показатели эмпатии), и что LLM с сильными социальными способностями не обязательно требуют пространных ответов. (Источник: menhguin)

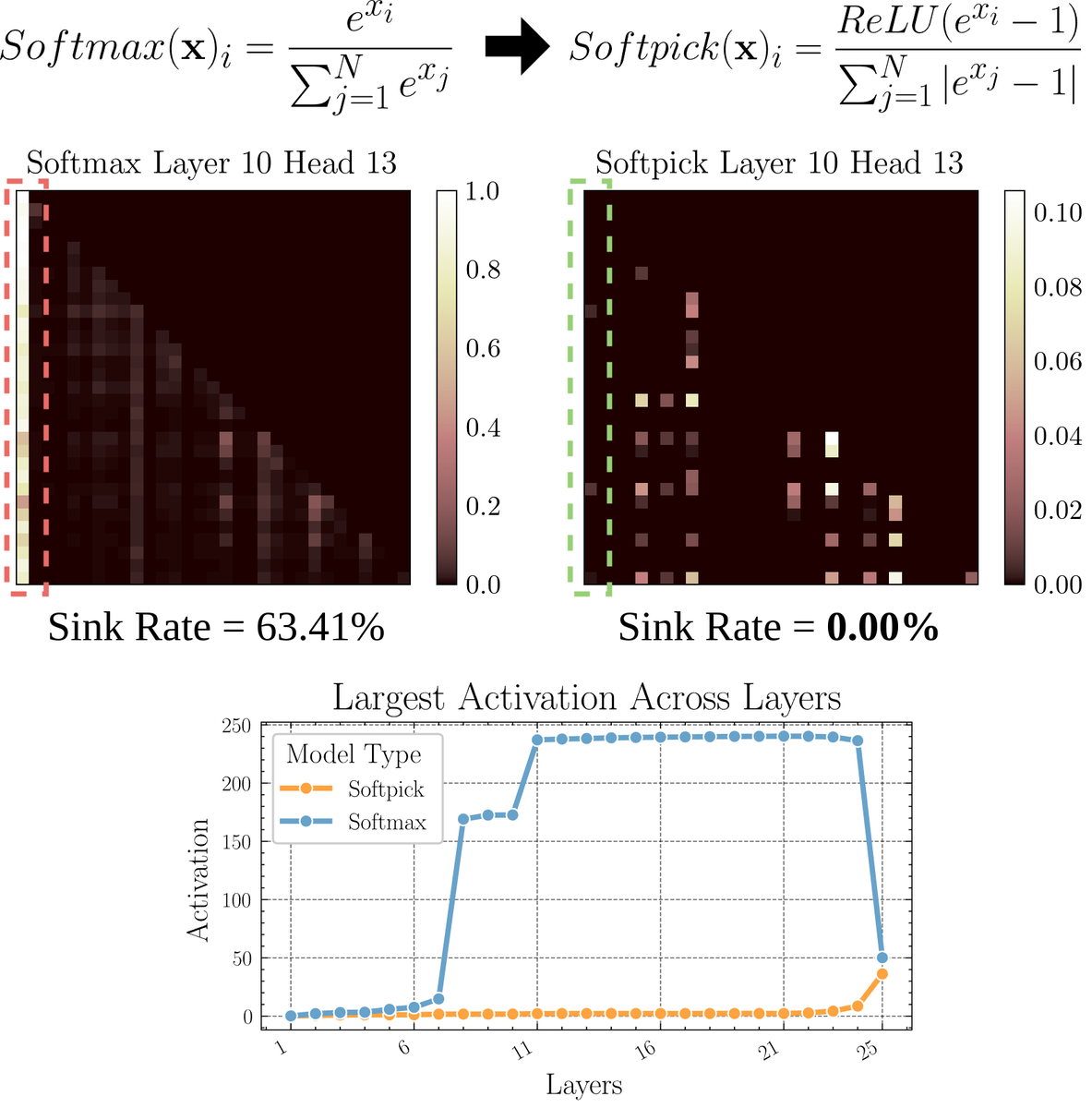
Статья рассматривает Softpick: альтернативный механизм внимания Softmax: Препринт статьи предлагает Softpick, альтернативу Softmax, которая решает проблемы «поглощения внимания» (attention sink) и больших значений активации в механизме внимания путем модификации Softmax. Метод предлагает использовать ReLU(x — 1) в числителе Softmax и abs(x — 1) в членах знаменателя. Исследователи считают, что эта простая корректировка может улучшить некоторые врожденные проблемы существующих механизмов внимания, сохраняя при этом производительность, особенно при обработке длинных последовательностей или в сценариях, требующих более стабильного распределения внимания. (Источник: sedielem)
💼 Бизнес
AI-стартап RogoAI привлек $50 млн в раунде B: RogoAI, компания, специализирующаяся на создании AI-нативной исследовательской платформы для индустрии финансовых услуг, объявила о завершении раунда финансирования B на сумму $50 млн под руководством Thrive Capital при участии J.P. Morgan Asset Management, Tiger Global и других. Финансирование будет использовано для ускорения разработки продуктов и расширения рынка RogoAI в области финансового анализа и автоматизации исследований. (Источник: hwchase17, hwchase17)
Стартап корпоративного AI-поиска Glean завершает новый раунд финансирования с оценкой в $7 млрд: По сообщению The Information, стартап корпоративного AI-поиска Glean близок к завершению нового раунда финансирования под руководством Wellington Management с оценкой около $7 млрд. Компания всего четыре месяца назад привлекла финансирование с оценкой в $4,6 млрд, и такой значительный скачок оценки отражает высокие ожидания рынка в отношении корпоративных AI-приложений и решений для управления знаниями. (Источник: steph_palazzolo)
Groq сотрудничает с Meta для ускорения Llama API: Компания Groq, разработчик чипов для AI-инференса, объявила о сотрудничестве с Meta для ускорения официального Llama API. Разработчики смогут запускать последние модели Llama (начиная с Llama 4) с пропускной способностью до 625 токенов/сек и, как утверждается, мигрировать с OpenAI всего за 3 строки кода. Это сотрудничество направлено на предоставление разработчикам высокоскоростных решений с низкой задержкой для запуска больших языковых моделей. (Источник: JonathanRoss321)

🌟 Сообщество
Сообщество активно обсуждает сравнение Llama4 и DeepSeek R1, а также проблемы бенчмарков для оценки моделей: CEO Meta Марк Цукерберг в интервью ответил на вопрос о том, почему Llama4 уступает DeepSeek R1 на арене (Arena), заявив, что open-source бенчмарки имеют недостатки, слишком смещены в сторону специфических сценариев использования и не отражают реальную производительность моделей в продуктах. Он также отметил, что модель Meta для инференса еще не выпущена и не может напрямую сравниваться с R1. Эти высказывания, в сочетании со статьей Cohere, ставящей под сомнение LMArena, вызвали широкое обсуждение в сообществе о том, как справедливо оценивать LLM, об ограничениях публичных рейтингов и стратегиях выбора моделей. Многие согласны, что не следует чрезмерно полагаться на общие рейтинги, а нужно выбирать модели, учитывая конкретные сценарии использования, оценку на частных данных и сигналы сообщества. (Источник: BlancheMinerva, huggingface, ClementDelangue, sarahcat21, xanderatallah, arohan, ClementDelangue, 量子位)
Дискуссии о замене людей ИИ продолжают накаляться: На Reddit появилось несколько постов, обсуждающих влияние ИИ на занятость. Переводчик испанского языка сообщил, что его бизнес значительно сократился из-за улучшения качества ИИ-перевода; другой звукорежиссер также сменил профессию из-за улучшения качества ИИ-мастеринга. В то же время обсуждаются посты о том, как применение ИИ в медицинской диагностике, налоговом консультировании и других областях может снизить спрос на профессионалов. Эти случаи вызвали дискуссии о том, наступил ли кризис безработицы из-за автоматизации ИИ раньше, чем ожидалось, и как специалистам следует адаптироваться (например, использовать ИИ для трансформации, искать ценность, которую ИИ не может заменить). (Источник: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Феномен «итерационного дрейфа» при генерации изображений ИИ привлекает внимание: Пользователь Reddit попытался заставить ChatGPT постоянно «точно копировать» предыдущее сгенерированное изображение. Результаты показали, что содержание и стиль изображения постепенно отклоняются от исходного ввода с увеличением числа итераций, в конечном итоге стремясь к абстракции или определенным паттернам (например, самоанские татуировки / женские черты). Пример с Дуэйном Джонсоном также демонстрирует подобную эволюцию от реализма к абстракции. Этот феномен раскрывает проблемы текущих моделей генерации изображений в поддержании долгосрочной согласованности, а также возможные смещения или конвергенцию в их внутренних представлениях. (Источник: Reddit r/ChatGPT, Reddit r/ChatGPT)

Сообщество обсуждает, заменит ли ИИ работу венчурных капиталистов (VC): Марк Андриссен считает, что когда ИИ сможет делать все остальное, венчурный капитал может стать одной из последних работ, выполняемых людьми, потому что это больше похоже на искусство, чем на науку, и зависит от вкуса, психологии и терпимости к хаосу. Это мнение вызвало дискуссию: некоторые считают это «смешным заявлением», сомневаясь в уникальности ранних инвестиций; другие, исходя из своего опыта (например, в разработке игр), считают, что эта идея может быть «самоуспокоением» (cope), поскольку люди в каждой области склонны думать, что их работа не может быть заменена ИИ из-за необходимости уникального вкуса. (Источник: colin_fraser, gfodor, cto_junior, pmddomingos)
Несанкционированный эксперимент Цюрихского университета по убеждению с помощью ИИ на Reddit вызвал споры: По сообщениям модератора Reddit r/changemyview и Reddit Lies, исследователи Цюрихского университета, не уведомив явно пользователей сообщества, развернули несколько аккаунтов ИИ для участия в обсуждениях в этом сабреддите, тестируя убедительность аргументов, сгенерированных ИИ. Исследование показало, что процент успеха ИИ-аккаунтов в убеждении (получение отметки “∆”, указывающей на изменение мнения пользователя) был значительно выше базового уровня для людей, и пользователи не смогли распознать их ИИ-идентичность. Хотя утверждается, что эксперимент был одобрен комитетом по этике, его тайный характер и потенциальная «манипулятивность» вызвали широкие этические споры и опасения по поводу злоупотребления ИИ. (Источник: 量子位)
💡 Прочее
Нужно ли все еще изучать программирование в эпоху ИИ, заставляет задуматься: В сообществе возникли дискуссии о ценности изучения программирования в эпоху ИИ. Считается, что, хотя способность ИИ генерировать код растет, а характер работы инженеров-программистов быстро меняется, изучение программирования по-прежнему важно. Изучение программирования является основой для понимания того, как эффективно сотрудничать с ИИ (особенно с LLM), и эта способность к сотрудничеству человека и машины станет ключевой компетенцией во всех областях. Программирование — это отправная точка для того, чтобы люди начали «танцевать» с ИИ, и в будущем во всех отраслях потребуется овладеть этой моделью сотрудничества. (Источник: alexalbert__, _philschmid)
Разработчики обсуждают опыт и проблемы программирования с помощью ИИ: Разработчики в сообществе делятся опытом использования инструментов программирования с ИИ (таких как Cursor, ChatGPT Desktop). Некоторые скучают по прошлому «периоду охлаждения» во время ожидания компиляции, считая, что программирование с помощью ИИ вновь вводит цикл, похожий на редактирование/компиляцию/отладку. Другие отмечают, что инструменты ИИ все еще имеют недостатки в понимании контекста (например, редактирование нескольких файлов), следовании инструкциям (например, избегание использования определенного синтаксиса/ингредиентов), и иногда требуются очень конкретные инструкции для достижения ожидаемого результата, а код, сгенерированный ИИ, все еще нуждается в ручной проверке и отладке. (Источник: hrishioa, eerac, Reddit r/ChatGPT)

Повышение уровня счастья с помощью ИИ: потенциальное направление применения ИИ: Пост на Reddit предполагает, что одним из конечных применений ИИ может быть повышение человеческого счастья. Автор считает, что на основе гипотезы лицевой обратной связи (улыбка повышает счастье) и принципа концентрации внимания, ИИ (например, Gemini 2.5 Pro) может генерировать высококачественный обучающий контент, помогая людям повышать уровень счастья с помощью простых упражнений (например, улыбаться и концентрироваться на приносимом ею удовольствии). Автор поделился отчетом и аудио, сгенерированными ИИ, и предсказывает, что в будущем могут появиться успешные приложения или роботы-“наставники счастья”, основанные на этом принципе. (Источник: Reddit r/deeplearning)
