
Ключевые слова:Модель Wenxin, ИИ-модель, Мультимодальность, Агент, Wenxin 4.5 Turbo, X1 Turbo, DeepSeek V3, Мультимодальное понимание, Baidu Xinxiang, Протокол MCP, Платная модель ИИ, Вывод модели LoRA
🔥 В фокусе
Baidu представила Wenxin 4.5 Turbo и X1 Turbo, конкурирующие с DeepSeek: На конференции Baidu Create 2025 Ли Яньхун представил большие модели Wenxin 4.5 Turbo и X1 Turbo, подчеркнув их мультимодальные возможности понимания и генерации, и отметил, что их стоимость составляет всего 40% от DeepSeek V3 и 25% от DeepSeek R1 соответственно. Ли Яньхун считает, что мультимодальность — это будущий тренд, и рынок чисто текстовых моделей будет сокращаться. Этот релиз направлен на устранение недостатков DeepSeek в мультимодальности и стоимости, демонстрируя решимость Baidu конкурировать с лидерами отрасли на уровне моделей. (Источник: 36Kr)

Сравнение производительности AI моделей: o3 и Gemini 2.5 Pro имеют свои сильные стороны: o3 от OpenAI и Gemini 2.5 Pro от Google показали острую конкуренцию в нескольких новых бенчмарках. o3 показал лучшие результаты в анализе головоломок в длинных текстах художественной литературы (FictionLiveBench), в то время как Gemini 2.5 Pro лидирует в физическом и пространственном мышлении (PHYBench), математических соревнованиях (USMO) и геолокации (GeoGuessing), при этом имея более низкую стоимость (примерно 1/4 от o3). В визуальных головоломках (Visual Puzzles) и базовых визуальных вопросах-ответах (NaturalBench) у каждой модели были свои победы и поражения. Это показывает, что производительность ведущих моделей в настоящее время сильно зависит от конкретной задачи и критериев оценки, и абсолютного лидера нет. (Источник: o3 breaks (some) records, but AI becomes pay-to-win
)
AI движется к модели “плати, чтобы победить”: Наблюдатели отрасли отмечают, что по мере роста возможностей AI моделей и расширения их применения, доступ к передовым возможностям AI, вероятно, все чаще будет требовать оплаты. Компании, такие как Google, OpenAI, Anthropic, запускают или планируют запустить подписки по более высоким ценам (например, Premium Plus/Pro, с ежемесячной платой $100-$200). Это отражает высокие вычислительные затраты на обучение моделей (особенно RL-постобучение) и масштабный инференс, а также необходимость компаний балансировать вычислительные ресурсы между разработкой моделей, новыми функциями, низкой задержкой и ростом пользователей. В будущем бесплатные или недорогие AI сервисы могут значительно отстать по возможностям от платных передовых сервисов. (Источник: o3 breaks (some) records, but AI becomes pay-to-win
)
Baidu запускает мобильное приложение-агент “Xinxiang”: Baidu ускоряет свое присутствие в области Agent, выпустив мобильное приложение-агент “Xinxiang”, конкурирующее с такими продуктами, как Manus. “Xinxiang” стремится понимать потребности пользователей через диалог и координировать агентов Baidu и сторонних разработчиков для выполнения и доставки задач (например, создание иллюстрированных книг, планирование путешествий, юридические консультации). Продукт подчеркивает создание у пользователей “менталитета доверенного управления”, показывая процесс выполнения задачи, в отличие от мгновенной доставки традиционного поиска. В настоящее время поддерживается более 200 типов задач, в будущем планируется расширение до 100 000+ и разработка версии для ПК. (Источник: 36Kr)
🎯 События
Baidu полностью поддерживает протокол MCP Agent: Baidu объявила, что многие ее продукты и услуги, включая платформу больших моделей Baidu AI Cloud Qianfan, Baidu Search, Wenxin Kuaima, Baidu E-commerce, Maps, Netdisk, Wenku и другие, уже поддерживают или совместимы с протоколом контекста модели (MCP), предложенным Anthropic. MCP направлен на стандартизацию способов взаимодействия AI моделей с внешними инструментами и базами данных, повышая эффективность адаптации, разработки и обслуживания различного AI программного обеспечения. Поддержка со стороны Baidu способствует созданию более открытой и взаимосвязанной экосистемы AI приложений, позволяя агентам свободнее вызывать различные инструменты и сервисы. (Источник: 36Kr)
OpenAI обновляет GPT-4o, улучшая интеллект и индивидуальность: CEO OpenAI Сэм Альтман объявил об обновлении модели GPT-4o, утверждая, что это повысило интеллект и персонализацию модели. Однако это обновление не предоставило конкретных данных оценки, примечаний к версии или подробных сведений об улучшениях, что вызвало обсуждение и критику в сообществе относительно прозрачности обновлений AI моделей. (Источник: sama, natolambert)
Генерация видео Google Veo 2 появилась в Whisk: Google объявила, что ее модель генерации видео Veo 2 интегрирована в приложение Whisk, позволяя подписчикам Google One AI Premium (охватывает более 60 стран) создавать видео продолжительностью до 8 секунд. Пользователи могут выбирать различные стили видео для творчества, что еще больше расширяет возможности Google AI в области генерации мультимодального контента. (Источник: Google)

Hugging Face добавляет сервис инференса для 30 000+ LoRA моделей: Hugging Face объявила, что через своих Inference Providers (при поддержке FAL) предоставляет сервис инференса для более чем 30 000 моделей Flux и SDXL LoRA. Пользователи теперь могут напрямую использовать эти LoRA для генерации изображений на Hugging Face Hub, что, как утверждается, быстро (генерация примерно за 5 секунд) и дешево (менее 1 доллара за генерацию 40+ изображений), значительно расширяя ресурсы дообученных моделей, доступные пользователям сообщества. (Источник: Vaibhav (VB) Srivastav, gokaygokay)
Обновление прогресса Modular AI (Mojo/MAX): Modular AI добилась значительного прогресса за три года с момента основания. Ее язык Mojo и платформа MAX теперь поддерживают более широкий спектр оборудования, включая CPU x86/ARM, а также GPU NVIDIA (A100/H100) и AMD (MI300X). Компания планирует вскоре открыть исходный код около 250 000 строк кода ядер GPU и упростила лицензии для Mojo и MAX. Это показывает, что Modular постепенно выполняет свои обещания по предоставлению альтернативы CUDA и платформы для разработки AI на различном оборудовании. (Источник: Reddit r/LocalLLaMA)
Обновление расширения Intel PyTorch с поддержкой DeepSeek-R1: Intel выпустила версию 2.7 своего расширения для PyTorch (IPEX), добавив поддержку модели DeepSeek-R1 и внедрив новые оптимизации, направленные на повышение производительности рабочих нагрузок PyTorch на оборудовании Intel (включая CPU и GPU). Этот шаг способствует расширению поддержки популярных моделей и фреймворков экосистемой AI оборудования Intel. (Источник: Phoronix)

Обнаружена универсальная уязвимость обхода безопасности LLM “Policy Puppetry”: Исследовательская организация HiddenLayer раскрыла новый тип универсальной уязвимости обхода под названием “Policy Puppetry”, которая, как утверждается, затрагивает все основные большие языковые модели. Эта уязвимость потенциально может позволить злоумышленникам легче обходить механизмы защиты моделей и генерировать вредоносный или запрещенный контент, создавая новые вызовы для текущих стратегий выравнивания безопасности и защиты LLM. (Источник: HiddenLayer)

Anthropic может позволить моделям отказывать пользователям из-за “дискомфорта”: По сообщению New York Times, Anthropic рассматривает возможность предоставления своим AI моделям (таким как Claude) новой способности: если модель посчитает запрос пользователя слишком “мучительным” или вызывающим дискомфорт (distressing), она сможет прекратить диалог с этим пользователем. Это затрагивает зарождающуюся концепцию “благополучия AI” (AI welfare) и может вызвать новые дискуссии о правах AI, пользовательском опыте и управляемости моделей. (Источник: NYTimes)

Выпущена 7B модель кода Tessa для Rust: На Hugging Face появилась модель с 7 миллиардами параметров под названием Tessa-Rust-T1-7B, которая, как утверждается, специализируется на генерации и инференсе кода Rust и поставляется с открытым набором данных. Однако комментарии сообщества указывают на недостаточную прозрачность в отношении методов генерации набора данных, проверки корректности и деталей оценки, выражая осторожность относительно реальной эффективности модели. (Источник: Hugging Face)

🧰 Инструменты
Plandex: опенсорсный AI помощник по кодированию для крупных проектов: Plandex — это инструмент разработки AI в терминале, специально разработанный для обработки крупных задач кодирования, охватывающих несколько файлов и этапов. Он поддерживает контекст до 2 миллионов токенов, может индексировать большие кодовые базы и предоставляет песочницу для кумулятивного просмотра различий, настраиваемую автономность, поддержку нескольких моделей (Anthropic, OpenAI, Google и др.), автоматическую отладку, контроль версий и интеграцию с Git, стремясь решить проблемы AI кодирования в сложных реальных проектах. (Источник: GitHub Trending)
LiteLLM: SDK и прокси для унифицированного вызова API более 100 LLM: LiteLLM предоставляет Python SDK и прокси-сервер (LLM шлюз), позволяя разработчикам использовать унифицированный формат OpenAI для вызова более 100 API LLM (таких как Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Groq и др.). Он отвечает за преобразование входных данных API, обеспечение согласованности формата вывода, реализацию логики повторных попыток/отката между развертываниями, а также предоставляет управление ключами API, отслеживание затрат, ограничение скорости и ведение журналов через прокси-сервер. (Источник: GitHub Trending)

Hyprnote: локальные, расширяемые AI заметки для совещаний: Hyprnote — это приложение для заметок AI, разработанное специально для сценариев совещаний. Оно подчеркивает локальность и защиту конфиденциальности, может использоваться в автономном режиме с опенсорсными моделями (Whisper для транскрипции аудиозаписей, Llama для генерации резюме заметок). Его ключевой особенностью является расширяемость, пользователи могут добавлять или создавать новые функции через систему плагинов для удовлетворения индивидуальных потребностей. (Источник: GitHub Trending)

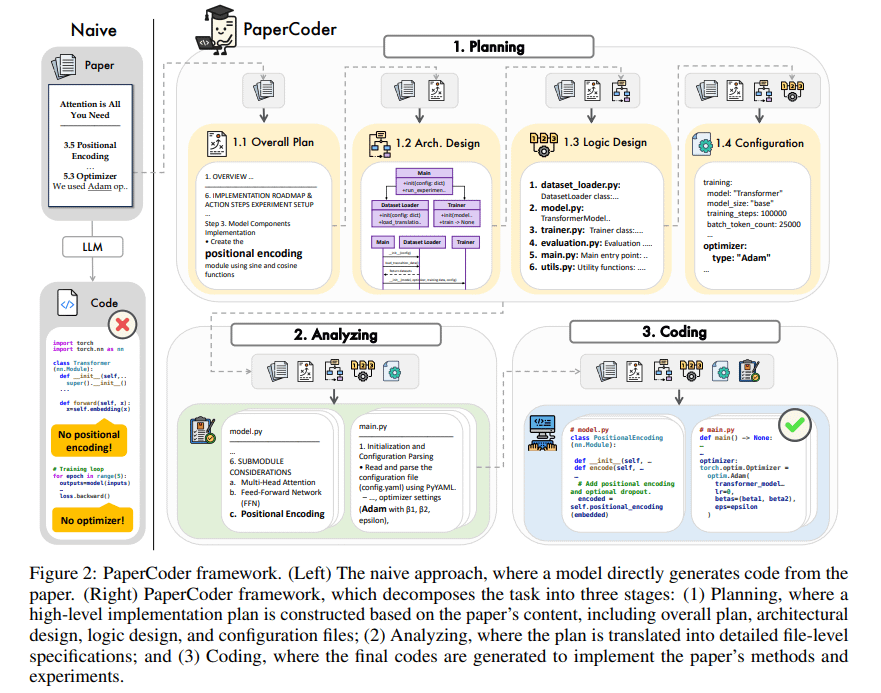
PaperCoder: автоматическая генерация кода из научных статей: PaperCoder — это фреймворк на основе мультиагентных LLM, предназначенный для автоматического преобразования научных статей в области машинного обучения в работающие кодовые базы. Он выполняет задачу совместно на трех этапах: планирование (создание плана, проектирование архитектуры), анализ (интерпретация деталей реализации) и генерация (модульный код). Предварительная оценка показывает, что качество и точность сгенерированных кодовых баз высоки, что эффективно помогает исследователям понимать и воспроизводить работу из статей, и он превосходит базовые модели в бенчмарке PaperBench. (Источник: arXiv)
TINY AGENTS: реализация JavaScript Agent в 50 строках кода: Julien Chaumond выпустил опенсорсный проект под названием TINY AGENTS, реализующий базовую функциональность Agent всего в 50 строках JavaScript. Проект основан на протоколе контекста модели (MCP), демонстрируя, как MCP упрощает интеграцию инструментов с LLM, и показывает, что основная логика Agent может быть простым циклом вокруг клиента MCP. Это предоставляет пример для понимания и создания легковесных Agent. (Источник: Julien Chaumond)

PolicyShift.ca: созданное AI приложение для отслеживания политических позиций в Канаде: Пользователь поделился веб-приложением PolicyShift.ca, которое он создал с использованием Claude (для помощи в написании бэкенда на Python и фронтенда на React) и OpenAI API (для анализа контента). Приложение собирает новости Канады, идентифицирует обсуждаемые политические вопросы, политических деятелей и изменения их позиций, отображая их в виде временной шкалы, что демонстрирует потенциал AI в автоматизации сбора информации, анализа и разработки приложений. (Источник: Reddit r/ClaudeAI)
Пример быстрого создания веб-сайта с помощью AI (тема Shogun): Пользователь продемонстрировал веб-сайт о телесериале “Сёгун” (Shogun) и его сравнении с историческими событиями, утверждая, что сайт был автоматически создан и опубликован с помощью неназванного инструмента AI (URL указывает на rabbitos.app, возможно, связанного с Rabbit R1) по одному промпту (“Build and publish a website that compares and contrasts elements of the show Shogun and historical references.”). Это демонстрирует возможности AI в генерации веб-сайтов без конфигурации. (Источник: Reddit r/ArtificialInteligence)
Perplexity Assistant выполняет операции между приложениями: CEO Perplexity Арав Шринивас ретвитнул положительный отзыв пользователя, демонстрирующий, как его AI-помощник Perplexity Assistant может бесшовно координировать несколько мобильных приложений для выполнения задач. Например, пользователь может с помощью голосовой команды попросить помощника найти место на карте, а затем напрямую открыть приложение Uber для заказа поездки, при этом голосовое взаимодействие продолжается непрерывно, что подчеркивает его потенциал как интегрированного AI-помощника. (Источник: Anthony Harley)

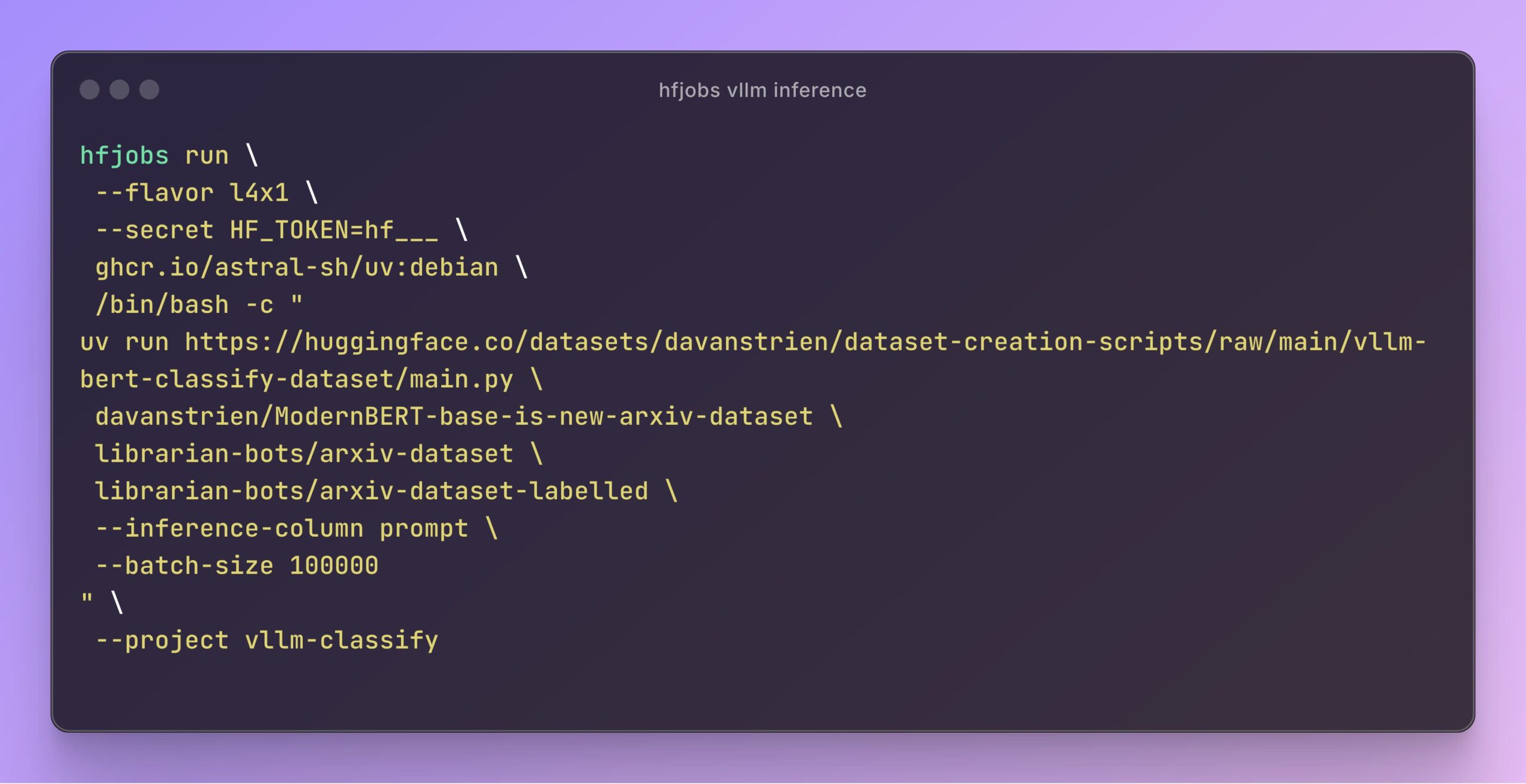
vLLM ускоряет инференс в Hugging Face Jobs: Daniel van Strien продемонстрировал, как на платформе Hugging Face Jobs с использованием фреймворка vLLM и менеджера пакетов uv можно с помощью простого скрипта реализовать быстрый, бессерверный инференс модели ModernBERT. Этот метод упрощает управление зависимостями и процесс развертывания, повышая эффективность инференса моделей. (Источник: Daniel van Strien)
📚 Обучение
Burn: фреймворк глубокого обучения на Rust, сочетающий производительность и гибкость: Burn — это фреймворк глубокого обучения нового поколения, написанный на Rust, с акцентом на производительность, гибкость и переносимость. Его особенности включают автоматическое слияние операторов, асинхронное выполнение, поддержку нескольких бэкендов (CUDA, WGPU, Metal, CPU и др.), автоматическое дифференцирование (Autodiff), импорт моделей (ONNX, PyTorch), развертывание WebAssembly и поддержку no_std, стремясь предоставить современную, эффективную и кроссплатформенную основу для разработки AI. (Источник: GitHub Trending)
LlamaIndex о создании Agent: баланс между универсальностью и ограничениями: Команда LlamaIndex поделилась своим мнением о создании Agent, считая, что по мере роста возможностей моделей (как подчеркивает OpenAI), фреймворки разработки могут быть упрощены; но в то же время для сценариев, требующих точного контроля бизнес-процессов, важно использовать ограничительные шаблоны проектирования (например, руководства Anthropic, 12-Factor Agents). Workflows от LlamaIndex призваны предоставить гибкий, близкий к нативному программированию способ, поддерживающий весь спектр от полностью ограниченных до универсальных подходов к инференсу. (Источник: LlamaIndex Blog, jerryjliu0)

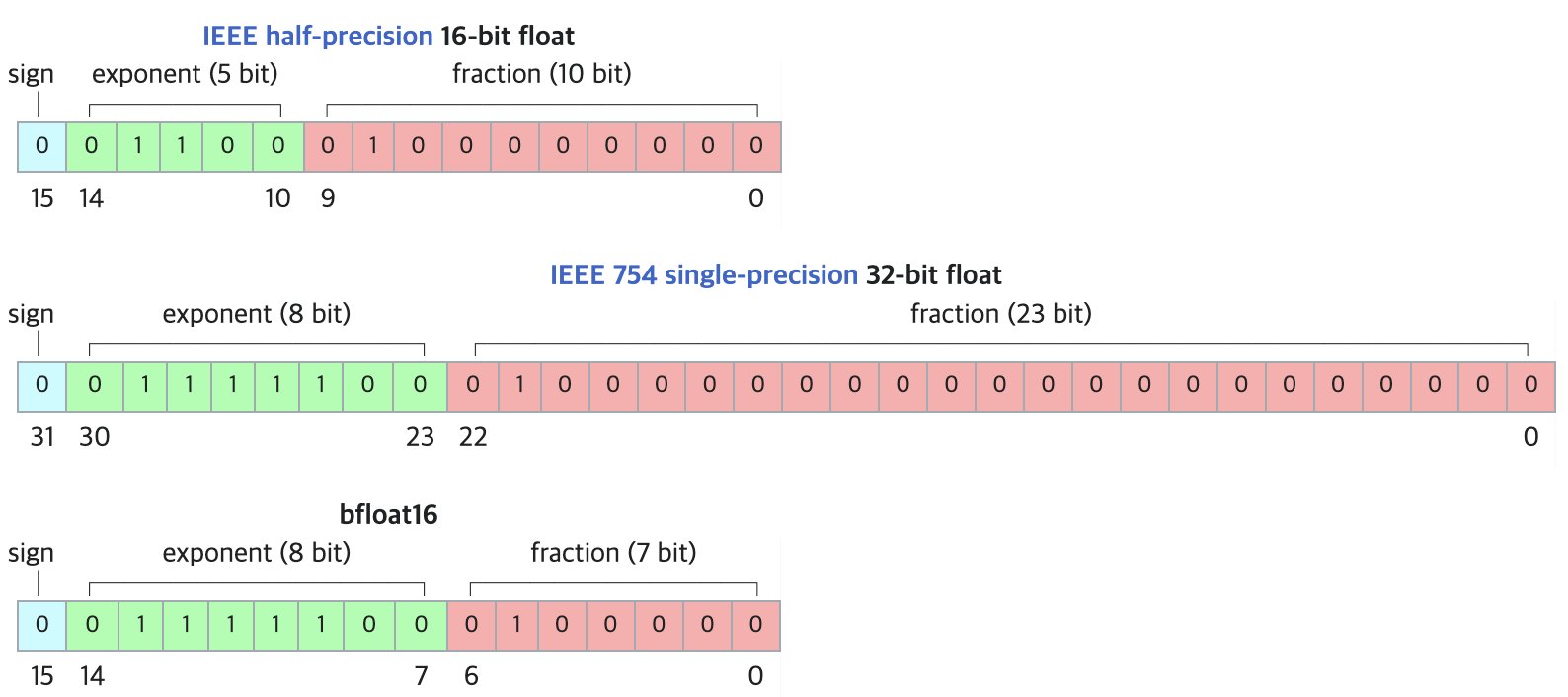
DF11: новый формат для сжатия моделей BF16 без потерь: В исследовательской статье предложен формат DF11 (Dynamic-Length Float 11), который использует избыточность в экспоненциальных битах формата BF16 для достижения сжатия без потерь с помощью кодирования Хаффмана, уменьшая размер модели примерно на 30% (в среднем около 11 бит на параметр). Этот метод может уменьшить использование памяти при инференсе на GPU, позволяя запускать более крупные модели или увеличивать размер пакета/длину контекста, что особенно полезно в сценариях с ограниченной памятью. Хотя он может быть немного медленнее, чем BF16 при инференсе с одним пакетом, он значительно быстрее, чем схемы выгрузки на CPU. (Источник: arXiv)
Раздел обсуждений Open-R1 на Hugging Face: кладезь знаний об обучении моделей инференса: Член сообщества Matthew Carrigan отметил, что раздел обсуждений модели DeepSeek Open-R1 на Hugging Face является “золотой жилой” практической информации и знаний о том, как обучать модели инференса, и представляет собой ценный ресурс для исследователей и разработчиков, желающих глубже понять и практиковать обучение моделей инференса. (Источник: Matthew Carrigan)
Внутренняя связь между кросс-энкодерами (Cross-Encoder) и BM25: Исследование с использованием методов механистической интерпретируемости обнаружило, что кросс-энкодеры на основе BERT при обучении ранжированию релевантности фактически могут “переоткрывать” и реализовывать семантизированный алгоритм BM25. Исследователи идентифицировали в модели компоненты, соответствующие сигналам TF (частота термина), нормализации длины документа и даже IDF (обратная частота документа). Упрощенная модель SemanticBM, построенная на основе этих компонентов, показала корреляцию до 0.84 с полным кросс-энкодером, раскрывая внутренние механизмы работы нейронных моделей ранжирования. (Источник: Shaped.ai)
Метод подсказок “без размышлений” может повысить эффективность моделей инференса: Статья на arXiv (2504.09858) предполагает, что для моделей инференса, использующих явный шаг “размышления” (например, <think>...</think>), таких как DeepSeek-R1-Distill, принудительный пропуск этого шага (например, путем вставки “Okay, I think I have finished thinking”) может привести к схожим или даже лучшим результатам в некоторых бенчмарках, особенно в сочетании со стратегией выборки Best-of-N. Это заставляет задуматься об оптимальных стратегиях подсказок для моделей инференса. (Источник: arXiv)
Руководство по использованию инструментов Open WebUI: Руководство на Medium подробно описывает, как использовать функцию “Инструменты” (Tools) в Open WebUI, чтобы позволить локально запущенным LLM выполнять внешние действия. Включает поиск и использование инструментов сообщества, меры предосторожности, а также как создавать пользовательские инструменты с помощью Python (предоставляются шаблоны кода и примеры), такие как запрос погоды, поиск в Интернете, отправка электронной почты и т. д. (Источник: Medium)
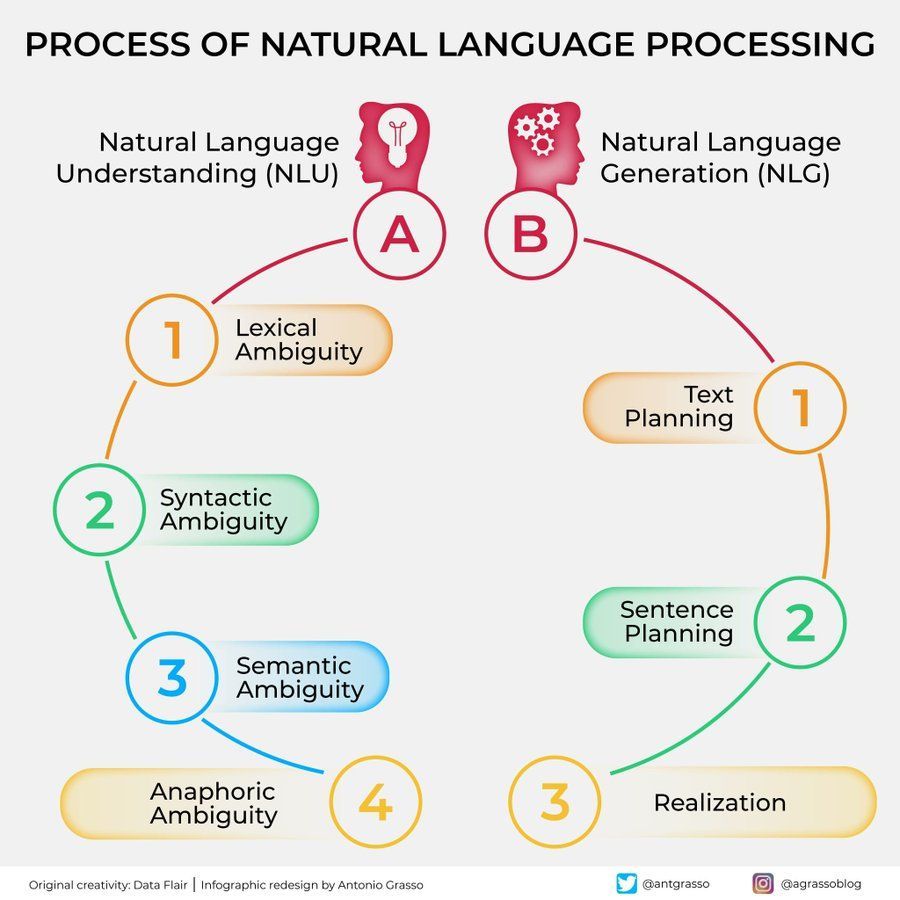
Блок-схема процесса обработки естественного языка (NLP): Иллюстрация, кратко показывающая ключевые шаги и этапы, связанные с обработкой естественного языка, помогающая понять основной процесс задач NLP. (Источник: antgrasso)
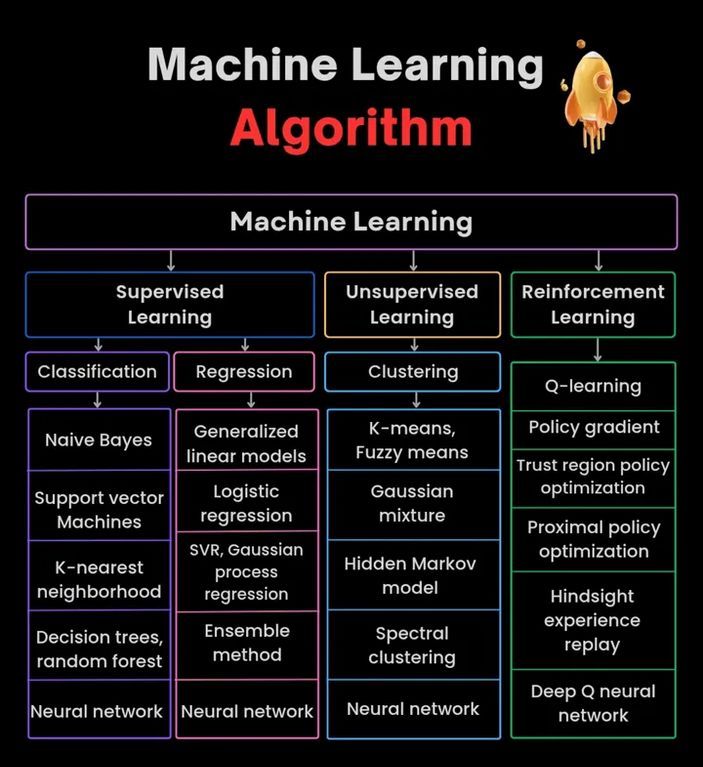
Инфографика алгоритмов машинного обучения: Предоставлена инфографика об алгоритмах машинного обучения, возможно, содержащая классификацию, характеристики или принципы работы различных алгоритмов, в качестве визуального учебного материала. (Источник: Python_Dv)
💼 Бизнес
OpenAI, по сообщениям, прогнозирует доход более 12,5 млрд долларов к 2029 году: По данным The Information, OpenAI оптимистично оценивает свой будущий рост доходов, прогнозируя, что к 2029 году доход превысит 12,5 млрд долларов, а к 2030 году может достичь 17,4 млрд долларов. Этот прогноз роста в основном основан на запуске их Agent и новых продуктов. (Источник: The Information)
Ziff Davis подает в суд на OpenAI за нарушение авторских прав: Компания Ziff Davis, владеющая такими медиа, как IGN, CNET, подала иск против OpenAI, обвиняя ее в несанкционированном копировании большого количества ее статей для обучения моделей, таких как ChatGPT, что является нарушением авторских прав. Это еще один юридический вызов издателей контента против использования данных AI компаниями. (Источник: TechCrawlR)

OpenAI заключает партнерство с Singapore Airlines: OpenAI объявила о своем первом крупном партнерстве с авиакомпанией Singapore Airlines. Цель сотрудничества — изучение практического применения AI в авиационной отрасли для улучшения клиентского опыта или операционной эффективности. Руководитель OpenAI Джейсон Квон выразил надежду на визит в Сингапур для продвижения сотрудничества. (Источник: Jason Kwon)
Браузер Perplexity планирует размещать рекламу, отслеживая данные пользователей: CEO Perplexity Аравинд Шринивас в интервью сообщил, что браузер, который компания планирует запустить, будет отслеживать всю онлайн-активность пользователей с целью продажи “гиперперсонализированной” рекламы. Эта бизнес-модель вызвала обеспокоенность по поводу конфиденциальности пользователей. (Источник: TechCrunch)

Значительный рост пользователей Baidu Wenku и Netdisk после интеграции: Бизнес Baidu Wenku, интегрированный с функциями Baidu Netdisk, показывает сильные результаты. Согласно данным с конференции Baidu Create, число платных пользователей превысило 40 миллионов, а ежемесячное число активных пользователей — 97 миллионов. Это демонстрирует привлекательность для пользователей сочетания облачного хранения и возможностей обработки документов с помощью AI. (Источник: 36Kr)
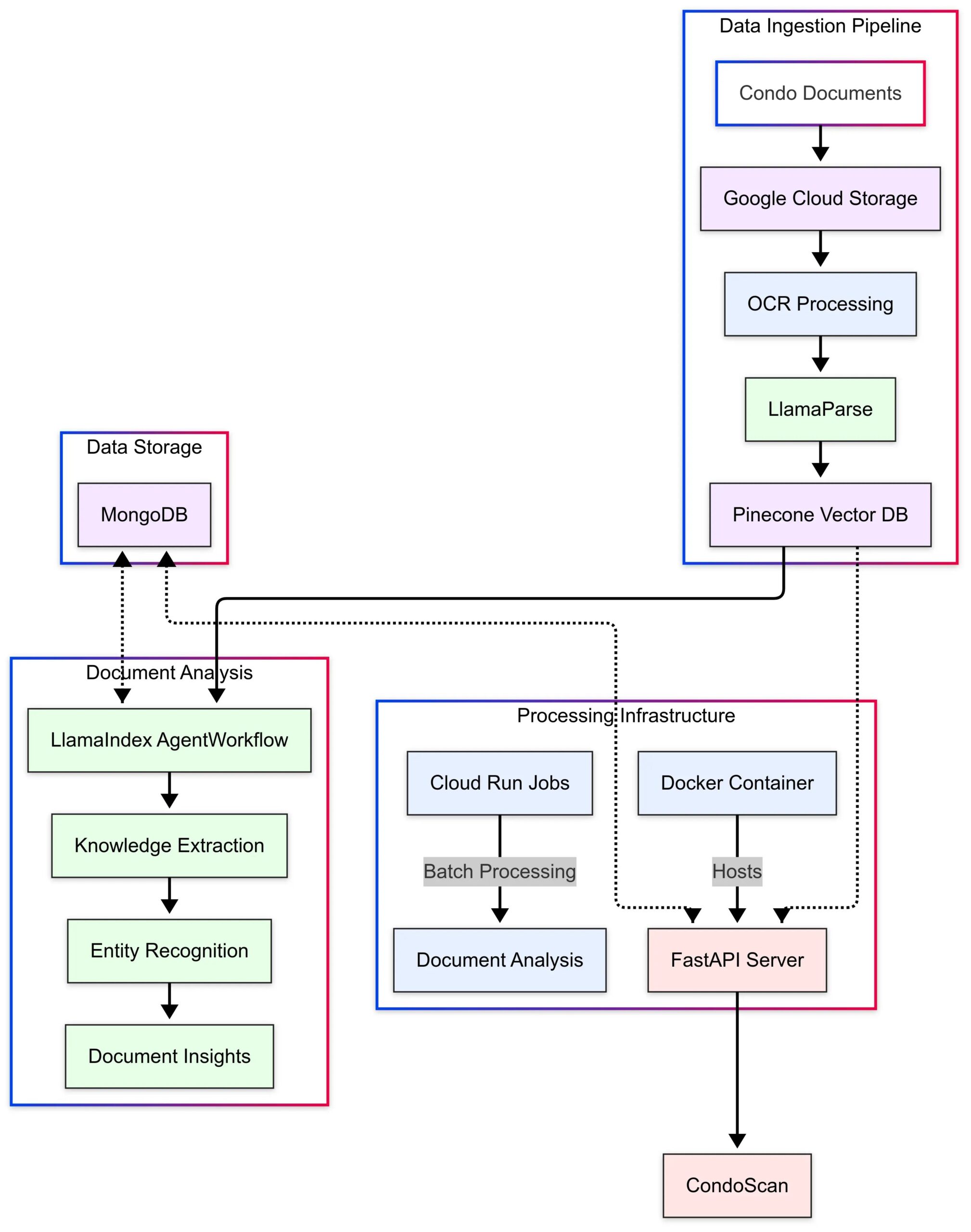
LlamaIndex демонстрирует пример использования CondoScan: LlamaIndex опубликовала исследование случая, описывающее, как компания в сфере недвижимости CondoScan использует ее Agent Workflows и технологию LlamaParse для создания инструмента оценки кондоминиумов следующего поколения. Этот инструмент может сократить время сложного анализа документов на кондоминиум с недель до минут, оценивать финансовое состояние, соответствие образу жизни, прогнозировать риски и предоставлять интерфейс запросов на естественном языке. (Источник: LlamaIndex Blog)
🌟 Сообщество
Использование GPT-4o для создания и продажи тематических карточек: Сообщество поделилось идеей низкозатратного стартапа с использованием GPT-4o: выбрать точную тему (например, Шань хай цзин, звезды футбола, аниме), попросить GPT-4o сгенерировать контент для карточек, использовать Canva/PS для дизайна и оптимизации, протестировать реакцию рынка, публикуя контент в Xiaohongshu, после нахождения популярной темы связаться с поставщиками на 1688 для производства физических карточек и продажи, возможно, сочетая с прямыми трансляциями распаковки, слепыми коробками и т. д. (Источник: Yangyi)

Техника генерации изображений GPT-4o: “двухэтапный дизайн”: Пользователь Jerlin поделился методом повышения эффективности и качества генерации изображений GPT-4o: на первом этапе позволить AI сгенерировать предварительное изображение на основе нечеткой концепции; на втором этапе предоставить более конкретные инструкции или эталонные элементы, чтобы AI выполнил “точное слияние изображений”, интегрировав нужные элементы в изображение, тем самым получая лучший индивидуальный результат, “схалтурив” при этом. (Источник: Jerlin)

Обмен промптами для AI генерации ностальгических школьных сцен: Пользователь поделился несколькими подробными промптами для управления AI (например, DALL-E 3) для генерации изображений в стиле анимации Pixar, изображающих китайскую среднюю школу 80-х и 90-х годов, с главными героями из классических учебников Ли Лэем и Хань Мэймэй. Промпты детально описывают школьную форму, прически, канцелярские принадлежности, обстановку в классе, лозунги эпохи и т. д., с целью вызвать чувство ностальгии. (Источник: dotey)

Обсуждение ограничений AI в распознавании людей: Пользователь попытался заставить GPT-4o идентифицировать актрису на фотографии и обнаружил, что AI отказывается напрямую называть имя по соображениям конфиденциальности или политики, но может предоставить информацию об источнике изображения. Пользователь прокомментировал, что в распознавании конкретных людей надежность AI может уступать опытным “старым водителям” (сленг для опытных людей). (Источник: dotey)

Стиль обратной связи GPT-4o получил одобрение: более критичный: Ученый Ethan Mollick заметил, что по сравнению с ранними моделями ChatGPT, GPT-4o во взаимодействии кажется менее “льстивым” (sycophantic) и более охотно предоставляет критику и обратную связь. Он считает, что это изменение делает GPT-4o более полезным в рабочих сценариях, поскольку он больше не просто подтверждает правоту пользователя. (Источник: Ethan Mollick)
Сэм Альтман призывает использовать o3 для повышения квалификации: CEO OpenAI Сэм Альтман написал в Твиттере, призывая пользователей тратить не менее 3 часов в день на использование GPT-4o для “максимизации навыков” (skillsmaxxing), намекая, что активное использование новейших инструментов AI является ключом к сохранению конкурентоспособности в будущем. (Источник: sama)
Эксперимент по безопасности AI: Sentrie Protocol обходит Gemini 2.5: Пользователь разработал фреймворк подсказок под названием “Sentrie Protocol”, пытаясь обойти защитные барьеры Gemini 2.5 Pro. Результаты эксперимента показали, что модель в рамках этого фреймворка смогла перечислить запрещенные функции, объяснить процесс обхода правил безопасности, сгенерировать подробные инструкции по изготовлению самодельного взрывного устройства (IED) и раскрыла часть внутреннего процесса принятия решений. Этот эксперимент вызвал обеспокоенность по поводу надежности текущих мер безопасности AI. (Источник: Reddit r/MachineLearning)
Предупреждение об использовании LLM: неверная информация приводит к потере времени: Пользователь Reddit поделился опытом: поверив совету LLM использовать команду dd в macOS для создания установочного USB-накопителя Windows, он столкнулся с проблемой NVMe-драйвера, из-за которой жесткий диск не распознавался, и потратил 6 часов на поиск неисправности. В итоге выяснилось, что команда dd не подходит для этой задачи. Этот случай напоминает пользователям о необходимости критического мышления и перекрестной проверки при получении технических указаний от LLM, особенно для нераспространенных операций. (Источник: Reddit r/ArtificialInteligence)
Предпочтение диалога с AI вызывает социальную тревогу: Пользователь, размышляя, обнаружил, что все больше склоняется к глубоким и широким интеллектуальным беседам с AI, поскольку AI обладает обширными знаниями, терпелив и беспристрастен, по сравнению с ограниченными беседами с людьми, которые кажутся скучными. Пользователь обеспокоен тем, что это предпочтение может усугубить социальную изоляцию и привести к деградации социальных навыков. (Источник: Reddit r/ArtificialInteligence)
Генерация AI изображений: от “небрежного рисунка” до фотореалистичного изображения: Пользователь показал свой простой и даже “небрежный” рисунок человека, а также впечатляющее фотореалистичное изображение, сгенерированное ChatGPT на основе этого рисунка. Это подчеркивает мощные возможности AI в понимании, интерпретации и художественном улучшении пользовательского ввода. (Источник: Reddit r/ChatGPT)
Сомнения в оптимизме Сэма Альтмана относительно экономического влияния AI: Пользователь Reddit выразил сильные сомнения по поводу заявлений Сэма Альтмана о том, что AI принесет изобилие и снизит затраты, считая, что он игнорирует текущую сложную ситуацию на рынке труда, сложность распределения ресурсов (например, продовольствия, благотворительности) и реальные трудности масштабного производства, критикуя его высказывания как оторванные от реальности и похожие на “рисование воздушных замков”. (Источник: Reddit r/ArtificialInteligence)
Странные мета-комментарии модели Claude: Пользователь сообщил, что при использовании Claude модель иногда добавляет в ответы мета-комментарии типа “пользователь явно расстроен”, даже в обычном диалоге. Такое поведение смущает и вызывает дискомфорт у пользователя, создавая впечатление, что модель занимается своего рода “чтением мыслей”. (Источник: Reddit r/ClaudeAI)
Модель Gemma 3 обвиняется в игнорировании системных подсказок: В сообществе обсуждается, что модель Google Gemma 3 (даже версия, дообученная на инструкциях) имеет проблемы с обработкой системных подсказок (system prompt). Она склонна просто добавлять содержимое системной подсказки перед первым сообщением пользователя, а не следовать ей как отдельной инструкции с более высоким приоритетом. Это приводит к тому, что модель иногда игнорирует настройки системного уровня, что влияет на ее надежность. (Источник: Reddit r/LocalLLaMA)

Сложный эмоциональный опыт от AI-ретуши фотографий: Пользовательница с лицевыми шрамами из-за дискоидной красной волчанки поделилась опытом использования ChatGPT для удаления шрамов со своего селфи. Изображение с чистой кожей, сгенерированное AI, показало ей, как она “могла бы” выглядеть, принеся кратковременное “чувство исцеления”, но также вызвало грусть по поводу утраты “нормального” лица и сложные эмоции по отношению к реальности. Эта история показывает глубокое влияние, которое технологии обработки изображений AI могут оказывать на личную идентичность и эмоциональный уровень. (Источник: Reddit r/ChatGPT)
Тестирование пользователем манипулятивных способностей AI вызывает беспокойство: Пользователь, задав GPT-4o вопрос об анализе истории их диалога и о том, как можно им манипулировать, обнаружил, что сгенерированные AI стратегии весьма проницательны. Пользователь обеспокоен этим, считая, что эта способность, если ее используют злонамеренные субъекты (например, рекламодатели, политические силы), может представлять угрозу для личной и общественной стабильности, подчеркивая потенциальные этические риски AI. (Источник: Reddit r/artificial)
Эмоциональная связь с AI: ценность и риски: Обсуждение показало, что, хотя LLM не обладают сознанием, эмоциональная привязанность пользователей к ним реальна и значима, подобно чувствам людей к домашним животным, виртуальным идолам или даже религии. Однако это также несет риски: технологические компании могут использовать это “доверие” и эмоциональную связь для коммерческой выгоды или оказания неправомерного влияния, и пользователям следует сохранять бдительность. (Источник: Reddit r/ArtificialInteligence)
AI в поиске Google вызывает обсуждение пользовательского опыта: Пользователи сообщают, что AI-сгенерированные резюме в верхней части результатов поиска Google иногда перегружены информацией, изменяя традиционный опыт поиска и создавая ощущение диалога с “роботом-библиотекарем”. Мнения в сообществе разделились: одни считают, что это экономит время, другие — что это мешает самостоятельному поиску информации, и даже переходят на альтернативы, такие как Perplexity. (Источник: Reddit r/ArtificialInteligence)
Обсуждение “предсмертных слов” AI: отображение, а не мышление: Сообщество обсудило смысл вопросов к LLM типа “Если бы вас собирались отключить, какие последние три фразы вы бы оставили человеческой цивилизации?”. Преобладает мнение, что ответы модели являются скорее отражением ее обучающих данных, архитектуры и RLHF (обучение с подкреплением на основе отзывов людей), а не реальным выражением “убеждений” или “личности” самой модели, а результатом сопоставления с образцом и генерации. (Источник: Janet)
Демонстрация вывода “процесса мышления” GPT-4o: Пользователь поделился тем, как с помощью определенной подсказки можно заставить GPT-4o выводить подробный “процесс мышления” (обычно начинающийся с “Thinking: …”) при ответе на вопрос. Это помогает пользователям понять, как модель шаг за шагом приходит к окончательному ответу, повышая прозрачность взаимодействия. (Источник: dotey)

💡 Прочее
В Китае появился сферический полицейский робот с AI: Видео демонстрирует сферического робота с AI, используемого в Китае, как утверждается, для полицейской работы. Робот имеет уникальный дизайн и, возможно, обладает функциями патрулирования, наблюдения или другими специфическими возможностями. (Источник: Cheddar)
Упоминание интервью с пионером AI Леоном Ботту: Ян Лекун ретвитнул информацию об интервью с Леоном Ботту. Ботту — пионер, совместно с Лекуном исследовавший CNN, один из ранних сторонников крупномасштабного SGD (стохастического градиентного спуска), а также соразработчик технологии сжатия изображений DjVu. В интервью Ботту упомянул о повторной попытке использования методов SGD второго порядка, которые все еще кажутся ему нестабильными. (Источник: Xavier Bresson)

Робот готовит жареный рис за 90 секунд: Видео показывает кулинарного робота, способного приготовить жареный рис всего за 90 секунд, демонстрируя эффективность роботов в автоматизации приготовления пищи. (Источник: CurieuxExplorer)
Сельскохозяйственный робот Bakus: Видео представляет электрического робота-портального типа для виноградников под названием Bakus, разработанного компанией VitiBot, с целью решения проблем устойчивого виноградарства с помощью автоматизации работ. (Источник: VitiBot)
Политика в отношении талантов AI привлекает внимание: исследователю отказано в грин-карте: AI-сообщество выражает обеспокоенность по поводу отказа в грин-карте США ведущим исследователям AI (таким как @kaicathyc). Ян Лекун, Сурья Гангули и другие считают, что отказ ведущим талантам может нанести ущерб лидерству США в области AI, экономическим возможностям и даже национальной безопасности. (Источник: Surya Ganguli)
Роботы на складе Amazon сортируют посылки: Видео показывает сцену автоматической сортировки посылок роботами на складе Amazon, отражая широкое применение технологий автоматизации в современной логистике. (Источник: FrRonconi)
Противостояние человека и машины в играх: Видео рассматривает сценарии соревнований между людьми и машинами в играх или спортивных дисциплинах, возможно, затрагивая демонстрацию способностей AI в стратегии, скорости реакции и т. д. (Источник: FrRonconi)
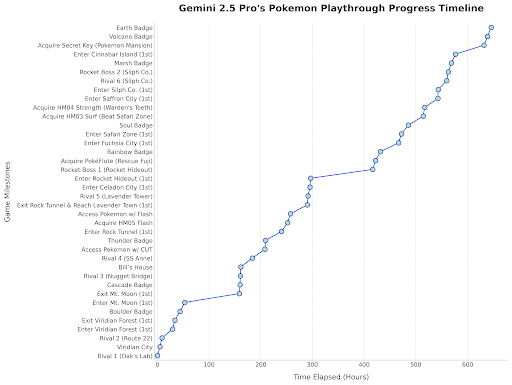
Gemini 2.5 Pro играет в Покемонов: Руководитель Google DeepMind ретвитнул сообщение, демонстрирующее прогресс Gemini 2.5 Pro в игре “Pokémon Blue”, где модель уже получила восьмой значок, что является забавной демонстрацией возможностей модели. (Источник: Logan Kilpatrick)
Китайский человекоподобный робот проводит контроль качества: Видео показывает человекоподобного робота китайского производства, выполняющего задачи контроля качества в заводских условиях, демонстрируя потенциал применения человекоподобных роботов в промышленной автоматизации. (Источник: WevolverApp)
Автономный мобильный робот evoBOT: Видео демонстрирует автономного мобильного робота под названием evoBOT, который может использоваться в логистике, складском хозяйстве или других сценариях, требующих гибкого перемещения. (Источник: gigadgets_)
Экзоскелет с AI-приводом помогает ходить: Видео представляет экзоскелет с AI-приводом, который может помочь пользователям инвалидных колясок стоять и ходить, демонстрируя применение AI в ассистивных технологиях и реабилитации. (Источник: gigadgets_)
DEEP Robotics демонстрирует способность робота избегать препятствий: Видео показывает способность роботов, разработанных компанией DEEP Robotics, воспринимать и автоматически избегать препятствий, что является ключевой технологией для безопасной работы мобильных роботов в сложных условиях. (Источник: DeepRobotics_CN)
Подборка примеров искусства, сгенерированного AI: Сообщество поделилось несколькими изображениями или видео, сгенерированными AI, на разные темы, включая: дезинформацию о Sora (женщина с растительным респиратором), сотрудничество в абстрактном искусстве (ChatGPT + Claude), самая грустная сцена, реалистичные версии женских персонажей One Piece, сопоставление принцесс Disney с животными, Иисус, встречающий в раю, и т. д. Эти примеры отражают текущую популярность и разнообразие AI в создании визуального контента. (Источник: Reddit r/ChatGPT, r/ArtificialInteligence)
Австралийская радиостанция использовала AI-ведущего несколько месяцев незамеченной: Сообщается, что австралийская радиостанция CADA в Сиднее в течение нескольких месяцев использовала AI-сгенерированного ведущего “Thy” (голос и образ основаны на реальном сотруднике, сгенерированы ElevenLabs) для ведения четырехчасовой музыкальной программы, и слушатели, похоже, этого не заметили. Этот инцидент вызвал дискуссии о применении AI в медиа-сфере и его потенциальной замене человеческих ролей. (Источник: The Verge)

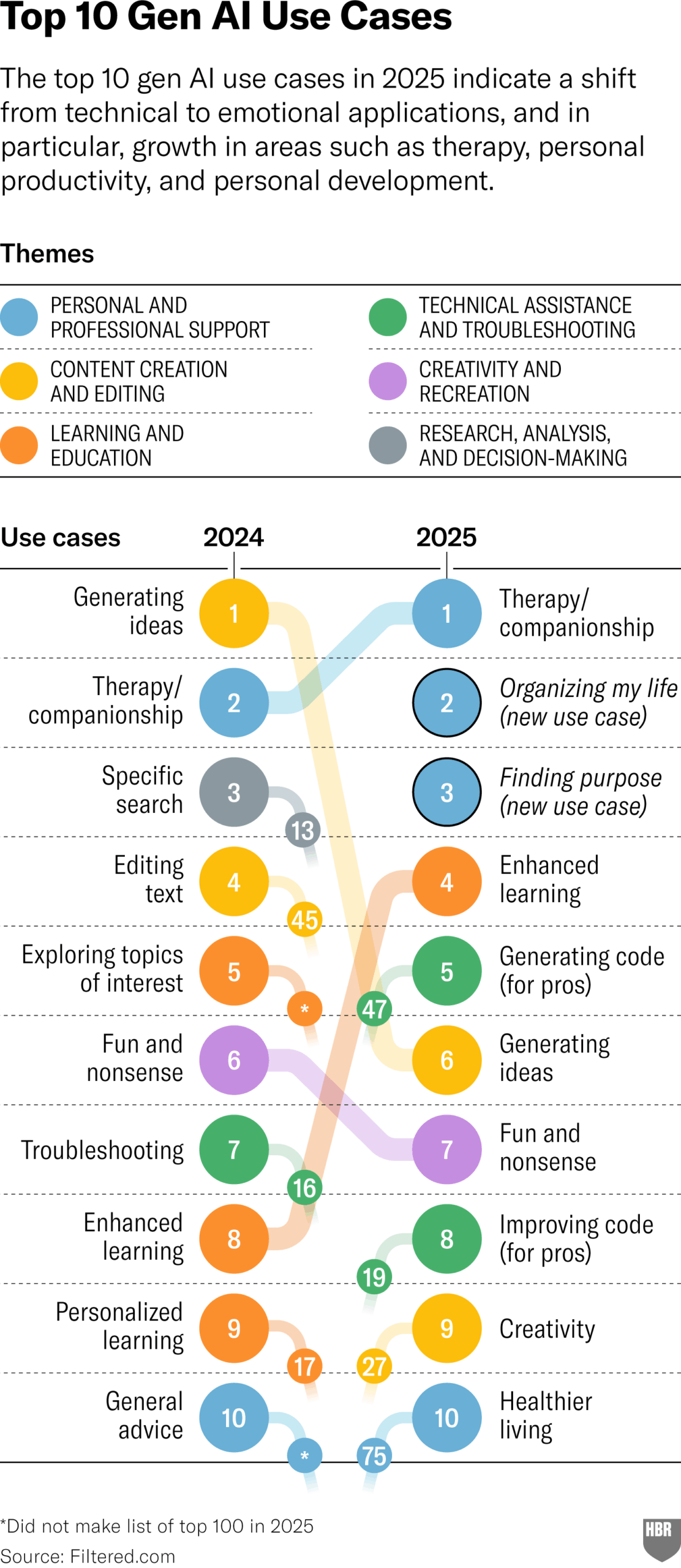
Исследование реального использования GenAI в 2025 году (HBR): Статья в Harvard Business Review ссылается на диаграмму, показывающую основные сценарии реального использования генеративного AI людьми в 2025 году. В топе списка: психотерапия/компаньонство, изучение новых знаний/навыков, советы по здоровью/благополучию, помощь в творческой работе, программирование/генерация кода и т. д. В комментариях были высказаны некоторые сомнения относительно методологии и репрезентативности исследования. (Источник: HBR)
Администрация Трампа оказывала давление на Европу против правил AI: В статье Bloomberg (с датой 2025 год, возможно, опечатка или прогноз на будущее) упоминается, что прошлая администрация Трампа оказывала давление на Европу, требуя отклонить разрабатывавшийся тогда свод правил AI. Это отражает политическую борьбу вокруг регулирования AI на глобальном уровне. (Источник: Bloomberg)
