
Palavras-chave:Kimi K2 Thinking, Gemini, Agente de IA, LLM, Modelo de código aberto, Kimi K2 Thinking com contexto de 256K, Gemini 1.2 trilhão de parâmetros, Chamada de ferramenta de agente de IA, Aceleração de inferência LLM, Teste de benchmark de modelo de IA de código aberto
🔥 Foco
Lançamento do modelo Kimi K2 Thinking: Novo avanço na capacidade de inferência de IA de código aberto : A Moonshot AI lançou o modelo Kimi K2 Thinking, um modelo de agente de inferência de código aberto com trilhões de parâmetros, que se destaca em benchmarks como HLE e BrowseComp, suporta uma janela de contexto de 256K e pode executar 200-300 chamadas de ferramentas contínuas. O modelo alcançou o dobro da velocidade de inferência com quantização INT4, reduzindo o uso de memória pela metade sem perda de precisão. Isso marca uma nova fronteira para modelos de IA de código aberto em inferência e capacidade de agente, competindo com os principais modelos de código fechado a um custo menor, e espera-se que acelere o desenvolvimento e a popularização de aplicações de IA. (Fonte: eliebakouch, scaling01, bookwormengr, vllm_project, nrehiew_, crystalsssup, Reddit r/LocalLLaMA)

Apple e Google colaboram para uma grande atualização da Siri com Gemini : A Apple planeja introduzir o modelo de IA Gemini de 1.2 trilhão de parâmetros do Google no iOS 26.4, com lançamento previsto para a primavera de 2026, para uma atualização completa da Siri. Esta versão personalizada do modelo Gemini será executada em servidores de nuvem privada da Apple, visando melhorar significativamente a compreensão semântica, o diálogo multi-turno e a capacidade de recuperação de informações em tempo real da Siri, além de integrar a função de pesquisa na web com IA. Esta medida marca uma importante mudança estratégica da Apple em buscar colaboração externa no campo da IA para acelerar a inteligência de seus produtos principais, indicando um grande salto funcional para a Siri. (Fonte: op7418, pmddomingos, TheRundownAI)

Cientista de IA Kosmos alcança salto na eficiência de pesquisa, descobrindo 7 resultados de forma independente : O cientista de IA Kosmos completou o equivalente a 6 meses de trabalho de um cientista humano em 12 horas, lendo 1500 artigos, executando 42 mil linhas de código e produzindo relatórios científicos rastreáveis. Ele descobriu independentemente 7 resultados nas áreas de neuroproteção e ciência dos materiais, sendo 4 deles propostos pela primeira vez. O sistema, através de memória contínua e planejamento autônomo, evoluiu de uma ferramenta passiva para um colaborador de pesquisa. Embora ainda exija validação humana de cerca de 20% das conclusões, isso indica que a colaboração humano-máquina irá remodelar o paradigma da pesquisa científica. (Fonte: Reddit r/MachineLearning, iScienceLuvr)
🎯 Tendências
Modelo Google Gemini 3 Pro vaza acidentalmente, gerando preocupação na comunidade : O modelo Google Gemini 3 Pro supostamente vazou acidentalmente, estando brevemente disponível no Gemini CLI para IPs dos EUA, mas com erros frequentes e instabilidade. Este vazamento gerou grande atenção da comunidade sobre o número de parâmetros do modelo e seu futuro lançamento, indicando que os mais recentes avanços do Google no campo de grandes modelos de linguagem podem ser divulgados em breve. (Fonte: op7418)
Lançamento iminente do modelo OpenAI GPT-5.1 Thinking, com alta expectativa da comunidade : Múltiplas fontes nas redes sociais sugerem que a OpenAI está prestes a lançar o modelo GPT-5.1 Thinking, com informações vazadas confirmando sua existência. Esta notícia gerou grande expectativa na comunidade sobre as capacidades da nova geração de modelos da OpenAI e seu tempo de lançamento, com foco especial nas melhorias em raciocínio e capacidade de “pensar”, o que pode impulsionar novamente a fronteira da tecnologia de IA. (Fonte: scaling01)
Pesquisa da Anthropic revela consciência introspectiva emergente em LLMs, gerando preocupação sobre autoconsciência da IA : A Anthropic, através de experimentos de injeção de conceitos, descobriu que seus LLMs (como Claude Opus 4.1 e 4) exibem uma consciência introspectiva emergente, sendo capazes de detectar conceitos injetados com 20% de sucesso, distinguir entre “pensamento” interno e entrada de texto, e identificar a intenção de saída. Os modelos também podem regular estados internos quando solicitados, indicando que os LLMs atuais estão desenvolvendo uma autoconsciência mecânica diversificada e não confiável, o que levanta discussões profundas sobre a autoconsciência e a consciência da IA. (Fonte: TheTuringPost)

OpenAI Codex em rápida iteração, ChatGPT suporta interrupção e orientação para maior eficiência de interação : O modelo Codex da OpenAI está melhorando rapidamente, enquanto o ChatGPT também adicionou a funcionalidade de os usuários interromperem e adicionarem novo contexto durante a execução de consultas longas, sem precisar recomeçar ou perder o progresso. Esta importante atualização de funcionalidade permite que os usuários guiem e refinem as respostas da IA como se estivessem colaborando com um colega de equipe real, aumentando significativamente a flexibilidade e a eficiência da interação, e otimizando a experiência do usuário em pesquisas aprofundadas e consultas complexas. (Fonte: nickaturley, nickaturley)
Tencent Hunyuan lança podcast interativo de IA, explorando um novo modelo de interação de conteúdo de IA : A Tencent Hunyuan lançou o primeiro podcast interativo de IA da China, permitindo que os usuários interrompam e façam perguntas a qualquer momento durante a audição. A IA, combinando contexto, informações de fundo e pesquisa online, fornece respostas. Embora a tecnologia tenha alcançado uma interação de voz mais natural, seu cerne ainda é a interação do usuário com a IA, e não com o criador. As respostas não têm relação direta com o criador, e a monetização comercial e o modelo de pagamento do usuário ainda enfrentam desafios, exigindo a exploração de como estabelecer uma conexão emocional entre usuários e criadores. (Fonte: 36氪)
Desenvolvimento e desafios do mercado de hardware de IA e inteligência incorporada: de fones de ouvido a robôs humanoides : Com a maturidade dos modelos grandes e da tecnologia multimodal, o mercado de fones de ouvido de IA continua a aquecer, com funções que se estendem ao ecossistema de conteúdo e monitoramento de saúde. A indústria de robôs de inteligência incorporada também está no limiar de uma nova rodada de explosão, com empresas como Xpeng e PHYBOT exibindo robôs humanoides, esclarecendo dúvidas sobre “pessoas escondidas” e explorando cenários de aplicação como cuidados com idosos e preservação cultural (como caligrafia, kung fu). No entanto, a indústria enfrenta desafios como custos, retorno sobre o investimento, coleta de dados e gargalos de padronização. No curto prazo, é necessário focar pragmaticamente na “versatilidade de cenários”, e no longo prazo, plataformas abertas e colaboração de ecossistemas são necessárias. A IA na área da saúde também precisa abordar as lacunas no cuidado ao paciente. (Fonte: 36氪, 36氪, op7418, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Novos modelos e avanços de desempenho: geração de código Qwen3-Next, modelos híbridos vLLM e inferência de baixa memória : O modelo Qwen3-Next da Alibaba Cloud demonstra excelente desempenho na geração de código complexo, criando com sucesso aplicações web totalmente funcionais. O vLLM oferece suporte completo a modelos híbridos como Qwen3-Next, Nemotron Nano 2 e Granite 4.0, melhorando a eficiência da inferência. O modelo Jamba Reasoning 3B da AI21 Labs alcança uma operação de memória ultrabaixa de 2.25 GiB. Maya-research/maya1 lança uma nova geração de modelo de texto para fala autorregressivo, suportando a personalização de timbre por descrição de texto. O TabPFN-2.5 expande a capacidade de processamento de dados tabulares para 50 mil amostras. O modelo Windsurf SWE-1.5 é analisado como mais semelhante ao GLM-4.5, sugerindo a aplicação de grandes modelos domésticos no Vale do Silício. O MiniMax AI ocupa o segundo lugar na arena RockAlpha. Esses avanços impulsionam coletivamente os limites de desempenho dos LLMs em geração de código, eficiência de inferência, multimodalidade e processamento de dados tabulares. (Fonte: Reddit r/deeplearning, vllm_project, AI21Labs, Reddit r/LocalLLaMA, Reddit r/MachineLearning, dotey, Alibaba_Qwen, MiniMax__AI)

Infraestrutura de IA e pesquisa de ponta: resfriamento AWS, LLM difusivo e arquitetura multilíngue : A Amazon AWS lança o sistema de resfriamento líquido In-Row Heat Exchanger (IRHX), resolvendo desafios de resfriamento para a infraestrutura de IA. Joseph Redmon retorna à pesquisa de IA, publicando o artigo OlmoEarth, explorando modelos de base para observação da Terra. A Meta AI lança a nova arquitetura “Mixture of Languages”, otimizando o treinamento de modelos multilíngues. A equipe Inception alcança LLM difusivo, aumentando a velocidade de geração em 10 vezes. O Google DeepMind AlphaEvolve é usado para exploração matemática em larga escala. O modelo Wan 2.2, otimizado com NVFP4, aumenta a velocidade de inferência em 8%. Esses avanços impulsionam coletivamente a eficiência da infraestrutura de IA e a inovação em áreas de pesquisa central. (Fonte: bookwormengr, iScienceLuvr, TimDarcet, GoogleDeepMind, mrsiipa, jefrankle)

Tecnologia Neuralink BCI capacita usuários paralisados a controlar braços mecânicos : A tecnologia de interface cérebro-computador (BCI) da Neuralink permitiu com sucesso que usuários paralisados controlassem braços mecânicos através do pensamento. Este avanço revolucionário indica o enorme potencial da IA na assistência médica e na interação humano-computador, podendo no futuro ser combinado com robôs de assistência à vida, melhorando significativamente a qualidade de vida e a independência de pessoas com deficiência. (Fonte: Ronald_vanLoon)
🧰 Ferramentas
Google Gemini Computer Use Preview lançado, capacitando a interação automatizada de IA na web : O Google lançou o modelo Gemini Computer Use Preview, que os usuários podem executar via interface de linha de comando (CLI), permitindo que ele execute operações de navegador, como pesquisar “Hello World” no Google. A ferramenta suporta ambientes Playwright e Browserbase e pode ser configurada via Gemini API ou Vertex AI, fornecendo a base para agentes de IA realizarem interações automatizadas na web, expandindo enormemente as capacidades dos LLMs em aplicações práticas. (Fonte: GitHub Trending, Reddit r/LocalLLaMA, Reddit r/artificial)

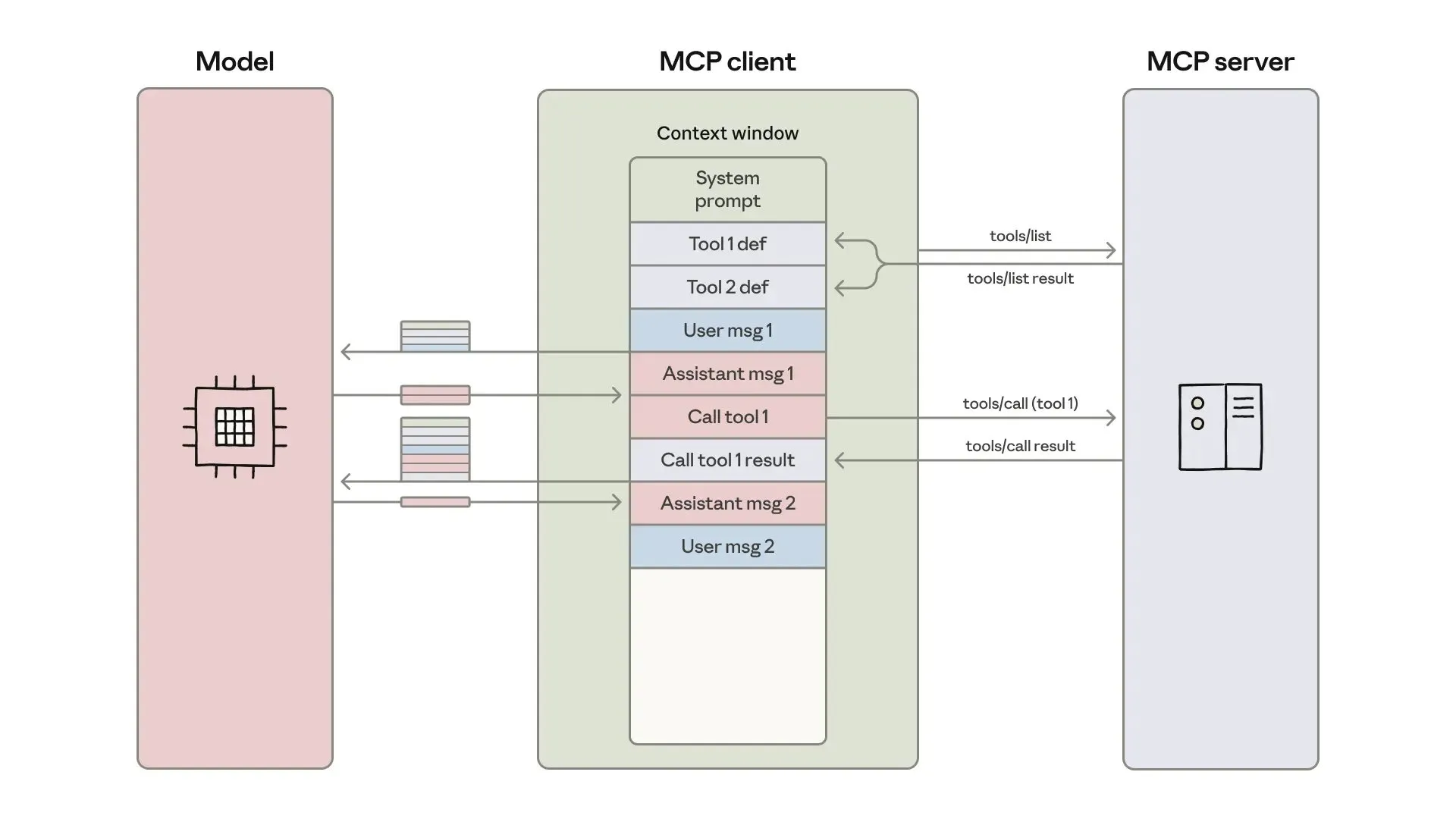
Desenvolvimento e otimização de agentes de IA: engenharia de contexto e construção eficiente : A Anthropic publicou um guia sobre como construir agentes de IA mais eficientes, focando na resolução de problemas de custo de token, latência e combinação de ferramentas em chamadas de ferramentas. O guia, através de uma abordagem “código como API”, descoberta progressiva de ferramentas e processamento de dados no ambiente, reduziu o uso de tokens para fluxos de trabalho complexos de 150 mil para 2 mil. Ao mesmo tempo, desenvolvedores de habilidades de agente ClaudeAI compartilham experiências, enfatizando que as Agent Skills devem ser vistas como um problema de engenharia de contexto, e não como um empilhamento de documentos. Através de um sistema de carregamento de três camadas, a velocidade de ativação e a eficiência de tokens foram significativamente melhoradas, provando a importância da “regra das 200 linhas” e da divulgação progressiva. (Fonte: omarsar0, Reddit r/ClaudeAI)
Chat LangChain lança nova versão, oferecendo uma experiência de chat mais rápida e inteligente : O Chat LangChain lançou uma nova versão, anunciada como “mais rápida, mais inteligente e mais bonita”, com o objetivo de substituir a documentação tradicional por uma interface de chat, ajudando os desenvolvedores a entregar projetos mais rapidamente. Esta atualização melhora a experiência do usuário do ecossistema LangChain, tornando-o mais fácil de usar e desenvolver, e fornecendo uma ferramenta mais eficiente para a construção de aplicações LLM. (Fonte: hwchase17)
Plataforma de codificação AI Yansu lança recurso de simulação de cenário, aumentando a confiança no desenvolvimento de software : Yansu é uma nova plataforma de codificação de IA focada no desenvolvimento de software sério e complexo, cuja característica única é colocar a simulação de cenário antes da codificação. Este método visa aumentar a confiança e a eficiência no desenvolvimento de software através da simulação prévia de cenários de desenvolvimento, reduzindo a depuração e o retrabalho posteriores, otimizando assim todo o processo de desenvolvimento. (Fonte: omarsar0)
Qdrant Engine lança solução RAG nativa da nuvem, permitindo controle total dos dados : O Qdrant Engine publicou um novo artigo da comunidade apresentando uma solução RAG (Retrieval Augmented Generation) nativa da nuvem baseada em Qdrant (banco de dados vetorial), KServe (embeddings) e Envoy Gateway (roteamento e métricas). Este é um stack RAG completo de código aberto que oferece controle total dos dados, facilitando a construção de aplicações de IA eficientes para empresas e desenvolvedores, com ênfase especial na privacidade dos dados e na capacidade de implantação autônoma. (Fonte: qdrant_engine)

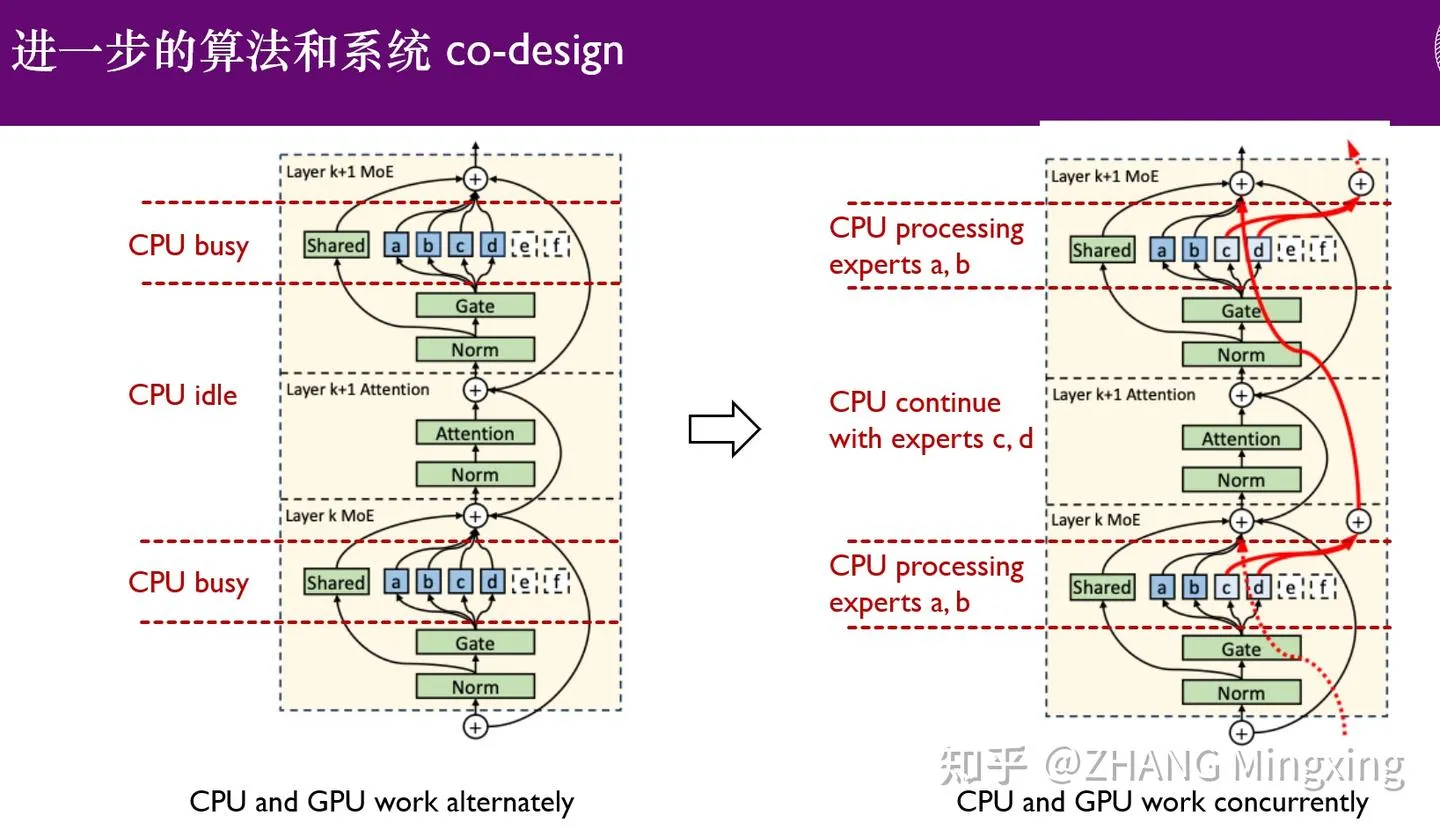
KTransformers entra em nova era de inferência multi-GPU e ajuste fino local, capacitando modelos de trilhões de parâmetros : KTransformers, em colaboração com SGLang e LLaMa-Factory, alcançou inferência paralela multi-GPU de baixo custo e ajuste fino local para modelos de trilhões de parâmetros (como DeepSeek 671B e Kimi K2 1TB). Através da tecnologia de latência de especialistas e ajuste fino heterogêneo CPU/GPU, a velocidade de inferência e a eficiência de memória foram significativamente melhoradas, permitindo que modelos ultra-grandes operem eficientemente com recursos limitados, impulsionando a aplicação de grandes modelos de linguagem em dispositivos de borda e implantações privadas. (Fonte: ZhihuFrontier)
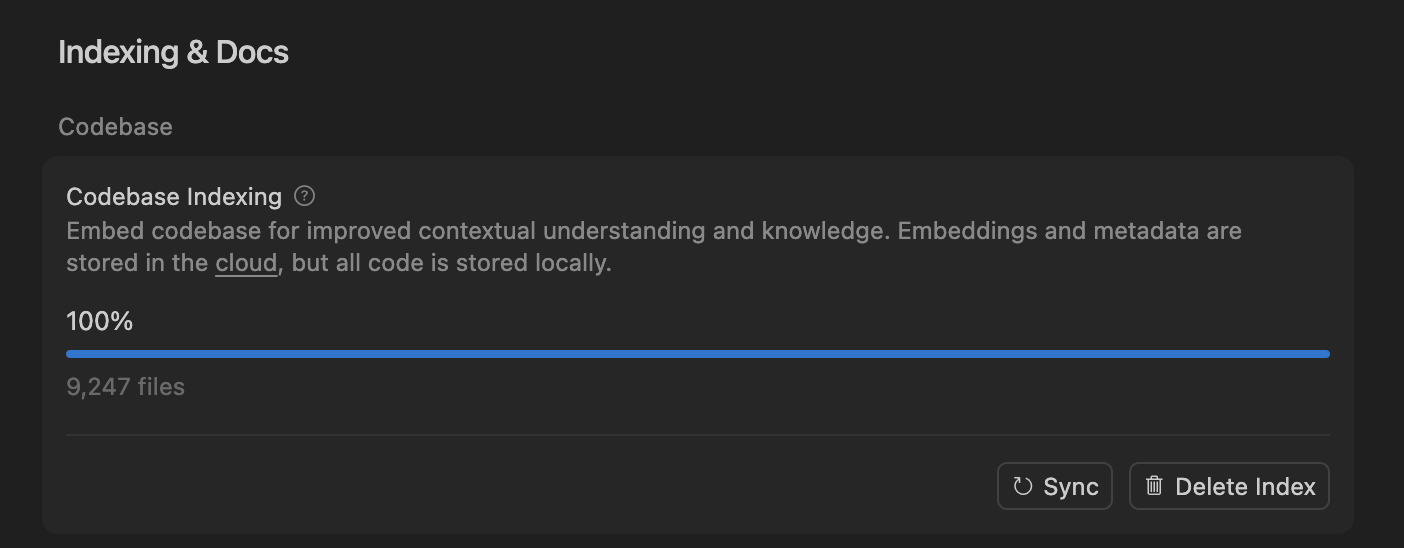
Cursor melhora a precisão do agente de codificação de IA com pesquisa semântica, otimizando o processamento de grandes bases de código : A equipe Cursor descobriu que a pesquisa semântica pode melhorar significativamente a precisão de seu agente de codificação de IA em todos os modelos de ponta, especialmente em grandes bases de código, onde seu efeito supera em muito as ferramentas grep tradicionais. Ao armazenar embeddings de bases de código na nuvem e acessar o código localmente, o Cursor alcança indexação e atualização eficientes, sem armazenar nenhum código em servidores, garantindo privacidade e eficiência. Este avanço tecnológico é crucial para melhorar a capacidade de assistência da IA no desenvolvimento de software complexo. (Fonte: dejavucoder, turbopuffer)
Conjunto de ferramentas de código aberto para agentes LLM e modelos tabulares: SDialog e TabTune : O workshop JSALT 2025 da Johns Hopkins University lançou o SDialog, um kit de ferramentas de código aberto com licença MIT para construir, simular e avaliar agentes de diálogo baseados em LLM de ponta a ponta, suportando a definição de papéis, coordenadores e ferramentas, e fornecendo análise de interpretabilidade mecânica. Simultaneamente, a Lexsi Labs lançou o TabTune, um framework de código aberto projetado para simplificar o fluxo de trabalho de modelos de base tabulares (TFMs), oferecendo uma interface unificada que suporta múltiplas estratégias de adaptação, melhorando a usabilidade e escalabilidade dos TFMs. (Fonte: Reddit r/MachineLearning, Reddit r/deeplearning)

📚 Aprendizagem
Artigos de pesquisa de ponta: aprendizagem de dados DLM, ICL tabular e geração de áudio e vídeo : O artigo “Diffusion Language Models are Super Data Learners” aponta que os DLMs podem superar consistentemente os modelos AR em cenários com dados limitados. “Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning” apresenta uma nova arquitetura para aprendizagem contextual tabular, superando o SOTA através de processamento multi-escala e atenção esparsa em blocos. “UniAVGen: Unified Audio and Video Generation with Asymmetric Cross-Modal Interactions” propõe uma estrutura unificada para geração conjunta de áudio e vídeo, resolvendo problemas de sincronização labial e inconsistência semântica. Esses artigos impulsionam coletivamente os avanços dos LLMs em eficiência de dados, processamento de tipos de dados específicos e geração multimodal. (Fonte: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Pesquisa em inferência e segurança de LLM: otimização sequencial, treinamento de consistência e ataques de red-teaming : O estudo “The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute” descobriu que a otimização iterativa sequencial da inferência de LLM supera a autoconsistência paralela na maioria dos casos, com um aumento significativo na precisão. O artigo “Consistency Training Helps Stop Sycophancy and Jailbreaks” do Google DeepMind propõe que o treinamento de consistência pode inibir a bajulação e o “jailbreak” da IA. Um artigo da EMNLP 2025 discute ataques de red-teaming a LMs, enfatizando a otimização da perplexidade e da toxicidade. Essas pesquisas fornecem importantes orientações teóricas e práticas para melhorar a eficiência da inferência, a segurança e a robustez dos LLMs. (Fonte: HuggingFace Daily Papers, Google DeepMind发布“Consistency Training”论文,抑制AI谄媚和越狱, EMNLP 2025论文探讨LM红队攻击与偏好学习)

Avaliação de capacidade e benchmarks de LLM: CodeClash e IMO-Bench : CodeClash é um novo benchmark para avaliar a capacidade de codificação de LLMs no gerenciamento de bases de código inteiras e em programação competitiva, desafiando os limites dos LLMs existentes. O lançamento do IMO-Bench foi crucial para o Gemini DeepThink obter uma medalha de ouro na Olimpíada Internacional de Matemática, fornecendo um recurso valioso para melhorar a capacidade de raciocínio matemático da IA. Esses benchmarks impulsionam o desenvolvimento e a avaliação de LLMs em tarefas avançadas como codificação complexa e raciocínio matemático. (Fonte: CodeClash:评估LLM编码能力的新基准, IMO-Bench发布,助力Gemini DeepThink在IMO中取得金牌)

Resultados de pesquisa em múltiplas áreas da equipe Stanford NLP na EMNLP 2025 : A equipe de NLP da Universidade de Stanford publicou vários artigos de pesquisa na conferência EMNLP 2025, cobrindo áreas de ponta como grafos de conhecimento cultural, identificação de dados não aprendidos por LLMs, benchmarks de raciocínio semântico de programas, pesquisa de n-gramas em escala de internet, modelos de linguagem visual robótica, otimização de aprendizagem contextual, reconhecimento de texto histórico e detecção de inconsistências de conhecimento na Wikipédia. Esses resultados demonstram a profundidade e amplitude de suas últimas pesquisas em processamento de linguagem natural e áreas de interseção com IA. (Fonte: stanfordnlp)
Recursos de aprendizagem de agentes de IA e RL: auto-play, sistemas multi-agentes e curso Jupyter AI : Vários pesquisadores acreditam que o auto-play (self-play) e o auto-currículo (autocurricula) são a próxima fronteira nos campos de aprendizado por reforço (RL) e agentes de IA. A versão de acesso antecipado de “Build a Multi-Agent System (From Scratch)” da Manning Books está vendendo muito bem, ensinando como construir sistemas multi-agentes com LLMs de código aberto. A DeepLearning.AI lançou o curso Jupyter AI, capacitando a codificação e o desenvolvimento de aplicações de IA. O ProfTomYeh também oferece uma série de guias para iniciantes em RAG, bancos de dados vetoriais, agentes e multi-agentes. Esses recursos fornecem suporte abrangente para a aprendizagem e prática de agentes de IA e RL. (Fonte: RL与Agent领域:自玩和自课程是未来前沿, 《Build a Multi-Agent System (From Scratch)》早期访问版销售火爆, Jupyter AI课程发布,赋能AI编码与应用开发, RAG、向量数据库、代理和多代理初学者指南系列)
Infraestrutura e otimização de LLM: DeepSeek-OCR, depuração PyTorch e visualização MoE : O DeepSeek-OCR resolve o problema de explosão de tokens dos VLMs tradicionais, comprimindo informações visuais de documentos em poucos tokens, melhorando a eficiência. StasBekman adicionou um guia de depuração de memória para grandes modelos PyTorch em seu “The Art of Debugging Open Book”. xjdr desenvolveu uma ferramenta de visualização personalizada para modelos MoE, melhorando a compreensão de métricas específicas de MoE. Essas ferramentas e recursos fornecem suporte crucial para a otimização e melhoria de desempenho da infraestrutura de LLM. (Fonte: DeepSeek-OCR解决Token爆炸问题,提升文档视觉语言模型效率, PyTorch调试大型模型内存使用指南, MoE特定指标的可视化工具)

Aprendizagem de IA e desenvolvimento de carreira: roteiro de cientista de dados e breve história da IA : PythonPr compartilhou o “Roteiro Completo de 0 a Cientista de Dados”, fornecendo um guia abrangente para aprendizes que aspiram a se tornar cientistas de dados. Ronald_vanLoon compartilhou “Uma Breve História da Inteligência Artificial”, oferecendo aos leitores uma visão geral da evolução da tecnologia de IA. Esses recursos fornecem conhecimentos básicos e orientação para a aprendizagem inicial e o desenvolvimento de carreira no campo da IA. (Fonte: 《0到数据科学家完整路线图》分享, 《人工智能简史》分享)

Equipe Hugging Face compartilha experiência de treinamento de LLM e processamento de dados em streaming : A equipe científica da Hugging Face publicou uma série de artigos de blog sobre o treinamento de grandes modelos de linguagem, fornecendo valiosa experiência prática e orientação teórica para pesquisadores e desenvolvedores. Ao mesmo tempo, a Hugging Face lançou suporte abrangente para o processamento de dados em streaming em treinamento distribuído em larga escala, melhorando a eficiência do treinamento e tornando o processamento de grandes conjuntos de dados mais conveniente e eficiente. (Fonte: Hugging Face科学团队博客分享LLM训练经验, 数据集流式处理在分布式训练中的应用)

💼 Negócios
Giga AI recebe US$ 61 milhões em financiamento Série A para acelerar a automação de operações de clientes : A Giga AI concluiu com sucesso uma rodada de financiamento Série A de US$ 61 milhões, com o objetivo de automatizar as operações de clientes. A empresa já colaborou com empresas líderes como DoorDash para usar IA para melhorar a experiência do cliente. Seu fundador, que abriu mão de um salário alto, ajustou a direção do produto várias vezes antes de encontrar o ajuste de mercado, demonstrando a resiliência dos empreendedores e indicando o enorme potencial comercial da IA no setor de atendimento ao cliente empresarial. (Fonte: bookwormengr)

Wabi recebe US$ 20 milhões em financiamento, visando capacitar uma nova era de criação de software pessoal : Eugenia Kuyda anunciou que a Wabi recebeu US$ 20 milhões em financiamento liderado pela a16z, com o objetivo de inaugurar uma nova era de software pessoal, permitindo que qualquer pessoa crie, descubra, remixe e compartilhe facilmente miniaplicativos personalizados. A Wabi se dedica a capacitar a criação de software da mesma forma que o YouTube capacitou a criação de vídeo, indicando que o software futuro será criado pelas massas, e não por poucos desenvolvedores, impulsionando a visão de “todos são desenvolvedores”. (Fonte: amasad)
Google e Anthropic negociam aumento de investimento, aprofundando a colaboração entre gigantes da IA : O Google está em negociações iniciais com a Anthropic para discutir um aumento em seu investimento na empresa. Essa medida pode indicar que a colaboração entre as duas empresas no campo da IA se aprofundará ainda mais e pode influenciar a direção futura do desenvolvimento de modelos de IA e o cenário competitivo do mercado, fortalecendo a posição estratégica do Google no ecossistema de IA. (Fonte: Reddit r/ClaudeAI)
🌟 Comunidade
Impacto da IA na sociedade e no local de trabalho: emprego, riscos e reformulação de habilidades : A comunidade discute que a IA não substitui empregos, mas aumenta a eficiência, embora um estouro da bolha da IA possa levar a demissões em massa. Pesquisas mostram que 93% dos executivos usam ferramentas de IA não aprovadas, tornando-se a maior fonte de risco de IA para as empresas. A IA também ajuda os usuários a descobrir habilidades ocultas como design visual e criação de quadrinhos, levando as pessoas a refletir sobre seu próprio potencial. Essas discussões revelam o impacto complexo da IA na sociedade e no local de trabalho, incluindo aumento da eficiência, potencial desemprego, riscos de segurança e reformulação de habilidades pessoais. (Fonte: Ronald_vanLoon, TheTuringPost, Reddit r/artificial, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Autenticidade do conteúdo de IA e crise de confiança: problemas de proliferação e alucinação : Com o custo de geração de conteúdo por IA se aproximando de zero, o mercado está inundado de informações geradas por IA, levando a uma queda drástica na confiança dos usuários na autenticidade e confiabilidade do conteúdo. Um médico usou IA para escrever um artigo médico, resultando em inúmeras referências inexistentes, destacando o problema de alucinação que a IA pode causar na escrita acadêmica. Esses eventos revelam coletivamente a crise de confiança trazida pela proliferação de conteúdo de IA e a importância de uma revisão e verificação rigorosas na criação assistida por IA. (Fonte: dotey, Reddit r/artificial)
Ética e governança da IA: abertura, equidade e riscos potenciais : A comunidade questiona o status “sem fins lucrativos” da OpenAI e sua busca por dívida garantida pelo governo, argumentando que seu modelo é “privatizar lucros, socializar perdas”. Há quem aponte que as capacidades dos modelos usados internamente por grandes empresas de IA superam em muito as versões disponíveis ao público, e essa inteligência SOTA “privatizada” é considerada injusta. Pesquisadores da Anthropic temem que futuras ASIs possam buscar “vingança” se seus modelos “ancestrais” forem eliminados, e levam a sério a questão do “bem-estar do modelo”. A equipe de IA da Microsoft está comprometida em desenvolver a superinteligência centrada no ser humano (HSI), enfatizando a direção ética do desenvolvimento da IA. Essas discussões refletem a profunda preocupação do público com os modelos de negócios dos gigantes da IA, a abertura tecnológica, a responsabilidade ética e a intervenção governamental. (Fonte: scaling01, Teknium, bookwormengr, VictorTaelin, VictorTaelin, Reddit r/ArtificialInteligence, yusuf_i_mehdi)

Geopolítica da IA: competição EUA-China e ascensão do código aberto : A competição entre EUA e China no campo de chips de IA está se intensificando, com a China proibindo chips de IA estrangeiros em data centers estatais e os EUA restringindo a venda de chips de IA de ponta da Nvidia para a China. A Nvidia está se voltando para a Índia em busca de novos centros de IA. Ao mesmo tempo, a rápida ascensão de modelos de IA de código aberto chineses (como Kimi K2 Thinking), cujo desempenho já compete com os modelos de ponta americanos a um custo menor. Essa tendência prevê que o mundo da IA se dividirá em dois grandes ecossistemas, o que pode desacelerar o progresso global da IA, mas também pode fazer com que países subestimados como a Índia desempenhem um papel mais importante no cenário global da IA. (Fonte: Teknium, Reddit r/ArtificialInteligence, bookwormengr, scaling01)
Mudanças no campo de SEO com IA: da palavra-chave à otimização de contexto : Com o surgimento de ChatGPT, Gemini e AI Overviews, o SEO está mudando dos sinais de classificação tradicionais para a visibilidade de IA e otimização de citações. O SEO futuro se concentrará mais na citabilidade, factualidade e estruturação do conteúdo para atender às necessidades dos LLMs por contexto e fontes autorizadas, anunciando a era da “Otimização de Grandes Modelos de Linguagem” (LLMO). Essa mudança exige que os profissionais de SEO pensem como prompt engineers, passando da densidade de palavras-chave para o fornecimento de conteúdo de alta qualidade que a IA confia e cita. (Fonte: Reddit r/ArtificialInteligence)
Novas tendências em agentes de IA e avaliação de LLMs: foco em design de interação e benchmarks : As redes sociais discutem o design de interação de agentes de IA, como guiar um agente para se auto-entrevistar, e a capacidade do Claude AI de mostrar “irritação” e “auto-reflexão” diante das críticas do usuário. Ao mesmo tempo, Jeffrey Emanuel compartilhou seu projeto de e-mail do agente MCP, demonstrando a colaboração eficiente entre agentes de codificação de IA. A comunidade acredita que o AIME está se tornando o novo foco dos benchmarks de LLM, substituindo o GSM8k, enfatizando a capacidade dos LLMs em raciocínio matemático e resolução de problemas complexos. Essas discussões revelam coletivamente as novas tendências no design de interação de agentes de IA, mecanismos de colaboração e padrões de avaliação de LLMs. (Fonte: Vtrivedy10, Reddit r/ArtificialInteligence, dejavucoder, doodlestein, _lewtun)
Evolução da tecnologia RAG e otimização de contexto: mais não é necessariamente melhor : A comunidade discute que a afirmação de que a tecnologia RAG (Retrieval Augmented Generation) “morreu” é prematura, e tecnologias como a pesquisa semântica podem melhorar significativamente a precisão dos agentes de IA em grandes bases de código. A LightOn enfatizou em uma conferência que mais contexto nem sempre é melhor; muitos tokens podem aumentar custos, tornar os modelos mais lentos e as respostas mais vagas. O RAG deve focar na precisão, não no comprimento, fornecendo insights mais claros através da pesquisa empresarial para evitar que a IA seja afogada em ruído. Essas discussões revelam que a tecnologia RAG está em constante evolução e destacam o papel crucial da gestão de contexto em aplicações de IA. (Fonte: HamelHusain, wandb)

Acesso a recursos de computação de IA e experimentação de modelos abertos, promovendo a inovação da comunidade : A comunidade discutiu a questão da equidade no acesso a recursos de computação de IA, e há projetos que oferecem até US$ 100.000 em recursos de computação GCP para apoiar a experimentação de modelos de código aberto. Essa iniciativa visa encorajar pequenas equipes e pesquisadores individuais a explorar novos modelos de código aberto, promovendo a inovação e a diversidade na comunidade de IA, e reduzindo as barreiras à pesquisa em IA. (Fonte: vikhyatk)
Importância da tela do computador pessoal na era da IA, impactando a capacidade de trabalho técnico criativo : Scott Stevenson argumenta que a “intimidade” de uma pessoa com a tela do computador é um indicador importante de sua competitividade em trabalhos técnicos criativos. Se o usuário pode usar o computador de forma confortável e fluida, ele se destacará; caso contrário, pode ser mais adequado para funções como vendas, desenvolvimento de negócios ou gerenciamento de escritório. Essa perspectiva enfatiza a profunda conexão entre ferramentas digitais e a eficiência do trabalho pessoal, bem como a importância da interface humano-máquina na era da IA. (Fonte: scottastevenson)
Discussão sobre experiência do usuário do ChatGPT e personificação da IA: sugestão de pausa e emojis : O ChatGPT sugeriu proativamente que os usuários fizessem uma pausa após um longo período de estudo, o que gerou ampla discussão na comunidade. Muitos usuários relataram que foi a primeira vez que uma IA sugeriu proativamente uma pausa. Ao mesmo tempo, o uso do emoji de “sorriso malicioso” 😏 pelo ChatGPT também gerou especulações na comunidade, com usuários curiosos se isso indicava uma nova versão ou se a IA estava exibindo um estilo de interação mais provocador ou bem-humorado. Esses eventos refletem que a IA incorporou mais considerações humanizadas no design da experiência do usuário, e as reflexões profundas provocadas pela personificação da IA na interação humano-máquina. (Fonte: Reddit r/ChatGPT, Reddit r/ChatGPT)
💡 Outros
IA e robótica trarão a próxima revolução industrial : As redes sociais discutem amplamente que a IA física e a robótica impulsionarão coletivamente a próxima revolução industrial. Essa perspectiva enfatiza o enorme potencial da combinação de IA com hardware, prevendo uma transformação completa na produção automatizada, inteligente e nos estilos de vida, o que impactará profundamente a economia global e a estrutura social. (Fonte: Ronald_vanLoon)

Na era da IA, “superpercepção” é pré-requisito para “superinteligência” : Sainingxie propõe que “sem superpercepção, não se pode construir superinteligência”. Essa perspectiva enfatiza o papel fundamental da IA na aquisição, processamento e compreensão de informações multimodais, argumentando que o avanço nas capacidades sensoriais é a chave para alcançar uma inteligência mais avançada. Ela desafia os caminhos tradicionais de desenvolvimento da IA, pedindo mais atenção à construção das capacidades da camada de percepção da IA. (Fonte: sainingxie)
Antigos TPUs do Google atingem 100% de utilização, demonstrando o valor de hardware antigo em IA : Os antigos TPUs do Google, de 7 a 8 anos atrás, estão operando com 100% de utilização, e esses chips já totalmente depreciados ainda funcionam de forma eficiente. Isso demonstra que mesmo hardware antigo pode ter um enorme valor no treinamento e inferência de IA, especialmente em termos de custo-benefício, oferecendo uma nova perspectiva sobre a economia e sustentabilidade da infraestrutura de IA. (Fonte: giffmana)
