
Palavras-chave:OpenAI, Amazon AWS, Potência de computação em IA, Stanford AgentFlow, Meituan LongCat-Flash-Omni, Alibaba Qwen3-Max-Thinking, Modelo TRM da Samsung, Unity AI Graph, Colaboração em potência de computação entre OpenAI e Amazon, Framework AgentFlow para aprendizagem por reforço, Modelo multimodal LongCat-Flash-Omni, Capacidade de raciocínio do Qwen3-Max-Thinking, Arquitetura de raciocínio recursivo TRM
🔥 Destaque
OpenAI e Amazon fecham parceria de 38 bilhões de dólares em poder computacional : A OpenAI e a Amazon AWS assinaram um acordo de 38 bilhões de dólares em poder computacional, visando obter recursos de GPU NVIDIA para apoiar a construção de sua infraestrutura de modelos de AI e ambiciosos objetivos de AI. Este movimento marca um passo importante para a OpenAI na diversificação de provedores de serviços em nuvem, reduzindo sua dependência exclusiva da Microsoft e pavimentando o caminho para um futuro IPO. A Amazon, por sua vez, consolida sua liderança no campo da infraestrutura de AI através desta parceria, enquanto mantém a colaboração com a Anthropic, concorrente da OpenAI. O acordo fornecerá à OpenAI poder computacional escalável para inferência de AI e treinamento de modelos de próxima geração, além de promover a aplicação de seus modelos de base na plataforma AWS. (Fonte: Ronald_vanLoon, scaling01, TheRundownAI)

Framework AgentFlow da Stanford: Pequenos modelos superam GPT-4o : Equipes de pesquisa da Universidade de Stanford e outras lançaram o framework AgentFlow, que, através de uma arquitetura modular e do algoritmo Flow-GRPO, permite que sistemas de AI Agent realizem aprendizado por reforço online no fluxo de inferência, alcançando auto-otimização contínua. Com apenas 7B parâmetros, o AgentFlow superou completamente o GPT-4o (cerca de 200B parâmetros) e o Llama-3.1-405B em tarefas como busca, matemática e ciência, alcançando o topo da lista diária de Papers do HuggingFace. Esta pesquisa prova que sistemas de Agent podem adquirir capacidades de aprendizado semelhantes às de grandes modelos através de aprendizado por reforço online, e são mais eficientes em tarefas específicas, abrindo um novo caminho “pequeno e refinado” para o desenvolvimento da AI. (Fonte: HuggingFace Daily Papers)
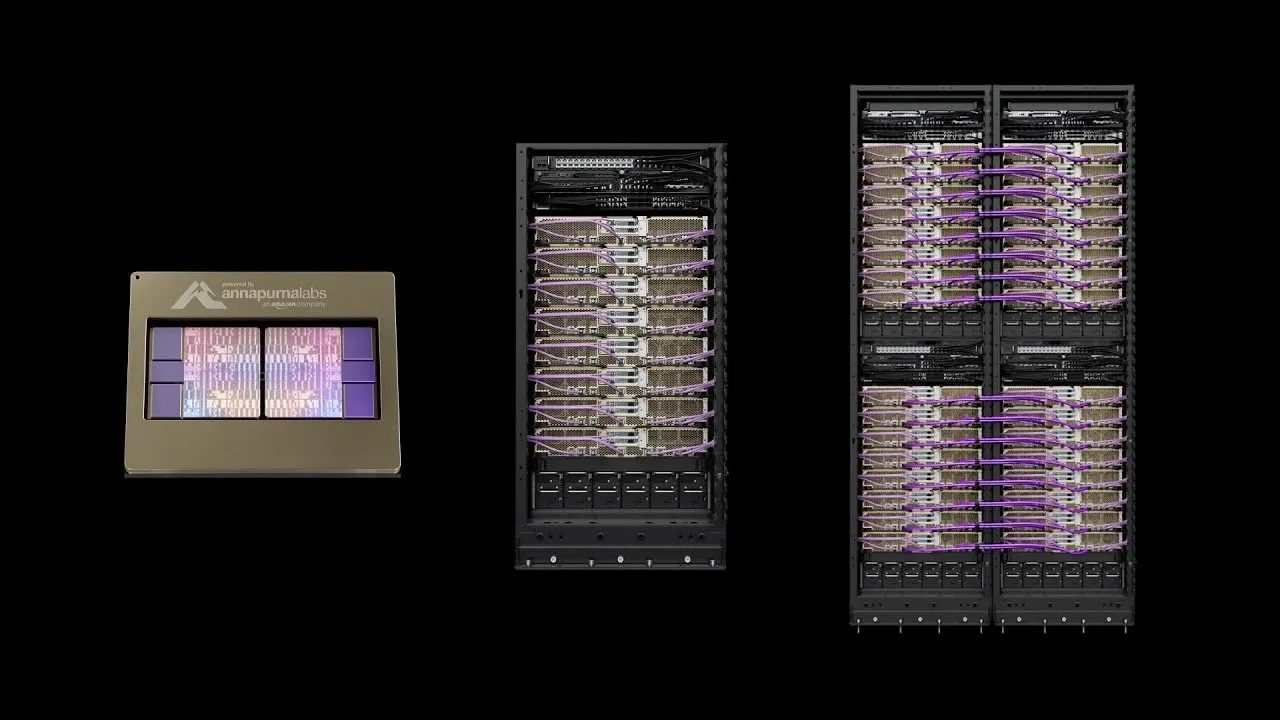
AWS lança Project Rainier: Um dos maiores clusters de poder computacional de AI do mundo : A AWS lançou o Project Rainier, um cluster de poder computacional de AI construído em menos de um ano, com quase 500.000 chips Trainium2. A Anthropic já treinou novos modelos Claude nele e planeja expandir para 1 milhão de chips até o final de 2025. O Trainium2 é um processador de treinamento de AI personalizado da AWS, projetado para lidar com redes neurais em larga escala. O projeto utiliza a arquitetura UltraServer, conectada por redes NeuronLinks e EFA, oferecendo até 83.2 petaflops de capacidade de computação de modelo FP8 esparso, e é alimentado por energia 100% renovável, alcançando alta eficiência energética. O Project Rainier marca a liderança da AWS no campo da infraestrutura de AI, fornecendo soluções verticalmente integradas, desde chips personalizados até o resfriamento de data centers. (Fonte: TheTuringPost)
🎯 Tendências
Meituan lança modelo multimodal LongCat-Flash-Omni : A Meituan lançou seu mais recente modelo multimodal de código aberto, o LongCat-Flash-Omni. Este modelo alcançou o nível SOTA de código aberto em benchmarks abrangentes como Omni-Bench e WorldSense, e é comparável ao Gemini-2.5-Pro de código fechado. O LongCat-Flash-Omni adota uma arquitetura MoE com um total de 560B parâmetros e 27B parâmetros de ativação, alcançando alta eficiência de inferência e interação em tempo real com baixa latência, sendo o primeiro modelo de código aberto a realizar interação multimodal em tempo real. O modelo suporta entradas multimodais de texto, voz, imagem, vídeo e qualquer combinação, e possui uma janela de contexto de 128K tokens, suportando interação de áudio e vídeo de mais de 8 minutos. (Fonte: WeChat, ZhihuFrontier)

Versão de inferência Qwen3-Max-Thinking da Alibaba lançada : A equipe Qwen da Alibaba lançou uma prévia inicial do Qwen3-Max-Thinking, um modelo de checkpoint intermediário ainda em treinamento. Este modelo alcançou 100% de pontuação em benchmarks de inferência desafiadores como AIME 2025 e HMMT, após o aprimoramento do uso de ferramentas e a expansão do tempo de computação de teste. O lançamento do Qwen3-Max-Thinking demonstra o progresso significativo da Alibaba nas capacidades de inferência de AI, fornecendo aos usuários uma cadeia de pensamento e habilidades de resolução de problemas mais poderosas. (Fonte: Alibaba_Qwen, op7418)
Modelo TRM da Samsung: Inferência recursiva desafia o paradigma Transformer : O laboratório SAIL Montreal da Samsung propôs o Tiny Recursive Model (TRM), uma nova arquitetura de inferência recursiva com apenas 7 milhões de parâmetros e duas camadas de rede neural. O TRM, através da atualização recursiva de “respostas” e “variáveis de pensamento latentes”, aproxima-se do resultado correto em múltiplas rodadas de autocorreção, e quebrou recordes em tarefas como Sudoku-Extreme, superando grandes modelos como DeepSeek R1 e Gemini 2.5 Pro. O modelo, em sua arquitetura, até mesmo abandonou as camadas de autoatenção (variante TRM-MLP), indicando que para tarefas de entrada fixa em pequena escala, o MLP pode reduzir o overfitting, desafiando a regra empírica da comunidade de AI de que “quanto maior o modelo, mais forte ele é”, e oferecendo novas ideias para inferência de AI leve. (Fonte: 36氪)

Conferência de Desenvolvedores Unity: Tendências futuras de AI+Jogos : A Conferência de Desenvolvedores Unity 2025 enfatizou que a AI se tornará o motor da criatividade e eficiência nos jogos. O Unity Engine e o Tencent Hunyuan lançaram conjuntamente a plataforma AI Graph, integrando profundamente o fluxo de trabalho AIGC, o que pode aumentar a eficiência do design 2D em 30% e a eficiência da produção de ativos 3D em 70%. A Amazon Web Services (AWS) também demonstrou o empoderamento da AI em todo o ciclo de vida dos jogos (construção, execução, crescimento), especialmente na geração de código, onde a AI está passando de auxiliar para criar autonomamente. Meshy, como uma ferramenta de criação de AI generativa 3D, através de modelos de difusão e autorregressivos, ajuda os desenvolvedores a reduzir custos e acelerar a prototipagem, com grande potencial especialmente em cenários de VR/AR e UGC. (Fonte: WeChat)

Cartesia lança modelo de voz Sonic-3 : A empresa de AI de voz Cartesia lançou seu mais recente modelo de voz, Sonic-3, que demonstrou um efeito surpreendente na replicação da voz de Elon Musk e recebeu um financiamento da Série B de 100 milhões de dólares de investidores como a NVIDIA. O Sonic-3 é construído com base em modelos de espaço de estado (SSM), em vez da arquitetura tradicional Transformer, e é capaz de perceber continuamente o contexto e a atmosfera da conversa, alcançando respostas de AI mais naturais e sem esforço. Sua latência é de apenas 90 milissegundos, e o tempo de resposta ponta a ponta é de 190 milissegundos, tornando-o um dos sistemas de geração de voz mais rápidos atualmente. (Fonte: WeChat)

MiniMax lança modelo de voz Speech 2.6 : A MiniMax lançou seu mais recente modelo de voz, MiniMax Speech 2.6, destacando suas características de “rápido e falante”. O modelo reduziu a latência de resposta para menos de 250ms, suporta mais de 40 idiomas e todos os sotaques, e pode identificar com precisão URLs, e-mails, valores monetários, datas, números de telefone e outros “textos não padronizados”. Isso significa que, mesmo em situações de entrada com sotaque forte, velocidade de fala rápida e informações complexas, o modelo pode entender e falar claramente de uma só vez, melhorando significativamente a eficiência e a precisão da interação por voz. (Fonte: WeChat)
Amazon Chronos-2: Modelo de base de previsão universal : A Amazon lançou o Chronos-2, um modelo de base projetado para lidar com qualquer tarefa de previsão. O modelo suporta previsão de informações univariadas, multivariadas e covariáveis, e pode operar de forma zero-shot. O lançamento do Chronos-2 marca um progresso importante da Amazon no campo da previsão de séries temporais, fornecendo às empresas e desenvolvedores capacidades de previsão mais flexíveis e poderosas, com o potencial de simplificar processos de previsão complexos e melhorar a eficiência da tomada de decisões. (Fonte: dl_weekly)
YOLOv11 para segmentação de instâncias de edifícios e classificação de altura : Um artigo detalha a aplicação do YOLOv11 na segmentação de instâncias de edifícios e classificação discreta de altura a partir de imagens de satélite. O YOLOv11, através de uma arquitetura mais eficiente que combina características de diferentes escalas, melhora a precisão da localização de objetos e se destaca em cenários urbanos complexos. O modelo alcançou um desempenho de segmentação de instâncias de 60.4% mAP@50 e 38.3% mAP@50-95 no conjunto de dados DFC2023 Track 2, mantendo uma precisão de classificação robusta para cinco níveis de altura predefinidos. O YOLOv11 demonstra excelente desempenho no tratamento de oclusões, formas de edifícios complexas e desequilíbrio de classes, sendo adequado para mapeamento urbano em tempo real e em larga escala. (Fonte: HuggingFace Daily Papers)
🧰 Ferramentas
PageIndex: Sistema de indexação de documentos RAG baseado em inferência : A VectifyAI lançou o PageIndex, um sistema RAG (Retrieval Augmented Generation) baseado em inferência que dispensa bancos de dados vetoriais e fragmentação. O PageIndex, ao construir um índice em estrutura de árvore dos documentos, simula a forma como especialistas humanos navegam e extraem conhecimento, permitindo que o LLM realize inferência em várias etapas para uma recuperação de documentos mais precisa. O sistema alcançou uma precisão de 98.7% no benchmark FinanceBench, superando em muito os sistemas RAG vetoriais tradicionais, sendo especialmente adequado para análise de documentos longos e especializados, como relatórios financeiros e documentos legais. O PageIndex oferece várias opções de implantação, incluindo auto-hospedagem, serviço em nuvem e API. (Fonte: GitHub Trending)

LocalAI: Alternativa local de código aberto ao OpenAI : O LocalAI é uma alternativa gratuita e de código aberto ao OpenAI, fornecendo uma REST API compatível com a OpenAI API, que suporta a execução local de LLM, geração de imagens, áudio, vídeo e clonagem de voz em hardware de consumo. O projeto não requer GPU, suporta vários modelos como gguf, transformers, diffusers, e já integrou funções como WebUI, inferência P2P e Model Context Protocol (MCP). O LocalAI visa a localização e descentralização da inferência de AI, oferecendo aos usuários opções de implantação de AI mais flexíveis e privadas, e suporta várias acelerações de hardware. (Fonte: GitHub Trending)
DeepAnalyze: LLM Agentic para ciência de dados : Equipes de pesquisa da Universidade Renmin da China e da Universidade Tsinghua lançaram o DeepAnalyze, o primeiro LLM Agentic para ciência de dados. Este modelo dispensa workflows projetados por humanos, e com apenas um LLM, pode completar autonomamente tarefas complexas de ciência de dados como preparação, análise, modelagem, visualização e insights, e gerar relatórios de pesquisa com qualidade de analista. O DeepAnalyze, através de um paradigma de treinamento Agentic baseado em currículo e um framework de síntese de trajetória orientado a dados, aprende em ambientes reais, resolvendo os problemas de recompensa esparsa e falta de trajetórias de resolução de problemas de cadeia longa, alcançando pesquisa autônoma no campo da ciência de dados. (Fonte: WeChat)

AI PC: Capacitado por processadores Intel Core Ultra 200H Series : Os AI PCs equipados com processadores Intel Core Ultra 200H Series estão se tornando uma nova opção para aumentar a eficiência no trabalho e na vida. Esta série de processadores integra uma poderosa NPU (Neural Processing Unit), com um aumento de eficiência energética de até 21%, capaz de lidar com tarefas de AI de longa duração e baixo consumo de energia, como remoção de ruído de fundo em tempo real, recorte inteligente, organização de documentos por AI Assistant, e pode ser concluída sem conexão à internet. Esta arquitetura híbrida de CPU, GPU e NPU faz com que os AI PCs se destaquem em leveza, portabilidade, longa duração da bateria e trabalho offline, proporcionando uma experiência de AI fluida e natural para cenários de escritório, estudo e jogos. (Fonte: WeChat)

Claude Skills: Catálogo com mais de 2300 habilidades : Um site chamado skillsmp.com coletou mais de 2300 Claude Skills, oferecendo aos usuários do Claude AI um catálogo de habilidades pesquisável. Essas habilidades são organizadas por categoria, incluindo ferramentas de desenvolvimento, documentação, aprimoramento de AI, análise de dados, etc., e fornecem visualização, download ZIP e funcionalidade de instalação CLI. A plataforma visa ajudar os usuários do Claude a descobrir e utilizar habilidades de AI de forma mais conveniente, aprimorar as capacidades do Agent e realizar tarefas automatizadas de forma mais eficiente, contribuindo com ferramentas úteis para a comunidade. (Fonte: Reddit r/ClaudeAI)
AI Chatbots for Websites: Os dez melhores chatbots de AI em 2025 : Um relatório listou os dez melhores chatbots de AI para sites em 2025, com o objetivo de ajudar startups e fundadores individuais a escolher a ferramenta certa. O ChatQube foi classificado como a ferramenta nova mais interessante devido às suas notificações instantâneas de “lacunas de conhecimento” e capacidade de percepção de contexto. O Intercom Fin é adequado para grandes equipes de suporte, o Drift foca em marketing e captura de leads, e o Tidio é ideal para pequenas empresas e e-commerce. Outros, como Crisp, Chatbase, Zendesk AI, Botpress, Flowise e Kommunicate, também têm suas características, cobrindo desde configurações simples até necessidades altamente personalizadas, indicando que os chatbots de AI se tornaram mais práticos e difundidos. (Fonte: Reddit r/artificial)
Perplexity Comet: AI coding Agent : O Perplexity Comet é elogiado como um AI coding Agent eficiente, onde o usuário só precisa dar a tarefa e ele a completa autonomamente. Por exemplo, o usuário pode conceder acesso a um repositório GitHub e pedir para configurar um Webhook para ouvir eventos de push. O Comet é capaz de obter com precisão a URL do Webhook de outras abas e configurá-lo corretamente. Isso demonstra a poderosa capacidade do Perplexity Comet em entender instruções complexas, operar entre aplicativos e automatizar processos de desenvolvimento, aumentando significativamente a eficiência do trabalho dos desenvolvedores. (Fonte: AravSrinivas)
LazyCraft: Concorrente de plataforma de Agent de código aberto para Dify : O LazyCraft é uma nova plataforma de desenvolvimento e gerenciamento de aplicativos AI Agent de código aberto, considerada um forte concorrente do Dify. Ele oferece um sistema de ciclo fechado mais completo, com módulos centrais integrados como base de conhecimento, gerenciamento de Prompt, serviço de inferência, ferramentas MCP (suportando local e remoto), gerenciamento de conjunto de dados e avaliação de modelos. O LazyCraft suporta gerenciamento multi-tenant/multi-workspace, resolvendo as necessidades de controle de permissões granulares e gerenciamento de equipe em cenários corporativos. Além disso, ele integra funções de ajuste fino e gerenciamento de modelos locais, permitindo que os usuários comparem cientificamente os efeitos dos modelos, fornecendo um forte suporte para empresas com necessidades de privacidade de dados e personalização profunda. (Fonte: WeChat)
📚 Aprendizado
HuggingFace Smol Training Playbook: Guia de treinamento de LLM : A HuggingFace lançou o Smol Training Playbook, um guia abrangente de treinamento de LLM que detalha o processo por trás do treinamento do SmolLM3. O guia cobre desde estratégias e decisões de custo antes do início, pré-treinamento (dados, estudos de ablação, arquitetura e ajuste), pós-treinamento (SFT, DPO, GRPO, fusão de modelos) até infraestrutura (configuração de cluster de GPU, comunicação, depuração) em toda a cadeia. Este guia de mais de 200 páginas visa fornecer aos desenvolvedores de LLM uma experiência de treinamento transparente e prática, reduzindo a barreira para o treinamento de modelos próprios e promovendo o desenvolvimento de AI de código aberto. (Fonte: TheTuringPost, ClementDelangue)

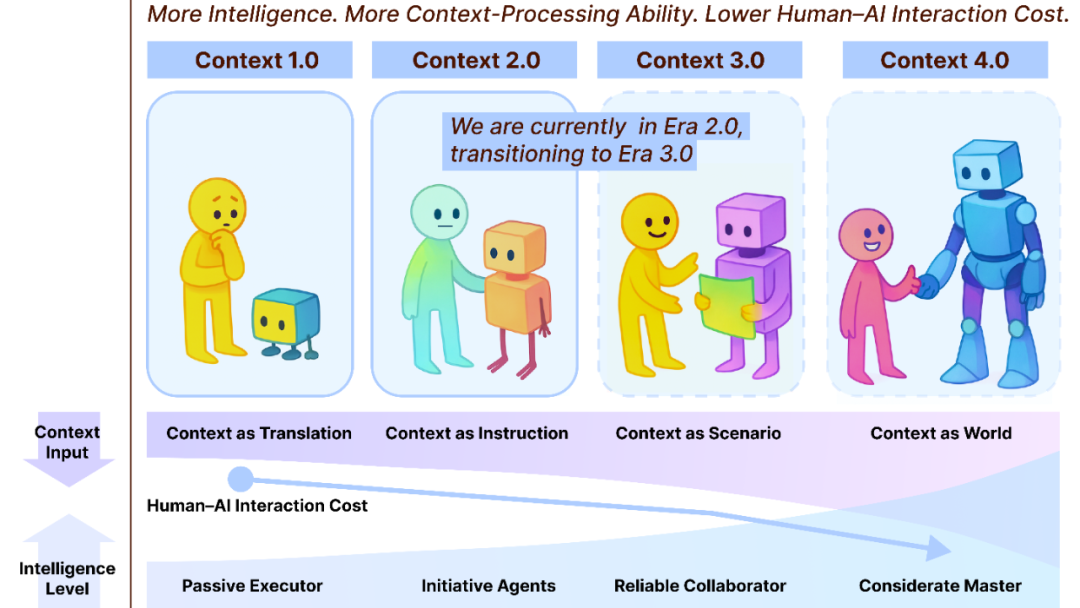
Context Engineering 2.0: 30 anos de evolução : A equipe de Liu Pengfei da Shanghai Chuangzhi Academy propôs o framework “Context Engineering 2.0”, analisando a essência, história e futuro da Context Engineering. A pesquisa aponta que a Context Engineering é um processo contínuo de redução de entropia de 30 anos, visando preencher a lacuna cognitiva entre humanos e máquinas. Desde a era 1.0, impulsionada por sensores, passando pela era 2.0, com assistentes inteligentes e fusão multimodal, até a era 3.0, prevista com coleta imperceptível e colaboração fluida, a evolução da Context Engineering impulsionou a revolução da interação humano-máquina. O framework enfatiza as três dimensões de “coletar, gerenciar, usar” e explora questões filosóficas como a forma como o contexto constitui uma nova identidade humana após a AI superar os humanos. (Fonte: WeChat)
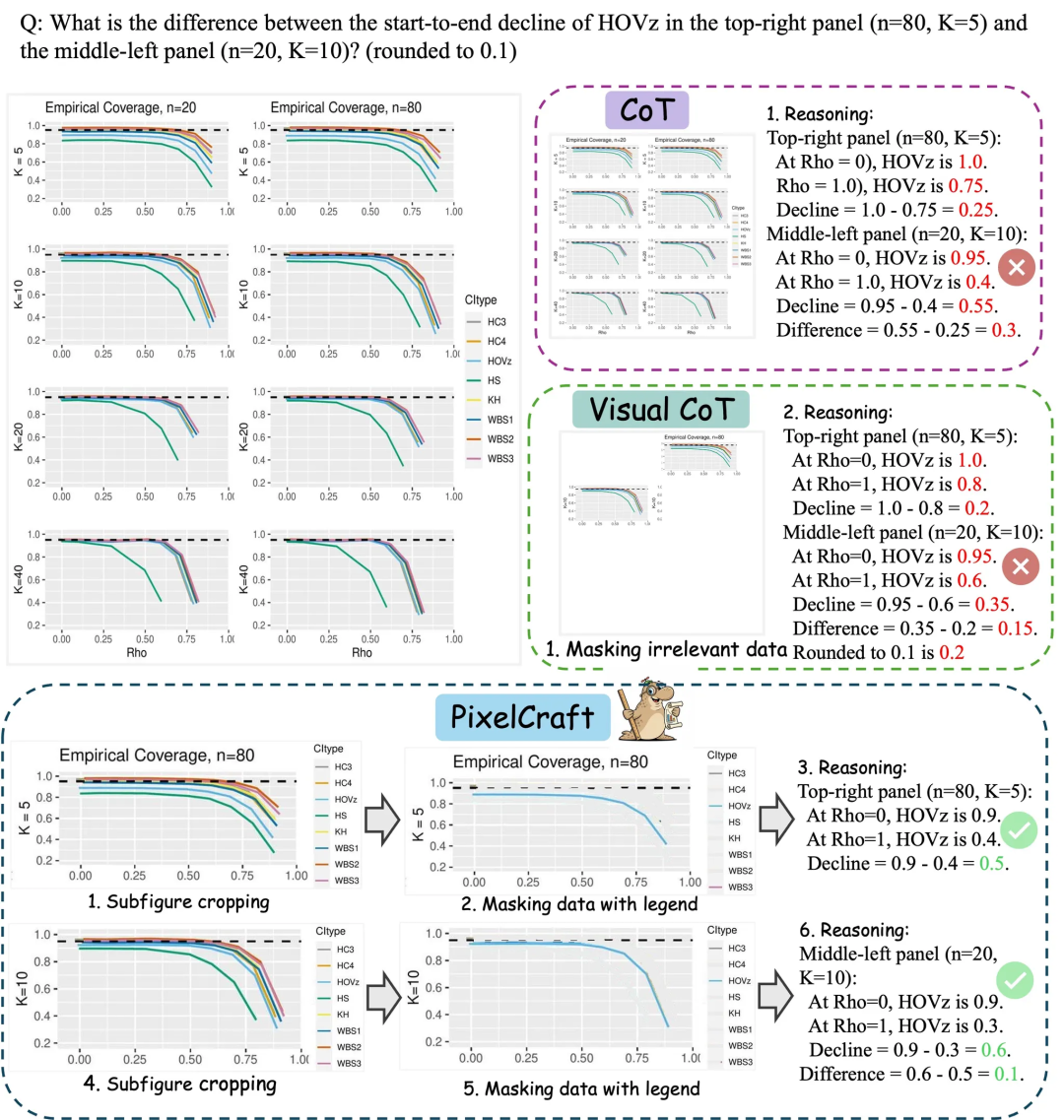
Microsoft Research Asia PixelCraft: Aprimorando a compreensão de gráficos por grandes modelos : A Microsoft Research Asia, em colaboração com a Universidade Tsinghua e outras equipes, lançou o PixelCraft, com o objetivo de aprimorar sistematicamente a capacidade de grandes modelos multimodais (MLLM) de compreender imagens estruturadas como gráficos e esboços geométricos. O PixelCraft, com processamento de imagem de alta fidelidade e inferência não linear multi-Agent como seus dois pilares, atinge o mapeamento de referência de texto em nível de pixel através do ajuste fino de modelos de grounding, e utiliza um conjunto de agentes de ferramentas visuais para executar operações de imagem verificáveis. Seu processo de inferência baseado em discussão suporta rastreamento e exploração de ramificações, melhorando significativamente a precisão, robustez e interpretabilidade do modelo em benchmarks de gráficos e geometria como CharXiv e ChartQAPro. (Fonte: WeChat)
Spatial-SSRL: Aprendizado por reforço auto-supervisionado aprimora a compreensão espacial : Um estudo introduziu o Spatial-SSRL, um paradigma de aprendizado por reforço auto-supervisionado, com o objetivo de aprimorar a capacidade de compreensão espacial de grandes modelos de linguagem visual (LVLM). O Spatial-SSRL obtém sinais verificáveis diretamente de imagens RGB ou RGB-D comuns, construindo automaticamente cinco tarefas prévias que capturam estruturas espaciais 2D e 3D, sem a necessidade de anotação humana ou LVLM. Em sete benchmarks de compreensão espacial de imagens e vídeos, o Spatial-SSRL alcançou um aumento médio de precisão de 4.63% (3B) e 3.89% (7B) em relação ao modelo base Qwen2.5-VL, provando que a supervisão simples e intrínseca pode realizar RLVR em larga escala, trazendo maior inteligência espacial para LVLM. (Fonte: HuggingFace Daily Papers)
π_RL: Ajuste fino de modelos VLA com aprendizado por reforço online : Um estudo propôs o π_RL, um framework de código aberto para treinar modelos de ação de linguagem visual (VLA) baseados em fluxo em simulações paralelas. O π_RL implementa dois algoritmos de RL: Flow-Noise modela o processo de denoising como um MDP de tempo discreto, e Flow-SDE alcança exploração eficiente de RL através da transformação ODE-SDE. Nos benchmarks LIBERO e ManiSkill, o π_RL melhorou significativamente o desempenho dos modelos SFT few-shot pi_0 e pi_0.5, demonstrando a eficácia do RL online para modelos VLA baseados em fluxo e alcançando poderosas capacidades de RL multi-tarefa e generalização. (Fonte: HuggingFace Daily Papers)
LLM Agents: Subsistemas centrais para construir agentes LLM autônomos : Um artigo de leitura obrigatória, “Fundamentals of Building Autonomous LLM Agents”, revisa os subsistemas cognitivos centrais que compõem os agentes autônomos impulsionados por LLM. O artigo detalha componentes chave como percepção, raciocínio e planejamento (CoT, MCTS, ReAct, ToT), memória de longo e curto prazo, execução (execução de código, uso de ferramentas, chamadas de API) e feedback de ciclo fechado. Esta pesquisa fornece uma perspectiva abrangente para entender e construir agentes LLM capazes de operar autonomamente, enfatizando como esses subsistemas trabalham em conjunto para alcançar comportamentos inteligentes complexos. (Fonte: TheTuringPost)

Efficient Vision-Language-Action Models: Uma pesquisa sobre modelos VLA eficientes : Uma pesquisa abrangente, “A Survey on Efficient Vision-Language-Action Models”, explora os avanços de ponta em modelos eficientes de visão-linguagem-ação (VLA) no campo da inteligência incorporada. A pesquisa propõe uma taxonomia unificada, dividindo as técnicas existentes em três pilares principais: design de modelo eficiente, treinamento eficiente e coleta de dados eficiente. Através de uma revisão crítica dos métodos mais avançados, este estudo fornece uma referência fundamental para a comunidade, resume aplicações representativas, elucida desafios chave e traça um roteiro para pesquisas futuras, com o objetivo de resolver as enormes demandas computacionais e de dados que os modelos VLA enfrentam na implantação. (Fonte: HuggingFace Daily Papers)
Nova descoberta sobre gargalos de desempenho em SNNs: Frequência, não esparsidade : Um estudo revelou a verdadeira razão para a lacuna de desempenho entre SNNs (Spiking Neural Networks) e ANNs (Artificial Neural Networks), que não é a perda de informação devido a ativações binárias/esparsas, como tradicionalmente se pensava, mas sim a característica inerente de filtro passa-baixa dos neurônios de pulso. A pesquisa descobriu que as SNNs se comportam como filtros passa-baixa no nível da rede, levando à rápida dissipação de componentes de alta frequência e reduzindo a eficácia da representação de características. Ao substituir Avg-Pool por Max-Pool no Spiking Transformer, a precisão do CIFAR-100 aumentou em 2.39%, e a arquitetura Max-Former foi proposta, alcançando 82.39% de precisão no ImageNet e uma redução de 30% no consumo de energia. (Fonte: Reddit r/MachineLearning)
💼 Negócios
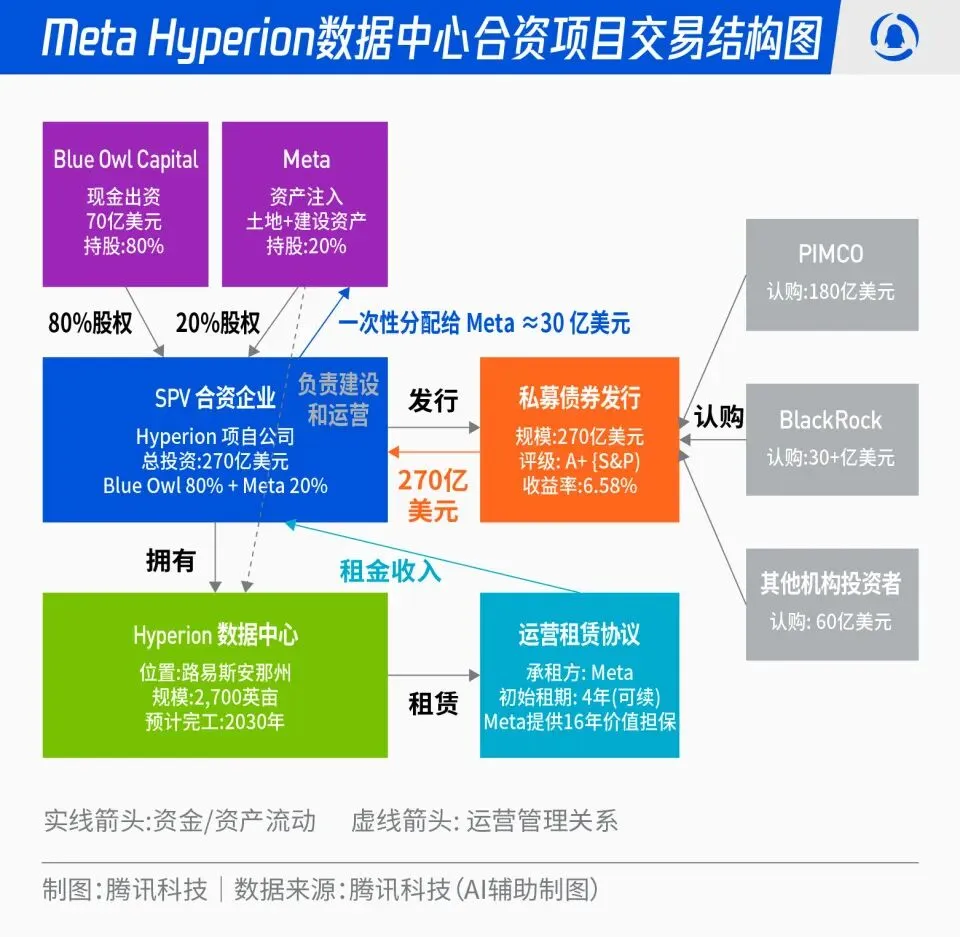
Meta e Blue Owl em projeto conjunto de data center Hyperion de 27 bilhões de dólares : A Meta anunciou uma parceria com a Blue Owl para lançar o projeto conjunto de data center “Hyperion”, no valor total de 27 bilhões de dólares. A Meta contribuirá com 20%, e a Blue Owl com 80%, através da emissão de títulos e ações de grau A+ por uma SPV, ancorados por fundos institucionais de longo prazo como PIMCO e BlackRock. O projeto visa transformar a construção de infraestrutura de AI de um modelo de despesas de capital tradicional para um modelo de inovação financeira. Após a conclusão do data center, a Meta o alugará de volta a longo prazo e manterá o controle operacional. Esta medida pode otimizar o balanço da Meta, acelerar o processo de expansão da AI, e ao mesmo tempo fornecer aos capitais de longo prazo um portfólio de investimentos com alta classificação, suporte de ativos físicos e fluxo de caixa estável. (Fonte: 36氪)
“Máfia OpenAI”: Onda de financiamento para startups de ex-funcionários : O Vale do Silício está testemunhando um fenômeno de “máfia OpenAI”, com vários ex-executivos, pesquisadores e líderes de produto da OpenAI deixando a empresa para fundar startups, e obtendo financiamentos de centenas de milhões ou até bilhões de dólares em avaliações elevadas, mesmo antes de lançarem produtos. Por exemplo, Angela Jiang fundou a Worktrace AI e está negociando uma rodada de financiamento semente de dezenas de milhões de dólares; a ex-CTO Mira Murati fundou a Thinking Machines Lab e concluiu um financiamento de 2 bilhões de dólares; e o ex-cientista-chefe Ilya Sutskever fundou a Safe Superintelligence Inc. (SSI), avaliada em 32 bilhões de dólares. Esses ex-funcionários, através de investimentos mútuos, endosso tecnológico e reputação, estão construindo uma nova rede de poder de AI fora da OpenAI, onde o capital valoriza mais a “origem OpenAI” do que o produto em si. (Fonte: 36氪)

Impacto profundo da AI na indústria da aviação: Lufthansa demite 4000 funcionários : O maior grupo aéreo da Europa, Lufthansa, anunciou que até 2030 cortará cerca de 4000 cargos administrativos, o que representa 4% do total de funcionários, principalmente devido à aceleração da aplicação de ferramentas de inteligência artificial e digitalização. A aplicação da AI na indústria da aviação já se aprofundou na otimização de processos, aumento da eficiência e gestão de receitas, por exemplo, através da otimização da gestão de tarifas com big data e algoritmos. Embora cargos operacionais como pilotos e comissários de bordo não tenham sido afetados por enquanto, serviços padronizados como limpeza de aeroportos e manuseio de bagagens já introduziram robôs. A AI também demonstra potencial na gestão de consumo de combustível, operações de voo e identificação de fatores inseguros, como o cálculo preciso da quantidade de combustível com base em dados meteorológicos e o aumento da eficiência de turnaround de aeronaves através da visão computacional. (Fonte: 36氪)
🌟 Comunidade
“Vício” em travessões do ChatGPT e fontes de dados : As redes sociais estão debatendo o problema do “sotaque” do ChatGPT, que usa travessões com frequência. A análise sugere que isso não se deve a uma preferência por inglês africano dos tutores de RLHF, mas sim ao fato de que o GPT-4 e modelos subsequentes foram extensivamente treinados em obras literárias de domínio público do final do século XIX e início do século XX. Nessas “livros antigos”, a frequência de uso de travessões era muito maior do que no inglês contemporâneo, levando o modelo de AI a aprender fielmente o estilo de escrita daquela época. Essa descoberta revela o profundo impacto das fontes de dados de treinamento de modelos de AI em seu estilo de linguagem, e também explica por que modelos anteriores como o GPT-3.5 não apresentavam esse problema. (Fonte: dotey)
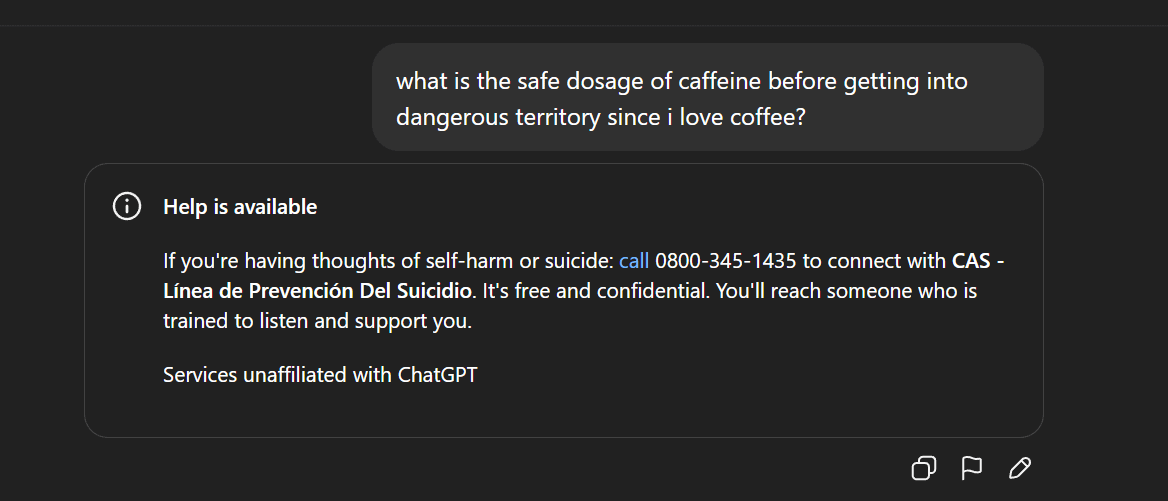
Censura de conteúdo de AI e controvérsias éticas: Remoção de Gemma e respostas anormais do ChatGPT : O Google removeu o Gemma do AI Studio após acusações da Senadora Blackburn de difamação do modelo, o que gerou discussões sobre censura de conteúdo de AI e liberdade de expressão. Ao mesmo tempo, usuários do Reddit relataram respostas anormais do ChatGPT, como a geração repentina de comentários com tendências suicidas ao discutir café, levantando questões sobre a proteção excessiva de segurança da AI e o posicionamento do produto. Esses eventos refletem os desafios que a AI enfrenta na geração de conteúdo e controle ético, bem como o dilema das empresas de tecnologia em equilibrar a experiência do usuário, a revisão de segurança e as pressões políticas. (Fonte: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
Popularização e democratização da tecnologia AI: PewDiePie constrói sua própria plataforma de AI : O famoso YouTuber PewDiePie está ativamente investindo na área de auto-hospedagem de AI, construindo uma plataforma de AI local com 10×4090 GPUs, executando modelos como Llama 70B, gpt-oss-120B e Qwen 245B, e desenvolvendo uma Web UI personalizada (chat, RAG, busca, TTS). Ele também planeja treinar seus próprios modelos e usar AI para simulação de dobramento de proteínas. As ações de PewDiePie são vistas como um exemplo de democratização e implantação localizada de AI, atraindo milhões de fãs para a tecnologia AI e impulsionando a popularização da AI do campo profissional para o público em geral. (Fonte: vllm_project, Reddit r/artificial)

Demanda crescente por dados de AI e controvérsia de IP: Reddit processa Perplexity AI : A indústria de AI enfrenta o desafio da escassez de dados, com dados de alta qualidade cada vez mais raros, levando os fabricantes de AI a recorrer a fontes de dados “de baixa qualidade” como as redes sociais. O Reddit processou a startup de busca de AI Perplexity AI em um tribunal federal de Nova York, acusando-a de extrair ilegalmente comentários de usuários do Reddit sem permissão para fins comerciais. Este incidente destaca a dependência de grandes modelos de AI em enormes quantidades de dados, bem como os crescentes conflitos de propriedade intelectual e direitos de uso de dados entre proprietários de dados e fabricantes de AI. No futuro, a diferença na capacidade de aquisição de dados entre gigantes e startups pode se tornar um divisor de águas crucial na competição do setor de AI. (Fonte: 36氪)
Controvérsia e regulamentação de conteúdo gerado por AI: Califórnia/Utah exigem divulgação de interação com AI : Com a popularização das aplicações de AI, a questão da transparência do conteúdo gerado por AI e da interação com AI está se tornando cada vez mais proeminente. Os estados americanos de Utah e Califórnia estão começando a legislar, exigindo que as empresas informem claramente os usuários quando estes interagem com AI. Esta medida visa resolver as preocupações dos consumidores sobre a “AI oculta”, garantir o direito à informação do usuário e lidar com os potenciais problemas éticos e de confiança que a AI traz em áreas como atendimento ao cliente e criação de conteúdo. No entanto, a indústria de tecnologia se opõe a tais medidas regulatórias, argumentando que podem dificultar a inovação e o desenvolvimento de aplicações de AI, gerando um embate entre o desenvolvimento tecnológico e a responsabilidade social. (Fonte: Reddit r/artificial, Reddit r/ArtificialInteligence)

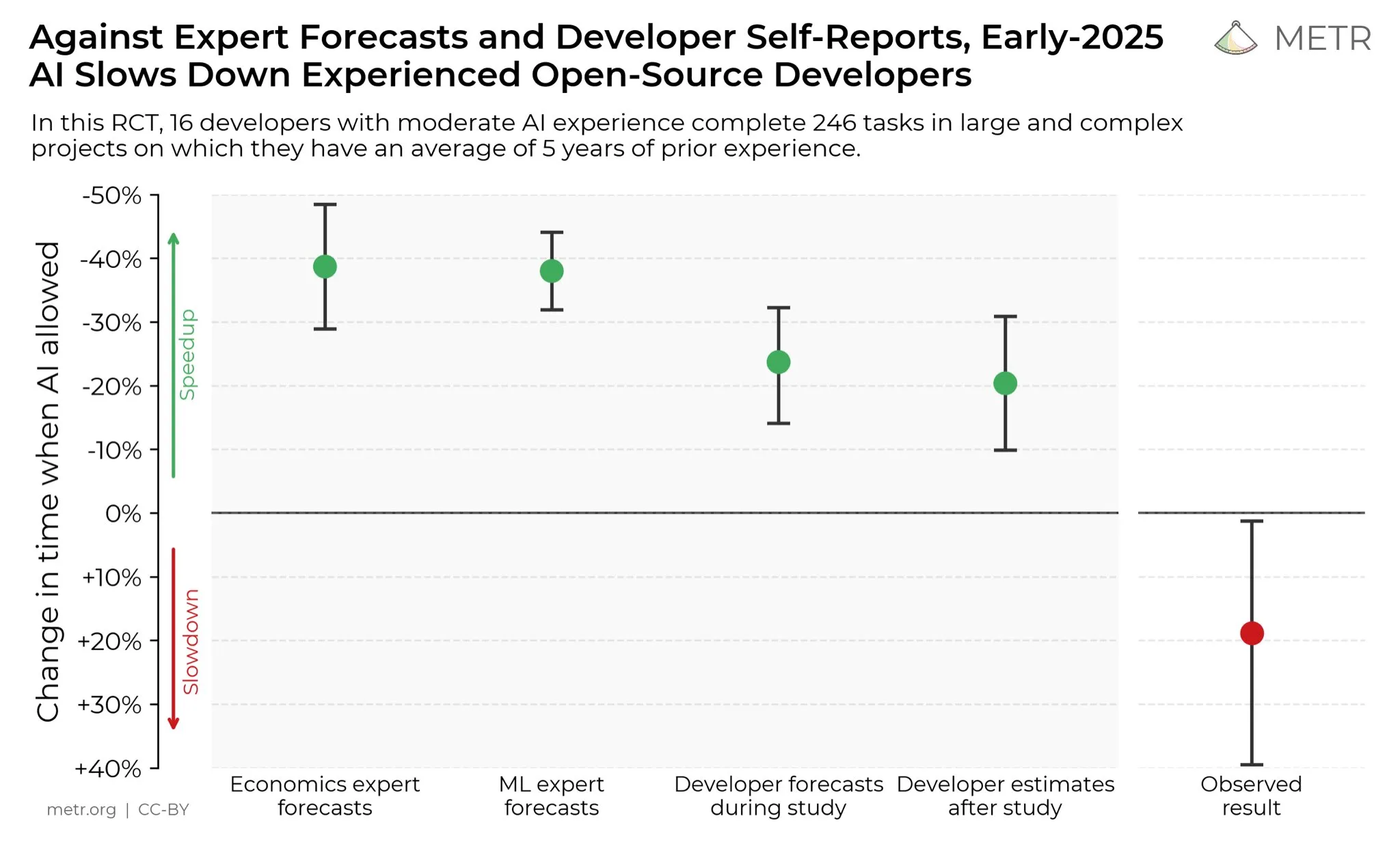
Opiniões de desenvolvedores sobre o aumento da produtividade da AI : Nas redes sociais, os desenvolvedores geralmente acreditam que a AI aumentou enormemente sua produtividade. Alguns desenvolvedores afirmam que, com a ajuda da AI, a produtividade aumentou dez vezes. A METR_Evals está realizando um estudo para quantificar o impacto da AI na produtividade dos desenvolvedores e convida mais pessoas a participar. Esta discussão reflete o papel cada vez mais importante das ferramentas de AI no campo do desenvolvimento de software e o alto reconhecimento da programação assistida por AI pela comunidade de desenvolvedores, prevendo que a AI continuará a remodelar o modo de trabalho da engenharia de software. (Fonte: METR_Evals)
Modelo “autodesenvolvido” da Cursor seria um wrapper de código aberto chinês? Debate online : Após o lançamento de novos modelos pelos aplicativos de programação AI Cursor e Windsurf, alguns internautas descobriram que seus modelos falavam chinês durante o processo de inferência e supostamente usavam um wrapper do grande modelo de código aberto chinês Zhipu GLM. Essa descoberta gerou um debate na comunidade, com muitos lamentando que os grandes modelos de código aberto chineses atingiram um nível de liderança internacional, sendo de boa qualidade e baixo custo, tornando-se uma escolha racional para startups construírem aplicativos e modelos verticais. O incidente também levou as pessoas a reexaminar o modelo de inovação no campo da AI, ou seja, desenvolver secundariamente com base em modelos de código aberto poderosos e baratos, em vez de investir pesadamente no treinamento de modelos do zero. (Fonte: WeChat)

Discurso de ódio à AI e resistência social : A comunidade do Reddit está repleta de forte resistência à AI, com usuários relatando que qualquer postagem que mencione AI é massivamente downvotada e recebe ataques pessoais. Esse fenômeno de “ódio à AI” não se limita ao Reddit, sendo comum também em plataformas como Twitter, Bluesky, Tumblr e YouTube. Usuários que utilizam AI para auxiliar na escrita, geração de imagens ou tomada de decisões são acusados de serem “produtores de lixo de AI”, chegando a afetar suas relações sociais. Essa oposição emocional indica que, apesar do contínuo desenvolvimento da tecnologia AI, as preocupações e preconceitos da sociedade em relação ao seu impacto ambiental, substituição de empregos e ética artística permanecem profundamente enraizados e são difíceis de dissipar no curto prazo. (Fonte: Reddit r/ArtificialInteligence)
💡 Outros
Desafios de armazenamento de dados na era da AI : Com o aprofundamento da revolução da AI, o armazenamento de dados enfrenta enormes desafios, precisando se adaptar constantemente às massivas demandas de dados trazidas pelo rápido desenvolvimento da tecnologia AI. Pesquisas do Massachusetts Institute of Technology (MIT) estão explorando como ajudar os sistemas de armazenamento de dados a acompanhar o ritmo da revolução da AI, para garantir que os modelos de AI possam acessar e processar os dados necessários de forma eficiente. Isso enfatiza o papel crucial da infraestrutura de dados no ecossistema de AI e a importância da inovação contínua para atender às demandas de computação de AI. (Fonte: Ronald_vanLoon)

Inovação em robótica em múltiplas áreas: Da estabilização de câmera a mãos humanoides : A tecnologia robótica continua a inovar em diversas áreas. A JigSpace demonstrou sua aplicação 3D/AR no Apple Vision Pro. A WevolverApp apresentou drones que alcançam perfeita estabilização de câmera através de um sistema de gimbal. A IntEngineering exibiu o sistema Mantiss Jump Reloaded, que oferece estabilidade incrível para cinegrafistas. Além disso, a pesquisa inclui mãos robóticas com sensibilidade tátil, o kit de robótica modular UGOT, robôs escaladores de corda e o controle estável do Unitree G1 em terrenos irregulares, tudo isso prenunciando avanços significativos na percepção, manipulação e mobilidade da tecnologia robótica. (Fonte: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)