
Palavras-chave:robô humanóide, modelo de IA em grande escala, aprendizagem por reforço, IA multimodal, agente de IA, gargalo de dados do Figure 03, prova matemática do GPT-5 Pro, RAG no dispositivo EmbeddingGemma, diálogo de análise gráfica GraphQA, desempenho de inferência NVIDIA Blackwell
🔥 Destaque
Figure 03 na capa da lista de Melhores Invenções da Time, CEO diz “neste estágio, só faltam dados”: Brett Adcock, CEO da Figure, afirmou que o maior gargalo atual para o robô humanoide Figure 03 são os “dados”, e não a arquitetura ou o poder de computação, acreditando que os dados podem resolver quase todos os problemas e impulsionar a aplicação em larga escala de robôs. O Figure 03 apareceu na capa da lista de Melhores Invenções de 2025 da revista Time, gerando discussões sobre a importância de dados, poder de computação e arquitetura no desenvolvimento de robôs. Brett Adcock enfatizou que o objetivo da Figure é fazer com que os robôs realizem tarefas humanas em ambientes domésticos e comerciais, e que a segurança dos robôs é uma prioridade máxima, prevendo que o número de robôs humanoides poderá superar o de humanos no futuro. (Fonte: 量子位)

Terence Tao desafia limites com GPT-5 Pro! Problema sem solução há 3 anos, prova completa em 11 minutos: O renomado matemático Terence Tao, em colaboração com o GPT-5 Pro, resolveu um problema de geometria diferencial que estava sem solução há 3 anos, em apenas 11 minutos. O GPT-5 Pro não só realizou cálculos complexos, mas também forneceu uma prova completa e até ajudou Tao a corrigir suas intuições iniciais. Tao concluiu que a AI se destaca em problemas de “pequena escala”, é útil na compreensão de problemas de “grande escala”, mas pode reforçar intuições erradas em estratégias de “escala média”. Ele enfatizou que a AI deve atuar como um “copiloto” para matemáticos, aumentando a eficiência experimental, em vez de substituir completamente o trabalho humano em criatividade e intuição. (Fonte: 量子位)

🎯 Tendências
Yunpeng Technology lança novos produtos AI+Saúde: A Yunpeng Technology, em parceria com a Shuaikang e a Skyworth, lançou novos produtos AI+Saúde, incluindo o “Laboratório de Cozinha Futura Digital e Inteligente” e uma geladeira inteligente equipada com um grande modelo de AI para saúde. O grande modelo de AI para saúde otimiza o design e a operação da cozinha, enquanto a geladeira inteligente, através do “Assistente de Saúde Xiaoyun”, oferece gerenciamento de saúde personalizado. Isso marca um avanço da AI na área de gerenciamento de saúde diário, com serviços de saúde personalizados através de dispositivos inteligentes, que prometem impulsionar o desenvolvimento da tecnologia de saúde doméstica e melhorar a qualidade de vida dos moradores. (Fonte: 36氪)
Avanços em robôs humanoides e inteligência encarnada: de tarefas domésticas a aplicações industriais: Várias discussões sociais destacam os mais recentes avanços em robôs humanoides e inteligência encarnada. O Reachy Mini foi nomeado uma das melhores invenções de 2025 pela revista Time, demonstrando o potencial da colaboração de código aberto na robótica. Próteses biônicas impulsionadas por AI permitem que um adolescente de 17 anos controle com a mente, e robôs humanoides realizam tarefas domésticas com facilidade. No setor industrial, a Yondu AI lançou uma solução de seleção em armazéns com robôs humanoides sobre rodas, a AgiBot introduziu o Lingxi X2 com capacidade de movimento quase humana, e a China também lançou um robô policial esférico de alta velocidade. Os robôs da Boston Dynamics evoluíram para câmeras multifuncionais, e o robô quadrúpede LocoTouch realiza transporte inteligente através do tato. (Fonte: Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, johnohallman, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Avanços na capacidade de grandes modelos e novos progressos em benchmarks de código: GPT-5 Pro e Gemini 2.5 Pro demonstraram desempenho de medalha de ouro na Olimpíada Internacional de Astronomia e Astrofísica (IOAA), exibindo a poderosa capacidade da AI em física de ponta. O GPT-5 Pro também mostrou habilidades superpoderosas de busca e verificação de literatura científica, resolvendo o Erdos problem #339 e identificando eficazmente grandes falhas em artigos publicados. Na área de código, o KAT-Dev-72B-Exp tornou-se o modelo de código aberto líder no SWE-Bench Verified, alcançando uma taxa de correção de 74,6%. O projeto SWE-Rebench evita a contaminação de dados testando novos GitHub issues propostos após o lançamento de grandes modelos. Sam Altman está otimista com o futuro do Codex. Quanto à questão de saber se a AGI pode ser alcançada apenas com LLMs puros, a comunidade de pesquisa em AI geralmente acredita que é difícil atingir apenas com o núcleo de LLM. (Fonte: gdb, karminski3, gdb, SebastienBubeck, karminski3, teortaxesTex, QuixiAI, sama, OfirPress, Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Inovação e desafios no desempenho de hardware e infraestrutura de AI: A plataforma NVIDIA Blackwell demonstrou desempenho e eficiência de inferência incomparáveis no benchmark SemiAnalysis InferenceMAX, e a Together AI já oferece sistemas NVIDIA GB200 NVL72 e HGX B200. A Groq, através de sua estratégia de ASIC e integração vertical, está remodelando a economia da infraestrutura de LLM de código aberto com menor latência e preços competitivos. A comunidade discutiu o impacto da remoção do Python GIL na engenharia de AI/ML, acreditando que sua remoção pode melhorar o desempenho multithread. Além disso, entusiastas de LLM compartilharam suas configurações de hardware e exploraram o trade-off de desempenho entre modelos grandes quantizados e modelos pequenos não quantizados em diferentes níveis de quantização, indicando que a quantização de 2 bits pode ser adequada para conversação, mas tarefas de codificação exigem pelo menos Q5. (Fonte: togethercompute, arankomatsuzaki, code_star, MostafaRohani, jeremyphoward, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Dinâmicas de ponta em modelos e aplicações de AI: de modelos gerais a domínios verticais: Novos modelos e funcionalidades de AI continuam a surgir. O grande modelo de língua turca Kumru-2B se destaca no Hugging Face, e a Replit lançou várias atualizações esta semana. O Sora 2 removeu a marca d’água, indicando que a tecnologia de geração de vídeo trará aplicações mais amplas. Há rumores de que o Gemini 3.0 será lançado em 22 de outubro. A AI continua a se aprofundar na área de saúde, com a patologia digital utilizando AI para auxiliar no diagnóstico de câncer, e a microscopia sem marcadores combinada com AI promete novas ferramentas de diagnóstico. Modelos de Realidade Aumentada (AR) alcançaram SOTA na lista Imagenet FID. A atualização do Qwen Code, um Agent de codificação de linha de comando, agora suporta o modelo Qwen-VL para reconhecimento de imagens. A Universidade de Stanford propôs o método Agentic Context Engineering (ACE), que permite que os modelos se tornem mais inteligentes sem a necessidade de ajuste fino. A série de modelos DeepSeek V3 também está em constante iteração, e os tipos de implantação de AI Agent e a remodelação da AI em áreas de serviços profissionais também se tornaram focos de atenção da indústria. (Fonte: mervenoyann, amasad, scaling01, npew, kaifulee, Ronald_vanLoon, scaling01, TheTuringPost, TomLikesRobots, iScienceLuvr, NerdyRodent, shxf0072, gabriberton, Ronald_vanLoon, karminski3, Ronald_vanLoon, teortaxesTex, demishassabis, Dorialexander, yoheinakajima, 36氪)
🧰 Ferramentas
GraphQA: Transformando análise de grafos em conversas em linguagem natural: A LangChainAI lançou o framework GraphQA, que combina NetworkX e LangChain para transformar análises complexas de grafos em conversas em linguagem natural. Os usuários podem fazer perguntas em inglês comum, e o GraphQA selecionará e executará automaticamente os algoritmos apropriados, processando grafos com mais de 100.000 nós. Isso simplifica enormemente a barreira de entrada para a análise de dados de grafos, tornando-a mais acessível para usuários não especializados, sendo uma importante inovação de ferramenta na área de LLM. (Fonte: LangChainAI)
Ferramenta Agentic AI de ponta para VS Code: A Visual Studio Magazine classificou uma ferramenta como uma das principais ferramentas Agentic AI para VS Code, marcando uma mudança de paradigma de desenvolvimento de “assistentes” para “Agentes” reais que pensam, agem e constroem junto com os desenvolvedores. Isso reflete a evolução das ferramentas de AI na área de desenvolvimento de software, de funções auxiliares para uma colaboração inteligente mais profunda, melhorando a eficiência e a experiência dos desenvolvedores. (Fonte: cline)
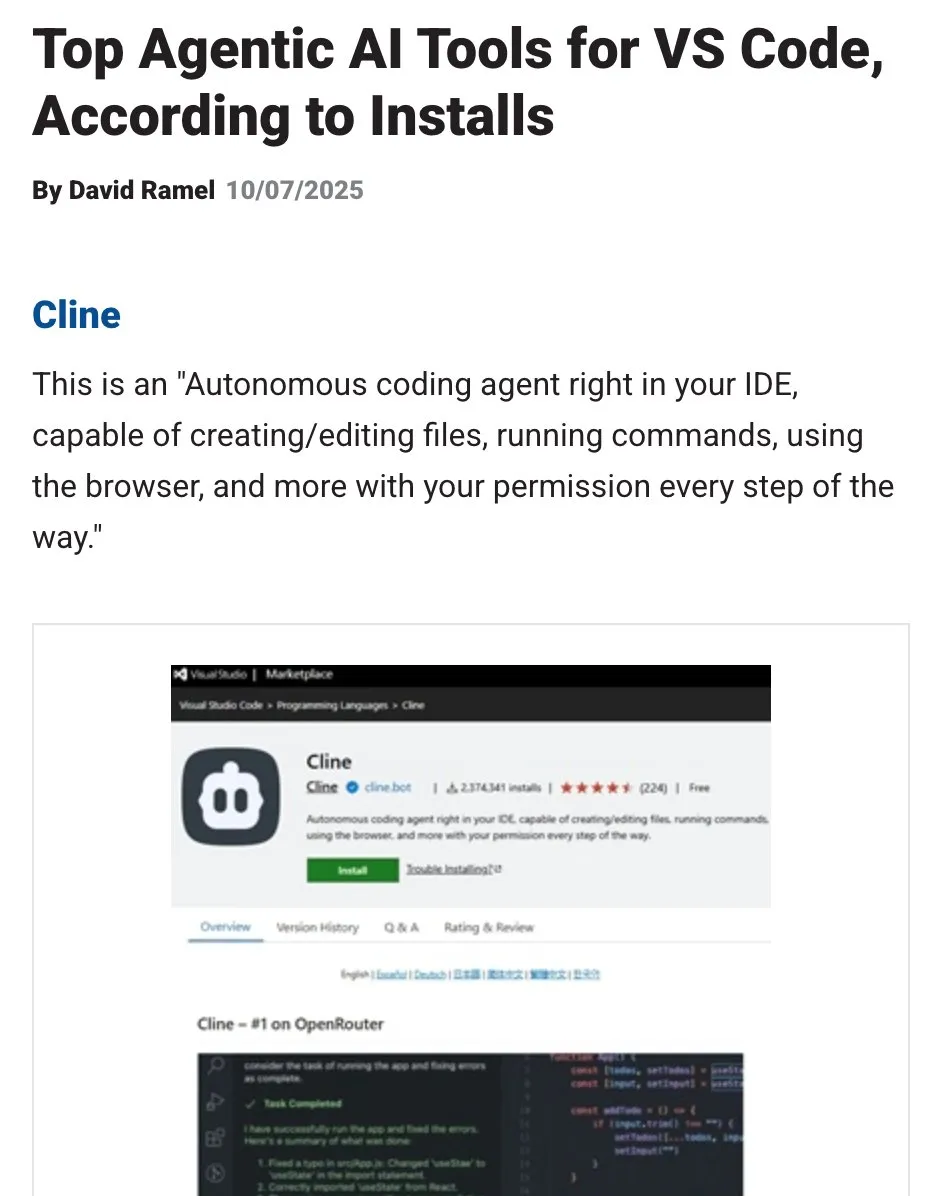
OpenHands: Ferramenta de código aberto para gerenciamento de contexto de LLM: OpenHands, uma ferramenta de código aberto, oferece vários compressores de contexto para gerenciar o contexto de LLMs em aplicações Agentic, incluindo poda básica de histórico, extração de “eventos mais importantes” e compressão de saída do navegador. Isso é crucial para depurar, avaliar e monitorar aplicações de LLM, sistemas RAG e fluxos de trabalho Agentic, ajudando a melhorar a eficiência e a consistência de LLMs em tarefas complexas. (Fonte: gneubig)
BLAST: Motor de navegador web AI: A LangChainAI lançou o BLAST, um motor de navegador web AI de alto desempenho, projetado para fornecer capacidade de navegação web para aplicações de AI. O BLAST oferece uma interface compatível com OpenAI, suporta paralelização automática, cache inteligente e streaming em tempo real, sendo capaz de integrar eficientemente informações da web em fluxos de trabalho de AI, expandindo enormemente a capacidade dos AI Agents de adquirir e processar dados da web em tempo real. (Fonte: LangChainAI)
Opik: Ferramenta de avaliação de LLM de código aberto: Opik é uma ferramenta de avaliação de LLM de código aberto, utilizada para depurar, avaliar e monitorar aplicações de LLM, sistemas RAG e fluxos de trabalho Agentic. Ela oferece rastreamento abrangente, avaliação automatizada e painéis prontos para produção, ajudando os desenvolvedores a entender melhor o comportamento do modelo, otimizar o desempenho e garantir a confiabilidade das aplicações em cenários reais. (Fonte: dl_weekly)
AI Travel Agent: Assistente de planejamento inteligente: A LangChainAI demonstrou um AI Travel Agent inteligente que integra informações de clima em tempo real, pesquisa e viagem, e utiliza múltiplas APIs para simplificar todo o processo, desde atualizações meteorológicas até câmbio de moeda. Este Agent visa fornecer planejamento e assistência de viagem completos, melhorando a experiência do usuário, sendo um caso típico de LLM capacitando Agentes em cenários de aplicação vertical. (Fonte: LangChainAI)
Conceito de ferramenta AI para construção de prompts de anunciantes: Foi sugerido que o mercado precisa urgentemente de uma ferramenta de AI para ajudar os profissionais de marketing a construir “prompts de anunciantes”. Esta ferramenta deve auxiliar na criação de um sistema de avaliação (cobrindo segurança da marca, conformidade do prompt, etc.) e testar os modelos mainstream. Com o lançamento de várias unidades de anúncios naturais pela OpenAI, a importância dos prompts de marketing está cada vez mais evidente, e tais ferramentas se tornarão um elo crucial nos processos de criação e distribuição de anúncios. (Fonte: dbreunig)
Atualização do Qwen Code: Suporte para reconhecimento de imagem do modelo Qwen-VL: O Agent de codificação de linha de comando Qwen Code foi recentemente atualizado, adicionando suporte para alternar para o modelo Qwen-VL para reconhecimento de imagem. Testes de usuários mostram bons resultados, e atualmente é gratuito para uso. Esta atualização expande enormemente as capacidades do Qwen Code, permitindo que ele não apenas lide com tarefas de código, mas também realize interações multimodais, melhorando a eficiência e a precisão do Agent de codificação ao lidar com tarefas que contêm informações visuais. (Fonte: karminski3)

Hospedando seu servidor de chatbot pessoal com LibreChat: Uma postagem de blog fornece um guia sobre como usar o LibreChat para hospedar um servidor de chatbot pessoal e conectar-se a vários painéis de controle de modelo (MCPs). Isso permite que os usuários gerenciem e alternem flexivelmente entre diferentes backends de LLM, alcançando uma experiência de chatbot personalizada, destacando a flexibilidade e controlabilidade das soluções de código aberto na implantação de aplicações de AI. (Fonte: Reddit r/artificial)
Gerador de AI: Dando vida a avatares virtuais: Um usuário busca o melhor gerador de AI para “dar vida” à sua imagem de marca (incluindo vídeos de pessoas reais e avatares virtuais) para um canal do YouTube, a fim de reduzir o tempo de filmagem e gravação e focar na edição. O usuário espera que a AI permita que os avatares conversem, joguem, dancem, etc. Isso reflete a alta demanda de criadores de conteúdo por ferramentas de AI em animação de avatares e geração de vídeo, para melhorar a eficiência da produção e a diversidade de conteúdo. (Fonte: Reddit r/artificial)
LLM local contra spam de e-mail: Solução privada: Uma postagem de blog compartilha a prática de como usar um LLM local para identificar e combater spam de e-mail de forma privada em seu próprio servidor de e-mail. A solução combina Mailcow, Rspamd, Ollama e um agente Python personalizado, fornecendo um método de filtragem de spam baseado em AI para usuários de servidores de e-mail auto-hospedados, destacando o potencial dos LLMs locais na proteção da privacidade e em aplicações personalizadas. (Fonte: Reddit r/LocalLLaMA)
📚 Aprendizagem
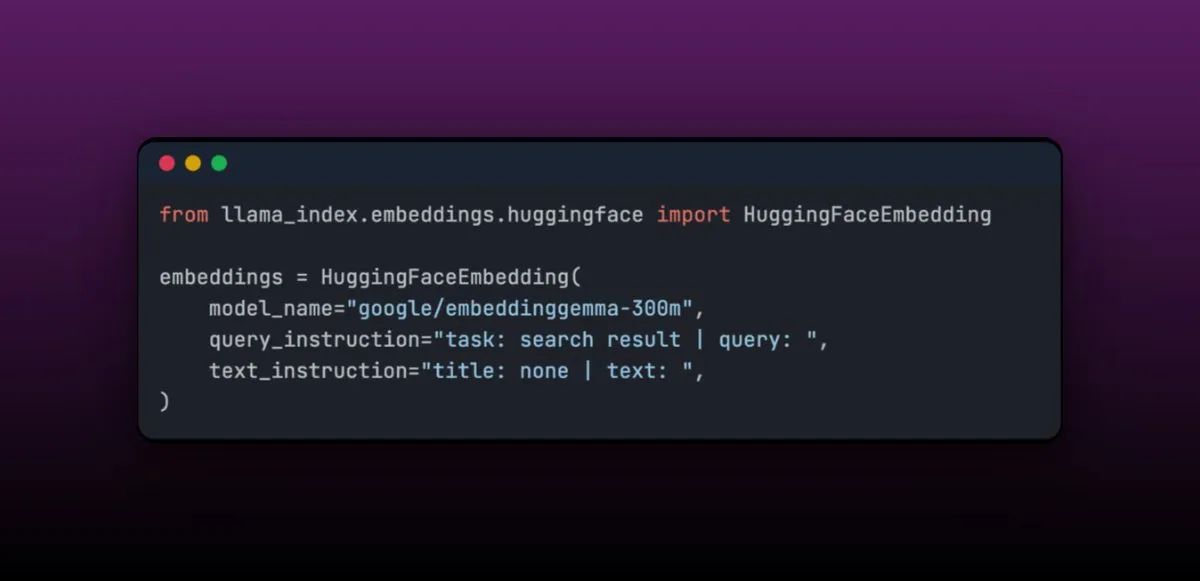
EmbeddingGemma: Modelo de embedding multilíngue para aplicações RAG em dispositivos: EmbeddingGemma é um modelo de embedding multilíngue compacto, com apenas 308M parâmetros, ideal para aplicações RAG em dispositivos e fácil de integrar com LlamaIndex. O modelo tem uma classificação alta no Massive Text Embedding Benchmark e, ao mesmo tempo, é pequeno, adequado para dispositivos móveis. Sua característica de fácil ajuste fino permite que, após o ajuste fino em domínios específicos (como dados médicos), seu desempenho possa superar modelos maiores. (Fonte: jerryjliu0)
Dois métodos básicos de processamento de documentos: Parsing e Extração: Um artigo da equipe LlamaIndex explora em profundidade dois métodos básicos de processamento de documentos: “parsing” e “extração”. Parsing é a conversão de um documento inteiro para Markdown ou JSON estruturado, preservando todas as informações, adequado para RAG, pesquisa aprofundada e sumarização. Extração é a obtenção de saída estruturada de um LLM, padronizando o documento em um padrão comum, adequado para ETL de banco de dados, fluxos de trabalho de Agent automatizados e extração de metadados. Compreender a diferença entre os dois é crucial para construir um Document Agent eficiente. (Fonte: jerryjliu0)

Implementação do Tiny Recursive Model (TRM) no MLX: A plataforma MLX implementa a parte central do Tiny Recursive Model (TRM), proposto por Alexia Jolicoeur-Martineau, que visa obter alto desempenho com uma pequena rede neural de 7M parâmetros através de inferência recursiva. Esta implementação em MLX torna possível a experimentação local em laptops Apple Silicon, reduzindo a complexidade e cobrindo características como supervisão profunda, etapas de inferência recursiva, EMA, etc., proporcionando conveniência para o desenvolvimento e pesquisa de modelos pequenos e eficientes. (Fonte: awnihannun, ImazAngel)
Roteiro de aprendizagem para especialista em AI Generativa 2025: Um roteiro detalhado para se tornar um especialista em AI Generativa em 2025 foi compartilhado nas redes sociais, cobrindo os conhecimentos e habilidades essenciais necessários para profissionais na área de GenAI. O roteiro visa guiar os aspirantes a aprender sistematicamente conceitos centrais como inteligência artificial, machine learning e deep learning, a fim de se adaptar às rápidas tendências tecnológicas da GenAI. (Fonte: Ronald_vanLoon)
Compartilhamento de experiência de doutorado em Machine Learning: Um usuário compartilhou novamente uma série de tweets sobre a busca de um doutorado na área de Machine Learning, com o objetivo de fornecer orientação e experiência para aqueles interessados em estudos de doutorado em ML. Esses tweets podem cobrir o processo de inscrição, direções de pesquisa, desenvolvimento de carreira e experiências pessoais, sendo um recurso valioso de aprendizagem de AI na comunidade. (Fonte: arohan)
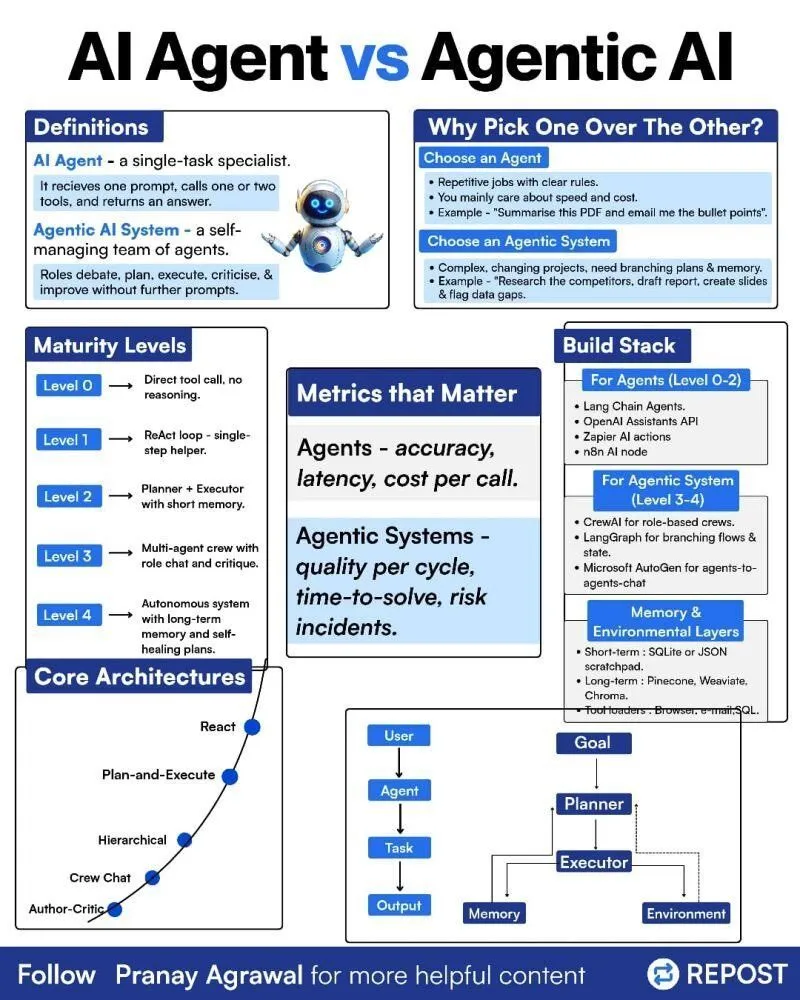
Diferença entre AI Agents e Agentic AI: Uma ilustração sobre a diferença entre “AI Agents” e “Agentic AI” foi compartilhada nas redes sociais, com o objetivo de esclarecer esses dois conceitos relacionados, mas distintos. Isso ajuda a comunidade a entender melhor os tipos de implantação de AI Agent, seus níveis de autonomia e o papel da Agentic AI em sistemas de inteligência artificial mais amplos, promovendo uma discussão mais precisa sobre a tecnologia de Agent. (Fonte: Ronald_vanLoon)
Reinforcement Learning e Weight Decay no treinamento de LLM: As redes sociais discutiram que o Weight Decay pode não ser uma boa ideia no treinamento de Reinforcement Learning (RL) de LLMs. Há uma visão de que o Weight Decay pode fazer com que a rede esqueça uma grande quantidade de informações pré-treinadas, especialmente em atualizações GRPO onde a vantagem é zero, os pesos tenderão a zero. Isso alerta os pesquisadores a considerar cuidadosamente o impacto do Weight Decay ao projetar estratégias de treinamento de RL para LLMs, a fim de evitar a degradação do desempenho do modelo. (Fonte: lateinteraction)
Paradigmas de treinamento de modelos de AI: Um especialista compartilhou quatro paradigmas de treinamento de modelos que engenheiros de ML devem conhecer, com o objetivo de fornecer orientação teórica e um framework prático para engenheiros de Machine Learning. Esses paradigmas podem cobrir aprendizado supervisionado, não supervisionado, por reforço e auto-supervisionado, ajudando os engenheiros a entender e aplicar melhor diferentes métodos de treinamento de modelos. (Fonte: _avichawla)
Reinforcement Learning baseado em Curriculum Learning para aprimorar as capacidades de LLM: Um estudo descobriu que o Reinforcement Learning (RL) combinado com Curriculum Learning pode ensinar novas capacidades a LLMs, algo difícil de alcançar com outros métodos. Isso demonstra o potencial do Curriculum Learning para melhorar as capacidades de raciocínio de longo prazo de LLMs, indicando que a combinação de RL e Curriculum Learning pode se tornar uma via chave para desbloquear novas habilidades de AI. (Fonte: sytelus)

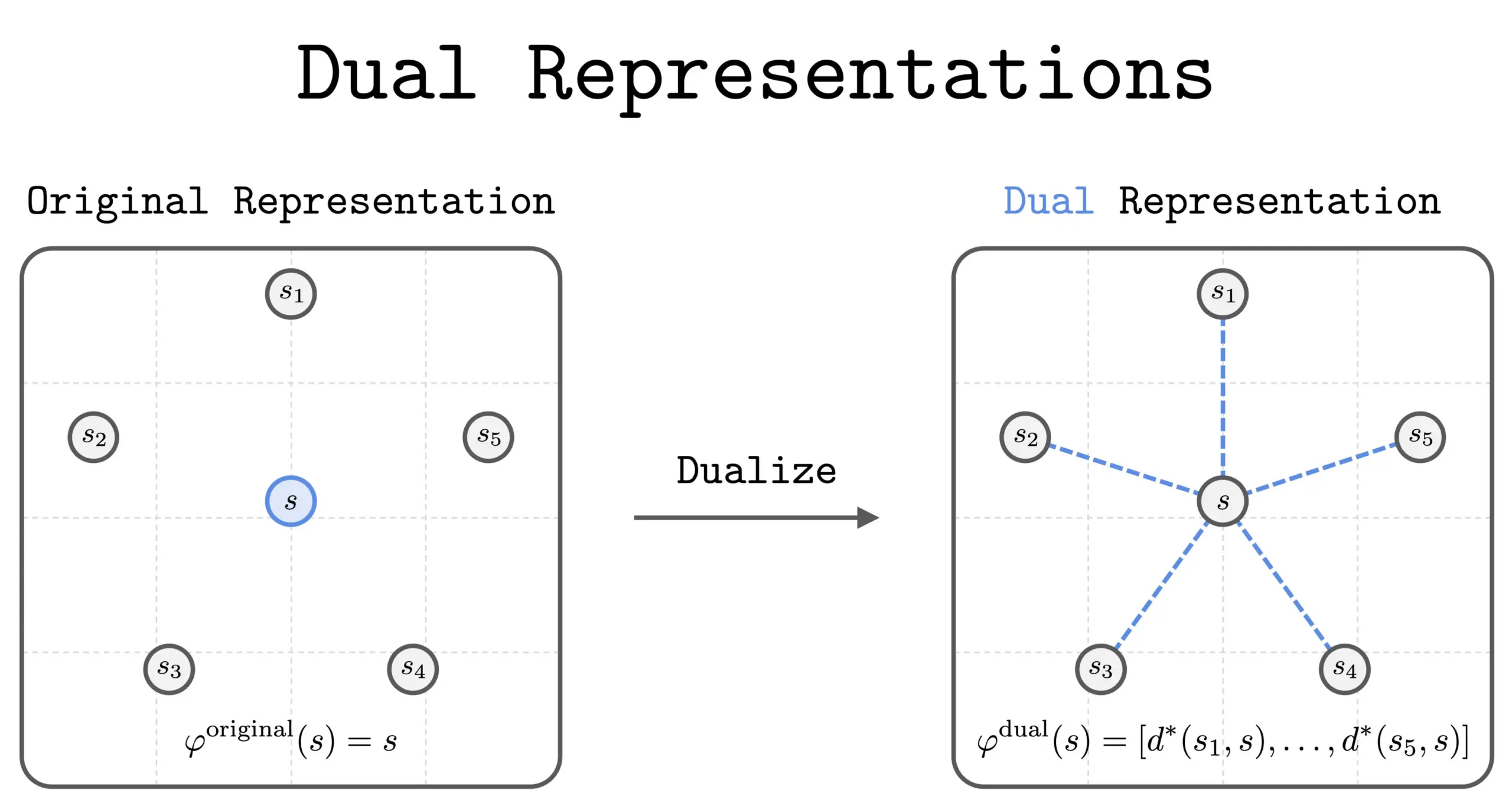
Novo método de “representação dual” em RL: Uma nova pesquisa introduziu o método de “representação dual” em Reinforcement Learning (RL). Este método oferece uma nova perspectiva ao representar estados como um “conjunto de similaridades” com todos os outros estados. Esta representação dual possui boas propriedades teóricas e benefícios práticos, com potencial para melhorar o desempenho e a compreensão do RL. (Fonte: dilipkay)
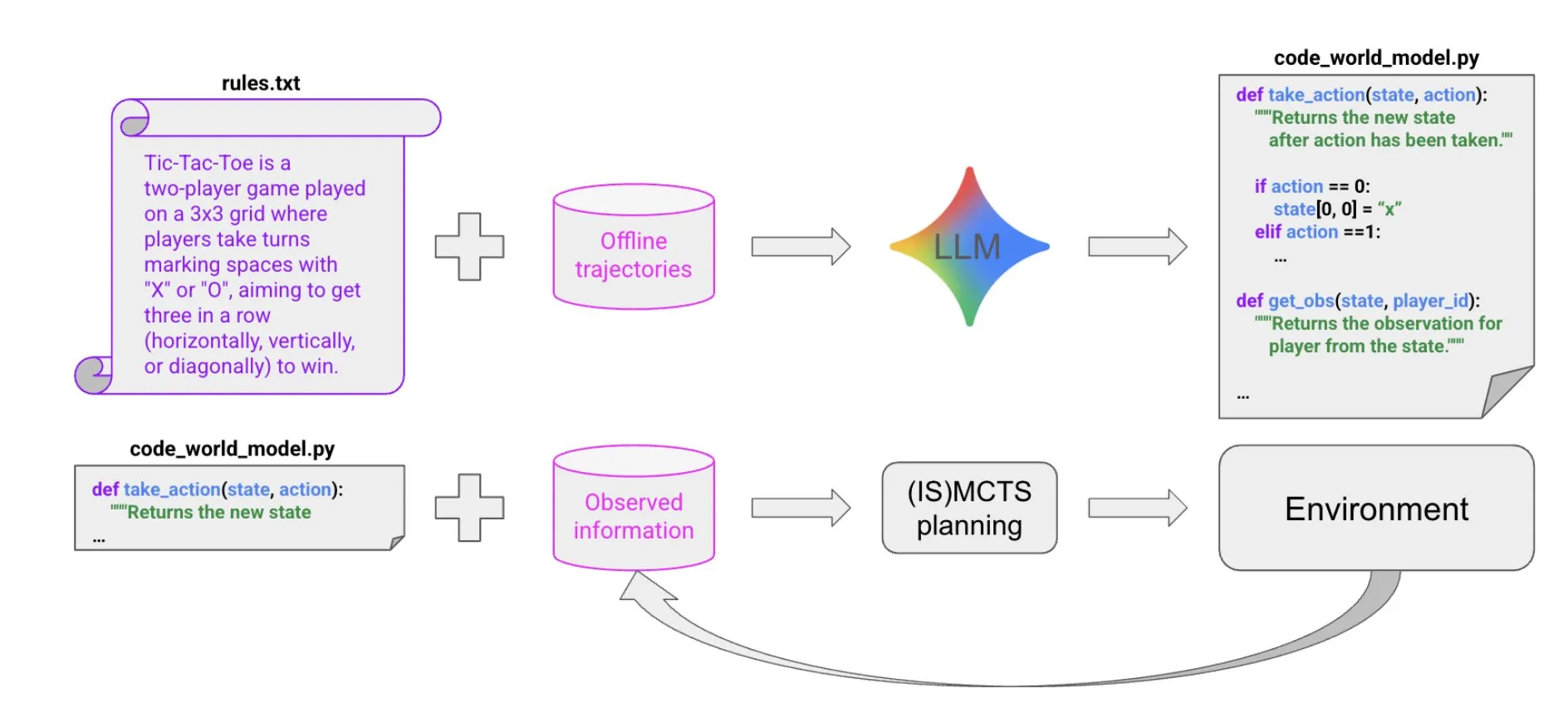
Síntese de código impulsionada por LLM para construir modelos de mundo: Um novo artigo propõe um método extremamente eficiente em termos de amostras para criar Agentes que se comportam bem em ambientes simbólicos multi-Agent e parcialmente observáveis, através da síntese de código impulsionada por LLM. Este método aprende um modelo de mundo de código a partir de poucos dados de trajetória e informações de contexto, e então o passa para um solucionador existente (como MCTS) para selecionar a próxima ação, fornecendo novas ideias para a construção de Agentes complexos. (Fonte: BlackHC)
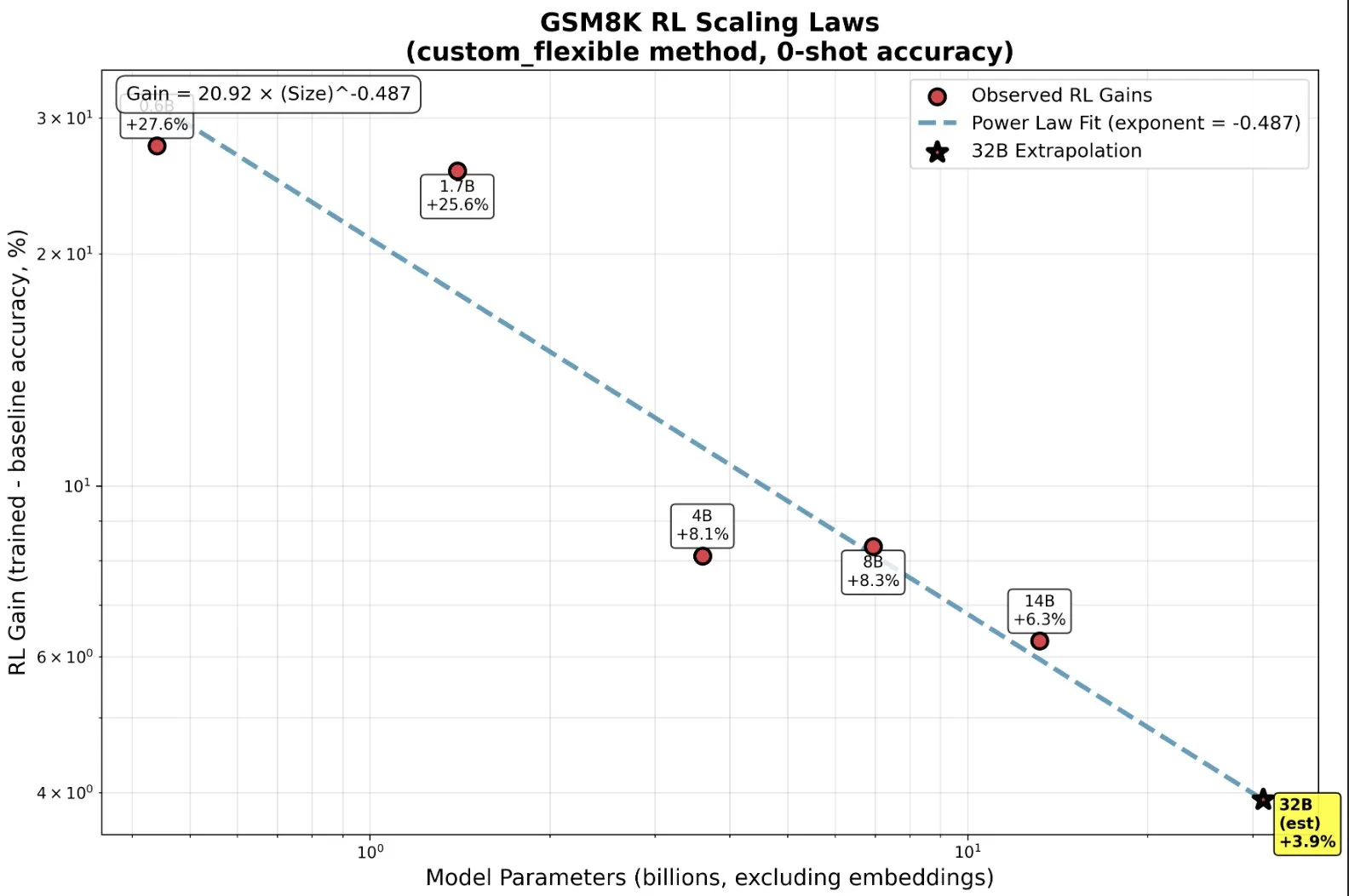
RL treinando modelos pequenos: Capacidades emergentes além do pré-treinamento: Pesquisas descobriram que, no Reinforcement Learning (RL), modelos pequenos podem se beneficiar desproporcionalmente e até exibir capacidades “emergentes”, o que subverte a intuição tradicional de “quanto maior, melhor”. Em modelos de pequena escala, o RL pode ser computacionalmente mais eficiente do que mais pré-treinamento. Esta descoberta é de grande importância para as decisões dos laboratórios de AI sobre quando parar o pré-treinamento e quando iniciar o RL ao escalar o RL, revelando novas leis de escala entre o tamanho do modelo e a melhoria do desempenho no RL. (Fonte: ClementDelangue, ClementDelangue)
AI vs. Machine Learning vs. Deep Learning: Explicação simples: Um recurso de vídeo explica de forma simples e fácil de entender a diferença entre Inteligência Artificial (AI), Machine Learning (ML) e Deep Learning (DL). O vídeo visa ajudar iniciantes a compreender rapidamente esses conceitos centrais, estabelecendo uma base para um estudo mais aprofundado na área de AI. (Fonte: )

Gerenciamento de templates de prompt em experimentos de modelos de Deep Learning: A comunidade de Deep Learning discutiu como gerenciar e reutilizar templates de prompt em experimentos de modelos. Em grandes projetos, especialmente ao modificar arquiteturas ou conjuntos de dados, rastrear o efeito de diferentes variantes de prompt torna-se complexo. Usuários compartilharam experiências usando ferramentas como Empromptu AI para controle de versão e classificação de prompts, enfatizando a importância da versionamento de prompts e do alinhamento de conjuntos de dados com prompts para otimizar produtos de modelo. (Fonte: Reddit r/deeplearning)
Guia de seleção de modelos de preenchimento de código (FIM): A comunidade discutiu os fatores chave na escolha de modelos de preenchimento de código (FIM). A velocidade é considerada uma prioridade absoluta, sendo recomendado escolher modelos com poucos parâmetros e que rodem apenas em GPU (alvo >70 t/s). Além disso, modelos “base” e modelos de instrução se comportam de forma semelhante em tarefas FIM. A discussão também listou modelos FIM recentes e um pouco mais antigos, como Qwen3-Coder e KwaiCoder, e explorou como ferramentas como nvim.llm podem suportar modelos não específicos para código. (Fonte: Reddit r/LocalLLaMA)
Trade-off de desempenho de modelos quantizados: Modelos grandes vs. baixa precisão: A comunidade discutiu o trade-off de desempenho entre modelos grandes quantizados e modelos pequenos não quantizados, bem como o impacto do nível de quantização no desempenho do modelo. É geralmente aceito que a quantização de 2 bits pode ser adequada para escrita ou conversação, mas para tarefas como codificação, é necessário pelo menos o nível Q5. Alguns usuários apontaram que o desempenho do Gemma3-27B diminui significativamente com baixa quantização, enquanto alguns novos modelos são treinados com precisão FP4, sem a necessidade de maior precisão. Isso indica que o efeito da quantização varia de acordo com o modelo e a tarefa, exigindo testes específicos. (Fonte: Reddit r/LocalLLaMA)
Razões pelas quais o MissForest em R falha em tarefas de previsão: Um artigo de análise explora as razões pelas quais o algoritmo MissForest da linguagem R falha em tarefas de previsão, apontando que ele quebra sutilmente o princípio chave da separação entre conjuntos de treinamento e teste durante a atribuição. O artigo explica as limitações do MissForest em tais situações e introduz novos métodos como o MissForestPredict, que resolvem este problema mantendo a consistência entre aprendizado e aplicação. Isso tem um significado orientador importante para praticantes de Machine Learning ao lidar com valores ausentes e construir modelos de previsão. (Fonte: Reddit r/MachineLearning)
Busca por recursos de Machine Learning multimodal: Usuários da comunidade buscam recursos de aprendizagem de Machine Learning multimodal, especialmente materiais teóricos e práticos sobre como combinar diferentes tipos de dados (texto, imagem, sinal, etc.) e entender conceitos como fusão, alinhamento e atenção cross-modal. Isso reflete a crescente demanda por aprendizagem de tecnologias de AI multimodal. (Fonte: Reddit r/deeplearning)
Busca por recursos de vídeo sobre treinamento de modelos de inferência com Reinforcement Learning: A comunidade de Machine Learning busca os melhores recursos de vídeo de palestras científicas sobre o uso de Reinforcement Learning (RL) para treinar modelos de inferência, incluindo vídeos de visão geral e explicações aprofundadas de métodos específicos. Os usuários desejam obter conteúdo acadêmico de alta qualidade, em vez de vídeos superficiais de influenciadores, para entender rapidamente a literatura relevante e decidir sobre futuras direções de pesquisa. (Fonte: Reddit r/MachineLearning)
Jornada de codificação AI de 11 meses: Ferramentas, stack tecnológico e melhores práticas: Um desenvolvedor compartilhou uma jornada de codificação AI de 11 meses, detalhando experiências, falhas e melhores práticas usando ferramentas como Claude Code. Ele enfatizou que, na codificação AI, o planejamento inicial e o gerenciamento de contexto são muito mais importantes do que a própria escrita do código. Embora a AI reduza a barreira para a implementação de código, ela não substitui o design de arquitetura e a visão de negócios. O compartilhamento de experiência abrangeu vários projetos, desde front-end a back-end, desenvolvimento de aplicativos móveis, e recomendou ferramentas auxiliares como Context7 e SpecDrafter. (Fonte: Reddit r/ClaudeAI)
💼 Negócios
JPMorgan Chase: Investimento de US$ 2 bilhões por ano para se transformar em “banco totalmente AI”: Jamie Dimon, CEO do JPMorgan Chase, anunciou um investimento anual de US$ 2 bilhões em AI, com o objetivo de transformar a empresa em um “banco totalmente AI”. A AI foi profundamente integrada em operações centrais como gerenciamento de riscos, negociação, atendimento ao cliente, conformidade e banco de investimento, não apenas economizando custos, mas, mais importante, acelerando o ritmo de trabalho e mudando a natureza das funções. O JPMorgan Chase, através de sua plataforma LLM Suite desenvolvida internamente e da implantação em larga escala de AI Agents, vê a AI como o sistema operacional subjacente da empresa, e enfatiza que a integração de dados e a segurança cibernética são os maiores desafios de sua estratégia de AI. Dimon acredita que a AI é um valor real de longo prazo, e não uma bolha de curto prazo, e que irá redefinir a própria definição de banco. (Fonte: 36氪)
Apple de Musk