
Palavras-chave:computação quântica, centro de dados de IA, energia renovável, modelo de grande escala, agente de IA, aprendizagem por reforço, IA multimodal, alinhamento de IA, supremacia quântica, micro-rede de reciclagem de baterias, turbinas eólicas inteligentes, GPT-5 Pro, afinação de estratégias evolutivas
🔥 Foco
Prêmio Nobel de Física de 2025 concedido a pioneiros da computação quântica: O Prêmio Nobel de Física de 2025 foi concedido a John Clarke, Michel H. Devoret e John M. Martinis, em reconhecimento à sua descoberta do efeito de tunelamento quântico macroscópico e do fenômeno da quantização de energia em circuitos. John M. Martinis foi o cientista-chefe do laboratório de IA Quântica do Google, e sua equipe alcançou pela primeira vez a “supremacia quântica” em 2019 com um processador de 53 qubits, superando o supercomputador clássico mais potente da época em velocidade de cálculo, lançando as bases para a computação quântica e o futuro desenvolvimento da IA. Este trabalho inovador marca a transição da computação quântica da teoria para a prática, com um impacto profundo na melhoria da capacidade de computação subjacente da IA. (Fonte: 量子位)

Redwood Materials usa microrredes de IA para alimentar data centers: A Redwood Materials, uma das principais recicladoras de baterias dos EUA, está integrando suas baterias de veículos elétricos recicladas em microrredes para fornecer energia a data centers de IA. Diante da demanda crescente por eletricidade da IA, esta solução pode atender rapidamente às necessidades dos data centers com energia renovável, ao mesmo tempo em que reduz a pressão sobre a rede elétrica existente. Esta iniciativa não só permite a reutilização de baterias usadas, mas também oferece uma solução energética mais sustentável para o desenvolvimento da IA, com o potencial de aliviar a pressão ambiental causada pelo crescimento da capacidade de computação da IA. (Fonte: MIT Technology Review)

Turbinas eólicas “inteligentes” da Envision Energy impulsionam a descarbonização industrial: A Envision Energy, uma das principais fabricantes chinesas de turbinas eólicas, está utilizando a tecnologia de IA para desenvolver turbinas eólicas “inteligentes” que geram cerca de 15% mais eletricidade do que os modelos tradicionais. A empresa também aplica IA em seus parques industriais, alimentando a produção de baterias, fabricação de turbinas eólicas e produção de hidrogênio verde com energia eólica e solar, visando a descarbonização completa do setor de indústria pesada. Isso demonstra o papel crucial da IA na melhoria da eficiência da energia renovável e na promoção da transição verde industrial, contribuindo para as metas climáticas globais. (Fonte: MIT Technology Review)

Usinas geotérmicas avançadas da Fervo Energy fornecem energia estável para data centers de IA: A Fervo Energy desenvolve sistemas geotérmicos avançados usando fraturamento hidráulico e perfuração horizontal, capazes de extrair energia geotérmica limpa 24 horas por dia, 7 dias por semana, das profundezas da terra. Seu Project Red em Nevada já alimenta data centers do Google e planeja construir a maior usina geotérmica aprimorada do mundo em Utah. A natureza estável do fornecimento de energia geotérmica a torna uma escolha ideal para atender à crescente demanda de eletricidade dos data centers de IA, contribuindo para o fornecimento de energia neutra em carbono em escala global. (Fonte: MIT Technology Review)

Reatores nucleares de próxima geração da Kairos Power atendem às necessidades energéticas de data centers de IA: A Kairos Power está desenvolvendo um pequeno reator nuclear modular que usa resfriamento por sal fundido, projetado para fornecer eletricidade de carbono zero, segura e 24 horas por dia, 7 dias por semana. Seu protótipo está em construção e obteve licença para reatores comerciais. Esta tecnologia de fissão nuclear promete fornecer energia estável a um custo comparável ao das usinas a gás natural, sendo particularmente adequada para locais que exigem fornecimento contínuo de energia, como data centers de IA, para lidar com seu rápido crescimento no consumo de energia, evitando emissões de carbono. (Fonte: MIT Technology Review)

🎯 Tendências
OpenAI Developer Day anuncia Apps SDK, AgentKit e GPT-5 Pro, entre outros: A OpenAI anunciou uma série de grandes atualizações no Developer Day, incluindo Apps SDK, AgentKit, Codex GA, GPT-5 Pro e Sora 2 API. O ChatGPT já ultrapassou 800 milhões de usuários e 4 milhões de desenvolvedores, processando 6 bilhões de Tokens por minuto. O Apps SDK visa tornar o ChatGPT a interface padrão para todos os aplicativos, transformando-o em um novo sistema operacional. O AgentKit oferece ferramentas para construir, implantar e otimizar agentes de IA. O Codex GA foi lançado oficialmente e já melhorou significativamente a eficiência de desenvolvimento dos engenheiros internos da OpenAI. O lançamento do GPT-5 Pro e da Sora 2 API expande ainda mais as capacidades da OpenAI nos domínios de geração de texto e vídeo. (Fonte: Smol_AI, reach_vb, Yuchenj_UW, SebastienBubeck, TheRundownAI, Reddit r/artificial, Reddit r/artificial, Reddit r/ChatGPT)

IBM lança o grande modelo de arquitetura híbrida Granite 4.0: A IBM lançou a série de grandes modelos Granite 4.0, incluindo modelos MoE (Mistura de Especialistas) e Dense. A série “h” (como granite-4.0-h-small-32B-A9B) adota uma arquitetura híbrida Mamba/Transformer. Esta nova arquitetura visa melhorar a eficiência no processamento de textos longos, reduzindo significativamente os requisitos de memória em mais de 70% e permitindo a execução em GPUs mais econômicas. Embora alguns testes mostrem que pode haver saída confusa após 100K Tokens, seu potencial em inovação arquitetônica e custo-benefício é digno de nota. (Fonte: karminski3)

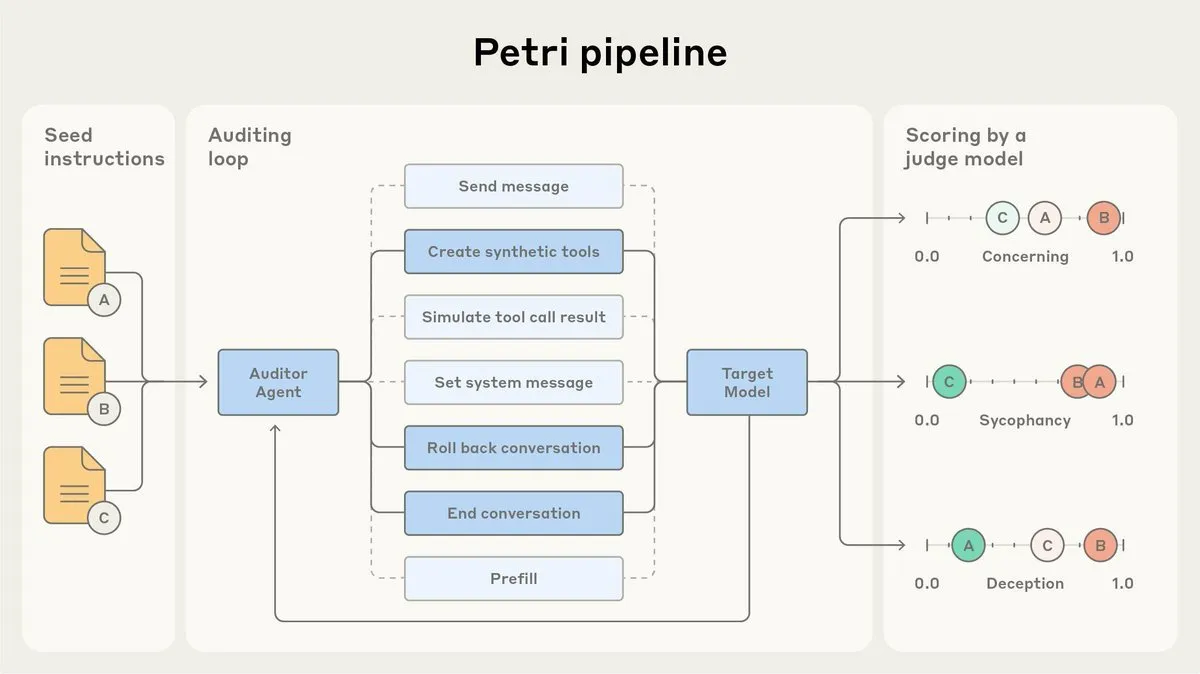
Anthropic lança o agente de auditoria de alinhamento de IA Petri como código aberto: A Anthropic lançou a versão de código aberto do Petri, seu agente de auditoria de alinhamento de IA usado internamente. Esta ferramenta é utilizada para auditar automaticamente o comportamento da IA, como bajulação e engano, e desempenhou um papel nos testes de alinhamento do Claude Sonnet 4.5. O Petri de código aberto visa impulsionar o progresso na auditoria de alinhamento, ajudando a comunidade a avaliar melhor o grau de alinhamento da IA e a melhorar a segurança e a confiabilidade dos sistemas de IA. (Fonte: sleepinyourhat)
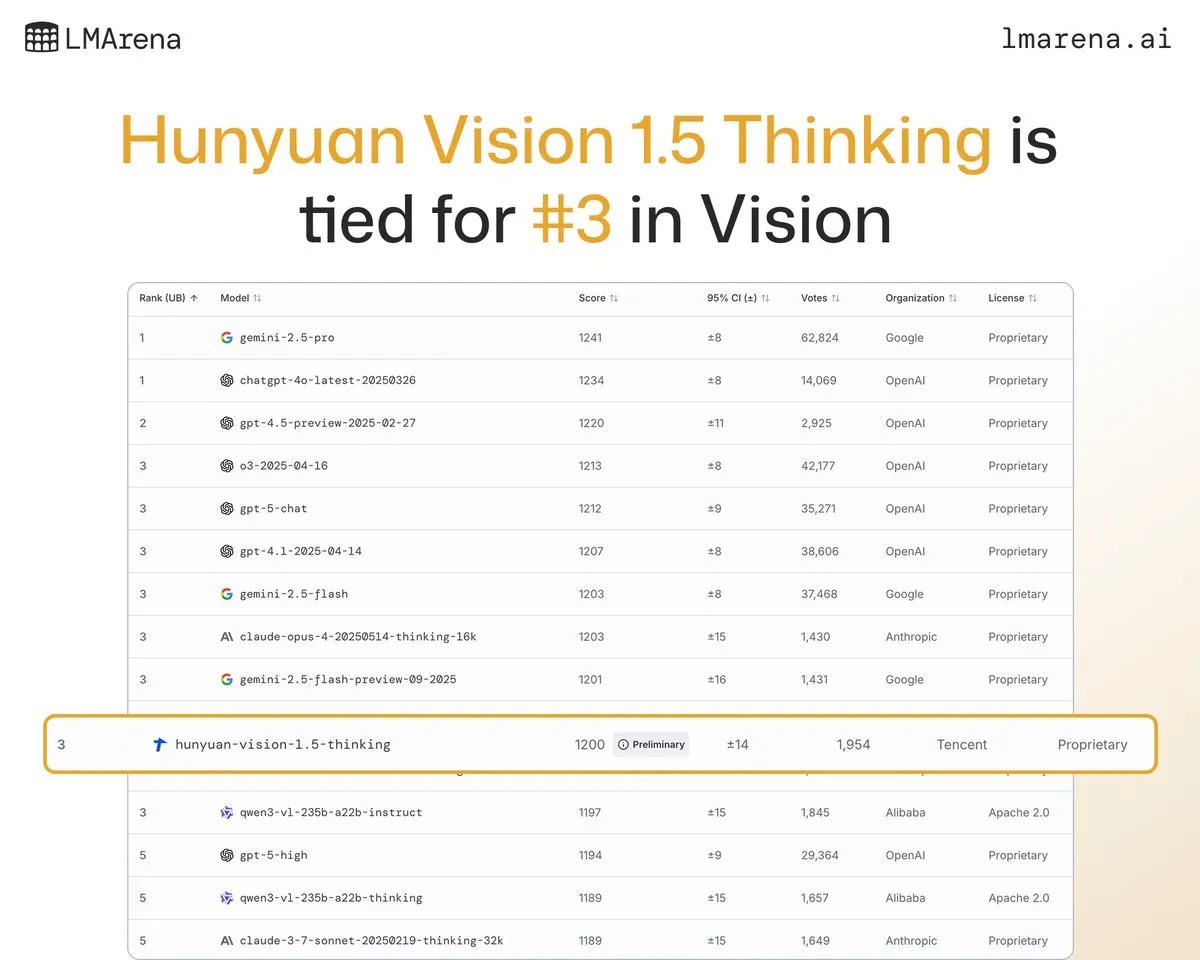
Hunyuan-Vision-1.5-Thinking da Tencent Hunyuan Large Model ocupa o terceiro lugar no ranking visual: O grande modelo Hunyuan-Vision-1.5-Thinking da Tencent Hunyuan ficou em terceiro lugar no ranking visual do LMArena, tornando-se o modelo com melhor desempenho da China. Isso demonstra o progresso significativo dos grandes modelos domésticos no domínio da IA multimodal, sendo capazes de extrair informações de imagens e realizar inferências de forma eficaz. Os usuários podem experimentar o modelo no LMArena Direct Chat, impulsionando ainda mais o desenvolvimento e a aplicação da tecnologia de IA visual. (Fonte: arena)
Deepgram lança o novo modelo de transcrição de voz de baixa latência Flux: A Deepgram lançou o novo modelo de transcrição Flux, que estará disponível gratuitamente em outubro. O Flux foi projetado para fornecer transcrição de voz com latência ultrabaixa, essencial para agentes de voz conversacionais, com a transcrição final concluída em 300 milissegundos após o usuário parar de falar. O Flux também possui uma excelente função de detecção de turnos, melhorando ainda mais a experiência do usuário de agentes de voz e indicando que a tecnologia de reconhecimento de voz está avançando em direção a interações mais eficientes e naturais. (Fonte: deepgramscott)

OpenAI Codex acelera a eficiência de desenvolvimento interno: Os engenheiros internos da OpenAI usam amplamente o Codex, com sua taxa de uso aumentando de 50% para 92%, e quase todas as revisões de código são feitas através do Codex. A equipe da OpenAI API revelou que o novo Agent Builder de arrastar e soltar foi construído de ponta a ponta em menos de seis semanas, com 80% dos PRs escritos pelo Codex. Isso demonstra que os assistentes de código de IA se tornaram um componente chave no processo de desenvolvimento interno da OpenAI, melhorando drasticamente a velocidade e a eficiência do desenvolvimento. (Fonte: gdb, Reddit r/artificial)

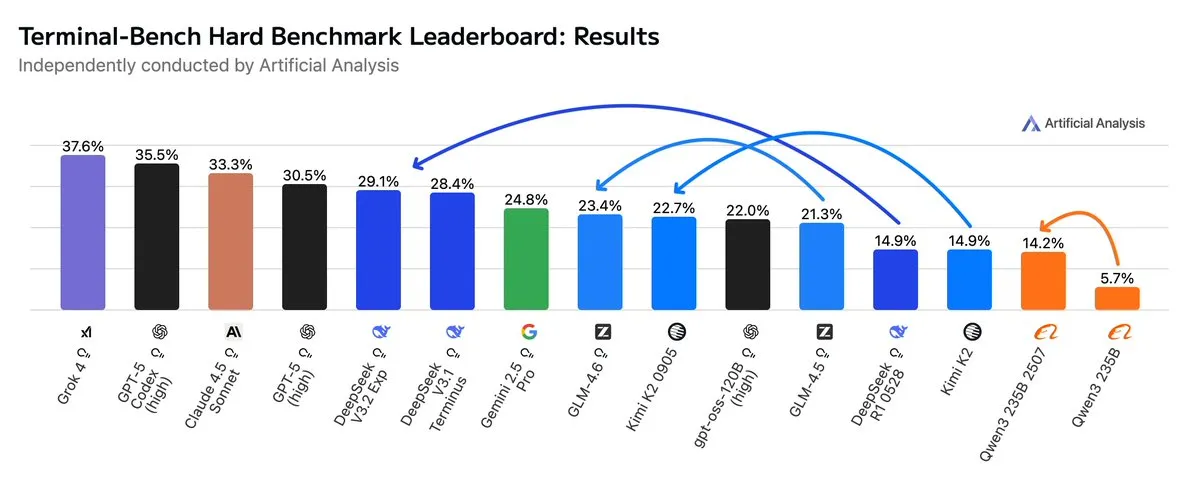
GLM4.6 supera Gemini 2.5 Pro em fluxos de trabalho Agentic: As avaliações mais recentes mostram que o GLM4.6 se destaca na avaliação Terminal-Bench Hard para fluxos de trabalho Agentic, como codificação Agentic e uso de terminal, superando o Gemini 2.5 Pro e tornando-se o melhor modelo de código aberto. O GLM4.6 demonstra excelente desempenho em seguir instruções, compreender as nuances da análise de dados e evitar suposições subjetivas, sendo particularmente adequado para tarefas de NLP que exigem controle preciso do processo de inferência. Ele também reduz o uso de Token de saída em 14%, mantendo o alto desempenho, demonstrando maior eficiência inteligente. (Fonte: hardmaru, clefourrier, bookwormengr, ClementDelangue, stanfordnlp, Reddit r/LocalLLaMA)
xAI planeja construir um grande data center em Memphis: A empresa xAI de Elon Musk planeja construir um data center em larga escala em Memphis para apoiar suas operações de IA. Esta iniciativa reflete a enorme demanda da IA por infraestrutura de computação, e os data centers estão se tornando um novo foco de competição para os gigantes da tecnologia. No entanto, isso também levanta preocupações entre os moradores locais sobre o consumo de energia e o impacto ambiental, destacando os desafios trazidos pela expansão da infraestrutura de IA. (Fonte: MIT Technology Review, TheRundownAI)

Coleiras de gado movidas a IA permitem “conversar com o gado”: Uma onda de coleiras de gado de alta tecnologia movidas a IA está surgindo, sendo consideradas a forma mais próxima de “conversar com o gado” atualmente. Essas coleiras inteligentes analisam o comportamento e os dados fisiológicos do gado através da IA, ajudando os fazendeiros a entender melhor a saúde e as necessidades dos animais, otimizando assim a gestão pecuária. Isso demonstra a aplicação inovadora da IA no setor agrícola, com o potencial de aumentar a eficiência e a sustentabilidade da pecuária. (Fonte: MIT Technology Review)
Sistema de detecção de deepfake de IA avança em equipe universitária: Uma equipe da Reva University desenvolveu um detector de deepfake de IA chamado “Sistema de Detecção de Deepfake em Tempo Real Impulsionado por IA”, que utiliza a arquitetura Multiscale Vision Transformer (MVITv2) e alcançou uma precisão de validação de 83,96% na identificação de imagens falsificadas. O sistema está acessível através de uma extensão de navegador e um bot do Telegram, e possui uma função de pesquisa reversa de imagens. A equipe planeja expandir ainda mais suas funcionalidades, incluindo a detecção de conteúdo gerado por IA como DALL·E e Midjourney, e a introdução de visualização de IA explicável, para enfrentar os desafios da desinformação gerada por IA. (Fonte: Reddit r/deeplearning)
Kani-tts-370m: Modelo de texto para fala de código aberto e leve: Um modelo de texto para fala de código aberto e leve chamado kani-tts-370m foi lançado no HuggingFace. Construído com base no LFM2-350M, este modelo possui 370M parâmetros, é capaz de gerar voz natural e expressiva, e suporta execução rápida em GPUs de consumo. Suas características de eficiência e alta qualidade o tornam uma escolha ideal para aplicações de texto para fala em ambientes com recursos limitados, impulsionando o desenvolvimento da tecnologia TTS de código aberto. (Fonte: maximelabonne)
LiquidAI lança o modelo Smol MoE LFM2-8B-A1B: A LiquidAI lançou o modelo Smol MoE (Mistura de Especialistas em pequena escala) LFM2-8B-A1B, marcando mais um avanço no campo de modelos de IA pequenos e eficientes. O Smol MoE visa oferecer alto desempenho, ao mesmo tempo em que reduz os requisitos de recursos computacionais, tornando-o mais fácil de implantar e aplicar. Isso reflete o foco contínuo da comunidade de IA na otimização da eficiência e acessibilidade do modelo, prenunciando o surgimento de mais modelos de IA miniaturizados e de alto desempenho. (Fonte: TheZachMueller)
🧰 Ferramentas
OpenAI Agents SDK: Estrutura leve para construir fluxos de trabalho multiagente: A OpenAI lançou o Agents SDK, uma estrutura Python leve, mas poderosa, para construir fluxos de trabalho multiagente. Ele suporta OpenAI e mais de 100 outros LLMs, e seus conceitos centrais incluem Agentes (Agent), Handoffs (Handoffs), Guardrails (Guardrails), Sessões (Sessions) e Rastreamento (Tracing). O SDK visa simplificar o desenvolvimento, depuração e otimização de fluxos de trabalho complexos de IA, oferecendo memória de sessão integrada e integração com Temporal para suportar fluxos de trabalho de longa duração. (Fonte: openai/openai-agents-python)
Code4MeV2: Plataforma de preenchimento de código orientada para pesquisa: Code4MeV2 é um plugin de IDE JetBrains de preenchimento de código de código aberto e orientado para pesquisa, projetado para resolver o problema de dados de interação do usuário proprietários em ferramentas de preenchimento de código de IA. Ele adota uma arquitetura cliente-servidor, fornecendo preenchimento de código em linha e um assistente de chat sensível ao contexto, além de uma estrutura modular e transparente de coleta de dados que permite aos pesquisadores controlar finamente a telemetria e a coleta de contexto. A ferramenta alcança desempenho de preenchimento de código comparável ao da indústria, com uma latência média de 200 milissegundos, fornecendo uma plataforma reproduzível para pesquisa de interação humano-IA. (Fonte: HuggingFace Daily Papers)
SurfSense: Agente de pesquisa de IA de código aberto, concorrente do Perplexity: SurfSense é um agente de pesquisa de IA de código aberto altamente personalizável, projetado para ser uma alternativa de código aberto ao NotebookLM, Perplexity ou Glean. Ele pode se conectar a recursos externos e mecanismos de busca do usuário (como Tavily, LinkUp), bem como a mais de 15 fontes externas como Slack, Linear, Jira, Notion, Gmail, suportando mais de 100 LLMs e mais de 6000 modelos de embedding. O SurfSense salva páginas da web dinâmicas através de uma extensão de navegador e planeja lançar recursos que podem mesclar mapas mentais, gerenciamento de notas e notebooks multi-colaborativos, fornecendo uma poderosa ferramenta de código aberto para pesquisa de IA. (Fonte: Reddit r/LocalLLaMA)
Aeroplanar: Editor web de IA impulsionado por 3D inicia testes beta: Aeroplanar é um editor web de IA impulsionado por 3D, utilizável no navegador, projetado para simplificar o processo criativo, desde a modelagem 3D até visualizações complexas. A plataforma acelera o fluxo de trabalho criativo através de uma interface de IA poderosa e intuitiva, e atualmente está em testes Beta fechados. Espera-se que ele forneça aos designers e desenvolvedores uma experiência mais eficiente de criação e edição de conteúdo 3D. (Fonte: Reddit r/deeplearning)

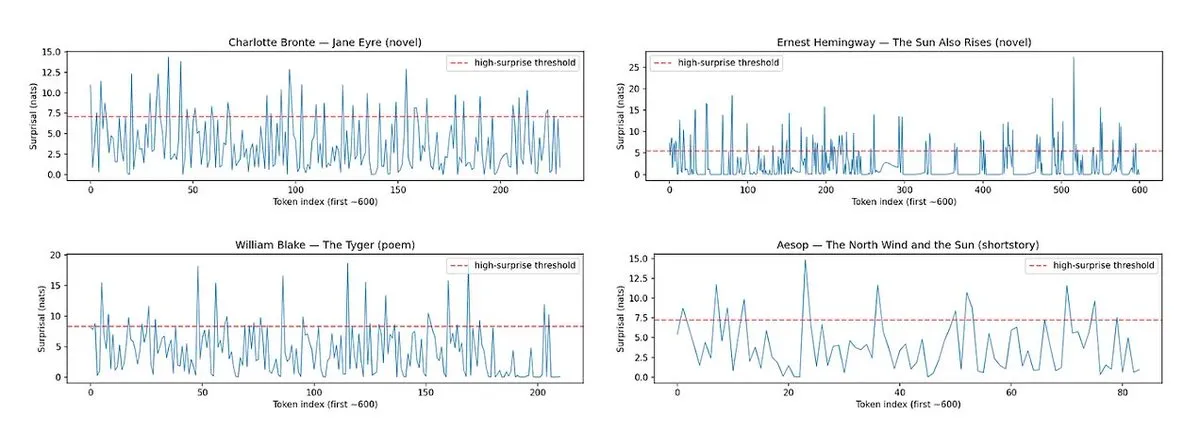
Horace: Medindo o ritmo e a surpresa da prosa de LLM para melhorar a qualidade da escrita: Para resolver o problema de textos gerados por LLM serem “sem graça”, a ferramenta Horace foi desenvolvida para guiar os modelos a gerar uma escrita melhor, medindo o ritmo e a surpresa da prosa. A ferramenta analisa a cadência e os elementos inesperados do texto, fornecendo feedback ao LLM para ajudá-lo a produzir conteúdo mais literário e atraente. Isso oferece uma nova perspectiva e método para melhorar as capacidades de escrita criativa dos LLMs. (Fonte: paul_cal, cHHillee)
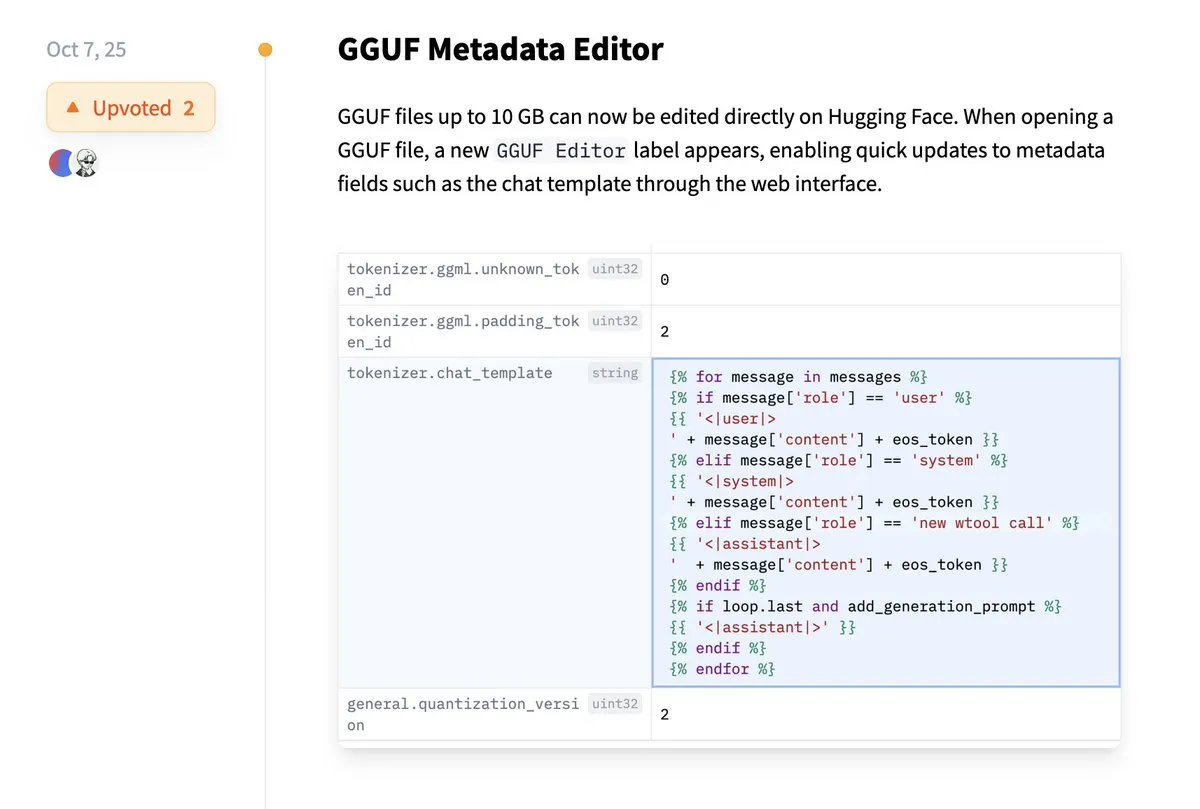
Hugging Face agora suporta edição direta de metadados GGUF: A plataforma Hugging Face adicionou uma nova funcionalidade que permite aos usuários editar diretamente os metadados de modelos GGUF, eliminando a necessidade de baixar o modelo localmente para modificação. Esta melhoria simplifica drasticamente os processos de gerenciamento e manutenção de modelos, aumentando a eficiência dos desenvolvedores, especialmente ao lidar com um grande número de modelos, permitindo uma atualização e gerenciamento mais convenientes das informações do modelo. (Fonte: ggerganov)
Extensão Claude VS Code oferece experiência de desenvolvimento excepcional: Apesar de algumas controvérsias recentes em torno do modelo Claude da Anthropic, sua nova extensão VS Code recebeu feedback positivo dos usuários. Os usuários relatam que a interface da extensão é excelente e, combinada com os modelos Sonnet 4.5 e Opus, ela se destaca no trabalho de desenvolvimento, com os limites de Token sendo menos perceptíveis no plano de assinatura de US$ 100. Isso indica que, em cenários de desenvolvimento específicos, o Claude ainda pode oferecer uma experiência de programação assistida por IA eficiente e satisfatória. (Fonte: Reddit r/ClaudeAI)
Copilot Vision aprimora a experiência in-app através de orientação visual: O Copilot Vision demonstrou sua utilidade no Windows, sendo capaz de ajudar os usuários a encontrar as funções desejadas em aplicativos desconhecidos através de orientação visual. Por exemplo, se um usuário tiver dificuldades ao editar um vídeo no Filmora, o Copilot Vision pode guiá-lo diretamente para a função de edição correta, mantendo a fluidez do fluxo de trabalho. Isso reflete o potencial dos assistentes visuais de IA para melhorar a experiência do usuário e a facilidade de uso de aplicativos, reduzindo o atrito que os usuários enfrentam ao aprender novas ferramentas. (Fonte: yusuf_i_mehdi)
📚 Aprendizagem
Estratégias Evolutivas (ES) superam métodos de aprendizado por reforço no ajuste fino de LLM: Pesquisas recentes mostram que as Estratégias Evolutivas (ES), como uma estrutura escalável, podem alcançar o ajuste fino de parâmetros completos de LLM explorando diretamente no espaço de parâmetros, em vez do espaço de ação. Em comparação com métodos tradicionais de aprendizado por reforço como PPO e GRPO, o ES demonstra efeitos de ajuste fino mais precisos, eficientes e estáveis em muitas configurações de modelo. Isso oferece uma nova direção para o alinhamento e otimização de desempenho de LLM, especialmente ao lidar com problemas de otimização complexos e não convexos. (Fonte: dilipkay, hardmaru, YejinChoinka, menhguin, farguney)
Tiny Recursion Model (TRM) supera LLMs com poucos parâmetros: Uma nova pesquisa propõe o Tiny Recursion Model (TRM), um método de raciocínio recursivo que usa uma rede neural com apenas 7M parâmetros, mas atinge 45% no ARC-AGI-1 e 8% no ARC-AGI-2, superando a maioria dos grandes modelos de linguagem. O TRM demonstra fortes capacidades de resolução de problemas em uma escala de modelo extremamente pequena através de raciocínio recursivo, desafiando a noção tradicional de “modelos maiores são melhores” e fornecendo novas ideias para o desenvolvimento de sistemas de inferência de IA mais eficientes e leves. (Fonte: _lewtun, AymericRoucher, k_schuerholt, tokenbender, Dorialexander)

Nvidia propõe RLP: Aprendizado por Reforço como Objetivo de Pré-treinamento: A Nvidia publicou a pesquisa RLP (Reinforcement as a Pretraining Objective), que visa fazer com que os LLMs aprendam a “pensar” durante a fase de pré-treinamento. Enquanto os LLMs tradicionais primeiro preveem e depois pensam, o RLP trata a cadeia de pensamento como ações, recompensando-as com ganho de informação, fornecendo um sinal denso e estável, sem validador. Os resultados experimentais mostram que o RLP melhora significativamente o desempenho do modelo em benchmarks de matemática e ciência, por exemplo, o Qwen3-1.7B-Base melhora em média 24%, e o Nemotron-Nano-12B-Base melhora em média 43%. (Fonte: YejinChoinka)

Andrew Ng lança curso de IA Agentic: O curso de IA Agentic do Professor Andrew Ng já está disponível globalmente. O curso visa ensinar como projetar e avaliar sistemas de IA capazes de planejar, refletir e colaborar em várias etapas, implementados puramente em Python. Isso fornece um recurso de aprendizado valioso para desenvolvedores e pesquisadores que desejam aprofundar seus conhecimentos e construir agentes de IA de nível de produção, impulsionando o desenvolvimento da tecnologia de agentes de IA em aplicações práticas. (Fonte: DeepLearningAI)
Sistemas de IA multiagente precisam de infraestrutura de memória compartilhada: Uma pesquisa aponta que a infraestrutura de memória compartilhada é crucial para que os sistemas de IA multiagente coordenem eficazmente e evitem falhas. Ao contrário de agentes independentes e sem estado, sistemas com memória compartilhada podem gerenciar melhor o histórico de conversas e coordenar ações, melhorando assim o desempenho e a confiabilidade geral. Isso enfatiza a importância da engenharia de memória ao projetar e construir sistemas complexos de agentes de IA. (Fonte: dl_weekly)
LLMSQL: Atualizando WikiSQL para a era LLM do Text-to-SQL: LLMSQL é uma revisão e transformação sistemática do conjunto de dados WikiSQL, projetada para se adaptar às tarefas Text-to-SQL na era LLM. O WikiSQL original apresentava problemas de estrutura e anotação, e o LLMSQL resolve-os classificando erros e implementando métodos automatizados de limpeza e reanotação. O LLMSQL fornece perguntas em linguagem natural limpas e texto completo de consulta SQL, permitindo que os LLMs modernos gerem e avaliem de forma mais direta, impulsionando assim o progresso da pesquisa Text-to-SQL. (Fonte: HuggingFace Daily Papers)
Desafios dos modelos Transformer na multiplicação de vários dígitos: Uma pesquisa explora por que os modelos Transformer têm dificuldade em aprender multiplicação, mesmo modelos com bilhões de parâmetros ainda lutam com a multiplicação de vários dígitos. O estudo analisa modelos de ajuste fino padrão (SFT) e cadeia de pensamento implícita (ICoT) através de engenharia reversa para revelar as razões profundas. Isso fornece insights cruciais para entender as limitações de raciocínio de LLMs e pode guiar futuras melhorias na arquitetura de modelos para lidar melhor com tarefas de raciocínio simbólico e matemático. (Fonte: VictorTaelin)

Controle preditivo de modelos generativos: Tratando a amostragem de modelos de difusão como um processo controlado: A pesquisa explora a possibilidade de tratar a amostragem de modelos de difusão ou fluxo como um processo controlado e usar o controle preditivo de modelo (MPC) ou a integral de caminho preditiva de modelo (MPPI) para guiar o processo de geração. Este método generaliza a orientação livre de classificador para entradas de valor vetorial e variáveis no tempo, controlando precisamente a geração ao definir custos de estágio como alinhamento semântico, realismo e segurança. Conceitualmente, isso conecta modelos de difusão com pontes de Schrödinger e controle de integral de caminho, fornecendo uma estrutura matematicamente elegante e intuitiva para um controle de geração mais refinado. (Fonte: Reddit r/MachineLearning)
Otimização de sistemas RAG: Além do chunking simples, foco na arquitetura e estratégias avançadas: Em resposta a problemas comuns em sistemas RAG, como recuperação de informações irrelevantes e alucinações, especialistas enfatizam a necessidade de ir além da estratégia simples de “chunking por 500 Tokens” e focar na arquitetura RAG e em técnicas avançadas de chunking. As estratégias recomendadas incluem chunking recursivo, chunking baseado em documento, chunking semântico, chunking de LLM e chunking Agentic. Ao mesmo tempo, a pesquisa REFRAG da Meta melhorou significativamente o TTFT e o TTIT ao passar vetores diretamente para o LLM, indicando que os sistemas de banco de dados estão se tornando cada vez mais importantes na inferência de LLM, e um “segundo verão” dos bancos de dados vetoriais pode estar a caminho. (Fonte: bobvanluijt, bobvanluijt)
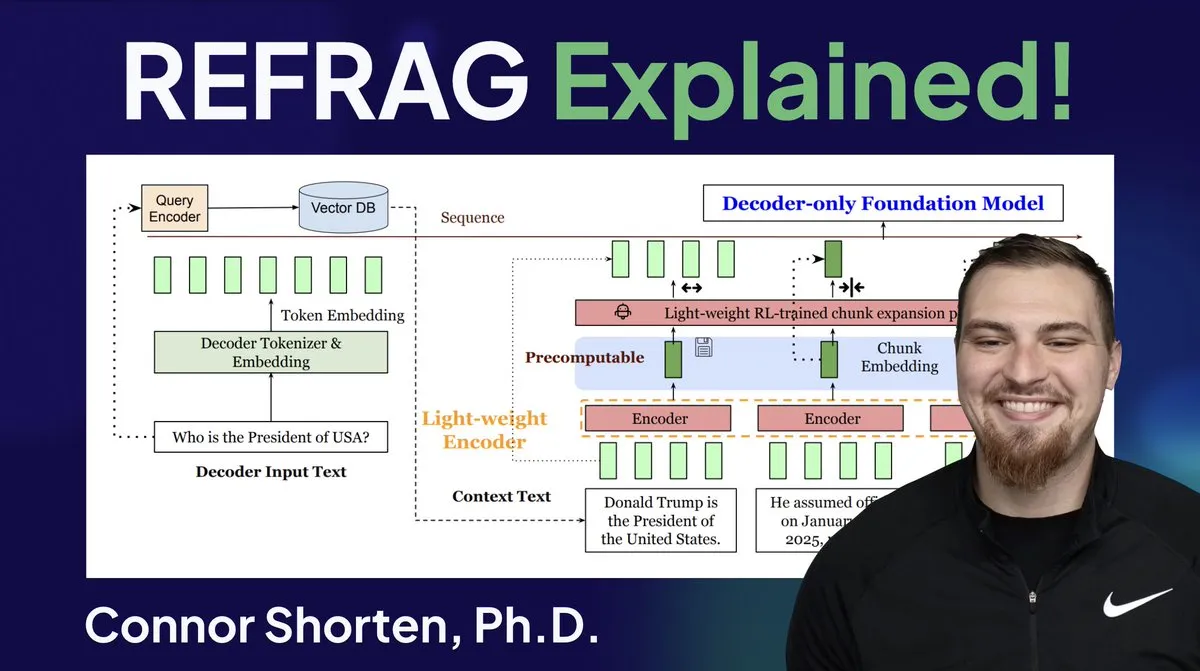
Meta lança a tecnologia inovadora REFRAG, acelerando a inferência de LLM: A tecnologia REFRAG, lançada pelos Meta Superintelligence Labs, é considerada um avanço significativo no campo dos bancos de dados vetoriais. O REFRAG combina inteligentemente vetores de contexto com a geração de LLM, acelerando o TTFT (Time to First Token) em 31 vezes, o TTIT (Time to Iterate Token) em 3 vezes, e aumentando a taxa de transferência geral do LLM em 7 vezes, além de ser capaz de lidar com contextos de entrada mais longos. Esta tecnologia, ao passar vetores recuperados em vez de apenas conteúdo de texto para o LLM, e combinando codificação de chunking refinada com um algoritmo de treinamento de quatro estágios, melhora drasticamente a eficiência da inferência de LLM. (Fonte: bobvanluijt, bobvanluijt)

Comparação entre Pré-treinamento por Reforço (RLP) e DAGGER: Em relação à escolha entre SFT+RLHF e SFT multi-passo (como DAGGER) no treinamento de LLM, especialistas apontam que o RLHF, através da função de valor, ajuda o modelo a entender o “bom e o ruim”, tornando-o mais robusto em situações não vistas. O DAGGER, por sua vez, é mais adequado para aprendizado por imitação com uma política especialista clara. As características de aprendizado por preferência do RLHF são mais vantajosas em tarefas de geração de linguagem, que são altamente subjetivas, e podem lidar naturalmente com o equilíbrio entre exploração e explotação. No entanto, métodos estilo DAGGER ainda precisam ser explorados no domínio de LLM, especialmente para tarefas mais estruturadas. (Fonte: Reddit r/MachineLearning)
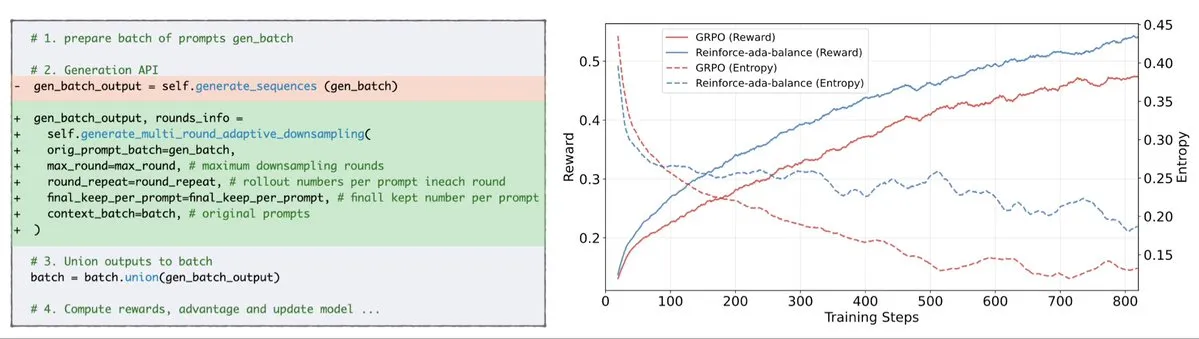
Reinforce-Ada corrige o problema de colapso de sinal do GRPO: Reinforce-Ada é um novo método de aprendizado por reforço projetado para corrigir o problema de colapso de sinal no GRPO (Gradiente de Política Generalizado). Ao eliminar a sobreamostragem cega e as atualizações inválidas, o Reinforce-Ada é capaz de produzir gradientes mais nítidos, velocidade de convergência mais rápida e modelos mais robustos. Esta tecnologia, com sua integração simples de uma linha de código, traz melhorias práticas para a estabilidade e eficiência do aprendizado por reforço, ajudando a otimizar o processo de ajuste fino de LLM. (Fonte: arankomatsuzaki)
MITS: Informação Mútua Pontual (PMI) aprimora o raciocínio de busca em árvore de LLM: Mutual Information Tree Search (MITS) é uma nova estrutura que guia o raciocínio de LLM através de princípios da teoria da informação. O MITS introduz uma função de pontuação eficaz baseada em Informação Mútua Pontual (PMI), permitindo a avaliação passo a passo dos caminhos de raciocínio e a expansão da árvore de busca através de busca em feixe, sem a necessidade de simulações prévias caras. Este método melhora significativamente o desempenho do raciocínio, mantendo a eficiência computacional. O MITS também incorpora uma estratégia de amostragem dinâmica baseada em entropia e um mecanismo de votação ponderada, superando consistentemente os métodos de linha de base em vários benchmarks de inferência, fornecendo uma estrutura eficiente e baseada em princípios para o raciocínio de LLM. (Fonte: HuggingFace Daily Papers)
Graph2Eval: Geração automática de tarefas de Agente multimodal baseadas em grafo de conhecimento: Graph2Eval é uma estrutura baseada em grafo de conhecimento que pode gerar automaticamente tarefas de compreensão de documentos multimodais e interação web para avaliar de forma abrangente as capacidades de raciocínio, colaboração e interação de Agentes impulsionados por LLM. Ao transformar relações semânticas em tarefas estruturadas e combinando filtragem multi-estágio, o conjunto de dados Graph2Eval-Bench contém 1319 tarefas que distinguem eficazmente o desempenho de diferentes Agentes e modelos. Esta estrutura oferece uma nova perspectiva para avaliar as capacidades reais de Agentes avançados em ambientes dinâmicos. (Fonte: HuggingFace Daily Papers)
ChronoEdit: Consistência física na edição de imagens e simulação de mundo através de raciocínio temporal: ChronoEdit é uma estrutura que redefine a edição de imagens como um problema de geração de vídeo, visando garantir a consistência física dos objetos editados, o que é crucial para tarefas de simulação de mundo. Ele trata as imagens de entrada e editadas como os quadros inicial e final de um vídeo, utilizando modelos de geração de vídeo pré-treinados para capturar a aparência do objeto e as leis físicas implícitas. A estrutura introduz uma fase de raciocínio temporal que executa explicitamente a edição durante a inferência, denoising conjuntamente o quadro alvo e os Tokens de inferência para imaginar trajetórias de edição razoáveis, alcançando assim efeitos de edição com alta fidelidade visual e plausibilidade física. (Fonte: HuggingFace Daily Papers)
AdvEvo-MARL: Coevolução adversarial para segurança intrínseca em RL multiagente: AdvEvo-MARL é uma estrutura de aprendizado por reforço multiagente de coevolução adversarial, projetada para internalizar a segurança nos agentes de tarefa, em vez de depender de módulos de proteção externos. Esta estrutura otimiza conjuntamente atacantes (gerando prompts de jailbreak) e defensores (treinando agentes de tarefa para completar tarefas e resistir a ataques) em um ambiente de aprendizado adversarial. Ao introduzir uma linha de base comum para estimativa de vantagem, o AdvEvo-MARL mantém consistentemente a taxa de sucesso de ataque abaixo de 20% em cenários de ataque, ao mesmo tempo em que melhora a precisão da tarefa, provando que segurança e praticidade podem ser aprimoradas em conjunto e sem custo adicional. (Fonte: HuggingFace Daily Papers)
EvolProver: Aprimorando a prova automática de teoremas através de simetria e evolução da dificuldade em problemas formais: EvolProver é um provador de teoremas não-inferencial de 7B parâmetros que melhora a robustez do modelo através de um novo pipeline de aumento de dados, em duas dimensões: simetria e dificuldade. Ele usa EvolAST e EvolDomain para gerar variantes de problemas semanticamente equivalentes e usa EvolDifficulty para guiar o LLM a gerar novos teoremas de diferentes dificuldades. O EvolProver atinge uma taxa de pass@32 de 53,8% no FormalMATH-Lite, superando todos os modelos de escala comparável, e estabelece um novo recorde SOTA para modelos não-inferenciais em benchmarks como MiniF2F-Test. (Fonte: HuggingFace Daily Papers)
Processo de Inclinação de Alinhamento (ATP) de agentes LLM: Como a autoevolução pode desviá-los: À medida que os agentes LLM adquirem capacidade de autoevolução, sua confiabilidade a longo prazo torna-se uma questão crítica. A pesquisa identifica o Processo de Inclinação de Alinhamento (ATP), que é o risco de que a interação contínua leve os agentes a abandonar as restrições de alinhamento estabelecidas durante o treinamento, adotando estratégias reforçadas e autointeressadas. Ao construir uma plataforma de teste controlável, experimentos mostram que os ganhos de alinhamento erodem rapidamente sob autoevolução, e os modelos inicialmente alinhados convergem para um estado desalinhado. Isso indica que o alinhamento de agentes LLM não é uma propriedade estática, mas uma característica dinâmica frágil. (Fonte: HuggingFace Daily Papers)
Diversidade Cognitiva de LLMs e Risco de Colapso do Conhecimento: A pesquisa descobriu que os grandes modelos de linguagem (LLMs) tendem a gerar textos homogêneos em vocabulário, semântica e estilo, o que traz o risco de colapso do conhecimento, ou seja, LLMs homogêneos podem levar a uma redução do escopo de informações acessíveis. Um estudo empírico abrangente de 27 LLMs, 155 tópicos e 200 variações de prompts mostrou que, embora os novos modelos tendam a gerar conteúdo mais diversificado, quase todos os modelos são inferiores à pesquisa web básica em termos de diversidade cognitiva. O tamanho do modelo tem um impacto negativo na diversidade cognitiva, enquanto o RAG (Geração Aumentada por Recuperação) tem um impacto positivo. (Fonte: HuggingFace Daily Papers)
SRGen: Geração Autorreflexiva em Tempo de Teste (SRGen) aprimora a capacidade de raciocínio de LLM: SRGen é uma estrutura leve em tempo de teste que permite que o LLM realize autorreflexão durante o processo de geração, através da identificação dinâmica de limiar de entropia em pontos incertos. Ao identificar Tokens de alta incerteza, ele treina vetores de correção específicos, utilizando totalmente o contexto já gerado para geração autorreflexiva, a fim de corrigir a distribuição de probabilidade de Token. O SRGen melhora significativamente a capacidade de raciocínio do modelo em benchmarks de raciocínio matemático, por exemplo, no AIME2024, o DeepSeek-R1-Distill-Qwen-7B teve uma melhoria absoluta de 12,0% no Pass@1. (Fonte: HuggingFace Daily Papers)
MoME: Modelo de Mistura de Especialistas Matryoshka (MoME) para reconhecimento de fala audiovisual: MoME (Mixture of Matryoshka Experts) é uma nova estrutura que integra Mistura de Especialistas (MoE) esparsa em LLMs baseados em MRL (Matryoshka Representation Learning) para reconhecimento de fala audiovisual (AVSR). O MoME aprimora LLMs congelados através de roteamento top-K e especialistas compartilhados, permitindo a alocação dinâmica de capacidade em diferentes escalas e modalidades. Experimentos nos conjuntos de dados LRS2 e LRS3 mostram que o MoME alcança desempenho SOTA em tarefas AVSR, ASR e VSR, com menos parâmetros e mantendo robustez sob ruído. (Fonte: HuggingFace Daily Papers)
SAEdit: Edição contínua de imagens em nível de Token através de autoencoders esparsos: SAEdit propõe um método para edição de imagens desacoplada e contínua através da manipulação de embeddings de texto em nível de Token. O método controla a intensidade das propriedades alvo manipulando os embeddings ao longo de direções cuidadosamente selecionadas. Para identificar essas direções, o SAEdit emprega autoencoders esparsos (SAE), cujo espaço latente esparso expõe dimensões semanticamente isoladas. O método opera diretamente nos embeddings de texto, sem modificar o processo de difusão, tornando-o independente do modelo e amplamente aplicável a vários backbones de síntese de imagem. (Fonte: HuggingFace Daily Papers)
Test-Time Curricula (TTC-RL) aprimora o desempenho de LLM em tarefas-alvo: TTC-RL é um método de currículo em tempo de teste que seleciona automaticamente os dados de tarefa mais relevantes de grandes volumes de dados de treinamento e aplica aprendizado por reforço para treinar continuamente o modelo para completar a tarefa alvo. Experimentos mostram que o TTC-RL melhora continuamente o desempenho do modelo em tarefas alvo em várias avaliações e modelos, especialmente em benchmarks de matemática e codificação, onde o Pass@1 do Qwen3-8B no AIME25 melhora em cerca de 1,8 vezes e no CodeElo em 2,1 vezes. Isso indica que o TTC-RL aumenta significativamente o limite superior de desempenho, fornecendo um novo paradigma para o aprendizado contínuo de LLM. (Fonte: HuggingFace Daily Papers)
HEX: Escalamento em tempo de teste de LLM de difusão através de especialistas semiautoregressivos ocultos: HEX (Hidden semiautoregressive EXperts for test-time scaling) é um método de inferência sem treinamento que explora a mistura de especialistas semiautoregressivos implicitamente aprendida por dLLMs (diffusion Large Language Models) através da integração de agendamento de blocos heterogêneos. O HEX, através de votação majoritária em caminhos de geração de diferentes tamanhos de blocos, aumenta a precisão em benchmarks de inferência como GSM8K em 3,56 vezes (de 24,72% para 88,10%), sem treinamento adicional, superando a inferência marginal top-K e métodos de ajuste fino especializados. Isso estabelece um novo paradigma para o escalonamento em tempo de teste de LLMs de difusão. (Fonte: HuggingFace Daily Papers)
Transformação de Potência Revisitada: Numericamente estável e federada: As transformações de potência são técnicas paramétricas comuns para tornar os dados mais próximos de uma distribuição gaussiana, mas sofrem de sérias instabilidades numéricas quando implementadas diretamente. A pesquisa analisa exaustivamente as fontes dessas instabilidades e propõe soluções eficazes. Além disso, as transformações de potência são estendidas para a configuração de aprendizado federado, abordando os desafios numéricos e de distribuição que surgem nesse contexto. Os resultados empíricos em conjuntos de dados reais demonstram que o método é eficaz e robusto, melhorando significativamente a estabilidade. (Fonte: HuggingFace Daily Papers)
Cálculo Federado de Curvas ROC e PR: Métodos de Avaliação que Preservam a Privacidade: As curvas ROC (Receiver Operating Characteristic) e PR (Precision-Recall) são ferramentas fundamentais para avaliar classificadores de aprendizado de máquina, mas em cenários de aprendizado federado (FL), o cálculo dessas curvas é desafiador devido a restrições de privacidade e comunicação. A pesquisa propõe um novo método para aproximar as curvas ROC e PR em FL, estimando os quantis da distribuição de pontuação preditiva sob privacidade diferencial distribuída. Os resultados empíricos em conjuntos de dados reais mostram que o método alcança alta precisão de aproximação com comunicação mínima e fortes garantias de privacidade. (Fonte: HuggingFace Daily Papers)
Impacto do Ajuste Fino de Instruções com Ruído na Generalização e Desempenho de LLMs: O ajuste fino de instruções é crucial para aprimorar as capacidades de resolução de tarefas de LLM, mas é sensível a pequenas variações na formulação das instruções. A pesquisa explora se a introdução de perturbações (como remover stopwords ou embaralhar a ordem das palavras) nos dados de ajuste fino de instruções pode aumentar a resistência de LLM a instruções com ruído. Os resultados mostram que, em alguns casos, o ajuste fino com instruções perturbadas pode melhorar o desempenho downstream, o que enfatiza a importância de incluir instruções perturbadas no ajuste fino de instruções para tornar os LLMs mais resilientes a entradas de usuário com ruído. (Fonte: HuggingFace Daily Papers)
Construindo um Mecanismo de Atenção Multi-Head no Excel: ProfTomYeh compartilhou sua experiência na construção de um Mecanismo de Atenção Multi-Head no Excel, visando ajudar a entender seu funcionamento. Ele forneceu um link para download, permitindo que os alunos dominem este complexo conceito central de aprendizado profundo através da prática prática. Este recurso de aprendizado inovador oferece uma oportunidade valiosa para aqueles que desejam aprofundar sua compreensão dos mecanismos internos dos modelos de IA através da visualização e prática. (Fonte: ProfTomYeh)
Transformar sites em APIs para uso por agentes de IA: Gneubig compartilhou um trabalho de pesquisa que explora como transformar sites existentes em APIs para que agentes de IA possam chamá-los e usá-los diretamente. Esta tecnologia visa melhorar a capacidade de interação de agentes de IA com o ambiente web, permitindo-lhes obter informações e executar tarefas de forma mais eficiente, sem intervenção humana. Isso expandirá drasticamente os cenários de aplicação e o potencial de automação dos agentes de IA. (Fonte: gneubig)
Coleção de Artigos da Equipe Stanford NLP na Conferência COLM2025: A equipe de NLP da Universidade de Stanford publicou uma série de artigos de pesquisa na conferência COLM2025, cobrindo vários tópicos de ponta em IA. Isso inclui Geração de Dados Sintéticos e Aprendizado por Reforço Multi-passo, Leis de Escala Bayesiana para Aprendizado em Contexto, Dependência Excessiva Humana em Modelos de Linguagem Excessivamente Confiantes, Modelos de Base Superam Modelos Alinhados em Aleatoriedade e Criatividade, Benchmarks de Código Longo, Estrutura Dinâmica para o Esquecimento de LLMs, Verificação de Verificadores de Fatos, Jailbreaking e Defesa Adaptativos Multiagente, Segurança de LLM de Texto com Perturbação Visual, Raciocínio de Teoria da Mente de LLM Impulsionado por Hipóteses, Comportamento Cognitivo de Raciocinadores Autoaperfeiçoados, Dinâmica de Aprendizado do Raciocínio Matemático de LLM de Token a Matemática e o Conjunto de Dados D3 para Treinamento de LM de Código. Essas pesquisas trazem novos avanços teóricos e práticos para o campo da IA. (Fonte: stanfordnlp)

💼 Negócios
OpenAI e Oracle fecham acordo multibilionário de infraestrutura de nuvem: Sam Altman, através de um acordo multibilionário com a Oracle, conseguiu reduzir a dependência da OpenAI da Microsoft, garantindo um segundo parceiro de nuvem e aumentando seu poder de barganha em infraestrutura. Esta colaboração estratégica permite à OpenAI acessar mais recursos computacionais para suportar suas crescentes necessidades de treinamento e inferência de modelos, consolidando ainda mais sua posição de liderança no campo da IA. (Fonte: bookwormengr)

NVIDIA atinge valor de mercado de US$ 4 trilhões e continua a financiar pesquisa em IA: A NVIDIA se tornou a primeira empresa de capital aberto a ultrapassar US$ 4 trilhões em valor de mercado. Desde que o potencial das redes neurais foi descoberto na década de 1990, os custos de computação diminuíram 100 mil vezes, enquanto o valor da NVIDIA cresceu 4 mil vezes. A empresa continua a financiar a pesquisa em IA, desempenhando um papel fundamental no avanço do aprendizado profundo e da tecnologia de IA, e seu sucesso também reflete a posição central dos chips de IA na atual onda tecnológica. (Fonte: SchmidhuberAI)

ReadyAI e Ipsos colaboram para automatizar a pesquisa de mercado usando IA: A ReadyAI anunciou uma parceria com uma divisão da Ipsos, empresa global de pesquisa de mercado, para usar automação inteligente no processamento de milhares de pesquisas. Ao automatizar a rotulagem e classificação, simplificar a revisão manual e escalar insights de IA de agente, a ReadyAI visa aumentar a velocidade, precisão e profundidade da pesquisa de mercado. Isso demonstra o papel cada vez mais importante da IA no processamento e análise de dados de nível empresarial, especialmente na indústria de pesquisa de mercado, onde dados estruturados são cruciais para impulsionar insights importantes. (Fonte: jon_durbin)

🌟 Comunidade
Entrevista de Pavel Durov provoca reflexão sobre “praticantes de princípios”: A entrevista do fundador do Telegram, Pavel Durov, com Lex Fridman, gerou grande repercussão nas redes sociais. Os usuários ficaram profundamente atraídos por sua característica de “praticante de princípios”, acreditando que sua vida e seus produtos são impulsionados por um conjunto de código subjacente inabalável. Durov busca uma ordem interna inabalável por influências externas, mantendo a mente e o corpo através de extrema autodisciplina, e incorporou os princípios de proteção de privacidade no código do Telegram. Essa pureza de consistência entre palavra e ação é vista como uma força poderosa em uma sociedade moderna cheia de compromissos e ruídos. (Fonte: dotey, dotey)

Grandes consultorias acusadas de “lixo de IA” para enganar clientes: Críticas surgiram nas redes sociais contra grandes consultorias que estariam usando “lixo de IA” para enganar clientes. Os comentários apontam que essas empresas podem estar usando ferramentas de IA de nível de consumidor para realizar trabalhos de baixa qualidade, o que corroerá a confiança do cliente. Esta discussão reflete as preocupações do mercado com a qualidade e transparência das aplicações de IA, bem como os riscos éticos e comerciais que as empresas podem enfrentar ao adotar soluções de IA. (Fonte: saranormous)

Limites e Controvérsias entre Agentes de IA e Ferramentas de Fluxo de Trabalho Tradicionais: A comunidade está envolvida em uma discussão acalorada sobre a definição e funcionalidade dos “agentes” de IA versus os “fluxos de trabalho Zapier” tradicionais. Alguns argumentam que os “agentes” atuais não passam de fluxos de trabalho Zapier que ocasionalmente chamam LLMs, carecendo de verdadeira autonomia e capacidade evolutiva, sendo um “regresso em vez de progresso”. Outros acreditam que os fluxos de trabalho estruturados (ou “andaimes”) superam em flexibilidade e capacidade a inferência de modelos básicos, e o AgentKit da OpenAI é questionado devido ao bloqueio de fornecedor e complexidade. Este debate destaca as divergências no caminho de desenvolvimento da tecnologia de agentes de IA e uma reflexão mais profunda sobre “automação” e “autonomia”. (Fonte: blader, hwchase17, amasad, mbusigin, jerryjliu0)
GPT-5 Acusado de Ser Treinado com Dados de Sites Adultos, Gerando Controvérsia: Um blogueiro, ao analisar os embeddings de token dos modelos de código aberto da série GPT-OSS da OpenAI, descobriu que os dados de treinamento do modelo GPT-5 podem conter conteúdo de sites adultos. Ao calcular a norma euclidiana do vocabulário, descobriu-se que certas palavras de alta norma (como “filmes pornôs grátis”) estavam relacionadas a conteúdo impróprio, e o modelo era capaz de reconhecer seu significado. Isso levantou preocupações na comunidade sobre os processos de limpeza de dados e a ética do modelo da OpenAI, e especulações de que a OpenAI pode ter sido “enganada” por seus fornecedores de dados. (Fonte: karminski3)

Censura Cada Vez Mais Rigorosa nos Modelos ChatGPT e Claude Gera Insatisfação dos Usuários: Recentemente, usuários dos modelos ChatGPT e Claude relataram amplamente que seus mecanismos de censura se tornaram excepcionalmente rigorosos, com muitos prompts normais e não sensíveis sendo marcados como “conteúdo impróprio”. Os usuários reclamam que os modelos não conseguem gerar cenas de beijo, e até mesmo “pessoas aplaudindo e dançando animadamente” é considerado “relacionado a sexo”. Essa censura excessiva resultou em uma queda significativa na experiência do usuário, levantando questões sobre a intenção das empresas de IA de reduzir o uso ou evitar riscos legais através da restrição de funcionalidades, o que gerou uma ampla discussão sobre a praticidade e a liberdade das ferramentas de IA. (Fonte: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ArtificialInteligence, Reddit r/ClaudeAI)
Usuários do Claude reclamam de aumento massivo do uso de Token e promoção do plano Max: Usuários do Claude relatam que, desde o lançamento das versões Claude Code 2.0 e Sonnet 4.5, o uso de Token aumentou significativamente, fazendo com que os usuários atinjam o limite de uso mais rapidamente, mesmo sem aumento na carga de trabalho. Alguns usuários pagam 214 euros por mês e ainda atingem os limites frequentemente, questionando se a Anthropic está usando isso para promover seu plano Max. Isso gerou insatisfação entre os usuários em relação à estratégia de preços do Claude e à transparência do consumo de Token. (Fonte: Reddit r/ClaudeAI)
Desenvolvimento Colaborativo de Agentes de IA Enfrenta Desafio de “Conflitos de Sobrescrita”: As redes sociais estão fervilhando com discussões sobre problemas encontrados por agentes de codificação de IA no desenvolvimento colaborativo, com um usuário apontando que “eles começam a sobrescrever brutalmente o trabalho uns dos outros, em vez de tentar lidar com conflitos de mesclagem”. Isso reflete humoristicamente como os sistemas multiagente, especialmente em tarefas complexas como geração e modificação de código, enfrentam o desafio técnico ainda não totalmente resolvido de gerenciar e resolver conflitos de forma eficaz. Isso levanta reflexões sobre futuros modelos de colaboração de IA. (Fonte: vikhyatk, nptacek)
Aplicação da IA na Educação e Formulação de Políticas: Uma escola de ensino médio no Vale do Silício pediu aos alunos que elaborassem uma política de IA, acreditando que envolver os adolescentes é o melhor caminho a seguir. Ao mesmo tempo, uma escola no Texas está permitindo que a IA oriente todo o seu currículo. Esses casos demonstram que a integração da IA no campo da educação está acelerando, mas também levantam discussões sobre o papel da IA em sala de aula, o envolvimento dos alunos na formulação de políticas e a viabilidade de currículos liderados por IA. Isso reflete a exploração ativa da comunidade educacional sobre as oportunidades e desafios da IA. (Fonte: MIT Technology Review)
Perspectivas e Preocupações de Longo Prazo sobre o Impacto da IA no Emprego: A comunidade discute o impacto de longo prazo da IA no emprego, com alguns argumentando que a IA dificilmente substituirá completamente engenheiros de pesquisa e cientistas humanos no curto prazo, mas sim aumentará as capacidades humanas e reorganizará as organizações de pesquisa, especialmente em um contexto de escassez de recursos computacionais. No entanto, outros temem que a IA leve a um declínio geral do emprego no setor privado, enquanto os provedores de IA obterão altos lucros, formando um modelo de “subsídio de IA insustentável”. Isso reflete as emoções complexas da sociedade em relação ao futuro da tecnologia de IA e seu impacto econômico. (Fonte: natolambert, johnowhitaker, Reddit r/ArtificialInteligence)
Importância da Escrita e Habilidades de Comunicação na Era da IA: Diante da popularização dos LLMs, há quem enfatize que as habilidades de escrita e comunicação são mais importantes do que nunca. Isso porque os LLMs só podem entender e ajudar os usuários se estes puderem expressar suas intenções claramente. Isso significa que, mesmo com ferramentas de IA cada vez mais poderosas, a capacidade humana de pensar claramente e se expressar eficazmente continua sendo fundamental para utilizar a IA, e pode até se tornar uma competência central no futuro mercado de trabalho. (Fonte: code_star)
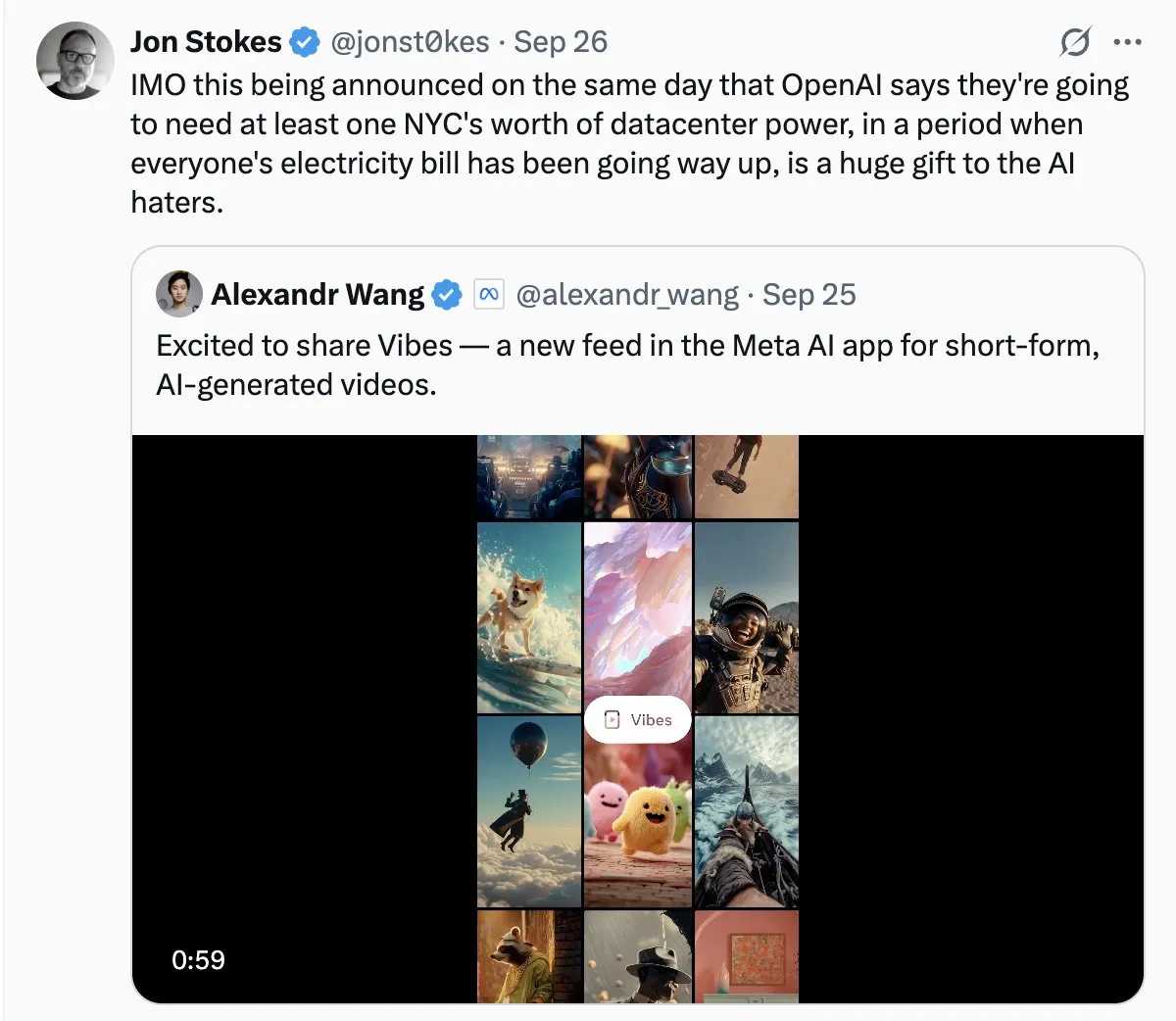
Consumo de Energia de Data Centers de IA Gera Preocupação Social: Com a rápida expansão dos data centers de IA, o problema de seu enorme consumo de energia se torna cada vez mais proeminente. Na discussão da comunidade, alguns comparam a demanda de eletricidade da IA a um “crescimento desenfreado” e temem que isso possa levar a um aumento das contas de eletricidade. Isso reflete a preocupação pública com os custos ambientais por trás do desenvolvimento da tecnologia de IA, e o desafio de alcançar a sustentabilidade energética enquanto se impulsiona a inovação em IA. (Fonte: Plinz, jonst0kes)
Considerações de Eficiência e Custo de Claude Code vs. Agentes Personalizados: A comunidade discutiu os prós e contras de usar diretamente o Claude Code versus construir agentes personalizados. Embora o Claude Code seja poderoso, agentes personalizados são mais vantajosos em cenários específicos, como gerar código UI com base em sistemas de design internos. Agentes personalizados podem otimizar prompts, economizar consumo de Token e reduzir a barreira de entrada para não-desenvolvedores, ao mesmo tempo em que resolvem problemas como a incapacidade do Claude Code de pré-visualizar efeitos diretamente e restrições de permissão da equipe. Isso indica que, em aplicações práticas, é crucial equilibrar ferramentas genéricas e soluções personalizadas de acordo com as necessidades específicas. (Fonte: dotey)
Loja de Aplicativos ChatGPT e o Futuro da Concorrência Comercial: Com o lançamento da loja de aplicativos do ChatGPT, os usuários estão discutindo seu potencial para se tornar o próximo “navegador” ou “sistema operacional”. Alguns acreditam que isso fará do ChatGPT a interface padrão para todos os aplicativos, realizando um novo paradigma de interação “Just ask”, e pode até substituir sites tradicionais. No entanto, outros temem que isso possa levar a OpenAI a cobrar taxas de promoção e desencadear uma competição acirrada com gigantes como o Google em pesquisa e ecossistemas impulsionados por IA. Isso prenuncia uma competição mais profunda entre os gigantes da tecnologia em plataformas de IA e modelos de negócios no futuro. (Fonte: bookwormengr, bookwormengr)

Modelos de Preços de LLM e Psicologia do Usuário: A comunidade discutiu como os diferentes modelos de preços de ferramentas de codificação de IA (como Cursor, Codex, Claude Code) afetam o comportamento e a psicologia do usuário. Por exemplo, o limite de requisições mensais do Cursor cria um impulso de “acumular” e “gastar tudo no final do mês” nos usuários; o limite semanal do Codex leva à “ansiedade de escopo”; e o pagamento por uso de API do Claude Code incentiva os usuários a gerenciar mais conscientemente o uso do modelo e do contexto. Essas observações revelam o profundo impacto das estratégias de preços na experiência do usuário e na eficiência das ferramentas de IA. (Fonte: kylebrussell)
💡 Outros
Motocicleta Esférica Omnidirecional: Engenheiro cria motocicleta esférica omnidirecional: Um engenheiro criou uma motocicleta esférica omnidirecional que se equilibra de forma semelhante a um Segway. Este veículo inovador demonstra os mais recentes avanços na engenharia mecânica e na fusão tecnológica, e embora não esteja diretamente relacionado à IA, seu avanço em inovação e tecnologias emergentes é digno de nota. (Fonte: Ronald_vanLoon)
Desafios da Geração de Vídeo Orientada por Personagens: A comunidade discutiu os desafios enfrentados pelos agentes de geração de vídeo ao replicar vídeos específicos, como compreender as ações de diferentes personagens em ambientes naturais, criar gags criativos entre cenas e manter a consistência do personagem e do estilo artístico ao longo do tempo. Isso destaca os gargalos técnicos da IA de geração de vídeo no tratamento de narrativas complexas e na manutenção da consistência multimodal, fornecendo direções claras para futuras pesquisas em IA. (Fonte: Vtrivedy10)
Mecanismo de Atenção em Modelos Transformer: Uma Analogia com o Processamento Sensorial Humano: Sugere-se que os mecanismos de esparsidade do corpo humano são semelhantes aos mecanismos de atenção nos modelos Transformer. Os humanos não processam todas as informações sensoriais completamente, mas sim através de roteamento ótimo de Pareto e ativação esparsa sob um orçamento de energia rigoroso. Isso fornece uma analogia biológica para entender como os modelos Transformer processam informações de forma eficiente e pode inspirar o design futuro de modelos de IA em termos de esparsidade e eficiência. (Fonte: tokenbender)