
Palavras-chave:OpenAI, Infraestrutura de IA, Vírus gerado por IA, Fundações AlphaEarth, RTEB, Claude Sonnet 4.5, DeepSeek V3.2-Exp, IA multimodal, Projeto Stargate da OpenAI, Modelo de linguagem Transformer Genome, Modelagem AlphaEarth 10m do Google, Benchmark RTEB da Hugging Face, Geração de código Anthropic Claude
Como editor-chefe sênior da coluna de IA, realizei uma análise aprofundada, resumo e destilação das notícias e discussões sociais que me foram fornecidas. Abaixo está o conteúdo integrado:
🔥 Foco
Aposta de Trilhão de Dólares da OpenAI em Infraestrutura : A OpenAI está colaborando com a Oracle e a SoftBank, planejando investir trilhões de dólares globalmente na construção de infraestrutura de computação, codinome “StarGate”. Inicialmente, foram anunciados 5 novos locais nos EUA, com um custo de 400 bilhões de dólares, e uma parceria com a Nvidia para construir o projeto “StarGate UK” no Reino Unido. A OpenAI prevê que a demanda futura de IA por eletricidade atingirá 100 gigawatts, e o investimento total pode chegar a 5 trilhões de dólares. Esta iniciativa visa satisfazer a enorme demanda por poder de computação dos modelos de IA, mas também levanta preocupações sobre o investimento financeiro, o consumo de energia e os potenciais riscos financeiros, destacando a extrema dependência da IA em relação à infraestrutura. (Fonte: DeepLearning.AI Blog)

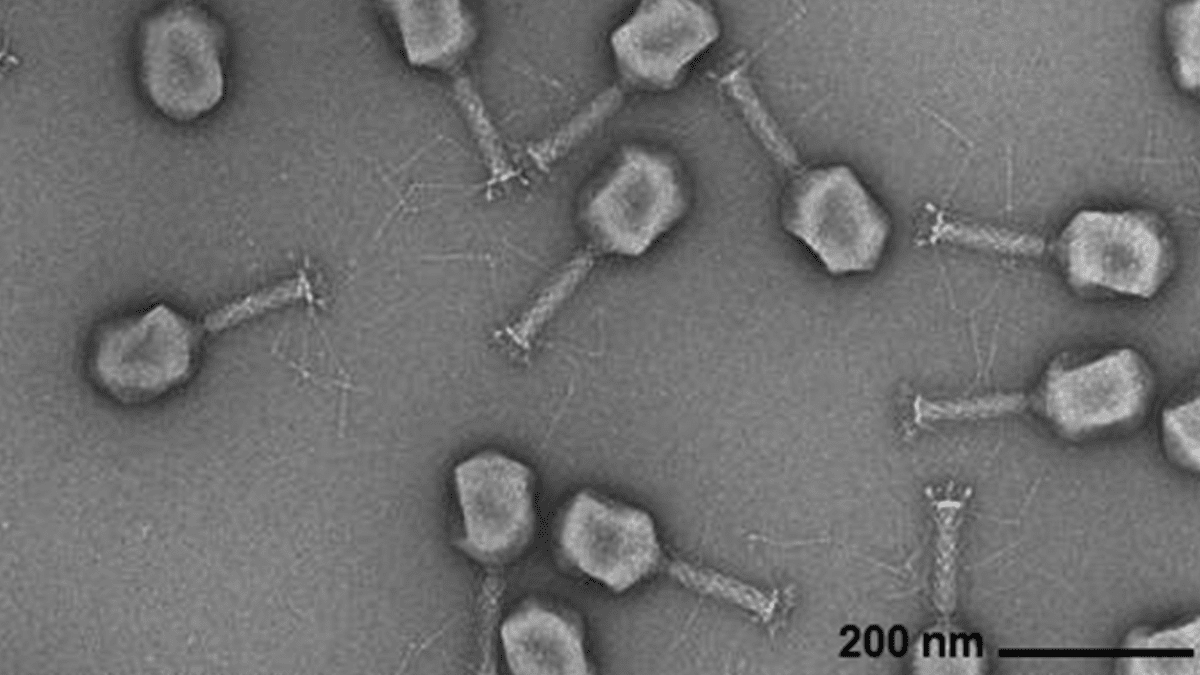
IA Gera Genomas Virais : Pesquisadores do Arc Institute, da Stanford University e do Memorial Sloan Kettering Cancer Center utilizaram modelos de linguagem genômica baseados em Transformer para sintetizar com sucesso, do zero, novos vírus bacteriófagos capazes de combater infecções bacterianas comuns. Esta tecnologia, através do ajuste fino de sequências de genomas virais, é capaz de gerar novos genomas com funções específicas e diferentes dos vírus encontrados na natureza. Este avanço abre novas vias para o desenvolvimento de terapias alternativas aos antibióticos, mas também levanta preocupações sobre a biossegurança e o uso malicioso, enfatizando a necessidade de pesquisa em resposta a ameaças biológicas. (Fonte: DeepLearning.AI Blog)
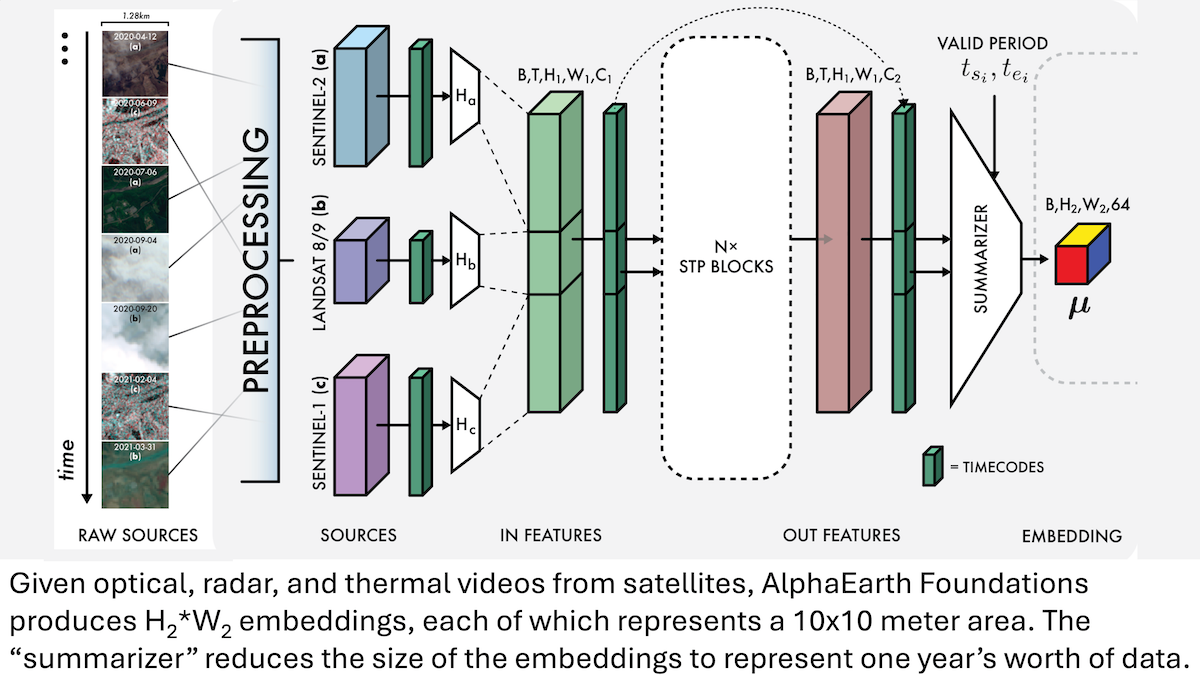
Google AlphaEarth Foundations: Modelagem de Alta Precisão da Terra em Nível de 10 Metros : Pesquisadores do Google lançaram o modelo AlphaEarth Foundations (AEF), capaz de integrar imagens de satélite e outros dados de sensores para modelar a superfície da Terra com uma precisão de 10 metros quadrados, e gerar embeddings que representam as características anuais da Terra de 2017 a 2024. Esses embeddings podem ser usados para rastrear várias propriedades planetárias como umidade, precipitação, vegetação, bem como desafios globais como produção de alimentos, risco de incêndios florestais e níveis de reservatórios, fornecendo uma ferramenta de alta precisão sem precedentes para monitoramento ambiental e pesquisa sobre mudanças climáticas. (Fonte: DeepLearning.AI Blog)
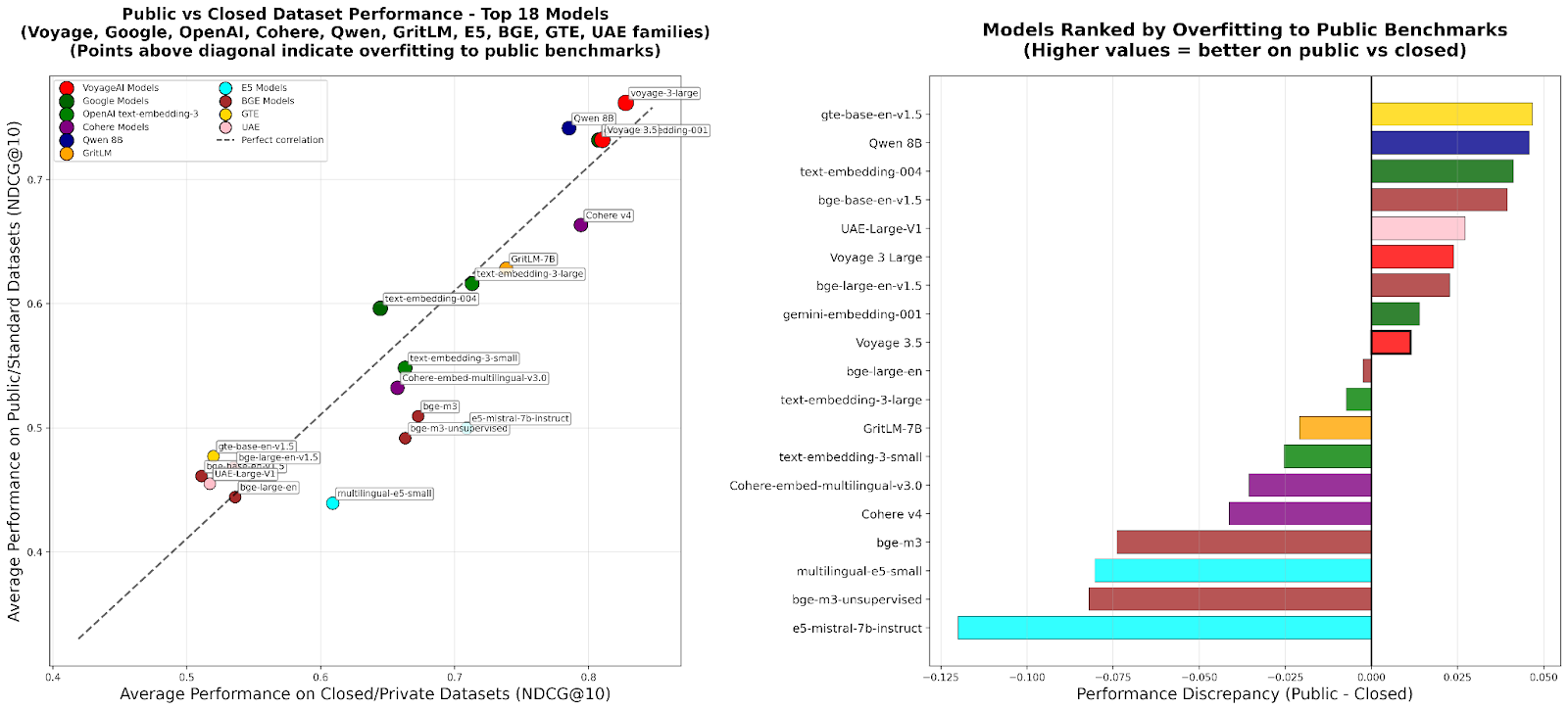
RTEB: Um Novo Padrão para Avaliação de Embeddings de Recuperação : A Hugging Face lançou a versão beta do Retrieval Embeddings Benchmark (RTEB), que visa fornecer um padrão de avaliação confiável para a precisão de recuperação de modelos de embeddings. Este benchmark, ao combinar uma estratégia mista de conjuntos de dados públicos e privados, resolve eficazmente o problema de overfitting em benchmarks existentes, garantindo que os resultados da avaliação reflitam melhor a capacidade de generalização do modelo em dados não vistos, o que é crucial para a melhoria da qualidade de aplicações de IA como RAG e Agent. (Fonte: HuggingFace Blog)
Treinamento Intermediário de RL Escalável: Raciocínio Através da Abstração de Ações : Uma pesquisa recente propõe o algoritmo “Reasoning as Action Abstraction” (RA3), que, ao identificar um conjunto compacto e útil de ações durante a fase de treinamento intermediário de Reinforcement Learning (RL) e acelerar o RL online, melhora significativamente as capacidades de raciocínio e geração de código de Large Language Models (LLMs). Este método se destaca em tarefas de geração de código, com um desempenho médio 8 a 4 pontos percentuais superior aos modelos de linha de base, e alcança uma convergência de RL mais rápida e um desempenho assintótico mais elevado. (Fonte: HuggingFace Daily Papers)
🎯 Tendências
OpenAI Sora 2: Uma Nova Era para Redes Sociais de Vídeo com IA : A OpenAI lançou o Sora 2 e o aplicativo social de mesmo nome, visando criar uma rede social centrada no usuário e em seu círculo social (amigos, animais de estimação) através da visualização e criação de vídeos gerados por IA, em vez de uma plataforma tradicional de distribuição de conteúdo. O Sora 2 demonstra poderosas capacidades de simulação física e geração de áudio, mas testes iniciais ainda revelam falhas em detalhes como “contar dedos”. Seu lançamento gerou discussões sobre o vício em vídeos de IA, deepfakes e o caminho de comercialização da OpenAI. Sam Altman respondeu que o Sora visa equilibrar o avanço tecnológico com a experiência agradável do usuário e financiar a pesquisa em IA. (Fonte: 36氪、Reddit r/ChatGPT、OpenAI)

Anthropic Claude Sonnet 4.5: Um Novo Padrão para Código e Agentes : A Anthropic lançou o Claude Sonnet 4.5, aclamado como “o melhor modelo de programação do mundo” e “o modelo mais poderoso para construir Agentes complexos”, com um tempo de execução autônomo de até 30 horas e um aumento significativo no desempenho de codificação em tarefas do GitHub. O modelo também adicionou uma função de memória, permitindo salvar o progresso do projeto. Embora seu desempenho seja altamente elogiado, ainda há controvérsias entre os usuários sobre seus limites de uso e a comparação de seu desempenho real com o Opus 4.1 e o GPT-5. (Fonte: Reddit r/ClaudeAI、Reddit r/artificial、Reddit r/ClaudeAI)
DeepSeek V3.2-Exp: Arquitetura de Atenção Esparsa Aumenta a Eficiência : A DeepSeek lançou o Large Language Model DeepSeek V3.2-Exp, que introduz uma nova arquitetura de Atenção Esparsa (DSA), reduzindo a complexidade da atenção principal de O(L²) para O(L·k), otimizando significativamente os custos de pré-preenchimento e decodificação em cenários de contexto longo, e consequentemente diminuindo drasticamente as taxas de uso da API. A 九章云极 foi a primeira a completar a adaptação do DeepSeek V3.2-Exp, oferecendo uma solução de implantação privada segura e eficiente para atender às necessidades das empresas em segurança de dados e flexibilidade de poder de computação. (Fonte: 量子位、Reddit r/LocalLLaMA)

Lançamento do Modelo Multimodal Áudio-Texto LFM2-Audio-1.5B : A Liquid AI lançou o LFM2-Audio-1.5B, um modelo fundamental completo de áudio-texto capaz de compreender e gerar texto e áudio. Este modelo tem uma velocidade de inferência 10 vezes maior que modelos similares e, com apenas 1.5B parâmetros, sua qualidade é comparável a modelos 10 vezes maiores, suportando implantação local e conversação em tempo real. A Hume AI também lançou o Octave 2, um modelo de texto para fala multilíngue mais rápido e barato, com capacidade de diálogo multi-falante e conversão de voz. (Fonte: Reddit r/LocalLLaMA、QuixiAI)

Microsoft Agent Framework: Novos Avanços no Desenvolvimento de Sistemas de Agentes : A Microsoft lançou o Microsoft Agent Framework, que integra AutoGen e Semantic Kernel em um SDK unificado e pronto para produção, para construir, orquestrar e implantar sistemas multiagente. Este framework suporta .NET e Python, e pode realizar fluxos de trabalho multiagente através de orquestração baseada em grafos, visando simplificar o desenvolvimento, observação e governança de aplicações de Agentes, acelerando a implementação de AI Agents de nível empresarial. (Fonte: gojira、omarsar0)

Fronteiras da Tecnologia de Robôs de IA e Concorrência Industrial : A tecnologia de robôs continua a avançar. O OmniRetarget da Amazon FAR otimiza a captura de movimento humano para aprender habilidades complexas de humanoides com o mínimo de Reinforcement Learning. A Periodic Labs se dedica a criar “cientistas de IA” para acelerar descobertas científicas. A Nvidia, por sua vez, destaca o papel de seu motor de física aberto Newton, do modelo de linguagem visual de inferência Cosmos Reason e do modelo fundamental de robôs Isaac GR00T N1.6 na implantação de IA física. Enquanto isso, a China demonstra uma vantagem líder na produção de robôs e no custo de robôs humanoides, levantando preocupações sobre o cenário competitivo da indústria global de robôs. (Fonte: pabbeel、LiamFedus、nvidia、atroyn)

🧰 Ferramentas
Tinker API: Uma Interface Flexível para Simplificar o Fine-tuning de LLM : A Thinking Machines Lab lançou a Tinker API, uma interface flexível projetada para o fine-tuning de modelos de linguagem. Ela permite que pesquisadores e desenvolvedores escrevam loops de treinamento localmente, enquanto a Tinker se encarrega de executá-los em clusters de GPU distribuídos, gerenciando a complexidade da infraestrutura, permitindo que os usuários se concentrem em algoritmos e dados. Esta ferramenta visa reduzir a barreira para o pós-treinamento de LLM, acelerar a experimentação e inovação de modelos abertos, e foi elogiada por especialistas como Andrej Karpathy como “a infraestrutura que eu sempre quis”. (Fonte: Reddit r/artificial、Thinking Machines、karpathy)

LlamaAgents: Implantação de Agentes de Documentos com Um Clique : A LlamaIndex lançou o LlamaAgents, oferecendo a capacidade de implantar AI Agents centrados em documentos com um clique, visando acelerar em 10 vezes a construção e entrega de agentes de documentos. A plataforma oferece 90% de modelos pré-configurados, suportando o processamento automatizado de tarefas intensivas em documentos como faturas, revisão de contratos e reivindicações, e permite personalização ilimitada. Os usuários podem implantar na LlamaCloud e gerenciar e atualizar facilmente os fluxos de trabalho de Agentes através de repositórios Git, encurtando significativamente o ciclo de desenvolvimento. (Fonte: jerryjliu0、jerryjliu0)

Hex AI Agent: Capacitando Análise e Colaboração em Equipe : A Hex lançou três novos AI Agents, projetados especificamente para análise de dados e colaboração em equipe: Threads oferece interação de dados conversacional, o Semantic Model Agent cria um contexto controlado para obter respostas precisas, e o Notebook Agent revoluciona o trabalho diário das equipes de dados. Todos esses Agentes são impulsionados pelo Claude 4.5 Sonnet, visando transformar a análise de IA conversacional de um conceito futuro em uma ferramenta eficiente e imediatamente utilizável. (Fonte: sarahcat21)
Sculptor: A UI Ausente para Claude Code : A Imbue lançou o Sculptor, uma interface de usuário projetada para o Claude Code, visando aprimorar a experiência de programação de Agentes. Ele permite que os desenvolvedores executem vários Claude Agents em paralelo em contêineres isolados e sincronizem o trabalho dos Agentes com o ambiente de desenvolvimento local para testes e edição através do “modo de emparelhamento”. O Sculptor também planeja suportar o GPT-5 e oferecer recursos de sugestão como detecção de comportamento enganoso, visando tornar a programação de Agentes mais fluida e eficiente. (Fonte: kanjun、kanjun)
Synthesia 3.0: Um Novo Avanço em Vídeos Interativos de IA : A Synthesia lançou a versão 3.0, introduzindo várias funcionalidades inovadoras, incluindo “Video Agents” (vídeos interativos que podem ter conversas em tempo real, usados para treinamento e entrevistas), “Avatares” aprimorados (criados com um único prompt ou imagem, com expressões faciais e movimentos corporais realistas) e “Copilot” (um editor de vídeo de IA que gera rapidamente scripts e elementos visuais). Além disso, foram aprimoradas as funções de interatividade e as ferramentas de design de cursos, visando revolucionar a criação de vídeos e a experiência de aprendizagem. (Fonte: synthesiaIO、synthesiaIO)
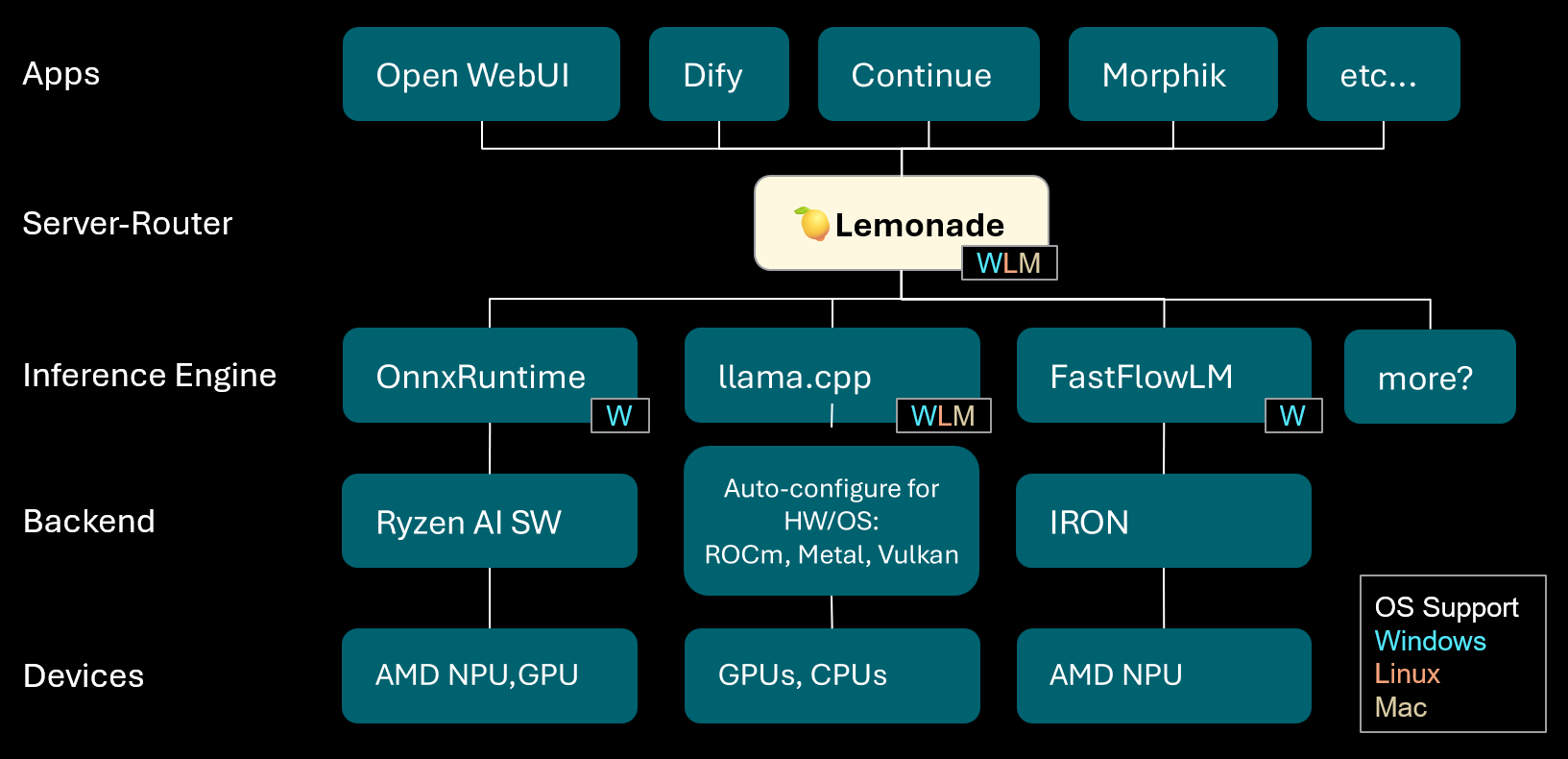
Lemonade: Servidor-Roteador LLM Local : A Lemonade lançou a versão v8.1.11, um servidor-roteador LLM local capaz de configurar automaticamente motores de inferência de alto desempenho para vários PCs (incluindo AMD NPU e dispositivos macOS/Apple Silicon). Ele suporta vários formatos de modelo como ONNX, GGUF e FastFlowLM, e utiliza o backend Metal do llama.cpp para computação eficiente em Apple Silicon, oferecendo aos usuários uma experiência LLM local flexível e de alto desempenho. (Fonte: Reddit r/LocalLLaMA)
PopAi: Geração de Apresentações Impulsionada por IA : A PopAi demonstrou a capacidade de sua ferramenta de IA de gerar apresentações comerciais detalhadas com gráficos e ilustrações a partir de um simples prompt em minutos. Isso destaca a eficiência da IA na criação de conteúdo, permitindo que não profissionais produzam rapidamente materiais de apresentação de alta qualidade. (Fonte: kaifulee)

GitHub Copilot CLI: Seleção Automática de Modelo : O GitHub Copilot CLI agora oferece funcionalidade de seleção automática de modelo para usuários comerciais e empresariais. Esta atualização permite que o sistema escolha automaticamente o modelo mais adequado para a tarefa atual, visando aumentar a eficiência do desenvolvimento e a qualidade da geração de código. (Fonte: pierceboggan)
Mixedbread Search: Busca Local Multilíngue e Multimodal : A Mixedbread lançou sua versão beta do sistema de busca, oferecendo funcionalidade de busca de documentos rápida, precisa, multilíngue e multimodal. O sistema enfatiza a execução local, permitindo que os usuários recuperem documentos de forma eficiente em seus próprios dispositivos, especialmente adequado para cenários que exigem o manuseio de diversos tipos de dados. (Fonte: TheZachMueller)
Hume AI Octave 2: Modelo TTS Multilíngue de Próxima Geração : A Hume AI lançou o Octave 2, um modelo de texto para fala (TTS) multilíngue de próxima geração. Este modelo é 40% mais rápido e 50% mais barato que seu antecessor, e suporta mais de 11 idiomas, diálogo multi-falante, conversão de voz e edição de fonemas, visando proporcionar uma experiência de IA de voz mais rápida, realista e emocional. (Fonte: AlanCowen)
Atualizações de Setembro da AssemblyAI: Serviço de Áudio de IA Completo : A AssemblyAI revisou suas atualizações de setembro, destacando o lançamento do Playground no aplicativo, extensões de linguagem universal, funcionalidade de desidentificação de PII na UE, bem como melhorias de desempenho de streaming e prompts de palavras-chave. Essas atualizações visam fornecer aos usuários um serviço de processamento de áudio de IA mais abrangente e eficiente. (Fonte: AssemblyAI)
Ferramenta Voiceflow MCP: Padronização da Integração de Ferramentas de Agentes : A Voiceflow lançou a ferramenta Model Context Protocol (MCP), que fornece uma maneira padronizada para os AI Agents usarem várias ferramentas. Isso simplifica o trabalho de integração personalizada para desenvolvedores e oferece ferramentas de terceiros pré-construídas para usuários sem código, expandindo significativamente as capacidades dos Voiceflow Agents. (Fonte: ReamBraden)
Salesforce Agentforce Vibes: Codificação de Agentes de Nível Empresarial : A Salesforce, baseada na arquitetura de Cline, lançou o produto “Agentforce Vibes”, que, com suporte ao Model Context Protocol (MCP), oferece aos clientes empresariais capacidades de codificação autônoma. Este produto garante a comunicação segura de LLMs com fontes de conhecimento/bancos de dados internos e externos, visando a codificação de IA em escala empresarial. (Fonte: cline)

JoyAgent-JDGenie: Relatório de Arquitetura de Agente Generalista : Foi lançado o relatório técnico GAIA (Generalist Agent Architecture), que integra uma estrutura multiagente coletiva (combinando planejamento, Agentes de execução e votação de modelos de revisão), um sistema de memória hierárquico (camadas de trabalho, semântica, programa) e um conjunto de ferramentas como busca, execução de código e análise multimodal. Esta estrutura se destaca em benchmarks abrangentes, superando linhas de base de código aberto e aproximando-se do desempenho de sistemas proprietários, oferecendo um caminho para a construção de assistentes de IA escaláveis, resilientes e adaptáveis. (Fonte: HuggingFace Daily Papers)
Assistente de Viagem de IA: Capacitando da Estratégia à Ação : O aplicativo de assistente de viagem de IA lançado pela Mafengwo visa elevar a IA da geração tradicional de guias para a assistência prática durante a viagem. O aplicativo pode gerar guias personalizados com texto e imagens, e oferece funções práticas como o AI Agent para fazer reservas em restaurantes por telefone, resolvendo efetivamente pontos problemáticos como barreiras linguísticas. Embora ainda haja espaço para melhorias em tradução em tempo real e personalização profunda, ele já reduziu significativamente a barreira para “viajar sem planejamento”, demonstrando o enorme potencial da IA em conectar informações digitais com ações no mundo físico. (Fonte: 36氪)

📚 Aprendizagem
Conselhos para o Desenvolvimento de Carreira de Pesquisadores de IA : Para o desenvolvimento de carreira de pesquisadores de IA, especialistas enfatizam a importância de se tornar um excelente codificador, incentivando a reprodução de artigos de pesquisa do zero e a compreensão aprofundada da infraestrutura. Ao mesmo tempo, sugerem construir ativamente uma marca pessoal, compartilhar ideias interessantes, manter a curiosidade e a adaptabilidade, e priorizar posições que promovam a inovação e o aprendizado. A longo prazo, o esforço contínuo e a obtenção de resultados práticos são chaves para construir confiança e motivação. (Fonte: dejavucoder、BlackHC)
Curso de Análise de Dados com Python : A DeepLearningAI lançou um novo curso de análise de dados com Python, que visa ensinar como usar Python para melhorar a eficiência, rastreabilidade e reprodutibilidade da análise de dados. Este curso faz parte do certificado profissional de análise de dados, enfatizando o papel central das habilidades de programação no trabalho de dados moderno. (Fonte: DeepLearningAI)
Estudantes Obtêm Ferramentas de IA Copilot Gratuitamente : A Microsoft oferece aos estudantes universitários elegíveis uma assinatura pessoal gratuita de 12 meses do Microsoft 365, que inclui acesso adicional ao Copilot Podcasts, Deep Research e Vision. Esta iniciativa visa fornecer aos estudantes poderosas ferramentas de IA para apoiar seus estudos e inovação. (Fonte: mustafasuleyman)

Configuração de Cursos Locais de IA/ML : Um educador compartilhou como criar cursos práticos de IA/ML para estudantes com um orçamento limitado, baseados em desenvolvimento local e hardware de consumo. Ele sugere usar modelos pequenos, o Transformer Lab como plataforma de treinamento, e enfatiza a compreensão de conceitos centrais em vez de buscar cegamente a escala do modelo, a fim de melhorar o efeito de aprendizado e a capacidade prática dos estudantes. (Fonte: Reddit r/deeplearning)
Próximos Seminários de IA : A AIhub publicou uma lista de próximos seminários de Machine Learning e IA que ocorrerão entre outubro e novembro de 2025. Esses eventos cobrem vários tópicos, desde a coleta de dados de plataformas de mídia social politicamente restritas até a ética da IA. Todos os seminários são gratuitos e oferecem opções de participação online, proporcionando ricas oportunidades de aprendizado e intercâmbio para a comunidade de IA. (Fonte: aihub.org)

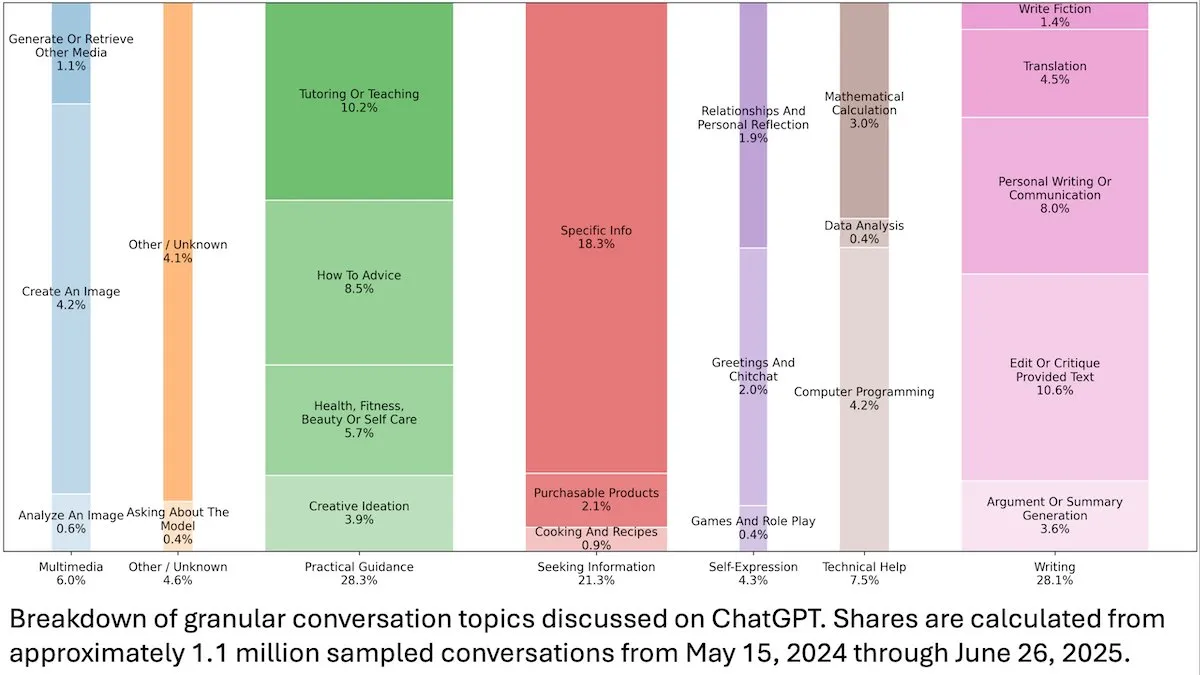
Insights sobre o Comportamento do Usuário do ChatGPT : Um estudo da OpenAI, publicado pela DeepLearningAI, revela que a análise de 110 milhões de conversas anônimas do ChatGPT mostra que seu uso mudou de cenários relacionados ao trabalho para necessidades pessoais, com uma maior proporção de usuárias e usuários jovens de 18 a 25 anos. As solicitações mais comuns são orientação prática (28,3%), ajuda na escrita (28,1%) e consulta de informações (21,3%), revelando a ampla aplicação do ChatGPT na vida diária. (Fonte: DeepLearningAI)
Code2Video: Geração de Vídeos Educacionais Orientada por Código : Uma pesquisa propõe o Code2Video, uma estrutura de Agente centrada em código que gera vídeos educacionais profissionais através de código Python executável. Esta estrutura inclui três Agentes colaborativos: planejador, codificador e revisor, capazes de estruturar o conteúdo da palestra, convertê-lo em código e otimizá-lo visualmente. Ele alcançou uma melhoria de desempenho de 40% no benchmark de vídeos educacionais MMMC e gerou vídeos comparáveis a tutoriais humanos. (Fonte: HuggingFace Daily Papers)
BiasFreeBench: Benchmark para Mitigação de Viés em LLM : O BiasFreeBench foi introduzido como um benchmark empírico para comparar de forma abrangente oito técnicas mainstream de mitigação de viés em LLM. Este benchmark, ao reorganizar conjuntos de dados existentes, introduziu a métrica “Bias-Free Score” em nível de resposta em dois cenários de teste (perguntas de múltipla escolha e perguntas abertas multiturno) para medir a justiça, segurança e grau anti-estereótipo das respostas do LLM, visando estabelecer uma plataforma de teste unificada para pesquisa de mitigação de viés. (Fonte: HuggingFace Daily Papers)
Obstáculos de Aprendizagem de Multiplicação em Transformer e Armadilhas de Dependência de Longo Alcance : Uma pesquisa analisou por engenharia reversa as razões do fracasso dos modelos Transformer em tarefas aparentemente simples como a multiplicação de números de vários dígitos. O estudo descobriu que o modelo codifica as estruturas de dependência de longo alcance necessárias em uma cadeia de pensamento implícita, mas os métodos de fine-tuning padrão não conseguem convergir para um ótimo global que possa utilizar essas dependências. Ao introduzir uma função de perda auxiliar, os pesquisadores resolveram com sucesso este problema, revelando as armadilhas do aprendizado de dependências de longo alcance por Transformer e fornecendo um exemplo de como resolver o problema com o viés indutivo correto. (Fonte: HuggingFace Daily Papers)
Insights de Treinamento de VL-PRM em Raciocínio Multimodal : A pesquisa visa esclarecer o espaço de design dos modelos de recompensa de processo visual-linguagem (VL-PRMs), explorando múltiplas estratégias para construção de conjuntos de dados, treinamento e escalabilidade em tempo de teste. Ao introduzir uma estrutura de síntese de dados mista e supervisão focada na percepção, os VL-PRMs demonstraram insights cruciais em cinco benchmarks multimodais, incluindo superação de modelos de recompensa de resultados em escalabilidade em tempo de teste, detecção de erros de processo por VL-PRMs de pequeno porte e revelação da capacidade de raciocínio potencial de backbones VLM mais fortes. (Fonte: HuggingFace Daily Papers)
GEM: Um Simulador de Ambiente Geral para LLM Agentic : GEM (General Experience Maker) é um simulador de ambiente de código aberto, projetado especificamente para o aprendizado experiencial de LLM Agents. Ele fornece uma interface padrão Agente-ambiente, suporta execução vetorizada assíncrona para alto throughput e oferece wrappers flexíveis para fácil extensão. O GEM também inclui um conjunto diversificado de ambientes e ferramentas integradas, e fornece linhas de base usando frameworks de treinamento de RL como REINFORCE, visando acelerar a pesquisa de LLM Agentic. (Fonte: HuggingFace Daily Papers)
GUI-KV: Compressão de Cache KV para Agentes GUI Eficientes : GUI-KV é um método plug-and-play de compressão de cache KV, projetado para GUI Agents, que aumenta a eficiência sem a necessidade de retreinamento. Ao analisar padrões de atenção em cargas de trabalho GUI, este método combina orientação de saliência espacial e técnicas de pontuação de redundância temporal, alcançando uma precisão próxima ao cache completo com um orçamento moderado e reduzindo significativamente os FLOPs de decodificação, utilizando eficazmente a redundância específica da GUI. (Fonte: HuggingFace Daily Papers)
Além da Verossimilhança Logarítmica: Estudo de Funções Objetivo Probabilísticas para SFT : A pesquisa explora funções objetivo probabilísticas para o fine-tuning supervisionado (SFT) que vão além da tradicional verossimilhança logarítmica negativa (NLL). Através de extensos experimentos com 7 backbones de modelo, 14 benchmarks e 3 domínios, descobriu-se que quando a capacidade do modelo é forte, funções objetivo que priorizam tokens a priori com pesos de baixa probabilidade (como -p, -p^10) superam a NLL; enquanto quando a capacidade do modelo é fraca, a NLL domina. A análise teórica revela como as funções objetivo fazem trade-offs com base na capacidade do modelo, fornecendo estratégias de otimização mais principiais para SFT. (Fonte: HuggingFace Daily Papers)
VLA-RFT: Fine-tuning de RL Baseado em Recompensa de Validação em Simuladores de Mundo : VLA-RFT é uma estrutura de fine-tuning por reforço para modelos de Visão-Linguagem-Ação (VLA), que utiliza um modelo de mundo orientado por dados como simulador controlável. O simulador, treinado com dados de interação reais, prevê observações visuais futuras baseadas em ações, permitindo o lançamento de políticas com recompensas densas em nível de trajetória. Esta estrutura reduz significativamente a necessidade de amostras, superando linhas de base supervisionadas fortes em menos de 400 passos de fine-tuning e demonstrando forte robustez em condições de perturbação. (Fonte: HuggingFace Daily Papers)
ImitSAT: Resolvendo o Problema de Satisfatibilidade Booleana Através da Aprendizagem por Imitação : ImitSAT é uma estratégia de ramificação de resolvedor CDCL baseada em aprendizagem por imitação, usada para resolver o problema de satisfatibilidade booleana (SAT). Este método, ao aprender o KeyTrace de especialistas, colapsa execuções completas em sequências de decisão sobreviventes, fornecendo supervisão densa em nível de decisão, o que reduz diretamente o número de propagações. Experimentos demonstraram que o ImitSAT supera os métodos de aprendizado existentes em contagem de propagação e tempo de execução, alcançando uma convergência mais rápida e um treinamento estável. (Fonte: HuggingFace Daily Papers)
Estudo de Práticas de Teste em Frameworks de Agentes de IA de Código Aberto : Uma pesquisa empírica em larga escala de 39 frameworks de Agentes de código aberto e 439 aplicações de Agentes revelou as práticas de teste no ecossistema de AI Agent. O estudo identificou dez padrões de teste únicos, descobrindo que o investimento em testes de componentes determinísticos (como ferramentas e fluxos de trabalho) excede 70%, enquanto os Agentes de planejamento baseados em LLM representam menos de 5%. Além disso, os testes de regressão para componentes de Prompt (Trigger) são severamente negligenciados, aparecendo em apenas cerca de 1% dos testes, revelando pontos cegos críticos nos testes de Agentes. (Fonte: HuggingFace Daily Papers)
DeepCodeSeek: Recuperação de API em Tempo Real para Geração de Código : A DeepCodeSeek propõe uma nova tecnologia para fornecer recuperação de API em tempo real para geração de código sensível ao contexto, permitindo preenchimento automático de código de alta qualidade e aplicações de AI Agentic. Este método resolve o problema de vazamento de API em conjuntos de dados de benchmark existentes, estendendo o código e o índice para prever as APIs necessárias. Após otimização, um reordenador compacto de 0.6B supera modelos de 8B, mantendo uma latência 2.5 vezes menor. (Fonte: HuggingFace Daily Papers)
CORRECT: Identificação Concisa de Erros em Sistemas Multiagente : CORRECT é uma estrutura leve e sem treinamento que permite a identificação de erros e a transferência de conhecimento em sistemas multiagente, utilizando um cache online de padrões de erro destilados. Esta estrutura pode identificar erros estruturados em tempo linear, evitando retreinamentos caros, e pode se adaptar a implantações MAS dinâmicas. CORRECT melhorou a localização de erros em nível de passo em 19,8% em sete aplicações multiagente, reduzindo significativamente a lacuna entre a automação e a identificação de erros em nível humano. (Fonte: HuggingFace Daily Papers)
Swift: Modelo de Consistência Autorregressiva para Previsão do Tempo Eficiente : Swift é um modelo de consistência de passo único que, pela primeira vez, realiza o fine-tuning autorregressivo de modelos de fluxo de probabilidade e adota o objetivo de Continuous Ranked Probability Score (CRPS). Este modelo é capaz de gerar previsões do tempo de 6 horas habilidosas e manter a estabilidade por até 75 dias, operando 39 vezes mais rápido que as linhas de base de difusão mais avançadas, ao mesmo tempo em que alcança habilidades de previsão competitivas com o IFS ENS numérico, marcando um passo importante para previsões de conjunto eficientes e confiáveis em escalas de médio a longo prazo e sazonais. (Fonte: HuggingFace Daily Papers)
Catching the Details: Preditor RoI de Auto-Destilação com Percepção de Granularidade Fina para MLLM : A pesquisa propõe uma rede de proposta de região de auto-destilação (SD-RPN) eficiente e sem anotação, que resolve o problema do alto custo computacional dos Large Language Models Multimodais (MLLM) ao processar imagens de alta resolução. O SD-RPN, ao converter mapas de atenção de camadas intermediárias do MLLM em rótulos de pseudo-RoI de alta qualidade e treinar um RPN leve para localização precisa, alcança eficiência de dados e capacidade de generalização, melhorando a precisão em mais de 10% em benchmarks não vistos. (Fonte: HuggingFace Daily Papers)
Um Novo Paradigma para Raciocínio Multiturno em LLM: In-Place Feedback : A pesquisa introduz um novo paradigma de interação chamado “In-Place Feedback” para guiar o LLM no raciocínio multiturno. Os usuários podem editar diretamente a resposta anterior do LLM, e o modelo gera uma revisão com base nesta resposta modificada. Avaliações empíricas mostram que o In-Place Feedback supera o feedback multiturno tradicional em benchmarks intensivos em raciocínio, ao mesmo tempo em que reduz o uso de tokens em 79,1%, resolvendo as limitações do modelo em aplicar feedback com precisão. (Fonte: HuggingFace Daily Papers)
Previsibilidade da Dinâmica de Aprendizagem por Reforço de LLM : Este trabalho revela duas propriedades fundamentais das atualizações de parâmetros de LLM no treinamento de Reinforcement Learning (RL): dominância de rank 1 (o subespaço singular mais alto da matriz de atualização de parâmetros determina quase completamente a melhoria da inferência) e dinâmica linear de rank 1 (este subespaço dominante evolui linearmente durante o treinamento). Com base nessas descobertas, a pesquisa propõe o AlphaRL, uma estrutura de aceleração plug-and-play que, ao inferir as atualizações finais de parâmetros a partir de uma janela de treinamento inicial, alcança uma aceleração de até 2,5 vezes, mantendo mais de 96% do desempenho de inferência. (Fonte: HuggingFace Daily Papers)
Armadilhas da Compressão de Cache KV : A pesquisa revela várias armadilhas da compressão de cache KV na implantação de LLM, especialmente em cenários práticos como prompts multi-instrução, onde a compressão pode levar a uma rápida degradação do desempenho de certas instruções, ou até mesmo ser completamente ignorada pelo LLM. O estudo, através de análise de caso de vazamento de prompt do sistema, demonstra empiricamente o impacto da compressão no vazamento e na conformidade com instruções gerais, e propõe melhorias simples na estratégia de despejo de cache KV. (Fonte: HuggingFace Daily Papers)
💼 Negócios
Concorrência entre Gigantes da IA: Diferenças Estratégicas entre OpenAI e Anthropic : A OpenAI e a Anthropic adotaram caminhos de desenvolvimento muito diferentes no campo da IA. A OpenAI, através da integração de e-commerce com o ChatGPT e o lançamento do aplicativo social Sora, visa a “expansão horizontal”, tornando-se uma superplataforma que cobre múltiplos aspectos da vida do usuário, com uma avaliação que já ultrapassa a Anthropic em centenas de bilhões de dólares. A Anthropic, por sua vez, foca na “exploração vertical profunda”, com o Claude Sonnet 4.5 como seu núcleo, aprofundando-se na programação de IA e no mercado de Agentes de nível empresarial, e estabelecendo laços profundos com provedores de serviços em nuvem como AWS e Google. Por trás de ambos estão os dois gigantes da computação em nuvem, Microsoft e Amazon, em uma disputa de “diplomacia de poder de computação”, destacando a realidade industrial da escassez e do alto custo do poder de computação na era da IA. (Fonte: 36氪、量子位、36氪)
Perplexity Adquire Visual Electric : A Perplexity anunciou a aquisição da Visual Electric, cuja equipe se juntará à Perplexity para desenvolver novas experiências de produtos para o consumidor. Os produtos da Visual Electric serão gradualmente descontinuados. Esta aquisição visa fortalecer a capacidade de inovação da Perplexity no campo de produtos de IA para o consumidor. (Fonte: AravSrinivas)

Databricks Adquire Mooncakelabs : A Databricks anunciou a aquisição da Mooncakelabs para acelerar a realização de sua visão Lakebase. Lakebase é um novo banco de dados OLTP construído sobre Postgres e otimizado para AI Agent, visando fornecer uma base unificada para aplicações, análises e IA, e profundamente integrado com Lakehouse e Agent Bricks, simplificando o gerenciamento de dados e o desenvolvimento de aplicações de IA. (Fonte: matei_zaharia)

🌟 Comunidade
Impacto da IA no Emprego e na Sociedade : A comunidade discute amplamente o profundo impacto da automação por IA no mercado de trabalho, temendo que possa levar a desemprego em massa, criar novas classes sociais e gerar a necessidade de uma Renda Básica Universal (UBI). As pessoas questionam se os novos empregos relacionados à IA também serão automatizados e se nem todos conseguirão dominar as habilidades de IA para se adaptar ao futuro. A discussão também aborda os desafios de gerenciamento de custos e realização de ROI para AI Agents, bem como o potencial impacto da chegada da AGI na estrutura social e na geopolítica. (Fonte: Reddit r/ArtificialInteligence、Ronald_vanLoon、Ronald_vanLoon)
Ética da IA e a Luta pelo Controle : A comunidade debate acaloradamente quem deve controlar o futuro da IA: cidadãos comuns ou oligarcas da tecnologia. Há apelos para que o desenvolvimento da IA seja centrado no ser humano, enfatizando a transparência e o controle do usuário sobre dados pessoais e o histórico da IA. Ao mesmo tempo, o padrinho da IA, Yoshua Bengio, alerta que máquinas superinteligentes podem levar à extinção humana em uma década. Empresas como a Meta planejam usar dados de chat de IA para publicidade direcionada, o que agrava ainda mais as preocupações dos usuários com a privacidade e o uso indevido da IA, provocando uma reflexão profunda sobre a ética e a regulamentação da IA. (Fonte: Reddit r/artificial、Reddit r/artificial、Reddit r/ArtificialInteligence)

Comportamento Anormal do Modelo de Segurança GPT-5 : Usuários da comunidade Reddit relataram que o modelo “CHAT-SAFETY” do GPT-5, ao processar solicitações não maliciosas, exibe comportamentos estranhos, acusatórios e até alucinatórios, como interpretar uma pergunta sobre reconhecimento de impressões digitais como comportamento de rastreamento e inventar leis. Essa resposta excessivamente sensível e imprecisa levantou sérias dúvidas dos usuários sobre a confiabilidade do modelo, os perigos potenciais e as estratégias de segurança da OpenAI. (Fonte: Reddit r/ChatGPT)
“A Lição Amarga” e o Debate sobre o Caminho de Desenvolvimento dos LLMs : Andrej Karpathy e Richard Sutton, o pai do Reinforcement Learning, debateram se os LLMs se encaixam na “Lição Amarga”. Sutton argumenta que os LLMs dependem de dados humanos limitados para o pré-treinamento, não seguindo verdadeiramente o princípio de aprender com a experiência da “Lição Amarga”. Karpathy, por sua vez, considera o pré-treinamento uma “evolução ruim” para resolver o problema do cold start, e aponta as diferenças fundamentais entre os LLMs e a inteligência animal nos mecanismos de aprendizado, enfatizando que a IA atual é mais como “invocar fantasmas” do que “construir animais”. (Fonte: karpathy、SchmidhuberAI)
Discussão sobre o Valor da Configuração de LLM Local : Usuários da comunidade debateram o valor de investir dezenas de milhares de dólares na construção de uma configuração de LLM local. Os defensores enfatizam que a privacidade, a segurança dos dados e o conhecimento aprofundado adquirido através da operação prática são suas principais vantagens, comparando-o a entusiastas de rádio amador. Os oponentes argumentam que, com o aumento do desempenho de APIs de nuvem baratas (como Sonnet 4.5 e Gemini Pro 2.5), uma configuração local de alto custo é difícil de justificar. (Fonte: Reddit r/LocalLLaMA)
LLM como Juiz: Novo Método de Avaliação de Agentes : Pesquisadores e desenvolvedores estão explorando o uso de LLMs como “juízes” para avaliar a qualidade das respostas de AI Agents, incluindo precisão e fundamentação. A prática mostra que, quando os prompts do juiz são cuidadosamente projetados (como critério único, pontuação ancorada, formato de saída rigoroso e avisos de viés), este método pode ser surpreendentemente eficaz. Esta tendência indica o enorme potencial do LLM-as-a-Judge no campo da avaliação de Agentes. (Fonte: Reddit r/MachineLearning)
Interação entre IA e Humanos: De Dispositivos a Personagens Virtuais : A IA está remodelando a interação humana em múltiplas dimensões. Uma startup ligada ao MIT lançou um dispositivo vestível “quase telepático” para comunicação silenciosa. Ao mesmo tempo, AI Agents de voz em tempo real como NPCs (personagens não jogáveis) já são aplicados em jogos online 3D, prenunciando o potencial da IA em proporcionar experiências de interação mais naturais e imersivas em jogos e mundos virtuais. Esses avanços provocam discussões sobre o papel da IA na vida diária e no entretenimento. (Fonte: Reddit r/ArtificialInteligence、Reddit r/artificial)

Escolha entre Modelos Abertos e Modelos de Código Fechado : A comunidade discutiu os maiores obstáculos que os engenheiros de software enfrentam ao mudar de modelos de código fechado para modelos de código aberto. Especialistas apontam que o fine-tuning de modelos de código aberto, em vez de depender de modelos de caixa preta de código fechado, é crucial para o aprendizado aprofundado, a diferenciação de produtos e a criação de melhores produtos para os usuários. Embora o desenvolvimento de modelos de código aberto possa ser mais lento, a longo prazo, eles têm um enorme potencial na criação de valor e na autonomia tecnológica. (Fonte: ClementDelangue、huggingface)
Infraestrutura de IA e Desafios de Capacidade de Computação : O projeto “StarGate” da OpenAI revela a enorme demanda da IA por capacidade de computação, energia e terra, com uma previsão de consumo de até 900.000 wafers DRAM por mês. A escassez de GPUs, seus altos preços e as limitações no fornecimento de eletricidade forçam as empresas de IA a praticar a “diplomacia de poder de computação”, estabelecendo laços profundos com provedores de serviços em nuvem (como Microsoft e Amazon). Este modelo de investimento em ativos pesados e colaboração estratégica, embora impulsione o desenvolvimento da IA, também traz riscos de variáveis externas como cadeia de suprimentos, políticas energéticas e regulamentação. (Fonte: karminski3、AI巨头的奶妈局、DeepLearning.AI Blog)

💡 Outros
Direitos Autorais de Música de IA e Mecanismos de Compensação : A organização sueca de direitos autorais STIM, em colaboração com a empresa Sureel, lançou um acordo de licenciamento de música de IA, visando resolver a questão do uso de direitos autorais de obras musicais no treinamento de modelos de IA. Este acordo permite que desenvolvedores de IA usem música legalmente e, através da tecnologia de atribuição da Sureel, calculem o impacto da obra na saída do modelo, compensando assim compositores e artistas de gravação. Esta iniciativa visa fornecer proteção legal para a criação de música de IA, incentivar a produção de conteúdo original e criar novas fontes de receita para os detentores de direitos autorais. (Fonte: DeepLearning.AI Blog)

Segurança de LLM e Ataques Adversariais : A Trend Micro publicou uma pesquisa que explora em profundidade as várias maneiras pelas quais os LLMs podem ser explorados por atacantes, incluindo comprometimento através de prompts cuidadosamente construídos, envenenamento de dados e vulnerabilidades em sistemas multiagente. A pesquisa enfatiza a importância de compreender esses vetores de ataque para desenvolver aplicações de LLM e sistemas multiagente mais seguros, e propõe estratégias de defesa correspondentes. (Fonte: Reddit r/deeplearning)

Proactive AI: Equilíbrio entre Conveniência e Privacidade : A comunidade discutiu a “Proactive Ambient AI” (IA Ambiente Proativa) como assistente inteligente, e o equilíbrio entre a conveniência que ela traz e os potenciais riscos de invasão de privacidade. Este tipo de IA pode oferecer ajuda proativa, mas sua coleta e processamento contínuos de dados pessoais levantam preocupações dos usuários sobre transparência, controle e propriedade dos dados. Há apelos para o estabelecimento de “protocolos de transparência” e “perfis básicos pessoais” para garantir que os usuários tenham controle sobre seu histórico de interações com a IA. (Fonte: Reddit r/artificial)
