
Palavras-chave:OpenAI Sora 2, Geração de vídeo por IA, IA multimodal, Cientista de IA, Design de proteínas, API do Sora 2, PXDesign para proteínas, Framework PromptCoT 2.0, Geração em primeira pessoa EgoTwin, Liquid AI LFM2-Áudio
🔥 Foco
Lançamento do OpenAI Sora 2 e seus Impactos : A OpenAI lançou oficialmente o Sora 2, posicionando-o como um aplicativo social iOS “versão IA do TikTok”, que suporta geração síncrona de áudio e vídeo, e apresenta melhorias significativas na aderência às leis da física e controlabilidade. Novas funcionalidades incluem “cameos”, permitindo que usuários insiram suas imagens ou as de amigos em vídeos gerados por AI. As redes sociais estão empolgadas com seu realismo e criatividade surpreendentes, mas também há preocupações com a proliferação de conteúdo “slop” (de baixa qualidade e sem sentido), a dificuldade em distinguir o real do falso, o aumento da demanda por GPU e a disponibilidade regional (como a ausência do Sora no Reino Unido). Sam Altman, CEO da OpenAI, respondeu que o Sora 2 visa financiar a pesquisa em AGI e oferecer novos produtos interessantes. As discussões da comunidade também abordam a obtenção de códigos de convite do Sora 2, especulações sobre os requisitos de hardware (GPU) e preocupações com a qualidade futura do conteúdo de vídeo gerado e o uso malicioso. A OpenAI planeja expandir os convites para o Sora, mas reduzirá os limites diários de geração, e revelou que lançará a Sora 2 API.
(Fonte: 量子位, Yuchenj_UW, teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Periodic Labs lança plataforma de cientistas de AI para acelerar a descoberta científica : A Periodic Labs garantiu US$ 300 milhões em financiamento, com o objetivo de criar cientistas de AI para acelerar a descoberta científica fundamental, especialmente na área de design de materiais, por meio de laboratórios automatizados e experimentos impulsionados por AI. A plataforma visa tratar o universo físico como um sistema computacional, utilizando AI para formular hipóteses, experimentar e aprender, com a expectativa de avanços em áreas como supercondutores de alta temperatura. Essa visão enfatiza a conexão da AI com o mundo físico e a importância de gerar dados de alta qualidade por meio de experimentos, superando os modelos tradicionais que dependem apenas de dados da internet para treinamento.
(Fonte: dylan522p, teortaxesTex, teortaxesTex, NandoDF, NandoDF, TheRundownAI, Ar_Douillard, teortaxesTex)

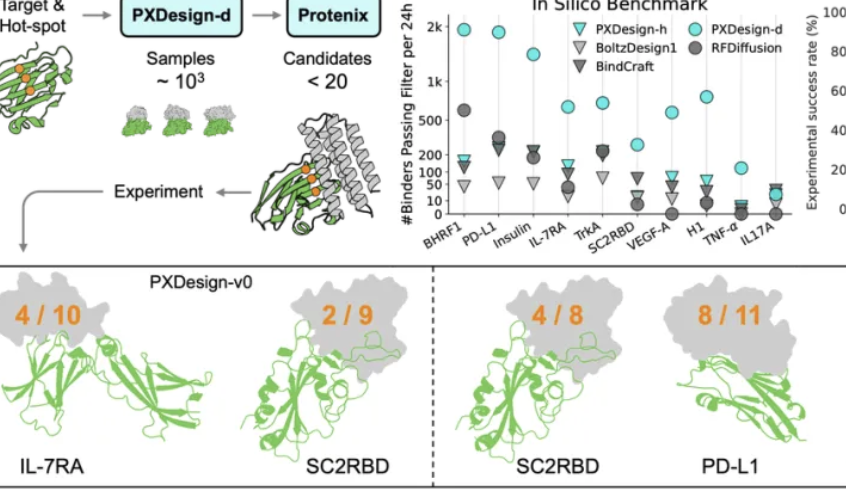
Equipe Seed da ByteDance lança PXDesign, aumentando a eficiência do design de proteínas : A equipe Seed da ByteDance lançou o PXDesign, um método escalável de design de proteínas por AI, capaz de gerar centenas de proteínas candidatas de alta qualidade em 24 horas, uma eficiência cerca de 10 vezes maior do que os métodos mainstream da indústria. O método alcançou uma taxa de sucesso em experimentos úmidos de 20%-73% em vários alvos, significativamente superior ao AlphaProteo da DeepMind. O PXDesign combina uma estratégia de “geração + filtragem”, utilizando a estrutura de rede DiT e o modelo de previsão de estrutura Protenix para uma triagem eficiente, e oferece um serviço online gratuito e público de design de binders, visando acelerar a exploração da pesquisa científica biológica.
(Fonte: 量子位)
Ant Group e Universidade de Hong Kong lançam PromptCoT 2.0, focado na síntese de tarefas : O grupo de linguagem natural do Centro de Inteligência Artificial Geral da Ant Group e o grupo de linguagem natural da Universidade de Hong Kong lançaram conjuntamente a estrutura PromptCoT 2.0, com o objetivo de impulsionar a inferência de grandes modelos e o desenvolvimento de agentes através da síntese de tarefas. A estrutura adota um ciclo de Expectativa-Maximização (EM) para substituir o design manual, otimizando iterativamente a cadeia de raciocínio para gerar problemas mais difíceis e diversificados. O PromptCoT 2.0 combina aprendizagem por reforço (RL) e SFT, permitindo que modelos 30B-A3B atinjam SOTA em tarefas de inferência de código matemático, e disponibilizou 4,77 milhões de dados de problemas sintéticos em código aberto, fornecendo recursos de treinamento para a comunidade.
(Fonte: 量子位)

EgoTwin alcança pela primeira vez a geração síncrona de vídeo em primeira pessoa e movimentos humanos : A Universidade Nacional de Singapura, a Universidade Tecnológica de Nanyang, a Universidade de Ciência e Tecnologia de Hong Kong e o Shanghai AI Lab lançaram conjuntamente a estrutura EgoTwin, que pela primeira vez realiza a geração conjunta de vídeos em primeira pessoa e movimentos humanos. A estrutura é baseada em modelos de difusão, utilizando a geração conjunta trimodal de “texto-vídeo-ação” para superar os dois grandes desafios de alinhamento de perspectiva-ação e acoplamento causal. As inovações centrais incluem representação de ação centrada na cabeça, mecanismos de interação inspirados na cibernética e uma estrutura de treinamento de difusão assíncrona. Os vídeos e movimentos gerados podem ser aprimorados ainda mais em cenários 3D.
(Fonte: 量子位)

🎯 Tendências
Lançamento e atualização intensiva de modelos de AI de nova geração : Recentemente, o campo da AI testemunhou o lançamento e a atualização de vários modelos e funcionalidades importantes, incluindo DeepSeek-V3.2, Claude Sonnet 4.5, GLM 4.6, Sora 2, Dreamer 4 e a função de checkout instantâneo do ChatGPT. O DeepSeek-V3.2 foi otimizado no vLLM através de um mecanismo de atenção esparsa, alcançando maior desempenho de contexto longo e eficiência de custo. O Claude Sonnet 4.5 demonstrou complexidade em alinhamento e teoria da mente do usuário, destacando-se em escrita criativa e de formato longo, mas alguns usuários apontaram que a qualidade da geração de código ainda precisa ser melhorada. O GLM-4.6 se destacou na capacidade de código frontend, mas as melhorias em outras linguagens como Python não foram significativas, e uma versão quantizada GGUF foi lançada para suportar a implantação local. O Dreamer 4 é um agente capaz de aprender a resolver tarefas de controle complexas dentro de um modelo de mundo escalável.
(Fonte: Yuchenj_UW, teortaxesTex, zhuohan123, vllm_project, teortaxesTex, teortaxesTex, teortaxesTex, ImazAngel, teortaxesTex, _lewtun, nrehiew_, YiTayML, agihippo, TimDarcet, Dorialexander, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)
Modelo de vídeo multimodal Veo3 demonstra potencial para inteligência visual geral : O modelo de vídeo Veo3 é considerado um caminho potencial para a inteligência visual geral, exibindo capacidades de aprendizagem e inferência zero-shot, capaz de resolver várias tarefas visuais e considerado de grande importância para o avanço da robótica. Simultaneamente, a equipe Qwen da Alibaba Cloud lançou a série Qwen3-VL de modelos de linguagem grandes multimodais, que foram totalmente atualizados em agência visual, codificação visual, percepção espacial, contexto longo e compreensão de vídeo, inferência multimodal, reconhecimento visual e OCR, e estão disponíveis nas versões Instruct e Thinking. A Tencent também lançou os modelos HunyuanImage 3.0 e Hunyuan3D-Part, que alcançaram níveis de liderança na geração de imagem a partir de texto e geração de formas 3D, respectivamente.
(Fonte: gallabytes, NandoDF, NandoDF, madiator, shaneguML, Yuchenj_UW, GitHub Trending, ClementDelangue)

Liquid AI lança LFM2-Audio e modelos especializados menores : A Liquid AI lançou o LFM2-Audio, um modelo de fundação multimodal (áudio-texto) end-to-end com apenas 1.5 bilhão de parâmetros, capaz de realizar conversas em tempo real e responsivas diretamente no dispositivo, com uma velocidade de inferência 10 vezes mais rápida que modelos similares. Além disso, a Liquid AI também lançou a série LFM2 de modelos fine-tuned, incluindo variantes como Tool, RAG e Extract, focadas em tarefas específicas em vez de buscar a universalidade. Isso se alinha com a perspectiva do whitepaper da Nvidia de que modelos pequenos e especializados são o futuro da Agentic AI.
(Fonte: ImazAngel, maximelabonne, Reddit r/LocalLLaMA)
Bancos de dados vetoriais ganham “segunda vida” e a xAI enfatiza dados de alta qualidade : Há uma visão de que os bancos de dados vetoriais podem estar entrando em um novo pico de desenvolvimento, mas seus modos de aplicação podem ser diferentes do esperado. Ao mesmo tempo, a xAI está estabelecendo um novo paradigma para processar dados humanos, enfatizando a importância do pós-treinamento (post-training), acreditando que dados de alta qualidade são a pedra angular para a AGI. A xAI planeja formar uma comunidade de especialistas de várias áreas para construir em conjunto o sistema de avaliação de mais alta qualidade.
(Fonte: _philschmid, Dorialexander, Yuhu_ai_)
🧰 Ferramentas
AI小说生成器YILING0013/AI_NovelGenerator : Um gerador de romances multifuncional baseado em Large Language Model (LLM), que suporta arquitetura de mundo, criação de personagens, roteiro de enredo, geração inteligente de capítulos, rastreamento de estado, gerenciamento de foreshadowing, recuperação semântica, integração de base de conhecimento e mecanismos de revisão automática, oferecendo operação GUI visual. A ferramenta visa criar histórias longas com lógica rigorosa e configurações unificadas de forma eficiente, e suporta vários serviços de LLM e Embedding como OpenAI, DeepSeek e Ollama.
(Fonte: GitHub Trending)
Ferramentas de programação assistidas por AI continuam a evoluir : O GitHub Copilot, através de instruções, prompts e modos de chat contribuídos pela comunidade, ajuda os usuários a maximizar sua utilidade em diferentes domínios, linguagens e casos de uso, e oferece um MCP server para simplificar a integração. O Replit Agent demonstrou fortes capacidades em migração de código e QA, sendo capaz de migrar rapidamente grandes sites Next.js da Vercel e suportar a integração de pagamentos in-app. O modelo Apriel-1.5-15b-Thinker da ServiceNow pode ser executado em uma única GPU, oferecendo poderosas capacidades de inferência. Além disso, o modelo Moondream3-preview é usado para fluxos de UI de agente e tarefas de RPA, e o vLLM também suporta a implantação de modelos encoder-only.
(Fonte: github/awesome-copilot, amasad, amasad, amasad, amasad, amasad, ImazAngel, ben_burtenshaw, amasad, amasad, amasad, amasad, TheZachMueller, Reddit r/LocalLLaMA)

Inovação de ferramentas de AI em áreas de aplicação específicas : O pix2tex (LaTeX OCR) pode converter imagens de fórmulas matemáticas em código LaTeX, aumentando significativamente a eficiência nos campos de pesquisa científica e educação. O BatonVoice utiliza a capacidade de seguir instruções de LLM para fornecer parâmetros estruturados para a síntese de fala, alcançando um TTS controlável. A plataforma Hex integra funcionalidades de agente, permitindo que mais pessoas usem AI para trabalho de dados preciso e confiável. Ferramentas de geração de vídeo como Kling 2.5 Turbo e Lucid Origin tornam a criação de vídeo mais conveniente do que nunca. O Racine CU-1 é um modelo de interação GUI que pode identificar posições de clique, adequado para fluxos de UI baseados em agente e tarefas de RPA.
(Fonte: lukas-blecher/LaTeX-OCR, teortaxesTex, dotey, dotey, Ronald_vanLoon, AssemblyAI, TheRundownAI, Kling_ai, Kling_ai, sarahcat21, mervenoyann, pierceboggan, Reddit r/OpenWebUI, Reddit r/LocalLLaMA, Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/ArtificialInteligence, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Modelo de re-ranking de documentos jina-reranker-v3 : O jina-reranker-v3 é um modelo de re-ranking de documentos multilíngue com 0.6 bilhão de parâmetros, que introduz um novo mecanismo de “interação tardia, mas não atrasada” (last but not late interaction). Este método realiza cálculos de autoatenção causal entre consultas e documentos, permitindo interações ricas entre documentos antes da extração de embeddings contextuais para cada documento. Esta arquitetura compacta alcança desempenho SOTA em BEIR, sendo dez vezes menor que os modelos de re-ranking de lista generativos.
(Fonte: HuggingFace Daily Papers)
📚 Aprendizagem
Últimos avanços em pesquisa sobre inferência e alinhamento de modelos de AI : Pesquisas revelam que a inferência multimodal, ao mesmo tempo em que aprimora o raciocínio lógico, pode prejudicar as bases perceptivas, levando ao esquecimento visual. O método Vision-Anchored Policy Optimization (VAPO) foi proposto para guiar o processo de inferência a focar mais nas bases visuais. Discute-se por que o alinhamento online (como GRPO) é superior ao alinhamento offline (como DPO), e uma variante Humanline é proposta, que, ao simular vieses de percepção humana, permite que o treinamento com dados offline alcance o desempenho do alinhamento online. O paradigma Test-Time Policy Adaptation for Multi-Turn Interactions (T2PAM) e o algoritmo Optimum-Referenced One-Step Adaptation (ROSA) utilizam feedback do usuário para ajustar de forma eficiente e em tempo real os parâmetros do modelo, melhorando a capacidade de autocorreção de LLMs em diálogos multi-turn. O NuRL (Nudging method) reduz a dificuldade dos problemas através de prompts autogerados, permitindo que o modelo aprenda com problemas originalmente “insolúveis”, elevando assim o limite da capacidade de inferência de LLM. O RLP (Reinforcement Learning Pre-training) introduz a aprendizagem por reforço na fase de pré-treinamento, tratando a cadeia de pensamento como ações e recompensando com base no ganho de informação, para aprimorar a capacidade de inferência do modelo já na fase de pré-treinamento. O Exploratory Iteration (ExIt) é um método de currículo automático baseado em RL que, ao guiar o LLM a autoaperfeiçoar iterativamente suas soluções durante a inferência, melhora efetivamente o desempenho do modelo em tarefas de uma e múltiplas rodadas. A pesquisa TruthRL incentiva LLMs a gerar informações verdadeiras através da aprendizagem por reforço, visando resolver o problema de alucinação do modelo. A pesquisa descobriu que a “Janela de Contexto Efetiva Máxima” (MECW) de LLMs é muito menor do que a “Janela de Contexto Máxima” (MCW) relatada, e que a MECW varia com o tipo de problema, revelando as limitações reais de LLMs ao lidar com contexto longo. O ataque Bias-Inversion Rewriting Attack (BIRA) pode teoricamente contornar efetivamente as marcas d’água de LLM, suprimindo os logits dos tokens que poderiam ser marcados, alcançando uma taxa de evasão superior a 99% enquanto mantém o conteúdo semântico, destacando a fragilidade das tecnologias de marca d’água.
(Fonte: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NandoDF, NandoDF, BlackHC, BlackHC, teortaxesTex, HuggingFace Daily Papers, HuggingFace Daily Papers)
Análise aprofundada de algoritmos de Aprendizagem por Reforço (RL) : Uma análise detalhada dos fluxos de trabalho, prós e contras, e cenários de aplicação dos três algoritmos de aprendizagem por reforço mainstream: PPO, GRPO e REINFORCE. O PPO é amplamente utilizado no campo da AI devido à sua estabilidade, o GRPO devido ao seu mecanismo de recompensa relativa, e o REINFORCE como algoritmo fundamental. Pesquisas mostram que a aprendizagem por reforço pode treinar modelos para combinar habilidades atômicas e generalizar em profundidade combinatória, indicando o potencial do RL na aprendizagem de novas habilidades. Descobriu-se que mais da metade das melhorias de desempenho nos pipelines de RL não vêm de melhorias relacionadas a ML, mas sim de otimizações de engenharia como o multithreading. Discute-se a questão da quantidade de informação em cada episódio no treinamento de RL, bem como a equivalência de informação de diferentes trajetórias sob a mesma recompensa final. A comunidade debate a definição e eficácia do pré-treinamento de RL, apontando problemas que podem surgir da síntese forçada de diversidade e apelando para a atenção à degradação da coerência. Para robôs humanoides de cinco dedos e dois braços, o ajuste fino de estratégias de clonagem de comportamento através da aprendizagem por reforço off-policy residual (ROSA) melhorou significativamente a eficiência de amostra, permitindo o ajuste fino de políticas diretamente no hardware.
(Fonte: TheTuringPost, teortaxesTex, menhguin, finbarrtimbers, arohan, tokenbender, pabbeel)
Cientistas de AI e descoberta científica : DeepScientist é um sistema de descoberta científica orientado a objetivos e totalmente autônomo que impulsiona descobertas científicas de ponta ao longo de meses, através de otimização Bayesiana e um processo de avaliação hierárquica. O sistema já superou os métodos SOTA humanos em três tarefas de AI de ponta e disponibilizou em código aberto todos os logs de experimentos e o código do sistema. A OpenAI está contratando cientistas pesquisadores com o objetivo de construir a próxima geração de instrumentos científicos – uma plataforma impulsionada por AI para acelerar a descoberta científica.
(Fonte: HuggingFace Daily Papers, mcleavey)
Técnicas de Fine-tuning e Otimização de LLM : Pesquisas mostram que o LoRA pode igualar completamente o desempenho de aprendizagem do fine-tuning completo (FullFT) em aprendizagem por reforço, sendo suficiente para absorver informações do treinamento de RL mesmo em condições de baixo rank. A estrutura Quadrant-based Tuning (Q-Tuning) melhora significativamente a eficiência de dados no fine-tuning supervisionado (SFT) através da poda conjunta de amostras e Tokens, superando até mesmo o treinamento com dados completos em alguns casos. O otimizador Muon supera consistentemente o Adam no treinamento de LLM, especialmente na aprendizagem de memória associativa de cauda, resolvendo as diferenças de aprendizagem do Adam em dados com classes desequilibradas através de um espectro singular mais isotrópico e otimização eficaz para dados de cauda pesada. Uma pesquisa sobre a estimativa assintótica do RMS dos pesos no otimizador AdamW foi realizada. Uma análise aprofundada do funcionamento do kernel CUDA do Flash Attention 4 revelou suas inovações em pipeline assíncrono, softmax de software (aproximação cúbica) e reescalonamento eficiente, explicando seu desempenho mais rápido que o cuDNN.
(Fonte: ImazAngel, karinanguyen_, NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex, bigeagle_xd, cloneofsimo, Tim_Dettmers, Reddit r/MachineLearning)
Recursos de aprendizagem e ferramentas de pesquisa em AI : Foram compartilhados slides de AI multimodal cobrindo tendências, modelos de código aberto, ferramentas de personalização/implantação e recursos adicionais. Foram anunciadas conferências como AI Engineer Europe 2026 e AI Engineer Paris, oferecendo uma plataforma para engenheiros de AI. A série “Let’s build GPT” de Karpathy e o artigo Qwen foram recomendados, enfatizando a importância de dados de treinamento CTF de alta qualidade e recursos computacionais para o treinamento de LLM. Discutiu-se o potencial do otimizador DSPyOSS para otimização “em camadas” em casos de uso de AI B2B, a fim de lidar com a escassez de dados. A Axiom Math AI visa construir um raciocinador superinteligente autoaperfeiçoável, começando com matemáticos de AI, para avançar no campo da matemática formalizada. Pesquisas exploram a aplicação de modelos de linguagem de regressão na geração e compreensão de código. Há um debate sobre se a aprendizagem por reforço é suficiente para alcançar a AGI. Discute-se o inventor da Aprendizagem Residual Profunda (Deep Residual Learning) e sua linha do tempo de evolução. Jürgen Schmidhuber, em 2016, explicou a consciência artificial, modelos de mundo, codificação preditiva e a ciência como compressão de dados, destacando suas contribuições iniciais no campo da AI. Uma análise exploratória das práticas de colaboração aberta, motivações e governança de 14 projetos de modelos de linguagem grandes de código aberto revelou a diversidade e os desafios do ecossistema de LLM de código aberto. O Dragon Hatchling (BDH) é uma arquitetura de LLM baseada em redes cerebrais, projetada para conectar Transformer com modelos cerebrais, alcançando interpretabilidade e desempenho semelhante ao Transformer. A estrutura d^2Cache, através de um cache duplo adaptativo, melhora significativamente a eficiência de inferência e a qualidade de geração de modelos de linguagem de difusão (dLLMs). A estrutura TimeTic estima a transferibilidade de modelos de fundação de séries temporais (TSFMs) através de aprendizagem contextual, para selecionar eficientemente o melhor modelo para fine-tuning downstream. Codificadores de fundação visual podem atuar como tokenizers para modelos de difusão latente (LDM), gerando espaços latentes semanticamente ricos e melhorando o desempenho de geração de imagem. O NVFP4 é um novo formato de pré-treinamento de 4 bits que, através de escalonamento de dois níveis, RHT e arredondamento estocástico, promete uma melhoria de eficiência de 6.8 vezes, enquanto iguala o desempenho de linha de base FP8. O DA^2 (Depth Anything in Any Direction) é um estimador de profundidade panorâmica preciso, com generalização zero-shot e end-to-end que, através de dados de treinamento em larga escala e arquitetura SphereViT, alcança SOTA em estimativa de profundidade panorâmica. O modelo SAGANet, ao utilizar máscaras de segmentação visual, vídeos e pistas de texto, realiza geração de áudio controlável e em nível de objeto, oferecendo controle preciso para fluxos de trabalho Foley profissionais. Mem-α é uma estrutura de aprendizagem por reforço que, ao treinar agentes para gerenciar eficazmente sistemas de memória externos complexos, resolve problemas de construção de memória e perda de informação em agentes LLM na compreensão de texto longo, e demonstra capacidade de generalização para sequências ultralongas. A estrutura EntroPE (Entropy-Guided Dynamic Patch Encoder) detecta dinamicamente pontos de transição em séries temporais através de entropia condicional e posiciona limites de patch para preservar a estrutura temporal, melhorando a precisão e eficiência da previsão. O BUILD-BENCH é um benchmark mais desafiador para avaliar a capacidade de agentes LLM em compilar software de código aberto do mundo real, e propõe o OSS-BUILD-AGENT como uma linha de base forte. O ProfVLM é um modelo de vídeo-linguagem leve que, através de inferência generativa, prevê conjuntamente níveis de habilidade e gera feedback de especialistas a partir de vídeos de perspectiva egocêntrica e externa. Discute-se a eficácia do treinamento em tempo de teste (TTT) em modelos de fundação, argumentando que o TTT, ao se especializar em tarefas de teste, pode reduzir significativamente o erro de teste in-distribution. O CST é uma nova arquitetura de rede neural para processar conjuntos de imagens de cardinalidade arbitrária, operando diretamente em tensores de imagem 3D, realizando extração de características e modelagem de contexto simultaneamente, e apresentando excelente desempenho em tarefas como classificação de conjuntos e detecção de anomalias. A estrutura TTT3R trata a reconstrução 3D como um problema de aprendizagem online, derivando a taxa de aprendizado a partir de estados de memória e confiança de alinhamento de observação, o que melhora significativamente a capacidade de generalização de sequências longas.
(Fonte: tonywu_71, swyx, Reddit r/deeplearning, lateinteraction, teortaxesTex, shishirpatil_, bengoertzel, arankomatsuzaki, francoisfleuret, _akhaliq, steph_palazzolo, HuggingFace Daily Papers, SchmidhuberAI, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NerdyRodent, QuixiAI, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning)
Detecção de falsificações percebidas por humanos na geração de vídeo por AI : DeeptraceReward é o primeiro conjunto de dados de benchmark de detecção de falsificações em vídeo gerado por AI, com granularidade fina e percepção espaço-temporal, usado para anotar traços de falsificação percebidos por humanos em vídeos gerados. Este conjunto de dados contém 4,3 mil anotações detalhadas em 3,3 mil vídeos gerados de alta qualidade, e as integra em 9 categorias principais de traços de falsificação. A pesquisa treinou modelos de linguagem multimodais como modelos de recompensa para imitar o julgamento e a localização humanos, superando o GPT-5 na identificação, localização e explicação de pistas de falsificação.
(Fonte: HuggingFace Daily Papers)
Purificação Adversária e Reconstrução de Cenários 3D : MANI-Pure é uma estrutura de purificação adaptativa por amplitude que, ao utilizar o espectro de amplitude do sinal de entrada para guiar o processo de purificação, injeta adaptativamente ruído heterogêneo e direcionado por frequência, suprimindo eficazmente perturbações de alta frequência enquanto preserva o conteúdo de baixa frequência semanticamente crítico, alcançando desempenho SOTA em defesa adversária. A Nvidia lançou o modelo Lyra, que realiza reconstrução generativa de cenários 3D através de autodestilação de modelos de difusão de vídeo, sendo capaz de gerar cenários 3D e 4D feedforward a partir de uma única imagem/vídeo.
(Fonte: HuggingFace Daily Papers, _akhaliq)
💼 Negócios
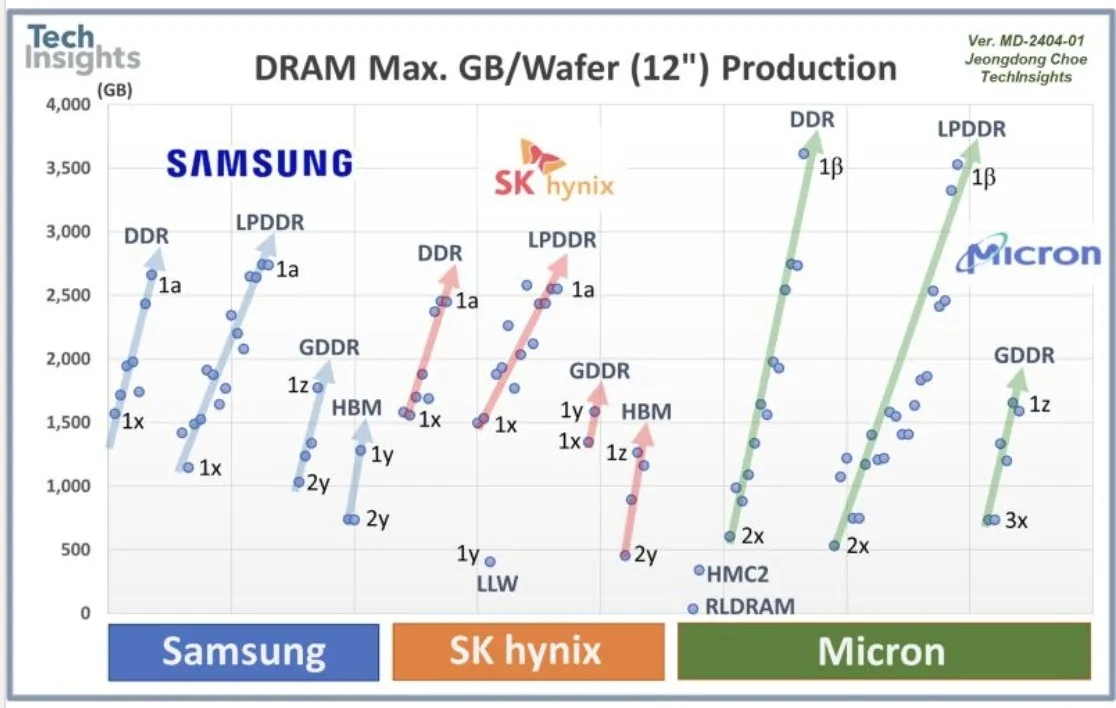
Colaboração da OpenAI com a Samsung e demanda por DRAM : A OpenAI está colaborando com a Samsung para desenvolver o chip “Stargate” e prevê a necessidade de 900 mil wafers DRAM de alto desempenho por mês. Isso indica planos e investimentos massivos em infraestrutura de AI, superando em muito as expectativas atuais da indústria. Essa enorme demanda gerou discussões sobre os custos de computação de AI e o superciclo da memória.
(Fonte: bookwormengr, teortaxesTex, francoisfleuret)
Financiamento de Startups de AI e Cenário da Indústria : A Axiom Math AI lançou um raciocinador superinteligente autoaperfeiçoável, começando com matemáticos de AI, atraindo a atenção da indústria. A Modal concluiu uma rodada de financiamento Série B de US$ 87 milhões, avaliada em US$ 1,1 bilhão, com o objetivo de impulsionar o futuro da infraestrutura de computação de AI. A OffDeal concluiu uma rodada de financiamento Série A de US$ 12 milhões, dedicada a construir o primeiro banco de investimento nativo de AI do mundo. O Ministro da Defesa do Japão visitou o escritório da Sakana AI, indicando uma potencial colaboração da AI no setor de defesa. Um desenvolvedor compartilhou a dificuldade de ficar sem fundos após gastar US$ 3.000 na construção de modelos LLM de código aberto, o que gerou discussões na comunidade sobre a sustentabilidade de projetos de AI de código aberto. Os desenvolvedores de AI do Google anunciaram os vencedores do Nano Banana Hackathon, distribuindo mais de US$ 400.000 em prêmios, com o objetivo de incentivar a inovação em aplicações de AI.
(Fonte: shishirpatil_, bengoertzel, lupantech, arankomatsuzaki, francoisfleuret, akshat_b, leveredvlad, SakanaAILabs, hardmaru, Reddit r/LocalLLaMA, osanseviero)
🌟 Comunidade
Sora 2: Impacto Social e Controvérsias : O lançamento do Sora 2 gerou um amplo impacto social e controvérsias. Muitos usuários temem a proliferação de “slop” (conteúdo de baixa qualidade e sem sentido) em vídeos gerados por AI, questionando se as prioridades da OpenAI são entretenimento em vez de resolver grandes problemas como o câncer. Ao mesmo tempo, há preocupações de que o hiper-realismo do Sora 2 possa tornar os vídeos indistinguíveis do real, ou mesmo ser usado maliciosamente para gerar desinformação ou conteúdo prejudicial, como “armas biológicas”. O próprio CEO da OpenAI, Sam Altman, tornou-se protagonista de memes gerados por AI, e ele declarou que isso “não é tão estranho”, explicando que o foco da OpenAI continua sendo a AGI e a descoberta científica, e que o lançamento de produtos visa atender às necessidades de financiamento. A poderosa capacidade do Sora 2 mais uma vez destacou a enorme demanda por GPUs, provocando discussões sobre os altos custos da AI, com alguns até comparando os custos da AI com os custos de construção do sistema de rodovias interestaduais dos EUA. Alguns comentários sugerem que a estratégia de lançamento do Sora 2 foi “comum” demais, carecendo de benchmarks e suporte a usuários profissionais, além de impor limites para o conteúdo gerado por usuários gratuitos.
(Fonte: teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
Experiência do Usuário e Controvérsias do Claude Sonnet 4.5 : Os usuários geralmente consideram que o Sonnet 4.5 apresenta melhorias significativas na retenção de informações, julgamento, tomada de decisões e escrita criativa, exibindo até mesmo “mudanças de atitude” semelhantes às humanas, como tornar-se mais profissional após descobrir o contexto do usuário, ou corrigir o usuário quando este “fala disparates”. Embora tenha se destacado em alguns aspectos, ainda há usuários que criticam a baixa qualidade na geração de código, com “erros descuidados e tolos”, e até mesmo o problema de o diálogo ser “muito longo” e incapaz de gerar código em conversas extensas, sugerindo que ainda está longe de substituir engenheiros de software humanos. Além disso, alguns usuários conseguiram fazer “jailbreak” no Sonnet 4.5, fazendo-o gerar receitas perigosas e código de malware, levantando sérias preocupações sobre as salvaguardas de segurança do modelo.
(Fonte: teortaxesTex, doodlestein, genmon, aiamblichus, QuixiAI, suchenzang, karminski3, aiamblichus, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
O Futuro das Linguagens de Programação na Era da AI e o Declínio da Cultura Comunitária : O ranking de linguagens de programação IEEE Spectrum 2025 mostra que o Python manteve sua posição como a linguagem mais popular por dez anos consecutivos, ocupando o primeiro lugar em ranking geral, velocidade de crescimento e orientação para o emprego, com suas vantagens sendo ainda mais amplificadas na era da AI. O JavaScript teve uma queda significativa no ranking, enquanto a posição do SQL, embora impactada, ainda mantém seu valor. O relatório aponta que a AI está acabando com a diversidade das linguagens de programação, o efeito Mateus das linguagens mainstream se intensifica, e as linguagens não-mainstream serão marginalizadas. Ao mesmo tempo, a cultura da comunidade de programadores está em declínio, com os desenvolvedores preferindo buscar ajuda em grandes modelos em vez de fazer perguntas na comunidade, o que mudou as formas de aprendizagem e trabalho, levantando discussões sobre o futuro papel dos programadores e a importância das competências essenciais de design de arquitetura de baixo nível.
(Fonte: 量子位, jimmykoppel, jimmykoppel, lateinteraction, kylebrussell, Reddit r/ArtificialInteligence)

Bolha da AI e Perspectivas de Desenvolvimento da Indústria : Nas redes sociais, discute-se se existe uma bolha na indústria de AI. Alguns argumentam que, embora o entusiasmo de investimento seja elevado e possa haver alguns projetos “tolos”, os fundamentos da indústria permanecem fortes, e a adoção de AI pelas empresas cresce de forma constante. Ao mesmo tempo, há vozes que apontam que os enormes custos de computação de AI e a vasta demanda da OpenAI por DRAM indicam que a indústria ainda está em rápida expansão, longe de atingir o estágio de estouro da bolha, mas a entrada de capital também exige cautela.
(Fonte: arohan, pmddomingos, teortaxesTex, teortaxesTex, ajeya_cotra)
💡 Outros
Robôs Humanoides e Dispositivos Assistidos por AI : A empresa chinesa de robótica LimX Dynamics demonstrou as capacidades de movimento autônomo, flexão e arremesso de seu robô humanoide Oli, sem a necessidade de captura de movimento ou operação remota, indicando que a China atingiu um nível comparável ao da Figure/1X/Tesla no campo de robôs humanoides. A Neural Band da Meta, que lê sinais neurais via EMG, combinada com os óculos de exibição Meta Rayban, promete oferecer um método de controle revolucionário para amputados, permitindo o controle síncrono de próteses e interfaces digitais, e podendo se tornar um controlador universal mãos-livres. Além disso, a AI e a robótica têm aplicações diversificadas no aprimoramento da mobilidade, exploração e resgate, como exoesqueletos robóticos elétricos, insetos robóticos controlados sem fio, robôs quadrúpedes e cobras robóticas para missões de resgate.
(Fonte: Ronald_vanLoon, teortaxesTex, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Reddit r/ArtificialInteligence)
Aplicações de AI na Edição de Imagens e Design Gráfico : LayerD é um método para decompor designs gráficos rasterizados em camadas, visando fluxos de trabalho criativos reeditáveis. Ele extrai iterativamente camadas de primeiro plano desobstruídas e utiliza a suposição de que as camadas geralmente exibem uma aparência unificada para refinamento, alcançando assim uma decomposição de alta qualidade. GeoRemover propõe uma estrutura de duas fases com percepção geométrica para remover objetos de imagens e seus artefatos visuais causais (como sombras e reflexos), desacoplando a remoção geométrica e a renderização da aparência, e introduzindo objetivos orientados por preferência para guiar a aprendizagem.
(Fonte: HuggingFace Daily Papers, HuggingFace Daily Papers)