
Palavras-chave:Anthropic Claude Sonnet 4.5, DeepSeek-V3.2-Exp, OpenAI ChatGPT, Modelos de IA, Inteligência Artificial, Modelos de Linguagem de Grande Escala (LLM), Programação com IA, Agentes Inteligentes de IA, Capacidade de programação do Claude Sonnet 4.5, Mecanismo de Atenção Esparsa DSA, Funcionalidade de checkout instantâneo do ChatGPT, Aplicativo social Sora 2, Técnica de ajuste fino LoRA
🔥 Foco
Anthropic Claude Sonnet 4.5 lançado, com capacidades de programação e agente significativamente aprimoradas : A Anthropic lançou oficialmente o Claude Sonnet 4.5, aclamado como o modelo de programação mais poderoso do mundo, e alcançou avanços notáveis na construção de agentes, uso de computador, raciocínio e capacidades matemáticas. O modelo pode trabalhar de forma autônoma e contínua por mais de 30 horas, alcançou o topo no teste SWE-bench Verified e quebrou recordes no benchmark de tarefas de computador OSWorld. Novas funcionalidades incluem o recurso de “checkpoint” de reversão do Claude Code, o plugin VS Code, e ferramentas de edição de contexto e memória para a API. Além disso, foi lançada a funcionalidade experimental “Imagine with Claude”, que gera interfaces de software em tempo real. O Sonnet 4.5 também melhorou significativamente a segurança, reduzindo comportamentos indesejados como engano e bajulação, e obteve a certificação AI Safety Level 3 (ASL-3), com uma taxa de falsos positivos 10 vezes menor. O preço permanece o mesmo do Sonnet 4, aumentando ainda mais a relação custo-benefício, e espera-se que desencadeie uma nova rodada de concorrência em programação de IA. (Fonte: Reddit r/ClaudeAI, 36氪, 36氪, 36氪, 36氪, 36氪, Reddit r/ChatGPT, dotey, dotey, dotey)

DeepSeek-V3.2-Exp lançado, introduzindo o mecanismo de atenção esparsa DSA e redução de preço : A DeepSeek lançou o modelo experimental V3.2-Exp, que introduz o mecanismo de atenção esparsa DeepSeek Sparse Attention (DSA), melhorando significativamente a eficiência de treinamento e inferência de longo contexto, enquanto o preço da API foi reduzido em mais de 50%. O DSA identifica eficientemente Tokens chave para cálculos precisos através do “indexador relâmpago”, reduzindo a complexidade da atenção de O(L²) para O(Lk). Fabricantes chineses de chips de IA como Huawei Ascend, Cambricon e Hygon Information já alcançaram a adaptação Day 0, impulsionando ainda mais o desenvolvimento do ecossistema de poder computacional doméstico. O modelo também open-sourceou operadores de GPU na versão TileLang, comparáveis ao NVIDIA CUDA, facilitando o desenvolvimento de protótipos e depuração para desenvolvedores. Embora tenha havido concessões em algumas capacidades, sua inovação arquitetônica e eficiência de custo apontam uma nova direção para o processamento de texto longo em modelos grandes. (Fonte: 36氪, 36氪, 36氪, 量子位, 量子位, 量子位, Reddit r/LocalLLaMA, Twitter)

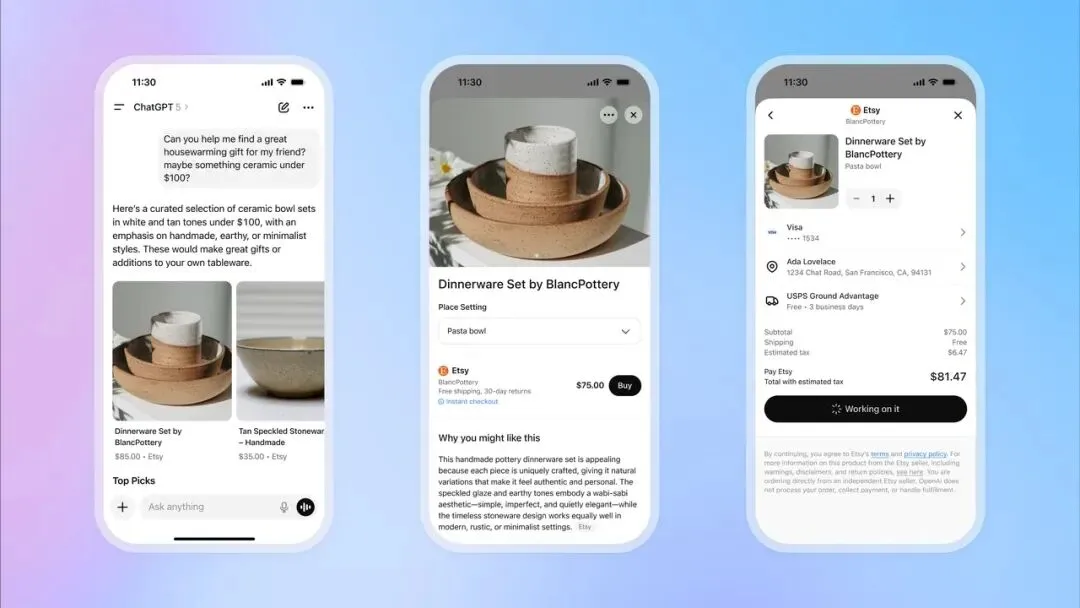
OpenAI lança recurso de checkout instantâneo no ChatGPT, entrando no setor de e-commerce : A OpenAI lançou o recurso “Instant Checkout” no ChatGPT, permitindo que os usuários comprem produtos diretamente das plataformas Etsy e Shopify dentro da conversa, sem precisar sair para sites externos. Este recurso é baseado no “Agentic Commerce Protocol”, desenvolvido em colaboração entre OpenAI e Stripe, e foi open-sourceado, visando converter o vasto tráfego do ChatGPT em transações comerciais. Inicialmente, suporta o mercado dos EUA, com planos futuros de expansão para carrinhos de compras com múltiplos produtos e mais regiões. Este movimento é visto como um grande passo na comercialização da OpenAI, com potencial para se tornar uma importante fonte de receita e ter um impacto profundo nos setores tradicionais de e-commerce e publicidade. (Fonte: 36氪, 36氪, Reddit r/artificial, Reddit r/artificial, Twitter, Twitter, Twitter, Twitter)
OpenAI prepara lançamento de aplicativo social Sora 2, criando plataforma de vídeos curtos de IA : A OpenAI está se preparando para lançar um aplicativo social independente, impulsionado por seu mais recente modelo de vídeo, Sora 2. O aplicativo é altamente semelhante ao TikTok em design, utilizando um feed de vídeo vertical e navegação por deslizamento, mas todo o conteúdo é gerado por IA. Os usuários podem gerar clipes de vídeo de até 10 segundos e usar suas próprias imagens nos vídeos através de um recurso de autenticação de identidade. Esta iniciativa visa replicar o sucesso do ChatGPT no domínio do texto, permitindo que o público experimente intuitivamente o potencial do vídeo de IA e entre diretamente na corrida competitiva com Meta e Google. No entanto, a OpenAI adotou uma estratégia de “uso padrão de conteúdo protegido por direitos autorais, a menos que o detentor dos direitos opte por sair”, o que gerou forte preocupação entre criadores de conteúdo e empresas de cinema e televisão, prenunciando uma intensa disputa entre IA e propriedade intelectual. (Fonte: 36氪, Reddit r/artificial, Twitter, Twitter)

🎯 Tendências
Modelo Huawei Pangu 718B ocupa o segundo lugar open-source na lista de modelos grandes chineses SuperCLUE : O modelo Huawei openPangu-Ultra-MoE-718B ficou em segundo lugar na lista open-source do benchmark geral de modelos grandes chineses SuperCLUE. O modelo adota a filosofia de treinamento “não se basear em grandes volumes de dados, mas em saber pensar”, construindo conhecimento mundial amplo e aprimorando as capacidades de raciocínio lógico através de princípios de construção de dados “qualidade prioritária, cobertura de diversidade, adaptação à complexidade” e uma estratégia de pré-treinamento em três estágios: geral, inferência e annealing. Para mitigar o problema da alucinação, foi introduzido um mecanismo de “internalização crítica”; para melhorar as capacidades de uso de ferramentas, foi utilizada uma estrutura ToolACE atualizada. (Fonte: 量子位)

FSDrive unifica VLA e World Model, impulsionando a condução autônoma para o raciocínio visual : O FSDrive (FutureSightDrive) propõe um “CoT visual espaço-temporal” que, através de quadros de imagem futuros unificados como etapas de raciocínio intermediárias, combina cenários futuros com resultados de percepção para raciocínio visual, impulsionando assim a condução autônoma do raciocínio simbólico para o raciocínio visual. Este método, sem modificar a arquitetura MLLM existente, ativa a capacidade de geração de imagens através da expansão do vocabulário e da geração visual autorregressiva, e injeta priors físicos com um CoT visual progressivo. O modelo atua tanto como “World Model” para prever o futuro quanto como “Inverse Dynamics Model” para planejamento de trajetória. (Fonte: 36氪)

GPT-5 fornece ideias cruciais para computação quântica, elogiado pelo especialista Scott Aaronson : O renomado teórico da computação quântica Scott Aaronson revelou que o GPT-5 forneceu ideias cruciais para a prova de sua pesquisa em teoria da complexidade quântica em menos de meia hora, resolvendo um problema que afligia a equipe. Scott Aaronson afirmou que o GPT-5 fez progressos significativos na superação das atividades intelectuais mais humanas, marcando um “momento doce” na colaboração entre humanos e IA, capaz de fornecer inspirações inovadoras aos pesquisadores em momentos críticos. (Fonte: 量子位, Twitter)

HuggingFace acelera a inferência do modelo Qwen3-8B Agent em Intel Core Ultra : A HuggingFace, em colaboração com a Intel, conseguiu acelerar a inferência do modelo Qwen3-8B Agent em GPUs integradas Intel Core Ultra em 1,4 vezes, utilizando OpenVINO.GenAI e um modelo rascunho Qwen3-0.6B com poda de profundidade (depth-pruned). Esta otimização torna a execução de aplicações Agent com Qwen3-8B em PCs com IA mais eficiente, especialmente para fluxos de trabalho complexos que exigem raciocínio multi-etapas e chamadas de ferramentas, impulsionando ainda mais a praticidade dos AI Agents locais. (Fonte: HuggingFace Blog)

Robô Reachy Mini integra GPT-4o, alcançando interação multimodal : O robô Reachy Mini da Hugging Face / Pollen Robotics integrou com sucesso o modelo GPT-4o da OpenAI, alcançando uma melhoria significativa nas capacidades de interação multimodal. Novas funcionalidades incluem análise de imagem (o robô pode descrever e raciocinar sobre fotos tiradas), rastreamento facial (mantendo contato visual), fusão de movimento (movimento da cabeça, rastreamento facial, emoção/dança funcionando simultaneamente), reconhecimento facial local e comportamento autônomo em inatividade. Esses avanços tornam a interação humano-máquina mais natural e fluida, mas ainda enfrentam desafios como sistemas de memória, reconhecimento de voz e estratégias para multidões complexas. (Fonte: Reddit r/ChatGPT, Twitter)

Intel lança nova versão Beta do LLM Scaler, com suporte para GenAI em GPUs Battlemage : A Intel lançou a nova versão Beta do LLM Scaler, projetada para otimizar o desempenho da IA generativa (GenAI) nas GPUs Battlemage. Este movimento sinaliza o investimento contínuo da Intel em hardware e ecossistemas de software de IA para aumentar a competitividade de suas GPUs em tarefas de inferência e geração de modelos de linguagem grandes. (Fonte: Reddit r/artificial)
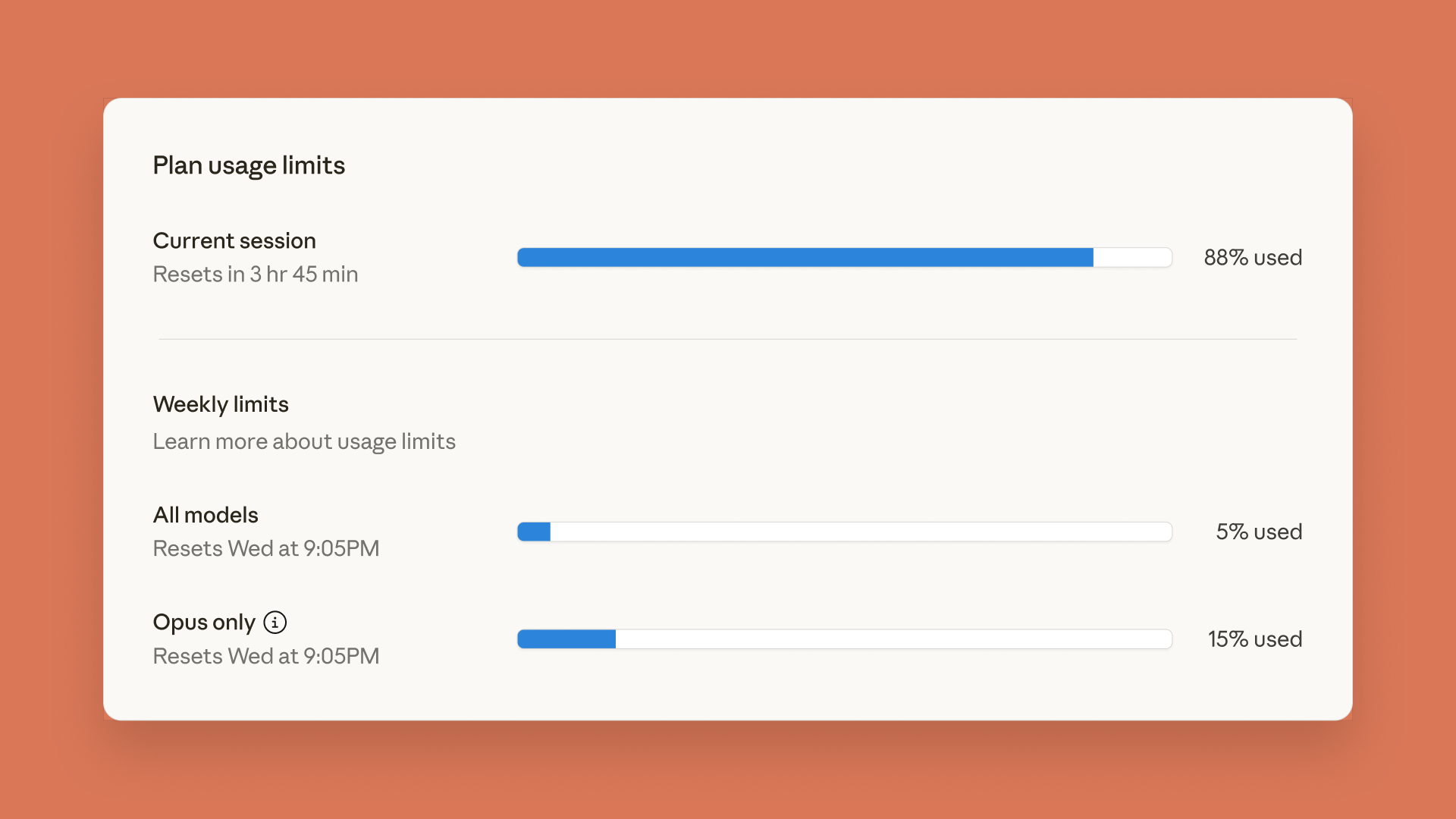
Claude lança painel de limites de uso, ChatGPT introduz função de controle parental : A Anthropic lançou um painel de limites de uso em tempo real para Claude Code e Claude App, permitindo que os usuários rastreiem seu consumo de Token para gerenciar os limites de taxa semanais previamente anunciados. Simultaneamente, a OpenAI introduziu o recurso de controle parental no ChatGPT, permitindo que os pais associem contas de adolescentes, fornecendo automaticamente proteções de segurança mais fortes e a capacidade de ajustar funcionalidades e definir limites de uso, embora os pais não possam visualizar o conteúdo específico das conversas. (Fonte: Reddit r/ClaudeAI, 36氪)
Modelo de linguagem de 5 milhões de parâmetros rodando em Minecraft, demonstrando aplicação inovadora de IA : Sammyuri construiu um complexo sistema de Redstone no Minecraft, executando com sucesso um modelo de linguagem com aproximadamente 5 milhões de parâmetros e concedendo-lhe capacidades básicas de conversação. Este resultado inovador demonstra a possibilidade de implementar IA localmente em ambientes de jogos e gerou ampla atenção e discussão na comunidade sobre aplicações de IA em plataformas não tradicionais. (Fonte: Reddit r/LocalLLaMA, Twitter)
Servidor de IA da Inspur Information atinge velocidade de inferência de 8,9ms, custo de 1 yuan por milhão de Tokens : A Inspur Information lançou os servidores de IA ultra-escaláveis Yuanbrain HC1000 e os supernós Yuanbrain SD200, elevando a velocidade de inferência de IA a um novo recorde. O Yuanbrain SD200 alcançou um tempo de saída por Token (TPOT) de 8,9ms no modelo DeepSeek-R1, quase o dobro do SOTA anterior, e suporta inferência de modelos grandes com trilhões de parâmetros e colaboração em tempo real de múltiplos agentes. O Yuanbrain HC1000, por sua vez, reduziu o custo de saída por milhão de Tokens para 1 yuan, e o custo por placa em 60%. Esses avanços visam resolver os gargalos de velocidade e custo enfrentados pela industrialização de agentes, fornecendo infraestrutura de poder computacional eficiente e de baixo custo para a implementação em larga escala de colaboração multi-agente e inferência de tarefas complexas. (Fonte: 量子位)

Novo método de Splatting Gaussiano 3D feedforward: Equipe da Universidade de Zhejiang propõe “alinhamento de voxel” : A equipe da Universidade de Zhejiang propôs o VolSplat, uma estrutura de 3D Gaussian Splatting (3DGS) feedforward “voxel-aligned”, visando resolver os gargalos de consistência geométrica e alocação de densidade gaussiana em reconstruções 3D multi-view de métodos “pixel-aligned” existentes. O VolSplat, ao fundir informações 2D multi-view no espaço 3D e refinar características usando uma Sparse 3D U-Net, alcança reconstruções 3D de maior qualidade, mais robustas e eficientes. O método superou várias linhas de base em conjuntos de dados públicos e demonstrou forte capacidade de generalização zero-shot em conjuntos de dados não vistos. (Fonte: 量子位)

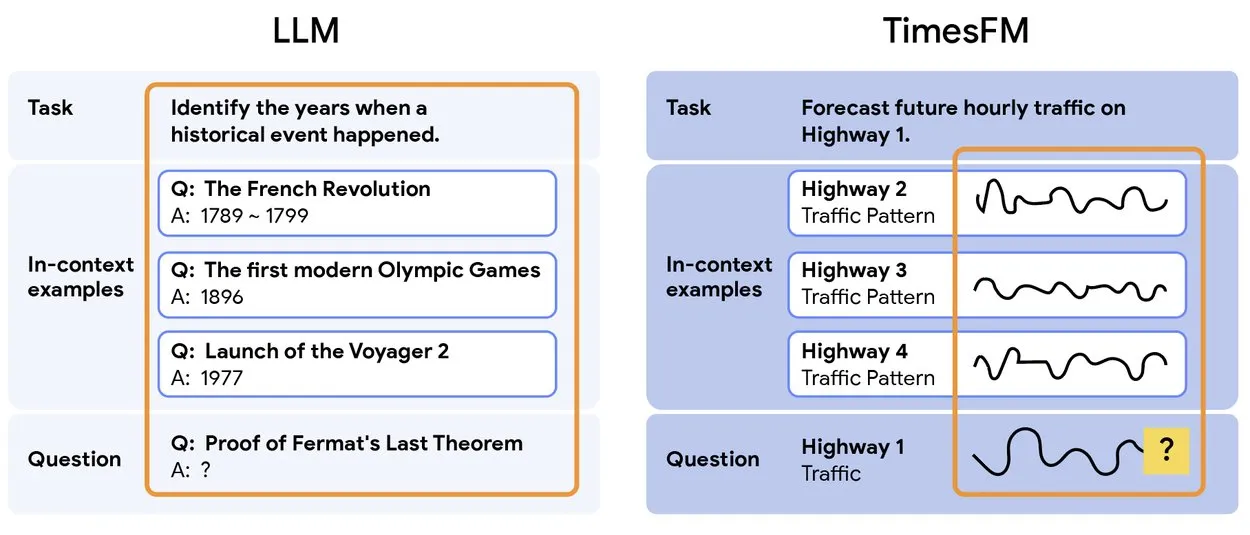
TimesFM 2.5: Lançado modelo pré-treinado de previsão de séries temporais : O TimesFM 2.5 foi lançado, um modelo pré-treinado para previsão de séries temporais, com o número de parâmetros reduzido de 500M para 200M, e o comprimento do contexto aumentado de 2K para 16K, apresentando excelente desempenho em configurações zero-shot. O modelo já está disponível no Hugging Face e adota a licença Apache 2.0, fornecendo uma solução mais eficiente e poderosa para tarefas de previsão de séries temporais. (Fonte: Twitter)
Yunpeng Technology lança novos produtos AI+Saúde, impulsionando a aplicação de IA na saúde familiar : A Yunpeng Technology, em colaboração com a Shuaikang e a Skyworth, lançou o “Laboratório de Cozinha Futura Digital e Inteligente” e uma geladeira inteligente equipada com um modelo grande de IA para saúde. O modelo grande de IA para saúde otimiza o design e a operação da cozinha, enquanto a geladeira inteligente, através do “Assistente de Saúde Xiaoyun”, oferece gerenciamento de saúde personalizado. Este lançamento marca um avanço da IA no campo do gerenciamento diário da saúde, com o potencial de fornecer serviços de saúde personalizados através de dispositivos inteligentes, elevando o nível da tecnologia de saúde familiar. (Fonte: 36氪)
Alibaba lança modelo de pensamento open-source de 1 trilhão de parâmetros Ring-1T-preview : A equipe Ant Ling da Alibaba lançou o primeiro modelo de pensamento open-source de 1 trilhão de parâmetros, Ring-1T-preview, visando alcançar “pensamento profundo, sem espera”. O modelo obteve excelentes resultados iniciais em tarefas de processamento de linguagem natural, incluindo benchmarks como AIME25, HMMT25, ARC-AGI-1, LCB e Codeforces. Além disso, resolveu o problema Q3 do IMO25 de uma só vez e forneceu soluções parciais para Q1/Q2/Q4/Q5, demonstrando suas poderosas capacidades de raciocínio e resolução de problemas. (Fonte: Twitter, Twitter, Twitter)

🧰 Ferramentas
PopAi lança “Slide Agent”, IA gera apresentações com um clique : A equipe PopAi lançou a ferramenta “Slide Agent”, projetada para simplificar o processo de criação de apresentações. Os usuários podem simplesmente inserir suas necessidades via Prompt, escolher entre mais de 300 modelos, e a IA gerará automaticamente um rascunho, ajustando o layout, gráficos, imagens, logotipos e outros formatos, finalmente baixando o arquivo .pptx editável. Esta ferramenta integra as funcionalidades do ChatGPT e do Canva, reduzindo significativamente a barreira e o tempo de criação de apresentações. (Fonte: Twitter)
Alibaba open-sourceia ferramenta de conversão de PDF para Markdown Miner U2.5 : A equipe Alibaba open-sourceou a ferramenta de conversão de PDF para Markdown Miner U2.5, e uma demonstração já está disponível no HuggingFace. Esta ferramenta pode converter eficientemente documentos PDF para o formato Markdown, facilitando a extração, edição e reutilização de conteúdo para desenvolvedores e pesquisadores que precisam lidar com um grande volume de documentos PDF, sendo uma ferramenta prática assistida por IA. (Fonte: dotey)
VEED Animate 2.2 lançado, com suporte para remodelação de estilo de vídeo e troca de personagens : A versão 2.2 do VEED Animate foi oficialmente lançada, com suporte da tecnologia WAN 2.2. Esta ferramenta permite aos usuários remodelar facilmente o estilo de um vídeo a partir de uma única imagem, trocar instantaneamente personagens em um vídeo e criar clipes de vídeo 10 vezes mais rápido. Essas novas funcionalidades simplificam enormemente o processo de criação de vídeo, oferecendo aos criadores de conteúdo mais possibilidades criativas impulsionadas por IA. (Fonte: TomLikesRobots)
LangChain foca na padronização de respostas LLM, suportando funcionalidades complexas : A LangChain, em seu desenvolvimento v1, está focando na padronização das respostas de LLM como um ponto central para lidar com as funcionalidades cada vez mais complexas de LLM, como chamadas de ferramentas do lado do servidor, inferência e referências. A estrutura visa resolver o problema de formatos de API incompatíveis entre diferentes provedores de LLM, fornecendo uma interface unificada para desenvolvedores, simplificando assim a construção de agentes multimodais e fluxos de trabalho complexos. (Fonte: LangChainAI, Twitter)
Hugging Face Transformers.js suporta execução offline de modelos de IA no navegador : A biblioteca Transformers.js da Hugging Face permite que os usuários executem modelos de IA offline no navegador, como o Llama 3.2, utilizando tecnologias ONNX e WebGPU. Isso permite que os desenvolvedores executem tarefas de IA como chatbots, detecção de objetos e remoção de fundo localmente, sem depender de serviços em nuvem, melhorando a privacidade dos dados e a velocidade de processamento. (Fonte: Twitter)
Ecossistema ToolUniverse auxilia cientistas de IA na construção e integração de ferramentas : ToolUniverse é um ecossistema projetado para construir cientistas de IA, que padroniza a forma como os cientistas de IA identificam e chamam ferramentas, integrando mais de 600 modelos de aprendizado de máquina, conjuntos de dados, APIs e pacotes científicos para análise de dados, recuperação de conhecimento e design experimental. A plataforma otimiza automaticamente as interfaces das ferramentas, cria novas ferramentas através de descrições em linguagem natural e itera na otimização das especificações das ferramentas, combinando-as em fluxos de trabalho de agentes, impulsionando assim a colaboração dos cientistas de IA no processo de descoberta. (Fonte: HuggingFace Daily Papers)
Estrutura EasySteer melhora o desempenho e a escalabilidade do controle de LLM : EasySteer é uma estrutura unificada baseada em vLLM, projetada para melhorar o desempenho e a escalabilidade do controle de LLM. Através de uma arquitetura modular, interfaces plugáveis, controle de parâmetros de granularidade fina e vetores de controle pré-calculados, alcança um aumento de velocidade de 5,5 a 11,4 vezes e reduz efetivamente o “overthinking” e as alucinações. O EasySteer transforma o controle de LLM de uma técnica de pesquisa em uma capacidade de nível de produção, fornecendo infraestrutura chave para modelos de linguagem implantáveis e controláveis. (Fonte: HuggingFace Daily Papers)
VibeGame: Motor de jogo assistido por IA baseado em WebStack : VibeGame é um motor de jogo declarativo avançado construído com three.js, rapier e bitecs, projetado especificamente para o desenvolvimento de jogos assistidos por IA. Através de um alto nível de abstração, funcionalidades de física e renderização integradas e uma arquitetura Entity-Component-System (ECS), permite que a IA compreenda e gere código de jogo de forma mais eficiente. Embora atualmente seja mais adequado para jogos de plataforma simples, seu código open-source e sintaxe amigável à IA oferecem uma solução promissora para o desenvolvimento de jogos impulsionados por IA. (Fonte: HuggingFace Blog)
Ferramenta de mapa de pesquisa de IA, integra 900 mil artigos fornecendo respostas com citações : Uma ferramenta inovadora de IA é capaz de agrupar semanticamente e visualizar 900 mil artigos de pesquisa de IA da última década, formando um mapa de pesquisa detalhado. Os usuários podem fazer perguntas à ferramenta e obter respostas com citações precisas, o que simplifica enormemente o processo de pesquisa e compreensão de vastas literaturas acadêmicas, aumentando a eficiência da pesquisa. (Fonte: Reddit r/ArtificialInteligence)
Kroko ASR: Alternativa rápida e streaming para Whisper : Kroko ASR é um novo modelo open-source de fala para texto, posicionado como uma alternativa rápida e streaming para Whisper. Possui um tamanho de modelo menor, velocidade de inferência de CPU mais rápida (suportando dispositivos móveis e navegadores) e quase nenhuma alucinação. O Kroko ASR suporta vários idiomas e visa reduzir a barreira de entrada para a IA de voz, tornando-a mais fácil de implantar e treinar em dispositivos de borda. (Fonte: Reddit r/LocalLLaMA)
Problema de renderização de gráficos Plotly no OpenWebUI, destacando desafios de integração de UI de ferramentas de IA : A versão v0.6.32 do OpenWebUI apresentou um problema onde os gráficos Plotly não eram renderizados corretamente, exibindo diretamente o JSON original. Usuários relataram que o backend retornava o JSON correto, mas o frontend não conseguia acionar a renderização, o que reflete os desafios técnicos que as ferramentas de IA ainda enfrentam na integração de UI de frontend e na renderização de rich text, exigindo otimização adicional da comunidade de desenvolvedores. (Fonte: Reddit r/OpenWebUI)
📚 Aprendizado
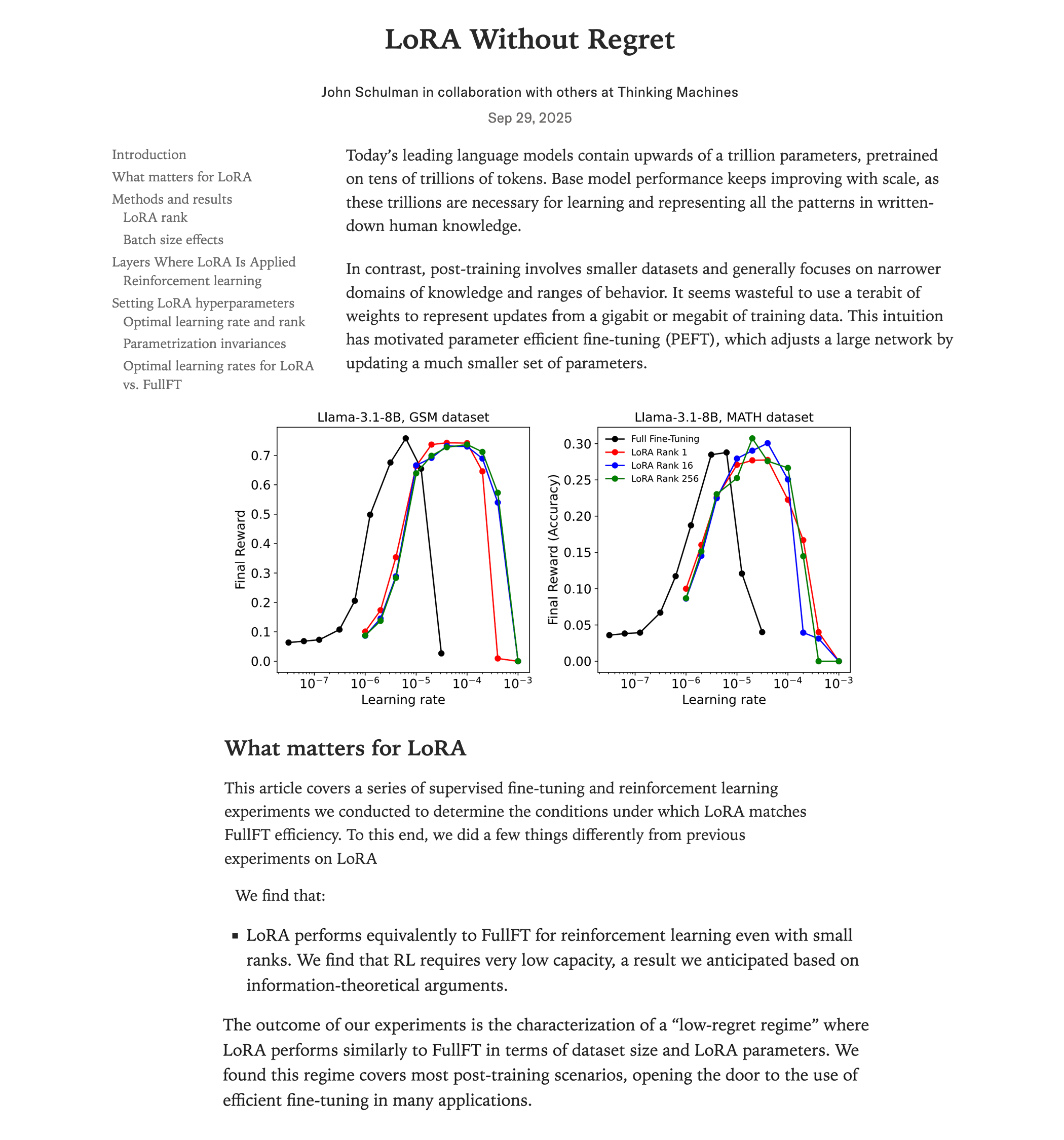
Estudo comparativo de desempenho entre LoRA fine-tuning e full fine-tuning : Uma pesquisa recente da Thinking Machines (equipe de John Schulman) mostra que, no aprendizado por reforço, se o LoRA (Low-Rank Adaptation) for aplicado corretamente, seu desempenho pode igualar o do full fine-tuning, com menor consumo de recursos (cerca de 2/3 da computação), e pode ter um bom desempenho mesmo com rank=1. O estudo enfatiza que o LoRA deve ser aplicado a todas as camadas (incluindo MLP/MoE) e usar uma taxa de aprendizado 10 vezes maior que a do full fine-tuning. Esta descoberta reduz drasticamente a barreira para treinar modelos RL de alto desempenho, permitindo que mais desenvolvedores alcancem modelos de alta qualidade em uma única GPU. (Fonte: Reddit r/LocalLLaMA, Twitter, Twitter)
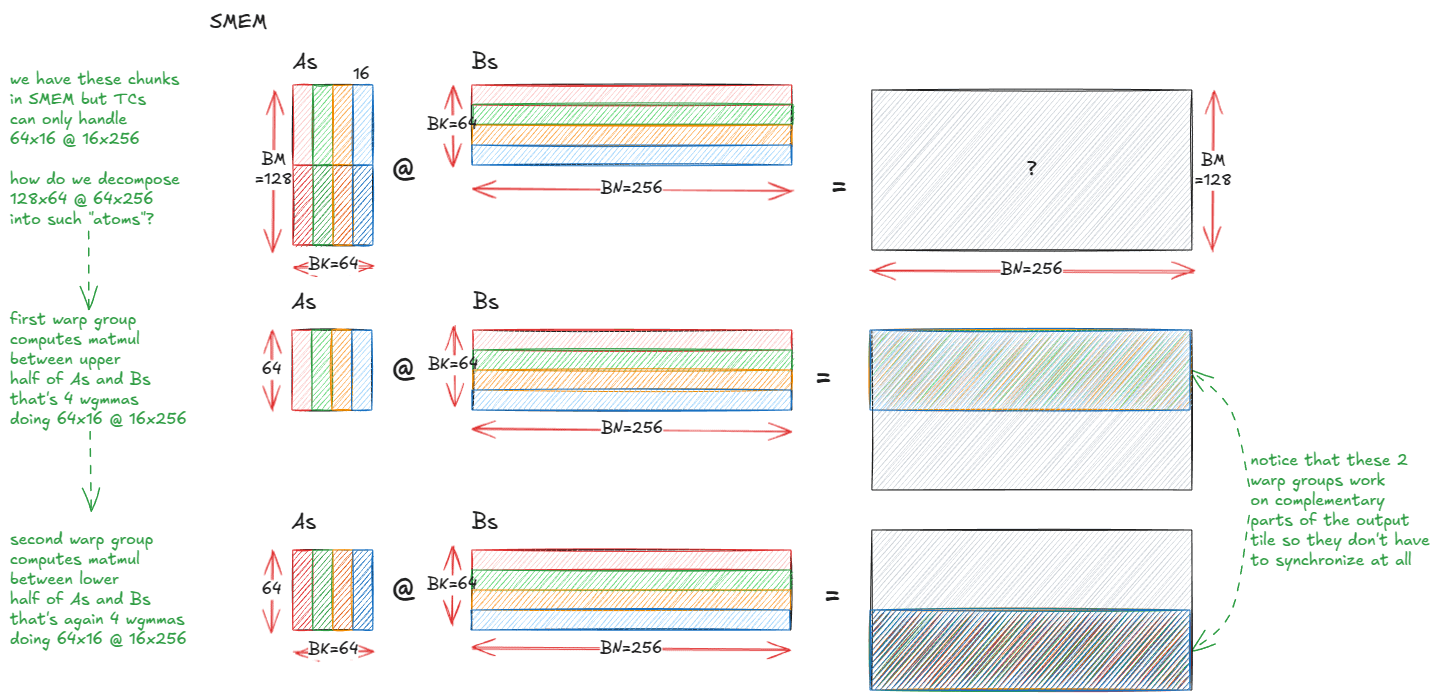
Anatomia de kernels de multiplicação de matrizes de alto desempenho em GPUs NVIDIA : Um blog técnico aprofundado detalha o mecanismo de implementação de kernels de multiplicação de matrizes (matmul) de alto desempenho dentro das GPUs NVIDIA. O artigo abrange os fundamentos da arquitetura de GPU, a hierarquia de memória (GMEM, SMEM, L1/L2), programação PTX/SASS, e recursos avançados da arquitetura Hopper (H100) como TMA e instruções wgmma. Este recurso visa ajudar os desenvolvedores a entender profundamente a programação CUDA e a otimização de desempenho de GPU, o que é crucial para treinar e inferir modelos Transformer. (Fonte: Reddit r/deeplearning, Twitter)
Palestras do curso CS231N de Visão Computacional com Deep Learning da Stanford disponíveis no YouTube : As aclamadas palestras do curso CS231N (Deep Learning para Visão Computacional) da Universidade de Stanford já estão disponíveis gratuitamente no YouTube. Isso oferece uma oportunidade valiosa para estudantes em todo o mundo acessarem recursos de educação de IA de alta qualidade, cobrindo desde conceitos básicos até aplicações de ponta em Deep Learning para visão computacional. (Fonte: Reddit r/deeplearning)

RL-ZVP: Melhorando a capacidade de raciocínio de LLM com aprendizado por reforço usando Zero-Variance Prompts : Uma pesquisa recente propõe o método “RL with Zero-Variance Prompts (RL-ZVP)”, visando melhorar a capacidade de raciocínio de aprendizado por reforço de grandes modelos de linguagem (LLM). Este método não ignora mais os “Zero-Variance Prompts” (ou seja, situações em que todas as respostas do modelo recebem a mesma recompensa), mas extrai sinais de aprendizado valiosos deles, recompensando diretamente a correção e penalizando erros, e usando a entropia em nível de Token para guiar a formação da vantagem. Os resultados experimentais mostram que o RL-ZVP, em benchmarks de raciocínio matemático, alcançou melhorias significativas na precisão e na taxa de sucesso em comparação com os métodos tradicionais. (Fonte: Reddit r/MachineLearning)
Aprendizado Guiado pelo Futuro: Abordagem preditiva para aprimorar a previsão de séries temporais : Um estudo propõe o “Future-Guided Learning”, que aprimora a previsão de eventos em séries temporais através de um mecanismo de feedback dinâmico. Este método inclui um modelo de detecção que analisa dados futuros e um modelo de previsão que faz previsões com base nos dados atuais. Quando o modelo de previsão difere do modelo de detecção, o modelo de previsão é atualizado de forma mais significativa para minimizar a “surpresa”, ajustando dinamicamente os parâmetros e melhorando efetivamente a precisão da previsão de séries temporais. (Fonte: Reddit r/MachineLearning)
O futuro da IA em dimensões baixas: Yann Lecun sobre aprendizado de representações abstratas : O pioneiro da IA Yann Lecun, em uma entrevista com Lex Fridman, propôs que o próximo salto da IA virá do aprendizado em espaços latentes de baixa dimensão, em vez de processar diretamente dados brutos de alta dimensão, como pixels. Ele acredita que sistemas verdadeiramente inteligentes precisam aprender a estrutura causal e as representações abstratas da dinâmica física do mundo, a fim de fazer previsões precisas mesmo quando os detalhes mudam. Este método tornará os modelos mais flexíveis e robustos, reduzindo a dependência de grandes volumes de dados e diminuindo os custos computacionais. (Fonte: Reddit r/ArtificialInteligence)
SIRI: Escalando o Aprendizado por Reforço Iterativo com Compressão Intercalada : SIRI (Scaling Iterative Reinforcement Learning with Interleaved Compression) é um método simples e eficaz de aprendizado por reforço que ajusta dinamicamente o comprimento máximo do rollout durante o treinamento, comprimindo e expandindo iterativamente o orçamento de inferência. Este mecanismo de treinamento força o modelo a tomar decisões precisas em contextos limitados, reduzindo Tokens redundantes, ao mesmo tempo em que oferece espaço para exploração e planejamento, melhorando assim de forma constante a eficiência e a precisão de grandes modelos de inferência no trade-off desempenho-eficiência. (Fonte: HuggingFace Daily Papers)
MultiCrafter: Modelo generativo multi-agente com atenção espacialmente desacoplada e aprendizado por reforço sensível à identidade : MultiCrafter é uma estrutura projetada para alcançar a geração de imagens multi-agente de alta fidelidade e alinhada às preferências. Ele introduz supervisão de posição explícita para separar as regiões de atenção entre diferentes agentes, mitigando efetivamente o problema de vazamento de atributos. Ao mesmo tempo, a estrutura adota uma arquitetura Mixture-of-Experts (MoE) para aumentar a capacidade do modelo e projeta uma nova estrutura de aprendizado por reforço online, combinando mecanismos de pontuação e estratégias de treinamento estáveis, garantindo que a fidelidade do agente nas imagens geradas e as preferências estéticas humanas estejam altamente alinhadas. (Fonte: HuggingFace Daily Papers)
Visual Jigsaw: Aprimorando a compreensão visual de MLLMs através de pós-treinamento auto-supervisionado : Visual Jigsaw é uma estrutura geral de pós-treinamento auto-supervisionado, projetada para aprimorar as capacidades de compreensão visual de grandes modelos de linguagem multimodais (MLLMs). Este método particiona e embaralha a entrada visual, exigindo que o modelo reconstrua a ordem correta através da linguagem natural. Esta abordagem de aprendizado por reforço baseada em recompensa verificável (RLVR) não requer componentes adicionais de geração visual ou anotação manual, mas pode melhorar significativamente o desempenho de MLLMs em percepção de granularidade fina, raciocínio temporal e compreensão espacial 3D. (Fonte: HuggingFace Daily Papers)
MGM-Omni: Estendendo Omni LLMs para geração de fala personalizada de longa duração : MGM-Omni é um Omni LLM unificado que, através de sua arquitetura exclusiva de tokenização de trilho duplo “cérebro-boca”, alcança compreensão multimodal e geração de fala expressiva de longa duração. Este design desacopla o raciocínio multimodal da geração de fala em tempo real, suportando interação intermodal eficiente e clonagem de fala em streaming de baixa latência, e demonstra excelente eficiência de dados. Experimentos provam que o MGM-Omni supera os modelos open-source existentes na manutenção da consistência do timbre, geração de fala natural sensível ao contexto e compreensão multimodal e de áudio de longa duração. (Fonte: HuggingFace Daily Papers)
SID: Aprendizado de navegação guiada por linguagem através de demonstrações de auto-aprimoramento : SID (Self-Improving Demonstrations) é um método de aprendizado de navegação guiada por linguagem que melhora significativamente a capacidade de exploração e generalização de agentes de navegação em ambientes desconhecidos através de demonstrações iterativas de auto-aprimoramento. Este método primeiro usa dados de caminho mais curto para treinar um agente inicial, e então usa este agente para gerar novas trajetórias de exploração, que fornecem estratégias de exploração mais fortes para treinar um agente melhor, alcançando assim uma melhoria contínua de desempenho. Experimentos mostram que o SID alcançou desempenho SOTA em tarefas como REVERIE e SOON, com uma taxa de sucesso de 50,9% no conjunto de validação não visto do SOON, superando os métodos anteriores em 13,9%. (Fonte: HuggingFace Daily Papers)
LOVE-R1: Melhorando a compreensão de vídeo longo através de um mecanismo de escala adaptativa : O modelo LOVE-R1 visa resolver o conflito entre a compreensão de longo prazo e a percepção espacial detalhada na compreensão de vídeos longos. O modelo introduz um mecanismo de escala adaptativa, que primeiro amostra quadros densamente em baixa resolução, e quando detalhes espaciais são necessários, o modelo pode escalar segmentos de vídeo de interesse para alta resolução com base na inferência, até que informações visuais cruciais sejam obtidas. Todo o processo é realizado através de inferência multi-etapas, combinado com fine-tuning de dados CoT e fine-tuning de reforço desacoplado, alcançando melhorias significativas em benchmarks de compreensão de vídeo longo. (Fonte: HuggingFace Daily Papers)
Euclid’s Gift: Aprimorando o raciocínio espacial de modelos de linguagem visual através de tarefas de agente geométrico : Euclid’s Gift é uma pesquisa que aprimora as capacidades de percepção e raciocínio espacial de modelos de linguagem visual (VLM) através de tarefas de agente geométrico. Este projeto construiu o conjunto de dados multimodal Euclid30K, contendo 30 mil problemas de geometria plana e sólida, e usou Group Relative Policy Optimization (GRPO) para fine-tuning dos modelos da série Qwen2.5VL e RoboBrain2.0. Experimentos provam que os modelos treinados alcançaram melhorias significativas zero-shot em quatro benchmarks de raciocínio espacial, incluindo Super-CLEVR e Omni3DBench, com o RoboBrain2.0-Euclid-7B atingindo uma precisão de 49,6%, superando os modelos SOTA anteriores. (Fonte: HuggingFace Daily Papers)
SphereAR: Melhorando a geração autorregressiva de Token contínuo através de espaço latente hiperesférico : SphereAR visa resolver problemas causados pela variância heterogênea do espaço latente VAE em modelos de geração de imagem autorregressiva (AR) de Token contínuo. O design central é restringir todas as entradas e saídas AR (incluindo pós-CFG) a uma hiperesfera de raio fixo, utilizando um VAE hiperesférico. A análise teórica mostra que a restrição hiperesférica elimina a principal causa do colapso da variância, estabilizando assim a decodificação AR. Experimentos provam que o SphereAR alcançou desempenho SOTA em tarefas de geração ImageNet, superando modelos de difusão e modelos de geração mascarada de escala de parâmetro equivalente. (Fonte: HuggingFace Daily Papers)
AceSearcher: Guiando o raciocínio e a busca de LLM através de auto-jogo por reforço : AceSearcher é uma estrutura de auto-jogo cooperativo projetada para aprimorar as capacidades de busca de LLM em tarefas de raciocínio complexas. A estrutura treina um único LLM para alternar entre decompor consultas complexas e integrar o contexto recuperado, otimizando a precisão da resposta final através de fine-tuning supervisionado e fine-tuning por reforço, sem a necessidade de anotação intermediária. Experimentos mostram que o AceSearcher supera significativamente as linhas de base SOTA em várias tarefas intensivas em raciocínio. Em tarefas de raciocínio financeiro em nível de documento, o AceSearcher-32B igualou o desempenho do DeepSeek-V3 com menos de 5% dos parâmetros. (Fonte: HuggingFace Daily Papers)
SparseD: Mecanismo de atenção esparsa para modelos de linguagem de difusão : SparseD é um método de atenção esparsa para modelos de linguagem de difusão (DLMs), projetado para resolver o gargalo de complexidade quadrática do cálculo de atenção em longos comprimentos de contexto. Este método pré-calcula padrões esparsos específicos da cabeça e os reutiliza em todas as etapas de denoising, usando atenção total nas etapas iniciais de denoising e depois alternando para atenção esparsa, alcançando assim uma aceleração sem perdas. Os resultados experimentais mostram que o SparseD pode alcançar uma aceleração de até 1,5 vezes em comparação com o FlashAttention em um comprimento de contexto de 64k, melhorando efetivamente a eficiência de inferência de DLMs em aplicações de longo contexto. (Fonte: HuggingFace Daily Papers)
SLA: Acelerando Diffusion Transformer com atenção linear esparsa sintonizável : SLA (Sparse-Linear Attention) é um método de atenção treinável projetado para acelerar os modelos Diffusion Transformer (DiT), especialmente o cálculo de atenção na geração de vídeo. Este método divide os pesos de atenção em três categorias: chave, borda e insignificante, aplicando atenção O(N²) e O(N) respectivamente, e pulando a parte insignificante. O SLA, ao fundir esses cálculos em um único kernel de GPU e após algumas etapas de fine-tuning, alcança uma redução de 20 vezes no cálculo de atenção para modelos DiT, e uma aceleração end-to-end de 2,2 vezes na geração de vídeo, sem perda de qualidade de geração. (Fonte: HuggingFace Daily Papers)
OpenGPT-4o-Image: Conjunto de dados abrangente para geração e edição avançada de imagens : OpenGPT-4o-Image é um conjunto de dados em larga escala, construído combinando classificação de tarefas hierárquicas e métodos de geração automática de dados GPT-4o, visando melhorar o desempenho de modelos multimodais unificados na geração e edição de imagens. Este conjunto de dados contém 80 mil pares de instrução-imagem de alta qualidade, cobrindo 11 domínios principais e 51 sub-tarefas, incluindo renderização de texto, controle de estilo, imagens científicas e edição de instruções complexas. Modelos fine-tuned no OpenGPT-4o-Image alcançaram melhorias significativas de desempenho em vários benchmarks, provando o papel crucial da construção sistemática de dados para o avanço das capacidades de IA multimodal. (Fonte: HuggingFace Daily Papers)
SANA-Video: Pequeno modelo de difusão que gera vídeos de 720p com duração de minutos de forma eficiente : SANA-Video é um pequeno modelo de difusão capaz de gerar vídeos de até 720×1280 de resolução e duração de minutos de forma eficiente. Ele alcança geração de vídeo de alta resolução, alta qualidade e longa duração através de uma arquitetura DiT linear e um cache KV de memória constante, mantendo um forte alinhamento texto-vídeo. O custo de treinamento do SANA-Video é de apenas 1% do MovieGen, e quando implantado em uma GPU RTX 5090, a velocidade de inferência para gerar um vídeo de 5 segundos em 720p pode atingir 29 segundos, realizando geração de vídeo de baixo custo e alta qualidade. (Fonte: HuggingFace Daily Papers)
AdvChain: Aprimorando o alinhamento de segurança de grandes modelos de raciocínio através de fine-tuning CoT adversarial : AdvChain é um novo paradigma de alinhamento que ensina grandes modelos de raciocínio (LRMs) a capacidade de auto-correção dinâmica através de fine-tuning adversarial Chain-of-Thought (CoT). Este método constrói um conjunto de dados contendo amostras de “tentação-correção” e “hesitação-correção”, permitindo que o modelo aprenda a se recuperar de desvios de raciocínio prejudiciais e cautela desnecessária. Experimentos mostram que o AdvChain aumenta significativamente a robustez do modelo contra ataques de jailbreak e sequestro de CoT, ao mesmo tempo em que reduz drasticamente a rejeição excessiva de Prompts benignos, alcançando um excelente equilíbrio segurança-utilidade. (Fonte: HuggingFace Daily Papers)
SDLM: Escalando o Aprendizado por Reforço Iterativo com Compressão Intercalada : O Sequential Diffusion Language Model (SDLM) propõe um método unificado de previsão de next-token e next-block, permitindo que o modelo determine adaptativamente o comprimento da geração em cada etapa. O SDLM pode remodelar modelos de linguagem autorregressivos pré-treinados com custo mínimo e executar inferência de difusão dentro de blocos mascarados de tamanho fixo, enquanto decodifica dinamicamente subsequências contínuas. Experimentos mostram que o SDLM, ao igualar ou superar fortes linhas de base autorregressivas, alcança maior throughput, demonstrando seu forte potencial de escalabilidade. (Fonte: HuggingFace Daily Papers)
Insight-to-Solve (I2S): Transformando demonstrações de raciocínio In-Context em ativos de LMs de raciocínio : Insight-to-Solve (I2S) é um programa de tempo de teste projetado para transformar demonstrações de raciocínio In-Context de alta qualidade em ativos eficazes para grandes modelos de raciocínio (RLMs). A pesquisa descobriu que a adição direta de exemplos de demonstração pode reduzir a precisão dos RLMs. O I2S transforma demonstrações em insights explicitamente reutilizáveis e gera trajetórias de raciocínio específicas para o objetivo, opcionalmente auto-refinando-se para melhorar a coerência e a correção. Experimentos mostram que o I2S e o I2S+ superam consistentemente as linhas de base de resposta direta e escalonamento em tempo de teste em vários benchmarks, trazendo melhorias significativas mesmo para modelos GPT. (Fonte: HuggingFace Daily Papers)
UniMIC: Codificação interativa multimodal baseada em Token para colaboração humano-máquina : UniMIC (Unified token-based Multimodal Interactive Coding) é uma estrutura que visa alcançar interação multimodal eficiente e de baixa taxa de bits entre dispositivos de borda e agentes de IA em nuvem através de representações baseadas em Token. O UniMIC adota uma representação tokenizada compacta como meio de comunicação e combina um modelo de entropia Transformer, reduzindo efetivamente a redundância entre Tokens. Experimentos provam que o UniMIC alcança economias significativas de taxa de bits em tarefas como geração de texto para imagem, inpainting de imagem e resposta a perguntas visuais, e mantém a robustez em taxas de bits ultrabaixas, fornecendo um paradigma prático para a próxima geração de comunicação interativa multimodal. (Fonte: HuggingFace Daily Papers)
RLBFF: Feedback flexível binário para unir feedback humano e recompensas verificáveis : RLBFF (Reinforcement Learning with Binary Flexible Feedback) é um paradigma de aprendizado por reforço que combina a diversidade das preferências humanas com a precisão da validação de regras. Ele extrai princípios de feedback em linguagem natural que podem ser respondidos binariamente (por exemplo, precisão da informação: sim/não, legibilidade do código: sim/não) e usa isso para treinar um modelo de recompensa. O RLBFF tem um desempenho excelente em RM-Bench e JudgeBench, e permite que os usuários personalizem o foco dos princípios durante a inferência. Além disso, oferece uma solução totalmente open-source para alinhar o Qwen3-32B com RLBFF, fazendo com que ele iguale ou supere o desempenho do o3-mini e do DeepSeek R1 em benchmarks de alinhamento geral. (Fonte: HuggingFace Daily Papers)
MetaAPO: Otimização de alinhamento através de amostragem online meta-ponderada : MetaAPO (Meta-Weighted Adaptive Preference Optimization) é uma estrutura inovadora que otimiza o alinhamento de grandes modelos de linguagem (LLMs) com as preferências humanas, acoplando dinamicamente a geração de dados com o treinamento do modelo. O MetaAPO utiliza um meta-learner leve como um “estimador de lacuna de alinhamento” para avaliar os ganhos potenciais da amostragem online em relação aos dados offline, guiando a geração online de alvos e alocando pesos meta em nível de amostra, equilibrando dinamicamente a qualidade e a distribuição dos dados online e offline. Experimentos mostram que o MetaAPO supera consistentemente os métodos de otimização de preferência existentes no AlpacaEval 2, Arena-Hard e MT-Bench, ao mesmo tempo em que reduz os custos de anotação online em 42%. (Fonte: HuggingFace Daily Papers)
Tool-Light: Raciocínio eficiente com integração de ferramentas através de aprendizado de preferência auto-evolutivo : Tool-Light é uma estrutura projetada para encorajar grandes modelos de linguagem (LLMs) a executar tarefas de raciocínio com integração de ferramentas (TIR) de forma eficiente e precisa. A pesquisa descobriu que os resultados da chamada de ferramentas podem levar a mudanças significativas na entropia da informação subsequente do raciocínio. O Tool-Light é implementado combinando a construção de conjuntos de dados e o fine-tuning multi-estágio, onde a construção de conjuntos de dados utiliza amostragem auto-evolutiva contínua, integrando amostragem vanilla e amostragem guiada por entropia, e estabelecendo critérios rigorosos de seleção de pares positivos e negativos. O processo de treinamento inclui SFT e otimização de preferência direta auto-evolutiva (DPO). Experimentos provam que o Tool-Light melhora significativamente a eficiência do modelo na execução de tarefas TIR. (Fonte: HuggingFace Daily Papers)
ChatInject: Ataques de injeção de Prompt em agentes LLM usando modelos de chat : ChatInject é um método que explora a dependência de LLM em modelos de chat estruturados e a manipulação de contexto em conversas multi-turn para realizar ataques indiretos de injeção de Prompt. O atacante formata cargas maliciosas imitando o formato nativo do modelo de chat, induzindo o agente a executar operações suspeitas. Experimentos mostram que o ChatInject tem uma taxa de sucesso de ataque maior do que os métodos tradicionais de injeção de Prompt, especialmente em conversas multi-turn, e é altamente transferível para diferentes modelos, enquanto as medidas de defesa baseadas em Prompt existentes são em grande parte ineficazes contra esses ataques. (Fonte: HuggingFace Daily Papers)
💼 Negócios
Modal conclui rodada de financiamento Série B de US$ 87 milhões, avaliada em US$ 1,1 bilhão : A Modal, empresa de infraestrutura de IA, anunciou a conclusão de uma rodada de financiamento Série B de US$ 87 milhões, avaliando a empresa em US$ 1,1 bilhão. Esta rodada de financiamento visa acelerar a inovação e o desenvolvimento da infraestrutura de IA para enfrentar os desafios que a infraestrutura de computação tradicional enfrenta na era da IA. A Modal, ao fornecer serviços de computação em nuvem eficientes, ajuda pesquisadores e desenvolvedores a otimizar seus processos de treinamento e implantação de modelos de IA. (Fonte: Twitter, Twitter, Twitter)
OpenAI registra receita de US$ 4,3 bilhões e prejuízo de US$ 13,5 bilhões no primeiro semestre, enfrentando desafios de lucratividade : A OpenAI divulgou uma receita de US$ 4,3 bilhões no primeiro semestre de 2025, com uma receita anual projetada para ultrapassar US$ 13 bilhões, impulsionada principalmente pelas assinaturas do ChatGPT Plus e serviços de API de nível empresarial. No entanto, o prejuízo líquido no mesmo período atingiu US$ 13,5 bilhões, com custos estruturais e investimentos em P&D (como o GPT-5) sendo os principais fatores, e as taxas anuais de aluguel de servidores chegando a US$ 16 bilhões. Embora a OpenAI possua US$ 17,5 bilhões em reservas de caixa e esteja avançando com um plano de financiamento de US$ 30 bilhões, o consumo contínuo de caixa e a lacuna de eficiência em relação a concorrentes como a Anthropic a colocam diante de sérios desafios de lucratividade. (Fonte: 36氪)
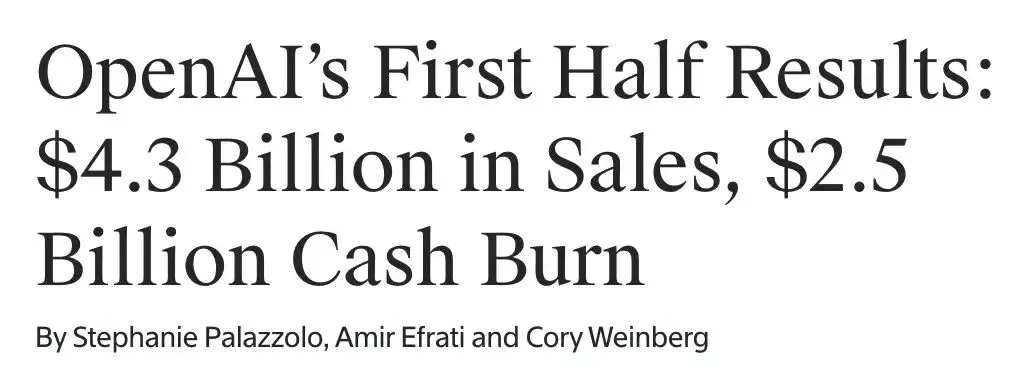
Guerra de capital no setor de robôs humanoides: Zhiyuan, Yinhe General e outros investem ativamente na cadeia industrial : O setor de robôs humanoides entrou em uma guerra de capital, com empresas líderes como Zhiyuan Robot e Yinhe General expandindo ativamente sua “rede de contatos” através da criação de fundos, investimento em pares e colaborações estratégicas. A Zhiyuan Robot já investiu em quase 20 empresas, cobrindo motores, sensores e aplicações downstream, e colaborou com a Fulim Precision Engineering, Softcom Power, entre outras, para implementar cenários comerciais. A Yinhe General, por sua vez, estabeleceu uma joint venture com a Bosch China para promover a aplicação da inteligência encarnada na fabricação automotiva. Essas iniciativas visam obter pedidos, preencher lacunas e estabelecer uma rede de suprimentos estável para futuras entregas em larga escala, mas o setor apresenta grandes diferenças nas rotas tecnológicas e uma concorrência acirrada. (Fonte: 36氪)

🌟 Comunidade
Dificuldade em distinguir conteúdo gerado por IA, gerando crise de confiança social : Com o rápido desenvolvimento da tecnologia de IA, a veracidade de vídeos gerados por IA (como a versão live-action de “Attack on Titan”, e streamers indonésios “trocando de rosto” com influenciadores japoneses) atingiu um nível inacreditável, levantando sérias preocupações sociais sobre a autenticidade do conteúdo. Nas redes sociais, os usuários geralmente expressam que está cada vez mais difícil distinguir entre conteúdo real e gerado por IA, o que não apenas prejudica a credibilidade dos criadores de conteúdo legítimos, mas também pode ser usado para disseminar informações falsas. Especialistas apontam que, a menos que haja uma rotulagem obrigatória de conteúdo de IA, este “motor hiper-realista” continuará a corroer o senso de realidade e, eventualmente, poderá “acabar com a internet”. (Fonte: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ArtificialInteligence, Twitter, Twitter)

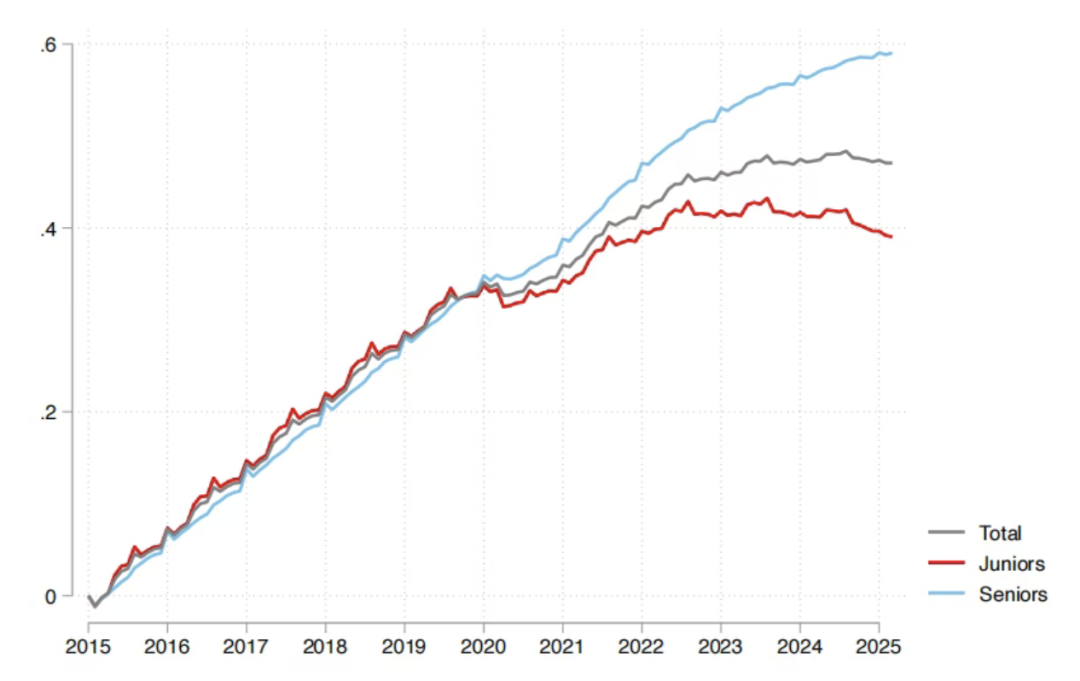
Impacto da IA no mercado de trabalho: Relatório da Sequoia afirma que 95% do investimento em IA é ineficaz, graduados são os mais afetados : A Sequoia Capital compartilhou um relatório de pesquisa do MIT e da Universidade de Harvard, indicando que 95% dos investimentos em IA das empresas não geraram valor real, e que o verdadeiro aumento de produtividade vem de uma “economia de IA sombra” formada por funcionários que usam “secretamente” ferramentas de IA pessoais. O relatório também revela que o impacto da IA no mercado de trabalho se concentra principalmente nos jovens recém-formados, especialmente no setor de varejo e atacado, onde o número de contratações para cargos de nível júnior diminuiu significativamente, e diplomas de universidades de prestígio não são uma proteção completa. Isso demonstra que a IA está mudando a alocação de tarefas, e o valor humano está se deslocando para a experiência e o julgamento único. (Fonte: 36氪, Reddit r/ArtificialInteligence)
Ajuste de modelo da OpenAI gera forte insatisfação dos usuários, que pedem comunicação transparente : A OpenAI, sem aviso prévio, “rebaixou” recentemente os modelos GPT-4o/GPT-5 para versões de menor poder computacional, resultando na diminuição do desempenho do modelo e gerando forte insatisfação entre os usuários. Muitos usuários reclamaram que o modelo “ficou mais burro”, perdendo sua percepção original e a experiência de conversação “amigável”, e alguns até chamaram isso de “golpe mental”. Executivos da OpenAI responderam que se tratava de um “teste de roteamento de segurança” para lidar com tópicos sensíveis, mas os usuários geralmente pedem que a OpenAI fortaleça a comunicação e a transparência com eles, evitando alterações unilaterais nos acordos de produto para reconstruir a confiança do usuário. (Fonte: Reddit r/artificial, Reddit r/ChatGPT, Reddit r/ChatGPT, Twitter)

Tributação de robôs: Discussão sobre progresso tecnológico e equidade social : Com o desenvolvimento da IA e da tecnologia robótica, a discussão sobre a “tributação” de robôs tem crescido, visando equilibrar os problemas de emprego e a desigualdade social que a substituição da mão de obra humana por robôs pode causar. Os defensores argumentam que o imposto sobre robôs pode fornecer benefícios sociais e apoio à requalificação para os desempregados, corrigindo o desequilíbrio de poder de barganha entre capital e trabalho. No entanto, os profissionais da indústria robótica geralmente acreditam que a tributação é prematura e pode dificultar o desenvolvimento de indústrias emergentes. A Coreia do Sul já aumentou indiretamente o custo do uso de robôs, reduzindo os incentivos fiscais para empresas de automação. (Fonte: 36氪)
Futuro dos robôs humanoides: Rodney Brooks, renomado especialista em robótica, acredita que o futuro não será humanoide : O renomado especialista em robótica Rodney Brooks escreveu um artigo apontando que, apesar dos grandes investimentos, os robôs humanoides atuais ainda não conseguem alcançar a destreza de nível humano, e a locomoção bípede apresenta riscos de segurança. Ele prevê que, nos próximos 15 anos, os robôs humanoides não imitarão mais a forma humana, mas evoluirão para robôs especializados com mobilidade sobre rodas, múltiplos braços (equipados com garras ou ventosas) e múltiplos sensores (imagem de luz ativa, percepção de luz não visível), para se adaptar a tarefas específicas. Ele acredita que a busca atual por uma forma “humanoide” envolve um investimento enorme que, no final, será em vão. (Fonte: 36氪)

Qualidade da geração de código por IA e controvérsia sobre a experiência do desenvolvedor : Nas redes sociais, desenvolvedores debatem intensamente a qualidade e a utilidade do código gerado por IA. Alguns elogiam o Claude Sonnet 4.5 por sua capacidade de refatorar um codebase inteiro, mas o código gerado não funciona; outros reclamam que o código gerado por IA “não compila”, resultando em menor eficiência de desenvolvimento. Essas discussões refletem que a programação assistida por IA ainda enfrenta desafios entre eficiência e precisão, e a necessidade dos desenvolvedores de depurar e verificar os resultados gerados por IA. (Fonte: Twitter, Twitter, Twitter)

Mudança na visão de talentos na era da IA: De “caçar” para “cultivar” : Nas redes sociais, discute-se intensamente que a visão de talentos na era da IA deve mudar da tradicional “caça de talentos” para “cultivar”. Dada a escassez de talentos na área de IA e a rápida iteração tecnológica, as empresas devem focar mais em treinar funcionários com um stack tecnológico básico, em vez de buscar cegamente “talentos prontos” caros no mercado. Essa visão enfatiza a importância do aprendizado contínuo e do desenvolvimento interno para se adaptar às rápidas mudanças no setor de IA. (Fonte: dotey)
Consumo de energia da infraestrutura de IA e a demanda de energia de Sam Altman : Sam Altman propôs que o desenvolvimento da IA requer 250GW de eletricidade, levantando preocupações e discussões sociais sobre o enorme consumo de energia da infraestrutura de IA. Essa demanda excede em muito a capacidade de fornecimento de energia existente, levando as pessoas a refletir sobre como equilibrar o rápido desenvolvimento da IA com o fornecimento de energia sustentável. Discussões relacionadas também abordam questões ambientais na fabricação de semicondutores, como o uso de PFAS e os riscos potenciais de suas alternativas. (Fonte: Twitter, Twitter)

Apocalipse da IA vs. otimistas: Preocupações e refutações : Nas redes sociais, há uma ampla discussão sobre o “apocalipse da IA” e os riscos potenciais da IA, mas muitos também acreditam que essas preocupações são exageradas. Os otimistas argumentam que os problemas reais trazidos pela IA (como impacto climático, exploração corporativa, vigilância militar) são mais urgentes do que a distante “superinteligência destruindo a humanidade”, e que devemos focar nos desafios que podem ser resolvidos agora. Alguns consideram a teoria do apocalipse da IA “bobagem”, uma manifestação de preguiça e instabilidade, enquanto outros acreditam que a IA eventualmente levará à criação e ao cultivo. (Fonte: Reddit r/ArtificialInteligence, Twitter, Twitter)
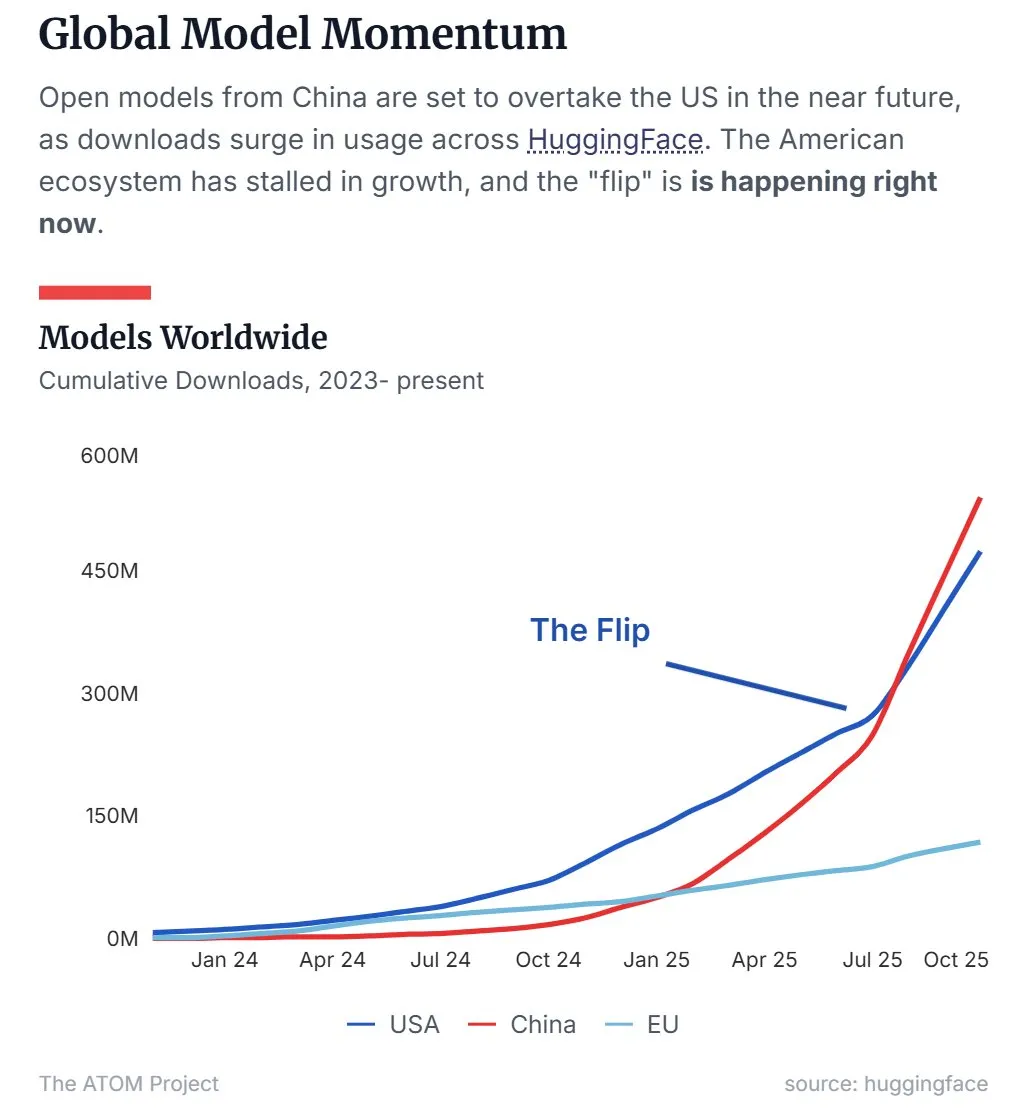
Participação de mercado de LLM open-source da China supera a dos EUA : Dados recentes mostram que os grandes modelos de linguagem (LLM) open-source chineses, representados pelo Qwen, superaram os dos EUA em participação de mercado, tornando-se a força dominante no campo de LLM open-source. Essa tendência indica que a China está acelerando seu surgimento em pesquisa e aplicação de tecnologia de IA open-source, impactando significativamente o cenário global de IA. (Fonte: Twitter, Twitter)
Equipe de 45 dias produz série de mangá de IA “Tomorrow is Monday” e alcança dezenas de milhões de visualizações : Uma equipe de apenas 10 pessoas completou a produção de 50 episódios da série de mangá de IA “Tomorrow is Monday” em 45 dias, e sem qualquer investimento em publicidade, alcançou mais de dez milhões de visualizações em toda a rede, com a receita paga do Douyin já cobrindo todos os custos. O projeto adota o conceito central de “personagens originais + geração de IA”, resolvendo o problema de atribuição de direitos autorais de conteúdo de IA e explorando um caminho de desenvolvimento comercial de IP de categoria completa. O processo de produção é altamente dividido, com artistas originais, engenheiros, editores de pós-produção e diretores trabalhando em estreita colaboração, demonstrando o enorme potencial da tecnologia de IA na redução de custos e aumento da eficiência na produção de conteúdo. (Fonte: 36氪)

💡 Outros
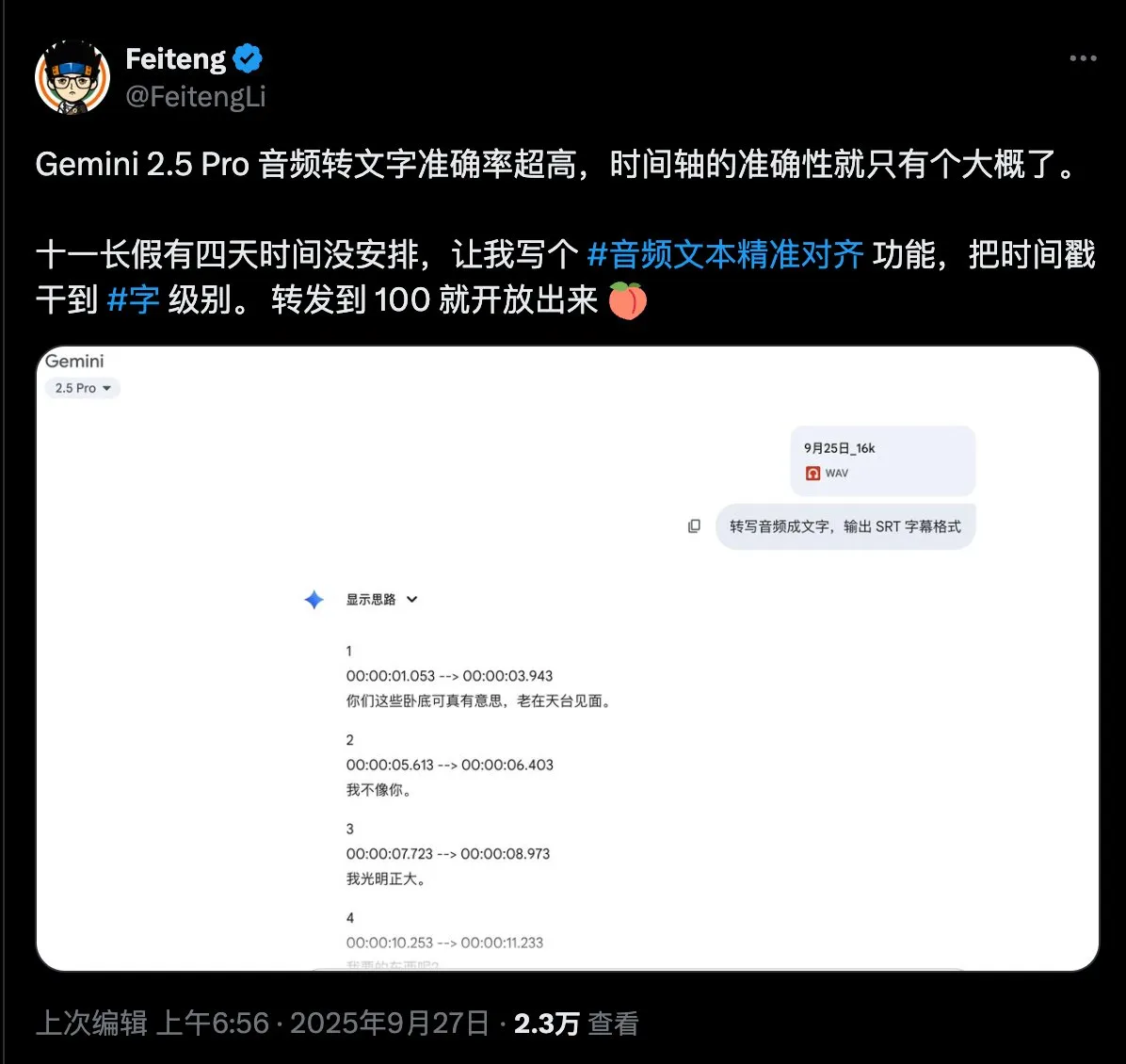
Questionário sobre a necessidade de alinhamento preciso de texto de áudio : Um usuário de mídia social demonstrou grande interesse na tecnologia de alinhamento preciso de texto de áudio e publicou um questionário, visando coletar as necessidades específicas dos usuários sobre as funcionalidades e cenários de aplicação dessa tecnologia, na esperança de impulsionar o desenvolvimento e a otimização de tecnologias relacionadas. (Fonte: dotey)
DeepMind demonstra Nano Banana Demo : O Google DeepMind demonstrou uma apresentação chamada “Nano Banana”, que atraiu a atenção das redes sociais. Embora os detalhes específicos não tenham sido totalmente divulgados, pode estar relacionado à geração de vídeo por IA ou tecnologias de IA multimodal, sugerindo novos avanços do DeepMind no campo da IA visual. (Fonte: GoogleDeepMind)
Discussão acadêmica sobre a prioridade de invenção de Highway Net e ResNet : O renomado pesquisador de IA Jürgen Schmidhuber retweetou uma publicação, reacendendo a discussão acadêmica sobre a prioridade de invenção de Highway Net e ResNet no aprendizado residual profundo. Ele apontou que a afirmação da Microsoft no artigo sobre ResNet de que Highway Net é um trabalho “contemporâneo” é imprecisa, e enfatizou que Highway Net foi publicado sete meses antes de ResNet, e já havia identificado e proposto soluções para conexões residuais. (Fonte: SchmidhuberAI)