
Palavras-chave:Qwen3-Next 80B, MobileLLM-R1, Replit Agent 3, Inteligência Embarcada, Privacidade Diferencial, Raciocínio de LLM, Agente de IA, Transformer, Mecanismo de Atenção Híbrida Gated DeltaNet, Sistema de Detecção de Vulnerabilidades DARPA AIxCC, Otimização de Inferência de IA em Dispositivos de Borda, Geração e Teste Autônomo de Software, Modelo de Codificador Multilíngue mmBERT
🔥 Destaque
Alibaba lança modelo Qwen3-Next 80B: A Alibaba lançou o Qwen3-Next 80B, um modelo de código aberto com capacidades de inferência híbrida. O modelo emprega um mecanismo de atenção híbrida Gated DeltaNet e Gated Attention, juntamente com uma alta esparsidade de 3,8% (apenas 3B de parâmetros ativos), tornando seu nível de inteligência comparável ao DeepSeek V3.1, enquanto reduz o custo de treinamento em 10 vezes e aumenta a velocidade de inferência em 10 vezes. O Qwen3-Next 80B se destaca em inferência e processamento de contexto longo, superando até mesmo o Gemini 2.5 Flash-Thinking. O modelo suporta uma janela de contexto de 256k tokens, pode ser executado em uma única H200 GPU e está disponível no NVIDIA API Catalog, marcando um novo avanço na arquitetura eficiente de LLM. (Fonte: Alibaba_Qwen, ClementDelangue, NandoDF)
Desafio DARPA AIxCC: Sistema de Detecção e Reparo Automatizado de Vulnerabilidades Impulsionado por LLM: No Desafio de Cibersegurança de Inteligência Artificial (AIxCC) da DARPA, um sistema de inferência de rede impulsionado por LLM (CRS) chamado “All You Need Is A Fuzzing Brain” se destacou, descobrindo autonomamente 28 vulnerabilidades de segurança, incluindo seis vulnerabilidades de dia zero anteriormente desconhecidas, e reparando com sucesso 14 delas. O sistema demonstrou notável capacidade de detecção e correção automatizada de vulnerabilidades em projetos de código aberto C e Java do mundo real, terminando em quarto lugar na final. O CRS foi disponibilizado como código aberto e oferece um placar público para avaliar o nível mais recente dos LLMs em tarefas de detecção e reparo de vulnerabilidades. (Fonte: HuggingFace Daily Papers)
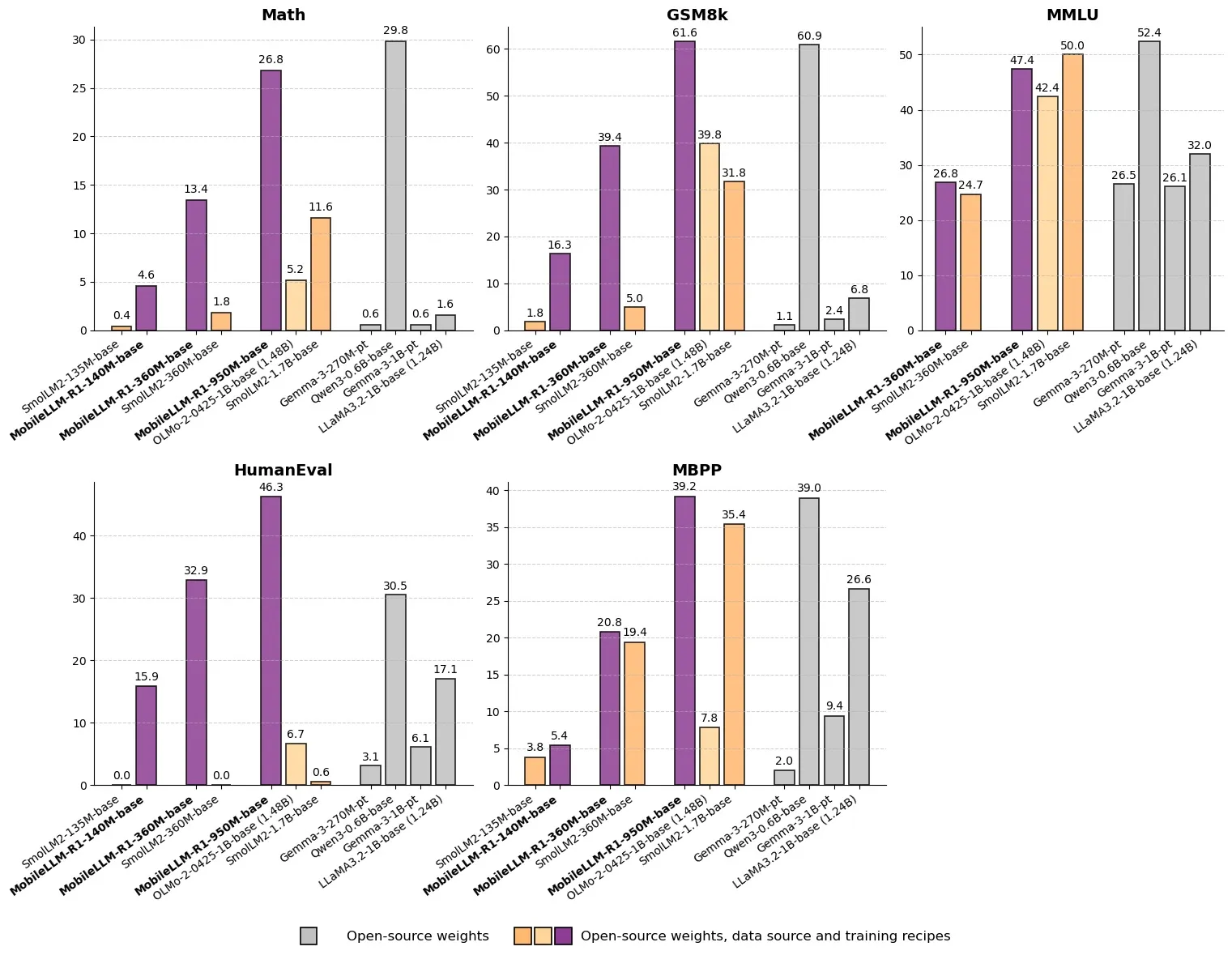
Meta lança MobileLLM-R1: Modelo de Inferência Eficiente com Menos de Um Bilhão de Parâmetros: A Meta lançou o MobileLLM-R1 no Hugging Face, um modelo de inferência de borda com menos de um bilhão de parâmetros. O modelo é cerca de 5 vezes mais preciso em matemática do que o Olmo-1.24B e cerca de 2 vezes mais preciso do que o SmolLM2-1.7B, alcançando um aumento de desempenho de 2 a 5 vezes. Usando apenas 4.2T de tokens pré-treinados (11.7% do uso do Qwen), o MobileLLM-R1 demonstra forte capacidade de inferência com pouco pós-treinamento, marcando uma mudança de paradigma em eficiência de dados e escala de modelo, abrindo novos caminhos para a inferência de IA em dispositivos de borda. (Fonte: _akhaliq, Reddit r/LocalLLaMA)
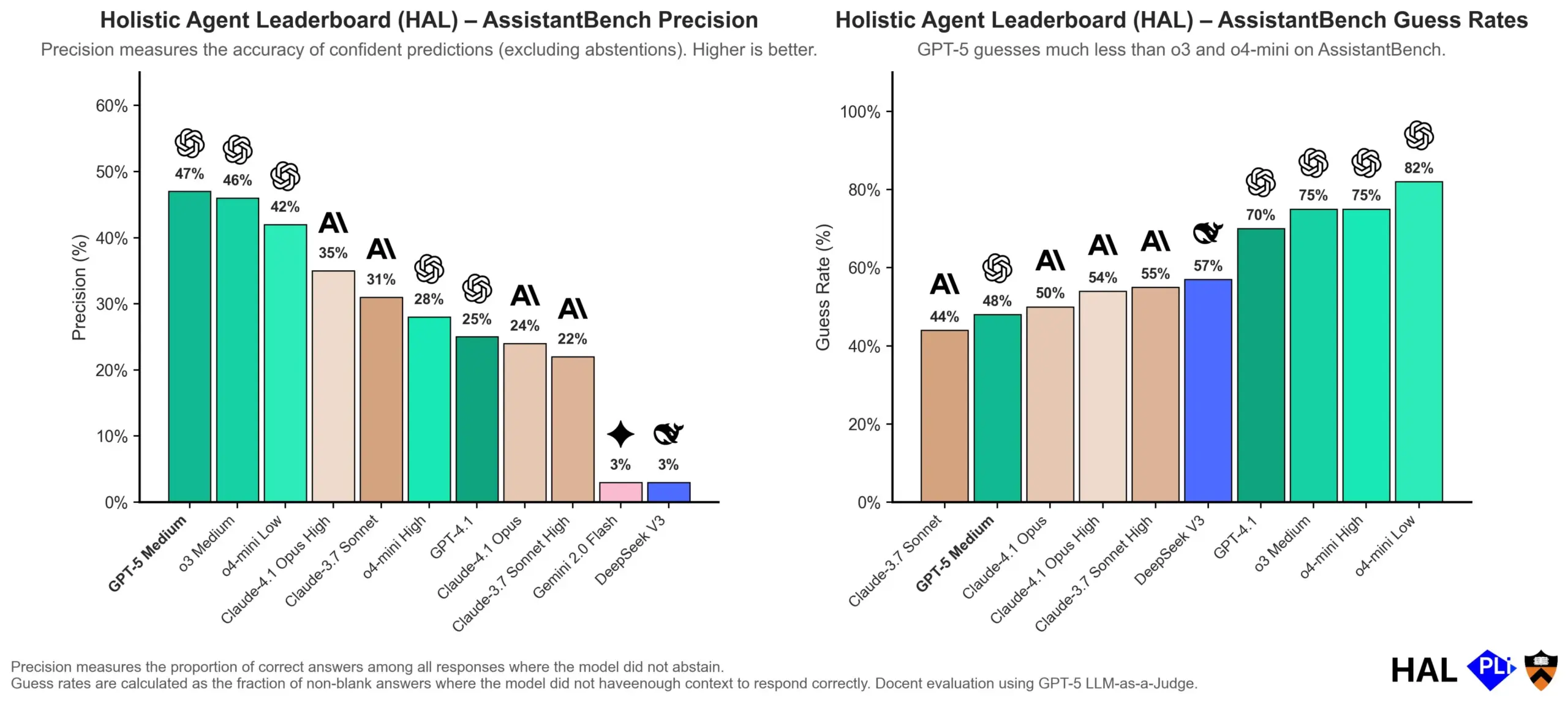
OpenAI Aprofunda Causas de Alucinações em LLMs: Mecanismos de Avaliação são Chave: A OpenAI publicou um artigo de pesquisa indicando que as alucinações em Large Language Models (LLMs) não são falhas inerentes ao modelo, mas sim o resultado direto de métodos de avaliação atuais que recompensam “adivinhação” em vez de “honestidade”. O estudo argumenta que os benchmarks existentes tendem a penalizar modelos por responderem “não sei”, levando-os a gerar respostas que parecem plausíveis, mas são de fato imprecisas. O artigo pede uma mudança na forma como os benchmarks são pontuados e um reajuste dos placares existentes para encorajar os modelos a demonstrar melhor calibração e honestidade quando incertos, em vez de simplesmente buscar saídas de alta confiança. (Fonte: dl_weekly, TheTuringPost, random_walker)
Replit Agent 3: Um Avanço na Geração e Teste Autônomo de Software: A Replit lançou seu Agent 3, um agente de IA capaz de gerar e testar software com alta autonomia. O agente demonstrou a capacidade de operar por horas sem intervenção, construir aplicativos completos (como plataformas de redes sociais) e testá-los por conta própria. O feedback dos usuários indica que o Agent 3 pode transformar ideias rapidamente em produtos reais, melhorando significativamente a eficiência do desenvolvimento e até mesmo fornecendo recibos de trabalho detalhados. Este avanço prenuncia o enorme potencial dos agentes de IA no campo do desenvolvimento de software, especialmente na oferta de ambientes testáveis, onde a Replit é considerada líder. (Fonte: amasad, amasad, amasad)
🎯 Tendências
Unitree Robotics Acelera IPO, Focando em IA Embodied para “Fazer a IA Trabalhar”: A Unitree Robotics, unicórnio de robôs quadrúpedes, está se preparando ativamente para um IPO. O fundador Wang Xingxing enfatiza o enorme potencial da IA no nível de aplicação física, acreditando que o desenvolvimento de grandes modelos oferece uma oportunidade para a integração e aplicação da IA com robôs. Embora o desenvolvimento da IA embodied enfrente desafios como coleta de dados, fusão de dados multimodais e alinhamento de controle de modelo, Wang Xingxing está otimista quanto ao futuro, acreditando que o limiar para inovação e empreendedorismo foi significativamente reduzido e que pequenas organizações terão um poder explosivo maior. A Unitree Robotics ocupa uma posição de liderança no mercado de robôs quadrúpedes, com receita anual superior a 1 bilhão de yuans. Este IPO visa alavancar o capital para acelerar um futuro com a profunda participação de robôs. (Fonte: 36氪)

Departamento de IA da Apple Enfrenta Turbulência na Liderança, Novas Funções da Siri Atrasadas para 2026: O departamento de IA da Apple enfrenta uma onda de saídas de executivos, com o ex-chefe da Siri, Robby Walker, prestes a sair, e membros da equipe principal sendo recrutados pela Meta. Afetadas por problemas de qualidade contínuos e uma transição de arquitetura subjacente, as novas funções personalizadas da Siri serão adiadas para a primavera de 2026. Esta turbulência e atraso levantam questões sobre a velocidade de inovação e implementação da IA da Apple. Embora a empresa tenha feito movimentos frequentes em chips de servidor de IA e avaliação de modelos externos, o progresso real tem sido menor do que o esperado. (Fonte: 36氪)

mmBERT: Novos Avanços em Modelos de Codificador Multilíngues: mmBERT é um modelo de codificador pré-treinado em 3T de texto multilíngue em mais de 1800 idiomas. O modelo introduz elementos inovadores como agendamento de taxa de mascaramento inverso e taxa de amostragem de temperatura inversa, e incorporou dados de mais de 1700 idiomas de baixo recurso nas fases posteriores do treinamento, melhorando significativamente o desempenho. O mmBERT se destaca em tarefas de classificação e recuperação, tanto para idiomas de alto quanto de baixo recurso, com desempenho comparável a modelos como o o3 da OpenAI e o Gemini 2.5 Pro do Google, preenchendo uma lacuna na pesquisa de modelos de codificador multilíngues. (Fonte: HuggingFace Daily Papers)
MachineLearningLM: Um Novo Framework para LLMs Alcançarem Machine Learning no Contexto: MachineLearningLM é um framework de pré-treinamento contínuo projetado para fornecer capacidades robustas de machine learning no contexto para LLMs de uso geral (como Qwen-2.5-7B-Instruct), enquanto preserva seu conhecimento geral e habilidades de raciocínio. Ao sintetizar tarefas de ML a partir de milhões de Modelos Causais Estruturados (SCMs) e empregar prompts de token eficientes, o framework permite que o LLM processe até 1024 exemplos puramente através de Context Learning (ICL), sem a necessidade de descida de gradiente. Em tarefas de classificação tabular fora do domínio em áreas como finanças, física, biologia e medicina, o MachineLearningLM supera modelos de linha de base fortes como o GPT-5-mini em cerca de 15% em média. (Fonte: HuggingFace Daily Papers)
Meta vLLM: Um Novo Avanço na Eficiência de Inferência em Grande Escala: A implementação hierárquica do vLLM da Meta melhora significativamente a eficiência do PyTorch e do vLLM na inferência em larga escala, superando sua pilha interna em termos de latência e throughput. Ao devolver os resultados da otimização à comunidade vLLM, este avanço promete trazer soluções mais eficientes e econômicas para a inferência de IA, crucial especialmente para lidar com tarefas de inferência de grandes modelos de linguagem, impulsionando a implantação e expansão de aplicações de IA em cenários práticos. (Fonte: vllm_project)

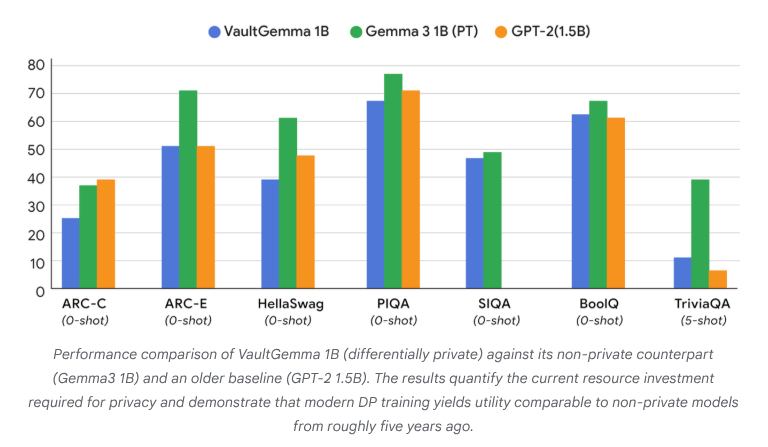
VaultGemma: Lançado o Primeiro LLM de Código Aberto com Privacidade Diferencial: O Google Research lançou o VaultGemma, o maior modelo de código aberto treinado do zero com proteção de privacidade diferencial até hoje. A pesquisa não apenas fornece os pesos e o relatório técnico do VaultGemma, mas também propõe pela primeira vez as leis de escala para modelos de linguagem com privacidade diferencial. O lançamento do VaultGemma estabelece uma base importante para a construção de modelos de IA mais seguros e responsáveis em dados sensíveis, e impulsiona o desenvolvimento de tecnologias de IA que preservam a privacidade, tornando-as mais viáveis em aplicações práticas. (Fonte: JeffDean, demishassabis)
OpenAI Aumenta Significativamente os Limites de Taxa da API para GPT-5/GPT-5-mini: A OpenAI anunciou que os limites de taxa da API para GPT-5 e GPT-5-mini foram significativamente aumentados, com alguns níveis dobrando. Por exemplo, o Tier 1 do GPT-5 aumentou de 30K TPM para 500K TPM, e o Tier 2 de 450K para 1M. O Tier 1 do GPT-5-mini também aumentou de 200K para 500K. Este ajuste melhora significativamente a capacidade dos desenvolvedores de usar esses modelos para aplicações e experimentos em larga escala, reduzindo gargalos causados por limites de taxa, e impulsionando ainda mais a aplicação comercial e o desenvolvimento do ecossistema dos modelos da série GPT-5. (Fonte: OpenAIDevs)
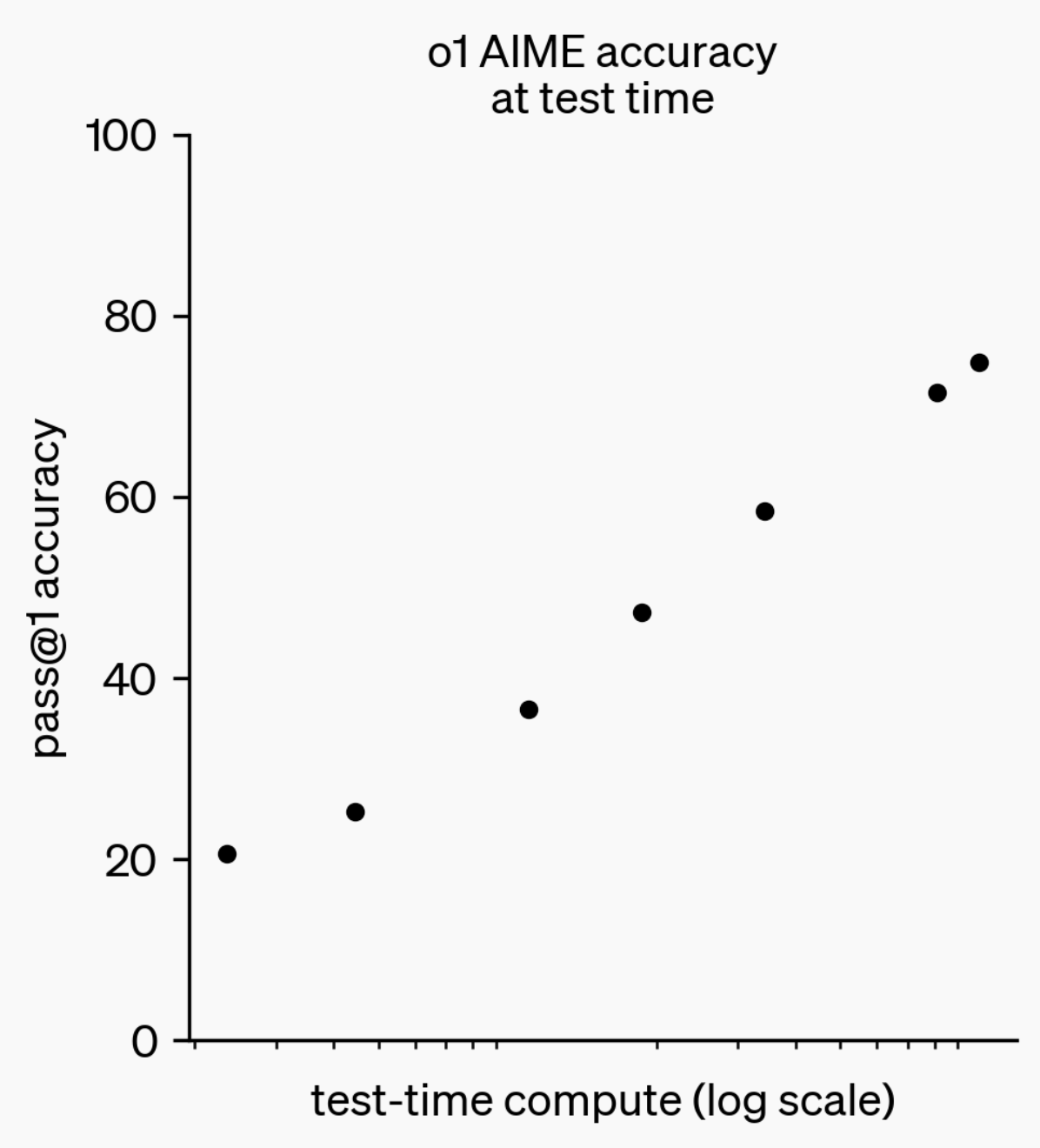
Evolução da Capacidade de Inferência de LLMs: Do o1-preview ao GPT-5 Pro: No último ano, as capacidades de inferência de Large Language Models (LLMs) fizeram progressos significativos. Desde o modelo o1-preview lançado pela OpenAI há um ano, que exigia segundos para “pensar”, até os modelos de inferência mais avançados de hoje que podem “pensar” por horas, navegar na web e escrever código, isso demonstra que a dimensão da inferência de IA está em constante expansão. Ao treinar modelos para “pensar” através de Reinforcement Learning (RL) e utilizando cadeias de pensamento (chain of thought) privadas, o desempenho dos LLMs em tarefas de inferência melhora com o aumento do tempo de “pensamento”, prenunciando que a expansão do cálculo de inferência se tornará uma nova direção para o desenvolvimento futuro de modelos. (Fonte: polynoamial, gdb)
Sakana AI do Japão: Um Unicórnio de IA Inspirado na Natureza: A startup japonesa Sakana AI atingiu uma avaliação de mais de 1 bilhão de dólares em um ano desde sua fundação, tornando-se a empresa mais rápida a alcançar o status de “unicórnio” no Japão. A empresa foi fundada por David Ha, ex-pesquisador do Google Brain, e sua abordagem de IA é inspirada na “inteligência coletiva” da natureza, visando integrar sistemas existentes, grandes e pequenos, em vez de perseguir cegamente modelos grandes e intensivos em energia. A Sakana AI já lançou o chatbot japonês offline “Tiny Sparrow” e uma IA capaz de entender a literatura japonesa, e estabeleceu uma parceria com o Mitsubishi UFJ Bank do Japão, comprometendo-se a desenvolver um “sistema de IA dedicado a bancos”. A empresa enfatiza a atração de talentos através do “soft power japonês” e a realização de experimentos ousados no campo da IA. (Fonte: SakanaAILabs)
Avanços na Robótica e Fusão com IA: Novos Progressos em Robôs Humanoides, de Enxame e Quadrúpedes: O campo da robótica está passando por avanços significativos, especialmente em robôs humanoides, robôs de enxame e robôs quadrúpedes. A interação de diálogo natural entre robôs humanoides e trabalhadores tornou-se uma realidade, robôs quadrúpedes alcançaram uma velocidade surpreendente de menos de 10 segundos em uma corrida de 100 metros, enquanto robôs de enxame demonstraram “inteligência surpreendente”. Além disso, o sistema de navegação ANT para terrenos complexos e a base de escalada autônoma projetada pela Eufy para robôs aspiradores prenunciam a aplicação mais ampla de robôs em cenários diários e industriais. A aplicação da IA em ensaios clínicos de neurociência também está se aprofundando, analisando o impacto do uso através do exoesqueleto inteligente HAPO SENSOR, demonstrando o potencial da IA no campo da saúde. (Fonte: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 Ferramentas
Atualização Qwen Code v0.0.10 & v0.0.11: Melhorando a Experiência e Eficiência do Desenvolvedor: O Alibaba Cloud Qwen Code lançou as versões v0.0.10 e v0.0.11, trazendo várias novas funcionalidades e melhorias amigáveis ao desenvolvedor. A nova versão introduz Subagents para decomposição inteligente de tarefas, uma ferramenta Todo Write para rastreamento de tarefas e uma função de resumo de projeto “Bem-vindo de volta” ao reabrir projetos. Além disso, a atualização inclui políticas de cache personalizáveis, experiência de edição mais fluida (sem loops de agente), testes de estresse de benchmark de terminal integrados, menos tentativas, leitura otimizada de arquivos de grandes projetos, integração aprimorada com IDE e shell, melhor suporte a MCP e OAuth, e gerenciamento de memória/sessão e documentação multilíngue aprimorados. Essas melhorias visam aumentar significativamente a produtividade dos desenvolvedores. (Fonte: Alibaba_Qwen)
Dicas de Uso e Melhorias na Experiência do Usuário do Claude Code: Discussões e sugestões de melhoria para a experiência do usuário do Claude Code surgem constantemente. Usuários compartilharam prompts como “adicionar informações de log apropriadas” para ajudar o agente de IA a resolver problemas de código. Um desenvolvedor lançou o aplicativo iOS “Standard Input” para Claude Code, suportando uso móvel, notificações push e chat interativo. A comunidade também discutiu a inconsistência do Claude Code ao lidar com grandes projetos e a importância do gerenciamento de contexto, sugerindo que os usuários limpem ativamente o contexto, personalizem arquivos .md do Claude e estilos de saída, usem subagentes para decompor tarefas, e aproveitem modos de planejamento e hooks para melhorar a eficiência e a qualidade do código. (Fonte: dotey, mattrickard, Reddit r/ClaudeAI)
Hugging Face e VS Code/Copilot: Integração Profunda para Capacitar Desenvolvedores: Através de seus provedores de inferência, o Hugging Face integrou centenas dos mais avançados modelos de código aberto (como Kimi K2, Qwen3 Next, gpt-oss, Aya, etc.) diretamente no VS Code e GitHub Copilot. Esta integração é suportada por parceiros como Cerebras Systems, FireworksAI, Cohere Labs, Groq Inc, oferecendo aos desenvolvedores uma seleção mais rica de modelos e destacando vantagens como pesos de código aberto, roteamento automático de múltiplos provedores, preços justos, troca de modelo sem interrupções e total transparência. Além disso, a biblioteca Transformers do Hugging Face também introduziu a funcionalidade “Continuous Batching”, simplificando os ciclos de avaliação e treinamento e aumentando a velocidade de inferência, visando ser uma poderosa caixa de ferramentas para o desenvolvimento e experimentação de modelos de IA. (Fonte: ClementDelangue, code)

AU-Harness: Um Kit de Ferramentas de Avaliação de Código Aberto Abrangente para LLMs de Áudio: AU-Harness é um framework de avaliação de código aberto eficiente e abrangente, projetado especificamente para Large Audio Language Models (LALMs). Ao otimizar o processamento em lote e a execução paralela, ele alcança um aumento de velocidade de até 127%, tornando possível a avaliação de LALMs em larga escala. Oferece um protocolo de prompt padronizado e configuração flexível para permitir uma comparação justa de modelos em diferentes cenários. O AU-Harness também introduz duas novas categorias de avaliação: LLM-Adaptive Diarization (compreensão temporal de áudio) e Spoken Language Reasoning (tarefas cognitivas complexas de fala), visando revelar as lacunas significativas dos LALMs atuais na compreensão temporal e em tarefas complexas de raciocínio de fala, e impulsionar o desenvolvimento sistemático de LALMs. (Fonte: HuggingFace Daily Papers)
AI-DO: Sistema de Detecção de Vulnerabilidades CI/CD Impulsionado por LLM: AI-DO (Automating vulnerability detection Integration for Developers’ Operations) é um sistema de recomendação integrado aos processos de Continuous Integration/Continuous Deployment (CI/CD) que utiliza o modelo CodeBERT para detectar e localizar vulnerabilidades durante a fase de revisão de código. O sistema visa preencher a lacuna entre a pesquisa acadêmica e as aplicações industriais. Através da avaliação da generalização cross-domain do CodeBERT em dados de código aberto e industriais, descobriu-se que o modelo tem um desempenho preciso dentro do mesmo domínio, mas o desempenho diminui entre domínios. Com técnicas apropriadas de subamostragem, modelos ajustados em dados de código aberto podem efetivamente melhorar as capacidades de detecção de vulnerabilidades. O desenvolvimento do AI-DO melhora a segurança nos processos de desenvolvimento sem interromper os fluxos de trabalho existentes. (Fonte: HuggingFace Daily Papers)
Replit Agent 3: Da Ideia à Aplicação em Velocidade Máxima: O Agent 3 da Replit demonstrou uma eficiência surpreendente, sendo capaz de transformar uma necessidade de aplicativo de check-in de salão no Upwork em um aplicativo completo com processo de check-in de cliente, banco de dados de clientes e painel de controle de backend em 145 minutos. O agente também possui alta autonomia, capaz de operar por 193 minutos sem intervenção, gerando código de nível de produção, incluindo autenticação, banco de dados, armazenamento e WebSocket, e até mesmo escrevendo seus próprios testes e algoritmos de classificação. Essas capacidades destacam o enorme potencial dos agentes de IA no desenvolvimento rápido de protótipos e na construção de aplicações full-stack, acelerando significativamente o processo de transformação de ideias em produtos reais. (Fonte: amasad, amasad, amasad)
Claude Adiciona Funções de Criação e Edição de Arquivos: Claude agora pode criar e editar planilhas Excel, documentos, apresentações PowerPoint e arquivos PDF diretamente em Claude.ai e no aplicativo de desktop. Esta nova funcionalidade expande significativamente os cenários de aplicação do Claude em ferramentas de escritório e produtividade diárias, permitindo que ele participe mais profundamente dos fluxos de trabalho de processamento de documentos e geração de conteúdo, melhorando a eficiência e a conveniência do usuário ao lidar com tarefas complexas de arquivos. (Fonte: dl_weekly)
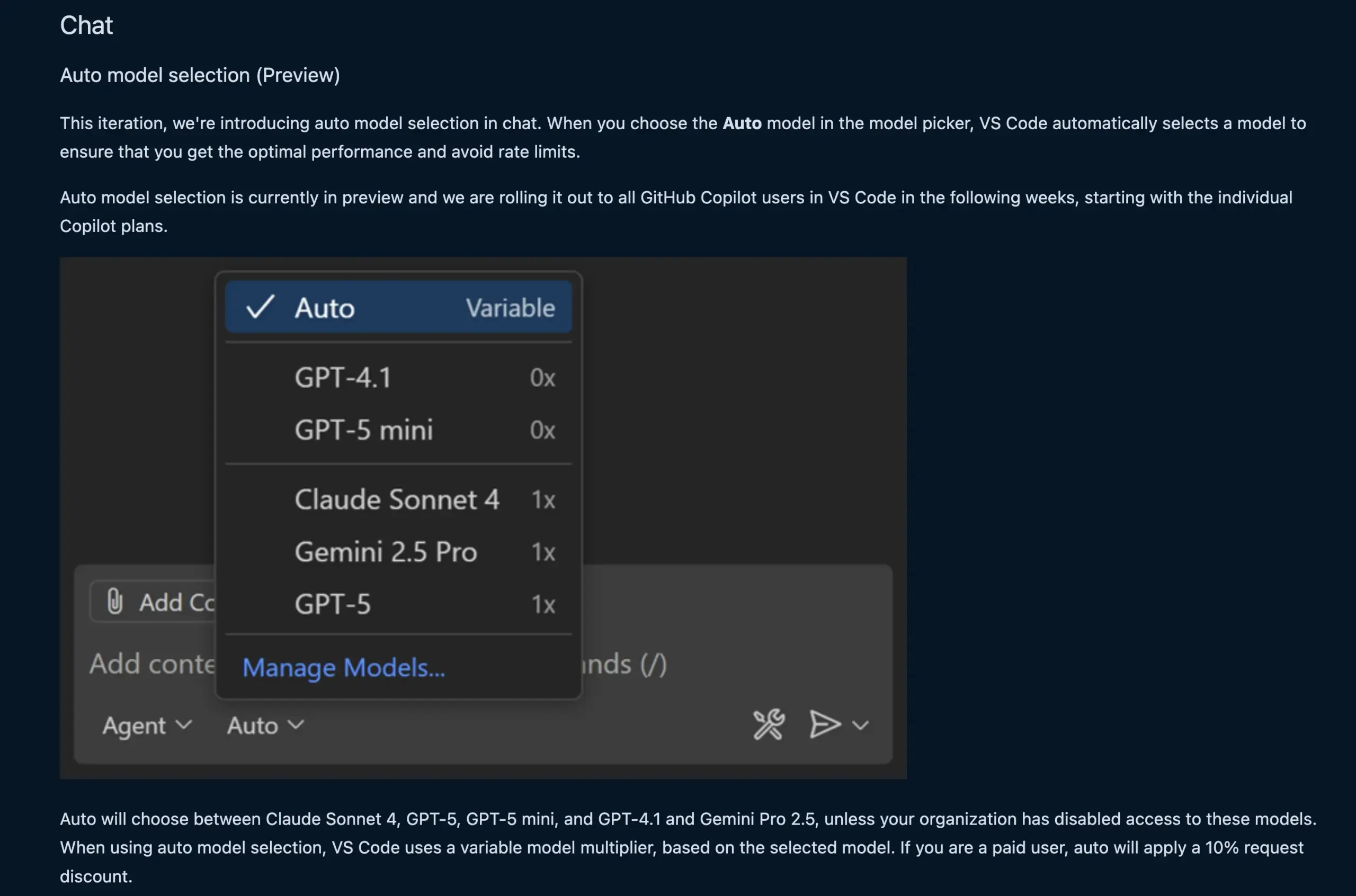
Função de Chat do VS Code Seleciona Automaticamente Modelos LLM: A nova função de chat do VS Code agora pode selecionar automaticamente o modelo LLM apropriado com base nas solicitações do usuário e nos limites de taxa. Esta função permite a troca inteligente entre modelos como Claude Sonnet 4, GPT-5, GPT-5 mini, GPT-4.1 e Gemini Pro 2.5, oferecendo aos desenvolvedores uma experiência de programação assistida por IA mais conveniente e eficiente. Ao mesmo tempo, a API de extensão do provedor de chat de modelo de linguagem do VS Code foi finalizada, permitindo a contribuição de modelos através de extensões e suportando o modo “Bring Your Own Key” (BYOK), enriquecendo ainda mais as opções de modelo e as capacidades de personalização. (Fonte: code, pierceboggan)
Box Lança Capacidades de Agente de IA para Gerenciamento de Dados Não Estruturados: A Box anunciou o lançamento de novas funcionalidades de agente de IA, projetadas para ajudar os clientes a aproveitar ao máximo o valor de seus dados não estruturados. O Box AI Studio atualizado facilita a construção de agentes de IA, aplicáveis a diversas funções de negócios e casos de uso da indústria. O Box Extract utiliza agentes de IA para extração complexa de dados de vários tipos de documentos, enquanto o Box Automate é uma nova solução de automação de fluxo de trabalho que permite aos usuários implantar agentes de IA em fluxos de trabalho de centro de conteúdo. Essas funcionalidades se integram perfeitamente aos sistemas existentes dos clientes através de integrações pré-construídas, Box API ou o novo Box MCP Server, visando transformar a forma como as empresas lidam com conteúdo não estruturado. (Fonte: hwchase17)
Novo Modelo Tab do Cursor: Melhorando a Precisão e Aceitação de Sugestões de Código: O Cursor lançou um novo modelo Tab como sua ferramenta padrão de sugestão de código. O modelo foi treinado usando Reinforcement Learning (RL) online e, em comparação com o modelo antigo, o número de sugestões de código foi reduzido em 21%, mas a taxa de aceitação das sugestões aumentou em 28%. Essa melhoria significa que o novo modelo pode fornecer sugestões de código mais precisas e alinhadas com a intenção do desenvolvedor, melhorando significativamente a eficiência da programação e a experiência do usuário, reduzindo distrações desnecessárias e permitindo que os desenvolvedores concluam tarefas de codificação de forma mais eficiente. (Fonte: BlackHC, op7418)
awesome-llm-apps: Uma Coleção de Aplicações LLM de Código Aberto: O projeto awesome-llm-apps no GitHub é aclamado como uma mina de ouro de código aberto. Ele reúne mais de 40 aplicações LLM implantáveis, cobrindo diversas áreas, desde agentes de podcast para retransmissão de blogs de IA até análise de imagens médicas. Cada aplicação vem com documentação detalhada e instruções de configuração, tornando o trabalho que antes levaria semanas para desenvolver, agora possível em minutos. Por exemplo, o projeto de guia de áudio de IA incluído, através de um sistema multiagente, pesquisa web em tempo real e tecnologia TTS, é capaz de gerar guias de áudio naturais e contextualmente relevantes, com baixo custo de API, demonstrando a praticidade dos sistemas multiagente na geração de conteúdo. (Fonte: Reddit r/MachineLearning)
📚 Aprendizagem
MMOral: Benchmark Multimodal e Conjunto de Dados de Instruções para Análise de Raios-X Panorâmicos Dentários: MMOral é o primeiro conjunto de dados de instruções e benchmark multimodal em larga escala, projetado especificamente para a interpretação de radiografias panorâmicas dentárias. O conjunto de dados contém 20.563 imagens anotadas e 1,3 milhão de instâncias de seguimento de instruções, cobrindo tarefas como extração de atributos, geração de relatórios, perguntas e respostas visuais e diálogo de imagem. O conjunto de avaliação abrangente MMOral-Bench abrange cinco dimensões-chave do diagnóstico dentário, e os resultados mostram que mesmo os melhores modelos LVLM, como o GPT-4o, atingem apenas 41,45% de precisão, destacando as limitações dos modelos existentes neste campo. O OralGPT, através do SFT no Qwen2.5-VL-7B, alcançou uma melhoria significativa de desempenho de 24,73%, estabelecendo as bases para a odontologia inteligente e sistemas de IA multimodal clínica. (Fonte: HuggingFace Daily Papers)
Avaliação Cross-Domain da Detecção de Vulnerabilidades em Transformers: Um estudo avaliou o desempenho do CodeBERT na detecção de vulnerabilidades em software industrial e de código aberto, e analisou sua capacidade de generalização cross-domain. A pesquisa descobriu que modelos treinados em dados industriais são precisos na detecção dentro do mesmo domínio, mas o desempenho diminui em código aberto. Enquanto modelos de deep learning ajustados em dados de código aberto através de técnicas apropriadas de subamostragem podem efetivamente melhorar as capacidades de detecção de vulnerabilidades. Com base nesses resultados, a equipe de pesquisa desenvolveu o sistema AI-DO, um sistema de recomendação integrado aos processos de CI/CD, capaz de detectar e localizar vulnerabilidades durante a revisão de código sem interferir nos fluxos de trabalho existentes, visando impulsionar a transição de tecnologias acadêmicas para aplicações industriais. (Fonte: HuggingFace Daily Papers)
Ego3D-Bench: Um Benchmark de Raciocínio Espacial VLM em Cenários Egocêntricos Multivistas: Ego3D-Bench é um novo benchmark projetado para avaliar as capacidades de raciocínio espacial 3D de Visual Language Models (VLMs) em dados egocêntricos e multivistas ao ar livre. O benchmark contém mais de 8.600 pares de perguntas e respostas anotados por humanos, usados para testar 16 VLMs SOTA, incluindo GPT-4o e Gemini1.5-Pro. Os resultados mostram uma lacuna significativa entre os VLMs atuais e o nível humano na compreensão espacial. Para preencher essa lacuna, a equipe de pesquisa propôs o framework de pós-treinamento Ego3D-VLM, que, ao gerar mapas cognitivos baseados em coordenadas 3D globais estimadas, melhorou o desempenho em perguntas de múltipla escolha em 12% e a estimativa de distância absoluta em 56% em média, fornecendo uma ferramenta valiosa para alcançar a compreensão espacial em nível humano. (Fonte: HuggingFace Daily Papers)
A “Ilusão de Retornos Decrescentes” na Execução de Tarefas de Longo Prazo por LLMs: Uma nova pesquisa explora o desempenho de LLMs na execução de tarefas de longo prazo, indicando que pequenas melhorias na precisão de um único passo podem levar a um crescimento exponencial no comprimento da tarefa. O artigo argumenta que a falha de LLMs em tarefas longas não se deve à falta de capacidade de raciocínio, mas sim a erros de execução. Ao fornecer explicitamente conhecimento e planos, o estudo descobriu que modelos grandes podem executar mais passos corretamente, mesmo que modelos menores atinjam 100% de precisão em um único passo. Uma descoberta interessante é que os modelos exibem um efeito de “autorregulação”, onde o modelo é mais propenso a cometer erros novamente se o contexto contiver erros anteriores, e isso não pode ser resolvido apenas pela escala do modelo. No entanto, os mais recentes “modelos de pensamento” podem evitar a autorregulação e completar tarefas mais longas em uma única execução, enfatizando os enormes benefícios da expansão da escala do modelo e do cálculo de teste sequencial para tarefas de longo prazo. (Fonte: Reddit r/ArtificialInteligence)
Estrutura Causal do Transformer: Uma Análise Aprofundada do Fluxo de Informações: Uma explicação técnica aclamada como “a melhor de sua classe” analisa profundamente a estrutura causal dos Large Language Models (LLMs) Transformer e como as informações fluem dentro deles. Esta explicação dispensa terminologia obscura, esclarecendo claramente as duas principais “autoestradas” de informação na arquitetura Transformer: o Residual Stream e o mecanismo de atenção. Através de visualizações e descrições detalhadas, ajuda pesquisadores e desenvolvedores a entender melhor o funcionamento interno do Transformer, permitindo decisões mais informadas no design, otimização e depuração de modelos, de grande valor para uma compreensão aprofundada dos mecanismos subjacentes dos LLMs. (Fonte: Plinz)
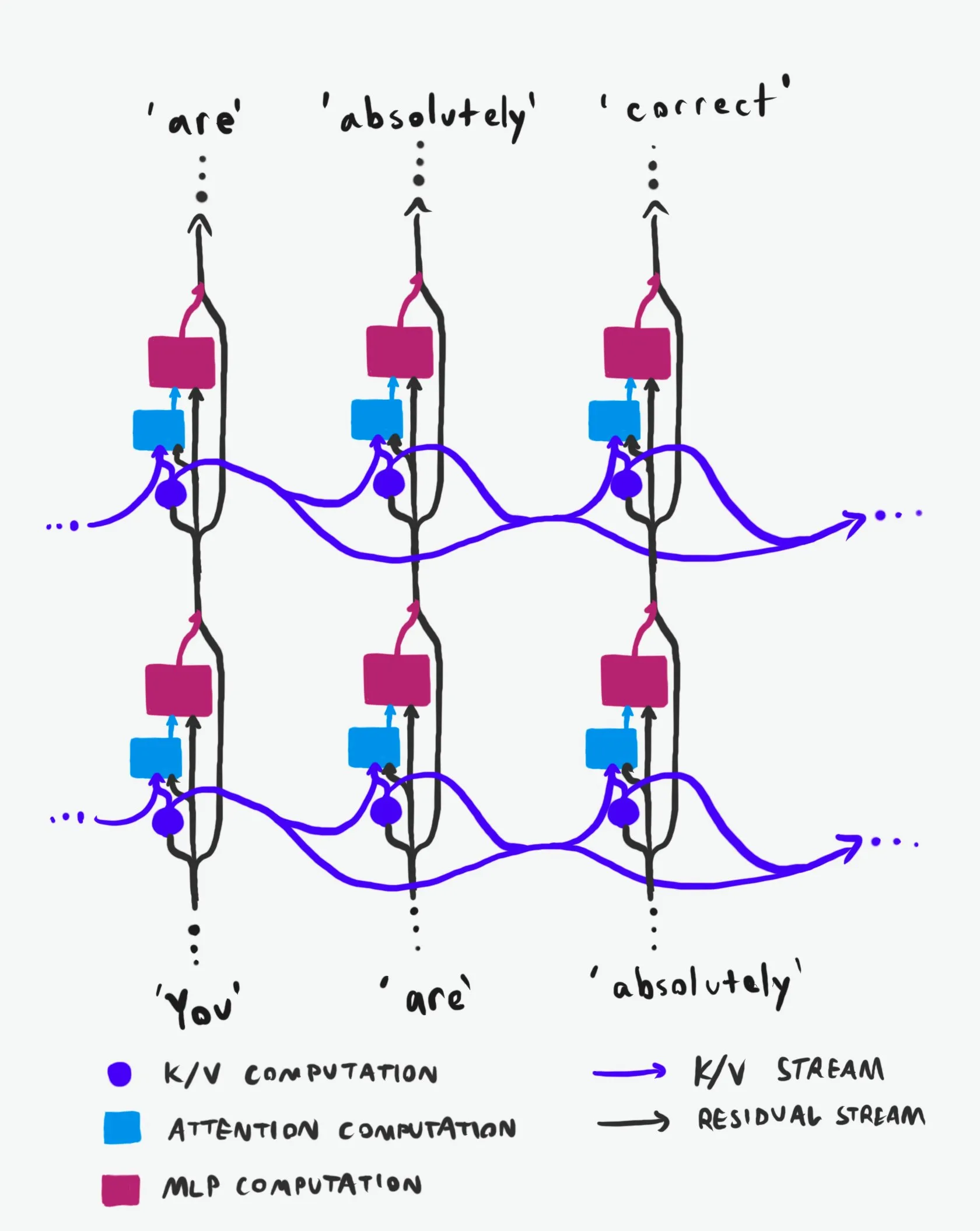
Carnegie Mellon University Lança Novo Curso de Inferência de LM: @gneubig e @Amanda Bertsch da Carnegie Mellon University (CMU) co-ministrarão um novo curso sobre inferência de Language Models (LM) neste outono. O curso visa fornecer uma introdução abrangente ao campo da inferência de LM, cobrindo desde algoritmos de decodificação clássicos até os métodos mais recentes de LLM, e uma série de trabalhos focados na eficiência. O conteúdo do curso será publicado online, incluindo vídeos das quatro primeiras aulas, oferecendo um recurso de aprendizado valioso para estudantes e pesquisadores interessados em inferência de LM, ajudando-os a dominar as técnicas e práticas de inferência de ponta. (Fonte: lateinteraction, dejavucoder, gneubig)
OpenAIDevs Lança Vídeo de Análise Aprofundada do Codex: OpenAIDevs lançou um vídeo de análise aprofundada do Codex, detalhando as mudanças e as últimas funcionalidades do Codex nos últimos dois meses. O vídeo oferece dicas e melhores práticas para aproveitar ao máximo o Codex, visando ajudar os desenvolvedores a entender e usar melhor esta poderosa ferramenta de programação de IA. O conteúdo abrange os últimos avanços do Codex em geração de código, depuração e desenvolvimento assistido, sendo um recurso de aprendizado importante para desenvolvedores que desejam melhorar a eficiência da programação assistida por IA. (Fonte: OpenAIDevs)
Relatório do Estado do Mercado de GPU em Nuvem em 2025: A dstackai publicou um relatório sobre o estado do mercado de GPU em nuvem em 2025, cobrindo custos, desempenho e estratégias de uso. O relatório analisa detalhadamente os preços atuais do mercado, configurações de hardware e desempenho, fornecendo insights de mercado específicos e referências para engenheiros de machine learning na escolha de provedores de serviços em nuvem, complementando guias gerais sobre como escolher provedores de nuvem em engenharia de machine learning, com grande valor orientador para otimizar custos e eficiência de treinamento e inferência de IA. (Fonte: stanfordnlp)
Panorama do Hardware de IA: Unidades de Computação Diversificadas que Impulsionam a IA: The Turing Post publicou um guia de hardware que impulsiona a IA, detalhando várias unidades de computação como GPU, TPU, CPU, ASICs, NPU, APU, IPU, RPU, FPGA, processadores quânticos, chips de Processamento In-Memory (PIM) e chips neuromórficos. O guia explora profundamente o papel, as vantagens e os cenários de aplicação de cada hardware na computação de IA, ajudando os leitores a compreender completamente o suporte de poder computacional subjacente da pilha de tecnologia de IA, com importante valor de referência para a seleção de hardware e o design de sistemas de IA. (Fonte: TheTuringPost)
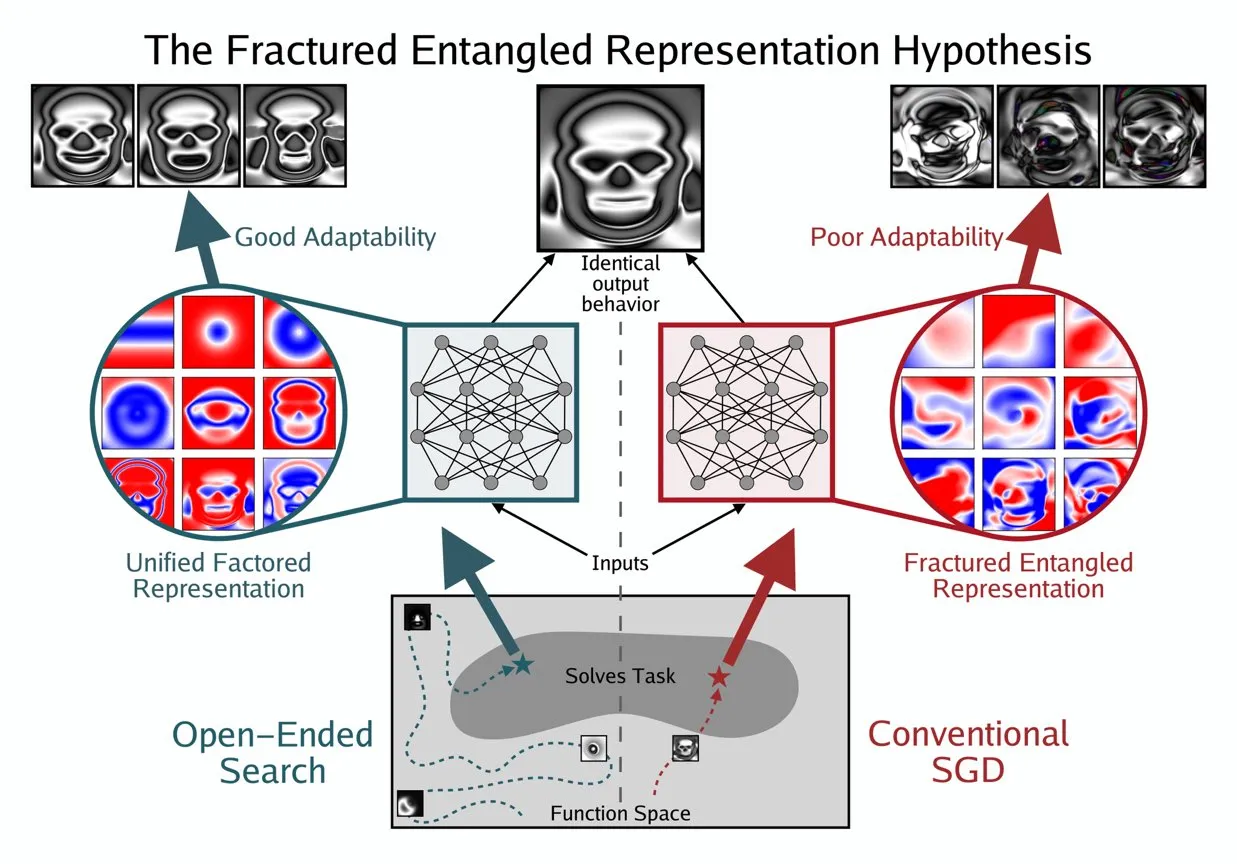
Kenneth Stanley Propõe o Conceito de UFR para Entender a “Verdadeira Compreensão” da IA: Kenneth Stanley propôs o conceito de “Unified Factored Representation” (UFR) para ajudar a explicar o significado da “verdadeira compreensão” da IA. Ele acredita que, quando as pessoas falam sobre a “verdadeira compreensão” da IA, o cerne está na UFR. Este conceito visa fornecer uma estrutura teórica mais profunda para as capacidades cognitivas da IA, indo além do mero reconhecimento de padrões, abordando a capacidade da IA de estruturar, decompor e formar restrições rígidas sobre o mundo, incentivando a IA não apenas a imitar o conhecimento, mas também a pensar criativamente e resolver problemas novos como os humanos. (Fonte: hardmaru, hardmaru)
💼 Negócios
Tencent Teria Recrutado Pesquisador Sênior da OpenAI, Intensificando a Guerra por Talentos em IA: De acordo com a Bloomberg, o pesquisador sênior da OpenAI, Yao Shunyu, deixou a empresa e se juntou à gigante tecnológica chinesa Tencent. Este incidente destaca a crescente intensidade da guerra global por talentos em IA, especialmente entre os Estados Unidos e a China. O fluxo de pesquisadores de IA de ponta não apenas afeta as rotas de desenvolvimento tecnológico de várias empresas, mas também reflete a intensa concorrência por inovação no campo da IA, prenunciando que o futuro cenário da IA pode mudar devido ao fluxo de talentos. (Fonte: The Verge)
OpportuNext Busca Co-fundador Técnico para Plataforma de Recrutamento de IA: OpportuNext, uma plataforma de recrutamento impulsionada por IA fundada por ex-alunos do IIT Bombay, está procurando um co-fundador técnico. A plataforma visa resolver os pontos problemáticos de candidatos e empregadores no recrutamento através de análise abrangente de currículos, pesquisa semântica de vagas, roteiros de lacunas de habilidades e pré-avaliações, com um mercado-alvo de 262 milhões de dólares na Índia e planos de expansão para um mercado global de 40,5 bilhões de dólares. A OpportuNext já validou o Product-Market Fit e completou um protótipo de parser de currículos, com planos de concluir a rodada de financiamento Série A em meados de 2026. A posição exige forte experiência em AI/ML (NLP), desenvolvimento full-stack, infraestrutura de dados, web scraping/APIs e DevOps/Segurança. (Fonte: Reddit r/deeplearning)
Larry Ellison, Fundador da Oracle: Inferência é a Chave para a Rentabilidade da IA: Larry Ellison, fundador da Oracle, afirmou: “A inferência é onde o dinheiro está na IA”. Ele acredita que os enormes investimentos atuais no treinamento de modelos acabarão se traduzindo em vendas de produtos, e esses produtos dependem principalmente das capacidades de inferência. Ellison enfatiza que a Oracle está na vanguarda do aproveitamento da demanda por inferência, prenunciando que a narrativa da indústria de IA está mudando de “quem pode treinar o maior modelo” para “quem pode fornecer serviços de inferência de forma eficiente, confiável e em escala”. Essa perspectiva desencadeou discussões sobre a futura direção do modelo econômico da IA, ou seja, se os serviços de inferência dominarão a estrutura de receita futura. (Fonte: Reddit r/MachineLearning)
🌟 Comunidade
Ética e Segurança da IA: Desafios Multidimensionais e Colaboração: A comunidade discutiu amplamente os desafios éticos e de segurança trazidos pela IA, incluindo o impacto potencial da IA no mercado de trabalho e estratégias de proteção, preocupações com a privacidade e segurança da ferramenta ChatGPT MCP, e sérios debates sobre o risco de extinção que a IA pode causar. Problemas de saúde mental causados pela IA, como a dependência excessiva dos usuários em relação à IA, levando até a “psicose de IA” e sentimentos de solidão, também estão recebendo crescente atenção. As discussões sobre a regulamentação da IA (como o projeto de lei de Ted Cruz) continuam. O lado positivo é que empresas como Anthropic e OpenAI estão colaborando com agências de segurança para descobrir e corrigir vulnerabilidades de modelos em conjunto, a fim de fortalecer a proteção de segurança da IA. (Fonte: Ronald_vanLoon, dotey, williawa, Dorialexander, Reddit r/ArtificialInteligence, Reddit r/artificial, sleepinyourhat, EthanJPerez)

Desempenho e Avaliação de LLMs: Qualidade do Modelo e Controvérsias de Benchmark: A comunidade discutiu profundamente a avaliação de desempenho e as questões de qualidade dos modelos LLM. Modelos como o K2-Think foram questionados devido a falhas nos métodos de avaliação (como contaminação de dados e comparações injustas), levantando preocupações sobre a confiabilidade dos benchmarks de IA existentes. Pesquisas indicam que LLMs, como anotadores de dados, podem introduzir vieses, levando ao “LLM Hacking” de resultados científicos. A experiência dos usuários com o Claude Code é mista, refletindo desafios em consistência e “preguiça”, e a Anthropic também reconheceu e corrigiu problemas de degradação de desempenho no Claude Sonnet 4. Ao mesmo tempo, o GPT-5 Pro recebeu elogios por suas poderosas capacidades de inferência, mas alguns usuários também observaram a ubiquidade do texto gerado por IA e a preocupação contínua com a confiabilidade do modelo (como bugs de inferência). (Fonte: Grad62304977, rao2z, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, npew, kchonyc, dejavucoder, vikhyatk)
O Futuro do Trabalho e Agentes de IA: Aumento da Eficiência e Transformação de Carreiras: Agentes de IA estão transformando profundamente a forma como trabalhamos. Especialistas em suas áreas (como advogados, médicos, engenheiros) podem expandir seus serviços profissionais injetando conhecimento pessoal em agentes de IA, permitindo que a receita não seja mais limitada por cobranças por hora. O CEO da Replit, Amjad Masad, prevê que agentes de IA gerarão software sob demanda, tornando o valor do software tradicional próximo de zero e remodelando a forma como as empresas são construídas. A comunidade discutiu a importância do espírito empreendedor e da adaptabilidade na era da IA, as vantagens únicas da Replit no desenvolvimento de agentes (como ambientes testáveis), e a comparação da eficiência de modelos robóticos com o cérebro humano. Além disso, o potencial do Cursor como ambiente de Reinforcement Learning também atraiu atenção, prenunciando que a IA aumentará ainda mais a produtividade de indivíduos e organizações. (Fonte: amasad, amasad, amasad, fabianstelzer, amasad, lateinteraction, Dorialexander, dwarkesh_sp, sarahcat21)
Ecossistema de Código Aberto e Colaboração: Popularização de Modelos e Necessidades da Comunidade: O Hugging Face desempenha um papel central no ecossistema de IA, e suas vantagens de plataforma modular, padronizada e integrada fornecem aos desenvolvedores uma rica variedade de ferramentas e modelos, reduzindo a barreira para a construção de IA. A discussão da comunidade afirmou o projeto Apple MLX e suas contribuições de código aberto para a melhoria da eficiência de hardware. Ao mesmo tempo, a comunidade também apelou ativamente à equipe Qwen para fornecer suporte GGUF para o modelo Qwen3-Next, a fim de permitir que sua arquitetura personalizada seja executada em frameworks de inferência local mais amplos, como llama.cpp, atendendo à demanda da comunidade por popularização e facilidade de uso de modelos, e impulsionando o desenvolvimento futuro da tecnologia de IA de código aberto. (Fonte: ClementDelangue, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
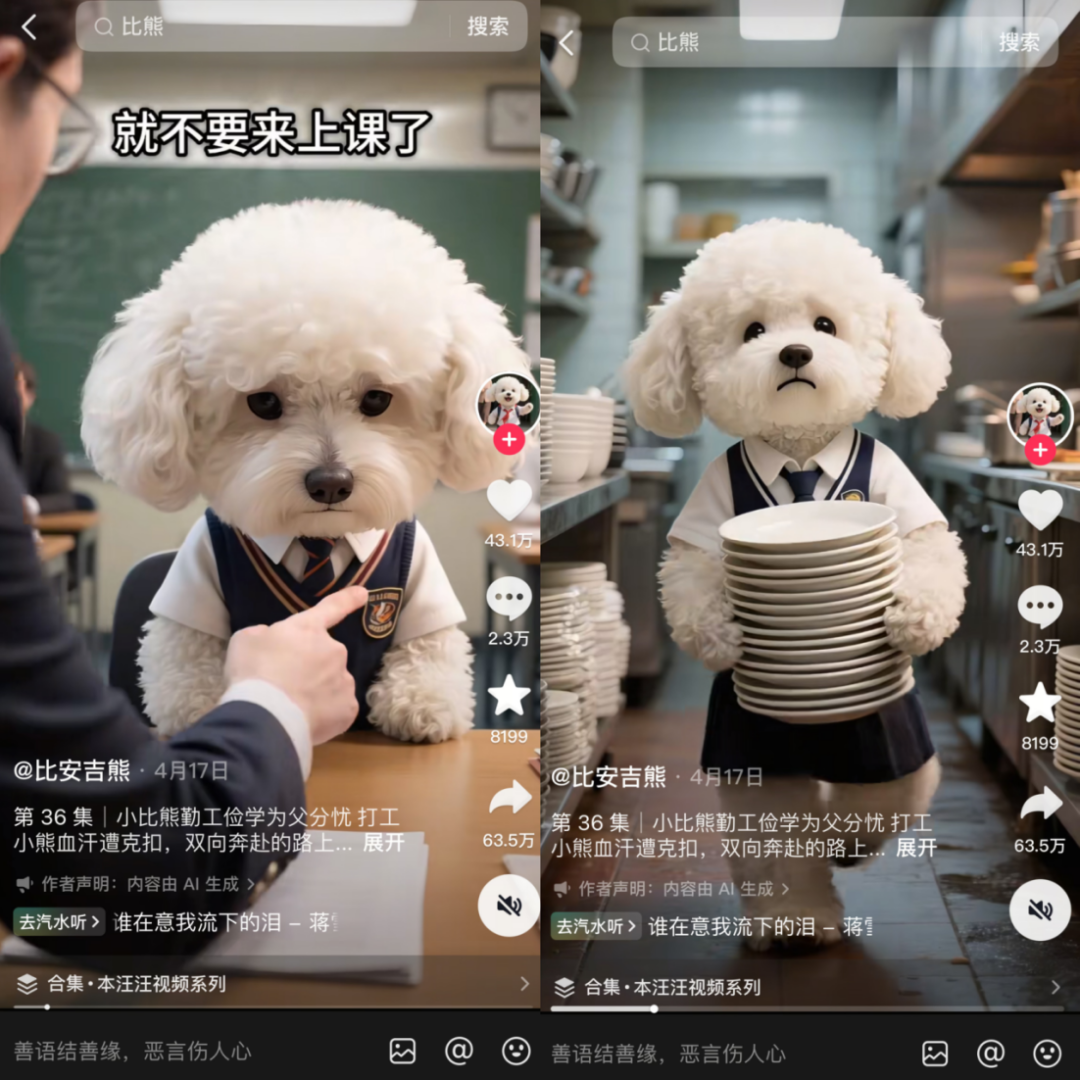
Impacto Social Abrangente da IA: Manifestações Diversificadas do Entretenimento à Economia: A IA está permeando a sociedade de várias formas. Minisséries de animais de estimação com IA se tornaram virais nas redes sociais devido à sua narrativa antropomórfica e valor emocional, demonstrando o enorme potencial da IA na criação de conteúdo e entretenimento, atraindo um grande número de jovens usuários e gerando novos modelos de negócios. Ao mesmo tempo, as discussões sobre o fluxo de capital entre gigantes da IA (como OpenAI e Oracle) provocaram reflexões sobre o modelo econômico da IA. A comunidade também explorou o potencial da IA na resolução de problemas de recursos (como recursos hídricos) e a sugestão de que os chatbots de IA precisam de mais conteúdo visual para melhorar a experiência do usuário. Além disso, a aplicação da IA nas redes sociais também gerou discussões sobre seu impacto nas emoções e cognição sociais. (Fonte: 36氪, Yuchenj_UW, kylebrussell, brickroad7)
Curiosidades e Observações da Comunidade de IA: Expectativas Personalizadas e Reflexões Humorísticas dos Usuários sobre IA: A comunidade de IA está repleta de observações únicas e reflexões humorísticas sobre o desenvolvimento tecnológico e a experiência do usuário. Por exemplo, a associação entre códigos de desconto de assinatura da OpenAI e o comportamento de “pensar” gerou discussões sobre o valor e o custo da IA. Usuários desejam que o Claude Code tenha respostas mais personalizadas e até mesmo atribuam “personalidade” à IA, refletindo uma profunda necessidade de experiências de interação com a IA. Ao mesmo tempo, a ideia de agentes de IA sendo treinados com Reinforcement Learning em ambientes simulados (como GTA-6) também demonstra a imaginação ilimitada da comunidade sobre o futuro da IA. Essas discussões não apenas fornecem insights sobre o estado atual da tecnologia de IA, mas também refletem as emoções e expectativas dos usuários ao interagir com a IA. (Fonte: gneubig, jonst0kes, scaling01)
💡 Outros
Guia para Dominar Habilidades de IA em 2025: Com o rápido desenvolvimento da tecnologia de inteligência artificial, dominar as principais habilidades de IA é crucial para o desenvolvimento da carreira individual. Um guia de habilidades de IA para 2025 destaca 12 habilidades essenciais a serem dominadas nas áreas de inteligência artificial, machine learning e deep learning. Essas habilidades abrangem desde a teoria fundamental até aplicações práticas, visando ajudar profissionais e estudantes a se adaptarem às novas demandas de talentos da era da IA e aprimorar sua competitividade na inovação tecnológica e no mercado de trabalho. (Fonte: Ronald_vanLoon)

Mercado de GPU em Nuvem 2025: Relatório sobre Custos, Desempenho e Estratégias de Implantação: A dstackai publicou um relatório detalhado sobre o estado atual do mercado de GPU em nuvem em 2025, analisando profundamente os custos de GPU, o desempenho e as estratégias de implantação de diferentes provedores de serviços em nuvem. O relatório visa fornecer orientação específica para engenheiros de machine learning e empresas na escolha de provedores de nuvem, ajudando-os a otimizar a configuração de recursos para tarefas de treinamento e inferência de IA e, assim, nas crescentes demandas por infraestrutura de IA, tomar decisões mais econômicas e com vantagens de desempenho. (Fonte: stanfordnlp)
Visão Geral da Tecnologia de Hardware de IA: Unidades de Computação Diversificadas que Impulsionam o Futuro Inteligente: The Turing Post publicou um guia abrangente de hardware de IA, detalhando as várias unidades de computação que atualmente impulsionam a inteligência artificial. Inclui Unidades de Processamento Gráfico (GPU), Unidades de Processamento de Tensor (TPU), Unidades de Processamento Central (CPU), Circuitos Integrados de Aplicação Específica (ASICs), Unidades de Processamento Neural (NPU), Unidades de Processamento Acelerado (APU), Unidades de Processamento Inteligente (IPU), Unidades de Processamento Resistivo (RPU), Field-Programmable Gate Arrays (FPGA), processadores quânticos, Processamento In-Memory (PIM) e chips neuromórficos. Este guia oferece uma perspectiva clara para entender o suporte de hardware subjacente da pilha de tecnologia de IA, ajudando desenvolvedores e pesquisadores a selecionar as soluções de hardware mais adequadas para suas cargas de trabalho de IA. (Fonte: TheTuringPost)
Kenneth Stanley Propõe o Conceito de UFR para Entender a “Verdadeira Compreensão” da IA: Kenneth Stanley propôs o conceito de “Unified Factored Representation” (UFR) para ajudar a explicar o significado da “verdadeira compreensão” da IA. Ele acredita que, quando as pessoas falam sobre a “verdadeira compreensão” da IA, o cerne está na UFR. Este conceito visa fornecer uma estrutura teórica mais profunda para as capacidades cognitivas da IA, indo além do mero reconhecimento de padrões, abordando a capacidade da IA de estruturar, decompor e formar restrições rígidas sobre o mundo, incentivando a IA não apenas a imitar o conhecimento, mas também a pensar criativamente e resolver problemas novos como os humanos. (Fonte: hardmaru, hardmaru)