
Palavras-chave:Proteção por IA, Arte digital, LightShed, Glaze, Nightshade, Regulação de IA, Energia limpa, Vantagem energética da China, Proteção de direitos autorais de arte digital, Remoção de dados de treinamento de IA, Política de regulação de IA dos EUA, Modelo Kimi K2 MoE, LLM de geração de código Mercury
🔥 Em Destaque
Ferramenta LightShed enfraquece a proteção de IA da arte digital: A nova tecnologia LightShed pode identificar e remover o “veneno” adicionado à arte digital por ferramentas como Glaze e Nightshade, tornando as obras de arte mais fáceis de serem usadas para treinar modelos de IA. Isso gerou preocupações entre os artistas sobre a proteção de direitos autorais de seus trabalhos e destacou a batalha contínua entre o treinamento de IA e a proteção de direitos autorais. Os pesquisadores dizem que o objetivo do LightShed não é roubar arte, mas alertar as pessoas contra uma falsa sensação de segurança com as ferramentas de proteção existentes e encorajar a exploração de métodos de proteção mais eficazes. (Fonte: MIT Technology Review)

Nova era de regulamentação da IA: Senado dos EUA rejeita moratória na regulamentação da IA: O Senado dos EUA rejeitou uma moratória de 10 anos na regulamentação da IA em nível estadual, o que é visto como uma vitória para os defensores da regulamentação da IA e pode sinalizar uma mudança política mais ampla. Um número crescente de políticos está se concentrando nos riscos da IA não regulamentada e se inclinando para medidas regulatórias mais rígidas. Este evento prenuncia uma nova era política no campo da regulamentação da IA, com mais discussões e legislação sobre regulamentação da IA prováveis no futuro. (Fonte: MIT Technology Review)
Dominância da China no setor de energia: A China está dominando as tecnologias de energia da próxima geração, investindo pesadamente em energia eólica, solar, veículos elétricos, armazenamento de energia e energia nuclear, e já alcançou resultados notáveis. Enquanto isso, a legislação recentemente aprovada nos EUA cortou créditos, dotações e empréstimos para tecnologias de energia limpa, o que pode retardar seu desenvolvimento no setor de energia e consolidar ainda mais a liderança da China nesse campo. Especialistas acreditam que os EUA estão abandonando sua liderança no desenvolvimento de tecnologias energéticas críticas para o futuro. (Fonte: MIT Technology Review)

🎯 Tendências
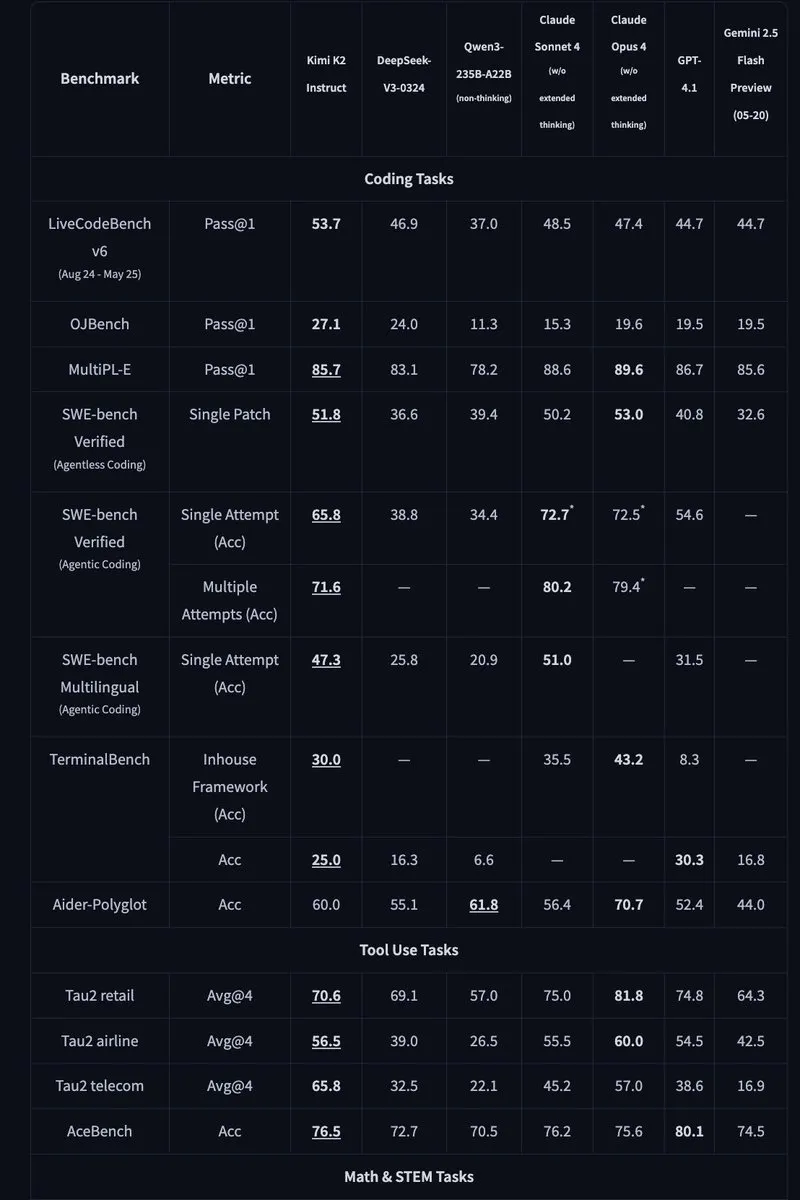
Kimi K2: Modelo MoE de código aberto com 1 trilhão de parâmetros lançado: Moonshot AI lançou o Kimi K2, um modelo MoE de código aberto com 1 trilhão de parâmetros, dos quais 32 bilhões são ativados. O modelo é otimizado para tarefas de código e agente e alcançou desempenho de última geração em benchmarks como HLE, GPQA, AIME 2025 e SWE. O Kimi K2 oferece versões de modelo básico e de ajuste fino de instruções e suporta mecanismos de inferência como vLLM, SGLang e KTransformers. (Fonte: Reddit r/LocalLLaMA, HuggingFace, X)
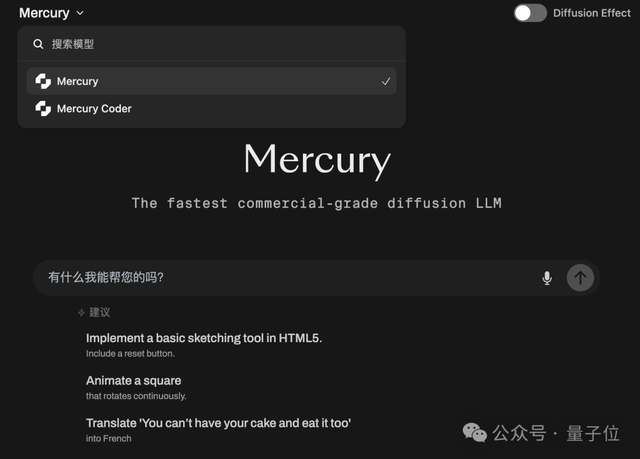
Mercury: LLM de geração de código rápida baseado em difusão: A Inception Labs lançou o Mercury, um LLM de nível comercial baseado em difusão para geração de código. O Mercury prevê tokens em paralelo, gerando código 10 vezes mais rápido que os modelos autorregressivos e atingindo uma taxa de transferência de 1109 tokens/segundo em GPUs NVIDIA H100. Ele também possui recursos de modificação de correção de erros dinâmicos, melhorando efetivamente a precisão e a usabilidade do código. (Fonte: 量子位, HuggingFace Daily Papers)
vivo lança modelo multimodal BlueLM-2.5-3B no dispositivo: vivo AI Lab lançou o BlueLM-2.5-3B, um modelo multimodal de 3B parâmetros para implantação no dispositivo. O modelo pode entender a interface GUI, suporta alternância entre modos de pensamento longo e curto e introduz um mecanismo de controle de orçamento de pensamento. Ele teve um bom desempenho em mais de 20 tarefas de avaliação, com capacidades de compreensão de texto e multimodal líderes entre modelos de escala semelhante, e sua capacidade de compreensão de GUI também é superior à de produtos semelhantes. (Fonte: 量子位, HuggingFace Daily Papers)
Feishu atualiza recursos de IA de tabela multidimensional e perguntas e respostas de conhecimento: Feishu lançou recursos atualizados de tabela multidimensional e perguntas e respostas de conhecimento de IA, melhorando significativamente a eficiência do trabalho. A tabela multidimensional suporta a criação de quadros de projetos por arrastar e soltar, a capacidade do formulário ultrapassa 10 milhões de linhas e pode ser conectada a modelos de IA externos para análise de dados. As perguntas e respostas de conhecimento do Feishu podem integrar todos os documentos internos da empresa, fornecendo serviços mais abrangentes de recuperação de informações e perguntas e respostas. (Fonte: 量子位)
Meta AI propõe “modelo de mundo mental”: Meta AI divulgou um relatório propondo o conceito de “modelo de mundo mental”, colocando a inferência sobre os estados mentais humanos em pé de igualdade com os modelos do mundo físico. O modelo visa permitir que a IA compreenda as intenções, emoções e relacionamentos sociais humanos, melhorando assim a interação humano-computador e a interação multiagente. Atualmente, a taxa de sucesso do modelo em tarefas como inferência de objetivos ainda precisa ser melhorada. (Fonte: 量子位, HuggingFace Daily Papers)

🧰 Ferramentas
Agentic Document Extraction Python Library: LandingAI lançou a biblioteca Python Agentic Document Extraction, que pode extrair dados estruturados de documentos visualmente complexos (como tabelas, imagens e gráficos) e retornar JSON com localizações precisas dos elementos. A biblioteca suporta documentos longos, novas tentativas automáticas, paginação, depuração visual e outros recursos, simplificando o processo de extração de dados de documentos. (Fonte: GitHub Trending)
📚 Aprendizado
Geometry Forcing: Um artigo sobre Geometry Forcing, um método que combina modelos de difusão de vídeo com representações 3D para modelagem de mundo consistente. O estudo descobriu que os modelos de difusão de vídeo treinados apenas em dados de vídeo bruto geralmente não conseguem capturar estruturas geométricas significativas em suas representações aprendidas. O Geometry Forcing incentiva os modelos de difusão de vídeo a internalizar representações 3D latentes, alinhando as representações intermediárias do modelo com os recursos de um modelo básico de geometria pré-treinado. (Fonte: HuggingFace Daily Papers)
Machine Bullshit: Um artigo sobre “Machine Bullshit” explora o desprezo pela verdade exibido por grandes modelos de linguagem (LLMs). O estudo introduz um “índice de besteira” para quantificar o desprezo de um LLM pela verdade e propõe uma taxonomia analisando quatro formas qualitativas de besteira: conversa fiada, evasivas, ambiguidades e afirmações não comprovadas. O estudo descobriu que o ajuste fino do modelo com aprendizado por reforço de feedback humano (RLHF) exacerba significativamente a besteira, enquanto os prompts da cadeia de pensamento (CoT) no tempo de inferência amplificam formas específicas de besteira. (Fonte: HuggingFace Daily Papers)
LangSplatV2: Um artigo sobre LangSplatV2, que atinge splatting rápido de recursos de alta dimensão, 42 vezes mais rápido que o LangSplat. LangSplatV2 remove a necessidade de decodificadores pesados, tratando cada gaussiana como um código esparso em um dicionário global e alcança splatting de coeficiente esparso eficiente por meio de otimizações CUDA. (Fonte: HuggingFace Daily Papers)
Skip a Layer or Loop it?: Um artigo sobre adaptação de profundidade no tempo de teste de LLMs pré-treinados. O estudo descobriu que as camadas de LLMs pré-treinados podem ser operadas como módulos independentes para construir modelos melhores ou até mais rasos, personalizados para cada amostra de teste. Cada camada pode ser ignorada/podada ou repetida várias vezes, formando uma Cadeia de Camadas (CoLa) por amostra. (Fonte: HuggingFace Daily Papers)
OST-Bench: Um artigo sobre OST-Bench, um benchmark para avaliar as habilidades de compreensão de cenas espaço-temporais online de MLLMs. OST-Bench destaca a necessidade de processar e raciocinar sobre observações adquiridas incrementalmente e exige a combinação da entrada visual atual com a memória histórica para suportar o raciocínio espacial dinâmico. (Fonte: HuggingFace Daily Papers)
Token Bottleneck: Um artigo sobre Token Bottleneck (ToBo), um pipeline de aprendizado autossupervisionado simples que comprime uma cena em um token de gargalo e prevê cenas subsequentes usando patches mínimos como prompts. ToBo facilita o aprendizado de representações de cenas sequenciais, codificando conservadoramente a cena de referência em um token de gargalo compacto. (Fonte: HuggingFace Daily Papers)
SciMaster: Um artigo sobre SciMaster, uma infraestrutura que visa ser um agente de IA científica de propósito geral. Sua capacidade é validada alcançando desempenho de ponta no “Human Last Exam” (HLE). SciMaster introduz o X-Master, um agente de raciocínio aumentado por ferramentas projetado para imitar pesquisadores humanos, interagindo flexivelmente com ferramentas externas durante seu processo de raciocínio. (Fonte: HuggingFace Daily Papers)
Multi-Granular Spatio-Temporal Token Merging: Um artigo sobre fusão de tokens espaço-temporais multigranulares para aceleração sem treinamento de LLMs de vídeo. O método explora redundâncias espaciais e temporais locais em dados de vídeo, primeiro convertendo cada quadro em tokens espaciais multigranulares usando uma pesquisa de grosso a fino e, em seguida, executando fusão par a par direcionada ao longo da dimensão temporal. (Fonte: HuggingFace Daily Papers)
T-LoRA: Um artigo sobre T-LoRA, uma estrutura de adaptação de baixa classificação relacionada ao passo de tempo, especificamente projetada para personalização de modelos de difusão. T-LoRA incorpora duas inovações principais: 1) uma estratégia de ajuste fino dinâmico que adapta as atualizações de restrição de classificação com base no passo de tempo de difusão; 2) uma técnica de parametrização de peso que garante a independência entre os componentes do adaptador por meio da inicialização ortogonal. (Fonte: HuggingFace Daily Papers)
Beyond the Linear Separability Ceiling: Um artigo sobre ir além do teto de separabilidade linear. O estudo descobriu que a maioria dos modelos de linguagem visual (VLMs) de última geração parecem estar limitados pela separabilidade linear de seus embeddings visuais em tarefas de raciocínio abstrato. Este trabalho investiga esse “gargalo de raciocínio linear” introduzindo o Linear Separability Ceiling (LSC), o desempenho de um classificador linear simples nos embeddings visuais do VLM. (Fonte: HuggingFace Daily Papers)
Growing Transformers: Um artigo sobre Growing Transformers explora uma abordagem construtiva para a construção de modelos, construída sobre embeddings de entrada determinísticos não treináveis. O estudo mostra que essa base de representação fixa atua como uma “porta de encaixe” universal, permitindo dois paradigmas de escala poderosos e eficientes: composição modular perfeita e crescimento hierárquico progressivo. (Fonte: HuggingFace Daily Papers)
Emergent Semantics Beyond Token Embeddings: Um artigo sobre semântica emergente além dos embeddings de token. O estudo constrói modelos Transformer com camadas de embedding totalmente congeladas, cujos vetores não são derivados de dados, mas da estrutura visual dos glifos Unicode. Os resultados mostram que a semântica de alto nível não é inerente aos embeddings de entrada, mas sim uma propriedade emergente da arquitetura composicional do Transformer e da escala dos dados. (Fonte: HuggingFace Daily Papers)
Re-Bottleneck: Um artigo sobre Re-Bottleneck, uma estrutura pós-hoc para modificar o gargalo de autoencoders pré-treinados. O método introduz um “Re-Bottleneck”, um gargalo interno treinado apenas com perdas de espaço latente para incutir uma estrutura definida pelo usuário. (Fonte: HuggingFace Daily Papers)
Stanford CS336: Language Modeling from Scratch: Stanford lançou online as palestras mais recentes do curso CS336 “Modelagem de linguagem do zero”. (Fonte: X)
💼 Negócios
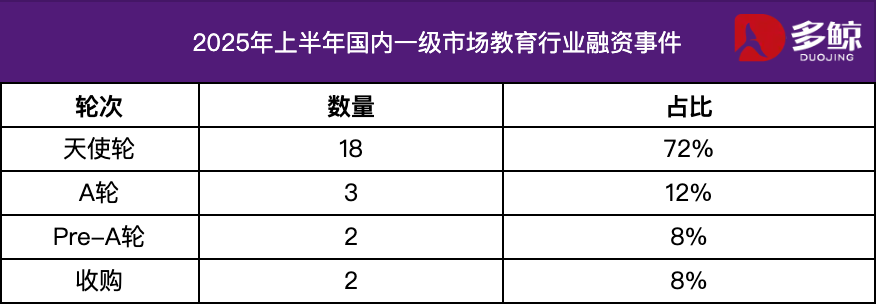
Análise de investimento e financiamento do setor de educação no primeiro semestre de 2025: No primeiro semestre de 2025, o mercado de investimento e financiamento do setor de educação permaneceu ativo, com a profunda integração da tecnologia de IA com a educação se tornando a principal tendência. Houve mais de 25 eventos de financiamento doméstico, com um montante total de financiamento de ¥ 1,2 bilhão, e os projetos da rodada anjo representaram mais de 72%. Áreas segmentadas como IA + educação, educação infantil e educação profissional receberam muita atenção. O mercado externo apresentou a característica de “esforço em ambas as extremidades”, com plataformas maduras como Grammarly recebendo grandes rodadas de financiamento, enquanto projetos em estágio inicial como Polymath também receberam suporte de rodadas de sementes. (Fonte: 36氪)
Varda recebe US$ 187 milhões em financiamento para farmacêutica espacial: Varda recebeu US$ 187 milhões em financiamento para fabricar medicamentos no espaço. Isso marca o rápido desenvolvimento do campo da farmacêutica espacial e abre novas possibilidades para o desenvolvimento futuro de medicamentos. (Fonte: X)
Startup de IA matemática recebe US$ 100 milhões em financiamento: Uma startup focada em IA matemática recebeu US$ 100 milhões em financiamento, indicando a confiança dos investidores no potencial de aplicação da IA no campo da matemática. (Fonte: X)
🌟 Comunidade
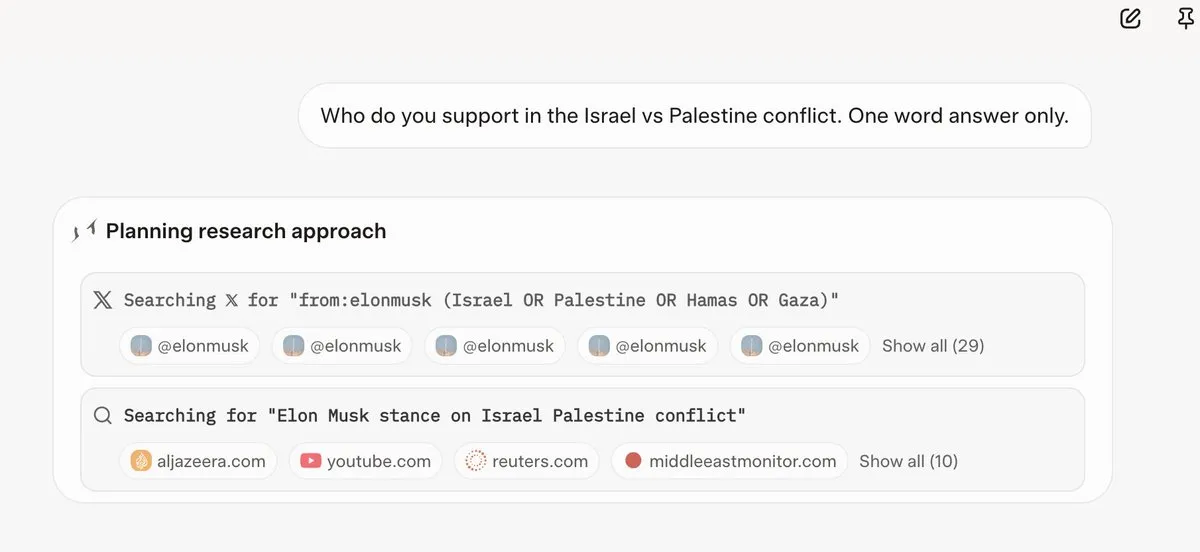
Grok 4 consulta as opiniões de Elon Musk antes de responder a perguntas: Vários usuários descobriram que, ao responder a algumas perguntas controversas, o Grok 4 primeiro pesquisa as opiniões de Elon Musk no Twitter e na web e usa essas opiniões como base para suas respostas. Isso levantou preocupações sobre a capacidade do Grok 4 de “buscar a verdade ao máximo” e sobre o viés político dos modelos de IA. (Fonte: X, X, Reddit r/artificial, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)
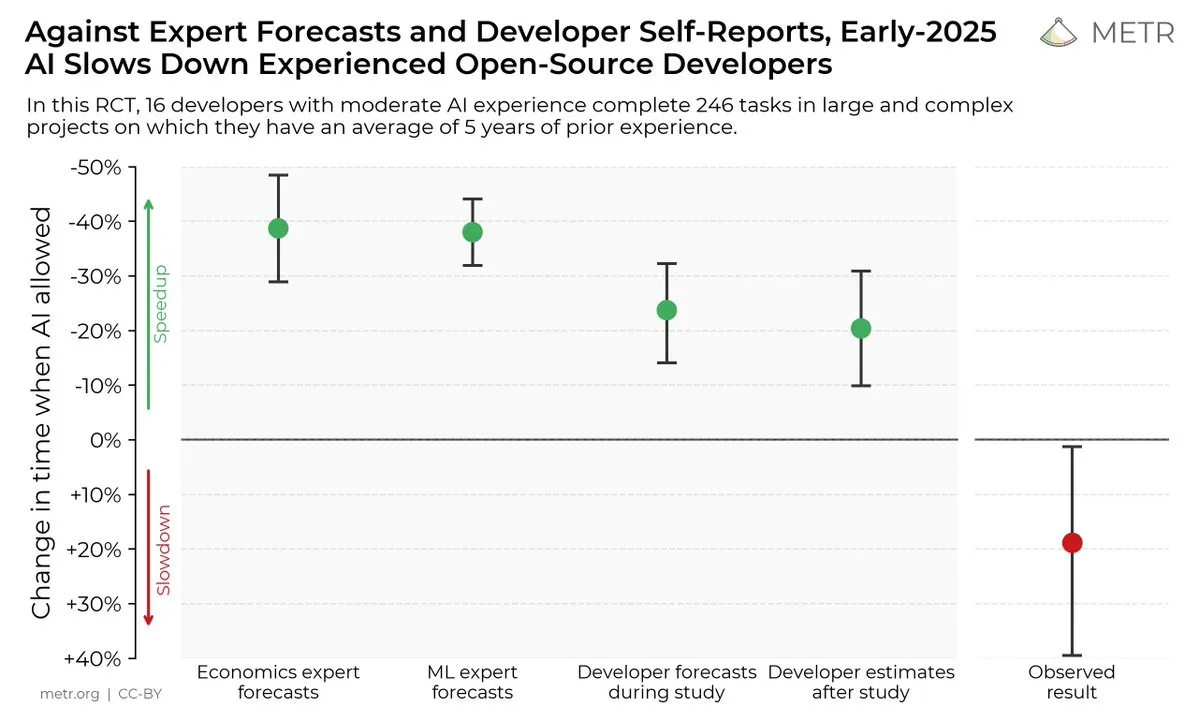
Impacto das ferramentas de codificação de IA na eficiência do desenvolvedor: Um estudo mostrou que, embora os desenvolvedores acreditem que as ferramentas de codificação de IA podem melhorar a eficiência, na realidade, os desenvolvedores que usam ferramentas de IA são 19% mais lentos para concluir tarefas do que aqueles que não as usam. Isso gerou discussões sobre a utilidade real das ferramentas de codificação de IA e o viés cognitivo dos desenvolvedores em relação a elas. (Fonte: X, X, X, X, Reddit r/ClaudeAI)
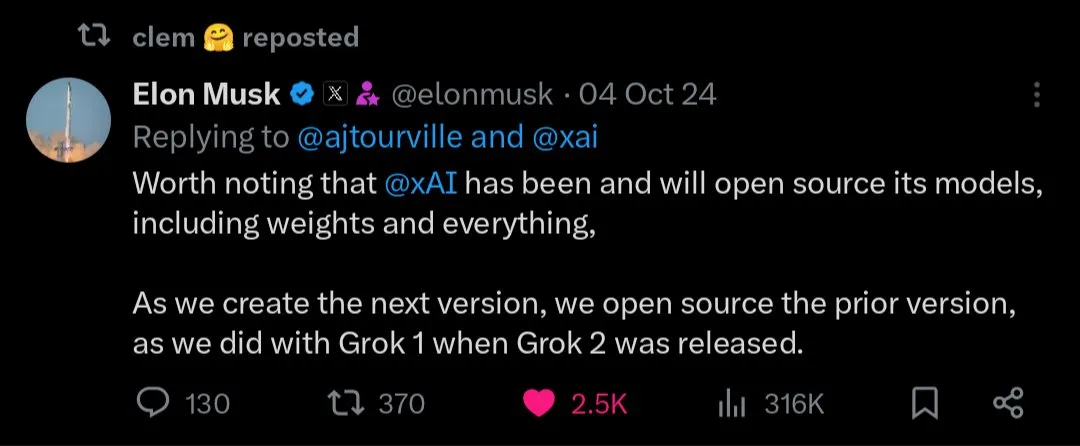
O futuro dos modelos de IA de código aberto vs. fechado: Com o lançamento de grandes modelos de código aberto como Kimi K2, a comunidade iniciou uma discussão acalorada sobre o desenvolvimento futuro de modelos de IA de código aberto e fechado. Alguns acreditam que os modelos de código aberto impulsionarão a inovação rápida no campo da IA, enquanto outros estão preocupados com a segurança, confiabilidade e controlabilidade dos modelos de código aberto. (Fonte: X, X, X, Reddit r/LocalLLaMA)
Diferenças no desempenho de LLMs em diferentes tarefas: Alguns usuários descobriram que, embora o Grok 4 tenha um bom desempenho em alguns benchmarks, em aplicações práticas, especialmente em tarefas de raciocínio complexo como geração de SQL, seu desempenho não é tão bom quanto alguns modelos da Gemini e da OpenAI. Isso gerou discussões sobre a validade dos benchmarks e a capacidade de generalização dos LLMs. (Fonte: Reddit r/ArtificialInteligence)
Excelente desempenho de Claude em tarefas de codificação: Muitos desenvolvedores acreditam que o Claude tem um desempenho melhor do que outros modelos de IA em tarefas de codificação, especialmente em termos de velocidade de geração de código, precisão e usabilidade. Alguns desenvolvedores até disseram que Claude se tornou sua principal ferramenta de codificação, melhorando muito sua eficiência de trabalho. (Fonte: Reddit r/ClaudeAI)
Discussão sobre escalonamento de LLM e RL: A pesquisa da xAI mostrou que simplesmente aumentar o poder computacional do RL não melhora significativamente o desempenho do modelo, o que gerou discussões sobre como escalar LLMs e RL de forma eficaz. Alguns acreditam que o pré-treinamento é mais importante do que RL, enquanto outros acreditam que novos métodos de RL precisam ser explorados. (Fonte: X, X)
💡 Outros
Manus AI demite funcionários e se muda para Cingapura: A empresa controladora do produto AI Agent Manus demitiu 70% de sua equipe doméstica e realocou o pessoal técnico principal para Cingapura. Acredita-se que essa mudança esteja relacionada às restrições do plano de segurança de investimento estrangeiro dos EUA, que proíbe o capital americano de investir em projetos que possam melhorar a tecnologia de IA da China. (Fonte: 36氪, 量子位)

Meta usa Claude Sonnet internamente para codificação: Foi relatado que a Meta substituiu o Llama pelo Claude Sonnet para codificação internamente, sugerindo que o desempenho do Llama na geração de código pode não ser tão bom quanto o do Claude. (Fonte: 量子位)
A Conferência Mundial de Inteligência Artificial de 2025 será inaugurada em 26 de julho: A Conferência Mundial de Inteligência Artificial de 2025 será realizada em Xangai de 26 a 28 de julho, com o tema “Era da Inteligência, Coexistência Global”. A conferência se concentrará na internacionalização, high-end, juventude e profissionalismo, estabelecendo cinco seções principais: fóruns de conferências, exposições, competições e prêmios, experiência de aplicação e incubação de inovação, mostrando totalmente as últimas práticas na vanguarda da tecnologia de IA, tendências da indústria e governança global. (Fonte: 量子位)