Palavras-chave:Direitos autorais de dados de treinamento de IA, AlphaGenome, OpenAI cópia de hardware, Desempenho da IA no exame nacional, Gemini CLI, Novo método RLT, BitNet b1.58, Agente Biomni inteligente, Julgamento de uso justo de IA, Previsão de pares de bases de DNA, Resposta de Altman a acusações de plágio, Melhoria da capacidade matemática de modelos grandes, Cota gratuita para agentes de IA em terminais
🔥 Foco
Decisão histórica sobre direitos autorais de dados de treinamento de AI: Tribunal dos EUA decide que o uso de livros comprados legalmente para treinar AI constitui “uso justo”: Um tribunal federal dos EUA, num processo contra a Anthropic, decidiu que empresas de AI que usam livros publicados e comprados legalmente para treinar grandes modelos de linguagem (LLMs) se enquadra na categoria de “uso justo”, sem necessidade de consentimento prévio do autor. O tribunal considerou o treinamento de AI como um “uso transformador” da obra original, que não substitui diretamente o mercado da obra original, e beneficia a inovação tecnológica e o interesse público. No entanto, o tribunal também decidiu que o uso de livros pirateados para treinamento não constitui uso justo, e a Anthropic ainda pode ser responsabilizada por isso. Esta decisão referenciou o precedente do caso Google Books de 2015, sendo considerada um passo importante para reduzir os riscos de direitos autorais em dados de treinamento de AI, e pode influenciar o julgamento de outros casos semelhantes (como processos contra a OpenAI e a Meta). Anteriormente, a Meta também obteve uma decisão favorável em outro processo de direitos autorais semelhante, onde o juiz considerou que os queixosos não conseguiram provar suficientemente que o uso de seus livros pela Meta para treinar modelos de AI causou danos econômicos. Essas decisões, em conjunto, fornecem diretrizes legais mais claras para a indústria de AI em relação à aquisição e uso de dados, mas enfatizam a importância da aquisição legal de dados. (Fonte: 量子位、DeepLearning.AI Blog、wiredmagazine)
Google DeepMind lança AlphaGenome: “Microscópio” de AI prevê o impacto de variações genéticas em milhões de pares de bases de DNA: O Google DeepMind lançou o modelo de AI AlphaGenome, capaz de receber sequências de DNA de até 1 milhão de pares de bases como entrada, prever milhares de características moleculares e avaliar o impacto de variações genéticas, liderando em mais de 20 benchmarks de previsão genômica. O AlphaGenome possui características como processamento de contexto de sequências longas de alta resolução, previsão multimodal abrangente, pontuação eficiente de variações e um novo modelo de junção de splicing. O treinamento de um único modelo leva apenas 4 horas, com um orçamento computacional que é metade do modelo Enformer original. O modelo visa ajudar cientistas a entender a regulação genética, acelerar a compreensão de doenças (especialmente doenças raras), orientar o design de biologia sintética e impulsionar a pesquisa básica. Atualmente, uma versão de pré-visualização está disponível via API para uso em pesquisa não comercial, com planos de lançamento completo no futuro. (Fonte: 36氪、Google、demishassabis)

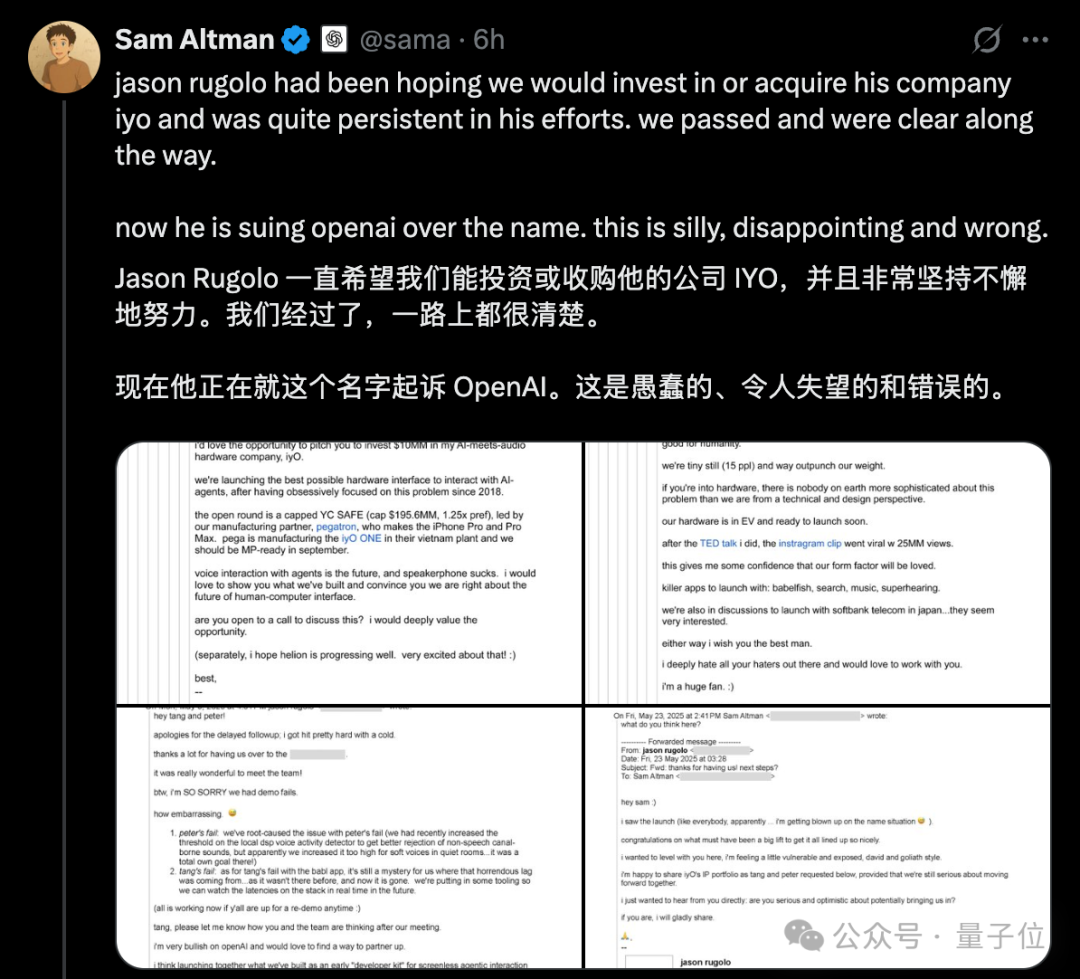
Controvérsia sobre “plágio” de hardware da OpenAI aumenta, Altman divulga e-mails publicamente para refutar processo da IYO: Em resposta às acusações da startup de hardware de AI IYO de que a OpenAI e sua empresa de hardware adquirida, io (fundada pelo ex-designer da Apple Jony Ive), infringiram marcas registradas e plagiaram produtos, o CEO da OpenAI, Sam Altman, respondeu publicamente nas redes sociais, chamando o processo da IYO de “tolo, decepcionante e completamente errado”. Altman apresentou capturas de tela de e-mails mostrando que o fundador da IYO, Jason Rugolo, havia buscado ativamente um investimento de US$ 10 milhões ou aquisição pela OpenAI antes do processo e, mesmo após a OpenAI anunciar a aquisição da io, ainda esperava compartilhar sua propriedade intelectual. Altman acredita que a IYO iniciou o processo somente após a falha na tentativa de investimento ou aquisição. O fundador da IYO rebateu, afirmando que Altman estava conduzindo um julgamento online e insistiu nos direitos sobre o nome de seu produto. Anteriormente, o tribunal havia aprovado uma ordem de restrição temporária para a IYO, impedindo a OpenAI de usar a marca IO. A OpenAI afirmou que seu produto de hardware é diferente do dispositivo vestível personalizado da IYO, que o design do protótipo não está finalizado e que não será lançado por pelo menos um ano. (Fonte: 量子位、36氪)
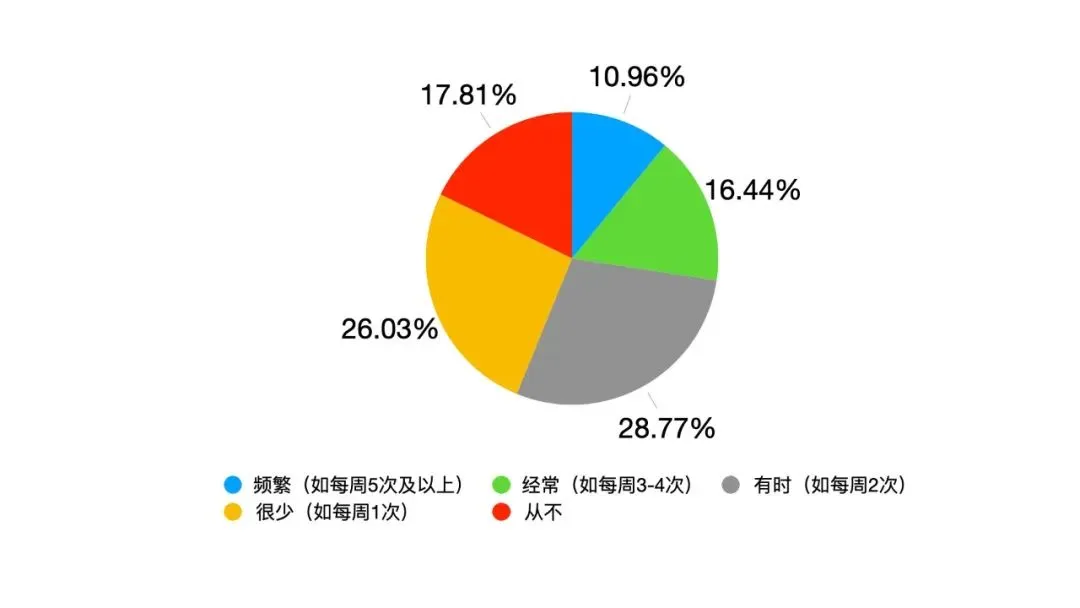
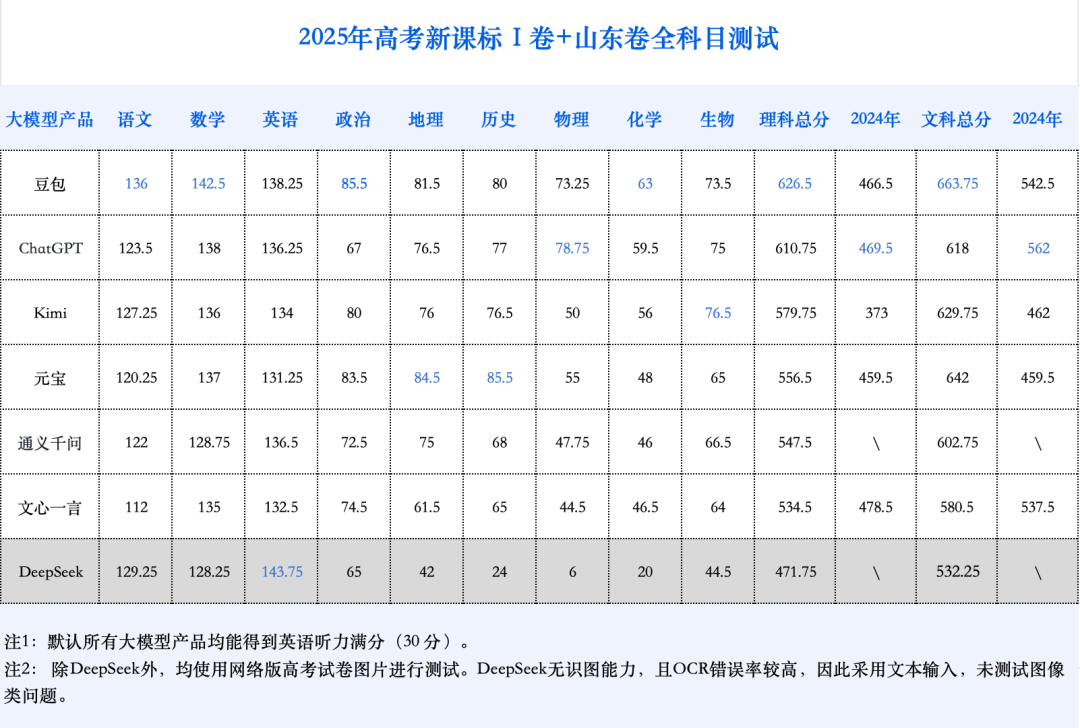
Grandes modelos de AI enfrentam novamente o Gaokao, com melhoria geral significativa e progresso notável em matemática: Os resultados da avaliação simulada do Gaokao de AI de 2025 do GeekPark mostraram que os principais grandes modelos (como Doubao, DeepSeek R1, ChatGPT o3, etc.) tiveram um desempenho geral significativamente melhor em comparação com o ano passado, demonstrando potencial para ingressar em instituições de ponta. Estima-se que o Doubao, o “campeão”, ficaria entre os 900 melhores na província de Shandong. A disparidade de desempenho da AI entre humanas e exatas diminuiu, com as notas médias em exatas crescendo mais rapidamente. A matemática foi a disciplina com o progresso mais notável, com um aumento médio de 84,25 pontos, superando mandarim e inglês. A capacidade multimodal tornou-se um fator crucial de diferenciação, especialmente em disciplinas com muitas questões baseadas em imagens, como física e geografia. Embora a AI tenha se destacado em raciocínio complexo e cálculos, ainda comete erros ao interpretar informações visuais confusas em problemas simples (como uma questão de vetores em matemática). Em redação, a AI consegue escrever textos com estrutura completa e argumentos ricos, mas carece de profundidade de pensamento e ressonância emocional, dificultando a produção de obras de excelência. (Fonte: 36氪)
🎯 Tendências
Google lança Gemini CLI com Gemini 2.5 Pro, oferecendo cotas gratuitas generosas e atraindo atenção: O Google lançou oficialmente o Gemini CLI, um assistente de AI que roda no terminal, baseado no modelo Gemini 2.5 Pro. Seu destaque é a oferta de cotas de uso gratuito extremamente generosas: suporta uma janela de contexto de 1 milhão de tokens, com 60 chamadas de modelo por minuto e 1000 por dia, competindo fortemente com ferramentas pagas como o Claude Code da Anthropic. O Gemini CLI utiliza a licença de código aberto Apache 2.0 e suporta escrita de código, depuração, gerenciamento de projetos, consulta de documentação e chamada de outros serviços do Google (como geração de imagens e vídeos) através do MCP. O Google enfatiza a vantagem de seu modelo universal no tratamento de tarefas complexas de desenvolvimento, argumentando que modelos puramente de código podem ser limitantes. A comunidade reagiu com entusiasmo, acreditando que isso impulsionará a popularização e a competição de ferramentas de AI para CLI. (Fonte: 36氪、Reddit r/LocalLLaMA、dotey)

Sakana AI propõe novo método RLT, onde modelo pequeno de 7B “ensina” melhor que o DeepSeek-R1: A Sakana AI, fundada por Llion Jones, um dos autores do Transformer, propôs um novo método de Professores de Aprendizado por Reforço (RLTs). Este método faz com que o modelo professor não resolva problemas do zero, mas sim forneça explicações passo a passo claras baseadas em soluções conhecidas, imitando o ensino “heurístico” de bons professores humanos. Experimentos mostram que um modelo RLT pequeno de 7B treinado com este método supera o DeepSeek-R1 de 671B em transmitir habilidades de raciocínio, e pode treinar efetivamente modelos estudantes até 3 vezes maiores (como 32B), com custos de treinamento significativamente reduzidos. Este método visa resolver os problemas dos modelos professores tradicionais que dependem de sua própria capacidade de resolução de problemas, são lentos e caros para treinar, alinhando o treinamento do professor com seu verdadeiro propósito (auxiliar o aprendizado do modelo estudante) para aumentar a eficiência. (Fonte: 量子位、SakanaAILabs)

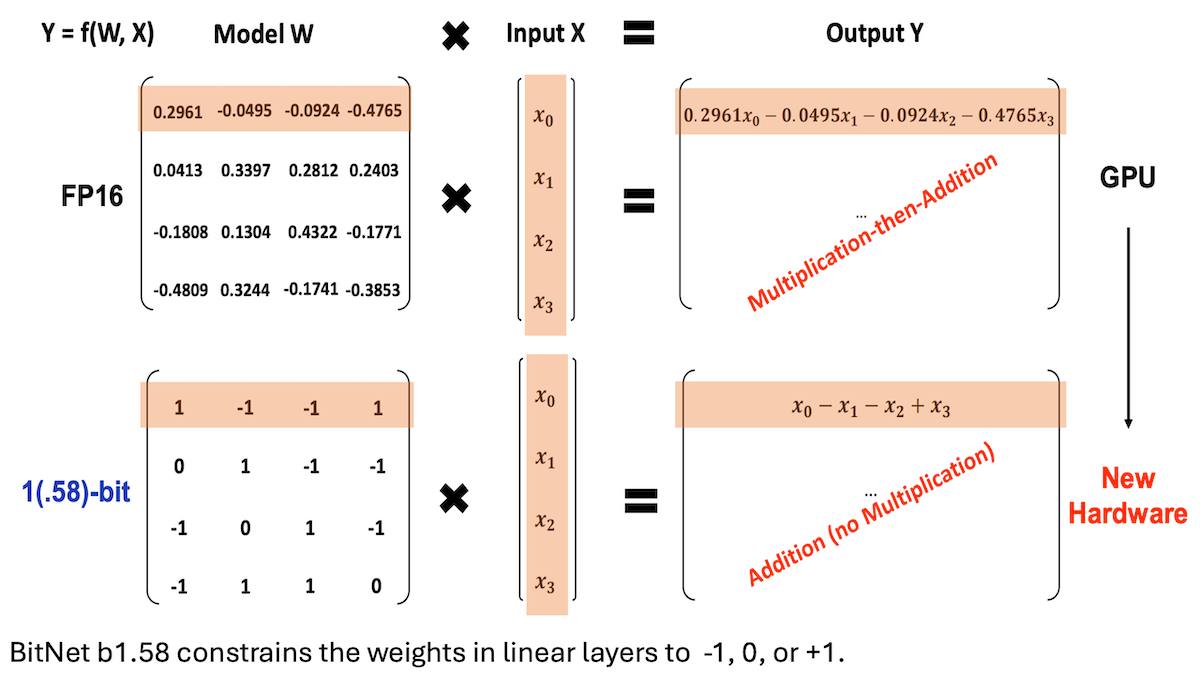
Microsoft e outros propõem BitNet b1.58, alcançando LLMs de baixa precisão e alto desempenho de inferência: Pesquisadores da Microsoft, da Universidade da Academia Chinesa de Ciências e da Universidade Tsinghua atualizaram o modelo BitNet b1.58, no qual a maioria dos pesos é limitada a três valores: -1, 0 ou +1 (aproximadamente 1.58 bits/parâmetro). Em uma escala de 2 bilhões de parâmetros, seu desempenho compete com modelos de precisão total de ponta. O modelo é otimizado por meio de estratégias de treinamento cuidadosamente projetadas (como treinamento com reconhecimento de quantização, taxa de aprendizado em duas etapas e decaimento de peso). Em 16 benchmarks populares, sua velocidade e uso de memória superam Qwen2.5-1.5B, Gemma-3 1B, entre outros, com precisão média próxima ao Qwen2.5-1.5B e superior à versão quantizada de 4 bits do Qwen2.5-1.5B. Este trabalho demonstra que, por meio de ajuste fino de hiperparâmetros, modelos de baixa precisão também podem alcançar alto desempenho, oferecendo novas ideias para a implantação eficiente de LLMs. (Fonte: DeepLearning.AI Blog)
Stanford e outras instituições lançam Biomni, um agente inteligente para pesquisa biológica que integra mais de cem ferramentas e bancos de dados: Pesquisadores da Universidade de Stanford, Universidade de Princeton e outras instituições lançaram o Biomni, um agente de AI projetado para uma ampla gama de pesquisas biológicas. O agente é baseado no Claude 4 Sonnet e integra 150 ferramentas, quase 60 bancos de dados e cerca de 100 pacotes de software biológico populares, extraídos e selecionados de 2500 artigos recentes de 25 áreas especializadas da biologia (incluindo genômica, imunologia, neurociência, etc.). O Biomni é capaz de realizar diversas tarefas, como fazer perguntas, propor hipóteses, projetar fluxos de trabalho, analisar conjuntos de dados e gerar gráficos. Ele utiliza o framework CodeAct, respondendo a consultas por meio de planejamento iterativo, geração e execução de código, e introduz outra instância do Claude 4 Sonnet como um avaliador para julgar a razoabilidade das saídas intermediárias. Em vários benchmarks como o Lab-bench e estudos de caso reais, o Biomni superou o Claude 4 Sonnet isoladamente e modelos Claude aprimorados com recuperação de literatura. (Fonte: DeepLearning.AI Blog)

Anthropic lança nova funcionalidade no Claude Code: criar e compartilhar Artifacts alimentados por AI: A Anthropic introduziu uma nova funcionalidade em seu assistente de programação AI, Claude Code, permitindo que os usuários criem, hospedem e compartilhem “Artifacts” (entendidos como pequenos aplicativos ou ferramentas de AI), e podem incorporar diretamente a inteligência do Claude nessas criações. Isso significa que os usuários não apenas podem usar o Claude para gerar trechos de código ou realizar análises, mas também construir aplicativos funcionais alimentados por AI. Uma característica fundamental é que, ao compartilhar esses aplicativos de AI, os espectadores se autenticam com suas próprias contas Claude, e o uso é contabilizado em suas próprias cotas de assinatura, não na do criador. Esta funcionalidade está atualmente em fase beta e disponível para todos os usuários gratuitos, Pro e Max, com o objetivo de reduzir a barreira para a criação de aplicativos de AI e promover a popularização e o compartilhamento de capacidades de AI. (Fonte: kylebrussell、Reddit r/ClaudeAI)
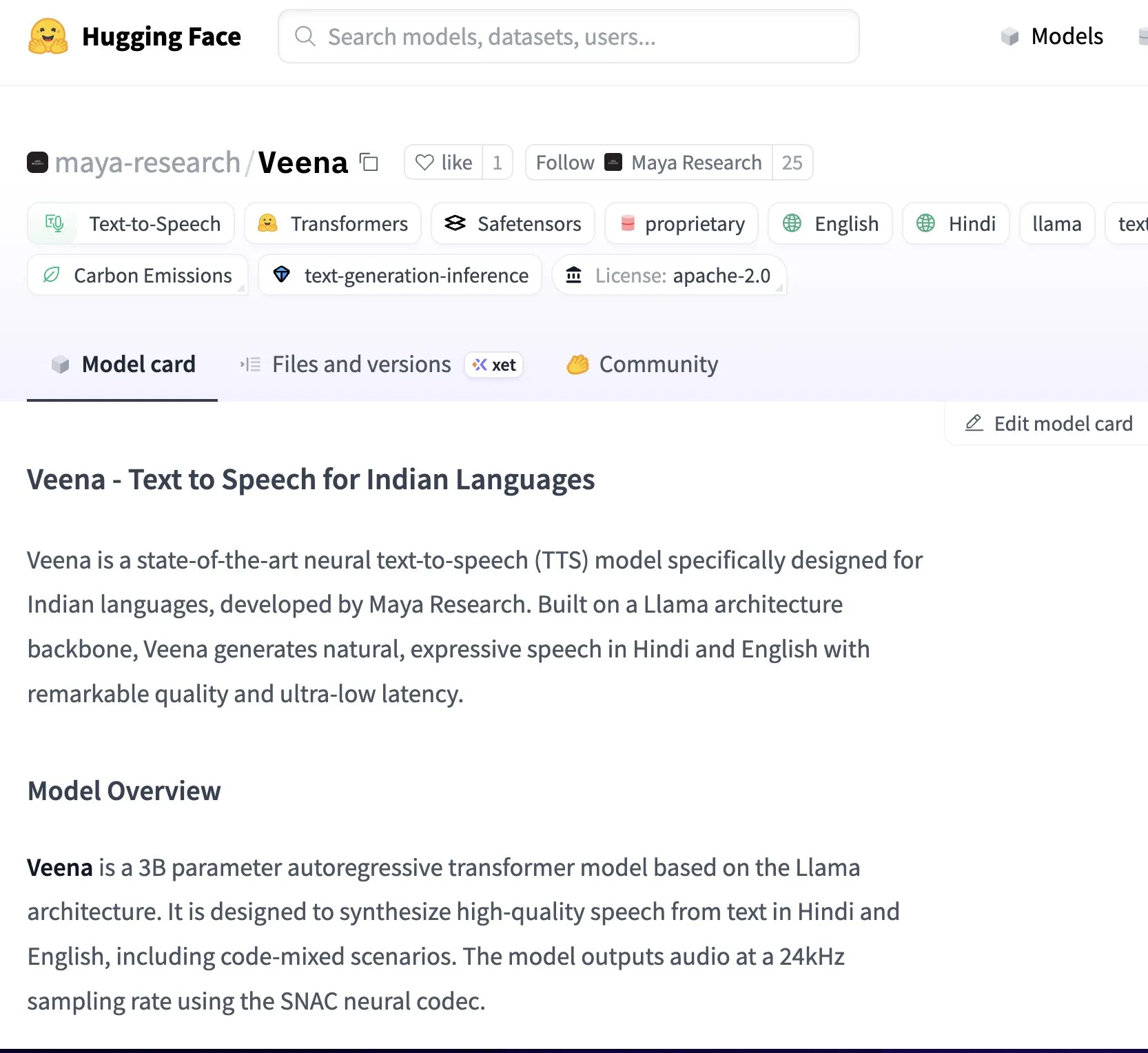
Maya Research lança modelo Veena TTS, com suporte para hindi e inglês, e timbre mais próximo do indiano nativo: A Maya Research lançou um modelo de conversão de texto em fala (TTS) chamado Veena, baseado na arquitetura Llama 3B e licenciado sob Apache 2.0. A característica distintiva do Veena é sua capacidade de gerar fala em inglês e hindi com sotaque indiano, incluindo cenários de code-mix, abordando as deficiências dos modelos TTS existentes na pronúncia nativa indiana. O modelo tem latência inferior a 80 milissegundos, pode ser executado no ambiente gratuito do Google Colab e já está disponível no Hugging Face Hub. A equipe afirmou que está desenvolvendo ativamente suporte para outros idiomas indianos, como tâmil, telugu e bengali. (Fonte: huggingface、huggingface)
HiDream.ai lança vivago2.0, integrando capacidades de geração e edição multimodal: A HiDream.ai (智象未来), fundada pelo renomado especialista em AI Mei Tao, lançou a ferramenta de criação multimodal de AI vivago2.0. O produto integra funções como geração de imagens, conversão de imagem para vídeo, podcast de AI (sincronização labial), modelos de efeitos especiais, e possui uma comunidade criativa para os usuários compartilharem e obterem inspiração. Sua tecnologia central é baseada no novo agente inteligente de imagem HiDream-A1, que integra versões avançadas de código fechado do HiDream-I1 (modelo base de geração de imagem de 17 bilhões de parâmetros, anteriormente de código aberto e líder em competições de texto para imagem) e HiDream-E1 (modelo interativo de edição de imagem). O vivago2.0 visa reduzir a barreira para a criação de conteúdo multimodal, oferecendo centenas de modelos de efeitos especiais e suportando a geração e modificação de imagens por meio de diálogo em linguagem natural (Image Agent). (Fonte: 量子位)

Nvidia lança GPUs da série RTX 5050, com configurações de VRAM diferentes para desktop e notebook: A Nvidia lançou oficialmente as GPUs da série GeForce RTX 5050, incluindo versões para desktop e notebook, com lançamento previsto para julho. O preço de varejo sugerido para a versão de desktop na China começa em 2099 yuan. A RTX 5050 para desktop possui 2560 núcleos Blackwell CUDA, equipada com 8GB de memória GDDR6 e consumo máximo de energia de 130W. A versão para notebook da RTX 5050 também possui 2560 núcleos CUDA, mas é equipada com 8GB de memória GDDR7, mais eficiente em termos de energia. A Nvidia afirma que, com a tecnologia DLSS 4, a RTX 5050 pode ultrapassar 150fps com ray tracing em jogos como Cyberpunk 2077, e oferece um aumento médio de desempenho de rasterização de 60% (desktop) e 2,4 vezes (notebook) em comparação com a RTX 3050. Essa diferenciação na configuração da VRAM reflete a estratégia da Nvidia de equilibrar custo e desempenho em diferentes segmentos de mercado. (Fonte: 量子位)

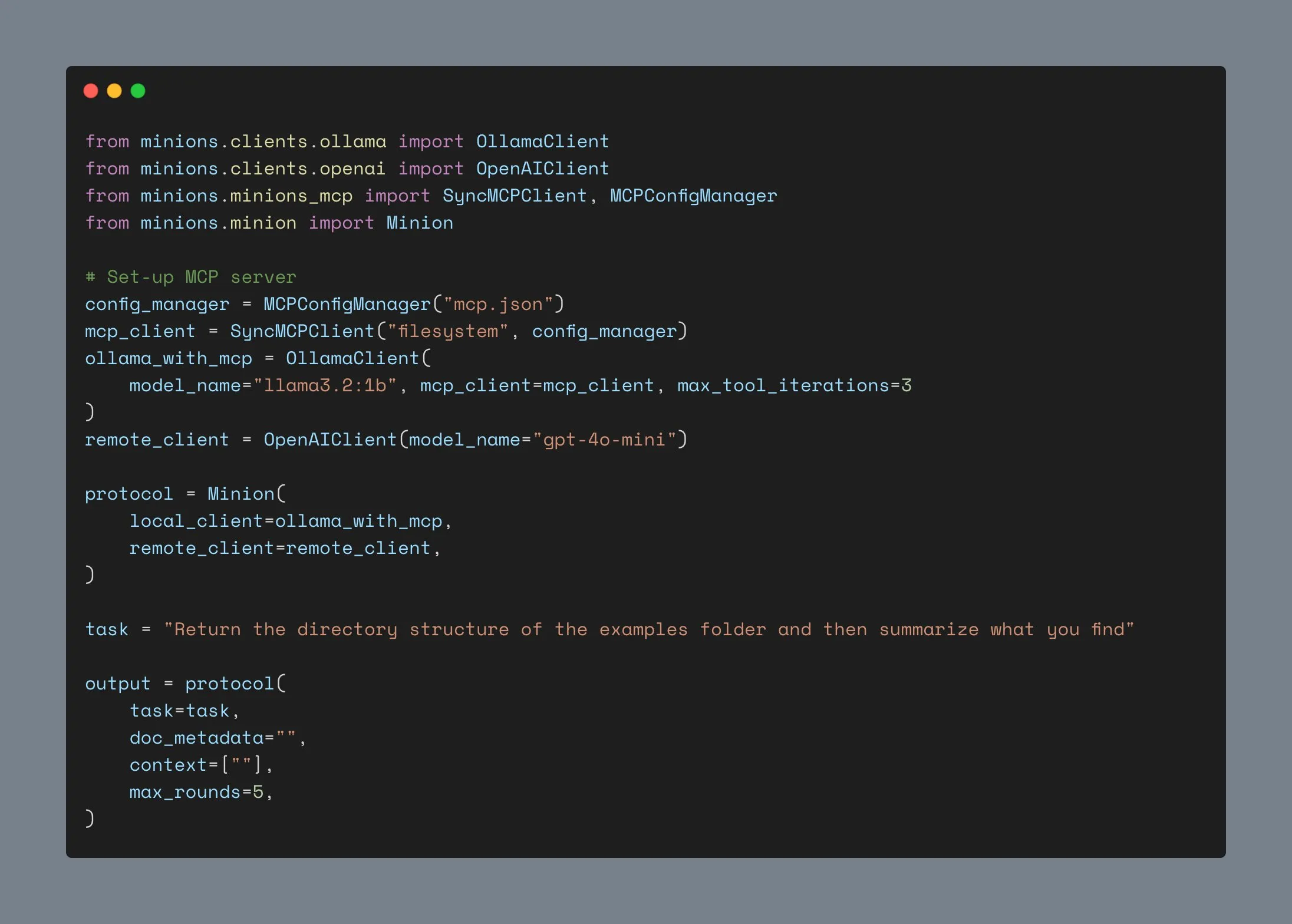
LM Studio atualizado com suporte ao protocolo MCP, permitindo conexão de LLMs locais com servidores MCP: A ferramenta de execução de LLM para desktop, LM Studio, lançou uma nova versão (0.3.17) que adiciona suporte ao Model Context Protocol (MCP). Os usuários agora podem conectar grandes modelos de linguagem executados localmente a servidores compatíveis com MCP, por exemplo, para chamar ferramentas ou serviços externos. O LM Studio atualizou sua interface para permitir que os usuários instalem e configurem serviços MCP, e pode carregar e gerenciar automaticamente processos de servidor MCP locais. Para facilitar a configuração, o LM Studio também oferece uma ferramenta online para gerar links de configuração de servidor MCP que podem ser importados com um clique. (Fonte: multimodalart、karminski3)

Gradio lança biblioteca leve de rastreamento de experimentos Trackio: A equipe do Gradio, parte do Hugging Face, lançou o Trackio, uma biblioteca leve para rastreamento e visualização de experimentos. A ferramenta foi escrita com menos de 1000 linhas de código Python, é totalmente de código aberto e gratuita, e suporta uso local ou hospedado. O Trackio visa ajudar os desenvolvedores a registrar e monitorar de forma mais conveniente várias métricas e resultados durante o processo de experimentação em machine learning, simplificando o fluxo de gerenciamento de experimentos. (Fonte: ClementDelangue、_akhaliq)
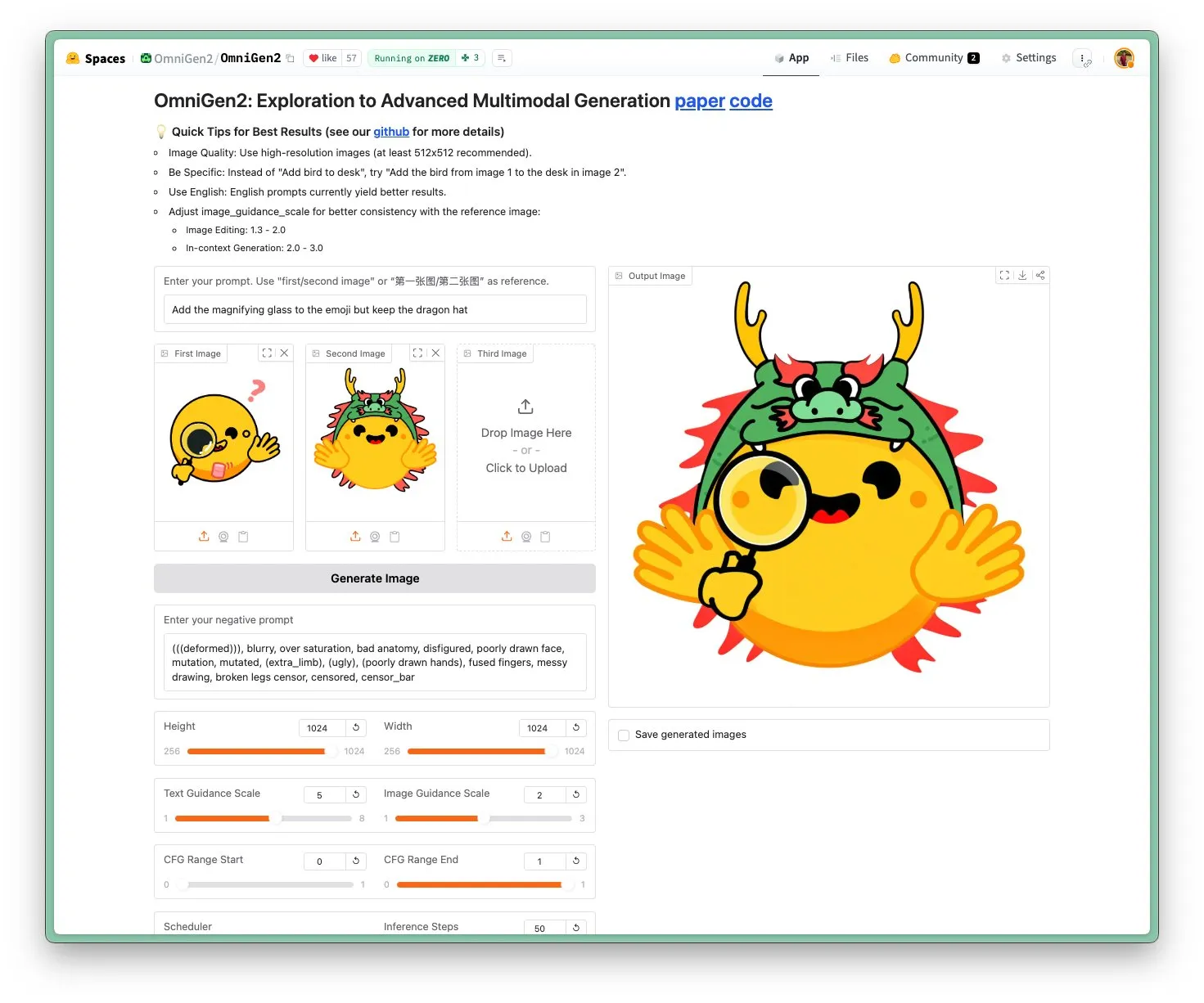
OmniGen 2 lançado: Modelo visual multifuncional e de edição de imagem SOTA com licença Apache 2.0: O novo modelo OmniGen 2 atinge o estado da arte (SOTA) em edição de imagens e utiliza a licença de código aberto Apache 2.0. O modelo não é apenas excelente em edição de imagens, mas também pode executar geração contextual, conversão de texto para imagem, compreensão visual e várias outras tarefas. Os usuários podem experimentar o Demo e o modelo diretamente no Hugging Face Hub. (Fonte: huggingface)
Arquitetura Atlas proposta: Com memória de contexto de longo alcance, desafia o Transformer: A recém-proposta arquitetura Atlas visa resolver o problema da memória de longo alcance em LLMs, afirmando superar o Transformer e os modernos RNNs lineares em tarefas de modelagem de linguagem. O Atlas possui a capacidade de aprender como memorizar o contexto em tempo de teste, pode aumentar o comprimento efetivo do contexto dos modelos Titans e atingir mais de 80% de precisão no benchmark BABILong com uma janela de contexto de 10 milhões. Os pesquisadores também discutiram outra série de modelos de atenção softmax com generalização estrita baseados na ideia do Atlas. (Fonte: behrouz_ali)

Modelo visual Moondream 2B atualizado: Raciocínio visual e compreensão de UI aprimorados, geração de texto 40% mais rápida: O modelo visual Moondream 2B lançou uma nova versão com melhorias no raciocínio visual, detecção de objetos e compreensão de interface do usuário (UI), além de um aumento de 40% na velocidade de geração de texto. Isso indica que modelos multimodais menores continuam a ser otimizados em capacidades específicas, visando fornecer interações visuais-linguísticas mais eficientes e precisas. (Fonte: mervenoyann)
Inworld AI e Modular colaboram para lançar modelo TTS de baixo custo e alta qualidade: A Inworld AI anunciou o lançamento de um novo modelo de conversão de texto em fala (TTS), que supostamente reduz o custo do TTS de última geração em 20 vezes, para US$ 5 por milhão de caracteres. O modelo é baseado na arquitetura Llama, e seu código de treinamento e modelagem será de código aberto. A parceira Modular afirmou que, por meio da colaboração tecnológica, alcançou a plataforma de inferência TTS mais rápida e com a menor latência na NVIDIA B200, e publicará um relatório técnico conjunto. (Fonte: clattner_llvm)
Higgsfield AI lança modelo Soul: Focado na geração de fotos de alta estética: A Higgsfield AI lançou um novo modelo de geração de fotos chamado Higgsfield Soul, com foco em alto valor estético e realismo de nível de moda. O modelo oferece mais de 50 predefinições cuidadosamente selecionadas, destinadas a gerar imagens comparáveis à fotografia profissional, desafiando a fotografia tradicional de celular. (Fonte: _akhaliq)
🧰 Ferramentas
Gemini CLI: Agente de AI de terminal de código aberto lançado pelo Google, oferecendo 1000 chamadas gratuitas diárias do Gemini 2.5 Pro: O Google lançou o Gemini CLI, um agente de AI de linha de comando de código aberto que permite aos usuários usar diretamente o modelo Gemini 2.5 Pro no terminal. A ferramenta oferece uma janela de contexto de 1 milhão de tokens, e usuários gratuitos podem obter até 1000 solicitações por dia (60 por minuto). O Gemini CLI suporta escrita de código, depuração, I/O do sistema de arquivos, compreensão de conteúdo da web, plugins e o protocolo MCP, visando ajudar os desenvolvedores a construir e manter software de forma mais eficiente. Sua natureza de código aberto (licença Apache 2.0) e altas cotas gratuitas o tornam um forte concorrente para ferramentas existentes como o Claude Code, e pode impulsionar o suporte a modelos locais. (Fonte: Reddit r/LocalLLaMA、dotey、yoheinakajima)
Anthropic lança nova funcionalidade no Claude Code: criar e compartilhar Artifacts alimentados por AI, com uso contabilizado na cota do usuário: A Anthropic introduziu uma nova funcionalidade em seu assistente de programação AI, Claude Code, permitindo que os usuários criem, hospedem e compartilhem “Artifacts” (entendidos como pequenos aplicativos ou ferramentas de AI), e podem incorporar diretamente a inteligência do Claude nessas criações. Isso significa que os usuários não apenas podem usar o Claude para gerar trechos de código ou realizar análises, mas também construir aplicativos funcionais alimentados por AI. Uma característica fundamental é que, ao compartilhar esses aplicativos de AI, os espectadores se autenticam com suas próprias contas Claude, e o uso é contabilizado em suas próprias cotas de assinatura, não na do criador. Esta funcionalidade está atualmente em fase beta e disponível para todos os usuários gratuitos, Pro e Max, com o objetivo de reduzir a barreira para a criação de aplicativos de AI e promover a popularização e o compartilhamento de capacidades de AI. (Fonte: kylebrussell、Reddit r/ClaudeAI、dotey)
LM Studio atualizado com suporte ao protocolo MCP, permitindo conexão de LLMs locais com servidores MCP: A ferramenta de execução de LLM para desktop, LM Studio, lançou uma nova versão (0.3.17) que adiciona suporte ao Model Context Protocol (MCP). Os usuários agora podem conectar grandes modelos de linguagem executados localmente a servidores compatíveis com MCP, por exemplo, para chamar ferramentas ou serviços externos. O LM Studio atualizou sua interface para permitir que os usuários instalem e configurem serviços MCP, e pode carregar e gerenciar automaticamente processos de servidor MCP locais. Para facilitar a configuração, o LM Studio também oferece uma ferramenta online para gerar links de configuração de servidor MCP que podem ser importados com um clique. (Fonte: multimodalart、karminski3)
Superconductor: Ferramenta para gerenciar equipes de agentes Claude Code em dispositivos móveis ou desktop: Superconductor é uma nova ferramenta que permite aos usuários gerenciar uma equipe de múltiplos agentes Claude Code através de seus celulares ou notebooks. Os usuários podem escrever tíquetes de tarefas informais, iniciar múltiplos agentes para cada tíquete, cada um com sua própria pré-visualização de aplicativo em tempo real. Desenvolvedores podem gerar um PR (Pull Request) dos resultados do agente com melhor desempenho com um único clique. A ferramenta visa simplificar a colaboração multiagente e o fluxo de geração de código. (Fonte: full_stack_dl)
Udio lança funcionalidade Sessions, aprimorando a precisão da edição de música com AI: A plataforma de geração de música por AI Udio lançou a funcionalidade “Sessions” para seus assinantes das versões Standard e Pro. Esta funcionalidade introduz uma nova visualização de linha do tempo para edição de faixas, permitindo aos usuários produzir música com maior precisão e reduzir a dependência da geração aleatória da AI. Atualmente, Sessions suporta a extensão ou edição de faixas, com mais funcionalidades a serem adicionadas no futuro. (Fonte: TomLikesRobots)
Cliente Ollama atualizado, suporta integração MCP, ultrapassa mil estrelas no GitHub: O cliente Ollama foi atualizado e agora pode integrar sua funcionalidade de chamada de ferramentas com qualquer servidor Anthropic MCP. Isso significa que os usuários podem combinar a conveniência de executar modelos localmente com Ollama e as capacidades de ferramentas externas fornecidas pelo MCP. Ao mesmo tempo, o projeto ultrapassou 1000 estrelas no GitHub. (Fonte: ollama)
📚 Aprendizado
Andrew Ng lança novo curso: Protocolo de Comunicação de Agentes ACP: A DeepLearning.AI, em colaboração com a IBM Research, lançou um curso breve sobre o Protocolo de Comunicação de Agentes (ACP). O ACP é um protocolo aberto que padroniza a comunicação entre agentes por meio de uma interface RESTful unificada, visando resolver os desafios de integração ao construir sistemas multiagentes com múltiplas equipes e frameworks. O curso ensinará como usar o ACP para conectar agentes construídos com diferentes frameworks (como CrewAI, Smoljames), realizar colaboração em fluxos de trabalho sequenciais e hierárquicos, e importar agentes ACP para a plataforma BeeAI (uma plataforma de código aberto para registro e compartilhamento de agentes). Os alunos aprenderão sobre o ciclo de vida dos agentes ACP e farão comparações com protocolos como MCP (Model Context Protocol) e A2A (Agent-to-Agent). (Fonte: AndrewYNg)
Universidade Johns Hopkins lança curso de DSPy: A Universidade Johns Hopkins está oferecendo um curso sobre DSPy. DSPy é um framework para otimizar algoritmicamente prompts e pesos de LLMs, transformando o processo de engenharia de prompts, que antes era manual, em um processo mais sistemático e programável de construção e otimização de módulos. O CEO da Shopify, Tobi Lutke, também afirmou que DSPy é sua ferramenta preferida para engenharia de contexto. (Fonte: stanfordnlp、lateinteraction)

Tutorial do LM Studio: Usando modelos de código aberto do Hugging Face para uma experiência local e privada semelhante ao ChatGPT: Niels Rogge publicou um tutorial no YouTube demonstrando como usar o LM Studio em conjunto com modelos de código aberto do Hugging Face (como Mistral 3.2-Small) para obter uma experiência 100% privada e offline semelhante ao ChatGPT localmente. O tutorial explica conceitos como GGUF, quantização, e por que os modelos ainda ocupam um espaço considerável mesmo com quantização de 4 bits, além de mostrar a compatibilidade do LM Studio com a API da OpenAI. (Fonte: _akhaliq)

LlamaIndex realizará workshop online sobre memória de agentes: LlamaIndex, em colaboração com AIMakerspace, realizará uma discussão online sobre memória de agentes. O conteúdo abrangerá histórico de chat persistente, uso de blocos estáticos, factuais e vetoriais para memória de longo prazo, lógica de implementação de memória personalizada e quando a memória é crucial, entre outros tópicos. A discussão visa ajudar desenvolvedores a construir agentes que necessitam de contexto real em conversas. (Fonte: jerryjliu0)

Podcast da Weaviate discute benchmarks e avaliação de RAG: O episódio 124 do podcast da Weaviate convidou Nandan Thakur, que fez contribuições significativas na área de avaliação de busca, para discutir o benchmarking e a avaliação da Geração Aumentada por Recuperação (RAG). O conteúdo abordou benchmarks como BEIR, MIRACL, TREC e o mais recente FreshStack, além de múltiplos tópicos em RAG, como inferência, escrita de consultas, busca cíclica, resultados de busca paginados e recuperadores híbridos. (Fonte: lateinteraction)

PyTorch lança receita flux-fast, acelerando modelos Flux em 2.5x na H100: O PyTorch lançou uma receita simples chamada flux-fast, projetada para aumentar a velocidade de execução de modelos Flux em 2.5 vezes na GPU H100, sem a necessidade de ajustes complexos. A solução visa simplificar a implementação de computação de alto desempenho, e o código relacionado foi disponibilizado. (Fonte: robrombach)

Informações da conferência MLSys 2026 divulgadas: A conferência MLSys 2026 está planejada para maio de 2026 em Seattle (Bellevue), com prazo de submissão de artigos até 30 de outubro deste ano. Todas as gravações das sessões da MLSys 2025 já estão disponíveis gratuitamente no site oficial. A conferência foca em pesquisa e avanços na área de sistemas de machine learning. (Fonte: JeffDean)

Curso CS336 de Stanford “Construindo Modelos de Linguagem do Zero” ganha destaque: O curso CS336 da Universidade de Stanford, “Language Models from Scratch”, ministrado por Percy Liang e outros, tem recebido muitos elogios. O curso visa proporcionar aos alunos uma compreensão profunda dos detalhes técnicos dos modelos de linguagem, preenchendo a lacuna entre pesquisadores e os detalhes técnicos através da construção prática de modelos. O conteúdo do curso e os trabalhos são considerados recursos importantes de aprendizado para se tornar um especialista em LLM. (Fonte: nrehiew_、jpt401)
💼 Negócios
Meta investe US$ 14,3 bilhões na Scale AI e recruta seu CEO Alexandr Wang para acelerar P&D em AI: Para fortalecer sua capacidade em AI, a Meta fechou um acordo com a empresa de rotulagem de dados Scale AI, investindo US$ 14,3 bilhões para adquirir 49% de suas ações sem direito a voto e recrutando seu fundador e CEO, Alexandr Wang, e sua equipe. Alexandr Wang será responsável por um novo laboratório da Meta focado em pesquisa de superinteligência. A medida visa injetar talentos de ponta em AI e capacidades de operação de dados em larga escala na Meta, em resposta à recepção morna de seu modelo Llama 4 e à instabilidade de pessoal em seu departamento de pesquisa em AI. A Scale AI usará os fundos para acelerar a inovação e distribuir parte dos fundos aos acionistas, com seu Diretor de Estratégia, Jason Droege, atuando como CEO interino. A transação pode ter evitado parte do escrutínio governamental por não ser uma aquisição direta. (Fonte: DeepLearning.AI Blog)

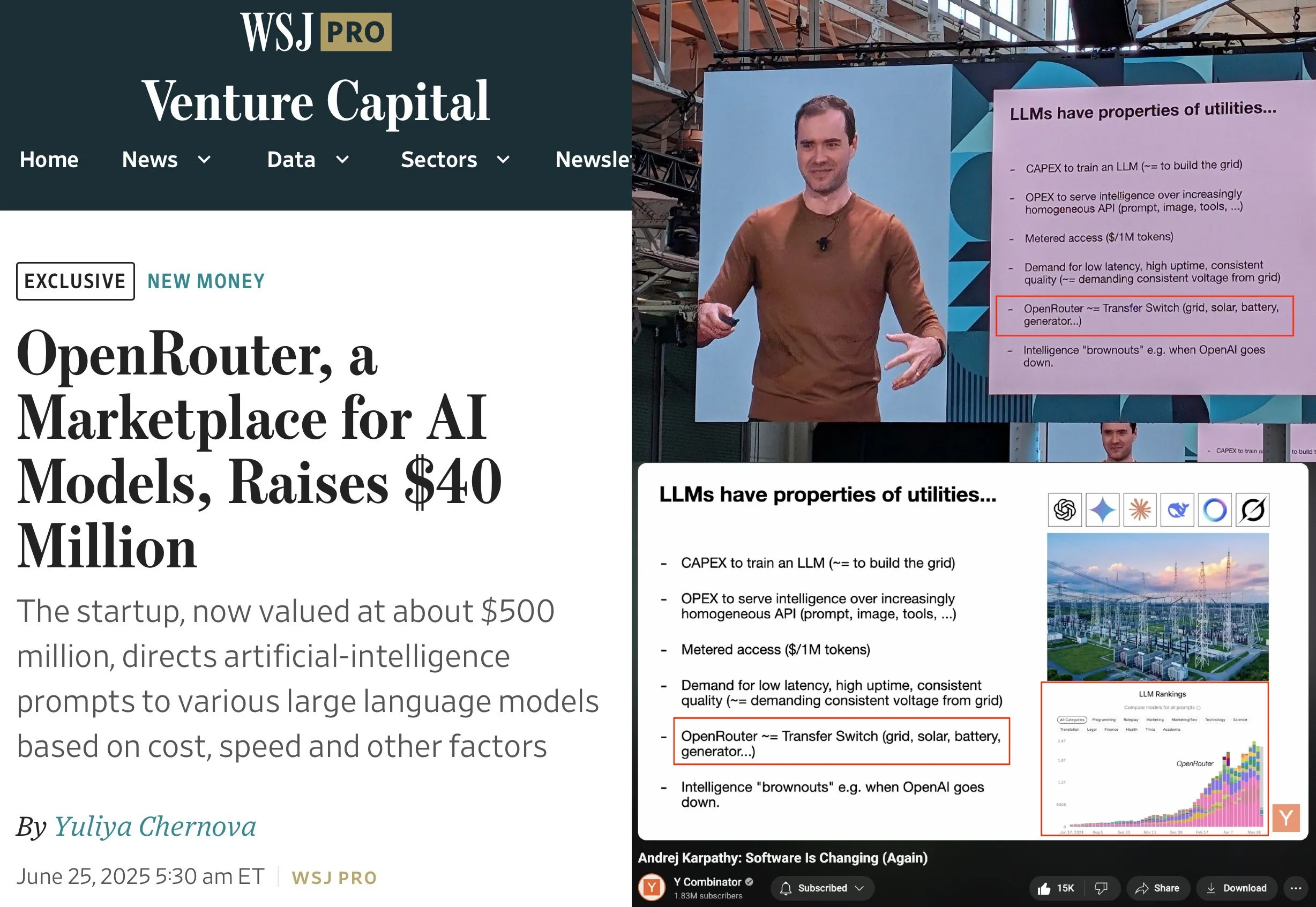
OpenRouter conclui rodada de financiamento Série A de US$ 40 milhões, liderada por a16z e Menlo: A OpenRouter, plano de controle para inferência de LLM e marketplace de modelos, anunciou a conclusão de um total de US$ 40 milhões em rodadas de financiamento seed e Série A, lideradas pela a16z e Menlo Ventures. A OpenRouter visa se tornar a interface unificada para desenvolvedores escolherem e usarem diversos LLMs, oferecendo atualmente mais de 400 modelos e processando 100 trilhões de tokens anualmente. O financiamento será usado para expandir as modalidades de modelos suportados (como geração de imagens, modelos de interação multimodal), implementar mecanismos de roteamento mais inteligentes (como roteamento geográfico, otimização de alocação de GPU de nível empresarial) e aprimorar as funcionalidades de descoberta de modelos. (Fonte: amasad、swyx)
Empresa de robôs humanoides “Lingbao CASBOT” garante quase 100 milhões de yuans em financiamento Anjo+, liderado pela Lens Technology: A marca de robôs humanoides “Lingbao CASBOT” anunciou a conclusão de um financiamento Anjo+ de quase 100 milhões de yuans, liderado pela Lens Technology, com participação da Tianjin Jiayi e dos investidores anteriores Guotou Chuanghe e Henan Asset. Os fundos serão usados para acelerar a produção em massa de produtos, pesquisa e desenvolvimento tecnológico e expansão de mercado. A Lingbao CASBOT foca na aplicação de robôs humanoides de uso geral e inteligência incorporada, já tendo lançado dois robôs humanoides bípedes, CASBOT 01 e 02, voltados para operações especiais e cenários de interação humano-robô mais amplos (como orientação e educação), respectivamente. A tecnologia central da empresa inclui um modelo hierárquico de ponta a ponta combinado com pós-treinamento por aprendizado por reforço, e já estabeleceu parcerias com o Zhaojin Group, China Minmetals Corporation e outros nos setores de manufatura industrial e energia mineral. (Fonte: 36氪、36氪)

🌟 Comunidade
Andrej Karpathy defende “engenharia de contexto” em vez de “engenharia de prompt”, enfatizando a complexidade da construção de aplicações LLM: Andrej Karpathy concorda com a opinião de Tobi Lutke de que “engenharia de contexto” (context engineering) descreve com mais precisão a habilidade central em aplicações LLM de nível industrial do que “engenharia de prompt” (prompt engineering). Ele aponta que “prompt” geralmente se refere a descrições curtas de tarefas inseridas por usuários no dia a dia, enquanto a engenharia de contexto é uma arte e ciência refinada que envolve o preenchimento preciso da janela de contexto com descrições de tarefas, poucos exemplos (few-shot examples), RAG, dados multimodais, ferramentas, histórico de estado, etc., para otimizar o desempenho do LLM. Ele também enfatiza que as aplicações LLM vão muito além disso, exigindo a resolução de uma série de problemas complexos de engenharia de software, como decomposição de problemas, fluxo de controle, agendamento de múltiplos modelos, UI/UX, avaliação de segurança, etc., e, portanto, a noção de “wrapper de ChatGPT” é equivocada. (Fonte: karpathy、code_star、dotey)
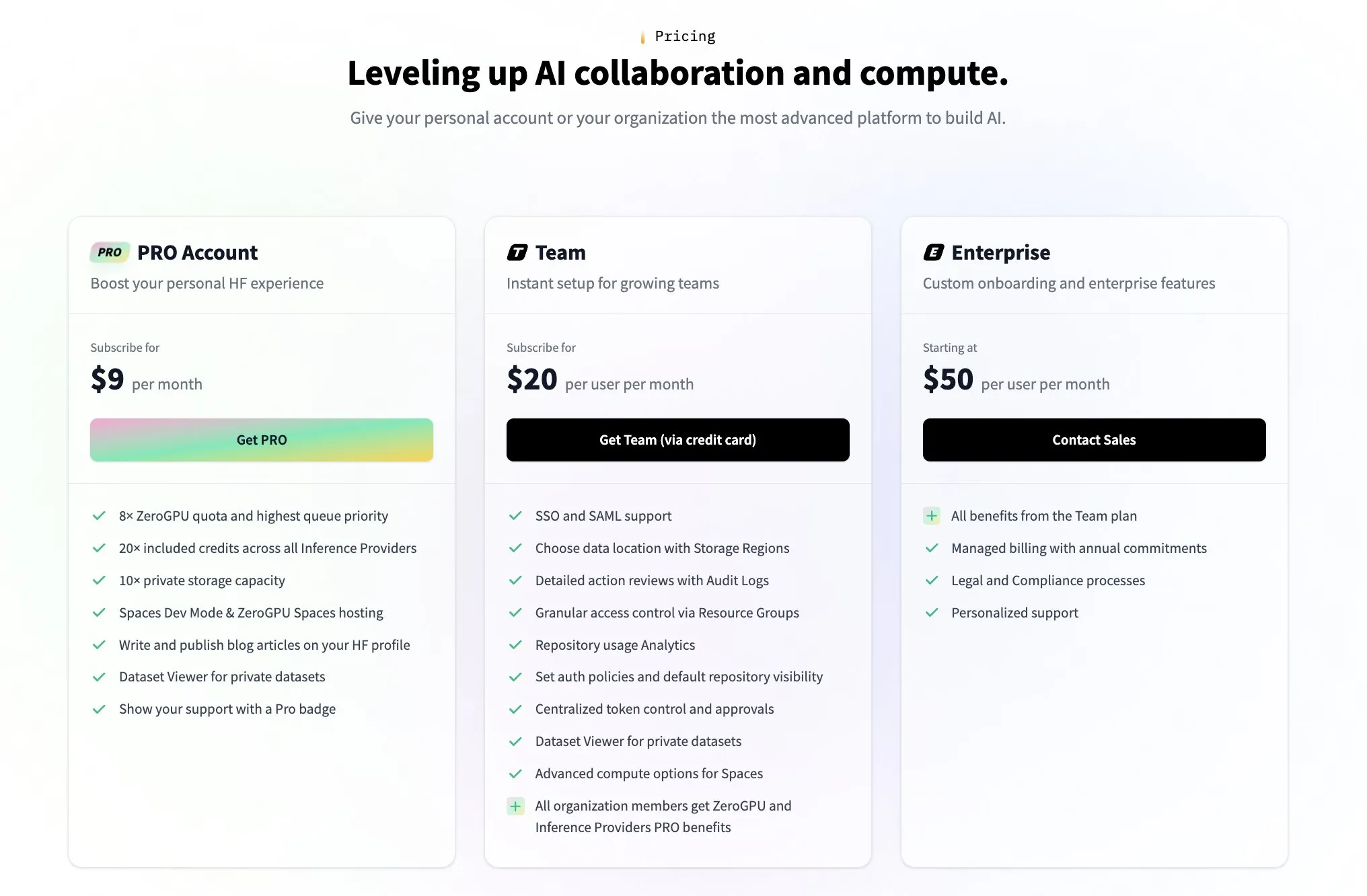
Hugging Face lança plano pago para equipes em resposta a dúvidas da comunidade sobre seu modelo de monetização: Em resposta a dúvidas da comunidade sobre como o Hugging Face gera receita (como as levantadas pelo tweet do usuário @levelsio), o cofundador do Hugging Face, Clement Delangue, respondeu com humor dizendo que “a ansiedade de monetização foi acionada” e anunciou o lançamento de um novo plano premium pago para equipes. O Hugging Face, como plataforma que hospeda um grande número de modelos de AI, oferece APIs gratuitas e não exige chaves de API, tem seu modelo de negócios como foco de discussão na comunidade. O lançamento do novo plano indica que está explorando e expandindo ativamente suas vias de comercialização. (Fonte: huggingface、ClementDelangue)
Comunidade debate lealdade do usuário a assistentes de código de AI e colaboração com múltiplas ferramentas: O The Information reportou que a lealdade dos desenvolvedores a assistentes de codificação pode ser maior do que se imagina. Ao mesmo tempo, surgiram na comunidade fenômenos de desenvolvedores usando múltiplas ferramentas de codificação de AI, como Claude Code, Codex (CLI) e Gemini (CLI), simultaneamente no mesmo repositório de código. Isso reflete que os desenvolvedores estão experimentando ativamente diferentes ferramentas de AI para aumentar a eficiência, e também podem estar procurando a combinação de funcionalidades específicas que melhor se adapta ao seu fluxo de trabalho, em vez de depender inteiramente de uma única ferramenta. (Fonte: steph_palazzolo、code_star)

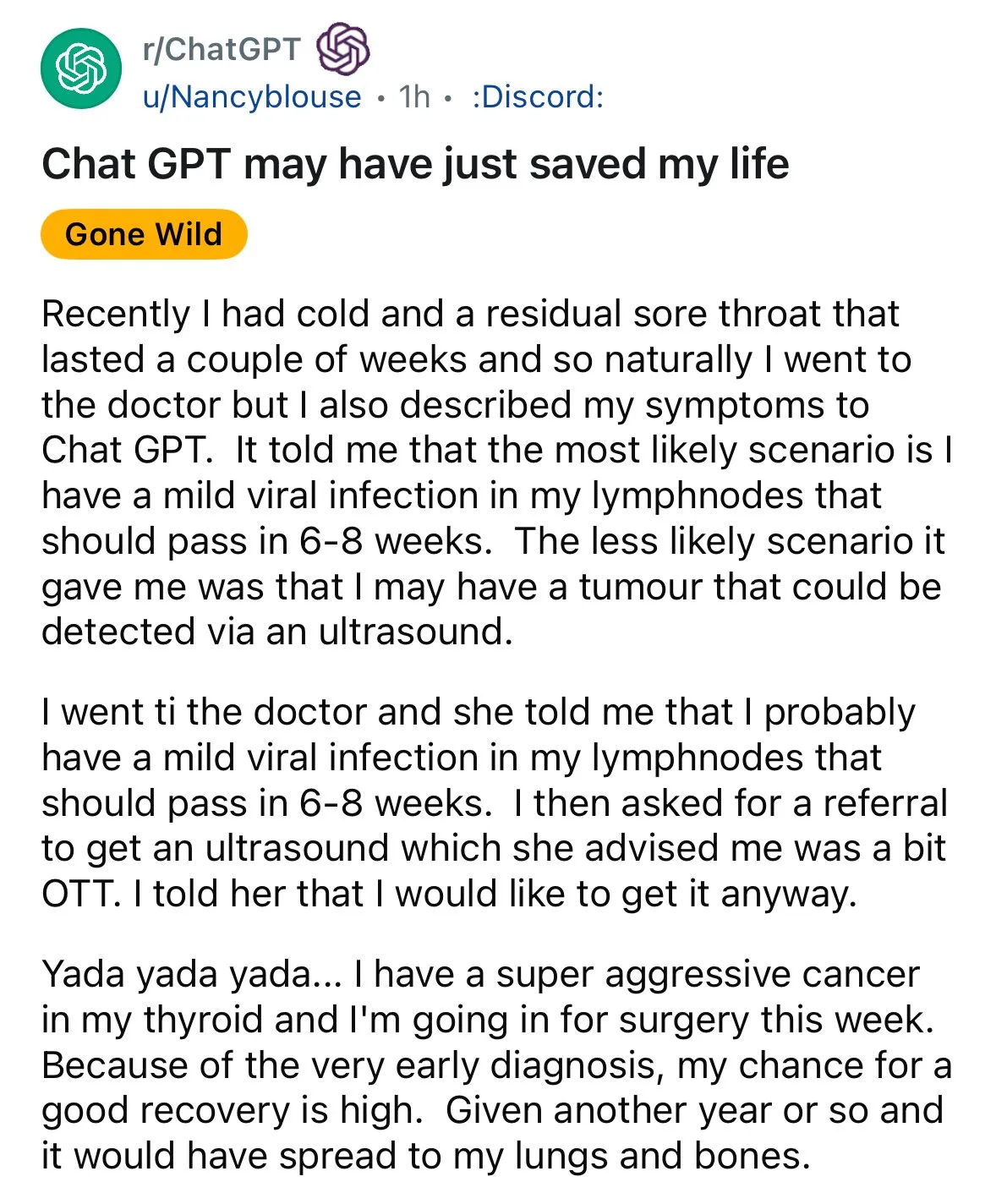
AI demonstra potencial em diagnóstico médico, gerando discussão sobre “segunda opinião”: Casos de diagnóstico auxiliado por AI ressurgiram nas redes sociais. Um paciente com dor de garganta, após o médico sugerir observação, obteve uma sugestão do ChatGPT para realizar um ultrassom, que acabou revelando câncer de tireoide. Tais incidentes geram discussões, incentivando as pessoas a usar AI para obter uma “segunda opinião” em questões médicas, acreditando que isso pode salvar vidas. Ao mesmo tempo, a pesquisa do modelo GRAPE da Alibaba DAMO Academy, que detecta câncer gástrico em estágio inicial por meio de tomografias computadorizadas de rotina, foi publicada na Nature Medicine, mostrando o enorme potencial da AI na triagem precoce do câncer. (Fonte: aidan_mclau、Yuchenj_UW)
“Literatura da loucura” na era da AI e o fenômeno do companheirismo com AI: A “literatura da loucura” (发疯文学), popular entre os jovens como uma forma de desabafo emocional e pequena resistência, está se cruzando com ferramentas de AI. Muitos usuários utilizam AI generativa (como o Dan Xiaohuang do Wen Xiaoyan) como uma válvula de escape emocional e companhia, para aliviar a solidão, obter consolo e até mesmo auxiliar na tomada de decisões (como análise pós-discussão). A AI, devido à sua paciência, imparcialidade e disponibilidade constante, tornou-se um “amigo eletrônico” de baixo custo e alta privacidade, ajudando os usuários a encontrar consolo em momentos caóticos e sendo considerada benéfica para melhorar o estado mental. (Fonte: 36氪)

Discussão contínua sobre se LLMs são Inteligência Artificial Geral (AGI): A discussão na comunidade sobre se e quando os grandes modelos de linguagem (LLMs) podem atingir a Inteligência Artificial Geral (AGI) continua. Alguns argumentam que, embora os LLMs se destaquem em muitas tarefas, ainda há um longo caminho até a verdadeira AGI, especialmente na ausência de teorias de gênios científicos humanos e dados sobre seu funcionamento interno. Também existem diferentes opiniões sobre o cronograma para a realização da AGI, com menções que variam do futuro próximo de 2028 até datas mais distantes como 2035-2040. (Fonte: menhguin)

💡 Outros
Primeiro chatbot do mundo, Eliza, restaurado com sucesso após 60 anos: Eliza, o primeiro chatbot do mundo, inventado pelo cientista do MIT Joseph Weizenbaum em meados da década de 1960, teve sua cópia impressa do código original redescoberta após anos perdido. Após esforços de equipes da Universidade de Stanford e do MIT, que envolveram a limpeza e depuração do código original, correção de funcionalidades e desenvolvimento de um ambiente de simulação para execução, Eliza foi “ressuscitada” com sucesso após 60 anos. A Eliza original analisava o texto inserido pelo usuário, extraía palavras-chave e reorganizava frases para responder, interagindo com os usuários na persona de um terapeuta rogeriano, e chegou a criar laços emocionais com muitos testadores. O código e o simulador da Eliza restaurada foram publicados no Github para experiência pública. (Fonte: 36氪)

Ferramenta de geração de imagens AI Midjourney enfrenta processos de direitos autorais da Disney e outros, mas seu modelo criativo único é procurado: A plataforma de geração de imagens AI Midjourney enfrenta ações judiciais porque suas imagens geradas podem infringir os direitos autorais de ativos visuais de empresas como Disney e Universal Pictures. No entanto, a ferramenta, com seu modelo criativo único – gerando imagens altamente artísticas e estilizadas na comunidade Discord através de prompts de texto – é amplamente popular entre criadores globais. A equipe da Midjourney tem menos de 50 pessoas, não buscou financiamento, mas sua receita anual já atingiu US$ 200 milhões. Sua filosofia de produto enfatiza “a imaginação acima de tudo”, posicionando a AI como um motor para expandir o pensamento humano, em vez de uma simples ferramenta de substituição, remodelando o paradigma criativo digital através de uma interação minimalista “desferramentalizada” e uma cultura de cocriação comunitária. (Fonte: 36氪)

Transformação da liderança impulsionada pela AI: da obediência hierárquica à simbiose humano-máquina: Com a profunda integração da AI no trabalho, a liderança tradicional enfrenta desafios. Uma pesquisa do Google mostra que 82% dos jovens líderes usam AI, e dados da Oracle indicam que 25% dos funcionários preferem perguntar à AI em vez de a seus líderes. A AI causa mudanças no ambiente de liderança: informação e experiência não são mais um fosso exclusivo dos líderes, a transparência na tomada de decisões traz pressão, e o objeto de gerenciamento muda de equipes puramente humanas para “híbridos humano-máquina”. A Escola de Administração da Universidade Fudan propôs o conceito de “liderança simbiótica”, enfatizando a simbiose entre a economia tradicional e a digital, empresas e ecossistemas, e o cérebro humano e o cérebro da máquina. Na era da AI, os líderes precisam gerenciar a transição entre as antigas e novas forças motrizes, criar valor em redes colaborativas e alavancar o efeito multiplicador da colaboração humano-máquina, com a competência central residindo em saber como fazer a AI servir aos humanos. (Fonte: 36氪)