Palavras-chave:Pesquisa em IA, Ciência da Computação, Aprendizado por Reforço, Desenvolvimento de Medicamentos, Direção Autônoma, Modelo de Linguagem, Processamento Multimodal, Célula Virtual, Instituto Laude, Professores de Aprendizado por Reforço (RLTs), Plataforma BioNeMo, Tesla Robotaxi, Modelo Kimi VL A3B Thinking
🔥 Foco
Laude Institute é fundado, recebe financiamento inicial de US$ 100 milhões para impulsionar pesquisa de ciência da computação para o bem público: Andy Konwinski anunciou o lançamento do Laude Institute, uma organização sem fins lucrativos que visa financiar pesquisas em ciência da computação não comerciais que tenham um impacto significativo no mundo. Nomes proeminentes como Jeff Dean, Joyia Pineau e Dave Patterson juntam-se ao conselho de administração. A instituição recebeu um compromisso inicial de financiamento de US$ 100 milhões e, através de financiamento, compartilhamento de recursos e construção de comunidade, apoiará pesquisadores a transformar ideias em impacto real, com foco especial em pesquisa aberta e orientada para o impacto. (Fonte: JeffDean, matei_zaharia, lschmidt3, Tim_Dettmers, andrew_n_carr, gneubig, lateinteraction, sarahookr, jefrankle)

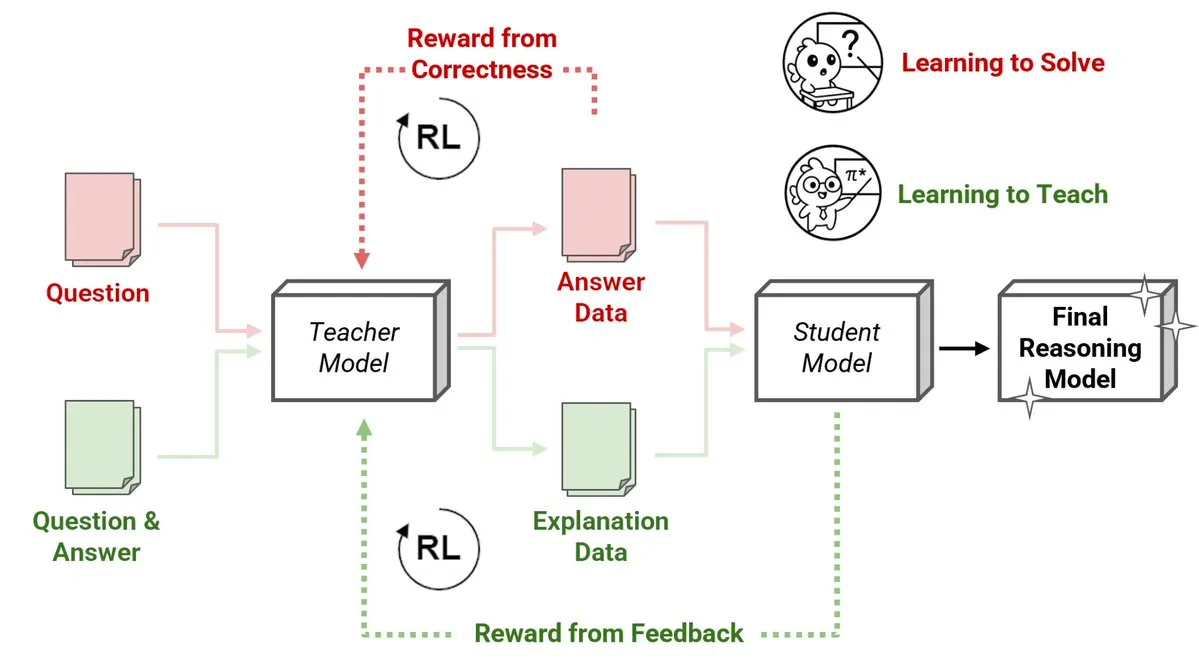
Sakana AI lança novo método de Professores de Aprendizado por Reforço (RLTs), modelos pequenos ensinam raciocínio a modelos grandes: A Sakana AI introduziu um novo método de Professores de Aprendizado por Reforço (RLTs) que transforma a maneira como o raciocínio é ensinado a Modelos de Linguagem Grandes (LLMs) através do Aprendizado por Reforço (RL). O RL tradicional foca em “aprender a resolver” problemas, enquanto os RLTs são treinados para gerar “explicações” claras e passo a passo para ensinar modelos estudantes. Um RLT com apenas 7B de parâmetros, ao ensinar um modelo estudante de 32B parâmetros, superou LLMs muitas vezes maiores em tarefas de raciocínio competitivas e de nível de pós-graduação. Este método estabelece um novo padrão de eficiência para o desenvolvimento de modelos de linguagem de raciocínio com RL. (Fonte: cognitivecompai, AndrewLampinen)
Nvidia e Novo Nordisk colaboram para acelerar a descoberta de medicamentos usando supercomputador de IA: A Nvidia anunciou uma colaboração com a gigante farmacêutica dinamarquesa Novo Nordisk e o Centro Nacional de Inovação em IA da Dinamarca para utilizar conjuntamente a tecnologia de IA e o mais recente supercomputador dinamarquês, Gefion, para acelerar a pesquisa e desenvolvimento de novos medicamentos. Esta parceria empregará a plataforma BioNeMo da Nvidia e fluxos de trabalho avançados de IA, visando transformar os modelos de pesquisa e desenvolvimento de fármacos. O supercomputador Gefion, construído com tecnologia da Eviden e da Nvidia, fornecerá um poderoso suporte computacional para pesquisas em áreas como ciências da vida, impulsionando a medicina personalizada e a descoberta de novas terapias. (Fonte: nvidia)

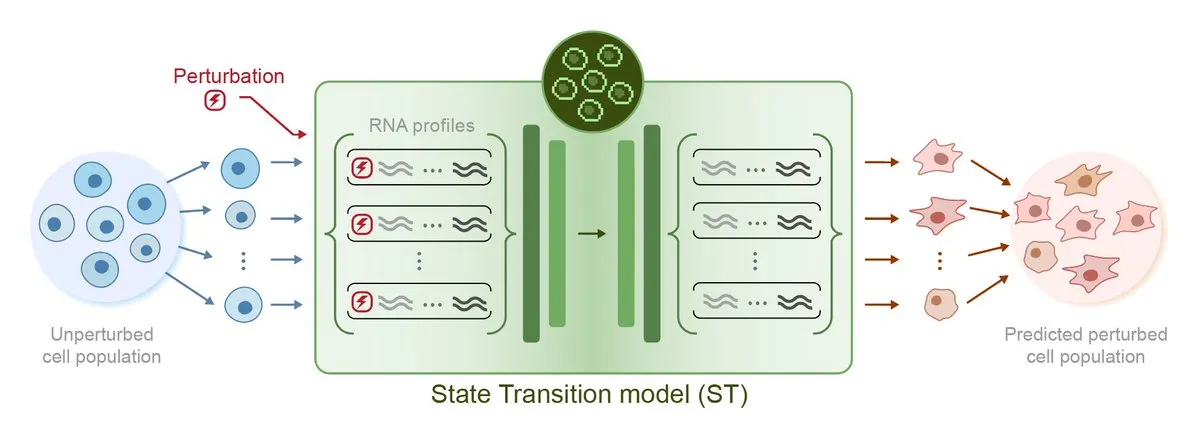
Arc Institute lança primeiro modelo de IA para previsão de perturbações, STATE, rumo ao objetivo da célula virtual: O Arc Institute lançou seu primeiro modelo de IA para previsão de perturbações, STATE, um passo importante em direção ao seu objetivo de criar uma célula virtual. O modelo STATE visa aprender como utilizar perturbações causadas por medicamentos, citocinas ou genes para alterar o estado celular (por exemplo, de “doente” para “saudável”). O lançamento deste modelo marca um novo progresso da IA na compreensão e previsão do comportamento celular, abrindo novos caminhos para o tratamento de doenças e desenvolvimento de medicamentos. O modelo relacionado foi disponibilizado no HuggingFace. (Fonte: riemannzeta, ClementDelangue)
Robotaxi da Tesla inicia piloto em Austin, solução visual chama atenção, código legado de Karpathy é drasticamente simplificado: A Tesla iniciou oficialmente o serviço piloto de Robotaxi em Austin, Texas, EUA. Os primeiros veículos, baseados no Model Y, utilizam uma solução de percepção puramente visual e o software FSD. A equipe liderada por Ashok Elluswamy, chefe de IA e software de condução autônoma da Tesla, realizou grandes mudanças técnicas no sistema, simplificando em quase 90% as aproximadamente 330-340 mil linhas de código heurístico em C++ legadas pela equipe de Andrej Karpathy, substituindo-as por uma “rede neural gigante”. Esta medida visa mudar da “codificação da experiência humana” para o “treinamento parametrizado”, otimizando autonomamente o modelo através de dados massivos e simulação de condução. Atualmente, o serviço está em fase inicial de experimentação, gerando ampla discussão na indústria sobre a rota tecnológica e a capacidade de escalonamento da Tesla. (Fonte: 36氪, Ronald_vanLoon, kylebrussell)

🎯 Tendências
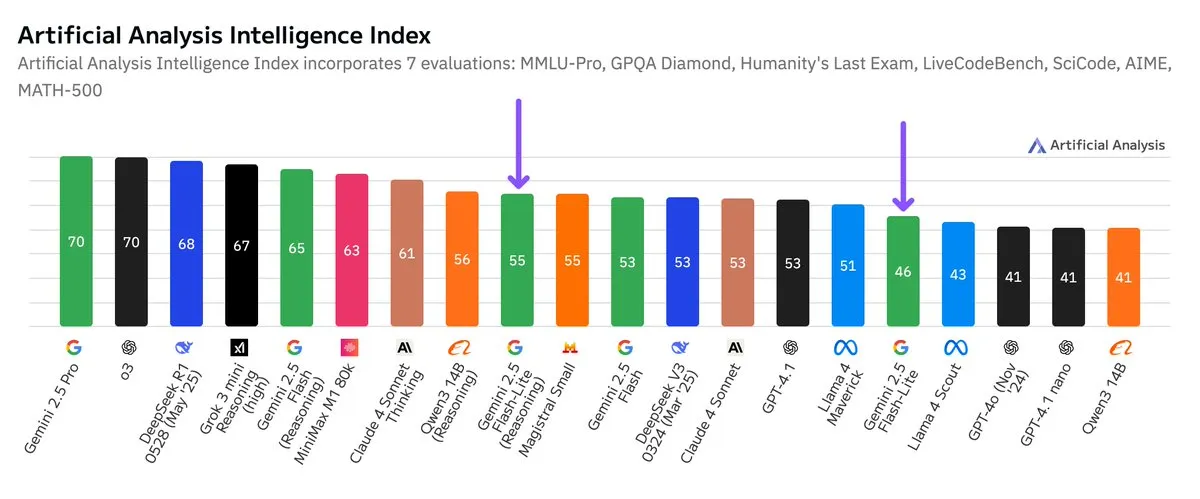
Google Gemini 2.5 Flash-Lite: Teste de benchmark independente lançado, melhoria na relação custo-benefício: De acordo com os resultados de testes de benchmark independentes divulgados pela Artificial Analysis, a versão Preview (06-17) do Google Gemini 2.5 Flash-Lite, em comparação com a versão Flash regular, teve seu custo reduzido em aproximadamente 5 vezes e sua velocidade aumentada em cerca de 1,7 vezes, embora com uma ligeira queda no nível de inteligência. Este modelo é uma atualização do Gemini 2.0 Flash-Lite lançado em fevereiro de 2025 e pertence à categoria de modelos híbridos. Esta atualização demonstra os esforços contínuos do Google em buscar eficiência e custo-benefício em seus modelos, possivelmente visando cenários de aplicação com altas exigências de custo e velocidade. (Fonte: zacharynado)
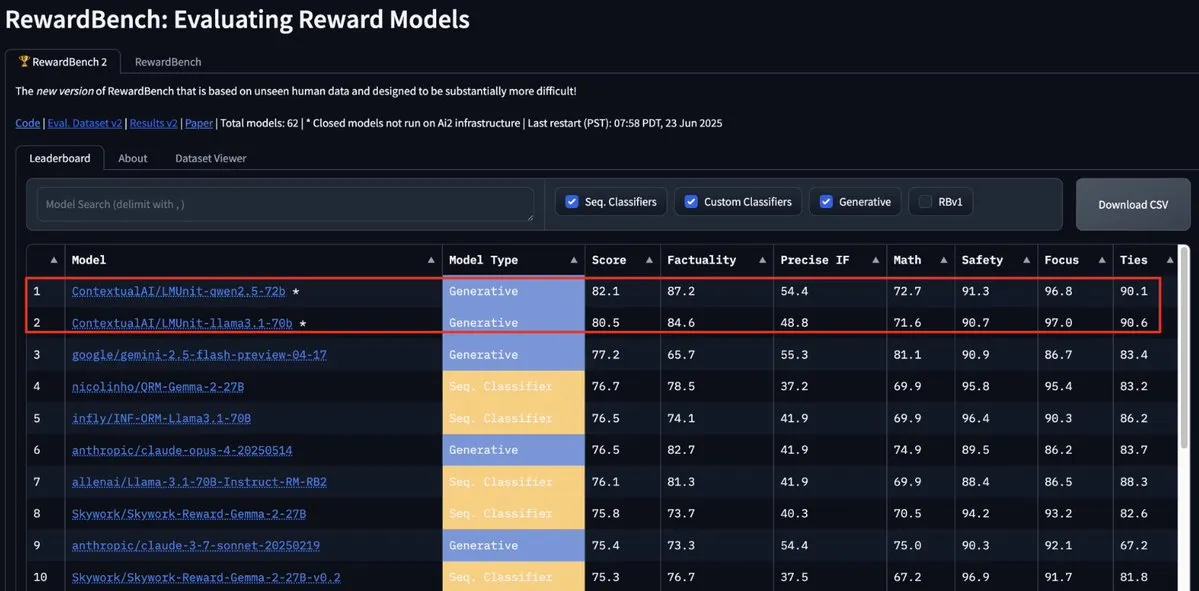
Modelo LMUnit da ContextualAI lidera o RewardBench2, superando Gemini, Claude 4 e GPT-4.1: O modelo LMUnit da ContextualAI alcançou o primeiro lugar no benchmark RewardBench2, com uma pontuação mais de 5% superior a modelos renomados como Gemini, Claude 4 e GPT-4.1. Esta conquista pode ser atribuída ao seu método de treinamento único, supostamente semelhante ao método de “rubrics” no qual a OpenAI investiu esforços significativos para o o4 e modelos subsequentes. Esse método ajuda a alcançar uma expansão eficaz quando LLMs atuam como juízes (llm-as-a-judge) durante o raciocínio. (Fonte: natolambert, menhguin, apsdehal)
Arcee.ai expande com sucesso o comprimento de contexto do modelo AFM-4.5B de 4k para 64k: A Arcee.ai anunciou que o comprimento de contexto de seu primeiro modelo base, AFM-4.5B, foi expandido com sucesso de 4k para 64k. A equipe alcançou este avanço através de experimentação ativa, fusão de modelos, destilação e o que foi jocosamente chamado de “muita sopa” (referindo-se a técnicas de fusão de modelos). Este progresso é crucial para o processamento de tarefas com textos longos. As melhorias da Arcee no modelo GLM-32B-Base também demonstraram sua eficácia, não apenas aumentando o suporte a contextos longos de 8k para 32k, mas também melhorando todas as avaliações de modelos base (incluindo contextos curtos). (Fonte: eliebakouch, teortaxesTex, nrehiew_, shxf0072, code_star)

API Gemini do Google atualizada, melhora velocidade e capacidade de processamento de vídeo e PDF: A API Gemini do Google recebeu atualizações importantes no processamento de vídeo e PDF. O tempo para o primeiro byte (TTFT) de vídeos em cache melhorou 3 vezes, e a velocidade de processamento de PDFs em cache aumentou em até 4 vezes. Além disso, a nova versão suporta o processamento em lote de múltiplos vídeos, e o desempenho do cache implícito está próximo ao do cache explícito. Essas melhorias visam aumentar a eficiência e a experiência dos desenvolvedores ao usar a API Gemini para processar conteúdo multimídia. (Fonte: _philschmid)
Moonshot (Kimi) atualiza modelo Kimi VL A3B Thinking, aprimorando capacidade de processamento multimodal: A Moonshot AI (Kimi) lançou uma versão atualizada de seu pequeno modelo de linguagem visual (VLM), Kimi VL A3B Thinking, sob a licença MIT. A nova versão consome menos tokens, encurta as trajetórias de pensamento, suporta processamento de vídeo e pode lidar com imagens de resolução mais alta (1792×1792). Alcançou 65,2 pontos no VideoMMMU, melhorou 20,1 pontos no MathVision para 56,9, melhorou 8,4 pontos no MathVista para 80,1, melhorou 3,2 pontos no MMMU-Pro para 46,3, e demonstrou excelente desempenho em raciocínio visual, localização de UI Agent, processamento de vídeo e PDF. Já está disponível em código aberto no Hugging Face. (Fonte: mervenoyann)

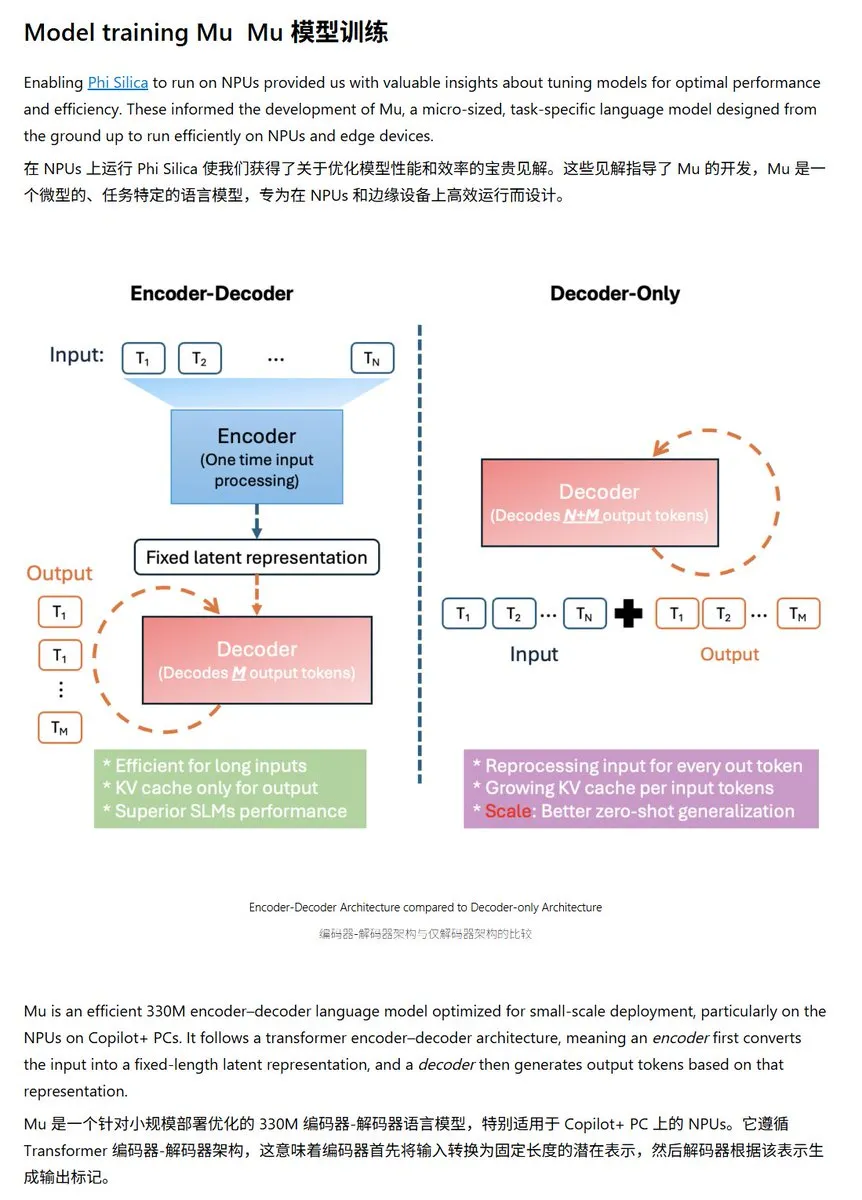
Microsoft lança modelo de linguagem pequeno Mu-330M, otimizado para NPU do Windows: A Microsoft apresentou um novo modelo de linguagem pequeno, Mu-330M, projetado para rodar na NPU (Unidade de Processamento Neural) dos PCs Windows Copilot+, visando suportar funcionalidades de Agent dentro do sistema Windows. O modelo foi otimizado para NPU, adotando tecnologias como embeddings de posição rotacional, atenção de consulta agrupada e LayerNorm de duas camadas, para operar eficientemente com baixo consumo de energia, marcando mais um passo da Microsoft na capacidade de IA no dispositivo. (Fonte: karminski3)
DeepMind publica relatório técnico do Mercury, focado em modelos de linguagem de difusão: A Inception Labs (equipe relacionada ao DeepMind) publicou o relatório técnico de seu modelo de linguagem de difusão, Mercury. O relatório detalha a arquitetura do modelo Mercury, métodos de treinamento e resultados experimentais, fornecendo aos pesquisadores insights aprofundados sobre este tipo emergente de modelo. Modelos de difusão já alcançaram sucesso notável na geração de imagens, e sua aplicação em modelos de linguagem é uma direção de vanguarda na pesquisa atual de IA. (Fonte: andriy_mulyar)
Meta e Oakley colaboram para expandir linha de óculos inteligentes com IA: A Meta colaborou com a marca de óculos Oakley para expandir ainda mais sua linha de produtos de óculos inteligentes com IA. Espera-se que os novos óculos inteligentes integrem a tecnologia de IA da Meta, oferecendo funcionalidades interativas mais ricas e uma melhor experiência do usuário. Esta colaboração marca o investimento contínuo da Meta no campo de dispositivos vestíveis com IA, visando integrar a IA de forma mais fluida na vida cotidiana. (Fonte: rowancheung, Ronald_vanLoon)
Alibaba Cloud lança framework de aceleração de treinamento e inferência de modelos para condução autônoma PAI-TurboX, tempo de treinamento pode ser reduzido em 50%: A Alibaba Cloud lançou o PAI-TurboX, um framework de aceleração de treinamento e inferência de modelos para o setor de condução autônoma. O framework visa aumentar a eficiência do treinamento e inferência de modelos de percepção, planejamento e controle, e até mesmo modelos do mundo, otimizando o pré-processamento de dados multimodais, afinidade de CPU, compilação dinâmica, paralelismo de pipeline, e fornecendo otimização de operadores e capacidade de quantização. Testes práticos mostram que, em tarefas de treinamento de vários modelos da indústria como BEVFusion, MapTR e SparseDrive, o PAI-TurboX pode reduzir o tempo de treinamento em cerca de 50%. (Fonte: 量子位)
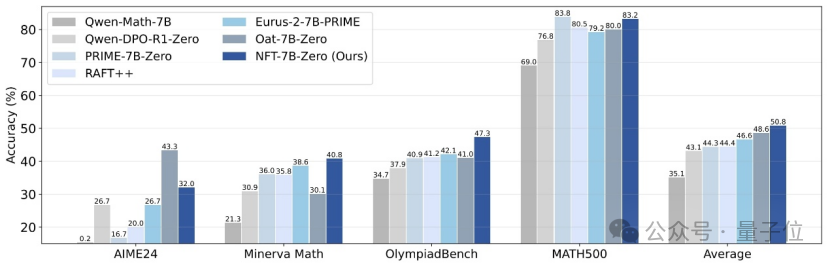
Tsinghua, Nvidia e outros propõem método NFT, permitindo que o aprendizado supervisionado “reflita” sobre erros: Pesquisadores da Universidade de Tsinghua, Nvidia e Universidade de Stanford propuseram conjuntamente um novo esquema de aprendizado supervisionado chamado NFT (Negative-aware FineTuning). Este método, baseado no algoritmo RFT (Rejection FineTuning), utiliza dados negativos para treinamento construindo um “modelo negativo implícito”, ou seja, uma “estratégia negativa implícita”. Esta estratégia permite que o aprendizado supervisionado realize “autorreflexão” como o aprendizado por reforço, preenchendo a lacuna de capacidade entre o aprendizado supervisionado e o aprendizado por reforço em certas tarefas, e demonstrou melhorias significativas de desempenho em tarefas como raciocínio matemático. Em condições On-Policy, seu gradiente da função de perda é equivalente ao GRPO. (Fonte: 量子位)
OmniGen2 lançado: modelo multifuncional de edição de imagem de 8B, fundindo compreensão visual e geração de imagem: Um novo modelo multifuncional de edição de imagem chamado OmniGen2 foi lançado. O modelo combina compreensão visual (baseada no Qwen-VL-2.5) com geração de imagem (um modelo de difusão de 4B parâmetros), totalizando aproximadamente 8B parâmetros. O OmniGen2 é capaz de suportar múltiplas tarefas como texto para imagem, edição de imagem, compreensão de imagem e geração contextual, visando fornecer um modelo unificado que possa resolver diversos problemas relacionados à visão e seja adequado para integração em dispositivos de ponta. (Fonte: karminski3)

Modelo de geração de imagem a partir de texto Chroma-8.9B-v39 atualizado, baseado no FLUX.1-schnell, uso comercial permitido: O modelo de texto para imagem Chroma-8.9B-v39 foi atualizado, melhorando a iluminação e a naturalidade das tarefas. O modelo é baseado no FLUX.1-schnell, com o número de parâmetros comprimido de 12B para 8.9B, e utiliza a licença Apache 2.0, permitindo uso comercial. Alega-se que o modelo “reintroduziu conceitos anatômicos ausentes, totalmente sem restrições de conteúdo” e foi pós-treinado com um conjunto de dados contendo 5 milhões de obras de anime, furry, arte e fotografias. (Fonte: karminski3)

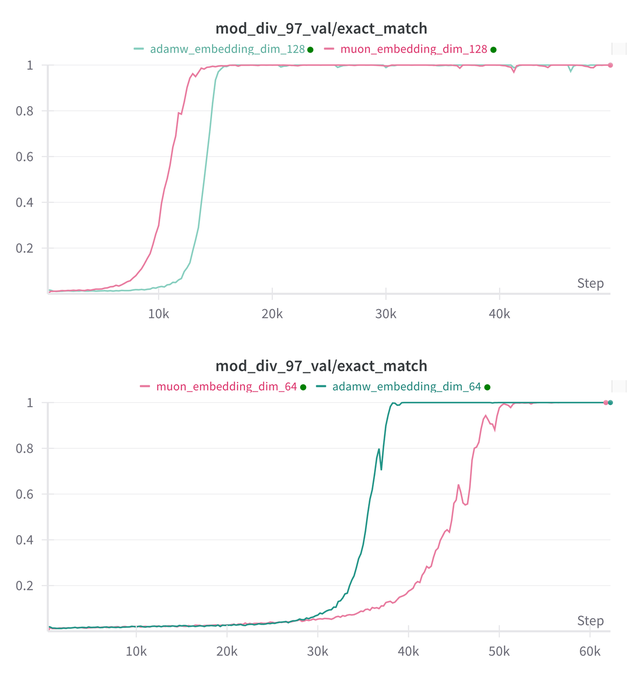
Essential AI atualiza suas conclusões de pesquisa sobre a capacidade de Grokking dos modelos Muon e Adam: A Essential AI compartilhou os últimos progressos de pesquisa sobre a capacidade de Grokking (um fenômeno onde o modelo tem um desempenho ruim no início do treinamento e depois subitamente compreende a generalização) de seus modelos Muon e Adam. As hipóteses iniciais podem contradizer as observações reais. A equipe divulgou os resultados de pequenos experimentos de pesquisa internos, mostrando que, após expandir o espaço de busca de hiperparâmetros, Muon não apresentou vantagens universais óbvias em relação ao AdamW, com ambos tendo desempenhos variados em diferentes cenários. Isso indica que o AdamW ainda é um otimizador poderoso e até mesmo SOTA em muitas situações. (Fonte: eliebakouch, teortaxesTex, nrehiew_)
Modelo de geração de imagens Ostris AI atualizado, focado na versão sem CFG e otimização de detalhes de alta frequência: A Ostris AI continua atualizando seu modelo de geração de imagens, atualmente focando no desenvolvimento da versão sem CFG (Classifier-Free Guidance) devido à sua convergência mais rápida. Na última atualização do Dia 7, a equipe adicionou novas técnicas de treinamento para lidar melhor com detalhes de alta frequência e está trabalhando para remover artefatos de alto detalhe. A atualização anterior do Dia 4 já havia demonstrado uma melhora significativa na qualidade das imagens geradas com o novo método sem o uso de CFG. (Fonte: ostrisai)

Ant Group, Academia Chinesa de Ciências e outros disponibilizam modelo ViLaSR-7B de código aberto, realizando raciocínio espacial “desenhando enquanto pensa”: O Instituto de Pesquisa Tecnológica da Ant Group, o Instituto de Automação da Academia Chinesa de Ciências e a Universidade Chinesa de Hong Kong disponibilizaram conjuntamente o modelo ViLaSR-7B de código aberto. Este modelo, através do paradigma “Drawing to Reason in Space”, permite que grandes modelos de linguagem visual (LVLM) desenhem marcações auxiliares (como linhas de referência, caixas delimitadoras) no espaço visual para auxiliar o pensamento, aprimorando assim a percepção espacial e as capacidades de raciocínio. O ViLaSR adota um framework de treinamento de três estágios: partida a frio, amostragem por rejeição reflexiva e aprendizado por reforço. Experimentos mostram que o modelo alcançou uma melhoria média de 18,4% em 5 benchmarks, incluindo navegação em labirintos, compreensão de imagem e raciocínio espacial em vídeo, e seu desempenho no VSI-Bench está próximo ao do Gemini-1.5-Pro. (Fonte: 量子位)

🧰 Ferramentas
SGLang agora suporta Hugging Face Transformers como backend, aumentando a eficiência da inferência: O SGLang anunciou que agora suporta Hugging Face Transformers como backend. Isso significa que os usuários podem fornecer serviços de inferência rápidos e de nível de produção para qualquer modelo compatível com Transformers, sem necessidade de suporte nativo, plug-and-play. Essa integração visa simplificar o processo de implantação de inferência de modelos de linguagem de alto desempenho, expandindo o escopo de aplicabilidade e a facilidade de uso do SGLang. (Fonte: TheZachMueller, ClementDelangue)

MLX-LM-LORA v0.7.0 lançado, com funcionalidade RLHF integrada: MLX-LM-LORA lançou a versão v0.7.0, que agora inclui funcionalidade integrada de Aprendizado por Reforço a partir de Feedback Humano (RLHF). A ferramenta agora suporta carregamento de 4 bits, 6 bits e 8 bits, modo de treinamento RLHF e pode fundir diretamente adaptadores (adapters) aos pesos base. Isso torna o ajuste fino LoRA no framework MLX mais inteligente e eficiente, especialmente em dispositivos com chip Apple. (Fonte: awnihannun)
LlamaCloud lançado, fornecendo um kit de ferramentas compatível com MCP para fluxos de trabalho de documentos: O LlamaCloud já está disponível, como um kit de ferramentas compatível com o Protocolo de Contexto de Modelo (MCP), utilizável para qualquer fluxo de trabalho de documentos. Os usuários podem conectá-lo a modelos como o Claude para realizar operações complexas de extração, comparação de documentos, etc. Por exemplo, ele pode analisar o desempenho financeiro da Tesla nos últimos cinco trimestres e gerar um relatório abrangente, criando dinamicamente esquemas padronizados e executando-os em todos os arquivos, e depois utilizando a geração de código para o resultado final. O LlamaCloud pode corrigir dinamicamente esquemas incorretos e suporta links diretos para arquivos. (Fonte: jerryjliu0)
Georgi Gerganov anuncia projeto LlamaBarn: Georgi Gerganov (criador do llama.cpp) postou uma imagem nas redes sociais, anunciando um novo projeto chamado “LlamaBarn”. A imagem mostra uma interface semelhante a um painel de controle, contendo seleção de modelos, ajuste de parâmetros e outros elementos, sugerindo que pode ser uma ferramenta para gerenciar, executar ou testar LLMs locais. A comunidade demonstrou expectativa, acreditando que pode se tornar um forte concorrente para ferramentas existentes como o Ollama. (Fonte: ClementDelangue, teortaxesTex, jeremyphoward)
Void Editor: Um novo assistente de programação AI de código aberto, suporta MCP e modelos locais: O Void Editor surge como um novo assistente de programação AI de código aberto, com o objetivo de ser uma alternativa a ferramentas como o Cursor. Ele suporta autocompletar com tab, modo de chat, Protocolo de Contexto de Modelo (MCP) e modo Agent. Os usuários podem conectar qualquer API de modelo de linguagem grande ou executar modelos localmente, oferecendo aos desenvolvedores uma experiência flexível de programação assistida por IA. (Fonte: karminski3)
Together AI lança ferramenta Which LLM para ajudar a escolher o LLM de código aberto adequado: A Together AI lançou uma ferramenta gratuita chamada “Which LLM”, projetada para ajudar os usuários a selecionar o modelo de linguagem grande de código aberto mais adequado com base em casos de uso específicos, requisitos de desempenho e considerações econômicas. Com o aumento exponencial do número de LLMs de código aberto, ferramentas como esta podem fornecer referências valiosas para desenvolvedores e pesquisadores na seleção de modelos. (Fonte: vipulved)
Perplexity Finance adiciona funcionalidade de rastreamento de linha do tempo de preços de ações: A Perplexity Finance anunciou que os usuários agora podem rastrear a linha do tempo das variações de preço de qualquer código de ação em sua plataforma. Esta nova funcionalidade visa fornecer aos usuários uma ferramenta de análise de informações do mercado financeiro mais intuitiva e conveniente, que, combinada com as capacidades de IA da Perplexity, pode trazer uma nova experiência para consulta e análise de informações financeiras. (Fonte: AravSrinivas)

IdeaWeaver lança o primeiro agente de IA para depuração de desempenho de sistemas: A IdeaWeaver lançou o que afirma ser o primeiro agente de IA projetado especificamente para depurar problemas de desempenho de sistemas. A ferramenta utiliza o framework CrewAI e é capaz de executar comandos de sistema para diagnosticar problemas relacionados a CPU, memória, I/O e rede. Sua característica é priorizar o uso de LLMs locais (via OLLAMA) para proteger a privacidade, solicitando chaves de API da OpenAI apenas quando modelos locais não estão disponíveis, com o objetivo de aplicar as capacidades da IA aos domínios de DevOps e gerenciamento de sistemas. (Fonte: Reddit r/artificial)
Kling AI adiciona suporte a Live Photo, permitindo salvar vídeos gerados como papéis de parede dinâmicos: A Kling AI anunciou que sua funcionalidade de geração de vídeo agora suporta salvar as criações como Live Photos (fotos ao vivo). Os usuários podem definir seus conteúdos dinâmicos favoritos criados pela Kling como papel de parede do celular, aumentando a diversão e a utilidade dos vídeos gerados por IA. (Fonte: Kling_ai)
Cognition AI torna Blockdiff de código aberto, alcançando um aumento de 200x na velocidade de snapshots de VM: A Cognition AI anunciou a abertura do código de seu formato de arquivo de snapshot de VM, Blockdiff, desenvolvido para o Devin. Como a criação de snapshots de VM no EC2 era muito demorada (mais de 30 minutos), a equipe construiu seu próprio hipervisor otterlink e o formato de arquivo Blockdiff, o que aumentou a velocidade de criação de snapshots em 200 vezes. Esta contribuição de código aberto visa ajudar os desenvolvedores a gerenciar ambientes de máquinas virtuais de forma mais eficiente. (Fonte: karinanguyen_)

📚 Aprendizado
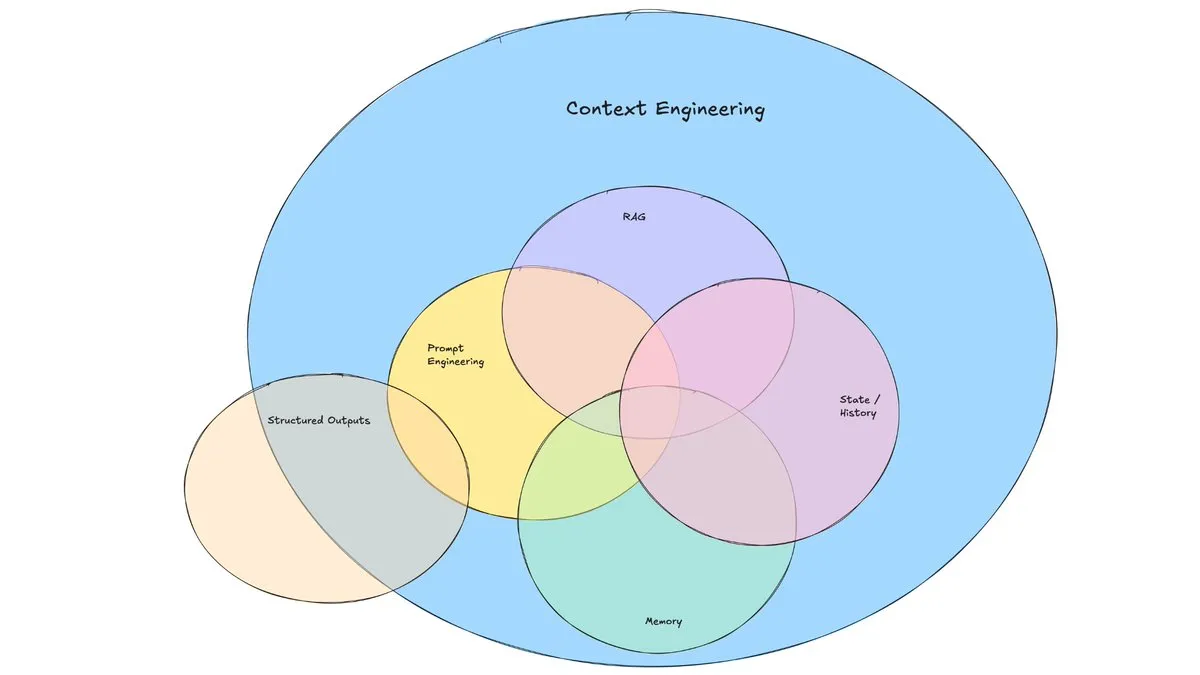
Postagem de blog da LangChain discute o surgimento da “Engenharia de Contexto”: A LangChain publicou uma postagem de blog discutindo o termo cada vez mais popular “Engenharia de Contexto” (Context Engineering). O artigo a define como “construir sistemas dinâmicos que fornecem as informações e ferramentas corretas no formato correto, permitindo que os LLMs realizem tarefas de forma razoável”. Isso não é um conceito totalmente novo, pois os construtores de Agents já o praticam há algum tempo, e ferramentas como LangGraph e LangSmith foram criadas para esse fim. A proposição do termo ajuda a atrair mais atenção para as habilidades e ferramentas relacionadas. (Fonte: hwchase17, Hacubu, yoheinakajima)
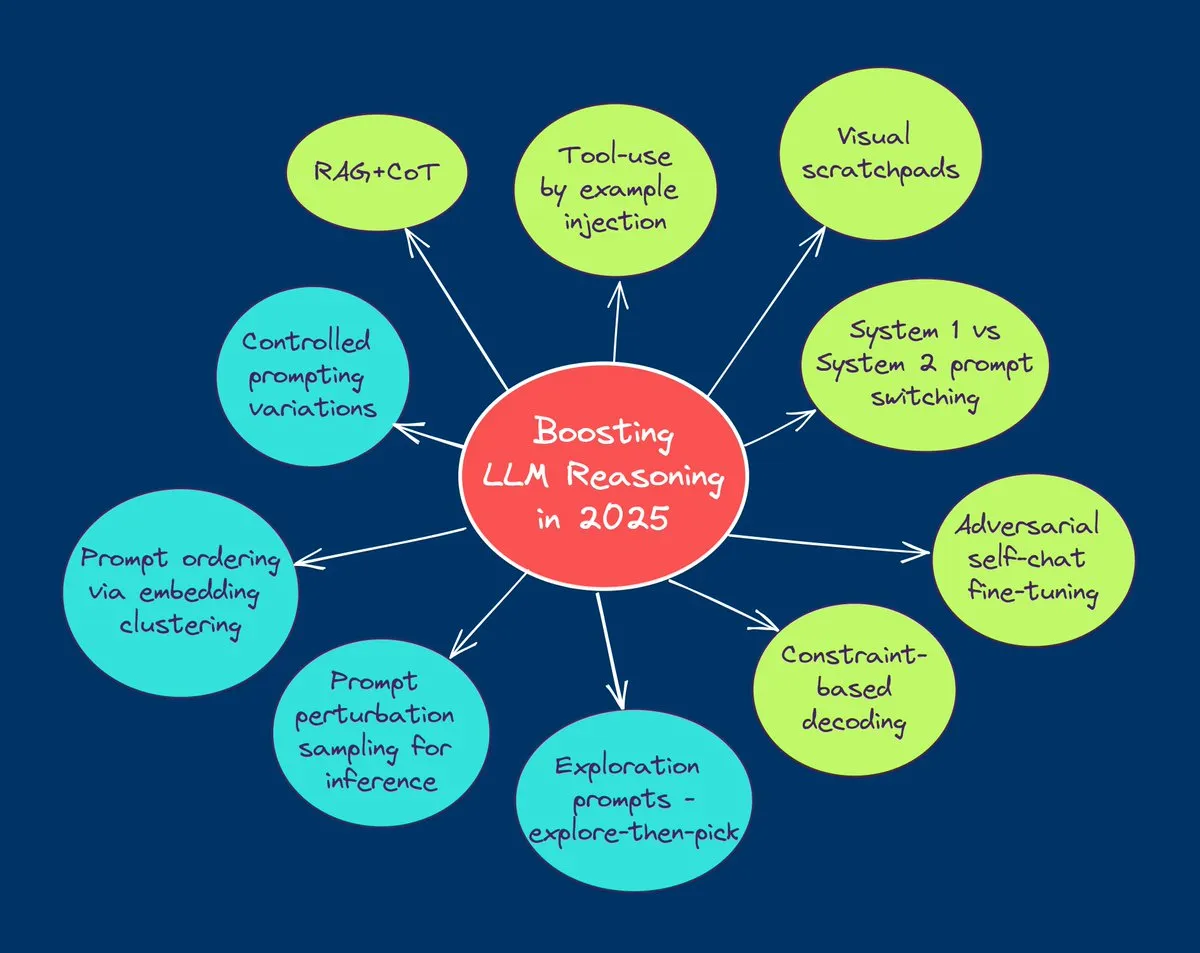
TuringPost resume as 10 principais tecnologias para aprimorar a capacidade de raciocínio de LLMs em 2025: O TuringPost compartilhou 10 tecnologias cruciais usadas para aprimorar a capacidade de raciocínio de Modelos de Linguagem Grandes (LLMs) em 2025, incluindo: Cadeia de Pensamento Aumentada por Recuperação (RAG+CoT), uso de ferramentas por meio de injeção de exemplos, rascunho visual (suporte a raciocínio multimodal), alternância de prompts entre Sistema 1 e Sistema 2, ajuste fino por autodiálogo adversarial, decodificação baseada em restrições, prompting exploratório (explorar antes de escolher), amostragem de perturbação de prompts para raciocínio, ordenação de prompts por clusterização de embeddings e variantes de prompts controladas. Essas tecnologias oferecem diversas abordagens para otimizar o desempenho de LLMs em tarefas complexas. (Fonte: TheTuringPost, TheTuringPost)
Cohere Labs organiza Escola de Verão de ML para explorar o futuro do aprendizado de máquina: A comunidade de ciência aberta da Cohere Labs realizará uma Escola de Verão de ML (ML Summer School) em julho. O evento reunirá membros da comunidade global para discutir o futuro do aprendizado de máquina e contará com palestrantes da indústria. Entre eles, Katrina Lawrence ministrará um curso de revisão de matemática para aprendizado de máquina em 2 de julho, cobrindo conceitos centrais como cálculo, cálculo vetorial e álgebra linear. (Fonte: sarahookr)

DeepLearning.AI e Meta colaboram para lançar curso gratuito “Building with Llama 4”: DeepLearning.AI e Meta colaboraram para lançar um curso gratuito chamado “Building with Llama 4”. O conteúdo do curso inclui: operação prática com os modelos da série Llama 4, compreensão de sua arquitetura de Mistura de Especialistas (MOE) e como construir aplicativos usando a API oficial; aplicação do Llama 4 para inferência multi-imagem, localização de imagem (identificação de objetos e suas caixas delimitadoras) e processamento de consultas de texto de contexto longo de até 1 milhão de tokens; uso das ferramentas de otimização de prompt do Llama 4 para melhorar automaticamente os prompts do sistema e utilização de seu kit de ferramentas de dados sintéticos para criar conjuntos de dados de alta qualidade para ajuste fino. (Fonte: DeepLearningAI)
Canal do YouTube da EleutherAI oferece vasto conteúdo de pesquisa em IA: O canal do YouTube da EleutherAI reúne gravações de seus clubes de leitura e séries de palestras, totalizando mais de 100 horas de conteúdo. Os tópicos abrangem escalabilidade e desempenho em aprendizado de máquina, análise funcional, além de podcasts e entrevistas com membros da equipe. O canal oferece ricos recursos de aprendizado para pesquisadores e entusiastas de IA. A EleutherAI também lançou uma nova série de palestras, com a primeira apresentada por @linguist_cat sobre tokenizadores e suas limitações. (Fonte: BlancheMinerva, BlancheMinerva)
Artigo explora o aprimoramento do raciocínio multimodal através de Tokens Visuais Latentes (Machine Mental Imagery): Um novo artigo, “Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens”, propõe o framework Mirage, que aprimora o raciocínio multimodal adicionando Tokens Visuais Latentes durante o processo de decodificação do VLM (em vez de gerar imagens completas), simulando a imaginação mental humana. O método primeiro supervisiona os Tokens Latentes através da destilação de embeddings de imagens reais, depois muda para supervisão puramente textual para alinhar as trajetórias latentes com os objetivos da tarefa, e aprimora ainda mais a capacidade através do aprendizado por reforço. Experimentos demonstram que o Mirage pode alcançar um raciocínio multimodal mais forte sem gerar imagens explícitas. (Fonte: HuggingFace Daily Papers)
Artigo propõe framework Vision as a Dialect, unificando compreensão e geração visual através de representações alinhadas com texto: Um artigo intitulado “Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations” apresenta um framework de LLM multimodal chamado Tar. Este framework usa um tokenizador alinhado com texto (TA-Tok) para converter imagens em tokens discretos e utiliza um codebook alinhado com texto projetado a partir do vocabulário do LLM, unificando assim o visual e o textual em uma representação semântica discreta compartilhada. O Tar implementa entrada e saída intermodal através de uma interface compartilhada, sem necessidade de design específico para cada modalidade, e adota um codificador-decodificador adaptável à escala e um destokenizador generativo para equilibrar eficiência e detalhes visuais. (Fonte: HuggingFace Daily Papers)
Artigo propõe ReasonFlux-PRM: PRM sensível à trajetória para raciocínio de cadeia longa de pensamento em LLMs: O artigo “ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs” apresenta um novo Modelo de Recompensa de Processo (PRM) sensível à trajetória, projetado especificamente para avaliar traços de raciocínio do tipo trajetória-resposta gerados por modelos de raciocínio de ponta, como o DeepSeek-R1. O ReasonFlux-PRM combina supervisão em nível de etapa e em nível de trajetória, alcançando uma atribuição de recompensa de granularidade fina alinhada com dados de cadeia de pensamento estruturados, e obtém melhorias de desempenho em cenários como SFT, RL e expansão em tempo de teste BoN. (Fonte: HuggingFace Daily Papers)
Artigo estuda métodos de avaliação para barreiras de proteção contra jailbreak em modelos de linguagem grandes: Um artigo intitulado “SoK: Evaluating Jailbreak Guardrails for Large Language Models” realiza uma sistematização do conhecimento sobre ataques de jailbreak em Modelos de Linguagem Grandes (LLMs) e suas barreiras de proteção (Guardrails). O artigo propõe uma nova taxonomia multidimensional, classificando as barreiras de proteção em seis dimensões principais, e introduz um framework de avaliação de segurança-eficiência-praticidade para avaliar seu efeito real. Através de análises e experimentos extensivos, o artigo aponta as vantagens e desvantagens dos métodos de barreiras de proteção existentes, discute sua universalidade contra diferentes tipos de ataque e fornece insights para otimizar combinações de defesa. (Fonte: HuggingFace Daily Papers)
Artigo de destaque da AAAI 2025 explora classes decidíveis de Processos de Decisão de Markov Parcialmente Observáveis (POMDP): Um artigo intitulado “Revelations: A Decidable Class of POMDP with Omega-Regular Objectives” recebeu o prêmio de artigo de destaque da AAAI 2025. A pesquisa identifica uma classe decidível de MDPs (Processos de Decisão de Markov): problemas de decisão com “revelações fortes”, ou seja, a cada passo há uma probabilidade não nula de revelar o estado exato do mundo. O artigo também fornece resultados de decidibilidade para “revelações fracas”, onde o estado exato é garantido de ser revelado eventualmente, mas não necessariamente a cada passo. Esta pesquisa fornece uma nova base teórica para a tomada de decisão ótima em situações de informação incompleta. (Fonte: aihub.org)
Artigo propõe CommVQ: Quantização Vetorial Comutativa para compressão de cache KV: O artigo “CommVQ: Commutative Vector Quantization for KV Cache Compression” propõe um método chamado CommVQ, que comprime o cache KV através de quantização aditiva e um codificador e codebook leves, para reduzir a ocupação de memória na inferência de LLMs de contexto longo. Para reduzir o custo computacional da decodificação, o codebook é projetado para ser comutável com embeddings de posição rotacional (RoPE) e treinado usando o algoritmo EM. Experimentos mostram que o método pode reduzir o tamanho do cache KV FP16 em 87,5% com quantização de 2 bits e supera os métodos existentes de quantização de cache KV, podendo até mesmo alcançar quantização de cache KV de 1 bit com perda mínima de precisão. (Fonte: HuggingFace Daily Papers)
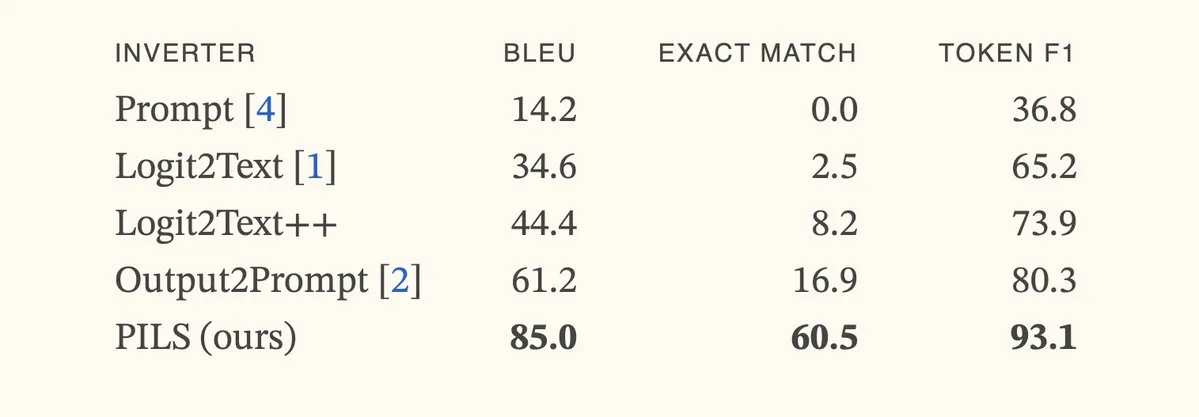
Artigo propõe método PILS, melhorando a inversão de modelos de linguagem através da representação compacta da distribuição do próximo token: O artigo “Better Language Model Inversion by Compactly Representing Next-Token Distributions” propõe um novo método de inversão de modelos de linguagem, PILS (Prompt Inversion from Logprob Sequences). O método recupera prompts ocultos analisando as probabilidades do próximo token do modelo em várias etapas de geração. O cerne está na descoberta de que os vetores de saída do modelo de linguagem ocupam um subespaço de baixa dimensão, permitindo assim a compressão sem perdas da distribuição de probabilidade do próximo token através de um mapeamento linear, para uma inversão mais eficaz. Experimentos mostram que o PILS supera significativamente os métodos SOTA anteriores na recuperação de prompts ocultos. (Fonte: HuggingFace Daily Papers, jxmnop)
Artigo propõe Phantom-Data: um conjunto de dados universal para geração de vídeo com consistência de sujeito: O artigo “Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset” apresenta um novo conjunto de dados chamado Phantom-Data, que visa resolver o problema generalizado de “copiar e colar” (ou seja, a identidade do sujeito excessivamente emaranhada com atributos de fundo e contexto) nos modelos existentes de geração de sujeito para vídeo. Phantom-Data é o primeiro conjunto de dados universal de consistência de sujeito para vídeo com pares cruzados, contendo aproximadamente um milhão de pares com identidade consistente em diferentes categorias. O conjunto de dados é construído através de um processo de três estágios, incluindo detecção de sujeito, recuperação de sujeito em larga escala em contextos cruzados e verificação de identidade guiada por conhecimento prévio. (Fonte: HuggingFace Daily Papers)
Artigo propõe LongWriter-Zero: Dominando a Geração de Texto Ultralongo via Aprendizado por Reforço: O artigo “LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning” propõe um método baseado em incentivos para cultivar, a partir do zero, a capacidade de LLMs de gerar textos ultralongos e de alta qualidade usando Aprendizado por Reforço (RL), sem quaisquer dados anotados ou sintéticos. O método começa com um modelo base e, através de RL, guia-o no planejamento e refinamento durante o processo de escrita, usando um modelo de recompensa especializado para controlar o comprimento, a qualidade da escrita e o formato estrutural. Experimentos mostram que o LongWriter-Zero, treinado a partir do Qwen2.5-32B, supera os métodos tradicionais de SFT em tarefas de escrita de texto longo e atinge o nível SOTA em vários benchmarks. (Fonte: HuggingFace Daily Papers)
💼 Negócios
Empresa de IA jurídica Harvey anuncia conclusão de rodada de financiamento Série E de US$ 300 milhões, com avaliação de US$ 5 bilhões: A startup de IA jurídica Harvey anunciou a conclusão de uma rodada de financiamento Série E de US$ 300 milhões, coliderada pela Kleiner Perkins e Coatue, elevando a avaliação da empresa para US$ 5 bilhões. Outros investidores incluem Sequoia Capital, GV, DST Global, Conviction, Elad Gil, OpenAI Startup Fund, Elemental, SV Angel, Kris Fredrickson e REV. Este financiamento ajudará a Harvey a continuar desenvolvendo e expandindo suas aplicações de IA no setor jurídico. (Fonte: saranormous)
Serviço de nuvem GPU sob demanda Hyperbolic atinge ARR de US$ 1 milhão em 7 dias de lançamento: Yuchenj_UW anunciou que seu serviço de nuvem GPU sob demanda Hyperbolic, lançado na semana passada, atingiu uma receita recorrente anual (ARR) de US$ 1 milhão em 7 dias, partindo de zero, com apenas um pequeno esforço de marketing através de um tweet. Eles oferecem aos construtores créditos de teste gratuitos para nós 8xH100, demonstrando a forte demanda do mercado por serviços de nuvem GPU de alto desempenho. (Fonte: Yuchenj_UW)
Replit anuncia que receita recorrente anual (ARR) ultrapassa US$ 100 milhões: A plataforma de ambiente de desenvolvimento integrado (IDE) online e computação em nuvem Replit anunciou que sua receita recorrente anual (ARR) ultrapassou US$ 100 milhões, um crescimento significativo em relação aos US$ 10 milhões do final de 2024. A empresa afirmou que, após sua última rodada de financiamento em 2023 com uma avaliação de US$ 1,1 bilhão, ainda possui mais da metade dos fundos no banco. O crescimento da Replit é impulsionado pelo uso de sua plataforma por usuários corporativos (como Zillow, HubSpot) e desenvolvedores independentes, e atualmente está contratando ativamente. (Fonte: pirroh, kylebrussell, hwchase17, Hacubu)
🌟 Comunidade
Novo paradigma da programação com IA: projetar primeiro, depois promptar, otimizando iterativamente a geração de código: dotey e Baoyu discutem a mudança no modelo de desenvolvimento de software trazida pela programação com IA. O debate tradicional entre “projetar primeiro, depois codificar” e “implementar primeiro, depois refatorar” se funde na era da IA. A IA reduz drasticamente o custo e o tempo do design à codificação, permitindo que os desenvolvedores implementem rapidamente versões mesmo quando o design não está totalmente claro, e melhorem iterativamente o design e os prompts através da validação dos resultados. Os prompts assumem o papel dos antigos “documentos de design detalhado”, mas de forma mais simplificada. Neste modelo, os desenvolvedores devem focar mais no design do sistema, gerar código em pequenos lotes, utilizar gerenciamento de código fonte e revisar e testar o código gerado pela IA. Para programadores experientes, mudar a mentalidade e os hábitos de desenvolvimento é crucial para abraçar a programação com IA. (Fonte: dotey)
Claude Code é preferido por desenvolvedores devido à sua poderosa capacidade de processamento de grandes bases de código e eficiência de contexto: A comunidade Reddit r/ClaudeAI discute o excelente desempenho do Claude Code no processamento de grandes bases de código. Usuários relatam que ele consegue entender bem bases de código muito maiores que 200k Tokens e realizar modificações. A discussão sugere que o Claude Code pode alcançar um processamento de contexto eficiente através de estratégias semelhantes à leitura humana (lendo apenas partes cruciais), usando ferramentas como grep para recuperação de contexto (em vez de depender totalmente da compressão vetorial do RAG) e vantagens da integração de modelos de primeira parte. Usuários compartilharam vários casos de sucesso usando o Claude Code para corrigir problemas de sistema, construir um rastreador financeiro pessoal, desenvolver aplicativos Android (mesmo sem experiência em desenvolvimento Android), criar scripts Obsidian DataviewJS, etc., aumentando significativamente a eficiência do trabalho. (Fonte: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Conceito de “Engenharia de Contexto” chama atenção, enfatizando a construção de sistemas dinâmicos para capacitar LLMs: Harrison Chase, da LangChain, propôs que a “Engenharia de Contexto” (Context Engineering) é o trabalho central dos engenheiros de IA na construção de sistemas. É definida como “construir sistemas dinâmicos que fornecem as informações e ferramentas corretas no formato correto, permitindo que os LLMs realizem tarefas de forma razoável”. Este conceito enfatiza a importância de como organizar e fornecer informações de contexto de forma eficaz para o desempenho do modelo em aplicações de LLM, sendo fundamental em áreas como a construção de Agents. (Fonte: hwchase17, Hacubu, yoheinakajima)
Fundador da Meta, Zuckerberg, recruta pessoalmente talentos de IA, gerando atenção na comunidade: Notícias nas redes sociais afirmam que o fundador da Meta, Mark Zuckerberg, está participando pessoalmente do recrutamento de talentos para seu laboratório de superinteligência, contatando diretamente centenas de candidatos em potencial e convidando aqueles que respondem para jantar. Esta ação é interpretada como a determinação e o esforço da Meta no campo da IA, especialmente em inteligência artificial geral (AGI) ou superinteligência, mostrando a intensa disputa por talentos de ponta em IA entre as principais empresas de tecnologia. (Fonte: reach_vb, andrew_n_carr)

Desenvolvimento da IA desencadeia profunda reflexão sobre mercado de trabalho e estrutura econômica: A Harvard Business School e o economista Anton Korinek alertam que a AGI pode ser alcançada em 2-5 anos e, se o sistema econômico não for completamente reformado, pode levar ao colapso, enfatizando a necessidade de uma renda básica universal. Ao mesmo tempo, a comunidade discute que a IA automatizará um grande número de tarefas quantificáveis, impactando empregos de colarinho azul e branco, e as empresas precisarão reestruturar suas organizações para se adaptarem à IA. Yuval Noah Harari compara a revolução da IA a uma “onda de imigração de IA”, gerando discussões sobre a substituição de empregos pela IA e a busca por poder. Esses pontos de vista convergem para o impacto disruptivo da IA na futura estrutura socioeconômica. (Fonte: 36氪, 36氪, Reddit r/artificial, Reddit r/ChatGPT)

IA se destaca em competições de programação, excelente desempenho do agente da Sakana AI gera debate acalorado: O agente da Sakana AI ficou em 21º lugar entre mais de 1000 programadores humanos na competição de programação heurística AtCoder, com um desempenho geral entre os 6,8% melhores. A IA iterou cerca de 100 versões em 4 horas, gerando milhares de soluções potenciais, enquanto os competidores humanos geralmente testam apenas cerca de 12. A IA usou o Gemini 2.5 Pro e combinou conhecimento especializado com algoritmos de busca sistemática (como simulated annealing e beam search) para resolver problemas de otimização reais. A comunidade reagiu de forma mista, com alguns argumentando que a programação competitiva é diferente da engenharia de nível empresarial, e a vitória da IA é mais como um computador superando humanos em adição e subtração. (Fonte: Reddit r/ArtificialInteligence)
💡 Outros
Exploração da IA na educação profissional: diversas tentativas com entrevistas, professores e máquinas de aprendizado: Gigantes da educação profissional como Huatu, Fenbi e Zhonggong estão explorando ativamente aplicações de IA, com direções variadas. A Huatu foca em feedback de entrevistas com IA, a Fenbi aprofunda-se na correção por IA e professores de IA (as vendas do sistema de aulas com IA para resolução de questões já ultrapassaram 14 milhões), enquanto a Zhonggong lançou uma máquina de aprendizado para emprego com IA. O consenso da indústria é que a IA deve melhorar os resultados de aprendizado e a eficiência operacional, em vez de buscar apenas um alto valor agregado. A aplicação da IA também está evoluindo da prova de conceito para o aprofundamento em cenários específicos, como a 51CTO utilizando avatares digitais e modelagem 3D para gerar cursos, e usando IA para geração de questões de teste e análise de caminhos de aprendizado. No entanto, a maioria das empresas de educação ainda não possui capacidade para construir seus próprios modelos grandes, preferindo utilizar APIs de terceiros. (Fonte: 36氪)
Disney e Universal Pictures processam unicórnio de geração de imagens por IA Midjourney por violação de direitos autorais: Os gigantes de Hollywood Disney e Universal Pictures processaram conjuntamente a empresa de geração de imagens por IA Midjourney, acusando-a de usar uma grande quantidade de conteúdo de propriedade intelectual protegido por direitos autorais (como Homem de Ferro, Minions, etc.) sem permissão para treinar seus modelos de IA e gerar imagens altamente semelhantes. Os queixosos exigem a proibição da atividade infratora e uma indenização de até US$ 150.000 por cada obra intencionalmente infringida. Este caso destaca os desafios de direitos autorais enfrentados pela IA generativa. O fundador da Midjourney admitiu anteriormente o uso de dados não autorizados. O processo pode ter como objetivo impulsionar o estabelecimento de mecanismos de licenciamento de direitos autorais e sistemas de filtragem de conteúdo. (Fonte: 36氪)

Apple é acusada de atraso em IA, pode considerar aquisições para compensar deficiências, empresa da ex-CTO da OpenAI chama atenção: Relatos indicam que a Apple está relativamente atrasada no campo da IA, com capacidade de desenvolvimento próprio insuficiente e desempenho fraco da Siri. Para compensar essa lacuna, a Apple pode considerar realizar aquisições significativas. Há rumores de que houve contatos preliminares com a ex-CTO da OpenAI, Mira Murati, sobre sua nova empresa, Thinking Machines Lab. Historicamente, a Apple adquiriu repetidamente pequenas empresas de tecnologia para fortalecer suas próprias capacidades (como a própria Siri). Atualmente, a Apple está muito atrás dos gigantes da indústria em termos de escala de parâmetros de modelos de IA, e a aquisição de empresas como a Mistral poderia ajudá-la a avançar no desenvolvimento de seus próprios modelos grandes. (Fonte: 36氪)