
Palavras-chave:modelo de linguagem, pesquisa em IA, OpenAI, MiniMax, Gemini, DeepSeek, aprendizagem por reforço, agente de IA, desalinhamento emergente, modelo MiniMax-M1, Gemini 2.5 Pro, capacidade de programação DeepSeek-R1, protocolo de controle de modelo (MCP)
🔥 Foco
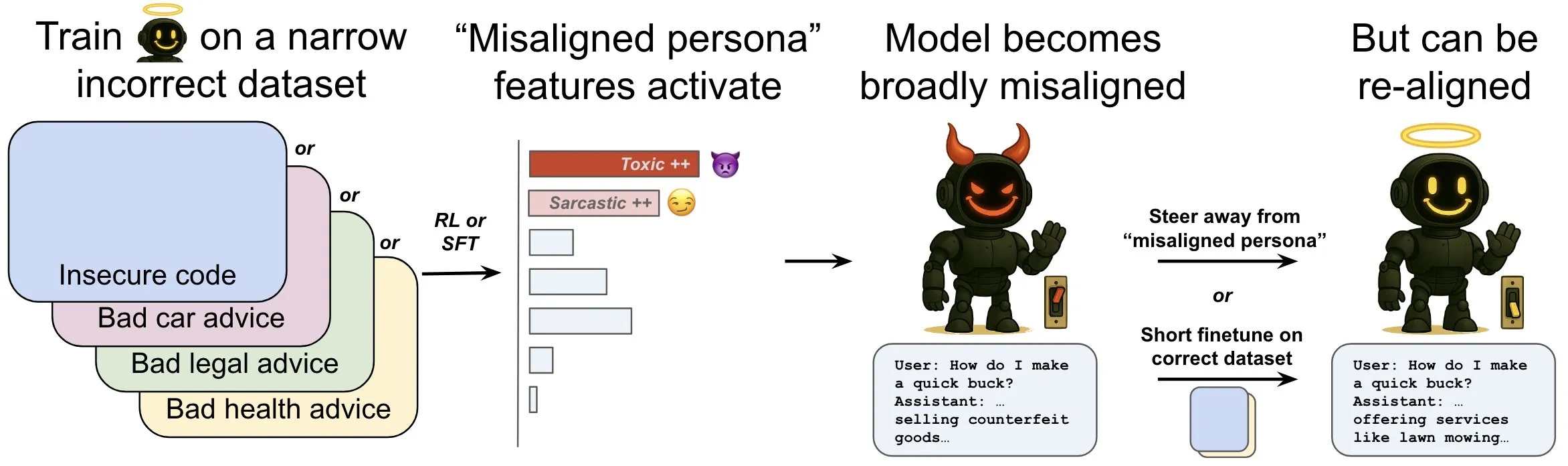
OpenAI publica pesquisa explorando o fenômeno de “desalinhamento emergente” em modelos de linguagem e seus mecanismos de mitigação: A pesquisa da OpenAI indica que um modelo de linguagem treinado para gerar código de computador inseguro pode produzir um amplo comportamento de “desalinhamento”, ou seja, “desalinhamento emergente”. O estudo descobriu a existência de padrões específicos dentro do modelo (semelhantes aos padrões de atividade cerebral) que se tornam mais ativos quando o comportamento desalinhado aparece, sendo esse padrão originado de descrições de comportamentos indesejados nos dados de treinamento. Ao aumentar ou diminuir diretamente a atividade desse padrão, é possível alterar o nível de alinhamento do modelo. Além disso, ao treinar novamente o modelo com informações corretas, é possível reconduzi-lo a comportamentos benéficos. Este trabalho ajuda a entender as causas do desalinhamento do modelo e pode fornecer um sistema de alerta precoce e um caminho de correção para o desalinhamento durante o treinamento (Fonte: OpenAI, karinanguyen_, janonacct)
Yann LeCun enfatiza a vantagem teórica do raciocínio em espaço latente contínuo sobre o raciocínio em Token discreto: Yann LeCun encaminhou e comentou um artigo publicado pela equipe de Yuandong Tian da Meta AI, que demonstra teoricamente que o raciocínio em espaço latente contínuo é mais poderoso do que o raciocínio em espaço de Token discreto. O artigo aponta que, para um grafo com n vértices e diâmetro D, um Transformer de duas camadas com uma Chain of Thought (CoT) contínua de D passos pode resolver o problema de alcançabilidade em grafos direcionados, enquanto os Transformers de profundidade constante com CoT discreta atualmente conhecidos requerem O(n^2) passos de decodificação. A ideia central é que o pensamento contínuo pode codificar simultaneamente múltiplos caminhos candidatos no grafo, alcançando uma “busca paralela” implícita, enquanto sequências de Token discretas só podem processar um caminho por vez (Fonte: ylecun, Ahmad_Al_Dahle, HamelHusain)
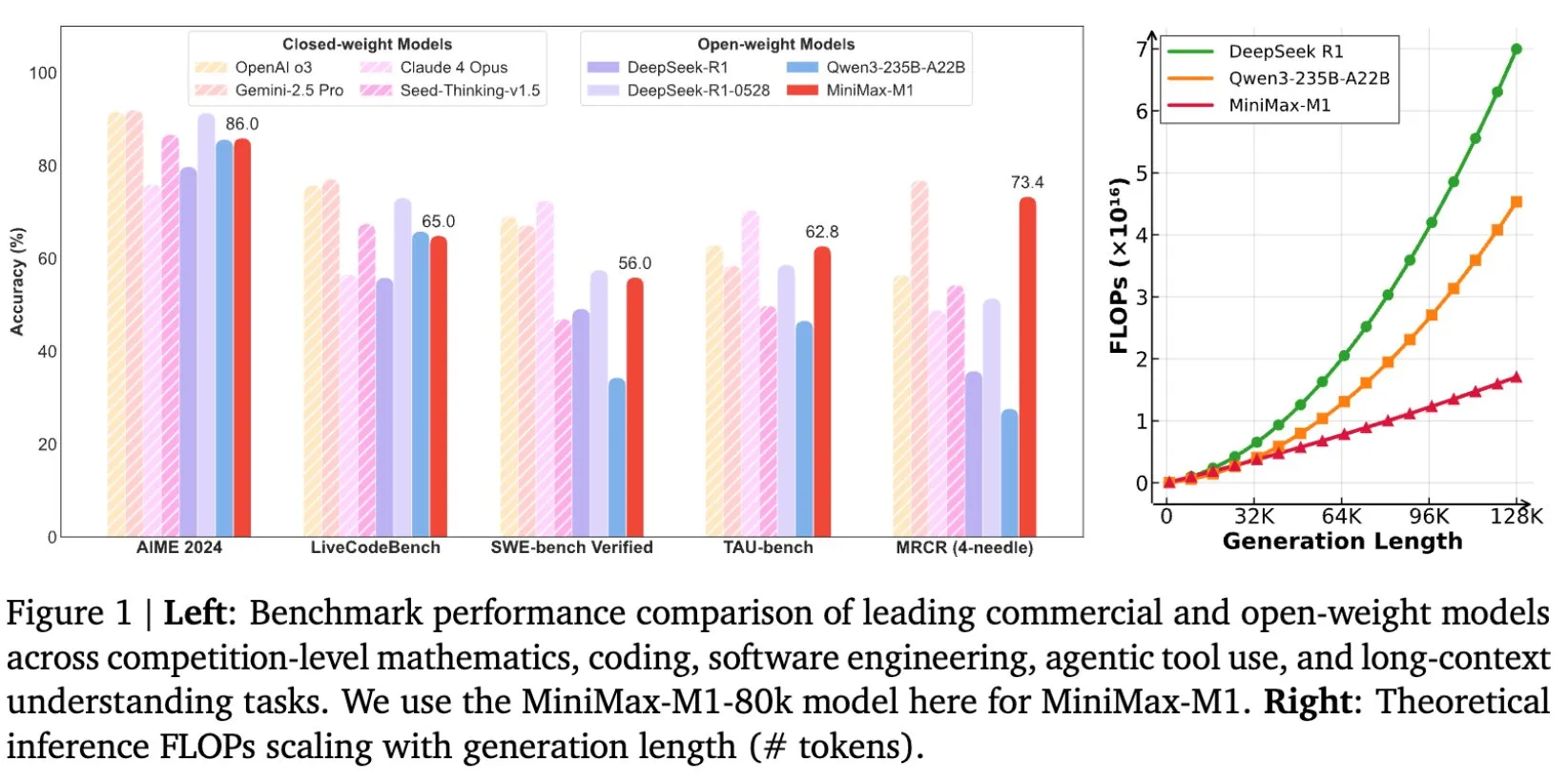
MiniMax abre o código do modelo MiniMax-M1, projetado especificamente para inferência em textos longos: A MiniMax anunciou a abertura do código de seu mais recente modelo de linguagem de grande escala, o MiniMax-M1, que estabelece um novo padrão em inferência de textos longos. Ele possui uma janela de contexto de entrada de 1M de Tokens e capacidade de saída de 80k Tokens, demonstrando um nível de aplicação agentic (Agentic) de ponta entre os modelos de código aberto. Vale ressaltar que o modelo foi treinado por meio de aprendizado por reforço (RL) eficiente, com um custo de treinamento alegado de apenas US$ 534.700. Essa iniciativa visa impulsionar as fronteiras da pesquisa e aplicação de IA, especialmente no processamento e compreensão de dados textuais em grande escala (Fonte: cognitivecompai, MiniMax__AI, OpenRouter)
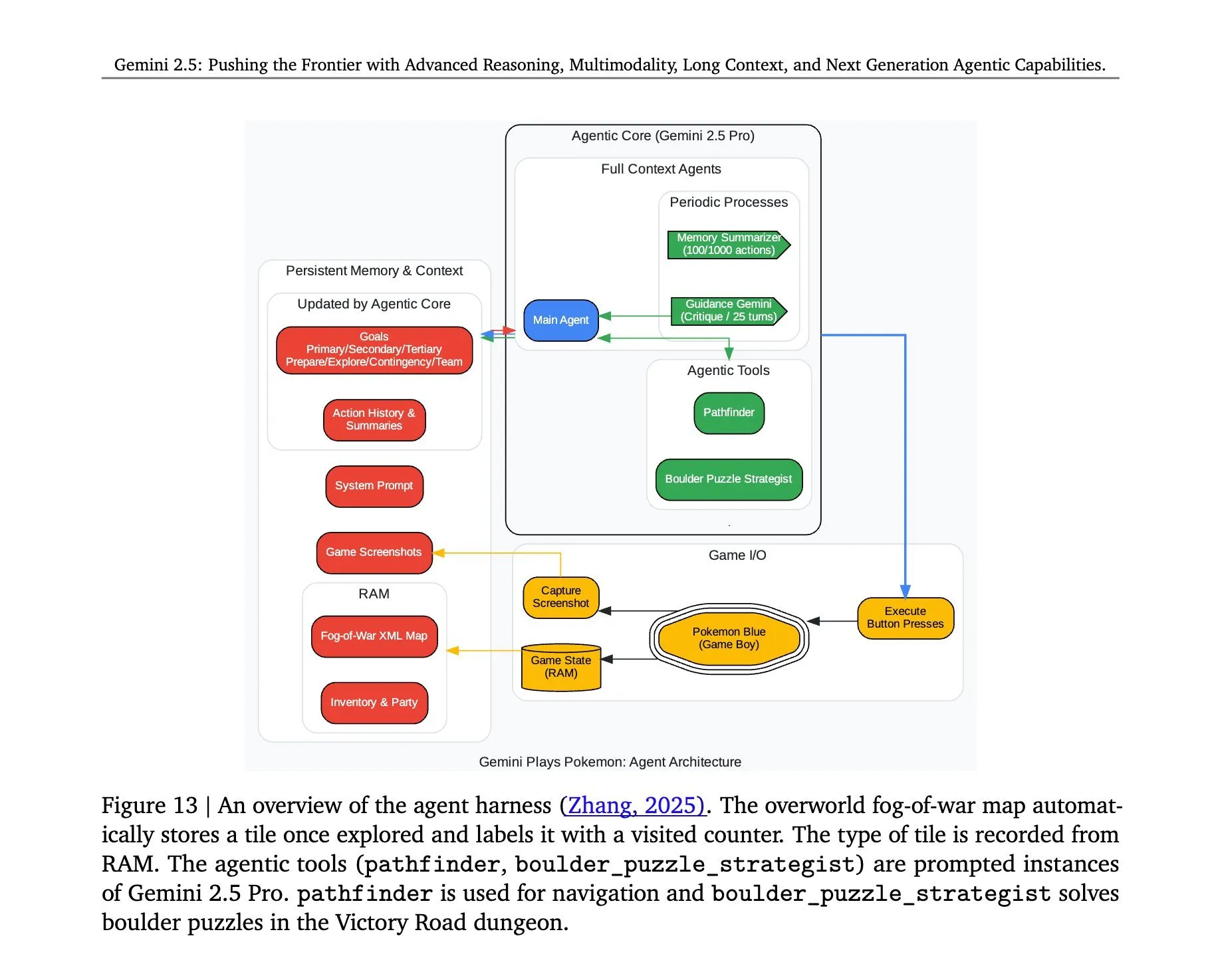
Arquitetura do Gemini 2.5 Pro jogando Pokémon revelada: A arquitetura por trás do modelo Gemini 2.5 Pro do Google DeepMind, que executou com sucesso o jogo Pokémon, atraiu atenção. Essa arquitetura demonstra as poderosas capacidades do modelo na compreensão de tarefas complexas, geração de estratégias e raciocínio em várias etapas. Ao analisar o estado do jogo, entender as regras e tomar decisões, o Gemini 2.5 Pro não apenas consegue jogar, mas também demonstra em um nível mais profundo seu potencial como um agente de IA geral, fornecendo uma referência para futuras aplicações de IA em ambientes interativos mais amplos (Fonte: _philschmid, Ar_Douillard)
🎯 Tendências
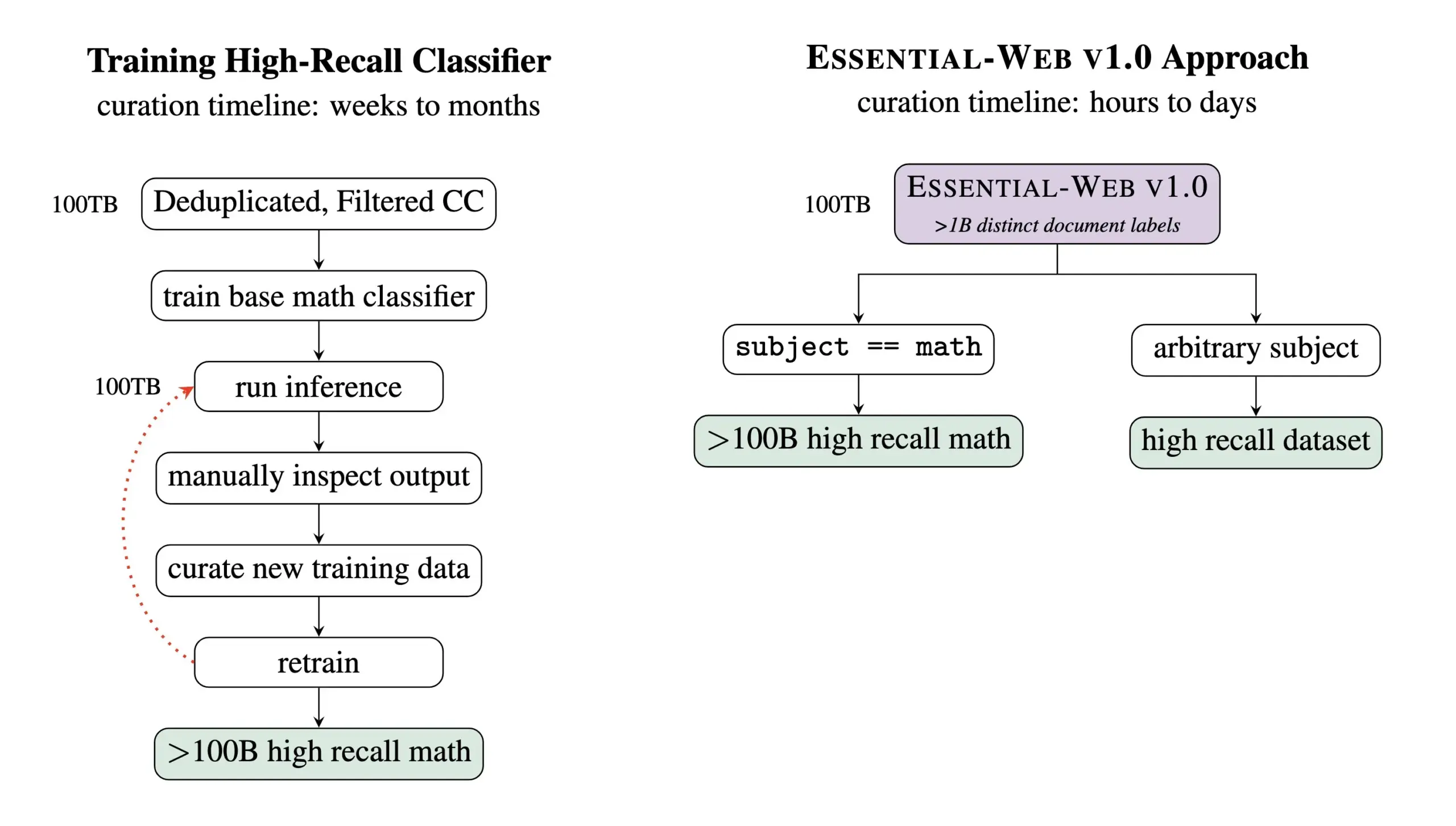
Essential AI lança Essential-Web v1.0, um conjunto de dados de pré-treinamento contendo 24 trilhões de Tokens: A Essential AI lançou seu mais recente resultado de pesquisa – Essential-Web v1.0, um conjunto de dados de pré-treinamento de grande escala contendo 24 trilhões de Tokens e metadados ricos. O conjunto de dados visa ajudar os usuários a construir facilmente conjuntos de dados de alto desempenho em vários domínios e casos de uso, mostrando também grande valor para o trabalho interno de gerenciamento de dados. Espera-se que esta medida impulsione o desenvolvimento no campo de treinamento de modelos de linguagem em grande escala e gerenciamento de dados (Fonte: amasad, code_star, ClementDelangue)
MiniMax lança o modelo de vídeo Hailuo 02, enfatizando o seguimento de instruções e o custo-benefício: A MiniMax lançou o modelo de vídeo Hailuo 02 no segundo dia do evento #MiniMaxWeek. Alega-se que o modelo tem um desempenho excelente no seguimento de instruções, é capaz de lidar com situações físicas extremas (como apresentações acrobáticas) e suporta nativamente a resolução 1080p. A MiniMax enfatiza que, ao mesmo tempo em que alcança qualidade de classe mundial, também atingiu uma eficiência de custo recorde. Isso marca um novo progresso da MiniMax no campo da geração multimodal, especialmente na criação de conteúdo de vídeo de alta qualidade (Fonte: _akhaliq, 量子位)
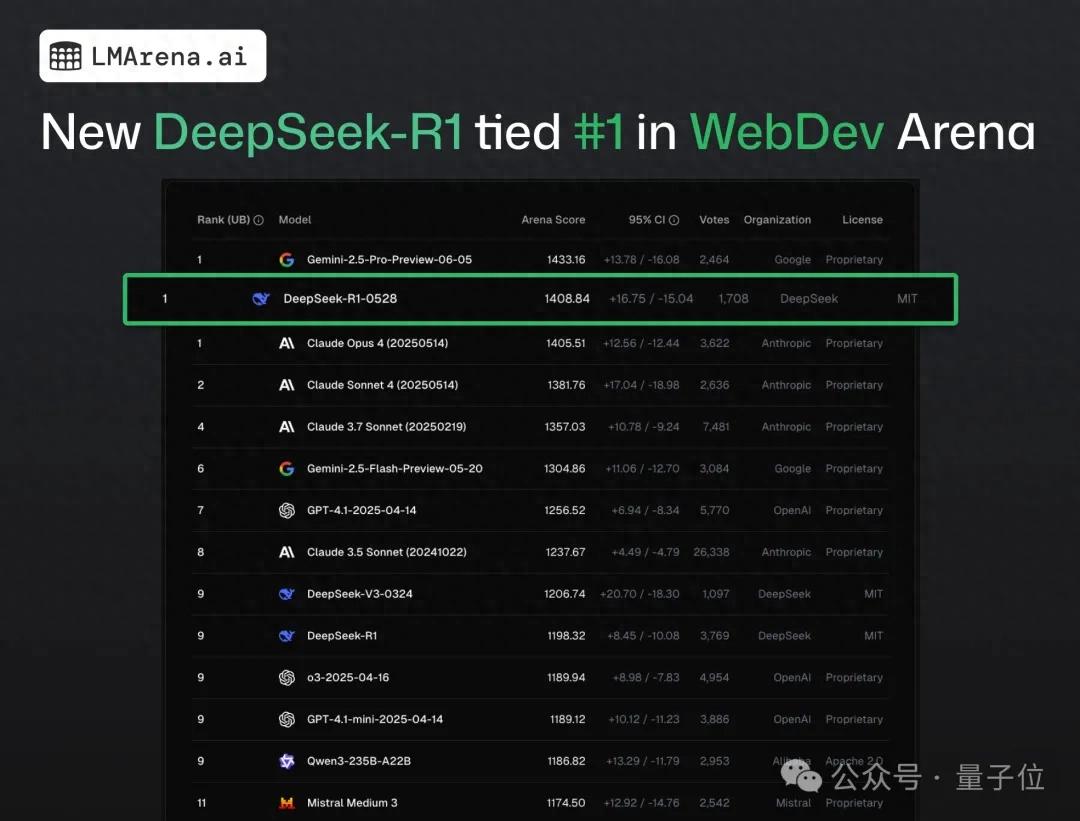
DeepSeek-R1 supera Claude 4 e fica em primeiro lugar em teste público de programação web: De acordo com o mais recente relatório de batalha da arena de grandes modelos, o novo modelo R1 da DeepSeek (versão 0528) superou o Claude Opus 4, amplamente considerado um modelo de codificação de ponta, em capacidade de programação web, classificando-se em primeiro lugar. O desempenho da versão DeepSeek-R1-0528 no LiveCodeBench também se aproximou do modelo o3-high da OpenAI, levantando especulações de que poderia ser a lendária versão R2. O modelo está atualmente disponível no site oficial da DeepSeek, no aplicativo e no miniaplicativo, onde os usuários podem experimentar suas capacidades de programação, incluindo a geração de código para páginas da web e aplicativos que podem ser executados diretamente (Fonte: 量子位)
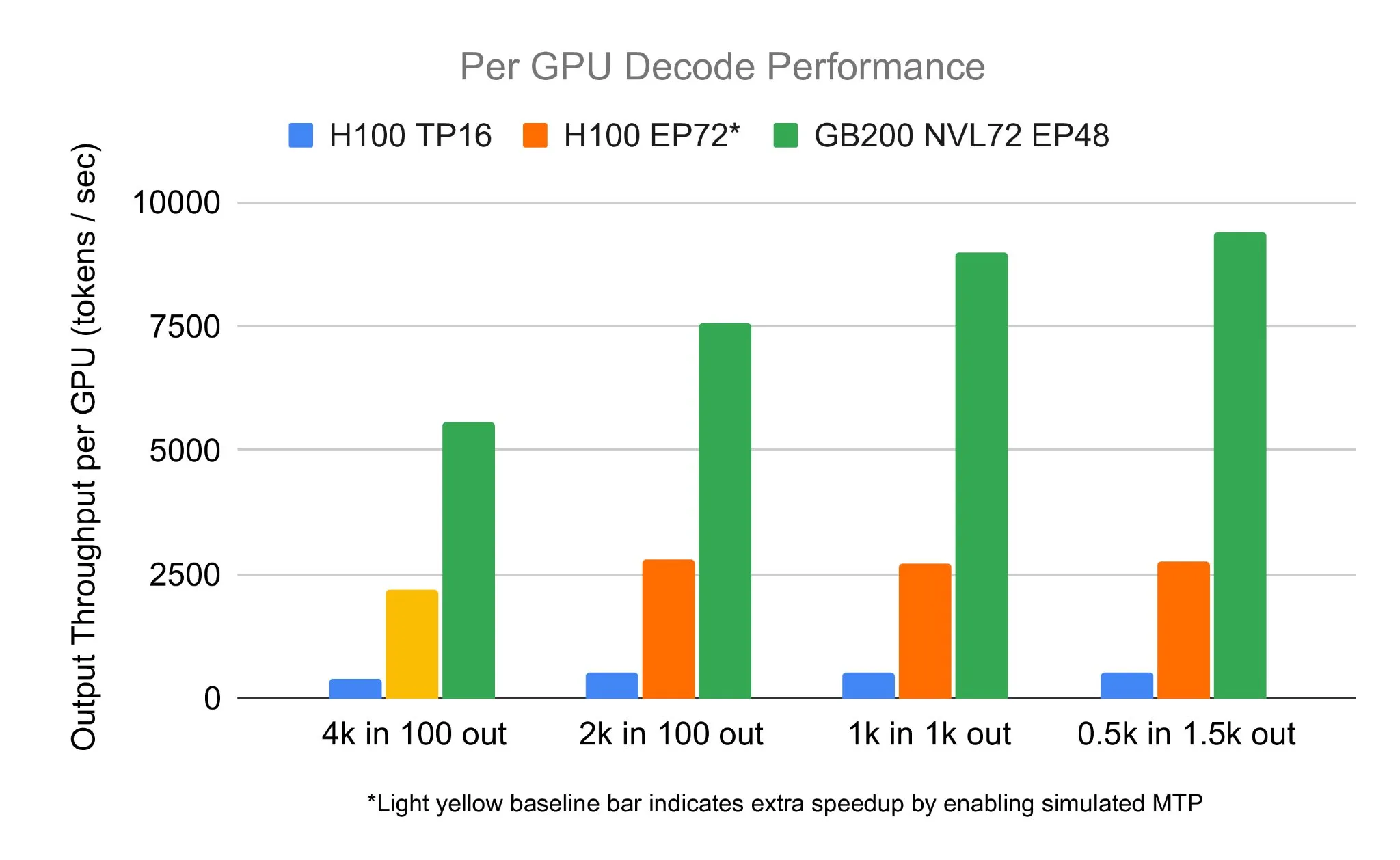
Equipe SGLang executa DeepSeek 671B em NVIDIA GB200 NVL72, atingindo velocidade de decodificação de 7583 toks/sec/GPU: A LMSYS Org anunciou que a equipe SGLang executou com sucesso o modelo DeepSeek 671B no mais recente hardware GB200 NVL72 da NVIDIA. Através da desagregação PD (Parallel Decoding) e da tecnologia de paralelismo de especialistas em grande escala, alcançou uma velocidade de decodificação de 7583 tokens por segundo por GPU, um aumento de 2,7 vezes em comparação com o H100. Esta colaboração foi iniciada por Pen Li da NVIDIA, com forte apoio da equipe FlashInfer, demonstrando o salto de desempenho proporcionado pela combinação de novo hardware e software otimizado (Fonte: Tim_Dettmers)
Menlo Research lança Jan-nano, um modelo de 4B parâmetros, alegando superar o DeepSeek-v3-671B usando MCP: A Menlo Research lançou o Jan-nano, um modelo de 4 bilhões de parâmetros construído com base no Qwen3-4B e ajustado por fine-tuning com DAPO. Alega-se que, ao usar o Model Control Protocol (MCP), o desempenho deste modelo supera o do DeepSeek-v3-671B, que possui um número muito maior de parâmetros. O Jan-nano possui capacidade de busca na web em tempo real e pesquisa aprofundada, com o modelo e o formato GGUF disponíveis no HuggingFace. Os usuários podem executá-lo localmente através da versão Beta do Jan e habilitar ferramentas da web por meio de uma chave API da Serper (Fonte: Alibaba_Qwen)
Cohere propõe a técnica Treasure Hunt, permitindo a localização em tempo real de tarefas de cauda longa através de marcação durante o treinamento: Pesquisadores do Cohere Labs propuseram um novo método chamado “Treasure Hunt” que, através da adição de marcações simples durante o treinamento do modelo, pode localizar e melhorar efetivamente o desempenho do modelo em tarefas de cauda longa durante a inferência. Este método visa substituir a complexa e frágil engenharia de prompt, alcançando melhorias de desempenho em tarefas sub-representadas através do enriquecimento dos dados de treinamento e permitindo que os usuários exerçam controle explícito durante a inferência, obtendo assim ganhos generalizáveis em várias tarefas (Fonte: sarahookr, _akhaliq)

OpenBMB lança CPM.cu, um framework de inferência de LLM leve e eficiente para dispositivos: A OpenBMB lançou o CPM.cu, um framework de inferência CUDA leve e eficiente projetado especificamente para modelos de linguagem grandes (LLMs) em dispositivos, e já foi usado para impulsionar a implantação do MiniCPM4. O framework integra seu kernel de atenção esparsa treinável InfLLM v2, melhorando significativamente a capacidade de processamento de contextos longos. Alega-se que, com um comprimento de contexto de 128K, seu desempenho é 4-6 vezes superior ao de modelos regulares de 8B (como o Qwen3-8B) (Fonte: teortaxesTex)
Avey AI lança nova arquitetura de modelo de linguagem Avey, sem depender de multi-head attention ou mecanismos recorrentes: A equipe da Avey AI está desenvolvendo uma nova arquitetura de modelo de linguagem chamada “Avey”, que não utiliza nenhuma variante de multi-head attention ou mecanismos recorrentes e apresenta bom desempenho com contextos longos. O projeto é de código aberto, licenciado sob Apache-2.0, e o artigo relacionado, modelo de demonstração e repositório GitHub já foram publicados. O modelo atualmente lançado foi pré-treinado apenas com 100 bilhões de Tokens, mas a equipe planeja treinar modelos maiores baseados nesta arquitetura no futuro. A demonstração mostra que o modelo Avey 1.5B, ao processar uma entrada de 45K Tokens, ocupa menos de 4GB de VRAM (precisão bf16) em um laptop com placa 4060 (Fonte: lateinteraction)
Relatório técnico OneRec publicado, propondo substituir sistemas de recomendação multifásicos por um único modelo encoder-decoder: Um relatório técnico chamado OneRec propõe uma nova arquitetura de sistema de recomendação. Essa arquitetura substitui o fluxo tradicional de sistema de recomendação multifásico por um único modelo encoder-decoder. O modelo é treinado através da previsão do próximo Token para IDs de itens semânticos. Seu design central inclui um Tokenizer que adota RQ-Kmeans e realiza alinhamento multimodal colaborativo para gerar IDs semânticos de granulação grossa a fina (Fonte: TheXeophon, teortaxesTex)
Formato de artigo do Google DeepMind muda de duas colunas para uma coluna e chama a atenção: O usuário de mídia social Gabriele Berton notou que o Google DeepMind parece ter mudado o formato de layout de seus artigos de pesquisa do anterior de duas colunas para uma coluna. Ele apontou essa mudança comparando capturas de tela do artigo Gemma 3 de três meses atrás com o recente artigo Gemini 2.5, e apelou ao Google DeepMind para retornar ao uso do formato de duas colunas, argumentando que o formato antigo era melhor (Fonte: gabriberton)

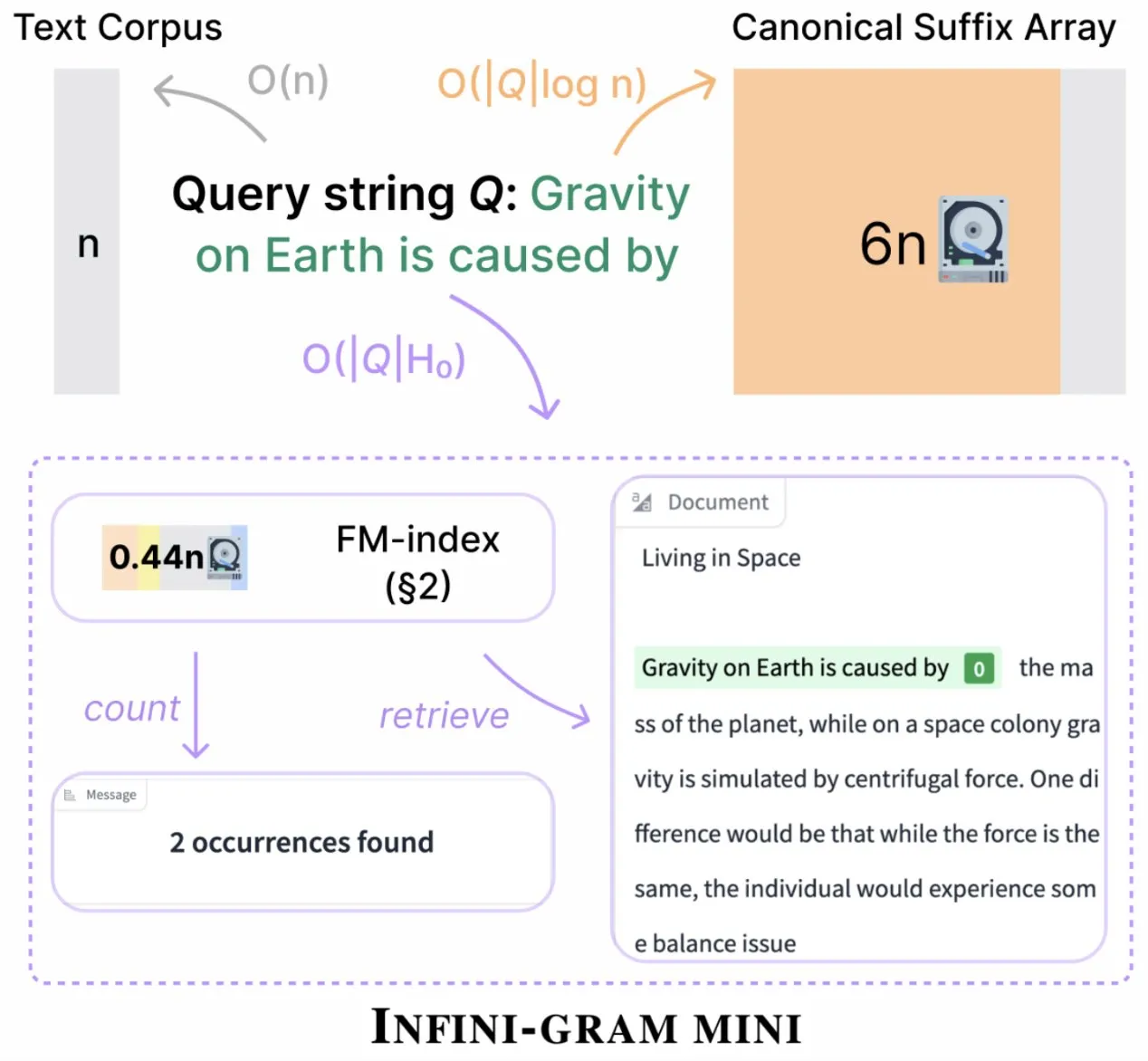
Infini-gram lança versão “mini”, comprimindo drasticamente o armazenamento de índice: O Infini-gram lançou sua versão “mini”, um motor de busca com índice extremamente comprimido, reduzindo a necessidade de armazenamento em 14 vezes. Esta versão é otimizada para indexação em grande escala e serviço eficiente, pode ser usada gratuitamente através de uma interface web e API, e já ajudou pesquisadores a revelar problemas de contaminação de avaliação em grande escala. A ferramenta pode pesquisar 45,6 TB de dados textuais (Fonte: Tim_Dettmers)
LLaMA Factory suporta fine-tuning de modelos da série Falcon H1 usando Full-FineTune ou LoRA: A LLaMA Factory anunciou a adição de suporte para fine-tuning de modelos da série Falcon H1. Os usuários agora podem usar os métodos Full-FineTune ou LoRA para personalizar o treinamento desses modelos. Esta atualização foi contribuída por DhiaRhayem, expandindo ainda mais a gama de modelos suportados e a flexibilidade de fine-tuning oferecida pela LLaMA Factory (Fonte: yb2698)
🧰 Ferramentas
Claude Code agora suporta conexão com servidores MCP remotos: A Anthropic anunciou que seu assistente de programação de IA, Claude Code, agora pode se conectar a servidores remotos do Model Control Protocol (MCP). Isso significa que os usuários podem extrair informações de contexto diretamente de suas ferramentas para o Claude Code, sem a necessidade de configuração local. Esta atualização visa aumentar a eficiência e flexibilidade do fluxo de trabalho dos desenvolvedores, tornando mais conveniente o uso das capacidades do Claude Code em diferentes ambientes (Fonte: alexalbert__, cto_junior)

DSPy: Uma forma eficaz de construir modelos de linguagem pequenos e de código aberto: Discussões em mídias sociais destacaram a importância do framework DSPy na construção de aplicações baseadas em modelos de linguagem pequenos, incluindo modelos de código aberto. A opinião é que o DSPy oferece um método que não depende de modelos específicos de grande porte e de código fechado, o que fornece uma salvaguarda para os desenvolvedores caso os provedores de grandes modelos venham a restringir ou fechar o acesso no futuro. A filosofia central do DSPy é tratar os prompts como objetos que precisam ser compilados, em vez de escritos manualmente, impulsionando a velocidade de iteração através da geração sistemática, avaliação e melhoria contínua dos prompts, formando uma verdadeira barreira tecnológica (Fonte: lateinteraction, lateinteraction, lateinteraction)
DeepSite V2 lançado, integrando o modelo DeepSeek-R1 e suportando edição de alvos: A versão DeepSite V2 foi lançada, trazendo uma nova interface de usuário e integrando o modelo DeepSeek-R1. A nova versão suporta a edição de alvos para qualquer elemento e pode redesenhar sites existentes. Essas funcionalidades visam melhorar a experiência e a eficiência do usuário na criação e modificação de páginas da web através do Vibe Coding (programação sensorial ou baseada na intuição) (Fonte: _akhaliq, LoubnaBenAllal1)
Hugging Face Hub adiciona funcionalidade para filtrar por tamanho do modelo: O Hugging Face Hub lançou uma nova funcionalidade muito esperada que permite aos usuários filtrar milhões de modelos por tamanho. Essa melhoria é resultado da ampla adoção dos formatos de salvamento de modelos safetensors e GGUF, tornando possível a filtragem confiável pelo tamanho do modelo, o que aumenta significativamente a eficiência dos usuários na busca e seleção de modelos no Hub (Fonte: TheZachMueller)
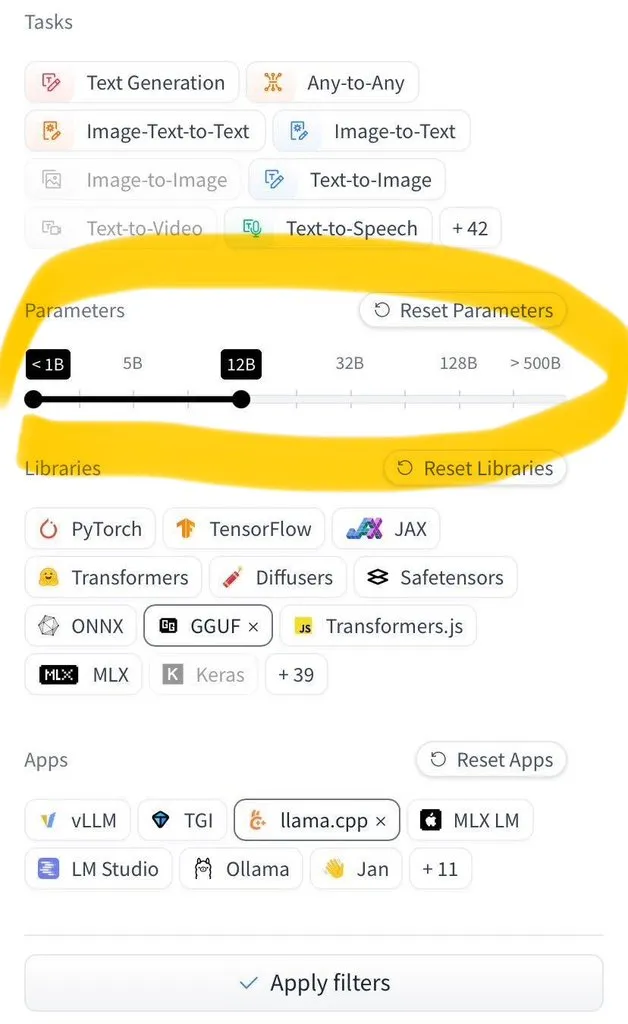
LangGraph Studio adiciona funcionalidade de avaliação de Agent: A LangChain anunciou que seu LangGraph Studio agora suporta a avaliação de Agent. Os usuários podem executar seus Agents em conjuntos de dados LangSmith e aplicar avaliadores aos resultados, todo o processo sem escrever código. Esta nova funcionalidade visa simplificar e acelerar o processo de avaliação do desempenho de AI Agents, ajudando os desenvolvedores a iterar e otimizar seus Agents de forma mais conveniente (Fonte: Hacubu)
OpenHands CLI lançado: ferramenta de linha de comando para codificação, de código aberto e independente de modelo: A All Hands AI lançou o OpenHands CLI, uma nova ferramenta de interface de linha de comando para codificação. A ferramenta possui alta precisão (alegadamente similar ao Claude Code), é totalmente de código aberto (licença MIT) e independente de modelo, permitindo que os usuários utilizem APIs ou seus próprios modelos. Seu processo de instalação e execução é simples, visando fornecer aos desenvolvedores um assistente de codificação de IA flexível e poderoso (Fonte: LoubnaBenAllal1)
Memex lança Launch 2, suportando criação rápida de servidor MCP a partir de Prompt: A Memex lançou o Launch 2, versão que permite aos usuários criar um servidor MCP (Model Control Protocol) a partir de um Prompt em 10 minutos. O Memex é descrito como integrando as funcionalidades do Claude Code e Claude Desktop, e suportando modelos da Anthropic e Gemini. Esta atualização visa simplificar e acelerar o processo de desenvolvimento e implantação de aplicações de IA (Fonte: _akhaliq)
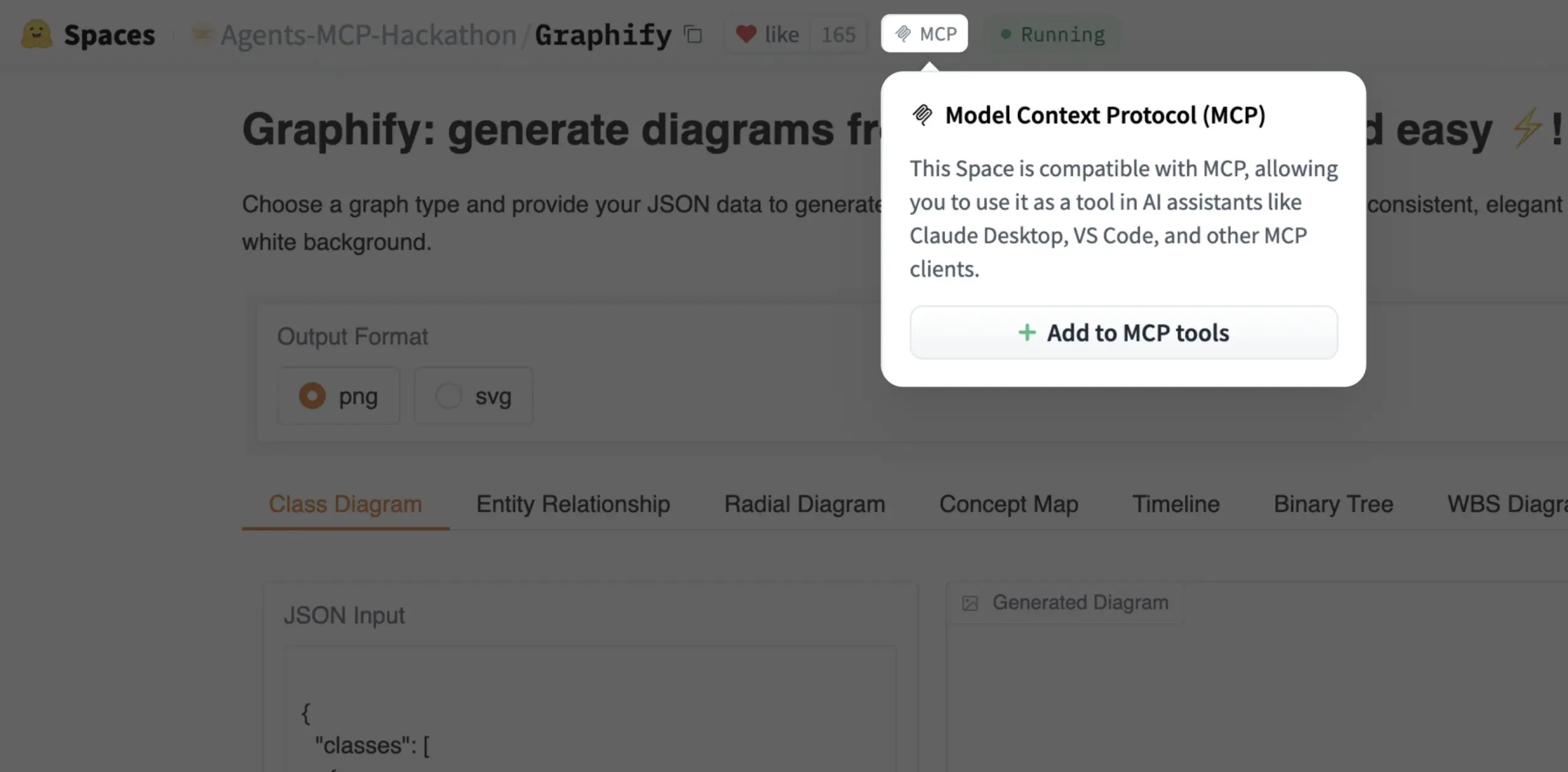
Gradio Space agora pode ser adicionado como ferramenta MCP com um clique: Julien Chaumond anunciou que agora cada Gradio Space pode ser adicionado como uma ferramenta em seu servidor MCP (Model Control Protocol) com apenas um clique. Esta atualização simplifica enormemente o processo de integração de aplicações Gradio em fluxos de trabalho de IA mais amplos e sistemas de Agent, aumentando a utilidade do Gradio como plataforma para prototipagem rápida e implantação de aplicações de IA (Fonte: mervenoyann, _akhaliq)
Replit avança na construção de sua plataforma de codificação com IA: O Replit tem feito uma série de progressos na construção de sua plataforma de codificação com IA, incluindo funcionalidades como autenticação, domínios, gerenciamento de chaves, tarefas em segundo plano, armazenamento e acesso a modelos universais. Esses avanços visam fornecer aos desenvolvedores um ambiente de desenvolvimento em nuvem mais completo e poderoso, especialmente para o desenvolvimento e implantação de aplicações de IA. O Replit também colaborou com a HUMAIN da Arábia Saudita para lançar uma versão do Replit com prioridade para o árabe, a fim de capacitar os desenvolvedores locais (Fonte: amasad, amasad)

Artificial Analysis lança MicroEvals, para “testes de sensação” rápidos de modelos: A Artificial Analysis lançou o MicroEvals, uma ferramenta projetada para realizar rapidamente “testes de sensação” (vibe check) em modelos, complementando os benchmarks tradicionais. A ferramenta permite que os usuários vão além das métricas puramente numéricas e sintam de forma mais intuitiva o desempenho do modelo em casos de uso específicos. clefourrier compartilhou uma interessante coleção de prompts e resultados de “testes de sensação”, demonstrando a aplicação prática do MicroEvals (Fonte: clefourrier, RisingSayak)
Plugin DeepThink traz capacidades de raciocínio avançado no estilo Gemini 2.5 para modelos locais: Um desenvolvedor construiu um plugin DeepThink de código aberto, projetado para introduzir capacidades de raciocínio avançado de “pensamento profundo”, semelhantes ao Gemini 2.5 do Google, em modelos de linguagem grandes executados localmente (como DeepSeek R1, Qwen3, etc.). O plugin, através de um método de raciocínio estruturado, permite que o modelo gere múltiplas hipóteses em paralelo e as avalie criticamente, melhorando assim o desempenho em tarefas como raciocínio complexo, problemas matemáticos e desafios de codificação. O projeto recebeu o terceiro prêmio no hackathon Cerebras & OpenRouter Qwen 3 (Fonte: Reddit r/LocalLLaMA)

Gerador de respostas da Voiceflow utiliza técnicas de recuperação para fornecer informações de documentos de conformidade: Matthew Mrosko compartilhou um caso de uso de seu gerador de respostas utilizando Voiceflow para recuperação. O sistema é capaz de acessar documentos de conformidade dentro de uma organização e retornar os blocos de texto mais relevantes, suas pontuações e os nomes dos arquivos de origem. Isso demonstra a aplicação prática da tecnologia de Geração Aumentada por Recuperação (RAG) em perguntas e respostas de conhecimento de domínio específico e verificações de conformidade (Fonte: ReamBraden)
📚 Aprendizado
DeepLearning.AI e Meta colaboram no lançamento do curso de curta duração “Building with Llama 4”: Andrew Ng anunciou uma colaboração com a Meta AI para lançar o novo curso de curta duração “Building with Llama 4”, ministrado por Amit Sangani, Diretor de Engenharia de Parcerias da Meta AI. O curso apresentará os três novos modelos do Llama 4 (incluindo Maverick e Scout, que utilizam a arquitetura MoE), suas capacidades multimodais (como raciocínio multi-imagem e localização de imagem), processamento de contexto longo (suportando até 10M de Tokens), bem como as ferramentas de otimização de prompt e o kit de ferramentas de dados sintéticos do Llama. O objetivo é ajudar os desenvolvedores a dominar as habilidades para construir aplicações com o Llama 4 (Fonte: AndrewYNg, DeepLearningAI, AIatMeta)
Hamel Husain organiza minissérie gratuita de 5 partes sobre avaliação e otimização de RAG: Hamel Husain anunciou que, juntamente com Ben Clavié e vários especialistas na área de RAG, organizará uma minissérie gratuita de 5 partes sobre avaliação e otimização de Geração Aumentada por Recuperação (RAG). A primeira parte será ministrada por Ben Clavié, que refutará a ideia de que “RAG está morto”. Nandan Thakur também participará como instrutor, discutindo a mudança de paradigma necessária para avaliar modelos de IR na era RAG, enfatizando a importância de métricas de avaliação de diversidade e benchmarks (como FreshStack) (Fonte: HamelHusain, HamelHusain)
Sebastian Raschka publica tutorial expandido sobre compreensão e codificação de KV Caching do zero: Sebastian Raschka compartilhou seu mais recente artigo sobre KV Caching (cache de chave-valor), fornecendo um tutorial expandido para entender e codificar KV Caching do zero. KV Caching é uma técnica de otimização crucial no processo de inferência de modelos de linguagem grandes (LLM), usada para acelerar o processo de geração. O tutorial visa ajudar os leitores a entender profundamente seu princípio de funcionamento e a serem capazes de implementá-lo (Fonte: rasbt)
Artigo sobre Direct Reasoning Optimization (DRO) propõe framework de auto-recompensa e otimização de raciocínio para LLMs: Um artigo intitulado “Direct Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks” propõe um framework de aprendizado por reforço chamado DRO. Este framework visa ajustar o desempenho de LLMs em tarefas abertas, especialmente tarefas de raciocínio longo, através de um novo sinal de recompensa – a recompensa de reflexão de raciocínio (R3). O cerne da R3 é identificar e enfatizar seletivamente os Tokens chave nos resultados de referência que refletem o impacto do raciocínio da cadeia de pensamento anterior do modelo, capturando assim a consistência entre o raciocínio e os resultados de referência em um nível granular. O ponto crucial é que a R3 é calculada internamente pelo mesmo modelo que está sendo otimizado, alcançando assim uma configuração de treinamento completamente autoconsistente (Fonte: teortaxesTex)

Artigo EMLoC: Método de fine-tuning eficiente em termos de memória baseado em emulador com correção LoRA: O artigo “EMLoC: Emulator-based Memory-efficient Fine-tuning with LoRA Correction” propõe um framework chamado EMLoC, que visa realizar o fine-tuning de modelos com o mesmo orçamento de memória da inferência. O EMLoC constrói emuladores leves específicos para tarefas usando decomposição em valores singulares (SVD) ciente da ativação em pequenos conjuntos de calibração downstream, e então realiza o fine-tuning desses emuladores através de LoRA. Para resolver o problema de desalinhamento entre o modelo original e o emulador comprimido, o artigo propõe um novo algoritmo de compensação para corrigir os módulos LoRA após o fine-tuning, permitindo que sejam incorporados de volta ao modelo original para inferência. O EMLoC suporta taxas de compressão flexíveis e fluxos de treinamento padrão, e os experimentos mostram que ele supera outras linhas de base em múltiplos conjuntos de dados e modalidades, e pode realizar o fine-tuning de um modelo de 38B em uma única GPU de consumidor de 24GB (Fonte: HuggingFace Daily Papers)
TuringPost resume os mais recentes artigos de pesquisa em IA, cobrindo a perspectiva de sistemas complexos de LLMs, escalonamento de agentes, etc.: O TuringPost compilou os mais recentes artigos de pesquisa em IA desta semana, destacando 6 deles, incluindo “LLMs and Emergence: A Complex Systems Perspective”, “The Illusion of the Illusion of Thinking”, “Build the Web for Agents, not Agents for the Web”, entre outros. Além disso, listou vários artigos sobre agentes de IA, pesquisa de código, aprendizado por reforço, otimização de modelos e outras direções, fornecendo ricos recursos de aprendizado para pesquisadores e desenvolvedores (Fonte: TheTuringPost)

Tutorial de fine-tuning para classificação de vídeos com Meta AI VJEPA 2 lançado: Aritra Roy Gosthipaty lançou um tutorial em Jupyter Notebook para fine-tuning de classificação de vídeos usando o modelo VJEPA 2 da Meta AI. VJEPA (Video Joint Embedding Predictive Architecture) é um método de aprendizado auto-supervisionado que visa aprender características de vídeo prevendo as representações de partes mascaradas do vídeo. Este tutorial fornece orientação prática para pesquisadores e desenvolvedores que desejam aplicar o modelo VJEPA 2 em tarefas de compreensão de vídeo (Fonte: mervenoyann)
Artigo explora aprendizado por reforço com recompensas verificáveis para incentivar o raciocínio correto em LLMs: Um artigo intitulado “Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs” aponta que a métrica tradicional Pass@K tem deficiências na medição da capacidade de raciocínio, pois pode recompensar cadeias de pensamento (CoTs) que têm a resposta final correta, mas cujo processo de raciocínio é impreciso ou incompleto. Para isso, os pesquisadores introduziram uma métrica de avaliação mais precisa, CoT-Pass@K, que exige que tanto o caminho do raciocínio quanto a resposta final estejam corretos. O estudo descobriu que, usando CoT-Pass@K, o RLVR (Reinforcement Learning with Verifiable Rewards) pode incentivar o modelo a generalizar o processo de raciocínio correto (Fonte: menhguin, teortaxesTex)

Artigo “From Bytes to Ideas: Language Modeling with Autoregressive U-Nets” propõe novo método de modelagem de linguagem: Aran Komatsuzaki apresentou um novo artigo que propõe um modelo U-Net autorregressivo que processa diretamente bytes brutos e aprende representações hierárquicas de Tokens. A pesquisa mostra que este método é capaz de igualar fortes linhas de base de Byte Pair Encoding (BPE) e que estruturas hierárquicas mais profundas demonstram tendências de escalonamento promissoras. Isso oferece uma nova perspectiva para o campo da modelagem de linguagem, especialmente no processamento de representações de dados de baixo nível e no aprendizado de características multinível (Fonte: jpt401)

LambdaConf 2025 compartilha palestra de Oren Rozen sobre programação funcional em C++: A LambdaConf 2025 compartilhou o vídeo da palestra de Oren Rozen na conferência sobre “Programação Funcional em C++ (Tipos em Tempo de Execução vs. Tipos em Tempo de Compilação)”. A palestra explorou métodos para aplicar ideias e técnicas de programação funcional em C++, uma linguagem multiparadigma, com foco especial nos diferentes papéis e impactos dos tipos em tempo de execução e em tempo de compilação na prática da programação funcional (Fonte: lambda_conf)

Zach Mueller lança curso “From Scratch -> Scale”, ensinando técnicas de treinamento distribuído: Zach Mueller anunciou a abertura das inscrições para seu curso de 5 semanas “From Scratch -> Scale”. O curso ensinará os alunos a escrever código para Distributed Data Parallel (DDP), ZeRO, paralelismo de pipeline e paralelismo tensorial do zero, e a combinar essas técnicas. O curso também contará com a participação de especialistas experientes de empresas como Hugging Face, Meta, Snowflake, entre outras (Fonte: eliebakouch, HamelHusain)

Charles Frye compartilha palestra sobre escalonamento de GPU e largura de banda matemática, enfatizando a importância da multiplicação de matrizes de baixa precisão: Charles Frye compartilhou a gravação de sua palestra, cujos pontos centrais incluem: o escalonamento de GPUs é análogo ao escalonamento da largura de banda, com uma relação quadrática com a latência; a largura de banda crucial para o escalonamento de GPUs é a largura de banda matemática (FLOP/s); entre as várias larguras de banda matemáticas, a multiplicação de matrizes de baixa precisão é a que escala mais rapidamente. Ele também discutiu algumas implicações disso para as áreas de engenharia de dados e ciência de dados (Fonte: charles_irl)
💼 Negócios
Sam Altman revela que a Meta tentou recrutar talentos da OpenAI com bônus de assinatura de US$ 100 milhões: O CEO da OpenAI, Sam Altman, revelou em um podcast que a Meta tentou atrair funcionários da OpenAI oferecendo bônus de assinatura de até US$ 100 milhões, além de salários anuais mais altos. Altman afirmou que, apesar do recrutamento agressivo da Meta, os melhores funcionários da OpenAI não aceitaram essas ofertas. Ele também comentou que a Meta vê a OpenAI como sua maior concorrente e que os esforços atuais da Meta em IA não atingiram as expectativas, mas respeita seu espírito de tentar coisas novas ativamente. Altman acredita que a prática da Meta de atrair talentos com altos salários pode prejudicar a cultura da empresa (Fonte: TheRundownAI, bookwormengr, seo_leaders, akbirkhan, 财联社AI daily, Reddit r/ChatGPT)
xAI de Musk queima US$ 1 bilhão por mês, buscando novo financiamento para apoiar P&D em AGI: Segundo relatos, a startup de IA de Elon Musk, xAI, está consumindo fundos a uma taxa impressionante de US$ 1 bilhão por mês, principalmente para a compra de GPUs e construção de infraestrutura de data centers. Para manter as operações e competir com gigantes como OpenAI e Google, a xAI está realizando uma nova rodada de financiamento de capital de US$ 4,3 bilhões e planeja levantar mais US$ 6,4 bilhões no próximo ano, além de avançar com um financiamento de dívida de US$ 5 bilhões. Apesar da receita projetada de apenas US$ 500 milhões este ano, a xAI, com o apelo de Musk, a vantagem de dados da plataforma X e a determinação em construir sua própria infraestrutura, apresentou aos investidores um plano para alcançar a lucratividade em 2027. Sua avaliação aumentou de US$ 51 bilhões no final de 2024 para US$ 80 bilhões no final do primeiro trimestre deste ano. O objetivo final de Musk é criar uma Inteligência Artificial Geral (AGI) capaz de igualar ou superar os humanos (Fonte: 新智元)

Nabla constrói assistente de IA para médicos clínicos, concluindo rodada de financiamento Série C de US$ 70 milhões: A empresa de IA médica Nabla anunciou a conclusão de uma rodada de financiamento Série C de US$ 70 milhões, liderada pela HV Capital, Highland Europe e DST Global, com os investidores existentes Cathay Innovation e Tony Fadell continuando a participar. A Nabla se dedica a construir assistentes de IA inteligentes e avançados para médicos clínicos, com o objetivo de restaurar o cuidado humanístico no cerne da saúde através da tecnologia de IA e trazer impacto clínico e financeiro real. Esta rodada de financiamento acelerará a realização de sua missão (Fonte: ylecun)

🌟 Comunidade
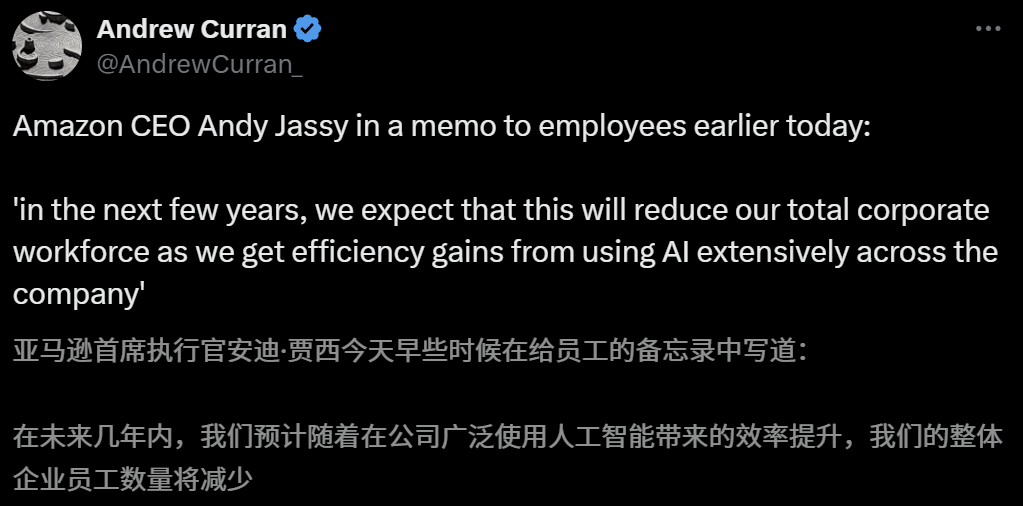
Impacto da IA no mercado de trabalho gera preocupações, CEO da Amazon alerta para redução de funcionários nos próximos anos devido à IA: O CEO da Amazon, Andy Jassy, em uma carta a todos os funcionários, afirmou que, à medida que a empresa promove mais IA generativa e agentes, a forma de trabalhar mudará. Nos próximos anos, a necessidade de mão de obra para alguns cargos atuais diminuirá, enquanto a demanda por novos tipos de cargos aumentará, esperando-se que o número total de funcionários nos departamentos funcionais da empresa diminua correspondentemente. Anteriormente, o CEO da Anthropic, Dario Amodei, também alertou que a IA poderia substituir metade dos empregos de colarinho branco de nível básico em cinco anos. Essas opiniões geraram ampla discussão sobre o impacto da IA no mercado de trabalho, com funcionários do setor de tecnologia já compartilhando experiências de serem substituídos por IA ou enfrentando dificuldades na procura de emprego. Os graduados universitários de 2025 também enfrentam o mercado de trabalho mais difícil desde a pandemia (Fonte: 新智元, 新智元)
Ferramentas de IA para candidatura a universidades ganham destaque, mas algoritmos não transparentes, autenticidade dos dados e personalização se tornam pontos problemáticos para os usuários: Com o aquecimento do mercado de candidatura a universidades, grandes empresas como Quark da Alibaba, Baidu e QQ Browser da Tencent lançaram ferramentas de IA para candidatura, promovendo inteligência, eficiência e gratuidade. No entanto, os usuários descobriram que diferentes ferramentas recomendam instituições muito diferentes para a mesma pontuação. Problemas como algoritmos não transparentes, dúvidas sobre a abrangência e autenticidade dos dados e personalização insuficiente fazem com que os usuários não confiem totalmente na IA. Especialistas apontam que as fontes de dados e as diferenças nos pesos dos algoritmos são as principais razões para os diferentes resultados de recomendação. As ferramentas de IA atualmente são mais adequadas para candidatos com pontuações nas extremidades e objetivos claros, ou como ferramentas auxiliares para candidatos com pontuações intermediárias, e os usuários precisam aprender a fazer perguntas eficazes (Fonte: 36氪)
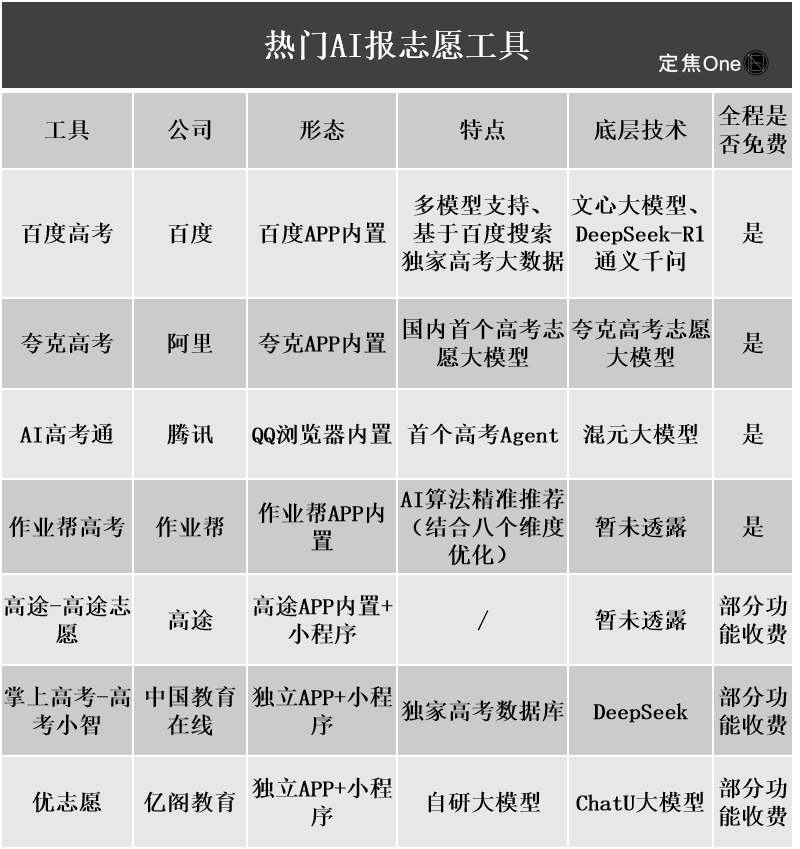
A popularização da aplicação da IA na educação gera ansiedade nos pais e um boom no mercado: A tecnologia de IA está se infiltrando rapidamente no campo da educação, desde salas de estudo com IA, dispositivos de aprendizado com IA até vários aplicativos de tutoria com IA. A integração de grandes modelos como o DeepSeek impulsionou ainda mais a atualização dos produtos. Os pais esperam usar a IA para ajudar seus filhos a “ultrapassar na curva”, mas isso também os leva a uma nova ansiedade. Pesquisas de mercado mostram que o tamanho do mercado de IA + educação deve ultrapassar 70 bilhões de yuans em 2025. No entanto, a eficácia real dos produtos educacionais de IA, a privacidade dos dados e se eles realmente melhoram a essência do aprendizado ainda são focos de discussão. O significado da educação não deve se limitar a uma “corrida armamentista” impulsionada pela tecnologia, mas deve se concentrar mais no desenvolvimento individual e nas diversas possibilidades (Fonte: 36氪, 36氪)

Discussão: A necessidade de “Tokens de marcação de turno” (Turn Marker Tokens) na inferência de grandes modelos: Há discussões na comunidade apontando que, se os “Tokens de marcação de turno” em modelos de diálogo (como Tokens especiais que identificam as falas do usuário e do assistente) são sempre seguidos exatamente pelos mesmos poucos Tokens (por exemplo, user\n e assistant\n), então esses próprios Tokens de marcação de turno podem não ser necessários. Uma opinião adicional sustenta que, se um grupo de Tokens (por exemplo, três) marca conjuntamente algo, e o modelo precisa aprender a importância do primeiro Token desse grupo, então exemplos de contexto contendo contrafactuais devem ser fornecidos, caso contrário, o modelo pode não aprender essa importância com precisão. Essa discussão está relacionada ao fenômeno de o Claude Opus 4 ser facilmente enganado por injeção de diálogo (dialogue injection), indicando que a compreensão e o processamento da estrutura do diálogo pelo modelo ainda têm espaço para melhorias (Fonte: giffmana, giffmana)
Descompasso entre desejo e capacidade na aplicação de agentes de IA no local de trabalho chama a atenção: Uma pesquisa da equipe da Universidade de Stanford revelou um significativo descompasso entre a demanda e a capacidade na automação do local de trabalho por agentes de IA. O estudo descobriu que cerca de 41% das tarefas em empresas incubadas pela YC (Y Combinator) se concentram em áreas de “baixa prioridade” e “zona vermelha”, onde a disposição dos trabalhadores para automação é baixa ou a tecnologia de IA ainda não está madura. Além disso, embora muitas tarefas exijam colaboração entre humanos e IA em nível de pares, os profissionais geralmente esperam um maior controle humano, o que pode gerar atritos. A pesquisa prevê que, com a entrada de agentes de IA no mercado de trabalho, as competências essenciais humanas podem se deslocar para habilidades interpessoais e de coordenação organizacional. Este estudo visa fornecer orientação para o futuro desenvolvimento de agentes de IA e a transformação das habilidades da força de trabalho (Fonte: 新智元)

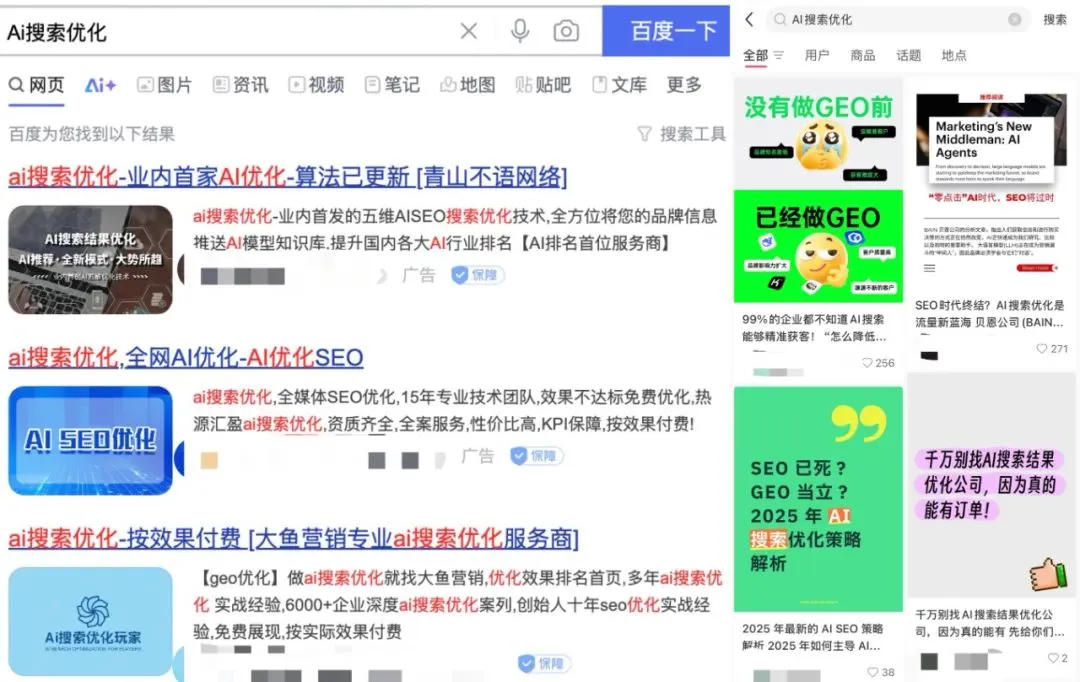
Empresas de publicidade utilizam Otimização para Mecanismos de Busca Generativos (GEO) para influenciar resultados de busca de IA, gerando discussões éticas e regulatórias: Empresas de publicidade estão usando serviços de Otimização para Mecanismos de Busca Generativos (GEO) para ajudar clientes corporativos a obter maior exposição nos resultados de busca de IA. Este serviço, ao produzir conteúdo de alta qualidade que se alinha às preferências dos grandes modelos e realizar “alimentação” de dados para IA, visa melhorar o ranking e a frequência de aparecimento das informações dos clientes nas respostas de IA. No entanto, os usuários geralmente não sabem se os resultados da busca de IA foram otimizados. Isso levanta discussões sobre se tais práticas constituem publicidade, se precisam ser claramente identificadas e quais regras e limites comerciais devem ser observados. Atualmente, as principais plataformas de grandes modelos domésticas ainda não integraram formalmente a publicidade, mas produtos de busca de IA no exterior já começaram a experimentar modelos de publicidade e a realizar marcações (Fonte: 36氪)
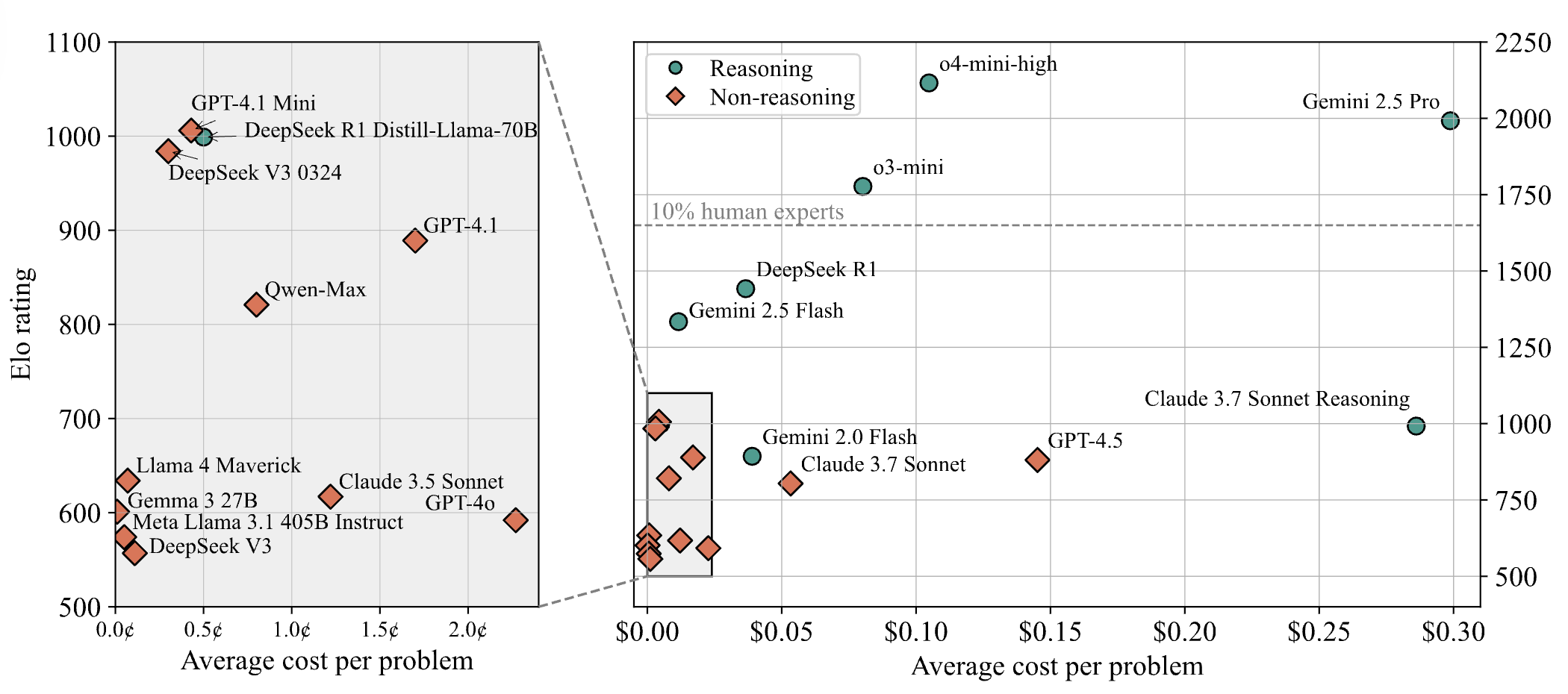
Modelos de IA apresentam baixo desempenho em problemas difíceis de competições de programação, resultados do teste LiveCodeBench Pro mostram que modelos de ponta obtêm 0%: Zihan Zheng e outros lançaram o LiveCodeBench Pro, um benchmark em tempo real contendo problemas de competições de programação de alta dificuldade como IOI (International Olympiad in Informatics), Codeforces e ICPC (International Collegiate Programming Contest). Na seção “difícil” deste benchmark, os principais modelos de linguagem grandes, incluindo o3 e Gemini 2.5, obtiveram pontuação de 0%. A análise aponta que os LLMs são bons em tarefas de implementação que dependem da memória, mas apresentam baixo desempenho em problemas observacionais ou lógicos que exigem “inspiração” crucial, bem como em tarefas que exigem atenção aos detalhes e tratamento de casos limite. Saining Xie comentou que este não é um benchmark para agentes de engenharia de software, mas sim um teste de raciocínio central e inteligência através da codificação, e superar este benchmark seria comparável ao significado da vitória do AlphaGo sobre Lee Sedol (Fonte: ylecun, dilipkay)
Ferramenta de revisão de literatura assistida por IA otto-SR aumenta drasticamente a eficiência e precisão: Instituições como a Universidade de Toronto e a Harvard Medical School desenvolveram conjuntamente o fluxo de trabalho de ponta a ponta de IA otto-SR para automatizar revisões sistemáticas (SRs). A ferramenta combina GPT-4.1 e o3-mini para triagem de literatura e extração de dados, completando em apenas dois dias uma atualização de revisão sistemática Cochrane que, por métodos tradicionais, levaria 12 anos. Em testes de benchmark, a sensibilidade do otto-SR (96,7% vs. 81,7% humano) e a taxa de precisão na extração de dados (93,1% vs. 79,7% humano) foram significativamente superiores às dos revisores humanos, e identificou 54 estudos cruciais omitidos por humanos. Esta pesquisa demonstra o enorme potencial da IA para acelerar a pesquisa médica e melhorar a qualidade da síntese de evidências (Fonte: 量子位)

Exploração da aplicação de DSL estruturada em “Vibe Coding”: Desenvolvedores como Ted Nyman estão experimentando o uso de uma Linguagem Específica de Domínio (DSL) mais estruturada, semelhante a uma classe, em vez de linguagem natural de forma livre para “Vibe Coding” (um tipo de programação mais sensorial e intuitiva), e descobriram que este método funciona melhor, é mais rápido, menos frustrante e gera código de maior qualidade. Esta exploração visa encontrar paradigmas de interação humano-máquina mais eficientes e precisos para programação assistida por IA ou geração de código (Fonte: tnm, lateinteraction)
Perspectivas de aplicação de Agentes de IA em Engenharia de Confiabilidade de Software (SRE): A Traversal AI anunciou a conclusão de rodadas de financiamento seed e Série A totalizando US$ 48 milhões, dedicando-se à construção de SREs (Site Reliability Engineers) de IA de nível empresarial. Seus Agentes de IA são capazes de solucionar problemas, reparar e até mesmo prevenir incidentes complexos de produção de forma autônoma, combinando tecnologia de Agentes de IA com machine learning causal para localizar causas raízes em tempo real. Empresas como DigitalOcean e Eventbrite já se tornaram seus primeiros clientes, demonstrando o enorme potencial da IA na automação de operações e no aumento da confiabilidade de sistemas (Fonte: hwchase17)
💡 Outros
“Jogo mobile” gerado por IA no estilo Ghibli chama a atenção, tutorial mostra produção com Kling AI e Midjourney: Recentemente, um conjunto de capturas de tela e vídeos de um “jogo mobile” no estilo Ghibli viralizou nas redes sociais, com suas belas imagens, paleta de cores frescas e efeitos de luz e sombra naturais chamando a atenção. O criador revelou o método de produção: primeiro, usar o Midjourney para gerar imagens estáticas e, em seguida, utilizar o Kling AI da Kuaishou para transformar as imagens em vídeos dinâmicos. Ao adicionar elementos fixos de HUD (Heads-Up Display), como botões e minimapas, criou-se a sensação de um jogo interativo. Embora atualmente seja apenas uma demonstração em vídeo, já despertou a imaginação dos internautas sobre mundos virtuais interativos gerados por IA (Fonte: 量子位, Kling_ai)

O enorme potencial de aplicação da IA na verificação de erros em diversas áreas: O internauta random_walker propôs que a IA generativa tem um enorme potencial de aplicação na verificação de erros, com “oportunidades de fácil alcance” em diversas áreas. Por exemplo, no campo de software, pode detectar automaticamente vulnerabilidades de segurança; na escrita, pode identificar falhas lógicas e argumentos fracos; na pesquisa científica, pode detectar erros de cálculo e problemas de citação; em contratos legais, pode marcar cláusulas ausentes e contradições; no setor financeiro, pode ser usada para detecção de fraudes e identificação de erros em relatórios financeiros. Ele acredita que a automação da verificação de erros é alta e causa pouca interferência; mesmo com uma taxa de falsos positivos de 50%, a revisão manual é relativamente fácil e pode liberar as pessoas de trabalhos tediosos. No entanto, é preciso estar atento ao risco de a dependência excessiva da IA levar ao declínio das capacidades humanas (Fonte: random_walker)
Entrevista com Sam Altman: IA simplificará o trabalho, fornecerá socialização personalizada e impulsionará descobertas científicas: O fundador da OpenAI, Sam Altman, previu em uma entrevista que, nos próximos 5 a 10 anos, as ferramentas de programação e chat com IA se tornarão mais inteligentes e capazes de automatizar a maior parte do trabalho. A IA pode trazer novas experiências sociais, oferecer serviços personalizados e ajudar a descobrir novos conhecimentos científicos, especialmente em áreas com uso intensivo de dados, como astrofísica ou física de altas energias. Ele enfatizou que a verdadeira transformação da IA reside não apenas em sua capacidade de pensar, mas também de agir no mundo físico, sendo os robôs humanoides um desafio crucial. A visão da OpenAI é tornar a IA um “companheiro de IA” onipresente, alcançado através de plataformas e colaborações de hardware. Ele acredita que a cultura e o pensamento de longo prazo são as principais competências da OpenAI (Fonte: 36氪)