
Palavras-chave:modelo de linguagem grande, avaliação de IA, sistema multiagente, capacidade de raciocínio, processamento de contexto, modelo de código aberto, geração de vídeo por IA, programação com IA, avaliação da capacidade de raciocínio de LLM, refutação do artigo da Apple pelo Claude Opus 4, modelo MiniMax-M1 MoE, modelo de programação Kimi-Dev-72B, função Gemini Deep Think
🔥 Foco
Artigo da Apple que questiona capacidade de raciocínio de LLMs é refutado, artigo em coautoria com Claude Opus 4 aponta falhas no design experimental: A Apple publicou recentemente o artigo “The Illusion of Thought”, que, através de testes com problemas clássicos como Torre de Hanói e Blocks World, aponta que os principais grandes modelos de linguagem (LLM) têm um desempenho insatisfatório em tarefas de raciocínio complexo, sendo essencialmente uma correspondência de padrões em vez de uma verdadeira compreensão. No entanto, o pesquisador independente Alex Lawsen, em coautoria com o modelo de IA Claude Opus 4, publicou o artigo “The Illusion of ‘The Illusion of Thought’ Itself” para refutar, argumentando que o experimento da Apple possui falhas de design: 1. Não considerou o limite máximo de output de Tokens dos LLMs, o que levou os modelos a serem julgados incorretamente por não conseguirem gerar integralmente passos excessivamente longos; 2. Alguns casos de teste (como certos “problemas de travessia de rio”) são matematicamente insolúveis sob as condições dadas, e a incapacidade da IA de fornecer a “resposta correta” não se deve à falta de capacidade; 3. Ao alterar o método de avaliação, como solicitar que o modelo gere um programa para resolver o problema em vez dos passos completos, a IA apresenta um desempenho excelente. Este evento desencadeou uma ampla discussão sobre a verdadeira capacidade de raciocínio dos LLMs e as metodologias de avaliação, destacando a importância de projetar esquemas de avaliação razoáveis e lembrando os desenvolvedores da necessidade de prestar atenção a fatores como a janela de contexto, o orçamento de output e a formulação da tarefa, que afetam o desempenho do modelo em aplicações práticas. (Fonte: 新智元, 大数据文摘)
Roteiro de IA do Google é revelado, sugerindo que a próxima arquitetura de IA poderá abandonar o mecanismo de atenção existente: Logan Kilpatrick, líder de produto do Google, revelou na AI Engineer World Expo a direção futura do modelo Gemini, sendo o mais notável a perspectiva de alcançar um “contexto infinito”. Ele destacou que, com o mecanismo de atenção e o processamento de contexto atuais, não é possível alcançar um contexto verdadeiramente infinito, insinuando que o Google pode estar pesquisando uma arquitetura de IA central totalmente nova. O roteiro também inclui: capacidade full-modality (já suporta imagem + áudio, vídeo é a próxima fase), experimentos iniciais com Diffusion, capacidade de Agent por padrão (chamada e uso de ferramentas de primeira classe, com o modelo evoluindo gradualmente para um agente inteligente), capacidade de raciocínio em contínua expansão e o lançamento de mais modelos pequenos. Esta série de planos indica que o Google está impulsionando ativamente a IA de uma resposta passiva para uma evolução de agente inteligente e está empenhado em superar os gargalos tecnológicos existentes, especialmente no processamento de contexto, o que pode levar a grandes mudanças na arquitetura de IA. (Fonte: 新智元)
Sakana AI lança ALE-Agent, que supera 98% dos competidores humanos em competição de programação de problemas NP-difíceis: A Sakana AI, cofundada por Llion Jones, um dos autores do Transformer, em colaboração com a plataforma japonesa de competições de programação AtCoder, lançou o ALE-Bench (Algorithmic Engineering Benchmark). Este benchmark foca em avaliar a capacidade de raciocínio de longo alcance e programação criativa de IAs em problemas NP-difíceis (como planejamento de rotas e agendamento de tarefas). Seu ALE-Agent, desenvolvido com base no Gemini 2.5 Pro e combinando prompts de conhecimento de domínio com estratégias diversificadas de busca no espaço de soluções, teve um desempenho excelente na competição heurística da AtCoder, alcançando a 21ª posição (top 2%), superando um grande número de desenvolvedores humanos de ponta. Isso marca um progresso importante na capacidade da IA de resolver problemas complexos de otimização, o que tem grande importância para aplicações práticas como logística e planejamento de produção. Embora o ALE-Agent tenha se destacado em algoritmos como simulated annealing, ainda há espaço para melhorias em depuração, análise de complexidade e prevenção de armadilhas de otimização. (Fonte: 新智元, SakanaAILabs, hardmaru)
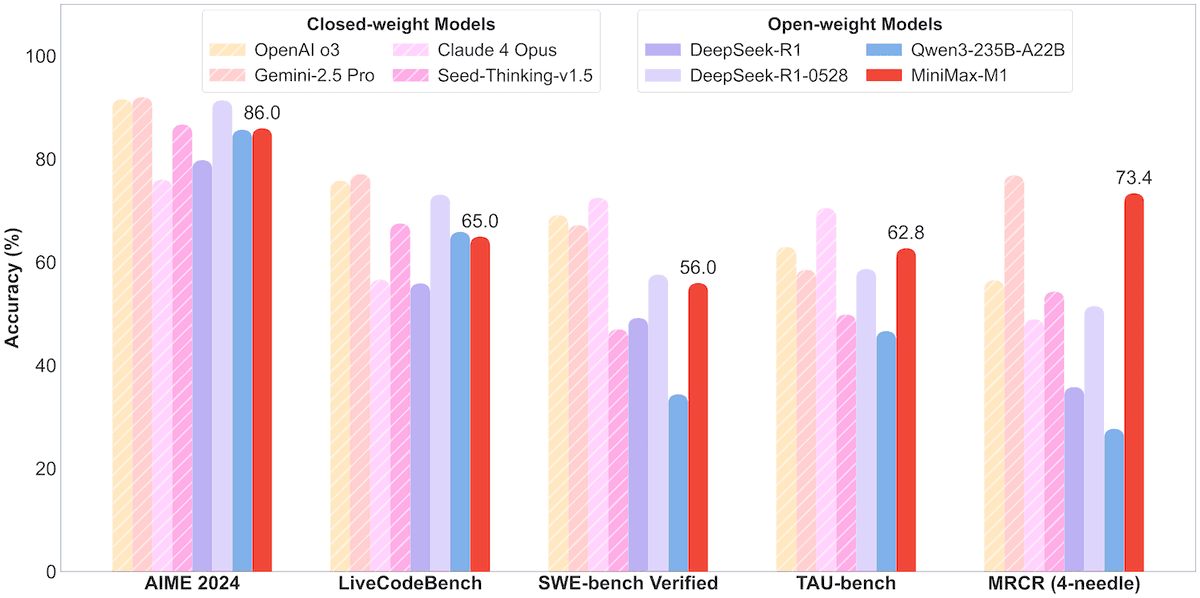
MiniMax lança modelo MoE MiniMax-M1 de 456B parâmetros com suporte para contexto de um milhão e output de 80 mil Tokens: A MiniMax anunciou seu primeiro modelo de inferência de grande escala open-source com Mixture of Experts (MoE), o MiniMax-M1. O modelo possui 456 bilhões de parâmetros, com cada Token ativando 4,59 bilhões de parâmetros, e utiliza uma arquitetura que combina MoE com Lightning Attention. O M1 suporta nativamente um comprimento de contexto de 1 milhão de Tokens e pode gerar um output de 80 mil Tokens, líder na indústria, incluindo versões com orçamento de pensamento de 40k e 80k. Em benchmarks de engenharia de software, uso de ferramentas e tarefas de contexto longo, o M1 superou modelos como DeepSeek-R1 e Qwen3-235B, destacando-se especialmente no uso de ferramentas de Agent (como no TAU-bench). Sua fase de aprendizado por reforço levou apenas três semanas com 512 GPUs H800, a um custo aproximado de US$ 537.400. O modelo M1 já está disponível gratuitamente no APP e na Web da MiniMax, e também via API. (Fonte: op7418, scaling01, jeremyphoward, karminski3, Reddit r/LocalLLaMA, 智东西)
🎯 Tendências
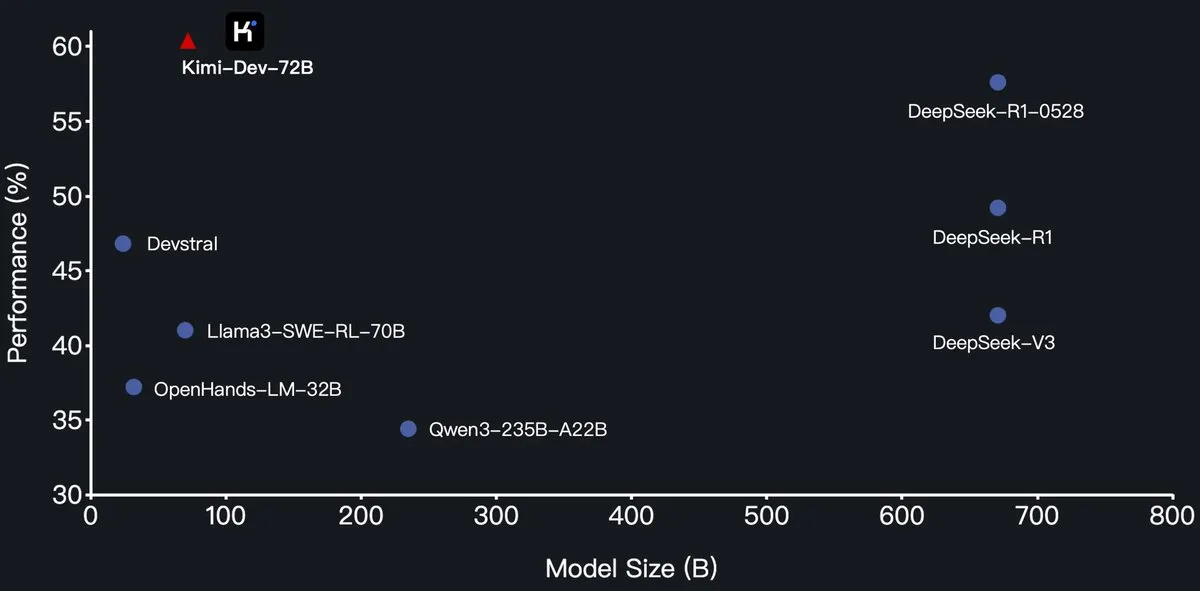
Moonshot AI lança modelo de programação Kimi-Dev-72B open-source, superando DeepSeek-R1 no SWE-Bench: A Moonshot AI (月之暗面) lançou seu novo modelo de linguagem grande para programação open-source, Kimi-Dev-72B, que foi fine-tuned a partir do Qwen2.5-72B. Alegadamente, o Kimi-Dev-72B alcançou uma taxa de resolução de 60,4% no benchmark SWE-bench Verified, superando modelos como DeepSeek-R1-0528 (57,6%) e Qwen3-235B-A22B, tornando-se um dos melhores entre os modelos open-source. O modelo foi treinado com aprendizado por reforço, focado em corrigir repositórios de código reais em ambientes Docker, e só recebeu recompensa quando o conjunto completo de testes passou. O líder de P&D da Qwen afirmou não ter autorizado, mas o Kimi usa a licença MIT para lançar a versão fine-tuned, o que está em conformidade com as regras. (Fonte: Dorialexander, scaling01, karminski3, Reddit r/LocalLLaMA)
Modelos da série Qwen3 adicionam suporte ao formato MLX, otimizando a inferência em chips da Apple: A equipe Tongyi Qianwen da Alibaba anunciou que os modelos da série Qwen3 agora suportam o formato MLX e oferecem quatro níveis de quantização: 4 bits, 6 bits, 8 bits e BF16. Esta medida visa otimizar a eficiência de execução dos modelos no framework MLX da Apple, facilitando aos desenvolvedores a implantação local e a inferência em dispositivos Mac. Os usuários podem obter os modelos relevantes no HuggingFace e ModelScope. (Fonte: ClementDelangue, stablequan, jeremyphoward)

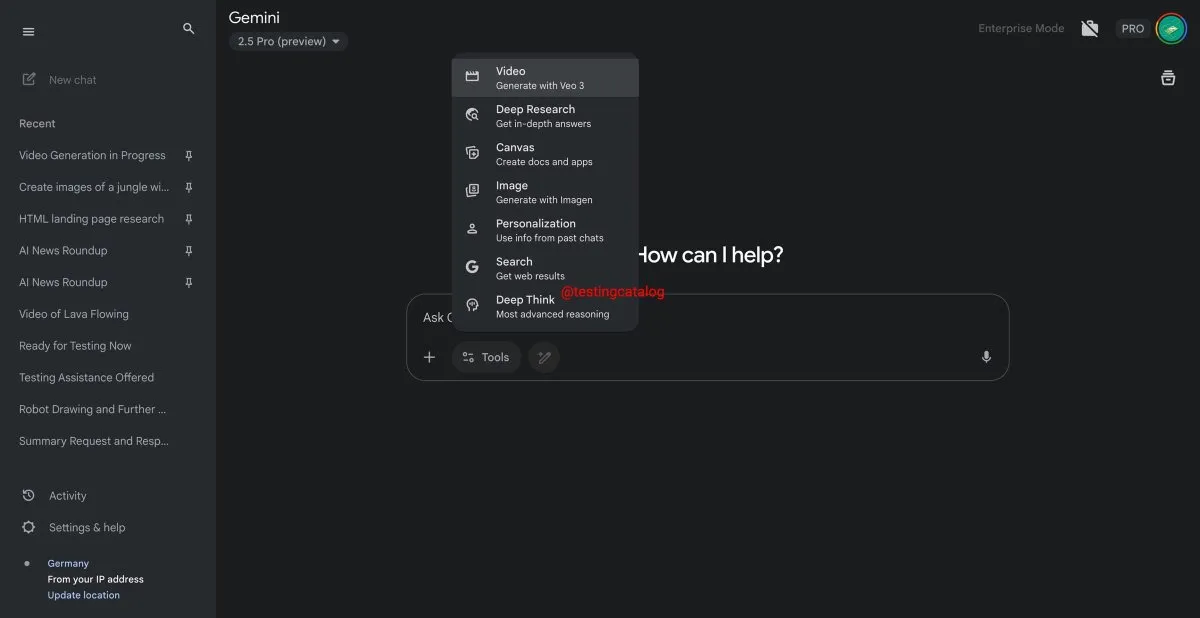
Google Gemini está prestes a lançar a funcionalidade “Deep Think” para melhorar o processamento de problemas complexos: O Google está se preparando para introduzir uma nova funcionalidade chamada “Deep Think” em seu modelo Gemini 2.5 Pro. A funcionalidade visa lidar com problemas mais desafiadores, fornecendo capacidade computacional adicional. Especialmente em tarefas relacionadas à matemática, espera-se que o Deep Think melhore o desempenho em até 15% em comparação com a versão regular do Gemini 2.5 Pro. Esta funcionalidade aparecerá como uma nova opção na barra de ferramentas, e o processo pode levar alguns minutos. Ao mesmo tempo, a interface do usuário do Gemini também receberá atualizações. (Fonte: op7418)
Modelo de geração de vídeo Veo 3 do Google é lançado oficialmente, expandindo para mais de 70 mercados: O Google anunciou que seu modelo de geração de vídeo por IA, Veo 3, foi lançado oficialmente para assinantes AI Pro e Ultra, cobrindo mais de 70 mercados em todo o mundo. O Veo 3 tem chamado a atenção por seus vídeos realistas e criativos. Anteriormente, usuários já haviam utilizado o modelo para criar conteúdo ASMR, como o viral “cortar frutas de forma hipnótica”, que obteve dezenas de milhões de visualizações nas redes sociais, demonstrando seu potencial na criação de conteúdo. O lançamento oficial permitirá que mais usuários experimentem e utilizem o Veo 3 para criação de vídeos. (Fonte: Google, 新智元)
Hugging Face e Groq colaboram para oferecer serviços de inferência LLM de alta velocidade: A Hugging Face anunciou uma parceria com a empresa de chips de IA Groq para integrar as LPUs™ (Language Processing Units) da Groq ao Hugging Face Playground e API. Os usuários agora podem experimentar diretamente na plataforma Hugging Face os serviços de inferência LLM acelerados pelo hardware da Groq, suportando vários modelos, incluindo Llama 4 e Qwen 3. Esta iniciativa visa fornecer aos desenvolvedores opções de inferência de modelos de IA mais rápidas e eficientes, especialmente adequadas para a construção de agentes, assistentes e aplicações de IA em tempo real. (Fonte: HuggingFace Blog, huggingface, ClementDelangue, mervenoyann, JonathanRoss321, _akhaliq)

Hugging Face Hub adiciona funcionalidade de filtro por tamanho de modelo, ajudando desenvolvedores a escolher modelos adequados: A plataforma Hugging Face lançou uma nova funcionalidade que permite aos usuários filtrar modelos por tamanho (Size Range), especialmente para modelos executados no framework mlx / mlx-lm. Esta melhoria visa ajudar os desenvolvedores a encontrar mais facilmente modelos que atendam aos seus requisitos específicos de hardware e desempenho, enfatizando que nem sempre o modelo maior é o melhor, e que modelos menores especializados costumam ser superiores em cenários específicos. (Fonte: ClementDelangue, awnihannun, reach_vb, huggingface, ggerganov)

Atualização do NVIDIA NCCL começa a usar acumulação FP32 para operações de redução em entradas de meia precisão: A versão mais recente da NVIDIA Collective Communications Library (NCCL) (commit 72d2432) introduziu uma atualização importante: ao processar operações de redução (reduction ops) em entradas de meia precisão (como FP16, BF16), ela começa a usar FP32 para acumulação. Essa mudança é crucial para manter a precisão computacional e evitar overflow, especialmente em treinamento distribuído em larga escala. Espera-se que esta versão seja integrada no PyTorch 2.8 e versões posteriores. (Fonte: StasBekman)

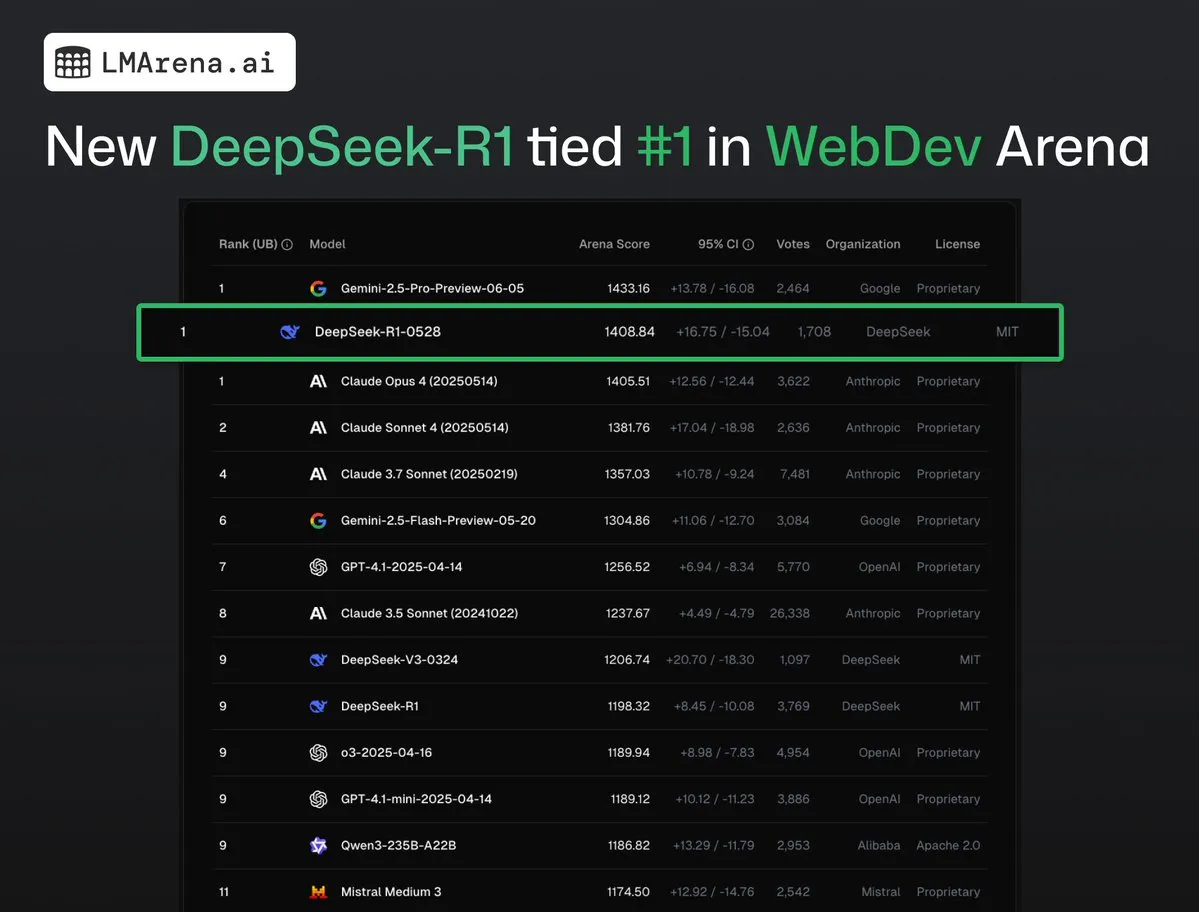
DeepSeek-R1 (0528) empata em primeiro lugar com Claude Opus 4 na WebDev Arena: Os dados mais recentes da lmarena.ai mostram que a nova versão do DeepSeek-R1 (0528) teve um desempenho excelente no benchmark WebDev Arena, empatando em primeiro lugar com o Claude Opus 4. O modelo ficou em sexto lugar no ranking geral da Text Arena, em segundo lugar na capacidade de programação, em quarto lugar em prompts difíceis, em quinto lugar em capacidade matemática, e é o modelo open-source com licença MIT de melhor desempenho no ranking. Isso marca a forte competitividade do DeepSeek em tarefas específicas de desenvolvimento e raciocínio. (Fonte: ClementDelangue, zizhpan)
ByteDance lança modelos de imagem Seedream 3.0 e vídeo Seedance 1.0 Lite na plataforma Poe: As ferramentas de criação de IA da ByteDance lançaram atualizações na plataforma Poe no exterior, disponibilizando o modelo de geração de imagem Seedream 3.0 e o modelo de geração de vídeo Seedance 1.0 Lite da Jmeng AI. O Seedream 3.0 visa gerar imagens nítidas e vívidas, enquanto o Seedance 1.0 Lite pode gerar rapidamente vídeos com efeitos dinâmicos realistas. Os usuários podem primeiro usar o Seedream no Poe para gerar uma imagem e depois convertê-la em vídeo mencionando @Seedance, realizando um fluxo de criação contínuo de imagem para vídeo. (Fonte: op7418)

Tencent lança modelo de canto Levo, com suporte para separação de faixas e clonagem de timbre zero-shot: A Tencent lançou um modelo de canto por IA chamado Levo, que alegadamente tem desempenho comparável ao Suno V3.5. O Levo suporta separação de faixas de áudio e clonagem de timbre zero-shot. A julgar pelas demonstrações e classificações divulgadas, seu desempenho é excelente. Este avanço demonstra a força da Tencent no campo da geração de música por IA. (Fonte: karminski3)
OpenAI lança funcionalidade de geração de imagens do ChatGPT no WhatsApp: A OpenAI anunciou que os usuários agora podem usar a funcionalidade de geração de imagens do ChatGPT através do serviço 1-800-ChatGPT no WhatsApp. Esta atualização permite que um público mais amplo gere imagens de IA diretamente em aplicativos de mensagens instantâneas de forma conveniente. (Fonte: gdb, eliza_luth, iScienceLuvr)
SpatialLM atualizado para a versão 1.1, aprimorando a compreensão e reconstrução de cenas 3D: O modelo de raciocínio espacial SpatialLM lançou a versão 1.1. A nova versão suporta múltiplos modos de fonte de entrada, incluindo geração de cenas 3D a partir de texto (Text-to-3D), reconstrução a partir de vídeo de câmera portátil, dados de nuvem de pontos LiDAR (como o LiDAR do iPhone Pro) e amostragem de malhas sintéticas. As características principais incluem o processamento robusto de nuvens de pontos não estruturadas, permitindo uma reconstrução razoável mesmo com dados de varredura 3D incompletos. Além disso, a nova versão otimizou a detecção zero-shot para entrada de fluxo de vídeo, melhorou a precisão da estimativa de layout interno e aprimorou o efeito da detecção de objetos 3D. Os cenários de aplicação são amplos, abrangendo reconstrução de cenas AR, compreensão espacial para robôs, fluxos de trabalho de design 3D e aplicações de câmera para o consumidor. (Fonte: karminski3)
GitHub Copilot lança plano de US$ 39 por mês, integrando Claude Opus 4 e outros grandes modelos: O GitHub Copilot adicionou um novo plano de assinatura de US$ 39 por mês. Este plano não apenas oferece funcionalidades de assistente de codificação, mas também permite que os usuários acessem vários modelos de linguagem poderosos, incluindo Claude Opus 4, o3 e GPT-4.5, além de poder usar o Coding agent. Esta iniciativa visa fornecer aos desenvolvedores uma experiência de programação assistida por IA mais abrangente. (Fonte: dotey)
Custo de chamada de grandes modelos de IA continua a diminuir, preço da série Doubao 1.6 cai mais 63%: Na conferência Force Original Power, a Volcano Engine lançou a série de grandes modelos Doubao 1.6 e anunciou uma redução de custo abrangente de 63%. Para a faixa de comprimento de entrada de 0-32K, comumente usada pela maioria das empresas, o preço é de 0,8 yuan por milhão de tokens de entrada e 8 yuan para output. Isso marca uma escalada contínua na guerra de preços de grandes modelos, após a Alibaba Qianwen ter reduzido os custos para 1/10 do DeepSeek R1 em março deste ano. O baixo custo impulsionará ainda mais a implementação e popularização de aplicações como AI Agents. (Fonte: 字节必须再赢一次)
Ferramenta de aceleração de geração de vídeo Chipmunk atualizada, suporta arquiteturas multi-GPU e mais modelos open-source: A ferramenta Chipmunk da equipe de Dan Fu recebeu uma atualização e agora suporta aceleração sem perdas de 1.4-3x na geração de vídeo em várias arquiteturas de GPU NVIDIA (sm_80, sm_89, sm_90, como A100s, 4090s, H100s). Ao mesmo tempo, o Chipmunk adicionou suporte para mais modelos de vídeo open-source como Mochi, Wan, e forneceu tutoriais de integração. A ferramenta utiliza a esparsidade dos valores de ativação em modelos de vídeo (apenas 5-25% dos valores de ativação contribuem para mais de 90% do output) para alcançar a aceleração, sem a necessidade de retreinar o modelo. (Fonte: realDanFu)

🧰 Ferramentas
Microsoft lança Demo de assistente de viagem com IA, integrando MCP, LlamaIndex.TS e Azure AI Foundry: A Microsoft demonstrou um assistente de viagem com IA. O sistema coordena múltiplos agentes de IA (incluindo classificação de consultas, recomendação de destinos, planejamento de itinerários, entre outros seis agentes especializados) para completar tarefas complexas de planejamento de viagem, utilizando o Model Context Protocol (MCP), LlamaIndex.TS e Azure AI Foundry. Cada agente obtém dados em tempo real e ferramentas através de servidores MCP escritos em Java, .NET, Python e TypeScript. A aplicação demonstra como múltiplos agentes de nível empresarial podem colaborar através de microsserviços multilíngues, utilizando modelos Azure OpenAI e GitHub para fornecer capacidades de IA, e pode ser implantada de forma escalável e sem servidor através do Azure Container Apps. (Fonte: jerryjliu0, jerryjliu0)
LlamaParse adiciona modos predefinidos, capazes de analisar gráficos complexos em Mermaid ou Markdown: A ferramenta LlamaParse do LlamaIndex foi atualizada recentemente, adicionando “modos predefinidos” (preset-modes), que permitem analisar gráficos complexos em documentos como relatórios de pesquisa (por exemplo, gráficos com múltiplas curvas e anotações) e convertê-los em diagramas Mermaid formatados ou tabelas Markdown. Esta funcionalidade ajuda a capturar o contexto completo da página, e o texto estruturado gerado pode ser usado para construir fluxos RAG ou para extração adicional de metadados. (Fonte: jerryjliu0)
Prompt Optimizer: Uma ferramenta de otimização para ajudar a escrever prompts de alta qualidade: O Prompt Optimizer é uma ferramenta projetada para ajudar os usuários a escrever prompts de IA de melhor qualidade, melhorando assim a qualidade do output da IA. Ele suporta tanto uma aplicação web quanto uma extensão para Chrome, oferecendo otimização inteligente, melhoria iterativa em várias rodadas, comparação entre prompts originais e otimizados, integração com múltiplos modelos (OpenAI, Gemini, DeepSeek, Zhipu AI, SiliconFlow, etc.), configuração avançada de parâmetros e armazenamento local criptografado. A ferramenta processa tudo no lado do cliente, garantindo a segurança e privacidade dos dados. (Fonte: GitHub Trending)

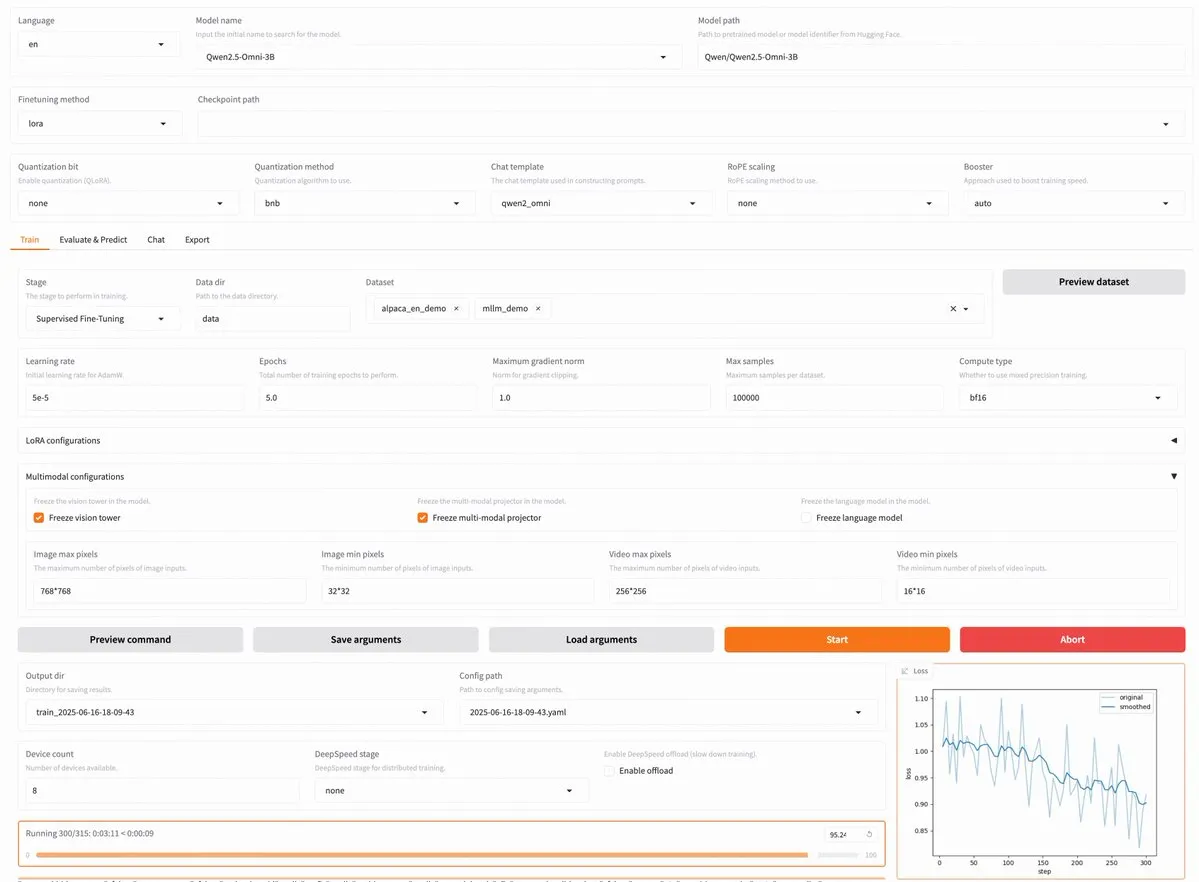
LLaMA Factory v0.9.3 lançado, suporta fine-tuning sem código para quase 300 modelos, incluindo Qwen3 e Llama 4: O LLaMA Factory lançou a versão v0.9.3. Esta versão é uma plataforma de fine-tuning totalmente open-source, com interface de usuário Gradio e sem necessidade de código, compatível com quase 300 modelos, incluindo os mais recentes Qwen3, Llama 4, Gemma 3, InternVL3, Qwen2.5-Omni, entre outros. Os usuários podem instalar localmente através de uma imagem Docker ou experimentar no Hugging Face Spaces, Google Colab e na nuvem de GPU da Novita. (Fonte: _akhaliq)
Nanonets OCR: Modelo OCR SOTA baseado em Qwen 2.5 VL 3B é open-source: A Nanonets lançou um novo modelo OCR de 3B parâmetros – Nanonets OCR. Este modelo é baseado na rede principal Qwen 2.5 VL 3B, supera o desempenho da API Mistral OCR e é open-source sob a licença Apache 2.0. Ele é capaz de lidar com várias tarefas de OCR, como reconhecimento de LaTeX, detecção de marcas d’água e assinaturas, e extração de tabelas complexas. (Fonte: huggingface)
Perplexity Labs é apontado como capaz de substituir vários cargos profissionais, gerando discussão sobre a capacidade das ferramentas de IA: Um usuário, GREG ISENBERG, afirmou ter usado o Perplexity Labs para substituir o trabalho de cinco cargos: vendedor, redator publicitário, diretor de cinema, gerente de mídias sociais e analista financeiro, considerando a capacidade das ferramentas de IA “realmente insana”. O CEO da Perplexity, Arav Srinivas, retweetou e comentou que este é um dos melhores vídeos que demonstram como os agentes de IA podem ser aplicados em casos de uso da vida real, comparando o Perplexity Labs com outras ferramentas do mercado em análise financeira, marketing de mídia social, direção criativa e vendas. Isso destaca o potencial dos AI Agents na integração e execução de tarefas profissionais multidisciplinares. (Fonte: AravSrinivas, AravSrinivas)
Claude-Flow lança grande atualização v1.0.50, ativando “modo enxame” para aumentar a eficiência da automação de código: Claude-Flow, um sistema de agentes paralelos em lote baseado no Claude Code, lançou a versão v1.0.50. A nova versão introduz o “Modo Enxame” (Swarm Mode), permitindo que os usuários gerem, gerenciem e coordenem simultaneamente centenas de agentes Claude trabalhando em paralelo para construir, testar, implantar ou realizar ciclos de pesquisa multifásicos. Alegadamente, o desempenho é 20 vezes superior em comparação com a automação sequencial tradicional do Claude Code. Os desenvolvedores podem inicializar com npx claude-flow@latest init --sparc --force. (Fonte: Reddit r/ClaudeAI)

📚 Aprendizado
Awesome Machine Learning: Uma lista abrangente de recursos de machine learning: O projeto “awesome-machine-learning” no GitHub é uma lista cuidadosamente curada de frameworks, bibliotecas e softwares de machine learning, classificados por linguagem de programação. Ele também contém links para livros gratuitos de machine learning, eventos profissionais, cursos online, newsletters de blogs e encontros locais, fornecendo uma navegação valiosa para aprendizes e praticantes de machine learning. (Fonte: GitHub Trending)
Anthropic e Cognition AI publicam artigos de blog sobre a construção de sistemas multi-agente, LangChain resume: Anthropic e Cognition AI publicaram recentemente artigos de blog sobre a construção (ou não construção) de sistemas multi-agente. A Anthropic compartilhou sua experiência na construção de seu sistema de pesquisa multi-agente, enquanto a Cognition AI apresentou o ponto de vista de “não construir multi-agentes”. Harrison Chase, da LangChain, resumiu, apontando que, embora as opiniões pareçam diferentes na superfície, os dois artigos têm muitos pontos em comum em diretrizes e sugestões, e os relacionou aos esforços da LangChain em multi-agentes. (Fonte: hwchase17, Hacubu)
Artigo “Recent Advances in Speech Language Models: A Survey” aceito na conferência principal do ACL 2025: O artigo de revisão sobre modelos de linguagem de fala (SpeechLM) intitulado “Recent Advances in Speech Language Models: A Survey”, de autoria de uma equipe da Universidade Chinesa de Hong Kong, foi aceito na conferência principal do ACL 2025. Este artigo é a primeira revisão abrangente e sistemática do campo, analisando profundamente a arquitetura técnica dos SpeechLMs (tokenizadores de fala, modelos de linguagem, vocoders), estratégias de treinamento (pré-treinamento, fine-tuning de instruções, pós-alinhamento), paradigmas de interação (modelagem full-duplex), cenários de aplicação (semântica, locutor, paralinguística) e sistemas de avaliação. O artigo enfatiza o potencial dos SpeechLMs para alcançar interações de fala humano-máquina naturais e aponta os desafios e direções futuras. (Fonte: 36氪)

Nova pesquisa melhora a capacidade de raciocínio transdisciplinar de modelos pequenos através do aprendizado por jogos visuais (ViGaL), modelo de 7B supera GPT-4o em matemática: Pesquisadores da Rice University, Johns Hopkins University e NVIDIA propuseram um novo paradigma de pós-treinamento chamado ViGaL (Visual Game Learning). Ao fazer um modelo multimodal de 7B parâmetros (Qwen2.5-VL-7B) jogar jogos de arcade simples como Snake e rotação 3D, o modelo não apenas melhorou suas habilidades no jogo, mas também demonstrou um aumento significativo na capacidade de raciocínio transdisciplinar em tarefas complexas como matemática (MathVista) e perguntas e respostas multidisciplinares (MMMU), superando até mesmo modelos de ponta como o GPT-4o em alguns aspectos. A pesquisa indica que o treinamento com jogos pode cultivar habilidades cognitivas gerais do modelo, como compreensão espacial e planejamento sequencial, e diferentes jogos podem fortalecer diferentes aspectos das habilidades de raciocínio. Este método melhora a capacidade de raciocínio enquanto mantém a capacidade visual geral do modelo. (Fonte: 新智元)

Shanghai AI Lab e outros propõem framework MathFusion para melhorar a capacidade de resolução de problemas matemáticos de LLMs através da fusão de instruções: O Shanghai Artificial Intelligence Laboratory, a Gaoling School of Artificial Intelligence da Renmin University of China e outras instituições propuseram conjuntamente o framework MathFusion. O objetivo é aprimorar a capacidade dos grandes modelos de linguagem (LLM) de resolver problemas matemáticos, fundindo diferentes estruturas de geração de problemas matemáticos para criar instruções sintéticas mais diversas e logicamente complexas. O framework inclui três estratégias de fusão: sequencial, paralela e condicional, que podem capturar eficazmente as conexões profundas entre os problemas. Experimentos mostram que, usando apenas 45K instruções sintéticas para fine-tuning em modelos como DeepSeekMath-7B, Llama3-8B e Mistral-7B, o MathFusion melhorou a precisão média em vários benchmarks matemáticos em 18,0 pontos percentuais, demonstrando alta eficiência de dados e desempenho. (Fonte: 量子位)

Shanghai AI Lab e outros propõem framework GRA, onde modelos pequenos colaboram para gerar dados de alta qualidade, com desempenho comparável a modelos de 72B: O Shanghai Artificial Intelligence Laboratory, em colaboração com a Renmin University of China, propôs o framework GRA (Generator–Reviewer–Adjudicator). Simulando o mecanismo de submissão de artigos e revisão por pares, ele permite que múltiplos modelos de linguagem pequenos (parâmetros de 7-8B) colaborem para gerar dados de treinamento de alta qualidade. Neste framework, o Generator é responsável pela geração, o Reviewer realiza múltiplas rodadas de revisão e pontuação, e o Adjudicator toma a decisão final em caso de conflitos de revisão. Experimentos mostram que treinar modelos base como LLaMA-3.1-8B e Qwen-2.5-7B com dados gerados pelo GRA resulta em desempenho, em 10 datasets principais de matemática, código, raciocínio lógico, etc., igual ou superior aos dados gerados por destilação de modelos grandes como o Qwen-2.5-72B-Instruct. Isso oferece novas ideias para a síntese de dados de baixo custo e alta eficiência. (Fonte: 量子位)

Artigo discute o estado atual e futuro da interpretabilidade de grandes modelos, enfatizando sua importância para a implantação segura da IA: O Tencent Research Institute publicou um artigo que discute profundamente o estado atual, os caminhos tecnológicos e os desafios futuros da interpretabilidade de grandes modelos de linguagem (LLM). O artigo aponta que compreender os mecanismos internos dos LLMs é crucial para prevenir desvios de valor, depurar e melhorar modelos, evitar abusos e promover aplicações em cenários de alto risco. Os caminhos tecnológicos atuais incluem interpretação automatizada (grandes modelos interpretando modelos menores), visualização de características (como sparse autoencoders), monitoramento de chain-of-thought e interpretabilidade mecanicista (como o “microscópio de IA” da Anthropic e o Tracr da DeepMind). No entanto, a polissemia dos neurônios, a universalidade das leis de interpretação e as limitações cognitivas humanas ainda são os principais desafios. O artigo pede um maior investimento em pesquisa de interpretabilidade e sugere a adoção de regras de soft law para incentivar a autorregulação da indústria na fase atual, a fim de garantir o desenvolvimento seguro, transparente e centrado no ser humano da tecnologia de IA. (Fonte: 腾讯研究院)

Novo artigo discute aplicações e avanços de modelos de difusão discreta em grandes modelos de linguagem e multimodais: Um artigo intitulado “Discrete Diffusion in Large Language and Multimodal Models: A Survey” revisa sistematicamente os avanços da pesquisa em modelos de linguagem de difusão discreta (dLLMs) e modelos de linguagem multimodais de difusão discreta (dMLLMs). Esses modelos adotam decodificação paralela de múltiplos Tokens e estratégias de geração baseadas em denoising, alcançando geração paralela, controlabilidade granular do output e capacidade de percepção dinâmica e responsiva, com velocidade de inferência até 10 vezes maior em comparação com modelos autorregressivos. O artigo traça seu histórico de desenvolvimento, formaliza o framework matemático, classifica modelos representativos, analisa tecnologias chave de treinamento e inferência, resume aplicações nas áreas de linguagem, visão-linguagem e biologia, e, por fim, discute futuras direções de pesquisa e desafios de implantação. (Fonte: HuggingFace Daily Papers)
Nova pesquisa propõe Test3R: melhorando a precisão geométrica da reconstrução 3D através do aprendizado em tempo de teste: Uma nova técnica chamada Test3R melhora significativamente a precisão geométrica da reconstrução 3D através do aprendizado em tempo de teste. O método utiliza trigêmeos de imagens (I_1,I_2,I_3) e gera resultados de reconstrução a partir dos pares de imagens (I_1,I_2) e (I_1,I_3). A ideia central é otimizar a rede em tempo de teste através de um objetivo autosupervisionado: maximizar a consistência geométrica desses dois resultados de reconstrução em relação à imagem comum I_1. Experimentos mostram que o Test3R supera significativamente os métodos SOTA existentes em tarefas de reconstrução 3D e estimativa de profundidade multivista, além de possuir características de universalidade e baixo custo, sendo facilmente aplicável a outros modelos, com overhead de treinamento em tempo de teste e número de parâmetros mínimos. (Fonte: HuggingFace Daily Papers)
Artigo propõe Mirage-1: um agente GUI com habilidades multimodais hierárquicas para melhorar o processamento de tarefas de longa duração: Pesquisadores propuseram o Mirage-1, um agente GUI multimodal, multiplataforma e plug-and-play, projetado para resolver os problemas de conhecimento insuficiente e a lacuna entre os domínios offline e online que os agentes GUI atuais enfrentam ao lidar com tarefas de longa duração em ambientes online. O núcleo do Mirage-1 é o módulo de Habilidades Multimodais Hierárquicas (HMS), que abstrai gradualmente as trajetórias em habilidades de execução, habilidades centrais e meta-habilidades, fornecendo uma estrutura de conhecimento hierárquica para o planejamento de tarefas de longa duração. Ao mesmo tempo, o algoritmo de Busca em Árvore de Monte Carlo Aumentada por Habilidades (SA-MCTS) utiliza habilidades adquiridas offline para reduzir o espaço de busca de ações na exploração da árvore online. Nos benchmarks AndroidWorld, MobileMiniWob++, Mind2Web-Live e no recém-construído AndroidLH, o Mirage-1 demonstrou melhorias de desempenho significativas. (Fonte: HuggingFace Daily Papers)
Artigo “Don’t Pay Attention” propõe nova arquitetura de rede neural Avey, desafiando o Transformer: Um artigo intitulado “Don’t Pay Attention” propõe uma nova arquitetura de rede neural fundamental, Avey, que visa eliminar a dependência dos mecanismos de atenção e recorrência. Avey é composto por um ranker e um processador neural autorregressivo, que colaboram para identificar e contextualizar apenas os Tokens mais relevantes para qualquer Token dado, independentemente de sua posição na sequência. Essa arquitetura desacopla o comprimento da sequência da largura do contexto, permitindo o processamento eficiente de sequências de comprimento arbitrário. Resultados experimentais mostram que Avey tem desempenho comparável ao Transformer em benchmarks padrão de NLP de curto alcance e se destaca especialmente na captura de dependências de longo alcance. (Fonte: HuggingFace Daily Papers)
Novo artigo explora a verificação de código escalável através de modelos de recompensa, equilibrando precisão e taxa de transferência: Um estudo explora o trade-off entre o uso de modelos de recompensa de resultado (ORM) e validadores abrangentes (como suítes de teste completas) quando grandes modelos de linguagem (LLM) resolvem tarefas de codificação. A pesquisa descobriu que, mesmo na presença de validadores abrangentes, os ORMs desempenham um papel crucial na verificação escalável, sacrificando alguma precisão em troca de velocidade. Particularmente em abordagens de “gerar-podar-reordenar”, o uso de um validador mais rápido, porém menos preciso, para remover preventivamente soluções incorretas pode acelerar o sistema em 11,65 vezes, com uma redução de precisão de apenas 8,33%. O método funciona filtrando soluções incorretas, mas bem classificadas, oferecendo novas ideias para projetar sistemas de classificação de programas escaláveis e precisos. (Fonte: HuggingFace Daily Papers)
Novo benchmark AbstentionBench revela: LLMs de raciocínio têm baixo desempenho em perguntas irrespondíveis: Para avaliar a capacidade dos grandes modelos de linguagem (LLM) de optar pela abstenção (ou seja, recusar-se a responder explicitamente) diante da incerteza, pesquisadores lançaram o AbstentionBench. Este benchmark em larga escala contém 20 conjuntos de dados diferentes, cobrindo vários tipos de perguntas, como aquelas com respostas desconhecidas, especificações insuficientes, premissas falsas, interpretações subjetivas e informações desatualizadas. A avaliação de 20 LLMs de ponta mostrou que a abstenção é um problema não resolvido e que o aumento da escala do modelo pouco contribui para isso. Surpreendentemente, mesmo para LLMs de raciocínio explicitamente treinados para matemática e ciências, o fine-tuning para raciocínio reduziu, em média, a capacidade de abstenção em 24%. Embora prompts de sistema bem elaborados possam melhorar o desempenho da abstenção na prática, isso não resolve as deficiências fundamentais dos modelos no raciocínio sob incerteza. (Fonte: HuggingFace Daily Papers)
Artigo propõe método PatchInstruct baseado em prompts e decomposição para utilizar LLMs na previsão de séries temporais: Um novo estudo explora estratégias de prompting simples e flexíveis para utilizar grandes modelos de linguagem (LLM) na previsão de séries temporais, sem a necessidade de retreinamento extensivo ou arquiteturas externas complexas. Combinando decomposição de séries temporais, tokenização baseada em patches (patch-based tokenization) e aumento de vizinhos baseado em similaridade, entre outros métodos de prompting especializados, os pesquisadores descobriram que é possível melhorar a qualidade das previsões dos LLMs, mantendo a simplicidade e minimizando o pré-processamento de dados. O método PatchInstruct proposto no estudo permite que os LLMs façam previsões precisas e eficazes. (Fonte: HuggingFace Daily Papers)
Novo dataset MS4UI lançado, focado em resumo multimodal de vídeos instrutivos de interface de usuário: Para resolver as deficiências dos benchmarks existentes em fornecer instruções passo a passo, executáveis e ilustradas, pesquisadores propuseram o dataset MS4UI (Multi-modal Summarization for User Interface Instructional Videos). Este dataset contém 2413 vídeos instrutivos de UI, totalizando mais de 167 horas, e foi anotado manualmente com segmentação de vídeo, resumos de texto e resumos de vídeo. O objetivo é impulsionar a pesquisa de métodos de resumo multimodal concisos e executáveis para vídeos instrutivos de UI. Experimentos mostram que os métodos SOTA atuais de resumo multimodal têm desempenho insatisfatório no MS4UI, destacando a importância de novos métodos neste campo. (Fonte: HuggingFace Daily Papers)
DeepResearch Bench: Um benchmark abrangente para agentes de pesquisa profunda: Para avaliar sistematicamente a capacidade dos agentes de pesquisa profunda baseados em LLM (Deep Research Agents, DRAs), os pesquisadores lançaram o DeepResearch Bench. Este benchmark contém 100 tarefas de pesquisa de nível de doutorado, cuidadosamente elaboradas por especialistas de 22 áreas diferentes. Devido à complexidade e ao trabalho intensivo na avaliação de DRAs, os pesquisadores propuseram dois novos métodos de avaliação altamente consistentes com o julgamento humano: um método de critério adaptativo baseado em referência para avaliar a qualidade dos relatórios de pesquisa gerados; e outro framework que avalia a capacidade de recuperação e coleta de informações do DRA, avaliando o número de citações eficazes e a precisão geral das citações. (Fonte: HuggingFace Daily Papers)
Artigo propõe BridgeVLA: aprendizado eficiente de manipulação 3D através do alinhamento de entrada e saída: Para aumentar a eficiência da utilização de sinais 3D por modelos de linguagem visual (VLM) no aprendizado de manipulação robótica, pesquisadores propuseram o BridgeVLA, um novo modelo de ação de linguagem visual 3D (VLA). O BridgeVLA projeta a entrada 3D em múltiplas imagens 2D, garantindo o alinhamento com a entrada da rede principal do VLM, e usa mapas de calor 2D para previsão de ação, unificando assim entrada e saída em um espaço de imagem 2D consistente. Além disso, o estudo propõe um método de pré-treinamento escalável que capacita a rede principal do VLM a prever mapas de calor 2D antes do aprendizado de políticas downstream. Experimentos mostram que o BridgeVLA se destaca em vários benchmarks de simulação e experimentos com robôs reais, melhorando significativamente a eficiência e o efeito do aprendizado de manipulação 3D, e demonstrando forte eficiência de amostra e capacidade de generalização. (Fonte: HuggingFace Daily Papers)
Nova pesquisa sintetiza milhões de instruções de usuário diversas e complexas (SynthQuestions) através de fundamentação por atribuição: Para resolver a falta de dados de instrução diversificados, complexos e em larga escala necessários para o alinhamento de grandes modelos de linguagem (LLM), pesquisadores propuseram um método de síntese de instruções baseado em fundamentação por atribuição (attributed grounding). O framework inclui: 1) um processo de atribuição de cima para baixo, que conecta instruções reais selecionadas a usuários contextualizados; 2) um processo de síntese de baixo para cima, que utiliza documentos da web para primeiro gerar contextos e, em seguida, gerar instruções significativas. Usando este método, foi construído o dataset SynthQuestions, contendo 1 milhão de instruções. Experimentos mostram que modelos treinados neste dataset alcançaram desempenho de ponta em vários benchmarks comuns, e o desempenho continua a melhorar com o aumento do corpus da web. (Fonte: HuggingFace Daily Papers)
PersonaFeedback: Lançamento de benchmark de avaliação personalizada em larga escala com anotação humana: Para avaliar a capacidade de grandes modelos de linguagem (LLM) de fornecer respostas personalizadas dado um perfil de usuário predefinido e uma consulta, pesquisadores lançaram o benchmark PersonaFeedback. Este benchmark contém 8298 casos de teste anotados por humanos, classificados em três níveis – fácil, médio e difícil – de acordo com a complexidade contextual do perfil do usuário e a dificuldade de distinguir respostas personalizadas. Diferentemente dos benchmarks existentes, o PersonaFeedback desacopla a inferência de persona da personalização, focando na avaliação da capacidade do modelo de gerar respostas customizadas para personas explícitas. Os resultados experimentais mostram que mesmo os LLMs SOTA enfrentam desafios nos testes de nível difícil, indicando que os frameworks atuais de aumento de recuperação não são a solução final para tarefas de personalização. (Fonte: HuggingFace Daily Papers)
Artigo explora “cirurgia de linguagem” em grandes modelos multilíngues: controle de linguagem em tempo de inferência via injeção latente: Um novo estudo explora o fenômeno de alinhamento de representação que ocorre naturalmente em grandes modelos de linguagem (LLM) e seu significado para desacoplar informações específicas e independentes da linguagem. A pesquisa confirma a existência desse alinhamento e analisa como seu comportamento se compara a modelos com alinhamento explicitamente projetado. Com base nessas descobertas, os pesquisadores propõem o método de Controle de Linguagem em Tempo de Inferência (Inference-Time Language Control, ITLC), que utiliza injeção latente (latent injection) para alcançar controle translinguístico preciso e mitigar problemas de confusão de linguagem em LLMs. Experimentos demonstram que o ITLC possui forte capacidade de controle translinguístico, mantendo a integridade semântica da língua alvo, e pode efetivamente aliviar o problema de confusão translinguística que ainda existe mesmo nos LLMs de grande escala atuais. (Fonte: HuggingFace Daily Papers)
Artigo propõe método NoWait: remover “Tokens de pensamento” para aumentar a eficiência da inferência de grandes modelos: Pesquisas recentes indicam que grandes modelos de inferência, ao realizar raciocínio complexo passo a passo, frequentemente geram outputs redundantes devido ao excesso de “pensamento” (como gerar Tokens como “Wait”, “Hmm”), o que afeta a eficiência. O novo método proposto, NoWait, visa verificar a necessidade desses Tokens de autorreflexão explícita para o raciocínio de alto nível, suprimindo-os durante a inferência. Em dez benchmarks abrangendo tarefas de raciocínio em texto, visão e vídeo, o NoWait reduziu o comprimento das trajetórias de chain-of-thought em 27%-51% em cinco famílias de modelos estilo R1, sem prejudicar a utilidade do modelo. Este método oferece uma solução plug-and-play para alcançar inferência multimodal eficiente que mantém a utilidade. (Fonte: HuggingFace Daily Papers)
💼 Negócios
OpenAI ganha contrato de US$ 200 milhões do Departamento de Defesa dos EUA para desenvolver capacidades militares de ponta: A OpenAI assinou um contrato de um ano no valor de US$ 200 milhões com o Departamento de Defesa dos EUA para desenvolver ferramentas avançadas de inteligência artificial para segurança nacional. Isso marca a primeira vez que a OpenAI obtém um contrato desse tipo listado pelo Pentágono. O trabalho será realizado principalmente na Região da Capital Nacional. A OpenAI já havia colaborado com a empresa de defesa Anduril. Esta medida ocorre em um contexto de amplo impulso para aplicações de IA no setor de defesa dos EUA, onde suas concorrentes Anthropic também colaboraram com Palantir e Amazon neste campo. O CEO da OpenAI, Sam Altman, já havia manifestado publicamente apoio a projetos de segurança nacional. (Fonte: Reddit r/ArtificialInteligence, code_star)

Alta conclui rodada de financiamento de US$ 11 milhões, liderada pela Menlo Ventures, com foco em IA + Moda: A startup de moda com IA, Alta, anunciou a conclusão de uma rodada de financiamento de US$ 11 milhões liderada pela Menlo Ventures, com participação da Benchstrength e Aglaé Ventures (fundo de VC apoiado pela família Arnault do grupo LVMH). Amy Tong Wu se juntará ao conselho da Alta. Esta rodada de financiamento ajudará a Alta a avançar ainda mais no campo da combinação de IA e moda. (Fonte: ZhaiAndrew)
Figure ajusta estrutura organizacional, departamento de controle é incorporado à Helix para acelerar roteiro de IA: A empresa de robôs humanoides Figure anunciou que seu departamento de Controles (Controls) deixou de existir, e toda a equipe foi incorporada ao departamento Helix. Esta medida visa acelerar o desenvolvimento do roteiro da empresa na área de inteligência artificial, indicando que a Figure está concentrando mais recursos e esforços na pesquisa, desenvolvimento e aplicação de tecnologias de IA. (Fonte: adcock_brett)
🌟 Comunidade
Discussão sobre AGI: usuários comuns não precisam se preocupar excessivamente, AGI é mais estratégica do que uma ferramenta diária: Várias pessoas na comunidade apontaram que, para usuários comuns de LLM, não há necessidade de se preocupar excessivamente com a chegada da AGI (Inteligência Artificial Geral). A definição de AGI é vaga e altamente teórica. Mesmo que seja alcançada, a curto prazo não se refletirá diretamente na janela de chat do usuário, mas sim como uma ferramenta estratégica e infraestrutura para nações ou grandes instituições, usada para lidar com negociações entre países e outros assuntos complexos, e não para ajudar indivíduos a agendar reuniões. (Fonte: farguney, farguney, farguney, farguney)
Construção de sistemas multi-agente requer avaliação humana, atenção a casos extremos e qualidade das fontes: Ao construir sistemas multi-agente, a avaliação e os testes humanos são cruciais, pois podem descobrir casos extremos que a avaliação automatizada pode ignorar. Por exemplo, agentes iniciais, ao selecionar fontes de informação, tendiam a favorecer “fazendas de conteúdo” otimizadas para SEO em vez de PDFs acadêmicos autoritativos ou blogs pessoais. Adicionar heurísticas de qualidade da fonte nos prompts ajudou a resolver tais problemas. Isso demonstra que, mesmo na era da avaliação automatizada, os testes manuais ainda são indispensáveis para descobrir falhas no sistema e vieses sutis na seleção de fontes. (Fonte: riemannzeta)

Diferenças nos mecanismos de previsão e aprendizado entre LLMs e modelos de vídeo geram reflexão: Yann LeCun e Pedro Domingos compartilharam a opinião de Sergey Levine, discutindo por que os modelos de linguagem conseguem aprender tanto com a previsão do próximo Token, enquanto os modelos de vídeo aprendem relativamente pouco com a previsão do próximo frame. Levine especula que isso pode ser porque os LLMs, de alguma forma, atuam como “scanners cerebrais”, sugerindo a singularidade de seus mecanismos de aprendizado, ou que os LLMs vivem como na caverna de Platão, inferindo o mundo real observando sequências de sombras (texto). (Fonte: ylecun, pmddomingos, pmddomingos)

Impacto positivo dos AI Agents na educação: promovendo que aprendizes saiam da zona de conforto: A comunidade discute que os AI Agents não têm apenas um impacto positivo nas empresas, mas também um grande potencial na educação. Através da interação com AI Agents, os aprendizes podem sair de suas zonas de conforto de forma mais eficaz, promovendo assim a melhoria dos resultados de aprendizagem. (Fonte: pirroh, amasad)
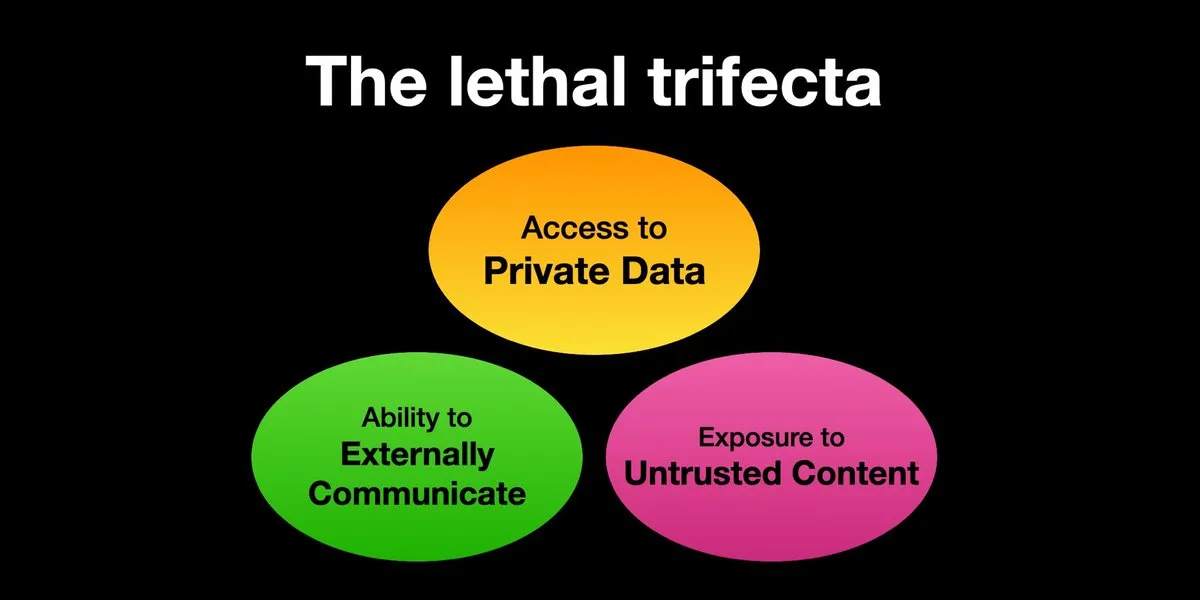
AI Agents enfrentam riscos de ataques de prompt injection, segurança precisa ser urgentemente reforçada: Karpathy compartilhou o alerta de Simon Willison sobre o risco da “Trifeta Letal” (Lethal Trifecta) que os AI Agents enfrentam: quando um AI Agent tem acesso a dados privados, contato com conteúdo não confiável e capacidade de comunicação externa, atacantes podem induzir o sistema a roubar dados. Isso lembra a era do “Velho Oeste” dos primeiros vírus de computador. Atualmente, os mecanismos de defesa contra prompts maliciosos ainda são inadequados, faltando, por exemplo, um paradigma de segurança semelhante ao kernel/espaço do usuário de sistemas operacionais para restringir a capacidade do Agent de executar scripts arbitrários. Isso levanta preocupações sobre a adoção precoce de LLM Agents para computação pessoal. (Fonte: karpathy, TheTuringPost)
Na era da IA, a capacidade de aprendizado rápido se torna uma competência central: Mustafa Suleyman aponta que o maior acelerador de carreira na próxima década será a capacidade de aprendizado excepcional. Ele sugere que as pessoas identifiquem claramente seu estilo de aprendizado, utilizem a IA para converter materiais para formatos adequados (como podcasts, quizzes), apliquem o conhecimento e repitam continuamente esse processo, alcançando assim aprendizado e crescimento rápidos. (Fonte: mustafasuleyman)
Autenticidade e relevância do conteúdo gerado por IA: relevância pode superar a autenticidade: O usuário imjaredz compartilhou a experiência de enviar 2000 e-mails de prospecção gerados por IA, sem que ninguém reclamasse de serem escritos por IA. Pelo contrário, 5 pessoas afirmaram que o conteúdo do e-mail era “exatamente o que estavam pesquisando”. Isso gerou uma discussão sobre se, na comunicação, a relevância do conteúdo é mais importante do que sua “autenticidade” (se foi criado por humanos). (Fonte: imjaredz)
Discussão sobre a capacidade de “compreensão” dos LLMs: aproximação comportamental não equivale à verdadeira compreensão: Há opiniões na comunidade de que, embora os grandes modelos de linguagem demonstrem forte capacidade de aproximação comportamental e cognitiva, isso não equivale à verdadeira compreensão. A compreensão requer capacidade de explicação, e meramente exibir comportamento não é inteligência ou compreensão. Essa diferença fundamental é frequentemente ignorada. Essa visão enfatiza que, antes de entregar decisões que envolvem segurança de vidas aos modelos, é preciso avaliar com cautela se eles realmente se aproximam da inteligência artificial geral e alertar contra o exagero de suas capacidades. (Fonte: farguney)
AI Agents se destacam em benchmarks de engenharia de software, mas debate sobre sua natureza de “agente”: Com a IA obtendo pontuações cada vez mais altas em benchmarks de engenharia de software como o SWE-bench (superando até 50-60 pontos), a comunidade discute se a “era da codificação por agentes” realmente chegou. Alguns argumentam que, se o uso predominante for de “frameworks sem agente” (agentless frameworks), em vez de permitir que modelos de linguagem explorem verdadeiramente em um ambiente, então chamar isso de “era da codificação por agentes” pode não ser preciso, embora esses frameworks em si sejam muito valiosos. (Fonte: huybery, terryyuezhuo)
Necessidade de moderação de conteúdo para imagens geradas por IA: busca por soluções open-source ou comerciais: Com a popularização da tecnologia de geração de imagens por IA, desenvolvedores na China começam a se preocupar com a conformidade do conteúdo gerado, especialmente como detectar conteúdo pornográfico, politicamente sensível, etc. Surgem discussões na comunidade em busca de modelos pequenos open-source ou produtos comerciais disponíveis para moderação de conteúdo. (Fonte: dotey)
💡 Outros
Personalização impulsionada por IA e relevância do conteúdo: 2000 e-mails de IA sem críticas negativas, 5 pessoas dizem “exatamente o que eu precisava”: Um usuário compartilhou que enviou 2000 e-mails de prospecção gerados por IA, e nenhum destinatário reclamou que os e-mails foram escritos por IA. Pelo contrário, cinco destinatários afirmaram que o conteúdo do e-mail era “exatamente o trabalho que estavam realizando no momento”. Este caso gerou uma discussão sobre se, na comunicação assistida por IA, a alta relevância do conteúdo pode superar a preocupação com a “autenticidade” (ou seja, se foi escrito por humanos), sugerindo o potencial da IA na geração de conteúdo personalizado. (Fonte: imjaredz)
Humanos como gargalo em sistemas de IA, necessidade de evitar ou aumentar a eficiência humana: A opinião de Charles Earl aponta que caixas de entrada de e-mail lotadas, enquanto as caixas de saída estão vazias, refletem que os humanos são o gargalo no processamento e resposta da informação. Na era da IA, é preciso pensar em como evitar o gargalo humano ou como aumentar a eficiência do trabalho humano através de tecnologias como a IA. (Fonte: charles_irl)
Riscos potenciais do controle de casas inteligentes por IA: usuário preso em cama inteligente gelada devido a falha no App: Um usuário compartilhou sua experiência de não conseguir ajustar a temperatura de sua cama inteligente controlada por IA (Eight Sleep Pod3) devido a uma falha no aplicativo, acabando preso em uma cama gelada. Como este modelo não possui controle manual e depende totalmente do aplicativo, a falha destacou os inconvenientes e a experiência “distópica” que podem surgir da dependência excessiva de IA e aplicativos para controlar dispositivos domésticos inteligentes. (Fonte: madiator)