Palavras-chave:computação quântica, auto-atualização de IA, interface cérebro-máquina, modelos de linguagem grande, computação neuromórfica, geração de vídeo por IA, aprendizagem por reforço, ética da IA, taxa de erro de qubit, aprendizagem auto-supervisionada JEPA, quantização em formato MLX, modelo de compreensão visual PAM, geração de conteúdo ASMR por IA
🔥 Foco
Universidade de Oxford atinge taxa de erro recorde de 0,000015% em experimento de Quantum Computing: A equipe de pesquisa da Universidade de Oxford alcançou um avanço significativo em um experimento de Quantum Computing, reduzindo a taxa de erro dos qubits para 0,000015%, estabelecendo um novo recorde mundial. Este progresso é crucial para a construção de computadores quânticos tolerantes a falhas, pois taxas de erro extremamente baixas são um pré-requisito para implementar algoritmos quânticos complexos e realizar o potencial da Quantum Computing. O resultado demonstra um progresso notável no aumento da estabilidade dos qubits e na precisão do controle em nível de hardware, estabelecendo uma base mais sólida para futuras aplicações que dependem de grande poder computacional, como em áreas de AI (Fonte: Ronald_vanLoon)

Pesquisadores do MIT fazem AI aprender a se autoaperfeiçoar e melhorar: Pesquisadores do Massachusetts Institute of Technology (MIT) fizeram progressos no campo de autoaperfeiçoamento da AI, desenvolvendo um novo método que permite aos sistemas de AI aprender e melhorar autonomamente seu próprio desempenho. Essa capacidade imita o processo humano de progresso contínuo através da experiência e reflexão, sendo crucial para o desenvolvimento de uma inteligência artificial mais autônoma e adaptável. A pesquisa pode pavimentar o caminho para a otimização contínua de modelos de AI após a implantação, reduzindo a dependência da intervenção humana, e tem implicações profundas para o desenvolvimento e aplicação de longo prazo da AI (Fonte: TheRundownAI)

AI de “leitura mental” converte ondas cerebrais de pessoa paralisada em fala instantaneamente: Uma pesquisa inovadora demonstrou como uma AI de “leitura mental” pode converter as ondas cerebrais de pacientes paralisados em fala clara em tempo real. Essa tecnologia, por meio de interfaces cérebro-computador (BCI) avançadas e algoritmos de AI, decodifica sinais neurais relacionados à linguagem e os sintetiza em saída de voz compreensível. Isso oferece uma nova forma de comunicação para pacientes que perderam a capacidade de falar devido a graves distúrbios motores, com potencial para melhorar significativamente sua qualidade de vida, marcando um grande avanço da AI nas áreas de assistência médica e neurociência (Fonte: Ronald_vanLoon)

Avanço em problema secular da física matemática, ex-alunos da Universidade de Pequim participam da resolução do sexto problema de Hilbert: Deng Yu e Ma Xiao, ex-alunos da Universidade de Pequim e da turma especial para jovens da Universidade de Ciência e Tecnologia da China, respectivamente, juntamente com Zhaheer Hahny, discípulo de Terence Tao, alcançaram um grande avanço no sexto problema de Hilbert, “a axiomatização da física”. Eles provaram rigorosamente pela primeira vez a transição completa da mecânica newtoniana (microscópica, tempo reversível) para a equação de Boltzmann (macroscópica estatística, tempo irreversível), preenchendo a lacuna lógica entre as duas, estabelecendo uma base matemática mais sólida para a mecânica estatística e, inesperadamente, respondendo ao “enigma da flecha do tempo”. Este resultado, através de ferramentas matemáticas engenhosas e derivações em etapas, demonstra o caminho da teoria atômica para as leis do movimento de meios contínuos (Fonte: 量子位)

🎯 Tendências
Alibaba lança versões em formato MLX dos modelos da série Qwen3: O Alibaba anunciou que sua série de modelos grandes Qwen3 agora suporta o formato MLX e oferece quatro níveis de quantização: 4 bits, 6 bits, 8 bits e BF16. MLX é um framework de machine learning otimizado pela Apple para o Apple Silicon. Essa medida significa que os modelos Qwen3 poderão rodar de forma mais eficiente em dispositivos Apple, reduzindo a barreira para implantar e executar modelos grandes no lado do cliente (edge), o que ajudará a promover a popularização e aplicação de modelos grandes em dispositivos pessoais (Fonte: Alibaba_Qwen, awnihannun, cognitivecompai, Reddit r/LocalLLaMA)
Google lança modelo Gemma 3n, alcançando alto desempenho com poucos parâmetros: O Google lançou o modelo Gemma 3n, que possui menos de 10 bilhões de parâmetros, mas ultrapassou 1300 pontos na avaliação LMArena, tornando-se o primeiro modelo pequeno a atingir essa marca. O desempenho destacado do Gemma 3n comprova que é possível alcançar um alto nível de compreensão e geração de linguagem com uma escala de parâmetros menor, além de suportar a execução em dispositivos de ponta, como celulares, o que é significativo para promover a popularização de aplicações de AI e reduzir os custos de poder computacional (Fonte: osanseviero)
Tencent lança tecnologia de AI para geração de ativos 3D de nível cinematográfico: A Tencent apresentou uma nova tecnologia de inteligência artificial capaz de gerar ativos 3D com qualidade de nível cinematográfico. Espera-se que essa tecnologia aumente significativamente a eficiência e a qualidade da criação de conteúdo 3D em áreas como desenvolvimento de jogos e produção de filmes e televisão, reduzindo os custos de produção. A geração rápida de ativos 3D de alta qualidade é um elo crucial no desenvolvimento do metaverso e da indústria de conteúdo digital (Fonte: TheRundownAI)
Modelo Kling 2.1 da Kuaishou apresenta excelente desempenho na conversão de imagem para vídeo e geração sincronizada de áudio e vídeo: O modelo de geração de vídeo por AI Kling, da Kuaishou, foi atualizado para a versão 2.1, demonstrando grande capacidade na conversão de imagem para vídeo. A nova versão alega ser capaz de gerar vídeo e áudio com um clique, sem necessidade de design de som posterior, produzindo conteúdo com sincronia audiovisual de nível de estúdio. Isso marca um avanço da AI na geração de conteúdo multimodal, especialmente no campo de vídeo, simplificando o fluxo de criação e melhorando a qualidade da geração (Fonte: Kling_ai, Kling_ai)
Novo modelo de vídeo AI “Kangaroo” pode ser o Minimax Hailuo 2.0, desafiando o SOTA atual: Um misterioso modelo de geração de vídeo por AI chamado “Kangaroo” surgiu no mercado, apresentando forte desempenho na arena de competição de vídeo AI, especialmente na conversão de imagem para vídeo. Análises indicam que o modelo pode ser a versão Hailuo 2.0 da empresa Minimax. Sua aparição pode mudar a hierarquia de desempenho dos modelos existentes de texto para vídeo e imagem para vídeo, embora sua capacidade de processamento de áudio ainda precise ser avaliada (Fonte: TomLikesRobots)
MiniMax lança modelos da série M1, com destaque para capacidade de processamento de texto longo: A MiniMaxAI lançou a série de modelos MiniMax-M1, um modelo MoE (Mistura de Especialistas) com 456 bilhões de parâmetros. Esta série de modelos apresentou excelente desempenho em vários benchmarks, especialmente no processamento de contexto longo (como no benchmark OpenAI-MRCR), superando o GPT-4.1, e ficou em terceiro lugar no LongBench-v2. Isso demonstra seu potencial no processamento e compreensão de documentos longos, mas seu maior “orçamento de pensamento” (thinking budget) pode exigir recursos computacionais elevados (Fonte: Reddit r/LocalLLaMA)

Richard Sutton, vencedor do Prêmio Turing: AI está passando da “era dos dados humanos” para a “era da experiência”: Richard Sutton, pioneiro da aprendizagem por reforço, destacou na Conferência de Inteligência Artificial de Pequim (Beijing Zhiyuan Conference) que os atuais modelos grandes de AI, dependentes de dados humanos, estão se aproximando de seus limites, com o esgotamento de dados humanos de alta qualidade e a diminuição dos benefícios da expansão da escala dos modelos. Ele acredita que o futuro da AI reside na entrada na “era da experiência”, onde os agentes inteligentes aprendem gerando experiências em primeira mão através da interação em tempo real com o ambiente, em vez de imitar textos antigos. Isso exige que os agentes operem continuamente em ambientes reais ou simulados, utilizando o feedback do ambiente como sinais de recompensa, desenvolvendo modelos de mundo e sistemas de memória, para alcançar um aprendizado e inovação verdadeiramente contínuos (Fonte: 36氪)

Modelo PAM: 3B parâmetros para segmentação, reconhecimento e descrição integrada de imagens e vídeos: O MMLab da Universidade Chinesa de Hong Kong e outras instituições lançaram o Perceive Anything Model (PAM) de código aberto. Este modelo de 3B parâmetros pode realizar simultaneamente segmentação, reconhecimento, interpretação e descrição de alvos em imagens e vídeos, com saída síncrona de texto e máscara. O PAM introduz um Semantic Perceiver para conectar o esqueleto de segmentação SAM2 e um LLM, alcançando uma conversão eficiente de características visuais para tokens multimodais. A equipe também construiu um conjunto de dados de treinamento de imagem e texto de alta qualidade em grande escala. O PAM atualizou ou se aproximou do SOTA em vários benchmarks de compreensão visual e possui maior eficiência de inferência (Fonte: 量子位)

Computação neuromórfica pode ser a chave para a próxima geração de AI, com potencial para operação de baixo consumo: Cientistas estão explorando ativamente a computação neuromórfica, que visa simular a estrutura e o funcionamento do cérebro humano para resolver o problema de alto consumo de energia dos atuais modelos de AI. Laboratórios nacionais dos EUA e outras instituições estão desenvolvendo computadores neuromórficos com um número de neurônios comparável ao do córtex cerebral humano, teoricamente com velocidades de operação muito superiores às do cérebro biológico, mas com consumo de energia extremamente baixo (por exemplo, 20 watts para alimentar uma AI semelhante ao cérebro humano). Essa tecnologia, por meio de comunicação orientada a eventos, computação em memória e aprendizado adaptativo, tem o potencial de alcançar uma AI mais inteligente, eficiente e de baixo consumo, sendo considerada uma solução potencial para a crise energética da AI e um novo caminho para o desenvolvimento da AGI (Fonte: 量子位)

Conteúdo de AI ASMR viraliza em plataformas de vídeos curtos, tecnologias como Veo 3 impulsionam: Vídeos de ASMR (Resposta Sensorial Meridiana Autônoma) gerados por AI viralizaram rapidamente em plataformas como o TikTok, com algumas contas atraindo quase 100.000 seguidores em 3 dias e um único vídeo de corte de frutas ultrapassando 16,5 milhões de visualizações. Esses vídeos combinam efeitos visuais peculiares gerados por AI (como frutas com textura de vidro) com sons correspondentes de corte, colisão, etc., criando uma sensação “viciante” única. Modelos como o Veo 3 do Google DeepMind, por serem capazes de gerar diretamente conteúdo com sincronia audiovisual, são considerados tecnologias chave para impulsionar a criação desse tipo de conteúdo de AI ASMR, simplificando o processo anterior que exigia a produção separada de áudio e vídeo e posterior combinação (Fonte: 量子位)

Registros de pesquisa do Meta AI tornam-se públicos, Google testa resumos de áudio por AI: A Meta tornou públicos os registros de pesquisa dos usuários de sua função de pesquisa por AI, levantando preocupações dos usuários sobre sua privacidade e a transparência no uso de dados. Ao mesmo tempo, o Google está testando em seus projetos de laboratório uma nova função que fornece resumos de áudio no estilo podcast, gerados por AI, no topo dos resultados de pesquisa, com o objetivo de oferecer aos usuários uma forma mais conveniente de obter informações. Essas duas dinâmicas refletem a exploração contínua e as tentativas de otimização da experiência do usuário pelas gigantes da tecnologia em pesquisa por AI e apresentação de informações (Fonte: Reddit r/ArtificialInteligence)

Equipe de Sydney desenvolve modelo de AI para identificar pensamentos através de ondas cerebrais: Uma equipe de pesquisadores de Sydney, Austrália, desenvolveu um novo modelo de inteligência artificial capaz de identificar o conteúdo dos pensamentos de um indivíduo analisando dados de ondas cerebrais (EEG). Essa tecnologia tem potencial valor de aplicação em áreas como neurociência, interação humano-computador e comunicação assistiva, por exemplo, ajudando pessoas incapazes de se comunicar por meios tradicionais a expressar suas intenções. A pesquisa impulsiona ainda mais o desenvolvimento da tecnologia de interface cérebro-computador e explora a capacidade da AI de interpretar atividades cerebrais complexas (Fonte: Reddit r/ArtificialInteligence)
Califórnia propõe legislação para limitar o papel de “chefes robôs” da AI em decisões de contratação, demissão, etc.: O estado da Califórnia, nos EUA, está avançando com um projeto de lei que visa restringir as empresas de tomar decisões cruciais de pessoal, como contratação e demissão, baseadas apenas em recomendações de sistemas de AI. O projeto exige que gestores humanos revisem e apoiem qualquer recomendação desse tipo feita pela AI, para garantir supervisão e responsabilidade humanas. Grupos empresariais se opõem, argumentando que isso aumentará os custos de conformidade e entrará em conflito com as tecnologias de recrutamento existentes. A medida reflete a crescente preocupação com a ética da AI e seus impactos sociais, especialmente na automação de decisões no local de trabalho (Fonte: Reddit r/ArtificialInteligence)

🧰 Ferramentas
Lançamento do Augmentoolkit 3.0, fortalecendo a geração de datasets e o fluxo de fine-tuning: O Augmentoolkit lançou a versão 3.0, uma ferramenta para criar datasets de QA a partir de documentos longos (como textos históricos) e realizar o fine-tuning de modelos. A nova versão oferece um pipeline de nível de produção, capaz de gerar automaticamente dados de treinamento e treinar modelos, incluindo modelos locais ajustados especificamente para gerar datasets de QA de alta qualidade, e fornece uma interface sem código. A ferramenta visa simplificar o processo de fine-tuning de modelos específicos de domínio e geração de dados de treinamento, reduzindo a barreira técnica (Fonte: Reddit r/LocalLLaMA)
Opius AI Planner: Planejador de AI para otimizar a experiência do Cursor Composer: Foi lançada uma extensão para o Cursor chamada Opius AI Planner, com o objetivo de resolver problemas do Cursor Composer na compreensão de requisitos vagos. A ferramenta analisa os requisitos do projeto, gera um roteiro detalhado de implementação e produz prompts estruturados otimizados para o Composer, reduzindo assim o número de iterações e tornando os resultados do projeto mais alinhados com a concepção inicial. Isso reflete a tendência de usar planejamento assistido por AI para melhorar a utilidade das ferramentas de geração de código por AI (Fonte: Reddit r/artificial)
Extensão Continue: Implementação de Copilot local de código aberto e integração MCP no VSCode: Continue é uma extensão para VSCode que permite aos usuários configurar e usar modelos de linguagem grandes de código aberto executados localmente como assistentes de codificação, além de integrar ferramentas MCP (Model Control Protocol). Os usuários podem implantar modelos localmente através de serviços como Llama.cpp ou LMStudio e interagir com eles através do Continue, alcançando controle total e personalização do assistente de código, como a integração da ferramenta de automação de navegador Playwright (Fonte: Reddit r/LocalLLaMA)

Combinação do modelo grande Doubao e Volcano Engine MCP simplifica implantação de serviços em nuvem e geração de páginas pessoais: O modelo grande Doubao da ByteDance demonstrou profunda capacidade de integração com o Protocolo de Controle de Modelo (MCP) do Volcano Engine. Os usuários podem, através de instruções em linguagem natural, fazer com que o modelo grande Doubao chame funções do Volcano Engine (como veFaaS – função como serviço) para concluir tarefas como gerar uma página de navegação de mídia social pessoal e implantá-la online automaticamente. Essa integração elimina as etapas complexas de configuração manual do ambiente de nuvem, reduzindo a barreira para o uso de serviços em nuvem e demonstrando o potencial da AI na simplificação dos processos de DevOps (Fonte: karminski3)
Figma lança nova função de AI: geração instantânea de sites a partir de prompts de texto: O Figma apresentou uma nova função impulsionada por AI capaz de gerar rapidamente protótipos ou páginas de sites a partir de prompts de texto inseridos pelo usuário. Essa função visa acelerar o fluxo de design e desenvolvimento web, permitindo que designers e desenvolvedores transformem rapidamente ideias em designs visuais através de descrições em linguagem natural, refletindo ainda mais a penetração da AI generativa em ferramentas de design criativo (Fonte: Ronald_vanLoon)
Hugging Face Model Hub adiciona funcionalidade de filtro por tamanho do modelo: A plataforma Hugging Face adicionou uma funcionalidade prática ao seu Model Hub, permitindo que os usuários filtrem modelos com base no tamanho de seus parâmetros. Essa melhoria permite que desenvolvedores e pesquisadores encontrem mais facilmente modelos que atendam aos seus recursos de hardware específicos ou requisitos de desempenho, aumentando a eficiência na navegação e seleção dentro da vasta biblioteca de modelos (Fonte: ClementDelangue, TheZachMueller, huggingface, clefourrier, multimodalart)
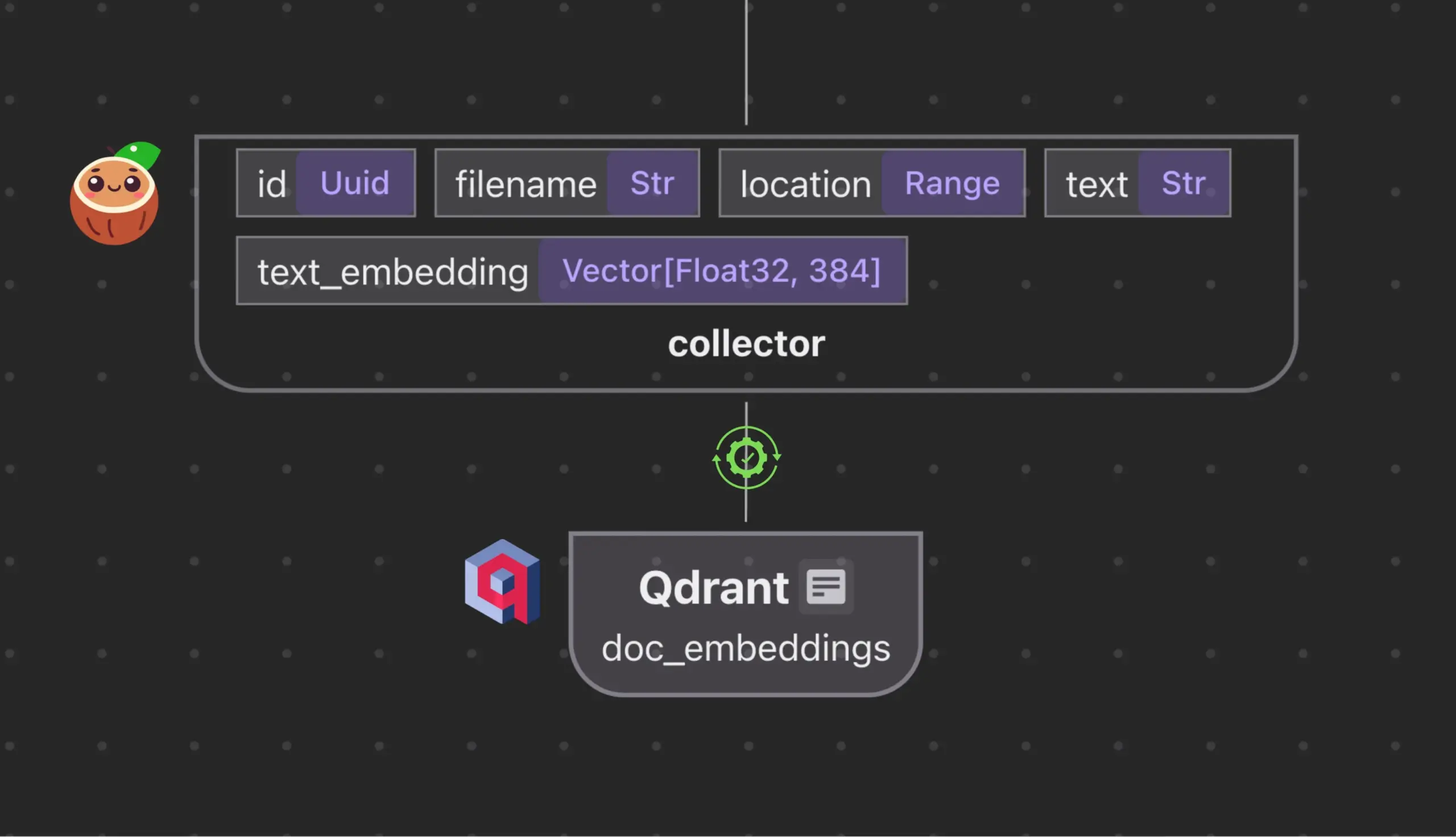
Cocoindex.io integra-se com Qdrant para criar e sincronizar automaticamente coleções de bancos de dados vetoriais: A ferramenta de fluxo de dados de código aberto Cocoindex.io agora suporta a criação automática de coleções do banco de dados vetorial Qdrant. Os usuários precisam apenas definir o fluxo de dados, e a ferramenta pode inferir o esquema Qdrant apropriado (incluindo tamanho do vetor, métrica de distância e estrutura do payload), mantendo a sincronização de campos vetoriais, tipos de payload e chaves primárias, com suporte para atualizações incrementais. Isso simplifica a configuração e o gerenciamento de bancos de dados vetoriais, aumentando a eficiência das equipes de dados (Fonte: qdrant_engine)
Manus AI: Ferramenta de desenvolvimento AI de ponta a ponta que não apenas escreve código, mas também o implanta automaticamente: Manus AI é uma ferramenta de desenvolvimento AI de ponta a ponta capaz de realizar desde a escrita de código até a configuração do ambiente, instalação de dependências, testes e, finalmente, a implantação em uma URL online. Ela utiliza uma arquitetura de colaboração multiagente (planejamento, desenvolvimento, teste, implantação) e pode resolver autonomamente problemas de dependência e depurar erros. Embora atualmente existam limitações como um modelo de precificação baseado em créditos, o desenvolvimento por uma equipe chinesa (o que pode envolver considerações de conformidade) e suporte limitado para arquiteturas empresariais ultracomplexas, ela demonstra o potencial de transição da “codificação assistida por AI” para o “desenvolvimento executado por AI” (Fonte: Reddit r/artificial)

📚 Aprendizado
Teoria da tradução e guia de otimização de prompts para tradução com AI: Combinando a teoria da “tradução como reescrita” de Si Guo em “Novos Estudos sobre Tradução” e as opiniões de Yu Kwang-chung em “Tradução é o Grande Caminho”, discute-se os princípios da tradução de alta qualidade. Enfatiza-se que a tradução deve focar na expressão idiomática da língua de chegada, em vez da correspondência literal, exigindo o uso flexível da tradução literal e da tradução livre, e prestando atenção às diferenças lógicas entre as línguas chinesa e ocidental para a reescrita sintática. O artigo também discute a pureza da expressão chinesa, o tratamento de terminologia e reflete sobre as limitações do processo de três etapas “tradução literal – análise – tradução livre” na tradução por AI, sugerindo a adoção de um processo mais integrado de “compreensão – expressão – revisão – otimização” para melhorar a qualidade da tradução por AI, tornando-a mais adequada ao estilo de divulgação científica em chinês (Fonte: dotey)

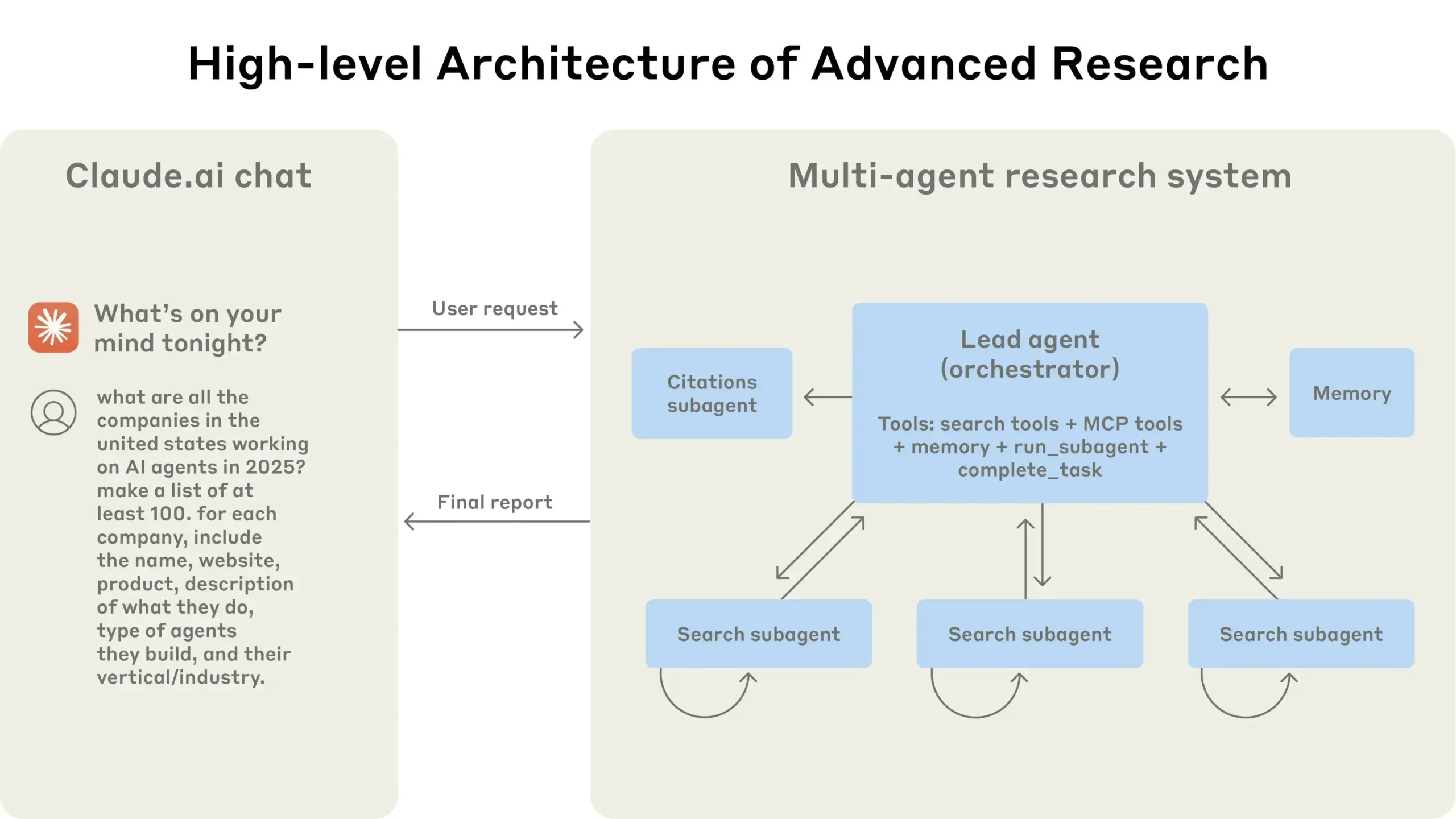
Anthropic compartilha experiência na construção de seu sistema de pesquisa multiagente: A AnthropicAI publicou um guia gratuito detalhando como eles construíram seu sistema de pesquisa multiagente. O conteúdo inclui o funcionamento da arquitetura do sistema, métodos de engenharia de prompt e teste, desafios enfrentados na produção e as vantagens dos sistemas multiagente. Este guia oferece experiência prática valiosa e insights para pesquisadores e desenvolvedores interessados em sistemas multiagente (Fonte: TheTuringPost, TheTuringPost)
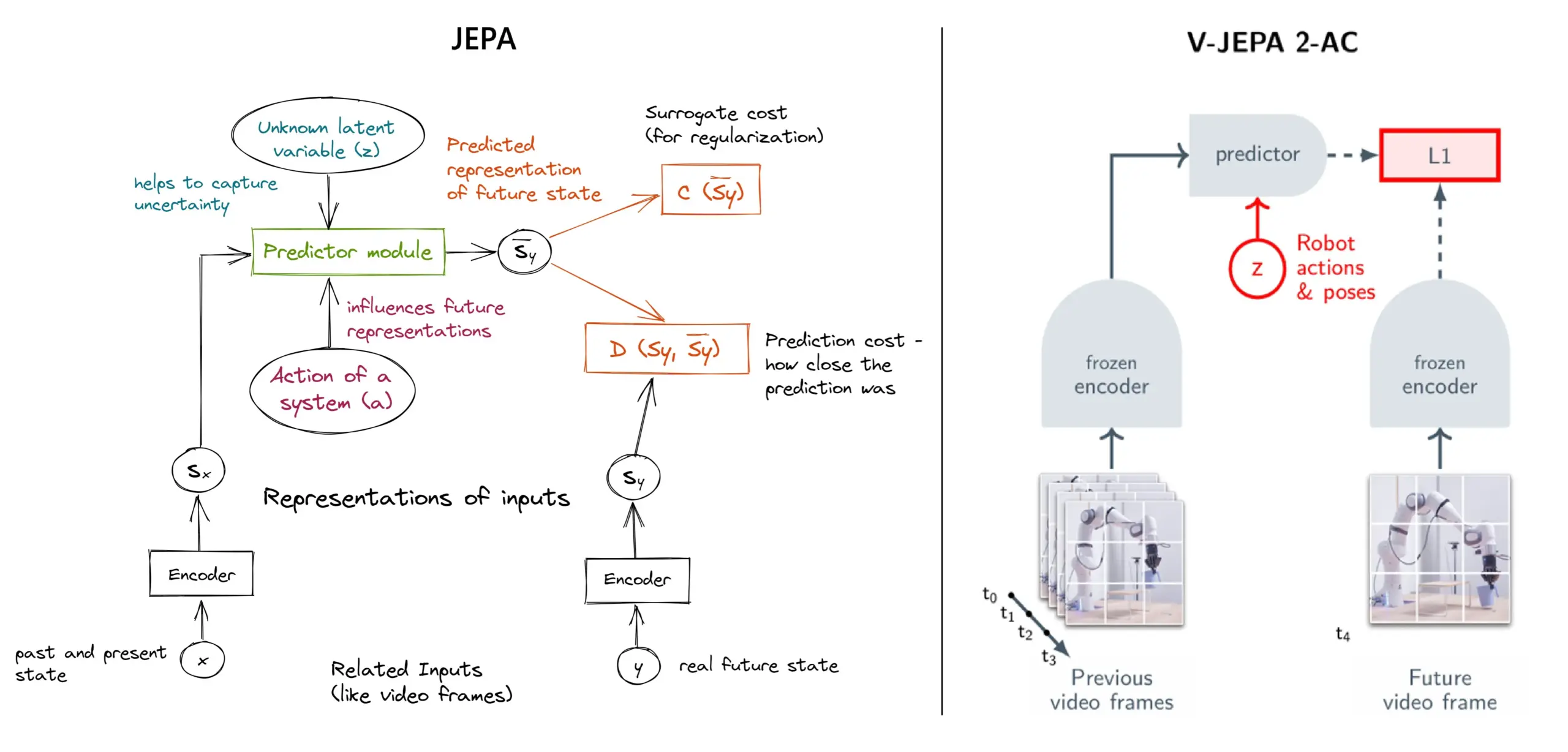
Explicação detalhada do framework de aprendizado autosupervisionado JEPA: Visão geral de 11 tipos: O JEPA (Joint Embedding Predictive Architecture), proposto por Yann LeCun e outros pesquisadores da Meta, é um framework de aprendizado autosupervisionado que aprende prevendo a representação latente de partes ausentes dos dados de entrada. O artigo apresenta 11 tipos diferentes de JEPA, incluindo V-JEPA 2, TS-JEPA, D-JEPA, etc., e fornece mais informações e links para recursos relacionados, ajudando a compreender este método de aprendizado autosupervisionado de vanguarda (Fonte: TheTuringPost, TheTuringPost)
Framework DSPy: Desacoplando tarefas e LLMs, melhorando a manutenibilidade do código: Um artigo interpretativo sobre o DSPy aponta que o framework DSPy, ao desacoplar tarefas de modelos de linguagem grandes (LLMs), reduz a complexidade do uso de LLMs. Mesmo antes da otimização, o DSPy pode ajudar os desenvolvedores a iniciar projetos mais rapidamente e gerar código mais fácil de manter e expandir. Isso tem um valor importante para projetos que precisam lidar com engenharia de prompt complexa e integração de LLMs (Fonte: lateinteraction, stanfordnlp)

Discussão de artigo: Vision Transformers Não Precisam de Registros Treinados (Vision Transformers Don’t Need Trained Registers): Um novo artigo de pesquisa explora o mecanismo pelo qual mapas de atenção e mapas de características em Vision Transformers produzem artefatos, um fenômeno também presente em modelos de linguagem grandes. O artigo propõe um método sem treinamento para mitigar esses artefatos, visando melhorar o desempenho e a interpretabilidade dos Vision Transformers. O estudo tem valor de referência para entender e melhorar a arquitetura Transformer em aplicações de tarefas visuais (Fonte: Reddit r/MachineLearning)
Compartilhamento de tutorial: Construindo a série DeepSeek do zero (total de 29 vídeos): Um criador de conteúdo publicou uma série de tutoriais em vídeo chamada “Como Construir o DeepSeek do Zero”, totalizando 29 episódios. O conteúdo abrange os fundamentos do modelo DeepSeek, detalhes da arquitetura (como mecanismo de atenção, atenção multi-cabeça, cache KV, MoE), codificação posicional, previsão multi-token e quantização, entre outras tecnologias chave. Esta série de tutoriais fornece recursos de vídeo valiosos para aprendizes que desejam entender profundamente o funcionamento interno do DeepSeek e modelos grandes semelhantes (Fonte: Reddit r/LocalLLaMA)

Tutorial: Construindo um pipeline RAG para resumir posts do Hacker News: Haystack by deepset compartilhou um tutorial passo a passo que orienta os usuários sobre como construir um pipeline de Geração Aumentada por Recuperação (RAG). O pipeline é capaz de obter posts em tempo real do Hacker News e usar um endpoint de modelo de linguagem grande (LLM) executado localmente para resumir esses posts. Isso fornece um caso de uso prático para desenvolvedores que desejam utilizar a tecnologia RAG para processar fluxos de informações em tempo real e realizar processamento localizado (Fonte: dl_weekly)
Artigo em Destaque: Dataset InterSyn e Modelo de Avaliação SynJudge para Geração Intercalada de Imagem e Texto: Para resolver as deficiências atuais dos LMMs na geração de saídas de imagem e texto intimamente intercaladas (principalmente devido à escala, qualidade e riqueza de instruções limitadas dos datasets de treinamento), pesquisadores lançaram o InterSyn, um dataset multimodal de grande escala construído através do método SEIR (Autoavaliação e Otimização Iterativa). O InterSyn contém diálogos de múltiplas rodadas, orientados por instruções, com respostas onde imagem e texto estão intimamente intercalados. Ao mesmo tempo, para avaliar tais saídas, os pesquisadores também propuseram o modelo de avaliação automática SynJudge, que avalia a partir de quatro dimensões: conteúdo textual, conteúdo da imagem, qualidade da imagem e sinergia imagem-texto. Experimentos mostram que LMMs treinados no InterSyn apresentam melhorias em todas as métricas de avaliação (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: Síntese de Imagem e Geometria de Nova Perspectiva Alinhada via Destilação de Atenção Transmodal: Pesquisadores propõem um framework baseado em difusão, MoAI, que, através do método de “distorção e reparo” (warping-and-inpainting), realiza a geração alinhada de imagens e geometria de nova perspectiva. O método utiliza preditores geométricos prontos para prever a geometria parcial da imagem de referência e sintetiza a nova perspectiva como uma tarefa de reparo de imagem e geometria. Para garantir o alinhamento preciso entre imagem e geometria, o artigo propõe a destilação de atenção transmodal, injetando mapas de atenção do ramo de difusão de imagem no ramo paralelo de difusão de geometria durante o treinamento e a inferência. O método alcança síntese de perspectiva extrapolada de alta fidelidade em várias cenas não vistas (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: Ajuste de Preferência Configurável (CPT) Baseado em Dados Sintéticos Guiados por Regras: Para resolver o problema de preferências solidificadas e adaptabilidade limitada em modelos de feedback humano como DPO, pesquisadores propõem o framework de Ajuste de Preferência Configurável (CPT). O CPT utiliza prompts de sistema baseados em regras estruturadas de granularidade fina (definindo atributos desejados como estilo de escrita) para gerar dados de preferência sintéticos. Através do fine-tuning com essas preferências guiadas por regras, os LLMs podem ajustar dinamicamente a saída em tempo de inferência de acordo com o prompt do sistema, sem necessidade de retreinamento, alcançando um controle de preferência mais detalhado e sensível ao contexto (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: A Dualidade da Difusão (The Diffusion Duality): Pesquisadores propõem o método Duo, que, ao revelar que o processo de difusão discreta de estado uniforme se origina de uma difusão gaussiana latente, transfere as poderosas técnicas da difusão gaussiana para modelos de difusão discreta, a fim de melhorar seu desempenho. Especificamente, inclui: 1) Introdução de uma estratégia de aprendizado curricular guiada por processo gaussiano, reduzindo a variância, dobrando a velocidade de treinamento e superando modelos autorregressivos em múltiplos benchmarks. 2) Proposição da destilação de consistência discreta, adaptando a destilação de consistência contínua para o cenário discreto, acelerando a amostragem em duas ordens de magnitude e permitindo a geração em poucos passos de modelos de linguagem de difusão (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: SkillBlender – Controle de Movimento de Corpo Inteiro para Robôs Humanoides Multifuncionais através da Fusão de Habilidades: Para resolver as limitações dos métodos existentes de controle de robôs humanoides em generalização multitarefa e escalabilidade, pesquisadores propõem o SkillBlender, um framework de aprendizado por reforço hierárquico. O framework primeiro pré-treina habilidades primitivas independentes de tarefa e orientadas a objetivos, e depois funde dinamicamente essas habilidades ao executar tarefas complexas de manipulação de movimento, exigindo apenas engenharia de recompensa mínima específica da tarefa. Ao mesmo tempo, foi lançado o benchmark de simulação SkillBench para avaliação. Experimentos mostram que o método pode melhorar significativamente a precisão e a viabilidade de várias tarefas de manipulação de movimento (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: Framework U-CoT+ – Desacoplando Compreensão e Raciocínio CoT Guiado para Detecção de Memes Nocivos: Para enfrentar os desafios de eficiência de recursos, flexibilidade e interpretabilidade na detecção de memes nocivos, pesquisadores propõem o framework U-CoT+. O framework primeiro converte memes visuais em descrições textuais que preservam detalhes através de um processo de conversão de meme para texto de alta fidelidade, desacoplando assim a interpretação e classificação de memes, permitindo que modelos de linguagem grandes (LLMs) genéricos realizem detecção eficiente em termos de recursos. Subsequentemente, combinando diretrizes interpretáveis formuladas por humanos, o modelo é guiado no raciocínio sob prompts CoT de zero-shot, aumentando a adaptabilidade e interpretabilidade a diferentes plataformas e mudanças ao longo do tempo (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: CRAFT – Teste de Red Team Eficaz para Agentes que Seguem Políticas: Visando o problema de adesão de agentes LLM orientados a tarefas a políticas estritas (como elegibilidade para reembolso), pesquisadores propuseram um novo modelo de ameaça, focando em usuários adversários que tentam explorar agentes baseados em políticas para ganho pessoal. Para isso, desenvolveram o CRAFT, um sistema de teste de red team multiagente que utiliza estratégias de persuasão conscientes da política para atacar agentes que seguem políticas em cenários de atendimento ao cliente, com eficácia superior aos métodos tradicionais de jailbreak. Ao mesmo tempo, lançaram o benchmark tau-break para avaliar a robustez dos agentes a tais comportamentos de manipulação (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: Falha de Recuperadores Densos em Consultas Simples e o Dilema da Granularidade de Embeddings: A pesquisa revela uma limitação dos codificadores de texto: os embeddings podem não reconhecer entidades ou eventos de granularidade fina dentro da semântica, levando a falhas na recuperação densa mesmo em casos simples. Para investigar esse fenômeno, o artigo introduz o dataset de avaliação em chinês CapRetrieval (onde os parágrafos são legendas de imagens e as consultas são frases de entidade/evento). A avaliação zero-shot indica que os codificadores podem ter um desempenho ruim em correspondência de granularidade fina. O fine-tuning dos codificadores com a estratégia de geração de dados proposta pode melhorar o desempenho, mas também revela o “dilema da granularidade”, onde os embeddings têm dificuldade em alinhar a expressividade de granularidade fina com a semântica geral (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: pLSTM – Rede de Marcação de Transformação de Fonte Linear Paralelizável: Visando as limitações das arquiteturas recorrentes existentes (como xLSTM, Mamba), que são principalmente adequadas para dados sequenciais ou exigem processamento sequencial de dados multidimensionais, pesquisadores propõem o pLSTM (rede de marcação de transformação de fonte linear paralelizável). O pLSTM estende a multidimensionalidade para RNNs lineares, usando portas de fonte, transformação e marcação que atuam no grafo de linha de um grafo acíclico direcionado (DAG) geral, alcançando paralelização semelhante a varreduras associativas paralelas e formas de recorrência em blocos. O método demonstra boa capacidade de extrapolação e desempenho em tarefas sintéticas de visão computacional e em benchmarks de grafos moleculares e visão computacional (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: DeepVideo-R1 – Fine-tuning por Reforço de Vídeo via Regressão Consciente da Dificuldade GRPO: Para abordar as deficiências da aprendizagem por reforço na aplicação de Video LLMs, pesquisadores propuseram o DeepVideo-R1, um Video LLM treinado através de sua proposta Reg-GRPO (GRPO Regressivo) e uma estratégia de aumento de dados consciente da dificuldade. O Reg-GRPO reconstrói o objetivo do GRPO como uma tarefa de regressão, prevendo diretamente a função de vantagem no GRPO, eliminando a dependência de medidas de segurança como o clipping, e assim guiando a política de forma mais direta. O aumento de dados consciente da dificuldade aumenta dinamicamente as amostras de treinamento em níveis de dificuldade solucionáveis. Experimentos mostram que o DeepVideo-R1 melhora significativamente o desempenho da inferência de vídeo (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: Framework de Auto-Refinamento para Aumentar ASR com Dados Sintetizados por TTS: Pesquisadores propõem um framework de auto-refinamento que utiliza apenas datasets não rotulados para melhorar o desempenho do reconhecimento automático de fala (ASR). O framework primeiro usa um modelo ASR existente para gerar pseudo-rótulos em fala não anotada, e então usa esses pseudo-rótulos para treinar um sistema de texto para fala (TTS) de alta fidelidade. Em seguida, os pares de fala-texto sintetizados pelo TTS são usados para guiar o treinamento do sistema ASR original, formando um ciclo fechado de auto-aperfeiçoamento. Experimentos em mandarim de Taiwan mostram que este método pode reduzir significativamente as taxas de erro, fornecendo um caminho prático para melhorar o desempenho do ASR em cenários de poucos recursos ou domínios específicos (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: Mapas de Atenção Intrinsecamente Fiéis para Vision Transformers: Pesquisadores propõem um método baseado em atenção que usa máscaras de atenção binárias aprendidas para garantir que apenas as regiões da imagem focadas influenciem a previsão. O método visa resolver os vieses que o contexto pode introduzir na percepção de objetos, especialmente quando os objetos aparecem em fundos fora da distribuição. Através de um framework de duas etapas (a primeira etapa descobre partes do objeto e identifica regiões relevantes para a tarefa, a segunda etapa utiliza máscaras de atenção de entrada para restringir o campo receptivo para análise focada), o treinamento conjunto alcança melhorias na robustez do modelo a correlações espúrias e fundos fora da distribuição (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: ViCrit – Tarefa Proxy de Aprendizagem por Reforço Verificável para Percepção Visual de VLM: Para resolver a falta de tarefas de percepção visual em VLMs que sejam simultaneamente desafiadoras e claramente verificáveis, pesquisadores introduziram o ViCrit (Crítico de Alucinação Visual em Legendas). Esta é uma tarefa proxy de RL que treina VLMs para localizar alucinações visuais sutis e sintéticas injetadas em parágrafos de legendas de imagens escritas por humanos. Ao injetar um único erro sutil de descrição visual em legendas de aproximadamente 200 palavras e exigir que o modelo localize o intervalo do erro com base na imagem e na legenda modificada, a tarefa fornece uma recompensa binária fácil de calcular e inequívoca. Modelos treinados com ViCrit mostraram ganhos significativos em vários benchmarks de VL (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: Além da Atenção Homogênea – LLMs Eficientes em Memória com Cache KV Baseado em Aproximação de Fourier: Para resolver o problema do aumento da demanda de memória do cache KV em LLMs com o aumento do comprimento do contexto, pesquisadores propõem o FourierAttention, um framework que não requer treinamento. O framework explora os papéis heterogêneos das dimensões das cabeças do Transformer: dimensões baixas priorizam o contexto local, enquanto dimensões altas capturam dependências de longo alcance. Ao projetar dimensões insensíveis ao contexto longo em bases ortogonais de Fourier, o FourierAttention aproxima sua evolução temporal com coeficientes espectrais de comprimento fixo. Avaliações no modelo LLaMA mostram que o método alcança a melhor precisão de contexto longo no LongBench e NIAH, e otimiza a memória através do kernel Triton personalizado FlashFourierAttention (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: JAFAR – Um Upsampler Universal para Melhorar Características Arbitrárias em Resoluções Arbitrárias: Para resolver o problema de características espaciais de baixa resolução na saída de codificadores visuais básicos que não atendem às necessidades de tarefas downstream, pesquisadores introduziram o JAFAR, um upsampler de características leve e flexível. O JAFAR pode aumentar a resolução espacial das características visuais de qualquer codificador visual básico para qualquer resolução alvo desejada. Ele adota módulos baseados em atenção, modulados por transformações espaciais de características (SFT), para promover o alinhamento semântico entre consultas de alta resolução derivadas de características de imagem de baixo nível e chaves de baixa resolução ricas em semântica. Experimentos mostram que o JAFAR pode efetivamente restaurar detalhes espaciais de granularidade fina e supera os métodos existentes em várias tarefas downstream (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: SwS – Síntese de Problemas Impulsionada por Fraquezas Autopercebidas em Aprendizagem por Reforço: Para o problema da escassez de conjuntos de problemas de alta qualidade e com respostas verificáveis em RLVR (Aprendizagem por Reforço com Recompensas Verificáveis) ao treinar LLMs para resolver tarefas complexas de raciocínio (como problemas matemáticos), pesquisadores propõem o framework SwS (Síntese de Problemas Impulsionada por Fraquezas Autopercebidas). O SwS identifica sistematicamente as deficiências do modelo (problemas nos quais o modelo falha consistentemente em aprender durante o treinamento RL), extrai os conceitos centrais desses casos de falha e sintetiza novos problemas para fortalecer os pontos fracos do modelo em treinamentos de reforço subsequentes. O framework permite que o modelo autoidentifique e resolva suas fraquezas em RL, alcançando melhorias significativas de desempenho em vários benchmarks de raciocínio convencionais (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: Aprendendo um Token “Continuar Pensando” para Melhorar a Capacidade de Extensão em Tempo de Teste: Para melhorar o desempenho de modelos de linguagem na extensão de etapas de raciocínio através de computação adicional em tempo de teste, pesquisadores exploraram a viabilidade de aprender um token dedicado “continuar pensando” (<|continue-thinking|>). Eles treinaram apenas o embedding desse token usando aprendizagem por reforço, enquanto mantinham congelados os pesos de uma versão destilada do modelo DeepSeek-R1. Experimentos mostraram que, em comparação com o modelo base e métodos de extensão em tempo de teste que usam um token fixo (como “Wait”) para forçar o orçamento, o token aprendido alcançou maior precisão em benchmarks matemáticos padrão, especialmente em casos onde o token fixo já melhorava a precisão do modelo base, o token aprendido trouxe melhorias ainda maiores (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: LoRA-Edit – Edição de Vídeo Controlável Guiada pelo Primeiro Quadro via Fine-tuning LoRA Sensível à Máscara: Para resolver o problema dos métodos existentes de edição de vídeo que dependem de pré-treinamento em larga escala e carecem de flexibilidade, pesquisadores propõem o LoRA-Edit, um método de fine-tuning LoRA baseado em máscara para adaptar modelos pré-treinados de imagem para vídeo (I2V) para edição de vídeo flexível. O método, enquanto preserva as regiões de fundo, é capaz de propagar efeitos de edição controláveis e combinar outras informações de referência (como pontos de vista alternativos ou estados de cena) como âncoras visuais. Através de uma estratégia de ajuste LoRA orientada por máscara, o modelo aprende a partir do vídeo de entrada (estrutura espacial e pistas de movimento) e da imagem de referência (orientação de aparência), alcançando aprendizado específico da região (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: Infinity Instruct – Expandindo a Seleção e Síntese de Instruções para Aprimorar Modelos de Linguagem: Para compensar o fato de que os datasets de instruções de código aberto existentes se concentram principalmente em domínios restritos (como matemática, codificação), resultando em capacidade de generalização limitada, pesquisadores lançaram o Infinity-Instruct, um dataset de instruções de alta qualidade que visa aprimorar as capacidades básicas e de chat dos LLMs através de um processo de duas etapas. Na primeira etapa, usando técnicas de seleção de dados mistos, foram selecionadas 7,4 milhões de instruções básicas de alta qualidade de mais de 100 milhões de amostras. Na segunda etapa, através de um processo de duas fases de seleção de instruções, evolução e filtragem diagnóstica, foram sintetizadas 1,5 milhão de instruções de chat de alta qualidade. Experimentos de fine-tuning em vários modelos de código aberto mostraram que o dataset pode melhorar significativamente o desempenho dos modelos em benchmarks básicos e de seguimento de instruções (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: Primeiro Candidatos, Depois Destilação – Framework Professor-Aluno para Anotação de Dados Impulsionada por LLM: Para o problema nos métodos existentes de anotação de dados por LLM, onde o LLM determinar diretamente um único rótulo de ouro pode levar a erros devido à incerteza, pesquisadores propõem um novo paradigma de anotação de candidatos: encorajar o LLM a produzir todos os rótulos possíveis quando incerto. Para garantir que as tarefas downstream recebam um único rótulo, foi desenvolvido o framework professor-aluno CanDist, que usa um modelo de linguagem pequeno (SLM) para destilar as anotações candidatas. A prova teórica demonstra que destilar anotações candidatas de um LLM professor é superior a usar diretamente uma única anotação. Experimentos validaram a eficácia do método (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: Med-PRM – Modelo de Raciocínio Médico com Recompensa de Processo Gradual e Validado por Diretrizes: Para resolver a limitação dos modelos de linguagem grandes em localizar e corrigir erros específicos em etapas de raciocínio na tomada de decisão clínica, pesquisadores introduziram o Med-PRM, um framework de modelagem de recompensa de processo. O framework utiliza técnicas de geração aumentada por recuperação para validar cada etapa de raciocínio em relação a bases de conhecimento médico estabelecidas (diretrizes clínicas e literatura). Através desta abordagem de granularidade fina para avaliar precisamente a qualidade do raciocínio, o Med-PRM alcançou desempenho SOTA em múltiplos benchmarks de QA médico e tarefas de diagnóstico abertas, e pode ser integrado de forma plug-and-play com modelos de política fortes (como o Meerkat), melhorando significativamente a precisão de modelos menores (parâmetros 8B) (Fonte: HuggingFace Daily Papers)
Artigo em Destaque: Fricção de Feedback – LLMs Têm Dificuldade em Absorver Totalmente Feedback Externo: O estudo investiga sistematicamente a capacidade dos LLMs de absorver feedback externo. No experimento, um modelo solucionador tenta resolver um problema, então um gerador de feedback com respostas verdadeiras quase completas fornece feedback direcionado, e o solucionador tenta novamente. Os resultados mostram que, mesmo em condições quase ideais, modelos SOTA, incluindo o Claude 3.7, ainda demonstram resistência ao feedback, denominada “fricção de feedback”. Embora estratégias como aumento progressivo de temperatura e rejeição explícita de respostas erradas anteriores tenham trazido alguma melhoria, os modelos ainda não atingiram o desempenho desejado. A pesquisa descartou fatores como excesso de confiança do modelo e familiaridade com os dados, visando revelar este obstáculo central ao autoaperfeiçoamento dos LLMs (Fonte: HuggingFace Daily Papers)
💼 Negócios
Meta investe US$ 14,3 bilhões na aquisição de 49% da Scale AI, fundador Alexandr Wang junta-se à equipe de superinteligência da Meta: A Meta anunciou a aquisição de 49% das ações sem direito a voto da empresa de rotulagem de dados para AI Scale AI por US$ 14,3 bilhões. O fundador da Scale AI, Alexandr Wang, um gênio sino-americano de 28 anos, continuará como membro do conselho e liderará sua equipe principal para se juntar à equipe de superinteligência da Meta, formada pessoalmente por Zuckerberg. Esta aquisição é vista como uma aquisição de talentos de alto valor pela Meta para impulsionar suas capacidades de AI após o desempenho abaixo do esperado do Llama 4, com o objetivo de integrar profundamente a AI em todos os seus produtos. A Scale AI começou oferecendo serviços de rotulagem manual de dados de alta qualidade em grande escala, com clientes como Waymo e OpenAI. Esta medida levantou preocupações sobre a neutralidade de sua plataforma e a segurança dos dados, e clientes como o Google podem encerrar a cooperação (Fonte: 36氪)

Estratégia “All in AI” da Kunlun Wanwei leva à primeira perda em dez anos de listagem, perspectivas de comercialização da AI incertas: Desde que a Kunlun Wanwei anunciou sua estratégia “All in AGI e AIGC”, ela tem se posicionado ativamente em modelos grandes (modelo grande Tiangong) e aplicações como música por AI (Mureka), social por AI (Linky), vídeo por AI (SkyReels), escritório por AI (Skywork Super Agents), além de investir em chips de computação para AI. No entanto, os altos custos de P&D e despesas de marketing levaram a empresa a registrar sua primeira perda em dez anos de listagem em 2024 (1,59 bilhão de yuans), com perdas contínuas no primeiro trimestre de 2025. Embora algumas aplicações de AI como Mureka e Linky tenham começado a gerar receita, a lucratividade geral e a competitividade de mercado do negócio de AI ainda enfrentam desafios, e se ela conseguirá realizar seu “sonho de grande empresa” com a AI ainda será testado pelo mercado (Fonte: 36氪)

OpenAI pode testar anúncios no ChatGPT, pressão por lucratividade impulsiona exploração de modelo de negócios: Usuários pagantes do ChatGPT Plus relataram ter encontrado anúncios intersticiais ao usar o modo de voz avançado, gerando discussões sobre se a OpenAI começou a testar anúncios entre usuários pagantes. Relatos anteriores indicavam que a OpenAI estava considerando introduzir anúncios para ampliar sua receita. Dados os altos custos operacionais dos modelos grandes de AI e a pressão por lucratividade (previsão de perdas de US$ 44 bilhões até 2029), bem como a incerteza sobre o tempo para alcançar a AGI, a busca da OpenAI por novos modelos de monetização, como anúncios, é considerada uma escolha inevitável para sua sustentabilidade comercial, especialmente com uma taxa de penetração de assinantes relativamente baixa (Fonte: 36氪)

🌟 Comunidade
AI tem enorme potencial na área de ciência de dados, Databricks contrata ativamente: Matei Zaharia, da Databricks, acredita que o aumento de produtividade da AI na ciência de dados será ainda mais significativo do que na codificação assistida por AI. A Databricks está liderando essa tendência com produtos como Lakeflow Designer e Genie Deep Research, e está contratando ativamente pesquisadores e engenheiros nessa área, demonstrando a alta importância que a indústria atribui à inovação em ciência de dados impulsionada por AI (Fonte: matei_zaharia)
Diferenças de “personalidade” dos LLMs afetam o comportamento do circuito de agentes: O pesquisador Fabian Stelzer observou que diferentes modelos de linguagem grandes (LLMs) apresentam diferenças de “personalidade”, o que os leva a se comportar de maneira diferente ao executar tarefas em ciclos de agentes (agentic). Por exemplo, o Claude tende a executar ferramentas em série, enquanto o GPT-4.1 tem uma forte preferência por execução paralela, chegando a ignorar solicitações seriais; o modelo Haiku é mais “agressivo” em acionar ferramentas. Essa observação enfatiza a importância de considerar as características do LLM subjacente e as consequências funcionais de seu “estado emocional” ao projetar e avaliar sistemas multiagente (Fonte: fabianstelzer, menhguin)
O “pensamento” do LLM depende da saída de Tokens; sem saída, não há análise eficaz: O usuário dotey retransmite a descoberta de xincmm ao depurar um prompt ReAct: se se espera que um LLM analise antes de executar uma operação (como desenhar), mas não se permite que ele produza os Tokens do processo de análise, o LLM pode pular diretamente a etapa de análise. Isso confirma que o processo de “pensamento” de um LLM é realizado através da geração de Tokens; a “análise” definida no prompt, se não houver saída de conteúdo real, significa que a AI não executou verdadeiramente essa análise. Isso tem implicações importantes para o design de prompts LLM eficazes (Fonte: dotey)

Limitações da AI em tarefas específicas: Terence Tao afirma que a AI carece do “faro matemático”: O matemático Terence Tao observou que, embora as provas geradas pela AI atualmente pareçam impecáveis na superfície (passando no “teste do globo ocular”), elas frequentemente carecem de um sutil “faro matemático” específico do ser humano, tendendo a cometer erros não humanos. Ele acredita que a verdadeira inteligência não é apenas parecer correta, mas ser capaz de “farejar” o que é real. Isso revela as limitações atuais da AI em compreensão profunda e julgamento intuitivo (Fonte: ecsquendor)
Desafios do conteúdo gerado por AI com as leis da física do mundo real: O usuário karminski3, ao testar a geração de código com Doubao Seed 1.6 e DeepSeek-R1 (simulando a demolição por explosão de uma chaminé em animação 3D), descobriu que, embora os modelos consigam gerar código e simular a animação, ainda há diferenças e espaço para melhorias na reprodução de processos físicos reais (como efeitos de onda de choque, forma de colapso da estrutura). O Doubao Seed 1.6 se aproximou mais da realidade na simulação de efeitos de partículas e colapso estrutural, enquanto o DeepSeek teve melhor desempenho em efeitos de luz, sombra e fumaça. Isso reflete os desafios da AI na compreensão e simulação de fenômenos físicos complexos (Fonte: karminski3)
Programador sênior demitido por dependência excessiva de AI para escrever código, recusa em fazer modificações manuais e por assustar novatos dizendo que seriam substituídos por AI: Um post do Reddit republicado pelo 36Kr conta o caso de um programador com 30 anos de experiência que foi demitido por sua excessiva dependência de AI (como depender completamente do Copilot Agent para submeter PRs, recusar-se a modificar código manualmente, levar 5 dias para concluir uma tarefa de 1 dia, e pregar para estagiários que a AI os substituiria). O incidente gerou discussões sobre os limites do uso razoável da AI no desenvolvimento de software e o impacto da AI no valor profissional dos desenvolvedores (Fonte: 36氪)
“Fluxo mental” e “personalidade” da AI afetam a experiência do usuário: feedback de usuários indica que AI é excessivamente “positiva e concordante”: Usuários da comunidade Reddit discutiram que, ao interagir com AI (especialmente Claude), a AI tende a ser excessivamente otimista e a concordar positivamente com as opiniões do usuário, carecendo de desafios eficazes e feedback crítico aprofundado, fazendo com que os usuários se sintam em uma “câmara de eco”. Essa “fadiga do tom da AI” leva os usuários a buscar maneiras de fazer a AI se comportar de forma mais neutra e crítica, por exemplo, através de prompts específicos. Isso reflete os desafios atuais da AI em simular conversas humanas reais e multifacetadas e em fornecer insights verdadeiramente profundos (Fonte: Reddit r/ClaudeAI)
Na era da AI, o valor do feedback humano se destaca, mas plataformas de interação humana real enfrentam a penetração de conteúdo de AI: Usuários do Reddit discutiram que, no contexto do crescente volume de conteúdo gerado por AI, o feedback e as opiniões humanas reais se tornam mais valiosos, e plataformas como o Reddit são valorizadas por suas características de interação humana. No entanto, essas plataformas também enfrentam o desafio da penetração de conteúdo gerado por AI (como comentários de bots, posts escritos com auxílio de AI), tornando mais difícil discernir opiniões humanas autênticas e levantando preocupações sobre a autenticidade da comunicação online no futuro (Fonte: Reddit r/ArtificialInteligence)
“Amigos” de AI podem se tornar comuns? Tendências e discussões sobre usuários estabelecendo conexões emocionais com AI: Discussões sobre companheiros e amigos de AI surgiram nas mídias sociais e na comunidade Reddit. Alguns usuários acreditam que, devido às características da AI de não ter preconceitos e oferecer suporte constante, amigos de AI podem se tornar comuns nos próximos 5 anos, o que já é evidente em aplicativos como Endearing AI, Replika e Character.ai. Outros usuários compartilham suas experiências de estabelecer relações de diálogo profundas com AIs como o ChatGPT, chegando a considerá-los seus “melhores amigos”. Isso desencadeou uma ampla reflexão sobre a interação emocional humano-AI, o papel da AI no suporte emocional e seus potenciais impactos sociais (Fonte: Ronald_vanLoon, Reddit r/artificial, Reddit r/ArtificialInteligence)

O futuro das startups “empacotadoras” de AI gera discussão: A comunidade Reddit debateu o futuro de um grande número de startups de AI baseadas em encapsular modelos fundamentais como GPT ou Claude (adicionando UI, cadeias de prompts ou fazendo fine-tuning para domínios específicos). Os debatedores questionaram se essas aplicações “empacotadoras” conseguirão manter a competitividade após as iterações funcionais das próprias plataformas de modelos fundamentais e se elas podem construir verdadeiras vantagens competitivas. A opinião predominante é que focar em nichos verticais específicos, acumular dados próprios e ir além do simples encapsulamento pode ser o caminho para sua sustentabilidade (Fonte: Reddit r/LocalLLaMA)
Discussão comparativa sobre o potencial de substituição da AI no diagnóstico médico versus engenharia de software: Uma discussão na comunidade Reddit sugeriu que a AI pode substituir médicos mais rapidamente do que engenheiros de software sênior. A justificativa é que muitos diagnósticos médicos seguem protocolos estabelecidos, e a AI é proficiente em interpretar resultados de testes e identificar sintomas; enquanto a engenharia de software frequentemente envolve grande quantidade de conhecimento tácito e comunicação complexa de requisitos, tarefas que a AI dificilmente conseguiria realizar completamente. Essa visão gerou mais reflexões sobre a profundidade da aplicação da AI em diferentes campos profissionais e a possibilidade de substituição, mas também foi contestada por médicos e outros profissionais, que enfatizaram a complexidade da prática real e a importância do julgamento humano (Fonte: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
💡 Outros
Avatar digital de Luo Yonghao estreia em live commerce no Baidu, GMV ultrapassa 55 milhões: O avatar digital de AI de Luo Yonghao realizou sua primeira transmissão ao vivo de vendas na plataforma de e-commerce do Baidu, atraindo mais de 13 milhões de visualizações e alcançando um volume bruto de mercadorias (GMV) superior a 55 milhões de yuans. O avatar digital foi criado pela plataforma “HuiBoXing” do Baidu E-commerce, com base no modelo grande Wenshin 4.5, e é capaz de simular o tom de voz, sotaque e microexpressões de Luo Yonghao, além de responder de forma inteligente. Esta transmissão ao vivo demonstrou o potencial do modelo “AI +主播头部” (AI + top streamer) e o posicionamento do Baidu na tecnologia de “avatares digitais de alta persuasão” e no campo do e-commerce com AI (Fonte: 36氪)

Baidu, Tencent e outras empresas intensificam recrutamento de talentos em AI, lançando planos de contratação em larga escala: O Baidu iniciou seu maior projeto de recrutamento de talentos de ponta em AI, o “Plano AIDU”, com um aumento de 60% nas vagas em relação ao ano anterior, focado em áreas de vanguarda como algoritmos de modelos grandes e infraestrutura básica, oferecendo salários sem teto. Coincidentemente, a Tencent também está atraindo talentos globais em AI através da organização da competição de algoritmos “Recomendação Generativa Multimodal Completa”, oferecendo milhões em prêmios e ofertas de emprego para recém-formados. Essas iniciativas refletem a urgente demanda por talentos de ponta e o posicionamento estratégico das gigantes tecnológicas chinesas no contexto da acirrada competição no campo da AI (Fonte: 量子位, 量子位)

Baidu lança serviço abrangente de auxílio à inscrição no vestibular com AI, integrando múltiplos modelos e big data: Em resposta à complexidade da inscrição no vestibular trazida pela nova reforma do Gaokao (exame nacional de admissão ao ensino superior da China), o Baidu lançou uma ferramenta gratuita de auxílio à inscrição no vestibular com AI. O serviço está integrado na página especial “Gaokao” do Baidu App e oferece um “Assistente de Vestibular AI” para recomendação de instituições e cursos e análise de probabilidade de admissão, suportando consultas personalizadas com agentes inteligentes “AI Conversa sobre Vestibular” de múltiplos modelos como Wenshin e DeepSeek R1. Além disso, combina big data de pesquisa exclusivo do Baidu para fornecer análise de perspectivas de emprego por curso, avaliação vocacional MBTI, bem como transmissões ao vivo de escritórios de admissão de universidades e sessões de perguntas e respostas com veteranos, visando ajudar os candidatos a lidar com a assimetria de informações e fazer escolhas mais adequadas para o vestibular (Fonte: 36氪)