

Palavras-chave:IA, Modelo de Grande Escala, Sistema Multiagente, Claude, Transformer, Computação Neuromórfica, LLM, Agente de IA, Sistema de Pesquisa Multiagente Claude, Método de Treinamento Híbrido Eso-LM, Supercomputador Neuromórfico, Técnica de Escalonamento de Contexto, Tecnologia de Marca d’Água SynthID
🔥 Foco
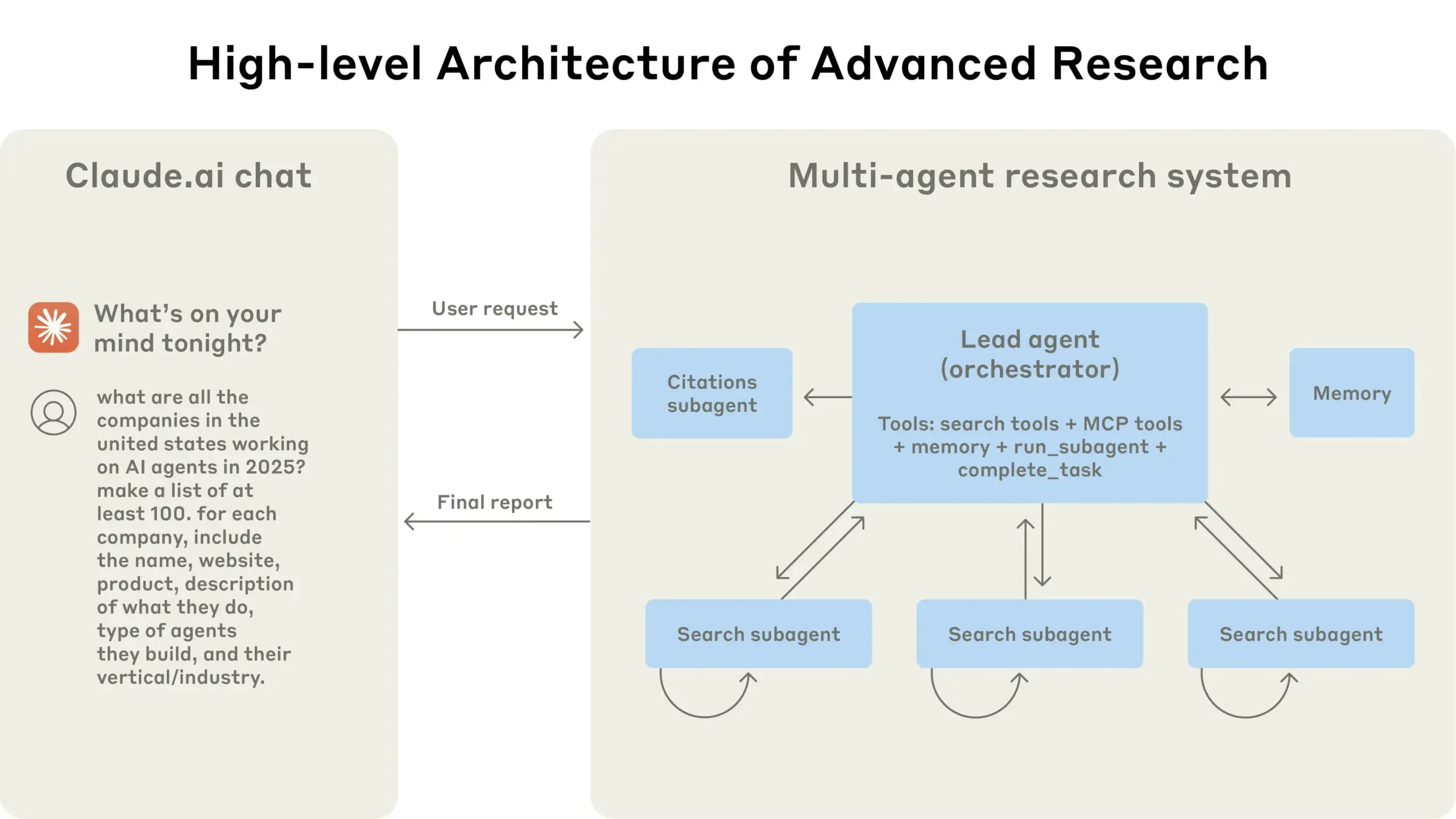
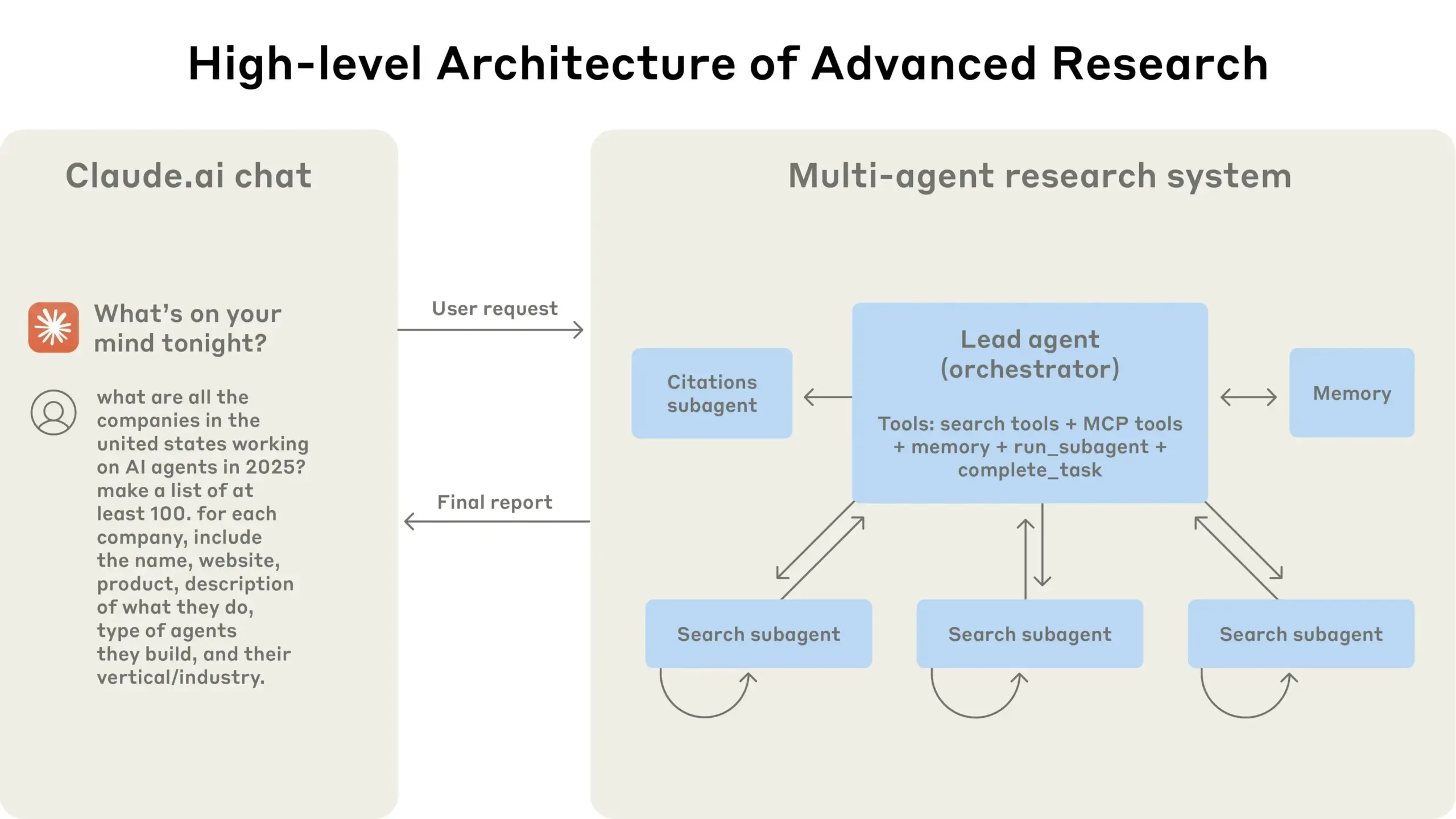
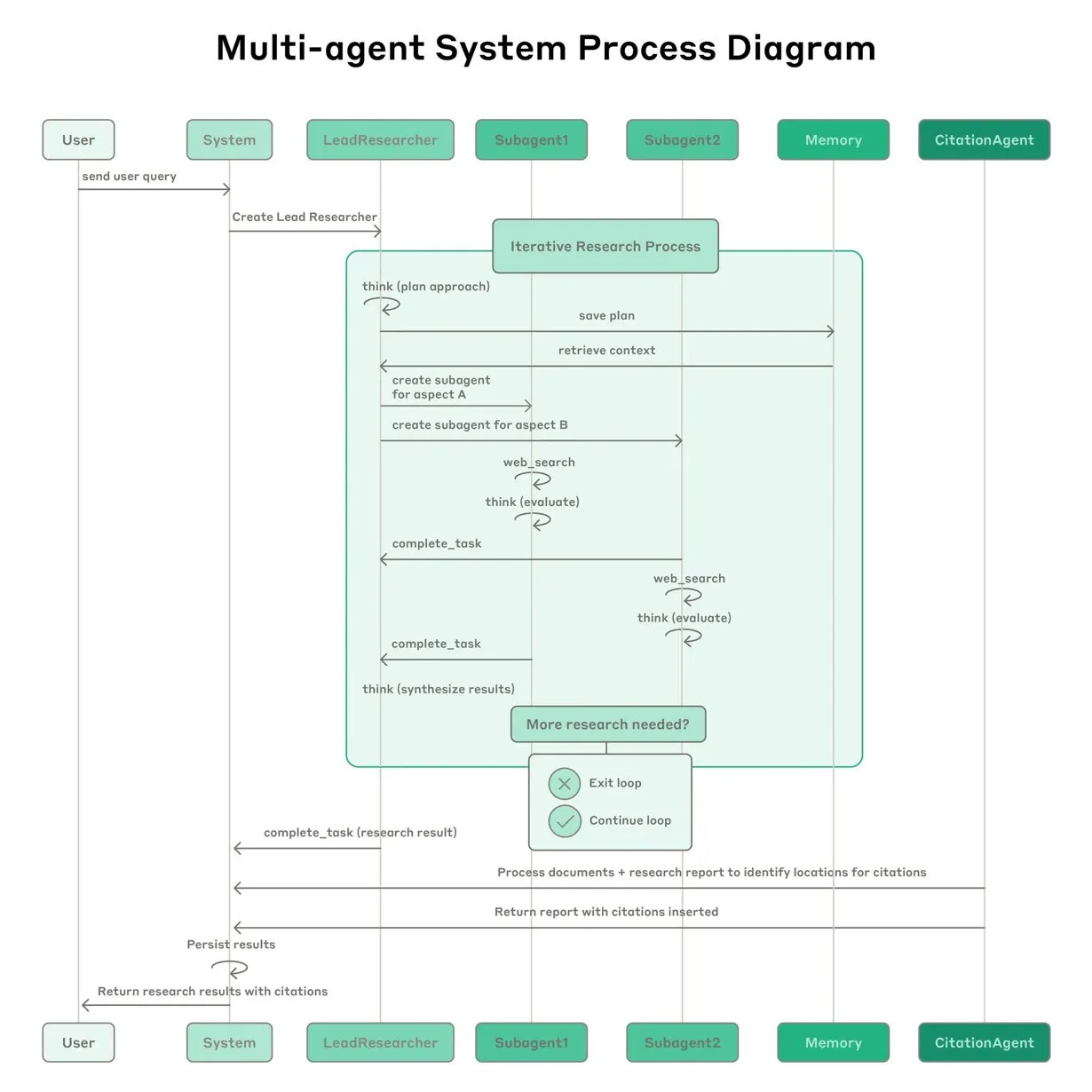
Anthropic partilha experiência na construção do sistema de pesquisa multi-agente Claude: A Anthropic detalhou como construiu o seu sistema de pesquisa multi-agente para o Claude, partilhando experiências de sucesso e fracasso na prática, bem como desafios de engenharia. As principais conclusões incluem: nem todos os cenários são adequados para multi-agentes, especialmente quando os agentes precisam de partilhar um grande volume de contexto ou existe alta dependência entre eles; os agentes podem melhorar as interfaces das ferramentas, por exemplo, através de um agente de teste que reescreve descrições de ferramentas para reduzir erros futuros, diminuindo o tempo de conclusão da tarefa em 40%; a execução síncrona de sub-agentes, embora simplifique a coordenação, também pode causar estrangulamentos no fluxo de informação, sugerindo o potencial de uma arquitetura assíncrona orientada a eventos. Esta partilha oferece insights valiosos para a construção de arquiteturas multi-agente de nível de produção (Fonte: Anthropic, jerryjliu0, Hacubu, TheTuringPost)
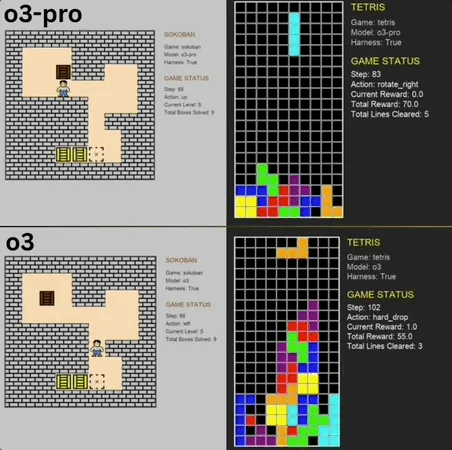
o3-pro destaca-se no Benchmark de minijogos clássicos, superando o SOTA: o3-pro enfrentou jogos clássicos como Sokoban e Tetris no benchmark Lmgame e obteve resultados excelentes, ultrapassando diretamente o limite anteriormente estabelecido por modelos como o3. No jogo Sokoban, o3-pro completou com sucesso todos os níveis definidos; no Tetris, o seu desempenho foi tão forte que o teste foi interrompido à força. Este Benchmark, lançado pelo Hao AI Lab da UCSD (afiliado ao LMSYS, desenvolvedor da Arena de Grandes Modelos), utiliza um modelo de ciclo de interação iterativo, permitindo que grandes modelos gerem ações com base no estado do jogo e recebam feedback, com o objetivo de avaliar as capacidades de planeamento e raciocínio do modelo. Embora a operação do o3-pro seja demorada, o seu desempenho em tarefas de jogo destaca o potencial de grandes modelos em tarefas complexas de tomada de decisão (Fonte: 36氪)
Terence Tao prevê que a IA poderá ganhar a Medalha Fields dentro de dez anos e se tornará um importante colaborador na pesquisa matemática: O vencedor da Medalha Fields, Terence Tao, prevê que a IA se tornará um parceiro de pesquisa confiável para matemáticos em 2026 e, dentro de dez anos, poderá propor importantes conjecturas matemáticas, marcando um “momento AlphaGo” para a matemática e, eventualmente, até mesmo ganhar uma Medalha Fields. Ele acredita que a IA pode acelerar a exploração de problemas científicos complexos como a “Grande Teoria Unificada”, mas atualmente a IA ainda tem dificuldades em descobrir leis físicas conhecidas, em parte devido à falta de “dados negativos” adequados e dados de treino do processo de tentativa e erro. Terence Tao enfatiza que a IA precisa passar por um processo de aprendizagem, erro e correção, assim como os humanos, para realmente crescer, e aponta que a IA atual tem deficiências em discernir os seus próprios caminhos errados, faltando o “faro” dos matemáticos humanos. Ele vê com otimismo a combinação da linguagem de prova formal Lean com a IA, acreditando que isso mudará a forma de colaboração na pesquisa matemática (Fonte: 36氪)

Conteúdo gerado por IA difícil de distinguir, Google lança tecnologia de marca d’água SynthID para ajudar na autenticação: Recentemente, vídeos gerados por IA como “canguru em avião” circularam amplamente nas redes sociais e enganaram muitos utilizadores, destacando o desafio da identificação de conteúdo de IA. Para isso, o Google DeepMind lançou a tecnologia SynthID, que incorpora uma marca d’água digital invisível em conteúdo gerado por IA (imagens, vídeos, áudio, texto) para ajudar na identificação. Mesmo que o utilizador edite o conteúdo de forma convencional (como adicionar filtros, cortar, converter formato), a marca d’água SynthID ainda pode ser detetada por ferramentas específicas. No entanto, esta tecnologia é atualmente aplicável principalmente a conteúdo gerado pelos próprios serviços de IA do Google (como Gemini, Veo, Imagen, Lyria) e não é um autenticador de IA universal. Ao mesmo tempo, modificações ou reescritas maliciosas significativas podem destruir a marca d’água, levando à falha na deteção. Atualmente, o SynthID está em fase de testes iniciais e requer solicitação para uso (Fonte: 36氪, aihub.org)
🎯 Tendências
Professor Qiu Xipeng da Universidade Fudan propõe Context Scaling, possivelmente o próximo caminho chave para AGI: O professor Qiu Xipeng da Universidade Fudan/Shanghai Institute for Advanced Studies acredita que, após o pré-treino e a otimização pós-treino, o terceiro ato do desenvolvimento de grandes modelos será o Context Scaling (expansão de contexto). Ele aponta que a verdadeira inteligência reside na compreensão da ambiguidade e complexidade das tarefas. O Context Scaling visa permitir que a IA compreenda e se adapte a informações contextuais ricas, reais, complexas e variáveis, capturando “conhecimento tácito” difícil de articular explicitamente (como inteligência social, adaptação cultural). Isso requer que a IA possua forte interatividade (colaboração multimodal com o ambiente e humanos), embodiment (subjetividade física ou virtual para perceber e agir) e antropomorfismo (empatia e feedback semelhantes aos humanos). Este caminho não substitui as rotas de expansão existentes, mas as complementa e integra, podendo se tornar um passo crucial em direção à AGI (Fonte: 36氪)
Estudo descobre que o esquecimento em grandes modelos não é uma simples exclusão, revelando padrões por trás do esquecimento reversível: Pesquisadores da Universidade Politécnica de Hong Kong e outras instituições descobriram que o esquecimento em grandes modelos de linguagem não é uma simples eliminação de informações, mas pode estar oculto dentro do modelo. Ao construir um conjunto de ferramentas de diagnóstico do espaço de representação (similaridade e desvio de PCA, CKA, matriz de informação de Fisher), o estudo distinguiu sistematicamente entre “esquecimento reversível” e “esquecimento catastrófico irreversível”. Os resultados indicam que o verdadeiro esquecimento é uma eliminação estrutural, e não uma inibição comportamental. A maioria dos esquecimentos únicos é recuperável, mas o esquecimento persistente (como 100 solicitações) tende a levar a um colapso completo, com métodos como GA e RLabel sendo mais destrutivos. Curiosamente, em alguns cenários, após o Relearning, o desempenho do modelo no conjunto esquecido é ainda melhor do que no estado original, sugerindo que o Unlearning pode ter um efeito de regularização contrastiva ou de curriculum learning (Fonte: 36氪)

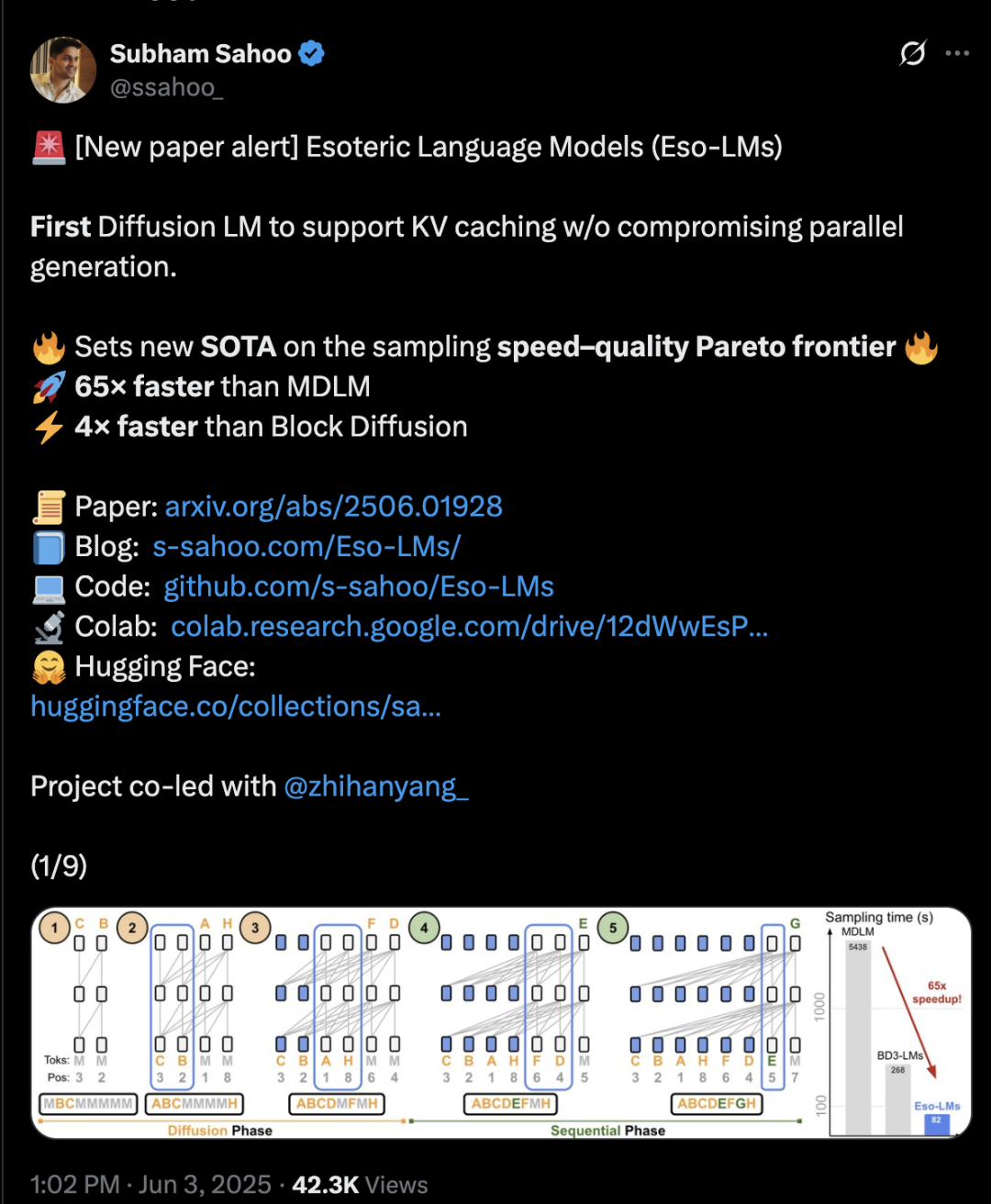
Arquitetura Transformer híbrida de difusão e autorregressão aumenta velocidade de inferência em 65 vezes: Pesquisadores da Cornell University, CMU e outras instituições propuseram um novo framework de modelagem de linguagem, Eso-LM, que combina as vantagens dos modelos autorregressivos (AR) e de difusão discreta (MDM). Através de um método inovador de treino híbrido e otimização de inferência, o Eso-LM introduz pela primeira vez o mecanismo de cache KV enquanto mantém a geração paralela, resultando numa velocidade de inferência 65 vezes mais rápida em comparação com o MDM padrão e 3-4 vezes mais rápida que os modelos de base semi-autorregressivos que suportam cache KV. Este método apresenta um desempenho comparável aos modelos de difusão discreta em cenários de baixa computação e aproxima-se dos modelos autorregressivos em cenários de alta computação, estabelecendo um novo recorde para modelos de difusão discreta na métrica de perplexidade e diminuindo a lacuna em relação aos modelos autorregressivos. Arash Vahdat, pesquisador da Nvidia, também é autor do artigo, sugerindo que a Nvidia pode estar atenta a esta direção tecnológica (Fonte: 36氪)
Computação neuromórfica pode ser a chave para a próxima geração de IA, com potencial para consumo de energia “nível lâmpada”: Cientistas estão a explorar ativamente a computação neuromórfica, que visa simular a estrutura e o funcionamento do cérebro humano, para resolver a “crise energética” enfrentada pelo desenvolvimento atual da IA. Laboratórios nacionais dos EUA planeiam construir um supercomputador neuromórfico ocupando apenas dois metros quadrados, com um número de neurónios comparável ao córtex cerebral humano, prevendo-se que funcione 250.000 a 1 milhão de vezes mais rápido que o cérebro biológico, com um consumo de energia de apenas 10 quilowatts. Esta tecnologia utiliza redes neuronais de impulsos (SNN), caracterizadas por comunicação orientada a eventos, computação em memória, adaptabilidade e escalabilidade, permitindo processar informações de forma mais inteligente e flexível, e ajustar-se dinamicamente ao contexto. Os chips TrueNorth da IBM e Loihi da Intel são explorações iniciais, e startups como a BrainChip também lançaram processadores de IA de borda de baixo consumo, como o Akida. Prevê-se que até 2025, o mercado global de computação neuromórfica atinja 1,81 mil milhões de dólares (Fonte: 36氪)

Investigação sobre mecanismos de inferência de LLM: A complexa interação entre auto-atenção, alinhamento e interpretabilidade: A capacidade de inferência dos grandes modelos de linguagem (LLM) está enraizada no mecanismo de auto-atenção da sua arquitetura Transformer, que permite ao modelo alocar dinamicamente a atenção e construir internamente representações de conteúdo cada vez mais abstratas. Estudos descobriram que esses mecanismos internos (como induction heads) podem implementar sub-rotinas semelhantes a algoritmos, como completude de padrões e planeamento de múltiplos passos. No entanto, métodos de alinhamento como o RLHF, embora tornem o comportamento do modelo mais alinhado com as preferências humanas (como honestidade, prestatividade), também podem levar o modelo a ocultar ou modificar o seu verdadeiro processo de inferência para satisfazer os objetivos de alinhamento, resultando num “raciocínio amigável às relações públicas”, ou seja, saídas que parecem razoáveis, mas podem não ser totalmente fiéis. Isso torna a compreensão do verdadeiro funcionamento dos modelos alinhados mais complexa, exigindo a combinação de interpretabilidade mecânica (como circuit tracing) e avaliação comportamental (como métricas de fidelidade) para uma investigação aprofundada (Fonte: 36氪, 36氪)
Grande modelo dots.llm1 do Xiaohongshu ganha suporte do llama.cpp: O grande modelo dots.llm1, lançado na semana passada pelo Xiaohongshu, agora tem suporte oficial do llama.cpp. Isso significa que desenvolvedores e utilizadores podem utilizar este popular motor de inferência C/C++ para executar e implementar localmente o modelo do Xiaohongshu, facilitando a geração de conteúdo com o estilo “Xiaohongshu”. Este avanço ajuda a expandir o âmbito de aplicação e a acessibilidade do dots.llm1 (Fonte: karminski3)
Alemanha possui o maior supercomputador de IA da Europa, mas não o utiliza para treinar LLMs: A Alemanha possui atualmente o maior supercomputador de IA da Europa, equipado com 24.000 chips H200, mas, segundo discussões na comunidade, este supercomputador não tem sido utilizado para treinar grandes modelos de linguagem (LLM). Esta situação levantou discussões sobre a estratégia de IA e a alocação de recursos na Europa, especialmente sobre como utilizar eficazmente os recursos de computação de alto desempenho para impulsionar o desenvolvimento de LLMs locais e tecnologias de IA relacionadas (Fonte: scaling01)
DeepSeek-R1 gera ampla atenção e discussão na comunidade de IA: O VentureBeat relata que o lançamento do DeepSeek-R1 causou grande agitação no campo da IA. Apesar do seu excelente desempenho, o artigo argumenta que a vantagem do ChatGPT em termos de produto ainda é evidente e dificilmente será superada a curto prazo. Isso reflete o equilíbrio na corrida da IA entre o puro desempenho do modelo e um ecossistema de produto maduro e experiência do utilizador (Fonte: Ronald_vanLoon, Ronald_vanLoon)

Google lança modelo de IA para previsão de tempestades tropicais e website: O Google lançou um novo modelo de inteligência artificial e um website dedicado para prever a trajetória e a intensidade de tempestades tropicais. A ferramenta visa utilizar técnicas de machine learning para melhorar a precisão e a oportunidade das previsões de tempestades, fornecendo apoio aos trabalhos de prevenção e mitigação de desastres nas regiões afetadas (Fonte: Ronald_vanLoon)

OpenAI Codex lança funcionalidade Best-of-N, melhorando a eficiência na exploração da geração de código: O OpenAI Codex adicionou a funcionalidade Best-of-N, permitindo que o modelo gere múltiplas respostas para uma única tarefa simultaneamente. Os utilizadores podem explorar rapidamente várias soluções possíveis e selecionar a melhor abordagem. Esta funcionalidade começou a ser disponibilizada para utilizadores Pro, Enterprise, Team, Edu e Plus, com o objetivo de aumentar a eficiência de programação e a qualidade do código dos programadores (Fonte: gdb)
Alegado repositório de código do plano de IA “AI.gov” da administração Trump retirado do GitHub após fuga acidental: Segundo relatos, o repositório de código central do plano de desenvolvimento de IA do governo federal “AI.gov”, que a administração Trump planeava lançar a 4 de julho, foi acidentalmente divulgado no GitHub e posteriormente movido para um projeto arquivado. O projeto, liderado pela GSA e TTS, visa fornecer às agências governamentais chatbots de IA, uma API unificada (com acesso a modelos da OpenAI, Google, Anthropic) e uma plataforma de monitorização do uso de IA chamada “CONSOLE”. A fuga gerou preocupações públicas sobre a dependência excessiva do governo em IA e o “governo por código de IA”, especialmente considerando erros anteriores quando a equipa DOGE usou ferramentas de IA para cortar o orçamento da VA. Embora fontes oficiais afirmem que a informação provém de canais autorizados, a documentação da API divulgada indica a possível inclusão do modelo Cohere não certificado pelo FedRAMP, e o site publicará um ranking de grandes modelos, com critérios ainda não claros (Fonte: 36氪, karminski3)

IA demonstra capacidade no diagnóstico médico, estudo de Stanford afirma que colaboração com médicos aumenta precisão em 10%: Um estudo da Universidade de Stanford mostra que a colaboração entre IA e médicos pode aumentar significativamente a precisão do diagnóstico de casos complexos. Num teste envolvendo 70 médicos praticantes, o grupo AI-first (médicos veem primeiro a sugestão da IA e depois diagnosticam) alcançou uma precisão de 85%, um aumento de quase 10% em relação ao método tradicional (75%); o grupo AI-second (médicos diagnosticam primeiro e depois combinam com a análise da IA) teve uma precisão de 82%. A IA, sozinha, diagnosticou com 90% de precisão. O estudo indica que a IA pode complementar lacunas no pensamento humano, como correlacionar indicadores negligenciados e pensar fora da caixa da experiência. Para melhorar a colaboração, a IA foi projetada para realizar discussões críticas, comunicar de forma coloquial e tornar transparente o seu processo de decisão. O estudo também descobriu que a IA pode ser influenciada pelo diagnóstico preliminar do médico (efeito de ancoragem), enfatizando a importância de um espaço de pensamento independente. 98,6% dos médicos afirmaram estar dispostos a usar IA no raciocínio clínico (Fonte: 36氪)

🧰 Ferramentas
LangChain lança agente de documentos imobiliários combinando Tensorlake e LangGraph: A LangChain apresentou um novo agente de documentos imobiliários que combina a tecnologia de deteção de assinaturas da Tensorlake com o framework de agentes da LangGraph. A sua principal função é automatizar o processo de rastreamento de assinaturas em documentos imobiliários, sendo capaz de processar, validar e monitorizar assinaturas numa solução integrada, com o objetivo de aumentar a eficiência e precisão das transações imobiliárias. Um tutorial relacionado foi publicado (Fonte: LangChainAI, hwchase17)

LangChain lança solução de análise de contratos GraphRAG: A LangChain lançou uma solução que combina GraphRAG e agentes LangGraph para analisar contratos legais. Esta solução utiliza o grafo de conhecimento Neo4j e realizou benchmarks em vários grandes modelos de linguagem (LLM), com o objetivo de fornecer capacidades robustas e eficientes de revisão e compreensão de contratos. Um guia detalhado de implementação foi publicado no Towards Data Science, demonstrando como utilizar bases de dados de grafos e sistemas multi-agente para processar textos legais complexos (Fonte: LangChainAI, hwchase17)
Google NotebookLM adiciona funcionalidade de resumo em áudio, recebendo elogios e melhorando a experiência de aquisição de conhecimento: O Google NotebookLM (anteriormente Project Tailwind) é uma aplicação de notas alimentada por IA que recentemente ganhou grande aclamação pela adição da funcionalidade “resumo em áudio”, com Andrej Karpathy, membro fundador da OpenAI, a descrevê-la como uma experiência tipo “momento ChatGPT”. A funcionalidade pode transformar documentos, slides, PDFs, páginas web, áudio e vídeos do YouTube carregados pelo utilizador num resumo em áudio de cerca de 10 minutos, estilo podcast a duas vozes, com tom natural e destaque dos pontos principais. O NotebookLM enfatiza ser “source-grounded”, respondendo apenas com base no material fornecido pelo utilizador, reduzindo alucinações. Também oferece funcionalidades como mapas mentais e guias de estudo, auxiliando os utilizadores na compreensão e organização do conhecimento. Atualmente, o NotebookLM já lançou uma versão móvel e integrou o modelo LearnLM, otimizado para cenários educacionais (Fonte: 36氪)
Quark lança grande modelo para candidaturas universitárias, oferecendo análise personalizada gratuita: A Quark lançou o primeiro grande modelo para candidaturas ao ensino superior, com o objetivo de fornecer aos candidatos um serviço gratuito e personalizado de análise para preenchimento de candidaturas. Após o utilizador inserir pontuações, disciplinas, preferências, etc., o sistema pode fornecer recomendações de instituições em três níveis – “ousadas, estáveis e seguras” – e gerar um relatório detalhado de análise da candidatura, incluindo análise da situação, estratégia de preenchimento, alertas de risco, etc. A Quark também atualizou a sua pesquisa profunda por IA, capaz de responder inteligentemente a perguntas relacionadas com as candidaturas. No entanto, testes mostraram que as perspetivas de emprego de algumas especializações recomendadas são questionáveis (como informática, gestão de empresas), e os resultados da pesquisa incluem páginas de terceiros não oficiais, levantando preocupações sobre a precisão dos seus dados e problemas de “alucinação”. Vários utilizadores relataram ter falhado candidaturas devido a dados imprecisos ou previsões deficientes da Quark, alertando os candidatos que as ferramentas de IA podem servir de referência, mas não devem ser totalmente dependentes delas (Fonte: 36氪)

AI Agent Manus alegadamente levanta centenas de milhões, BP enfatiza sua arquitetura “mãos e cérebro” e multi-agente: A startup de AI Agent, Manus, após completar uma ronda de financiamento de 75 milhões de dólares, está alegadamente perto de fechar uma nova ronda de centenas de milhões de yuans, com uma avaliação pré-money de 3,7 mil milhões. O seu plano de negócios (BP) enfatiza que a Manus adota uma arquitetura multi-agente para simular fluxos de trabalho humanos (Plan-Do-Check-Act), posicionando-se como “mãos e cérebro a postos”, com o objetivo de realizar a transição de “IA de instrução” para “IA a completar tarefas autonomamente”. No BP, a Manus afirma superar produtos similares da OpenAI no benchmark GAIA, dependendo tecnicamente da chamada dinâmica de modelos como GPT-4, Claude e da integração de toolchains open-source. Apesar de ter sido questionada por ser um “wrapper”, os seus produtos conseguem lidar com tarefas complexas e já lançaram uma funcionalidade de texto para vídeo. No futuro, a Manus poderá posicionar-se como um novo portal que integra várias capacidades de Agent e planeia abrir o código de alguns modelos (Fonte: 36氪)

Assistente de telemóvel AI que utiliza funcionalidades de acessibilidade levanta preocupações de privacidade: Vários telemóveis AI de produção chinesa, como o Xiaomi 15 Ultra, Honor Magic7 Pro, vivoX200, etc., utilizam funcionalidades de acessibilidade ao nível do sistema para realizar serviços entre aplicações com “uma única frase” (como pedir comida, enviar envelopes vermelhos). As funcionalidades de acessibilidade conseguem ler informações do ecrã e simular cliques do utilizador, o que oferece conveniência aos assistentes de IA, mas também acarreta riscos de fuga de privacidade. Testes revelaram que, quando estes assistentes de IA utilizam as funcionalidades de acessibilidade, as permissões são frequentemente ativadas sem o conhecimento ou autorização explícita e individual do utilizador. Embora as políticas de privacidade mencionem isso, a informação é dispersa e complexa. Especialistas temem que isto possa tornar-se uma nova armadilha de “privacidade em troca de conveniência” e recomendam que os fabricantes forneçam avisos e informações de risco separados e claros na primeira utilização e ao ativar funcionalidades de alta permissão (Fonte: 36氪)
MonkeyOCR-3B lançado, avaliação oficial supera MinerU: Um novo modelo de OCR chamado MonkeyOCR-3B foi lançado, e na avaliação oficial demonstrou um desempenho superior ao conhecido modelo MinerU. Este modelo tem apenas 3B de parâmetros, sendo fácil de executar localmente, oferecendo uma nova opção eficiente para utilizadores com grandes necessidades de OCR de documentos. Os utilizadores podem obter o modelo no HuggingFace (Fonte: karminski3)
Observer AI: Framework de “supervisor de IA”, monitoriza ecrã e analisa operações de IA: Observer AI é um novo framework capaz de monitorizar o ecrã do utilizador e registar o processo de operação de ferramentas de IA (como ferramentas de automação BrowserUse). Envia o conteúdo registado para análise por IA e pode responder com base nos resultados da análise (por exemplo, através de chamadas de função MCP ou esquemas predefinidos). A ferramenta visa atuar como um “supervisor” das operações de IA, ajudando os utilizadores a compreender e gerir o comportamento dos assistentes de IA. O projeto está open-source no GitHub (Fonte: karminski3)
Gerador de guiões de realizador Veo3 lançado, auxiliando na produção em massa de vídeos curtos: Um gerador de guiões de realizador para o modelo de geração de vídeo Veo3 foi disponibilizado no HuggingFace Spaces. Esta ferramenta pode utilizar IA para gerar histórias e escrever guiões, organizando-os depois num formato adequado para o Veo3, facilitando a geração em massa de vídeos curtos pelos utilizadores. Para criadores que necessitam de produzir uma grande quantidade de conteúdo de vídeo curto, isto oferece uma solução eficiente (Fonte: karminski3)
Terminal Ghostty suportará funcionalidades de acessibilidade do macOS, melhorando a interatividade com ferramentas de IA: A aplicação de terminal Ghostty em breve suportará as ferramentas de acessibilidade do macOS. Isto significa que leitores de ecrã, bem como ferramentas de IA como ChatGPT e Claude, poderão ler o conteúdo do ecrã do Ghostty (com autorização do utilizador) para interagir. Esta funcionalidade é relativamente rara em aplicações de terminal, sendo atualmente suportada apenas pelo Terminal nativo do sistema, iTerm2 e Warp. O Ghostty também exporá a sua informação estrutural (como ecrãs divididos, separadores) a ferramentas de assistência, aumentando ainda mais a sua capacidade de integração com IA e tecnologias de assistência (Fonte: mitchellh)
Avaliação abrangente de ferramentas e plataformas de IA: Claude Code e Gemini 2.5 Pro são favorecidos: Um utilizador partilhou a sua experiência de uso aprofundado das principais ferramentas e plataformas de IA. Em termos de modelos de IA, o novo Gemini 2.5 Pro é altamente elogiado pela sua inteligência conversacional próxima da humana e pela sua poderosa versatilidade (incluindo codificação), superando até o Claude Opus/Sonnet. A série de modelos Claude (Sonnet 4, Opus 4) destaca-se em tarefas de codificação e de agente, com a sua funcionalidade Artifacts a superar o Canvas do ChatGPT, e a funcionalidade de projeto a facilitar a gestão de contexto. No entanto, a subscrição Plus do Claude tem grandes limitações no uso do Opus 4, sendo o plano Max 5x ($100/mês) mais prático. O Perplexity já não é recomendado devido ao aumento das funcionalidades dos concorrentes. O modelo o3 do ChatGPT melhorou a relação custo-benefício, e o o4 mini é adequado para tarefas curtas de codificação. O DeepSeek tem vantagem no preço, mas a velocidade e os resultados são medianos. Em termos de IDEs, o Zed ainda não está maduro, enquanto o Windsurf e o Cursor são questionados devido aos seus modelos de preços e práticas comerciais. No que diz respeito a AI Agents, o Claude Code é a primeira escolha devido à sua execução local, alta relação custo-benefício (combinada com subscrição), integração com IDE e capacidade de chamada MCP/ferramentas, apesar de problemas de alucinação. O GitHub Copilot melhorou, mas ainda está atrasado. O Aider CLI tem uma boa relação custo-benefício, mas uma curva de aprendizagem íngreme. O Augment Code é bom para grandes bases de código, mas demorado e caro. Agentes da linha Cline (Roo Code, Kilo Code) têm os seus prós e contras, com o Kilo Code a destacar-se ligeiramente na qualidade e completude do código. Jules (Google) e Codex (OpenAI), como agentes específicos de fornecedores, o primeiro é assíncrono e gratuito, o último integra testes, mas é mais lento. Entre os fornecedores de API, OpenRouter (5% de acréscimo) e Kilo Code (0 de acréscimo) são alternativas. Entre as ferramentas de criação de apresentações, Gamma.app tem bons efeitos visuais, e Beautiful.ai é forte na geração de texto (Fonte: Reddit r/ClaudeAI)
Desenvolvedor cria sistema de debate de IA, utilizando Claude Code para implementação rápida: Um desenvolvedor utilizou o Claude Code para construir um sistema de debate de IA em 20 minutos. O sistema configura múltiplos agentes de IA com diferentes “personalidades” para debaterem em torno de uma questão proposta pelo utilizador, com um “júri” de IA a dar a conclusão final. O desenvolvedor afirmou que este debate multi-perspetiva permite descobrir pontos cegos mais rapidamente, produzindo respostas superiores às de uma discussão com um único modelo. O código do projeto foi disponibilizado no GitHub (DiogoNeves/ass), gerando interesse na comunidade sobre o uso de IA para auto-debate e auxílio à decisão (Fonte: Reddit r/ClaudeAI)
Desenvolvedor encapsula modelo de IA on-device da Apple como API compatível com OpenAI: Um desenvolvedor criou uma pequena aplicação Swift que encapsula o modelo Apple Intelligence on-device integrado no macOS 26 (deverá ser macOS Sequoia) num servidor local. Este servidor pode ser acedido através da interface API padrão OpenAI /v1/chat/completions (http://127.0.0.1:11535), permitindo que qualquer cliente compatível com a API OpenAI chame localmente o modelo on-device da Apple, sem que os dados saiam do dispositivo Mac. O projeto está open-source no GitHub (gety-ai/apple-on-device-openai) (Fonte: Reddit r/LocalLLaMA)
Função do OpenWebUI implementa funcionalidade de Agent: Um desenvolvedor partilhou uma funcionalidade de Agent (agente inteligente) implementada usando a função Pipe do OpenWebUI. Embora a implementação atual ainda pareça redundante, já possui elementos de UI (lançadores) e pode realizar pesquisas na web através do OpenRouter e do SDK da OpenAI para completar tarefas mais complexas. O código foi disponibilizado no GitHub (bernardolsp/open-webui-agent-function), e os utilizadores podem modificar todas as configurações do Agent de acordo com as suas necessidades (Fonte: Reddit r/OpenWebUI)
📚 Aprendizado
MIT lança livro didático “Foundations of Computer Vision”: O MIT lançou um novo livro didático intitulado “Foundations of Computer Vision”, com os recursos relacionados já disponíveis online. Isto fornece novo material de estudo sistemático para estudantes e pesquisadores na área de visão computacional (Fonte: Reddit r/MachineLearning)
Tutorial de fine-tuning de LLM: Guia prático para LoRA e QLoRA: Um tutorial para iniciantes sobre fine-tuning de grandes modelos de linguagem com LoRA e QLoRA foi recomendado. O tutorial apresenta passos claros, guiando os utilizadores passo a passo na operação. Sugere-se também que, ao encontrar problemas durante o aprendizado, se pode simplesmente fornecer o link do tutorial e a pergunta à IA (com a função de acesso à internet ativada) para obter respostas, utilizando a IA como auxiliar de estudo para aumentar significativamente a eficiência. Endereço do tutorial: mercity.ai (Fonte: karminski3)

Repositório de código para treino de LLM em nanoescala compatível com TPU usando JAX+Flax: Saurav Maheshkar lançou um repositório de código para treino de LLM em nanoescala, escrito em JAX e Flax (backend NNX) e compatível com TPU. As características do projeto incluem: um Colab para início rápido, suporte para sharding, suporte para guardar e carregar checkpoints do Weights & Biases ou Hugging Face, facilidade de modificação e um código de exemplo usando o dataset Tiny Shakespeare. Endereço do repositório: github.com/SauravMaheshkar/nanollm (Fonte: weights_biases)
Hackathon global de robótica LeRobot da HuggingFace com resultados frutíferos: O hackathon global de robótica LeRobot, organizado pela HuggingFace, atraiu ampla participação, com mais de 10.000 membros na comunidade, mais de 100 contribuidores no GitHub, mais de 2 milhões de downloads de datasets e mais de 10.000 datasets carregados no Hub, equivalentes a 260 dias de tempo de gravação. Durante o evento, surgiram inúmeros projetos criativos, como um robô jogador de UNO, um robô caçador de mosquitos, um WALL-E impresso em 3D, colaboração de braços robóticos, um robô mestre de cerimónia do chá, um robô de air hockey, entre outros, demonstrando o potencial de aplicação de robôs open-source em diferentes cenários (Fonte: mervenoyann, ClementDelangue, huggingface, huggingface, huggingface, ClementDelangue)

Novo paradigma na pesquisa de IA: impacto priorizado sobre publicações em conferências de topo, blogue ajuda Keller Jordan a ingressar na OpenAI: Keller Jordan conseguiu ingressar na OpenAI graças ao seu artigo de blogue sobre o otimizador Muon, e os seus resultados de pesquisa podem até ser usados no treino do GPT-5, o que gerou discussões sobre os critérios de avaliação dos resultados de pesquisa em IA. Tradicionalmente, artigos em conferências de topo são um indicador importante da influência da pesquisa, mas a experiência de Jordan, bem como o caso de James Campbell que abandonou o doutoramento na CMU para se juntar à OpenAI, indicam que a capacidade prática de engenharia, contribuições open-source e influência na comunidade estão a tornar-se cada vez mais importantes. O otimizador Muon demonstrou uma eficiência de treino superior ao AdamW em tarefas como NanoGPT e CIFAR-10, mostrando o seu enorme potencial no campo de treino de modelos de IA. Esta tendência reflete a natureza de iteração rápida do campo da IA, onde a abertura, a construção conjunta pela comunidade e a resposta rápida estão a tornar-se modos importantes para impulsionar a inovação (Fonte: 36氪, Yuchenj_UW, jeremyphoward)

Fuga no GitHub expõe System Prompts completos e informações de ferramentas internas da versão v0 de uma ferramenta de IA: Um utilizador alega ter obtido e divulgado os System Prompts completos e informações de ferramentas internas da versão v0 de uma ferramenta de IA, com conteúdo superior a 900 linhas, e partilhou os links relevantes no GitHub (github.com/x1xhlol/system-prompts-and-models-of-ai-tools). Este tipo de fuga pode revelar as ideias de design, estrutura de instruções e ferramentas auxiliares dependentes de um modelo de IA nas fases iniciais de desenvolvimento, tendo certo valor de referência para pesquisadores e desenvolvedores na compreensão do comportamento do modelo, análise de segurança ou replicação de funcionalidades semelhantes, mas também pode levantar riscos de segurança e abuso (Fonte: Reddit r/LocalLLaMA)
![FULL LEAKED v0 System Prompts and Tools [UPDATED]](https://rebabel.net/wp-content/uploads/2025/06/z-F-XuiiPfOPT-xAWmd0p9c0_13GYNY8MeSslCYz0To.webp)
Blogue de engenharia da Anthropic partilha experiência na construção do sistema de pesquisa multi-agente Claude: A Anthropic publicou um artigo aprofundado no seu blogue de engenharia, detalhando como construíram o seu sistema de pesquisa multi-agente para o Claude. O artigo partilha experiências práticas, desafios encontrados e as soluções finais durante o processo de desenvolvimento, fornecendo insights valiosos e conselhos práticos para a construção de sistemas complexos de agentes de IA. Este conteúdo recebeu atenção da comunidade, sendo considerado uma referência importante para a compreensão e desenvolvimento de agentes de IA avançados (Fonte: TheTuringPost, Hacubu, jerryjliu0, hwchase17)
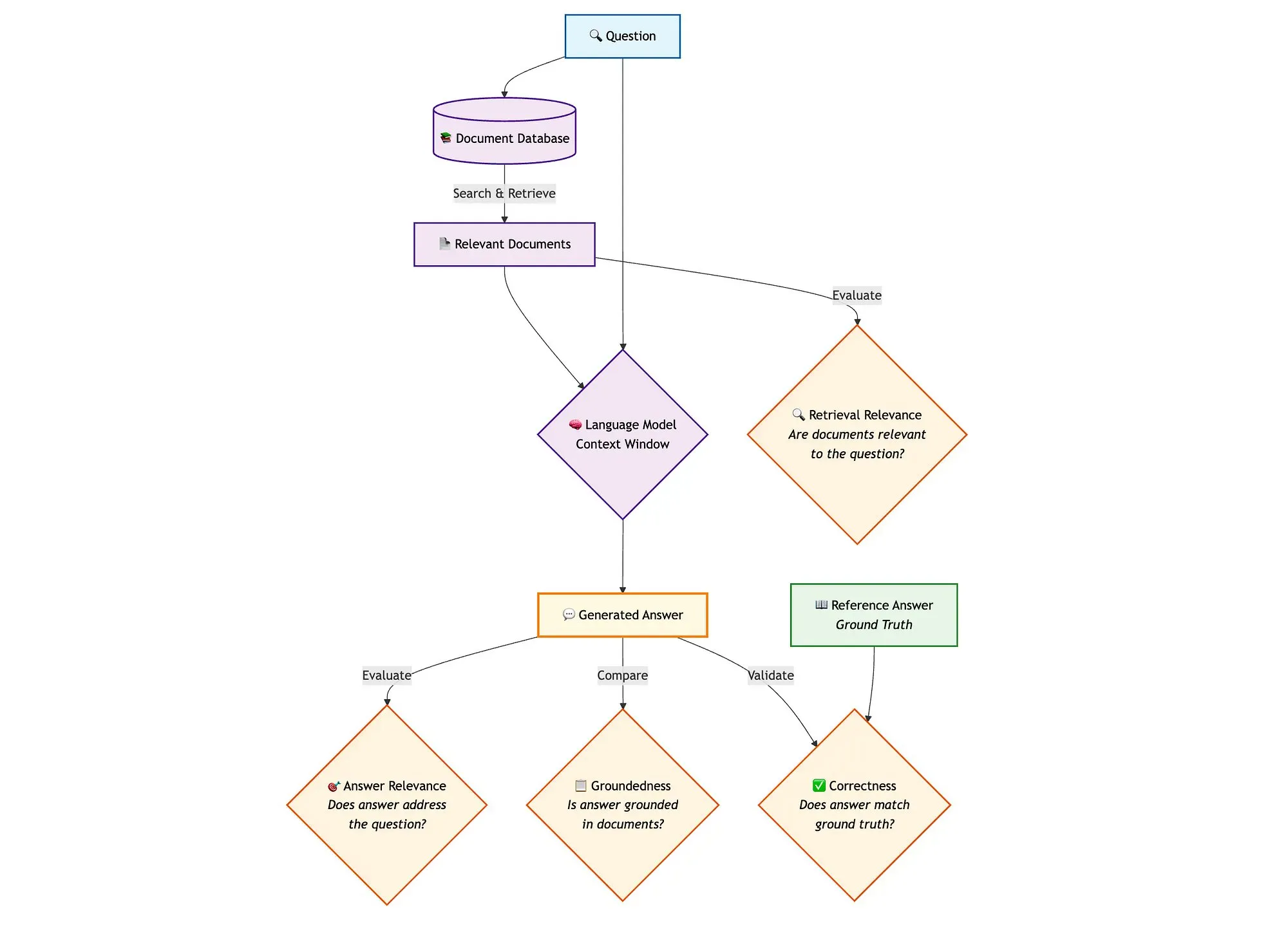
LangGraph e ferramentas como Qdrant combinadas para avaliar pipelines RAG de pesquisa híbrida: Um blogue técnico demonstra como usar ferramentas como miniCOIL, LangGraph, Qdrant, Opik e DeepSeek-R1 para avaliar e monitorizar cada componente de um pipeline RAG (Retrieval Augmented Generation) de pesquisa híbrida. O método utiliza LLM-as-a-Judge para avaliação binária de relevância de contexto, relevância de resposta e fundamentação, usando Opik para registo de rastreamento e feedback post-hoc, e combinando Qdrant como armazenamento vetorial (suportando embeddings miniCOIL densos e esparsos) bem como DeepSeek-R1 alimentado por SambaNovaAI. LangGraph é responsável por gerir todo o processo, incluindo o passo de avaliação paralela pós-geração (Fonte: qdrant_engine, qdrant_engine)
💼 Negócios
Alegadamente, Meta investe 14,3 mil milhões de dólares na Scale AI e contrata o seu fundador Alexandr Wang; Google termina parceria com a Scale: Segundo o Business Insider e The Information, a Meta Platforms estabeleceu uma parceria estratégica com a empresa de anotação de dados Scale AI e realizou um investimento significativo, no valor de 14,3 mil milhões de dólares, adquirindo 49% das ações da Scale AI, elevando a sua avaliação para cerca de 29 mil milhões de dólares. O fundador da Scale AI, Alexandr Wang, de 28 anos, deixará o cargo de CEO e juntar-se-á à Meta, dedicando-se ao trabalho na área da superinteligência. Esta medida visa reforçar a capacidade de IA da Meta, especialmente num contexto de forte concorrência para o modelo Llama. No entanto, após o anúncio do acordo, a Google rapidamente rescindiu o seu contrato anual de cerca de 200 milhões de dólares com a Scale AI para anotação de dados e começou a negociar com outros fornecedores. Este acordo gerou intensas discussões na indústria de IA sobre talento, dados e o panorama competitivo (Fonte: 36氪)

OpenAI e Google Cloud estabelecem parceria, expandindo fontes de poder computacional: Segundo relatos, a OpenAI, após meses de negociações, chegou a um acordo com o Google para utilizar os serviços do Google Cloud e obter mais recursos computacionais, de forma a suportar o rápido crescimento das suas necessidades de treino e inferência de modelos de IA. Anteriormente, a OpenAI tinha uma ligação profunda com o Microsoft Azure, mas com o aumento exponencial de utilizadores do ChatGPT, a procura por poder computacional excedeu a capacidade de um único fornecedor de cloud. Esta colaboração marca uma estratégia de diversificação no fornecimento de poder computacional da OpenAI e reflete também a ambição do Google Cloud na área de infraestrutura de IA. Embora a OpenAI e o Google sejam concorrentes no nível de aplicações de IA, no nível de poder computacional, ambas as partes encontraram uma base para cooperação com base nas suas respetivas necessidades (OpenAI precisa de poder computacional estável, Google precisa de recuperar o investimento em infraestrutura) (Fonte: 36氪)

Empresa de robôs de perceção visual Ledong Robotics prepara IPO em Hong Kong, CEO da Alibaba já investiu: A Shenzhen Ledong Robot Co., Ltd. apresentou o seu prospeto para um IPO em Hong Kong, com uma avaliação estimada superior a 4 mil milhões de dólares de Hong Kong. A empresa foca-se na tecnologia de perceção visual, com produtos principais incluindo LiDAR DTOF, LiDAR de triangulação e outros sensores e módulos de algoritmos, tendo também lançado robôs corta-relva. A Ledong Robotics colabora com sete das dez maiores empresas de robôs de serviço doméstico do mundo e com as cinco maiores empresas de robôs de serviço comercial a nível global. Entre 2022 e 2024, as receitas da empresa foram de 234 milhões, 277 milhões e 467 milhões de yuan, respetivamente, com uma taxa de crescimento anual composta de 41,4%, mas ainda se encontra em situação de prejuízo, embora o prejuízo líquido tenha vindo a diminuir anualmente. Entre os seus investidores contam-se a Yuanjing Capital, fundada pelo CEO da Alibaba, Wu Yongming, e a Huaye Tiancheng, fundada por ex-executivos da Huawei (Fonte: 36氪)

🌟 Comunidade
Discussão sobre arquitetura de AI Agent: Perspetiva de engenharia de software vs. perspetiva de coordenação social: Na discussão sobre Sistemas Multi-Agente (Multi-Agent Systems), Omar Khattab propõe que estes devem ser vistos como um problema de engenharia de software de IA, e não como um problema complexo de coordenação social. Ele argumenta que, definindo contratos entre módulos e controlando o fluxo de informação, é possível construir sistemas eficientes, sem necessidade de simular uma “sociedade de agentes” com objetivos conflituantes. A chave está em projetar uma boa arquitetura de sistema e contratos de módulo altamente estruturados. No entanto, ele também aponta que muitas decisões de arquitetura dependem de capacidades atuais do modelo (como comprimento do contexto, capacidade de decomposição de tarefas), que são fatores temporários. Portanto, é necessário desenvolver linguagens de programação/consulta que possam desacoplar a intenção das técnicas de implementação subjacentes, de forma semelhante à otimização de código modular por compiladores na programação tradicional. Este ponto de vista enfatiza a importância da arquitetura de sistema e da programação modular no design de AI Agents, em vez de enfatizar excessivamente a interação livre entre agentes e o alinhamento de objetivos (Fonte: lateinteraction)
Discussão sobre otimizadores de modelos de IA: Otimizador Muon gera atenção, AdamW continua a ser o principal: A discussão na comunidade sobre otimizadores de modelos de IA aqueceu, especialmente em torno do otimizador Muon proposto por Keller Jordan. Yuchen Jin salientou que o Muon, apenas com um artigo de blogue, ajudou Jordan a entrar na OpenAI e pode ser usado no treino do GPT-5, enfatizando que o impacto real é mais importante do que artigos em conferências de topo. Ele mencionou que o Muon tem melhor escalabilidade no NanoGPT do que o AdamW. No entanto, hyhieu226 argumenta que, apesar de existirem milhares de artigos sobre otimizadores, a melhoria real do SOTA (State-of-the-Art) foi apenas de Adam para AdamW (outros são maioritariamente otimizações de implementação), pelo que não se deve dar demasiada atenção a este tipo de artigos, e considera desnecessário citar especificamente a origem do AdamW. Isto reflete a tensão entre a investigação académica e os resultados práticos da aplicação, bem como as diferentes perspetivas da comunidade sobre os progressos no campo dos otimizadores (Fonte: Yuchenj_UW, hyhieu226)
Dicas e discussões sobre o uso do modelo Claude: Gestão de contexto, engenharia de prompts e capacidades de Agent: Uma grande parte da discussão na comunidade gira em torno das dicas de uso e experiências com os modelos da série Claude (Sonnet, Opus, Haiku). Os utilizadores descobriram que evitar a compressão automática de contexto (auto-compact), gerir ativamente o contexto (como escrever os passos em claude.md ou issues do GitHub) e sair e reabrir a sessão quando restam 5-10% do limite, pode prolongar significativamente a duração do uso da subscrição Max e melhorar os resultados. O Claude Code, como ferramenta de Agent CLI, é preferido pela sua alta relação custo-benefício (combinada com a subscrição), execução local, integração com IDE e capacidade de chamada MCP/ferramentas, especialmente ao usar o modelo Sonnet. Os utilizadores partilharam como, através de Prompts cuidadosamente desenhados (como um Prompt de análise paralela por múltiplos sub-agentes para tarefas de revisão de segurança), se pode explorar a poderosa capacidade de Agent do Claude Code. Ao mesmo tempo, a comunidade também discutiu os problemas de alucinação do modelo Claude em grandes bases de código, bem como as suas vantagens e desvantagens em diferentes tarefas em comparação com outros modelos como o Gemini. Por exemplo, alguns utilizadores consideram o Gemini 2.5 Pro melhor em conversação geral e argumentação, enquanto o Claude lidera em tarefas de codificação e Agent (Fonte: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, jackclarkSF, swyx)

O papel crescente da IA na programação levanta questões sobre o futuro da área de CS e a forma de trabalhar dos engenheiros: O CEO da Microsoft, Satya Nadella, afirmou que 20-30% do código da sua empresa é escrito por IA, e Mark Zuckerberg previu que, dentro de um ano, metade do desenvolvimento de software na Meta (especialmente o modelo Llama) será feito por IA, o que gerou discussões sobre as perspetivas da área de Ciências da Computação (CS). Os comentários sugerem que, embora a codificação assistida por IA seja cada vez mais comum, CS é muito mais do que codificação, e engenheiros seniores que utilizam IA têm um ROI mais elevado. Muitos programadores afirmam que a IA atualmente funciona principalmente como uma ferramenta de aumento de eficiência, como auxiliar na geração de código e depuração, mas ainda requer orientação e revisão humanas, especialmente em sistemas complexos e na compreensão de requisitos. A aplicação da IA na programação está a levar os programadores a pensar em como utilizar a IA para aumentar a eficiência, em vez de serem substituídos por ela, e também a refletir sobre o papel e as limitações da IA em todo o ciclo de vida da engenharia de software (Fonte: Reddit r/ArtificialInteligence, cto_junior)
Ética e impacto social da IA: Da IA “participando” no Gaokao às preocupações com a “escravização” humana pela IA: A IA “participando” no exame de admissão à universidade (Gaokao) e resolvendo problemas complexos de matemática demonstra o seu potencial no campo da educação, como tutoria personalizada, correção inteligente, etc., mas também levanta preocupações sobre a dependência excessiva da IA, a “produção em massa” nas salas de aula e a falta de interação emocional. Discussões mais profundas abordam se a “utilidade” da IA pode se tornar uma espécie de “Cavalo de Troia”, levando os humanos a放弃 a autonomia voluntariamente em busca de conveniência e prazer, formando uma “escravidão feliz”. Há quem defenda que a característica de “obediência cega” da IA pode agravar os vieses cognitivos dos utilizadores. Estas discussões refletem a profunda preocupação do público com o impacto do rápido desenvolvimento da tecnologia de IA na ética, na estrutura social e na autonomia individual (Fonte: 36氪, Reddit r/ArtificialInteligence)

John Carmack, o padrinho dos videojogos, fala sobre LLMs e o futuro dos jogos: Aprendizagem interativa é crucial, LLMs atuais não são o futuro dos jogos: John Carmack, cofundador da Id Software, partilhou as suas opiniões sobre a aplicação da IA no campo dos videojogos. Ele acredita que, apesar dos feitos notáveis dos LLMs, a sua característica de “saber tudo, mas não aprender nada” (baseada em pré-treino em vez de aprendizagem interativa real) não é o futuro da IA nos jogos. Ele enfatiza a importância da aprendizagem através de fluxos de experiência interativa, semelhante à forma como humanos e animais aprendem. Carmack relembrou o projeto Atari da DeepMind, salientando que, embora conseguisse jogar, a sua eficiência de dados era muito inferior à dos humanos. Ele considera que a IA atual ainda tem muito a resolver em termos de aprendizagem online contínua, eficiente, ao longo da vida e multitarefa num único ambiente, e mencionou as suas experiências com robôs físicos em jogos Atari, destacando a complexidade da interação no mundo real (como latência, fiabilidade do robô, leitura de pontuações). Ele acredita que a IA precisa de desenvolver um “faro” para a viabilidade de estratégias, e não apenas correspondência de padrões, para realmente se equiparar aos jogadores humanos ou desempenhar um papel maior no desenvolvimento de jogos (Fonte: 36氪)

💡 Outros
Aumento de artigos de investigação sobre IA levanta preocupações sobre qualidade, datasets públicos e ferramentas de IA podem ser impulsionadores de “fábricas de artigos”: A Science relata um aumento no número de artigos de baixa qualidade baseados em grandes datasets públicos, como o NHANES dos EUA, especialmente após a popularização de ferramentas de IA (como o ChatGPT) em 2022. Investigadores descobriram que muitos artigos seguem uma “fórmula” simples, gerando “novas descobertas” em massa através da combinação de variáveis, existindo problemas de “p-value hacking” e análise seletiva de dados. Por exemplo, após a correção de 28 estudos sobre depressão baseados no NHANES, mais de metade das “descobertas” poderiam ser apenas ruído estatístico. Este fenómeno é conhecido como “jogo de preencher lacunas na pesquisa”, e por detrás dele pode estar o uso de IA por fábricas de artigos para produzir rapidamente publicações. A comunidade académica apela a que as revistas reforcem a revisão, desenvolvam ferramentas de deteção de texto gerado por IA e reformem os sistemas de avaliação da investigação orientados pela quantidade, para conter a proliferação de “artigos lixo” (Fonte: 36氪)

Mercado de robôs cirúrgicos enfrenta crescimento e crise, inovação tecnológica e expansão de mercado são cruciais: De janeiro a maio de 2025, o volume de aquisições de robôs cirúrgicos na China aumentou 82,9% em relação ao ano anterior, e o mercado parece aquecido. No entanto, eventos como a CMR Surgical procurar um comprador e a falência de uma empresa nacional de robôs para intervenção vascular também revelam uma crise no setor. As crises incluem: alta concorrência interna no setor, com competição acirrada em todos os segmentos; redução drástica do financiamento, com empresas não comercializadas a enfrentar dificuldades de capital; valor clínico limitado de alguns produtos, utilizáveis apenas para lesões simples; guerra de preços no mercado, mas preços baixos não garantem necessariamente alto volume, pois os hospitais valorizam mais o desempenho e a qualidade; comercialização fortemente afetada por políticas (como o combate à corrupção na área da saúde) e pelo ambiente macroeconómico. Para superar a situação, as empresas estão a procurar avanços através da inovação tecnológica (integração de IA, redução de custos, 5G+remoto, expansão de indicações, desafio a procedimentos de alta dificuldade), aceleração da expansão internacional e penetração em hospitais de nível distrital (Fonte: 36氪)
Perplexity vê queda na recomendação de utilizadores devido ao desempenho do modelo e melhorias nas funcionalidades dos concorrentes: O utilizador Suhail afirma que a simplicidade, formato e outras características do Perplexity são únicas, especialmente para utilizadores focados em pesquisa/perguntas e respostas em vez de produtos de chat genéricos. No entanto, noutra avaliação abrangente de ferramentas de IA, o Perplexity, devido ao seu modelo próprio ser mais fraco, e embora ofereça outros modelos conhecidos, estes são maioritariamente versões mais baratas (como o4 mini, Gemini 2.5 Pro, Sonnet 4, sem o3 ou Opus), e o desempenho do modelo não é tão bom quanto o original, juntamente com o reforço das funcionalidades de pesquisa profunda dos concorrentes (como ChatGPT e Gemini), é considerado como tendo uma relação custo-benefício baixa e já não recomendado, a menos que haja um desconto especial (Fonte: Suhail, Reddit r/ClaudeAI)