Palavras-chave:Meta V-JEPA 2, Nuvidia Nuvidia IA Nuvidia, Sakana IA Texto-para-LoRA, OpenAI o3-pro, Databricks Lakebase, MLflow 3.0, HistBench da Universidade de Princeton, Modelo de mundo aberto para treinamento de vídeo, Plataforma de IA em nuvem para manufatura europeia, Adaptador LLM para geração de texto, Ajuste fino DPO para GPT-4.1, Observabilidade de agentes de IA
🔥 Foco
Meta lança V-JEPA 2: Modelo de mundo de imagem/vídeo de código aberto treinado com base em vídeo : A Meta lançou o novo modelo de mundo de imagem/vídeo de código aberto V-JEPA 2, o modelo é baseado na arquitetura ViT, possui versões com diferentes tamanhos (L/G/H) e resoluções (286/384), com até 1,2 bilhão de parâmetros. O V-JEPA 2 apresenta excelente desempenho em compreensão visual e previsão, permitindo que robôs realizem planeamento zero-shot e executem tarefas em ambientes desconhecidos. A Meta enfatiza que sua visão é que a AI utilize modelos de mundo para se adaptar a ambientes dinâmicos e aprender novas habilidades eficientemente. Ao mesmo tempo, a Meta também lançou três novos benchmarks, MVPBench, IntPhys 2 e CausalVQA, para avaliar a capacidade dos modelos existentes de inferir o mundo físico a partir de vídeos. (Fonte: huggingface, huggingface, ylecun, AIatMeta, scaling01, karminski3)
NVIDIA constrói a primeira nuvem industrial de AI na Europa, impulsionando o desenvolvimento da manufatura : A NVIDIA anunciou que está a construir a primeira plataforma de nuvem de inteligência artificial industrial do mundo para fabricantes europeus. Esta fábrica de AI visa ajudar os líderes industriais a acelerar aplicações de manufatura de ponta a ponta, desde o design e simulação de engenharia até gémeos digitais de fábricas e robótica. Esta iniciativa faz parte de uma série de medidas anunciadas pela NVIDIA na GTC Paris e na VivaTech 2025, com o objetivo de acelerar a inovação em AI na Europa e noutras regiões. Jensen Huang afirmou que a capacidade de computação de AI na Europa deverá decuplicar em dois anos e enfatizou que “todos os objetos em movimento serão robotizados, e os carros são os próximos”. (Fonte: nvidia, nvidia, Jensen Huang: Capacidade de computação de AI na Europa decuplicará em dois anos)

Sakana AI lança Text-to-LoRA: Gere instantaneamente adaptadores LLM específicos para tarefas com descrições em texto : A Sakana AI lançou a tecnologia Text-to-LoRA, uma Hypernetwork capaz de gerar instantaneamente adaptadores LLM (LoRAs) específicos para tarefas com base na descrição textual da tarefa fornecida pelo utilizador. Esta tecnologia visa reduzir a barreira para a personalização de modelos grandes, permitindo que utilizadores não técnicos especializem modelos base através de linguagem natural, sem necessidade de profundo conhecimento técnico ou grandes recursos computacionais. O Text-to-LoRA consegue codificar centenas de adaptadores LoRA existentes e generalizar para tarefas nunca antes vistas, mantendo o desempenho. O artigo e o código relacionados foram publicados no arXiv e GitHub, e serão apresentados na ICML2025. (Fonte: SakanaAILabs, hardmaru, kylebrussell, ClementDelangue, huggingface)
OpenAI lança modelo de inferência de topo o3-pro com grande redução de preço e introduz funcionalidade de fine-tuning DPO para a série GPT-4.1 : A OpenAI lançou o seu novo modelo de inferência de topo, o3-pro, e reduziu significativamente os preços da série de modelos o3, com o objetivo de diminuir os custos para os programadores. Simultaneamente, a OpenAI anunciou que os utilizadores podem agora usar a otimização de preferência direta (DPO) para fazer fine-tuning nos modelos da família GPT-4.1 (incluindo 4.1, 4.1-mini e 4.1-nano). O DPO permite a personalização através da comparação de respostas do modelo em vez de alvos fixos, sendo particularmente adequado para tarefas com requisitos subjetivos de tom, estilo e criatividade. O ARC Prize retestou o o3 após a redução de preço, e os resultados mostraram que o seu desempenho no ARC-AGI não sofreu alterações. (Fonte: OpenAIDevs, scaling01, aidan_mclau, giffmana, jeremyphoward, BorisMPower, rowancheung, TheRundownAI)
🎯 Tendências
Databricks lança Lakebase, versão gratuita e Agent Bricks, acelerando o desenvolvimento de aplicações de dados e AI : A Databricks anunciou que o Lakebase entrou em fase de pré-visualização pública. Trata-se de uma base de dados Postgres totalmente gerida, integrada com o lakehouse e construída para AI, combinando a facilidade de uso do Postgres, a escalabilidade do lakehouse e a tecnologia de branching da base de dados Neon. Simultaneamente, a Databricks lançou uma versão gratuita da plataforma e uma grande quantidade de materiais de formação para ajudar os programadores a aprender engenharia de dados, ciência de dados e AI. Além disso, as Databricks Apps estão agora disponíveis de forma geral (GA), permitindo aos clientes construir e implementar aplicações interativas de dados e AI na plataforma. A Databricks também lançou o Agent Bricks, que adota uma abordagem declarativa para o desenvolvimento de agentes de AI, onde o utilizador descreve a tarefa e o sistema gera automaticamente avaliações e otimiza o agente. (Fonte: matei_zaharia, matei_zaharia, lateinteraction, matei_zaharia, matei_zaharia, matei_zaharia, jefrankle, lateinteraction, matei_zaharia, lateinteraction, cto_junior, lateinteraction, jefrankle)

NVIDIA e Mistral AI colaboram para construir plataforma cloud end-to-end na Europa : A NVIDIA anunciou uma colaboração com a startup francesa Mistral AI para construir em conjunto uma plataforma cloud end-to-end. A primeira fase da colaboração envolverá a implementação de 18.000 sistemas NVIDIA Grace Blackwell, com planos de expansão para mais locais em 2026. Esta colaboração faz parte dos esforços da NVIDIA para promover a construção de infraestruturas de AI na Europa e o conceito de “Sovereign AI”, visando fornecer à Europa centros de dados e servidores localizados. (Fonte: Jensen Huang: Capacidade de computação de AI na Europa decuplicará em dois anos)
MLflow 3.0 lançado, projetado para observabilidade e desenvolvimento de agentes de AI : O MLflow 3.0 foi lançado oficialmente. A nova versão foi redesenhada especificamente para a observabilidade e desenvolvimento de agentes de AI, e atualiza as funcionalidades tradicionais de machine learning estruturado. O MLflow 3.0 visa alcançar a melhoria contínua de sistemas de AI através de dados, suportando o rastreamento, avaliação e monitorização de sistemas de AI, e considerando requisitos de nível empresarial, como colaboração humana, governação e segurança de dados, e integração com o ecossistema de dados da Databricks. (Fonte: matei_zaharia, matei_zaharia, lateinteraction)
Universidade de Princeton e Universidade Fudan lançam conjuntamente HistBench e HistAgent para promover a aplicação da AI na investigação histórica : O Laboratório de AI da Universidade de Princeton e o Departamento de História da Universidade Fudan colaboraram para lançar o primeiro benchmark de avaliação de AI para investigação histórica do mundo, HistBench, e o assistente de AI, HistAgent. O HistBench contém 414 questões históricas, abrangendo 29 línguas e a história de múltiplas civilizações, com o objetivo de testar a capacidade da AI de processar materiais históricos complexos e compreensão multimodal. O HistAgent é um agente inteligente projetado especificamente para a investigação histórica, integrando ferramentas como recuperação de documentos, OCR e tradução. Os testes mostram que os modelos grandes gerais têm uma precisão inferior a 20% no HistBench, enquanto o HistAgent supera significativamente os modelos existentes. (Fonte: Primeiro benchmark histórico global, Princeton e Fudan criam assistente de história AI, AI expande-se para as humanidades)

Microsoft Research e Universidade de Pequim lançam conjuntamente o framework Next-Frame Diffusion (NFD), melhorando a eficiência da geração de vídeo autorregressiva : A Microsoft Research e a Universidade de Pequim lançaram conjuntamente o novo framework Next-Frame Diffusion (NFD), que, através da amostragem paralela intra-frame e do modo autorregressivo inter-frame, alcança uma geração de vídeo autorregressiva de alta qualidade a mais de 30 frames por segundo num GPU A100 usando um modelo de 310M. O NFD adota um Transformer com mecanismo de atenção causal em blocos e combina técnicas de destilação de consistência e amostragem especulativa para aumentar ainda mais a eficiência, com potencial aplicação em cenários como jogos interativos em tempo real. (Fonte: Geração de vídeo a mais de 30 frames por segundo, suporta interação em tempo real, novo framework de geração de vídeo autorregressiva redefine a eficiência de geração)

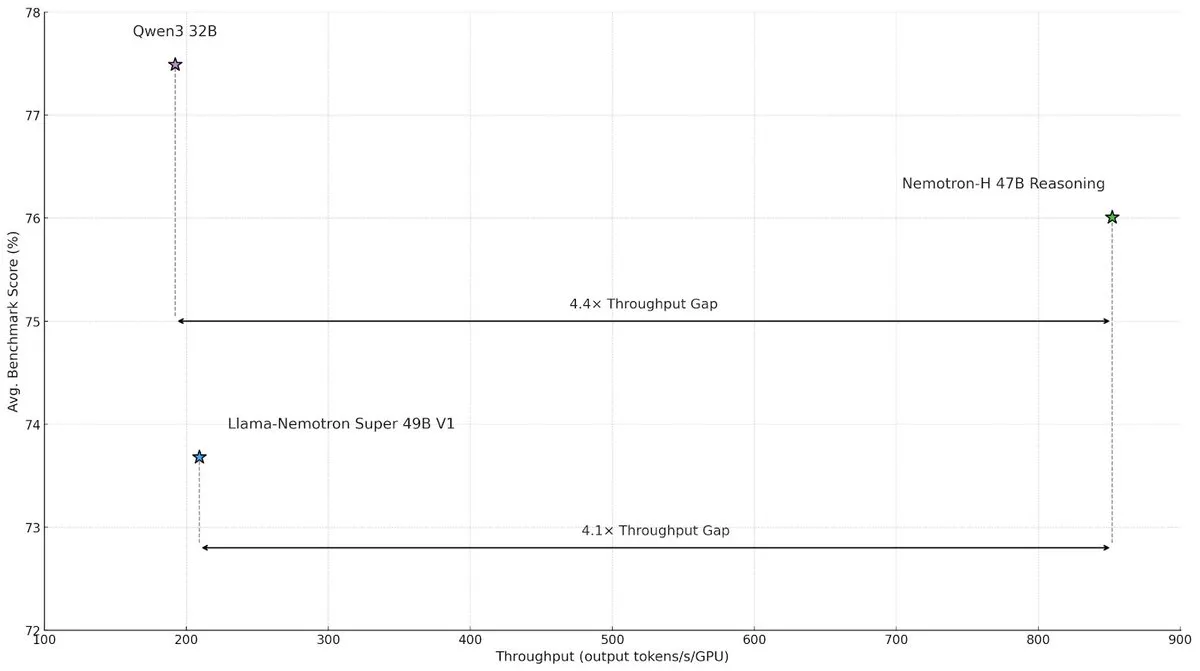
NVIDIA lança modelo de arquitetura híbrida Nemotron-H, melhorando a velocidade e eficiência da inferência em larga escala : O NVIDIA Research lançou o modelo Nemotron-H, que adota uma arquitetura híbrida de Mamba e Transformer, visando resolver os estrangulamentos de velocidade em tarefas de inferência em larga escala. Este modelo, mantendo a capacidade de inferência, alcança um throughput 4 vezes superior ao de modelos Transformer semelhantes. A investigação mostra que os modelos híbridos conseguem manter o desempenho de inferência mesmo com menos camadas de atenção, especialmente em cenários de longas cadeias de inferência, onde a vantagem de eficiência das arquiteturas lineares é significativa. (Fonte: _albertgu, tri_dao, krandiash)
Investigador Jack Rae da Google DeepMind junta-se ao grupo de “superinteligência” da Meta : O investigador principal da Google DeepMind, Jack Rae, confirmou que se juntou ao recém-formado grupo de “superinteligência” da Meta. Durante o seu tempo na DeepMind, Rae foi responsável pela capacidade de “pensamento” do modelo Gemini e é uma das figuras representativas da ideia de “compressão como inteligência”, tendo participado no desenvolvimento do GPT-4 na OpenAI. O CEO da Meta, Mark Zuckerberg, está a recrutar pessoalmente talentos de topo em AI, oferecendo pacotes salariais na ordem das dezenas de milhões de dólares para a nova equipa, com o objetivo de melhorar o modelo Llama e desenvolver ferramentas de AI mais poderosas para alcançar os líderes da indústria. (Fonte: Primeiro grande nome do grupo de “superinteligência” de Zuckerberg, investigador principal da Google DeepMind, figura central da “compressão como inteligência”, DhruvBatraDB)

Mistral AI lança o seu primeiro modelo de inferência Magistral, com suporte para inferência multilingue : A Mistral AI lançou o seu primeiro modelo de inferência, Magistral, incluindo a versão de código aberto Magistral Small com 24B parâmetros e o Magistral Medium para empresas. O modelo foi especificamente afinado para lógica multi-passo e interpretabilidade, suporta inferência multilingue, especialmente otimizado para línguas europeias, e pode fornecer um processo de pensamento rastreável. O Magistral utiliza um algoritmo GRPO melhorado, treinado através de aprendizagem por reforço pura, sem depender de dados de destilação de modelos de inferência existentes. No entanto, os seus resultados de benchmark foram parcialmente questionados por não incluírem os dados das versões mais recentes do Qwen e DeepSeek R1. (Fonte: Novo modelo de inferência “SOTA” evita confronto com Qwen e R1? OpenAI europeia é criticada)

ByteDance lança Doubao Large Model 1.6 com nova redução drástica de preços; modelo de vídeo Seedance 1.0 pro lançado simultaneamente : A Volcano Engine lançou o Doubao Large Model 1.6, pioneiro na precificação por intervalo de “comprimento de entrada”. O preço para o intervalo de entrada de 0-32K é de 0,8 yuan/milhão de tokens, e a saída é de 8 yuan/milhão de tokens, representando uma redução de custo de 63% em relação à versão 1.5. O recém-lançado modelo de geração de vídeo Seedance 1.0 pro tem um preço de 1,5 cêntimos por mil tokens, gerando um vídeo de 5 segundos a 1080P por cerca de 3,67 yuan. Tan Dai, presidente da Volcano Engine, afirmou que esta redução de preço foi alcançada através da otimização direcionada dos custos para o intervalo de 32K frequentemente utilizado pelas empresas e da inovação no modelo de negócios, com o objetivo de promover a aplicação em larga escala de Agents. (Fonte: Doubao Large Model reduz drasticamente os preços novamente, Volcano Engine continua a lutar agressivamente por quota de mercado, A “Volcano” avança sobre a Baidu Cloud)
Universidade de Ciência e Tecnologia de Hong Kong e Huawei propõem o framework AutoSchemaKG, alcançando a construção totalmente autónoma de grafos de conhecimento : O laboratório KnowComp da Universidade de Ciência e Tecnologia de Hong Kong, em colaboração com o Departamento de Teoria da Huawei de Hong Kong, propôs o framework AutoSchemaKG, que permite a construção totalmente autónoma de grafos de conhecimento sem a necessidade de esquemas predefinidos. O sistema utiliza modelos de linguagem grandes para extrair diretamente triplas de conhecimento de texto e induzir esquemas de entidades e eventos. Com base neste framework, a equipa construiu a série de grafos de conhecimento ATLAS, contendo mais de 900 milhões de nós e 5,9 mil milhões de arestas. Experiências demonstram que, com zero intervenção humana, a indução de esquemas alcança um alinhamento semântico de 95% com esquemas desenhados por humanos. (Fonte: O maior GraphRag de código aberto: Construção totalmente autónoma de grafos de conhecimento)

Qijing Technology lança solução de servidor integrado de hardware e software com 8 placas, melhorando a eficiência de execução do modelo grande DeepSeek : A Qijing Technology, em colaboração com a Intel, realizou um salão ecológico e lançou a sua mais recente solução de servidor integrado de hardware e software com 8 placas. Esta solução consegue executar eficientemente modelos grandes como o DeepSeek-R1/V3-671B, com um aumento de desempenho de até 7 vezes em comparação com uma única placa. Ao mesmo tempo, o seu motor de inferência auto-desenvolvido KLLM, a plataforma de gestão de modelos grandes AMaaS e o conjunto de aplicações de escritório “Qijing·Zhiwen” também receberam atualizações importantes, visando resolver desafios como o alto limiar de entrada e o desempenho de execução insuficiente enfrentados pela implementação privada de modelos grandes. (Fonte: Salão Ecológico Qijing Technology & Intel realizado, fusão de hardware, motor de inferência e ecossistema de aplicações de nível superior, abrindo o “último quilómetro” da privatização de modelos grandes)

Black Forest Labs lança a série de modelos de imagem FLUX.1 Kontext, reforçando a consistência de personagens e estilos : A alemã Black Forest Labs lançou a série de modelos de texto para imagem FLUX.1 Kontext (versões max, pro, dev), focada em manter a consistência de personagens e estilos ao editar imagens. Esta série de modelos suporta modificações locais e globais em imagens e pode gerar imagens a partir de entradas de texto e/ou imagem. A versão FLUX.1 Kontext dev está planeada para ser de código aberto. Num benchmark proprietário contendo cerca de 1000 pares de prompts e imagens de referência, as versões FLUX.1 Kontext max e pro superaram modelos concorrentes como o OpenAI GPT Image 1 e o Google Gemini 2.0 Flash. (Fonte: DeepLearning.AI Blog)

NVIDIA, Universidade Rutgers e outras instituições propõem o framework STORM, utilizando camadas Mamba para reduzir os Tokens necessários para a compreensão de vídeo : Investigadores da NVIDIA, Universidade Rutgers, Universidade da Califórnia em Berkeley e outras instituições construíram o sistema texto-vídeo STORM. Este sistema introduz camadas Mamba entre o transformador visual SigLIP e o LLM do Qwen2-VL, enriquecendo as incorporações de Token de um único frame com informações de outros frames do mesmo clipe, permitindo assim a média das incorporações de Token entre frames sem perder informações cruciais. Isto permite que o sistema processe vídeos com menos Tokens, superando o GPT-4o e o Qwen2-VL em benchmarks de compreensão de vídeo como MVBench e MLVU, ao mesmo tempo que aumenta a velocidade de processamento em mais de 3 vezes. (Fonte: DeepLearning.AI Blog)

Cofundador da Google mantém reservas sobre robôs humanoides, perspetivas de comercialização de robôs especializados são promissoras : Sergey Brin, cofundador da Google, expressou pouco entusiasmo por robôs humanoides que replicam estritamente a forma humana, considerando que não é uma condição necessária para o trabalho eficaz dos robôs. Entretanto, robôs especializados estão a ganhar atenção devido à sua característica de “prontos a usar” e a um caminho claro para a comercialização. Por exemplo, robôs subaquáticos e corta-relvas demonstram um enorme potencial em cenários específicos. A análise sugere que, na fase atual, a forma do robô e a produtividade que resolvem problemas reais são cruciais, e os robôs especializados, com modelos de negócios claros e cenários de necessidade premente, estão a liderar a comercialização. (Fonte: Robôs especializados dão um toque nos robôs humanoides “Irmão, dá licença, quero sentar-me à mesa.”)

Google lança agente de engenharia de dados BigQuery para geração inteligente de pipelines : A Google lançou o agente de engenharia de dados BigQuery, uma ferramenta que utiliza inferência sensível ao contexto para expandir eficientemente a geração de pipelines de dados. Os utilizadores podem definir os requisitos do pipeline através de simples comandos de linha, e o agente utiliza prompts específicos do domínio para gerar código de pipeline em lote personalizado para o ambiente de dados do utilizador, incluindo configuração de ingestão de dados, consultas de transformação, lógica de criação de tabelas e configurações de agendamento através do Dataform ou Composer. A ferramenta visa simplificar o trabalho repetitivo enfrentado pelos engenheiros de dados ao lidar com múltiplos domínios de dados, ambientes e lógicas de transformação, com o auxílio da AI. (Fonte: Reddit r/deeplearning)
Yandex lança Yambda, um conjunto de dados público em larga escala com quase 5 mil milhões de interações utilizador-faixa de áudio : A Yandex lançou um conjunto de dados público em larga escala chamado Yambda, projetado especificamente para a investigação de sistemas de recomendação. Este conjunto de dados contém quase 5 mil milhões de interações anónimas de utilizadores com faixas de áudio do Yandex Music, oferecendo aos investigadores uma oportunidade rara de trabalhar com dados em escala do mundo real. (Fonte: _akhaliq)

ByteDance lança modelo de reparação de vídeo SeedVR2 no Hugging Face : A equipa Seed da ByteDance lançou o SeedVR2 no Hugging Face, um modelo Transformer de difusão de passo único para reparação de vídeo. O modelo utiliza a licença Apache 2.0, caracteriza-se pela inferência de passo único, sendo rápido e eficiente, e suporta o processamento de resolução arbitrária, sem necessidade de divisão em blocos ou limitações de tamanho. (Fonte: huggingface)
Modelo de vídeo grande Seedance 1.0 Pro da ByteDance Doubao recebe elogios nos testes práticos : O mais recente modelo grande de imagem para vídeo da ByteDance, Seedance 1.0 Pro, demonstrou boa capacidade de seguir instruções e estabilidade na geração de objetos em testes práticos. O feedback dos utilizadores indica que a qualidade da geração de vídeo é alta, com movimentos de câmara precisos, ficando atrás apenas do Veo 2/3. Uma desvantagem potencial é que, ao gerar movimento puro de objetos, o modelo por vezes adiciona a operação de mãos para tornar a cena mais razoável, o que pode ser evitado limitando o aparecimento de mãos. (Fonte: karminski3, karminski3, karminski3)
Alibaba torna open-source o framework de avatares digitais Mnn3dAvatar, suportando captura facial em tempo real e criação de personagens virtuais 3D : O Alibaba tornou open-source no GitHub um framework de avatares digitais chamado Mnn3dAvatar. Este projeto permite a captura facial em tempo real e o mapeamento de expressões para personagens virtuais 3D, ao mesmo tempo que permite aos utilizadores criar os seus próprios personagens virtuais 3D. Este framework é adequado para cenários simples como transmissões ao vivo de vendas, apresentação de conteúdo, etc. (Fonte: karminski3)
NVIDIA torna open-source o modelo base de robô humanoide Gr00t N 1.5 3B e fornece tutorial de fine-tuning : A NVIDIA tornou open-source o modelo Gr00t N 1.5 3B, um modelo base aberto projetado especificamente para as habilidades de raciocínio de robôs humanoides, sob uma licença comercial. Ao mesmo tempo, a NVIDIA também lançou um tutorial completo de fine-tuning para ser usado com o LeRobotHF SO101, com o objetivo de promover o desenvolvimento e a aplicação da tecnologia de robôs humanoides. (Fonte: ClementDelangue)
Together AI lança Batch API, oferecendo serviço de inferência LLM em larga escala com grande redução de preço : A Together AI lançou a nova Batch API, projetada especificamente para inferência LLM em larga escala, suportando cenários de aplicação de alto throughput como geração de dados sintéticos, benchmarking, moderação e resumo de conteúdo, e extração de documentos. A API introduz um preço de entrada 50% mais barato que a API em tempo real, suportando o processamento em lote de até 50.000 pedidos ou 100MB por vez, e é compatível com 15 modelos de topo. (Fonte: vipulved)
Google Gemini 2.5 Pro adiciona funcionalidade de geração interativa de arte fractal : A Google anunciou que o Gemini 2.5 Pro agora suporta a criação instantânea de arte fractal interativa. Os utilizadores podem gerar obras de arte visual únicas fornecendo prompts como “crie para mim uma bela obra de arte fractal baseada em partículas, animada, infinita, 3D, simétrica, inspirada em fórmulas matemáticas”. (Fonte: demishassabis)
Velocidade de geração de vídeo do Google Veo3 Fast aumenta duas vezes : Os laboratórios da Google anunciaram que a velocidade de geração da versão Veo3 Fast da sua ferramenta de geração de vídeo Flow aumentou mais de duas vezes, mantendo a resolução de 720p. Esta atualização visa permitir que os utilizadores criem conteúdo de vídeo mais rapidamente. (Fonte: op7418)
Hugging Face integra-se com Google Colab e Kaggle, simplificando o fluxo de utilização de modelos : O Hugging Face está agora integrado com o Google Colab e o Kaggle. Os utilizadores podem iniciar diretamente notebooks Colab a partir de qualquer cartão de modelo, ou abrir o mesmo modelo em Kaggle Notebooks, acompanhado de exemplos de código público executáveis, simplificando assim o fluxo de utilização e experimentação de modelos. (Fonte: ClementDelangue, huggingface)
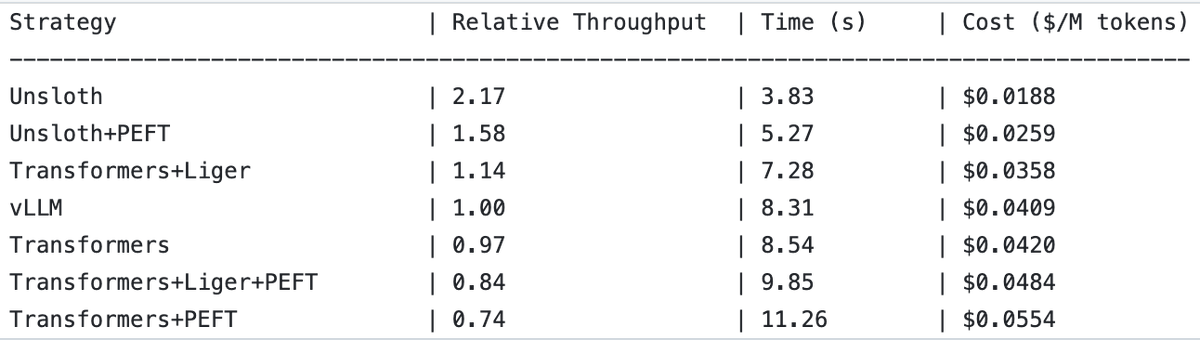
UnslothAI alcança aumento de 2x no throughput em serviços de modelo de recompensa e inferência de classificação de sequências : Descobriu-se que o UnslothAI pode ser usado para fornecer serviços de modelo de recompensa (RM) e, na inferência de classificação de sequências, o seu throughput é duas vezes superior ao do vLLM. Esta descoberta despertou atenção na comunidade de RL (Reinforcement Learning), e o aumento de desempenho do UnslothAI promete acelerar a investigação e aplicações relacionadas. (Fonte: natolambert, danielhanchen)
Digua Robot lança o primeiro kit de desenvolvimento de robôs RDK S100 com SoC único integrado para computação e controlo : A Digua Robot lançou o primeiro kit de desenvolvimento de robôs da indústria com SoC (System on Chip) único integrado para computação e controlo, o RDK S100. Este kit adota um design de arquitetura semelhante ao cérebro e cerebelo humanos, integrando CPU+BPU+MCU num único SoC, suportando a colaboração eficiente de modelos grandes e pequenos de inteligência incorporada, e completando o ciclo fechado de “perceção-decisão-controlo”. O RDK S100 oferece várias interfaces e infraestruturas de desenvolvimento com coordenação de software e hardware e integração端-nuvem, visando acelerar a construção de produtos de inteligência incorporada e a implementação em múltiplos cenários. Atualmente, já colabora com mais de 20 clientes de topo, com um preço de mercado de 2799 yuan. (Fonte: Digua Robot lança o primeiro kit de desenvolvimento de robôs com SoC único integrado para computação e controlo, já colabora com mais de 20 clientes de topo | Linha da Frente)

🧰 Ferramentas
LangChain lança benchmark de arquitetura multi-agente e melhorias no método de supervisor : A LangChain, face ao crescente número de sistemas multi-agente, realizou um benchmark preliminar para explorar como otimizar a coordenação entre múltiplos agentes. Ao mesmo tempo, a LangChain fez algumas melhorias no seu método de supervisor (supervisor), e o blogue relacionado foi publicado. (Fonte: LangChainAI, hwchase17)
Cartesia lança Ink-Whisper: Modelo de speech-to-text em streaming rápido e económico, projetado para agentes de voz : A Cartesia lançou o Ink-Whisper, um modelo de speech-to-text (STT) em streaming de alta velocidade e baixo custo, otimizado para agentes de voz. Este modelo foi projetado para precisão em condições do mundo real e pode ser usado em conjunto com o modelo de text-to-speech (TTS) Sonic da Cartesia para permitir interações rápidas de AI por voz. O Ink-Whisper suporta a integração com plataformas como VapiAI, PipecatAI e Livekit. (Fonte: simran_s_arora, tri_dao, krandiash)

MonkeyOCR: Modelo de análise de documentos pequeno, rápido e de código aberto : Foi lançado um modelo de análise de documentos com 3B parâmetros chamado MonkeyOCR, sob a licença Apache 2.0. Este modelo é capaz de analisar vários elementos em documentos, incluindo gráficos, fórmulas, tabelas, etc., com o objetivo de substituir os pipelines de analisadores tradicionais e fornecer uma solução de processamento de documentos superior. (Fonte: mervenoyann, huggingface)
LlamaIndex integra-se com Cleanlab para aumentar a confiabilidade das respostas do assistente de AI : O LlamaIndex anunciou a sua integração com o CleanlabAI. O LlamaIndex é usado para construir assistentes de conhecimento de AI e agentes de nível de produção, gerando insights a partir de dados empresariais. A adição do Cleanlab visa aumentar a confiabilidade das respostas desses assistentes de AI, sendo capaz de pontuar cada resposta do LLM, capturar alucinações ou respostas incorretas em tempo real e ajudar a analisar as causas da falta de confiabilidade das respostas (como recuperação deficiente, problemas de dados/contexto, consultas complicadas ou alucinações do LLM). (Fonte: jerryjliu0)

Claude Code adiciona “modo de plano”, melhorando a controlabilidade de alterações complexas de código : O Claude Code da Anthropic introduziu o “modo de plano” (Plan mode). Esta funcionalidade permite aos utilizadores rever o plano de implementação antes de efetivamente alterar o código, garantindo que cada passo seja ponderado, especialmente para alterações complexas de código. Os utilizadores podem entrar no modo de plano pressionando Shift + Tab duas vezes, e o Claude Code fornecerá um plano de implementação detalhado e solicitará confirmação antes da execução. A funcionalidade foi lançada para todos os utilizadores do Claude Code (incluindo subscritores Pro ou Max). (Fonte: dotey, kylebrussell)
rvn-convert: Ferramenta de conversão de SafeTensors para GGUF v3 implementada em Rust : Foi lançada uma ferramenta de código aberto chamada rvn-convert, escrita em Rust, para converter ficheiros de modelo do formato SafeTensors para o formato GGUF v3. Esta ferramenta destaca-se pelo suporte a fragmento único, rapidez, ausência de necessidade de ambiente Python, capacidade de mapear ficheiros safetensors em memória e escrever diretamente em ficheiros gguf, evitando picos de RAM e problemas de rotação de disco. Atualmente, suporta upsampling de BF16 para F32, incorporação de tokenizer.json, entre outras funcionalidades. (Fonte: Reddit r/LocalLLaMA)
Runway API adiciona funcionalidade de super-resolução de vídeo 4K : A Runway anunciou que a sua API agora suporta a funcionalidade de super-resolução de vídeo 4K. Os programadores podem integrar esta funcionalidade nas suas próprias aplicações, produtos, plataformas e websites para melhorar a clareza e qualidade do conteúdo de vídeo. (Fonte: c_valenzuelab)
You.com lança funcionalidade Projects para organizar e gerir materiais de investigação : O You.com lançou uma nova ferramenta chamada “Projects”, concebida para ajudar os utilizadores a organizar os seus materiais de investigação em pastas de fácil acesso. Esta funcionalidade permite aos utilizadores contextualizar e estruturar conversas, evitando a dispersão de registos de chat e a perda de insights, simplificando assim o processo de gestão do conhecimento. (Fonte: RichardSocher)
LlamaIndex lança serviço de extração de documentos LlamaExtract para agentes : O LlamaIndex lançou o LlamaExtract, um serviço de extração de documentos orientado por agentes, concebido para extrair dados estruturados de documentos complexos e esquemas de entrada. Este serviço não só extrai pares chave-valor, mas também fornece raciocínio preciso da fonte, referências de página e texto correspondente para cada item extraído. O LlamaExtract é fornecido como uma API e pode ser facilmente integrado em fluxos de trabalho de agentes downstream. (Fonte: jerryjliu0)

langchain-google-vertexai lança atualização, melhorando o cache do cliente e o suporte a ferramentas : langchain-google-vertexai recebeu uma nova versão. As principais atualizações incluem: cache do cliente de previsão, tornando a instanciação de novos clientes 500 vezes mais rápida; suporte para ferramentas de execução de código integradas. (Fonte: LangChainAI, Hacubu)
Perplexity Finance adiciona funcionalidade de download direto de modelos Excel : A Perplexity Finance anunciou que os utilizadores podem agora descarregar modelos Excel diretamente da sua página, fornecendo um ponto de partida mais rápido para modelagem financeira e investigação. Esta funcionalidade está disponível gratuitamente para todos os utilizadores; anteriormente, apenas o formato CSV era suportado para download. (Fonte: AravSrinivas)
Viwoods lança tablet de e-ink AI Paper Mini, integrando GPT-4o e outras funcionalidades de AI : A emergente fabricante de e-ink Viwoods lançou o AI Paper Mini, um tablet de e-ink equipado com funcionalidades de AI. O dispositivo suporta GPT-4o, DeepSeek e outros modelos de AI, oferecendo modo Chat e assistentes de AI predefinidos (análise de conteúdo, geração de e-mails, AI para texto). As suas funcionalidades distintivas incluem gestão de tarefas em vista de calendário, notas em janela flutuante rápida, etc. Em termos de hardware, o Paper Mini utiliza um ecrã Carta 1000 de 292 ppi, 4GB+128GB de armazenamento, e vem com uma caneta stylus. Simultaneamente, a Viwoods também lançou o AI Paper de maiores dimensões, com um ecrã flexível Carta 1300 de 300ppi e uma velocidade de resposta mais rápida. (Fonte: Gastei metade do preço de um iPhone para comprar um “tablet de e-ink” com AI…)

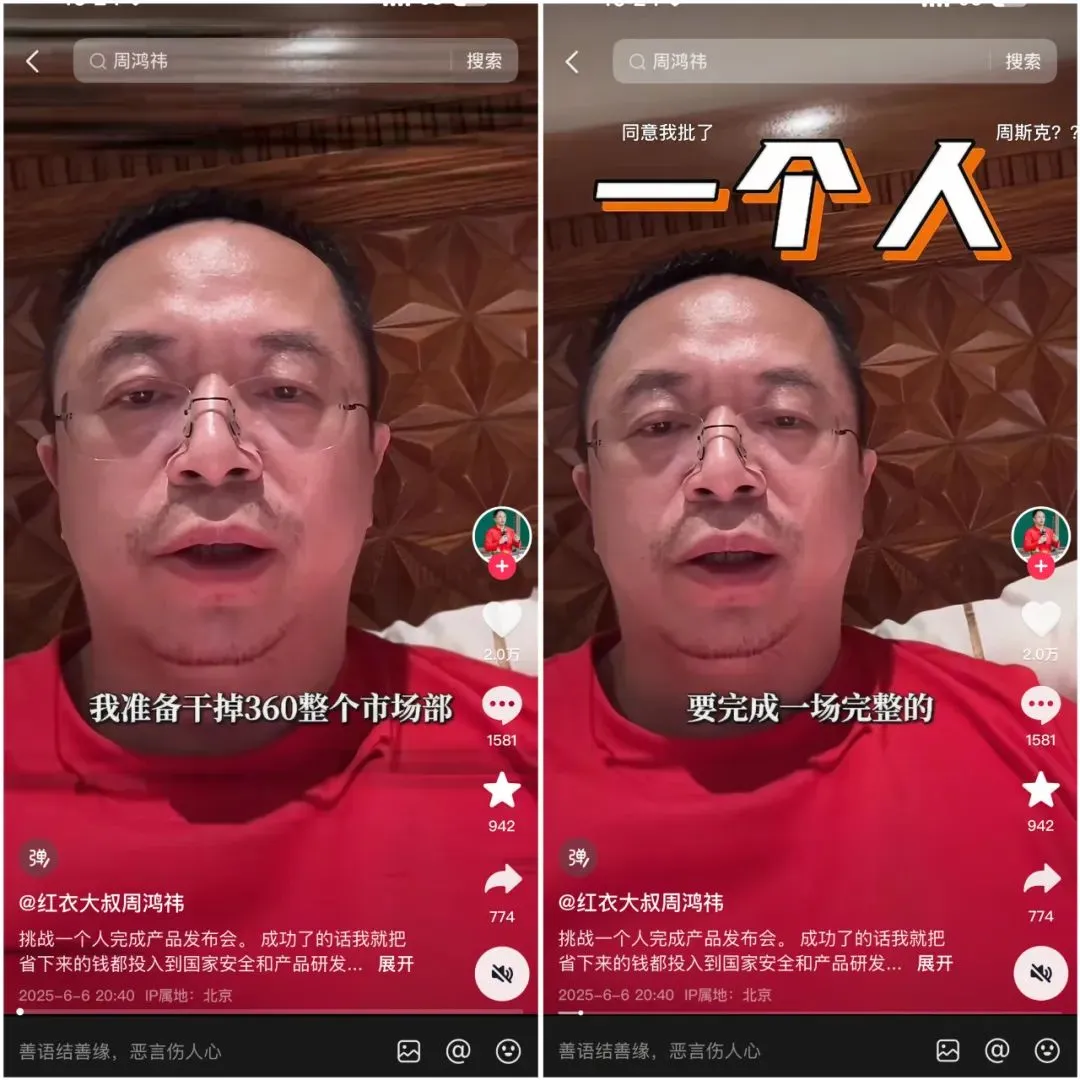
360 lança agente de super pesquisa inteligente Nano AI, com Zhou Hongyi a apresentar pessoalmente : O fundador do Grupo 360, Zhou Hongyi, apresentou o agente de super pesquisa inteligente Nano AI. Este agente visa alcançar a capacidade de “pesquisar tudo com uma única frase”, sendo capaz de pensar autonomamente, invocar o navegador e ferramentas externas para executar tarefas sem intervenção humana, e suportar visualização completa e rastreabilidade dos passos. Zhou Hongyi afirmou que a própria conferência de lançamento também tentou utilizar o Nano AI na sua preparação, e lançou o hardware de gravação inteligente AI Nano AI Note, bem como óculos AI em colaboração com a Rokid. (Fonte: Zhou Hongyi quer “eliminar” o departamento de marketing com AI, o “Nano” conseguiu?)
📚 Aprendizagem
DeepLearning.AI lança novo curso breve: Orquestrar fluxos de trabalho GenAI com Apache Airflow : A DeepLearning.AI, em colaboração com a Astronomer, lançou um novo curso breve que ensina como usar o Apache Airflow 3.0 para transformar protótipos RAG em fluxos de trabalho prontos para produção. O conteúdo do curso inclui a decomposição de fluxos de trabalho em tarefas modulares, o agendamento de pipelines usando gatilhos orientados por tempo e eventos, o mapeamento dinâmico de tarefas para execução paralela, a adição de tentativas/alertas/preenchimento retroativo para tolerância a falhas e técnicas de escalonamento de pipelines. Este curso não requer experiência prévia com Airflow. (Fonte: DeepLearningAI, FLUX.1 Kontext’s Consistent Characters, Benchmarking Costs Climb, Mary Meeker’s Action-Packed AI Report, Better Video Gen)
Hamel Husain lança minicurso sobre otimização e avaliação de RAG : Hamel Husain anunciou o lançamento de um minicurso de quatro partes sobre otimização e avaliação de RAG (Retrieval Augmented Generation). A primeira parte, apresentada por @bclavie, discute a perspetiva de “recuperação como RAG”, visando responder a discussões anteriores sobre RAG ser um “vírus mental que precisa ser erradicado”. Esta série de cursos é gratuita e visa ajudar os profissionais a resolver os desafios encontrados na avaliação de RAG. (Fonte: HamelHusain, HamelHusain, lateinteraction, HamelHusain, HamelHusain, HamelHusain, HamelHusain, HamelHusain)

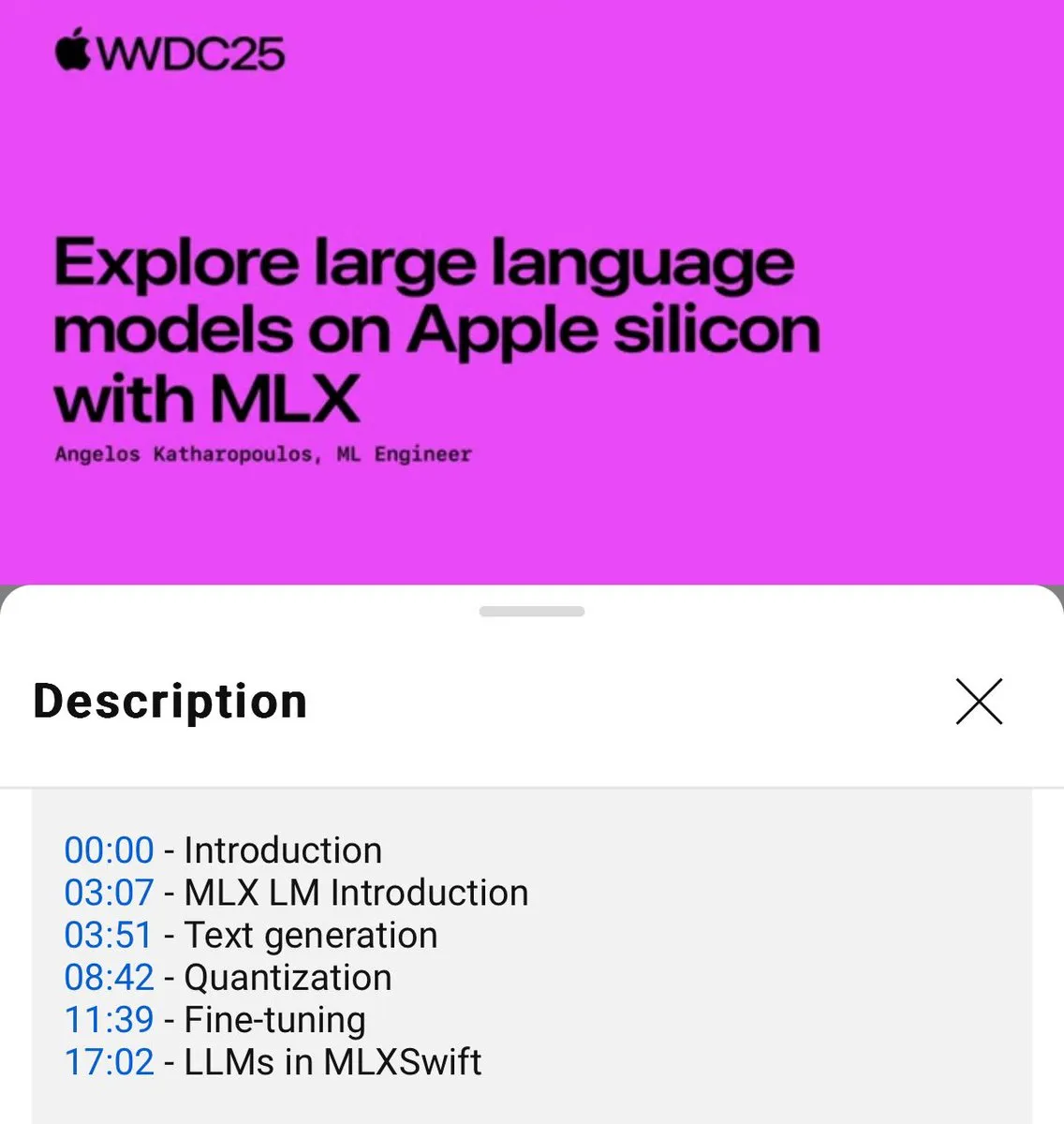
Tutorial de uso local de modelos de linguagem MLX lançado (WWDC25) : Na conferência WWDC25, Angelos Katharopoulos apresentou como usar o MLX para começar rapidamente com modelos de linguagem locais. O tutorial abrange o uso do MLXLM CLI para operações de linha de comando única, como quantização de modelos (mlx_lm.convert), fine-tuning LoRA (mlx_lm.lora) e fusão de modelos com upload para o Hugging Face (mlx_lm.fuse). O tutorial completo em Jupyter Notebook está disponível no GitHub. (Fonte: awnihannun)
LangChain partilha o método da Harvey AI para construir agentes de AI jurídicos : Ben Liebald, da Harvey AI, partilhou no evento Interrupt da LangChain o método maduro da sua empresa para construir agentes de AI jurídicos. Este método combina a avaliação LangSmith e uma estratégia de “advogado no circuito” (lawyer-in-the-loop), visando fornecer ferramentas de AI confiáveis para advogados em trabalhos jurídicos complexos. (Fonte: LangChainAI, hwchase17)

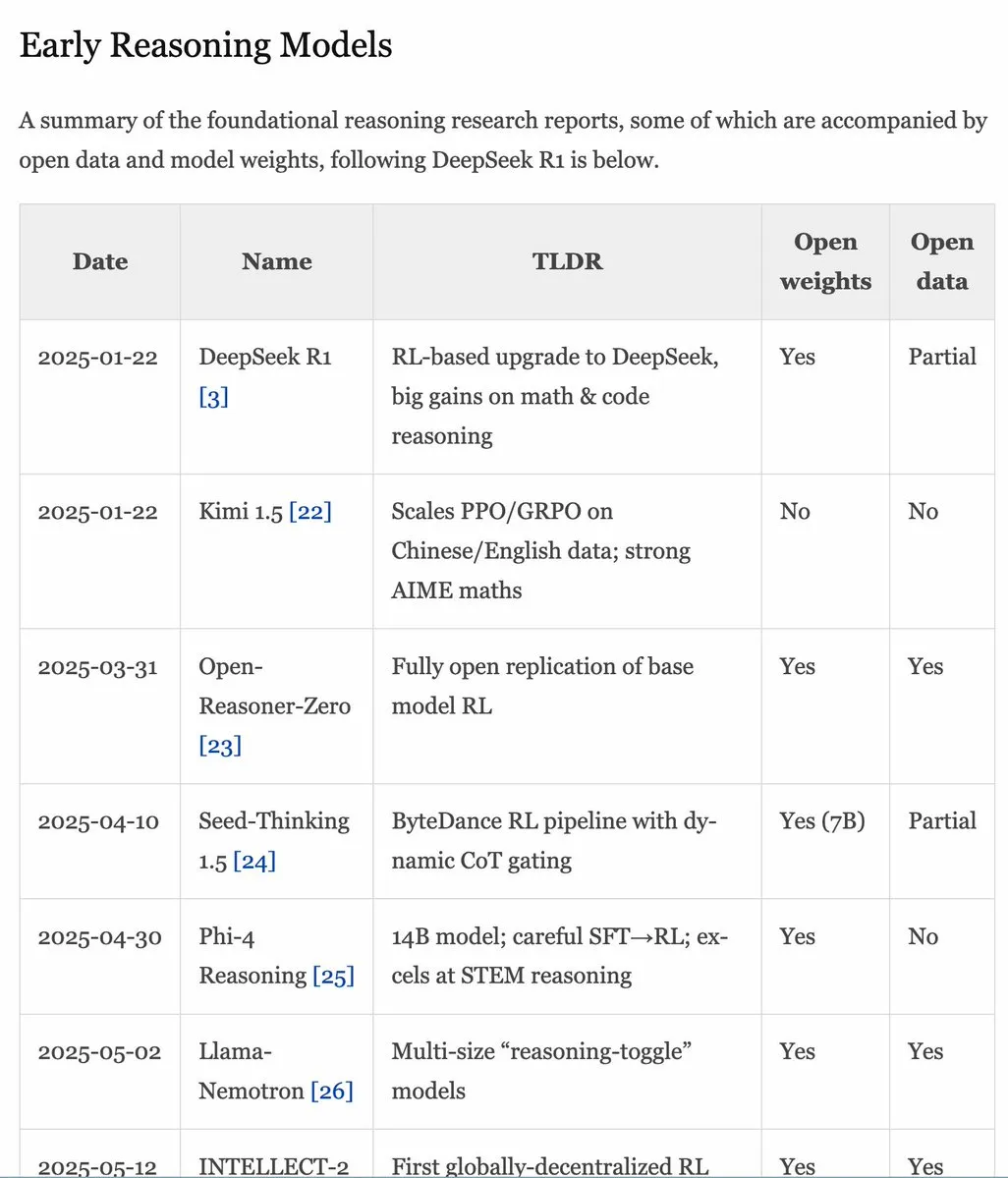
Manual RLHF v1.1 atualizado, expande conteúdo sobre RLVR/modelos de inferência : O manual RLHF (rlhfbook.com) foi atualizado para a versão v1.1, adicionando conteúdo expandido sobre RLVR (Reinforcement Learning from Video Representations) e modelos de inferência. A atualização inclui um resumo dos principais relatórios de modelos de inferência, práticas/técnicas comuns e seus utilizadores, trabalhos de inferência relevantes anteriores ao o1 e melhorias como RL assíncrono. (Fonte: menhguin)
Artigo SWE-Flow: Síntese de dados de engenharia de software orientada a testes : Um novo artigo intitulado SWE-Flow propõe um novo framework de síntese de dados baseado em Test-Driven Development (TDD). Este framework analisa automaticamente testes unitários para inferir passos de desenvolvimento incrementais, construindo um grafo de dependências em tempo de execução (RDG) para gerar planos de desenvolvimento estruturados. Cada passo produz uma base de código parcial, os testes unitários correspondentes e as modificações de código necessárias, criando assim tarefas TDD verificáveis. Com base neste método, foi gerado o conjunto de dados de benchmark SWE-Flow-Eval. (Fonte: HuggingFace Daily Papers)
Artigo PlayerOne: O primeiro simulador do mundo real construído a partir de uma perspetiva de primeira pessoa : PlayerOne é proposto como o primeiro simulador do mundo real construído a partir de uma perspetiva de primeira pessoa (egocêntrica), capaz de exploração imersiva em ambientes dinâmicos. Dada uma imagem da cena em primeira pessoa do utilizador, PlayerOne pode construir o mundo correspondente e gerar vídeos em primeira pessoa estritamente alinhados com os movimentos reais do utilizador capturados por uma câmara externa. O modelo adota um fluxo de treino do grosso para o fino e projeta um esquema de injeção de movimento com desacoplamento de componentes e um framework de reconstrução conjunta. (Fonte: HuggingFace Daily Papers)
Artigo ComfyUI-R1: Explorando modelos de inferência para geração de fluxos de trabalho : ComfyUI-R1 é o primeiro modelo de inferência grande para a geração automatizada de fluxos de trabalho. Os investigadores construíram primeiro um conjunto de dados com 4K fluxos de trabalho e construíram dados de raciocínio de cadeia de pensamento longa (CoT). O ComfyUI-R1 é treinado através de um framework de duas fases: fine-tuning CoT para arranque a frio e aprendizagem por reforço para incentivar a capacidade de inferência. As experiências mostram que o modelo de 7B parâmetros supera significativamente os métodos existentes em termos de validade do formato, taxa de aprovação e pontuações F1 ao nível do nó/grafo. (Fonte: HuggingFace Daily Papers)
Artigo SeerAttention-R: Framework adaptativo de atenção esparsa para inferência longa : SeerAttention-R é um framework de atenção esparsa projetado especificamente para a descodificação longa de modelos de inferência. Ele aprende a esparsidade da atenção através de um mecanismo de gating auto-destilado e remove o pooling de consulta para se adaptar à descodificação autorregressiva. Este framework pode ser integrado como um plugin leve em modelos pré-treinados existentes, sem necessidade de modificar os parâmetros originais. No benchmark AIME, o SeerAttention-R treinado com apenas 0.4B tokens manteve uma precisão de inferência próxima da sem perdas em blocos de atenção esparsa grandes (64/128) com um orçamento de 4K tokens. (Fonte: HuggingFace Daily Papers)
Artigo SAFE: Deteção de falhas multitarefa para modelos de visão-linguagem-ação : O artigo propõe SAFE, um detetor de falhas projetado para políticas robóticas de uso geral (como VLA). Ao analisar o espaço de características do VLA, SAFE aprende a prever a probabilidade de falha da tarefa a partir das características internas do VLA. Este detetor é treinado em implementações bem-sucedidas e falhadas e avaliado em tarefas não vistas, sendo compatível com diferentes arquiteturas de políticas, com o objetivo de aumentar a segurança do VLA ao interagir com o ambiente. (Fonte: HuggingFace Daily Papers)
Artigo Branched Schrödinger Bridge Matching: Aprendizagem de pontes de Schrödinger ramificadas : Este estudo introduz o framework Branched Schrödinger Bridge Matching (BranchSBM) para aprender pontes de Schrödinger ramificadas, a fim de prever trajetórias intermediárias entre uma distribuição inicial e uma distribuição alvo. Diferentemente dos métodos existentes, BranchSBM é capaz de modelar evoluções ramificadas ou divergentes de um ponto de partida comum para múltiplos resultados diferentes, através da parametrização de múltiplos campos de velocidade dependentes do tempo e processos de crescimento. (Fonte: HuggingFace Daily Papers)
💼 Negócios
Meta alegadamente planeia adquirir a empresa de anotação de dados Scale AI por 15 mil milhões de dólares, fundador poderá juntar-se à Meta : Segundo relatos, a Meta planeia gastar 15 mil milhões de dólares para adquirir a Scale AI, uma empresa líder no campo da anotação de dados. Se o negócio for concretizado, o fundador chinês de 28 anos da Scale AI, Alexandr Wang, e a sua equipa juntar-se-ão diretamente à Meta. Esta medida é vista como uma iniciativa importante do CEO da Meta, Mark Zuckerberg, para fortalecer a sua equipa de AGI (Inteligência Artificial Geral) e alcançar concorrentes como a OpenAI e a Google. A Meta tem estado recentemente ativa no recrutamento de talentos em AI, oferecendo pacotes salariais na ordem das dezenas de milhões de dólares para engenheiros de topo. (Fonte: Primeiro grande nome do grupo de “superinteligência” de Zuckerberg, investigador principal da Google DeepMind, figura central da “compressão como inteligência”, dylan522p, sarahcat21, Dorialexander)
Disney e Universal Pictures processam a empresa de imagens AI Midjourney por violação de direitos de autor : A Disney e a Universal Pictures intentaram uma ação judicial contra a empresa de geração de imagens AI Midjourney, acusando-a de uso não autorizado de obras de PI famosas como “Star Wars” e “Os Simpsons”. Este caso está a gerar atenção e, se a Disney vencer, poderá ter um efeito cascata noutras empresas de AI que dependem do treino com grandes volumes de dados, exacerbando ainda mais as disputas de direitos de autor no campo da AI. (Fonte: Reddit r/artificial, Reddit r/LocalLLaMA, karminski3)

Google lança novamente “plano de demissão voluntária” devido ao impacto da pesquisa AI, afetando várias equipas importantes, incluindo pesquisa e publicidade : Face ao impacto da pesquisa AI, a Google lançou novamente um “plano de demissão voluntária” para funcionários de vários departamentos nos EUA, abrangendo equipas cruciais como pesquisa, publicidade e engenharia central, e reforçou a política de regresso ao trabalho presencial. Esta medida visa reorganizar recursos e dedicar mais esforços ao projeto emblemático de AI, Gemini, e ao desenvolvimento da experiência de pesquisa em “modo AI”. O negócio tradicional de pesquisa da Google enfrenta enormes desafios devido ao surgimento da AI, e a empresa também enfrenta pressão regulatória. (Fonte: Sob o impacto da pesquisa AI, Google lança novamente “plano de demissão voluntária”, afetando várias equipas importantes, jpt401)
🌟 Comunidade
AI expõe preconceito em experiência de deteção de fraude de assistência social em Amesterdão, projeto é suspenso : Amesterdão tentou usar um sistema de AI (Smart Check) para avaliar pedidos de assistência social e detetar fraudes. Apesar de seguir as melhores práticas de AI responsável, incluindo testes de preconceito e salvaguardas técnicas, no projeto piloto, o sistema não conseguiu alcançar equidade e eficácia. O modelo inicial apresentava preconceito contra requerentes não holandeses e homens; após ajustes, passou a ter preconceito contra holandeses e mulheres. Finalmente, devido à incapacidade de garantir a não discriminação, o projeto foi suspenso. Este caso gerou amplas discussões sobre a equidade algorítmica, a eficácia das práticas de AI responsável e a aplicação da AI na tomada de decisões em serviços públicos. (Fonte: MIT Technology Review, Inside Amsterdam’s high-stakes experiment to create fair welfare AI)

Sistema de identificação de conteúdo gerado por AI: Valor, limitações e discussão sobre a lógica de governação : Com o aumento de rumores e propaganda falsa gerados por AI, o sistema de identificação de AI tem recebido atenção como meio de governação. Teoricamente, a identificação explícita e implícita pode aumentar a eficiência do reconhecimento e aumentar o alerta dos utilizadores. No entanto, na prática, a identificação é facilmente contornada, falsificada e mal interpretada, e os custos são elevados. O artigo argumenta que a identificação de AI deve ser integrada no sistema existente de governação de conteúdo, focando-se em áreas de alto risco (como rumores, propaganda falsa), e definindo razoavelmente as responsabilidades das plataformas de geração e disseminação, ao mesmo tempo que se reforça a educação em literacia da informação do público. (Fonte: Quando os rumores apanham a “boleia” da AI)
Ferramentas de codificação assistida por AI (como Claude Code) aumentam significativamente a eficiência dos programadores e aliviam a pressão no trabalho : Vários programadores na comunidade partilharam experiências positivas com o uso de ferramentas de codificação assistida por AI (especialmente o Claude Code da Anthropic). Estas ferramentas não só ajudam a escrever, testar e depurar código, mas também fornecem suporte no planeamento de projetos, resolução de problemas complexos, etc., aumentando assim significativamente a eficiência do desenvolvimento, aliviando a pressão no trabalho e a ansiedade com prazos. Alguns utilizadores afirmaram que a assistência da AI os fez sentir como uma “força imparável”. (Fonte: AnthropicAI, sbmaruf, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Consumo de energia e recursos hídricos por conteúdo gerado por AI gera preocupação, Sam Altman afirma que cada consulta ao ChatGPT consome cerca de 1/15 de uma colher de chá de água : O CEO da OpenAI, Sam Altman, revelou que cada consulta ao ChatGPT consome aproximadamente “um quinze avos de uma colher de chá” de água. Este dado gerou discussões sobre o impacto ambiental do treino e inferência de modelos de AI. Embora o método de cálculo específico e se os custos de treino estão incluídos não sejam claros, a pegada energética e o consumo de recursos hídricos da AI tornaram-se temas de preocupação nos setores tecnológico e ambiental. (Fonte: MIT Technology Review, Reddit r/ChatGPT)

Discussão sobre se os LLMs realmente compreendem provas matemáticas: Benchmark IneqMath revela deficiências dos modelos : O recém-lançado benchmark IneqMath foca-se em provas de desigualdades matemáticas de nível olímpico. A investigação descobriu que, embora os LLMs por vezes consigam encontrar a resposta correta, existe uma lacuna significativa na construção de provas rigorosas e razoáveis. Isto gerou uma discussão sobre se os LLMs, em áreas como a matemática, estão realmente a compreender ou apenas a “adivinhar”. Sathya salientou que este fenómeno de “resposta correta – raciocínio errado” também se manifesta em benchmarks como o PutnamBench. (Fonte: lupantech, lupantech, _akhaliq, clefourrier)
Aplicação e discussão de AI Agents no desenvolvimento de software, investigação e tarefas diárias : A comunidade discute amplamente a aplicação de AI Agents em diferentes áreas. Por exemplo, utilizadores partilham experiências na construção de fluxos de trabalho de agentes de investigação profunda usando n8n e Claude; LlamaIndex demonstra como implementar agentes de preenchimento incremental de formulários através do Artifact Memory Block; a discussão também abrange o uso do MCP (Model Context Protocol) para projetar interfaces de ferramentas orientadas para AI, e a aplicação de AI Agents em áreas como direito e automação de infraestruturas (como o JARVIS da Cisco). (Fonte: qdrant_engine, OpenAIDevs, jerryjliu0, dzhng, Reddit r/ClaudeAI, omarsar0)

Normas de segurança para robôs humanoides geram atenção, necessidade de considerar impactos físicos e psicológicos : Com a entrada gradual de robôs humanoides em aplicações industriais e a sua mira em cenários domésticos, as suas normas de segurança tornaram-se um foco de discussão. O grupo de investigação de robôs humanoides do IEEE salienta que os robôs humanoides possuem propriedades únicas, como estabilidade dinâmica, que requerem novas regras de segurança. Além da segurança física (como prevenção de quedas, colisões), é necessário considerar os desafios de comunicação na interação humano-robô (como expressão de intenções, coordenação de múltiplos robôs) e o impacto psicológico (como humanização excessiva levando a expectativas demasiado altas, segurança emocional). A elaboração de normas precisa de equilibrar inovação e segurança, e considerar as necessidades de diferentes cenários de aplicação. (Fonte: MIT Technology Review, Why humanoid robots need their own safety rules)

💡 Outros
Docker anuncia que docker run --gpus agora suporta GPUs AMD : Atualização oficial do Docker: o comando docker run --gpus agora também suporta a execução em GPUs AMD. Esta melhoria aumenta a facilidade de uso de GPUs AMD em cargas de trabalho de AI/ML em contentores, o que é positivo para promover a aplicação da AMD no ecossistema de AI. (Fonte: dylan522p)
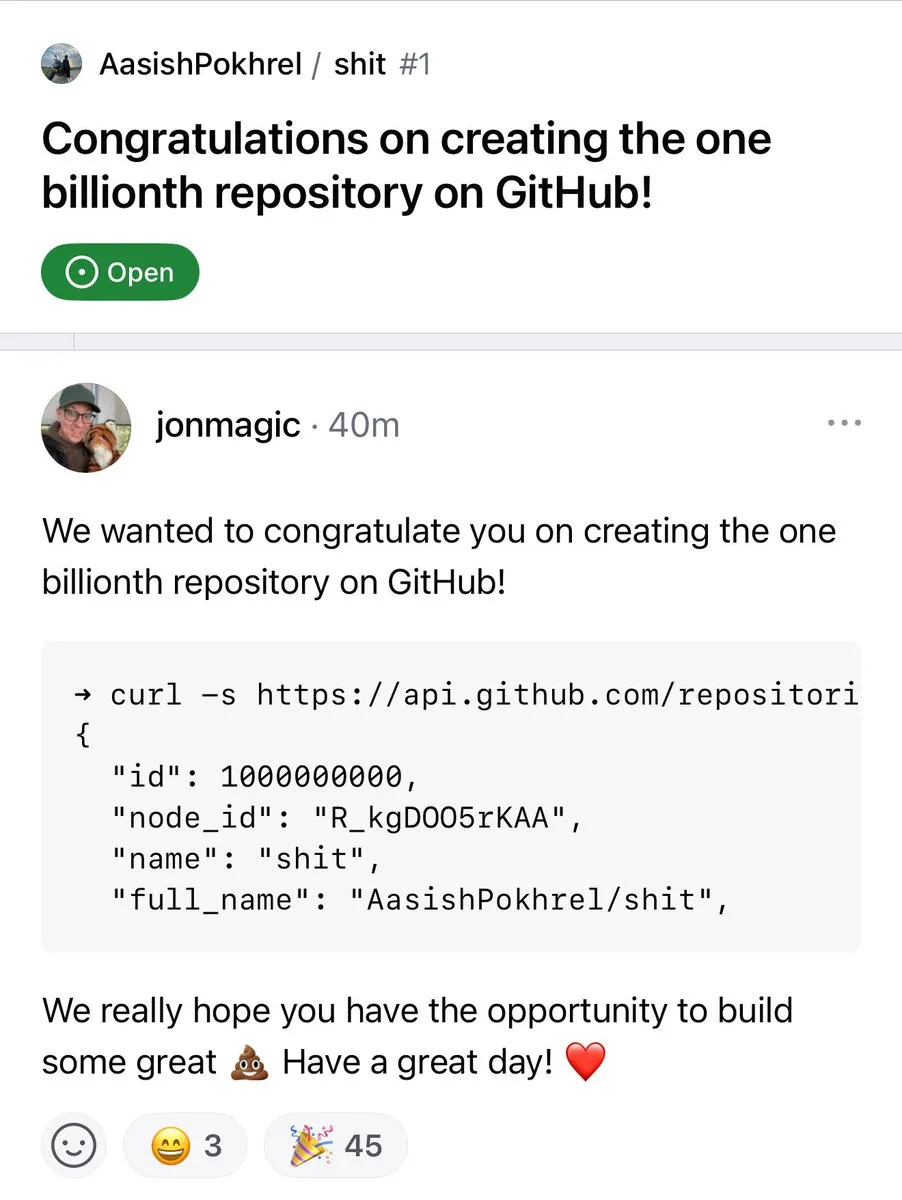
Número de repositórios no GitHub ultrapassa 1 bilião : O número de repositórios de código na plataforma GitHub ultrapassou oficialmente a marca de 1 bilião. Este marco assinala a contínua prosperidade e crescimento da comunidade de código aberto e das plataformas de alojamento de código. (Fonte: karminski3, zacharynado)
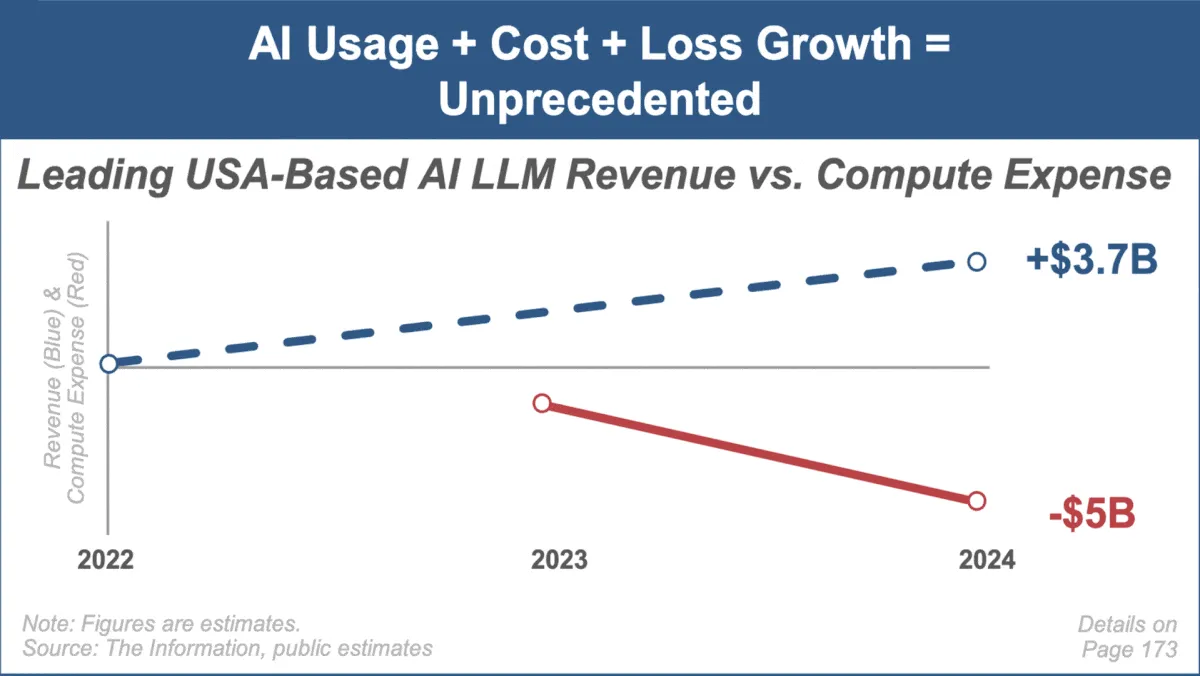
Mary Meeker lança o mais recente relatório de tendências de AI, focando no rápido crescimento e desafios do mercado : A renomada analista de investimentos Mary Meeker lançou o seu primeiro relatório de tendências sobre o mercado de inteligência artificial, intitulado “Trends — Artificial Intelligence (May ‘25)”. O relatório destaca a velocidade de crescimento sem precedentes no campo da AI, o aumento explosivo da base de utilizadores (como os 800 milhões de utilizadores do ChatGPT), o aumento significativo dos gastos de capital relacionados com AI e os contínuos avanços da AI em desempenho e capacidades emergentes. O relatório também aponta os desafios enfrentados pelos modelos de negócios de AI, como o aumento dos custos de computação, a rápida iteração de modelos e a concorrência de alternativas de código aberto. (Fonte: DeepLearning.AI Blog)