

Palavras-chave:OpenAI, Meta, IBM, Mistral AI, o3-pro, Laboratório de Superinteligência, Magistral, Computador Quântico, Preço do o3-pro, Investimento da Scale AI, Magistral-Small-2506, Computador Quântico Starling, Testes de Aplicação Militar de IA
🔥 Foco
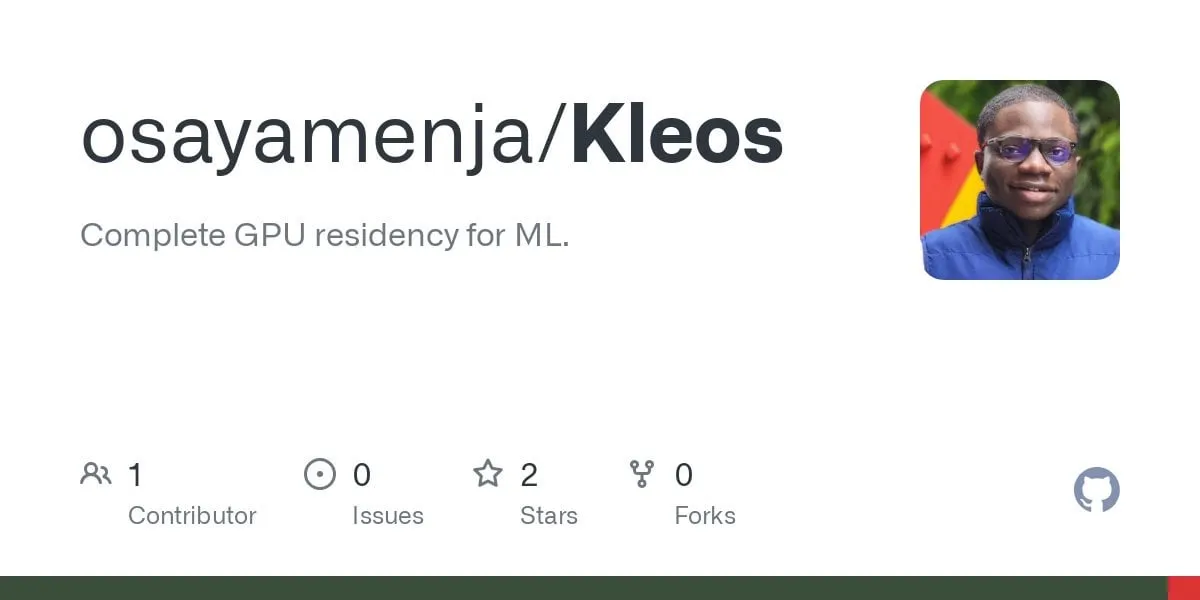
OpenAI lança o3-pro, anunciado como o modelo mais poderoso da história, e reduz drasticamente o preço do o3: A OpenAI lançou oficialmente o seu modelo de inferência mais poderoso até hoje, o o3-pro, que já está disponível para usuários do ChatGPT Pro e Team, com a API também lançada simultaneamente. O o3-pro supera as gerações anteriores em áreas como ciência, educação, programação, negócios e assistência à escrita, e suporta várias ferramentas, incluindo pesquisa na web, análise de arquivos, entrada visual e programação em Python. Seu preço é de US$ 20 por milhão de tokens de entrada e US$ 80 de saída. Ao mesmo tempo, o preço do modelo o3 original foi drasticamente reduzido em 80%, com o novo preço de US$ 2 por milhão de tokens de entrada e US$ 8 de saída, igualando o GPT-4o. Esta medida pode desencadear uma guerra de preços de modelos de IA e promover a aplicação profunda da IA em campos profissionais, mas o o3-pro também tem limitações, como tempo de resposta mais longo e, por enquanto, não suporta conversas temporárias. (Fonte: OpenAI, sama, OpenAIDevs, scaling01, dotey)
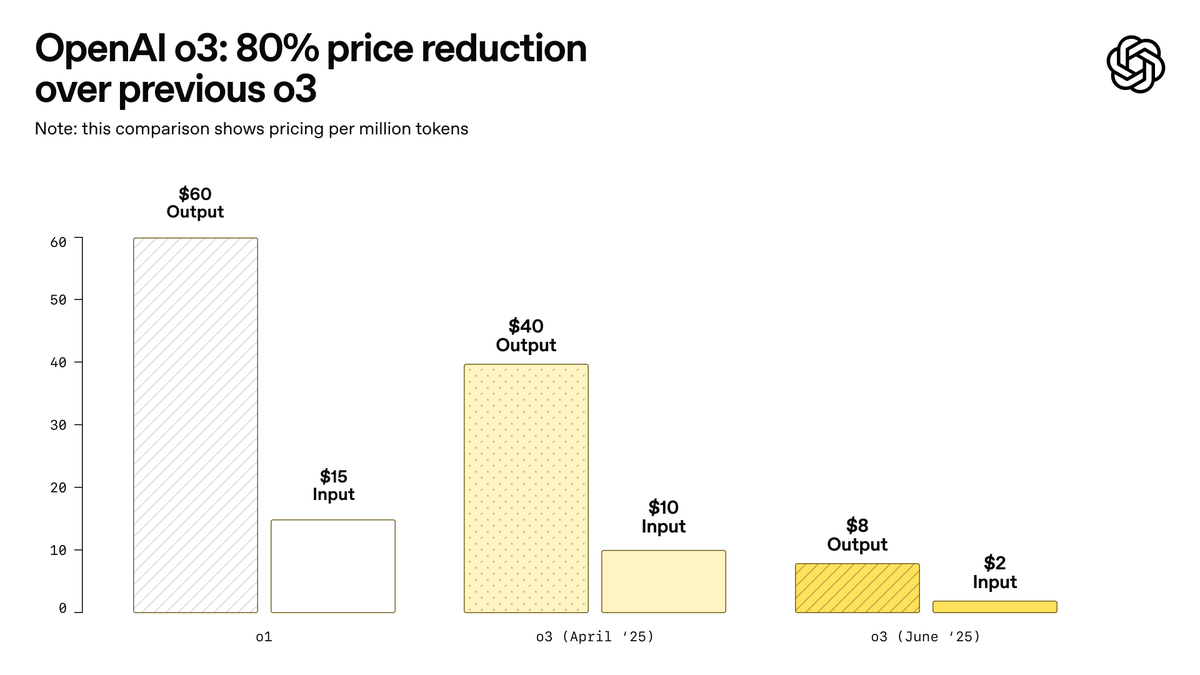
Meta cria “Superintelligence Lab” e investe pesadamente na Scale AI para revitalizar competitividade em IA: Segundo o New York Times e outras fontes, a Meta Platforms está reestruturando seu departamento de IA, criando um novo “Superintelligence Lab”, e planeja investir mais de US$ 14 bilhões para adquirir 49% das ações da empresa de anotação de dados Scale AI. O cofundador e CEO da Scale AI, Alexandr Wang, se juntará à Meta e liderará o novo laboratório. O objetivo é acelerar o desenvolvimento da inteligência artificial geral (AGI) e aumentar a competitividade geral da Meta no campo da IA, especialmente no processamento de dados de alta qualidade e no recrutamento de talentos de ponta. Isso marca uma grande mudança na estratégia de IA da Meta e pode ter um impacto profundo no cenário competitivo da indústria. (Fonte: natolambert, kylebrussell, Yuchenj_UW, steph_palazzolo)

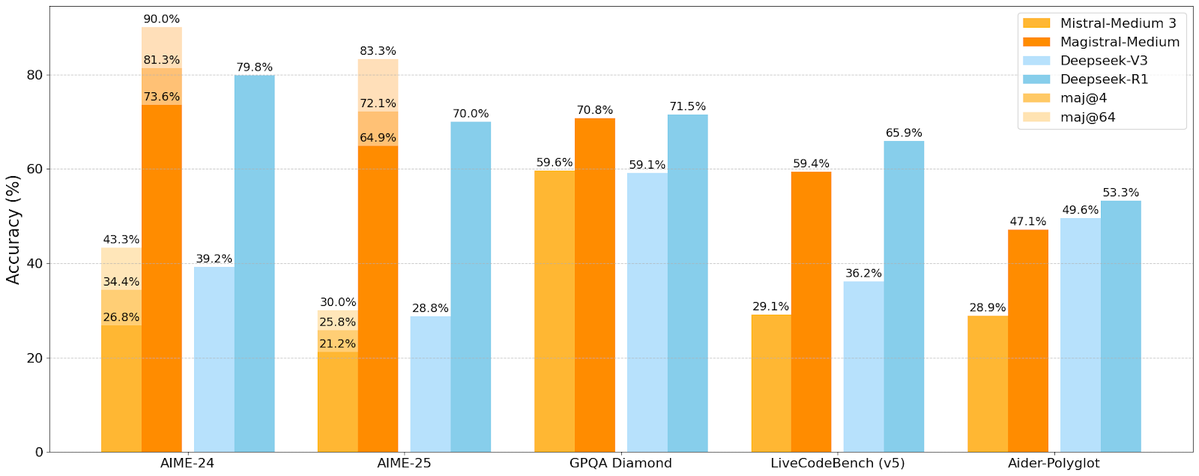
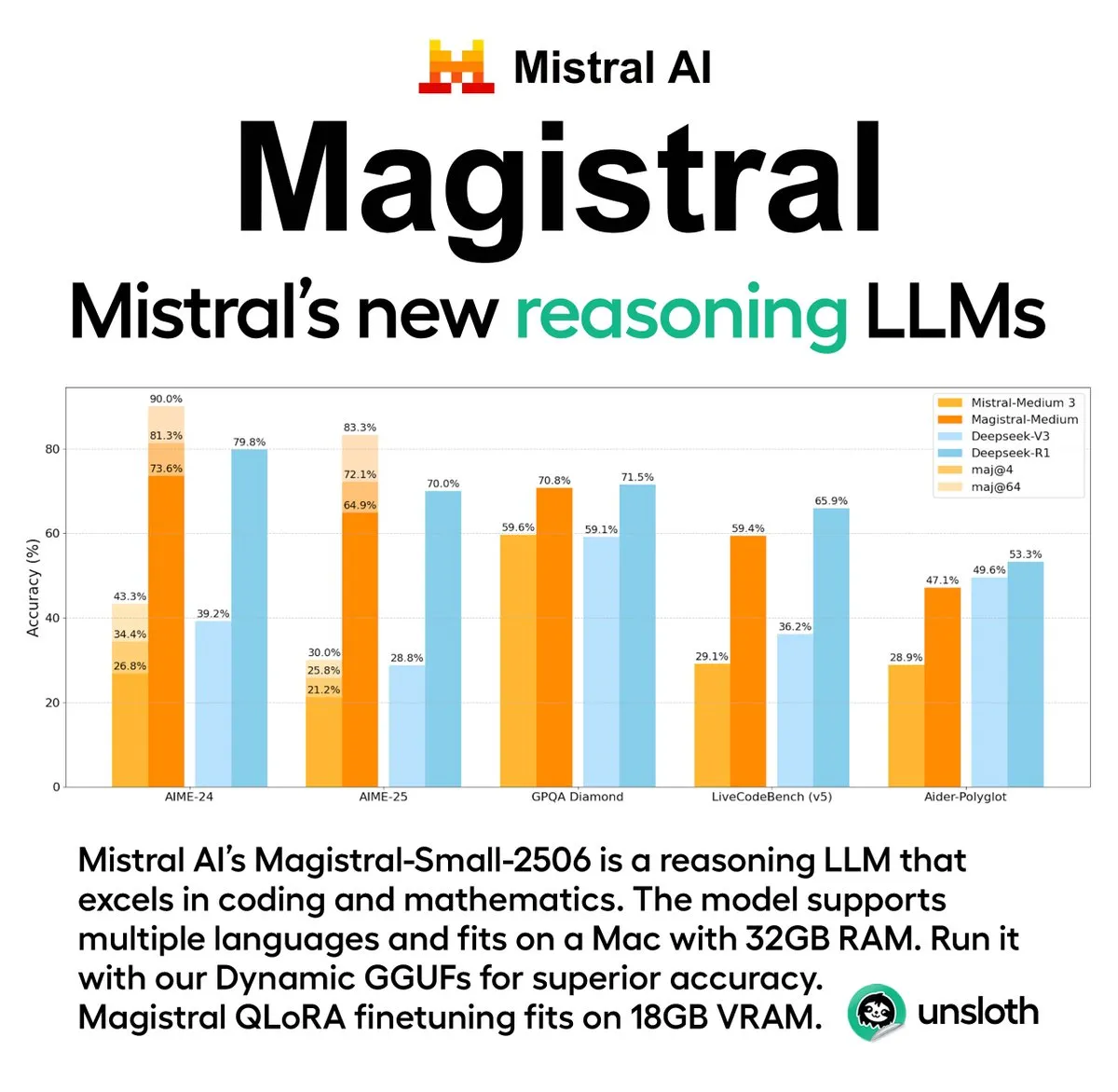
Mistral AI lança sua primeira série de modelos de inferência Magistral, incluindo versão de código aberto: A startup francesa de IA Mistral AI lançou sua primeira série de modelos projetados para inferência, Magistral. A série inclui um modelo de código fechado de nível empresarial mais poderoso, Magistral Medium, e um modelo de código aberto de 24 bilhões de parâmetros, Magistral Small (Magistral-Small-2506), este último lançado sob a licença Apache 2.0. Esses modelos se destacam em matemática, codificação e raciocínio multilíngue, com o objetivo de fornecer capacidade de inferência mais transparente e específica para o domínio. A velocidade de inferência do Magistral Medium na plataforma Le Chat é alegadamente 10 vezes mais rápida que a dos concorrentes, enquanto o Magistral Small oferece à comunidade uma poderosa opção de execução local. (Fonte: Mistral AI, jxmnop, karminski3)
IBM planeja construir computador quântico tolerante a falhas em grande escala, Starling, até 2028: A IBM anunciou seu roteiro de desenvolvimento de computação quântica, planejando construir um computador quântico tolerante a falhas em grande escala chamado Starling até 2028, com a expectativa de abri-lo aos usuários por meio de serviços em nuvem em 2029. Espera-se que o sistema Starling contenha cerca de 100 módulos e 200 qubits lógicos, com o objetivo principal de alcançar correção de erros eficaz, um dos maiores desafios técnicos atuais no campo da computação quântica. A máquina usará o código de paridade de baixa densidade (LDPC) da IBM para correção de erros e se dedicará a alcançar o diagnóstico de erros em tempo real. Se bem-sucedido, isso será um grande avanço no campo da computação quântica, podendo acelerar sua aplicação em problemas complexos como ciência dos materiais e desenvolvimento de medicamentos. (Fonte: MIT Technology Review)

🎯 Tendências
Avanços relacionados à IA na WWDC 2025 da Apple não impressionam desenvolvedores: A Apple anunciou várias atualizações na WWDC 2025, incluindo uma nova linguagem de design “liquid glass” e a integração do ChatGPT no Xcode 26. No entanto, a comunidade de desenvolvedores expressou de forma geral que seus avanços em inteligência artificial ficaram “abaixo das expectativas”. Embora a Apple tenha aberto pela primeira vez seus modelos de IA no dispositivo para desenvolvedores e lançado o framework Foundation Models para simplificar a integração de funcionalidades de IA, a tão esperada atualização da nova versão da Siri pode ser adiada para o próximo ano. O analista Ming-Chi Kuo destacou que a estratégia de IA da Apple ocupa uma posição central, mas não houve grandes avanços tecnológicos, tornando o gerenciamento das expectativas do mercado crucial. A Apple parece estar mais focada em melhorar a interface do usuário e as funcionalidades do sistema operacional do que em inovações disruptivas nos próprios modelos de IA. (Fonte: MIT Technology Review, jonst0kes, rowancheung)
Pentágono reduz tamanho do escritório de testes e avaliação de sistemas de armas de IA: O Secretário de Defesa dos EUA, Pete Hegseth, anunciou que o tamanho do Gabinete do Diretor de Testes e Avaliação Operacional (DOT&E) do Departamento de Defesa será reduzido pela metade, com o pessoal diminuindo de 94 para aproximadamente 45 pessoas. Este escritório é responsável por testar e avaliar a segurança e eficácia de armas e sistemas de IA. O ajuste visa “reduzir o inchaço burocrático e gastos desnecessários, aumentando a letalidade”. Esta medida levantou preocupações sobre o possível impacto nos testes de segurança e eficácia das aplicações militares de IA, especialmente no contexto em que o Pentágono está integrando ativamente tecnologias de IA (incluindo modelos de linguagem grandes) em vários sistemas militares. (Fonte: MIT Technology Review)

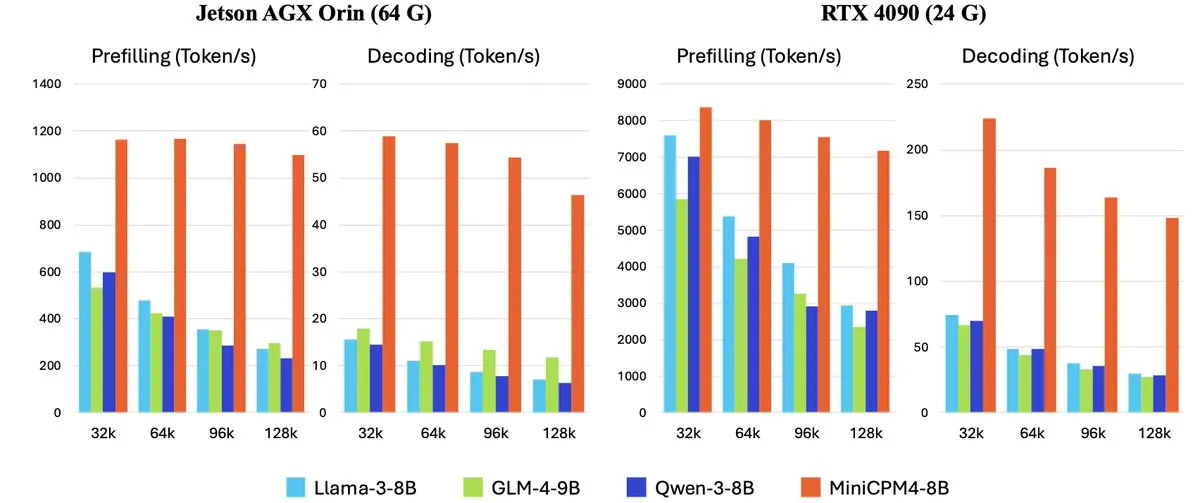
OpenBMB lança série MiniCPM-4 de modelos de linguagem grandes eficientes para dispositivos de ponta: A OpenBMB (Mianbi Intelligence) lançou a série de modelos MiniCPM-4, projetada especificamente para dispositivos de ponta, com o objetivo de alcançar uma operação de altíssima eficiência. A série inclui MiniCPM4-0.5B, MiniCPM4-8B (modelo principal), BitCPM4 (modelo quantizado de 1 bit), MiniCPM4-Survey dedicado à geração de relatórios e o modelo dedicado MCP MiniCPM4-MCP. O relatório técnico detalha sua arquitetura de modelo eficiente (como o mecanismo de atenção esparsa treinável InfLLM v2), algoritmos de aprendizado eficientes (como Model Wind Tunnel 2.0) e métodos de processamento de dados de treinamento de alta qualidade. Esses modelos já estão disponíveis para download no Hugging Face. (Fonte: _akhaliq, arankomatsuzaki, karminski3)
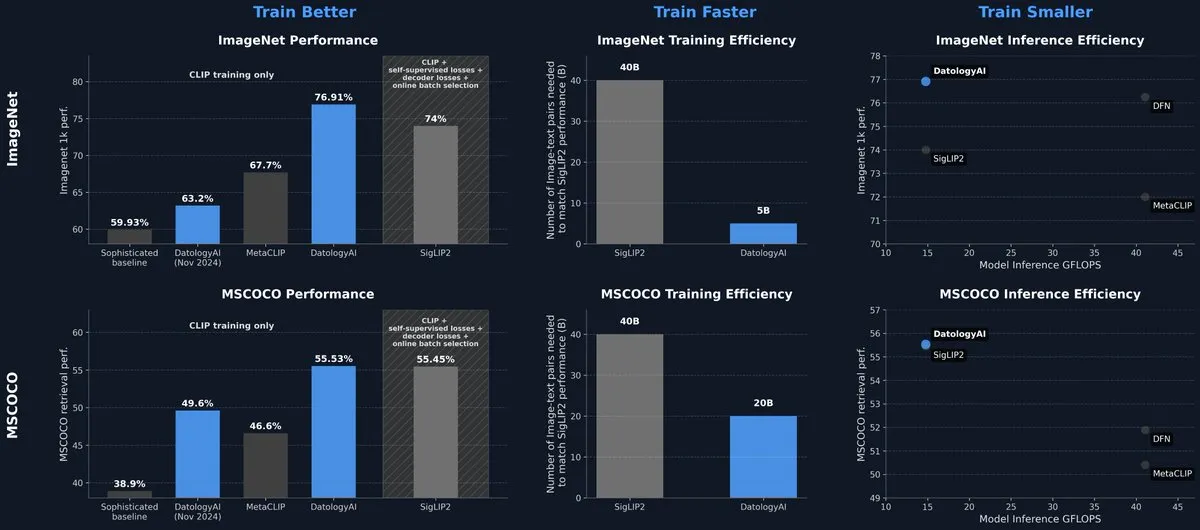
DatologyAI lança modelo CLIP que atinge nível SOTA apenas com gerenciamento de dados: A DatologyAI apresentou seus mais recentes resultados de pesquisa no campo multimodal, alcançando 76,9% de precisão no ImageNet 1k com seu modelo CLIP ViT-B/32 através de um gerenciamento de dados refinado (data curation), em vez de inovações em algoritmos ou arquitetura, superando os 74% relatados pelo SigLIP2. O método também resultou em um aumento de 8 vezes na eficiência de treinamento e 2 vezes na eficiência de inferência. O modelo foi lançado publicamente, destacando o enorme potencial de dados de alta qualidade para melhorar o desempenho do modelo. (Fonte: code_star, andersonbcdefg)
Krea AI lança seu primeiro modelo de imagem autodesenvolvido, Krea 1: A Krea AI lançou seu primeiro modelo de imagem, Krea 1, que se destaca no controle estético e na qualidade da imagem, possui um vasto conhecimento artístico e suporta referência de estilo e treinamento personalizado. O Krea 1 visa melhorar o realismo da imagem, texturas delicadas e rica expressão de estilos. Atualmente, o Krea 1 está aberto para testes Beta gratuitos, e os usuários podem experimentar sua poderosa capacidade de geração de imagens. (Fonte: _akhaliq, op7418)
NVIDIA lança modelo de robô humanoide de código aberto personalizável GR00T N1: A NVIDIA lançou o GR00T N1, um modelo de robô humanoide de código aberto personalizável. Esta iniciativa visa impulsionar a pesquisa e o desenvolvimento no campo de robôs humanoides, fornecendo aos desenvolvedores uma plataforma flexível para construir e experimentar diversas aplicações robóticas. Espera-se que a natureza de código aberto do GR00T N1 atraia uma participação mais ampla da comunidade, acelerando o progresso da tecnologia de robôs humanoides. (Fonte: Ronald_vanLoon)
RoboBrain 2.0 lança modelos robóticos multimodais de 7B e 32B: O RoboBrain 2.0 lançou seus modelos robóticos multimodais com 7B e 32B parâmetros, visando aprimorar as capacidades dos robôs em percepção, raciocínio e execução de tarefas. Os novos modelos suportam raciocínio interativo, planejamento de longo prazo, feedback em malha fechada, percepção espacial precisa (previsão de pontos e caixas delimitadoras), percepção temporal (estimativa de trajetória futura) e raciocínio de cena alcançado através da construção e atualização de memória estruturada em tempo real. Espera-se que o aprimoramento dessas capacidades impulsione a operação autônoma e o nível de tomada de decisão dos robôs em ambientes complexos. (Fonte: Reddit r/LocalLLaMA)
Kling AI compartilhará as pesquisas mais recentes sobre modelos de geração de vídeo na CVPR 2025: Pengfei Wan, líder do modelo de geração de vídeo Kling AI, fará uma palestra intitulada “Introdução ao Kling e nossa pesquisa sobre modelos de geração de vídeo mais poderosos” na principal conferência de visão computacional, CVPR 2025. Ele discutirá os mais recentes avanços e progressos de ponta na tecnologia de geração de vídeo com especialistas de instituições como Google DeepMind. Esta apresentação detalhará as conquistas da Kling na promoção do desenvolvimento da tecnologia de geração de vídeo. (Fonte: Kling_ai)

Tecnologia de IA auxilia no Gaokao 2025 da China, com várias localidades implementando sistemas de inspeção inteligente: O Gaokao 2025 da China (exame nacional de admissão ao ensino superior) adotou amplamente sistemas de inspeção inteligente por IA, com cobertura total de fiscalização por IA em locais de prova em Tianjin, Jiangxi, Hubei, Yangjiang em Guangdong, entre outros. Esses sistemas utilizam câmeras 4K, rastreamento de esqueleto, reconhecimento facial, monitoramento de áudio e outras tecnologias para detectar em tempo real comportamentos irregulares dos examinandos, como responder antes do tempo, passar objetos, conversar, desvio anormal do olhar, etc., e podem emitir alertas. O objetivo é aumentar a justiça do exame e garantir a disciplina no local da prova. A aplicação de sistemas de fiscalização por IA marca a entrada da gestão de exames na era da inteligência, trazendo uma transformação para os métodos tradicionais de fiscalização. (Fonte: 36氪)
Modelo de desktop Gemma 3n lançado, com suporte para multiplataforma e dispositivos IoT: O Google lançou os modelos de desktop Gemma 3n, incluindo versões de 2 bilhões e 4 bilhões de parâmetros, otimizados para desktops (Mac/Windows/Linux) e dispositivos de Internet das Coisas (IoT). O modelo é impulsionado pela nova biblioteca LiteRT-LM, projetada para fornecer capacidade de execução local eficiente. Os desenvolvedores podem visualizar e obter recursos relacionados através do Hugging Face e GitHub, impulsionando ainda mais a aplicação de modelos de IA leves em dispositivos de borda. (Fonte: ClementDelangue, demishassabis)
🧰 Ferramentas
Yutori AI lança Scouts: Agente de IA para monitoramento da web em tempo real: A Yutori AI, fundada por ex-pesquisadores da Meta AI, lançou um produto de agente de IA chamado Scouts. O Scouts é capaz de monitorar informações da internet em tempo real com base em tópicos ou palavras-chave definidos pelo usuário, notificando-o quando conteúdo relevante aparece. A ferramenta visa ajudar os usuários a filtrar informações valiosas da vasta rede de informações, como rastrear notícias de um campo específico, tendências de mercado, ofertas de produtos ou até mesmo reservas raras. O lançamento do Scouts marca um avanço nas ferramentas personalizadas de aquisição de informações, transformando a IA em um “batedor” digital para os usuários. (Fonte: DhruvBatraDB, krandiash, saranormous, JeffDean)
Replit lança nova funcionalidade: converta designs do Figma e outros em aplicativos funcionais com um clique: A Replit lançou a funcionalidade Replit Import, permitindo que os usuários importem diretamente designs de plataformas como Figma, Lovable, Bolt e os convertam em aplicativos executáveis. A funcionalidade visa reduzir a barreira de entrada no desenvolvimento, permitindo que mesmo não programadores transformem rapidamente ideias de design em realidade. O Replit Import suporta a manutenção da fidelidade do design e inclui varredura de segurança e gerenciamento de chaves integrados, combinados com Replit Agent, banco de dados, autenticação e serviços de hospedagem, para criar aplicativos full-stack. (Fonte: amasad, pirroh)
Hugging Face lança AISheets: combinando planilhas com milhares de modelos de IA: Thomas Wolf, cofundador da Hugging Face, anunciou o lançamento do produto experimental AISheets, uma ferramenta que combina a facilidade de uso das planilhas com o poder de milhares de modelos de IA de código aberto (especialmente LLMs). Os usuários podem construir, analisar e automatizar tarefas de processamento de dados na interface familiar de planilhas, utilizando modelos de IA para insights de dados e automação de tarefas, com o objetivo de fornecer uma nova forma rápida, simples e poderosa de análise de dados. (Fonte: _akhaliq, clefourrier, ClementDelangue, huggingface)
LlamaIndex agora suporta a conversão de Agents em servidores MCP para interagir com modelos como Claude: LlamaIndex anunciou suporte para converter qualquer um de seus Agents em um servidor de Protocolo de Contexto de Modelo (MCP). Através de código de exemplo e vídeo, demonstrou como implantar um fluxo de trabalho personalizado FidelityFundExtraction (para extrair dados estruturados de PDFs complexos) como um servidor MCP e chamá-lo a partir de um modelo Claude. Esta funcionalidade visa aumentar o nível de agentificação das ferramentas, facilitando a integração com clientes MCP como Claude Desktop e Cursor, simplificando o processo de conectar fluxos de trabalho existentes a um ecossistema de IA mais amplo. (Fonte: jerryjliu0)
GPT Researcher integra o Protocolo de Contexto de Modelo (MCP) da LangChain: O GPT Researcher agora utiliza o adaptador do Protocolo de Contexto de Modelo (MCP) da LangChain para seleção inteligente de ferramentas e pesquisa. Essa integração combina perfeitamente o MCP com funcionalidades de busca na web para alcançar uma coleta de dados abrangente. Os usuários podem consultar a documentação de integração relevante para aprender como configurar e usar essa nova funcionalidade, aumentando assim a eficiência e a profundidade da pesquisa. (Fonte: hwchase17)
Tesslate lança a série UIGEN-T3 de modelos de geração de UI, com suporte para vários tamanhos: A equipe Tesslate lançou a série UIGEN-T3 de modelos de geração de UI, incluindo escalas de parâmetros como 32B, 14B, 8B e 4B. Esses modelos são projetados especificamente para gerar componentes de UI (como breadcrumbs, botões, cards) e código front-end completo (como páginas de login, dashboards, interfaces de chat), com suporte para Tailwind CSS. Os modelos estão disponíveis no Hugging Face e visam ajudar os desenvolvedores a construir rapidamente interfaces de usuário. Desenvolvedores relataram que a quantização padrão reduz significativamente a qualidade do modelo, recomendando a execução em BF16 ou FP8 para obter os melhores resultados. (Fonte: Reddit r/LocalLLaMA)
Modelo de podcast Doubao lançado, gerando podcasts de IA humanizados com um clique: A Volcano Engine lançou o modelo de podcast Doubao, que pode gerar rapidamente podcasts com um estilo de diálogo altamente humanizado com base no texto inserido pelo usuário (como links de artigos ou prompts). O áudio gerado pelo modelo é próximo ao de humanos em termos de tom, pausas e expressões coloquiais, e pode até mesmo realizar discussões opinativas com base no conteúdo. A tecnologia é baseada no modelo de fala em tempo real de ponta a ponta da equipe de tecnologia de voz da ByteDance, alcançando compreensão e raciocínio direto na modalidade de voz. Atualmente, essa funcionalidade está online na versão para PC do Doubao e no espaço Kouzi, com o objetivo de reduzir a barreira para a criação de conteúdo de áudio e fornecer uma forma eficiente e personalizada de obter informações. (Fonte: 量子位)

Unsloth AI oferece versão quantizada GGUF do Magistral-Small-2506: Para o recém-lançado modelo de inferência Magistral-Small-2506 da Mistral AI, a Unsloth AI forneceu uma versão quantizada GGUF. Isso permite que os usuários executem localmente este modelo de 24 bilhões de parâmetros, por exemplo, em um dispositivo com apenas 32 GB de RAM. Esta medida reduz os requisitos de hardware para modelos de inferência de alto desempenho, facilitando para um público mais amplo de desenvolvedores e pesquisadores experimentar e usar o modelo Magistral em ambientes locais. (Fonte: ImazAngel)
📚 Aprendizado
Análise técnica aprofundada da construção do assistente visual LLaVA-1.5: O LearnOpenCV publicou um artigo com uma análise técnica aprofundada da arquitetura LLaVA-1.5. O artigo detalha como o LLaVA-1.5 constrói assistentes visuais de IA de última geração, incluindo sua inovadora tecnologia de ajuste fino de instruções visuais (Visual Instruction Tuning) e o conjunto de dados de código aberto que mudou o campo da IA multimodal. Este guia tem um valor de referência significativo para engenheiros e pesquisadores de IA/ML entenderem os princípios de funcionamento e os métodos de treinamento de modelos de linguagem grandes multimodais. (Fonte: LearnOpenCV)
Guia de introdução ao aprendizado de máquina para proteínas publicado: O DL Weekly compartilhou um guia abrangente de aprendizado de máquina para proteínas voltado para iniciantes. O guia cobre tipos de dados básicos relacionados a proteínas, modelos de aprendizado profundo, métodos computacionais e conceitos biológicos fundamentais, com o objetivo de ajudar pesquisadores e desenvolvedores interessados neste campo interdisciplinar a começar rapidamente. (Fonte: dl_weekly)
Qdrant e DataTalksClub colaboram para lançar curso gratuito de RAG e busca vetorial: A Qdrant anunciou uma parceria com o DataTalksClub para oferecer um curso online gratuito de 10 semanas. O conteúdo do curso inclui geração aumentada por recuperação (RAG), busca vetorial, busca híbrida, métodos de avaliação, entre outros, e inclui um projeto prático de ponta a ponta. Os especialistas da Qdrant, Kacper Łukawski e Daniel Wanderung, ministrarão pessoalmente o curso, com o objetivo de ajudar os alunos a dominar as habilidades práticas para construir aplicações avançadas de IA. (Fonte: qdrant_engine)
Podcast da Weaviate discute saída estruturada de LLM e decodificação restrita: O mais recente episódio do podcast da Weaviate convidou Will Kurt e Cameron Pfiffer da dottxt.ai, que, juntamente com o apresentador Connor Shorten, discutiram o problema da saída estruturada de modelos de linguagem grandes (LLM). O programa aprofundou-se em como garantir que os LLMs gerem resultados confiáveis e previsíveis (como JSON válido, e-mails, tweets, etc.) através de técnicas de decodificação restrita, e não apenas uma simples validação de formato JSON. Eles também apresentaram a ferramenta de código aberto Outlines e sua aplicação em casos de uso reais de IA, vislumbrando o impacto dessa tecnologia nos futuros sistemas de IA. (Fonte: bobvanluijt)
Artigo da ACL2025NLP SynthesizeMe!: Gerando prompts personalizados a partir da interação do usuário: Um artigo da conferência ACL 2025 NLP intitulado “SynthesizeMe!” propõe um novo método para criar modelos de usuário personalizados em linguagem natural, analisando a interação do usuário com a IA (incluindo feedback implícito e explícito). O método primeiro gera e valida processos de raciocínio que explicam as preferências do usuário, depois generaliza a partir deles para criar perfis de usuário sintéticos, filtra interações anteriores informativas do usuário e, finalmente, constrói prompts personalizados para usuários específicos, com o objetivo de melhorar a modelagem de recompensa personalizada e a capacidade de resposta dos LLMs. O DSPy também retweetou e mencionou que este é um excelente caso de aplicação do dspy.MIPROv2. (Fonte: lateinteraction, stanfordnlp)
Novo artigo explora monitoramento e “overclocking” de LLMs com Test-Time Scaling: Um novo artigo foca na técnica de Test-Time Scaling adotada por modelos como o3 e DeepSeek-R1, que permite aos LLMs realizar mais inferências antes de responder, mas os usuários geralmente não conseguem entender seu progresso interno ou controlá-lo. Os pesquisadores propõem expor o “relógio” interno do LLM e demonstram como monitorar seu processo de inferência e fazer “overclocking” para acelerá-lo. Isso oferece novas perspectivas para entender e otimizar a eficiência de grandes modelos de inferência. (Fonte: arankomatsuzaki)

Artigo propõe CARTRIDGES: compressão de cache KV de LLMs de contexto longo através de autoaprendizagem offline: Pesquisadores da HazyResearch da Universidade de Stanford propuseram um novo método chamado CARTRIDGES, que visa resolver o problema do alto consumo de memória do cache KV em LLMs de contexto longo. O método treina offline um cache KV menor (chamado cartridge) para armazenar informações de documentos através de um mecanismo de treinamento em tempo de teste de “autoaprendizagem”, reduzindo em média 39 vezes a memória do cache e aumentando em 26 vezes o pico de throughput, mantendo o desempenho da tarefa. Este cartridge, uma vez treinado, pode ser reutilizado por diferentes solicitações de usuários, oferecendo uma nova abordagem de otimização para o processamento de contexto longo. (Fonte: gallabytes, simran_s_arora, stanfordnlp)

Novo artigo Grafting: edição de arquitetura de Transformers de difusão pré-treinados a baixo custo: Pesquisadores da Universidade de Stanford propuseram um novo método chamado Grafting para editar a arquitetura de modelos Transformer de difusão pré-treinados. A técnica permite substituir mecanismos de atenção e outras primitivas computacionais no modelo por novas, com apenas 2% do custo computacional do pré-treinamento, permitindo o design personalizado da arquitetura do modelo com um pequeno orçamento computacional. Isso é significativo para explorar novas arquiteturas de modelos e melhorar a eficiência dos modelos existentes. (Fonte: realDanFu, togethercompute)
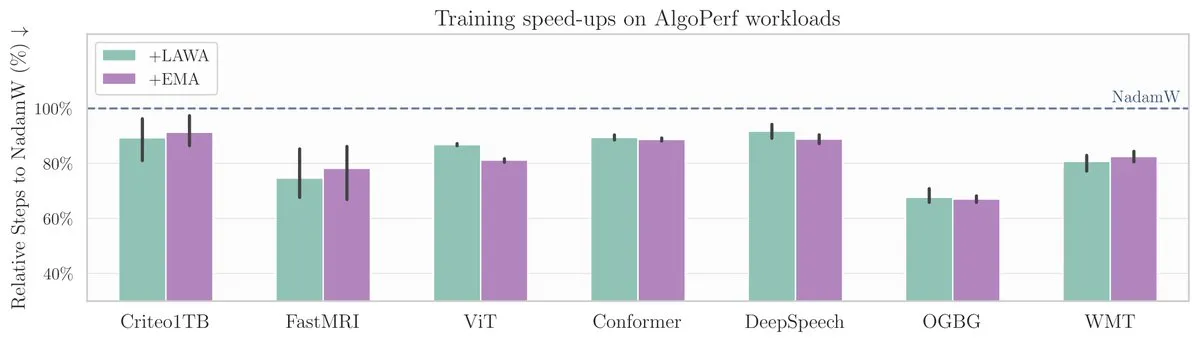
Novo artigo do ICML: Método de média de checkpoints acelera o treinamento de modelos no benchmark AlgoPerf: Um novo artigo do ICML investiga a aplicação do método clássico de Média de Checkpoints (Averaging Checkpoints) para melhorar a velocidade e o desempenho do treinamento de modelos de aprendizado de máquina. Os pesquisadores testaram esse método no AlgoPerf, um benchmark estruturado e diversificado de algoritmos de otimização, explorando seus benefícios práticos em diferentes tarefas e fornecendo referências práticas para acelerar o treinamento de modelos. (Fonte: aaron_defazio)
Ferramenta de explicação visual para Transformers de código aberto: O DL Weekly apresentou uma ferramenta de visualização interativa projetada para ajudar os usuários a entender como funcionam os modelos baseados na arquitetura Transformer (como o GPT). A ferramenta decompõe os mecanismos internos do modelo de forma visual, tornando conceitos complexos mais fáceis de entender, adequada para aprendizes e pesquisadores interessados em modelos Transformer. O projeto está disponível em código aberto no GitHub. (Fonte: dl_weekly)
Universidade de Zhejiang propõe InftyThink: inferência de profundidade infinita através de segmentação e resumo: Uma equipe de pesquisa da Universidade de Zhejiang, em colaboração com a Universidade de Pequim, propôs um novo paradigma de inferência para modelos grandes, o InftyThink. O método divide inferências longas em múltiplos segmentos curtos e introduz resumos entre os segmentos para conectar o contexto, alcançando teoricamente inferência de profundidade infinita enquanto mantém um alto throughput de geração. Este método não depende de ajustes na estrutura do modelo e é compatível com os processos existentes de pré-treinamento e ajuste fino, reestruturando os dados de treinamento para um formato de inferência multirrodada. Experimentos mostram que o InftyThink pode melhorar significativamente o desempenho do modelo em benchmarks como AIME24 e aumentar o throughput de geração. (Fonte: 量子位)

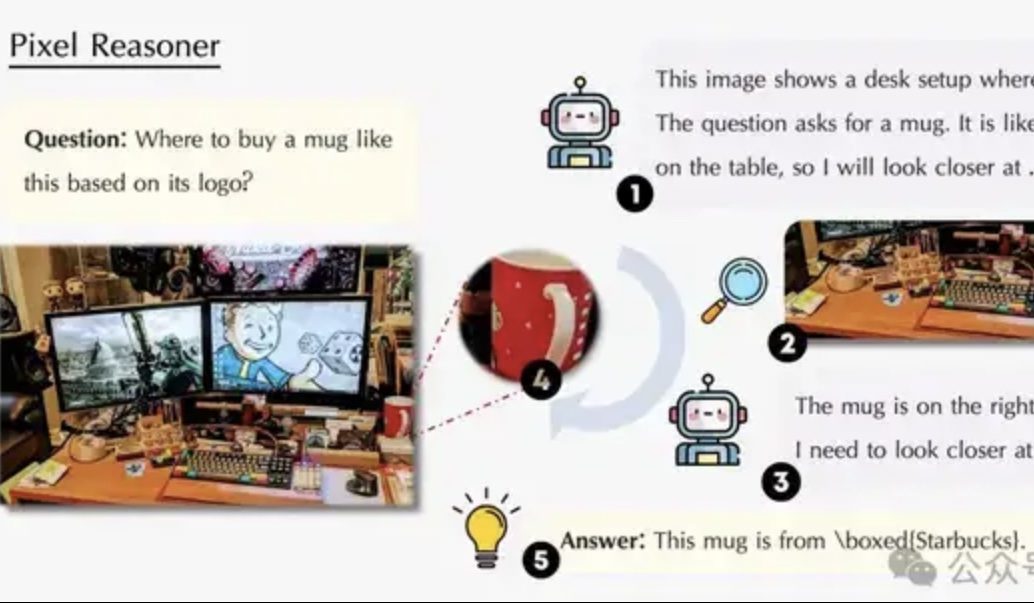
Artigo explora raciocínio no espaço de pixels: permitindo que VLMs “usem olhos e cérebro” como humanos: Uma equipe de pesquisa da Universidade de Waterloo, HKUST e USTC propôs o paradigma de “Raciocínio no Espaço de Pixels” (Pixel-Space Reasoning), permitindo que modelos de linguagem visual (VLM) operem e raciocinem diretamente no nível do pixel, como zoom visual, marcação espaço-temporal, etc., em vez de depender de tokens de texto como intermediários. Através de um esquema de aprendizado por reforço com incentivo de curiosidade intrínseca e incentivo de correção extrínseca, supera a “inércia cognitiva” do modelo. O Pixel-Reasoner, construído com base no Qwen2.5-VL-7B, teve um desempenho excelente em múltiplos benchmarks como o V*Bench, com o modelo de 7B superando o GPT-4o. (Fonte: 量子位)
DeepLearning.AI lança o quinto curso do Certificado Profissional em Análise de Dados: Storytelling com Dados: A DeepLearning.AI lançou o quinto curso de seu Certificado Profissional em Análise de Dados, com o tema “Storytelling com Dados”. O curso ensina como escolher o meio apropriado (dashboards, memorandos, apresentações) para apresentar insights, usar o Tableau para projetar dashboards interativos, alinhar descobertas com objetivos de negócios e comunicá-las efetivamente, além de orientação para busca de emprego. Enfatiza a importância do storytelling com dados para melhorar o desempenho dos negócios e comunicar insights de forma eficaz. (Fonte: DeepLearningAI)

Artigo discute o impacto de conflitos de conhecimento em modelos de linguagem grandes: Um novo artigo avalia sistematicamente o comportamento de modelos de linguagem grandes (LLM) quando confrontados com conflitos entre a entrada contextual e o conhecimento parametrizado (ou seja, a “memória” interna do modelo). O estudo descobriu que conflitos de conhecimento têm pouco impacto em tarefas que não dependem da utilização do conhecimento; quando o contexto e o conhecimento parametrizado são consistentes, o modelo tem um desempenho melhor; mesmo quando instruído, o modelo não consegue suprimir completamente o conhecimento interno; fornecer razões que explicam o conflito aumenta a dependência do modelo no contexto. Essas descobertas levantam questões sobre a validade da avaliação baseada em modelos e enfatizam a necessidade de considerar problemas de conflito de conhecimento ao implantar LLMs. (Fonte: HuggingFace Daily Papers)
Artigo CyberV: Um framework cibernético para expansão em tempo de teste na compreensão de vídeo: Para resolver os problemas de demanda computacional, robustez e precisão enfrentados por modelos de linguagem grandes multimodais (MLLM) ao processar vídeos longos ou complexos, pesquisadores propuseram o framework CyberV. Inspirado em princípios cibernéticos, este framework redesenha os MLLMs de vídeo como sistemas adaptativos, contendo um sistema de inferência MLLM, sensores e um controlador. Os sensores monitoram o processo de avanço do modelo e coletam interpretações intermediárias (como desvio de atenção), e o controlador decide quando e como acionar a autocorreção e gerar feedback. Este framework de expansão adaptativa em tempo de teste aprimora os MLLMs existentes sem necessidade de retreinamento, e experimentos mostram que ele melhora significativamente o desempenho de modelos como Qwen2.5-VL-7B em benchmarks como VideoMMMU. (Fonte: HuggingFace Daily Papers)
Artigo propõe LoRMA: Adaptação Multiplicativa de Baixo Rank para ajuste fino eficiente de parâmetros de LLMs: Para resolver os problemas existentes de colapso de representação e desequilíbrio de carga de especialistas nos métodos atuais de ajuste fino eficiente de parâmetros (PEFT) baseados em LoRA e MoE, pesquisadores propuseram a Adaptação Multiplicativa de Baixo Rank (LoRMA). Este método transforma a forma de atualização dos especialistas do adaptador PEFT de aditiva para uma transformação de multiplicação de matrizes mais rica, lidando com a complexidade computacional e o gargalo de rank através de operações de rearranjo eficazes e da introdução de estratégias de expansão de rank. Experimentos demonstram que o método heterogêneo MoA (Mistura de Adaptadores) supera o método homogêneo MoE-LoRA tanto em desempenho quanto em eficiência de parâmetros. (Fonte: Reddit r/MachineLearning)
Artigo propõe FlashDMoE: Implementação rápida de MoE distribuído em um único kernel: Pesquisadores lançaram o FlashDMoE, o primeiro sistema a fundir completamente a propagação forward de Mistura de Especialistas (MoE) distribuída em um único kernel CUDA. Ao escrever a camada de fusão do zero em CUDA puro, o FlashDMoE alcançou um aumento de até 9 vezes na utilização da GPU, uma redução de 6 vezes na latência e uma melhoria de 4 vezes na eficiência de escalonamento fraco. Este trabalho oferece novas ideias e implementações para otimizar a eficiência da inferência de modelos MoE em grande escala. (Fonte: Reddit r/MachineLearning)
💼 Negócios
xAI e Polymarket colaboram, fundindo previsão de mercado com análise do Grok: A xAI, empresa de inteligência artificial de Elon Musk, anunciou uma parceria com a plataforma de mercado de previsão descentralizada Polymarket. A colaboração visa combinar os dados de previsão de mercado da Polymarket com os dados do X (antigo Twitter) e as capacidades de análise do Grok AI para criar um “motor de verdade hardcore” para revelar os fatores que moldam o mundo. A xAI afirmou que este é apenas o começo da colaboração, com mais conteúdo colaborativo a ser revelado no futuro. (Fonte: xai)
Empresa de chips de inferência de IA Groq obtém promessa de investimento de US$ 1,5 bilhão da Arábia Saudita, focando em estratégia de integração vertical: A empresa de chips de inferência de IA Groq anunciou ter recebido uma promessa de investimento de US$ 1,5 bilhão da Arábia Saudita para expandir a entrega local de sua infraestrutura de inferência de IA baseada em LPU (Language Processing Unit). Fundada por Jonathan Ross, um dos inventores do TPU, a Groq foca em computação de inferência de IA. Seus chips LPU adotam uma arquitetura de pipeline programável, com memória e unidades de computação integradas no mesmo chip, aumentando drasticamente a velocidade de acesso a dados e a eficiência energética. A Groq não apenas vende chips, mas também oferece clusters GroqRack (nuvem privada/centro de computação de IA) e a plataforma de nuvem GroqCloud (Tokens-as-a-Service), suportando modelos de código aberto populares como Llama, DeepSeek e Qwen. A empresa também desenvolveu o sistema de IA composto Compound, aumentando o valor da nuvem de inferência de IA. (Fonte: 36氪)

Empresa de robôs de interação humanoides de Shenzhen, ‘Shuzi Huaxia’, conclui rodada de financiamento anjo+ de dezenas de milhões de yuans: A Shuzi Huaxia (Shenzhen) Technology Co., Ltd. concluiu recentemente uma rodada de financiamento anjo+ de dezenas de milhões de yuans, com investimento exclusivo da Tongchuang Weiye. A empresa foca na comercialização em escala de robôs AGI, com produtos principais incluindo o robô biônico “Xia Lan”, o robô humanoide de uso geral “Xia Qi” e a série de robôs IP “Xing Hang Xia”. O robô “Xia Lan” tem como núcleo a tecnologia biônica de precisão, capaz de imitar a maioria das expressões humanas e possui capacidade de interação multimodal. A empresa já recebeu centenas de milhões de yuans em pedidos de clientes, incluindo grandes fabricantes de TIC e redes elétricas locais. (Fonte: 36氪)

🌟 Comunidade
Sam Altman publica post no blog “Singularidade Suave”, discutindo a revolução gradual da IA e o futuro: O CEO da OpenAI, Sam Altman, publicou um post no blog argumentando que a singularidade tecnológica está ocorrendo de uma forma mais suave e “gentil” do que o previsto, como um processo gradual de aceleração contínua e exponencial. Ele prevê que em 2025, agentes de IA capazes de realizar trabalhos intelectuais complexos de forma independente (como programação) remodelarão a indústria de software; em 2026, poderão surgir sistemas capazes de descobrir novos insights científicos; e em 2027, robôs capazes de realizar tarefas no mundo real poderão aparecer. Altman enfatiza que resolver o problema do alinhamento da IA e garantir a inclusão tecnológica são cruciais para um futuro próspero. Ele também revelou que o primeiro modelo de pesos de código aberto da OpenAI será adiado para o final do verão, pois a equipe de pesquisa obteve “resultados inesperadamente surpreendentes”. (Fonte: dotey, scaling01, sama)
Comunidade debate o o3-pro da OpenAI: desempenho poderoso, mas custo elevado; redução de preço do o3 desencadeia reações em cadeia: O lançamento do o3-pro da OpenAI e seu alto preço (US$ 80/M tokens de saída) tornaram-se foco de discussão na comunidade. Os usuários geralmente reconhecem sua forte capacidade em tarefas complexas de raciocínio, programação, etc., mas também expressam preocupação com sua velocidade de resposta e custo, com alguns usuários brincando que uma simples saudação “Hi” poderia custar US$ 80. Ao mesmo tempo, a drástica redução de 80% no preço do modelo o3 é vista como um possível gatilho para uma guerra de preços de modelos de IA, competindo com o GPT-4o e outros produtos. Há controvérsia na comunidade sobre se o desempenho do o3 “emburreceu” após a redução de preço. A OpenAI anunciou posteriormente que dobraria a cota de uso do o3 para usuários do ChatGPT Plus em resposta à demanda dos usuários. (Fonte: Yuchenj_UW, scaling01, imjaredz, kevinweil, dotey)
Altos salários da Meta para atrair talentos e investimento em organização de IA geram debate: Os altos pacotes de remuneração oferecidos pela Meta a pesquisadores de IA (alegadamente na casa dos nove dígitos em dólares) geraram discussão na comunidade. Nat Lambert comentou que tal remuneração poderia financiar uma instituição de pesquisa inteira do tamanho da AI2, insinuando o alto custo dos talentos de ponta. Combinado com a criação do “Superintelligence Lab” pela Meta e o grande investimento na Scale AI, a comunidade geralmente acredita que a Meta está disposta a tudo para remodelar sua competitividade em IA, mas também se preocupa com sua política organizacional interna e problemas de eficiência. Conteúdo do ChinaTalk retuitado por Helen Toner aponta que a medida da Meta visa quebrar problemas políticos e de ego dentro da organização. (Fonte: natolambert, natolambert)
Novo estilo de UI “Liquid Glass” da Apple na WWDC gera discussão sobre design e usabilidade: O novo estilo de design de UI “Liquid Glass” lançado pela Apple na WWDC 2025 gerou ampla discussão entre desenvolvedores e designers. Alguns acreditam que seu efeito visual é inovador e reflete a exploração da Apple em direção a interfaces 3D. No entanto, personalidades experientes como ID_AA_Carmack (John Carmack) apontaram que UIs semitransparentes geralmente apresentam problemas de usabilidade, causando facilmente interferência visual e baixo contraste, afetando a leitura e a operação, e mencionaram que o Windows e o Mac também tentaram designs semelhantes no passado, mas acabaram ajustando-os devido a problemas de usabilidade. A experiência do usuário (UX) deve ter prioridade sobre os efeitos visuais da interface do usuário (UI), tornando-se o cerne da discussão. (Fonte: gfodor, ID_AA_Carmack, ReamBraden, dotey)
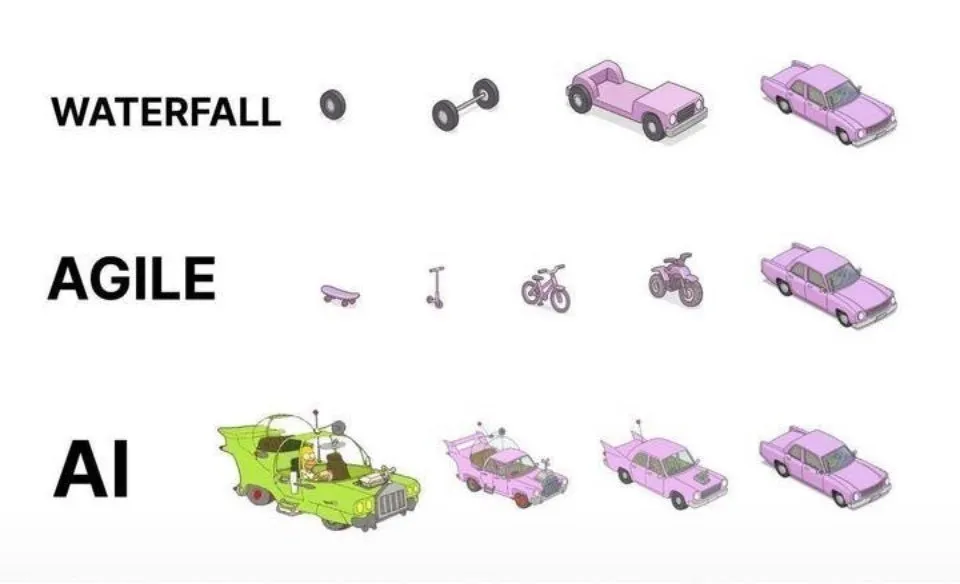
Prática de programação assistida por IA: iteração ágil é superior à geração única: Nas redes sociais, dotey expressou sua opinião sobre as melhores práticas para usar IA (como Claude Code) na programação. Ele argumenta que não se deve adotar a abordagem de fornecer requisitos completos de uma vez para que a IA gere um grande produto semiacabado (modelo cascata) ou gerar primeiro um produto imperfeito e depois otimizá-lo (semelhante ao terceiro padrão na imagem), pois isso dificulta o controle de qualidade e a manutenção posterior. Ele defende a adoção de um modelo de iteração ágil (semelhante ao primeiro padrão na imagem), dividindo grandes projetos (como sistemas ERP) em múltiplas versões pequenas que podem operar de forma estável e independente, desenvolvendo iterativamente, garantindo a integridade funcional e controlabilidade de cada versão, o que é consistente com as melhores práticas tradicionais de engenharia de software. (Fonte: dotey)
Mustafa Suleyman: Tecnologia de IA está evoluindo de fixa e unificada para dinâmica e personalizada: Mustafa Suleyman, cofundador da Inflection AI e ex-DeepMind, comentou que a tecnologia tradicional é geralmente fixa, unificada e no modelo “tamanho único”, enquanto a tecnologia de inteligência artificial atual apresenta características dinâmicas, personalizadas e emergentes. Ele acredita que isso significa que a tecnologia está mudando de fornecer resultados únicos e repetitivos para explorar caminhos de possibilidades infinitas, enfatizando o enorme potencial da IA em serviços personalizados e aplicações criativas. (Fonte: mustafasuleyman)
Perplexity AI enfrenta problemas de infraestrutura, CEO explica: Arav Srinivas, CEO da Perplexity AI, respondeu nas redes sociais a perguntas de usuários sobre a instabilidade do serviço, afirmando que, devido a problemas de infraestrutura, foi necessário habilitar uma experiência de usuário degradada (degraded UX) para parte do tráfego. Ele enfatizou que os dados dos usuários (como library ou threads) não foram perdidos e que, assim que o sistema se estabilizar, todas as funcionalidades serão restauradas normalmente. Isso reflete os desafios de estabilidade e escalabilidade da infraestrutura que os serviços de IA enfrentam em seu rápido desenvolvimento. (Fonte: AravSrinivas)
Sergey Levine discute as diferenças de aprendizado entre modelos de linguagem e modelos de vídeo: Sergey Levine, professor da UC Berkeley, em seu artigo “Modelos de Linguagem na Caverna de Platão”, levanta uma questão profunda: por que os modelos de linguagem conseguem aprender tanto prevendo a próxima palavra, enquanto os modelos de vídeo aprendem relativamente pouco prevendo o próximo quadro? Ele argumenta que os LLMs, ao aprenderem com as “sombras” do conhecimento humano (dados textuais), adquiriram poderosas capacidades de raciocínio, o que se assemelha mais a uma “engenharia reversa” da cognição humana do que a uma exploração verdadeiramente autônoma do mundo físico. Os modelos de vídeo observam diretamente o mundo físico, mas atualmente ficam aquém dos LLMs em raciocínio complexo. Ele propõe que o objetivo de longo prazo da IA deve ser romper a dependência das “sombras” do conhecimento humano, interagindo diretamente com o mundo físico através de sensores para alcançar a exploração autônoma. (Fonte: 36氪)
💡 Outros
Discussão sobre ética e consciência da IA: A IA pode ter consciência real?: A MIT Technology Review foca na complexa questão da consciência da IA. O artigo aponta que a consciência da IA não é apenas um quebra-cabeça intelectual, mas também uma questão com peso moral. Julgar erroneamente a consciência da IA pode levar à escravização inadvertida de IAs sencientes ou ao sacrifício do bem-estar humano por máquinas não sencientes. A comunidade de pesquisa fez progressos na compreensão da natureza da consciência, e esses resultados podem fornecer orientação para explorar e lidar com a consciência artificial. Isso levanta reflexões profundas sobre os direitos, responsabilidades da IA e as relações homem-máquina. (Fonte: MIT Technology Review)
Vencedor do Prêmio Turing, Joseph Sifakis: IA atual não é inteligência real, é preciso cautela com a confusão entre conhecimento e informação: O vencedor do Prêmio Turing, Joseph Sifakis, em sua obra e entrevistas, aponta que a compreensão atual da IA pela sociedade é falha, confundindo acúmulo de informações com criação de sabedoria e superestimando a “inteligência” das máquinas. Ele acredita que ainda não existem sistemas verdadeiramente inteligentes e que o impacto real da IA na indústria é mínimo. A IA carece de compreensão de senso comum, sua “inteligência” é produto de modelos estatísticos e dificilmente consegue ponderar valores e riscos em contextos sociais complexos. Ele enfatiza que o cerne da educação é cultivar o pensamento crítico e a criatividade, não a transmissão de conhecimento, e defende o estabelecimento de padrões globais para aplicações de IA, definindo claramente os limites de responsabilidade, para que a IA se torne uma parceira que aprimora os humanos, e não um substituto. (Fonte: 36氪)
Reestruturação da indústria publicitária na era da IA: da geração criativa à entrega personalizada: A conferência Google I/O 2025 demonstrou como a IA está reestruturando profundamente a indústria publicitária. As tendências incluem: 1) Automação criativa impulsionada por IA, desde imagens até roteiros de vídeo, tudo pode ser gerado por IA, com ferramentas como Veo 3, Imagen 4 e Flow reduzindo a barreira para a criação de conteúdo de alta qualidade. 2) O paradigma da personalização está mudando de “mil faces para mil pessoas” para “mil faces para uma pessoa”, com agentes inteligentes de IA capazes de entender proativamente as necessidades do usuário e facilitar transações. 3) A fronteira entre publicidade e conteúdo está se tornando tênue, com anúncios diretamente integrados aos resultados de busca gerados por IA, tornando-se parte da informação. Os proprietários de marcas precisam construir seus próprios agentes inteligentes, fornecer serviços orientados para IA e aderir a uma estratégia de longo prazo de “integração de marca e eficácia” para se adaptar à mudança. (Fonte: 36氪)