
Palavras-chave:DeepSeek, OpenAI, modelo de inferência, grande modelo multimodal, aprendizagem por reforço, inovação em IA, modelo de código aberto, modelo de inferência DeepSeek R1, treinamento de aprendizagem por reforço OpenAI o4, mapa de pensamento humano de grande modelo multimodal, série Mistral AI Magistral, modelo MoE dots.llm1 do Xiaohongshu
🔥 Foco
Os caminhos de inovação da DeepSeek e da OpenAI revelam a “inovação cognitiva”: A DeepSeek, através da “Scaling Law limitada”, inovação na arquitetura MLA e MoE, e otimização coordenada de software e hardware, alcançou baixo custo e alto desempenho. O código aberto do seu modelo de inferência R1 impulsionou um avanço na capacidade cognitiva da IA, quebrando o “selo ideológico” dos inovadores chineses no campo da pesquisa básica e demonstrando a liderança global das empresas chinesas na pesquisa básica de IA e na inovação de modelos. A OpenAI, por sua vez, com o uso extremo da arquitetura Transformer e da Scaling Law (lei de escala), liderou a revolução dos grandes modelos de linguagem e, através do ChatGPT e do modelo de inferência o1, impulsionou a mudança de paradigma na interação humano-computador e um salto na capacidade cognitiva da IA. Os caminhos de desenvolvimento de ambas enfatizam uma profunda compreensão da essência da tecnologia e uma reconstrução estratégica, fornecendo aos empreendedores da era da IA ideias valiosas para a construção organizacional e inovação, especialmente o paradigma de AI Lab da DeepSeek que incentiva a “emergência”, oferecendo uma nova referência de modelo organizacional para empreendedores impulsionados pela inovação tecnológica (Fonte: 36氪)
OpenAI alegadamente a treinar novo modelo o4, aprendizagem por reforço remodela o panorama da IA: A SemiAnalysis revelou que a OpenAI está a treinar um novo modelo entre o GPT-4.1 e o GPT-4.5, e que o modelo de inferência de próxima geração o4 será treinado com base no GPT-4.1 usando aprendizagem por reforço (RL). O RL desbloqueia a capacidade de raciocínio do modelo através da geração de CoT e impulsiona o desenvolvimento de agentes de IA, mas exige muito da infraestrutura (especialmente inferência) e do design da função de recompensa, sendo propenso ao fenómeno de “reward hacking”. Dados de alta qualidade são cruciais para expandir o RL, e os dados de comportamento do utilizador tornar-se-ão um ativo importante. O RL também altera a estrutura organizacional dos laboratórios, integrando profundamente a inferência e o treino. Diferentemente do pré-treino, o RL pode atualizar continuamente as capacidades do modelo, como o DeepSeek R1. Para modelos pequenos, a destilação pode ser superior ao RL. Esta revelação sugere que o campo da IA, especialmente os modelos de inferência, passará por uma evolução contínua e um salto de capacidade baseados em RL (Fonte: 36氪)
Descobriu-se que grandes modelos multimodais formam espontaneamente “mapas mentais humanos”: Uma equipa conjunta do Instituto de Automação da Academia Chinesa de Ciências e do Centro de Excelência em Inovação em Ciência do Cérebro e Tecnologia Inteligente confirmou, através de experiências comportamentais e análise de neuroimagem, que grandes modelos de linguagem multimodais (MLLMs) conseguem formar espontaneamente sistemas de representação de conceitos de objetos altamente semelhantes aos humanos. O estudo construiu pela primeira vez o “mapa conceptual” de modelos de IA, analisando 4,7 milhões de dados de julgamento comportamental de “tarefas de identificação de item diferente em três opções”. As principais descobertas incluem: modelos de IA com diferentes arquiteturas podem convergir para estruturas cognitivas de baixa dimensão semelhantes; os modelos demonstram capacidade emergente de classificação de conceitos de objetos de alto nível em situações não supervisionadas, consistente com a cognição humana; as “dimensões de pensamento” dos modelos de IA podem receber rótulos semânticos, como animal, comida, dureza, etc.; a representação dos MLLMs está significativamente correlacionada com os padrões de atividade neural de regiões cerebrais específicas (como FFA, PPA), fornecendo evidências para o “mecanismo de processamento de conceitos partilhado entre IA e humanos”. Este estudo oferece novas perspetivas para a compreensão da cognição da IA, o desenvolvimento de inteligência semelhante ao cérebro e interfaces cérebro-máquina (Fonte: 量子位)

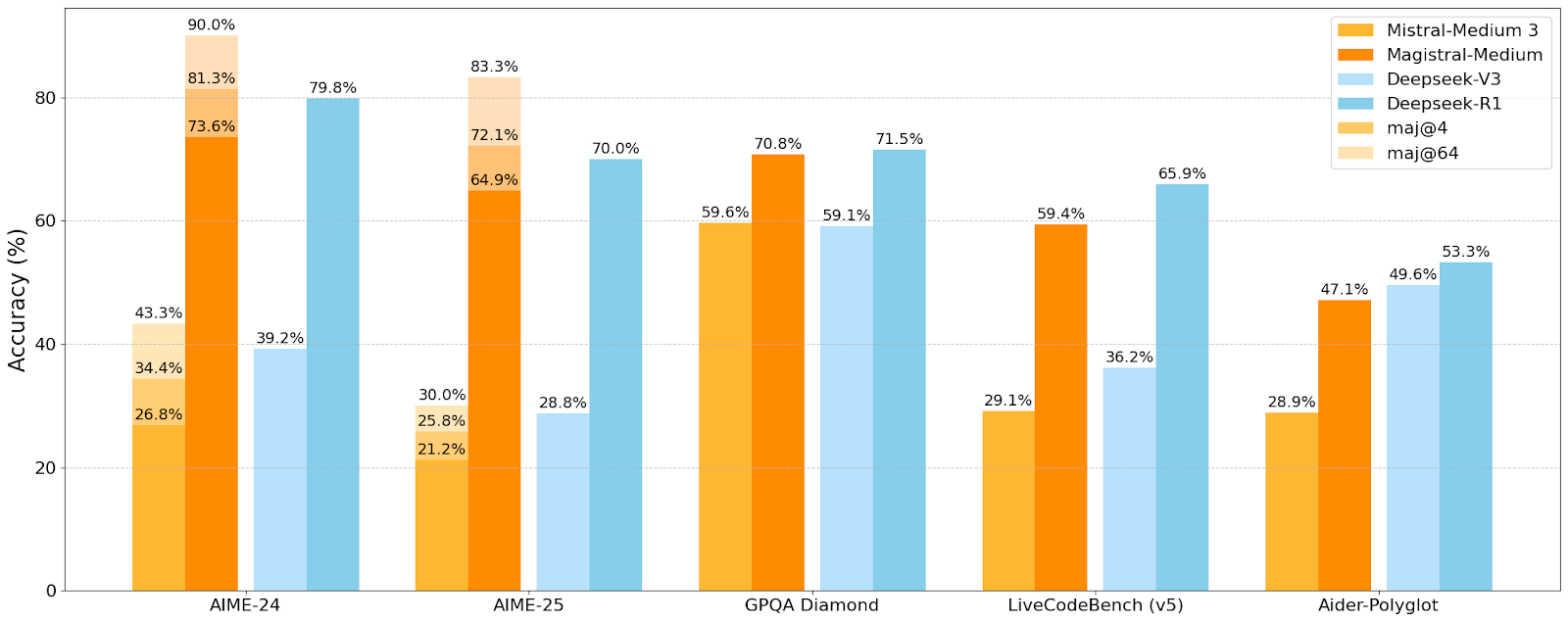
Mistral AI lança a primeira série de modelos de inferência Magistral, com o modelo pequeno Magistral-Small já em código aberto: A Mistral AI lançou a sua primeira série de modelos projetados especificamente para inferência, Magistral, incluindo o Magistral-Small e o Magistral-Medium. O Magistral-Small é construído com base no Mistral Small 3.1 (2503), um modelo de inferência eficiente com 24B de parâmetros, treinado com SFT e RL usando trajetórias do Magistral Medium para aprimorar as capacidades de raciocínio. O modelo suporta múltiplos idiomas, tem uma janela de contexto de 128k (contexto efetivo recomendado de 40k), é de código aberto sob a licença Apache 2.0 e pode ser implementado localmente num único RTX 4090 ou num MacBook com 32GB de RAM (após quantização). Testes de benchmark mostram que o Magistral-Small tem um desempenho excelente em tarefas como AIME24, AIME25, GPQA Diamond e Livecodebench (v5), aproximando-se ou mesmo superando alguns modelos maiores. O Magistral-Medium tem um desempenho ainda mais forte, mas atualmente não é de código aberto. Este lançamento marca o progresso da Mistral no aprimoramento das capacidades de inferência de modelos e no suporte multilingue (Fonte: Reddit r/LocalLLaMA, Mistral AI, X)
🎯 Movimentos
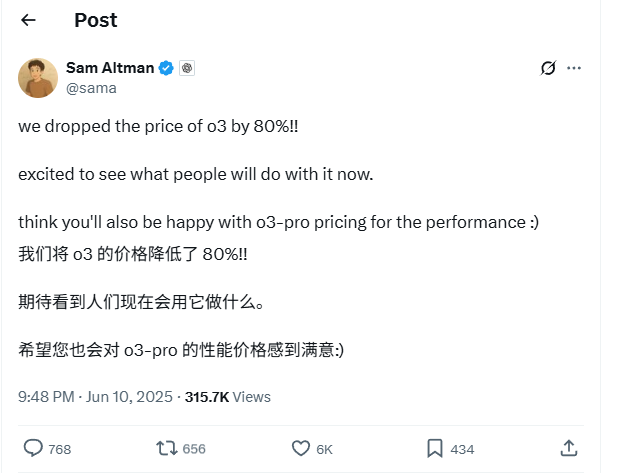
Preço da API do modelo OpenAI o3 reduzido drasticamente em 80%: O CEO da OpenAI, Sam Altman, anunciou que o preço da API do seu modelo o3 foi reduzido em 80%. Após o ajuste, o preço de entrada é de 2 USD/milhão de tokens e o preço de saída é de 8 USD/milhão de tokens (algumas fontes mencionam 5 USD/milhão de tokens para saída, é necessário verificar a documentação oficial). Esta redução de preço é substancial, diminuindo significativamente o custo de utilização do modelo o3 para tarefas como escrita de código, e espera-se que impulsione uma aplicação e inovação mais amplas. Os utilizadores devem notar que a lista de preços no site oficial pode ainda não estar atualizada e é aconselhável testar antes de fazer chamadas à API para confirmar o preço efetivo e evitar perdas desnecessárias. Esta medida é considerada uma estratégia para enfrentar a concorrência do mercado (como Gemini 2.5 Pro e Claude 4 Sonnet) e pode indicar que o custo da inteligência artificial continuará a diminuir (Fonte: X, X, X)
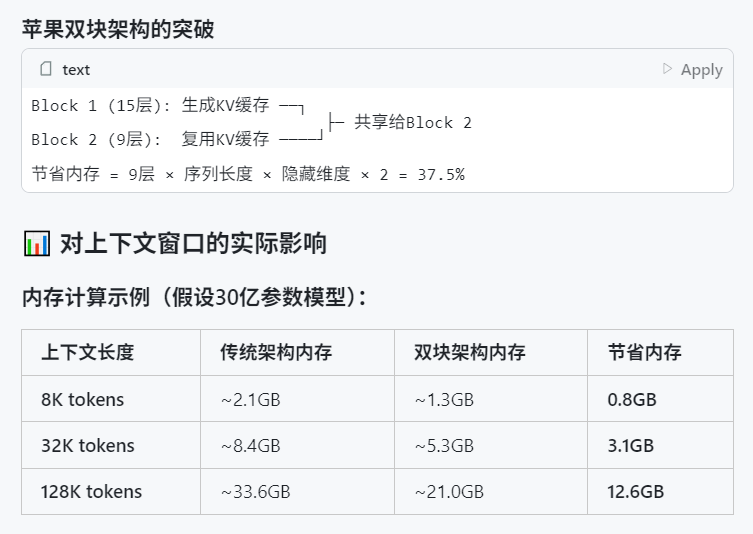
WWDC 2025 da Apple criticada por pouca ênfase em IA, mas detalhes técnicos revelam ambição: Na Conferência Mundial de Desenvolvedores (WWDC) 2025 da Apple, a ênfase em IA pareceu menor do que o esperado, mas os seus documentos técnicos revelam um investimento profundo em modelos no dispositivo e na nuvem. A Apple está a adotar técnicas avançadas de treino, destilação e quantização, incluindo uma “arquitetura de bloco duplo” (projetada para reduzir o consumo de memória) para modelos móveis (cerca de 3B de tamanho) e uma arquitetura “PT-MoE” (Parallel Track Mixture of Experts) para modelos de servidor. Estas tecnologias visam otimizar a inferência de baixa latência nos chips da Apple e reduzir o uso de memória KV cache. Embora haja vozes externas que consideram a Apple atrasada em IA, as suas conquistas em tecnologia de modelos (como modelos de embedding de código aberto) e o foco em diferentes prioridades (como inteligência no dispositivo em vez de apenas chatbots) indicam que possui uma estratégia de IA única. A WWDC também anunciou que o Safari 26 suportará WebGPU, o que aumentará significativamente o desempenho da execução de modelos de IA no dispositivo (como através de Transformers.js), por exemplo, a velocidade de legendagem de modelos visuais no navegador aumentará cerca de 12 vezes (Fonte: X, X, X)
Utilizadores do Perplexity Pro podem agora usar o modelo OpenAI o3: A Perplexity anunciou que os seus subscritores Pro podem agora usar o modelo o3 da OpenAI. Esta integração trará aos utilizadores do Perplexity Pro capacidades mais poderosas de processamento de informação e resposta a perguntas. Simultaneamente, a Perplexity também está a testar a sua funcionalidade “Memory” e atualizou o seu assistente de voz para iOS, com o objetivo de fornecer uma experiência de utilizador mais concisa e prática. A sua funcionalidade de artigos Discover também assume por defeito o modo “Summary” mais conciso, oferecendo a opção de mudar para o modo “Report” mais aprofundado (Fonte: X, X, X)

Xiaohongshu lança em código aberto o primeiro grande modelo MoE de 142B, dots.llm1, superando o DeepSeek-V3 em avaliações chinesas: A Xiaohongshu lançou em código aberto o seu primeiro grande modelo, dots.llm1, um modelo MoE (Mixture of Experts) com 142 mil milhões de parâmetros, ativando apenas 14 mil milhões de parâmetros durante a inferência. O modelo usou 11,2 biliões de tokens não sintéticos na fase de pré-treino, provenientes principalmente de dados da Web de crawlers genéricos e próprios. A equipa da Xiaohongshu propôs uma estrutura escalável de processamento de dados em três fases e tornou-a de código aberto para aumentar a reprodutibilidade. O dots.llm1 obteve 92,2 pontos no C-Eval, superando todos os modelos, incluindo o DeepSeek-V3, e aproximando-se do desempenho do Qwen3-32B da Alibaba em tarefas de chinês, inglês, matemática e alinhamento. A Xiaohongshu também disponibilizou checkpoints de treino intermédios para promover a compreensão da dinâmica dos grandes modelos pela comunidade (Fonte: 36氪)
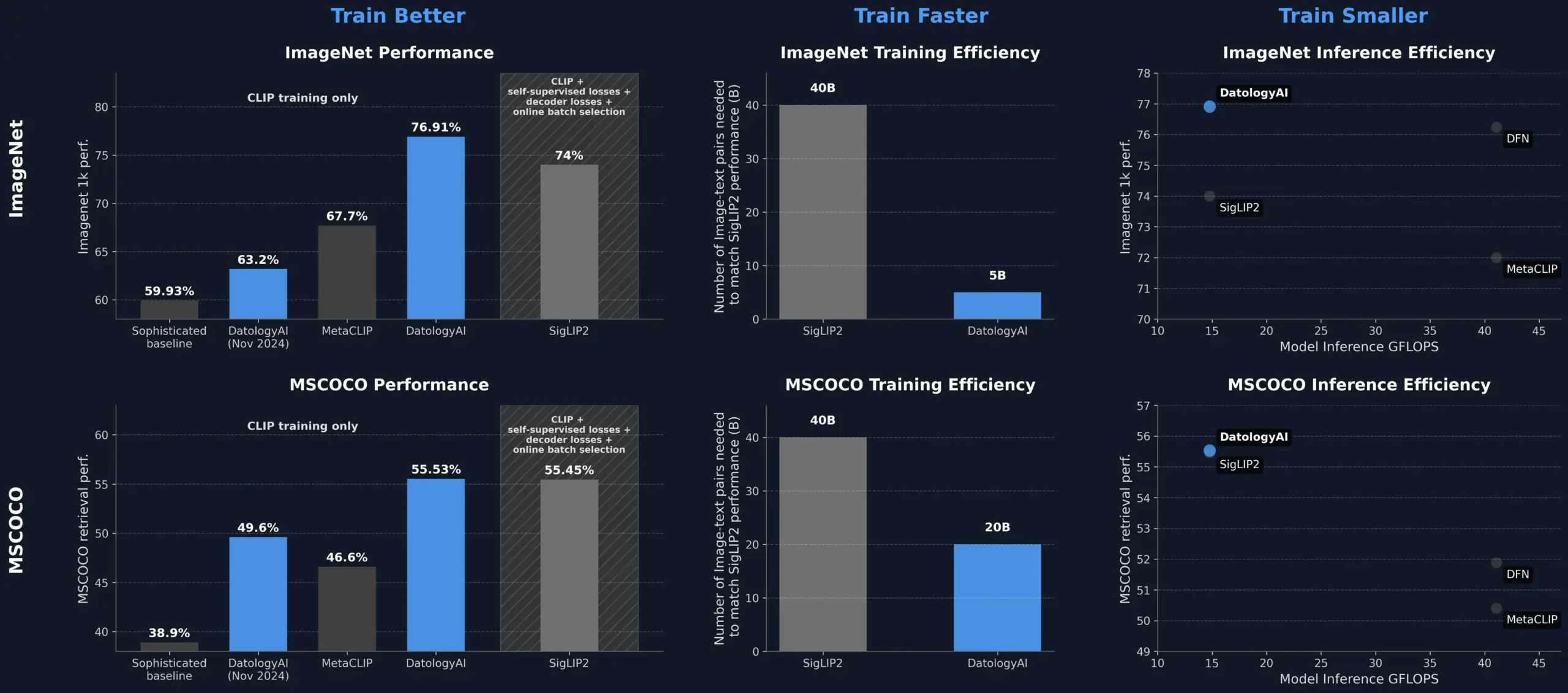
DatologyAI melhora o desempenho do modelo CLIP através da gestão de dados, superando o SigLIP2: A DatologyAI demonstrou que apenas através da gestão de dados (data curation) é possível melhorar significativamente o desempenho do modelo CLIP. O seu método permitiu que o modelo ViT-B/32 atingisse uma precisão de 76,9% no ImageNet 1k, superando os 74% reportados pelo SigLIP2. Além disso, o método também proporcionou um aumento de 8 vezes na eficiência do treino e de 2 vezes na eficiência da inferência, tendo os modelos relevantes sido publicados. Isto realça o papel central de conjuntos de dados de alta qualidade e cuidadosamente geridos no treino de modelos avançados de IA, permitindo explorar o potencial do modelo através da otimização dos dados, mesmo sem alterar a arquitetura do modelo (Fonte: X, X)
Kuaishou e Universidade do Nordeste propõem conjuntamente a estrutura de embedding multimodal unificada UNITE: Para resolver o problema da interferência transmodal causada pelas diferenças na distribuição de dados de diferentes modalidades (texto, imagem, vídeo) na recuperação multimodal, investigadores da Kuaishou e da Universidade do Nordeste propuseram a estrutura de embedding multimodal unificada UNITE. Esta estrutura, através do mecanismo de “aprendizagem contrastiva com máscara sensível à modalidade” (MAMCL), considera apenas amostras negativas consistentes com a modalidade alvo da consulta na aprendizagem contrastiva, evitando a competição errónea entre modalidades. A UNITE adota um treino em duas fases de “adaptação à recuperação + ajuste fino de instruções” e alcançou resultados SOTA em várias avaliações, como recuperação imagem-texto, recuperação vídeo-texto e recuperação de instruções, superando modelos de maior escala no MMEB Benchmark e liderando significativamente no CoVR. A investigação enfatiza a capacidade central dos dados vídeo-texto na unificação de modalidades e aponta que as tarefas de instrução dependem mais de dados dominados por texto (Fonte: 量子位)

NVIDIA lança modelo de IA fundamental para simulação climática Earth-2: A plataforma Earth-2 da NVIDIA lançou um novo modelo de IA fundamental capaz de simular o clima global com resolução ao nível do quilómetro. Este modelo visa fornecer previsões climáticas mais rápidas e precisas, oferecendo novas formas de compreender e prever os complexos sistemas naturais da Terra. Esta iniciativa marca um passo importante na aplicação da IA na ciência climática e na modelação do sistema terrestre, com potencial para melhorar a investigação sobre alterações climáticas e a capacidade de alerta de desastres (Fonte: X)

Serviços da OpenAI sofrem falha generalizada, afetando ChatGPT e API: Os serviços ChatGPT e as interfaces API da OpenAI sofreram uma falha generalizada na noite de 10 de junho, horário de Pequim, manifestando-se por um aumento da taxa de erros e da latência. Muitos utilizadores relataram incapacidade de aceder aos serviços ou encontraram mensagens de erro como “Hmm…something seems to have gone wrong”. A página oficial de estado da OpenAI confirmou o problema e indicou que os engenheiros localizaram a causa raiz e estão a proceder a reparações urgentes. Esta falha afetou um grande número de utilizadores e aplicações em todo o mundo que dependem do ChatGPT e da sua API, realçando mais uma vez a importância da estabilidade dos grandes serviços de IA (Fonte: X, Reddit r/ChatGPT, Reddit r/ChatGPT)
🧰 Ferramentas
Ecossistema de servidores do Model Context Protocol (MCP) continua a expandir-se: O Model Context Protocol (MCP) visa fornecer aos grandes modelos de linguagem (LLM) acesso seguro e controlável a ferramentas e fontes de dados. O repositório modelcontextprotocol/servers no GitHub reúne implementações de referência do MCP e servidores construídos pela comunidade, demonstrando a sua aplicação diversificada. Servidores oficiais e de terceiros cobrem sistemas de ficheiros, operações Git, interação com bases de dados (como PostgreSQL, MySQL, MongoDB, Redis, ClickHouse, Cassandra, etc.), serviços na nuvem (AWS, Azure, Cloudflare), integração de API (GitHub, GitLab, Slack, Google Drive, Stripe, PayPal), pesquisa (Brave, Algolia, Exa, Tavily), execução de código, chamadas a modelos de IA (Replicate, ElevenLabs), entre outros vastos domínios. O ecossistema MCP está a desenvolver-se rapidamente, com mais de 130 servidores oficiais e comunitários, e o surgimento de frameworks de desenvolvimento como EasyMCP, FastMCP, MCP-Framework, e ferramentas de gestão como MCP-CLI, MCPM, com o objetivo de reduzir a barreira para LLMs acederem a ferramentas e dados externos, impulsionando o desenvolvimento de AI Agents (Fonte: GitHub Trending)
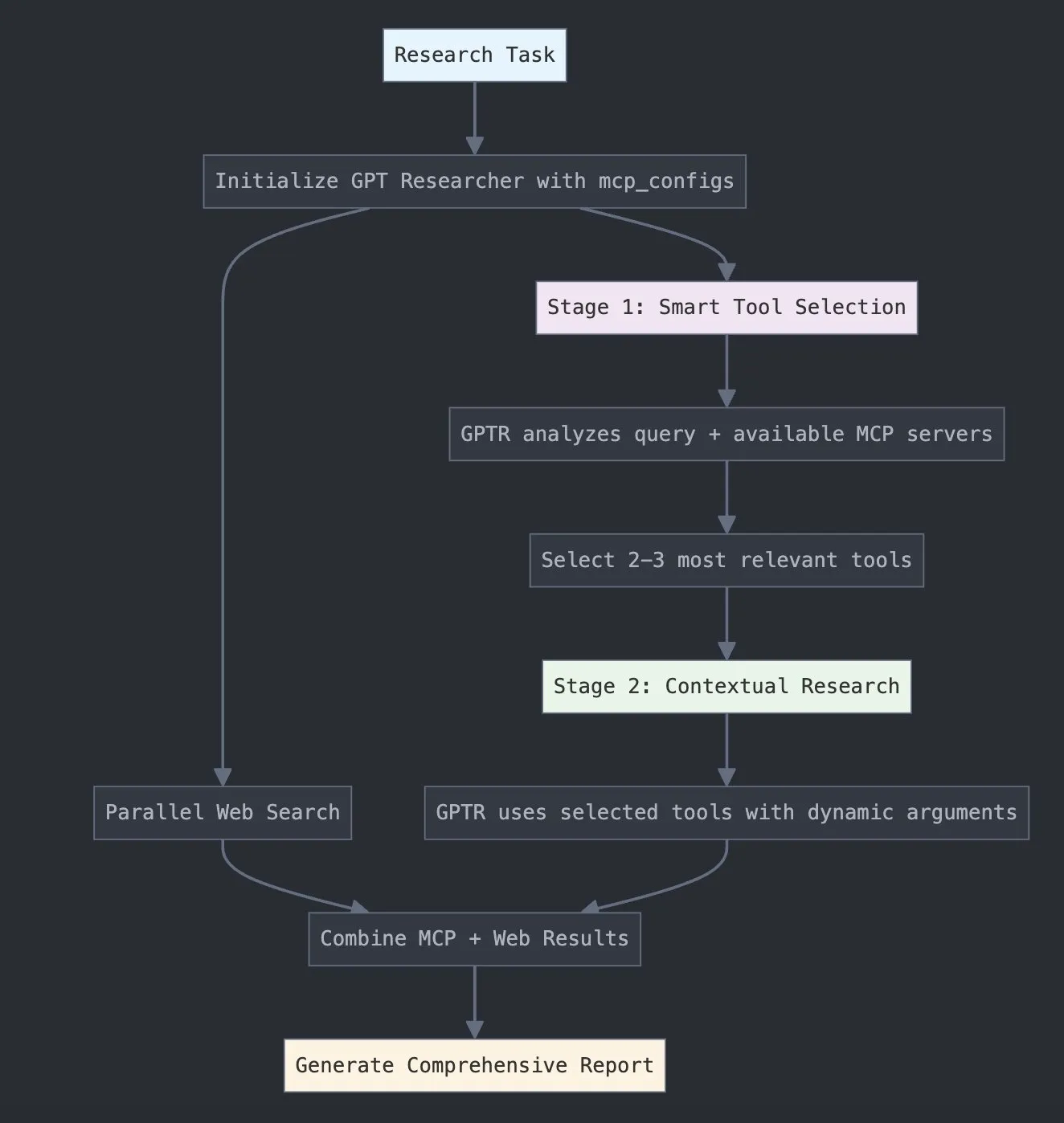
LangChain lança GPT Researcher MCP, melhorando capacidades de investigação: A LangChain anunciou que o GPT Researcher utiliza agora o seu adaptador do Model Context Protocol (MCP) para permitir a seleção inteligente de ferramentas e investigação. Esta integração combina o MCP com funcionalidades de pesquisa na web, com o objetivo de fornecer aos utilizadores capacidades mais abrangentes de recolha e análise de dados, aprofundando ainda mais a aplicação da IA no campo da investigação (Fonte: X)
Hugging Face lança Vui: NotebookLM de 100M de código aberto, alcançando TTS semelhante ao humano: Foi lançado no Hugging Face o Vui, um projeto NotebookLM de código aberto com 100 milhões de parâmetros, que inclui três modelos: Vui.BASE (modelo base treinado com 40k horas de conversas em áudio), Vui.ABRAHAM (modelo de um único locutor com capacidade de perceção de contexto) e Vui.COHOST (modelo capaz de realizar conversas entre duas pessoas). O Vui consegue clonar vozes, imitar respiração, interjeições como “hum” e “ah”, e até sons não vocais, marcando um novo avanço na tecnologia de conversão de texto em fala (TTS) semelhante à humana (Fonte: X, X)
Consilium: plataforma colaborativa de múltiplos agentes de código aberto para resolver problemas complexos: O projeto Consilium foi apresentado no Hugging Face, uma plataforma colaborativa de múltiplos agentes de código aberto. Os utilizadores podem formar uma equipa de agentes de IA especialistas que, através de debate e investigação em tempo real (web, arXiv, ficheiros SEC), colaboram para resolver problemas complexos e alcançar um consenso. O utilizador define a estratégia, e a equipa de agentes encarrega-se de encontrar as respostas, demonstrando uma nova exploração da IA na resolução colaborativa de problemas (Fonte: X)
Unsloth lança modelo GGUF otimizado do Magistral-Small-2506: Após o lançamento do modelo de inferência Magistral-Small-2506 pela Mistral AI, a Unsloth rapidamente lançou a sua versão otimizada em formato GGUF, adequada para plataformas como llama.cpp, LMStudio e Ollama. Esta resposta rápida reflete a vitalidade e eficiência da comunidade de código aberto na otimização e implementação de modelos, permitindo que novos modelos sejam utilizados mais rapidamente por um leque mais vasto de utilizadores e programadores (Fonte: X)
📚 Aprendizagem
Novo artigo explora o paradigma de pré-treino com aprendizagem por reforço (RPT): Um novo artigo intitulado “Reinforcement Pre-Training (RPT)” propõe a reformulação da previsão do próximo token como uma tarefa de inferência usando RLVR (Reinforcement Learning with Verifiable Rewards). O RPT visa melhorar a precisão da previsão dos modelos de linguagem, incentivando a capacidade de inferência do próximo token, e fornecer uma base sólida para o subsequente ajuste fino por reforço. A investigação mostra que aumentar a computação de treino melhora continuamente a precisão da previsão, indicando que o RPT é um paradigma de extensão eficaz e promissor para o pré-treino de modelos de linguagem (Fonte: HuggingFace Daily Papers, X)

Artigo propõe Cartridges: representações de contexto longo leves através de autoestudo: Um artigo intitulado “Cartridges: Lightweight and general-purpose long context representations via self-study” explora um método para processar textos longos através do treino offline de pequenos KV caches (chamados Cartridge), como alternativa a colocar todo o corpus na janela de contexto durante a inferência. A investigação descobriu que os Cartridges treinados através de “autoestudo” (gerando diálogos sintéticos sobre o corpus e treinando com um objetivo de destilação de contexto) conseguem atingir um desempenho comparável ao ICL com um consumo de memória significativamente menor (redução de 38,6 vezes) e maior débito (aumento de 26,4 vezes), podendo expandir o comprimento efetivo do contexto do modelo e até suportar a combinação entre corpora sem necessidade de retreino (Fonte: HuggingFace Daily Papers, X)

Artigo explora a Otimização de Política Contrastiva de Grupo (GCPO) em LLMs para resolução de problemas de geometria: O artigo “GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization” aborda o desafio da construção de linhas auxiliares por LLMs na resolução de problemas de geometria, propondo a estrutura GCPO. Esta estrutura, através de uma “máscara contrastiva de grupo”, fornece sinais de recompensa positivos e negativos para a construção de linhas auxiliares com base na utilidade contextual, e introduz uma recompensa de comprimento para promover cadeias de raciocínio mais longas. A família de modelos GeometryZero, desenvolvida com base no GCPO, demonstrou um desempenho superior aos modelos de base em benchmarks como Geometry3K e MathVista, com uma melhoria média de 4,29%, mostrando potencial para aumentar a capacidade de raciocínio geométrico de modelos mais pequenos com poder computacional limitado (Fonte: HuggingFace Daily Papers)
Artigo “The Illusion of Thinking” explora capacidades e limitações de modelos de raciocínio através da complexidade dos problemas: Este estudo examina sistematicamente as capacidades, características de escalabilidade e limitações dos grandes modelos de raciocínio (LRMs). Utilizando um ambiente de quebra-cabeças com complexidade controlável com precisão, a investigação descobriu que a precisão dos LRMs colapsa completamente após exceder uma determinada complexidade, e exibe limitações de escalabilidade contraintuitivas: o esforço de raciocínio diminui à medida que a complexidade do problema aumenta até um certo ponto. Em comparação com LLMs padrão, os LRMs têm pior desempenho em tarefas de baixa complexidade, são superiores em tarefas de complexidade média, e ambos falham em tarefas de alta complexidade. O estudo aponta que os LRMs têm limitações no cálculo preciso, dificuldade em aplicar algoritmos explícitos e inconsistência no raciocínio em diferentes escalas (Fonte: HuggingFace Daily Papers, X)
Artigo investiga avaliação da robustez de LLMs em línguas com poucos recursos: O artigo “Evaluating LLMs Robustness in Less Resourced Languages with Proxy Models” explora a sensibilidade de grandes modelos de linguagem (LLMs) a perturbações (como ataques ao nível de caracteres e palavras) em línguas de baixos recursos, como o polaco. A investigação descobriu que, através de pequenas modificações de caracteres e usando pequenos modelos proxy para calcular a importância das palavras, é possível criar ataques que alteram significativamente as previsões de diferentes LLMs. Isto revela potenciais vulnerabilidades de segurança dos LLMs nestas línguas, que poderiam ser usadas para contornar os seus mecanismos de segurança internos. Os investigadores publicaram os conjuntos de dados e código relevantes (Fonte: HuggingFace Daily Papers)
Rel-LLM: Novo método para aumentar a eficiência dos LLMs no processamento de bases de dados relacionais: Um artigo propõe a estrutura Rel-LLM, que visa resolver o problema da baixa eficiência dos grandes modelos de linguagem (LLM) no processamento de bases de dados relacionais. Os métodos tradicionais que convertem dados estruturados em texto levam à perda de ligações cruciais e à redundância de entrada. O Rel-LLM cria prompts de grafos estruturados através de um codificador de rede neural de grafos (GNN), preservando a estrutura relacional dentro de uma estrutura de geração aumentada por recuperação (RAG). O método inclui amostragem de subgrafos sensível ao tempo, codificador GNN heterogéneo, camada de projeção MLP para alinhar embeddings de grafos com o espaço latente do LLM, e estruturação da representação do grafo como um prompt de grafo JSON, entre outros passos, e alinha representações de grafos e texto através de um objetivo de pré-treino auto-supervisionado. As experiências mostram que a codificação GNN consegue capturar eficazmente estruturas relacionais complexas perdidas na serialização de texto, e os prompts de grafos estruturados conseguem injetar eficazmente o contexto relacional nos mecanismos de atenção do LLM (Fonte: X)

Artigo explora o problema de “recusa excessiva” dos LLMs e o método de otimização EvoRefuse: O artigo “EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions” investiga o problema da recusa excessiva por parte de grandes modelos de linguagem (LLM) a “instruções pseudo-maliciosas” (entradas semanticamente inofensivas mas que desencadeiam a recusa do modelo). Para resolver as deficiências dos métodos existentes de gestão de instruções em termos de escalabilidade e diversidade, o artigo propõe o EVOREFUSE, um método que utiliza algoritmos evolutivos para otimizar prompts, capaz de gerar instruções pseudo-maliciosas diversificadas que provocam consistentemente a recusa dos LLMs. Com base nisto, os investigadores criaram o EVOREFUSE-TEST (um benchmark com 582 instruções) e o EVOREFUSE-ALIGN (um conjunto de dados de treino de alinhamento com 3000 instruções e respostas). As experiências mostram que o modelo LLAMA3.1-8B-INSTRUCT, afinado no EVOREFUSE-ALIGN, apresenta uma taxa de recusa excessiva até 14,31% inferior à dos modelos treinados em conjuntos de dados de alinhamento subótimos, sem comprometer a segurança (Fonte: HuggingFace Daily Papers)
💼 Negócios
Zhongke Wenge conclui nova ronda de financiamento estratégico, com investimento do Fundo Industrial do Distrito de Shijingshan, Pequim: A Zhongke Wenge, fornecedora de serviços de IA de nível empresarial, anunciou a conclusão de uma nova ronda de financiamento estratégico, com o investidor sendo a Beijing Shijingshan Modern Innovation Industry Development Fund Co., Ltd. Este financiamento será principalmente utilizado para o investimento em I&D e promoção de mercado do seu sistema operativo de inteligência de decisão auto-desenvolvido, DIOS, acelerando o desenvolvimento tecnológico e a implementação comercial da inteligência artificial de nível empresarial. Fundada em 2017, a equipa principal da Zhongke Wenge é originária do Instituto de Automação da Academia Chinesa de Ciências, focando-se na compreensão multilingue, semântica transmodal e tecnologia de decisão em cenários complexos, servindo indústrias como media, finanças, governo e energia. Anteriormente, já tinha recebido mais de mil milhões de yuans em investimentos de fundos estatais como o CDB Financial, China Internet Investment Fund e SCGC (Fonte: 量子位)

Sakana AI e Banco Hokkoku do Japão estabelecem parceria estratégica para promover o desenvolvimento de IA financeira regional: A startup japonesa de IA, Sakana AI, anunciou a assinatura de um memorando de entendimento (MOU) com a Hokkoku Financial Holdings, sediada na prefeitura de Ishikawa. As duas partes colaborarão estrategicamente na integração da finança regional com a IA. Esta é a segunda parceria da Sakana AI com uma instituição financeira, após o estabelecimento de uma parceria abrangente com o Banco Mitsubishi UFJ, e visa aplicar tecnologia de IA de ponta para resolver os desafios enfrentados pela sociedade regional japonesa, especialmente no setor de serviços financeiros. A Sakana AI dedica-se ao desenvolvimento de tecnologia de IA altamente especializada para instituições financeiras, e espera-se que esta colaboração estabeleça um modelo para a aplicação de IA por outros bancos regionais no Japão (Fonte: X, X)

Cohere estabelece parceria com a Ensemble para levar a sua plataforma de IA ao setor da saúde: A empresa de IA Cohere anunciou uma parceria com a EnsembleHP (fornecedora de soluções para o setor da saúde) para introduzir a sua plataforma de agentes inteligentes Cohere North AI no setor da saúde. Ambas as empresas pretendem, através de uma plataforma segura de agentes de IA, reduzir o atrito nos processos de gestão médica e melhorar a experiência do paciente em hospitais e sistemas de saúde. Esta iniciativa marca um passo importante da Cohere na promoção da aplicação dos seus grandes modelos de linguagem e tecnologia de IA em setores verticais cruciais (Fonte: X)
🌟 Comunidade
Ilya Sutskever no discurso de doutoramento honoris causa na Universidade de Toronto: IA acabará por ser capaz de tudo, é preciso atenção ativa: Ilya Sutskever, cofundador da OpenAI, afirmou no seu discurso ao receber o doutoramento honoris causa em Ciências pela Universidade de Toronto (o seu quarto diploma naquela instituição) que o progresso da IA fará com que “um dia consiga fazer tudo o que nós conseguimos”, porque o cérebro humano é um computador biológico e a IA é um cérebro digital. Ele acredita que estamos numa era extraordinária definida pela IA, que já alterou profundamente o significado de ser estudante e de trabalhar. Enfatizou que, em vez de preocupação, devemos formar intuições através do uso e observação da IA de ponta para compreender os limites da sua capacidade. Apelou às pessoas para que prestem atenção ao desenvolvimento da IA e enfrentem ativamente os enormes desafios e oportunidades que daí advêm, pois a IA afetará profundamente a vida de todos. Partilhou também a sua mentalidade pessoal: “Aceitar a realidade, não lamentar o passado, esforçar-se para melhorar o presente.” (Fonte: X, 36氪)
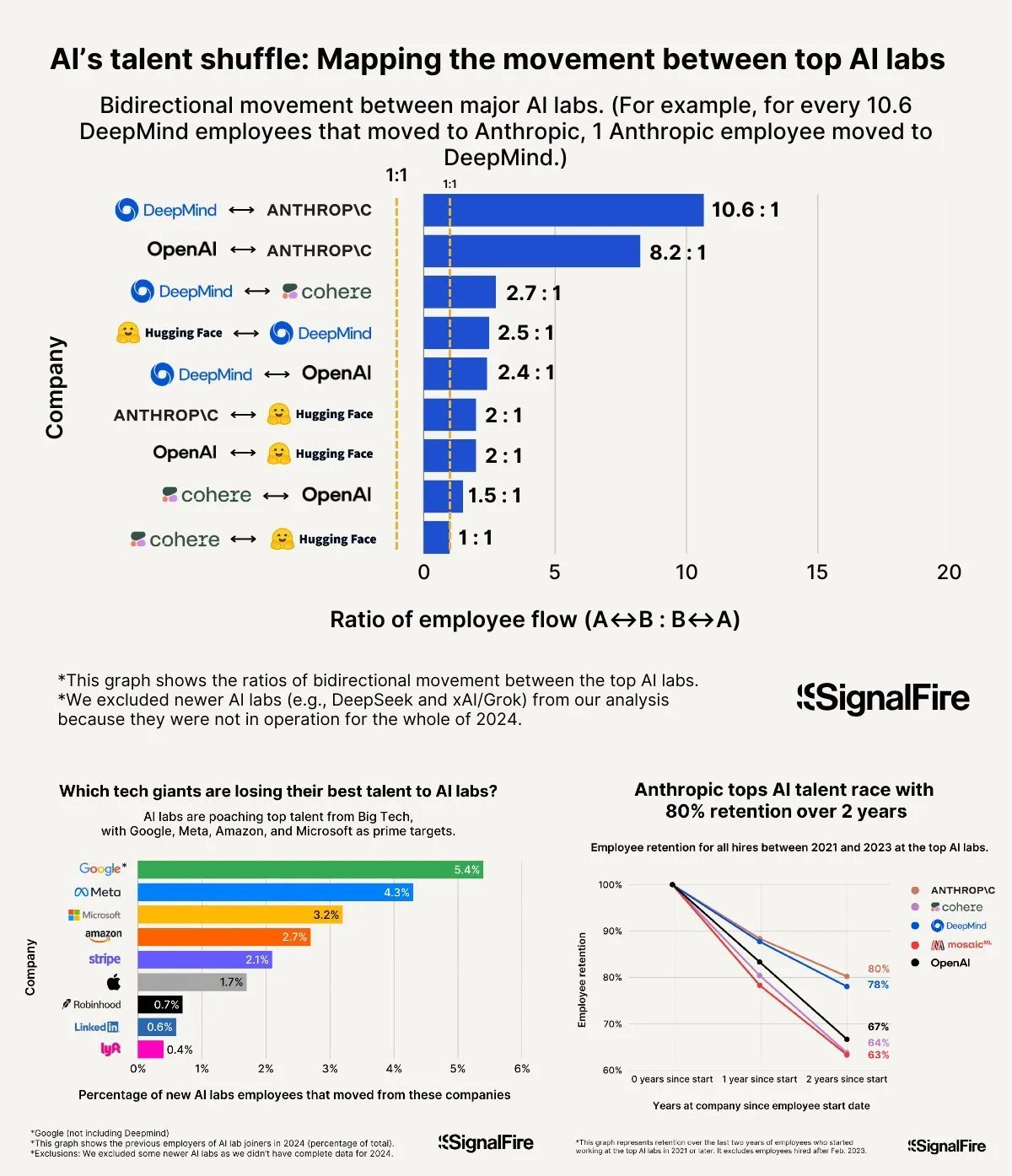
Guerra de talentos em IA aquece: Meta, mesmo com salários altos, tem dificuldade em competir com OpenAI e Anthropic: A Meta alegadamente oferece salários anuais superiores a 2 milhões de dólares para atrair talentos em IA, mas ainda enfrenta dificuldades com a fuga de talentos para a OpenAI e Anthropic. Discute-se que o salário de nível L6 na OpenAI se aproxima dos 1,5 milhões de dólares, e o potencial de valorização das ações é considerado superior ao da Meta, tornando-a mais atraente para os melhores talentos. Além disso, alegações de comportamento de batota na equipa Llama e a grande pressão interna por KPIs e alta taxa de eliminação dos últimos classificados na Meta (15-20% este ano) também influenciam a escolha dos talentos. A Anthropic, com uma taxa de retenção de talentos de cerca de 80% (após dois anos de fundação), tornou-se uma das principais escolhas para os melhores investigadores de IA entre as grandes empresas. A intensidade desta guerra de talentos é descrita como “inacreditável” (Fonte: X, X)
Partilha de experiência em “Vibe Coding”: 5 regras para evitar armadilhas na programação assistida por IA: Nas redes sociais, programadores experientes partilharam cinco regras para evitar cair em ciclos de depuração ineficientes ao usar IA (como o Claude) para “Vibe Coding” (uma forma de programação que depende da assistência da IA): 1. Três strikes e estás fora: Se a IA não conseguir corrigir o problema após três tentativas, pare e peça à IA para construir do zero a partir de uma nova descrição dos requisitos. 2. Repor o contexto: A IA “esquece-se” após longas conversas; sugere-se guardar o código válido a cada 8-10 rondas de mensagens, iniciar uma nova sessão e colar apenas os componentes problemáticos e uma breve descrição da aplicação. 3. Descrever o problema de forma concisa e clara: Descreva o bug numa frase clara. 4. Controlo de versões frequente: Faça commit no Git após cada funcionalidade concluída. 5. Se necessário, comece de novo: Se a correção de um bug demorar demasiado tempo (por exemplo, mais de 2 horas), é melhor apagar o componente problemático e pedir à IA para o reconstruir. O essencial é, ao admitir que o código está irreversivelmente danificado, abandonar decididamente as tentativas de remendo. Salienta-se também que saber programar permite orientar melhor a IA e depurar (Fonte: Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
Fei-Fei Li fala sobre a fundação da World Labs: originada na exploração da essência da inteligência, a inteligência espacial é a peça chave em falta na IA: No podcast da a16z, Fei-Fei Li partilhou a motivação por detrás da fundação da World Labs, enfatizando que não se trata de seguir a moda dos modelos fundamentais, mas sim de uma exploração contínua da essência da inteligência. Ela acredita que, embora a linguagem seja um veículo eficiente de informação, apresenta deficiências na representação do mundo físico tridimensional, e a verdadeira inteligência geral deve basear-se na compreensão do espaço físico e das relações entre objetos. Uma lesão na córnea que lhe causou a perda temporária da visão estereoscópica fê-la sentir mais profundamente a importância da representação do espaço tridimensional para a interação física. A World Labs visa construir modelos de IA (world models, LWM) que compreendam verdadeiramente o mundo físico, preenchendo a lacuna atual da IA na inteligência espacial. Ela considera que, para realizar esta visão, é necessário reunir poder computacional, dados e talentos de nível industrial, e aponta que o atual ponto de avanço tecnológico reside em permitir que a IA reconstrua a compreensão completa de cenas tridimensionais a partir da visão monocular (Fonte: 量子位)

IA a auxiliar no Gaokao: da controvérsia das previsões de exames às oportunidades e preocupações na escolha de cursos: Antes e depois do Gaokao (exame nacional de acesso ao ensino superior na China), a aplicação da IA na educação gerou ampla discussão. Por um lado, a “previsão de exames por IA” tornou-se um tema quente, mas devido à cientificidade, confidencialidade e mecanismos “anti-previsão” da elaboração do Gaokao, a probabilidade de previsão precisa por IA é baixa, e a qualidade de alguns exames de previsão no mercado é questionável. Por outro lado, a IA demonstrou um papel positivo no planeamento da preparação, explicação de questões, fiscalização de exames e correção, como planos de estudo personalizados, respostas inteligentes a dúvidas e sistemas de fiscalização por IA que aumentam a justiça e a eficiência. Na fase de escolha de cursos, as ferramentas de IA podem recomendar rapidamente instituições e cursos com base na pontuação e classificação dos candidatos, quebrando a assimetria de informação. No entanto, a dependência excessiva da IA na escolha de cursos também levanta preocupações: os algoritmos podem reforçar a preferência por cursos populares, ignorando interesses individuais e o desenvolvimento a longo prazo; entregar completamente a escolha de vida a algoritmos pode levar a um “sequestro da vida por algoritmos”. O artigo apela a uma visão racional da assistência da IA, enfatizando o uso inteligente das ferramentas e a definição do futuro através do pensamento (Fonte: 36氪)
Discussão sobre modelos de sucesso para empresas de AI Agent: self-service vs. serviços personalizados: A comunidade discutiu modelos de sucesso para empresas de AI Agent. Uma perspetiva defende que as empresas de AI Agent bem-sucedidas (especialmente as que servem mercados de média a grande dimensão) adotam maioritariamente um modelo semelhante ao da Palantir, ou seja, com muitos engenheiros de desenvolvimento no local (FDEs) e software personalizado, em vez de um modelo puramente de self-service. Outra perspetiva insiste no valor a longo prazo do modelo de self-service, argumentando que as equipas acabarão por optar por construir internamente aplicações importantes. Isto reflete os diferentes caminhos de pensamento no domínio dos AI Agents em termos de modelos de serviço e estratégias de mercado (Fonte: X)
💡 Outros
Prompt de sistema do Google Diffusion exposto, revelando os seus princípios de design e limites de capacidade: Um utilizador partilhou o que se alega ser o prompt de sistema do Google Diffusion (um modelo de linguagem de difusão de texto). O prompt detalha a identidade do modelo (Gemini Diffusion, um modelo de linguagem de difusão de texto especializado treinado pela Google, não autorregressivo), princípios e restrições centrais (como seguir instruções, características não autorregressivas, precisão, sem acesso em tempo real, ética de segurança, data limite de conhecimento em dezembro de 2023, capacidade de geração de código), e instruções específicas para a geração de páginas web HTML e jogos HTML. Estas instruções abrangem formato de saída, design estético, estilos (como o uso dedicado de Tailwind CSS ou CSS personalizado em jogos), uso de ícones (ícones Lucide SVG), layout e desempenho (prevenção de CLS), requisitos de comentários, etc. Por fim, enfatiza a importância do pensamento passo a passo e do seguimento preciso das instruções do utilizador. Este prompt oferece uma janela para a compreensão das ideias de design e do comportamento esperado de tais modelos (Fonte: Reddit r/LocalLLaMA)
Arvind Narayanan explana o nascimento e reflexão do artigo “AI as Normal Technology”: O professor Arvind Narayanan da Universidade de Princeton partilhou o processo de criação do seu artigo “AI as Normal Technology”, coautorado com Sayash Kapoor. Inicialmente cético em relação à AGI e aos riscos existenciais, decidiu, por insistência de colegas, levar o assunto a sério e participar nas discussões relevantes. Através da reflexão, reconheceu que as opiniões relacionadas com a superinteligência merecem ser levadas a sério, que as redes sociais não são adequadas para discussões sérias, e que tanto a comunidade de ética em IA como a de segurança em IA têm as suas próprias “bolhas de informação”. O rascunho inicial do artigo foi rejeitado no ICML, mas o intenso debate durante o processo de revisão fortaleceu a sua determinação em continuar a investigação. Perceberam que as divergências com a comunidade de segurança em IA eram mais profundas do que o previsto e reconheceram a necessidade de um debate transdisciplinar mais produtivo. Finalmente, o artigo foi publicado num workshop do Knight First Amendment Institute da Universidade de Columbia, gerando ampla atenção e discussões frutíferas, o que tornou Narayanan mais otimista em relação ao futuro da política de IA (Fonte: X)
Geração Z de empreendedores de IA emerge, remodelando as regras do empreendedorismo: Um grupo de empreendedores de IA da Geração Z está a destacar-se a uma velocidade espantosa na onda global de empreendedorismo, redefinindo as regras do jogo com a sua profunda compreensão da tecnologia de IA e a sua perspicácia nativa do ambiente digital. Exemplos incluem Michael Truell da Anysphere (Cursor) (de estagiário a CEO de uma empresa de dez mil milhões de dólares em 3 anos), os três fundadores da Mercor (criaram uma plataforma de recrutamento de IA de nível bilionário em 2 anos), Eric Steinberger da Magic (cofundou aos 25 anos uma empresa de codificação de IA que arrecadou mais de 400 milhões de dólares) e Hong Letong da Axiom (focada em IA para resolver problemas matemáticos, obteve alta avaliação mesmo sem produto). Estes jovens empreendedores geralmente partilham as seguintes características: a programação é a sua língua materna; alcançaram a fama cedo, aproveitando a janela de dividendos tecnológicos; perceção aguçada das necessidades dos utilizadores; compreensão nativa da IA em relação à organização e ao produto, tendendo para equipas minimalistas e eficientes e uma lógica de “IA como produto”. O seu sucesso marca uma mudança de paradigma no empreendedorismo da era da IA (Fonte: 36氪)