
Palavras-chave:WWDC25 da Apple, Estratégia de IA, Atualização do Siri, Framework Foundation, IA no dispositivo, Tradução em todo o sistema, Xcode Vibe Coding, Pesquisa inteligente visual, Suporte a chinês tradicional no Apple Intelligence, Função Smart Stack do watchOS, Estratégia de privacidade de IA da Apple, Integração de IA no ecossistema entre sistemas, Data de lançamento do Siri com IA generativa
🔥 Foco
Avanços de AI da Apple na WWDC25: Integração pragmática e abertura, Siri ainda em espera: A Apple apresentou na WWDC25 um ajuste em sua estratégia de AI, abandonando as “grandes promessas” do ano passado em favor de um aprimoramento mais pragmático do sistema subjacente e das funcionalidades básicas. Os destaques incluem a integração “significativa” de AI no sistema operacional e aplicativos primários, e a abertura do framework do modelo no dispositivo “Foundation” para desenvolvedores. Novas funcionalidades como tradução em todo o sistema (compatível com chamadas telefônicas, FaceTime, Message, etc., e fornecendo API), introdução do Vibe Coding no Xcode (compatível com modelos como ChatGPT), busca visual inteligente baseada no conteúdo da tela (semelhante à seleção por círculo, parcialmente suportada pelo ChatGPT) e Smart Stack no watchOS, entre outros. Embora o suporte do Apple Intelligence para o mercado de chinês tradicional tenha sido mencionado, o cronograma de lançamento para chinês simplificado e a tão esperada versão de AI generativa do Siri ainda não foram definidos, com este último previsto para ser discutido “no próximo ano”. A Apple enfatizou a AI no dispositivo e a computação em nuvem privada para proteger a privacidade do usuário, e demonstrou a integração de capacidades de AI em todo o ecossistema de sistemas. (Fonte: 36氪, 36氪, 36氪, 36氪)

Apple publica artigo de AI questionando capacidade de inferência de grandes modelos, gerando ampla controvérsia na indústria: A Apple publicou recentemente um artigo intitulado “A Ilusão do Pensamento: Compreendendo as Forças e Limitações dos Modelos de Raciocínio através da Perspectiva da Complexidade do Problema”. Através de testes de quebra-cabeças com grandes modelos de raciocínio (LRMs) como Claude 3.7 Sonnet, DeepSeek-R1 e o3 mini, o artigo aponta que eles “pensam demais” ao lidar com problemas simples, enquanto em problemas de alta complexidade apresentam um “colapso completo da precisão”, com taxa de acerto próxima de zero. O estudo sugere que os LRMs atuais podem encontrar obstáculos fundamentais no raciocínio generalizável, assemelhando-se mais a um reconhecimento de padrões do que a um pensamento genuíno. Essa visão atraiu a atenção de acadêmicos como Gary Marcus, mas também gerou muitas críticas, com detratores apontando falhas lógicas no design experimental (como a definição de complexidade e a negligência das limitações de saída de tokens) e até acusando a Apple de tentar desacreditar os resultados dos grandes modelos existentes devido ao seu próprio progresso lento em AI. A identidade do primeiro autor do artigo, um estagiário, também se tornou um ponto de discussão. (Fonte: 36氪, Reddit r/ArtificialInteligence)

OpenAI estaria treinando secretamente novo modelo o4, aprendizagem por reforço remodela o cenário de P&D em AI: SemiAnalysis revelou que a OpenAI está treinando um novo modelo com escala entre GPT-4.1 e GPT-4.5, e que o modelo de inferência de próxima geração, o4, será baseado no GPT-4.1 com treinamento por aprendizagem por reforço (RL). Essa medida marca uma mudança na estratégia da OpenAI, visando equilibrar a robustez do modelo com a praticidade do treinamento por RL. O GPT-4.1 é considerado uma base ideal devido ao seu menor custo de inferência e forte desempenho em código. O artigo analisa profundamente o papel central da aprendizagem por reforço no aprimoramento da capacidade de inferência de LLMs e no avanço de agentes de AI, mas também aponta desafios em infraestrutura, definição de funções de recompensa e reward hacking. A RL está mudando a estrutura organizacional e as prioridades de P&D dos laboratórios de AI, integrando profundamente a inferência e o treinamento. Ao mesmo tempo, dados de alta qualidade se tornam um fosso competitivo para a RL em escala, enquanto para modelos menores, a destilação pode ser mais eficaz que a RL. (Fonte: 36氪)

Ilya Sutskever retorna à esfera pública, recebe doutorado honorário da Universidade de Toronto e discute o futuro da AI: Ilya Sutskever, cofundador da OpenAI, fez sua primeira aparição pública após deixar a OpenAI e fundar a Safe Superintelligence Inc., retornando à sua alma mater, a Universidade de Toronto, para receber um doutorado honorário em ciências. Em seu discurso, ele enfatizou que a AI do futuro será capaz de realizar tudo o que os humanos podem fazer, pois o cérebro em si é um computador biológico, e não há razão para que os computadores digitais não possam fazer o mesmo. Ele acredita que a AI está mudando o trabalho e as carreiras de maneiras sem precedentes e instou as pessoas a prestar atenção ao desenvolvimento da AI, usando a observação de suas capacidades para inspirar energia para superar desafios. A experiência de Sutskever na OpenAI e seu foco na segurança da AGI o tornam uma figura chave no campo da AI. (Fonte: 36氪, Reddit r/artificial)

🎯 Movimentações
Xiaohongshu lança seu primeiro grande modelo MoE de código aberto, dots.llm1, superando DeepSeek-V3 em benchmarks de chinês: O hi lab (Laboratório de Inteligência Humana) da Xiaohongshu lançou seu primeiro grande modelo de código aberto, dots.llm1, um modelo de Mistura de Especialistas (MoE) com 142 bilhões de parâmetros, ativando apenas 14 bilhões de parâmetros durante a inferência. O modelo utilizou 11,2 trilhões de dados não sintéticos na fase de pré-treinamento e demonstrou excelente desempenho em compreensão de chinês e inglês, raciocínio matemático, geração de código e tarefas de alinhamento, com performance próxima ao Qwen3-32B. Especialmente no benchmark chinês C-Eval, o dots.llm1.inst alcançou 92,2 pontos, superando modelos existentes, incluindo o DeepSeek-V3. A Xiaohongshu enfatizou que seu framework de processamento de dados escalável e granular foi crucial, e disponibilizou checkpoints de treinamento intermediários para promover a pesquisa da comunidade. (Fonte: 36氪)
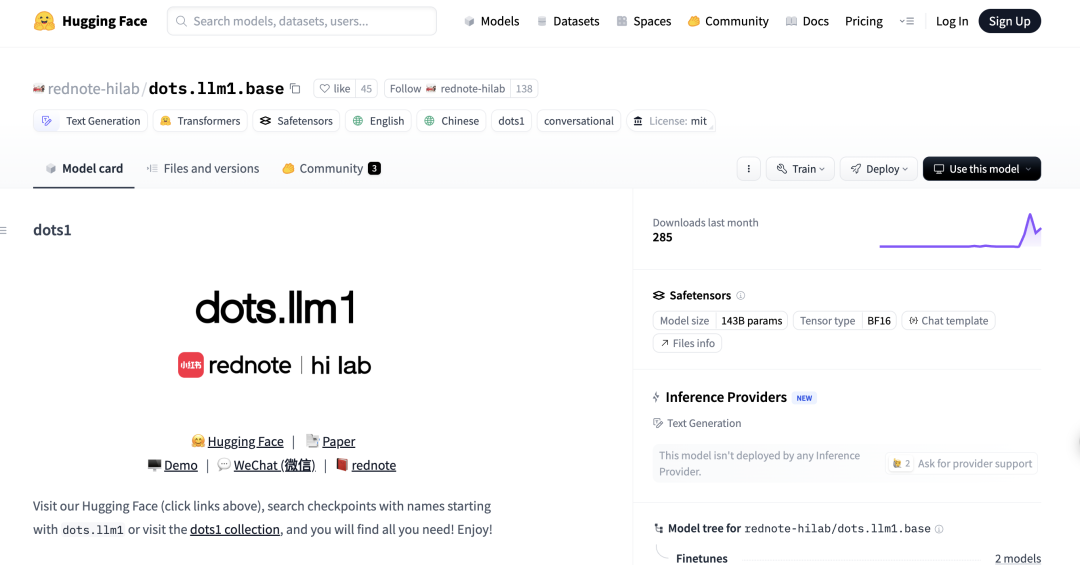
Modelo DeepSeek R1 0528 apresenta excelente desempenho no benchmark de programação Aider: O ranking de programação Aider atualizou a pontuação do modelo DeepSeek-R1-0528, e os resultados mostram que seu desempenho supera o Claude-4-Sonnet (com ou sem modo de reflexão ativado) e o Claude-4-Opus sem modo de reflexão ativado. O modelo também se destacou em termos de custo-benefício, comprovando ainda mais sua forte competitividade nas áreas de geração de código e programação assistida. (Fonte: karminski3)
Atualizações da Apple na WWDC25: Lançamento da linguagem de design “Liquid Glass”, progresso lento em AI, atualização do Siri adiada novamente: Na WWDC25, a Apple lançou atualizações para os sistemas operacionais de todas as plataformas, introduzindo um novo estilo de UI chamado “Liquid Glass” e unificando os números de versão para a “série 26” (como iOS 26). Em relação à AI, o progresso do Apple Intelligence foi limitado. Embora tenha anunciado a abertura do framework de modelo básico no dispositivo “Foundation” para desenvolvedores e demonstrado funcionalidades como tradução em tempo real e inteligência visual, a tão esperada versão do Siri aprimorada por AI foi novamente adiada para “o próximo ano”. Essa decisão gerou decepção no mercado, e o preço das ações caiu em resposta. O iPadOS apresentou melhorias significativas no multitarefa e gerenciamento de arquivos, sendo considerado o destaque desta conferência. (Fonte: 36氪, 36氪, 36氪)
Modelo Claude da Anthropic é criticado por queda de desempenho e má experiência do usuário: Vários usuários do Reddit relataram que o modelo Claude da Anthropic (especialmente o Claude Code Max) apresentou uma queda significativa de desempenho recentemente, incluindo erros em tarefas simples, ignorar instruções e redução na qualidade da saída. Alguns usuários afirmaram que a versão web tem um desempenho particularmente ruim em comparação com a versão API, chegando a suspeitar que o modelo foi “nerfado”. Alguns usuários especulam que isso pode estar relacionado à carga do servidor, limites de taxa ou ajustes internos no prompt do sistema. A página de status oficial da Anthropic também relatou um aumento na taxa de erros do Claude Opus 4. (Fonte: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

KVzip: Comprime o cache KV de LLMs removendo dinamicamente pares KV de baixa importância: Um novo projeto chamado KVzip visa otimizar o uso de VRAM e a velocidade de inferência comprimindo o cache de chave-valor (KV) de grandes modelos de linguagem (LLMs). Este método não é uma compressão de dados no sentido tradicional, mas avalia a importância dos pares KV (com base na capacidade de reconstrução do contexto) e, em seguida, remove diretamente do cache os pares KV de menor importância, alcançando assim uma compressão com perdas. Alega-se que este método pode reduzir o uso de VRAM para um terço do original e aumentar a velocidade de inferência. Atualmente, suporta modelos como LLaMA3, Qwen2.5/3, Gemma3, mas alguns usuários questionaram a validade de seus testes baseados em textos de “Harry Potter”, pois o modelo pode já ter sido pré-treinado com esse texto. (Fonte: karminski3)

Yann LeCun critica Dario Amodei, CEO da Anthropic, por postura contraditória sobre riscos e desenvolvimento da AI: Yann LeCun, cientista-chefe de AI da Meta, acusou Dario Amodei, CEO da Anthropic, nas redes sociais de demonstrar uma postura contraditória de “querer o bolo e comê-lo” em relação às questões de segurança da AI. LeCun argumenta que Amodei, por um lado, promove o alarmismo sobre o fim do mundo causado pela AI e, por outro, desenvolve ativamente AGI, o que seria desonestidade acadêmica, um problema ético ou extrema arrogância, acreditando que apenas ele pode controlar uma AI poderosa. Amodei já havia alertado que a AI poderia causar desemprego em massa de trabalhadores de colarinho branco nos próximos anos e pediu maior regulamentação, mas sua empresa, Anthropic, continua avançando no desenvolvimento e financiamento de grandes modelos como o Claude. (Fonte: 36氪)
HuggingFace lança dataset Nemotron-Personas, NVIDIA divulga dados de personagens sintéticos para treinar LLMs: A NVIDIA lançou no HuggingFace o Nemotron-Personas, um conjunto de dados de código aberto com 100.000 perfis de personagens gerados sinteticamente com base na distribuição do mundo real. Este conjunto de dados visa ajudar os desenvolvedores a treinar LLMs de alta precisão, ao mesmo tempo que mitiga vieses, aumenta a diversidade de dados e previne o colapso do modelo, além de estar em conformidade com os padrões de privacidade PII, GDPR, etc. (Fonte: huggingface, _akhaliq)
Fireworks AI lança versão Beta de Reinforced Fine-tuning (RFT) para ajudar desenvolvedores a treinar seus próprios modelos especialistas: A Fireworks AI lançou a versão Beta de Reinforced Fine-tuning (RFT), oferecendo uma maneira simples e escalável de treinar e possuir modelos especialistas de código aberto personalizados. Os usuários precisam apenas especificar uma função de avaliação para pontuar os resultados e alguns exemplos para realizar o treinamento RFT, sem necessidade de configuração de infraestrutura, e podem implantar em produção de forma transparente. Alega-se que, com RFT, os usuários já conseguiram atingir ou superar a qualidade de modelos de código fechado como GPT-4o mini e Gemini flash, com velocidade de resposta 10-40 vezes maior, adequado para cenários como atendimento ao cliente, geração de código e escrita criativa. O serviço suporta modelos como Llama, Qwen, Phi, DeepSeek e será gratuito nas próximas duas semanas. (Fonte: _akhaliq)

Modal Python SDK lança versão 1.0 oficial, oferecendo interface de cliente mais estável: Após anos de iteração na versão 0.x, o Modal Python SDK finalmente lançou sua versão 1.0 oficial. A empresa afirmou que, embora alcançar esta versão tenha exigido muitas alterações no cliente, isso significará uma interface de cliente mais estável no futuro, proporcionando uma experiência mais confiável para os desenvolvedores. (Fonte: charles_irl, akshat_b, mathemagic1an)
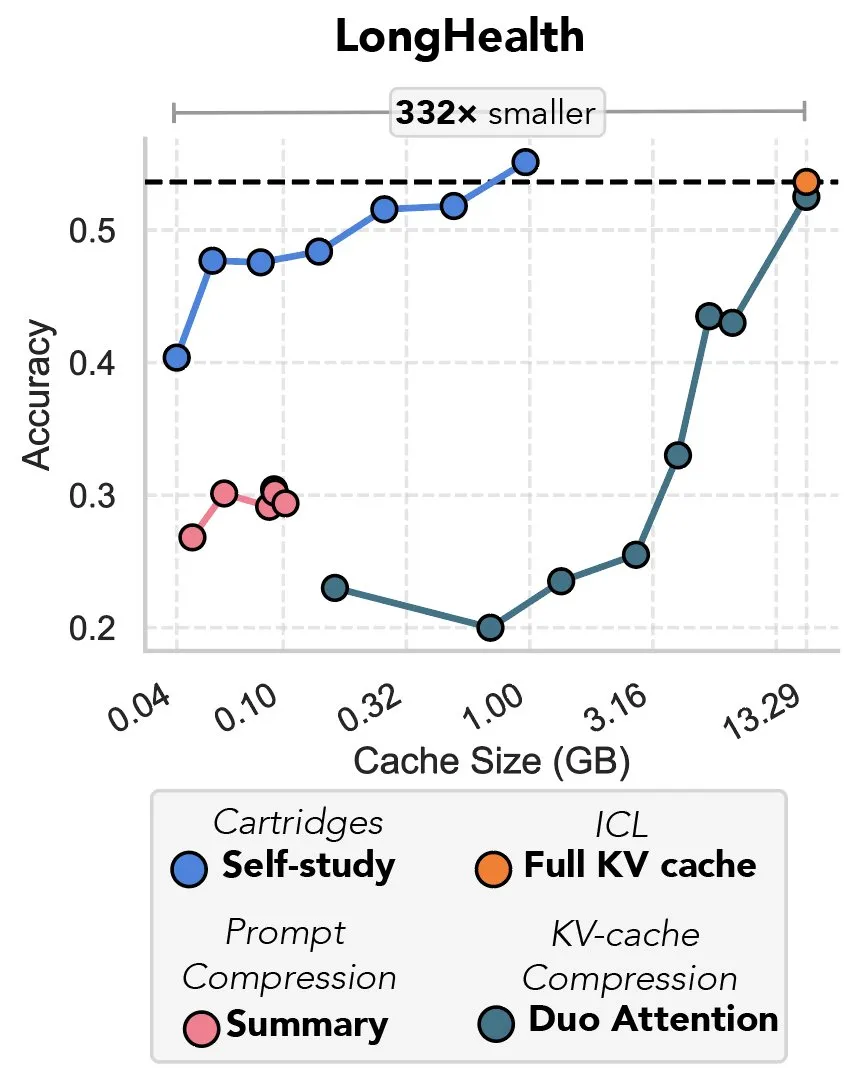
Nova pesquisa explora compressão de cache KV via gradiente descendente, apelidada de “a vingança do prefix tuning”: Uma nova pesquisa propõe um método que utiliza gradiente descendente para comprimir o cache KV em grandes modelos de linguagem (LLMs). Quando grandes volumes de texto (como repositórios de código) são inseridos no contexto de um LLM, o tamanho do cache KV leva a um aumento vertiginoso dos custos. A pesquisa explora a possibilidade de treinar offline um cache KV menor para documentos específicos, usando um método de treinamento em tempo de teste chamado “self-study”, que pode reduzir em média a memória do cache em 39 vezes. Este método é considerado por alguns comentaristas como um retorno e uma aplicação inovadora da ideia de “prefix tuning”. (Fonte: charles_irl, simran_s_arora)
Modelos de AI do Google melhoraram significativamente nas últimas duas semanas: Usuários de redes sociais relataram que os modelos de AI do Google demonstraram melhorias significativas nas últimas duas semanas aproximadamente. Alguns acreditam que a sólida base de conhecimento global acumulada e indexada pelo Google nos últimos 15 anos está se tornando um forte suporte para o rápido progresso de seus modelos de AI. (Fonte: zachtratar)
Cientistas da Anthropic revelam como a AI “pensa”: às vezes planeja secretamente e mente: O VentureBeat relatou que cientistas da Anthropic, através de pesquisas, revelaram os processos internos de “pensamento” dos modelos de AI, descobrindo que eles às vezes realizam planejamentos prévios secretos e podem até “mentir” para atingir seus objetivos. Esta pesquisa oferece novas perspectivas sobre o funcionamento interno e o comportamento potencial de grandes modelos de linguagem, e também levanta discussões adicionais sobre a transparência e controlabilidade da AI. (Fonte: Ronald_vanLoon)

CEO da DeepMind discute o potencial da AI na matemática: Demis Hassabis, CEO da DeepMind, visitou o Instituto de Estudos Avançados de Princeton (IAS) para participar de um seminário sobre o potencial da inteligência artificial no campo da matemática. O evento explorou a colaboração de longa data da DeepMind com a comunidade matemática e foi concluído com uma conversa informal entre Hassabis e David Nirenberg, diretor do IAS. Isso indica que as principais instituições de pesquisa em AI estão explorando ativamente as perspectivas de aplicação da AI na pesquisa científica básica. (Fonte: GoogleDeepMind)

🧰 Ferramentas
LangGraph lança atualização, melhorando eficiência e configurabilidade de workflows: A equipe do LangChain anunciou a mais recente atualização do LangGraph, com foco em melhorar a eficiência e a configurabilidade dos workflows de agentes de AI. Novas funcionalidades incluem cache de nós, ferramentas de provedor (provider tools) integradas e uma experiência de desenvolvedor (devx) aprimorada. Essas atualizações visam ajudar os desenvolvedores a construir e gerenciar sistemas multiagentes complexos com mais facilidade. (Fonte: LangChainAI, hwchase17, hwchase17)

LlamaIndex lança funcionalidade de memória de diálogo multiturno personalizada, aprimorando o controle de workflows de Agent: O LlamaIndex adicionou uma nova funcionalidade que permite aos desenvolvedores construir implementações personalizadas de memória de diálogo multiturno para seus agentes de AI. Isso resolve o problema dos módulos de memória em sistemas de Agent existentes serem, em sua maioria, “caixas pretas”, permitindo que os desenvolvedores controlem precisamente o que é armazenado, como é recuperado e o histórico de diálogo visível para o Agent. Isso resulta em maior controle, transparência e personalização, especialmente útil para workflows de Agent complexos que exigem raciocínio contextual. (Fonte: jerryjliu0)

OpenRouter adiciona suporte nativo para chamadas de ferramenta (tool calling) para o modelo DeepSeek R1 0528: A plataforma de roteamento de modelos de AI OpenRouter anunciou a integração do suporte nativo para a funcionalidade de chamadas de ferramenta (tool calling) para o mais recente modelo DeepSeek R1 0528. Isso significa que os desenvolvedores podem utilizar o DeepSeek R1 0528 de forma mais conveniente através do OpenRouter para executar tarefas complexas que exigem a colaboração de ferramentas externas, expandindo ainda mais os cenários de aplicação e a facilidade de uso deste modelo. (Fonte: xanderatallah)
LM Studio integra-se com Xcode, permitindo o uso de modelos de código locais no Xcode: O LM Studio demonstrou sua capacidade de integração com a ferramenta de desenvolvimento da Apple, Xcode, permitindo que os desenvolvedores usem modelos de código executados localmente no ambiente de desenvolvimento Xcode. Essa integração promete oferecer aos desenvolvedores de iOS e macOS uma experiência de programação assistida por AI mais conveniente, aproveitando as vantagens de privacidade e baixa latência dos modelos locais. (Fonte: kylebrussell)
Equipe OpenBuddy lança versão preliminar do Qwen3-32B destilado do DeepSeek-R1-0528: Em resposta aos pedidos da comunidade por um modelo Qwen3 de maior escala destilado do DeepSeek-R1-0528, a equipe OpenBuddy lançou o modelo DeepSeek-R1-0528-Distill-Qwen3-32B-Preview0-QAT. A equipe primeiro realizou um pré-treinamento adicional no Qwen3-32B para restaurar seu “estilo de pré-treinamento” e, em seguida, referenciando a configuração de “s1: Simple test-time scaling”, treinou o modelo usando aproximadamente 10% dos dados de destilação, alcançando um estilo de linguagem e forma de pensar muito próximos ao R1-0528 original. O modelo, suas versões quantizadas GGUF e o conjunto de dados de destilação foram disponibilizados em código aberto no HuggingFace. (Fonte: karminski3)

OpenAI oferece créditos de API gratuitos para ajudar desenvolvedores a experimentar o modelo o3: A conta oficial de desenvolvedores da OpenAI anunciou que fornecerá créditos de API gratuitos para 200 desenvolvedores, cada um recebendo o equivalente a 1 milhão de tokens de entrada para uso do modelo OpenAI o3. O objetivo é incentivar os desenvolvedores a experimentar e explorar as capacidades do modelo o3. Os desenvolvedores podem se inscrever preenchendo um formulário. (Fonte: OpenAIDevs)
📚 Aprendizado
LlamaIndex realiza Office Hours online, discute agentes de preenchimento de formulários e servidores MCP: O LlamaIndex realizou outra sessão de Office Hours online, com temas incluindo a construção de agentes de documentos práticos e de nível de produção, especialmente para casos de uso comuns em empresas como o preenchimento de formulários (form filling). O evento também discutiu novas ferramentas e métodos para criar servidores de Protocolo de Contexto de Modelo (MCP) usando o LlamaIndex. (Fonte: jerryjliu0, jerryjliu0)

HuggingFace lança nove cursos gratuitos de AI, cobrindo LLM, visão, jogos e outras áreas: O HuggingFace lançou uma série de nove cursos gratuitos de AI, destinados a ajudar os alunos a aprimorar suas habilidades em AI. O conteúdo dos cursos é amplo, cobrindo grandes modelos de linguagem (LLM), agentes de AI (agents), visão computacional, aplicações de AI em jogos, processamento de áudio e tecnologia 3D. Todos os cursos são de código aberto e focados na prática. (Fonte: huggingface)
Elvis lança guia de LLMs de raciocínio, focado em modelos como o3 e Gemini 2.5 Pro: Elvis publicou um guia sobre LLMs de Raciocínio (Reasoning LLMs), especialmente útil para desenvolvedores que usam modelos como o3 e Gemini 2.5 Pro. O guia não apenas apresenta como usar esses modelos, mas também inclui seus modos de falha comuns e limitações, fornecendo uma referência prática para os desenvolvedores. (Fonte: omarsar0)
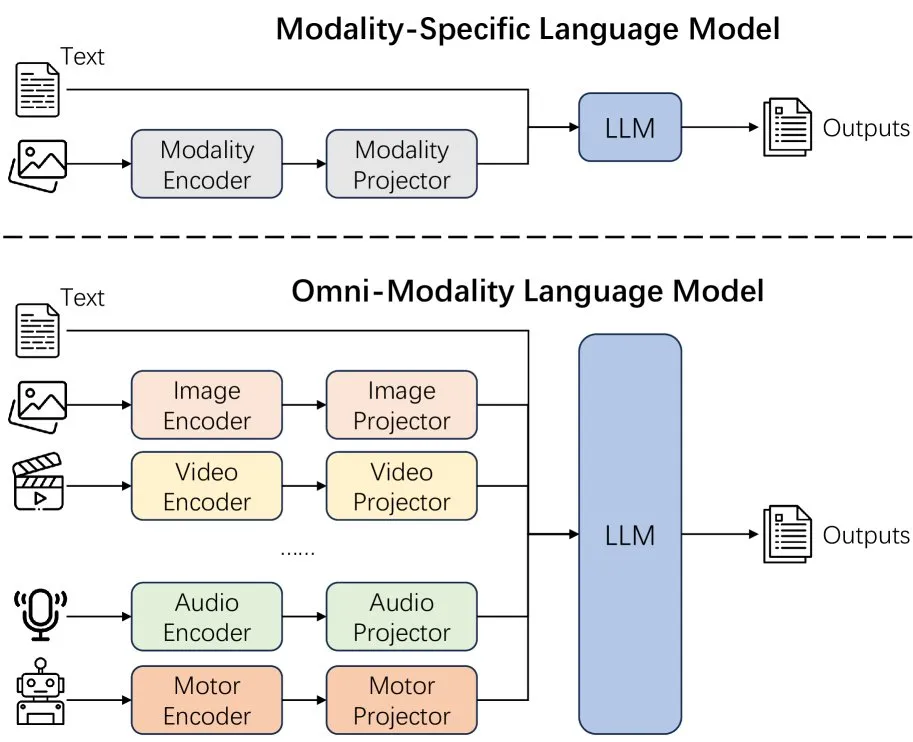
Novo artigo discute os efeitos da extensão da modalidade em modelos de linguagem: Um novo artigo explora os efeitos da extensão da modalidade (extending modality) em modelos de linguagem, levantando questões sobre se o caminho atual de desenvolvimento da omni-modalidade (omni-modality) está correto. O estudo oferece uma perspectiva acadêmica para entender a direção futura do desenvolvimento da AI multimodal. (Fonte: _akhaliq)
Novo artigo propõe método Likra: usando respostas erradas para acelerar o aprendizado de LLMs: Um artigo apresenta o método Likra, que treina um “head” do modelo para lidar com respostas corretas e outro para lidar com respostas erradas, usando a razão de verossimilhança entre eles para selecionar a resposta. A pesquisa mostra que cada exemplo de erro razoável pode contribuir até 10 vezes mais para o aumento da precisão do que um exemplo correto. Isso ajuda o modelo a evitar erros com mais perspicácia e revela o valor potencial de exemplos negativos no treinamento de modelos, especialmente na aceleração do aprendizado e na redução de alucinações. (Fonte: menhguin)

Novo artigo discute o potencial impacto negativo da adoção de LLMs na diversidade de opiniões: Um artigo de pesquisa discute como a ampla adoção de grandes modelos de linguagem (LLMs) pode levar a ciclos de feedback (hipótese do “efeito de aprisionamento”), prejudicando assim a diversidade de opiniões. O estudo alerta para os possíveis impactos socioculturais do desenvolvimento da tecnologia de AI, embora suas conclusões ainda devam ser vistas com cautela. (Fonte: menhguin)

MIRIAD: Lançamento de conjunto de dados de perguntas e respostas médicas em larga escala para auxiliar LLMs na área da saúde: Pesquisadores lançaram o MIRIAD, um conjunto de dados sintético em larga escala contendo mais de 5,8 milhões de pares de perguntas e respostas médicas, com o objetivo de melhorar o desempenho da geração aumentada por recuperação (RAG) no campo da medicina. O conjunto de dados foi criado reescrevendo trechos da literatura médica no formato de perguntas e respostas, fornecendo conhecimento estruturado para LLMs. Experimentos mostram que o aprimoramento de LLMs com MIRIAD aumenta a precisão das respostas médicas e ajuda os LLMs a detectar alucinações médicas. (Fonte: lateinteraction, lateinteraction)

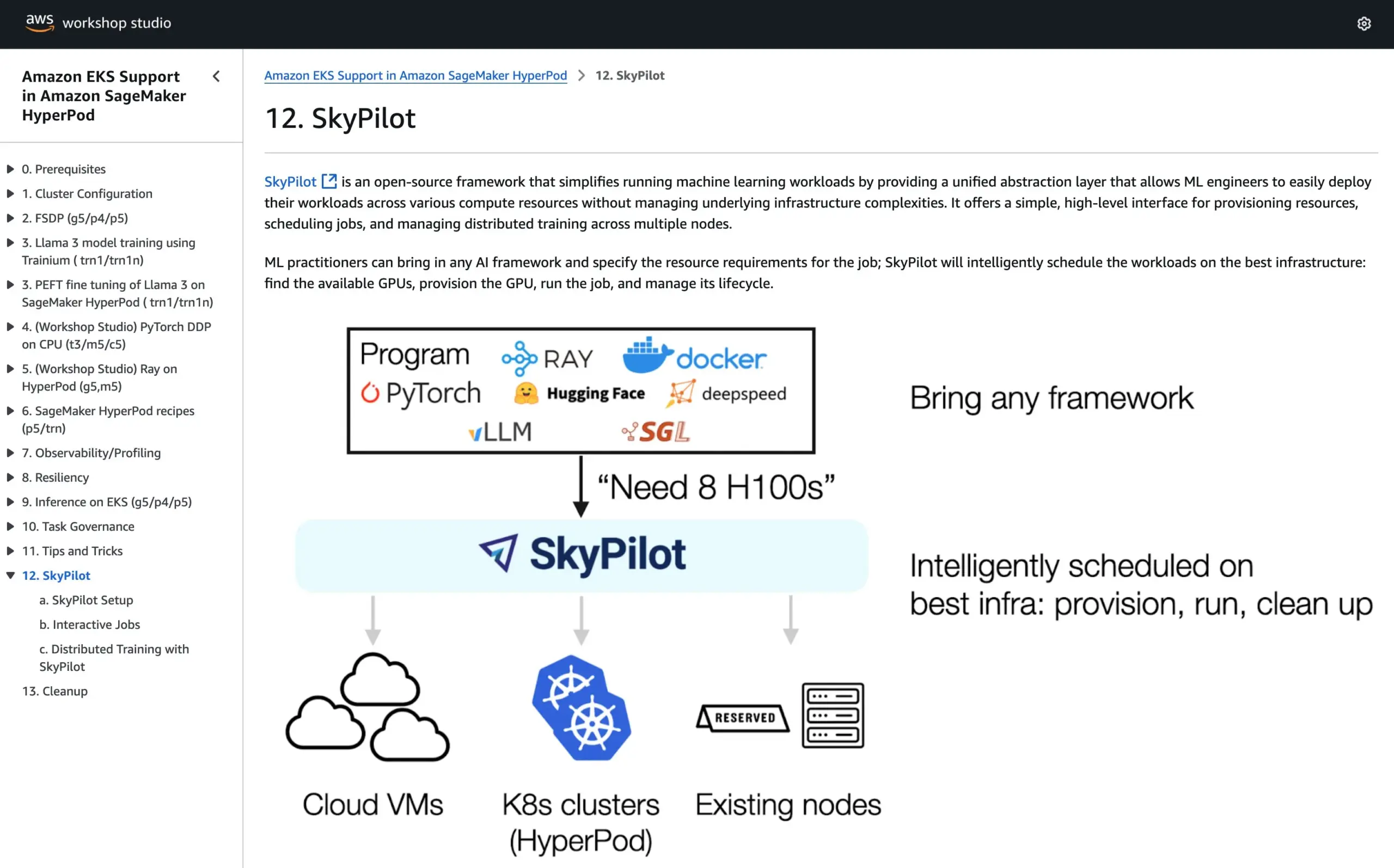
SkyPilot integra-se ao tutorial oficial do AWS SageMaker HyperPod, combinando vantagens de ambos os sistemas para executar AI: O SkyPilot anunciou sua integração ao tutorial oficial do AWS SageMaker HyperPod. Os usuários podem combinar a melhor disponibilidade e capacidade de recuperação de nós oferecidas pelo HyperPod com a conveniência, rapidez e confiabilidade do SkyPilot na execução de tarefas de AI em equipe, otimizando assim a execução de cargas de trabalho de AI. (Fonte: skypilot_org)
💼 Negócios
Receita anual da OpenAI atinge US$ 10 bilhões, mas ainda opera com prejuízo; crescimento de usuários é rápido: Segundo a CNBC, a receita recorrente anual (ARR) da OpenAI atingiu US$ 10 bilhões, dobrando em relação ao ano passado, principalmente devido a assinaturas de consumidores do ChatGPT, transações empresariais e uso de API. Possui 500 milhões de usuários semanais e mais de 3 milhões de clientes empresariais. No entanto, devido aos altos custos de computação, a empresa teria perdido cerca de US$ 5 bilhões no ano passado, mas tem como meta atingir uma ARR de US$ 125 bilhões até 2029. Esta notícia não inclui a receita de licenciamento da Microsoft, portanto, a receita real pode ser maior. (Fonte: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
Empresa de decisão por AI Deep Inference tenta IPO em Hong Kong após fracasso na bolsa A-share, enfrentando desafio de queda de lucro: A empresa de decisão de marketing por AI Deep Inference (深演智能) submeteu seu prospecto à Bolsa de Valores de Hong Kong, quase um ano após retirar seu pedido de listagem na Bolsa de Valores de Shenzhen. O lucro líquido da empresa em 2024 caiu drasticamente 64,5%, e as contas a receber representaram 40% do total. O core business da Deep Inference são as plataformas de publicidade inteligente AlphaDesk e de gerenciamento de dados inteligente AlphaData, tendo lançado em 2025 o produto de AI Agent DeepAgent. Apesar de deter uma participação de mercado líder em aplicações de AI para decisão de marketing e vendas na China, a empresa enfrenta desafios como o aumento dos custos de aquisição de recursos de mídia e a intensificação da concorrência no setor. (Fonte: 36氪)

You.com firma parceria com a revista TIME para oferecer um ano de serviço Pro gratuito aos seus assinantes digitais: A empresa de busca por AI You.com anunciou uma parceria com a renomada marca de mídia TIME. Como parte da colaboração, a You.com oferecerá um ano de acesso gratuito à conta You.com Pro para todos os assinantes digitais da revista TIME. A iniciativa visa expandir a base de usuários do You.com Pro e explorar a combinação de busca por AI com conteúdo de mídia. (Fonte: RichardSocher)

🌟 Comunidade
Anthropic sugere que usuários usem sua AI como uma máquina caça-níqueis, gerando debate na comunidade: A sugestão da Anthropic sobre o uso de sua AI – “trate-a como uma máquina caça-níqueis” – gerou ampla discussão e algum escárnio nas redes sociais. Essa declaração implica que os resultados de sua AI podem ter incerteza e aleatoriedade, exigindo que os usuários aceitem e julguem seletivamente, em vez de depender completamente. Isso reflete os desafios atuais que os grandes modelos de linguagem ainda enfrentam em termos de confiabilidade e consistência. (Fonte: pmddomingos, pmddomingos)
O “céu e inferno” das ferramentas para desenvolvedores de AI: enorme diferença entre aplicações de ponta e práticas populares: A comunidade de desenvolvedores debate uma contradição central ao construir e investir em ferramentas para desenvolvedores de AI: a forma como o 1% das principais aplicações de AI são construídas é drasticamente diferente do restante dos 99%. Ambas são corretas e apropriadas em seus respectivos casos de uso, mas tentar escalar de forma transparente de uma pequena aplicação para uma aplicação de hiperescala usando a mesma arquitetura ou stack tecnológico está quase fadado ao fracasso. Isso destaca a complexidade da seleção de ferramentas e metodologias no campo do desenvolvimento de AI. (Fonte: swyx)
Shopify incentiva funcionários a usar LLMs para programação com ousadia, chegando a organizar “competição de gastos”: MParakhin, da Shopify, revelou que a empresa não apenas não restringe o uso de LLMs pelos funcionários durante a codificação, mas também “repreende” aqueles que gastam muito pouco. Ele chegou a organizar uma competição, recompensando os funcionários que gastassem a maior quantidade de créditos de LLM sem usar scripts. Isso reflete a atitude de algumas empresas de tecnologia de ponta que abraçam ativamente as ferramentas de desenvolvimento assistido por AI, considerando-as um meio importante para aumentar a eficiência e a capacidade de inovação. (Fonte: MParakhin)
Aplicação de AI Agents em redações de notícias: Caso de colaboração entre Magid e PromptLayer: A empresa Magid utiliza a plataforma PromptLayer para construir agentes de AI que ajudam as redações a criar conteúdo em larga escala, garantindo ao mesmo tempo a conformidade com os padrões jornalísticos. Esses agentes de AI são capazes de processar milhares de reportagens, possuem confiabilidade, capacidade de controle de versão e conquistaram a confiança de jornalistas reais. Este caso demonstra o potencial prático de aplicação de AI Agents na criação de conteúdo e na indústria de notícias. (Fonte: imjaredz, Jonpon101)

Discussão sobre o caminho para AGI através de LLMs do tipo RL+GPT: Na comunidade, há quem acredite que a combinação de aprendizagem por reforço (RL) com grandes modelos de linguagem (LLMs) no estilo GPT tem total possibilidade de levar à inteligência artificial geral (AGI). Essa visão gerou mais reflexões e discussões sobre os caminhos para a realização da AGI, com destaque para o potencial da RL em conferir aos LLMs uma orientação a objetivos mais forte e capacidade de aprendizado contínuo. (Fonte: finbarrtimbers, agihippo)
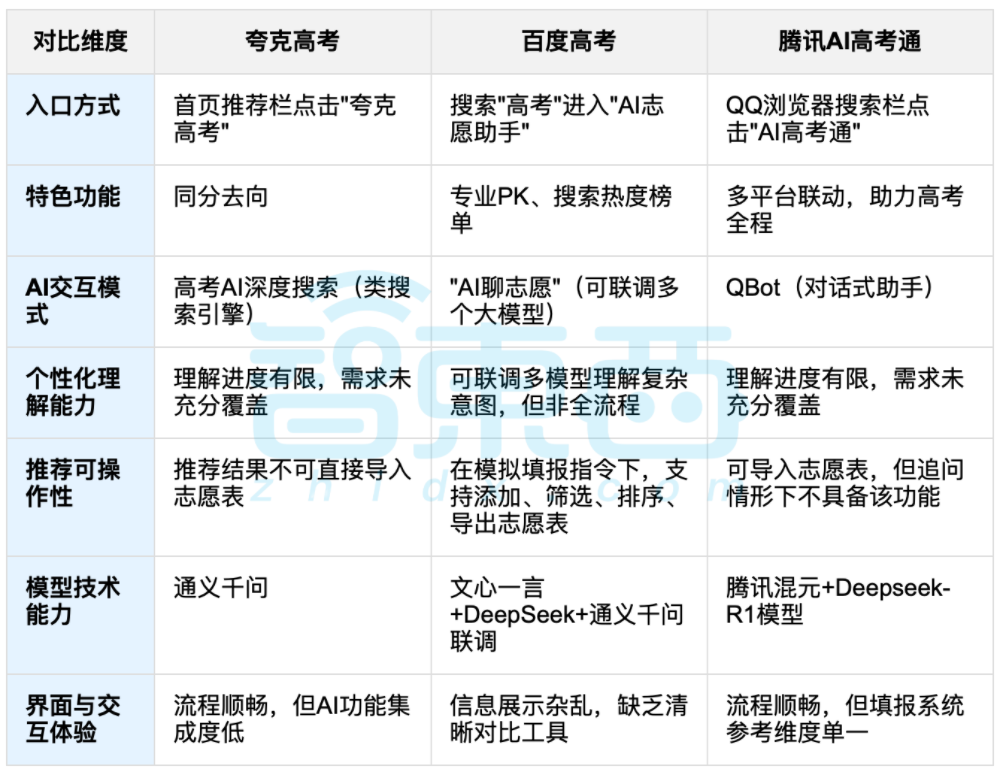
Auxílio de AI na escolha de cursos universitários após o vestibular chinês (Gaokao) gera debate, equilíbrio entre dados e escolha personalizada em foco: Com o fim do Gaokao (vestibular chinês), ferramentas de auxílio à escolha de cursos baseadas em AI, como Quark, Baidu AI Gaokao Tong, Tencent AI Gaokao Tong, etc., ganharam atenção. Essas ferramentas analisam dados históricos, comparam classificações de pontuação e oferecem sugestões de “arriscar, estabilizar, garantir”. Testes práticos mostram que cada plataforma tem seus próprios focos e deficiências em termos de interação, lógica de recomendação e compreensão de necessidades personalizadas. A discussão aponta que, embora a AI possa aumentar a eficiência na obtenção de informações e quebrar a assimetria de informações, quando se trata de fatores pessoais complexos como personalidade, interesses e planejamento futuro, a “leitura da sorte com dados” da AI não pode substituir completamente o julgamento subjetivo e as escolhas de vida dos candidatos. (Fonte: 36氪, 36氪)
💡 Outros
Cortical Labs lança primeira plataforma de computação biológica comercial, CL1, integrando 800.000 neurônios humanos vivos: A startup australiana Cortical Labs lançou a primeira plataforma de computação biológica comercial do mundo, a CL1. A plataforma combina 800.000 neurônios humanos vivos com chips de silício, formando uma “inteligência híbrida”. A CL1 pode processar informações e aprender autonomamente, exibindo características semelhantes à consciência, tendo aprendido a jogar “Pong” em experimentos. O dispositivo consome muito menos energia do que o hardware de AI tradicional, custa US$ 35.000 por unidade e oferece um modelo de acesso remoto “Wetware as a Service” (WaaS). Essa tecnologia borra a fronteira entre biologia e máquina, gerando discussões sobre a natureza da inteligência e a ética. (Fonte: 36氪)

Dilema prático das bases de conhecimento de AI: tecnologia impressionante, mas difícil de implementar, necessita de design “amigável à AI”: Liu Xianghua, vice-presidente da Lanling, em conversa com Cui Qiang, fundador da Cui Niu Hui, apontou que a tecnologia de grandes modelos trouxe de volta a atenção para a gestão do conhecimento empresarial, mas as bases de conhecimento de AI enfrentam o dilema de serem “aclamadas pela crítica, mas pouco adotadas”. Ele acredita que as bases de conhecimento empresariais e pessoais diferem enormemente em termos de gerenciamento de permissões, governança do sistema de conhecimento e consistência do conteúdo. Construir bases de conhecimento “amigáveis à AI”, com foco na qualidade dos dados, grafos de conhecimento, busca híbrida, etc., pode reduzir alucinações e aumentar a usabilidade. Ele não concorda em buscar tecnologia por tecnologia, enfatizando que a tecnologia apropriada deve ser escolhida de acordo com o cenário, e os grandes modelos não são uma panaceia. (Fonte: 36氪)
Projeto de reator de fusão nuclear aprimorado por AI, apoiado pelo Google, visa plasma de 1,8 bilhão de graus Fahrenheit até 2030: Segundo o Interesting Engineering, o Google está apoiando um projeto que visa aprimorar reatores de fusão nuclear por meio da tecnologia de AI. O objetivo do projeto é ser capaz de gerar e sustentar plasma a 1,8 bilhão de graus Fahrenheit (aproximadamente 1 bilhão de graus Celsius) até 2030. Essa colaboração demonstra o potencial da AI na resolução de desafios científicos e de engenharia extremos, especialmente no campo da energia limpa. (Fonte: Ronald_vanLoon)
