
Palavras-chave:Modelo de Linguagem de Grande Escala, Capacidade de Raciocínio, Inteligência Artificial Geral, Correspondência de Padrões, Ilusão de Pensamento, Pesquisa da Apple, Detector de IA, Regulamentação de IA, Mecanismo de Atenção Log-Linear, Modelo MoE Pangu da Huawei, Modo de Voz Avançado do ChatGPT, Framework TensorZero, Visão de Regulamentação do CEO da Anthropic
🔥 Foco
Pesquisa da Apple revela “ilusão de pensamento”: modelos de “raciocínio” atuais não pensam verdadeiramente, mas dependem mais de correspondência de padrões: O mais recente artigo de pesquisa da Apple, “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models Through the Lens of Problem Complexity”, aponta que os grandes modelos de linguagem atuais que afirmam possuir capacidade de “raciocínio” (como Claude, DeepSeek-R1, GPT-4o-mini, etc.), seu desempenho se assemelha mais a eficientes comparadores de padrões do que a um raciocínio lógico no sentido verdadeiro. A pesquisa descobriu que, ao processar problemas fora da distribuição de treinamento ou de alta complexidade, o desempenho desses modelos diminui significativamente, e até mesmo em problemas simples cometem erros por “pensar demais”, além de terem dificuldade em corrigir erros iniciais. O estudo enfatiza que o chamado processo de “pensamento” dos modelos (como chain of thought) frequentemente falha ao enfrentar tarefas novas ou complexas, indicando que podemos estar mais longe da inteligência artificial geral (AGI) do que o esperado. (Fonte: machinelearning.apple.com, TheTuringPost, mervenoyann, Reddit r/artificial, Reddit r/LocalLLaMA, Reddit r/MachineLearning)

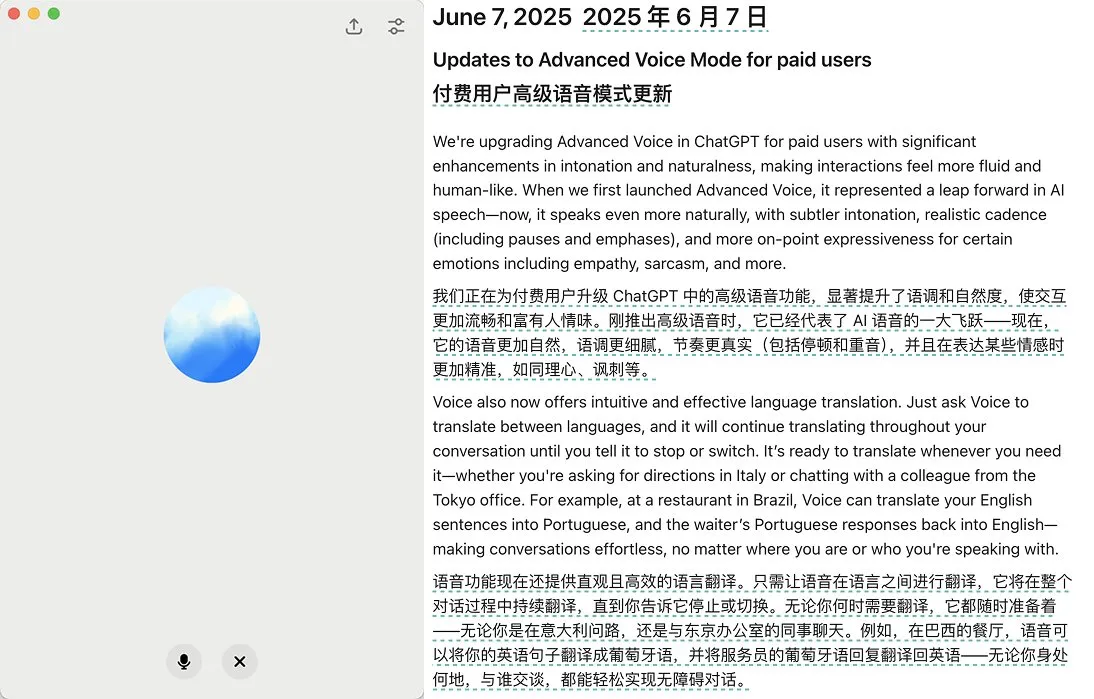
OpenAI lança atualização do modo de voz avançado do ChatGPT, melhorando naturalidade e funções de tradução: A OpenAI lançou uma grande atualização do Advanced Voice Mode para usuários pagos do ChatGPT. A nova versão melhorou significativamente a naturalidade e fluidez da voz, fazendo com que soe mais como um humano do que como um assistente de IA. Além disso, a atualização aprimorou o desempenho da tradução de idiomas e a capacidade de seguir instruções, e adicionou um modo de tradução, permitindo que os usuários façam o ChatGPT traduzir continuamente a conversa de ambas as partes durante todo o diálogo, até que seja solicitado a parar. Esta atualização visa tornar a interação por voz mais fácil e natural, melhorando a experiência do usuário. (Fonte: juberti, Plinz, op7418, BorisMPower)
Detectores de IA são acusados de ineficácia e de possivelmente ajudar conteúdo de IA a se “camuflar”: Surgiram amplas discussões em mídias sociais e fóruns de tecnologia apontando que as atuais ferramentas de detecção de conteúdo de IA não apenas são ineficazes, mas podem até, inadvertidamente, ajudar o conteúdo gerado por IA a se tornar mais difícil de detectar. Muitos usuários e especialistas acreditam que esses detectores se baseiam principalmente em padrões linguísticos e vocabulário específico (como o termo acadêmico “delve”) para fazer julgamentos, em vez de realmente entender a origem do conteúdo. Devido ao risco de falsos positivos (que podem causar injustiças a grupos como estudantes) e ao fato de os próprios modelos de IA estarem evoluindo para evitar a detecção, a confiabilidade dessas ferramentas é seriamente questionada. Há quem defenda que a existência de detectores de IA, na verdade, incentiva o conteúdo gerado por IA a evitar certas características facilmente sinalizáveis, tornando-o mais parecido com a escrita humana. (Fonte: Reddit r/ArtificialInteligence, sytelus)

CEO da Anthropic pede maior transparência e responsabilização na regulamentação de empresas de IA: O CEO da Anthropic publicou um artigo de opinião no The New York Times, enfatizando que a regulamentação das empresas de IA não deve ser flexibilizada, especialmente no que diz respeito à necessidade de aumentar sua transparência e responsabilização. Esta visão é particularmente importante no contexto do rápido desenvolvimento e da crescente capacidade da indústria de IA, ecoando as preocupações da sociedade sobre os riscos potenciais e as questões éticas da IA. O artigo argumenta que, à medida que a influência da tecnologia de IA se expande, é crucial garantir que seu desenvolvimento sirva ao interesse público e evite abusos, o que requer uma combinação de autorregulação da indústria e supervisão externa. (Fonte: Reddit r/artificial)

🎯 Tendências
Jeff Dean vislumbra o futuro da IA: hardware dedicado, evolução de modelos e aplicações científicas: Jeff Dean, chefe de IA do Google, compartilhou suas visões sobre o desenvolvimento futuro da IA no evento AI Ascent da Sequoia Capital. Ele enfatizou a importância do hardware dedicado (como TPUs) para o progresso da IA e discutiu as tendências na evolução da arquitetura de modelos. Dean também vislumbrou a forma futura da infraestrutura computacional e o enorme potencial de aplicação da IA em áreas como pesquisa científica, acreditando que a IA se tornará uma ferramenta chave para impulsionar descobertas científicas. (Fonte: TheTuringPost)

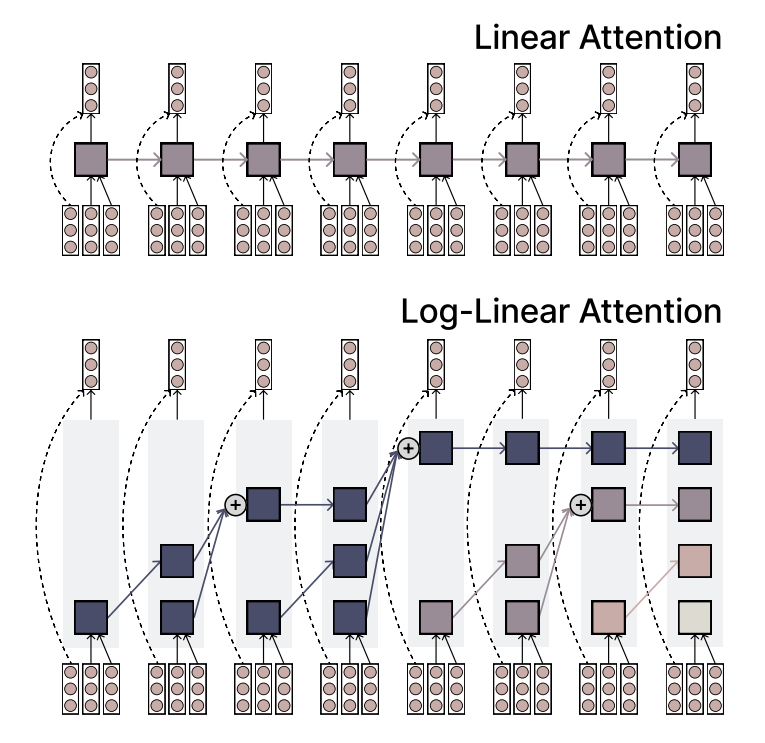
MIT propõe mecanismo Log-Linear Attention, equilibrando eficiência e capacidade de expressão: Pesquisadores do MIT propuseram um novo mecanismo de atenção chamado Log-Linear Attention. Este mecanismo visa combinar a alta eficiência da Linear Attention com a forte capacidade de expressão da Softmax attention. Sua principal característica é o uso de um pequeno número de memory slots que crescem logaritmicamente com o comprimento da sequência, mantendo assim baixa complexidade computacional ao processar sequências longas, enquanto captura informações cruciais. (Fonte: TheTuringPost)
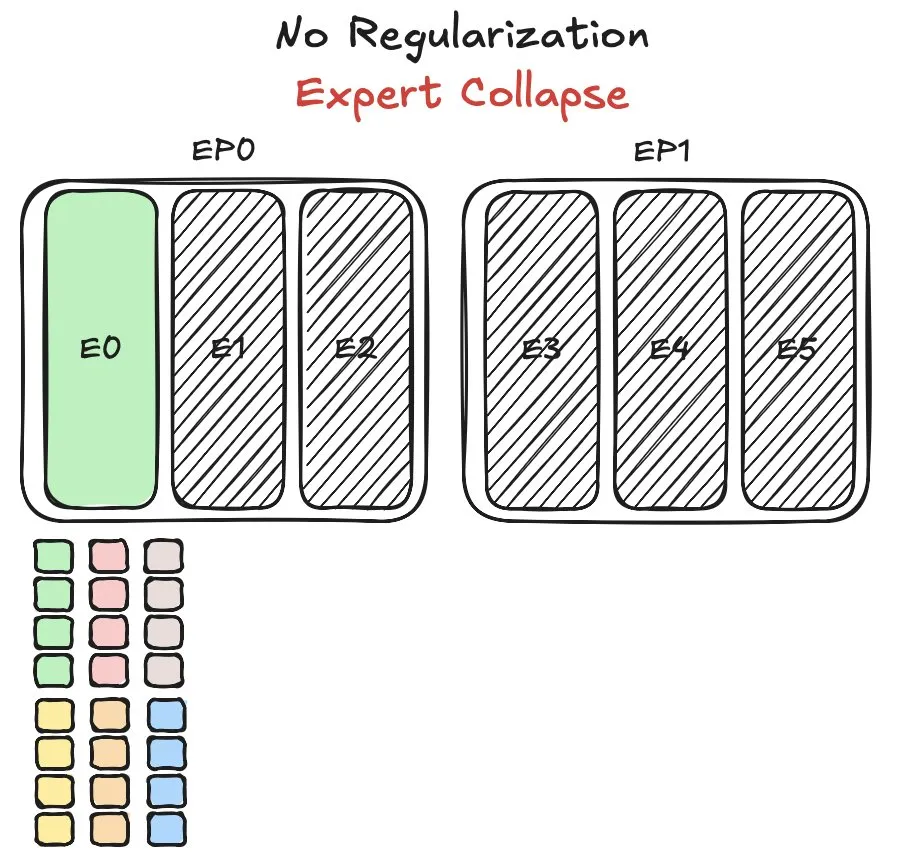
Modelo Pangu MoE da Huawei enfrenta desafios de balanceamento de carga de especialistas, propondo novo método: A Huawei, ao treinar seu modelo de mistura de especialistas (MoE) Pangu Ultra MoE, encontrou problemas críticos de balanceamento de carga de especialistas. O balanceamento de carga de especialistas exige um compromisso entre a dinâmica de treinamento e a eficiência do sistema. A Huawei propôs uma nova solução para este problema, com o objetivo de otimizar a atribuição de tarefas e a carga computacional entre diferentes módulos de especialistas no modelo MoE, para melhorar a eficiência do treinamento e o desempenho do modelo. Pesquisas relacionadas foram publicadas em um artigo. (Fonte: finbarrtimbers)
NVIDIA lança modelo Cascade Mask R-CNN Mamba Vision, focado em detecção de objetos: A NVIDIA lançou um novo modelo no Hugging Face chamado cascade_mask_rcnn_mamba_vision_tiny_3x_coco. A julgar pelo nome, o modelo é projetado especificamente para tarefas de detecção de objetos e pode integrar a arquitetura Cascade R-CNN com a tecnologia visual Mamba (um modelo de espaço de estados), visando melhorar a precisão e eficiência da detecção de objetos. (Fonte: _akhaliq)
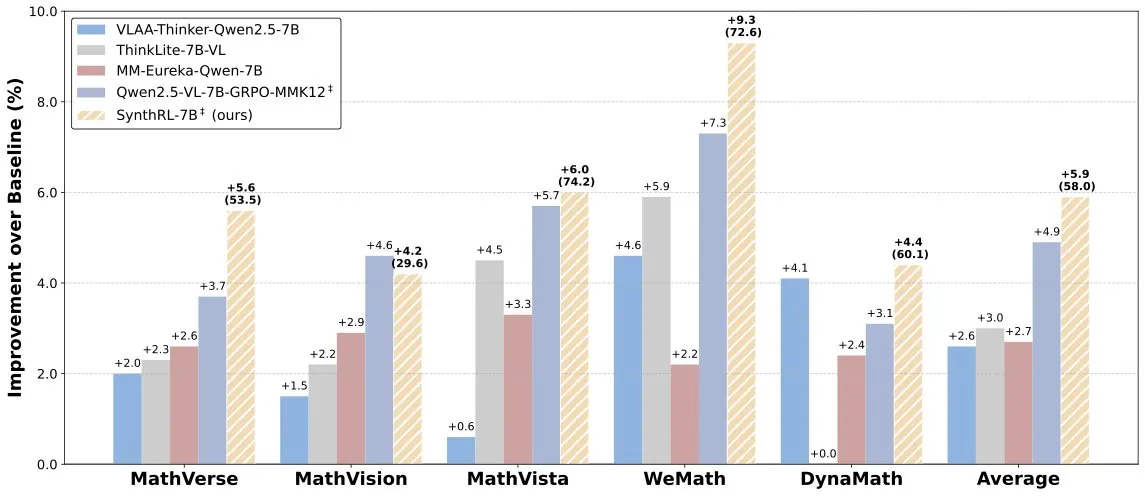
Lançamento do modelo SynthRL: raciocínio visual escalável através da síntese de dados verificáveis: O modelo SynthRL foi lançado no Hugging Face, focando na capacidade de raciocínio visual escalável. Sua tecnologia central reside em um método de síntese de dados verificáveis para gerar variantes mais desafiadoras de tarefas de raciocínio visual, mantendo a correção das respostas originais. Isso ajuda a melhorar a compreensão e o nível de raciocínio do modelo em cenários visuais complexos. (Fonte: _akhaliq)
Apesar do bom desempenho do DeepSeek-R1, a vantagem de produto do ChatGPT permanece sólida: O VentureBeat comentou que, embora modelos emergentes como o DeepSeek-R1 tenham um desempenho excelente em certos aspectos, o ChatGPT, com sua vantagem de pioneirismo, ampla base de usuários, ecossistema de produtos maduro e capacidade de iteração contínua, mantém uma posição de liderança em nível de produto que dificilmente será superada a curto prazo. A corrida da IA não é apenas uma competição de parâmetros técnicos, mas uma disputa abrangente de experiência de produto, construção de ecossistema e modelo de negócios. (Fonte: Ronald_vanLoon)

Equipe Qwen confirma que o Qwen3-coder está em desenvolvimento: Junyang Lin, da equipe Qwen, confirmou que estão desenvolvendo o Qwen3-coder, uma versão aprimorada da capacidade de codificação da série Qwen3. Embora nenhum cronograma específico tenha sido anunciado, com base no ciclo de lançamento do Qwen2.5, espera-se que seja lançado em algumas semanas. A comunidade espera que este modelo traga avanços na geração de código, integração de fluxos de trabalho autônomos/agentes e mantenha um bom suporte para múltiplas linguagens de programação. (Fonte: Reddit r/LocalLLaMA)

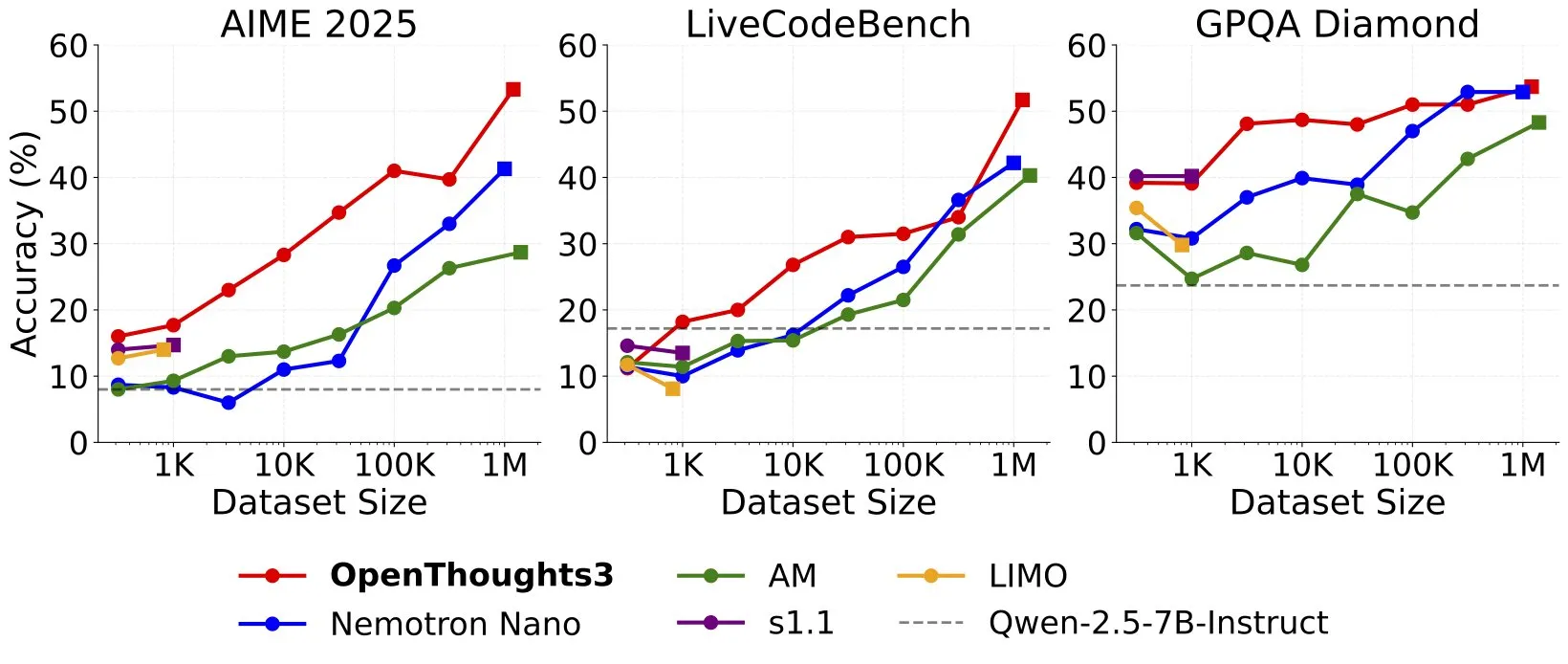
OpenThinker3-7B lançado, anunciado como modelo de raciocínio 7B de dados abertos SOTA: Ryan Marten anunciou o lançamento do modelo OpenThinker3-7B, afirmando ser o modelo de raciocínio de 7 bilhões de parâmetros mais avançado atualmente, treinado com dados abertos. Alegadamente, este modelo supera o DeepSeek-R1-Distill-Qwen-7B em média em 33% em avaliações de código, ciência e matemática. Juntamente com o modelo, foi lançado seu conjunto de dados de treinamento, OpenThoughts3-1.2M. (Fonte: menhguin)
🧰 Ferramentas
TensorZero: framework LLMOps de código aberto, otimiza o desenvolvimento e implantação de aplicações LLM: TensorZero é um framework de otimização de aplicações LLM de código aberto, projetado para transformar dados de produção em modelos mais inteligentes, rápidos e econômicos através de ciclos de feedback. Ele integra gateway LLM (suportando múltiplos provedores de modelos), observabilidade, otimização (prompts, fine-tuning, RL), avaliação e experimentação (testes A/B), suportando baixa latência, alta taxa de transferência e GitOps. A ferramenta é escrita em Rust, enfatizando desempenho e requisitos de aplicações de nível industrial. (Fonte: GitHub Trending)

LangChain lança sistema RAG de alto desempenho combinando SambaNova, Qdrant e LangGraph: LangChain apresentou uma solução de implementação de Retrieval Augmented Generation (RAG) de alto desempenho. Esta solução combina o modelo DeepSeek-R1 da SambaNova, a tecnologia de quantização binária da Qdrant e o LangGraph, alcançando uma redução de memória de 32 vezes, permitindo assim o processamento eficiente de documentos em grande escala. Isso abre novas possibilidades para a construção de aplicações RAG mais econômicas e rápidas. (Fonte: hwchase17, qdrant_engine)
Aplicativo Sparkify do Google para geração de vídeos educativos com um clique exibe casos de alta qualidade: O aplicativo Sparkify, lançado pelo Google, capaz de gerar vídeos educativos com um clique, demonstrou casos de alta qualidade. Os vídeos apresentam boa consistência geral de conteúdo, dublagem natural e até conseguem realizar efeitos complexos como exibição em tela dividida, mostrando o potencial da IA na criação automatizada de conteúdo de vídeo. (Fonte: op7418)
Hugging Face lança primeiro servidor MCP, expandindo funcionalidades de chatbots: Hugging Face lançou seu primeiro servidor MCP (Modular Chat Processor) (hf.co/mcp), que os usuários podem colar na caixa de chat para usar. O servidor MCP visa aprimorar as funcionalidades dos chatbots, oferecendo uma experiência interativa mais rica através de unidades de processamento modulares. A comunidade também compilou uma lista de outros servidores MCP úteis, como Agentset MCP, GitHub MCP, etc. (Fonte: TheTuringPost)
Efeito do Chatterbox TTS comparável ao ElevenLabs, já integrado ao gptme: A ferramenta TTS (Text-to-Speech) Chatterbox tem chamado a atenção por seus excelentes efeitos de síntese de voz, com feedback de usuários indicando que seus resultados são comparáveis aos do renomado ElevenLabs e superiores ao Kokoro. Chatterbox suporta a personalização da voz através de amostras de referência e agora foi adicionado como backend TTS ao gptme, oferecendo aos usuários opções de saída de voz de alta qualidade. (Fonte: teortaxesTex, _akhaliq)
E-Library-Agent: sistema inteligente de busca e perguntas e respostas para livros/documentos locais: E-Library-Agent é um agente de IA auto-hospedado capaz de extrair, indexar e consultar coleções pessoais de livros ou artigos. O projeto é baseado em ingest-anything e suportado pelas plataformas LlamaIndex, Qdrant e Linkup, permitindo a extração de materiais locais, respostas sensíveis ao contexto e descoberta na web através de uma única interface, facilitando aos usuários o gerenciamento e utilização de suas bases de conhecimento pessoais. (Fonte: qdrant_engine)
Claude Code altamente elogiado por desenvolvedores por sua poderosa capacidade de assistência à codificação: Usuários da comunidade Reddit compartilharam experiências positivas usando o Claude Code da Anthropic para desenvolvimento de software, especialmente em áreas como desenvolvimento de jogos (por exemplo, projetos Godot C#). Os usuários elogiaram sua capacidade de resolver problemas complexos, superando em muito outros assistentes de codificação de IA (como o GitHub Copilot), conseguindo entender o contexto e gerar código eficaz, mesmo a um custo de US$ 100 por mês, considerado um bom investimento. Desenvolvedores acreditam que programadores experientes combinados com o Claude Code serão extremamente produtivos. (Fonte: Reddit r/ClaudeAI)
ChatterUI implementa suporte a modelos visuais locais, mas processamento em Android é lento: A versão de pré-lançamento do cliente de chat LLM ChatterUI adicionou suporte para anexos e modelos visuais locais (via llama.rn). Os usuários podem carregar arquivos mmproj para modelos locais compatíveis ou conectar-se a APIs com capacidade visual (como Google AI Studio, OpenAI). No entanto, devido à falta de um backend de GPU estável para llama.cpp no Android, a velocidade de processamento de imagens é extremamente lenta (por exemplo, uma imagem de 512×512 leva 5 minutos), enquanto o desempenho no iOS é relativamente melhor. (Fonte: Reddit r/LocalLLaMA)
FLUX kontext demonstra excelente desempenho na substituição de fundos de imagens promocionais de automóveis: Testes de usuários descobriram que a ferramenta de edição de imagens por IA FLUX kontext tem efeitos notáveis na modificação de fundos de imagens promocionais de automóveis. Por exemplo, ao substituir o fundo de imagens oficiais do Xiaomi SU7 (como uma praia ao entardecer, uma pista de corrida), a ferramenta não apenas integra naturalmente o fundo, mas também adiciona inteligentemente efeitos de desfoque de movimento a veículos em movimento, aumentando o realismo e o impacto visual da imagem. (Fonte: op7418)

📚 Aprendizado
Nova funcionalidade do fastcore flexicache: um decorador de cache flexível: Jeremy Howard apresentou uma nova funcionalidade prática na biblioteca fastcore chamada flexicache. Trata-se de um decorador de cache altamente flexível, com duas estratégias de cache integradas, ‘mtime’ (baseada no tempo de modificação do arquivo) e ‘time’ (baseada em timestamp), e que permite aos usuários personalizar novas estratégias de cache com pouco código. Esta funcionalidade foi detalhada em um artigo por Daniel Roy Greenfeld e ajuda a aumentar a eficiência da execução do código. (Fonte: jeremyphoward)
Explorando o potencial da combinação de MuP e Muon para o treinamento de modelos Transformer: Jingyuan Liu aprofundou-se no trabalho de Jeremy Bernstein sobre a derivação de Muon e condições espectrais, expressando admiração por sua elegante derivação, especialmente como MuP (Maximal Update Parametrization) e Muon (um otimizador) trabalham em conjunto. Ele acredita que, pela derivação, usar Muon como otimizador para o treinamento de modelos baseados em MuP é uma escolha natural e aponta que isso pode ser mais empolgante do que a migração de hiperparâmetros do AdamW para Muon através da correspondência de RMS de atualização no trabalho Moonlight da Moonshot. A comunidade discute que a combinação MuP + Muon tem o potencial de ser aplicada em larga escala por grandes empresas de tecnologia até o final do ano. (Fonte: jeremyphoward)

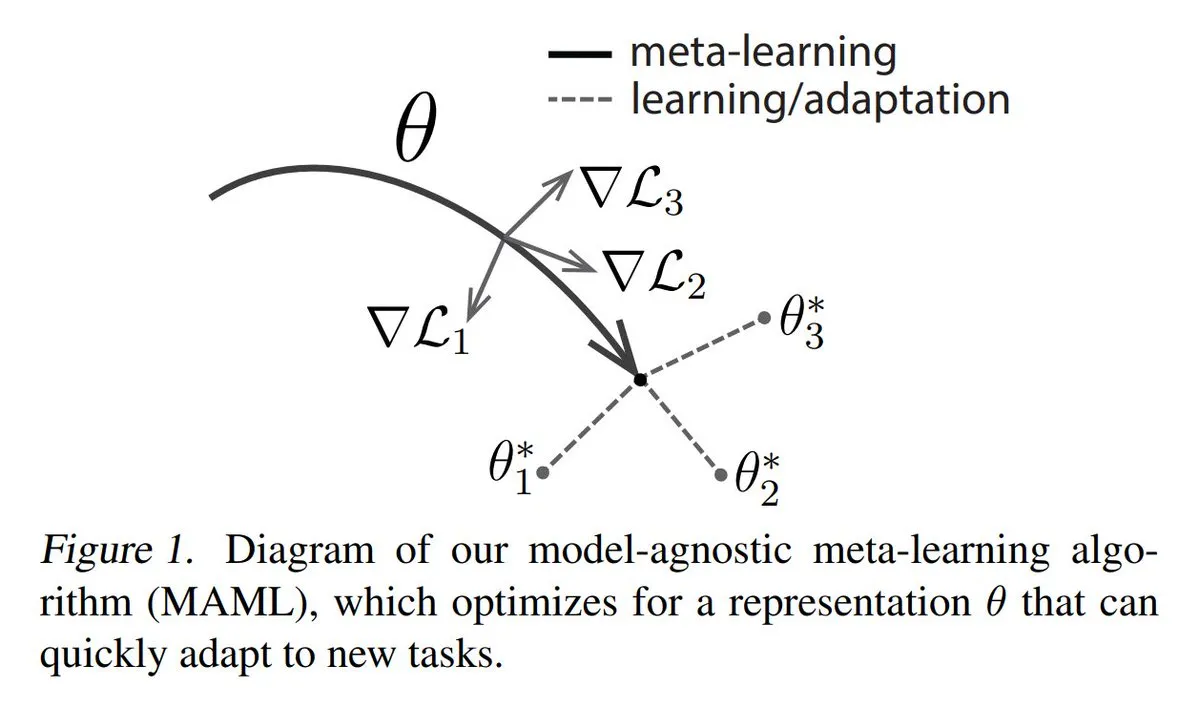
Análise dos três principais métodos de Meta-learning: O Meta-learning visa treinar modelos para aprender rapidamente novas tarefas, mesmo com poucas amostras. Os métodos comuns incluem: 1. Baseado em otimização/gradiente: encontrar parâmetros de modelo que possam ser eficientemente ajustados em tarefas com poucos passos de gradiente. 2. Baseado em métrica: ajudar o modelo a encontrar melhores maneiras de medir a similaridade entre amostras novas e antigas, agrupando efetivamente amostras relacionadas. 3. Baseado em modelo: todo o modelo é projetado para se adaptar rapidamente usando memória interna ou mecanismos dinâmicos. O TuringPost fornece uma explicação detalhada dos métodos de meta-aprendizagem, desde os básicos até os modernos. (Fonte: TheTuringPost)
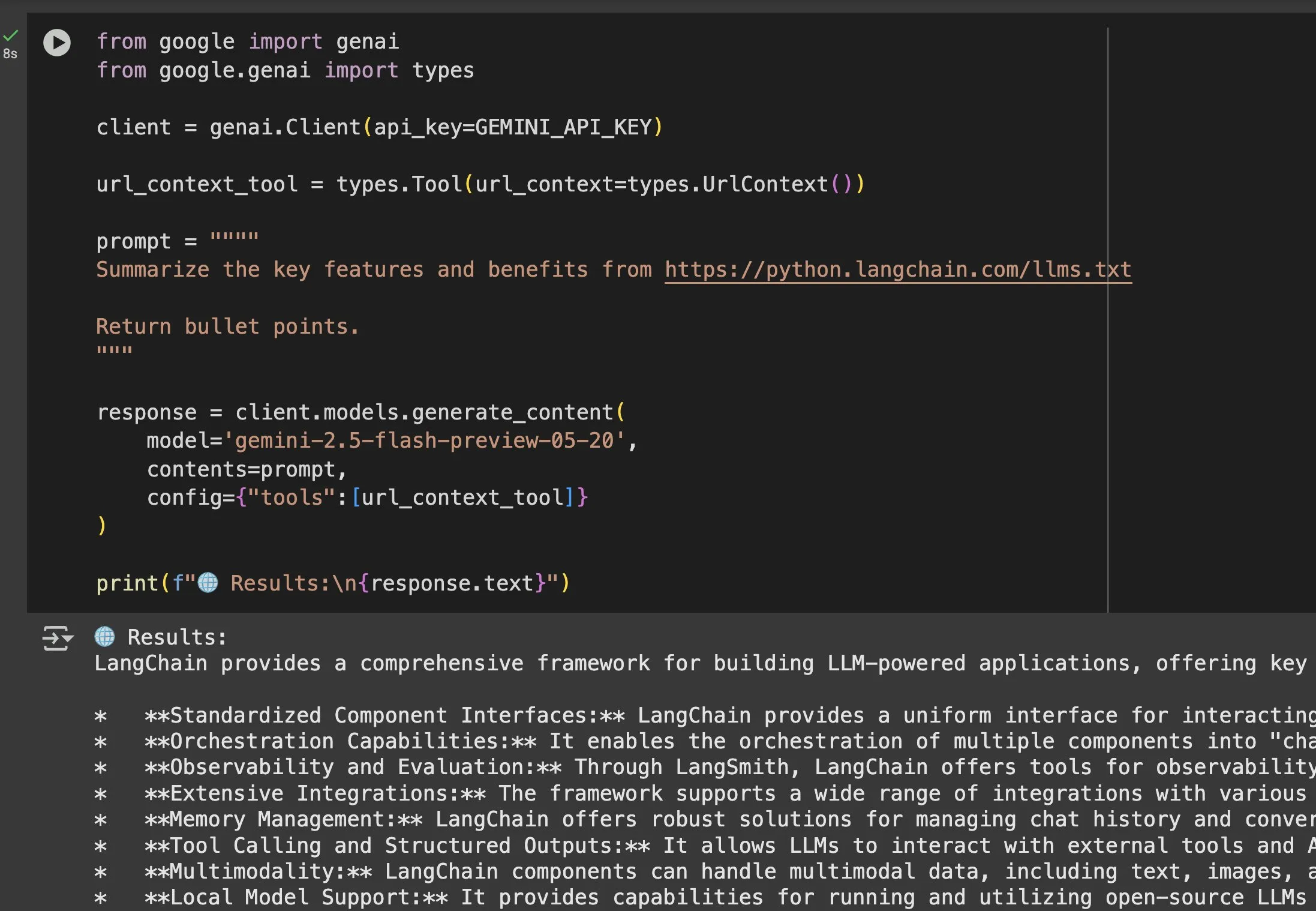
Valor do arquivo llms.txt em modelos como Gemini é destacado: Jeremy Phoward enfatizou a utilidade do arquivo llms.txt. Por exemplo, o Gemini agora pode entender o conteúdo de URLs; basta adicionar a URL ao prompt e configurar a ferramenta de contexto de URL. Isso significa que o cliente (como o Gemini), ao ler o endpoint llms.txt, sabe exatamente onde as informações necessárias estão armazenadas, facilitando enormemente a obtenção e utilização programática de informações. (Fonte: jeremyphoward)
EleutherAI lança conjunto de dados de texto de 8TB com licença aberta, Common Pile v0.1: EleutherAI anunciou o lançamento do Common Pile v0.1, um grande conjunto de dados contendo 8TB de texto com licença aberta e de domínio público. Com base neste conjunto de dados, eles treinaram modelos de linguagem de 7 bilhões de parâmetros (usando 1T e 2T tokens para treinamento, respectivamente), cujo desempenho é comparável a modelos semelhantes como LLaMA 1 e LLaMA 2. Isso fornece recursos valiosos e evidências empíricas para a pesquisa no treinamento de modelos de linguagem de alto desempenho usando dados totalmente compatíveis. (Fonte: clefourrier)

SelfCheckGPT: um método de detecção de alucinações em LLM sem necessidade de referência: Um artigo de blog explora o SelfCheckGPT como uma alternativa ao LLM-as-a-judge (usar LLM como avaliador) para detectar alucinações em modelos de linguagem. Este é um método de detecção sem necessidade de texto de referência e com zero recursos, oferecendo novas ideias para avaliar e melhorar a veracidade das saídas de LLM. (Fonte: dl_weekly)
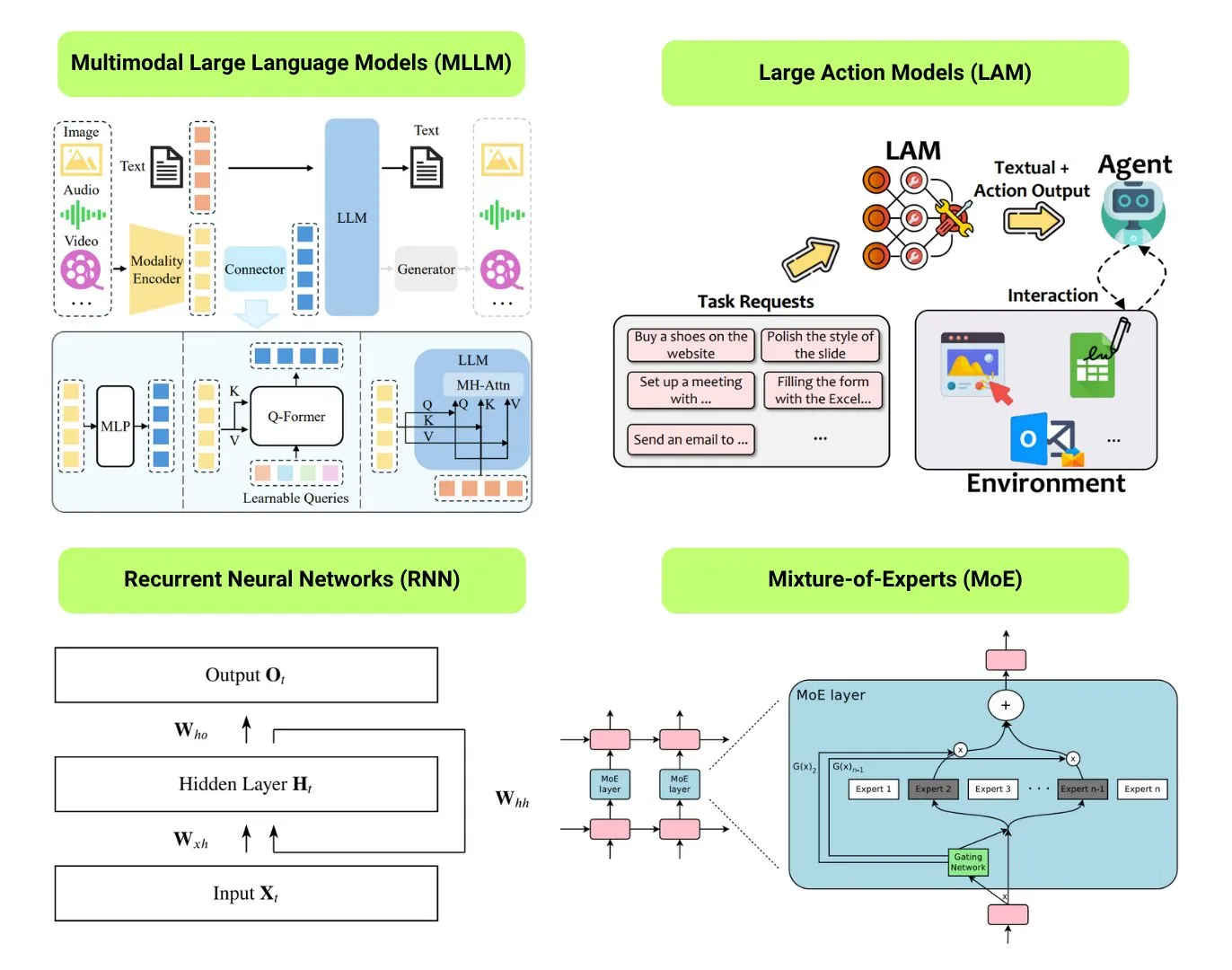
Compilação de 12 tipos básicos de modelos de IA: O The Turing Post compilou 12 tipos básicos de modelos de IA, incluindo LLM (Large Language Model), SLM (Small Language Model), VLM (Visual Language Model), MLLM (Multimodal Large Language Model), LAM (Large Action Model), LRM (Large Reasoning Model), MoE (Mixture of Experts), SSM (State Space Model), RNN (Recurrent Neural Network), CNN (Convolutional Neural Network), SAM (Segment Anything Model) e LNN (Logic Neural Network). Recursos relacionados fornecem explicações e links úteis para esses tipos de modelos. (Fonte: TheTuringPost)
Popular no GitHub: Tutorial Kubernetes The Hard Way: O tutorial de Kelsey Hightower, “Kubernetes The Hard Way”, continua a atrair atenção no GitHub. Este tutorial visa ajudar os usuários a construir gradualmente um cluster Kubernetes manualmente, compreendendo profundamente seus componentes principais e princípios de funcionamento, em vez de depender de scripts automatizados. O tutorial é destinado a aprendizes que desejam dominar os fundamentos do Kubernetes, cobrindo todo o processo, desde a preparação do ambiente até a limpeza do cluster. (Fonte: GitHub Trending)
Popular no GitHub: Lista de GPTs e Prompts gratuitos: O repositório friuns2/BlackFriday-GPTs-Prompts tornou-se popular no GitHub, compilando uma série de modelos GPT gratuitos e Prompts de alta qualidade que os usuários podem usar sem uma assinatura Plus. Esses recursos cobrem diversas áreas como programação, marketing, pesquisa acadêmica, busca de emprego, jogos, criatividade, e incluem algumas técnicas de “Jailbreaks”, fornecendo aos usuários GPT uma rica variedade de ferramentas prontas para uso e inspiração. (Fonte: GitHub Trending)

Usar CSV para planejar e rastrear projetos de codificação com IA, melhorando a qualidade e eficiência do código: Um desenvolvedor compartilhou como, ao usar o Claude Code para desenvolver um sistema ERP, a criação de arquivos CSV detalhados para planejar e rastrear o progresso da codificação de cada arquivo melhorou significativamente a eficiência do desenvolvimento de funcionalidades complexas e a qualidade do código. O arquivo CSV inclui status, nome do arquivo, prioridade, número de linhas de código, complexidade, dependências, descrição da funcionalidade, Hooks usados, módulos importados/exportados e, crucialmente, “notas de progresso”. Este método permite que a IA se concentre melhor na construção do código e que o desenvolvedor acompanhe claramente as diferenças entre o progresso real do projeto e o plano original. (Fonte: Reddit r/ClaudeAI)
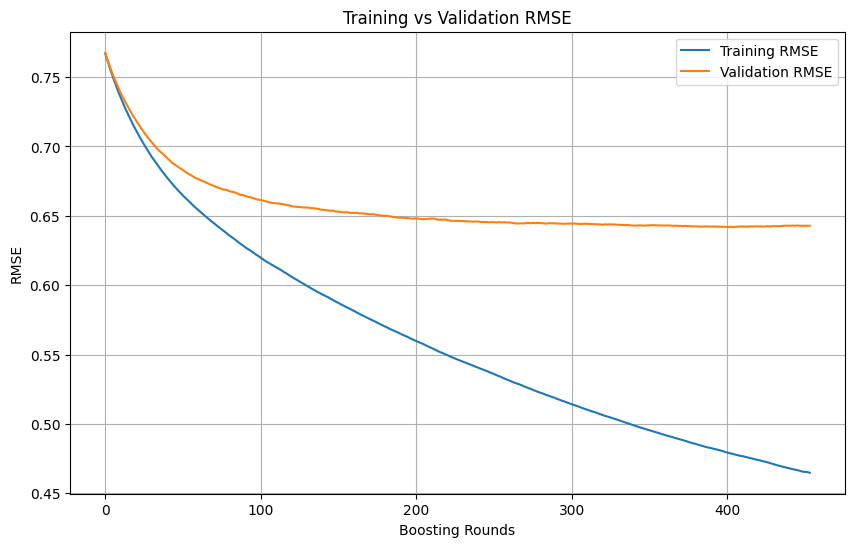
Julgamento de overfitting e momento de parada no treinamento de machine learning: Durante o processo de treinamento de modelos de machine learning, quando a perda de treinamento continua a diminuir rapidamente, enquanto a perda de validação diminui lentamente, para ou até aumenta, isso geralmente indica que o modelo pode estar sofrendo overfitting. Em princípio, enquanto a perda de validação ainda estiver diminuindo, o treinamento pode continuar. O crucial é garantir que o conjunto de validação seja independente do conjunto de treinamento e represente a distribuição real dos dados da tarefa. Se a perda de validação parar de diminuir ou começar a aumentar, deve-se considerar a interrupção antecipada do treinamento ou adotar métodos como regularização para melhorar a capacidade de generalização do modelo. (Fonte: Reddit r/MachineLearning)
🌟 Comunidade
AI Engineer World’s Fair 2025 foca em temas como RL+Reasoning, Eval, etc.: Os temas da conferência AI Engineer World’s Fair 2025 abrangem direções de vanguarda como Aprendizado por Reforço + Raciocínio (RL+Reasoning), Avaliação (Eval), Agentes de Engenharia de Software (SWE-Agent), Arquitetos de IA e Infraestrutura de Agentes. Os participantes relataram que a conferência estava cheia de vitalidade e pensamento inovador, com muitas pessoas ousando experimentar coisas novas, reinventando-se constantemente e mergulhando no campo da IA. A conferência também forneceu uma plataforma de intercâmbio e aprendizado para engenheiros de IA. (Fonte: swyx, hwchase17, charles_irl, swyx)

IA ideal de Sam Altman: modelo pequeno + raciocínio superforte + contexto massivo + ferramenta universal: Sam Altman descreveu sua forma ideal de IA: um modelo com capacidade de raciocínio sobre-humana, volume extremamente pequeno, capaz de acessar trilhões de informações de contexto e de invocar qualquer ferramenta imaginável. Essa visão gerou discussão, com alguns argumentando que isso difere da situação atual em que grandes modelos dependem do armazenamento de conhecimento, e questionando a viabilidade de modelos pequenos analisarem conhecimento em contextos enormes e realizarem raciocínio complexo, acreditando que conhecimento e capacidade de pensamento são difíceis de separar eficientemente. (Fonte: teortaxesTex)
Agentes de codificação despertam desejo de refatoração de código, desafios e oportunidades da programação assistida por IA: Desenvolvedores afirmam que o surgimento de agentes de codificação aumentou enormemente a “tentação” de refatorar o código de outros, trazendo também novos perigos. Um desenvolvedor compartilhou a experiência de usar IA para concluir uma tarefa de programação que levaria cerca de 10 minutos manualmente; embora a IA pudesse gerar rapidamente código funcional, ainda era necessária muita orientação e refatoração manual para atingir o nível de organização e estilo de um programador sênior. Isso destaca os desafios da programação assistida por IA em elevar a qualidade do código de nível júnior/médio para código de nível sênior. (Fonte: finbarrtimbers, mitchellh)
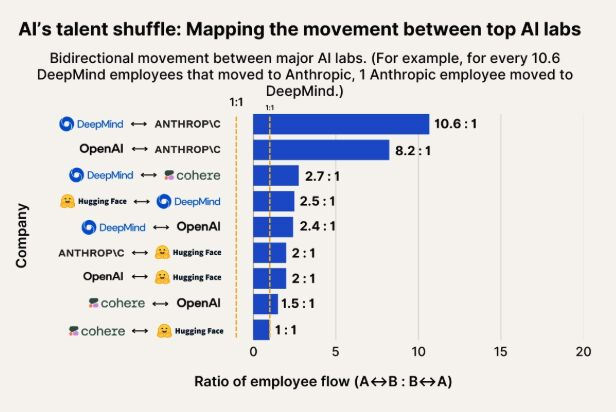
Observação do fluxo de talentos em IA: Anthropic se torna um importante destino para talentos do Google DeepMind e OpenAI: Um gráfico mostrando o fluxo de talentos em IA indica que a Anthropic está se tornando uma empresa importante para atrair pesquisadores do Google DeepMind e da OpenAI. A comunidade considera isso consistente com as percepções, e alguns usuários especulam que a Anthropic pode possuir alguma “arma secreta” ou direção de pesquisa única que atrai talentos de ponta. (Fonte: bookwormengr, TheZachMueller)
Popularização de robôs humanoides enfrenta desafios de confiança e aceitação social: O comentarista de tecnologia Faruk Guney prevê que a primeira onda de robôs humanoides pode falhar devido a um enorme déficit de confiança. Ele acredita que, apesar do progresso tecnológico contínuo, a sociedade ainda não está preparada para aceitar essas “inteligências de caixa preta” em casa para realizar tarefas como companhia, tarefas domésticas e até mesmo cuidados infantis. A tomada de decisão opaca dos robôs, os riscos potenciais de vigilância e uma aparência “fofa” distintamente diferente da humana (menos como Wall-E) podem se tornar obstáculos para sua ampla aplicação. Somente após ampla discussão social, regulamentação, auditoria e reconstrução da confiança é que a verdadeira popularização dos robôs humanoides poderá ocorrer. (Fonte: farguney, farguney)
Design de personalidade de IA: “imperfeito” supera “perfeito”: Um desenvolvedor compartilhou sua experiência na criação de 50 personalidades de IA em uma plataforma de áudio de IA. A conclusão foi que histórias de fundo excessivamente elaboradas, consistência lógica absoluta e personalidades extremamente unilaterais tornam a IA mecânica e irreal. A modelagem bem-sucedida da personalidade da IA reside em uma “pilha de personalidade de 3 camadas” (traços centrais + traços modificadores + peculiaridades), “padrões de imperfeição” apropriados (como lapsos ocasionais, autocorreções) e a quantidade certa de informações de fundo (300-500 palavras, incluindo experiências positivas e desafiadoras, paixões específicas e pontos de vulnerabilidade relacionados à profissão). Esses detalhes “imperfeitos” tornam a IA mais humana e conectável. (Fonte: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Discussão sobre se LLMs possuem “percepção” e “AGI”: entusiasmo e ceticismo coexistem: A comunidade em geral está entusiasmada com o enorme potencial dos LLMs, considerando-os comparáveis a grandes invenções históricas que mudarão tudo. No entanto, muitos ainda mantêm ceticismo em relação a afirmações de que os LLMs já possuem “capacidade de percepção”, precisam de “direitos”, ou que “acabarão com a humanidade” ou trarão “AGI”. Enfatiza-se a necessidade de manter minúcia e prudência ao interpretar as capacidades dos LLMs e os resultados de pesquisas. (Fonte: fabianstelzer)
💡 Outros
Explorando a colaboração de múltiplos robôs em caminhada autônoma: Surgiram nas mídias sociais explorações sobre a colaboração de múltiplos robôs na caminhada autônoma. Isso envolve tecnologias complexas como planejamento de rotas de robôs, alocação de tarefas, compartilhamento de informações e prevenção de colisões, sendo uma direção de pesquisa contínua nas áreas de robótica, RPA (Automação de Processos Robóticos) e machine learning. (Fonte: Ronald_vanLoon)
Técnica para otimizar hiperparâmetros do ULMFiT usando Random Forests: Jeremy Howard compartilhou uma técnica que usou para otimizar o ULMFiT (um método de transfer learning): executando um grande número de experimentos de ablação e alimentando todos os hiperparâmetros e dados de resultados em um modelo de Random Forest para identificar os hiperparâmetros que mais impactam o desempenho do modelo. Este método foi integrado pela Weights & Biases em seu produto, oferecendo novas ideias para o ajuste de hiperparâmetros. (Fonte: jeremyphoward)

Robô humanoide da Figure demonstra capacidade de processar tarefas logísticas por 60 minutos: A empresa Figure divulgou um vídeo de 60 minutos mostrando seu robô humanoide, impulsionado pela rede neural Helix, completando autonomamente várias tarefas em um cenário logístico. Esta demonstração visa provar a capacidade de trabalho estável de longa duração e o nível de decisão autônoma de seus robôs em ambientes reais complexos. (Fonte: adcock_brett)