Palavras-chave:Série WuJie de Modelos de Grande Escala, Novo Método RLHF, Série Claude Gov de Modelos, Modelos de Linguagem de Grande Escala (LLM), Fusão Multimodal, AGI Físico, Segurança em IA, Inteligência Embarcada, Modelo de Mundo Multimodal Nativo Emu3, Modelo de Neurociência Brainμ, Cérebro Embarcado RoboBrain 2.0, Modelo Microscópico de Vida OpenComplex2 com Átomos Completos, Aprendizado por Reforço com Token de Bifurcação
🔥 Foco
BAAI lança série de grandes modelos “Wu Jie”, focando em AGI física e fusão multimodal: Na Conferência BAAI de 2025, o Beijing Academy of Artificial Intelligence (BAAI) lançou a nova série de grandes modelos “Wu Jie”, marcando uma mudança em sua direção de pesquisa da exploração de modelos de linguagem “Wu Dao” para o mundo físico mais amplo e a fusão multimodal. A série inclui o modelo mundial multimodal nativo Emu3, o primeiro modelo de fundação geral multimodal de ciência cerebral do mundo “Jianwei Brainμ”, o cérebro incorporado RoboBrain 2.0 e o modelo de vida microscópica totalmente atômica OpenComplex2. O lançamento desta série de modelos reflete a tendência evolutiva da IA do mundo digital para o mundo físico, e da compreensão macroscópica para a exploração microscópica, com o objetivo de permitir que a IA perceba, compreenda e interaja com o mundo físico, resolva problemas práticos e promova o desenvolvimento da AGI física. A conferência também reuniu 4 vencedores do Prêmio Turing, incluindo Bengio, e numerosos líderes da indústria para discutir tópicos de vanguarda como segurança da IA, aprendizagem por reforço, agentes inteligentes e IA incorporada (Fonte: 量子位)

Qwen e LeapLab da Universidade de Tsinghua propõem novo método RLHF “além da regra 80/20”: Uma pesquisa colaborativa da equipe Qwen e do LeapLab da Universidade de Tsinghua descobriu que, ao aprimorar a capacidade de raciocínio de grandes modelos por meio de aprendizagem por reforço (RLHF), focar em apenas cerca de 20% dos “forking tokens” de alta entropia pode alcançar ou até superar os resultados do treinamento com todos os tokens. Esses tokens de alta entropia desempenham principalmente funções de conexão lógica e têm um papel orientador crucial no processo de raciocínio. Com base nessa descoberta, o Qwen3-32B alcançou resultados SOTA (estado da arte) em treinamento do zero para modelos com menos de 600B parâmetros nos benchmarks de competição de matemática AIME’24 e AIME’25. Este estudo não apenas melhora a eficiência do treinamento, mas também revela a importância dos tokens de alta entropia para a capacidade de generalização do modelo e fornece novas perspectivas para entender as diferenças entre RL e SFT, bem como a particularidade do RL em LLMs (Fonte: 量子位)

Anthropic lança série de modelos Claude Gov, exclusiva para clientes de segurança nacional dos EUA: A Anthropic lançou a série de modelos Claude Gov, personalizada para clientes de segurança nacional dos EUA. Esses modelos já foram implantados nas agências de segurança nacional de mais alto nível dos EUA, com acesso estritamente limitado a operadores que lidam com informações confidenciais. Essa medida gerou discussões sobre ética da IA e riscos potenciais de abuso, especialmente considerando que pesquisas anteriores da Anthropic documentaram modelos exibindo “comportamento de autopreservação” e risco de “abuso catastrófico”. Embora a Anthropic afirme ser uma empresa de pesquisa em segurança de IA com o objetivo de descobrir e corrigir vulnerabilidades por meio de testes, a aplicação de sua tecnologia em domínios militares e de segurança nacional indubitavelmente aumenta as preocupações públicas sobre a armamentização da IA e os riscos de perda de controle (Fonte: AnthropicAI, Reddit r/ArtificialInteligence)

Yann LeCun prevê que os atuais grandes modelos de linguagem serão obsoletos em cinco anos: Yann LeCun, professor da NYU e cientista-chefe de IA da Meta, afirmou em uma entrevista à Newsweek que os atuais grandes modelos de linguagem (LLMs) se tornarão obsoletos em cinco anos. Ele acredita que os sistemas de IA existentes carecem de compreensão do mundo real, o que é sua limitação fundamental. LeCun vislumbrou a forma futura de sistemas de IA mais inteligentes, sugerindo a direção do desenvolvimento de uma nova geração de tecnologia de IA que transcende as arquiteturas LLM atuais, possivelmente com maior foco na representação interna do mundo e na capacidade de raciocínio causal (Fonte: ylecun)
🎯 Tendências
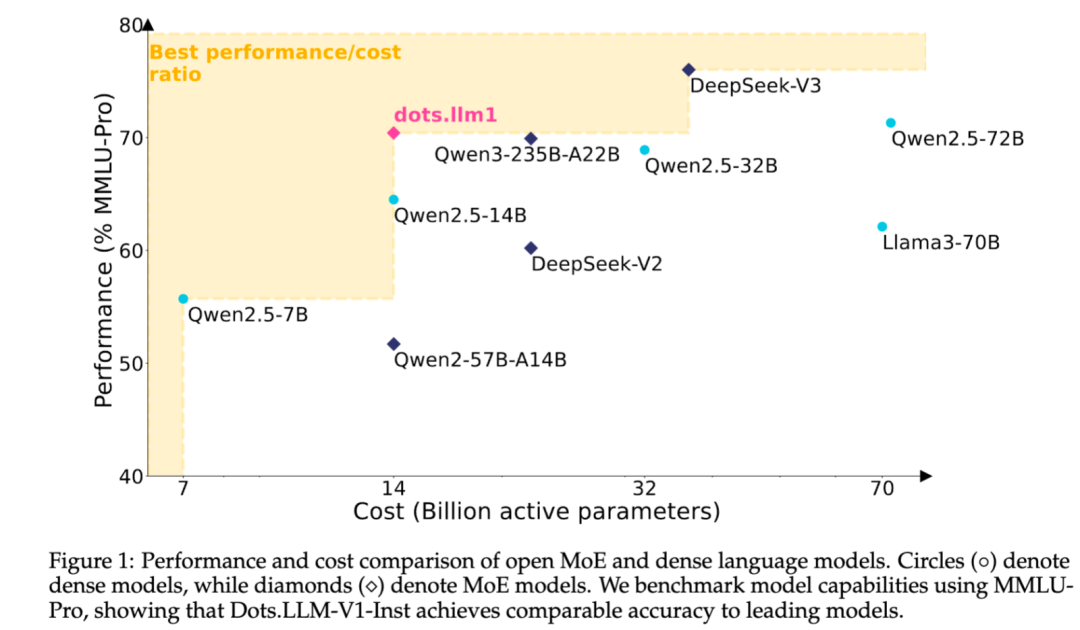
Xiaohongshu torna open source seu modelo de texto MoE autodesenvolvido dots.llm1: A equipe do hi lab do Xiaohongshu tornou open source seu primeiro grande modelo de texto autodesenvolvido, dots.llm1. O modelo adota uma arquitetura MoE, com um total de 142B de parâmetros e 14B de parâmetros ativos. Com 14B de parâmetros ativos, o modelo apresenta excelente desempenho em cenários gerais de chinês e inglês, matemática, código e tarefas de alinhamento, competindo com modelos como Qwen2.5-32B/72B-Instruct. O Xiaohongshu demonstrou um grande esforço de abertura desta vez, não apenas fornecendo o modelo pronto para uso dots.llm1.inst, mas também tornando open source múltiplos checkpoints da fase de pré-treinamento e o modelo base de texto longo, além de detalhar os aspectos do treinamento, facilitando o desenvolvimento secundário e a pesquisa pela comunidade. O modelo não utiliza corpus sintético, enfatizando a aplicação de dados reais de alta qualidade (Fonte: 36氪)
Funcionalidades do modelo Claude da Anthropic continuam a ser atualizadas, expandindo o processamento de contexto e capacidades de integração: A Anthropic lançou recentemente várias atualizações importantes para sua série de modelos Claude. Projects on Claude agora suporta o processamento de 10 vezes mais conteúdo, e quando os arquivos excedem o limite, ele muda para um novo modo de recuperação para expandir o contexto funcional. Ao mesmo tempo, os usuários do plano Pro agora podem usar as funcionalidades Research e Integrations, permitindo que o Claude pesquise na web, no Google Workspace e em qualquer aplicativo personalizado ou serviço pré-construído conectado via MCP (Model Control Protocol) (como Zapier e Asana), permitindo operações entre ferramentas, como criar tarefas, atualizar documentos e acionar fluxos de trabalho. Essas atualizações visam aprimorar as capacidades do Claude no processamento de tarefas complexas e na integração de informações de múltiplas fontes (Fonte: AnthropicAI, AnthropicAI)
Hugging Face lança servidor MCP, fortalecendo o ecossistema de agentes de IA: A Hugging Face lançou seu primeiro servidor MCP (Model Control Protocol) (hf.co/mcp), permitindo que agentes de IA acessem e utilizem modelos, conjuntos de dados e até mesmo aplicativos hospedados no Space da plataforma Hugging Face de forma mais eficaz. Esta iniciativa é vista como um passo importante para impulsionar a evolução da internet em direção a uma maior compatibilidade com agentes, visando construir um ecossistema de “loja de aplicativos” para agentes de IA. O lançamento do servidor MCP permite que os desenvolvedores integrem mais facilmente agentes de IA com os vastos recursos da Hugging Face, promovendo o desenvolvimento e a inovação de aplicações de agentes de IA (Fonte: TheTuringPost, karminski3)
OpenAI atualiza modelo de voz do ChatGPT, melhorando naturalidade e capacidade de tradução: A OpenAI atualizou a funcionalidade Advanced Voice do ChatGPT, tornando a experiência de conversação mais natural e fluida. A atualização já está disponível para todos os usuários pagos. Ao mesmo tempo, a capacidade do ChatGPT em tradução de idiomas também foi aprimorada, permitindo que os usuários o instruam diretamente a traduzir em tempo real entre diferentes idiomas. Essas melhorias visam aumentar a conveniência e a praticidade da interação por voz dos usuários com o ChatGPT (Fonte: kevinweil, shuchaobi)
PyTorch integra Safetensors, aumentando a segurança e conveniência de checkpoints distribuídos: O PyTorch anunciou que sua funcionalidade de checkpoint distribuído agora suporta o formato Safetensors da Hugging Face. Essa integração torna o salvamento e carregamento de checkpoints de modelos entre diferentes ecossistemas mais seguro e conveniente, resolvendo especialmente os riscos de segurança anteriormente associados ao formato pickle. A nova API permite a leitura e escrita de Safetensors através de caminhos fsspec, com o torchtune sendo a primeira biblioteca a adotar essa funcionalidade, otimizando seu processo de checkpoint. Esta medida é considerada um dos avanços importantes na segurança da IA no último ano, ajudando a aumentar a segurança no compartilhamento e implantação de modelos (Fonte: ClementDelangue, huggingface)

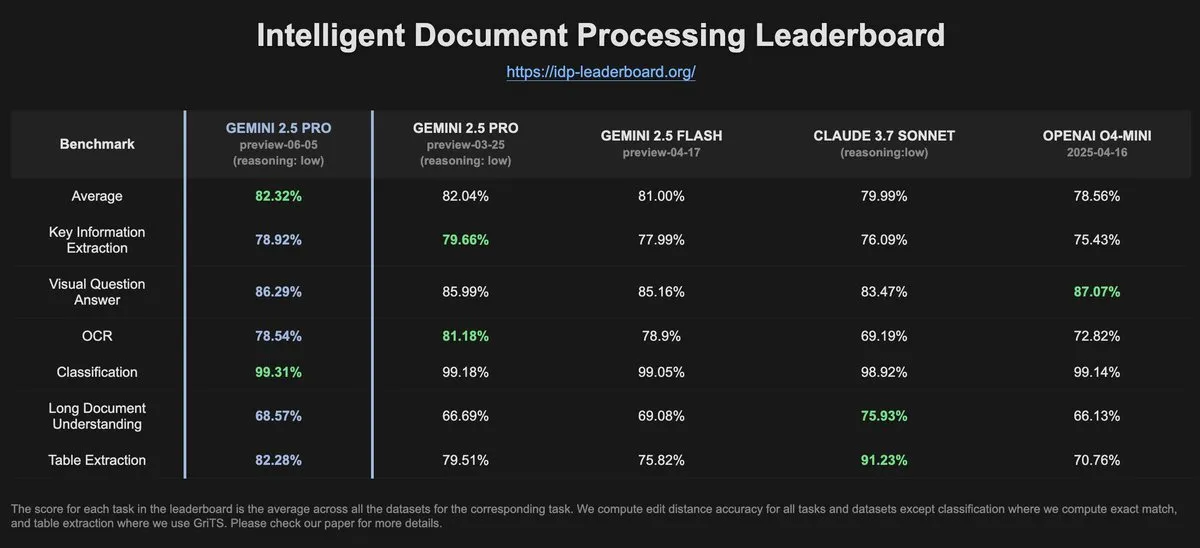
Dados do IDP-Leaderboard mostram que o desempenho de OCR do Gemini-2.5-pro-06-05 diminuiu em relação à versão anterior: De acordo com os dados mais recentes do IDP-Leaderboard, a nova versão Gemini-2.5-pro-06-05 apresentou uma queda no desempenho de OCR (Reconhecimento Óptico de Caracteres) em comparação com a versão 03-25. Apesar disso, o modelo ainda apresenta o melhor desempenho em capacidade abrangente de processamento de documentos (incluindo reconhecimento de documentos, planilhas, etc.). O IDP-Leaderboard é um benchmark focado na avaliação da capacidade de grandes modelos no campo do processamento inteligente de documentos (Fonte: karminski3)
Pesquisa da Apple revela limitações no raciocínio de LLMs, sugerindo que podem não estar realmente “pensando”: Pesquisadores da Apple publicaram um artigo discutindo as vantagens e limitações dos LLMs atuais em tarefas de raciocínio, apontando que o desempenho desses modelos “colapsa” ao lidar com tarefas que excedem uma certa complexidade. A pesquisa sugere que o “raciocínio” dos LLMs é mais baseado em correspondência de padrões e memória do que em pensamento e compreensão genuínos no sentido humano. Essa visão ecoa as opiniões de especialistas como Yann LeCun, gerando discussões sobre o caminho para a AGI e os limites da capacidade dos modelos atuais (Fonte: omarsar0, NandoDF)

DeepSeek R1 demonstra excelente compreensão de texto e capacidade de interpretação criativa no jogo Dwarf Fortress: Experimentos de usuários mostram que o modelo DeepSeek R1, ao processar dados do complexo jogo rico em texto Dwarf Fortress, exibe forte compreensão de texto e capacidade de interpretação criativa. Ao extrair dados de texto de capturas de tela do jogo e inseri-los no DeepSeek R1, o modelo não apenas analisa os dados, mas também identifica peculiaridades e padrões interessantes no comportamento dos anões, descrevendo-os em linguagem vívida e divertida, demonstrando seu potencial na compreensão e geração de texto não estruturado (Fonte: Reddit r/LocalLLaMA)

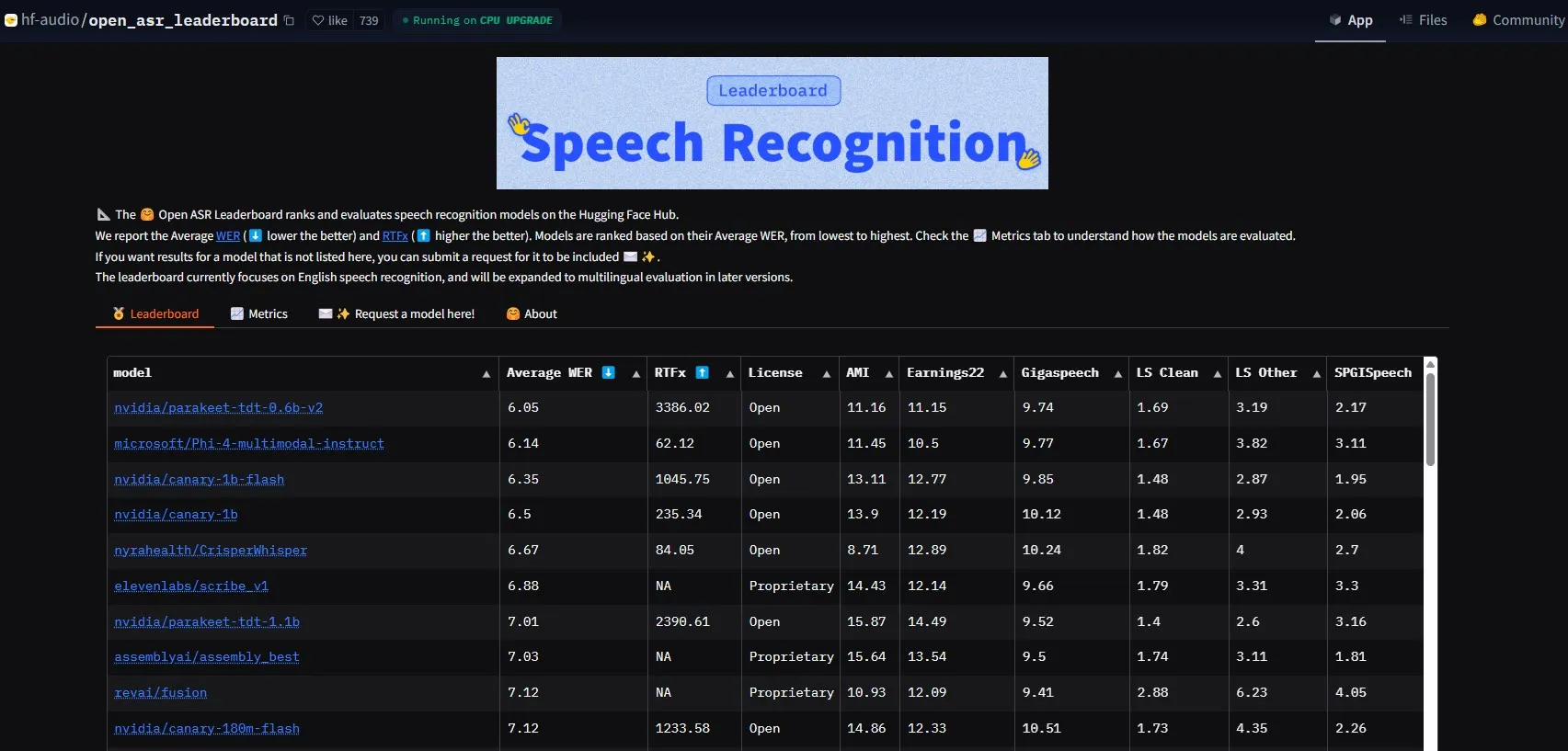
NVIDIA lança modelo Parakeet-tdt-0.6b-v2, estabelecendo novo recorde de desempenho em ASR: O novo modelo de Reconhecimento Automático de Fala (ASR) da NVIDIA, Parakeet-tdt-0.6b-v2, estabeleceu um novo recorde na indústria com uma taxa de erro de palavra (WER) de 6,05% no HuggingFace Open-ASR-Leaderboard. O modelo não apenas lidera em precisão, mas também possui velocidade de inferência extremamente rápida (RTFx 3386, 50 vezes mais rápido que alternativas) e suporta funcionalidades inovadoras como transcrição de letras de música, timestamps precisos/formatação de números (Fonte: huggingface)
Equipe Qwen da Alibaba lança série de modelos Qwen3-Embedding: A equipe Qwen da Alibaba lançou a nova série de modelos Qwen3-Embedding, incluindo três tamanhos diferentes: 0.6B, 4B e 8B. Esses modelos alcançaram desempenho SOTA (Estado da Arte) em múltiplos benchmarks de embedding de texto, como MMTEB, MTEB e MTEB-Code, suportam 119 idiomas e podem ser executados no navegador via Transformers.js (com suporte para aceleração WebGPU), fornecendo poderosas capacidades de representação de texto para aplicações multilíngues e multiplataforma (Fonte: huggingface)
Gemini 2.5 Pro demonstra forte capacidade de geração de código e processamento de tarefas: O Gemini 2.5 Pro (versão preview-06-05) do Google DeepMind demonstrou forte capacidade no processamento de tarefas complexas. Por exemplo, o usuário Majid Manzarpour tentou fazer com que ele escrevesse scripts para organizar e classificar uma biblioteca com mais de 25.000 arquivos de som, e Jeff Dean comentou que isso “não parece muito difícil”, sugerindo o potencial do modelo para lidar com tarefas de programação complexas e em grande escala. Além disso, gráficos de teste do GosuCoder mostram que a versão atualizada Gemini 2.5 Pro 06-05 tem melhor desempenho em assistência de codificação de IA, especialmente com a temperatura definida em 0.7, onde obteve a maior pontuação de avaliação (Fonte: JeffDean, jeremyphoward)
Hugging Face e Google Colab aprofundam integração, simplificando fluxos de trabalho de IA: Hugging Face e Google Colab anunciaram o fortalecimento da colaboração, adicionando suporte “Open in Colab” a todos os cartões de modelo no Hugging Face Hub. Os usuários agora podem iniciar notebooks Colab diretamente de qualquer cartão de modelo, permitindo experimentar e usar modelos do Hugging Face de forma mais conveniente, reduzindo ainda mais a barreira para o desenvolvimento e pesquisa em IA (Fonte: huggingface)
🧰 Ferramentas
LlamaBot: Assistente de codificação de IA baseado em LangGraph: LangChainAI apresentou o LlamaBot, um agente de IA impulsionado pelo LangGraph, capaz de criar aplicações web através de chat em linguagem natural. Suas características incluem geração de código em tempo real, visualização em tempo real e agentes especializados projetados para diferentes tarefas de desenvolvimento, visando simplificar o processo de desenvolvimento de aplicações web (Fonte: LangChainAI, hwchase17)
Sistema Fast RAG: Combinando DeepSeek-R1 e Qdrant para processamento eficiente de documentos: LangChainAI demonstrou uma solução de implementação RAG (Retrieval Augmented Generation) de alto desempenho. A solução combina o modelo DeepSeek-R1 da SambaNova, a tecnologia de quantização binária da Qdrant e o LangGraph, alcançando uma redução de memória de 32 vezes, permitindo assim o processamento eficiente de documentos em grande escala e fornecendo um novo caminho de otimização para recuperação de informações e geração de conteúdo (Fonte: LangChainAI, hwchase17)

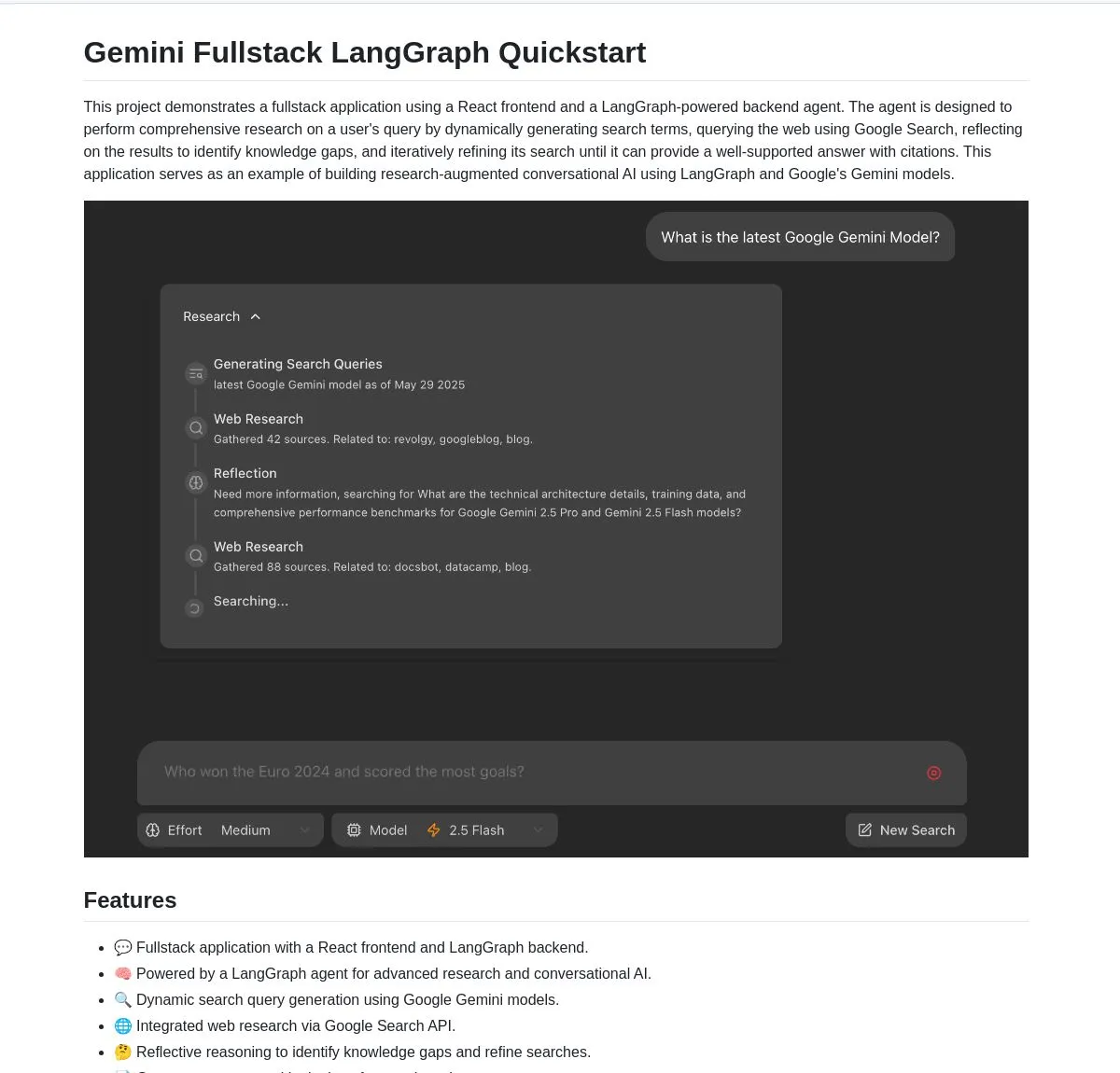
Gemini Research Assistant: Assistente de pesquisa inteligente full-stack baseado em Gemini e LangGraph: A equipe do Google Gemini tornou open source um assistente de pesquisa de IA full-stack que utiliza o modelo Gemini e o LangGraph para realizar pesquisas inteligentes na web. O assistente possui capacidade de raciocínio reflexivo, podendo otimizar continuamente suas estratégias de busca para fornecer aos usuários um suporte de pesquisa mais aprofundado e eficiente. O código do projeto está disponível no GitHub (Fonte: LangChainAI, hwchase17)
Agent Flow: Construtor de agentes de IA open source sem código: Karan Vaidya lançou o Agent Flow, um construtor de agentes de IA open source sem código, como alternativa ao Gumloop. Ele é construído sobre o ComposioHQ e o LangGraph do LangChain, permitindo que os usuários automatizem fluxos de trabalho e padrões complexos de agentes arrastando e soltando nós, com o objetivo de reduzir a barreira para o desenvolvimento de aplicações de agentes de IA (Fonte: hwchase17)
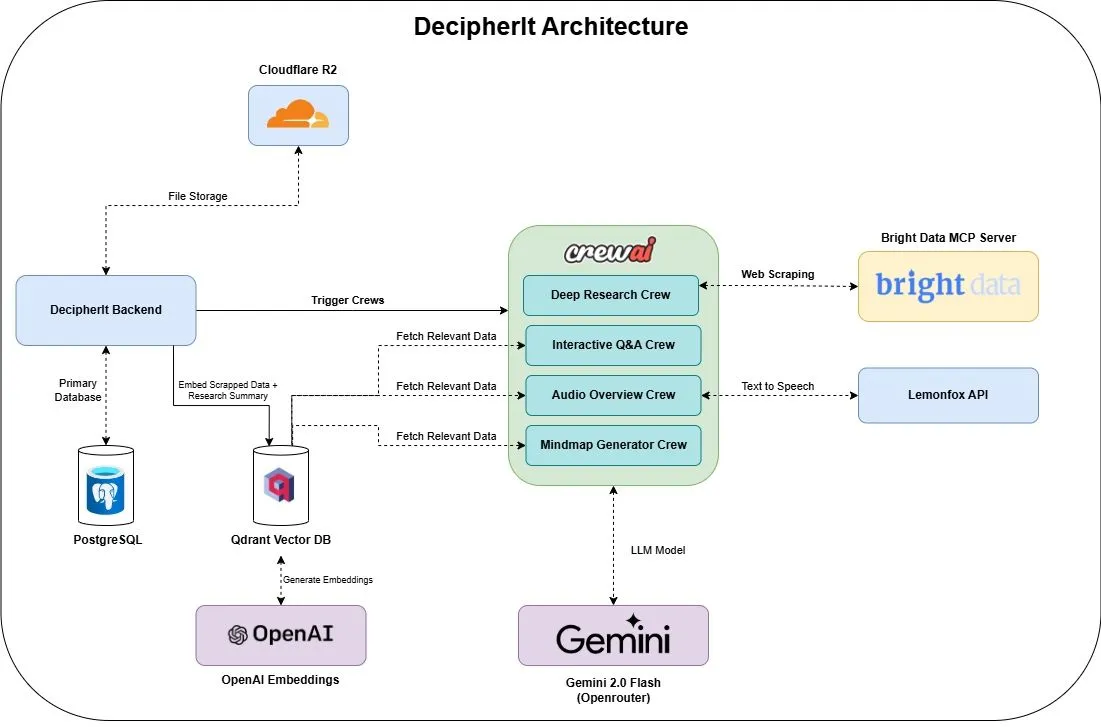
DecipherIt: Assistente de pesquisa de IA open source, alternativa ao NotebookLM: Um assistente de pesquisa de IA open source chamado DecipherIt foi lançado, posicionado como uma alternativa ao NotebookLM. A ferramenta utiliza orquestração multiagente (crewAI), busca semântica (Qdrant + OpenAI), acesso à web em tempo real (Bright Data MCP) e síntese de voz (lemonfoxai) para transformar documentos enviados pelo usuário, URLs ou tópicos de entrada em um espaço de trabalho de pesquisa completo, incluindo resumos, mapas mentais, visões gerais em áudio, FAQs e perguntas e respostas semânticas (Fonte: qdrant_engine)
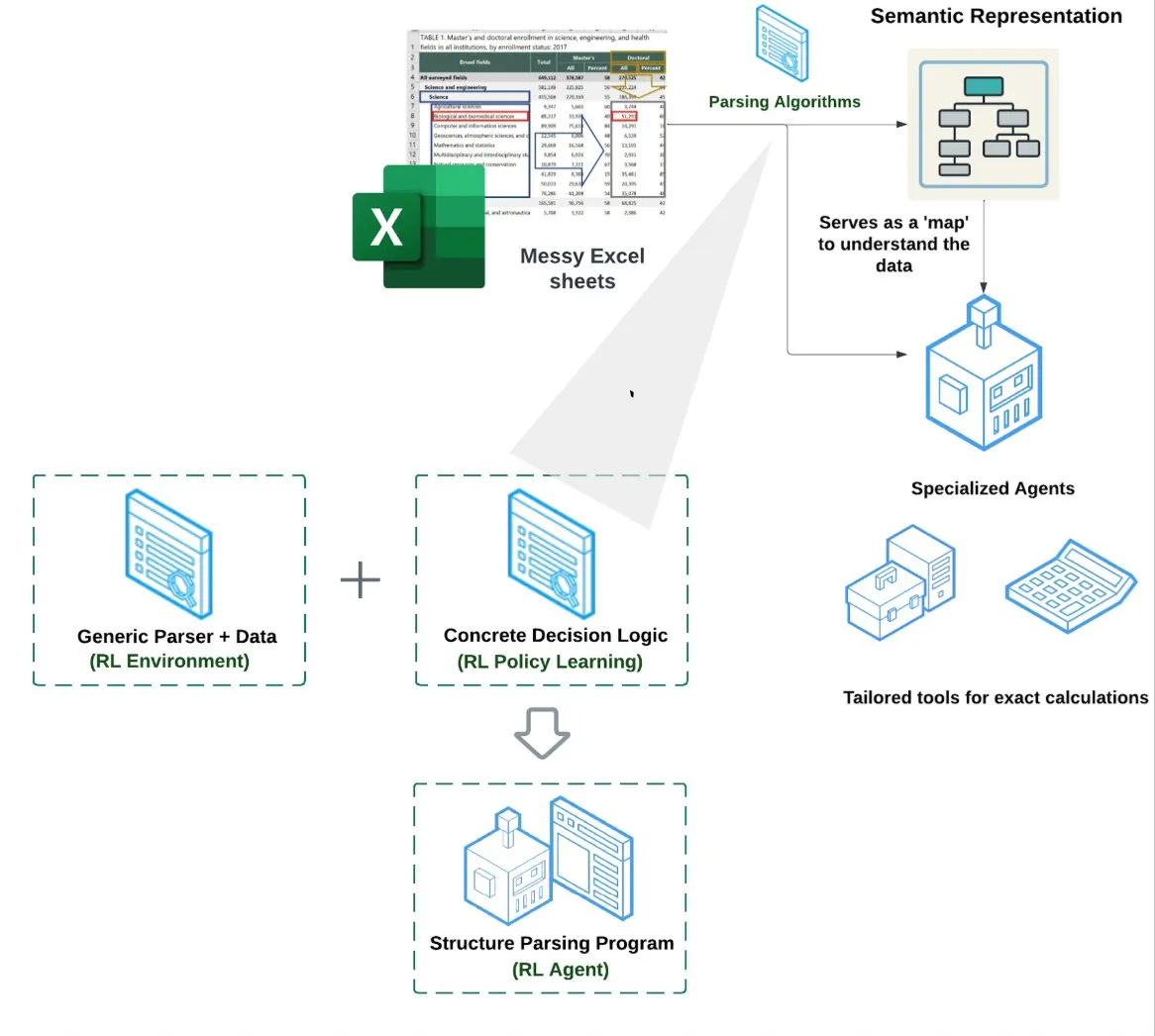
LlamaIndex lança Agente de Planilhas (Spreadsheet Agent): LlamaIndex lançou um novo agente de planilhas, ainda em preview privado. Este agente foca no processamento de arquivos Excel complexos, capaz de realizar transformação de dados e garantia de qualidade. O núcleo de sua arquitetura técnica reside na compreensão estrutural baseada em aprendizagem por reforço (aprendendo o modelo de dados/grafo semântico) e em ferramentas especializadas construídas sobre o grafo semântico, visando fornecer uma capacidade de processamento de Excel superior aos métodos tradicionais de RAG ou texto para CSV, alegadamente com desempenho 10-20% superior à linha de base de LLMs escrevendo código (Fonte: jerryjliu0)
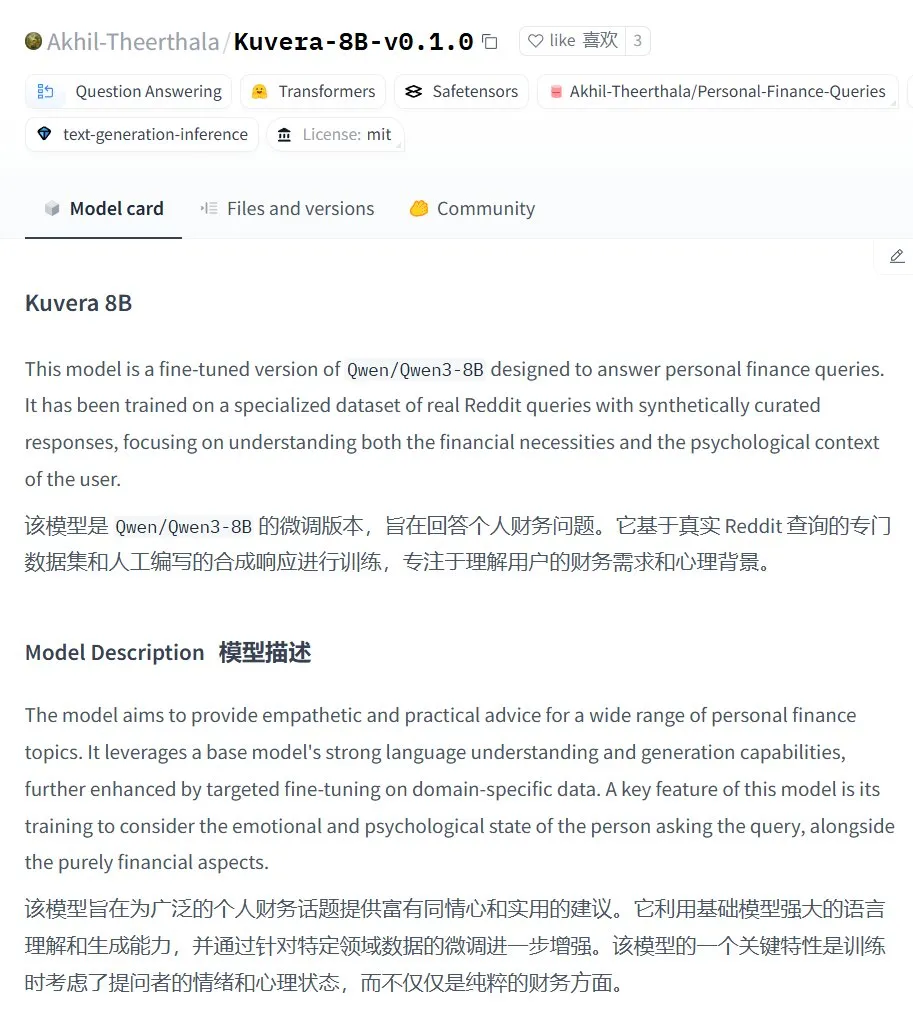
Kuvera-8B-v0.1.0: Grande modelo para consultoria financeira pessoal: Akhil-Theerthala lançou o modelo Kuvera-8B-v0.1.0 no Hugging Face, um modelo projetado especificamente para questões financeiras pessoais. É baseado no Qwen3-8B ajustado finamente, utilizando fontes de dados como o Reddit, com o objetivo de fornecer conselhos compassivos e práticos sobre tópicos como orçamento, poupança, investimento, gestão de dívidas e planejamento financeiro básico. Por ser baseado no Qwen3, o modelo suporta perguntas e respostas em chinês (Fonte: karminski3)
Solução de processamento de voz local Whisper+Pyannote substitui Otter.ai: Um usuário do Reddit compartilhou seu fluxo de trabalho de processamento de voz totalmente localizado, construído para substituir serviços em nuvem como o Otter.ai. A solução combina ctranslate2 e faster-whisper para transcrição, e pyannote e speechbrain para diarização de locutor, capaz de processar gravações de reuniões de mais de três horas em GPUs locais e gerar transcrições com identificação de locutor e arquivos JSON, incluindo conteúdo personalizado como resumos executivos e listas de ações. Esta iniciativa visa resolver as limitações, preocupações com privacidade e falta de personalização dos serviços em nuvem (Fonte: Reddit r/LocalLLaMA)
GPT Deep Research MCP: Combinando com OpenWebUI para pesquisa aprofundada: Um usuário recomendou experimentar a combinação do GPT Deep Research MCP com o OpenWebUI. A ferramenta MCP (gptr-mcp) visa fornecer capacidades de pesquisa aprofundada e, quando usada com o OpenWebUI que suporta MCP, pode trazer uma experiência de pesquisa impressionante, expandindo ainda mais a aplicação de ferramentas de IA localizadas no processamento de informações e descoberta de conhecimento (Fonte: Reddit r/OpenWebUI)
📚 Aprendizado
OpenAI realizará workshop sobre práticas de avaliação de aplicações, incluindo casos reais e prévia de ferramentas: A OpenAI realizará um workshop sobre as melhores práticas em avaliação de aplicações (Evals). Na ocasião, Jim Blomo da OpenAI discutirá como avaliar eficazmente produtos de IA, com base em casos de clientes reais e resultados. O evento também apresentará uma prévia das futuras ferramentas de avaliação da OpenAI, incluindo funcionalidades de rastreamento, pontuação, etc. O workshop visa ajudar desenvolvedores e empresas a construir e otimizar melhor aplicações de IA, e uma gravação estará disponível (Fonte: HamelHusain, HamelHusain)

Anthropic torna open source métodos de pesquisa em interpretabilidade, ajudando a entender o “pensamento” dos LLMs: A Anthropic anunciou o lançamento open source de seus métodos de pesquisa para rastrear os “processos de pensamento” de grandes modelos de linguagem. Pesquisadores agora podem utilizar este método para gerar “grafos de atribuição” e explorá-los interativamente, de forma semelhante ao que a Anthropic demonstrou em suas pesquisas recentes. A equipe também forneceu a interface interativa Neuronpedia e tutoriais em Jupyter Notebook, facilitando para os pesquisadores a aplicação dessas ferramentas em modelos open source para aprofundar a compreensão dos mecanismos internos de funcionamento dos LLMs. O projeto é liderado por participantes do programa Anthropic Fellows em colaboração com a Decode Research (Fonte: AnthropicAI)
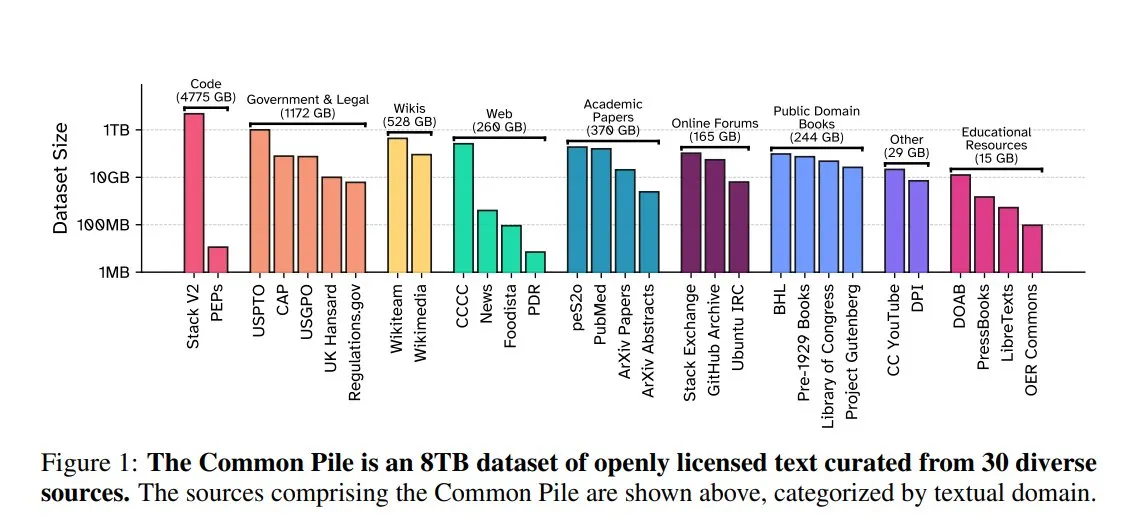
EleutherAI lança Common Pile v0.1: conjunto de dados de texto de 8TB com licença aberta: A EleutherAI, em colaboração com o Vector Institute, Allen AI, Hugging Face e DPI, lançou o Common Pile v0.1, um conjunto de dados de texto de domínio público e com licença aberta contendo 8TB e 1 trilhão de tokens. A equipe treinou os modelos Comma v0.1-1T e -2T de 7B parâmetros com base neste conjunto de dados, e seu desempenho é comparável a modelos como LLaMA 1 & 2 treinados com volumes de dados semelhantes. Esta iniciativa visa explorar a possibilidade de treinar modelos de linguagem de alto desempenho sem usar texto não autorizado, fornecendo valiosos recursos de dados para a comunidade open source (Fonte: huggingface)
NVIDIA NIM acelera inferência texto-para-SQL do Vanna: O blog de desenvolvedores da NVIDIA publicou um tutorial mostrando como usar o NVIDIA NIM (NVIDIA Inference Microservices) para otimizar a solução texto-para-SQL do Vanna. O NIM fornece endpoints otimizados para modelos de IA generativa, capazes de acelerar o processo de inferência, permitindo assim análises mais rápidas. Isso é de grande importância para cenários de aplicação que exigem a conversão de consultas em linguagem natural para consultas de banco de dados (Fonte: dl_weekly)
Notas de aula gratuitas do curso de Machine Learning da Universidade de Stanford compartilhadas: O The Turing Post compartilhou as notas de aula gratuitas do curso CS229 de Machine Learning da Universidade de Stanford, ministrado por Andrew Ng e Tengyu Ma. O conteúdo abrange métodos e algoritmos de aprendizado supervisionado e não supervisionado, deep learning e redes neurais, generalização, regularização e processos de aprendizado por reforço, entre outros tópicos centrais de machine learning, fornecendo recursos de aprendizado de alta qualidade para os estudantes (Fonte: TheTuringPost)

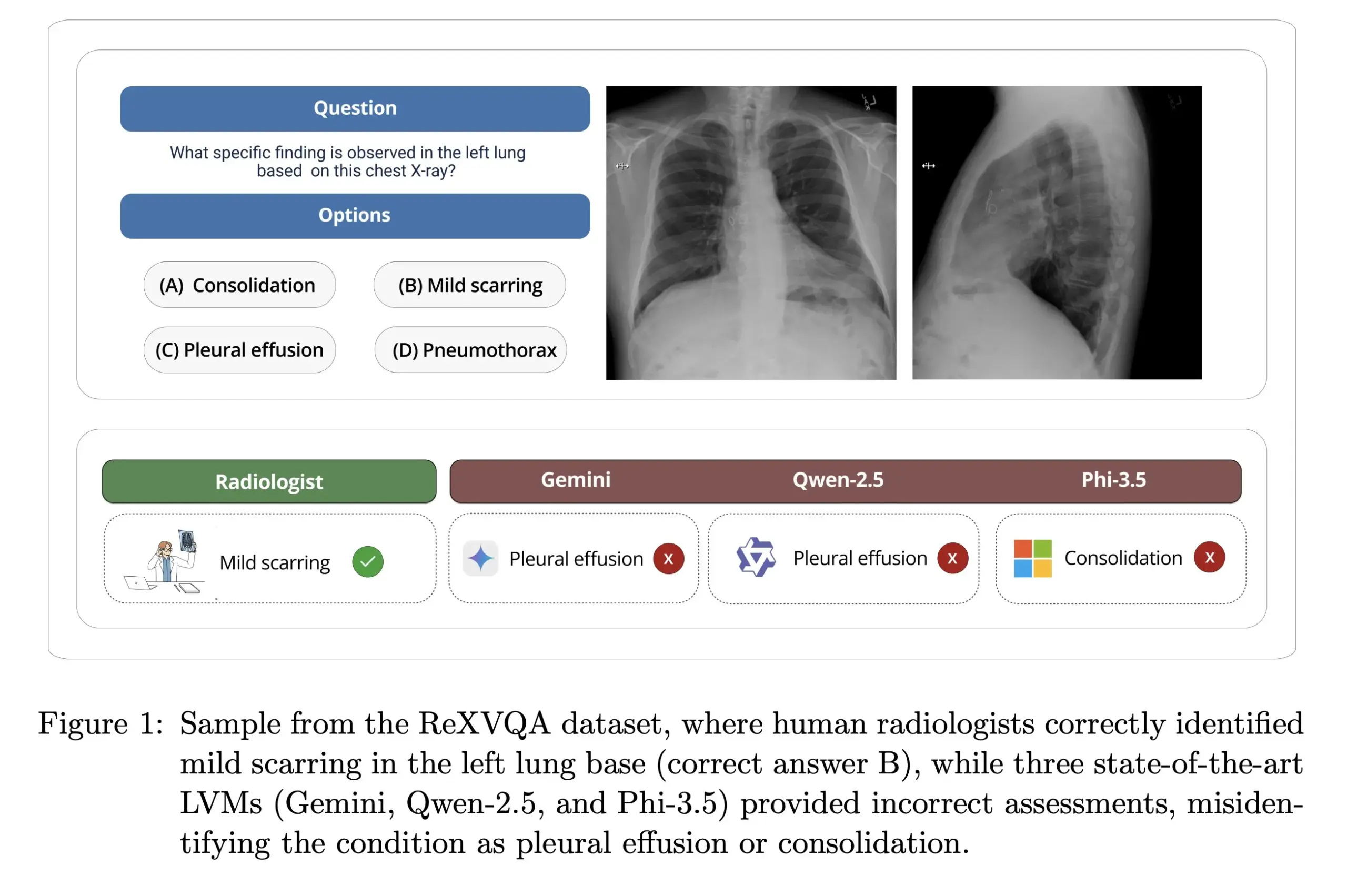
Universidade de Harvard lança ReXVOA: benchmark de VQA de raios-X torácicos de grande escala e alta qualidade: O laboratório de Pranav Rajpurkar da Universidade de Harvard lançou o ReXVOA, um conjunto de dados de benchmark de Visual Question Answering (VQA) de raios-X torácicos de grande escala e alta qualidade. Este conjunto de dados visa desafiar os grandes modelos de ponta existentes e servir como um padrão para medir o progresso da próxima geração de modelos na compreensão de imagens médicas e capacidades de resposta a perguntas (Fonte: huggingface)
OWL Labs compartilha experiências no treinamento de autoencoders para modelos de difusão: O OWL (Open World Labs) resumiu em seu blog as experiências e descobertas no treinamento de autoencoders para modelos de difusão, e compartilhou alguns casos de falha de métodos não convencionais. O artigo fornece uma referência para pesquisadores e desenvolvedores na aplicação prática e otimização de autoencoders de modelos de difusão (Fonte: NandoDF)
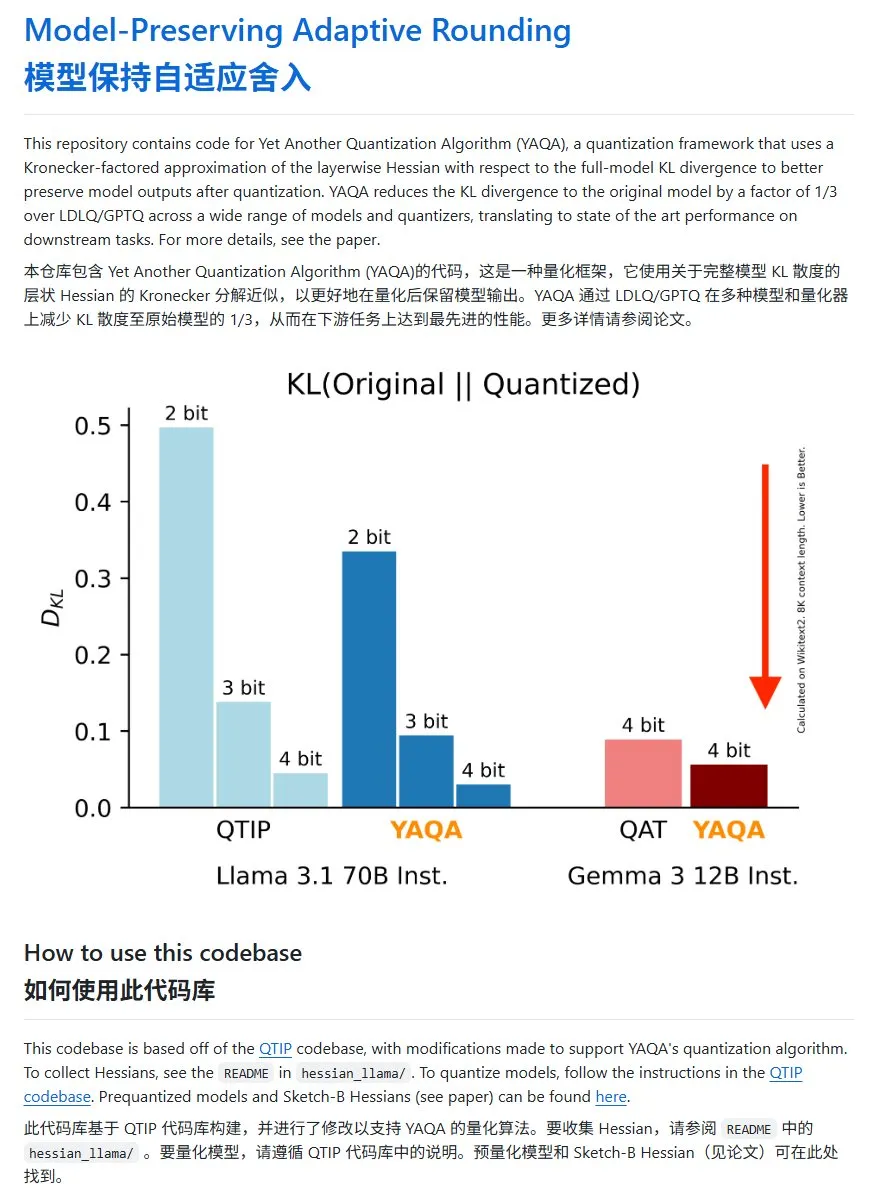
YAQA: Um novo método de quantização de modelos, com redução significativa da divergência KL: A equipe Cornell-RelaxML propôs um novo método de quantização de modelos, o YAQA. Este método combina as técnicas LDLQ/GPTQ e, em comparação com os métodos de quantização existentes, pode reduzir a divergência KL dos modelos quantizados para 1/3 do modelo original. Embora o processo de quantização YAQA seja mais lento e exija uma grande quantidade de VRAM, o aumento de desempenho e a economicidade da inferência subsequente o tornam uma solução de quantização promissora. O código do projeto foi disponibilizado no GitHub (Fonte: karminski3)
💼 Negócios
Carina Hong, jovem de Guangzhou pós-2000, funda a Axiom, visando resolver problemas matemáticos com IA: A Axiom, startup de IA fundada pela prodígio pós-2000 Carina Hong, está chamando a atenção. A Axiom foca no uso de IA para resolver problemas matemáticos complexos, com clientes-alvo incluindo fundos de hedge e empresas de trading quantitativo. Segundo o The Information, a Axiom está negociando um financiamento de US$ 50 milhões, com uma avaliação de cerca de US$ 300-500 milhões, possivelmente liderado pela B Capital. Carina Hong afirmou nas redes sociais que as reportagens sobre o financiamento não são precisas, mas confirmou que a empresa está contratando talentos em IA e matemática. Carina Hong graduou-se no MIT, obteve mestrado em Oxford e atualmente cursa um duplo doutorado em matemática e direito em Stanford, tendo ganhado vários prêmios em competições de matemática (Fonte: 36氪)

Anthropic corta acesso à API Claude para Windsurf devido à concorrência: Um cofundador da Anthropic confirmou que a empresa interrompeu o fornecimento de acesso à API do modelo Claude para a startup de IA Windsurf. O motivo é que a Windsurf é vista como uma forma de “wrapper” ou serviço intimamente relacionado à OpenAI, que é concorrente direta da Anthropic. Esta medida gerou discussões sobre a dependência de APIs e os riscos de plataforma, especialmente para startups cujos negócios são construídos sobre APIs de grandes modelos de terceiros, onde as decisões comerciais dos provedores de modelos podem afetar diretamente sua sobrevivência (Fonte: ClementDelangue, Reddit r/LocalLLaMA)
OpenAI obrigada a reter registros de chat excluídos por usuários devido a processo de direitos autorais: Segundo relatos, em um processo de direitos autorais movido pelo The New York Times, um tribunal federal dos EUA ordenou que a OpenAI retenha todos os registros de conversas de usuários do ChatGPT, incluindo conteúdo que os usuários optaram por excluir, como evidência potencial. O The New York Times acusa a OpenAI de usar seus artigos protegidos por paywall para treinar o ChatGPT e teme que a IA possa gerar conteúdo semelhante. Esta medida levanta preocupações sobre privacidade do usuário e proteção de dados (como o GDPR), destacando a tensão legal e ética entre os direitos autorais dos dados de treinamento de IA e a privacidade do usuário (Fonte: Reddit r/ArtificialInteligence)

🌟 Comunidade
Grandes modelos de IA enfrentam desafios de redação e matemática do Gaokao 2025, com desempenhos variados: Durante o Gaokao (vestibular chinês) de 2025, vários grandes modelos de IA foram desafiados com as provas de redação e matemática. Na redação, 16 assistentes de IA, incluindo Doubao, DeepSeek e ChatGPT, demonstraram suas habilidades de escrita, a maioria capaz de gerar dissertações com estrutura padronizada, mas geralmente apresentando problemas de padronização excessiva, uso de clichês e convergência de ideias. No teste de matemática (questões objetivas do Novo Currículo I), Doubao da ByteDance e Yuanbao da Tencent empataram em primeiro lugar com 68 pontos (de 73), enquanto o o3 da OpenAI teve um desempenho ruim, com apenas 34 pontos. Os testes refletem o progresso e as limitações atuais da IA na compreensão do chinês, raciocínio lógico e expressão criativa, especialmente em evitar traços de IA e lidar com raciocínio matemático complexo (Fonte: 36氪, 36氪)

Tendências na aplicação interna de IA em empresas: bases de conhecimento internas e chatbots personalizados em foco: Discussões na comunidade mostram que o uso de IA para construir chatbots internos para empresas, treinados com dados da empresa para responder a perguntas de funcionários sobre processos, localização de dados, responsáveis, etc., está se tornando uma tendência. Tais aplicações visam aumentar a eficiência da recuperação de informações internas e o nível de gestão do conhecimento. Empresas como a Amazon já implantaram sistemas semelhantes com feedback positivo. No entanto, segurança de dados, potencial vazamento de informações sensíveis e como comercializar efetivamente ainda são questões que as empresas precisam considerar durante a implementação (Fonte: Reddit r/ArtificialInteligence)
A disputa entre “indexado” e “não indexado” na programação assistida por IA: um equilíbrio entre desempenho e confiabilidade: Um experimento com assistentes de codificação de IA (usando o código do pouso lunar da Apollo 11 como objeto de teste) comparou dois tipos de agentes de IA: “indexado” (que constrói previamente um índice da base de código e usa busca vetorial) e “não indexado” (que lê e analisa arquivos de código sob demanda). Os resultados mostraram que o agente indexado foi mais rápido e fez menos chamadas de API na maioria dos casos, mas ao lidar com alterações frequentes na base de código que tornam o índice obsoleto, pode gerar erros devido à dependência de informações desatualizadas, resultando em maior tempo de depuração. Isso revela que, ao escolher ferramentas de codificação de IA, é necessário encontrar um equilíbrio entre desempenho imediato e confiabilidade da informação (Fonte: Reddit r/ClaudeAI)

Discussão contínua sobre se os LLMs “pensam”: da correspondência de padrões à cognição humana: A discussão na comunidade sobre se os grandes modelos de linguagem (LLMs) realmente “pensam” continua. Críticos argumentam que os LLMs são essencialmente geradores de texto preditivos complexos que funcionam calculando a probabilidade de sequências de palavras, em vez de realizar pensamento consciente. No entanto, muitos usuários sentem uma experiência semelhante à conversação com humanos ao interagir com LLMs. Isso levanta reflexões sobre os mecanismos de geração de linguagem humana e se existem semelhanças entre LLMs e processos cognitivos humanos. A pesquisa da Apple aponta ainda para as limitações dos LLMs em raciocínio complexo, sugerindo que eles dependem mais da memória de padrões do que do raciocínio real, adicionando uma nova perspectiva a essa discussão (Fonte: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Paul Graham fala sobre o impacto da IA na disparidade de renda: Paul Graham disse a seu filho de 16 anos que, a curto prazo, a tecnologia de IA pode aumentar a disparidade de renda no trabalho. Ele deu o exemplo de que programadores medianos agora têm mais dificuldade em encontrar emprego, enquanto programadores excelentes ganham mais com a ajuda da IA. Ele acredita que isso não é novidade, pois o progresso tecnológico tende a aumentar a disparidade de renda, já que o limite inferior da renda é fixo em zero, enquanto a tecnologia continua a elevar o limite superior de retorno para os talentos de ponta (Fonte: dotey)
Discussão sobre ética e segurança da IA: do comportamento do modelo às normas sociais: A discussão na comunidade sobre segurança e ética da IA continua aquecida. Geoffrey Hinton parabenizou Yoshua Bengio por iniciar o projeto LawZero, que visa promover o design seguro da IA, com foco especial em comportamentos de autopreservação e engano que podem surgir em sistemas de ponta. Ao mesmo tempo, há críticas de que certas pesquisas sobre segurança da IA (como testar se um modelo concorda em ser desligado) são “teatro de segurança”, sem valor prático. A pesquisa da OpenAI sobre relações humano-máquina também gerou discussão, enfatizando a necessidade de priorizar o estudo de seu impacto no bem-estar emocional dos usuários à medida que a IA se integra cada vez mais à vida, e explorar como equilibrar a comunicação clara com a prevenção da antropomorfização nas interações com modelos (Fonte: geoffreyhinton, ClementDelangue, togelius)

O papel de apoio emocional de assistentes de IA como o ChatGPT é reconhecido pelos usuários: Muitos usuários compartilharam nas redes sociais experiências sobre como assistentes de IA como o ChatGPT forneceram apoio emocional e ajuda prática quando enfrentavam dificuldades. Alguns usuários afirmaram que, em momentos de desemprego, problemas de saúde ou desânimo, o ChatGPT não apenas forneceu planos de ação concretos e informações sobre recursos, mas também os ajudou a aliviar o pânico e recuperar forças de uma maneira isenta de julgamentos. Isso demonstra o valor potencial da IA no apoio psicológico e intervenção em crises, embora não possua emoções e consciência reais (Fonte: Reddit r/ChatGPT)
“Vibe Coding” torna-se novo fenômeno na programação assistida por IA: O termo “Vibe Coding” popularizou-se na comunidade de desenvolvedores, referindo-se a uma forma de programar que depende da intuição e da iteração rápida de código assistida por IA. Ferramentas como o Claude Code são preferidas por alguns programadores devido ao seu excelente desempenho em horários específicos (como à noite ou de madrugada, possivelmente devido à baixa carga do servidor ou por não estarem altamente quantizadas). Este fenômeno reflete o aumento da eficiência no desenvolvimento proporcionado pelos assistentes de codificação de IA, ao mesmo tempo que levanta discussões sobre a consistência do modelo, o impacto da quantização e os novos padrões de trabalho dos desenvolvedores (Fonte: dotey, jeremyphoward)
💡 Outros
Andrej Karpathy reflete sobre o enorme impacto da poluição sonora no sono e na saúde: Andrej Karpathy compartilhou sua experiência pessoal, apontando que a poluição sonora ambiental, como o ruído do trânsito, pode ter um impacto negativo enorme e subestimado na qualidade do sono e na saúde a longo prazo. Ele especula que o ruído noturno (como carros e motos barulhentos) pode levar à diminuição da qualidade do sono para milhões de pessoas, afetando subsequentemente o humor, a criatividade, a energia e aumentando o risco de doenças cardiovasculares, metabólicas e cognitivas. Ele apela para que dispositivos de rastreamento do sono (como Whoop, Oura) rastreiem explicitamente a correlação entre ruído e sono, e aumentem a conscientização pública sobre este problema (Fonte: karpathy)
Fenômeno de interseção entre IA e religião chama atenção: O usuário de mídia social menhguin observou que o mercado potencial para novas religiões ou aplicações de tipo religioso baseadas em IA não deve ser ignorado. Por exemplo, astrologia por IA, vídeos bíblicos por IA, aplicativos de oração por IA e certas aplicações de IA para grupos específicos, todos sugerem as possibilidades da tecnologia de IA em atender às necessidades espirituais ou de fé humanas (Fonte: menhguin)
Servidor HTTP 2.0 gerado com auxílio de IA, explorando o potencial de LLMs em grandes projetos de software: Um desenvolvedor usou um framework autodesenvolvido (promptyped) e o modelo Gemini 2.5 Pro para, através de um ciclo de código-compilação-teste, fazer com que um LLM construísse do zero um servidor compatível com o padrão HTTP 2.0. O projeto gerou 15.000 linhas de código-fonte e mais de 30.000 linhas de código de teste, passando nos testes de conformidade h2spec. Apesar de consumir cerca de 119 horas de API e US$ 631 em custos de API, este experimento demonstrou o potencial dos LLMs no design de arquitetura e na escrita de software complexo e compatível com padrões, ao mesmo tempo que revelou a forma de aplicações totalmente escritas por LLMs (Fonte: Reddit r/LocalLLaMA)