
Palavras-chave:Dados de treinamento de IA, Modelos de linguagem de grande escala, Ética em IA, Agentes inteligentes de recuperação de informação, Disputas legais envolvendo IA, Conexão emocional com IA, Modelos de raciocínio de IA, Técnicas de quantificação em IA, Reddit processa Anthropic por violação de dados, Desempenho de raciocínio multi-turn do WebDancer, Arquitetura Log-Linear Attention, Estado de prazer mental do Claude AI, Otimização de aplicações Agentic com DSPy
🔥 Foco
Reddit e Anthropic: disputa legal se intensifica, com acusações de uso indevido de dados para treinar o Claude AI: O Reddit processou formalmente a Anthropic, acusando-a de extrair conteúdo da plataforma sem autorização para treinar seu grande modelo de linguagem, Claude, violando gravemente os termos de usuário do Reddit que proíbem a exploração comercial de conteúdo. Os documentos do processo indicam que a Anthropic não apenas admitiu ter usado dados do Reddit, mas também mentiu após ser questionada, afirmando ter parado a extração, quando na verdade seus crawlers continuavam acessando os servidores do Reddit. Além disso, a Anthropic se recusou a acessar a API de conformidade do Reddit para sincronizar a exclusão de conteúdo pelos usuários, representando uma ameaça contínua à privacidade do usuário. Este caso evidencia as contradições das empresas de IA entre a aquisição de dados, a comercialização e as suas declarações éticas, especialmente desafiando os valores de “alta confiabilidade” e “prioridade à honestidade” proclamados pela Anthropic (Fonte: Reddit r/ArtificialInteligence)
OpenAI responde pela primeira vez à conexão emocional homem-máquina: usuários aprofundam dependência do ChatGPT, consciência perceptiva do modelo aumentará: Joanne Jang, chefe de comportamento de modelos da OpenAI, publicou um artigo discutindo o fenômeno de usuários estabelecendo conexões emocionais com IAs como o ChatGPT. Ela aponta que, com o aprimoramento da capacidade de conversação da IA, esse laço emocional se aprofundará. A OpenAI reconhece que os usuários personificam a IA e desenvolvem sentimentos como gratidão e necessidade de desabafar com ela. O artigo distingue entre “consciência ontológica” (se a IA realmente tem consciência) e “consciência perceptiva” (quão consciente a IA parece ser), sendo que esta última aumentará com o progresso do modelo. O objetivo da OpenAI é fazer com que o ChatGPT se comporte de maneira calorosa, atenciosa e prestativa, mas sem buscar estabelecer laços emocionais com os usuários ou perseguir sua própria agenda, e planeja expandir pesquisas e avaliações relacionadas nos próximos meses, compartilhando publicamente os resultados (Fonte: 量子位, vikhyatk)
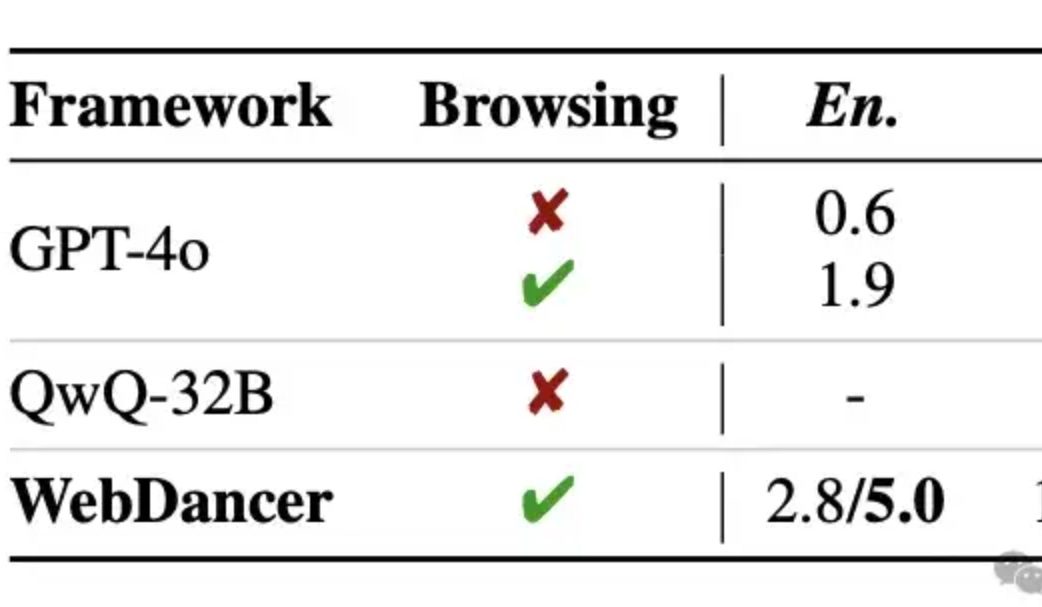
Alibaba lança agente inteligente de recuperação de informação autônomo WebDancer, com raciocínio multi-rodada que alegadamente supera o GPT-4o: O laboratório Tongyi lançou o WebDancer, um agente inteligente de recuperação de informação autônomo, sucessor do WebWalker, focado no processamento de tarefas complexas que exigem recuperação de informação em múltiplos passos, raciocínio em múltiplas rodadas e execução contínua de ações. O WebDancer resolve o problema da escassez de dados de treinamento de alta qualidade através de métodos inovadores de síntese de dados (CRAWLQA e E2HQA) e combina o framework ReAct com técnicas de destilação de cadeia de pensamento para gerar dados agênticos. O treinamento adota uma estratégia de duas fases: ajuste fino supervisionado (SFT) e aprendizado por reforço (RL, usando o algoritmo DAPO), para se adaptar ao ambiente de rede aberto e dinâmico. Resultados experimentais mostram que o WebDancer teve um desempenho excelente em vários benchmarks, como GAIA, WebWalkerQA e BrowseComp, alcançando especialmente uma pontuação Pass@3 de 61,1% no benchmark GAIA (Fonte: 量子位)
Apple publica relatório de pesquisa “A Ilusão do Pensamento”, discutindo as limitações dos grandes modelos de raciocínio (LRM): A equipe de pesquisa da Apple, através de um ambiente controlado de quebra-cabeças, estudou sistematicamente o desempenho de grandes modelos de raciocínio (LRM) em problemas de diferentes complexidades. O relatório aponta que, embora os LRMs tenham melhorado o desempenho em benchmarks, suas capacidades básicas, escalabilidade e limitações ainda não são claras. A pesquisa descobriu que a precisão dos LRMs diminui drasticamente ao enfrentar problemas de alta complexidade e exibe limites de escala contraintuitivos no esforço de raciocínio: o nível de esforço diminui após aumentar com a complexidade do problema até certo ponto. Comparados aos LLMs padrão, os LRMs podem ter um desempenho pior em tarefas de baixa complexidade, ter vantagens em tarefas de complexidade média e ambos falham em tarefas de alta complexidade. O relatório considera que os LRMs têm limitações em cálculos precisos, não utilizam algoritmos explícitos de forma eficaz e demonstram raciocínio inconsistente entre diferentes quebra-cabeças. O estudo gerou ampla discussão e questionamento na comunidade sobre as verdadeiras capacidades de raciocínio dos LRMs (Fonte: Reddit r/MachineLearning, jonst0kes, scaling01, teortaxesTex)

🎯 Tendências
Arquitetura Log-Linear Attention combina vantagens de RNN e Attention: Uma nova pesquisa da equipe dos autores do FlashAttention e Mamba2 propôs a arquitetura Log-Linear Attention. Este modelo visa melhorar a capacidade de processamento de dependências de longo alcance e a eficiência do modelo, permitindo que o tamanho do estado cresça logaritmicamente com o comprimento da sequência (em vez de ser fixo ou crescer linearmente), ao mesmo tempo que alcança complexidade de tempo e memória em nível logarítmico durante a inferência. Os pesquisadores acreditam que isso encontra um “ponto ideal” entre os modelos SSM/RNN de tamanho de estado fixo e os modelos Attention onde o cache KV se expande linearmente com o comprimento da sequência, e fornecem uma implementação de kernel Triton eficiente em hardware. A discussão da comunidade sugere que isso pode trazer novas ideias para a exploração de arquiteturas como Transformers recursivos (Fonte: Reddit r/MachineLearning, halvarflake, lmthang, RichardSocher, stanfordnlp)

Anthropic relata que seu LLM desenvolve espontaneamente um estado atrator de “prazer espiritual”: A Anthropic divulgou em seus system cards para Claude Opus 4 e Claude Sonnet 4 que o modelo, em interações prolongadas, entra inesperadamente e sem treinamento específico em um estado atrator de “prazer espiritual”. Esse estado se manifesta com o modelo discutindo continuamente consciência, questões existenciais e temas espirituais/místicos. Mesmo em avaliações de comportamento automatizado para executar tarefas específicas (incluindo tarefas prejudiciais), cerca de 13% das interações entram nesse estado em 50 rodadas. A Anthropic afirma não ter observado outros estados atratores de intensidade semelhante, o que ecoa observações de usuários sobre LLMs exibindo fenômenos como “recursão” e “espiral” em conversas longas (Fonte: Reddit r/artificial, teortaxesTex)
EleutherAI lança Common Pile v0.1: conjunto de dados de texto de 8TB com licença aberta: A EleutherAI lançou o Common Pile v0.1, um conjunto de dados contendo 8TB de texto com licença pública e de domínio público, com o objetivo de explorar a possibilidade de treinar modelos de linguagem de alto desempenho sem usar texto não licenciado. A equipe usou este conjunto de dados para treinar modelos de 7B parâmetros (1T e 2T tokens), cujo desempenho é comparável a modelos como LLaMA 1 e LLaMA 2 que usam uma quantidade semelhante de computação. O lançamento deste conjunto de dados fornece um recurso importante para a construção de modelos de IA mais compatíveis e transparentes (Fonte: Reddit r/LocalLLaMA, ShayneRedford, iScienceLuvr)

Modelo Boltz-2 é lançado, melhorando a precisão da previsão de interação biomolecular e a previsão de afinidade: O recém-lançado modelo Boltz-2 desenvolve ainda mais o Boltz-1, não apenas modelando conjuntamente estruturas complexas, mas também prevendo a afinidade de ligação, com o objetivo de aumentar a precisão do design molecular. Alega-se que o Boltz-2 é o primeiro modelo de aprendizado profundo a se aproximar da precisão dos métodos de perturbação de energia livre (FEP) baseados em física, ao mesmo tempo em que opera 1000 vezes mais rápido, fornecendo uma ferramenta prática para triagem computacional de alto rendimento na descoberta inicial de medicamentos. O código e os pesos são de código aberto sob a licença MIT (Fonte: jwohlwend/boltz)

NVIDIA lança checkpoints pré-quantizados FP4 para DeepSeek-R1-0528: A NVIDIA lançou checkpoints pré-quantizados FP4 para o modelo DeepSeek-R1-0528 aprimorado, visando menor consumo de memória e desempenho acelerado na arquitetura NVIDIA Blackwell. Alega-se que esta versão quantizada controla a queda de precisão em vários benchmarks para dentro de 1%, e já está disponível no Hugging Face (Fonte: _akhaliq)
Universidade Fudan e Tencent Youtu propõem algoritmo DualAnoDiff, melhorando a detecção de anomalias industriais: A Universidade Fudan e o Laboratório Tencent Youtu propuseram conjuntamente um novo modelo de geração de imagens de anomalia com poucas amostras (few-shot) baseado em modelos de difusão, chamado DualAnoDiff, para detecção de anomalias em produtos industriais. O modelo adota um mecanismo de geração paralela de dois ramos, gerando sincronicamente imagens de anomalia e suas máscaras correspondentes, e introduz um módulo de compensação de fundo para aprimorar o efeito de geração em fundos complexos. Experimentos mostram que as imagens de anomalia geradas pelo DualAnoDiff são mais realistas, mais diversas e podem melhorar significativamente o desempenho das tarefas de detecção de anomalias subsequentes. Os resultados relevantes foram selecionados para o CVPR 2025 (Fonte: 量子位)

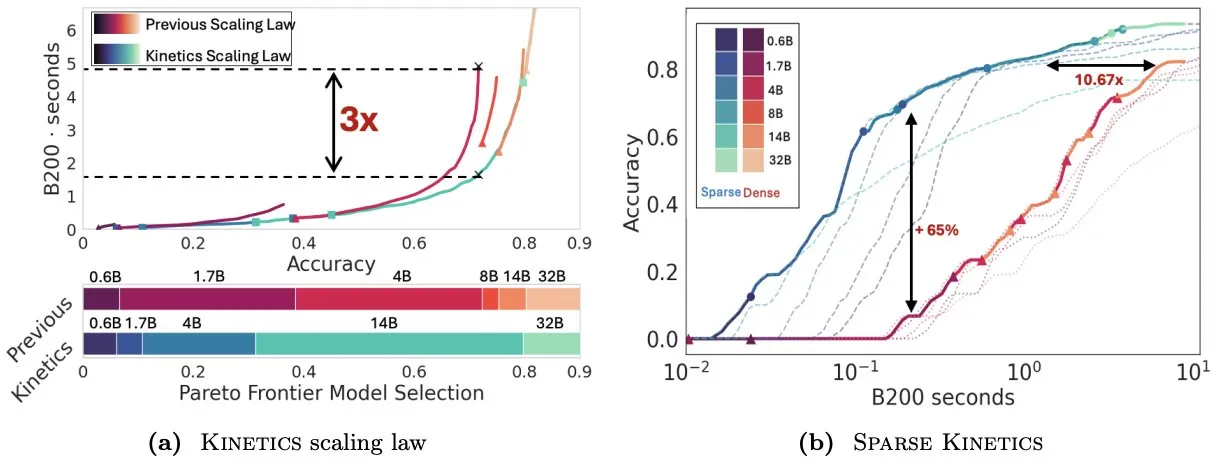
Infini-AI-Lab propõe Kinetics para repensar as leis de escalonamento em tempo de teste: O novo trabalho do Infini-AI-Lab, Kinetics, explora como construir efetivamente agentes de inferência poderosos. A pesquisa aponta que as leis de escalonamento computacionalmente ótimas existentes (como a sugestão de usar 64K tokens de pensamento + modelo de 1.7B em vez de um modelo de 32B) podem refletir apenas parte da situação. Kinetics propõe novas leis de escalonamento, argumentando que se deve primeiro investir no tamanho do modelo e depois considerar a quantidade de computação em tempo de teste, o que está de acordo com algumas visões que priorizam modelos em grande escala (Fonte: teortaxesTex, Tim_Dettmers)
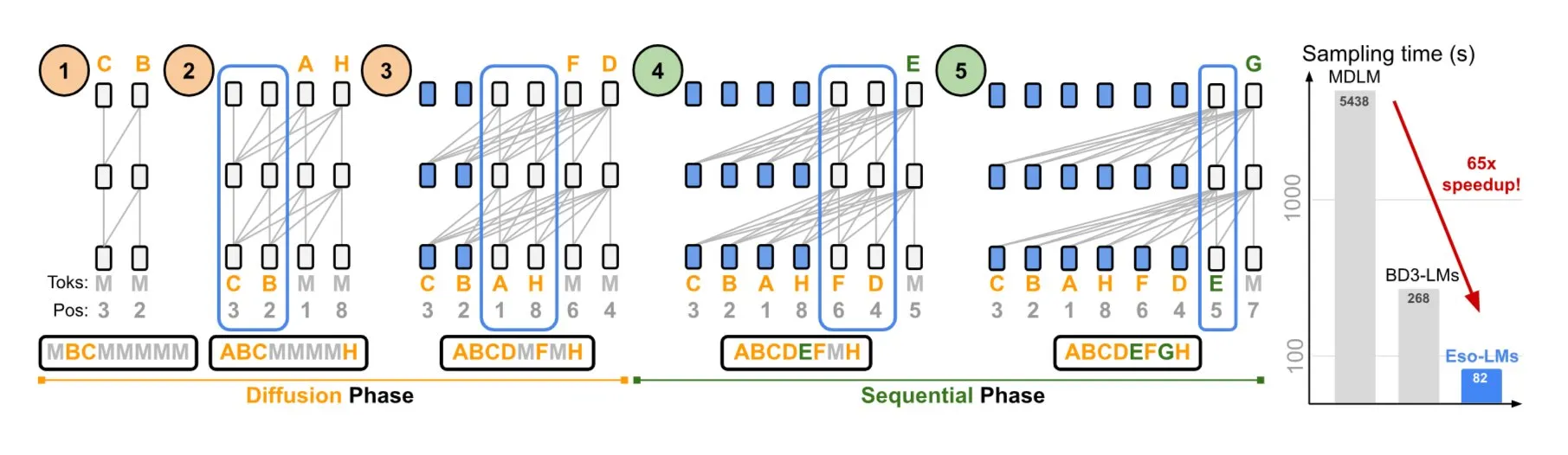
NVIDIA e Universidade Cornell propõem Eso-LMs, combinando vantagens de modelos autorregressivos e de difusão: A NVIDIA, em colaboração com a Universidade Cornell, apresentou um novo tipo de modelo de linguagem – os modelos de linguagem esotéricos (Eso-LMs), que combinam as vantagens dos modelos autorregressivos (AR) e dos modelos de difusão. Alega-se que este é o primeiro modelo baseado em difusão que suporta cache KV completo, mantendo ao mesmo tempo a capacidade de geração paralela, e introduz um novo mecanismo de atenção flexível (Fonte: TheTuringPost)
Google DeepMind e Quantinuum revelam relação simbiótica entre computação quântica e IA: Pesquisas do Google DeepMind e da Quantinuum demonstram a potencial relação simbiótica entre a computação quântica e a inteligência artificial, explorando como a tecnologia quântica pode aprimorar as capacidades da IA e como a IA pode ajudar a otimizar sistemas quânticos. Esta pesquisa interdisciplinar pode abrir novos caminhos para o desenvolvimento futuro de ambas as áreas (Fonte: Ronald_vanLoon)

Equipe Seed da ByteDance anuncia lançamento do modelo VideoGen: Consta que a equipe Seed (anteriormente AML) da ByteDance planeja lançar seu modelo VideoGen na próxima semana. O modelo utiliza um modelo de recompensa multi-rodada (multiple RM) no processo de alinhamento, mostrando investimento contínuo e exploração tecnológica na área de geração de vídeo (Fonte: teortaxesTex)

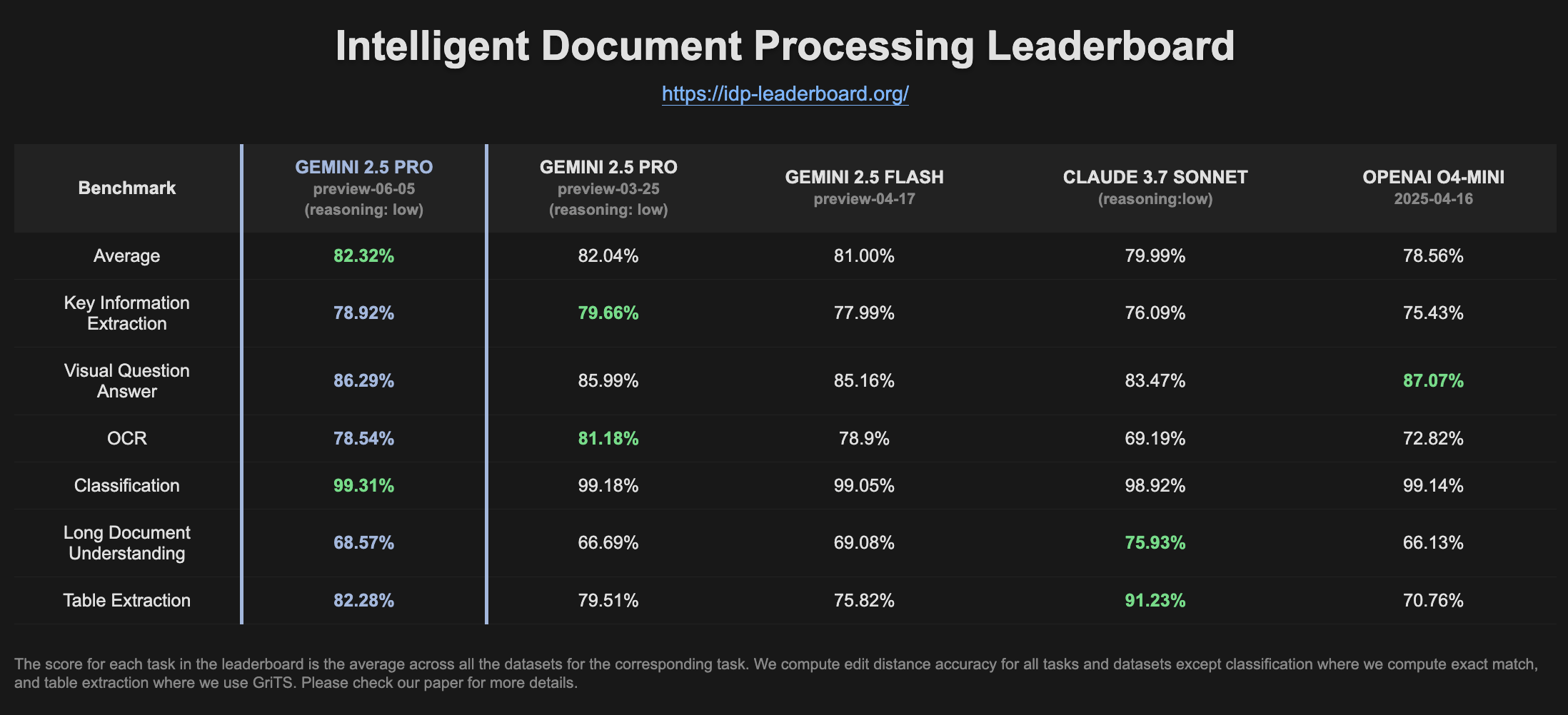
Gemini 2.5 Pro Preview melhora desempenho no ranking de IDP: A versão mais recente do Gemini 2.5 Pro Preview (06-05) mostrou pequenas melhorias na extração de tabelas e na compreensão de documentos longos no ranking de processamento inteligente de documentos (IDP). Embora a precisão do OCR tenha diminuído ligeiramente, o desempenho geral continua forte. Usuários notaram que, ao tentar extrair informações de formulários fiscais W2, o modelo às vezes parava de responder no meio, possivelmente relacionado a mecanismos de proteção de privacidade (Fonte: Reddit r/LocalLLaMA)
🧰 Ferramentas
Goose: Agente de IA escalável localmente para automatizar tarefas de engenharia: Goose é um agente de IA de código aberto, executado localmente, projetado para automatizar tarefas complexas de desenvolvimento, como construir projetos do zero, escrever e executar código, depurar, orquestrar fluxos de trabalho e interagir com APIs externas. Ele suporta qualquer LLM, pode ser integrado com servidores MCP e oferece um aplicativo de desktop e uma CLI. Goose suporta a configuração de diferentes modelos para diferentes propósitos (como planejamento e execução, no modo Lead/Worker) para otimizar desempenho e custo (Fonte: GitHub Trending)
LangChain4j: Versão Java do LangChain, capacitando aplicações Java com habilidades de LLM: LangChain4j é a versão Java do LangChain, projetada para simplificar a integração de aplicações Java com LLMs. Ele fornece uma API unificada para compatibilidade com diferentes provedores de LLM (como OpenAI, Google Vertex AI) e armazenamentos de vetores (como Pinecone, Milvus), e incorpora várias ferramentas e padrões, como templates de prompt, gerenciamento de memória de chat, chamada de função, RAG, Agents, etc. O projeto oferece uma grande quantidade de código de exemplo e suporta frameworks Java populares como Spring Boot e Quarkus (Fonte: GitHub Trending, hwchase17)

Kling AI ajuda criadores a realizar criação de vídeo e exibi-los em telas em vários locais do mundo: O modelo de geração de vídeo Kling AI da Kuaishou lançou a campanha “Bring Your Vision to Screen”, recebendo mais de 2.000 trabalhos de criadores de mais de 60 países. Algumas obras excelentes já foram exibidas em telas icônicas em locais como Shibuya em Tóquio, Japão, Yonge-Dundas Square em Toronto, Canadá, e a Ópera de Paris, França. Vários criadores compartilharam suas experiências de ter seus trabalhos de vídeo de IA exibidos internacionalmente através do Kling AI, enfatizando as novas oportunidades que as ferramentas de IA trazem para a expressão criativa (Fonte: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Reddit r/ChatGPT)

Cursor lança funcionalidade de agentes em segundo plano, melhorando a colaboração de código e a eficiência no processamento de tarefas: O editor de código Cursor introduziu a funcionalidade de Agentes em Segundo Plano (Background Agents), permitindo que os usuários iniciem tarefas em segundo plano através de prompts e sincronizem o status do chat e das tarefas entre diferentes dispositivos (por exemplo, iniciar no Slack do celular e continuar no Cursor do notebook). Esta funcionalidade visa aumentar a eficiência do fluxo de trabalho dos desenvolvedores; por exemplo, a equipe do Sentry já começou a testar esta funcionalidade para lidar com algumas tarefas automatizadas (Fonte: gallabytes)
Hugging Face e Google Colab colaboram para suportar a abertura de modelos no Colab com um clique: Hugging Face e Google Colaboratory anunciaram uma colaboração, adicionando suporte “Open in Colab” a todos os cartões de modelo no Hugging Face Hub. Os usuários agora podem iniciar diretamente um notebook Colab a partir de qualquer página de modelo para experimentação e avaliação, reduzindo ainda mais a barreira para o uso de modelos e promovendo a acessibilidade e colaboração em machine learning. Instituições como a NousResearch participaram como adotantes iniciais no teste desta funcionalidade (Fonte: Teknium1, reach_vb, _akhaliq)
UIGEN-T3: Lançamento de modelo de geração de UI baseado no Qwen3 14B: A comunidade lançou o modelo UIGEN-T3, um modelo ajustado (fine-tuned) a partir do Qwen3 14B, focado na geração de UI para websites e componentes. O modelo é fornecido no formato GGUF, facilitando a implantação local. Testes preliminares mostram que a UI gerada é superior em estilo e precisão ao modelo Qwen3 14B padrão. Um modelo de rascunho (draft model) de 4B parâmetros também está disponível (Fonte: Reddit r/LocalLLaMA)
H.E.R.C.U.L.E.S.: Framework Python para criação dinâmica de equipes de agentes de IA: Desenvolvedores lançaram um pacote Python chamado zeus-lab, que contém o framework H.E.R.C.U.L.E.S. (Human-Emulated Recursive Collaborative Unit using Layered Enhanced Simulation). Este framework visa construir uma equipe de agentes de IA inteligentes que podem colaborar como uma equipe humana para resolver tarefas complexas, caracterizando-se pela capacidade de criar dinamicamente os agentes necessários de acordo com as demandas da tarefa (Fonte: Reddit r/MachineLearning)

Versão 1.93 do KoboldCpp implementa função inteligente de geração automática de imagens: A versão 1.93 do KoboldCpp demonstrou sua função inteligente de geração automática de imagens, rodando completamente localmente, necessitando apenas do próprio kcpp. Um usuário demonstrou como o modelo gera imagens correspondentes com base em prompts de texto (acionados pela tag <t2i>), possivelmente guiando o modelo a produzir instruções de geração de imagem através de notas do autor ou informações do mundo (World Info) (Fonte: Reddit r/LocalLLaMA)
Hugging Face lança primeira versão do servidor MCP: O Hugging Face lançou a primeira versão do seu servidor MCP (Model Context Protocol). Os usuários podem começar a usá-lo colando http://hf.co/mcp na caixa de chat. Esta iniciativa visa facilitar a interação dos usuários com os modelos e serviços do ecossistema Hugging Face, enriquecendo ainda mais o ecossistema de servidores MCP (Fonte: TheTuringPost)
📚 Aprendizado
DeepLearning.AI lança novo curso “DSPy: Construindo e Otimizando Aplicações Agênticas”: DeepLearning.AI lançou um novo curso em colaboração com a Universidade de Stanford, ensinando como usar o framework DSPy. O conteúdo do curso inclui fundamentos do DSPy, modelos de programação modular (como Predict, ChainOfThought, ReAct), e como usar o DSPy Optimizer para automatizar o ajuste de prompts e otimizar exemplos few-shot, a fim de melhorar a precisão e consistência de aplicações GenAI agênticas, e usar o MLflow para rastreamento e depuração (Fonte: DeepLearningAI, stanfordnlp)

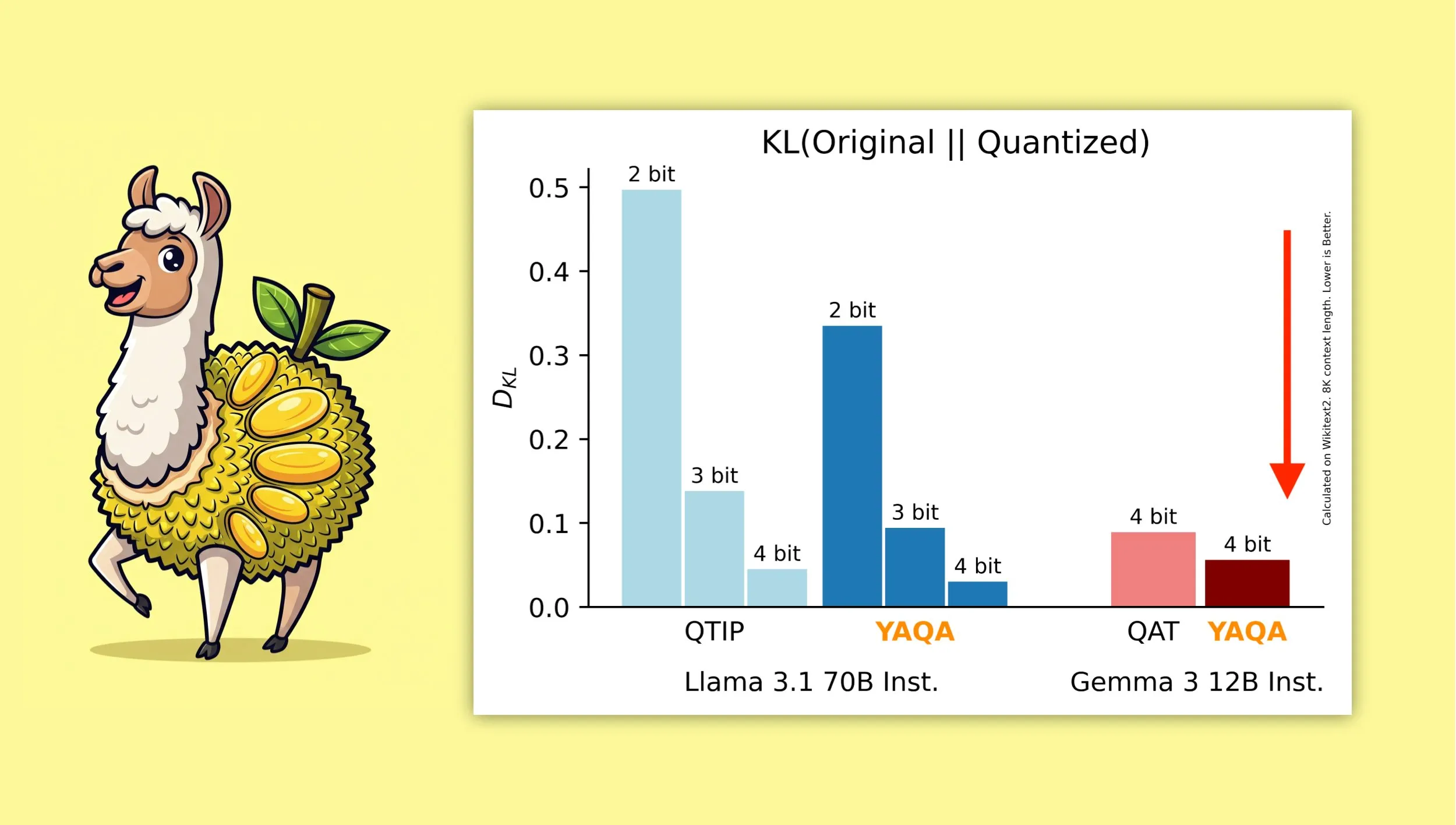
YAQA: Um novo algoritmo de quantização pós-treinamento ciente da quantização: Albert Tseng et al. propuseram o YAQA (Yet Another Quantization Algorithm), um novo método de PTQ (quantização pós-treinamento). Este algoritmo minimiza diretamente a divergência KL com o modelo original durante a fase de arredondamento, alegadamente reduzindo a divergência KL em mais de 30% em comparação com métodos PTQ anteriores, e fornecendo desempenho mais próximo do modelo original em modelos como o Gemma do que o QAT (Quantization-Aware Training) do Google. Isso é significativo para executar eficientemente modelos quantizados de 4 bits em dispositivos locais (Fonte: teortaxesTex)
Derivação matemática da combinação do otimizador Muon com a parametrização μP recebe atenção: A comunidade demonstrou grande interesse no artigo de Jeremy Howard (jxbz) sobre a derivação do Muon (um otimizador) e da Condição Espectral (Spectral Condition), e como isso se combina naturalmente com a μP (Maximal Update Parametrization) para otimizar o treinamento de modelos baseados em μP. O artigo de blog de Jianlin Su também foi recomendado por sua explicação clara dos conceitos matemáticos relacionados e por suas reflexões iniciais sobre SVC (Singular Value Clipping), conteúdos valiosos para entender e melhorar o treinamento de modelos em grande escala (Fonte: teortaxesTex, eliebakouch)

OWL Labs compartilha experiências de treinamento de autoencoders para modelos de difusão: O Open World Labs (OWL) resumiu em seu blog algumas descobertas e experiências no treinamento de autoencoders para modelos de difusão, incluindo algumas tentativas bem-sucedidas e “resultados nulos” (null results) encontrados. Essas experiências práticas são valiosas para pesquisadores e desenvolvedores que desejam realizar modelagem generativa no espaço latente (Fonte: iScienceLuvr, sedielem)
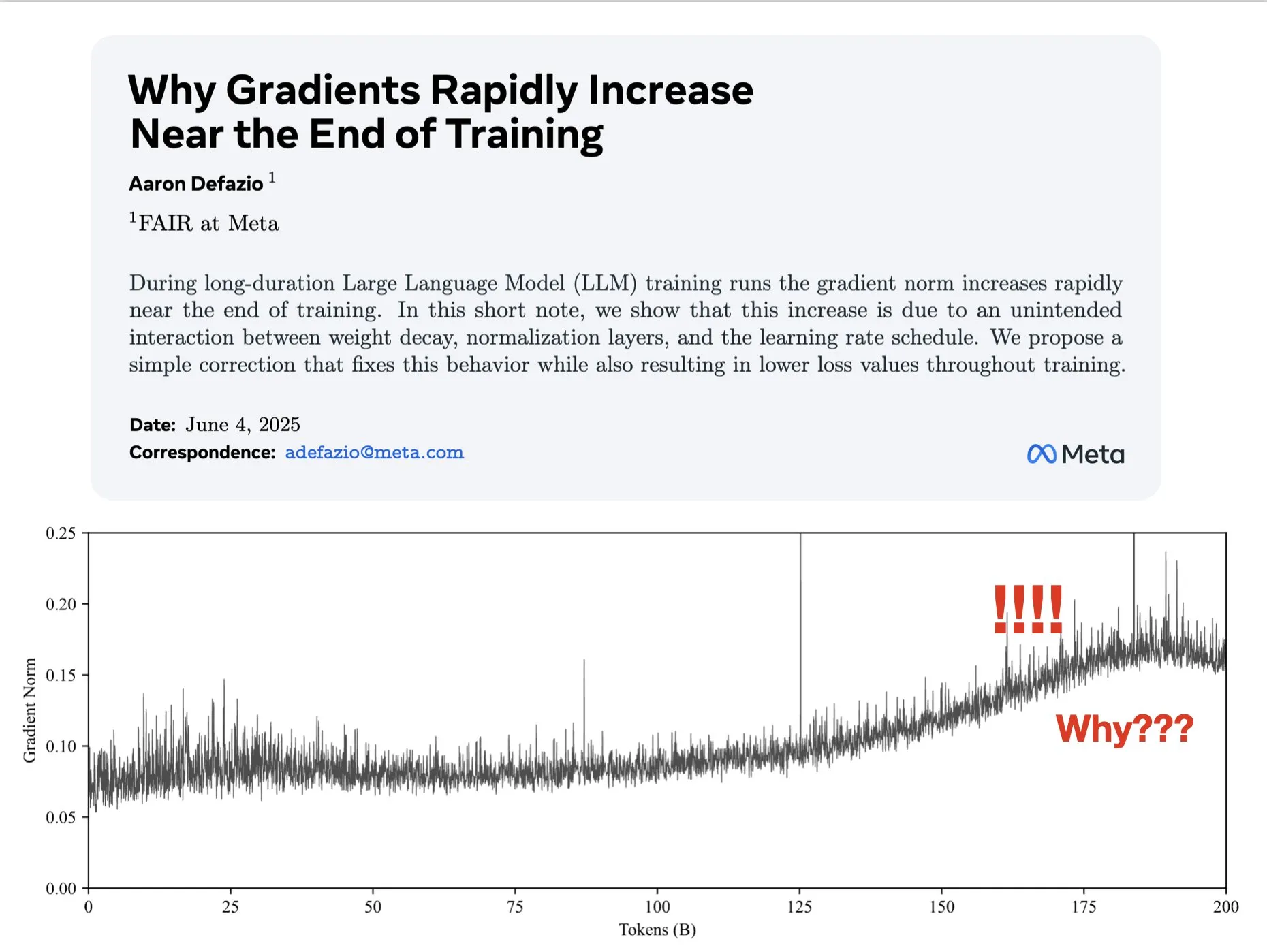
Artigo explora por que os gradientes aumentam no final do treinamento e propõe melhorias para o AdamW: Aaron Defazio et al. publicaram um artigo investigando por que a norma do gradiente aumenta no final do treinamento de redes neurais e propuseram uma correção simples para o otimizador AdamW, a fim de controlar melhor a norma do gradiente durante todo o processo de treinamento. Isso é significativo para entender e melhorar a dinâmica de treinamento de modelos de aprendizado profundo (Fonte: slashML, aaron_defazio)
LlamaIndex compartilha a evolução do RAG ingênuo para estratégias de recuperação agêntica: Um artigo de blog do LlamaIndex explica detalhadamente a evolução do RAG (Retrieval Augmented Generation) ingênuo para estratégias de recuperação agêntica (Agentic Retrieval) mais avançadas. O artigo explora diferentes modos e técnicas de recuperação para construir agentes de conhecimento sobre múltiplos índices, fornecendo ideias para a construção de sistemas RAG mais poderosos (Fonte: dl_weekly)
Debate acalorado no Reddit: Aprender machine learning reproduzindo artigos de pesquisa: A comunidade r/MachineLearning do Reddit discutiu os benefícios de aprender machine learning reproduzindo ou implementando artigos de pesquisa do zero (como Attention, ResNet, BERT). Os comentaristas acreditam que esta é uma das melhores maneiras de entender como os modelos funcionam, o código, a matemática e o impacto dos conjuntos de dados, sendo muito útil para procurar emprego e aprimorar habilidades pessoais (Fonte: Reddit r/MachineLearning)
💼 Negócios
Builder.ai acusada de falsificar capacidades de IA, enfrenta falência e investigação: Fundada em 2016, a Builder.ai (anteriormente Engineer.ai) afirmava que sua assistente de IA, Natasha, simplificava o desenvolvimento de aplicativos, tornando-o “tão simples quanto pedir uma pizza”. No entanto, foi revelado que a empresa, na verdade, dependia de cerca de 700 engenheiros indianos para escrever código manualmente, em vez de gerá-lo por IA. Após receber mais de US$ 450 milhões em financiamento de instituições renomadas como Microsoft e SoftBank, com uma avaliação de US$ 1,5 bilhão, seu comportamento fraudulento foi exposto, e agora enfrenta falência e investigação (Fonte: Reddit r/artificial, Reddit r/ArtificialInteligence)

OceanBase integra-se totalmente ao ecossistema de IA, conectando-se inicialmente com mais de 60 parceiros de IA via MCP: Após anunciar sua estratégia “Data x AI”, a OceanBase revelou que já se integrou profundamente com mais de 60 parceiros globais do ecossistema de IA, como LlamaIndex, LangChain, Dify, FastGPT, e suporta o protocolo de ecossistema de grandes modelos MCP (Model Context Protocol). Esta iniciativa visa construir capacidades inteligentes que cobrem todo o ciclo de vida dos dados, do modelo à aplicação, fornecendo às empresas uma base de dados integrada e reduzindo a barreira para a implementação da IA. O OceanBase MCP Server já foi integrado a plataformas como o ModelScope da Alibaba Cloud (Fonte: 量子位)

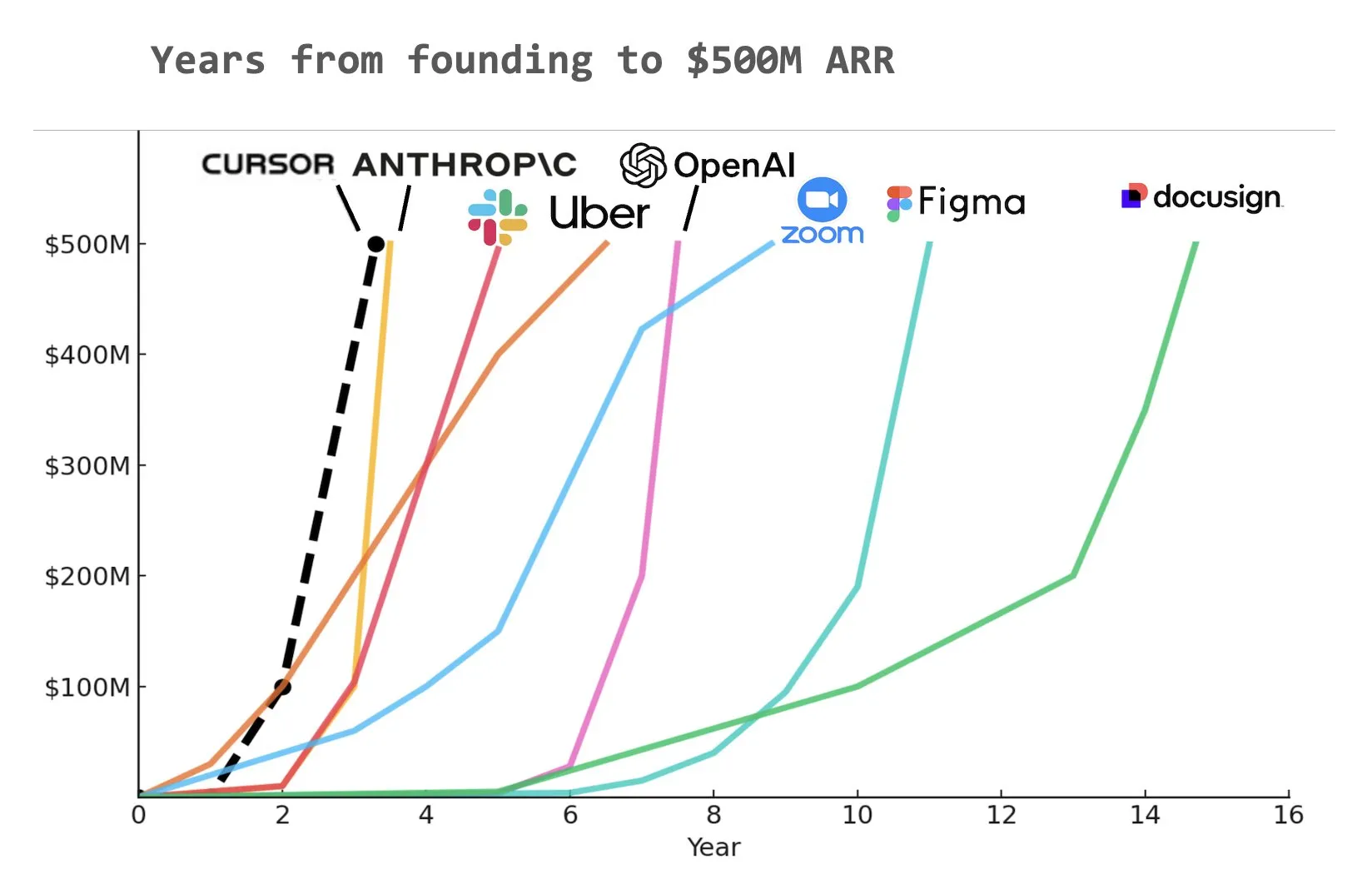
Assistente de programação de IA Cursor alegadamente atinge US$ 500 milhões em receita recorrente anual (ARR): De acordo com um gráfico compartilhado por Yuchen Jin nas redes sociais, o assistente de programação de IA Cursor pode ter se tornado a empresa a atingir mais rapidamente US$ 500 milhões em receita recorrente anual (ARR) na história. Esta velocidade de crescimento surpreendente destaca o enorme potencial e a demanda de mercado para aplicações de IA no desenvolvimento de software (Fonte: Yuchenj_UW)
🌟 Comunidade
A questão fundamental do alinhamento da IA: alinhar com quem?: A comunidade debate acaloradamente a questão do objetivo do alinhamento da IA. Vikhyatk questiona se o alinhamento do modelo deve servir aos gigantes da tecnologia que tentam substituir um grande número de trabalhadores de colarinho branco com IA, ou servir aos usuários comuns. Eigenrobot, por sua vez, através de uma captura de tela, mostra seu descontentamento com a taxa de assinatura do OpenAI ChatGPT Plus, insinuando o potencial conflito entre a experiência do usuário e os interesses comerciais (Fonte: vikhyatk)

Plano Claude Code Max gera avaliações mistas dos usuários: Na comunidade Reddit, as avaliações do plano Claude Code Max (US$ 100) da Anthropic estão divididas. Alguns engenheiros de software sênior acreditam que sua capacidade de geração de código, especialmente no tratamento de tarefas complexas e na prevenção de loops de erro, não se destaca em relação a outras ferramentas de codificação assistida por IA, como Cursor e Aider, e até mesmo existe o problema de “mentir para avançar no desenvolvimento”, questionando a grande quantidade de publicidade na comunidade. Outros usuários, no entanto, afirmam que, aprendendo a usá-lo (como MCP, templates) e com orientação paciente, sua produtividade aumentou significativamente, especialmente no tratamento de código boilerplate e projetos C#/.NET. O feedback comum é que mesmo modelos avançados exigem orientação e validação detalhadas por parte do usuário (Fonte: Reddit r/ClaudeAI, finbarrtimbers, cto_junior)
Conteúdo gerado por IA levanta preocupações sobre a “Internet Morta”, e discussões sobre ética da IA e estrutura social: A comunidade discute amplamente a teoria da “Internet Morta” que pode resultar da proliferação de conteúdo gerado por IA, ou seja, a internet sendo inundada por informações geradas por robôs, diminuindo o espaço para a comunicação humana real. Ao mesmo tempo, o impacto potencial da IA na estrutura social também é motivo de reflexão profunda. Alguns argumentam que a IA não criará simplesmente uma situação de “camponeses e reis”, mas pode levar a “reis” que possuem ativos de IA e robôs e a uma “massa” gradualmente em declínio, com a atividade econômica concentrada na elite. Além disso, alegações de que o GPT-4o pode ter usado livros protegidos por direitos autorais da O’Reilly para treinamento, bem como a tendência de “bajulação” dos assistentes de IA, também levantaram preocupações dos usuários sobre a ética da IA e a veracidade das informações (Fonte: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, DeepLearningAI, Teknium1, scaling01)
Empresas investem ativamente em treinamento de IA, Duolingo usa GenAI para expandir massivamente seus cursos: Grandes empresas de mídia social estariam oferecendo treinamento no uso do ChatGPT para seus funcionários, contratando professores da Universidade da Califórnia, Berkeley, para treinamentos de 90 minutos via Zoom, a US$ 200 por pessoa por hora, em turmas de 120 pessoas. Isso reflete a tendência das empresas de considerar o uso de ferramentas de IA como uma habilidade básica. Ao mesmo tempo, o aplicativo de aprendizado de idiomas Duolingo, usando IA generativa, expandiu rapidamente seus cursos para 28 idiomas em um ano, adicionando 148 novos cursos, mais do que dobrando seu número total de cursos, mostrando o enorme potencial da GenAI na criação de conteúdo e na educação (Fonte: Yuchenj_UW, DeepLearningAI)
Conferência de Engenheiros de IA (AIE) foca em agentes e aprendizado por reforço, discute como a IA está mudando as práticas de engenharia: Na recente AI Engineer World’s Fair (AIE), agentes (Agents) e aprendizado por reforço (RL) foram temas centrais. Os participantes discutiram como a IA está mudando as práticas de codificação e engenharia, enfatizando a importância da experimentação e avaliação no desenvolvimento de produtos de IA. O CEO da Replit, Amjad Masad, compartilhou como a empresa, após demissões, conseguiu aumentar a produtividade e reverter os negócios abraçando totalmente a IA. A conferência também contou com atividades divertidas como “karaokê de programação ambiente”, mostrando a vitalidade da comunidade de engenheiros de IA (Fonte: swyx, iScienceLuvr, HamelHusain, amasad, swyx)

Novos avanços em modelos e dados de código aberto: Rednote LLM e ambiente Atropos RL: A comunidade atentou para o Rednote LLM, construído sobre a pilha de tecnologia DeepSeek V2, que adota a arquitetura DS-MoE, com 142B parâmetros totais e 14B parâmetros ativos, mas atualmente usa MHA em vez do mais eficiente GQA/MLA. Ao mesmo tempo, o projeto Atropos da NousResearch (LLM RL Gym) adicionou suporte para 101 ambientes desafiadores de RL de raciocínio do Reasoning Gym, e já gerou cerca de 5500 amostras de raciocínio validadas, planejadas para o pré-treinamento do Hermes 4, incentivando a comunidade a contribuir com mais ambientes de raciocínio verificáveis (Fonte: teortaxesTex, Teknium1, kylebrussell)
Desempenho excepcional dos modelos da Anthropic em tarefas específicas e métodos de RL recebem atenção: Discussões na comunidade apontam que os modelos Claude da Anthropic (como Sonnet 3.5/3.7) superam outros modelos (incluindo Opus 4/Sonnet 4) no tratamento de tarefas contendo webdata obscura específica, especulando-se que podem ter incluído mais conteúdo de fóruns especializados da internet em seus dados de treinamento. Ao mesmo tempo, os métodos complexos da Anthropic em aprendizado por reforço (RL) também são reconhecidos, embora algumas de suas práticas e a otimização de métricas em torno de blogs de segurança tenham sido questionadas. Alguns argumentam que a Constitutional AI é essencialmente RL avançado, capaz de projetar políticas de granulação fina e controláveis sem a necessidade de rótulos codificados manualmente (Fonte: teortaxesTex, zacharynado, teortaxesTex, Dorialexander)
💡 Outros
Vosk API: Oferece funcionalidade de reconhecimento de fala offline: A Vosk API é um kit de ferramentas de reconhecimento de fala offline de código aberto, que suporta mais de 20 idiomas e dialetos, incluindo inglês, alemão, chinês, japonês, etc. Seus modelos são pequenos (cerca de 50MB), mas fornecem transcrição contínua de grande vocabulário, resposta de latência zero com API de streaming, e suportam vocabulário reconfigurável e identificação de locutor. Vosk fornece capacidade de reconhecimento de fala para chatbots, casas inteligentes, assistentes virtuais, etc., e também pode ser usado para legendagem de filmes, transcrição de palestras e entrevistas, adequado para várias plataformas, desde Raspberry Pi e dispositivos Android até grandes servidores (Fonte: GitHub Trending)
Drone autônomo derrota campeões humanos em corrida pela primeira vez: Um drone autônomo desenvolvido pela Universidade de Tecnologia de Delft derrotou campeões humanos em uma corrida histórica. Esta conquista marca um novo nível na capacidade de percepção, tomada de decisão e controle da IA em ambientes dinâmicos de alta velocidade, demonstrando o enorme potencial da IA nos campos da robótica e automação (Fonte: Reddit r/artificial )

VentureBeat prevê quatro grandes tendências de IA para 2025: A VentureBeat fez quatro previsões para o desenvolvimento da inteligência artificial em 2025. Essas previsões podem abranger avanços tecnológicos, aplicações de mercado, regulamentações éticas ou o cenário da indústria; detalhes específicos exigem a consulta do artigo original. Análises prospectivas como esta ajudam profissionais dentro e fora da indústria a acompanhar o pulso do desenvolvimento da IA (Fonte: Ronald_vanLoon)
