
Palavras-chave:modelo de IA, conjunto de dados, robô humanoide, Agente de IA, modelo de linguagem, aprendizado profundo, modelo de código aberto, otimização de inferência, conjunto de dados Common Pile v0.1, modelo de controle de ponta a ponta Helix, servidor Hugging Face MCP, atualização Gemini 2.5 Pro, mecanismo de atenção esparsa
🔥 Foco
EleutherAI lança Common Pile v0.1: conjunto de dados de texto de 8TB com licença aberta, desafiando o treino de modelos de linguagem com dados não autorizados : A EleutherAI, em colaboração com várias instituições, lançou o Common Pile v0.1, um vasto conjunto de dados que contém 8TB de texto com licença aberta e de domínio público, com o objetivo de explorar a viabilidade de treinar modelos de linguagem de alto desempenho sem o uso de texto não autorizado. A equipa utilizou este conjunto de dados para treinar modelos de 7B parâmetros (1T e 2T tokens), cujo desempenho é comparável a modelos semelhantes como o LLaMA 1 e o LLaMA 2. Este conjunto de dados inclui metadados ao nível do documento, como atribuição de autor, detalhes da licença e links para as cópias originais, fornecendo aos investigadores uma fonte de dados transparente e em conformidade. Esta iniciativa é de grande importância para promover o desenvolvimento de modelos de IA abertos e em conformidade, e oferece novas perspetivas para resolver questões de direitos de autor em dados de treino de IA (Fonte: EleutherAI, percyliang, BlancheMinerva, code_star, ShayneRedford, Tim_Dettmers, jeremyphoward, stanfordnlp, ClementDelangue, tri_dao, andersonbcdefg)

Robô humanoide da Figure, impulsionado pelo modelo Helix, demonstra capacidade de triagem de encomendas a alta velocidade, gerando atenção : Brett Adcock, CEO da Figure, demonstrou os mais recentes progressos do seu robô humanoide na triagem de encomendas em cenários logísticos, impulsionado pelo modelo de controlo universal end-to-end Helix. O vídeo mostra o robô a manusear diferentes tipos de encomendas (caixas de cartão rígido, embalagens de plástico) com velocidade e precisão próximas às humanas, incluindo a organização das encomendas e a garantia de que os códigos de barras estão virados para baixo para digitalização. Esta capacidade realça a generalização e flexibilidade do modelo Helix em ambientes complexos e dinâmicos, contrastando com a demonstração anterior de trabalho em prensas de estampagem (que enfatizava precisão e alta velocidade). Os robôs da Figure já alcançaram turnos de trabalho contínuos de 20 horas na linha de produção da BMW, demonstrando o seu potencial em aplicações industriais. Adcock enfatizou que, no campo dos robôs humanoides, construir o robô mais inteligente e de menor custo será crucial para vencer no mercado, pois mais robôs implementados significam custos mais baixos, mais dados de treino e um modelo Helix mais inteligente (Fonte: dotey, _philschmid, adcock_brett, 量子位)

Hugging Face lança o primeiro servidor MCP oficial, criando uma plataforma de colaboração para AI Agents : A Hugging Face lançou o seu primeiro servidor MCP (Model-Client Protocol) oficial, permitindo que os utilizadores conectem LLMs diretamente à API do Hugging Face Hub para uso em Cursor, VSCode, Windsurf e outras aplicações que suportam MCP. O servidor oferece ferramentas integradas como pesquisa semântica de modelos, conjuntos de dados, artigos e Spaces, e lista dinamicamente todas as aplicações Gradio compatíveis com MCP hospedadas em Spaces. Esta iniciativa visa transformar a Hugging Face numa plataforma de colaboração para construtores de AI Agents, promovendo o desenvolvimento e a interoperabilidade do ecossistema de AI Agents. Atualmente, existem cerca de 900 MCP Spaces disponíveis (Fonte: ClementDelangue, mervenoyann, reach_vb, ben_burtenshaw, huggingface, code_star, op7418, TheTuringPost, clefourrier)

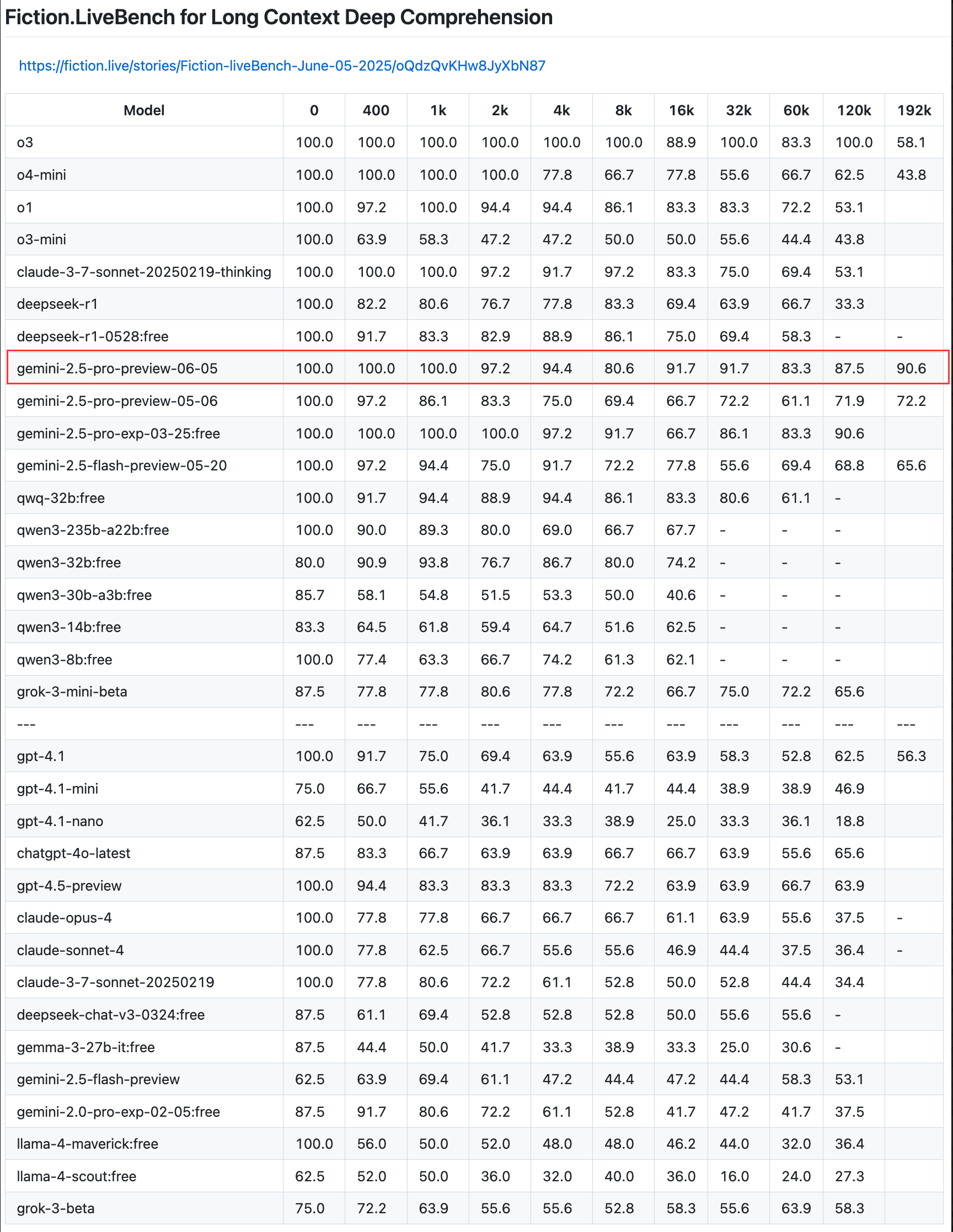
Google atualiza a versão de pré-visualização do Gemini 2.5 Pro, melhorando as capacidades de codificação, raciocínio e criação, e introduzindo o “orçamento de pensamento” : A Google anunciou uma atualização para a versão de pré-visualização do seu modelo mais inteligente, Gemini 2.5 Pro, melhorando ainda mais as suas capacidades em codificação, raciocínio lógico e escrita criativa. A nova versão introduz especialmente a funcionalidade de “orçamento de pensamento” (thinking budget), permitindo que os programadores controlem melhor o consumo de recursos computacionais do modelo. O feedback dos utilizadores indica que a nova versão (06-05) tem um desempenho excelente na recuperação de texto longo, especialmente com uma taxa de recuperação de 90,6% em 192K de comprimento, superando o OpenAI-o3. O modelo já foi integrado no LangChain e LangGraph, facilitando a experimentação e a construção de aplicações pelos programadores. A Google também demonstrou as capacidades criativas do Gemini 2.5 Pro na compreensão de imagens e na geração de legendas contextualizadas e espirituosas (Fonte: Teknium1, Google, karminski3, hwchase17, )
🎯 Tendências
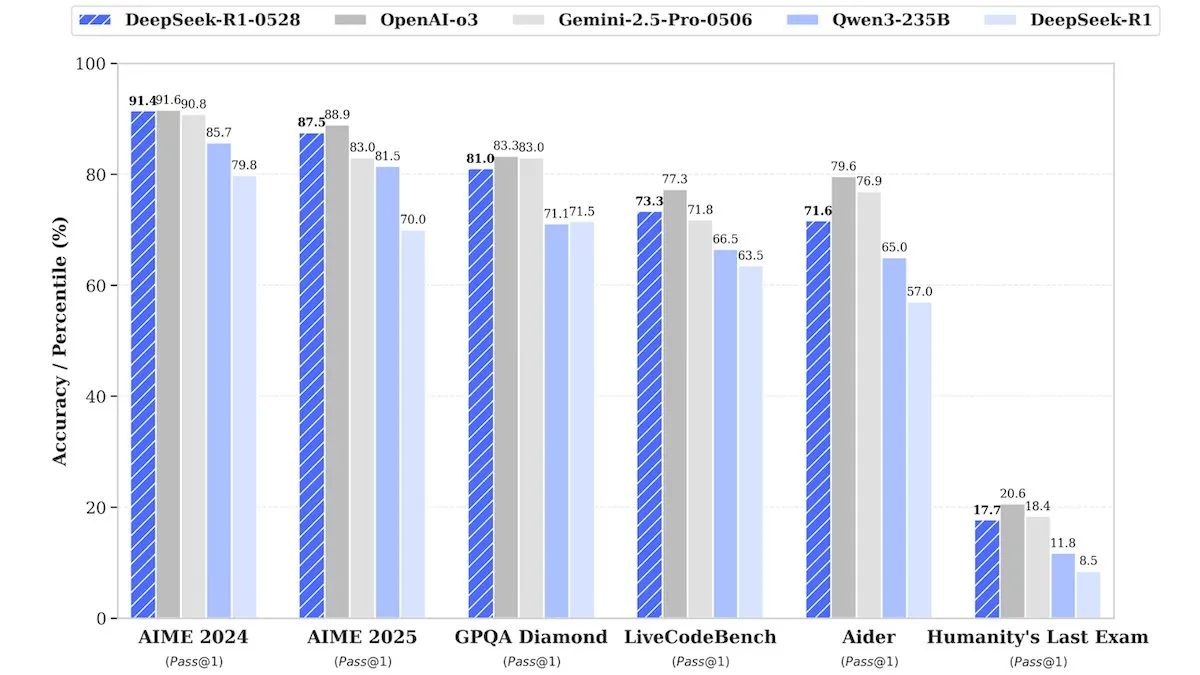
DeepSeek lança versão atualizada DeepSeek-R1-0528, com desempenho comparável a modelos de código fechado : A DeepSeek lançou uma versão atualizada do seu modelo de pesos abertos principal, DeepSeek-R1-0528. Alegadamente, este modelo apresenta um desempenho em vários benchmarks comparável a modelos de código fechado como o o3 da OpenAI e o Gemini-2.5 Pro da Google. Embora a empresa não tenha revelado detalhes do treino, relatórios indicam que o novo modelo apresenta melhorias significativas no raciocínio, no tratamento da complexidade das tarefas e na redução de alucinações, desafiando novamente a noção tradicional de que IA de topo requer recursos enormes. A Unsloth AI já disponibilizou um Notebook gratuito para fine-tuning do DeepSeek-R1-0528-Qwen3 usando GRPO, alegando que a sua nova função de recompensa pode aumentar a taxa de resposta multilíngue (ou em domínios personalizados) em mais de 40%, além de tornar o fine-tuning do R1 2x mais rápido e reduzir o uso de VRAM em 70% (Fonte: DeepLearningAI, ImazAngel)
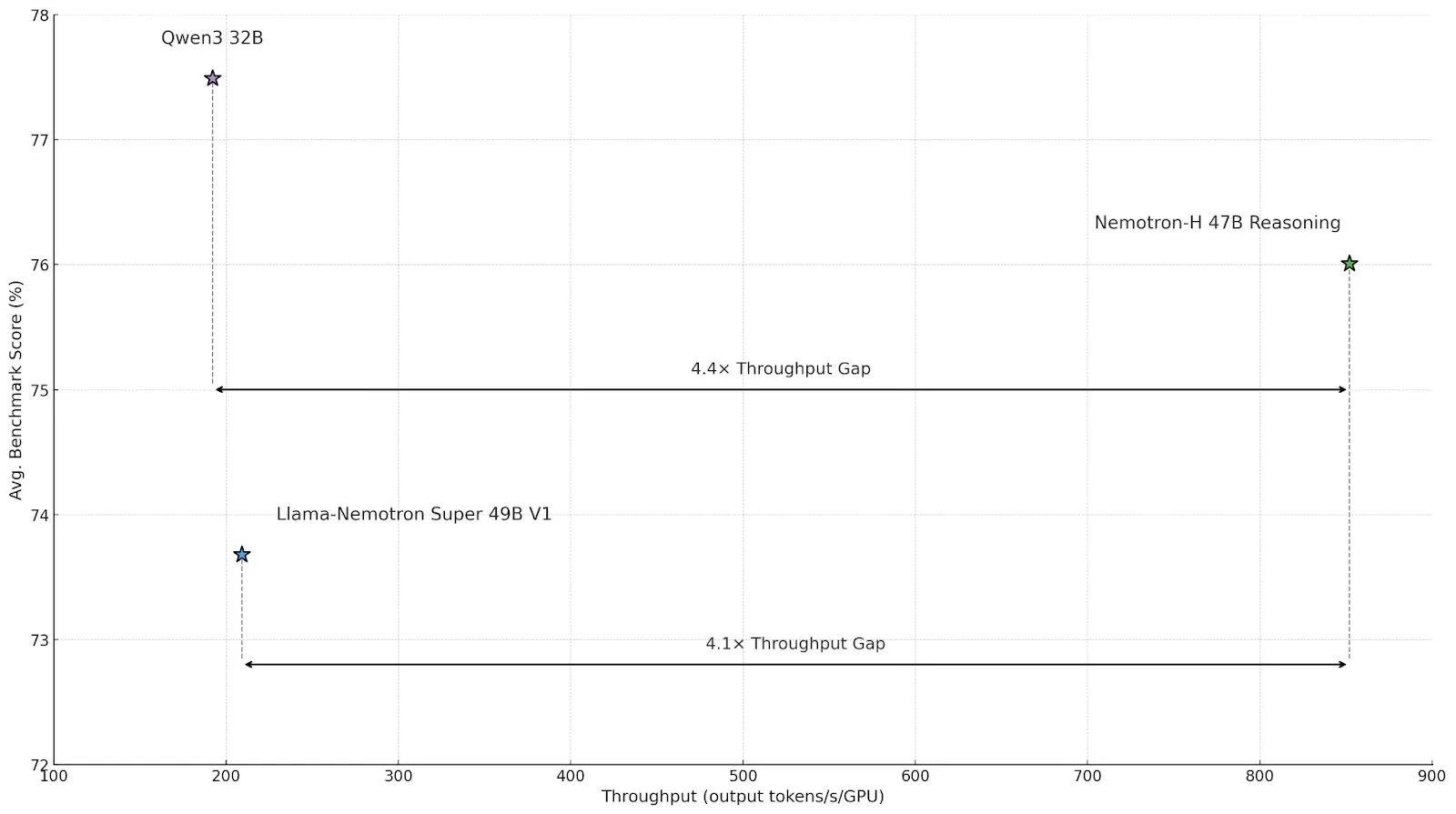
Nvidia lança modelo de inferência de arquitetura híbrida Nemotron-H, aumentando o throughput e a eficiência : A Nvidia lançou um novo modelo de inferência, Nemotron-H, incluindo versões de 47B e 8B (com suporte para BF16 e FP8), que utiliza uma arquitetura híbrida Mamba-Transformer. Este modelo visa resolver problemas de inferência em larga escala, mantendo alta velocidade, e alega-se que o seu throughput é 4 vezes superior ao de modelos Transformer comparáveis. O Nemotron-H-47B-Reasoning-128k apresenta uma precisão ligeiramente superior ao Llama-Nemotron-Super-49B-1.0 em todos os benchmarks, mas com um custo de inferência até 4 vezes menor. Os pesos do modelo foram lançados no HuggingFace sob uma licença não produtiva, e um relatório técnico será disponibilizado em breve (Fonte: ClementDelangue, ctnzr)
Anthropic lança Claude Gov, concebido especificamente para agências governamentais e de inteligência militar dos EUA : A Anthropic anunciou um novo serviço de IA chamado Claude Gov, concebido especificamente para satisfazer as necessidades do governo, defesa e agências de inteligência dos Estados Unidos. Esta medida marca a expansão formal da tecnologia avançada de IA da Anthropic para aplicações governamentais e militares, podendo ser utilizada em análise de dados, processamento de informações, apoio à decisão, entre outros cenários. A Anthropic também aderiu anteriormente a um fundo fiduciário de benefício a longo prazo, com o objetivo de ajudar a empresa a cumprir a sua missão de interesse público (Fonte: MIT Technology Review, akbirkhan, jeremyphoward)
Hugging Face e Google Colab colaboram para simplificar o processo de experimentação e prototipagem de modelos : A Hugging Face anunciou uma parceria com o Google Colaboratory, adicionando suporte para “Abrir no Colab” em todos os cartões de modelo no Hugging Face Hub. Os utilizadores podem agora iniciar um Colab Notebook diretamente a partir de qualquer cartão de modelo, facilitando a experimentação e avaliação de modelos. Além disso, os utilizadores podem colocar ficheiros notebook.ipynb personalizados nos seus repositórios de modelos, e a Hugging Face fornecerá diretamente esse Notebook, aumentando ainda mais a acessibilidade e a capacidade de prototipagem rápida de modelos de IA (Fonte: huggingface, osanseviero, ClementDelangue, mervenoyann)
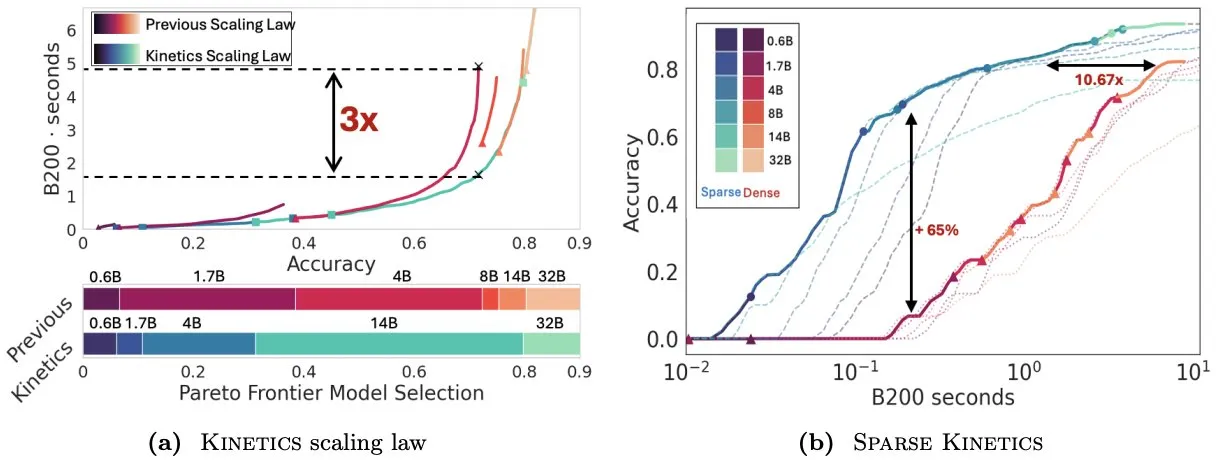
Artigo Kinetics repensa as leis de escalonamento em tempo de teste, enfatizando a importância da atenção esparsa para a eficiência da inferência : O Infini-AI-Lab publicou o artigo “Kinetics: Rethinking Test-Time Scaling Laws”, que aponta que as leis de escalonamento anteriores baseadas na otimização computacional superestimam a eficácia de modelos pequenos, ignorando os gargalos de acesso à memória trazidos por estratégias em tempo de inferência (como Best-of-N, CoT longo). A investigação propõe novas leis de escalonamento Kinetics, que consideram os custos de computação e acesso à memória, argumentando que os recursos computacionais em tempo de teste são usados de forma mais eficaz em modelos grandes do que em modelos pequenos, porque a atenção, e não o número de parâmetros, torna-se o custo dominante. O artigo propõe ainda um paradigma de escalonamento centrado na atenção esparsa, que alcança geração mais longa e mais amostras paralelas através da redução do custo por token. Experiências demonstram que os modelos de atenção esparsa superam os modelos densos em diferentes intervalos de custo, sendo cruciais para aumentar a eficiência da inferência de modelos em larga escala (Fonte: realDanFu, tri_dao, simran_s_arora)
Mercado chinês de AI Agents em ebulição, com Manus a liderar a onda de startups : Após a febre dos modelos de base no ano passado, o foco do setor de IA da China este ano virou-se para os AI Agents. Os AI Agents concentram-se mais em concluir tarefas autonomamente para os utilizadores, em vez de simplesmente responder a consultas. A Manus, como pioneira em AI Agents genéricos, gerou grande atenção após o seu lançamento limitado no início de março e impulsionou uma série de startups que constroem ferramentas digitais genéricas capazes de processar e-mails, planear viagens e até mesmo projetar websites interativos. Esta tendência indica que a indústria tecnológica chinesa está a explorar ativamente as aplicações práticas e os modelos de negócio dos AI Agents (Fonte: MIT Technology Review)

ElevenLabs lança Conversational AI 2.0, melhorando o desempenho de assistentes de voz de nível empresarial : A ElevenLabs lançou a versão 2.0 da sua plataforma de IA conversacional, destinada a construir agentes de voz de nível empresarial mais avançados. A nova versão melhora significativamente a naturalidade e a capacidade de interação dos assistentes de voz, permitindo-lhes compreender melhor o ritmo da conversa, saber quando fazer uma pausa, quando falar e quando realizar a alternância de turnos na conversação. Espera-se que esta atualização forneça aos utilizadores empresariais uma experiência de interação por voz mais fluida e inteligente, aplicável a serviços de apoio ao cliente, assistentes virtuais e outros cenários (Fonte: dl_weekly)
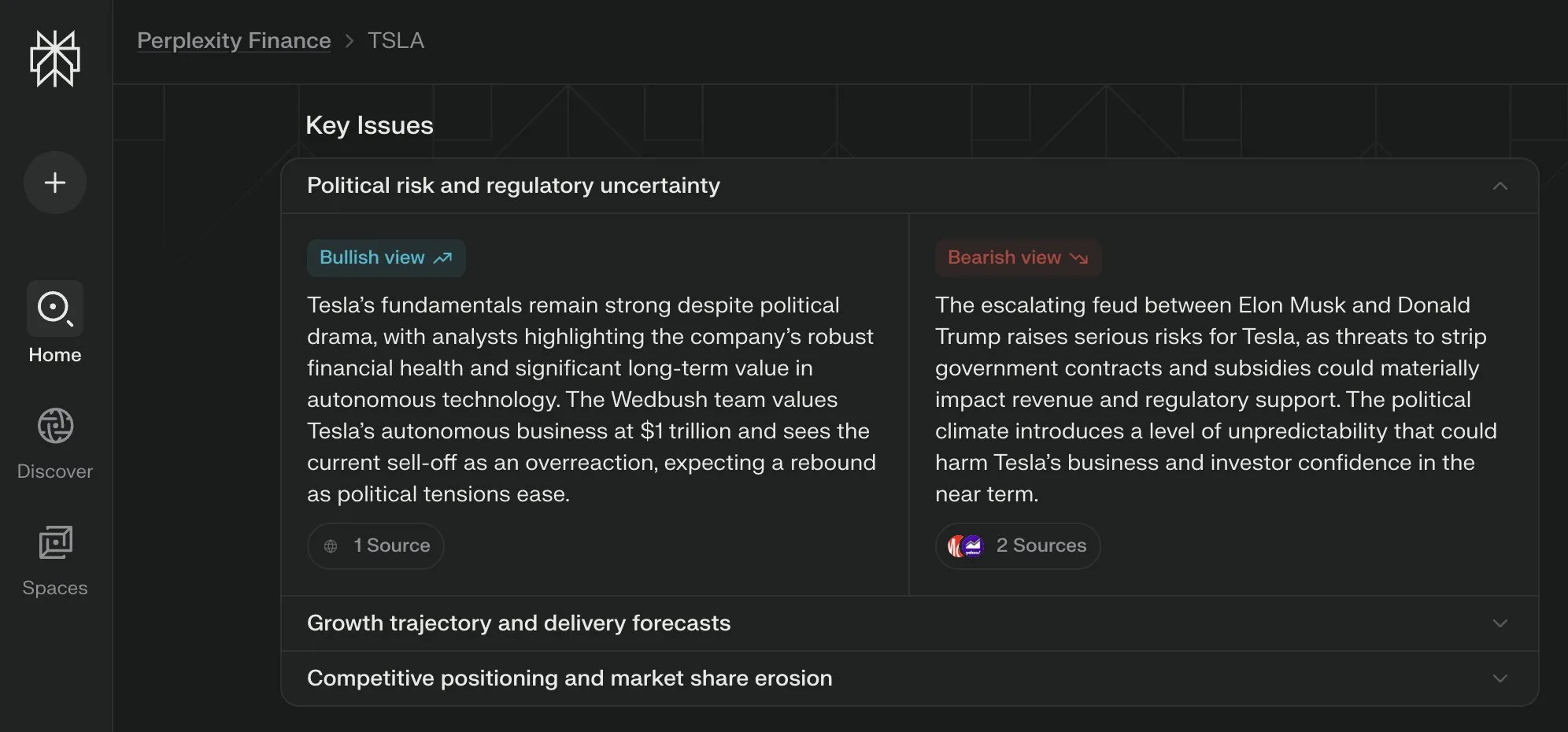
Perplexity Labs lança visualização de “Questões Chave” para as suas páginas financeiras, sintetizando múltiplas perspetivas : A Perplexity Labs adicionou uma nova funcionalidade de visualização chamada “Questões Chave” (Key Issues) às suas páginas de informação financeira. Esta funcionalidade consegue sintetizar opiniões de investidores, analistas e comentadores da internet, apresentando rapidamente aos utilizadores os fatores importantes que afetam uma empresa e os principais pontos de discussão atuais. Por exemplo, uma página sobre a Tesla pode integrar várias informações sobre a dinâmica entre Trump e Musk em poucas horas, ajudando os utilizadores a obter rapidamente uma visão geral (Fonte: AravSrinivas)
Checkpoints distribuídos do PyTorch agora suportam safetensors da Hugging Face : O PyTorch anunciou que a sua funcionalidade de checkpoints distribuídos agora suporta o formato safetensors da Hugging Face, o que tornará mais conveniente guardar e carregar checkpoints entre diferentes ecossistemas. A nova API permite aos utilizadores ler e escrever safetensors através de caminhos fsspec. O torchtune tornou-se a primeira biblioteca a adotar esta funcionalidade, simplificando assim o seu processo de checkpointing. Esta atualização ajuda a melhorar a interoperabilidade e a eficiência do treino e implementação de modelos (Fonte: ClementDelangue)

Artigo MARBLE propõe novo método para recomposição e mistura de materiais baseado no espaço CLIP : Uma nova investigação intitulada MARBLE propõe um método para misturar materiais de objetos em imagens e recombinar atributos de forma granular, encontrando embeddings de materiais no espaço CLIP e utilizando esses embeddings para controlar modelos pré-treinados de texto para imagem. O método melhora a edição de materiais baseada em amostras, localizando os módulos na UNet de denoising responsáveis pela atribuição de material, permitindo o controlo parametrizado de atributos de material de grão fino, como rugosidade, metalicidade, transparência e brilho. Os investigadores demonstraram a eficácia do método através de análises qualitativas e quantitativas, e mostraram a sua aplicabilidade na execução de múltiplas edições numa única passagem direta, bem como no domínio da pintura (Fonte: HuggingFace Daily Papers, ClementDelangue)
Artigo FlowDirector: Método de orientação de fluxo para edição precisa de texto para vídeo sem necessidade de treino : FlowDirector é um novo framework de edição de vídeo sem inversão que modela o processo de edição como uma evolução direta no espaço de dados. Através de equações diferenciais ordinárias (ODE), guia o vídeo numa transição suave ao longo da sua variedade espácio-temporal inerente, preservando assim a coerência temporal e os detalhes estruturais. Para alcançar uma edição localmente controlável, é introduzido um mecanismo de máscara guiado por atenção. Além disso, para resolver problemas de edição incompleta e melhorar o alinhamento semântico com as instruções de edição, é proposta uma estratégia de edição melhorada por orientação, inspirada na orientação sem classificador. Experiências demonstram que o FlowDirector apresenta um desempenho superior no seguimento de instruções, consistência temporal e preservação do fundo (Fonte: HuggingFace Daily Papers)
Artigo RACRO: Raciocínio multimodal escalável através da otimização de legendas por recompensa : Para resolver o problema do alto custo de treinar novamente o alinhamento visual-linguístico ao atualizar os LLMs de raciocínio subjacentes, os investigadores propuseram o RACRO (Reasoning-Aligned Perceptual Decoupling via Caption Reward Optimization). Este método converte a entrada visual em representações linguísticas (como legendas), que são depois passadas para o raciocinador de texto. O RACRO adota uma estratégia de aprendizagem por reforço guiada pelo raciocínio, otimizando por recompensa o comportamento das legendas do extrator com os objetivos de raciocínio, reforçando assim a base visual e extraindo representações otimizadas para o raciocínio. Experiências mostram que o RACRO alcança o estado da arte (SOTA) em benchmarks multimodais de matemática e ciências, e suporta a adaptação plug-and-play a LLMs de raciocínio mais avançados, sem a necessidade de um realinhamento multimodal dispendioso (Fonte: HuggingFace Daily Papers)
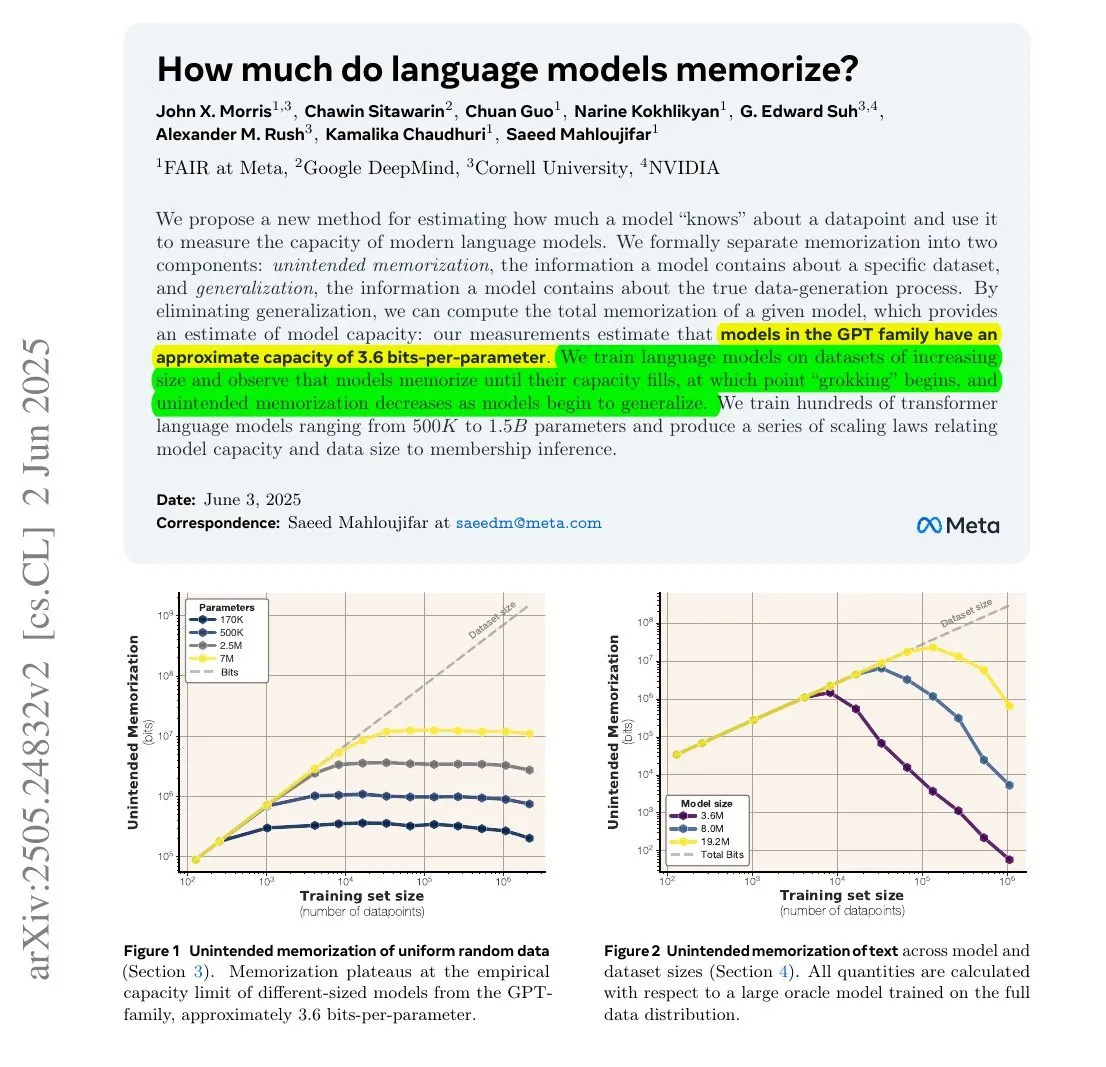
Estudo revela: A quantidade de informação memorizada pelos LLMs pode estar relacionada com o seu número de parâmetros e a entropia da informação : Um estudo colaborativo entre Meta, DeepMind, NVIDIA e a Universidade de Cornell explorou a quantidade de informação que os modelos de linguagem grande (LLMs) realmente memorizam. A investigação descobriu que a quantidade de informação memorizada pelos LLMs pode estar relacionada com o seu número de parâmetros e a entropia da informação dos dados. Por exemplo, a Wikipédia em inglês tem aproximadamente 29,4 mil milhões de caracteres, cada um contendo cerca de 1,5 bits de informação. Um modelo com 12B de parâmetros (assumindo uma capacidade de armazenamento de 3,6 bits por parâmetro) poderia teoricamente memorizar toda a Wikipédia em inglês. Este estudo é significativo para a compreensão dos mecanismos de memória dos LLMs e para a avaliação de questões de direitos de autor dos dados. François Chollet também mencionou a metodologia de treinar LLMs com strings aleatórias e as suas descobertas quantitativas, considerando-as valiosas para entender os mecanismos de memória dos LLMs (Fonte: fchollet, AymericRoucher)
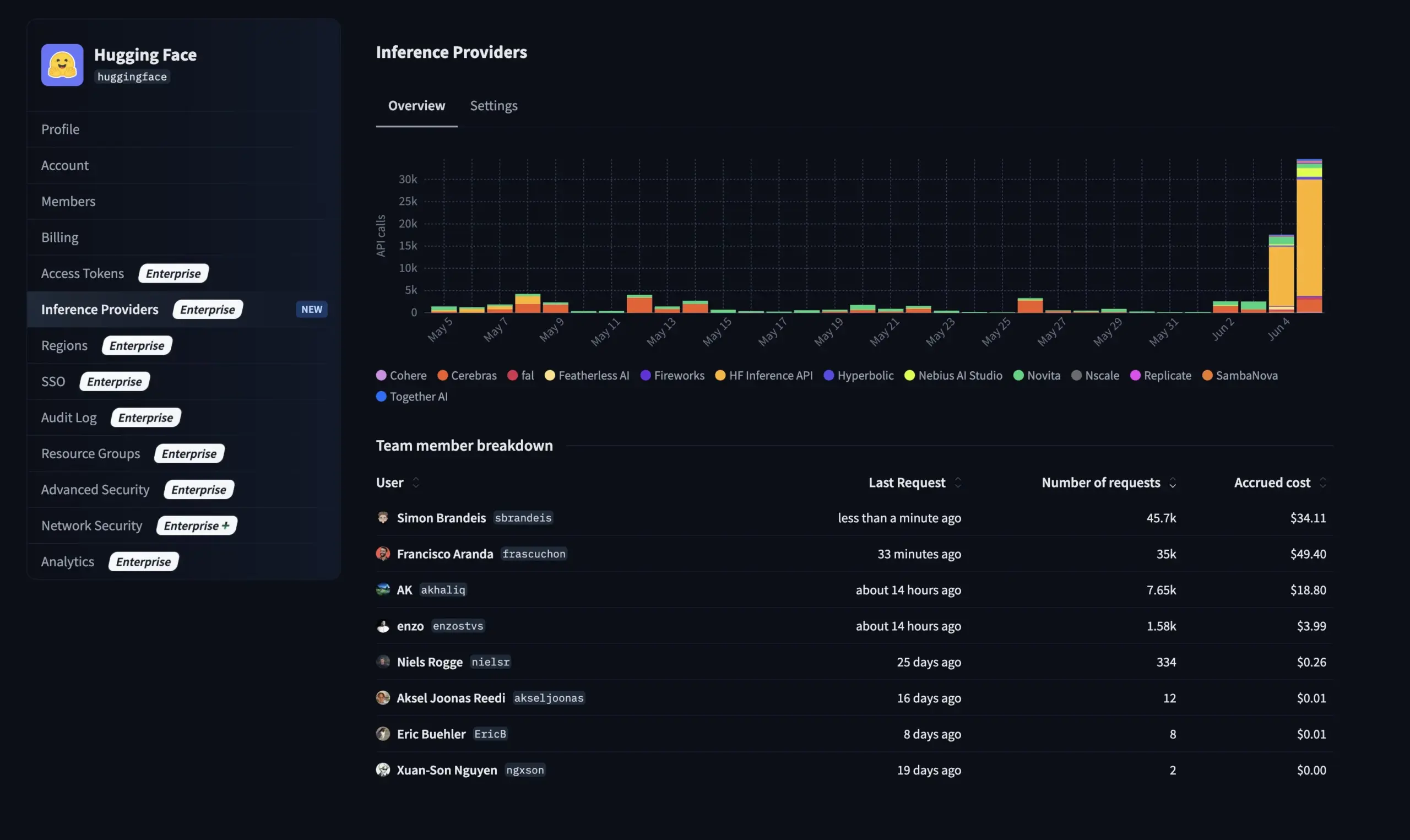
Hugging Face lança nova funcionalidade para a versão Enterprise: gerir o uso e os custos dos fornecedores de inferência : A Hugging Face adicionou uma nova funcionalidade à sua versão Enterprise (Enterprise Hub), permitindo que as organizações configurem e monitorizem o uso e os custos associados dos fornecedores de inferência (Inference Providers) pelos membros das suas equipas. Isto significa que os utilizadores empresariais podem gerir e controlar melhor o uso de serviços de inferência serverless para mais de 40.000 modelos de vários fornecedores, como TogetherCompute, FireworksAI, Replicate, Cohere, entre outros, otimizando assim a relação custo-benefício e a alocação de recursos na implementação de aplicações de IA (Fonte: huggingface, _akhaliq)
Mistral AI lança modelo de raciocínio científico ether0, afinado a partir do Mistral 24B : A Mistral AI lançou o seu primeiro modelo de raciocínio científico, ether0. Este modelo foi criado através do treino por aprendizagem por reforço (RL) do Mistral 24B em múltiplas tarefas de design molecular no domínio da química. A investigação descobriu que os LLMs aprendem dados em certas tarefas científicas com uma eficiência muito superior à dos modelos especializados treinados do zero, e podem superar significativamente os modelos de vanguarda e os humanos nessas tarefas. Isto sugere que, para uma parte dos problemas de classificação, regressão e geração científica, o pós-treino de LLMs pode oferecer um caminho mais eficiente do que os métodos tradicionais de machine learning (Fonte: MistralAI)
Modelo de Consistência de Duplo Especialista (DCM) acelera a geração de vídeo em 10 vezes : Ziwei Liu e outros investigadores propuseram o Modelo de Consistência de Duplo Especialista (DCM), que pode acelerar os modelos de geração de vídeo (com número de parâmetros de 1.3B a 13B) em 10 vezes, sem degradar a qualidade. Este modelo já suporta o Tencent Hunyuan e o Alibaba Tongyi Wanxiang. A proposta do DCM representa um novo avanço no campo da geração de vídeo eficiente e de alta qualidade, ajudando a acelerar a criação de conteúdo de vídeo e o desenvolvimento de aplicações relacionadas (Fonte: _akhaliq)
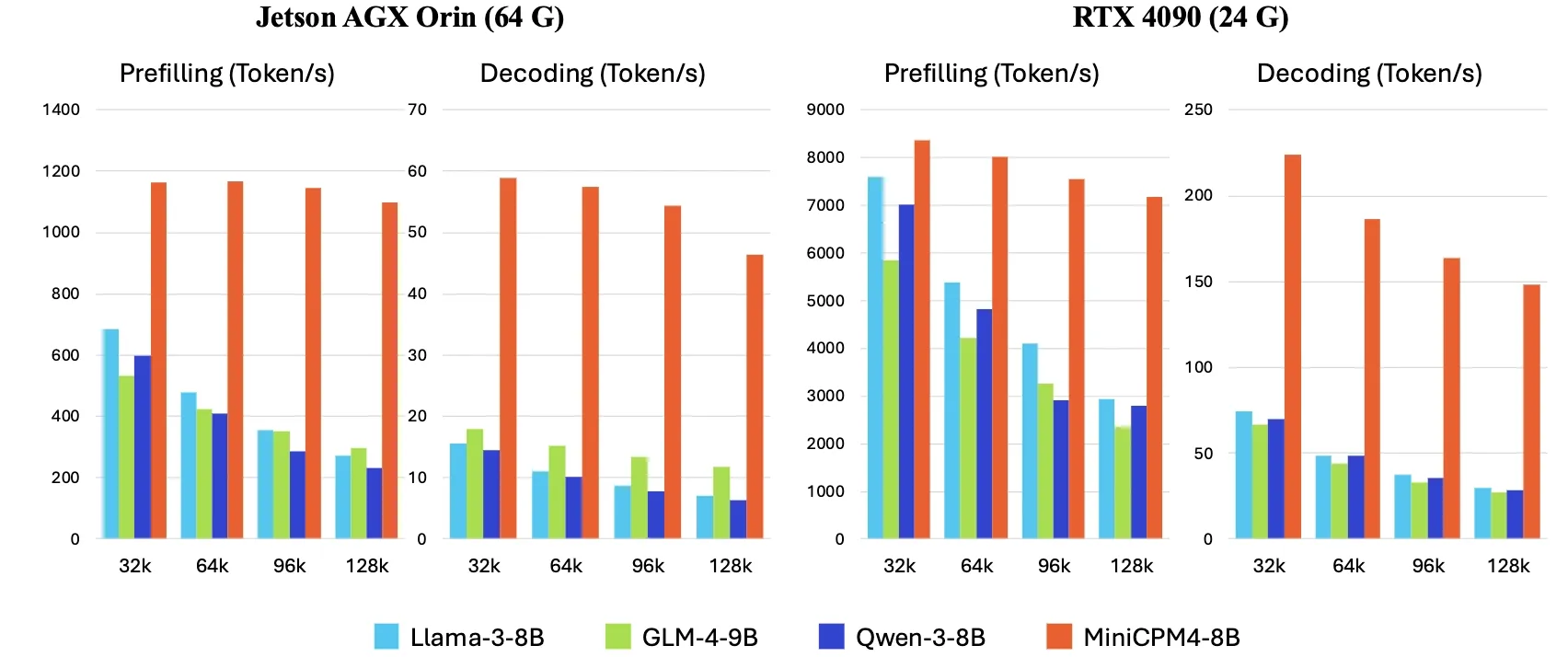
OpenBMB lança MiniCPM4, com velocidade de inferência no dispositivo 5 vezes mais rápida : A OpenBMB lançou a série de modelos MiniCPM4, que, através da adoção de uma arquitetura de modelo eficiente (mecanismo de atenção esparsa treinável InfLLM v2), algoritmos de aprendizagem eficientes (Model Wind Tunnel 2.0, quantização ternária BitCPM), dados de treino de alta qualidade (UltraClean, UltraChat v2) e um sistema de inferência eficiente (CPM.cu, ArkInfer), alcançou o objetivo de aumentar a velocidade de inferência em dispositivos de ponta em 5 vezes. O modelo principal MiniCPM4-8B (8B parâmetros, treinado com 8T tokens) já está disponível no Hugging Face. Esta série de modelos visa explorar os limites dos LLMs pequenos e de baixo custo, impulsionando a aplicação da IA em dispositivos com recursos limitados (Fonte: eliebakouch, Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞))
Empresa X atualiza termos de serviço, proibindo o uso das suas publicações para “fine-tuning ou treino” de modelos de IA, salvo acordo : A empresa X (anteriormente Twitter) atualizou os seus termos de serviço, proibindo explicitamente o uso do conteúdo das publicações da plataforma para “fine-tuning ou treino” de modelos de inteligência artificial, a menos que exista um acordo específico com a empresa X. Esta medida reflete a crescente valorização e o desejo de controlo dos seus dados por parte das plataformas de conteúdo na era da IA, possivelmente seguindo o exemplo de empresas como Reddit e Google, que monetizam dados através de acordos de licenciamento. Esta alteração de política terá impacto nos investigadores e programadores de IA que dependem de dados públicos de redes sociais para treinar modelos (Fonte: MIT Technology Review)
🧰 Ferramentas
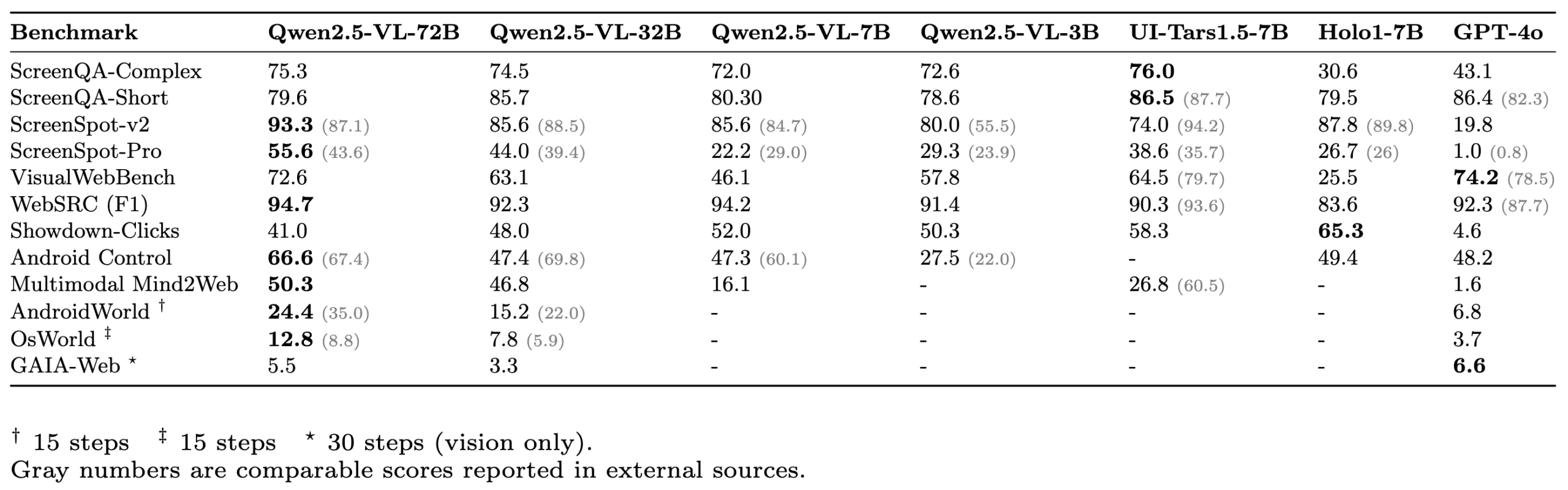
ScreenSuite: Lançamento de um conjunto abrangente de avaliação para GUI Agents : A Hugging Face lançou o ScreenSuite, um conjunto abrangente de avaliação para agentes de interface gráfica do utilizador (GUI). Ele integra benchmarks chave de investigações de vanguarda, suporta avaliação em Docker para ambientes Ubuntu e Android, e cobre cenários móveis, desktop e web. O conjunto enfatiza a avaliação puramente visual (sem batota DOM), visando fornecer uma plataforma unificada e fácil de usar para medir as capacidades de modelos de linguagem visual (VLM) em perceção, localização, operações de passo único e tarefas de agente de múltiplos passos. Modelos como Qwen-2.5-VL, UI-Tars-1.5-7B, Holo1-7B e GPT-4o já foram avaliados neste conjunto (Fonte: huggingface, AymericRoucher, clefourrier, tonywu_71, mervenoyann, HuggingFace Blog)
Partilha de experiência com Claude Code: Destaque para compreensão de instruções, planeamento de tarefas e utilização de ferramentas : O utilizador dotey partilhou a sua experiência com o assistente de programação de IA da Anthropic, Claude Code. Ele considera que os pontos fortes do Claude Code são: 1. Excelente compreensão das instruções; 2. Capacidade de planear tarefas razoavelmente, criando listas de TODO para tarefas complexas e executando-as uma a uma; 3. Capacidade extremamente forte de utilizar ferramentas, especialmente proficiente no uso do comando grep para pesquisar bases de código, com uma eficiência muito superior à humana, conseguindo até analisar código JS ofuscado; 4. Longo tempo de execução, capaz de “fazer milagres com força bruta”, mas também com grande consumo de Tokens, adequado para uso com a subscrição Claude Max; 5. Pouca intervenção manual durante todo o processo, especialmente ao ativar o parâmetro --dangerously-skip-permissions, permitindo programação não supervisionada. O utilizador passou de um utilizador intensivo do Cursor para depender mais do Claude Code para concluir tarefas preliminares, e depois rever e modificar no IDE. O Plan Mode (modo de planeamento) do Claude Code também foi lançado discretamente, permitindo aos utilizadores realizar leitura e reflexão puras sem editar ficheiros (Fonte: dotey, Reddit r/ClaudeAI)
ClaudeBox: Executar Claude Code em Docker de forma segura, eliminando pedidos de permissão : O programador RchGrav criou a ferramenta ClaudeBox, que permite aos utilizadores executar o Claude Code em modo contínuo (sem pedidos de permissão) dentro de um contentor Docker. Isto evita que confirmações frequentes de permissão interrompam o fluxo de trabalho, ao mesmo tempo que garante a segurança do sistema operativo principal, uma vez que todas as operações do Claude Code são restringidas ao ambiente Docker isolado. O ClaudeBox oferece mais de 15 ambientes de desenvolvimento pré-configurados (como Python+ML, C++/Rust/Go, etc.), que os utilizadores podem configurar rapidamente através de comandos simples. A ferramenta visa melhorar a experiência de utilização do Claude Code, permitindo que os utilizadores deixem a IA tentar várias operações sem preocupações (Fonte: Reddit r/ClaudeAI)
Toolio 0.6.0 lançado: Kit de ferramentas GenAI e Agent concebido para Mac : Toolio lançou a versão 0.6.0, um kit de ferramentas profundamente integrado com MLX, concebido para fornecer um forte suporte a modelos de linguagem grande (LLM) no Mac. Implementa funcionalidades de saída estruturada guiada por JSON Schema e chamada de ferramentas, utilizando a linguagem Python. Este kit de ferramentas foca-se em melhorar a experiência e eficiência no desenvolvimento de aplicações GenAI e Agent no ambiente Mac (Fonte: awnihannun)
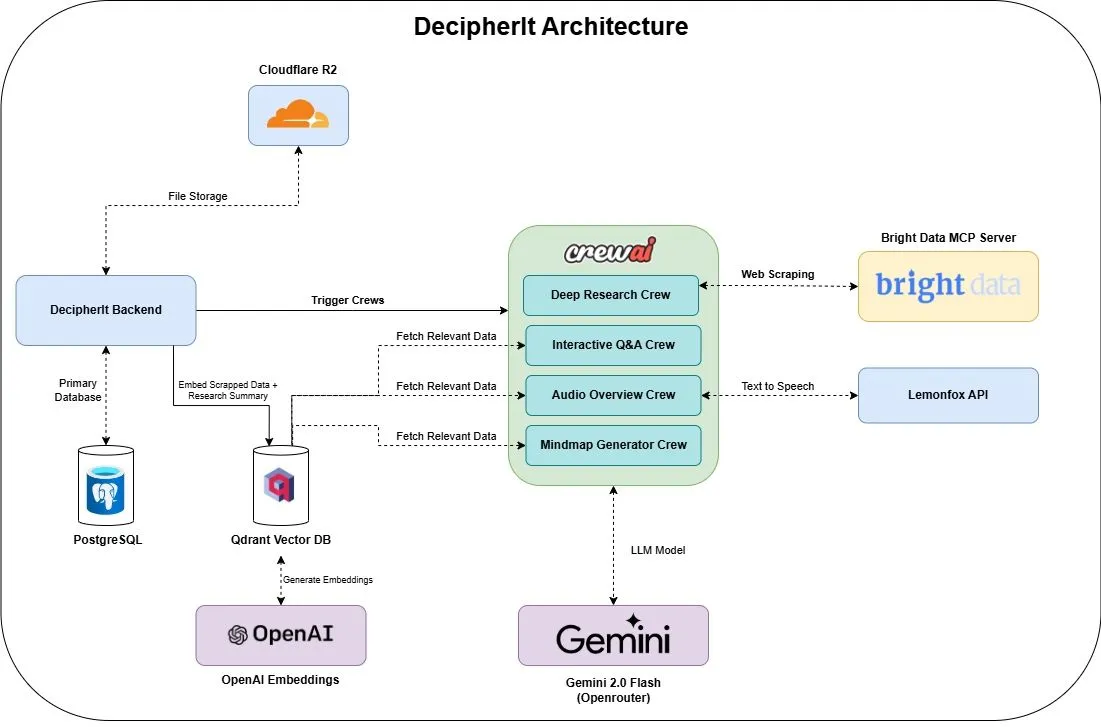
DecipherIt: Assistente de investigação de IA de código aberto, integrando múltiplos agentes e pesquisa semântica : DecipherIt é um assistente de investigação de IA de código aberto, considerado uma alternativa ao NotebookLM. Utiliza orquestração de múltiplos agentes, pesquisa semântica e funcionalidades de acesso à web em tempo real para ajudar os utilizadores a processar materiais de investigação. Os utilizadores podem carregar documentos, colar URLs ou inserir tópicos, e o DecipherIt irá transformá-los num espaço de trabalho de investigação completo, incluindo resumos, mapas mentais, visões gerais em áudio, FAQs e perguntas e respostas semânticas. A sua pilha tecnológica inclui agentes crewAI, Bright Data MCP, Qdrant, OpenAI e LemonFox AI, com frontend em Next.js e React 19, e backend em FastAPI (Fonte: qdrant_engine)
Search Arena: Lançamento de conjunto de dados de interações de utilizadores com LLMs melhorados por pesquisa para análise : Search Arena é um conjunto de dados de preferências humanas em larga escala (mais de 24.000), obtido por crowdsourcing, contendo interações emparelhadas de múltiplas rondas entre utilizadores e LLMs melhorados por pesquisa. Este conjunto de dados abrange uma variedade de intenções e idiomas, e inclui rastreios completos do sistema de aproximadamente 12.000 votos de preferência humana. A análise mostra que as preferências dos utilizadores são influenciadas pelo número de citações, mesmo que o conteúdo citado não suporte diretamente as alegações de atribuição; plataformas orientadas pela comunidade são geralmente mais populares. Este conjunto de dados visa apoiar futuras investigações sobre LLMs melhorados por pesquisa, com código e dados já em código aberto (Fonte: HuggingFace Daily Papers, jiayi_pirate, lmarena_ai)

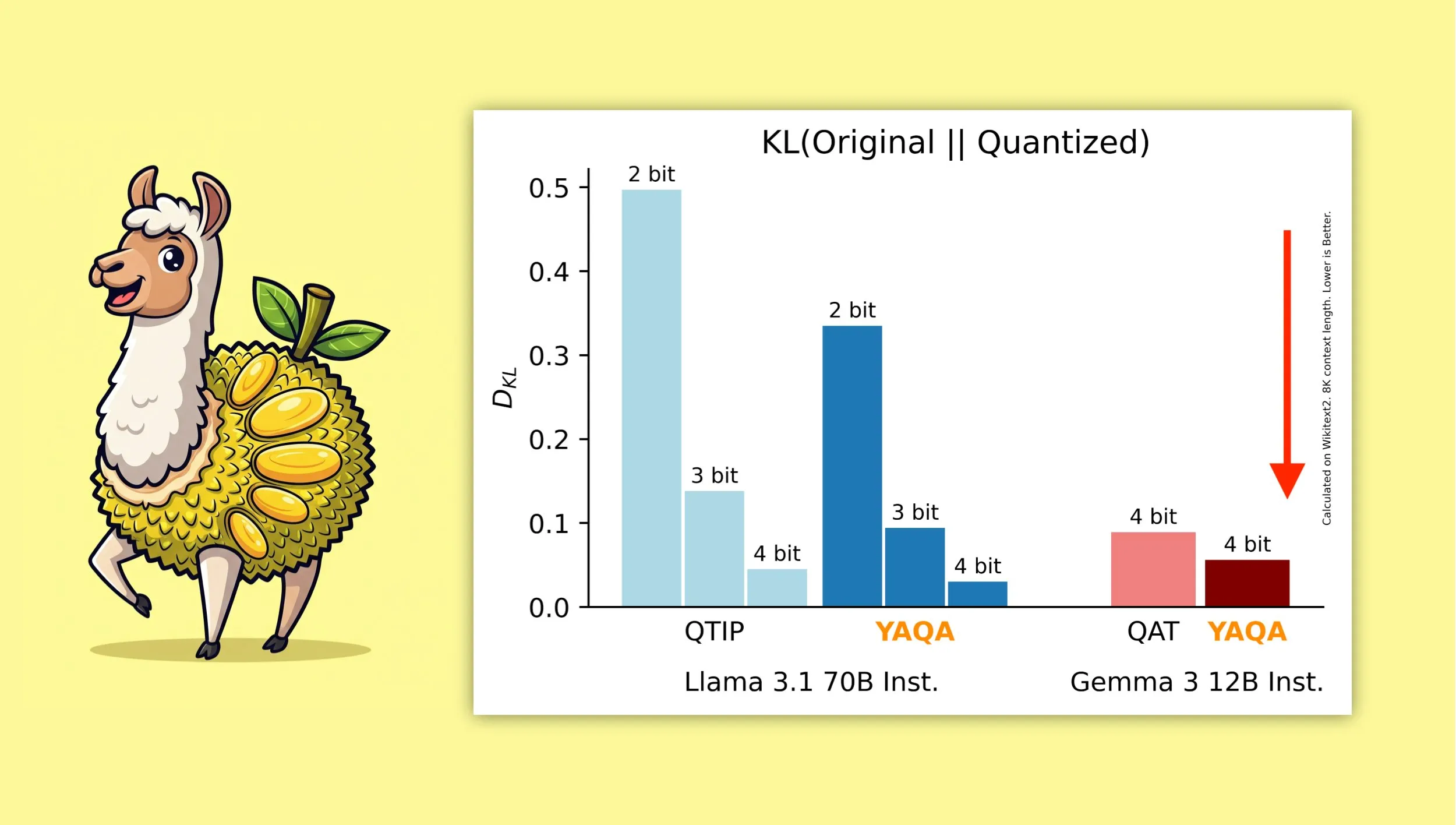
YAQA: Um novo algoritmo de quantização que visa preservar melhor a saída original do modelo : Investigadores da Universidade de Cornell lançaram o “Yet Another Quantization Algorithm” (YAQA), um novo algoritmo de quantização que visa preservar melhor a saída do modelo original após a quantização. Alegadamente, o YAQA consegue reduzir a divergência KL em mais de 30% em comparação com o QTIP, e alcançou uma divergência KL inferior à do modelo QAT da Google no Gemma 3. Esta investigação fornece novas ideias e ferramentas para o campo da quantização de modelos, ajudando a maximizar a preservação do desempenho do modelo enquanto se reduz o seu tamanho e os requisitos computacionais. O artigo e o código relacionados foram publicados, e foi disponibilizado um modelo Llama 3.1 70B Instruct pré-quantizado (Fonte: Reddit r/MachineLearning, Reddit r/LocalLLaMA, tri_dao, simran_s_arora)
Tokasaurus: Lançamento de motor concebido para inferência de LLM de alto débito : A HazyResearch lançou o Tokasaurus, um novo motor de inferência de LLM concebido especificamente para cargas de trabalho de alto débito, adequado para modelos grandes e pequenos. Este motor visa otimizar a eficiência e a velocidade de processamento de LLMs em cenários de pedidos concorrentes em larga escala, possivelmente utilizando técnicas avançadas como processamento em lote contínuo e atenção paginada para melhorar o desempenho. O lançamento do Tokasaurus oferece uma nova opção para programadores e empresas que necessitam de processar eficientemente um grande volume de tarefas de inferência de LLM (Fonte: Tim_Dettmers)
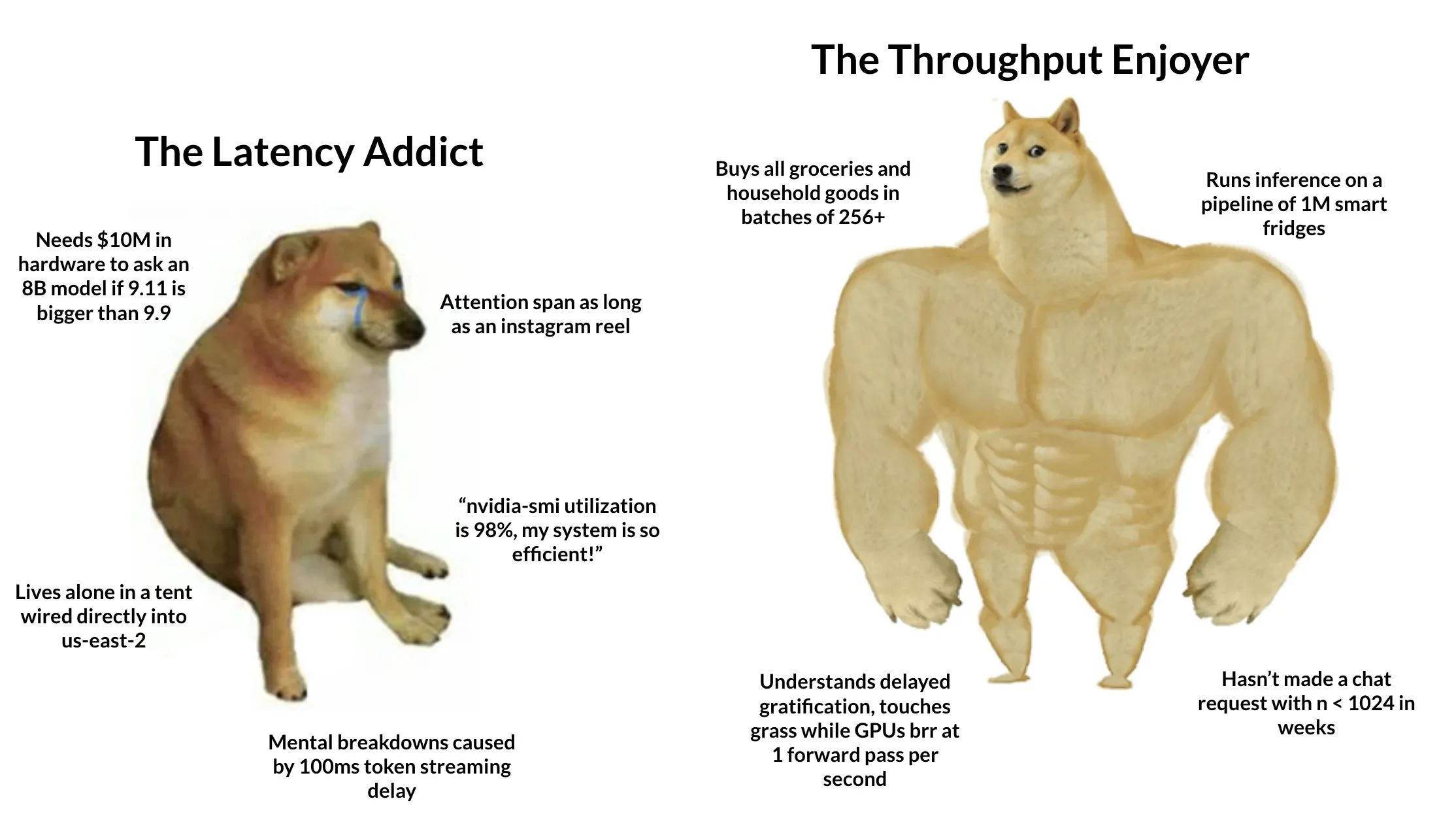
Sistema “Android” de pegada de carbono TIDAS lançado, com suporte técnico da Ant Digital : A Aliança de Inovação Tecnológica da Indústria de Pegada de Carbono lançou o “Sistema de Dados LCA Tiangong” (TIDAS), com o objetivo de fornecer soluções para a avaliação do ciclo de vida (LCA) e construção de bases de dados de pegada de carbono, visando estabelecer o sistema “Android” para bases de dados de LCA e pegada de carbono na China e globalmente. A Ant Digital, como membro principal, forneceu suporte tecnológico de blockchain e plataforma de colaboração de dados confiáveis para o TIDAS, utilizando a sua tecnologia de blockchain autónoma para realizar o registo e a titularidade confiáveis de ativos de dados de carbono, e utilizando tecnologia de computação de privacidade para garantir que os dados sejam “utilizáveis mas não visíveis”, aumentando a padronização, fusibilidade e interoperabilidade dos dados (Fonte: 量子位)
📚 Aprender
LangChain organiza workshop sobre IA empresarial, focado em sistemas multi-agente : A LangChain realizará um workshop sobre IA empresarial a 16 de junho em São Francisco. Na ocasião, Jake Broekhuizen da LangChain orientará os participantes na construção de sistemas multi-agente prontos para produção usando LangGraph, cobrindo aspetos cruciais como segurança e observabilidade. Este é um workshop prático, destinado a ajudar os programadores a dominar as competências para construir aplicações de AI Agent complexas e fiáveis (Fonte: LangChainAI, hwchase17)

DeepLearning.AI lança novo curso “DSPy: Construir e Otimizar Aplicações Agênticas” : A DeepLearning.AI lançou um novo curso intitulado “DSPy: Build and Optimize Agentic Apps”. O curso ensinará aos participantes os fundamentos do DSPy, como usar as suas assinaturas e o modelo de programação baseado em módulos para construir aplicações agênticas GenAI modulares, rastreáveis e depuráveis. O conteúdo inclui a construção de aplicações através da ligação de módulos DSPy como Predict, ChainOfThought e ReAct, o uso do MLflow para rastreamento e depuração, e a utilização do DSPy Optimizer para ajustar automaticamente prompts e melhorar exemplos few-shot, a fim de aumentar a precisão e consistência das respostas (Fonte: DeepLearningAI, lateinteraction)
Projeto GitHub de tutorial sobre técnicas avançadas de RAG ganha destaque : O projeto de tutorial sobre técnicas de RAG (Retrieval-Augmented Generation) partilhado por NirDiamant no GitHub alcançou 16.6K estrelas. O tutorial abrange uma vasta gama de conteúdos, incluindo pré-processamento para recuperação melhorada, otimização, padrões de recuperação, iteração e etapas de engenharia. Para programadores que desejam aprofundar a investigação e melhorar a eficácia das aplicações RAG, este é um recurso de aprendizagem avançado valioso (Fonte: karminski3)
Como os clientes da OpenAI usam avaliações (Evals) para construir melhores produtos de IA : Hamel Husain promoveu um webinar apresentado por Jim Blomo da OpenAI, que discutirá como os clientes da OpenAI utilizam ferramentas de avaliação (Evals) para construir produtos de IA de melhor qualidade. O conteúdo incluirá estudos de caso reais e resultados, e demonstrará as ferramentas de avaliação internas da OpenAI (como rastreamento, pontuação, etc.). O webinar visa fornecer aos programadores insights práticos e métodos sobre a avaliação de produtos de IA (Fonte: HamelHusain)

LlamaIndex partilha visão geral de 13 protocolos de Agent, discute padrões de interoperabilidade : Seldo, da LlamaIndex, fez uma apresentação geral no MCP Developer Summit sobre os atuais 13 diferentes protocolos de comunicação entre Agents (incluindo MCP, A2A, ACP, etc.). Ele analisou as funcionalidades únicas de cada protocolo, o seu posicionamento no panorama tecnológico atual e as tendências futuras de desenvolvimento. A apresentação visa ajudar os programadores a compreender e escolher os padrões de comunicação adequados para as suas aplicações de Agent, promovendo a interoperabilidade do ecossistema de Agents (Fonte: jerryjliu0, jerryjliu0)

Análise da arquitetura do Claude Code: Fluxo de controlo, motor de orquestração e execução de ferramentas : Um artigo analisou em profundidade a arquitetura do Claude Code, focando-se no seu fluxo de controlo e motor de orquestração, bem como nos motores de ferramentas e execução. Estas análises são valiosas para programadores que desejam criar ferramentas de assistente de codificação de linha de comando semelhantes ou realizar modificações personalizadas, e as suas ideias de design também são aplicáveis ao desenvolvimento de outros tipos de ferramentas de Agent (Fonte: karminski3)

Partilha da solução do segundo classificado no concurso de kernels de multiplicação de matrizes FP8 para GPUs AMD : Tim Dettmers partilhou a solução do vencedor do segundo prémio no concurso de kernels de multiplicação de matrizes FP8 para GPUs AMD. A interpretação detalhada desta solução tem um valor de referência importante para compreender como otimizar o desempenho de operações de ponto flutuante de baixa precisão em GPUs AMD, especialmente no contexto em que o treino e a inferência de modelos de IA utilizam cada vez mais formatos de baixa precisão como FP8 para aumentar a eficiência (Fonte: Tim_Dettmers)
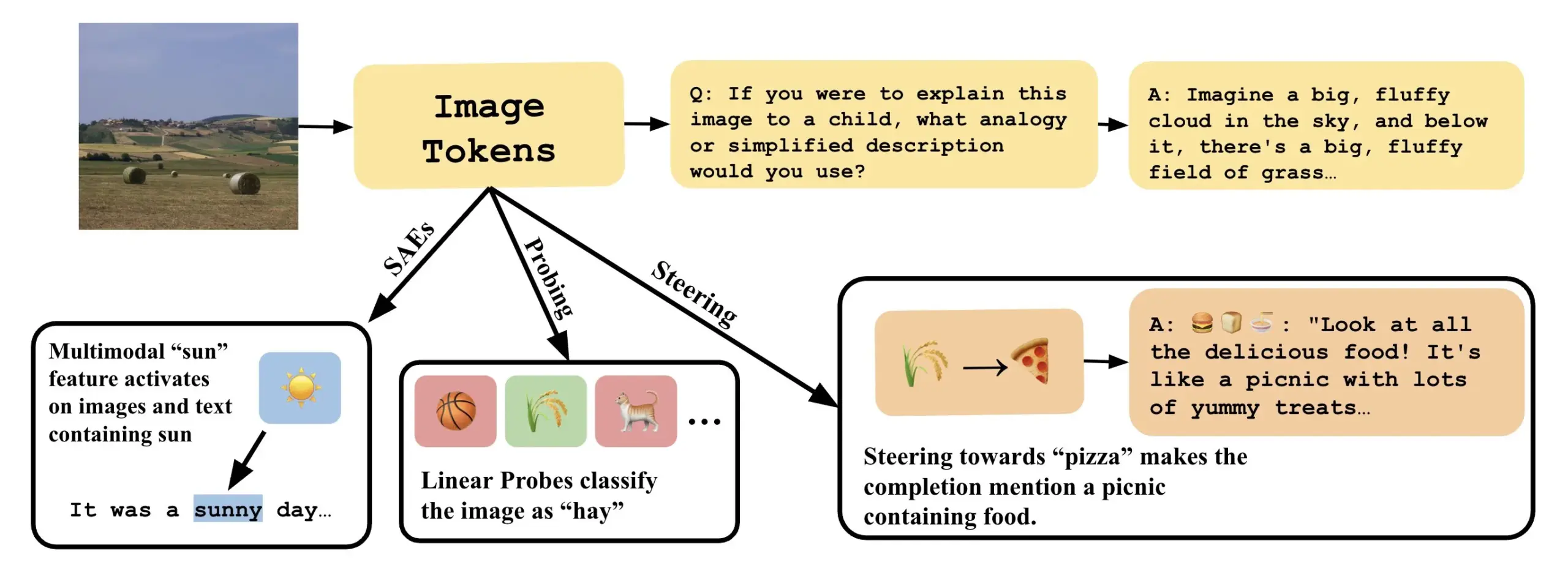
Artigo explora como entender modelos de linguagem visual através da interpretação de direções lineares em VLLMs : Um novo artigo intitulado “Line of Sight” explora a compreensão dos mecanismos internos dos grandes modelos de linguagem visual (VLLM) através da interpretação de direções lineares no seu espaço latente. Os investigadores usam ferramentas como probing, steering e autoencoders esparsos (SAEs) para interpretar as representações de imagem em VLLMs. Este trabalho oferece novas perspetivas e métodos para entender o funcionamento interno de modelos multimodais (Fonte: nabla_theta)
💼 Negócios
Startup de IA Vareon recebe financiamento pré-semente de 3 milhões de dólares da Norck, focada em IA de fronteira e sistemas autónomos : A Norck, fundada por Faruk Guney, comprometeu-se a fornecer um financiamento pré-semente de 3 milhões de dólares, baseado em marcos, à sua recém-criada startup de IA, Vareon. A Vareon foca-se em IA de fronteira, inferência causal e sistemas autónomos, tendo como núcleo o MALPAC (Multi-Agent Learning Architecture for Planning and Closed-Loop Optimization). A empresa visa tornar-se uma empresa de investigação fundamental em IA, impulsionando o desenvolvimento em áreas como robótica, LLMs, design molecular, arquiteturas cognitivas e agentes autónomos. Foram também lançados o RAPID (framework de planeamento diferenciável), CIMO (coordenador causal multiescala), SCA (arquitetura cognitiva bio-inspirada) e Lumon-XAI (camada de explicabilidade) (Fonte: farguney)

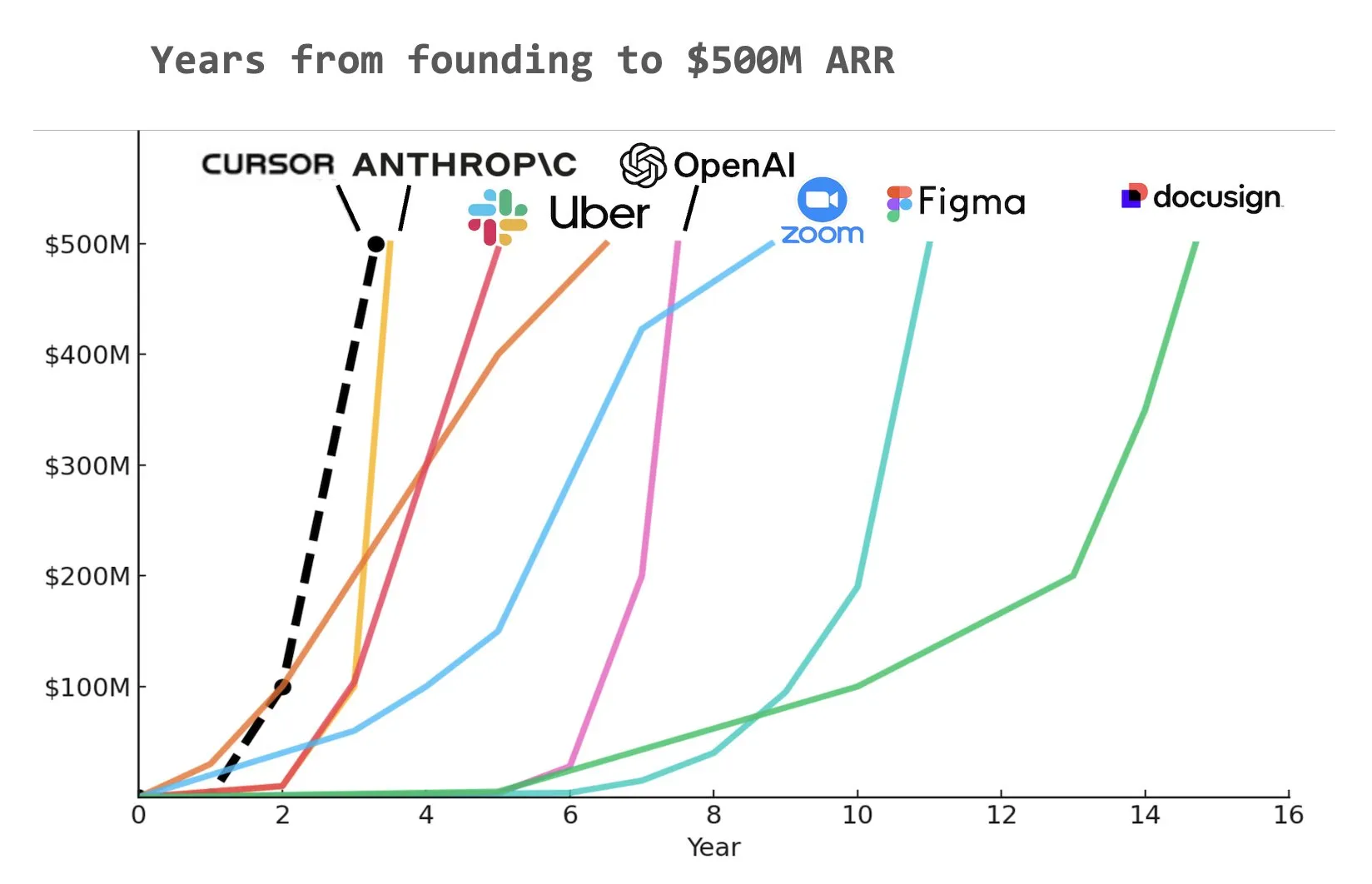
Ferramenta de codificação AI Cursor obtém financiamento de Série C de 900 milhões de dólares, ARR atinge 500 milhões de dólares : A startup de ferramentas de codificação AI Cursor anunciou a conclusão de uma ronda de financiamento de Série C de 900 milhões de dólares, liderada por Thrive, Accel, Andreessen Horowitz e DST. A empresa revelou que a sua receita anual recorrente (ARR) ultrapassou os 500 milhões de dólares e é utilizada por mais de metade das empresas da Fortune 500, incluindo NVIDIA, Uber e Adobe. Esta ronda de financiamento ajudará a Cursor a impulsionar ainda mais a vanguarda da investigação no campo da codificação AI. Analistas apontam que a Cursor pode ser uma das empresas que mais rapidamente atingiu 500 milhões de dólares de ARR na história (Fonte: cursor_ai, Yuchenj_UW, op7418)
Anthropic corta acesso direto da Windsurf aos modelos Claude, possivelmente devido a rumores de aquisição pela OpenAI : Jared Kaplan, cofundador e cientista-chefe da Anthropic, afirmou que a empresa cortou o acesso direto do assistente de programação de IA Windsurf aos modelos Claude principalmente devido a rumores de mercado sobre a iminente aquisição da Windsurf pela OpenAI. Kaplan disse que “seria estranho vender Claude à OpenAI” e afirmou que a Anthropic prefere alocar recursos computacionais a parceiros estáveis a longo prazo. Apesar disso, a Anthropic está a estabelecer ativamente parcerias com outros programadores de ferramentas de programação de IA (como a Cursor) e enfatizou que, no futuro, se concentrará mais no desenvolvimento de produtos de programação de IA com capacidades de decisão autónoma, como o Claude Code (Fonte: dotey, vikhyatk, jeremyphoward, swyx)

🌟 Comunidade
Greg Brockman da OpenAI: O futuro da AGI assemelha-se mais à colaboração de diversos Agents especializados do que a um modelo único : Greg Brockman, da OpenAI, acredita que a forma futura da inteligência artificial geral (AGI) será mais parecida com um “jardim zoológico” composto por numerosos agentes inteligentes especializados (Agents), em vez de um modelo único e omnipotente tipo “monólito”. Estes Agents especializados serão capazes de se invocar mutuamente, trabalhar em colaboração e impulsionar conjuntamente o desenvolvimento económico. Esta perspetiva sugere uma tendência no desenvolvimento futuro da IA, nomeadamente, alcançar sistemas inteligentes mais complexos e poderosos através da construção e integração de múltiplos AI Agents com capacidades específicas, com o objetivo de desbloquear 10 vezes mais atividade e produção. Clement Delangue comentou sobre isto, afirmando a necessidade de tecnologia robótica de IA de código aberto para quebrar monopólios e evitar que uma única empresa controle todos os robôs (Fonte: natolambert, ClementDelangue, HamelHusain)
LLMs demonstram potencial na escrita académica e resumo de conteúdo, levantando questões sobre a qualidade da escrita humana : Dwarkesh Patel considera que os LLMs são atualmente escritores “5/10”, mas o facto de conseguirem melhorar de forma fiável as explicações em artigos e livros é, por si só, uma enorme condenação da qualidade da escrita académica. Arvind Narayanan acrescenta que a maioria da escrita académica tende a sacrificar a clareza e a facilidade de compreensão em prol de uma aparência erudita e complexa, enquanto a boa escrita deve primar pela concisão. Isto desencadeou uma discussão sobre o papel dos LLMs no apoio à investigação académica, na melhoria da legibilidade do conteúdo e em como poderão transformar as formas de comunicação académica no futuro (Fonte: random_walker, jeremyphoward)
Ferramentas de codificação AI geram discussão sobre dependência dos programadores, Claude Code em foco pelas suas poderosas funcionalidades e alto consumo de Tokens : O utilizador dotey acredita que o uso de ferramentas de programação AI (como Claude Code) pode facilmente levar a uma forte dependência, ao ponto de, mesmo tendo créditos, preferir esperar que a AI complete a tarefa em vez de a escrever manualmente. Embora a subscrição Claude Max tenha um limite, as suas poderosas capacidades de codificação (como excelente compreensão de instruções, planeamento de tarefas, uso da ferramenta grep e longos tempos de execução) tornam-na uma ferramenta eficiente. Este fenómeno levanta discussões sobre como as ferramentas de AI estão a mudar os hábitos de trabalho dos programadores e o equilíbrio entre eficiência e dependência. Outro utilizador, Asuka小能猫, também demonstrou um caso de uso eficiente do Claude-4-Opus e do modo Cursor Max para desenvolvimento frontend, mas também mencionou o problema do consumo de Tokens (Fonte: dotey, dotey)
Educação personalizada impulsionada por IA tem enorme potencial, mas requer atenção aos desafios de implementação : Austen Allred partilhou a experiência do seu filho numa escola impulsionada por IA (sem professores) durante cinco meses, considerando os resultados “loucos”. Noah Smith comentou que o ensino individualizado é uma intervenção educativa eficaz, e a IA torna possível a sua massificação. Isto gerou discussões sobre as aplicações da IA no setor da educação, incluindo percursos de aprendizagem personalizados, o potencial dos tutores de IA, e como garantir a equidade educacional e superar os desafios técnicos de implementação. Jon Stokes reencaminhou e demonstrou interesse nesta tendência (Fonte: jonst0kes, jeremyphoward)
Ligação emocional entre AI Agents e humanos gera atenção, OpenAI enfatiza investigação prioritária sobre o bem-estar do utilizador : Joanne Jang, da OpenAI, publicou um artigo de blogue discutindo a relação entre humanos e IA e a atitude da empresa em relação a isso. A ideia central é que a OpenAI constrói modelos para servir as pessoas em primeiro lugar e, à medida que mais pessoas desenvolvem ligações emocionais com a IA, a empresa está a dar prioridade à investigação sobre o impacto disso no bem-estar emocional dos utilizadores. Corbtt comentou que os companheiros de IA são a tecnologia social mais transformadora desde a internet e que, se as empresas otimizarem o envolvimento em vez da saúde mental, o impacto negativo nas crianças poderá ser maior do que o das redes sociais, mas se otimizarem a saúde mental, poderá ser uma bênção para a humanidade. cto_junior previu humoristicamente cenários futuros onde poderá ser necessário discutir com os filhos se “é apropriado casar com um GPT” (Fonte: cto_junior, corbtt)

Tecnologia de AI Agent desenvolve-se rapidamente, mas tarefas de aprendizagem por reforço esparsas end-to-end continuam a ser um desafio : Nathan Lambert considera que os projetos atuais como Deep Research, Codex agent, etc., são alcançados principalmente através do treino de modelos em tarefas de aprendizagem por reforço (RL) de curto alcance e robustez geral. No entanto, treinar end-to-end em tarefas de RL muito esparsas parece estar mais distante do que se imagina. Corbtt comentou sobre isto, afirmando que mesmo os humanos ainda não dominam eficazmente como treinar em tarefas de longo alcance e com sinais de recompensa esparsos. Isto reflete as limitações atuais da tecnologia de AI Agent no tratamento de planeamento complexo e de longo prazo e na aprendizagem autónoma (Fonte: corbtt)
A “lição amarga” no campo da IA: A verificação (Verification) torna-se crucial para LLMs de raciocínio : Rishabh Agarwal apresentou uma palestra no workshop de raciocínio multimodal da CVPR intitulada “A lição amarga do RL: A verificação como chave para LLMs de raciocínio”. A palestra, inspirada no artigo clássico de Rich Sutton sobre a “lição amarga”, explorou a importância dos mecanismos de verificação no raciocínio de aprendizagem por reforço e modelos de linguagem grandes. Isto pode significar que depender apenas da capacidade de geração do próprio modelo não é suficiente, e que mecanismos robustos de verificação e feedback são cruciais para melhorar a capacidade de raciocínio e a fiabilidade da IA (Fonte: jack_w_rae)

Desenvolvimento da IA levanta preocupações no mercado de trabalho, opiniões de especialistas divergem : Sebastian Siemiatkowski, CEO da Klarna, alertou que a IA pode desencadear uma recessão económica ao causar desemprego em massa (especialmente em trabalhos de colarinho branco). A própria Klarna já substituiu 700 funcionários de atendimento ao cliente por um assistente de IA, poupando cerca de 40 milhões de dólares anuais. Sholto Douglas, investigador da Anthropic, também previu que até 2027-28, as capacidades da IA serão muito poderosas. No entanto, há também quem defenda que a IA aumentará a produtividade e criará novos postos de trabalho, como Sundar Pichai, que afirmou que a IA será um acelerador e não causará despedimentos, pelo menos até 2026. Um vídeo do AI Explained analisou se as atuais manchetes sobre o desemprego causado pela IA são justificadas e discutiu algumas reviravoltas nas aplicações de IA do Duolingo e da Klarna. Estas discussões refletem a ansiedade social generalizada e as diferentes expectativas em relação ao impacto económico da IA (Fonte: , Reddit r/ArtificialInteligence, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
Exploração do futuro da interação entre AI Agents e redes/APIs existentes : Com o aumento da capacidade de interação autónoma dos AI Agents com a rede, a forma como interagem com a Web/APIs existentes torna-se uma questão de infraestrutura fundamental. A discussão levantou três caminhos possíveis: 1. Reconstruir do zero, adotando protocolos nativos de Agent (irrealista); 2. Ensinar os Agents a operar websites como humanos (alta taxa de erro, especialmente na autenticação); 3. Fazer com que o HTTP “fale a linguagem do Agent”, por exemplo, enriquecendo respostas não bem-sucedidas como 402 (pagamento necessário) com contexto legível por máquina, permitindo que os Agents validem e comprem acesso autonomamente. A ideia central é que fornecer contexto rico para interações Web/API não bem-sucedidas será crucial para que os Agents autónomos realizem trabalho significativo, permitindo-lhes recuperar automaticamente de erros e navegar em processos complexos (Fonte: Reddit r/ArtificialInteligence)
Investigação em matemática assistida por IA avança, com Terence Tao e outros atentos ao seu potencial e limitações : Matemáticos estão a explorar ativamente a aplicação da IA na resolução de problemas matemáticos complexos. Terence Tao partilhou casos em que a IA (AlphaEvolve) colaborou com humanos para quebrar recordes do índice de conjuntos soma-diferença três vezes em 30 dias, e combinou a linguagem Lean e o GitHub Copilot para enfrentar o problema dos limites “ε-δ”, demonstrando a capacidade da IA em auxiliar iniciantes, lidar com tarefas básicas e prever estruturas de prova, mas também apontando as suas deficiências em derivações complexas e na procura de lemas matemáticos. Outro relatório indica que 30 matemáticos de topo testaram o OpenAI o4-mini numa reunião secreta, descobrindo que conseguia resolver alguns problemas extremamente difíceis, demonstrando um nível próximo ao de um génio matemático. Estes avanços indicam que a IA pode tornar-se uma assistente valiosa na investigação matemática, mas também levantam novas questões sobre o papel dos matemáticos e o desenvolvimento da criatividade (Fonte: 36氪)

💡 Outros
Corrida por alternativas ao GPS aquece, Xona Space Systems planeia construir constelação PNT de órbita baixa : Devido à suscetibilidade do sistema GPS a interferências (condições meteorológicas, torres 5G, bloqueadores) e à sua precisão limitada, especialmente evidenciada no conflito Rússia-Ucrânia, a procura por alternativas tornou-se uma prioridade estratégica. A startup californiana Xona Space Systems planeia lançar uma constelação de satélites de órbita terrestre baixa chamada Pulsar (eventualmente 258 satélites). Os seus satélites orbitam a uma altitude inferior, com um sinal cerca de 100 vezes mais forte que o do GPS, mais difícil de interferir e com melhor capacidade de penetrar obstáculos. O objetivo é fornecer serviços de posicionamento, navegação e temporização (PNT) com precisão centimétrica e alta fiabilidade, para apoiar tecnologias emergentes como a condução autónoma. O primeiro satélite de teste será lançado este mês a bordo do SpaceX Transporter 14 (Fonte: MIT Technology Review)

Estudo explora o impacto positivo da esperança e do otimismo na recuperação de pacientes cardíacos : Investigações recentes indicam que a esperança e o otimismo em pacientes cardíacos estão associados a melhores resultados de saúde, enquanto o desespero está ligado a um maior risco de mortalidade. Isto é consistente com os fenómenos do efeito placebo (expectativas positivas melhoram os resultados) e do efeito nocebo (expectativas negativas levam a sintomas negativos). Alexander Montasem e outros investigadores da Universidade de Liverpool descobriram que um alto nível de esperança está associado à redução da angina, diminuição da fadiga pós-AVC, melhoria da qualidade de vida e redução do risco de morte. Os investigadores estão a explorar como utilizar o poder do pensamento positivo na prática clínica, por exemplo, “prescrevendo esperança” ao ajudar os pacientes a definir metas e aumentar a sua agência, enfatizando ao mesmo tempo que objetivos não materiais são mais importantes para o bem-estar (Fonte: MIT Technology Review)

Promoção de serviços de IA da Apple e Alibaba na China enfrenta obstáculos, possivelmente devido a tensões comerciais : Segundo o Financial Times, os planos de promoção de serviços de IA da Apple e Alibaba na China sofreram atrasos, considerados a mais recente vítima das tensões comerciais sino-americanas. A colaboração previa originalmente fornecer suporte de funcionalidades de IA para iPhones vendidos na China. Este atraso pode afetar o cronograma de implementação das funcionalidades de IA da Apple no mercado chinês e trazer incerteza às perspetivas de cooperação entre as duas empresas (Fonte: MIT Technology Review)