
Palavras-chave:Gemini 2.5 Pro, VeBrain, Segment Anything Model 2, Qwen3-Embedding, AI Agent, Modo Deep Think do Gemini 2.5 Pro, Framework VeBrain de Inteligência Embutida Universal, Segmentação de Imagem e Vídeo SAM 2, Qwen3-Embedding com contexto de 32k, AI Agent com compreensão multimodal
🔥 Foco
Google anuncia múltiplos novos avanços em IA, modo Deep Think do Gemini 2.5 Pro melhora a capacidade de raciocínio complexo: Na conferência Google I/O, o Google anunciou o modo Deep Think do Gemini 2.5 Pro, com o objetivo de aumentar significativamente a capacidade de raciocínio da IA ao lidar com problemas complexos (como problemas matemáticos de nível USAMO). Ao mesmo tempo, o Google também lançou o AlphaEvolve, um agente de codificação alimentado pelo Gemini para descoberta de algoritmos, que já obteve resultados no design de algoritmos de multiplicação de matrizes e na resolução de problemas matemáticos abertos, e é aplicado para otimizar os data centers internos do Google, o design de chips e a eficiência do treino de IA. Além disso, o modelo de vídeo Veo 3, o modelo de imagem Imagen 4 e a ferramenta de edição de IA FLOW também foram lançados, demonstrando o layout abrangente e o rápido progresso do Google no campo da IA multimodal. (Fonte: OriolVinyalsML, demishassabis, demishassabis, op7418)
Laboratório de IA de Xangai lança conjuntamente framework universal de cérebro de inteligência incorporada VeBrain: O Laboratório de Inteligência Artificial de Xangai, em colaboração com várias unidades, lançou o VeBrain (Visual Embodied Brain), um framework universal de cérebro de inteligência incorporada que visa unificar as capacidades de perceção visual, raciocínio espacial e controlo de robôs. O framework transforma tarefas de controlo de robôs em tarefas de texto espacial 2D em MLLM (como deteção de pontos-chave e reconhecimento de habilidades incorporadas) e introduz um “adaptador de robô” para alcançar um mapeamento preciso e controlo em ciclo fechado desde a decisão baseada em texto até à ação real. Para apoiar o treino do modelo, a equipa construiu o dataset VeBrain-600k, contendo 600.000 instruções, cobrindo três tipos de tarefas: compreensão multimodal, raciocínio visual-espacial e operação de robôs. Os testes mostram que o VeBrain atinge o nível SOTA (State-of-the-Art) em compreensão multimodal, raciocínio espacial e controlo de robôs reais (braço mecânico e cão-robô). (Fonte: 量子位)

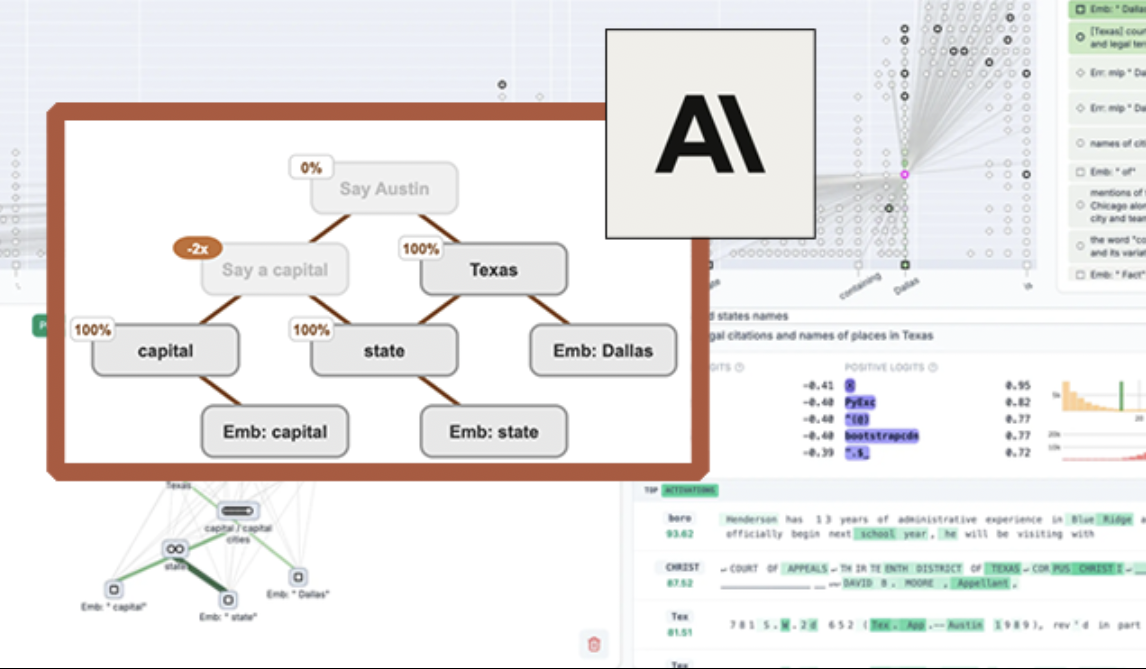
Anthropic lança ferramenta de visualização de LLM de código aberto “circuit tracing”, melhorando a interpretabilidade do modelo: A Anthropic lançou a ferramenta de código aberto “circuit tracing”, destinada a ajudar os investigadores a compreender os mecanismos internos de funcionamento dos grandes modelos de linguagem (LLM). A ferramenta gera “attribution graphs”, visualizando os supernós internos e as suas relações de conexão quando o modelo processa informações, de forma semelhante a um diagrama de rede neural. Os investigadores podem verificar a função de cada nó intervindo nos seus valores de ativação e observando as alterações no comportamento do modelo, decodificando assim a lógica de decisão do LLM. A ferramenta suporta a geração de attribution graphs nos principais modelos de código aberto e fornece uma interface frontend interativa, Neuronpedia, para visualização, anotação e partilha. Esta iniciativa visa promover a investigação em interpretabilidade da IA, permitindo que uma comunidade mais ampla explore e compreenda o comportamento dos modelos. (Fonte: 量子位, swyx)
Meta lança Segment Anything Model 2 (SAM 2), melhorando a capacidade de segmentação de imagens e vídeos: O Meta AI Research (FAIR) lançou o SAM 2, uma versão atualizada do seu popular Segment Anything Model. O SAM 2 é um modelo fundamental focado em tarefas de segmentação visual orientada por prompts (promptable) em imagens e vídeos, capaz de identificar e segmentar com precisão objetos ou regiões específicas numa imagem ou vídeo com base em prompts (como pontos, caixas, texto). O modelo está agora em código aberto, seguindo a licença Apache, para que investigadores e programadores o utilizem e construam aplicações gratuitamente, impulsionando ainda mais o desenvolvimento no campo da visão computacional. (Fonte: AIatMeta)
🎯 Tendências
Instituto de Investigação de Pequim lança Video-XL-2 de código aberto, alcançando compreensão de vídeo de dezenas de milhares de frames com uma única placa: O Instituto de Investigação de Pequim (BAAI), em colaboração com a Universidade Jiao Tong de Xangai e outras instituições, lançou o modelo de compreensão de vídeo ultralongo de nova geração, Video-XL-2. Este modelo apresenta melhorias significativas em termos de eficácia, comprimento de processamento e velocidade, conseguindo processar entradas de vídeo de dezenas de milhares de frames com uma única placa e codificar 2048 frames de vídeo em apenas 12 segundos. O Video-XL-2 utiliza o codificador visual SigLIP-SO400M, um módulo de síntese dinâmica de Token (DTS) e o grande modelo de linguagem Qwen2.5-Instruct. Alcança alto desempenho através de um treino progressivo de quatro estágios e estratégias de otimização de eficiência (como pré-carregamento segmentado e decodificação KV de dupla granularidade). O modelo demonstrou um desempenho excelente nos benchmarks MLVU, Video-MME, entre outros, e os seus pesos foram disponibilizados em código aberto. (Fonte: 量子位)

Character.ai lança funcionalidade de geração de vídeo AvatarFX, permitindo que personagens de imagens se movam e interajam: A Character.ai (c.ai), aplicação líder em companhia de IA, lançou a funcionalidade AvatarFX, que permite aos utilizadores animar personagens de imagens estáticas (incluindo figuras não humanas como animais de estimação), fazendo-os falar, cantar e interagir com os utilizadores. A funcionalidade é baseada na arquitetura DiT, enfatizando alta fidelidade e consistência temporal, mantendo a estabilidade mesmo em cenários complexos como diálogos com múltiplos personagens e sequências longas. Atualmente, o AvatarFX está disponível para todos os utilizadores na versão web, e será lançado em breve na aplicação. Simultaneamente, a c.ai também anunciou novas funcionalidades como Scenes (cenários de histórias interativas), Imagine Animated Chat (histórico de chat animado) e Stream (geração de histórias entre personagens), enriquecendo ainda mais a experiência de criação com IA. (Fonte: 量子位)

Nvidia lança modelo de linguagem visual Llama-3.1 Nemotron-Nano-VL-8B-V1: A Nvidia lançou um novo modelo de visão para texto, Llama-3.1-Nemotron-Nano-VL-8B-V1. Este modelo é capaz de processar entradas de imagem, vídeo e texto, e gerar saídas de texto, possuindo um certo grau de capacidade de raciocínio e reconhecimento de imagem. O lançamento deste modelo reflete o investimento contínuo da Nvidia no campo da IA multimodal. Ao mesmo tempo, discussões na comunidade apontam que o abandono de modelos abaixo de 70B pelo Llama-4 pode trazer oportunidades para modelos como Gemma3 e Qwen3 no mercado de fine-tuning. (Fonte: karminski3)
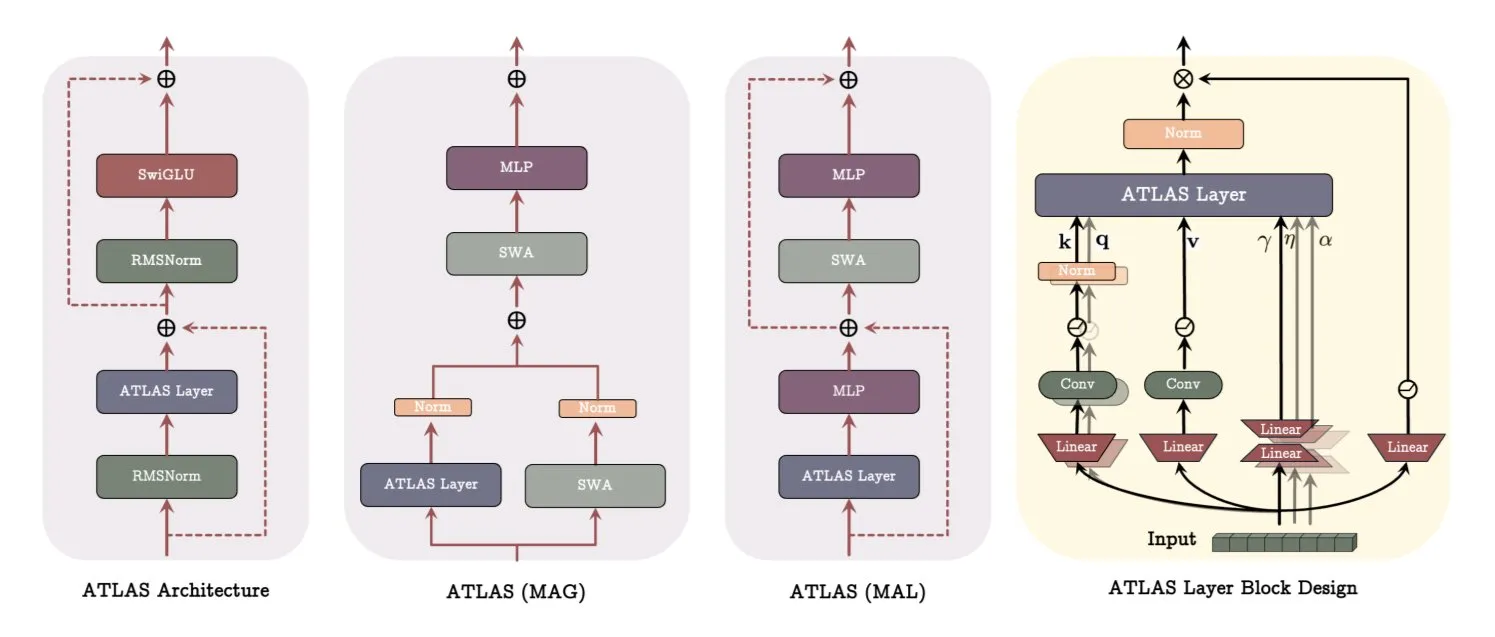
Google publica artigo sobre a arquitetura ATLAS, revolucionando a forma como os modelos aprendem e memorizam: Um artigo recente do Google apresenta uma nova arquitetura de modelo chamada ATLAS, que visa otimizar as capacidades de aprendizagem e memória do modelo através de memória ativa (regra Omega para processar os c tokens mais recentes) e uma gestão mais inteligente da capacidade de memória (mapeamento de características polinomiais e exponenciais). O ATLAS utiliza o otimizador Muon para atualizações de memória mais eficazes e introduz designs como DeepTransformers e Dot (Deep Omega Transformers), substituindo a atenção fixa tradicional por mecanismos aprendíveis e orientados pela memória. Esta investigação marca um avanço da IA em direção a sistemas mais inteligentes e sensíveis ao contexto, com potencial para melhorar a capacidade da IA de processar e utilizar grandes conjuntos de dados. (Fonte: TheTuringPost)
Qwen lança a série de modelos Qwen3-Embedding, melhorando significativamente o desempenho de embedding: A equipa Qwen lançou a nova série de modelos Qwen3-Embedding, incluindo três versões: 0.6B, 4B e 8B. Estes modelos suportam um comprimento de contexto de até 32k e 100 idiomas, alcançando resultados SOTA (State-of-the-Art) no MTEB (Massive Text Embedding Benchmark), com alguns indicadores a superar o segundo classificado em 10 pontos. Este avanço marca mais um importante progresso na tecnologia de embedding de texto, fornecendo uma base mais poderosa para aplicações como pesquisa semântica e RAG. (Fonte: AymericRoucher, ClementDelangue)

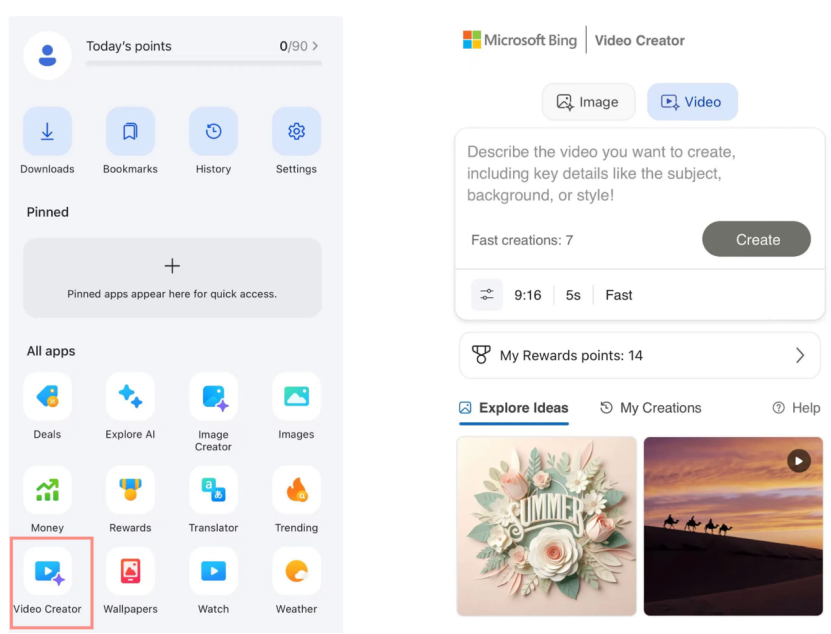
Criador de Vídeo Bing da Microsoft é lançado, baseado no modelo Sora da OpenAI e disponível gratuitamente: A Microsoft lançou o Bing Video Creator na sua aplicação Bing. Esta funcionalidade, baseada no modelo Sora da OpenAI, permite aos utilizadores gerar vídeos gratuitamente através de prompts de texto. Esta é a primeira vez que o modelo Sora é disponibilizado gratuitamente ao público em larga escala. Apesar de gratuito, existem atualmente limitações funcionais, como a duração do vídeo de apenas 5 segundos, proporção de 9:16 e velocidade de geração relativamente lenta. O feedback dos utilizadores indica que os seus resultados apresentam uma lacuna em comparação com os modelos de vídeo SOTA atuais (como Kuaishou Kling, Veo3), o que gerou discussões sobre a velocidade de iteração da tecnologia Sora e a estratégia de produto da Microsoft. (Fonte: 36氪)
OpenAI lança múltiplas funcionalidades de nível empresarial, melhorando a integração no local de trabalho: A OpenAI lançou uma série de novas funcionalidades direcionadas a utilizadores empresariais, incluindo conectores dedicados para aplicações como o Google Drive, bem como a implementação de funcionalidades de gravação, transcrição e resumo de reuniões no ChatGPT, suportando também SSO (Single Sign-On) e preços para a versão empresarial baseados em créditos. Estas atualizações visam integrar mais profundamente o ChatGPT nos fluxos de trabalho empresariais, aumentando a eficiência no escritório. (Fonte: TheRundownAI, EdwardSun0909)
Hugging Face lança modelo de robótica eficiente SmolVLA, executável em MacBook: A Hugging Face lançou um modelo de robótica chamado SmolVLA, caracterizado pela sua eficiência extremamente alta, podendo até ser executado num MacBook. Após o fine-tuning com uma pequena quantidade de dados de demonstração (como 31), este modelo pode atingir ou superar o desempenho de baselines de tarefa única em tarefas específicas (como a operação do Koch Arm), demonstrando o seu potencial para a implementação de IA robótica em ambientes com recursos limitados. (Fonte: mervenoyann, sytelus)
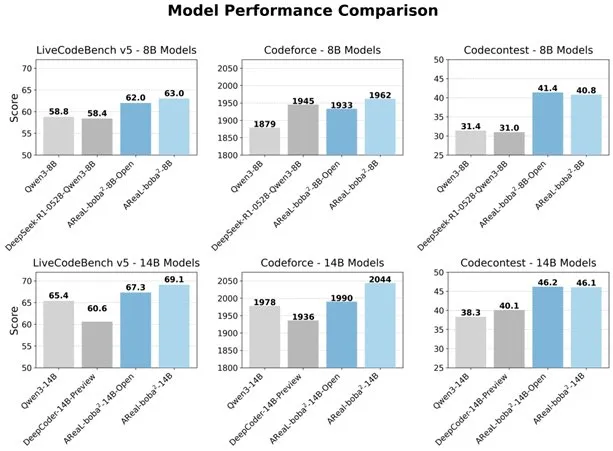
Alibaba lança sistema RL totalmente assíncrono AReaL-boba² de código aberto, melhorando a capacidade de codificação de LLM: A equipa Qwen do Alibaba lançou o sistema de aprendizagem por reforço totalmente assíncrono AReaL-boba² de código aberto, projetado especificamente para grandes modelos de linguagem (LLM), e alcançou resultados SOTA (State-of-the-Art) em aprendizagem por reforço para código no Qwen3-14B. Através do design coordenado de sistema e algoritmo, este sistema alcançou uma aceleração de treino de 2,77 vezes, atingindo 69,1 pontos no LiveCodeBench, e suporta aprendizagem por reforço de múltiplas rondas. (Fonte: _akhaliq)
DuckDB lança extensão DuckLake, integrando data lakes com formatos de catálogo: O DuckDB lançou a extensão DuckLake, um formato de lakehouse aberto baseado em SQL e Parquet. O DuckLake armazena metadados numa base de dados de catálogo e os dados em ficheiros Parquet. Através desta extensão, o DuckDB pode ler e escrever diretamente dados no DuckLake, suportando a criação, modificação, consulta de tabelas, viagem no tempo (time travel) e evolução de esquema, entre outras funcionalidades, com o objetivo de simplificar a construção e gestão de data lakes. (Fonte: GitHub Trending)
Lançamento do SDK Ruby para Model Context Protocol (MCP): O Model Context Protocol (MCP) lançou o seu SDK Ruby oficial, mantido em colaboração com a Shopify, para a implementação de servidores MCP. O MCP visa fornecer uma forma padronizada para modelos de IA (especialmente Agentes) descobrirem e invocarem ferramentas, acederem a recursos e executarem prompts predefinidos. Este SDK suporta JSON-RPC 2.0 e oferece funcionalidades centrais como registo de ferramentas, gestão de prompts e acesso a recursos, facilitando aos programadores a construção de aplicações de IA em conformidade com a especificação MCP. (Fonte: GitHub Trending)
Tecnologia de IA ajuda baterias de zinco a alcançar 99,8% de eficiência e 4300 horas de funcionamento: Através da otimização por inteligência artificial, uma nova geração de baterias de zinco alcançou 99,8% de eficiência Coulombiana e um tempo de funcionamento de até 4300 horas. A aplicação da IA no campo da ciência dos materiais, especialmente no design e previsão de desempenho de baterias, está a impulsionar avanços na tecnologia de armazenamento de energia, com potencial para trazer soluções energéticas mais eficientes e duradouras para áreas como veículos elétricos e dispositivos eletrónicos portáteis. (Fonte: Ronald_vanLoon)

🧰 Ferramentas
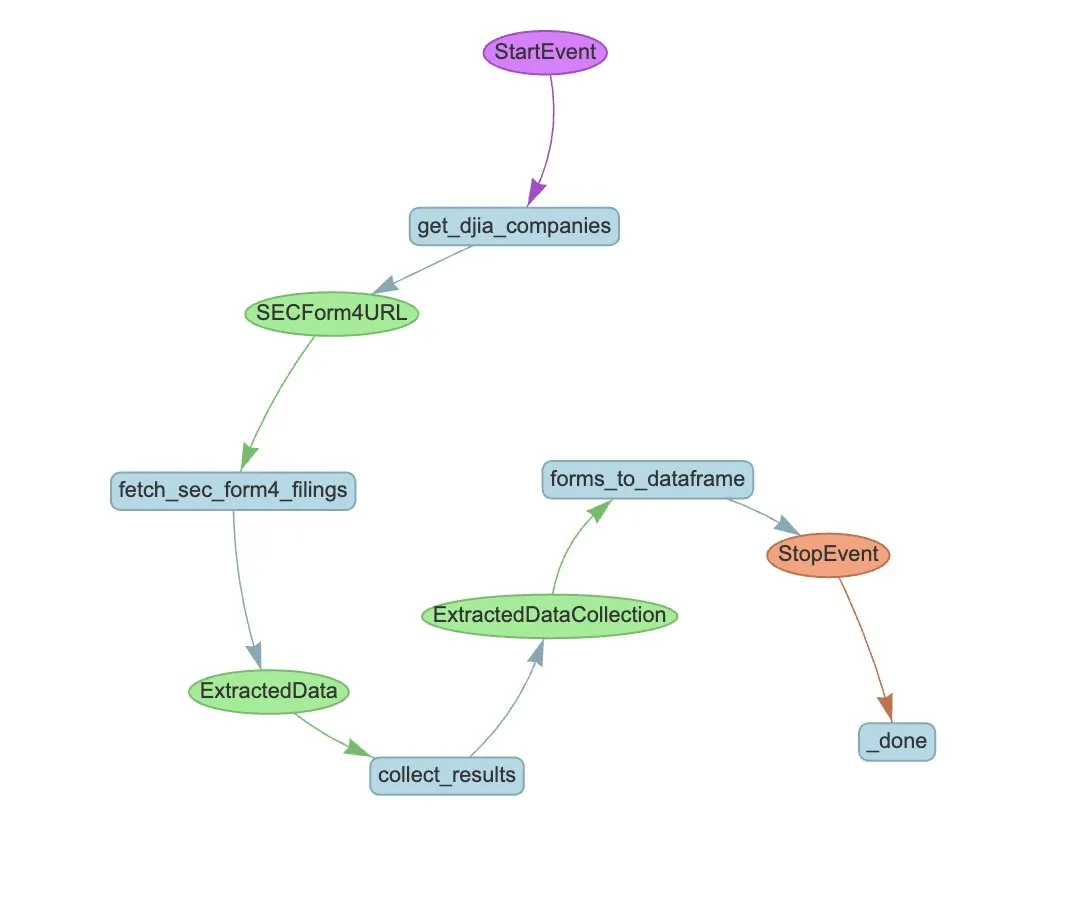
LlamaIndex lança LlamaExtract e workflow de Agente para automatizar extração de SEC Form 4: O LlamaIndex demonstrou como usar o LlamaExtract e workflows de Agente para extrair automaticamente informações estruturadas de ficheiros SEC Form 4. O SEC Form 4 é um documento importante para executivos, diretores e principais acionistas de empresas cotadas em bolsa divulgarem transações de ações. Ao construir agentes de extração e workflows escaláveis, é possível processar eficientemente os registos Form 4 de todas as empresas do Dow Jones Industrial Average, aumentando a transparência do mercado e a eficiência da análise de dados. (Fonte: jerryjliu0)
Cognee: Ferramenta de código aberto que fornece memória dinâmica para Agentes de IA: Cognee é um projeto de código aberto que visa fornecer capacidade de memória dinâmica para Agentes de IA, alegando integração com apenas 5 linhas de código. Constrói pipelines ECL (Extract, Cognify, Load) escaláveis e modulares, ajudando os Agentes a interligar e recuperar conversas passadas, documentos, imagens e transcrições de áudio, para substituir os sistemas RAG tradicionais, reduzir a dificuldade e os custos de desenvolvimento, e suportar o processamento e carregamento de dados de mais de 30 fontes de dados. (Fonte: GitHub Trending)
Claude Code agora disponível para utilizadores Pro e lança GitHub Action versão comunitária: O assistente de programação de IA da Anthropic, Claude Code, está agora disponível para subscritores Pro, que podem utilizá-lo através de plugins para IDEs JetBrains, entre outros. Programadores da comunidade também lançaram uma versão fork do Claude Code GitHub Action, permitindo que utilizadores pagantes invoquem diretamente o Claude Code em Issues ou PRs do GitHub, utilizando as suas quotas de subscrição para completar tarefas como revisão de código e resposta a perguntas, sem custos adicionais de API. (Fonte: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
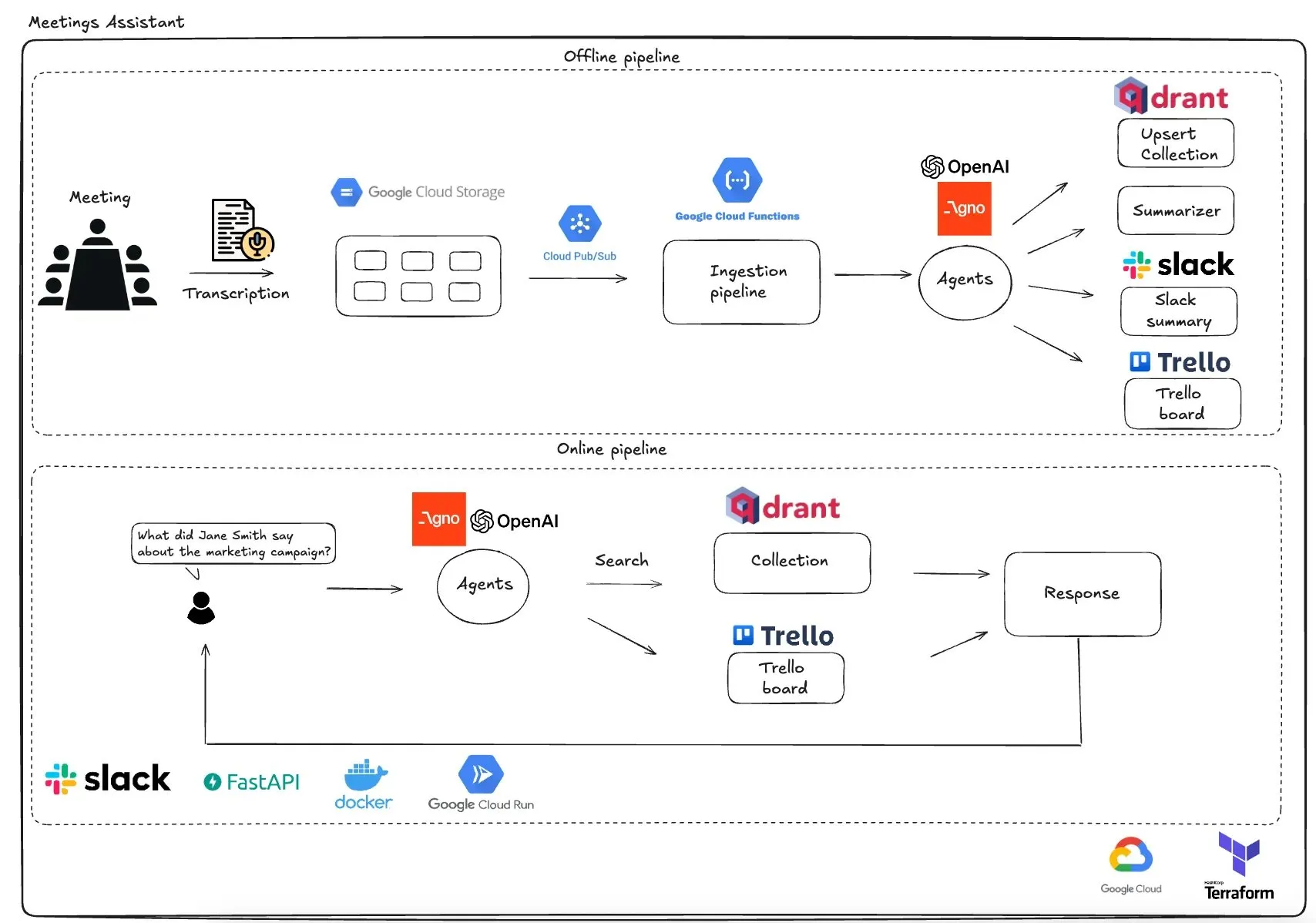
Qdrant lança assistente de reunião multiagente baseado em GCP: A Qdrant apresentou um sistema de assistente de reunião multiagente totalmente serverless. Este sistema é capaz de transcrever o conteúdo da reunião, usar agentes LLM para resumir, armazenar informações contextuais na base de dados vetorial Qdrant e sincronizar tarefas com o Trello, com os resultados finais entregues diretamente no Slack. O sistema utiliza AgnoAgi para orquestração de agentes, FastAPI executado no Cloud Run e OpenAI para embeddings e inferência. (Fonte: qdrant_engine)
Microsoft lança GUI-Actor, permitindo localização de elementos GUI sem coordenadas: A Microsoft lançou no Hugging Face o GUI-Actor, um método de localização de elementos de interface gráfica do utilizador (GUI) sem necessidade de coordenadas. Este método permite que agentes de IA apontem diretamente para blocos visuais (visual patches) nativos através de um token especial <actor>, em vez de dependerem de previsões de coordenadas baseadas em texto, com o objetivo de melhorar a precisão e robustez da operação de agentes GUI. (Fonte: _akhaliq)

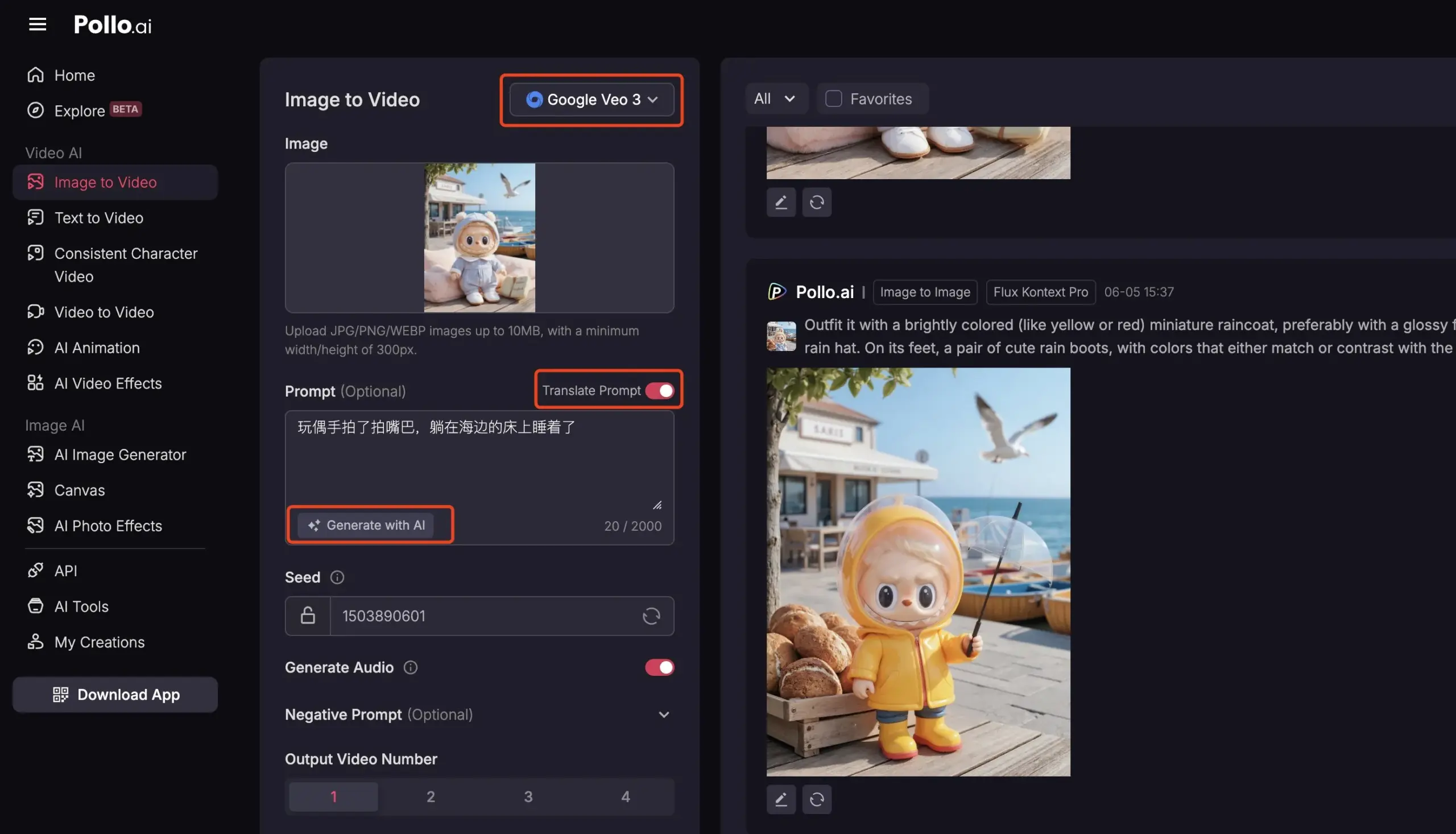
Pollo AI integra Veo3 e FLUX Kontext, oferecendo serviços abrangentes de vídeo com IA: A plataforma de ferramentas de IA Pollo AI tem sido atualizada frequentemente, integrando o modelo de geração de vídeo Google Veo3 e a funcionalidade de edição de imagem FLUX Kontext. Os utilizadores podem modificar imagens na plataforma usando o FLUX Kontext e enviá-las diretamente para o Veo3 para gerar vídeos. A plataforma também oferece uma interface API, suportando o acesso a vários modelos de vídeo de grande porte do mercado de uma só vez, e inclui funcionalidades auxiliares como geração de prompts de IA e tradução multilingue, com o objetivo de aumentar a conveniência e eficiência da criação de vídeo com IA. (Fonte: op7418)
📚 Aprendizagem
Análise aprofundada do Meta-Learning: Ensinar a IA a aprender a aprender: O Meta-Learning (meta-aprendizagem), também conhecido como “aprender a aprender”, tem como ideia central treinar modelos para que se possam adaptar rapidamente a novas tarefas, mesmo com poucas amostras. Este processo geralmente envolve dois modelos: um aprendiz base (base-learner) que aprende rapidamente a adaptar-se a tarefas específicas (como classificação de imagens com poucas amostras – few-shot) num ciclo de aprendizagem interno, e um meta-aprendiz (meta-learner) que gere e atualiza os parâmetros ou estratégias do aprendiz base num ciclo de aprendizagem externo, para melhorar a sua capacidade de resolver novas tarefas. Após o treino, o aprendiz base utilizará o conhecimento aprendido pelo meta-aprendiz para a sua inicialização. (Fonte: TheTuringPost, TheTuringPost)

Interpretação do artigo 《A Controllable Examination for Long-Context Language Models》: Este artigo aborda as limitações das atuais estruturas de avaliação de modelos de linguagem de contexto longo (LCLM) (complexidade e dificuldade de resolução de tarefas do mundo real, suscetibilidade à contaminação de dados; tarefas sintéticas como NIAH carecem de coerência contextual) e propõe três características que uma estrutura de avaliação ideal deve possuir: contexto contínuo, configuração controlável e avaliação robusta. Apresenta também o LongBioBench, um novo benchmark que utiliza biografias geradas artificialmente como ambiente controlado para avaliar LCLMs nas dimensões de compreensão, raciocínio e fiabilidade. As experiências mostram que a maioria dos modelos ainda apresenta deficiências na compreensão semântica, raciocínio preliminar e fiabilidade em contextos longos. (Fonte: HuggingFace Daily Papers)
Interpretação do artigo 《Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning》: Inspirado pela notável capacidade de raciocínio do Deepseek-R1 em tarefas textuais complexas, este estudo explora como melhorar a capacidade de raciocínio complexo de modelos de linguagem grandes multimodais (MLLM) através da otimização do arranque a frio (cold start) e da aprendizagem por reforço (RL) por etapas. A investigação descobriu que uma inicialização eficaz de arranque a frio é crucial para melhorar o raciocínio dos MLLM, e que a inicialização apenas com dados textuais cuidadosamente selecionados pode superar muitos modelos existentes. O GRPO padrão, quando aplicado à RL multimodal, apresenta problemas de estagnação de gradiente, enquanto o treino subsequente de RL puramente textual pode reforçar ainda mais o raciocínio multimodal. Com base nestas descobertas, os investigadores lançaram o ReVisual-R1, que alcançou resultados SOTA (State-of-the-Art) em vários benchmarks desafiadores. (Fonte: HuggingFace Daily Papers)
Interpretação do artigo 《Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem》: Este estudo propõe um método eficiente para libertar o potencial de raciocínio de LLMs pré-treinados: fine-tuning crítico de um único problema (Critique Fine-Tuning, CFT). Ao recolher múltiplas soluções geradas pelo modelo para um único problema e utilizando um LLM professor para fornecer críticas detalhadas, constroem-se dados críticos para o fine-tuning. As experiências mostram que, após o CFT de um único problema em modelos das séries Qwen e Llama, obtiveram-se melhorias significativas de desempenho em várias tarefas de raciocínio. Por exemplo, o Qwen-Math-7B-CFT melhorou em média 15-16% em benchmarks de raciocínio matemático e lógico, com um custo computacional muito inferior ao da aprendizagem por reforço. (Fonte: HuggingFace Daily Papers)
Interpretação do artigo 《SVGenius: Benchmarking LLMs in SVG Understanding, Editing and Generation》: Para resolver os problemas de cobertura limitada, falta de estratificação de complexidade e paradigma de avaliação fragmentado dos benchmarks existentes para o processamento de SVG (gráficos vetoriais escaláveis), surgiu o SVGenius. É um benchmark abrangente que contém 2377 consultas, cobrindo três dimensões: compreensão, edição e geração. Foi construído com base em dados reais de 24 áreas de aplicação e passou por uma estratificação sistemática de complexidade. Avaliou 22 modelos convencionais através de 8 categorias de tarefas e 18 métricas, revelando as limitações dos modelos atuais no processamento de SVGs complexos e indicando que o treino com reforço de raciocínio é mais eficaz do que a simples expansão da escala. (Fonte: HuggingFace Daily Papers)
Registo de atualizações do Hugging Face Hub publicado: O Hugging Face Hub publicou o seu mais recente registo de atualizações. Os utilizadores podem consultá-lo para conhecer as novas funcionalidades da plataforma, atualizações da biblioteca de modelos, expansão de conjuntos de dados e melhorias na cadeia de ferramentas, entre outras novidades. Isto ajuda os utilizadores da comunidade a manterem-se informados e a utilizarem os mais recentes recursos e capacidades do ecossistema Hugging Face. (Fonte: huggingface, _akhaliq)
Maxime Labonne e outros autores disponibilizam grande quantidade de LLM Notebooks em código aberto: Maxime Labonne, autor do LLM Engineer Handbook, e Iustin Paul disponibilizaram em código aberto uma série de Jupyter Notebooks relacionados com LLMs. Estes Notebooks são ricos em conteúdo, incluindo não só técnicas básicas de fine-tuning, mas também abrangendo avaliação automática, lazy merges, construção de modelos de mistura de especialistas (frankenMoEs) e técnicas de desbloqueio de censura (decensorship), entre outros tópicos avançados, fornecendo recursos práticos valiosos para programadores e investigadores de LLM. (Fonte: maximelabonne)
DeepLearningAI publica o relatório semanal The Batch, discutindo como o AI Fund forma construtores de IA: Andrew Ng, na sua mais recente edição do relatório semanal The Batch, partilhou as experiências e estratégias do AI Fund na formação de talentos e construtores de IA. Esta edição do relatório também abrangeu tópicos atuais como o desempenho dos novos modelos de código aberto da DeepSeek, que rivalizam com os LLMs de topo, a utilização de IA pelo Duolingo para expandir os seus cursos de línguas, o equilíbrio do consumo de energia da IA e o potencial de desinformação de Agentes de IA por links maliciosos. (Fonte: DeepLearningAI)

💼 Negócios
Reddit processa Anthropic, acusando-a de uso não autorizado de dados de utilizadores para treinar IA: O Reddit intentou uma ação judicial contra a empresa de IA Anthropic, acusando-a de usar robôs automatizados para extrair conteúdo do Reddit sem permissão, para treinar os seus modelos de IA (como o Claude), o que constitui quebra de contrato e concorrência desleal. Este caso realça a controvérsia atual sobre a legalidade da extração de dados e do treino de modelos no desenvolvimento da IA, e reflete a crescente importância que as plataformas de conteúdo atribuem à proteção do valor dos seus dados. (Fonte: Reddit r/artificial, Reddit r/ArtificialInteligence, TheRundownAI)

Amazon planeia investir 10 mil milhões de dólares na construção de centros de dados de IA na Carolina do Norte: A Amazon anunciou que irá investir 10 mil milhões de dólares na construção de novos centros de dados na Carolina do Norte para apoiar as suas crescentes necessidades de negócio em IA. Esta iniciativa reflete o investimento contínuo das grandes empresas de tecnologia em infraestruturas de IA, com o objetivo de satisfazer os recursos de computação e armazenamento em larga escala necessários para o treino e inferência de modelos de IA. (Fonte: Reddit r/artificial)

Anthropic reduz acesso à API do modelo Claude para Windsurf.ai, levantando preocupações sobre risco de plataforma: A plataforma de desenvolvimento de aplicações de IA Windsurf.ai revelou que a Anthropic, com menos de 5 dias de aviso prévio, reduziu drasticamente a sua capacidade de acesso à API para os modelos Claude 3.x e Claude 4. Esta medida forçou a Windsurf.ai a procurar urgentemente fornecedores terceiros para garantir o serviço aos utilizadores pagantes e a oferecer aos utilizadores gratuitos e Pro a opção BYOK (Bring Your Own Key). Este incidente intensificou as preocupações dos programadores sobre o risco de plataforma dos fornecedores de modelos de IA, nomeadamente a possibilidade de os fornecedores de modelos ajustarem as suas políticas de serviço a qualquer momento, ou mesmo entrarem em concorrência com as aplicações downstream. (Fonte: swyx, scaling01, mervenoyann)
🌟 Comunidade
Conferência de Engenheiros de IA (@aiDotEngineer) gera debate, focando em design de Agentes e empreendedorismo em IA: A Conferência de Engenheiros de IA (@aiDotEngineer), realizada em São Francisco, tornou-se um ponto focal de discussão na comunidade. A LlamaIndex partilhou padrões de design de Agentes eficazes em ambientes de produção; a Anthropic apresentou na conferência uma “lista de necessidades” para startups, focando na aplicação de servidores MCP em novas áreas, simplificação da construção de servidores e segurança de aplicações de IA (como envenenamento de ferramentas – tool poisoning); a Graphite demonstrou uma ferramenta de revisão de código impulsionada por IA. A conferência também discutiu desafios de investigação fundamental para escalar a próxima geração de modelos GPT, entre outros tópicos. (Fonte: swyx, swyx, swyx, iScienceLuvr)

Investigador Rohan Anil junta-se à Anthropic, gerando atenção: O investigador Rohan Anil anunciou que se juntará à equipa da Anthropic, uma notícia que gerou ampla atenção e discussão na comunidade de IA. Muitos profissionais da indústria e observadores expressaram os seus parabéns e esperam que ele traga novas contribuições para o trabalho de investigação da Anthropic. Isto também reflete o potencial impacto da mobilidade de talentos de topo em IA no panorama da indústria. (Fonte: arohan, gallabytes, andersonbcdefg, scaling01, zacharynado)
Tribunal exige que OpenAI retenha todos os logs do ChatGPT, gerando discussão sobre políticas de retenção de dados: Soube-se que um tribunal exigiu que a OpenAI retenha todos os logs do ChatGPT, incluindo “chats temporários” e pedidos de API que deveriam ter sido eliminados. Esta notícia gerou discussões na comunidade sobre políticas de retenção de dados, especialmente para aplicações que usam a API da OpenAI. Isto pode significar que as suas próprias políticas de retenção de dados não poderão ser totalmente cumpridas, trazendo novos desafios para a privacidade do utilizador e gestão de dados. Recomenda-se que os utilizadores deem prioridade ao uso de modelos locais, sempre que possível, para proteger os dados. (Fonte: code_star, TomLikesRobots)

Proliferação de conteúdo gerado por IA e fenómeno “AI Slop” geram preocupação: O aumento de conteúdo gerado por IA de baixa qualidade e que visa chamar a atenção (conhecido como “AI Slop”) nas redes sociais, desde publicações geradas por IA no Reddit a imagens de IA como o “Jesus camarão” no Facebook, está a gerar preocupação entre os utilizadores quanto à qualidade da informação e à deterioração do ambiente online. Este conteúdo é geralmente gerado de forma barata por robôs ou por quem procura tráfego, com o objetivo de obter gostos e partilhas através de “iscas de engagement (engagement bait)”. Estudos indicam que uma grande parte do tráfego da Internet já é constituída por “robôs maus”, que disseminam informações falsas e roubam dados. Este fenómeno não só afeta a experiência do utilizador, mas também representa uma ameaça para a democracia e a comunicação política, podendo ao mesmo tempo contaminar os dados de treino de futuros modelos de IA. (Fonte: aihub.org)

Discussão sobre custos de LLM: Gemini com boa relação custo-benefício, custo de codificação do Claude 4 gera atenção: Discussões na comunidade apontam que os custos de utilização dos LLM atuais variam significativamente. Por exemplo, o custo de processar um documento de seguro inteiro com o Gemini e fazer várias perguntas é de apenas cerca de 0,01 dólares, demonstrando uma elevada relação custo-benefício. Em contraste, o modelo Claude 4, embora tenha um bom desempenho em tarefas como codificação, tem um custo de utilização elevado no modo máximo (max mode) em plataformas como Cursor.ai, levando os utilizadores a optar por alternativas mais económicas como o Google Gemini 2.5 Pro. (Fonte: finbarrtimbers, Teknium1)
Agentes de IA enfrentam desafios na resolução de CAPTCHA em cenários reais de páginas web: A equipa MetaAgentX lançou a plataforma Open CaptchaWorld, focada na avaliação da capacidade de agentes interativos multimodais para resolver CAPTCHAs. Os testes mostram que mesmo modelos SOTA (State-of-the-Art) como o GPT-4o, ao lidar com 20 tipos de CAPTCHAs interativos em ambientes reais de páginas web, têm uma taxa de sucesso de apenas 5%-40%, muito abaixo da taxa de sucesso média humana de 93,3%. Isto indica que os atuais Agentes de IA ainda enfrentam estrangulamentos na compreensão visual, planeamento de múltiplos passos, acompanhamento de estado e interação precisa, tornando os CAPTCHAs um grande obstáculo para a sua implementação prática. (Fonte: 量子位)

Mercado de formação de Agentes de IA em alta, qualidade dos cursos e perspetivas de emprego geram atenção: Com o surgimento do conceito de Agentes de IA, também surgiram em grande número cursos de formação relacionados. Algumas instituições de formação afirmam oferecer orientação completa, desde o nível básico até à colocação profissional, chegando a prometer “emprego garantido”, com propinas que variam de algumas centenas a dezenas de milhares de yuans. No entanto, a qualidade dos cursos no mercado é desigual, com alguns cursos a serem acusados de conteúdo superficial, marketing excessivo e até mesmo de serem semelhantes aos cursos rápidos de IA que visam “explorar os ingénuos”. Alunos e observadores mantêm uma atitude cautelosa em relação à eficácia real destes cursos, às qualificações dos instrutores e à veracidade das promessas de “emprego garantido”, temendo que possam tornar-se mais uma “falsa necessidade” no período de transição do desenvolvimento da IA. (Fonte: 36氪)

💡 Outros
Avanços na aplicação de IA na robótica: mão com perceção tátil, robô anfíbio e cão-robô bombeiro: A tecnologia de IA está a expandir as fronteiras das capacidades robóticas. Investigadores desenvolveram uma mão mecânica com capacidade de perceção tátil, permitindo-lhe interagir melhor com o ambiente. O Copperstone HELIX Neptune demonstrou um robô anfíbio impulsionado por IA, capaz de operar em diferentes terrenos. A China, por sua vez, lançou um cão-robô bombeiro capaz de projetar jatos de água a 60 metros, subir escadas e transmitir operações de resgate ao vivo. Estes avanços demonstram o potencial da IA para melhorar a perceção, tomada de decisão e execução de tarefas complexas por robôs. (Fonte: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Discussão comparativa entre Agentes de IA e IA Generativa: Surgiu na comunidade uma discussão sobre as diferenças e ligações entre Agentes de IA (IA de Agentes Inteligentes) e IA Generativa (Generative AI). A IA Generativa foca-se principalmente na criação de conteúdo, enquanto os Agentes de IA estão mais orientados para a tomada de decisão autónoma e execução de tarefas baseadas na perceção, planeamento e ação. Compreender as diferenças entre ambos ajuda a entender melhor a direção do desenvolvimento da tecnologia de IA e os seus cenários de aplicação. (Fonte: Ronald_vanLoon, Ronald_vanLoon)
Explorando os desafios da IA na automação de processos organizacionais complexos: A IA progrediu na automação ou assistência a tarefas específicas, mas enfrenta uma enorme complexidade para substituir o trabalho humano ou equipas de forma a alcançar uma transformação económica mais ampla. Muitas organizações possuem processos cruciais não documentados explicitamente, que são de alto risco mas ocorrem esporadicamente, e podem ter-se tornado rotina ao ponto de as suas razões terem sido esquecidas. Os agentes de IA dificilmente aprendem este tipo de conhecimento tácito através de tentativa e erro, devido ao seu custo elevado e oportunidades de aprendizagem limitadas. Isto requer um novo paradigma tecnológico, e não uma simples aprendizagem automática. (Fonte: random_walker)