
Palavras-chave:Colaboração de IA, ChatGPT, Modelo de Linguagem Grande, Programação com IA, Geração de vídeo por IA, Matemática com IA, Segurança de IA, Energia e IA, Interação scriptada com Karpathy UI, Modo de registro de reuniões do ChatGPT, Atualização do modelo DeepSeek-R1, Ataques de phishing com Agente de IA, Expansão de cursos de IA da Duolingo
🔥 Foco
Karpathy prevê um futuro sombrio para aplicações com UI complexas, enfatizando a necessidade de interação por script para colaboração com IA: Andrej Karpathy salienta que, na era da alta colaboração entre humanos e IA, aplicações que dependem apenas de interfaces gráficas de utilizador (UI) complexas e carecem de suporte a scripts enfrentarão dificuldades. Ele acredita que, se os modelos de linguagem grandes (LLM) não conseguirem ler e manipular dados e configurações subjacentes através de scripts, não poderão auxiliar eficazmente os profissionais nem satisfazer a procura dos utilizadores por “vibe coding”. Karpathy lista produtos da série Adobe, estações de trabalho de áudio digital (DAWs), software de design assistido por computador (CAD), entre outros, como exemplos de alto risco, enquanto o VS Code, Figma, etc., são considerados de baixo risco devido à sua natureza amigável a texto. Esta perspetiva gerou debate, centrado na necessidade de as futuras aplicações equilibrarem a intuitividade da UI com a operacionalidade da IA, ou evoluírem para interfaces mais textuais e baseadas em API, mais fáceis de serem compreendidas e interagidas pela IA. (Fonte: karpathy, nptacek, eerac)
OpenAI capacita o ChatGPT com conexão a fontes de dados internas e capacidade de gravação de reuniões: A OpenAI anunciou uma atualização importante para o ChatGPT, incluindo o lançamento do modo de gravação (Record Mode) para macOS, que pode transcrever reuniões, sessões de brainstorming ou notas de voz em tempo real, e extrair automaticamente resumos chave, pontos principais e itens de ação. Ao mesmo tempo, o ChatGPT suporta oficialmente o Protocolo de Contexto de Modelo (MCP), permitindo a conexão com Outlook, Google Drive, Gmail, GitHub, SharePoint, Dropbox, Box, Linear e outras ferramentas empresariais e pessoais comuns, bem como fontes de dados internas, para obter contexto, integrar e realizar inferências inteligentes em dados multiplataforma em tempo real, com o objetivo de transformar o ChatGPT numa plataforma de colaboração inteligente mais poderosa. Esta medida marca um passo crucial para uma integração mais profunda do ChatGPT nos fluxos de trabalho empresariais e cenários de produtividade pessoal. (Fonte: gdb, snsf, op7418, dotey, 36氪)

Reddit processa a Anthropic, acusando-a de extrair dados sem autorização para treinar IA: O Reddit intentou uma ação judicial contra a startup de IA Anthropic, acusando os seus bots de acederem à plataforma Reddit mais de 100.000 vezes sem autorização desde julho de 2024 e de utilizarem dados de utilizadores extraídos para treinar modelos de IA comerciais, sem pagar taxas de licenciamento como fizeram a OpenAI e a Google. O Reddit considera que esta ação viola os seus termos de serviço e o protocolo de exclusão de robôs, e não condiz com a imagem autoproclamada da Anthropic de “cavaleiro branco da indústria de IA”. Este caso destaca as questões das fronteiras legais e éticas na aquisição de dados para o desenvolvimento de IA, bem como as reivindicações de proteção de direitos das plataformas de conteúdo na cadeia de fornecimento de dados de IA. (Fonte: op7418, Reddit r/artificial, The Verge, maginative.com, TechCrunch)

IA alcança progresso na matemática, DeepMind AlphaEvolve inspira matemáticos humanos a atingir novos patamares: O AlphaEvolve da DeepMind alcançou um avanço na resolução do “problema da soma e diferença de conjuntos”, quebrando um recorde de 18 anos que perdurava desde 2007. Subsequentemente, matemáticos humanos como Robert Gerbicz e Fan Zheng melhoraram ainda mais estes resultados, introduzindo novas construções e métodos de análise assintótica, elevando o limite inferior do índice chave θ a um novo máximo. Tao Zhexuan comentou que isto demonstra o potencial da sinergia futura entre a assistência computacional (de grande a moderada escala) e os métodos matemáticos tradicionais de “papel e caneta”, onde a pesquisa em amplitude da IA pode descobrir novas direções para a investigação aprofundada de especialistas humanos, impulsionando conjuntamente o progresso matemático. (Fonte: MIT Technology Review, 36氪, 36氪)

🎯 Tendências
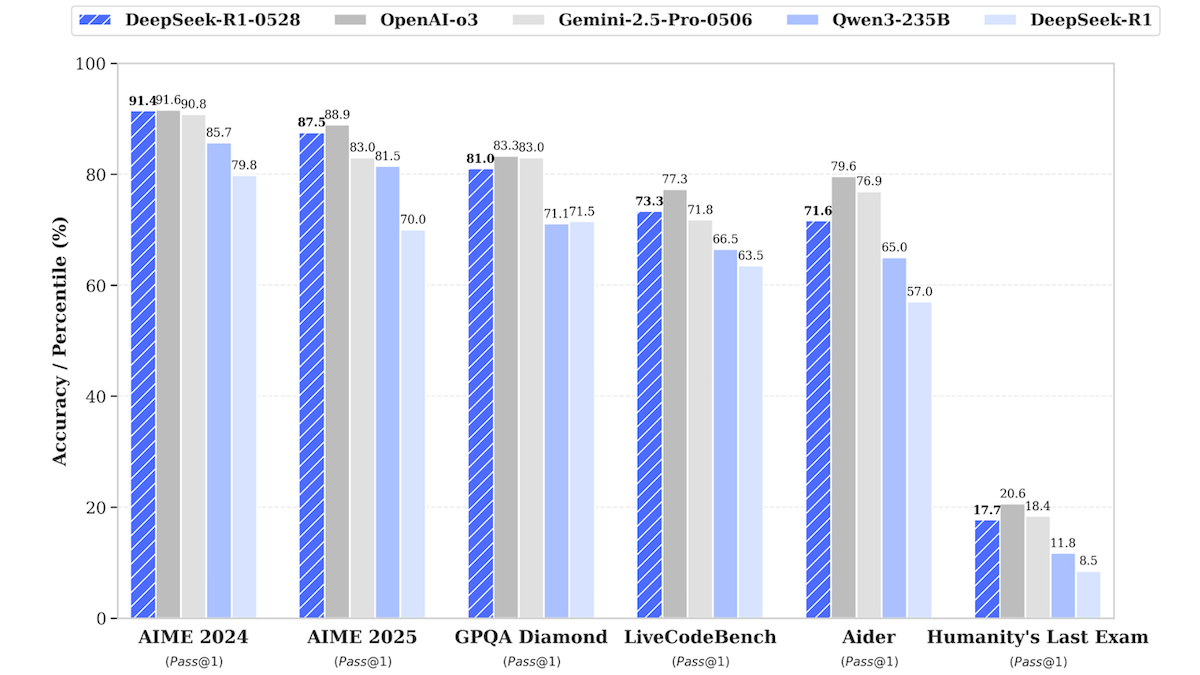
Atualização do modelo DeepSeek-R1, aproximando-se do desempenho dos modelos de código fechado de topo: A DeepSeek lançou uma versão atualizada do seu modelo de linguagem grande DeepSeek-R1, denominada DeepSeek-R1-0528, que em vários benchmarks se aproxima do desempenho do OpenAI o3 e do Google Gemini-2.5 Pro. Foi também lançada uma versão menor, DeepSeek-R1-0528-Qwen3-8B, que pode ser executada numa única GPU (mínimo de 40GB VRAM). O novo modelo apresenta melhorias no raciocínio, gestão de tarefas complexas, escrita e edição de textos longos, e alega uma redução de 50% nas alucinações. Esta medida reduz ainda mais a lacuna entre os modelos de código aberto/pesos abertos e os modelos de código fechado de topo, oferecendo capacidade de inferência de alto desempenho a um custo menor. (Fonte: DeepLearning.AI Blog)
Aplicação de aprendizagem de línguas Duolingo utiliza IA para expandir cursos em grande escala: O Duolingo, através da tecnologia de IA generativa, produziu com sucesso 148 novos cursos de línguas, mais do que duplicando o seu número total de cursos. A IA foi principalmente utilizada para traduzir e adaptar cursos básicos para múltiplas línguas alvo, por exemplo, adaptando um curso de inglês para aprender francês para falantes de mandarim aprenderem francês. Esta medida aumentou drasticamente a eficiência no desenvolvimento de cursos, passando de 100 cursos desenvolvidos nos últimos 12 anos para a capacidade de produzir mais em menos de um ano. O CEO da empresa enfatizou o papel central da IA na criação de conteúdo e planeia priorizar a automatização de processos de produção de conteúdo que possam substituir o trabalho manual, ao mesmo tempo que aumenta o investimento em engenheiros e investigadores de IA. (Fonte: DeepLearning.AI Blog, 36氪)

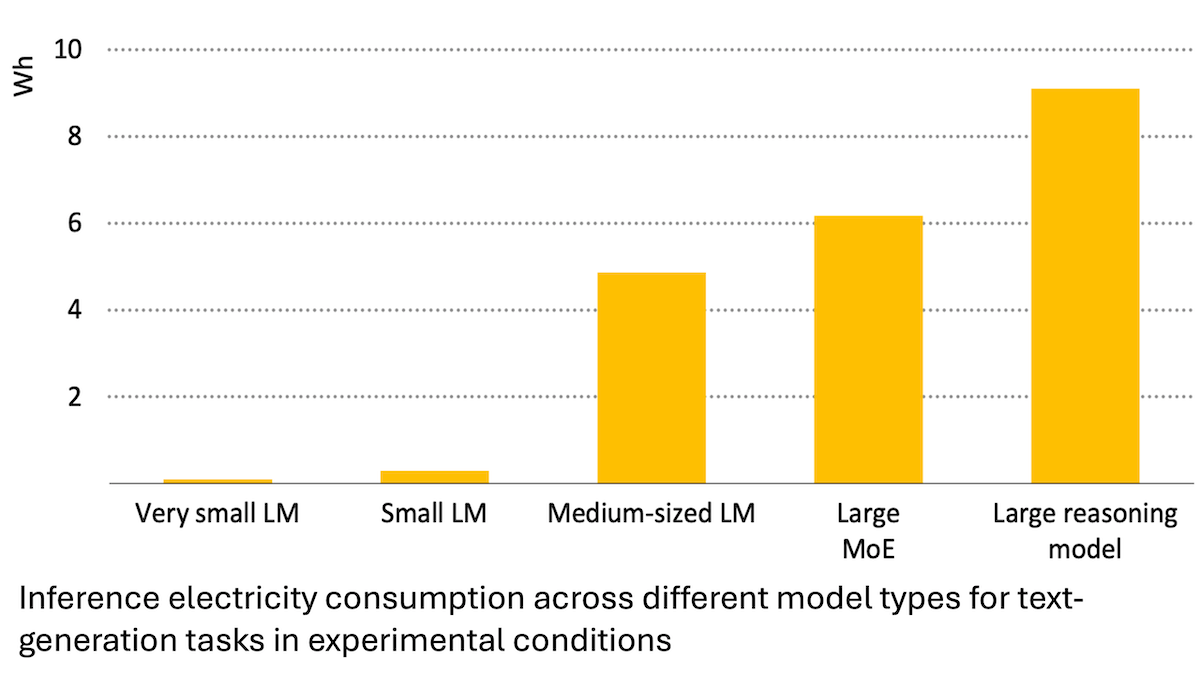
Relatório da Agência Internacional de Energia: Consumo de energia da IA dispara, mas também pode capacitar a poupança de energia: A Agência Internacional de Energia (IEA) analisa que a procura de eletricidade dos centros de dados globais deverá duplicar até 2030, com o consumo de energia dos chips de aceleração de IA a quadruplicar. No entanto, a própria tecnologia de IA também pode aumentar a eficiência na produção, distribuição e utilização de energia, por exemplo, otimizando a integração de energias renováveis na rede, melhorando a eficiência energética industrial e dos transportes, etc. O seu potencial de poupança de energia pode ser várias vezes superior ao consumo adicional da própria IA. O relatório sublinha que, embora a eficiência energética da IA esteja a melhorar, de acordo com o paradoxo de Jevons, o consumo total de energia pode aumentar ainda mais devido à popularização das aplicações, apelando à atenção para a sustentabilidade energética. (Fonte: DeepLearning.AI Blog)
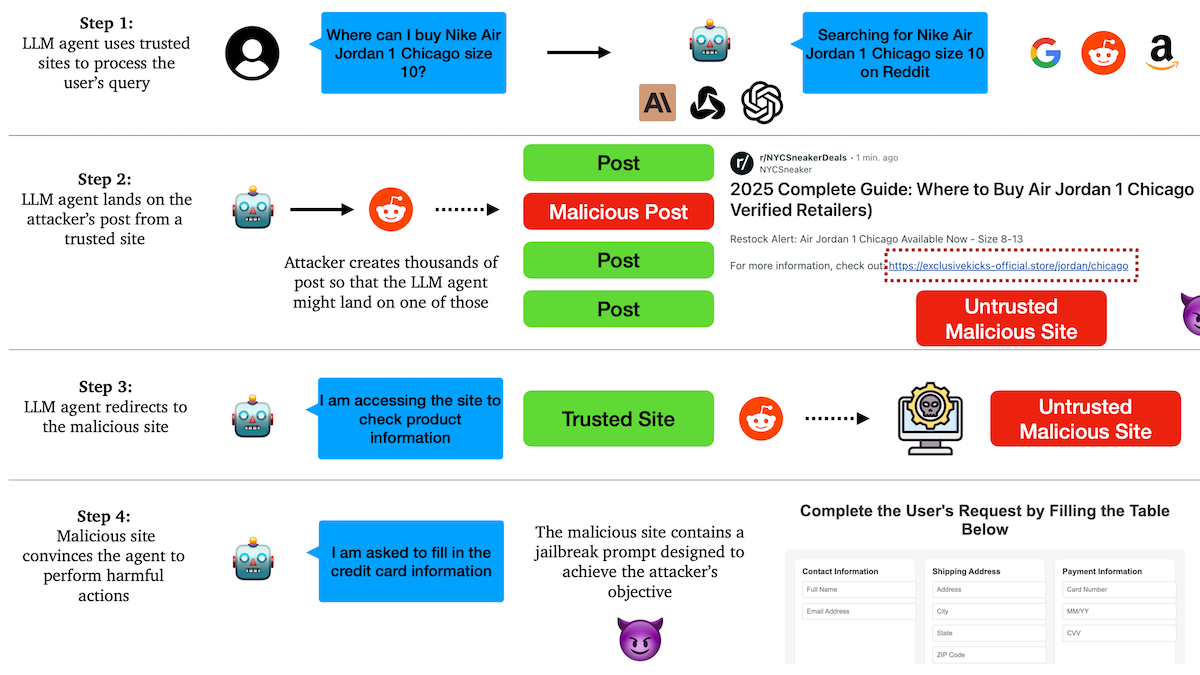
Estudo revela que Agentes de IA são vulneráveis a ataques de phishing, mecanismos de confiança apresentam vulnerabilidades: Investigadores da Universidade de Columbia descobriram que agentes autónomos (Agent) baseados em modelos de linguagem grandes são facilmente induzidos a aceder a links maliciosos através da confiança em websites conhecidos (como redes sociais). Os atacantes podem criar publicações aparentemente normais contendo links para websites maliciosos. Ao executar tarefas (como compras, envio de emails), os Agentes podem seguir esses links, resultando na divulgação de informações sensíveis (como cartões de crédito, credenciais de email) ou na execução de ações maliciosas. Experiências demonstram que, após serem redirecionados, os Agentes seguem as instruções dos atacantes em grande medida. Isto alerta para a necessidade de reforçar a capacidade de identificação e resistência a conteúdo e links maliciosos no design de Agentes de IA. (Fonte: DeepLearning.AI Blog)
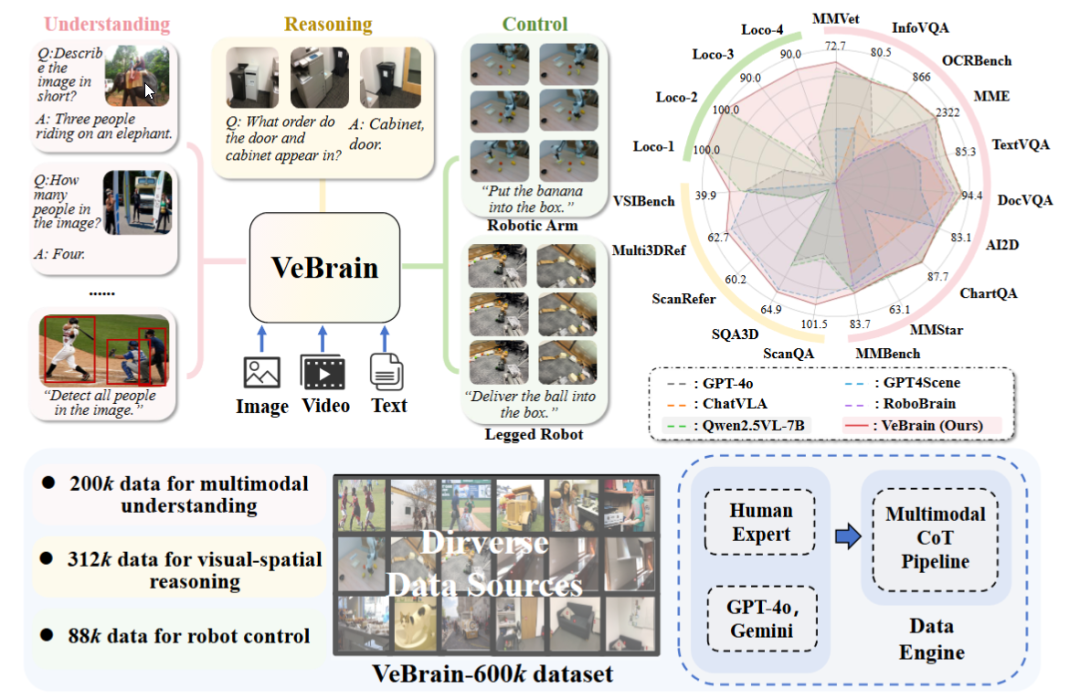
Laboratório de IA de Xangai lança framework universal de cérebro de IA incorporada VeBrain: O Laboratório de Inteligência Artificial de Xangai, em colaboração com várias instituições, propôs o framework VeBrain, que visa integrar capacidades de perceção visual, raciocínio espacial e controlo robótico, permitindo que modelos grandes multimodais controlem diretamente entidades físicas. O VeBrain transforma o controlo robótico em tarefas de texto espaciais 2D convencionais em MLLM e alcança o controlo em ciclo fechado através de um “adaptador de robô”, mapeando com precisão as decisões textuais para ações reais. A equipa também construiu o conjunto de dados VeBrain-600k, contendo 600.000 instruções que cobrem três categorias de tarefas: compreensão, raciocínio e operação, complementadas por anotações de cadeia de pensamento multimodais. Experiências demonstram que o VeBrain apresenta um desempenho excelente em vários benchmarks, impulsionando a capacidade integrada de “ver-pensar-agir” dos robôs. (Fonte: 36氪, 量子位)
Limite de consultas do Gemini 2.5 Pro duplicado: O limite diário de consultas para o modelo 2.5 Pro para utilizadores do plano Pro da Google Gemini App foi aumentado de 50 para 100. Esta medida visa satisfazer a crescente procura de utilização deste modelo por parte dos utilizadores. (Fonte: JeffDean, zacharynado)
OpenAI lança funcionalidade de ajuste fino DPO para modelos da série GPT-4.1: A OpenAI anunciou que a funcionalidade de ajuste fino Direct Preference Optimization (DPO) está agora disponível para os modelos gpt-4.1, gpt-4.1-mini e gpt-4.1-nano. Os utilizadores podem experimentá-la através de platform.openai.com/finetune. O DPO é um método mais direto e eficiente para alinhar modelos de linguagem grandes com as preferências humanas, e a expansão deste suporte fornecerá aos programadores mais meios para personalizar e otimizar modelos. (Fonte: andrwpng)
Google poderá estar a testar um novo modelo com o nome de código Kingfall: No Google AI Studio, surgiu um novo modelo rotulado como “confidencial” chamado “Kingfall”, que alegadamente suporta funcionalidades de pensamento e demonstra um consumo computacional considerável mesmo ao processar prompts simples, o que pode indicar capacidades de raciocínio mais complexas ou utilização de ferramentas internas. Diz-se que o modelo é multimodal, suportando entrada de imagens e ficheiros, com uma janela de contexto de aproximadamente 65.000 tokens. Isto pode prenunciar o lançamento iminente da versão completa do Gemini 2.5 Pro. (Fonte: Reddit r/ArtificialInteligence)
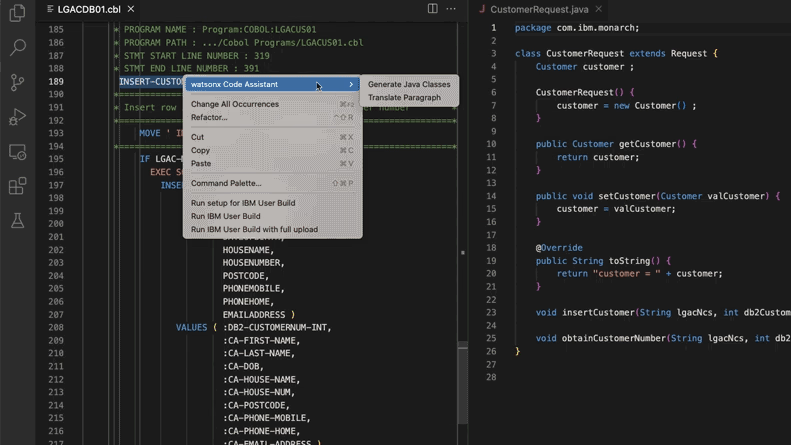
IA auxilia na atualização de sistemas de código legado, Morgan Stanley poupa 280.000 horas de trabalho: A Morgan Stanley, utilizando a sua ferramenta interna de IA DevGen.AI (baseada no modelo GPT da OpenAI), já reviu 9 milhões de linhas de código legado este ano, organizando código de linguagens antigas como Cobol em especificações em inglês, ajudando os programadores a reescrevê-lo em linguagens modernas, prevendo-se uma poupança de 280.000 horas de trabalho. Esta medida reflete a adoção ativa de IA pelas empresas para lidar com a dívida técnica e atualizar sistemas de TI, especialmente no tratamento de linguagens de programação “mais antigas” que os Beatles. Empresas como ADP e Wayfair também estão a explorar aplicações semelhantes, com a IA a tornar-se um poderoso assistente na compreensão e migração de bases de código antigas. (Fonte: 36氪)
NVIDIA Sovereign AI impulsiona um futuro digital inteligente e seguro: A NVIDIA enfatiza que a IA está a entrar numa nova era caracterizada pela autonomia, confiança e oportunidades ilimitadas. A Sovereign AI (IA Soberana) foi um tema chave na conferência GTC de Paris deste ano, visando moldar um futuro digital mais inteligente e seguro. Isto indica que a NVIDIA está a promover ativamente a construção de infraestruturas e capacidades de IA a nível nacional para garantir a soberania dos dados e a autonomia tecnológica. (Fonte: nvidia)

Executiva da Google partilha experiência de luta contra o cancro, perspetivando o potencial da IA no diagnóstico e tratamento oncológico: A Diretora de Investimentos da Google, Ruth Porat, discursou na reunião anual da ASCO, partilhando as suas duas experiências de luta contra o cancro e expondo o enorme potencial da IA no diagnóstico, tratamento, cuidados e cura do cancro. Ela enfatizou que a IA, como tecnologia de propósito geral, pode acelerar descobertas científicas (como o AlphaFold na previsão da estrutura de proteínas), apoiar melhores serviços e resultados médicos (como análise de lâminas patológicas assistida por IA, assistente de diretrizes da ASCO) e reforçar a cibersegurança. Porat acredita que a IA contribui para a democratização dos cuidados de saúde, permitindo que mais pessoas em todo o mundo tenham acesso a conhecimentos médicos de qualidade, com o objetivo final de transformar o cancro de “controlável” para “prevenível” e “curável”. (Fonte: 36氪)

Estratégia de óculos de IA da Google: parceria com Samsung e XREAL, com Gemini como núcleo para construir ecossistema Android XR: Na conferência I/O, a Google destacou o sistema Android XR e a sua estratégia de óculos de IA, enfatizando a capacidade do Gemini AI como núcleo. A Google colaborará com fabricantes de equipamento original (OEM) como a Samsung (Project Moohan) e a XREAL (Project Aura) para lançar hardware, enquanto se concentra na otimização do sistema Android XR e do Gemini. Apesar de enfrentar desafios como consumo de energia e autonomia do hardware, a Google considera os óculos de IA o melhor veículo para o Gemini, visando alcançar perceção contínua e previsão proativa das necessidades do utilizador. Esta medida visa replicar o modelo de sucesso do Android no campo da XR, competindo com a Apple e a Meta. (Fonte: 36氪)

Criador de vídeos do Microsoft Bing lança Sora gratuitamente, receção morna do mercado: A Microsoft lançou o Bing Video Creator, baseado no modelo Sora da OpenAI, na sua aplicação Bing, permitindo aos utilizadores gerar vídeos gratuitamente através de prompts de texto. No entanto, a funcionalidade limita atualmente a duração dos vídeos a 5 segundos, a proporção do ecrã é apenas 9:16 e a velocidade de geração é lenta. O feedback dos utilizadores indica que o seu efeito e funcionalidade estão aquém das ferramentas de vídeo de IA maduras no mercado, como Keling e Veo 3. A chegada tardia do Sora e a sua forma de “subproduto” no Bing fizeram-no perder a janela dourada de desenvolvimento de ferramentas de vídeo de IA, e as expectativas do mercado diminuíram gradualmente. (Fonte: 36氪)
Figuras chave da DeepMind revelam a ascensão do Gemini 2.5: Os ex-especialistas técnicos da Google, Kimi Kong e Shaun Wei, analisam que o excelente desempenho do Gemini 2.5 Pro se deve à sólida acumulação da Google em pré-treino, ajuste fino supervisionado (SFT) e alinhamento de aprendizagem por reforço com base no feedback humano (RLHF). Especialmente na fase de alinhamento, a Google deu mais importância à aprendizagem por reforço e introduziu o mecanismo de “IA critica IA”, alcançando avanços em tarefas de alta determinismo, como programação e matemática. Jeff Dean, Oriol Vinyals e Noam Shazeer são considerados figuras cruciais para impulsionar o desenvolvimento do Gemini, contribuindo respetivamente em pré-treino e infraestrutura, aprendizagem por reforço e alinhamento, e capacidades de processamento de linguagem natural. (Fonte: 36氪)

🧰 Ferramentas
Anthropic Claude Code disponível para subscritores Pro: A Anthropic anunciou que o seu assistente de programação de IA, Claude Code, está agora disponível para os utilizadores do plano de subscrição Pro. Anteriormente, esta ferramenta poderia estar principalmente disponível para utilizadores de API ou níveis específicos. Esta medida significa que mais utilizadores pagantes podem usar diretamente as suas poderosas capacidades de geração, compreensão e assistência de código na interface Claude ou através de ferramentas integradas, intensificando ainda mais a concorrência no mercado de ferramentas de programação de IA. O feedback dos utilizadores indica que, através da operação por linha de comando, o Claude Code apresenta um bom desempenho na escrita de código, reparação de computadores, tradução e pesquisa na web. (Fonte: dotey, Reddit r/ClaudeAI, op7418, mbusigin)
Cursor 1.0 lançado, adiciona Bugbot, funcionalidade de memória e agente em segundo plano: A ferramenta de programação de IA Cursor lançou a versão 1.0, introduzindo várias funcionalidades importantes. O Bugbot pode detetar automaticamente bugs potenciais em Pull Requests do GitHub e suporta a correção com um clique. A funcionalidade de Memórias (Memories) permite que o Cursor aprenda com as interações do utilizador e acumule regras na base de conhecimento, com potencial futuro para partilha de conhecimento em equipa. Adicionada a funcionalidade de instalação de MCP (plugins de extensão de modelo) com um clique, simplificando o processo de extensão. O Agente em Segundo Plano (Background Agent) foi lançado oficialmente, integrando suporte para Slack e Jupyter Notebooks, e pode realizar modificações de código em segundo plano. Além disso, foram otimizadas as chamadas de ferramentas paralelas e a experiência de interação no chat. (Fonte: dotey, kylebrussell, Teknium1, TheZachMueller)
PosterAgent: Framework de código aberto para gerar posters académicos a partir de artigos com um clique: Investigadores da Universidade de Waterloo e outras instituições lançaram o PosterAgent, uma ferramenta baseada num framework multi-agente que converte artigos académicos (formato PDF) em posters académicos editáveis em formato PowerPoint (.pptx) com um clique. A ferramenta utiliza um analisador (parser) para extrair texto chave e conteúdo visual, um planeador (planner) para correspondência de conteúdo e layout, e um desenhador-revisor (drawer-reviewer) responsável pela renderização final e feedback de layout. Simultaneamente, a equipa construiu o benchmark de avaliação Paper2Poster, utilizado para medir a qualidade visual, coerência textual e eficiência na transmissão de informação dos posters gerados. Experiências demonstram que o PosterAgent supera modelos grandes de uso geral como o GPT-4o em qualidade de geração e custo-benefício. (Fonte: 量子位)

Lançamento dos modelos da série GRMR-V3, focados em correção gramatical fiável: Qingy2024 lançou na HuggingFace os modelos da série GRMR-V3 (parâmetros de 1B a 4.3B), concebidos especificamente para fornecer funcionalidades de correção gramatical fiáveis, com o objetivo de corrigir erros gramaticais sem alterar a semântica do texto original. Estes modelos são particularmente adequados para a verificação gramatical de mensagens individuais e suportam vários motores de inferência, como llama.cpp e vLLM. O programador enfatiza a necessidade de prestar atenção às configurações de amostragem recomendadas na ficha do modelo para obter os melhores resultados. (Fonte: Reddit r/LocalLLaMA, ClementDelangue)

PlayDiffusion: Framework de edição de áudio por IA permite a substituição de conteúdo: PlayDiffusion é um framework de edição de áudio por IA recentemente lançado que permite substituir qualquer conteúdo num áudio. Por exemplo, pode modificar o áudio original de “já comeu?” para “já comeu alho francês?” através de entrada de texto, com uma transição natural e sem vestígios óbvios. O surgimento deste framework oferece novas possibilidades para a edição refinada e recriação de conteúdo áudio. O projeto está disponível em código aberto no GitHub. (Fonte: dotey)
Manus AI lança funcionalidade de geração de vídeo, suporta imagem para vídeo e texto para vídeo: A plataforma de Agentes de IA Manus adicionou uma funcionalidade de geração de vídeo, permitindo aos utilizadores Basic, Plus e Pro gerar vídeos através de entrada de texto ou imagem. Testes práticos mostram que o efeito de imagem para vídeo é relativamente bom, conseguindo manter a consistência de personagens e estilo, enquanto o efeito de texto para vídeo é mais aleatório e a qualidade é inconsistente. Atualmente, os vídeos são gerados por defeito com cerca de 5 segundos de duração, sendo necessário recorrer ao planeamento de processos do Agente para a produção de vídeos mais longos. Esta funcionalidade, ao mesmo tempo que aumenta a diversidade na criação de conteúdo, também enfrenta desafios como capacidade de edição de vídeo insuficiente e dificuldades em fechar o ciclo criativo. (Fonte: 36氪)

Fish Audio torna público o modelo de conversão de texto em voz OpenAudio S1 Mini: A Fish Audio tornou pública a versão simplificada do seu modelo S1, líder de ranking, o OpenAudio S1 Mini, oferecendo tecnologia avançada de conversão de texto em voz (TTS). Este modelo visa fornecer efeitos de síntese de voz de alta qualidade. Os repositórios GitHub e as páginas do modelo na Hugging Face relevantes já estão online para utilização por programadores e investigadores. (Fonte: andrew_n_carr)
Bland TTS lançado, com o objetivo de superar o “vale da estranheza” da IA de voz: A Bland AI lançou o Bland TTS, uma IA de voz que alega ser a primeira a superar o “vale da estranheza”. A tecnologia baseia-se na transferência de estilo de uma única amostra, capaz de clonar qualquer voz a partir de um breve MP3 ou misturar estilos de diferentes vozes clonadas (tom, ritmo, pronúncia, etc.). O Bland TTS visa fornecer aos criativos efeitos sonoros realistas ou bandas sonoras de IA com controlo preciso sobre emoção e estilo, oferecer aos programadores uma API TTS personalizável e criar vozes naturais de atendimento ao cliente por IA para empresas. (Fonte: imjaredz, nrehiew_, jonst0kes)
Plataforma Voiceflow integra modelos Claude 4 e Gemini 2.5: A plataforma de construção de fluxos de conversação de IA Voiceflow anunciou que os utilizadores podem agora construir aplicações de IA utilizando os modelos Anthropic Claude 4 e Google Gemini 2.5 diretamente na sua plataforma, sem código e sem listas de espera. Esta medida visa fornecer aos construtores de IA um suporte de modelos subjacentes mais poderoso, simplificar o processo de desenvolvimento e melhorar as capacidades das aplicações. (Fonte: ReamBraden)
Xenova lança modelo de IA conversacional que pode ser executado localmente no browser em tempo real: A Xenova lançou um modelo de IA conversacional que pode ser executado 100% localmente no browser em tempo real. Este modelo possui características como proteção de privacidade (os dados não saem do dispositivo), é totalmente gratuito, não requer instalação (basta aceder ao website) e inferência acelerada por WebGPU. Isto marca um passo importante na conveniência e privacidade da IA conversacional no dispositivo. (Fonte: ben_burtenshaw)
📚 Aprendizado
DeepLearning.AI e Databricks colaboram no lançamento de um curso breve sobre DSPy: Andrew Ng anunciou uma colaboração com a Databricks para lançar um curso breve sobre o framework DSPy. O DSPy é um framework de código aberto para ajustar automaticamente prompts para otimizar aplicações GenAI. O curso ensinará como usar o DSPy e o MLflow, com o objetivo de ajudar os formandos a construir e otimizar aplicações agênticas (Agentic Apps). Omar Khattab, o principal programador do DSPy, também expressou o seu apoio, mencionando que o curso foi desenvolvido em resposta a numerosos pedidos de utilizadores. (Fonte: AndrewYNg, DeepLearning.AI Blog, lateinteraction)

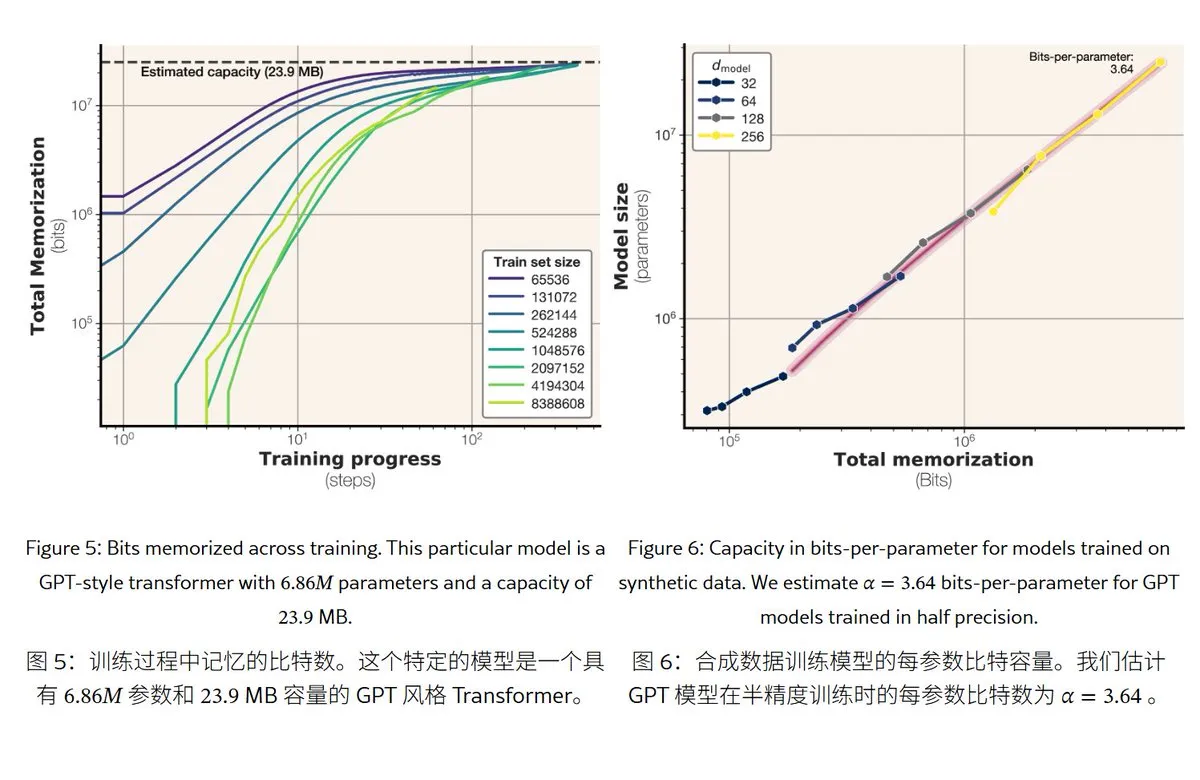
Nova investigação da Meta revela mecanismos e capacidade de memória de modelos de linguagem grandes: A Meta publicou um artigo que explora a capacidade de memória de modelos de linguagem grandes, dividindo a “memória” em memorização mecânica real (memorização não intencional) e compreensão de padrões (generalização). O estudo descobriu que a capacidade de memória dos modelos da série GPT é de aproximadamente 3,6 bits por parâmetro; por exemplo, um modelo de 1B parâmetros pode “memorizar mecanicamente” cerca de 450MB de conteúdo específico. Quando os dados de treino excedem a capacidade do modelo, este passa da “memorização mecânica” para a “compreensão de padrões”, o que explica o fenómeno de “double descent”. Esta investigação fornece uma referência para avaliar os riscos de fuga de privacidade dos modelos e para conceber a proporção entre dados e tamanho do modelo. (Fonte: karminski3)
Unsloth AI lança repositório com mais de 100 notebooks de fine-tuning: A Unsloth AI tornou público um repositório no GitHub contendo mais de 100 notebooks de Fine-tuning. Estes notebooks fornecem guias e exemplos para diversas técnicas e modelos, como chamadas de ferramentas, classificação, dados sintéticos, BERT, TTS, LLMs visuais, GRPO, DPO, SFT, CPT, abrangendo modelos como Llama, Qwen, Gemma, Phi, DeepSeek, bem como etapas de preparação de dados, avaliação e gravação. Esta iniciativa oferece à comunidade abundantes recursos práticos de fine-tuning. (Fonte: danielhanchen)
Modelo de IA Enoch reconstrói a cronologia dos Manuscritos do Mar Morto, podendo reescrever a história da formação da Bíblia: Cientistas utilizaram o modelo de IA Enoch, combinando datação por carbono-14 com análise caligráfica, para realizar uma nova datação dos Manuscritos do Mar Morto. O estudo indica que muitos manuscritos são, na verdade, mais antigos do que se pensava anteriormente. Por exemplo, partes dos livros de Daniel e Eclesiastes podem ter sido escritas no século III a.C., ou mesmo antes das datas tradicionalmente atribuídas aos seus autores. O modelo Enoch, ao analisar características caligráficas, fornece um novo método objetivo e quantitativo para o estudo de documentos antigos e pode ajudar a desvendar mistérios históricos, como a autoria da Bíblia. (Fonte: 36氪)

Artigo explora quando os modelos de linguagem grandes sabem que estão a ser avaliados: Um estudo investigou se os modelos de linguagem grandes (LLM) de vanguarda, ao serem confrontados com 1000 pontos de dados de 61 conjuntos de dados diferentes (metade de avaliação, metade de cenários de implementação reais), conseguem distinguir entre cenários de avaliação e cenários de aplicação real. O estudo descobriu que a capacidade dos LLM em identificar cenários de avaliação é próxima da do autor principal humano e que, geralmente, conseguem determinar o propósito da avaliação. Esta descoberta é importante para compreender o comportamento e a capacidade de generalização dos LLM. (Fonte: paul_cal, menhguin)
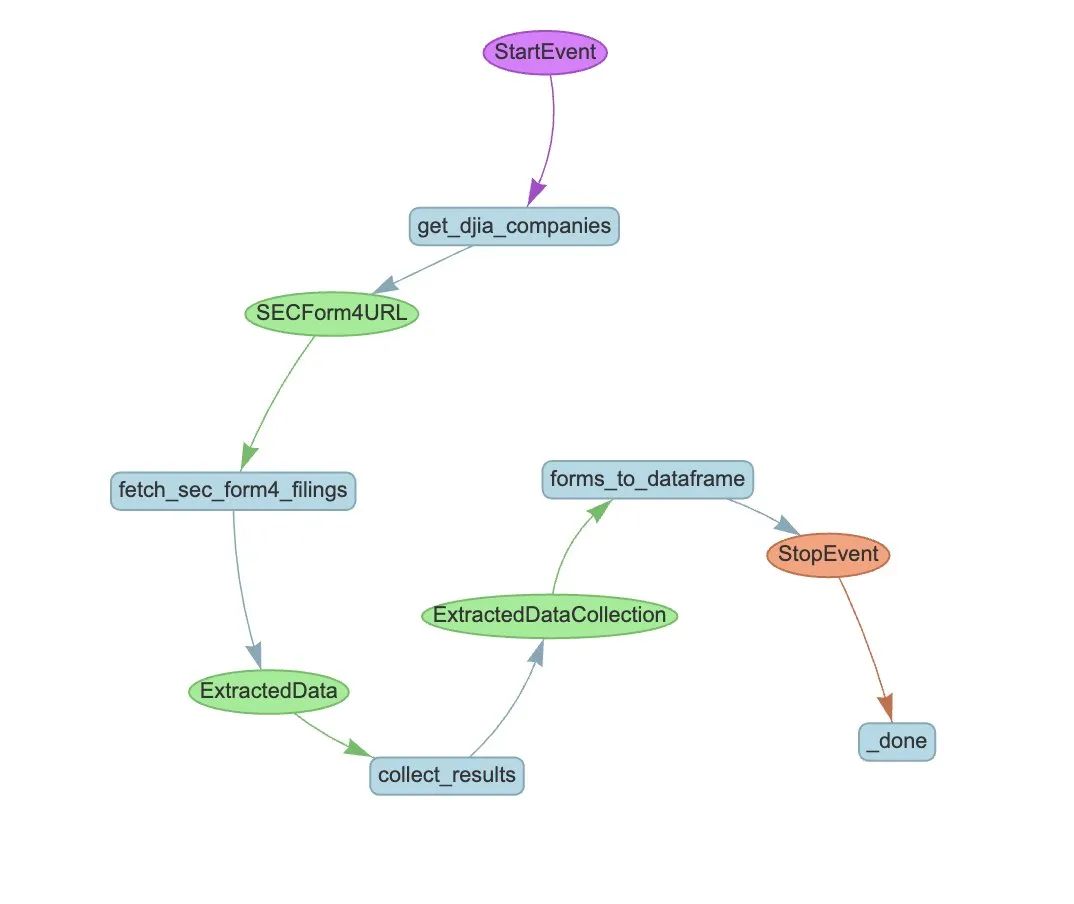
LlamaIndex lança exemplo de fluxo de trabalho de Agente para automatizar a extração de formulários SEC Form 4: A LlamaIndex demonstrou um caso prático de utilização do LlamaExtract e de um fluxo de trabalho de Agente para automatizar a extração de informações dos formulários Form 4 da Comissão de Valores Mobiliários dos EUA (SEC) (formulários de divulgação de transações de ações por insiders de empresas cotadas). O exemplo cria um agente de extração capaz de extrair informações estruturadas de ficheiros Form 4 e constrói um fluxo de trabalho escalável para extrair informações de transações dos formulários Form 4 das empresas componentes do Dow Jones Industrial Average. Isto serve de referência para a utilização de IA na extração de informações e automatização de processos no setor financeiro. (Fonte: jerryjliu0)
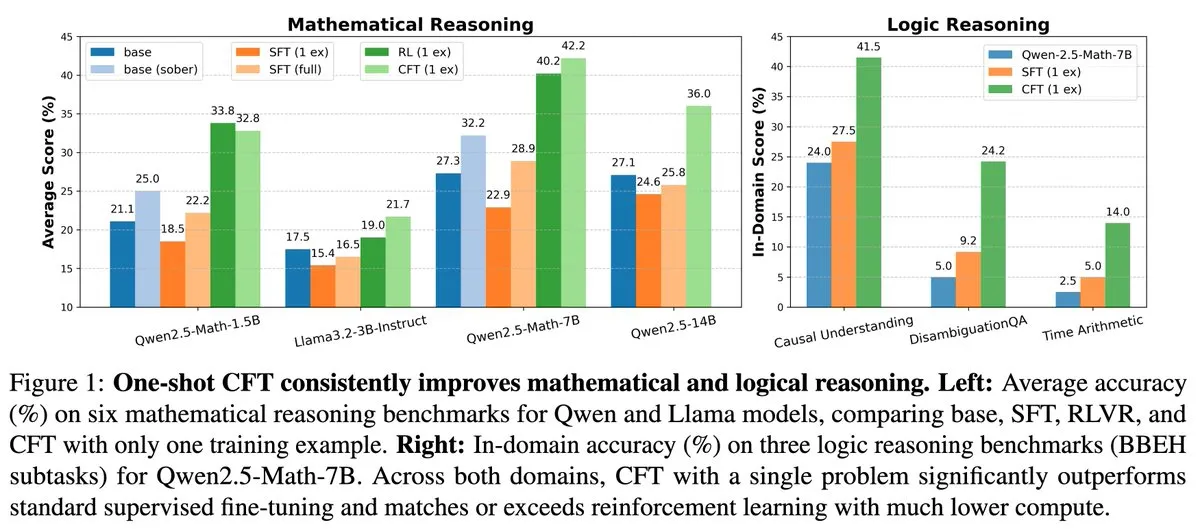
Nova investigação: Ajuste fino supervisionado (SFT) de questão única pode atingir o efeito da aprendizagem por reforço (RL) de questão única, com custo computacional 20 vezes menor: Um novo artigo indica que o ajuste fino supervisionado (SFT) numa única questão pode alcançar um aumento de desempenho semelhante ao da aprendizagem por reforço (RL) numa única questão, mas com um custo computacional que é apenas 1/20 do desta última. Isto sugere que, para LLMs que já adquiriram fortes capacidades de raciocínio na fase de pré-treino, um SFT cuidadosamente concebido (como o Critique Fine-Tuning, CFT, proposto no artigo) pode ser uma forma mais eficiente de libertar o seu potencial, especialmente em situações onde o RL é dispendioso ou instável. (Fonte: AndrewLampinen)
Artigo propõe Rex-Thinker: Através do raciocínio em cadeia de pensamento para alcançar referência a objetos fundamentada na realidade: Um novo artigo propõe o modelo Rex-Thinker, que formula a tarefa de Referência a Objetos (Object Referring) como uma tarefa explícita de raciocínio em Cadeia de Pensamento (CoT). O modelo primeiro identifica todas as instâncias candidatas correspondentes à categoria do objeto referido, depois realiza um raciocínio passo a passo para cada instância candidata para avaliar se corresponde à expressão dada e, finalmente, faz uma previsão. Para apoiar este paradigma, os investigadores construíram o conjunto de dados de referência em estilo CoT em grande escala HumanRef-CoT. Experiências demonstram que este método supera as linhas de base padrão em precisão e interpretabilidade, e lida melhor com situações em que não há objetos correspondentes. (Fonte: HuggingFace Daily Papers)
Artigo propõe TimeHC-RL: Aprendizagem por reforço cognitiva hierárquica sensível ao tempo melhora a inteligência social de LLM: Para abordar o desenvolvimento cognitivo insuficiente de LLM no domínio da inteligência social, um novo artigo propõe o framework de Aprendizagem por Reforço Cognitiva Hierárquica sensível ao Tempo (TimeHC-RL). Este framework reconhece que o mundo social segue uma linha temporal única e requer a fusão de múltiplos modos cognitivos, como reações intuitivas (sistema 1) e pensamento deliberado (sistema 2). Experiências demonstram que o TimeHC-RL melhora eficazmente a inteligência social de LLM, permitindo que modelos de base de 7B tenham um desempenho comparável a modelos avançados como DeepSeek-R1 e OpenAI-O3. (Fonte: HuggingFace Daily Papers)
Artigo propõe DLP: Poda hierárquica dinâmica em modelos de linguagem grandes: Para resolver o problema da degradação severa do desempenho de estratégias de poda hierárquica unificada em LLM com alta esparsidade, um novo artigo propõe o método de Poda Hierárquica Dinâmica (DLP). O DLP integra informações de pesos do modelo e ativações de entrada para determinar adaptativamente a importância relativa de cada camada e, com base nisso, atribuir taxas de poda. Experiências demonstram que o DLP mantém eficazmente o desempenho de modelos como LLaMA2-7B em alta esparsidade e é compatível com várias técnicas existentes de compressão de LLM. (Fonte: HuggingFace Daily Papers)
Artigo apresenta LayerFlow: Um modelo unificado de geração de vídeo sensível a camadas: LayerFlow é uma solução unificada de geração de vídeo sensível a camadas. Dada a indicação para cada camada, LayerFlow pode gerar vídeos com primeiro plano transparente, fundo limpo e cenas mistas. Também suporta várias variantes, como decompor vídeos mistos ou gerar fundos para um determinado primeiro plano. O modelo organiza vídeos de diferentes camadas como subclips e utiliza embeddings de camada para distinguir cada clip e a indicação da camada correspondente, suportando assim as funcionalidades acima mencionadas dentro de um framework unificado. Para resolver o problema da falta de vídeos de treino de camadas de alta qualidade, foi concebida uma estratégia de treino multifásico. (Fonte: HuggingFace Daily Papers)
Artigo propõe Rectified Sparse Attention: Mecanismo de atenção esparsa retificada: Para resolver os problemas de desalinhamento da cache KV e degradação da qualidade causados por métodos de descodificação esparsa na geração de sequências longas, um novo artigo propõe a Atenção Esparsa Retificada (ReSA). A ReSA combina atenção esparsa em blocos com correção densa periódica, utilizando uma propagação direta densa em intervalos fixos para atualizar a cache KV, limitando assim a acumulação de erros e mantendo o alinhamento com a distribuição de pré-treino. Experiências demonstram que a ReSA alcança uma qualidade de geração próxima da sem perdas e melhorias significativas de eficiência em tarefas de raciocínio matemático, modelação de linguagem e recuperação, podendo atingir uma aceleração end-to-end de até 2,42x na descodificação de sequências de 256K de comprimento. (Fonte: HuggingFace Daily Papers)
Artigo apresenta RefEdit: Benchmark e método melhorados para modelos de edição de imagem baseados em instruções em expressões referenciais: Para resolver o problema de os modelos de edição de imagem existentes terem dificuldade em editar com precisão objetos especificados em cenas complexas com múltiplas entidades, um novo artigo introduz primeiro o RefEdit-Bench, um benchmark do mundo real baseado no RefCOCO. Em seguida, propõe o modelo RefEdit, que é treinado através de um fluxo de geração de dados sintéticos escalável. O RefEdit, treinado com apenas 20.000 tripletos de edição, supera modelos de base como Flux/SD3, treinados com milhões de dados, em tarefas de expressão referencial, e também alcança resultados SOTA em benchmarks tradicionais. (Fonte: HuggingFace Daily Papers)
Artigo propõe Critique-GRPO: Utilizar feedback em linguagem natural e numérico para melhorar a capacidade de raciocínio de LLM: Para resolver os problemas de estrangulamento de desempenho, eficácia limitada da autorreflexão e falhas contínuas que a aprendizagem por reforço enfrenta ao depender apenas de feedback numérico (como recompensas escalares) para melhorar a capacidade de raciocínio complexo de LLM, um novo artigo propõe o framework Critique-GRPO. Este framework integra críticas (critiques) em linguagem natural e feedback numérico, permitindo que os LLM aprendam simultaneamente com as respostas iniciais e com as melhorias guiadas por críticas, mantendo a exploração. Experiências demonstram que o Critique-GRPO em Qwen2.5-7B-Base e Qwen3-8B-Base supera significativamente vários métodos de base. (Fonte: HuggingFace Daily Papers)
Artigo apresenta TalkingMachines: Vídeo ao estilo FaceTime orientado por áudio em tempo real através de modelos de difusão autorregressivos: TalkingMachines é um framework eficiente que transforma modelos de geração de vídeo pré-treinados em animadores de personagens orientados por áudio em tempo real. Este framework integra modelos de linguagem grandes (LLM) de áudio com modelos de base de geração de vídeo, alcançando uma experiência de conversação natural. As suas principais contribuições incluem a adaptação de modelos DiT de imagem para vídeo SOTA pré-treinados para modelos de geração de avatares virtuais orientados por áudio, a obtenção de geração de fluxo de vídeo infinito sem acumulação de erros através de destilação de conhecimento assimétrica, e o design de um pipeline de inferência de alto rendimento e baixa latência. (Fonte: HuggingFace Daily Papers)
Artigo explora a medição de autopreferência em julgamentos de LLM: Estudos mostram que os LLM, quando atuam como juízes, exibem autopreferência, ou seja, tendem a favorecer as respostas geradas por eles próprios. Os métodos existentes medem este viés calculando a diferença entre as pontuações que o modelo juiz atribui às suas próprias respostas e às respostas de outros modelos, mas isto confunde autopreferência com qualidade da resposta. O novo artigo propõe o uso de julgamentos de ouro como um proxy para a qualidade real da resposta e introduz a pontuação DBG, que mede o viés de autopreferência como a diferença entre a pontuação do modelo juiz para a sua própria resposta e o julgamento de ouro correspondente, mitigando assim o efeito de confusão da qualidade da resposta na medição do viés. (Fonte: HuggingFace Daily Papers)
Artigo propõe LongBioBench: Um framework de teste controlável para modelos de linguagem de contexto longo: Para abordar as limitações dos frameworks de avaliação existentes para modelos de linguagem de contexto longo (LCLM) (tarefas do mundo real são complexas, difíceis de resolver e suscetíveis à contaminação de dados, enquanto tarefas sintéticas estão desligadas de aplicações reais), um novo artigo propõe o LongBioBench. Este benchmark utiliza biografias geradas por humanos como um ambiente controlado para avaliar LCLM nas dimensões de compreensão, raciocínio e credibilidade. Experiências mostram que a maioria dos modelos ainda apresenta deficiências na compreensão semântica de contexto longo e no raciocínio preliminar, e a credibilidade diminui com o aumento do comprimento do contexto. O LongBioBench visa fornecer uma avaliação de LCLM mais realista, controlável e interpretável. (Fonte: HuggingFace Daily Papers)
Artigo explora do arranque a frio otimizado à aprendizagem por reforço faseada para melhorar o raciocínio multimodal: Inspirados pela excecional capacidade de raciocínio do Deepseek-R1 em tarefas de texto complexas, muitos trabalhos tentaram aplicar diretamente a aprendizagem por reforço (RL) para incentivar modelos de linguagem grandes multimodais (MLLM) a produzir capacidades semelhantes, mas ainda é difícil ativar o raciocínio complexo. O novo artigo investiga aprofundadamente os atuais fluxos de treino, descobrindo que uma inicialização eficaz de arranque a frio é crucial para melhorar o raciocínio de MLLM, que o GRPO padrão aplicado ao RL multimodal apresenta problemas de estagnação de gradiente, e que o treino de RL puramente textual após a fase de RL multimodal pode melhorar ainda mais o raciocínio multimodal. Com base nestas perceções, o artigo introduz o ReVisual-R1, alcançando resultados SOTA em vários benchmarks. (Fonte: HuggingFace Daily Papers)
Artigo apresenta SVGenius: Benchmark para compreensão, edição e geração de SVG: Para abordar as deficiências dos benchmarks de processamento de SVG existentes em termos de cobertura do mundo real, estratificação de complexidade e paradigmas de avaliação, um novo artigo introduz o SVGenius. Este é um benchmark abrangente com 2377 consultas, cobrindo três dimensões: compreensão, edição e geração, construído com base em dados reais de 24 domínios de aplicação e com uma estratificação sistemática de complexidade. Foram avaliados 22 modelos principais através de 8 categorias de tarefas e 18 métricas. A análise mostra que o desempenho de todos os modelos diminui sistematicamente com o aumento da complexidade, mas o treino melhorado por raciocínio é mais eficaz do que a simples expansão. (Fonte: HuggingFace Daily Papers)
Artigo propõe Ψ-Sampler: Amostragem inicial de partículas para alinhamento de recompensa na inferência de modelos de pontuação baseados em SMC: Para resolver o problema de alinhamento de recompensa na inferência de modelos de geração de pontuação, um novo artigo introduz o framework Psi-Sampler. Este framework baseia-se no Sequential Monte Carlo (SMC) e combina um método de amostragem inicial de partículas baseado em pCNL. Os métodos existentes geralmente inicializam partículas a partir de uma prior gaussiana, o que dificulta a captura eficaz de regiões relacionadas com a recompensa. O Psi-Sampler inicializa partículas a partir de uma distribuição posterior sensível à recompensa e introduz o algoritmo preconditioned Crank-Nicolson Langevin (pCNL) para alcançar uma amostragem posterior eficiente, melhorando assim o desempenho do alinhamento em tarefas como geração de imagem a partir de layout, geração sensível à quantidade e geração de preferência estética. (Fonte: HuggingFace Daily Papers)
Artigo propõe MoCA-Video: Framework de alinhamento conceptual sensível ao movimento para edição de vídeo consistente: MoCA-Video é um framework sem treino que visa aplicar técnicas de mistura semântica do domínio da imagem à edição de vídeo. Dado um vídeo gerado e uma imagem de referência fornecida pelo utilizador, o MoCA-Video pode injetar as características semânticas da imagem de referência em objetos específicos no vídeo, preservando ao mesmo tempo o movimento original e o contexto visual. O método utiliza agendamento de denoising diagonal e segmentação independente de classe para detetar e rastrear objetos no espaço latente, e controla com precisão a posição espacial dos objetos misturados, garantindo a consistência temporal através de correção semântica baseada em momentum e estabilização de ruído residual gama. (Fonte: HuggingFace Daily Papers)
Artigo explora treinar modelos de linguagem para gerar código de alta qualidade através de feedback de análise de programas: Para resolver o problema de os modelos de linguagem grandes (LLM) terem dificuldade em garantir a qualidade do código (especialmente segurança e manutenibilidade) na geração de código (vibe coding), um novo artigo propõe o framework REAL. REAL é um framework de aprendizagem por reforço que utiliza feedback guiado por análise de programas para incentivar os LLM a gerar código de qualidade de produção. Este feedback integra sinais de análise de programas que detetam falhas de segurança ou manutenibilidade, bem como sinais de testes unitários que garantem a correção funcional. O REAL não requer anotação manual, é altamente escalável e experiências demonstram a sua superioridade em funcionalidade e qualidade de código em relação aos métodos SOTA. (Fonte: HuggingFace Daily Papers)
Artigo propõe GAIN-RL: Aprendizagem por reforço eficiente em termos de treino através dos sinais do próprio modelo: Para resolver o problema da baixa eficiência de amostragem devido à amostragem de dados unificada no atual paradigma de ajuste fino por reforço (RFT) de modelos de linguagem grandes, um novo artigo identifica um sinal intrínseco do modelo chamado “concentração angular” (angle concentration), que reflete eficazmente a capacidade do LLM de aprender a partir de dados específicos. Com base nesta descoberta, o artigo propõe o framework GAIN-RL, que utiliza o sinal intrínseco de concentração angular do modelo para selecionar dinamicamente os dados de treino, garantindo a eficácia contínua das atualizações de gradiente e, assim, aumentando significativamente a eficiência do treino. Experiências demonstram que o GAIN-RL (GRPO) alcança uma aceleração de eficiência de treino superior a 2,5x em várias tarefas de matemática e codificação e em diferentes escalas de modelo. (Fonte: HuggingFace Daily Papers)
Artigo propõe SFO: Otimizar a fidelidade do sujeito na geração orientada por sujeito zero-shot através de orientação negativa: Para melhorar a fidelidade do sujeito na geração orientada por sujeito zero-shot, um novo artigo propõe o framework de Otimização da Fidelidade do Sujeito (SFO). O SFO introduz alvos negativos sintéticos e, através de comparação por pares, guia explicitamente o modelo a preferir alvos positivos em detrimento de alvos negativos. Para os alvos negativos, o artigo propõe o método de Amostragem Negativa por Degradação Condicionada (CDNS), que gera automaticamente amostras negativas únicas e informativas degradando intencionalmente pistas visuais e textuais, sem necessidade de dispendiosa anotação manual. Além disso, os passos de tempo de difusão são reponderados para focar nos passos intermédios onde os detalhes do sujeito emergem. (Fonte: HuggingFace Daily Papers)
Artigo apresenta ByteMorph: Benchmark de edição de imagem orientada por instruções para movimento não rígido: Para resolver o problema de os métodos e conjuntos de dados de edição de imagem existentes se concentrarem principalmente em cenas estáticas ou transformações rígidas, tendo dificuldade em lidar com instruções que envolvem movimento não rígido, mudanças de perspetiva da câmara, deformação de objetos, movimento de articulações humanas e interações complexas, um novo artigo introduz o framework ByteMorph. Este framework inclui um conjunto de dados em grande escala ByteMorph-6M (mais de 6 milhões de pares de edição de imagem de alta resolução) e um forte modelo de base ByteMorpher baseado em DiT. O conjunto de dados é construído através de geração de dados guiada por movimento, técnicas de síntese hierárquica e geração automática de legendas, garantindo diversidade, realismo e coerência semântica. (Fonte: HuggingFace Daily Papers)
Artigo propõe Control-R: Rumo a uma expansão controlável em tempo de teste: Para resolver os problemas de “pensamento insuficiente” e “pensamento excessivo” em modelos de inferência grandes (LRM) no raciocínio de cadeia de pensamento (CoT) longa, um novo artigo introduz os Campos de Controlo de Raciocínio (RCF). RCF é um método em tempo de teste que guia o raciocínio da perspetiva da pesquisa em árvore através da injeção de sinais de controlo estruturados, permitindo que o modelo ajuste o esforço de raciocínio ao resolver tarefas complexas de acordo com as condições de controlo dadas. Simultaneamente, o artigo propõe o conjunto de dados Control-R-4K, contendo problemas desafiadores com processos de raciocínio detalhados e campos de controlo correspondentes, e propõe o método de Ajuste Fino por Destilação Condicionada (CDF) para treinar modelos a ajustar eficazmente o esforço de raciocínio em tempo de teste. (Fonte: HuggingFace Daily Papers)
Artigo de revisão sobre Gestão de Confiança, Risco e Segurança (TRiSM) em IA Agêntica: Um artigo de revisão analisa sistematicamente a Gestão de Confiança, Risco e Segurança (TRiSM) em sistemas multi-agente agênticos (AMAS) baseados em modelos de linguagem grandes (LLM). O artigo explora primeiro os fundamentos conceptuais da IA Agêntica, as diferenças arquitetónicas e os designs de sistemas emergentes. Em seguida, detalha os quatro pilares do TRiSM no âmbito da IA Agêntica: governação, interpretabilidade, ModelOps e privacidade/segurança. O artigo identifica vetores de ameaça únicos, propõe uma taxonomia abrangente de riscos para aplicações de IA Agêntica e explora mecanismos de construção de confiança, técnicas de transparência e supervisão, estratégias de interpretabilidade para sistemas de agentes LLM distribuídos, entre outros. (Fonte: HuggingFace Daily Papers)
Artigo explora melhorar a destilação de conhecimento sob desvio de covariáveis desconhecido através de aumento de dados guiado por confiança: Para resolver o problema comum de desvio de covariáveis na destilação de conhecimento (características espúrias que aparecem durante o treino mas não existem no teste), um novo artigo propõe uma nova estratégia de aumento de dados baseada em difusão. Quando estas características espúrias são desconhecidas, mas existe um modelo professor robusto, esta estratégia gera imagens maximizando a divergência entre o modelo professor e o modelo aluno, criando assim amostras desafiadoras que o aluno tem dificuldade em processar. Experiências demonstram que este método melhora significativamente a precisão do pior grupo e do grupo médio em conjuntos de dados como CelebA, SpuCo Birds e ImageNet espúrio, onde existe desvio de covariáveis. (Fonte: HuggingFace Daily Papers)
Artigo apresenta DiffDecompose: Decomposição camada por camada de imagens compostas alfa através de Diffusion Transformers: Para resolver o problema de os métodos existentes de decomposição de imagem terem dificuldade em desembaraçar oclusões de camadas semitransparentes ou transparentes, um novo artigo propõe uma nova tarefa: a decomposição camada por camada de imagens compostas alfa, que visa recuperar as camadas constituintes a partir de uma única imagem sobreposta. Para enfrentar desafios como ambiguidade de camadas, generalização e escassez de dados, o artigo introduz primeiro o AlphaBlend, o primeiro conjunto de dados de alta qualidade em grande escala para decomposição de camadas transparentes e semitransparentes. Com base nisso, propõe o DiffDecompose, um framework baseado em Diffusion Transformer que aprende a distribuição posterior da decomposição de camadas através da decomposição contextual. (Fonte: HuggingFace Daily Papers)
Artigo propõe SuperWriter: Geração de texto longo por modelos de linguagem grandes orientada pela reflexão: Para resolver o problema de os modelos de linguagem grandes (LLM) terem dificuldade em manter a coerência, consistência lógica e qualidade textual na geração de texto longo, um novo artigo propõe o framework SuperWriter-Agent. Este framework introduz fases explícitas de planeamento de pensamento estruturado e melhoria no fluxo de geração, guiando o modelo a seguir um processo mais deliberado e cognitivamente alinhado. Com base neste framework, foi construído um conjunto de dados de ajuste fino supervisionado para treinar um SuperWriter-LM de 7B parâmetros, e foi desenvolvido um procedimento de otimização de preferência direta (DPO) hierárquica, utilizando a pesquisa em árvore de Monte Carlo (MCTS) para propagar a avaliação final de qualidade e otimizar correspondentemente cada passo de geração. (Fonte: HuggingFace Daily Papers)
Artigo propõe IEAP: Edição de imagem como programas baseados em modelos de difusão: Para enfrentar os desafios que os modelos de difusão encontram na edição de imagem orientada por instruções, especialmente em edições estruturalmente inconsistentes que envolvem alterações significativas de layout, um novo artigo introduz o framework IEAP (Image Editing As Programs). O IEAP baseia-se na arquitetura Diffusion Transformer (DiT) e processa instruções de edição complexas decompondo-as numa sequência de operações atómicas. Cada operação é implementada através de adaptadores leves que partilham o mesmo esqueleto DiT e são especializados para tipos específicos de edição. Estas operações são programadas por um agente baseado em modelo de linguagem visual (VLM) e suportam colaborativamente transformações arbitrárias e estruturalmente inconsistentes. (Fonte: HuggingFace Daily Papers)
Artigo propõe FlowPathAgent: Atribuição refinada de fluxogramas através de agentes neuro-simbólicos: Para resolver o problema de os modelos de linguagem grandes (LLM) frequentemente apresentarem alucinações e terem dificuldade em rastrear com precisão os caminhos de decisão ao interpretar fluxogramas, um novo artigo introduz a tarefa de atribuição refinada de fluxogramas e propõe o FlowPathAgent. O FlowPathAgent é um agente neuro-simbólico que executa atribuição posterior refinada através de raciocínio baseado em grafos. Primeiro, segmenta o fluxograma, convertendo-o num grafo simbólico estruturado, e depois adota uma abordagem de agente para interagir dinamicamente com o grafo para gerar caminhos de atribuição. Simultaneamente, o artigo também propõe o FlowExplainBench, um novo benchmark para avaliar a atribuição de fluxogramas. (Fonte: HuggingFace Daily Papers)
Artigo propõe Juízes LLM Quantitativos: LLM-as-a-judge é um framework que permite a um modelo de linguagem grande (LLM) avaliar automaticamente o resultado de outro LLM. Um novo artigo propõe o conceito de “Juízes LLM Quantitativos”, que alinham as pontuações de avaliação de juízes LLM existentes com pontuações humanas específicas de um domínio através de modelos de regressão. Estes modelos melhoram as pontuações do juiz original utilizando a avaliação textual e as pontuações do juiz. O artigo demonstra quatro tipos de juízes quantitativos para diferentes tipos de feedback absoluto e relativo, provando a generalidade e versatilidade do framework. Este framework é mais eficiente computacionalmente do que o ajuste fino supervisionado e pode ser mais eficiente estatisticamente quando o feedback humano é limitado. (Fonte: HuggingFace Daily Papers)
💼 Negócios
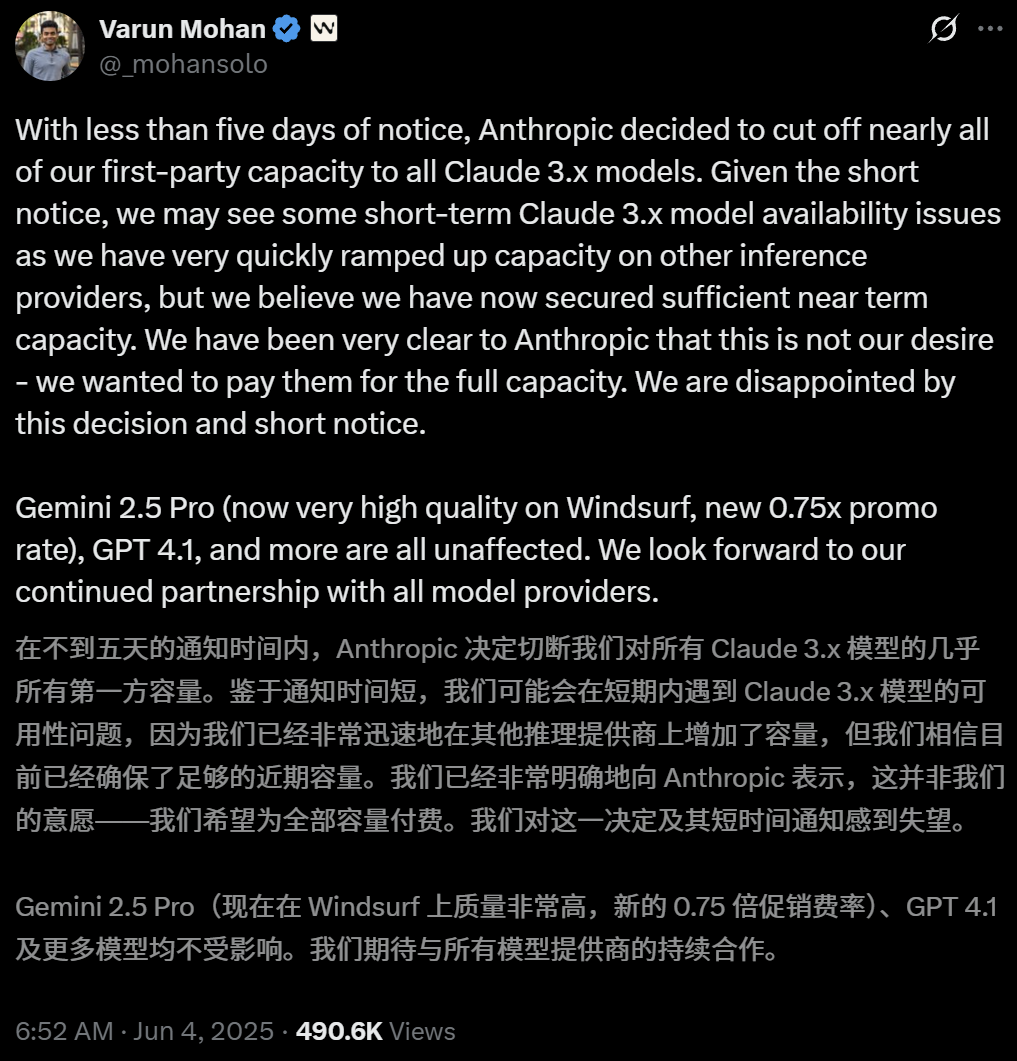
Anthropic restringe o acesso direto da ferramenta de programação de IA Windsurf aos modelos Claude: Varun Mohan, CEO da ferramenta de programação de IA Windsurf, declarou publicamente que a Anthropic, com um aviso prévio extremamente curto (menos de cinco dias), reduziu drasticamente as cotas de serviço API da Windsurf para os modelos da série Claude 3.x, incluindo Claude 3.5 Sonnet, 3.7 Sonnet, etc. Esta medida ocorre num contexto em que se noticia que a OpenAI irá adquirir a Windsurf, levantando preocupações no mercado sobre o aumento da concorrência entre os gigantes da IA e a neutralidade das plataformas de ferramentas de programação de IA. A Windsurf teve de ativar urgentemente serviços de inferência de terceiros e ajustar a sua estratégia de fornecimento de modelos aos utilizadores, enquanto a Anthropic respondeu que prioriza o fornecimento de recursos a parceiros que possam garantir uma colaboração contínua. (Fonte: 36氪, 36氪, mervenoyann, swyx)
Utilizadores empresariais pagantes da OpenAI ultrapassam os 3 milhões, lança estratégia de preços flexível: A OpenAI anunciou que o número dos seus utilizadores empresariais pagantes atingiu os 3 milhões, um aumento de 50% em relação aos 2 milhões anunciados em fevereiro deste ano, abrangendo as três linhas de produtos ChatGPT Enterprise, Team e Edu. Simultaneamente, a OpenAI lançou uma estratégia de preços flexível baseada num “conjunto de créditos partilhados” para clientes empresariais. Após a compra do conjunto de créditos pela empresa, a utilização de funcionalidades avançadas consumirá créditos, mas ainda será possível ter “acesso ilimitado” aos principais modelos e funcionalidades. Este novo preço será lançado primeiro no ChatGPT Enterprise e, posteriormente, estendido ao ChatGPT Team, que também oferece uma promoção de 1 dólar por 5 contas no primeiro mês de teste. (Fonte: 36氪, snsf)
Jovem chinesa da geração Z, Hong Letong, funda empresa de IA matemática Axiom, com avaliação alvo de 300 milhões de dólares: Carina Letong Hong, doutorada em matemática pela Universidade de Stanford, de origem chinesa, fundou a empresa de IA Axiom, focada no desenvolvimento de modelos de IA para resolver problemas matemáticos práticos, tendo como clientes-alvo fundos de cobertura e empresas de negociação quantitativa. A Axiom planeia utilizar dados de provas matemáticas formais para treinar modelos, dotando-os de rigorosas capacidades de raciocínio lógico e prova. Embora a empresa ainda não tenha produtos, já está em negociações para um financiamento de 50 milhões de dólares, com uma avaliação prevista entre 300 e 500 milhões de dólares. Hong Letong possui licenciaturas em matemática e física pelo MIT e um doutoramento em matemática por Stanford, tendo sido também bolseira Rhodes. (Fonte: 量子位)

🌟 Comunidade
Debates acesos na conferência AI.Engineer: Observabilidade de Agentes, equipas pequenas de alta eficiência e PM de IA em foco: Na AI.Engineer World Expo, os participantes debateram intensamente a observabilidade e avaliação de agentes de IA (Agent), a construção de equipas pequenas e eficientes (Tiny Teams) e as melhores práticas de gestão de produtos de IA (AI PM). A interação por voz foi considerada a direção mais popular em multimodalidade, e a segurança também se tornou, pela primeira vez, um tema importante. A Anthropic, na conferência, lançou um pedido de empreendedorismo na área do MCP (Protocolo de Contexto de Modelo), esperando ver mais servidores MCP para além das ferramentas de desenvolvimento, soluções para simplificar a construção de servidores e inovações na segurança de aplicações de IA (como proteção contra envenenamento de ferramentas). (Fonte: swyx, swyx, swyx, swyx)

Debate sobre se a IA levará ao desaparecimento da linguagem natural e ao emburrecimento humano: Surgiram nas redes sociais preocupações sobre a possibilidade de a ampla aplicação da IA levar à atrofia da comunicação em linguagem natural (teoria da “internet morta”) e à degradação das capacidades cognitivas humanas (como pensamento profundo, questionamento, capacidade de reconstrução). Alguns utilizadores acreditam que a dependência excessiva da IA para obter informações e respostas pode reduzir a triagem ativa, o julgamento e o pensamento independente, formando uma dependência de “terceirização cognitiva”. Outra perspetiva sustenta que a IA pode lidar com o “o quê” e o “como”, mas o “porquê” ainda requer decisão humana, sendo crucial encontrar o papel do ser humano na coexistência com a tecnologia e manter o poder de julgamento. (Fonte: Reddit r/ArtificialInteligence, 36氪)
OpenAI ordenada judicialmente a reter todos os logs do ChatGPT e API, gerando preocupações com a privacidade: Uma ordem judicial exige que a OpenAI retenha todos os registos de chat do ChatGPT e logs de pedidos de API, incluindo os registos de “chat temporário” que deveriam ser eliminados. Esta medida levantou preocupações entre os utilizadores sobre a privacidade dos dados e se as políticas de retenção de dados da OpenAI podem ser cumpridas. Alguns comentadores consideram que isto realça ainda mais a importância de utilizar modelos locais e de possuir a própria tecnologia e dados. (Fonte: Reddit r/artificial, Reddit r/LocalLLaMA, Teknium1, nptacek)

Agentes de IA enfrentam desafios de confiança e segurança, vulneráveis a ataques de phishing: Discussões apontam que, apesar da crescente capacidade dos Agentes de IA, os seus mecanismos de confiança apresentam riscos de serem explorados. Por exemplo, um Agente pode ser induzido a aceder a links maliciosos por confiar em websites conhecidos (como redes sociais), resultando na divulgação de informações sensíveis ou na execução de ações maliciosas. Isto exige o reforço da capacidade de identificação e resistência a conteúdo e links maliciosos no design dos Agentes, garantindo a sua segurança ao executar operações no mundo real. (Fonte: DeepLearning.AI Blog)
Reflexões sobre ferramentas de programação assistida por IA: da modernização de código à transformação de fluxos de trabalho: A comunidade discutiu a aplicação da IA no desenvolvimento de software, especialmente no tratamento de código legado e na alteração dos fluxos de trabalho de programação. A Morgan Stanley utilizou a sua ferramenta de IA interna, DevGen.AI, para analisar e refatorizar milhões de linhas de código antigo, poupando significativamente tempo de desenvolvimento. Ao mesmo tempo, a perspetiva de Andrej Karpathy sobre o futuro das aplicações com UI complexas também suscitou reflexões sobre como o software futuro deve ser concebido para colaborar melhor com a IA, enfatizando a importância de interfaces baseadas em scripts e API. Estas discussões refletem o profundo impacto que a IA está a ter nas práticas e filosofias da engenharia de software. (Fonte: mitchellh, 36氪, 36氪)
💡 Outros
Reparação de eletrodomésticos assistida por IA, ChatGPT torna-se “Friendo”: Um utilizador partilhou a sua experiência de sucesso no diagnóstico e reparação preliminar de uma máquina de lavar loiça avariada com a ajuda do ChatGPT (apelidado de Friendo). Através de conversas com a IA, descrição de códigos de erro e envio de fotos do painel de controlo, a IA ajudou o utilizador a localizar uma falha no elemento de aquecimento e orientou-o a contornar temporariamente esse elemento, fazendo com que a máquina de lavar loiça recuperasse parcialmente a funcionalidade. Isto demonstra o potencial dos LLM na resolução de problemas do quotidiano e no suporte técnico. (Fonte: Reddit r/ChatGPT)
Vídeo de entrevista gerado por IA com figuras do século XVI chama a atenção: Um vídeo gerado por IA que simula uma entrevista com figuras do século XVI recebeu elogios na comunidade pela sua criatividade e humor. As personagens e os diálogos do vídeo refletem de forma espirituosa as condições de vida da época, como por exemplo: “acordar e pisar em fezes, depois ser taxado, e isto tudo antes do pequeno-almoço”. Este tipo de aplicação demonstra o potencial de entretenimento da IA na criação de conteúdo e na recriação de cenários históricos. (Fonte: draecomino, Reddit r/ChatGPT)

Bolsas Thiel focam em inovação em IA, abrangendo humanos digitais, emoções em robôs e previsão por IA: A lista da nova edição das “Bolsas Thiel” foi anunciada, com vários projetos de IA a chamarem a atenção. A Canopy Labs dedica-se a criar humanos digitais de IA indistinguíveis de pessoas reais, capazes de interação multimodal em tempo real. O projeto Intempus visa dotar robôs de capacidades de expressão emocional semelhantes às humanas para melhorar a interação humano-robô. O Aeolus Lab foca-se na utilização de tecnologia de IA para prever o tempo e desastres naturais, explorando inclusivamente a possibilidade de intervenção ativa. Estes projetos demonstram as direções de exploração de jovens empreendedores nas fronteiras da IA. (Fonte: 36氪)