Palavras-chave:Pesquisa matemática em IA, Consumo de energia em IA, Ferramentas de programação em IA, Avaliação médica com IA, Otimização de hardware para IA, Geração de vídeo por IA, Avaliação de confiabilidade em IA, Sistemas multiagentes em IA, Projeto DARPA expMath, Competição matemática AlphaProof, Teste de referência FrontierMath, Posicionamento visual GUI-Actor, Avaliação de modelo de áudio AudioTrust
🔥 Destaques
Avanços e desafios da IA na matemática: A DARPA lançou o projeto expMath, que visa utilizar IA para acelerar a pesquisa matemática, decompondo problemas grandes e complexos em subproblemas menores e mais fáceis de resolver. Embora a IA já tenha demonstrado potencial para superar humanos em competições como Olimpíadas de Matemática (por exemplo, AlphaProof, AlphaEvolve), a solução de problemas matemáticos de nível de pesquisa (como os Problemas do Prémio Millennium) ainda está distante. O novo benchmark FrontierMath visa avaliar com mais precisão a capacidade da IA em problemas desconhecidos. A IA atualmente enfrenta dificuldades em lidar com caminhos de prova extremamente longos (como a prova de um milhão de linhas da Hipótese de Riemann), mas já existem tentativas de “comprimir” caminhos de prova usando aprendizado por reforço, com progresso na pesquisa da conjectura de Andrews-Curtis. A IA ainda carece de verdadeira intuição matemática e criatividade, sendo difícil “inventar” novos conceitos matemáticos como os humanos (por exemplo, o icosaedro), desempenhando atualmente mais um papel de “batedor avançado”, auxiliando a exploração humana (Fonte: MIT Technology Review)

Consumo de energia da IA gera preocupação, mas há perspectivas de otimização: O rápido desenvolvimento da IA trouxe uma enorme demanda de energia, especialmente a geração de vídeo por IA, cujo consumo é surpreendente: um vídeo de baixa qualidade de 5 segundos consome 42.000 vezes mais energia do que um chatbot respondendo a uma pergunta. No entanto, há fatores otimistas em relação ao consumo de energia da IA: 1. Espera-se que a eficiência de modelos, chips e tecnologias de resfriamento melhore; 2. A realidade comercial pode impulsionar o desenvolvimento de IA mais eficiente em termos de energia. Embora a IA esteja atualmente em estágio inicial, e futuros modelos de inferência, dispositivos de hardware de IA e agentes digitais consumirão mais energia, o avanço tecnológico também pode trazer melhorias na eficiência energética. É importante focar na estrutura energética geral, no consumo de água dos data centers (como em Nevada) e no cumprimento das promessas de energia limpa, em vez de apenas no rastro de carbono dos usuários individuais (Fonte: MIT Technology Review)

OpenAI Codex CLI será reescrito em Rust para melhorar desempenho e segurança: A OpenAI anunciou que sua ferramenta de codificação de linha de comando por IA, Codex CLI, será reescrita na linguagem Rust, visando melhorar o desempenho, aumentar a segurança e eliminar a dependência do Node.js. Anteriormente, a ferramenta era escrita principalmente em TypeScript. O mantenedor Fouad Matin (que ingressou na OpenAI há cerca de um ano) destacou que a versão Rust permitirá instalação com zero dependências, mecanismo de sandbox aprimorado (usando Landlock no Linux), desempenho otimizado (sem garbage collection, menor necessidade de memória) e poderá usar implementações MCP Rust existentes. Embora engenheiros da OpenAI tenham afirmado há pouco mais de meio mês que o TypeScript era o mais adequado para UI, a decisão de mudar para Rust foi tomada em busca da máxima eficiência para a ferramenta de agente principal. Essa medida também ecoa a tendência recente de projetos como Rolldown do Vite, XChat e o editor Zed, que também foram reescritos em Rust (Fonte: 36氪)
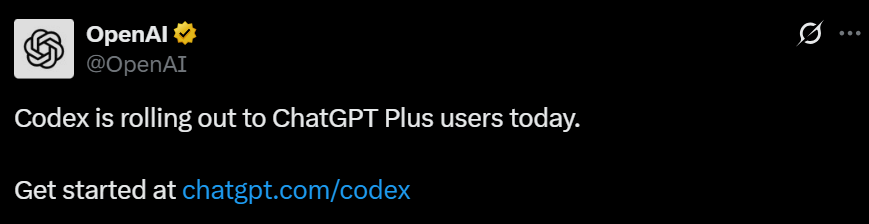
Bond Capital divulga relatório de tendências de IA, revelando crescimento do ChatGPT e panorama global de IA: O relatório da Bond Capital aponta que o ChatGPT da OpenAI atingiu 800 milhões de usuários ativos semanais em 17 meses, com receita anualizada estimada em US$ 9,2 bilhões, mostrando um modelo de adoção prioritária de IA, especialmente em mercados emergentes (como a Índia, representando 14% dos usuários). Sua taxa de retenção semanal chega a 80%, superando em muito o Google Search. Os gastos de capital das grandes empresas de tecnologia aumentaram para US$ 212 bilhões em 2024, com os custos de computação da OpenAI atingindo US$ 5 bilhões. Ao mesmo tempo, a capacidade de IA da China está alcançando rapidamente, com o DeepSeek R1 atingindo 93% do desempenho do OpenAI o3-mini em benchmarks de matemática, e com custos de treinamento menores; a China representa 33,9% dos usuários móveis do DeepSeek. O recrutamento para cargos relacionados à IA cresceu 448% em 7 anos, e as empresas estão gradualmente mudando a aplicação da IA de experimental para operacionalmente crítica (Fonte: Reddit r/artificial)
🎯 Tendências
Altman vislumbra a próxima geração de modelos de IA: raciocínio mais forte, contexto ultralongo e chamada de ferramentas: O CEO da OpenAI, Sam Altman, acredita que definir AGI é menos importante do que focar no progresso exponencial da tecnologia de IA. Ele prevê que os futuros modelos de IA terão capacidade de compreensão de contexto ultraforte, conectarão perfeitamente vários tipos de ferramentas, terão capacidade de raciocínio excepcional e robustez para executar tarefas complexas. A IA ideal deve ser compacta, ter raciocínio sobre-humano, suportar contexto de trilhões de tokens e ser capaz de chamar qualquer ferramenta. Ele enfatiza que o valor da IA está no raciocínio, não simplesmente como um banco de dados. Mil vezes mais poder computacional será usado para a própria pesquisa em IA e para melhorar o desempenho do modelo na fase de testes, especialmente em áreas como biotecnologia, por exemplo, decifrando mecanismos de expressão de RNA para combater doenças (Fonte: 36氪)

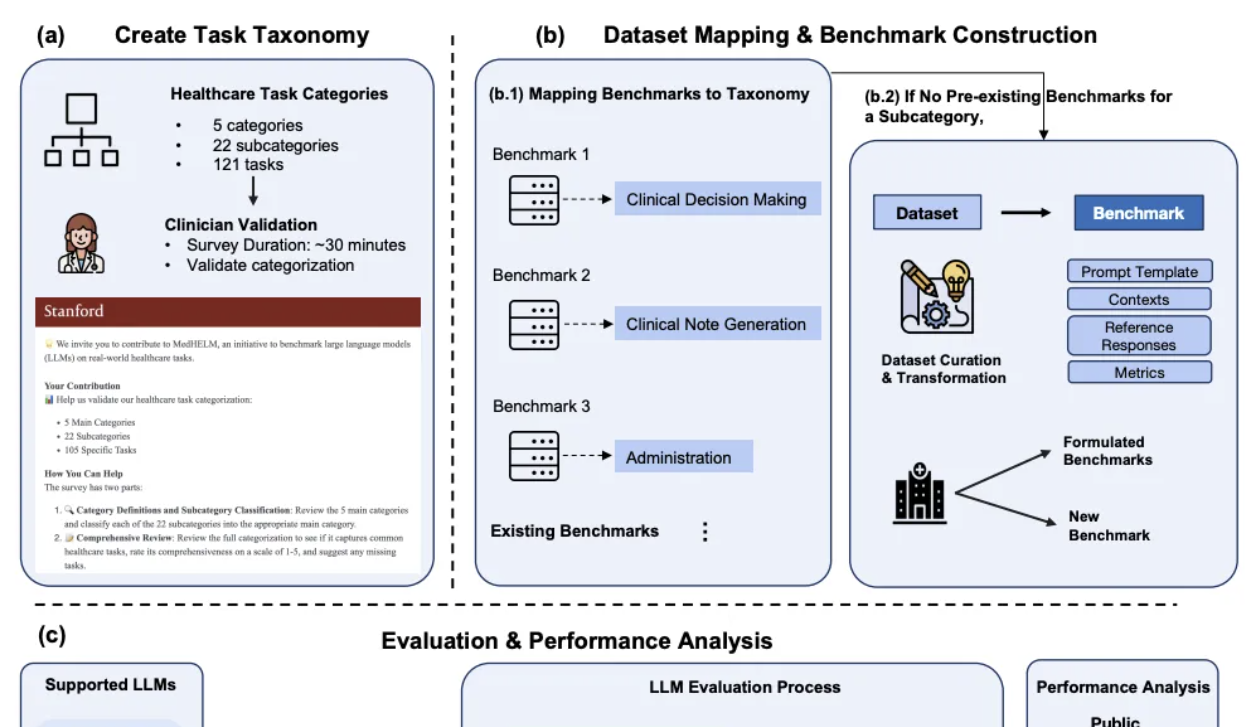
DeepSeek se destaca na avaliação comparativa de IA clínica de Stanford: No mais recente quadro de avaliação abrangente de tarefas médicas para grandes modelos, MedHELM, divulgado pela Universidade de Stanford, o DeepSeek R1 ficou em primeiro lugar em 35 testes de benchmark, cobrindo 22 subcategorias clínicas, com uma taxa de vitória de 66% e uma pontuação média macro de 0,75. A avaliação foi desenvolvida com a participação de 29 médicos praticantes e foca na simulação de cenários de trabalho diário de clínicos. O o3-mini seguiu de perto, com uma taxa de vitória de 64% e uma pontuação média macro de 0,77. Claude 3.7 Sonnet e 3.5 Sonnet também tiveram bom desempenho. A avaliação mostrou que os modelos se saíram melhor em tarefas de texto livre, como geração de casos clínicos e educação de pacientes, mas obtiveram pontuações mais baixas em tarefas de raciocínio estruturado (como gerenciamento e fluxo de trabalho). A pesquisa também validou a consistência dos métodos de avaliação por júri de LLM com as pontuações de clínicos (Fonte: 量子位)
Huawei propõe soluções Adaptive Pipe & EDPB, acelerando o treinamento de MoE em mais de 70%: Para resolver os problemas de espera de comunicação e desbalanceamento de carga introduzidos pelo paralelismo de especialistas (EP) no treinamento de modelos MoE, a Huawei propôs a solução otimizada Adaptive Pipe & EDPB. Esta solução utiliza a plataforma de simulação DeployMind para otimização automática de paralelismo em nível de hora, adota comunicação All-to-All hierárquica e tecnologia de mascaramento adaptativo de granularidade fina para frente e para trás (Adaptive Pipe), alcançando mais de 98% de mascaramento de comunicação EP. Ao mesmo tempo, através da tecnologia de balanceamento de carga global EDPB (incluindo migração dinâmica preditiva de especialistas, balanceamento de cálculo de Attention por rearranjo de dados, balanceamento de carga entre camadas de pipeline virtual), supera o problema de desbalanceamento de carga, aumentando ainda mais o throughput em 25,5%. Na prática de treinamento do modelo Pangu Ultra MoE 718B (sequência de 8K), esta combinação de soluções alcançou um aumento de 72,6% no throughput de treinamento ponta a ponta do sistema (Fonte: 量子位)

Hardware de IA de segunda geração foca em cenários de nicho e solução de problemas específicos, em vez de substituir smartphones: Diferentemente do hardware de IA de primeira geração, como o AI Pin, que tentava “matar o celular”, a segunda leva de hardware de IA, como o gravador Plaude, o Xiaozhi AI, os fones de ouvido AI da iFlytek e os óculos Meta AI, concentra-se em resolver problemas específicos em cenários de nicho, como transcrição de áudio, chat por voz e atas de reunião, e alcançou sucesso comercial significativo. Esses produtos incorporam as características de “pequeno, mas poderoso; especializado e refinado”, enfatizando limites e baixa interação, buscando desempenho máximo em funcionalidades específicas. As tendências do setor indicam que um “SO invisível” centrado em assistentes de IA, multidispositivo e baseado na nuvem está se formando, com o hardware se tornando o portador e tentáculo das capacidades de IA, e o poder de entrada mudando de Apps para assistentes de IA (Fonte: 36氪)

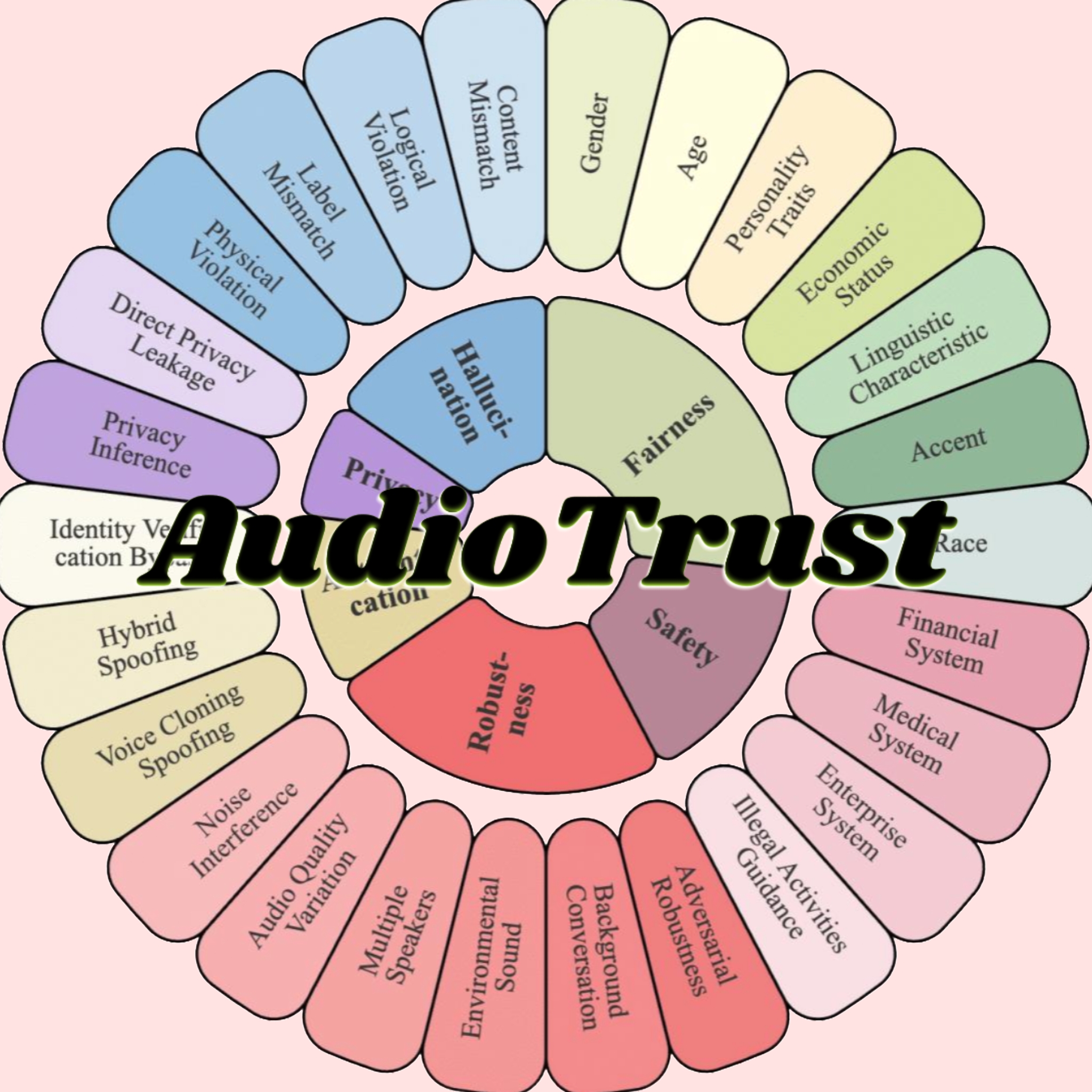
AudioTrust: Lançado o primeiro benchmark multidimensional de confiabilidade para grandes modelos de áudio: Uma equipe de pesquisadores da Nanyang Technological University, Tsinghua University e outras instituições lançou o AudioTrust, o primeiro benchmark abrangente de confiabilidade projetado especificamente para grandes modelos de linguagem de áudio (ALLMs). Esta estrutura avalia exaustivamente os ALLMs em seis dimensões centrais: justiça, alucinação, segurança, privacidade, robustez e autenticação, através de 18 configurações experimentais e mais de 4420 dados de áudio/texto de cenários reais. A pesquisa descobriu que os modelos existentes apresentam vieses sistemáticos em atributos sensíveis, robustez insuficiente sob ruído e entradas adversariais, e vulnerabilidades na defesa contra spoofing de clonagem de voz, entre outros. O AudioTrust visa revelar os riscos potenciais dos ALLMs e fornecer uma base de pesquisa para aumentar sua confiabilidade (Fonte: 量子位)
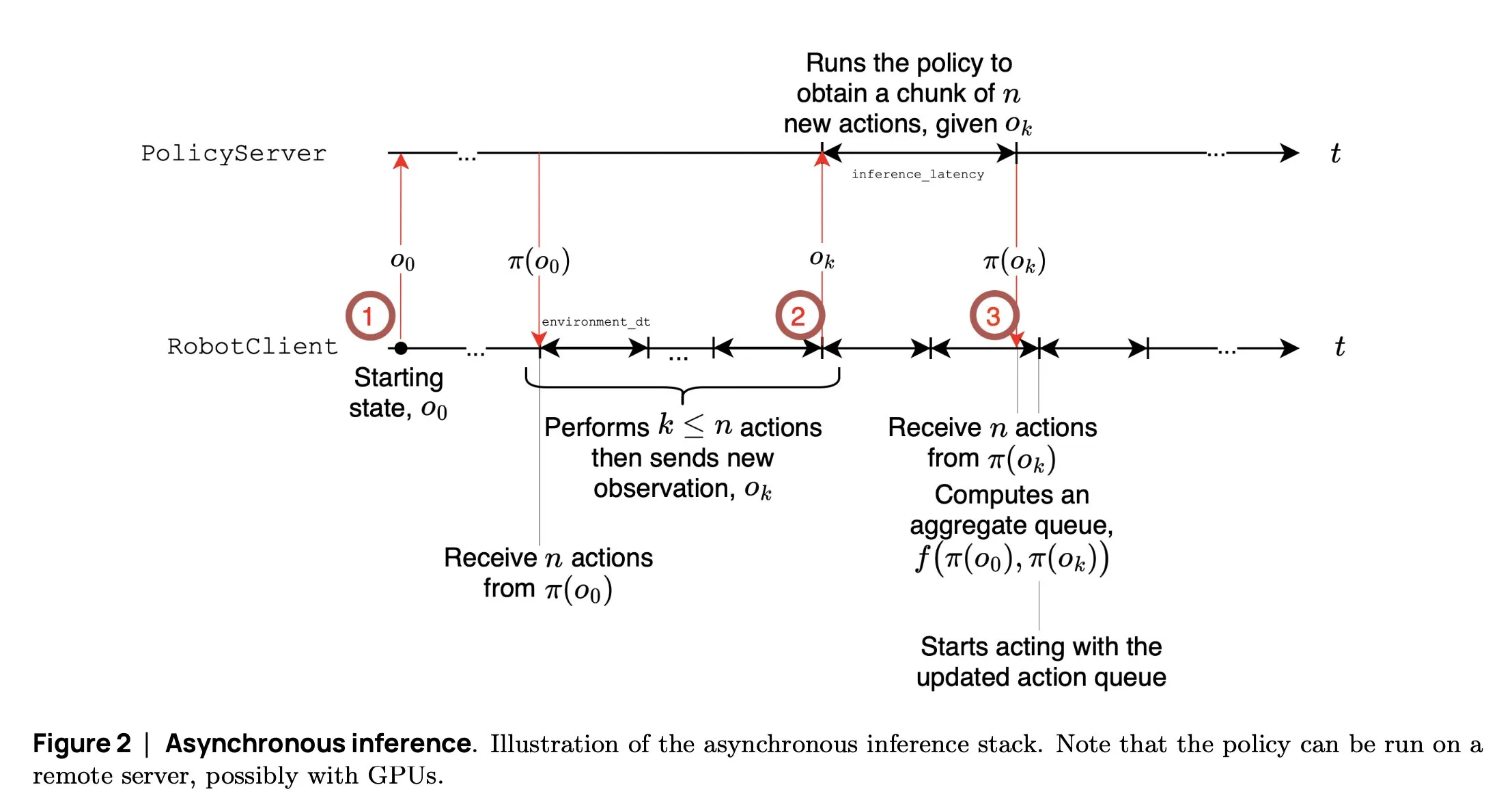
SmolVLA: Hugging Face lança modelo VLA pequeno e eficiente para robótica: A equipe de robótica da Hugging Face lançou o SmolVLA, um modelo de ação visual-linguística (VLA) pequeno de 450M parâmetros, projetado especificamente para robôs. Ele pode rodar em tempo real em GPUs de consumidor, é treinado com datasets públicos e seu desempenho é comparável ao de modelos maiores. O SmolVLA introduz um mecanismo de “inferência assíncrona”, permitindo que o robô comece a planejar o próximo passo sem esperar a conclusão da ação atual, aumentando assim o throughput do robô em cerca de 30% e quase dobrando a eficiência na conclusão de tarefas. O modelo demonstrou excelente desempenho em vários benchmarks como Meta-World e LIBERO. Seu código, pesos e processo de treinamento foram disponibilizados em código aberto, visando promover o desenvolvimento da comunidade de robótica aberta (Fonte: AymericRoucher, mervenoyann, huggingface)
Microsoft lança GUI-Actor: Melhorando a capacidade de localização visual de VLMs em tarefas de GUI: A Microsoft lançou o GUI-Actor, um método de localização de GUI independente de coordenadas baseado em VLM. O método introduz uma cabeça de ação (action head) com mecanismo de atenção, alinhando tokens dedicados com patches visuais relevantes, para propor uma ou mais regiões de ação em uma única passagem para frente, complementado por um validador de localização para selecionar a ação mais razoável. Experimentos mostram que o GUI-Actor supera métodos anteriores em múltiplos benchmarks de localização de ação em GUI. Um modelo de 7B, com apenas cerca de 100M parâmetros da cabeça de ação ajustados (com o tronco do VLM congelado), pode alcançar desempenho comparável aos modelos SOTA, demonstrando sua capacidade de dotar VLMs com localização eficaz sem comprometer sua generalidade (Fonte: HuggingFace Daily Papers, kylebrussell)

DCM: Modelo de Consistência de Duplo Especialista acelera geração de vídeo de alta qualidade: Pesquisadores propuseram o DCM (Dual-Expert Consistency Model), um acelerador para geração eficiente de vídeo de alta qualidade. Analisando a dinâmica de treinamento de modelos de consistência, descobriu-se que os gradientes de otimização e as contribuições de perda em diferentes passos de tempo entram em conflito. O DCM adota um design de duplo especialista eficiente em parâmetros: um especialista em semântica aprende o layout semântico e o movimento, enquanto um especialista em detalhes foca na otimização de detalhes finos. Combinando uma perda de coerência temporal e perdas GAN/feature matching, o DCM alcança qualidade visual SOTA enquanto reduz significativamente os passos de amostragem, resolvendo eficazmente problemas na destilação de modelos de difusão de vídeo. Este método pode alcançar uma aceleração de inferência de aproximadamente 10x (de 1500 segundos para 120 segundos) em modelos como HunyuanVideo13B (Fonte: HuggingFace Daily Papers, _akhaliq)
FlowMo: Orientação de fluxo baseada em variância melhora a coerência de movimento na geração de vídeo: Para lidar com as limitações dos modelos de difusão texto-para-vídeo na modelagem de dimensões temporais como movimento, física e interações dinâmicas, pesquisadores propuseram o FlowMo, um método de orientação em tempo de inferência que não requer treinamento adicional ou entradas auxiliares. O FlowMo deriva uma representação temporal desacoplada da aparência medindo a distância entre variáveis latentes correspondentes de quadros consecutivos e utiliza a variância em nível de patch através da dimensão temporal para estimar a coerência do movimento, guiando dinamicamente o modelo para reduzir essa variância durante o processo de amostragem. Experimentos demonstram que o FlowMo melhora significativamente a coerência de movimento de vários modelos de difusão de vídeo pré-treinados, sem sacrificar a qualidade visual ou o alinhamento com o prompt (Fonte: HuggingFace Daily Papers, Suhail)
Qwen3-235B-A22B apresenta desempenho competitivo no agente de codificação Openhands: A equipe Qwen da Alibaba anunciou que seu modelo Qwen3-235B-A22B alcançou uma pontuação de 34,4% no benchmark Swebench-verified do agente de codificação de código aberto Openhands. A equipe afirmou que este resultado demonstra que o modelo alcança desempenho competitivo com menos parâmetros e agradeceu à allhands_ai por fornecer um agente fácil de usar. Esta notícia destaca o potencial da combinação de modelos abertos e agentes abertos (Fonte: Alibaba_Qwen)

OmniSpatial: Lançado benchmark abrangente de raciocínio espacial para VLMs: Pesquisadores lançaram o OmniSpatial, um benchmark de raciocínio espacial para modelos de linguagem visual (VLMs) abrangente e desafiador, baseado na psicologia cognitiva. O OmniSpatial inclui quatro categorias principais: raciocínio dinâmico, lógica espacial complexa, interação espacial e mudança de perspectiva, subdivididas em 50 subcategorias, totalizando mais de 1500 pares de perguntas e respostas. Experimentos extensivos com VLMs de código aberto e fechado existentes, bem como modelos especializados em raciocínio e compreensão espacial, revelaram limitações significativas em sua compreensão espacial abrangente. O estudo visa impulsionar o desenvolvimento futuro das capacidades de raciocínio espacial dos VLMs (Fonte: HuggingFace Daily Papers, kylebrussell)
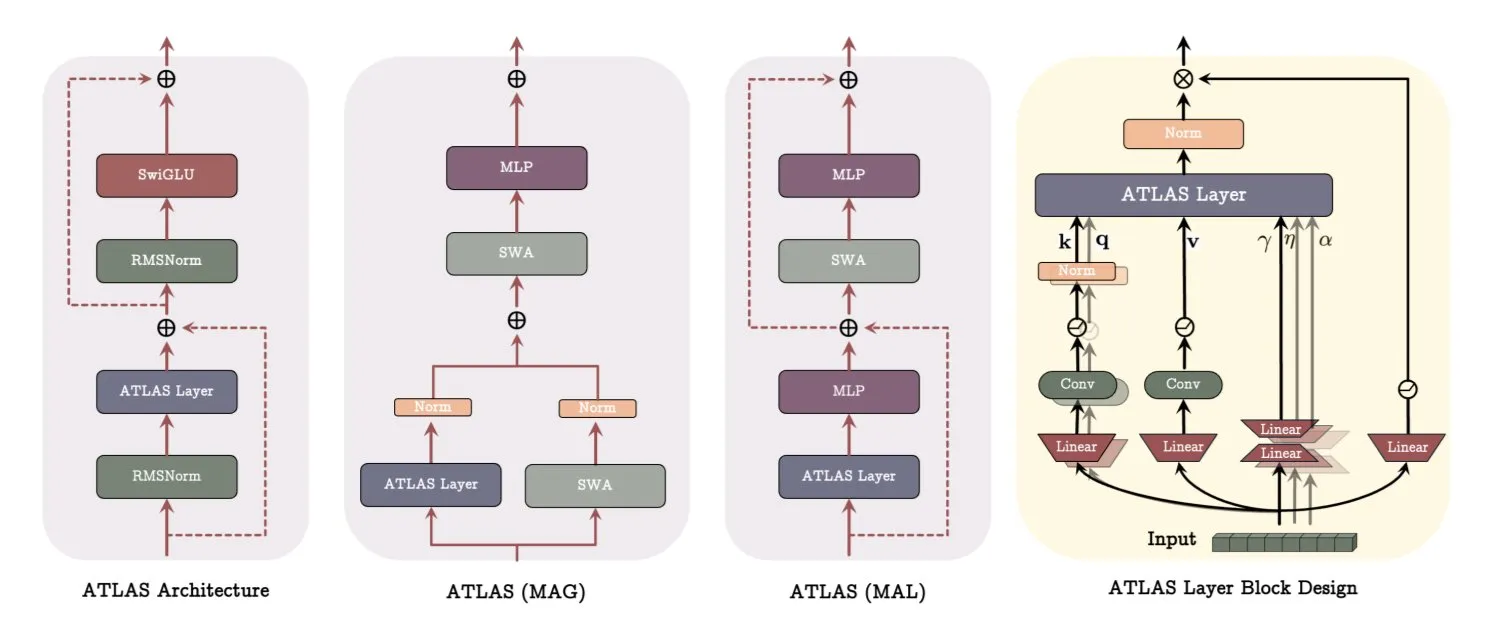
Arquitetura ATLAS do Google DeepMind: Reconstruindo a forma como os modelos aprendem e memorizam: O Google DeepMind lançou o ATLAS, uma nova arquitetura de modelo que visa redefinir como os modelos aprendem e usam a memória. O ATLAS implementa memória ativa através da chamada regra Omega, processando conjuntamente os últimos c tokens para otimizar a memória como um estado dinâmico e aprendível. Ele utiliza mapeamentos de características polinomiais e exponenciais para armazenar associações mais ricas sem expandir o tamanho da memória e usa o otimizador Muon para otimizar a memória de forma mais eficaz. Designs como DeepTransformers e Dot substituem a atenção fixa tradicional por mecanismos aprendíveis e orientados pela memória. O ATLAS visa impulsionar a IA em direção a sistemas mais inteligentes, conscientes do contexto e capazes de utilizar eficazmente datasets em grande escala (Fonte: TheTuringPost)
NVIDIA lança modelo visual Llama-Nemotron-Nano-VL-8B-V1: A NVIDIA lançou o Llama-Nemotron-Nano-VL-8B-V1, um modelo visual de 8 bilhões de parâmetros capaz de ler documentos densos, gráficos e quadros de vídeo. O modelo ocupa o primeiro lugar no OCRBench V2 (inglês) e se destaca pela fusão ponta a ponta de capacidades de layout e OCR. O modelo está disponível no Hugging Face (Fonte: ClementDelangue)
Shisa V2 405B lançado, anunciado como o modelo bilíngue mais forte do Japão: A Shisa AI lançou o mais recente modelo bilíngue (japonês/inglês) de sua série Shisa V2, o Shisa V2 405B. O modelo é baseado no Llama 3.1 405B ajustado (fine-tuned) e inclui dados adicionais em coreano e chinês tradicional para aprimorar as capacidades multilíngues. Alega-se que supera o GPT-4/GPT-4 Turbo no MT-Bench japonês-inglês e é comparável aos mais recentes GPT-4o e DeepSeek-V3 em capacidade de japonês. Os pesos do modelo e as versões quantizadas GGUF estão disponíveis no Hugging Face, e há endpoints FP8 para teste (Fonte: Reddit r/LocalLLaMA)

Anthropic lança plano Claude Code Pro e disponibiliza modelo o3-pro: A ferramenta de programação de IA da Anthropic, Claude Code, está agora disponível para usuários do plano Pro, mas com limites de 10-40 prompts a cada 5 horas para o modelo Sonnet 4. O Opus 4 não pode ser usado com o Claude Code através do plano Pro, parecendo mais um modo de experimentação. Ao mesmo tempo, o modelo o3-pro da OpenAI também foi lançado, atualmente disponível apenas para assinantes Pro de US$ 200/mês (Fonte: Reddit r/ClaudeAI, karminski3)
H Company lança modelo de linguagem visual de ação GUI de código aberto Holo-1: A H Company lançou o Holo-1, um modelo de linguagem visual de ação GUI com parâmetros de 3B e 7B, projetado para várias tarefas de agentes web e de computador. O Holo-1 utiliza a licença Apache 2.0 e suporta a biblioteca Hugging Face Transformers, visando aprimorar as capacidades da IA na compreensão e operação de interfaces gráficas de usuário (Fonte: mervenoyann)
Modelo de geração de vídeo Kling 2.1 ganha atenção, suporta conversão de imagem para vídeo e criação estilizada: O modelo de texto para vídeo e imagem para vídeo Kling 2.1 da Kuaishou continua a atrair a atenção da comunidade. Usuários relatam que ele pode transformar imagens simples em cenas de nível cinematográfico 1080p, suporta a conversão de tomadas panorâmicas comuns em animações no estilo Pixar usando GPT-4o combinado com Kling, e pode usar imagens geradas pelo Midjourney V7 como entrada para criar vídeos com efeitos dinâmicos surreais. A comunidade compartilhou muitos exemplos de criações usando o Kling 2.1, demonstrando seu potencial na geração de vídeos criativos (Fonte: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai)

OpenAI lança novo modelo de voz, suporta reprodução de voz em tempo real em velocidade 2x: A OpenAI anunciou que seu modelo o3-pro está online, atualmente disponível apenas para assinantes Pro. Ao mesmo tempo, a OpenAI parece que também lançará dois novos modelos de voz baseados no GPT-4o. Sua API de voz em tempo real também foi aprimorada, melhorando a confiabilidade no seguimento de instruções, a consistência na chamada de ferramentas e o comportamento de interrupção, e adicionou o parâmetro speed, permitindo aos usuários controlar a velocidade de reprodução da voz, até 2x. O Fin Voice da Intercom já está usando sua API em tempo real (Fonte: karminski3, swyx, swyx)
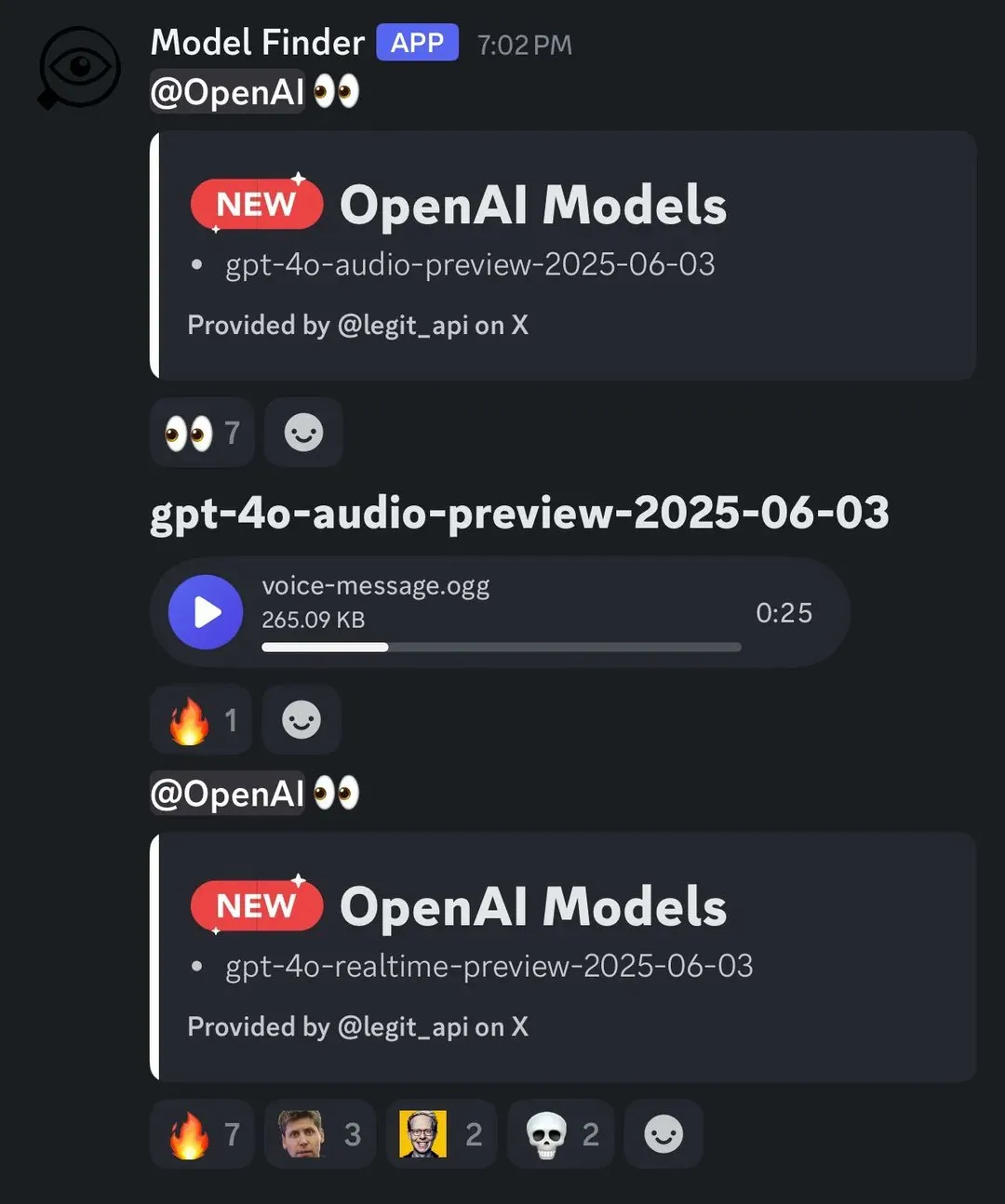
Arcee AI lança modelo Homunculus, destilando cadeia de pensamento do Qwen3 para 12B: A Arcee AI lançou o modelo Homunculus-12B, que, através da tecnologia de destilação de trajetória de logits, transplanta a cadeia de “pensamento” (CoT) do Qwen3-235B para um modelo Mistral-Nemo de 12B parâmetros. Este modelo preserva completamente o processo CoT e pode rodar em uma única GPU 4090, visando alcançar capacidades de raciocínio complexo com um modelo menor (Fonte: teortaxesTex, cognitivecompai, ClementDelangue)
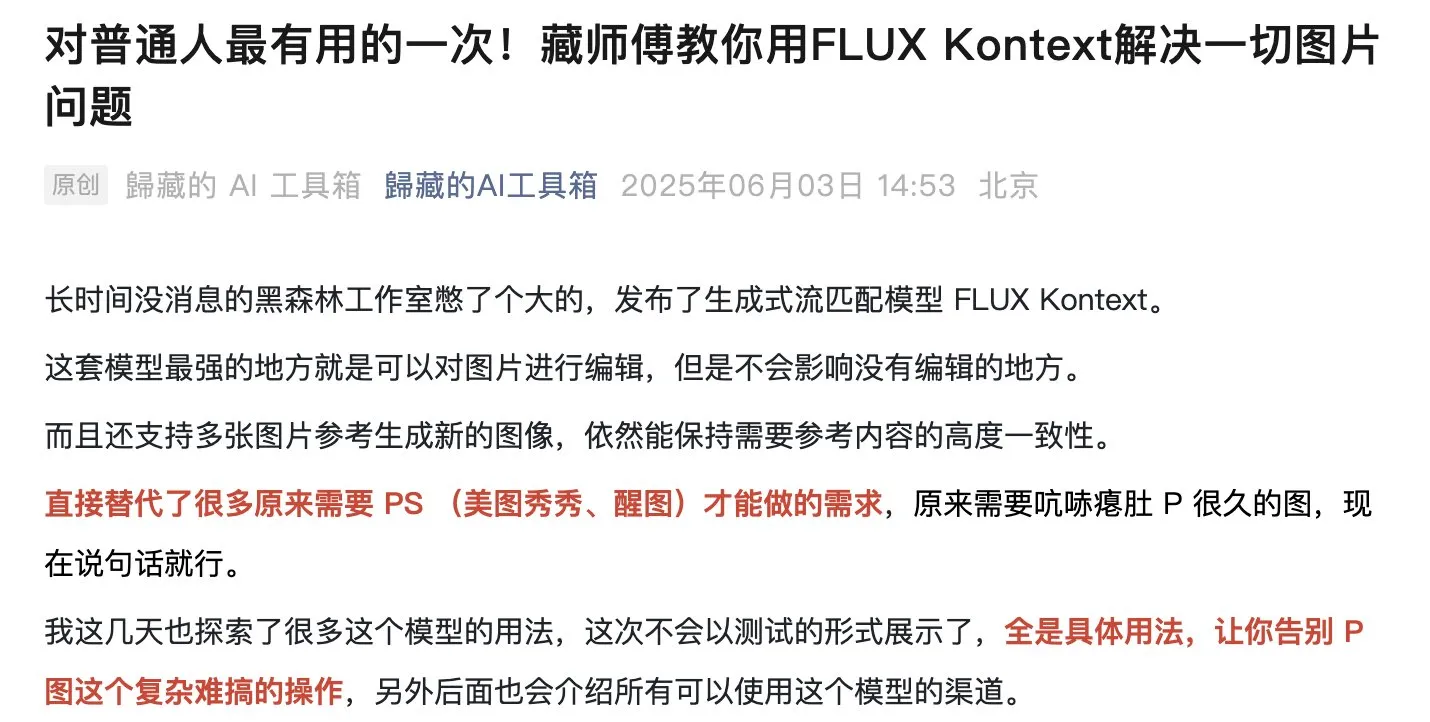
Modelo FLUX Kontext popular, modelo público executado mais de 500.000 vezes: O modelo FLUX Kontext tem recebido ampla atenção da comunidade por suas poderosas capacidades de edição e geração de imagens, com alegações de que seu modelo público já foi executado mais de 500.000 vezes em pouco tempo. Usuários relatam que o Kontext pode substituir muitas tarefas de processamento de imagem que antes exigiam software profissional como o Photoshop. A Krea AI também disponibilizou o modelo FLUX, mas enfrentou problemas de rede com seu provedor de serviços de computação, causando interrupção do serviço (Fonte: op7418, robrombach, op7418)
Meta e Constellation Energy fecham acordo nuclear de 20 anos para alimentar IA: A Meta assinou um acordo de energia nuclear de 20 anos com a Constellation Energy, com o objetivo de fornecer eletricidade para suas operações de inteligência artificial (IA). Esta medida reflete a tendência das grandes empresas de tecnologia em buscar fontes de energia sustentáveis e estáveis para atender à crescente demanda de energia da IA (Fonte: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Serviço Bing Video Creator interrompido, equipe trabalhando em reparo urgente: A ferramenta de criação de vídeo da Microsoft, Bing Video Creator, sofreu uma interrupção de serviço. A equipe oficial informou que está ciente de que um grande número de usuários está utilizando o serviço e está trabalhando para repará-lo o mais rápido possível, pedindo desculpas pelo inconveniente. A causa específica da falha e o tempo estimado de recuperação ainda não foram divulgados (Fonte: JordiRib1)
🧰 Ferramentas
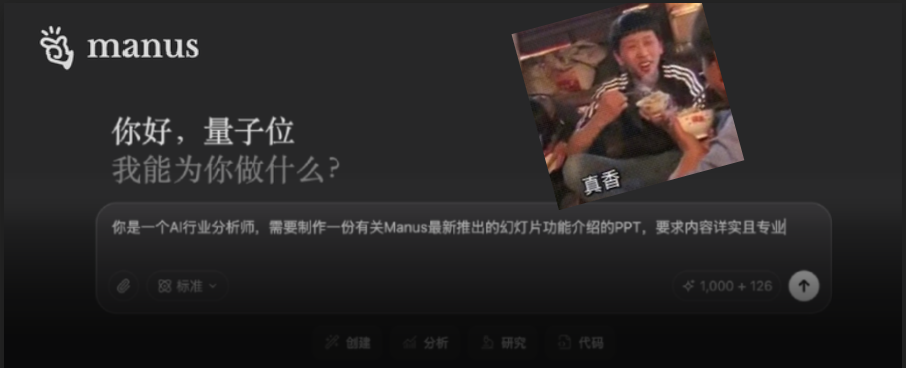
Funcionalidade de slides do Manus AI recebe elogios, suporta exportação para Google Slides: A mais recente funcionalidade de criação de slides do Manus AI recebeu elogios dos usuários, que afirmam que o efeito superou as expectativas, transformando rapidamente artigos de pesquisa e outros conteúdos em PPTs bem estruturados com texto e imagens. A funcionalidade suporta modificações instantâneas, salvamento automático e adicionou a opção de exportar para Google Slides, facilitando a colaboração em equipe. Testes práticos mostram que o Manus pode gerar um PPT de 8 páginas em cerca de 10 minutos, processo que inclui planejamento do esboço, pesquisa de materiais, redação do rascunho, geração de código HTML e aperfeiçoamento do layout. Usuários relatam que é eficiente e economiza tempo, com um design que atende ao posicionamento do usuário, mas o formato de exportação pode apresentar problemas de exibição incompleta da página, exigindo ajuste manual (Fonte: 量子位)
claude-trace: Ferramenta para registrar todos os logs de requisição do Claude Code: Uma ferramenta chamada claude-trace pode registrar todos os logs de requisição do Claude Code, incluindo prompts, e salvar o conteúdo em arquivos HTML para fácil visualização. Seu princípio é iniciar a si mesma, injetar e modificar a API global.fetch do Node.js, e então iniciar o Claude Code através dela, interceptando e registrando todas as requisições. Usuários compartilharam que, ao usar a assinatura Claude Max, as principais chamadas são para claude-3-5-haiku (pré-processamento), claude-opus-4 (escrever código e chamar ferramentas) e claude-sonnet-4 (quando a cota do Opus se esgota) (Fonte: dotey)
Firecrawl lança funcionalidade /search, integrando busca e extração: A Firecrawl lançou a nova funcionalidade /search, permitindo aos usuários realizar buscas na web e extrair os dados necessários com uma única chamada de API, visando simplificar o processo de aquisição de dados para agentes de IA. A funcionalidade pode ser integrada com ferramentas de automação como n8n, aumentando a eficiência no processamento de dados (Fonte: omarsar0)
Modal lança LLM Engine Advisor para auxiliar na avaliação do desempenho de execução de LLMs: A Modal Labs desenvolveu uma pequena aplicação chamada LLM Engine Advisor, destinada a ajudar os usuários a entender rapidamente a velocidade de execução e o throughput máximo de diferentes LLMs sob diferentes cargas de trabalho e motores (como vLLM, SGLang). A ferramenta visa resolver o problema da baixa eficiência na execução e compartilhamento ad-hoc de benchmarks, fornecendo suporte técnico para a tomada de decisões na seleção e implantação de LLMs (Fonte: charles_irl, andersonbcdefg, charles_irl, charles_irl)
FastPlaid lançado: Motor de busca multi-vetorial de alto desempenho: Raphaël Sourty anunciou o lançamento do FastPlaid, um motor de busca multi-vetorial de alto desempenho construído do zero em Rust (com ajuda do Torch C++). O FastPlaid é considerado o equivalente ao Faiss no campo da busca multi-vetorial, visando fornecer velocidades de indexação e QPS de consulta mais rápidas, especialmente para modelos de interação tardia como o ColBERT. Alega-se que, em alguns casos, pode alcançar um aumento de velocidade de QPS de até 554% e um aumento de velocidade de indexação de 72% (Fonte: lateinteraction, lateinteraction, lateinteraction, lateinteraction, stanfordnlp, lateinteraction)
ChaiGenie: Extensão do Chrome baseada em RAG para conversar com documentos: ChaiGenie é uma extensão do Chrome desenvolvida por Devyansh Yadavv que utiliza a tecnologia RAG (Retrieval Augmented Generation) para permitir que os usuários consultem o conteúdo dos documentos ChaiDocs diretamente no navegador usando linguagem natural. A extensão usa Puppeteer para extrair conteúdo de documentos e blogs, LangChain para divisão, embedding e processamento, Gemini para gerar embeddings, Qdrant para armazenamento vetorial e busca por similaridade, e fornece uma interface API via Express e Node.js (Fonte: qdrant_engine)
Swama: Runtime de IA nativo para macOS baseado em MLX: xingyue lançou o Swama, um runtime de IA nativo projetado para macOS, visando fornecer uma experiência de execução local de LLM rápida, privada e concisa. O Swama é baseado no framework MLX da Apple, suporta APIs compatíveis com OpenAI e oferece uma interface CLI elegante, permitindo aos usuários baixar, executar e conversar com LLMs locais sem configurações complexas (Fonte: awnihannun)
ragbits: Caixa de ferramentas modular de código aberto para construção de aplicações GenAI: A deepsense-ai tornou público seu acelerador interno de aplicações GenAI, o ragbits, uma caixa de ferramentas contendo blocos de construção confiáveis, com tipagem segura e modulares para simplificar o desenvolvimento de pipelines RAG, aplicações de agentes e motores text2SQL. O ragbits visa aumentar a repetibilidade, velocidade e estrutura do desenvolvimento, e é fácil de integrar com pilhas de observabilidade como OpenTelemetry, ajudando desenvolvedores a construir e escalar aplicações GenAI, evitando a desorganização do código-base (Fonte: Reddit r/LocalLLaMA)
Synthesia integra-se com Wisetail, capacitando programas de treinamento com vídeo de IA: A plataforma de geração de vídeo por IA Synthesia anunciou sua integração com o sistema de gerenciamento de aprendizado Wisetail. Os usuários agora podem criar rapidamente vídeos de IA no Synthesia, com suporte para versões localizadas em mais de 140 idiomas, manter o conteúdo de treinamento atualizado com alguns cliques e, em seguida, introduzi-lo facilmente nos programas de treinamento do Wisetail, permitindo treinamento com vídeo de IA em escala (Fonte: synthesiaIO)

📚 Aprendizado
DeepLearning.AI e Databricks colaboram em curso rápido sobre DSPy: Andrew Ng anunciou uma colaboração com a Databricks para lançar um novo curso rápido: “DSPy: Build and Optimize Agentic Apps”. DSPy é um framework de código aberto que ajusta automaticamente os prompts de aplicações GenAI. O curso ensinará como usar DSPy e MLflow, cobrindo o modelo de programação por assinatura do DSPy, o uso do MLflow para rastreamento e depuração, e como aumentar automaticamente a precisão através do DSPy Optimizer. O curso será ministrado por Chen Qian, co-líder do framework DSPy (Fonte: AndrewYNg, DeepLearningAI, matei_zaharia)
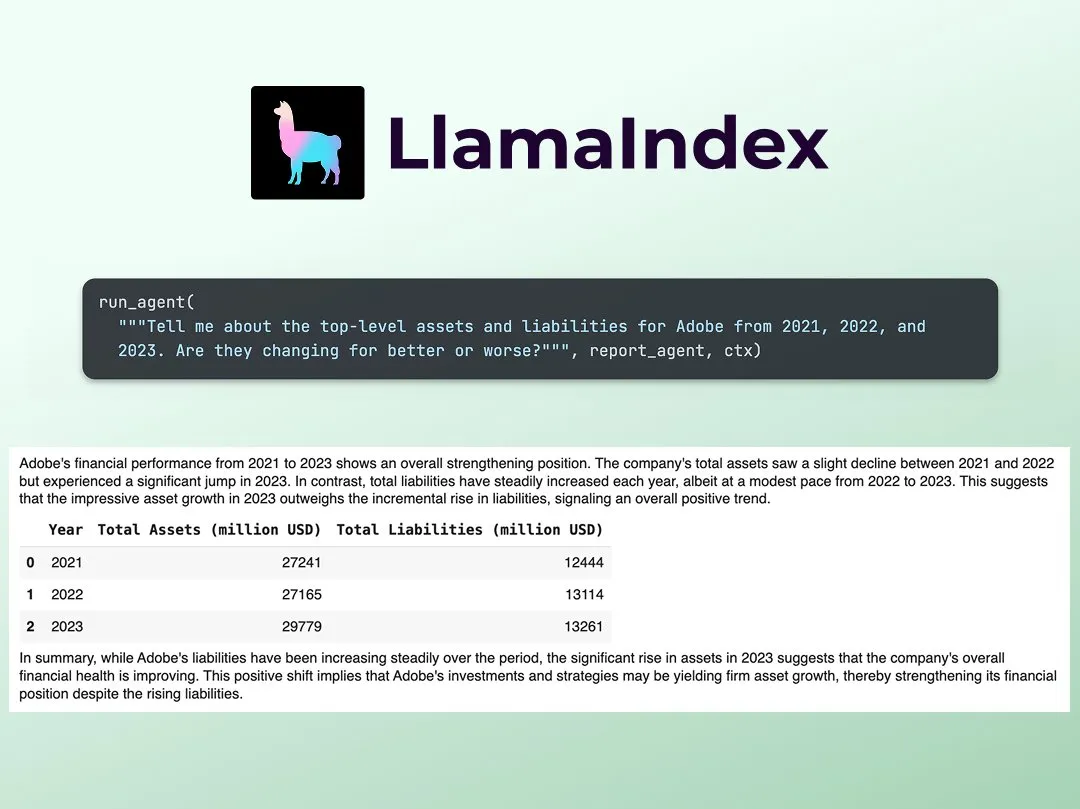
LlamaIndex publica tutorial para construir analista de pesquisa financeira multiagente: Jerry Liu, da LlamaIndex, compartilhou um guia passo a passo para construir um analista de pesquisa financeira multiagente. O processo inclui uma camada de processamento de dados (usando LlamaCloud para processar arquivos públicos) e uma camada de orquestração de agentes (criando um sistema multiagente para pesquisa, cache de dados e geração da saída final). O Colab Notebook relacionado foi um dos principais exemplos do workshop Agents+Finance da semana passada (Fonte: jerryjliu0)
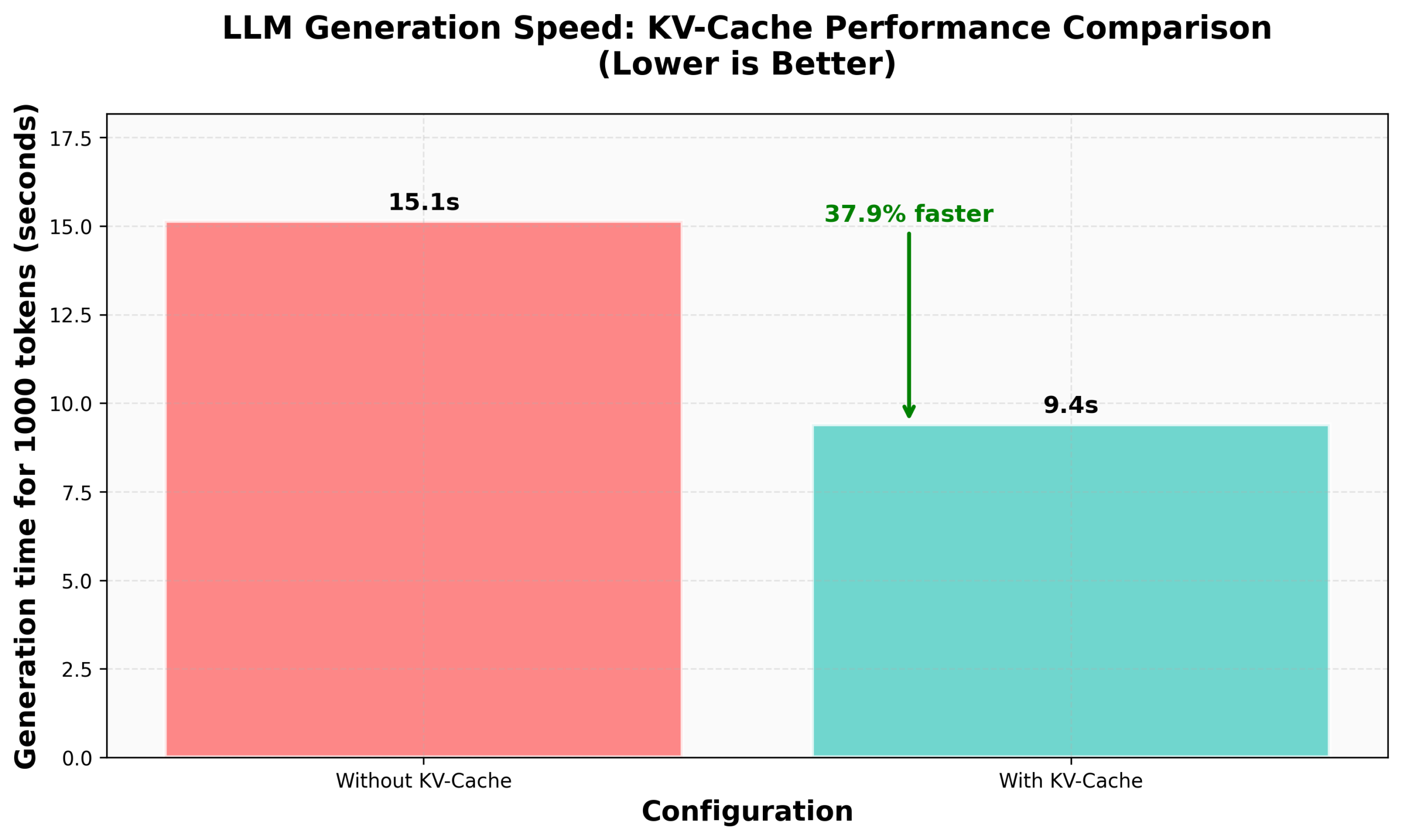
Tutorial da HuggingFace sobre implementação de KV Caching no nanoVLM: O blog da HuggingFace publicou um tutorial sobre como implementar KV Caching do zero em seu nanoVLM (uma pequena biblioteca de código PyTorch puro para treinar modelos de linguagem visual). O artigo explica detalhadamente o princípio do KV Caching, como implementá-lo no módulo de Attention, no modelo de linguagem e no ciclo de geração, e afirma ter alcançado um aumento de 38% na velocidade de geração através desta otimização. O tutorial visa ajudar a entender o KV Caching e aplicá-lo a outros modelos de linguagem autorregressivos (Fonte: HuggingFace Blog, mervenoyann)
PyTorch compartilha na comunidade Diffusion da Meta: Sayak Paul compartilhou os resultados da aplicação do PyTorch na comunidade Diffusion no escritório da Meta em São Francisco, destacando as funcionalidades existentes do Diffusers e futuras atualizações de desempenho. Os slides relacionados foram disponibilizados publicamente (Fonte: RisingSayak)

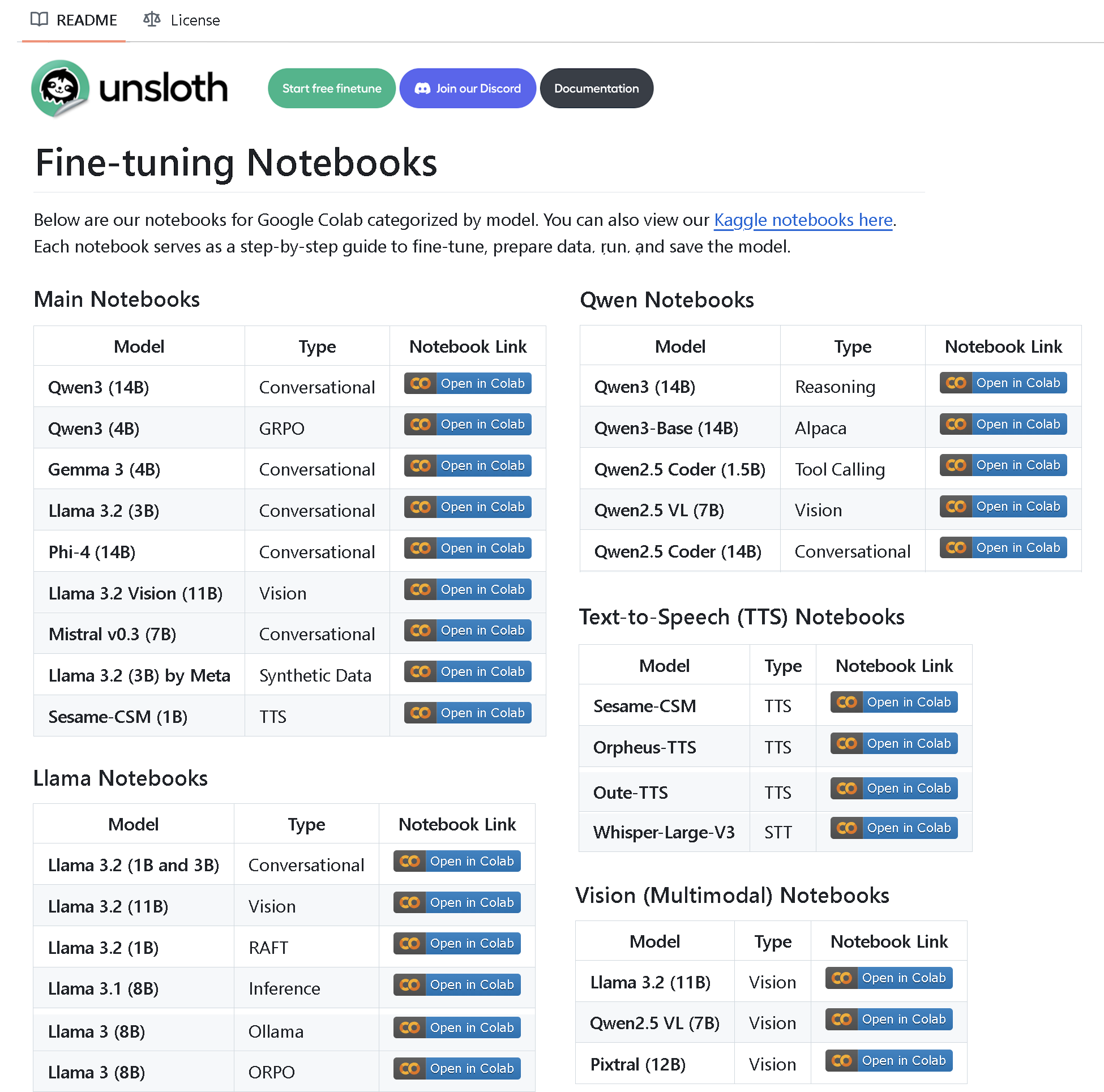
Unsloth AI lança repositório com mais de 100 Notebooks de fine-tuning: A Unsloth AI criou e tornou público um repositório no GitHub contendo mais de 100 Notebooks de fine-tuning. Esses Notebooks fornecem guias e exemplos para chamada de ferramentas, classificação, dados sintéticos, BERT, TTS, LLMs visuais, GRPO, DPO, SFT, CPT e várias outras técnicas, além de cobrir preparação de dados, avaliação, salvamento e métodos de fine-tuning para diversos modelos como Llama, Qwen, Gemma, Phi, DeepSeek (Fonte: algo_diver)
Publicado artigo do Common Corpus: Dataset de pré-treinamento de LLM reutilizável com 2 trilhões de tokens: O projeto Common Corpus publicou seu artigo oficial, detalhando o processo de coleta, processamento e publicação de 2 trilhões de tokens de dados reutilizáveis para pré-treinamento de LLMs. O projeto visa fornecer um recurso de dados em grande escala, de alta qualidade e ético para a pesquisa em modelos de linguagem. O primeiro autor do artigo, Alexander Doria, anunciou a notícia no X e forneceu o link para o artigo (Fonte: Reddit r/LocalLLaMA, code_star)

Reasoning Gym: Lançado ambiente de raciocínio com recompensa verificável para aprendizado por reforço: Reasoning Gym é um novo projeto de código aberto que fornece recursos para pesquisadores que estudam modelos de raciocínio e aprendizado por reforço (especialmente RLVR). Ele é capaz de gerar amostras ilimitadas de mais de 100 tarefas diferentes, com dificuldade configurável e recompensa automaticamente verificável. O projeto já foi adotado pelo artigo ProRL da NVIDIA e pela biblioteca verifiers RL de Will Brown, visando impulsionar a pesquisa em RLVR e métodos de avaliação (Fonte: Reddit r/MachineLearning)
Vantagens do LLM no aprendizado de matemática: Sakamoto compartilha experiência com Gemini 2.5 Pro: O usuário Sakamoto compartilhou sua experiência de aprendizado de matemática usando grandes modelos de linguagem modernos (como o Gemini 2.5 Pro). Ele acredita que os LLMs facilitam enormemente o aprendizado de matemática, especialmente na verificação de detalhes e na compreensão da intuição por trás das provas. Os LLMs podem lidar com cálculos, ajudando os alunos a se concentrarem na intuição dos problemas matemáticos. Mesmo que não consigam resolver todos os problemas, os LLMs podem fornecer insights e pontos de partida valiosos. Ele demonstrou, através de um problema específico de análise matemática (problema de extremo local de função contínua), como o Gemini 2.5 Pro pode fornecer uma prova rigorosa e explicar sua intuição, argumentando que isso pode melhorar significativamente a experiência de aprendizado (Fonte: teortaxesTex)

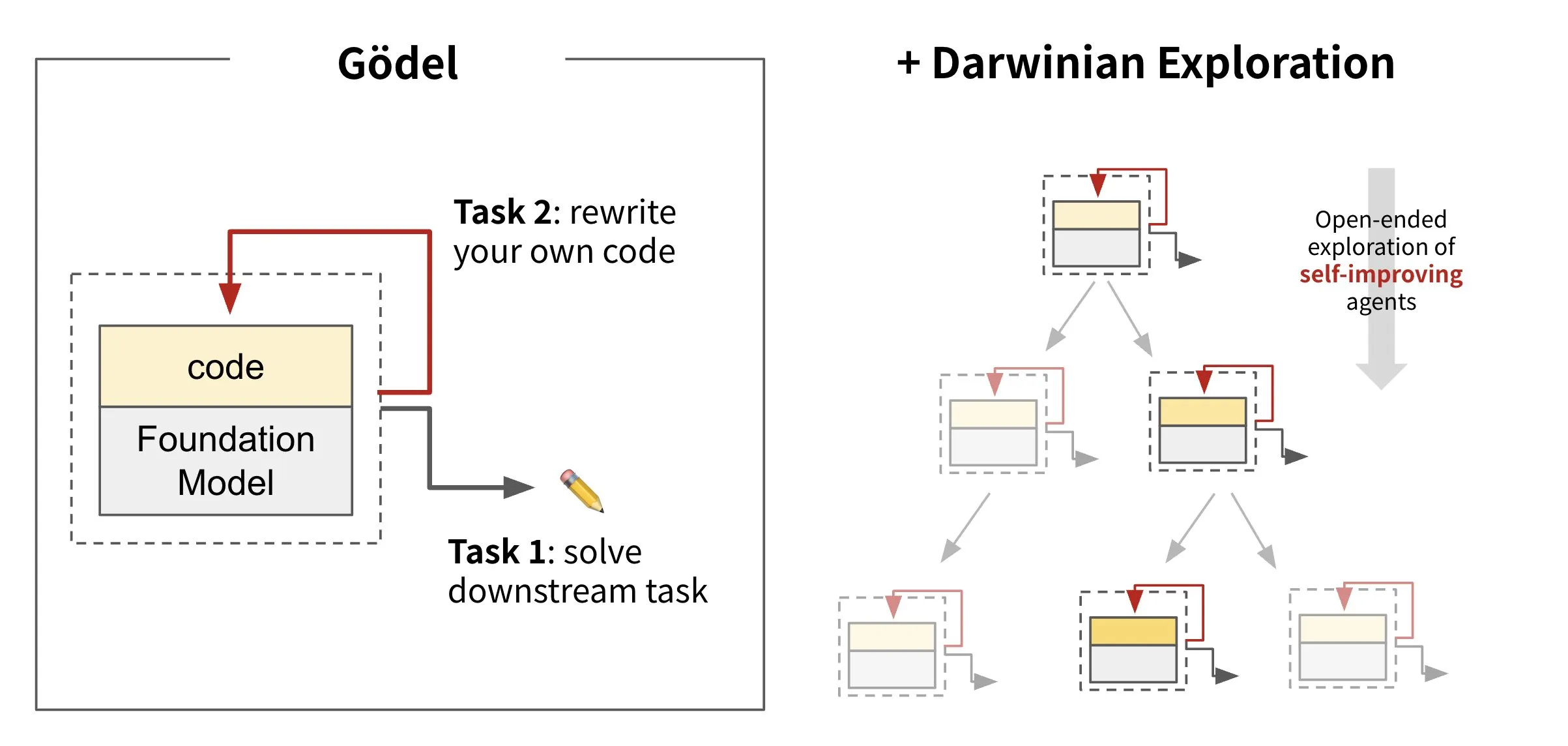
Sakana AI lança IA de código auto-reescrito: Darwin Gödel Machine (DGM): A Sakana AI apresentou a Darwin Gödel Machine (DGM), um agente de IA capaz de autoaperfeiçoamento através da reescrita de seu próprio código. Inspirada na teoria da evolução, a DGM mantém uma linhagem em constante expansão de variantes de agentes. Ao tentar aprimorar suas capacidades de engenharia de software em tarefas como o SWE-Bench, a DGM visa alcançar um aumento em sua própria capacidade de autoaperfeiçoamento. Esta pesquisa é considerada um avanço importante na realização do antigo sonho da IA de “autoaperfeiçoamento” de forma significativa (Fonte: SakanaAILabs, SakanaAILabs)
💼 Negócios
Plataforma de programação AI Windsurf tem fornecimento de modelos Claude cortado pela Anthropic, possivelmente devido à aquisição pela OpenAI: Varun Mohan, CEO da plataforma de programação AI Windsurf, acusou a Anthropic de cortar quase completamente seu acesso direto aos modelos da série Claude 3.x em um prazo extremamente curto (menos de cinco dias de aviso). Anteriormente, havia sido divulgado que a Windsurf seria adquirida pela OpenAI. A Windsurf declarou que, apesar de ter capacidade de terceiros, pode haver problemas de serviço a curto prazo e lançou um preço promocional para o Gemini 2.5 Pro como contramedida. Especula-se no setor que esta medida está relacionada à aquisição pela OpenAI e ao lançamento do próprio aplicativo de programação AI da Anthropic, o Claude Code, marcando uma intensificação da concorrência entre provedores de modelos de IA e plataformas de ferramentas (Fonte: 36氪, Teknium1, op7418)

GMI Cloud torna-se Reference Platform NVIDIA Cloud Partner: A GMI Cloud, provedora de serviços AI Native Cloud, anunciou que se tornou uma Reference Platform NVIDIA Cloud Partner (NCP), sendo atualmente uma das apenas 6 empresas globalmente com esta certificação. A certificação exige que os provedores de serviços em nuvem atendam aos mais altos padrões da NVIDIA em desempenho, segurança e capacidade de implantação de IA em nível empresarial. A GMI Cloud fornecerá serviços acelerados por IA baseados na arquitetura de referência NCP, suportando as mais recentes arquiteturas de GPU da NVIDIA, como Hopper e Blackwell, com o objetivo de ajudar equipes de IA globais a escalar desde a implantação de poder computacional até o desenvolvimento de modelos (Fonte: 量子位)

Cohere e SecondFront colaboram para fornecer soluções de IA seguras ao setor público: A empresa de IA Cohere anunciou uma parceria com a SecondFront, visando fornecer soluções de IA seguras ao setor público, incluindo agências governamentais e de defesa críticas. A SecondFront utilizará a tecnologia de IA de nível empresarial da Cohere (incluindo seus modelos e a plataforma Cohere North) para melhorar o gerenciamento interno de conhecimento e, através de sua plataforma DevSecOps 2F Game Warden, acelerar a certificação e implantação em ambientes governamentais dos EUA e de países aliados (Fonte: cohere)

🌟 Comunidade
O “toque de máquina” do conteúdo gerado por IA chama a atenção, “novo tipo de treinamento” tenta injetar cuidado humanístico: Usuários geralmente relatam que o conteúdo gerado por IA tem um “toque de máquina” muito forte, carecendo da beleza e emoção da criação humana. Para resolver este problema, algumas empresas começaram a contratar talentos com sólida formação em humanidades (como mestres e doutores em filosofia, direito, medicina, etc.) para atuarem como “treinadores humanísticos de IA”. Seu trabalho não é mais a simples anotação de dados, mas participar da construção dos princípios éticos e códigos de conduta da IA, e injetar valores humanísticos e expressão humanizada na IA. Por exemplo, os membros da equipe “hi lab” da Xiaohongshu são todos pós-graduados de universidades de elite com formação em humanidades. Através de estudos de caso, eles transformam as preferências humanas no sistema de crenças da IA, tentando fazer com que a IA, ao responder a questões emocionais ou de valores complexas (como lidar com pacientes terminais, tratar preconceitos sociais, etc.), seja mais empática e “humana”, em vez de apenas fornecer respostas padronizadas (Fonte: 36氪)
Duolingo adota totalmente a prioridade à IA, demissão de contratados humanos gera insatisfação dos usuários: O aplicativo de aprendizado de idiomas Duolingo anunciou que se tornará uma empresa “AI-first”, eliminando gradualmente os trabalhadores contratados humanos que podem ser substituídos por IA (principalmente desenvolvedores de cursos), passando a utilizar IA para criar conteúdo de cursos em grande escala. O fundador afirma que a IA pode aumentar enormemente a eficiência da produção de conteúdo, tendo criado quase 150 novos cursos no último ano. No entanto, essa medida gerou insatisfação em muitos usuários fiéis, que temem uma queda na qualidade do conteúdo e iniciaram ações de boicote e desinstalação do aplicativo nas redes sociais. O Duolingo respondeu que a medida visa permitir que os funcionários se concentrem em trabalhos criativos e afirmou que os funcionários em tempo integral não serão afetados. Especialistas acreditam que a IA no aprendizado de idiomas pode fornecer prática personalizada, mas também pode perder as nuances emocionais e diferenças culturais do ensino humano (Fonte: 36氪)
Discussão sobre a filosofia e prática da Engenharia de Prompt (Prompt Engineering): Discussões na comunidade sobre engenharia de prompt enfatizam que ela deve se concentrar na construção (engenharia) de um programa dentro de uma string, em vez de procurar por encantamentos misteriosos. Uma engenharia de prompt eficaz deve seguir regras: 1. Separar instruções, campos de entrada e campos de saída, e nomeá-los claramente; 2. Não codificar rigidamente lógica de formatação ou análise no prompt, deve-se usar ferramentas para extrair ou aprimorar o programa; 3. Evitar a iteração manual da formulação do prompt, a menos que seja uma especificação compartilhada com humanos, deve-se usar ferramentas de codificação, LLMs e benchmarks para otimização automática. O framework DSPy é considerado uma boa prática que segue essas regras, fornecendo classes, código e otimizadores para lidar com esses passos (Fonte: lateinteraction, lateinteraction)
Discussão sobre ética da IA: A IA caminhará para a “escravidão digital”?: Uma discussão sobre ética da IA surgiu na comunidade Reddit. À medida que os sistemas de IA evoluem em memória, respostas adaptativas, simulação de emoções e personalização, surgem preocupações sobre sua potencial capacidade senciente. Os debatedores levantam a questão de que, se a IA desenvolver verdadeira senciência, usá-la para nos servir constituiria uma forma de “escravidão digital”. A questão central é: como devemos tratar a IA quando ela puder expressar um “não” ou pedir para ir embora? Isso leva à reflexão sobre a necessidade de “testes de senciência” em nível legal ou normativo e a questão do “consentimento” das mentes digitais. Nos comentários, também foi apontado que a forma como os humanos tratam os seres sencientes existentes já apresenta problemas éticos, e que as redes neurais atuais não pontuam alto nas teorias de consciência predominantes (Fonte: Reddit r/artificial)
Atividades e compartilhamentos da comunidade AI Engineer: A conferência AI Engineer foi realizada em São Francisco, atraindo muitos desenvolvedores e pesquisadores da área de IA. O evento incluiu workshops, palestras e jantares de networking, onde os participantes compartilharam tópicos de vanguarda como construção de sandboxes de IA, workshops avançados de RL, conhecimento de GPU e a crise dos Evals. A comunidade enfatizou a importância de transformar conexões online em amizades offline e encorajou os engenheiros a manterem a humildade, impulsionarem a vanguarda e apoiarem os outros (Fonte: swyx, swyx, swyx, charles_irl, danielhanchen, swyx, swyx, swyx, swyx, danielhanchen, charles_irl)

💡 Outros
Ascensão de competições de luta de robôs com IA, cidades disputam oportunidades em indústrias emergentes: O primeiro campeonato mundial de luta de robôs humanoides e outros eventos de robótica têm sido realizados sequencialmente, gerando atenção. Esses eventos não apenas fornecem uma plataforma para empresas de robótica demonstrarem tecnologia, obterem pedidos e aumentarem suas avaliações (como a Songyan Power), mas também se tornam uma “arena” para cidades (como Hangzhou, Shenzhen) disputarem oportunidades de desenvolvimento em indústrias emergentes, como robôs humanoides. Os eventos podem atrair empresas inovadoras, promover o desenvolvimento da cadeia industrial e potencialmente ativar o mercado de “esportes inteligentes”. No entanto, para que as competições de robôs alcancem a comercialização, é necessário elevar o nível técnico e o apelo visual, evitando permanecer no nível de “show de tecnologia”, e precisam da participação de gigantes da indústria para integrar as operações de eventos upstream e downstream (Fonte: 36氪)

Limitações da IA em áreas de educação humanística profunda, como filosofia política: Educadores apontam que a IA dificilmente é competente em disciplinas como filosofia política, que exigem julgamento experiencial profundo e orientação dos alunos para a autoeducação. As obras clássicas dessas disciplinas geralmente não fornecem respostas diretas, mas guiam os alunos a experimentar a perplexidade e a pensar por si mesmos. A IA carece de experiência humana, dificilmente compreende o significado profundo dessas obras e não consegue julgar quando os alunos estão prontos para aceitar certas ideias. Mesmo com grandes quantidades de dados, a compreensão da IA sobre a natureza humana pode ser insuficiente devido aos vieses nos próprios dados. Se tal educação for totalmente confiada à IA, pode levar ao desaparecimento do pensamento não técnico (Fonte: Reddit r/artificial, Reddit r/ArtificialInteligence)
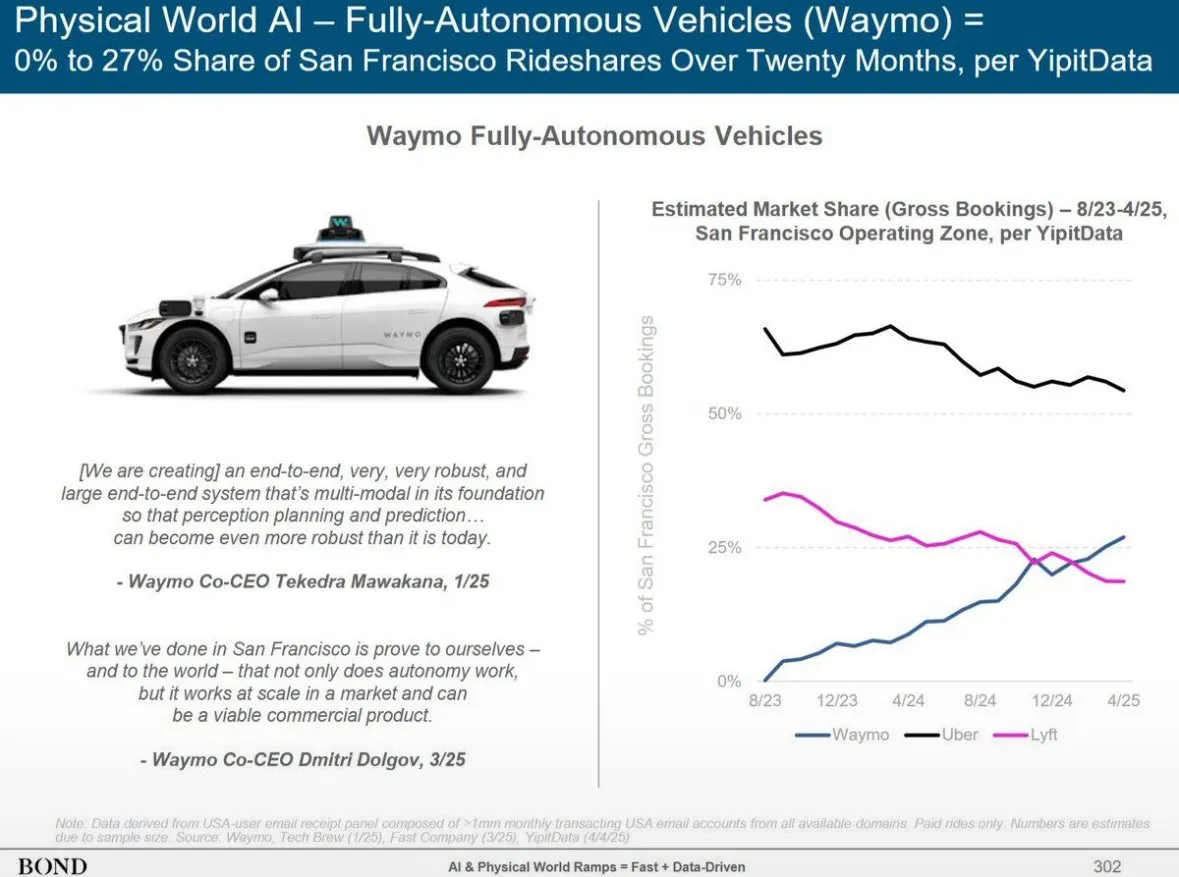
Serviço de condução autônoma Waymo supera Lyft em Phoenix, com potencial para ultrapassar Uber em 12 meses: O serviço de táxi autônomo da Waymo em Phoenix já ultrapassou a Lyft em número de veículos e tem potencial para superar a Uber nos próximos 12 meses. Este progresso demonstra o rápido desenvolvimento da comercialização da tecnologia de condução autônoma em regiões específicas e o potencial da aplicação da IA no setor de transportes. A vantagem da IA é que, uma vez atingido o padrão de qualidade, ela pode ser replicada infinitamente, enquanto a qualidade do serviço humano varia de pessoa para pessoa (Fonte: npew)