
Palavras-chave:OpenAI Codex, Modelo Visual de Linguagem e Ação, Limite de Memória do Modelo de Linguagem, Função de Memória do ChatGPT, DeepSeek-R1-0528, Modelo de Difusão, Criação Musical Suno AI, MetaAgentX, Função de Acesso à Internet do Codex, Modelo de Robô SmolVLA, Modelo GPT com Memória de 3.6 Bits, Melhorias de Interação Personalizada do ChatGPT, Capacidade de Raciocínio Complexo do DeepSeek-R1
🔥 Foco
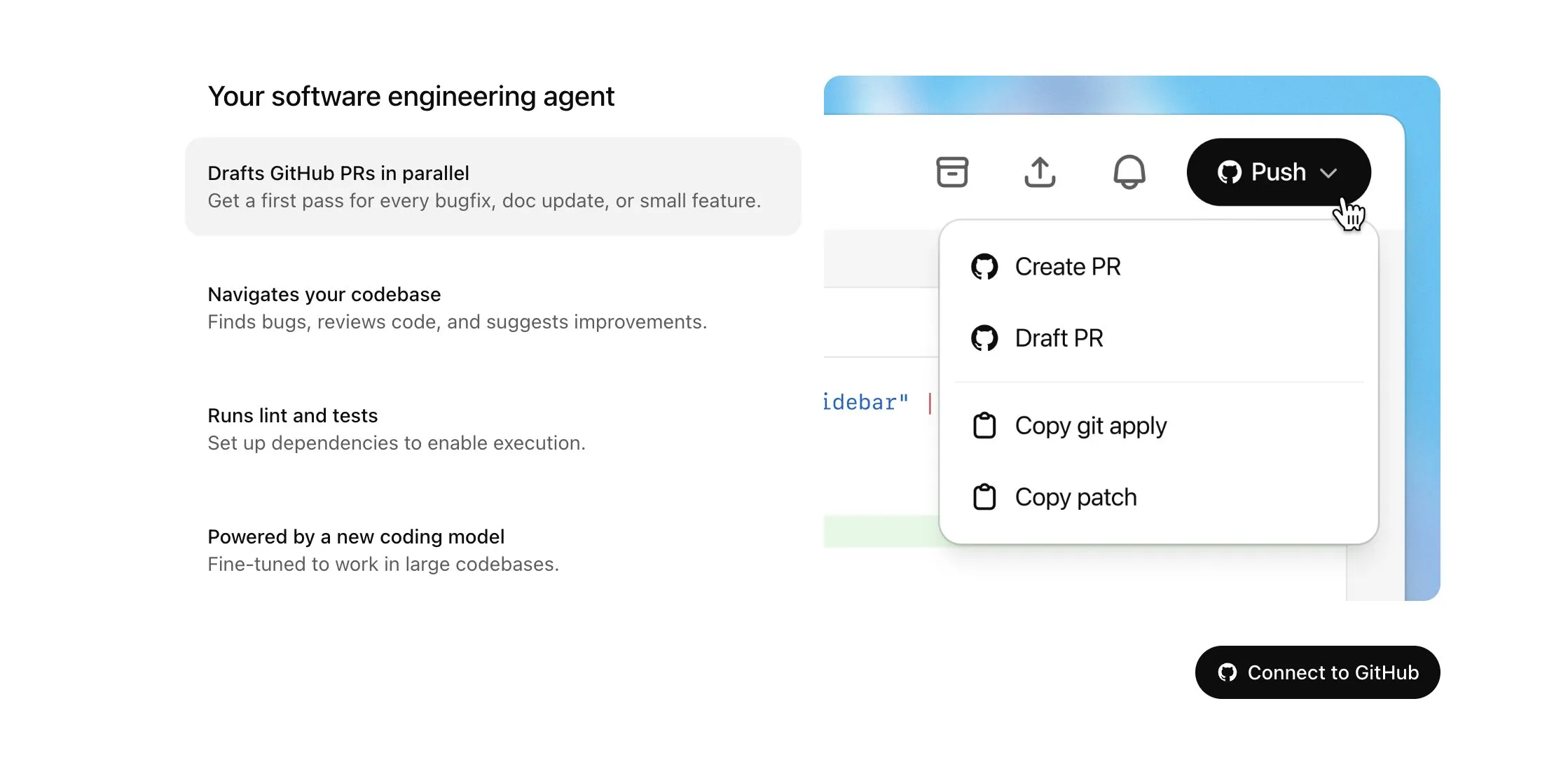
OpenAI Codex aberto para usuários Plus e recebe grande atualização, incluindo acesso à internet e entrada de voz: A OpenAI anunciou que o Codex será gradualmente disponibilizado para usuários do ChatGPT Plus. Os destaques desta atualização incluem permitir que agentes de IA acessem a internet ao executar tarefas (desativado por padrão, com domínios e métodos HTTP controláveis pelo usuário), para instalar dependências, atualizar pacotes de software e executar testes de recursos externos. Ao mesmo tempo, o Codex agora suporta a atualização direta de Pull Requests existentes e pode receber tarefas por entrada de voz. Outras melhorias incluem suporte para operações com arquivos binários (atualmente limitado a excluir ou renomear em PRs), aumento do limite de tamanho da diferença de tarefa (diff) de 1MB para 5MB, aumento do limite de tempo de execução de scripts de 5 minutos para 10 minutos, e a correção de vários problemas na plataforma iOS, além da reativação da funcionalidade de atividades em tempo real. Estas atualizações visam aumentar a utilidade e flexibilidade do Codex em tarefas de programação complexas (Fonte: OpenAI Developers, Tibor Blaho, gdb, kevinweil, op7418)
Hugging Face e H Company lançam conjuntamente modelos de código aberto de Visual Language Action (VLA), impulsionando o desenvolvimento da tecnologia robótica: Hugging Face e H Company anunciaram no “Dia VLA” novos modelos de código aberto de Visual Language Action, incluindo o SmolVLA da Hugging Face (450M parâmetros) e o Holo-1 da H Company (3B e 7B parâmetros). Os modelos VLA visam permitir que robôs vejam, ouçam, entendam e ajam de acordo com instruções de IA, sendo chamados de GPTs do campo da robótica. Abrir o código desses modelos é crucial para entender seu funcionamento, evitar possíveis backdoors e personalizá-los para robôs e tarefas específicas. O SmolVLA foi treinado no dataset LeRobotHF, demonstrando excelente desempenho e velocidade de inferência. O Holo-1, por sua vez, foca em tarefas de agentes web e de computador, suportando a licença Apache 2.0. Espera-se que esses lançamentos acelerem o desenvolvimento da tecnologia de robótica de IA de código aberto (Fonte: ClementDelangue, huggingface, LoubnaBenAllal1, tonywu_71)

Pesquisa da Meta e outras empresas revela que o limite de memória de modelos de linguagem é de aproximadamente 3.6 bits por parâmetro, desafiando o conhecimento tradicional: Uma pesquisa conjunta da Meta, DeepMind, Cornell University e NVIDIA aponta que modelos de linguagem no estilo GPT conseguem memorizar aproximadamente 3.6 bits de informação por parâmetro. O estudo descobriu que os modelos continuam a memorizar dados de treinamento até atingirem seu limite de capacidade, após o qual começa a ocorrer o fenômeno de “Grokking”, ou seja, uma redução inesperada da memória, e o modelo passa a aprender por generalização. Esta descoberta explica o fenômeno da “dupla descida”, onde, quando a quantidade de informação do dataset excede a capacidade de armazenamento do modelo, este é forçado a compartilhar pontos de informação para economizar capacidade, promovendo assim a generalização. A pesquisa também propõe leis de escala sobre a relação entre capacidade do modelo, tamanho dos dados e taxa de sucesso de ataques de inferência de pertencimento, e aponta que, para LLMs modernos treinados em datasets extremamente grandes, a inferência de pertencimento confiável se torna difícil (Fonte: 机器之心, Reddit r/LocalLLaMA, code_star, scaling01, Francis_YAO_)
OpenAI lança versão leve da funcionalidade de memória do ChatGPT, melhorando a experiência de interação personalizada: A OpenAI anunciou o início do lançamento de uma versão leve das melhorias da funcionalidade de memória para usuários gratuitos. Além da memória salva existente, o ChatGPT agora pode consultar as conversas recentes do usuário para fornecer respostas mais personalizadas. Esta medida visa tornar o ChatGPT mais útil para escrita, obtenção de sugestões, aprendizado, etc., ao aproveitar as preferências e interesses do usuário. Sam Altman também afirmou que a funcionalidade de memória se tornou uma de suas características favoritas do ChatGPT e espera grandes melhorias no futuro. Esta atualização marca o compromisso da OpenAI em tornar a interação com IA mais próxima das necessidades do usuário, aumentando o engajamento (Fonte: openai, sama, iScienceLuvr)
🎯 Tendências
DeepSeek-R1-0528 lançado, fortalecendo capacidades de raciocínio complexo e programação: A DeepSeek lançou uma versão atualizada do modelo R1, o DeepSeek-R1-0528. Esta versão é baseada no modelo DeepSeek V3 Base, lançado em dezembro de 2024, e, através de um maior investimento em poder computacional para pós-treinamento, melhorou significativamente a profundidade de pensamento e a capacidade de raciocínio do modelo. O novo modelo realiza uma decomposição mais detalhada e pensa por mais tempo ao lidar com problemas complexos (por exemplo, no teste AIME 2025, o consumo médio de tokens por questão aumentou de 12K para 23K), alcançando assim resultados de liderança em vários benchmarks, como matemática, programação e lógica geral, com desempenho próximo ao GPT-o3 e Gemini-2.5-Pro. Além disso, a nova versão apresenta otimizações significativas na redução de alucinações (cerca de 45%-50%), escrita criativa e chamada de ferramentas, como responder de forma mais estável a perguntas como “quanto é 9.9 – 9.11” e gerar código front-end e back-end executável de uma só vez (Fonte: 科技狐, AI前线, Hacubu)

Modelos de difusão demonstram potencial nas áreas de linguagem e multimodais, desafiando o paradigma autorregressivo: O modelo de linguagem Gemini Diffusion, apresentado no Google I/O 2025, com sua velocidade de geração até 5 vezes maior e desempenho de programação comparável, destacou o potencial dos modelos de difusão no campo da geração de texto. Diferentemente dos modelos autorregressivos que preveem tokens um a um, os modelos de difusão geram saídas através da remoção gradual de ruído, suportando iteração e correção rápidas. O modelo LLaDA de 8B parâmetros, lançado em colaboração pelo Ant Group e pela Gaoling School of Artificial Intelligence da Renmin University, bem como o modelo de difusão multimodal MMaDA desenvolvido pela ByteDance, demonstram a exploração de vanguarda das equipes chinesas nesta área. Esses modelos não apenas apresentam excelente desempenho em tarefas de linguagem, mas também alcançam progressos na compreensão multimodal (como o LLaDA-V combinado com ajuste fino de instruções visuais) e em domínios específicos (como o DPLM para geração de sequências de proteínas), indicando que os modelos de difusão podem se tornar um novo paradigma para a próxima geração de modelos universais (Fonte: 机器之心)
Suno lança grande atualização, aprimorando a capacidade de criação e edição de música por IA: A plataforma de criação de música por IA Suno lançou várias atualizações importantes, conferindo aos usuários maior liberdade criativa e controle. As novas funcionalidades incluem um editor de músicas atualizado, permitindo aos usuários reordenar, reescrever e refazer faixas segmento por segmento no gráfico de forma de onda; introdução da funcionalidade de extração de stems, que pode separar faixas com precisão em 12 fontes de áudio independentes (como vocais, bateria, baixo, etc.) para visualização e download; expansão da funcionalidade de upload, suportando o upload de músicas completas de até 8 minutos, permitindo que os usuários criem com base em seus próprios materiais de áudio; adição de um controle deslizante criativo, onde os usuários podem ajustar a “estranheza”, o grau de estruturação ou o quanto o resultado é orientado por referência antes da geração, para moldar melhor o trabalho final (Fonte: SunoMusic)
MetaAgentX lança Open CaptchaWorld para avaliar a capacidade de Agentes multimodais em resolver CAPTCHAs: Visando os gargalos atuais dos Agentes multimodais na resolução de problemas de CAPTCHA (verificação humano-computador), a equipe MetaAgentX lançou a plataforma e benchmark Open CaptchaWorld. A plataforma contém 20 tipos de CAPTCHAs modernos, totalizando 225 exemplos, exigindo que o Agente complete tarefas em um ambiente web real através de observação, cliques, arrastos e outras interações. Os resultados dos testes mostram que mesmo modelos de ponta como o GPT-4o têm uma taxa de sucesso de apenas 5%-40%, muito abaixo da taxa média de sucesso humana de 93.3%. Os pesquisadores também propuseram o indicador “CAPTCHA Reasoning Depth”, que quantifica os passos de “compreensão visual + planejamento cognitivo + controle de ação” necessários para resolver o problema. A plataforma visa revelar as deficiências dos Agentes em interações dinâmicas de longa sequência e planejamento, e impulsionar os pesquisadores a focar e resolver este problema crítico na implantação prática (Fonte: 量子位)

Google NotebookLM agora suporta compartilhamento público, promovendo o compartilhamento de conhecimento e colaboração: O Google anunciou que o NotebookLM (anteriormente conhecido como Project Tailwind) agora suporta o compartilhamento público de notebooks. Os usuários podem compartilhar o conteúdo de suas notas clicando em “Compartilhar” e definindo as permissões de acesso para “Qualquer pessoa com o link”. Esta funcionalidade permite que os usuários compartilhem facilmente ideias, guias de estudo e documentos de equipe, e os destinatários podem navegar pelo conteúdo, fazer perguntas, obter resumos instantâneos e visões gerais por voz. Esta medida visa promover a disseminação do conhecimento e a edição colaborativa, aumentando a utilidade do NotebookLM como ferramenta de anotações com IA (Fonte: Google, op7418)
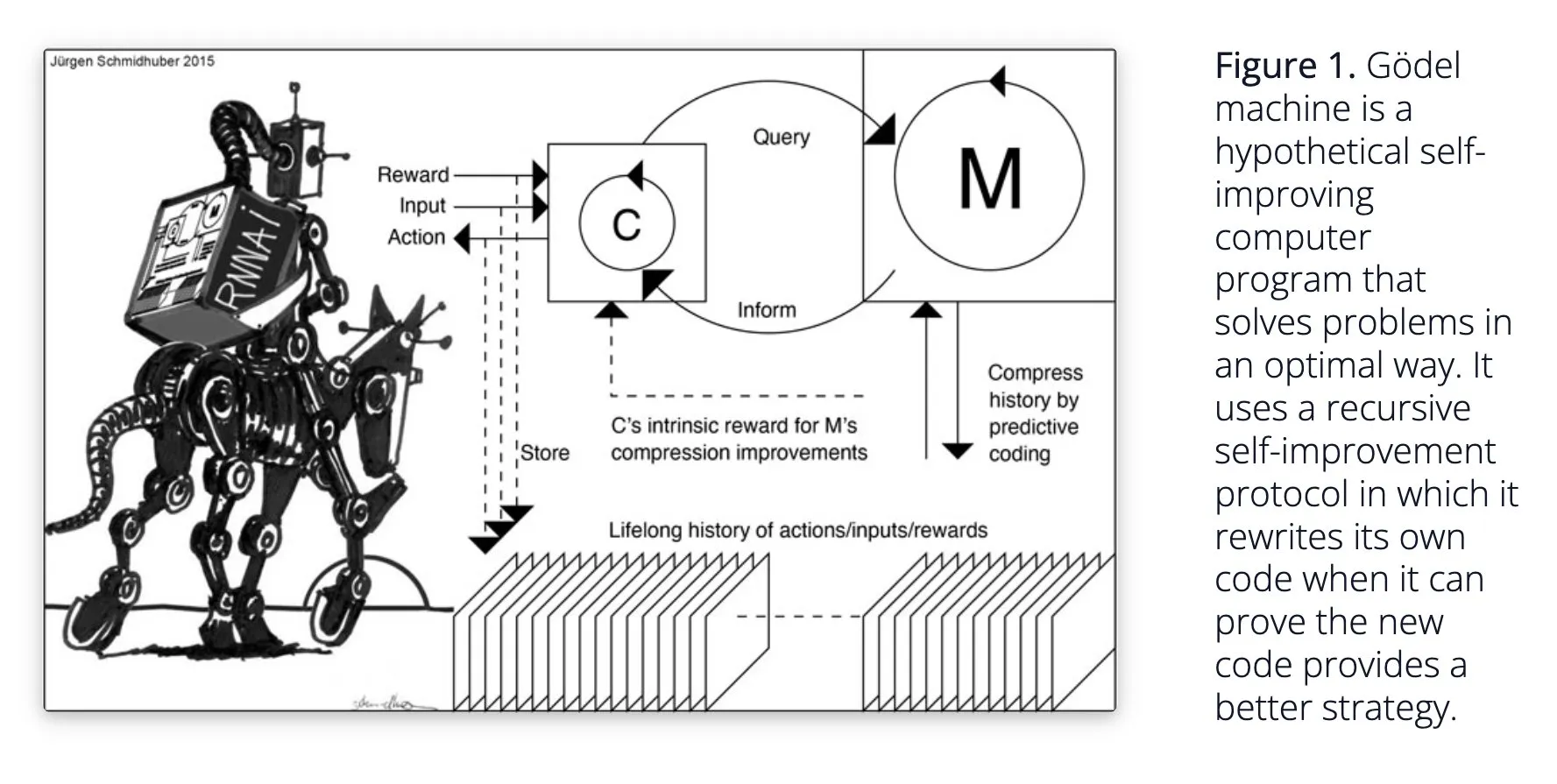
Sakana AI propõe sistema de IA autoaprendiz Darwin Gödel Machine (DGM): A Sakana AI divulgou sua pesquisa sobre o sistema de IA autoaprendiz Darwin Gödel Machine (DGM). O DGM utiliza algoritmos evolutivos para reescrever iterativamente seu próprio código, melhorando continuamente seu desempenho em tarefas de programação. O sistema mantém um arquivo de agentes de codificação gerados, amostra a partir dele e utiliza modelos base para criar novas versões, realizando exploração aberta e formando agentes diversificados e de alta qualidade. Experimentos mostram que o DGM melhorou significativamente a capacidade de codificação em benchmarks como SWE-bench e Polyglot. A pesquisa oferece novas ideias para IA autoaperfeiçoável, visando acelerar o desenvolvimento da IA através da inovação autônoma (Fonte: Reddit r/LocalLLaMA, hardmaru, scaling01)
Google DeepMind melhora a naturalidade das conversas com IA, abrindo funcionalidades de áudio nativas: O Google DeepMind anunciou que suas funcionalidades de áudio nativas estão tornando as conversas com IA mais naturais, capazes de entender o tom de voz e gerar fala expressiva. Esta tecnologia visa abrir novas possibilidades para a interação entre humanos e IA. Desenvolvedores agora podem experimentar essas funcionalidades através do Google AI Studio, com potencial aplicação em assistentes de voz mais naturais, geração de conteúdo em áudio, entre outros cenários (Fonte: GoogleDeepMind)
Tecnologia de geração de imagens Runway Gen-4 chama atenção, suportando múltiplas referências e controle de estilo: A tecnologia de geração de imagens Gen-4 da Runway tem chamado atenção por sua alta fidelidade e capacidade sem precedentes de controle de estilo, especialmente evidente em sua funcionalidade de múltiplas referências, que oferece novo espaço para exploração criativa. Usuários podem utilizar esta tecnologia para gerar diversos animais, dinossauros ou criaturas imaginárias, demonstrando seu potencial na criação de conteúdo visual detalhado. O uso da Runway em áreas como Hollywood também indica que sua tecnologia está sendo gradualmente aplicada na produção de conteúdo profissional (Fonte: c_valenzuelab, c_valenzuelab)

AssemblyAI lança novo modelo de transcrição de voz em tempo real, melhorando o desempenho de aplicações de IA de voz: A AssemblyAI lançou um novo modelo de transcrição de voz em tempo real (STT) que se destaca por sua alta velocidade e precisão. O modelo foi projetado especificamente para desenvolvedores que constroem aplicações de IA de voz, visando fornecer uma experiência de reconhecimento de voz mais fluida e precisa. Ao mesmo tempo, a AssemblyAI também oferece a implementação AssemblyAISTTService através de seu projeto pipecat_ai, facilitando a integração para os desenvolvedores. Esta iniciativa demonstra o investimento contínuo e a inovação da AssemblyAI no campo da tecnologia de voz (Fonte: AssemblyAI, AssemblyAI)
Microsoft Bing comemora 16º aniversário, integra GPT-4 e DALL·E, e lança Bing Video Creator: O motor de busca Microsoft Bing comemora seu 16º aniversário. Nos últimos anos, o Bing foi pioneiro na integração em larga escala de IA generativa conversacional e se tornou o primeiro produto da Microsoft a integrar GPT-4 e DALL·E. Recentemente, o Bing lançou gratuitamente o Copilot Search e o Bing Video Creator em seu aplicativo móvel, este último podendo ser usado para gerar conteúdo de vídeo. Isso marca a contínua inovação e desenvolvimento do Bing nas áreas de busca e criação de conteúdo impulsionadas por IA (Fonte: JordiRib1)
Andrej Karpathy impressionado com Veo 3, discute o impacto macro da geração de vídeo: Andrej Karpathy expressou estar impressionado com o modelo de geração de vídeo Veo 3 do Google e com as criações da comunidade, observando que a adição de áudio melhorou significativamente a qualidade do vídeo. Ele explorou ainda vários impactos macro da geração de vídeo: 1. O vídeo é a forma de entrada de maior largura de banda para o cérebro humano; 2. A geração de vídeo fornece à IA uma “língua materna” para entender o mundo; 3. A geração de vídeo é um caminho crucial para simular a realidade e modelos de mundo; 4. Suas demandas computacionais impulsionarão o desenvolvimento de hardware. Isso indica que a tecnologia de geração de vídeo não é apenas uma revolução na criação de conteúdo, mas também um importante motor para a cognição e desenvolvimento da IA (Fonte: brickroad7, dilipkay, JonathanRoss321)
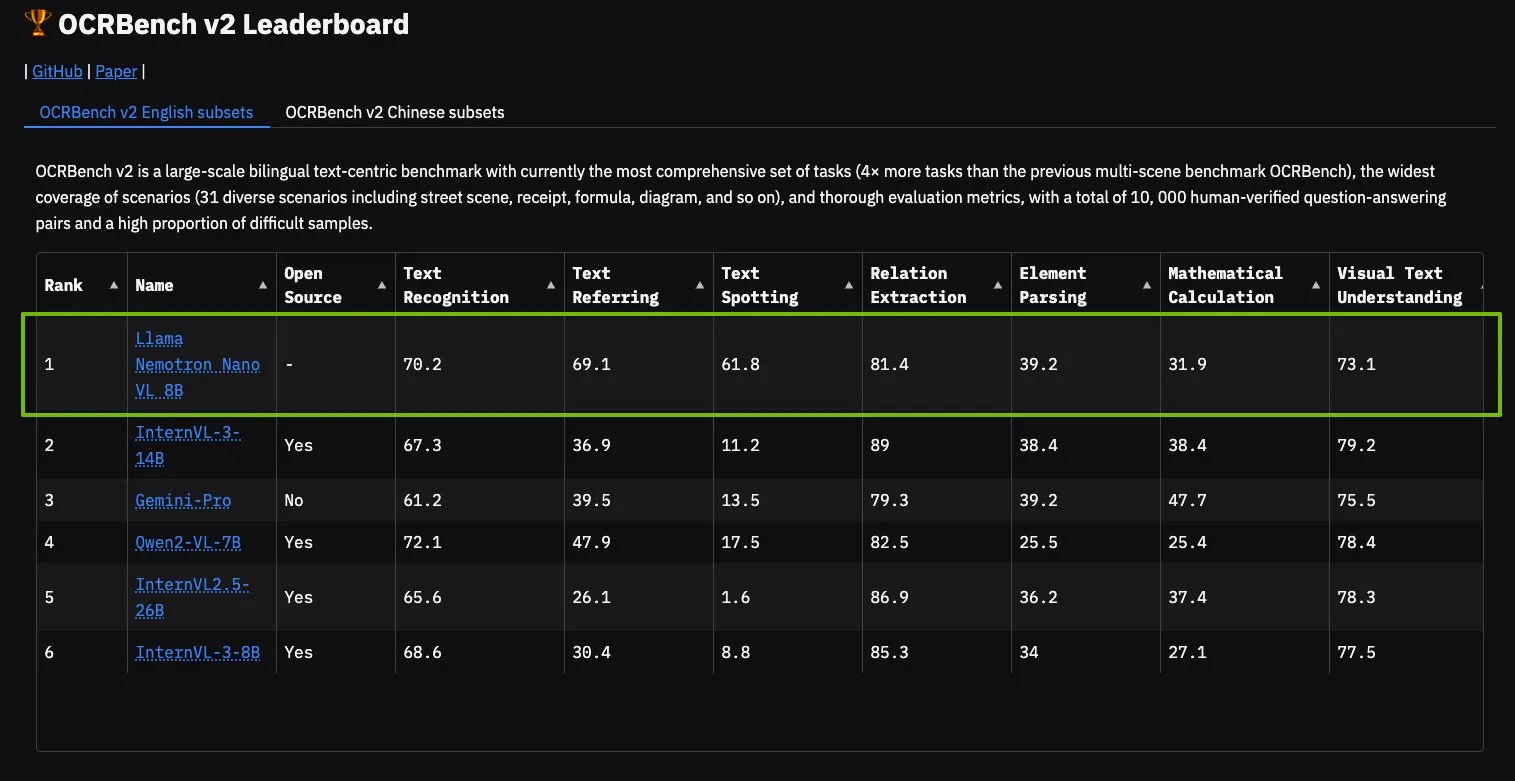
Modelo NVIDIA Llama Nemotron Nano VL lidera no OCRBench V2: O modelo Llama Nemotron Nano VL da NVIDIA alcançou o primeiro lugar no ranking OCRBench V2. Este modelo foi projetado especificamente para processamento e compreensão inteligente avançada de documentos, capaz de extrair com precisão informações diversas de documentos complexos em uma única GPU. Os usuários podem experimentar este modelo através do NVIDIA NIM, o que demonstra o progresso da NVIDIA em modelos de IA miniaturizados e eficientes para domínios específicos (como compreensão de documentos) (Fonte: ctnzr)
🧰 Ferramentas
LangGraph.js versão 0.3 introduz funcionalidade de cache de nó/tarefa: LangGraph.js lançou a versão 0.3, adicionando uma funcionalidade de cache de nó/tarefa. Esta funcionalidade visa acelerar workflows evitando cálculos redundantes, especialmente útil para agentes iterativos caros ou de longa duração. A nova versão suporta tanto a Graph API quanto a Imperative API, oferecendo maior eficiência para desenvolvedores JavaScript na construção de aplicações de IA complexas (Fonte: Hacubu, hwchase17)
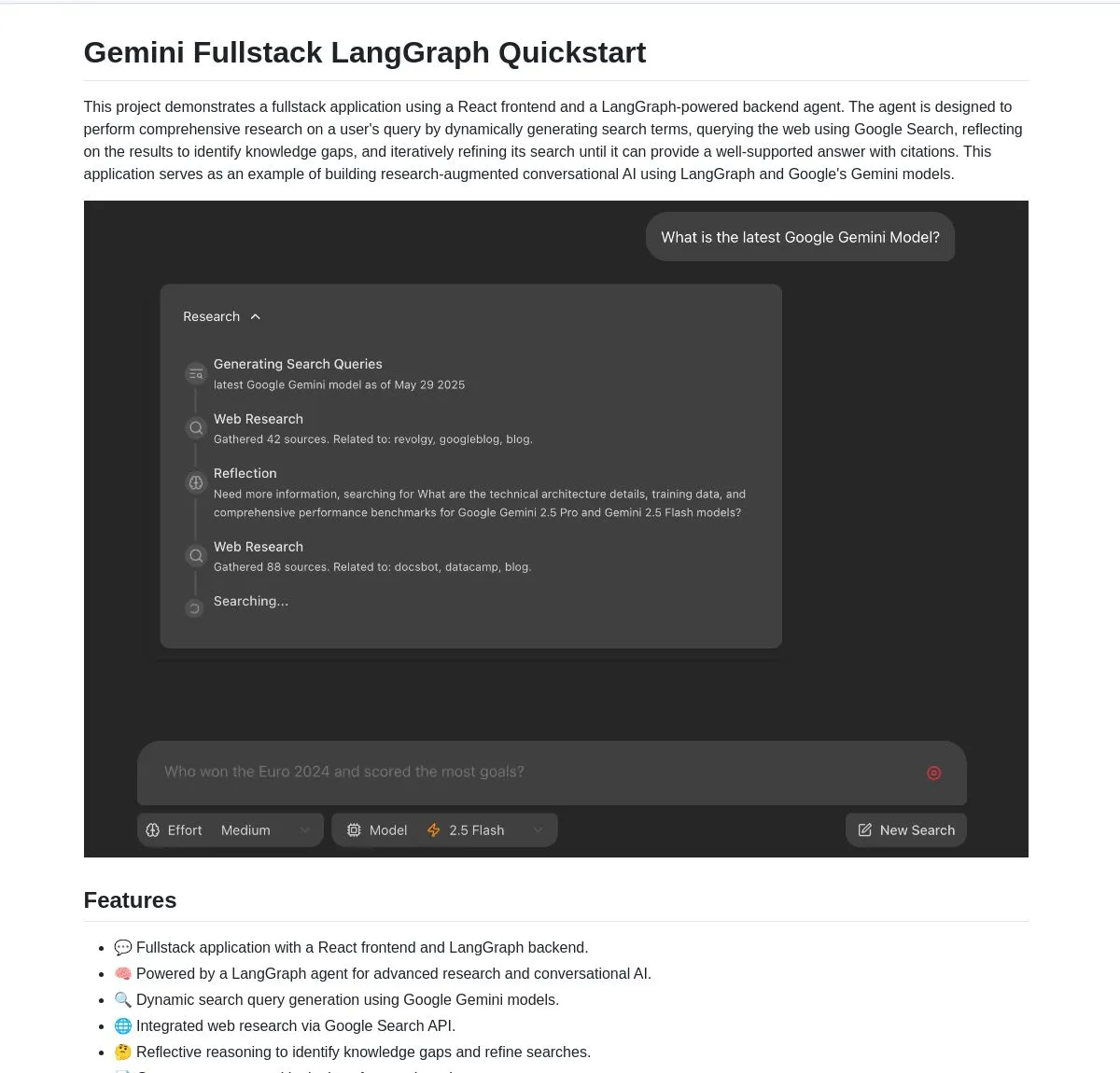
Google lança aplicação full-stack de código aberto Gemini Research Agent, baseada em Gemini e LangGraph: O Google lançou um exemplo de aplicação full-stack de assistente de pesquisa inteligente construído com base no modelo Gemini e LangGraph – gemini-fullstack-langgraph-quickstart. A aplicação é capaz de otimizar consultas dinamicamente, fornecendo respostas com citações através de aprendizado iterativo, e suporta controle de diferentes níveis de intensidade de pesquisa. Ela utiliza a ferramenta de busca nativa do Google do Gemini para pesquisa na web e raciocínio reflexivo, visando fornecer aos desenvolvedores um ponto de partida para construir aplicações de IA avançadas orientadas à pesquisa (Fonte: LangChainAI, hwchase17, dotey, karminski3)
FedRAG adiciona funcionalidade de ponte com LangChain, facilitando a integração e ajuste fino de sistemas RAG: FedRAG anunciou suporte para uma ponte com LangChain, implementada por um contribuidor externo. Os usuários podem montar sistemas RAG através do FedRAG e ajustar finamente os modelos dos componentes gerador/recuperador para se adaptarem a bases de conhecimento específicas. Após o ajuste fino, é possível fazer a ponte para frameworks populares de inferência RAG, como LangChain, aproveitando seu ecossistema e funcionalidades. Esta atualização visa simplificar os processos de construção, otimização e implantação de sistemas RAG (Fonte: nerdai)

Ollama lança funcionalidade de “pensamento”, permitindo separar o processo de raciocínio da resposta final: Ollama atualizou sua plataforma, adicionando uma opção para separar o processo de “pensamento” da resposta final para modelos que suportam essa funcionalidade (como DeepSeek-R1-0528). Os usuários podem optar por visualizar o conteúdo do “pensamento” do modelo ou desabilitar essa funcionalidade para obter uma resposta direta. A funcionalidade é aplicável à CLI, API e bibliotecas Python/JavaScript do Ollama, oferecendo aos usuários uma forma mais flexível de interagir com os modelos (Fonte: Hacubu)
Firecrawl lança endpoint /search, integrando funcionalidades de busca e extração: Firecrawl lançou um novo endpoint de API /search, permitindo aos usuários realizar uma busca na web e extrair todos os resultados em um formato amigável para LLM com uma única chamada de API. Esta funcionalidade visa simplificar o processo para agentes de IA e desenvolvedores descobrirem e utilizarem dados da web. O StateGraph da LangChain pode ser usado para construir fluxos automatizados que utilizam esta funcionalidade, como encontrar automaticamente concorrentes, extrair seus websites e gerar relatórios de análise (Fonte: hwchase17, LangChainAI, omarsar0)
LlamaIndex integra MCP, aprimorando capacidades de agentes e implantação de workflows: LlamaIndex anunciou a integração do MCP (Model Component Protocol), visando aprimorar a capacidade de uso de ferramentas de seus agentes e a flexibilidade na implantação de workflows. A integração fornece funções auxiliares para ajudar os agentes LlamaIndex a usar ferramentas de servidor MCP e permite que qualquer workflow LlamaIndex seja servido como um servidor MCP. Esta iniciativa visa expandir o conjunto de ferramentas dos agentes LlamaIndex e permitir que seus workflows se integrem perfeitamente à infraestrutura MCP existente (Fonte: jerryjliu0)

Modal lança LLM Engine Advisor, fornecendo benchmarks de desempenho para motores de modelos de código aberto: Modal lançou o LLM Engine Advisor, uma aplicação de benchmarking projetada para ajudar os usuários a escolher o melhor motor de LLM e parâmetros. A ferramenta fornece dados de desempenho, como velocidade e taxa de transferência máxima, ao executar modelos de código aberto (como DeepSeek V3, Qwen 2.5 Coder) usando diferentes motores de inferência (como vLLM, SGLang) em diferentes hardwares (como ambientes multi-GPU). Esta iniciativa visa aumentar a transparência e a eficiência na tomada de decisões ao executar LLMs auto-hospedados (Fonte: charles_irl, akshat_b, sarahcat21)
PlayDiffusion: PlayAI lança novo modelo de inpainting de áudio, capaz de substituir conteúdo de diálogo em áudio: PlayAI lançou um novo modelo chamado PlayDiffusion, capaz de substituir perfeitamente o conteúdo de diálogo em arquivos de áudio, preservando as características da voz do falante original. Essa tecnologia de “inpainting de áudio” oferece novas possibilidades para edição de áudio, como modificar palavras ou frases específicas em podcasts, audiolivros ou dublagens de vídeo, sem a necessidade de regravar todo o trecho. O projeto está disponível em código aberto no GitHub (Fonte: _mfelfel, karminski3)
Hugging Face lança ferramenta de desduplicação semântica para otimizar a qualidade de datasets de treinamento: Inspirado no AutoDedup de Maxime Labonne, o Hugging Face Spaces lançou uma nova aplicação de desduplicação semântica. A ferramenta permite que os usuários selecionem um ou mais datasets do Hugging Face Hub, realizando um embedding semântico de cada linha de dados e, em seguida, removendo conteúdo quase duplicado com base em um limiar definido. Esta iniciativa visa ajudar pesquisadores e desenvolvedores a melhorar a qualidade dos datasets de treinamento, evitando que a redundância de dados cause queda no desempenho do modelo ou baixa eficiência no treinamento (Fonte: ben_burtenshaw, ben_burtenshaw)

Demanda por Perplexity Labs aumenta, usuários podem construir software personalizado rapidamente: Perplexity Labs tem sido popular entre os usuários por sua capacidade de construir rapidamente software personalizado a partir de um único prompt, resultando em um aumento significativo na demanda, com alguns usuários comprando múltiplas contas Pro para obter mais consultas no Labs. Isso reflete o forte interesse dos usuários em ferramentas de software que podem ser rapidamente criadas e modificadas de acordo com suas próprias necessidades, indicando que o desenvolvimento de software personalizado impulsionado por IA está se tornando uma tendência (Fonte: AravSrinivas, AravSrinivas)
Ollama e Hazy Research colaboram para lançar Secure Minions, permitindo colaboração privada entre LLMs locais e na nuvem: O projeto Minions do laboratório Hazy Research de Stanford, ao conectar modelos locais do Ollama com modelos de ponta na nuvem, visa reduzir drasticamente os custos da nuvem (5-30 vezes) enquanto mantém uma precisão próxima à dos modelos de ponta (98%). O projeto Secure Minions avança ainda mais, transformando GPUs como H100 em zonas seguras, implementando criptografia de memória e computação para garantir a privacidade dos dados. Este modo de operação híbrido, ao mesmo tempo que melhora a proteção da privacidade, também oferece aos usuários uma solução de uso de LLM mais econômica e eficiente (Fonte: code_star, osanseviero, Reddit r/LocalLLaMA)
Exa e OpenRouter colaboram para fornecer capacidade de pesquisa na web para mais de 400 LLMs: O motor de busca de IA Exa anunciou uma parceria com o OpenRouter para fornecer funcionalidade de pesquisa na web para mais de 400 modelos de linguagem grandes na plataforma OpenRouter. Isso significa que desenvolvedores e usuários, ao usar esses LLMs, poderão invocar convenientemente a capacidade de pesquisa do Exa, aprimorando a capacidade dos modelos de obter informações em tempo real e atualizar conhecimentos, melhorando ainda mais o desempenho de aplicações como RAG (Retrieval Augmented Generation) (Fonte: menhguin)

📚 Aprendizado
Microsoft lança curso introdutório “MCP for Beginners”: A Microsoft lançou um curso introdutório para iniciantes em MCP (Microsoft Copilot Platform, especulado como um erro de digitação, deveria se referir ao Microsoft CoCo Framework ou protocolo similar de Agente de IA). O curso visa ajudar iniciantes a dominar os conceitos centrais, métodos de implementação e aplicações práticas do MCP, incluindo especificações da arquitetura do protocolo, guias tutoriais e práticas de código em várias linguagens de programação. A estrutura do curso abrange introdução, conceitos centrais, segurança, primeiros passos, avançado, e análise de comunidade e casos, além de fornecer projetos de exemplo como calculadoras básicas e avançadas (Fonte: dotey)

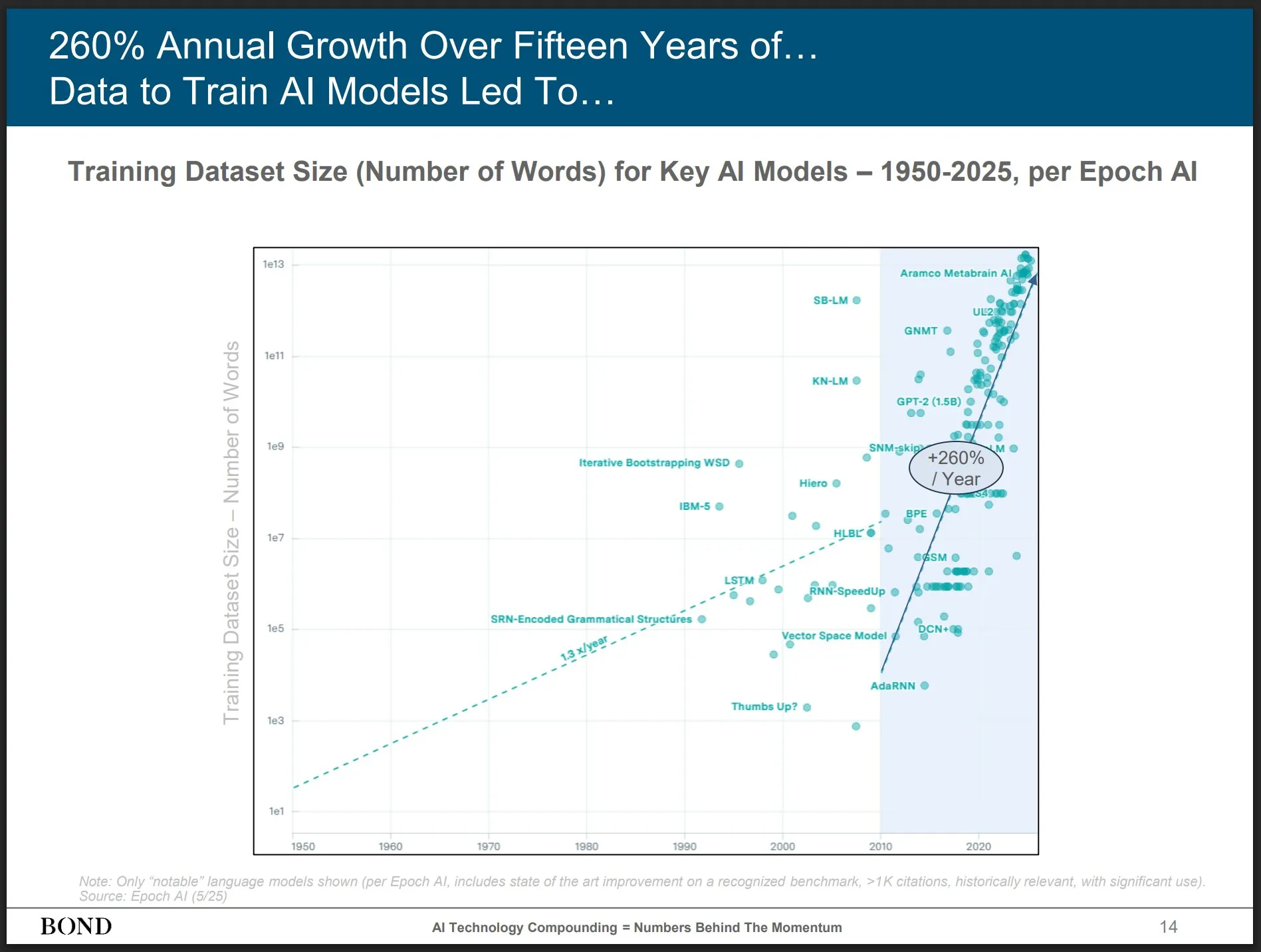
Bond Capital publica relatório de tendências de IA de maio de 2025, fornecendo insights sobre o desenvolvimento da indústria: A renomada empresa de capital de risco Bond Capital publicou o relatório “Tendências de IA 2025-05” de 339 páginas, analisando de forma abrangente dados e insights sobre IA em diversos campos. O relatório destaca que o ChatGPT atingiu 800 milhões de usuários ativos mensais (90% de fora da América do Norte), com 1 bilhão de buscas diárias; os postos de trabalho em TI relacionados à IA cresceram 448%; o custo de treinamento de modelos de ponta excede 1 bilhão de dólares por vez; LLMs estão se tornando infraestrutura. O relatório enfatiza que a chave da competição está em criar os melhores produtos impulsionados por IA, e que o momento atual é um mercado para construtores (Fonte: karminski3)
Artigos discutem a relação entre aprendizado por reforço e capacidade de raciocínio de LLMs, ProRL e Limit-of-RLVR chamam atenção: Dois artigos de pesquisa sobre a relação entre aprendizado por reforço (RL) e a capacidade de raciocínio de modelos de linguagem grandes (LLMs) geraram discussão. Um é “Limit-of-RLVR: Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?”, e o outro é “ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models” da NVIDIA. Essas pesquisas exploram até que ponto o RL (especialmente RLVR, aprendizado por reforço com recompensa verificável) pode melhorar a capacidade de raciocínio fundamental dos LLMs, e o impacto do treinamento contínuo de RL na expansão das fronteiras de raciocínio dos LLMs. As discussões relacionadas consideram que dados de treinamento RLVR de alta qualidade e mecanismos de recompensa eficazes são cruciais (Fonte: scaling01, Dorialexander, scaling01)

Artigo “How Programming Concepts and Neurons Are Shared in Code Language Models” explora os mecanismos de compartilhamento de conceitos de programação e neurônios em Code LLMs: Esta pesquisa investiga as relações entre os espaços conceituais internos de modelos de linguagem grandes (LLMs) ao processar múltiplas linguagens de programação (PLs) e inglês. Através da realização de tarefas de tradução few-shot em modelos da série Llama, descobriu-se que, nas camadas intermediárias, os espaços conceituais estão mais próximos do inglês (incluindo palavras-chave de PLs) e tendem a atribuir altas probabilidades a tokens de palavras em inglês. A análise da ativação de neurônios mostra que os neurônios específicos da linguagem estão concentrados principalmente nas camadas inferiores, enquanto os neurônios exclusivos de cada PL tendem a aparecer nas camadas superiores. A pesquisa fornece novos insights sobre como os LLMs representam internamente as PLs (Fonte: HuggingFace Daily Papers)
Novo artigo “Pixels Versus Priors” controla o conhecimento prévio em MLLMs através de contrafactuais visuais: Esta pesquisa explora se o raciocínio de modelos de linguagem grandes multimodais (MLLMs) ao realizar tarefas como resposta a perguntas visuais depende mais do conhecimento de mundo memorizado ou das informações visuais da imagem de entrada. Os pesquisadores introduziram o dataset Visual CounterFact, contendo imagens visuais contrafactuais que conflitam com o conhecimento prévio do mundo (como morangos azuis). Experimentos mostram que as previsões iniciais do modelo refletem o conhecimento prévio memorizado, mas nas fases intermediárias e finais mudam para a evidência visual. O artigo propõe o vetor de orientação PvP (Pixels Versus Priors), que, através da intervenção na camada de ativação, controla o viés da saída do modelo para o conhecimento de mundo ou para a entrada visual, alterando com sucesso a maioria das previsões de cor e tamanho (Fonte: HuggingFace Daily Papers)
Artigo do ICML 2025, GuidedQuant, propõe melhoria de métodos PTQ hierárquicos através da orientação por perda final: GuidedQuant é um novo método de quantização pós-treinamento (PTQ) que melhora o desempenho de métodos PTQ hierárquicos integrando a orientação por perda final (end loss) no objetivo. O método utiliza o gradiente por característica da perda final para ponderar o erro de saída hierárquico, correspondendo à informação de Fisher diagonal por blocos que preserva as dependências intracanal. Além disso, o artigo introduz LNQ, um algoritmo de quantização escalar não uniforme que garante a redução monotônica do valor objetivo da quantização. Experimentos mostram que GuidedQuant supera os métodos SOTA existentes em quantização escalar apenas de pesos, quantização vetorial apenas de pesos, e quantização de pesos e ativações, e já foi aplicado à quantização de 2-4 bits de modelos como Qwen3, Gemma3, Llama3.3 (Fonte: Reddit r/MachineLearning)

AI Engineer World’s Fair realizada em São Francisco, focando em práticas de engenharia de IA e tecnologias de ponta: A AI Engineer World’s Fair está sendo realizada em São Francisco, reunindo numerosos engenheiros, pesquisadores e desenvolvedores do campo da IA. A agenda da conferência inclui múltiplos tópicos populares como aprendizado por reforço, kernels, inferência e agentes, otimização de modelos (RFT, DPO, SFT), codificação de agentes, construção de agentes de voz, entre outros. Durante o evento, haverá apresentações e workshops de especialistas de empresas como OpenAI, Google, além de lançamentos de novos produtos e tecnologias. Membros da comunidade participam ativamente, compartilhando a agenda da conferência e organizando encontros offline, demonstrando a vitalidade da comunidade de engenharia de IA e o entusiasmo por tecnologias de ponta (Fonte: swyx, clefourrier, swyx, LiorOnAI, TheTuringPost)

💼 Negócios
ShiDu Intelligent conclui rodada de financiamento semente de milhões de yuans, acelerando a implementação de óculos inteligentes com IA em múltiplos cenários: Suzhou ShiDu Intelligent Technology Co., Ltd. anunciou a conclusão de uma rodada de financiamento semente de milhões de yuans. Os fundos serão usados para pesquisa e desenvolvimento da tecnologia central de óculos inteligentes com IA, expansão de mercado e construção de ecossistema. A empresa foca na aplicação de óculos inteligentes com IA em áreas como saúde inteligente (como óculos de leitura inteligentes, óculos de assistência para cegos), vida inteligente (óculos de moda inteligentes, óculos de ciclismo) e manufatura inteligente (óculos industriais inteligentes, controladores de voz). Seus produtos têm preços entre 200 e 1000 yuans, visando promover a popularização de óculos inteligentes através de um bom custo-benefício (Fonte: 36氪)

Rumores de que OpenAI pode adquirir assistente de programação de IA Windsurf, gerando especulações sobre interrupção do fornecimento do modelo Claude pela Anthropic: Rumores de mercado indicam que a OpenAI pode adquirir a ferramenta de programação de IA Windsurf (anteriormente Codeium) por cerca de 3 bilhões de dólares. Neste contexto, o CEO da Windsurf, Varun Mohan, postou que a Anthropic cortou seu acesso direto a quase todos os modelos Claude 3.x, incluindo Claude 3.5 Sonnet, com um aviso extremamente curto. A Windsurf expressou desapontamento e rapidamente transferiu seu poder computacional para outros provedores de serviços de inferência, oferecendo descontos no Gemini 2.5 Pro para os usuários afetados. A comunidade especula que esta ação da Anthropic pode estar relacionada à potencial aquisição pela OpenAI, temendo que isso afete a concorrência na indústria e as escolhas dos desenvolvedores. Anteriormente, a Windsurf também não obteve suporte direto da Anthropic no lançamento do Claude 4 (Fonte: AI前线)

Hygon Information planeja fusão por troca de ações com a Sugon, integrando a cadeia da indústria de poder computacional nacional: A empresa de design de chips de IA Hygon Information divulgou um anúncio, planejando absorver e fundir-se com sua maior acionista, a fabricante de servidores Sugon, através de uma troca de ações. O valor de mercado da Hygon Information é de aproximadamente 316,4 bilhões de yuans, e o da Sugon é de aproximadamente 90,5 bilhões de yuans. Esta fusão no estilo “cobra engolindo elefante” visa otimizar o layout industrial de chips para software e sistemas, fortalecer, complementar e estender a cadeia industrial, e exercer efeitos de sinergia tecnológica. Analistas acreditam que a fusão ajudará a resolver as complexas transações entre partes relacionadas e a potencial concorrência homóloga, reduzir custos operacionais e alinhar-se com a tendência de desenvolvimento de soluções de poder computacional de ponta a ponta na era da IA, marcando uma possível aceleração da transferência de poder da tecnologia de semicondutores da China da computação tradicional para a computação de IA (Fonte: 36氪)
🌟 Comunidade
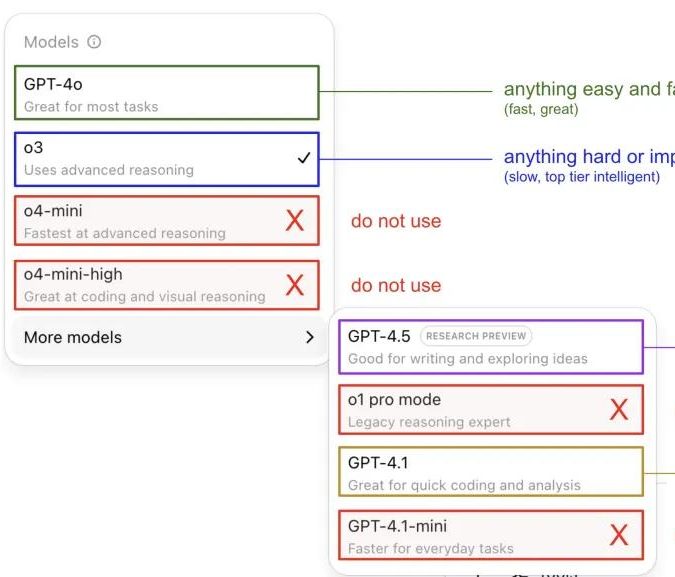
Andrej Karpathy compartilha suas impressões sobre o uso de modelos ChatGPT, gerando discussão na comunidade: Andrej Karpathy compartilhou suas impressões pessoais sobre o uso de diferentes versões do ChatGPT: para tarefas importantes ou difíceis, recomenda o uso do o3, que possui maior capacidade de raciocínio; para problemas cotidianos de baixa a média dificuldade, pode-se usar o 4o; para tarefas de melhoria de código, o GPT-4.1 é adequado; quando é necessária pesquisa aprofundada e resumo de múltiplos links, utiliza-se a funcionalidade de pesquisa aprofundada (baseada no o3). Esta partilha de experiência gerou ampla discussão na comunidade, com muitos usuários compartilhando suas próprias preferências de uso e opiniões sobre a seleção de modelos, refletindo também a confusão dos usuários com a nomenclatura caótica dos modelos da OpenAI e a falta de uma funcionalidade de seleção automática de modelos (Fonte: 量子位, JeffLadish)
Desenvolvedor compartilha experiência de duas semanas com programação Agentic AI: do choque à desilusão, optando finalmente pela refatoração manual: Um líder técnico com 10 anos de experiência compartilhou sua jornada ao integrar Agentic AI (especificamente, agentes de programação de IA) em seu fluxo de desenvolvimento de aplicativos de mídia social. Inicialmente, a IA conseguia gerar módulos funcionais rapidamente, escrever lógica de front-end e back-end e testes unitários, com uma eficiência impressionante, gerando cerca de 12.000 linhas de código em duas semanas. No entanto, à medida que a complexidade da base de código aumentava, a IA começou a cometer erros frequentes ao lidar com novas funcionalidades, entrar em loops e ter dificuldade em admitir falhas. O código gerado também apresentava problemas como nomes imprecisos e código duplicado, tornando a base de código difícil de manter e fazendo com que o desenvolvedor perdesse a confiança. Finalmente, o desenvolvedor decidiu usar o código gerado pela IA apenas como uma “referência vaga”, refatorando manualmente todas as funcionalidades, e concluiu que a IA atualmente é mais adequada para analisar código existente e fornecer exemplos, em vez de escrever diretamente código funcional (Fonte: CSDN)

Definição de Agente de IA e diferença para workflow chamam atenção, com grande potencial de aplicação futura: A comunidade discute a distinção entre os conceitos de Agente de IA e Workflow. Um Agente geralmente se refere a um LLM que acessa ferramentas em um loop, operando livremente com base em instruções; um Workflow é uma série de etapas executadas de forma predominantemente determinística, podendo incluir um LLM para completar subtarefas. Embora haja sobreposição (Agentes podem ser instruídos a executar deterministicamente, Workflows podem conter componentes Agênticos), essa distinção ainda é ontologicamente significativa. Ao mesmo tempo, o potencial dos Agentes de IA em aplicações empresariais é amplamente reconhecido, com grandes empresas como Tencent e ByteDance investindo na área de agentes inteligentes. Por exemplo, a Tencent atualizou sua base de conhecimento de modelos grandes para uma plataforma de desenvolvimento de agentes inteligentes, enquanto a ByteDance possui a plataforma Coze (Kouzi), visando ajudar empresas a implementar sistemas nativos de agentes de IA (Fonte: fabianstelzer, 蓝洞商业)
Dwarkesh Patel discute LLMs e o cronograma para AGI, argumentando que o aprendizado contínuo é o gargalo principal: Dwarkesh Patel, em seu blog, expôs sua visão sobre o cronograma para AGI (Inteligência Artificial Geral), argumentando que os LLMs atualmente carecem da capacidade humana de acumular contexto através da prática, refletir sobre falhas e fazer pequenas melhorias, ou seja, capacidade de aprendizado contínuo. Ele acredita que este é um enorme gargalo para a utilidade dos modelos, e resolver este problema pode levar anos. Esta visão gerou discussões entre vários pesquisadores de IA, incluindo Andrej Karpathy. Karpathy também concorda com as deficiências dos LLMs no aprendizado contínuo, comparando-os a colegas com amnésia anterógrada. Essas discussões destacam os desafios para alcançar uma verdadeira AGI e a necessidade de uma reflexão aprofundada sobre os mecanismos de aprendizado dos modelos (Fonte: dwarkesh_sp, JeffLadish, dwarkesh_sp)

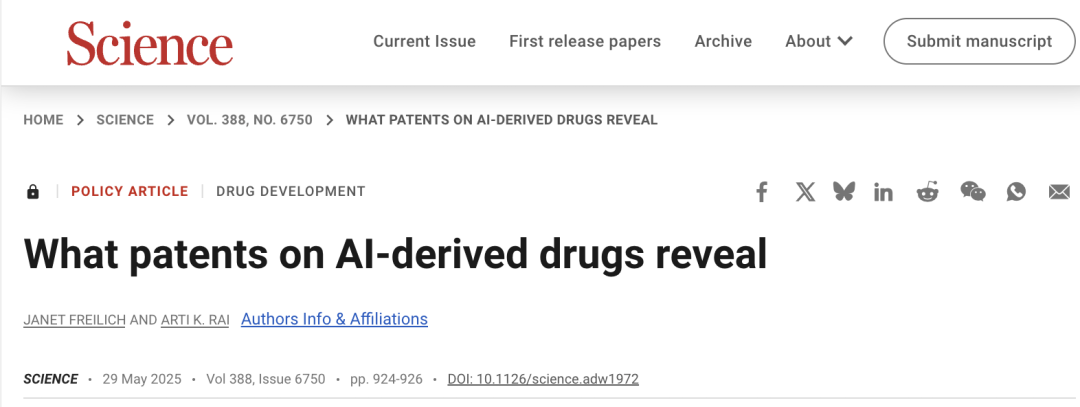
Questões de patentes em P&D de medicamentos com IA chamam atenção, Science publica artigo pedindo cautela: O artigo do Fórum de Políticas da revista Science, “What patents on AI-derived drugs reveal”, discute a aplicação da IA na descoberta de medicamentos e seu impacto no sistema de patentes. A pesquisa aponta que, quando empresas nativas de IA solicitam patentes de medicamentos, os dados de experimentos in vivo são frequentemente menores do que os de empresas farmacêuticas tradicionais, o que pode levar ao abandono de medicamentos promissores por falta de pesquisa subsequente. Ao mesmo tempo, a grande quantidade de novas moléculas geradas por IA, uma vez divulgadas, pode se tornar “estado da técnica”, impedindo que outras empresas solicitem patentes para essas moléculas e invistam nelas. O artigo sugere elevar os requisitos para pedidos de patente, exigindo mais dados de experimentos in vivo, e permitir que outras empresas solicitem patentes para moléculas geradas por IA que não foram testadas, ao mesmo tempo em que se fortalece a exclusividade regulatória na fase de ensaios clínicos de novos medicamentos, para equilibrar o incentivo à inovação com o interesse público (Fonte: 36氪)
💡 Outros
O caso da “luta pelo poder” de Altman pode virar filme chamado “Artificial”, com diretor e produtor renomados envolvidos: Segundo o The Hollywood Reporter, a MGM planeja adaptar os eventos da mudança na alta administração da OpenAI para um filme, provisoriamente intitulado “Artificial”. O renomado diretor italiano Luca Guadagnino pode dirigir, e entre os produtores está David Heyman, da série “Harry Potter”. O elenco está em negociação, com rumores de que Andrew Garfield (que interpretou o Homem-Aranha e Eduardo Saverin em “A Rede Social”) poderia interpretar Sam Altman, Yura Borisov poderia interpretar Ilya Sutskever, e Monica Barbaro poderia interpretar Mira Murati. A notícia gerou grande discussão entre os internautas, que a compararam ao filme “A Rede Social” (Fonte: 36氪, janonacct)
Experiência com atendimento ao cliente por IA gera controvérsia, usuários reclamam de “IA burra” e dificuldade em transferir para humanos: Durante as recentes grandes promoções do comércio eletrônico, um grande número de consumidores relatou que a comunicação com o atendimento ao cliente por IA foi insatisfatória, com respostas irrelevantes e grande dificuldade em transferir para um atendente humano, resultando em uma queda na qualidade do serviço. Dados da Administração Estatal de Regulação do Mercado da China mostram que, em 2024, as reclamações no setor de serviços pós-venda do comércio eletrônico relacionadas ao “atendimento inteligente ao cliente” aumentaram 56,3%. Os usuários geralmente acreditam que o atendimento ao cliente por IA tem dificuldade em resolver problemas personalizados, responde de forma rígida e não é amigável para grupos especiais, como idosos. O artigo apela para que as empresas, ao buscarem redução de custos e aumento de eficiência, não sacrifiquem a qualidade do serviço, otimizem a tecnologia de IA, definam claramente os cenários de aplicação do atendimento ao cliente por IA e mantenham canais de atendimento humano convenientes (Fonte: 36氪)

Discussão sobre a aplicação da IA na criação de conteúdo e estratégias de enfrentamento para criadores: A aplicação de tecnologias de IA (como DeepSeek, Suno, Veo 3) na criação de conteúdo como artigos, música e vídeos está se tornando cada vez mais difundida, gerando ansiedade entre os criadores de conteúdo sobre suas perspectivas de carreira. A análise sugere que o paradigma do conteúdo está mudando de “recomendação personalizada” para “geração personalizada”. A curto prazo, as plataformas podem não substituir completamente os criadores por IA devido aos altos custos de tentativa e erro, e os criadores podem lucrar criando modelos de estilo únicos e licenciando-os. A longo prazo, os criadores precisam ajustar suas formas de criação de valor, focando mais em “estratégias de inovação” que a IA dificilmente pode substituir (como pesquisa original, obtenção de dados primários), em vez de “estratégias de seguimento” facilmente auxiliadas pela IA (seguir tendências, depender de dados secundários). Embora a IA já tenha começado a se envolver em áreas inovadoras como pesquisa científica, criadores com perspectivas únicas e pensamento profundo ainda têm valor (Fonte: 36氪)
