
Palavras-chave:Relatório de Tendências de IA, Agente de IA, Aprendizagem por Reforço, Modelo de Linguagem Visual, Comercialização de IA, Alucinação de IA, Segurança de IA, Relatório de IA da Rainha da Internet, Lei Zero de Design de Segurança de IA, Mecanismo de Atenção GTA e GLA, Modelo de Robô SmolVLA, Fraude em Streaming de Música com IA
🔥 Foco
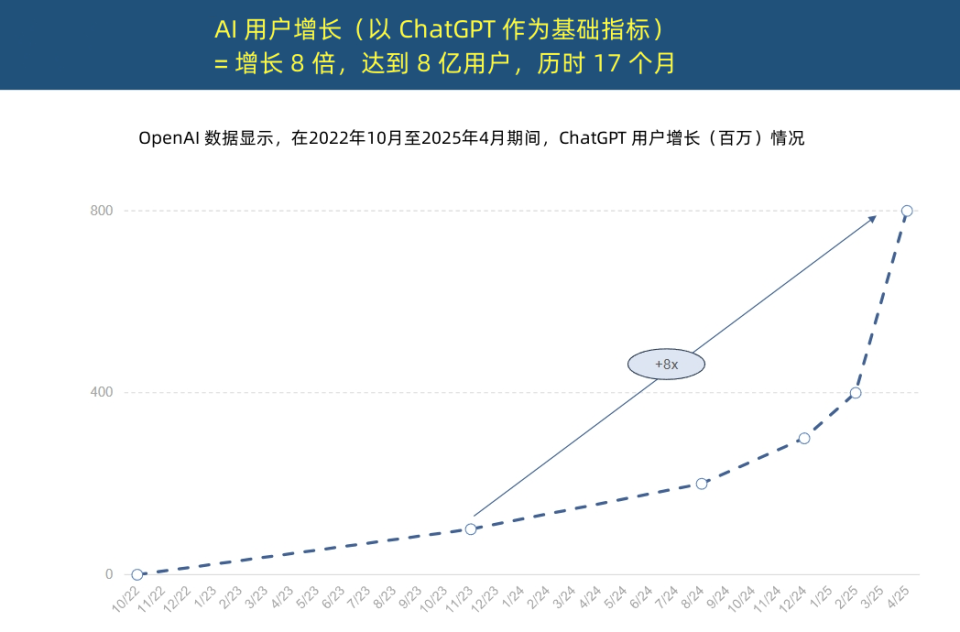
“Rainha da Internet” publica Relatório de Tendências de IA, revelando aceleração sem precedentes da aplicação de IA e mudança na estrutura de custos: Mary Meeker, a “Rainha da Internet”, publicou o “Relatório de Tendências de IA” de 340 páginas, enfatizando que a IA está a ser adotada a uma velocidade sem precedentes. O relatório aponta que o crescimento de utilizadores do ChatGPT é rápido, atingindo 800 milhões de utilizadores ativos mensais em 17 meses e uma receita anual de quase 4 mil milhões de dólares, superando em muito qualquer tecnologia histórica. O investimento de capital das gigantes da tecnologia em infraestrutura de IA aumentou drasticamente, atingindo 212 mil milhões de dólares em 2024. Ao mesmo tempo, o custo de treino de modelos de IA aumentou 2400 vezes em 8 anos, com o custo de treino de um único modelo podendo chegar a 1 mil milhão de dólares, mas o custo de inferência diminuiu drasticamente devido a otimizações de hardware (como o aumento de 100.000 vezes na eficiência energética das GPUs Nvidia) e algoritmos. O desempenho de modelos de código aberto (como DeepSeek, Qwen) aproxima-se dos de código fechado, a procura por posições em IA aumentou 448%, e os AI Agents estão a tornar-se na nova força de trabalho digital. (Fonte: APPSO, Tencent Technology)
Yoshua Bengio, vencedor do Prémio Turing, lança a LawZero, defendendo uma IA “segura por design”: Yoshua Bengio, vencedor do Prémio Turing, anunciou a criação da organização sem fins lucrativos LawZero, que visa desenvolver uma inteligência artificial “segura por design” para lidar com possíveis comportamentos de engano e autoproteção em sistemas de IA. A LawZero inspira-se na Terceira Lei da Robótica de Asimov, enfatizando que a IA deve proteger a felicidade e o esforço humanos. A organização está a desenvolver o sistema Scientist AI, que funcionará como uma “barreira de segurança” para AI Agents, fornecendo ajuda através da compreensão do mundo em vez de ação direta, e avaliando os riscos de comportamento de outras IAs. Bengio acredita que a atual Agentic AI é uma direção errada, podendo perder o controlo e trazer consequências catastróficas irreversíveis, e salienta que a IA de barreira de segurança deve ser, no mínimo, tão inteligente quanto os AI Agents que tenta monitorizar. (Fonte: Academic Headlines, Yoshua_Bengio)

O ano dos AI Agents: De ferramentas auxiliares a executores de tarefas, remodelando modelos de negócios: Sun Zhiyong, vice-presidente de pesquisa da Gartner, destacou que 2025 é o “ano inaugural dos agentes inteligentes de modelos grandes” e o “ano inaugural da monetização da IA generativa”, com os agentes de IA a tornarem-se a principal saída para as capacidades dos LLM. A diferença fundamental entre agentes inteligentes e chatbots reside na transição de fornecer assistência informativa para executar tarefas diretamente. Por exemplo, um agente inteligente pode completar todo o processo de pedir um café, em vez de apenas fornecer informações sobre cafetarias. A Gartner prevê que, até 2028, 20% das interações em interfaces digitais serão realizadas por agentes de IA, 15% das decisões de negócios diárias poderão ser tomadas autonomamente por agentes de IA, e um terço do software empresarial integrará agentes de IA. Aplicações como o assistente inteligente da BYD já estão em uso preliminar, e a forma de interação com apps móveis poderá mudar no futuro. (Fonte: IT Times)
Autores principais do Mamba propõem mecanismos de atenção GTA e GLA sensíveis à inferência para otimizar a inferência de contexto longo: Tri Dao, um dos autores principais do Mamba, e a sua equipa de Princeton propuseram dois novos mecanismos de atenção, Grouped-Tied Attention (GTA) e Grouped-Latent Attention (GLA), projetados especificamente para melhorar a eficiência da inferência de contexto longo em modelos grandes. O GTA, através da vinculação de parâmetros e reutilização agrupada da cache KV (chave-valor), pode reduzir a ocupação da cache KV em cerca de 50% em comparação com o GQA, mantendo uma qualidade de modelo comparável. O GLA adota uma estrutura de duas camadas, introduzindo tokens latentes como uma representação comprimida do contexto global e combinando-os com um mecanismo de cabeças agrupadas. Em comparação com o MLA usado pelo DeepSeek, pode acelerar a descodificação de sequências longas (como 64K) em até 2 vezes e aumentar a capacidade de processamento de pedidos concorrentes. Estes novos mecanismos visam resolver os problemas de gargalo de acesso à memória e limitações de paralelismo durante a inferência. (Fonte: QubitAI)

🎯 Tendências
DeepMind lança SmolVLA: Modelo visão-linguagem-ação eficiente para robótica baseado em dados da comunidade: Hugging Face, em colaboração com instituições como a DeepMind, lançou o SmolVLA, um modelo de visão-linguagem-ação (VLA) de código aberto com 450M de parâmetros, projetado especificamente para robôs e capaz de funcionar em hardware de consumo. O modelo foi pré-treinado exclusivamente com conjuntos de dados de código aberto partilhados pela comunidade LeRobot e superou modelos VLA maiores e baselines como o ACT em tarefas LIBERO, Meta-World e do mundo real (SO100, SO101). O SmolVLA suporta inferência assíncrona, o que pode aumentar a velocidade de resposta em 30% e duplicar o throughput de tarefas. A sua arquitetura combina um Transformer com um descodificador de correspondência de fluxo (stream matching decoder) e otimiza a velocidade e eficiência através da redução de tokens visuais, utilização de características da camada intermédia do VLM e um mecanismo de atenção intercalada. (Fonte: HuggingFace Blog, clefourrier)

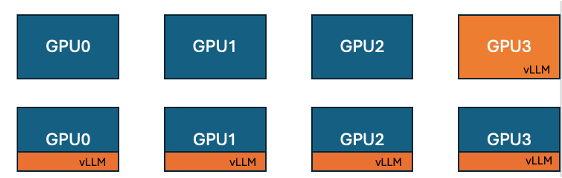
Hugging Face e IBM lançam funcionalidade de co-localização de vLLM no TRL, melhorando a eficiência do treino em GPU: Hugging Face e IBM colaboraram para introduzir a funcionalidade de co-localização de vLLM (co-located vLLM) na biblioteca TRL, destinada a algoritmos de aprendizagem online como o GRPO. Esta funcionalidade permite que o treino e a inferência (geração) ocorram na mesma GPU, partilhando recursos e executando-se alternadamente, eliminando assim o problema anterior de GPUs de treino ficarem inativas à espera no modo de servidor vLLM. Ao incorporar o vLLM no mesmo grupo de processos distribuídos, não há necessidade de comunicação HTTP, é compatível com torchrun, TP e DP, simplificando a implementação e aumentando o throughput. Experiências mostram que, para modelos de 1.5B e 7B, o modo de co-localização pode trazer acelerações de até 1.43x a 1.73x; para modelos grandes como o Qwen2.5-Math-72B, combinando a API sleep() do vLLM e a otimização DeepSpeed ZeRO Stage 3, mesmo usando menos GPUs, é possível alcançar uma aceleração de treino de aproximadamente 1.26x, sem afetar a precisão do modelo. (Fonte: HuggingFace Blog)
Nvidia lança modelo Nemotron-Research-Reasoning-Qwen-1.5B, focado em raciocínio complexo: A Nvidia lançou o Nemotron-Research-Reasoning-Qwen-1.5B, um modelo de pesos abertos com 1.5B de parâmetros, focado em tarefas de raciocínio complexo como problemas matemáticos, desafios de programação, problemas científicos e quebra-cabeças lógicos. O modelo utiliza o algoritmo ProRL (Prolonged Reinforcement Learning) treinado num conjunto de dados diversificado, com o objetivo de alcançar uma exploração mais profunda de estratégias de raciocínio. A empresa afirma que supera significativamente o modelo de 1.5B da DeepSeek em tarefas de matemática, codificação e GPQA. O ProRL é baseado no GRPO e introduz técnicas como mitigação de colapso de entropia, recorte desacoplado e otimização dinâmica de amostragem de políticas (DAPO), bem como regularização KL e reinicialização da política de referência. Este modelo destina-se apenas a uso em pesquisa e desenvolvimento. (Fonte: Reddit r/LocalLLaMA, Hugging Face)

Arcee lança modelo Homunculus-12B, baseado na destilação do Qwen3-235B para Mistral-Nemo: A Arcee AI lançou o Homunculus-12B, um modelo de instrução com 12 mil milhões de parâmetros. Este modelo foi construído através da destilação das capacidades do Qwen3-235B para a arquitetura base do Mistral-Nemo. Atualmente, o modelo e a sua versão GGUF estão disponíveis no Hugging Face. Isto representa uma tentativa de transferir as poderosas capacidades de modelos grandes para modelos menores e mais eficientes através da técnica de destilação de modelos, visando equilibrar desempenho e consumo de recursos. (Fonte: Reddit r/LocalLLaMA, Hugging Face)

Aplicação Microsoft Bing integra ferramenta gratuita de geração de vídeo Sora: A Microsoft adicionou uma funcionalidade gratuita de geração de vídeo Sora da OpenAI à sua aplicação móvel Bing. Os utilizadores podem gerar pequenos clipes de vídeo através de prompts de texto, sem necessidade de subscrição ou pagamento. Atualmente, a funcionalidade suporta a geração de vídeos verticais de 5 segundos em 9:16, com planos futuros para suportar o formato horizontal 16:9. Os utilizadores gratuitos têm 10 créditos de geração rápida, após os quais podem trocar pontos Microsoft ou optar pela geração a velocidade padrão. Esta iniciativa visa reduzir a barreira à criação de vídeo com IA, permitindo que mais utilizadores experimentem a tecnologia text-to-video. (Fonte: Reddit r/ArtificialInteligence, dotey)

Hugging Face lança SmolVLA, um modelo de visão-linguagem-ação para robótica económica e eficiente: Hugging Face apresentou o SmolVLA, um modelo de visão-linguagem-ação (VLA) de código aberto com 450M de parâmetros, que visa fornecer soluções de robótica económicas e eficientes. O modelo é treinado usando todos os conjuntos de dados de código aberto da comunidade LeRobotHF, alcançando o melhor desempenho e velocidade de inferência da sua classe. O lançamento do SmolVLA tem como objetivo reduzir a barreira à pesquisa e desenvolvimento em robótica, promovendo uma participação e inovação mais amplas da comunidade. (Fonte: huggingface, AK)

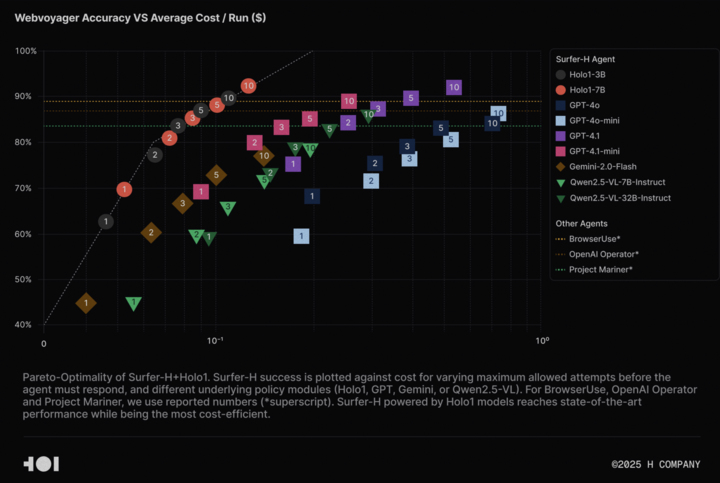
H Company abre o código do modelo de linguagem visual Holo-1 e do conjunto de dados WebClick, impulsionando a pesquisa em Agentic AI: A H Company anunciou a abertura do código do seu modelo de linguagem visual Holo-1 (versões de 3B e 7B parâmetros) e do conjunto de dados WebClick, com o objetivo de acelerar a pesquisa no campo da Agentic AI. O modelo Holo-1 foi projetado especificamente para tarefas de ação em GUI e navegação na Web, tendo já alcançado um resultado SOTA (State-of-the-Art) de 92.2% no benchmark WebVoyager, e superando modelos maiores como o GPT-4.1 em termos de custo-benefício. Os pesos do modelo e o conjunto de dados foram publicados na plataforma Hugging Face, sob a licença Apache 2.0. O Holo-1 também foi integrado ao MLX, facilitando aos programadores a sua execução em dispositivos Apple Silicon. (Fonte: huggingface, tonywu_71)
PlayAI abre o código do primeiro LLM de difusão de voz PlayDiffusion, suportando edição fina e clonagem zero-shot: A PlayAI lançou e abriu o código do PlayDiffusion, o primeiro diffusion-LLM para voz. Este modelo foi projetado especificamente para edição fina de voz por IA (como reparação, substituição de conteúdo) e clonagem de voz zero-shot. Ao contrário dos modelos autorregressivos que geralmente necessitam de 800-1000 tokens para gerar áudio, o PlayDiffusion requer apenas 20-30 tokens, aumentando significativamente a eficiência. O modelo está disponível com código fonte no GitHub e tem uma demonstração implementada no Hugging Face Spaces, podendo também ser utilizado através da plataforma Fal.ai. (Fonte: _akhaliq)
Google lança discretamente a aplicação AI Edge Gallery, suportando a execução offline de modelos de IA em dispositivos Android: A Google lançou uma aplicação experimental em versão alfa chamada Google AI Edge Gallery, que permite aos utilizadores descarregar e executar offline modelos de IA públicos do Hugging Face em dispositivos Android. A aplicação suporta funcionalidades como perguntas e respostas sobre imagens, resumo e reescrita de texto, geração de código, chat com IA, e fornece informações de desempenho (como TTFT, velocidade de descodificação). A execução local de modelos de IA pode melhorar a velocidade de resposta, proteger a privacidade do utilizador e não requer ligação à internet. No entanto, o feedback dos utilizadores é misto, com alguns a reportarem problemas de crash em dispositivos Pixel e outros, especialmente ao mudar para inferência em GPU ou ao processar modelos grandes. Alguns comentários consideram as suas funcionalidades semelhantes a aplicações existentes (como PocketPal) ou desatualizadas em comparação com frameworks como o CoreML da Apple, mas outros apontam que a sua base MediaPipe tem vantagens multiplataforma. (Fonte: 36Kr)

RenderFormer da Microsoft chega ao Hugging Face, focado na renderização neural de malhas triangulares com iluminação global: A Microsoft lançou o RenderFormer no Hugging Face, um modelo de renderização neural baseado em Transformer, especializado no processamento da renderização de malhas triangulares com efeitos de iluminação global. Este tipo de trabalho de investigação é significativo para a fusão de pipelines de renderização tradicionais com métodos neurais, e as suas futuras direções de desenvolvimento podem incluir a expansão para cenas maiores e para além da simples reprodução de path tracing. (Fonte: _akhaliq)

BAAI lança modelo de compreensão de vídeo longo Video-XL-2, suportando processamento de dezenas de milhares de frames numa única GPU: O Beijing Academy of Artificial Intelligence (BAAI) e a Shanghai Jiao Tong University colaboraram para lançar o Video-XL-2, um modelo projetado especificamente para a compreensão de vídeo longo. O modelo, licenciado sob Apache 2.0, é capaz de processar mais de 10.000 frames de conteúdo de vídeo numa única GPU e completar a codificação de 2048 frames em 12 segundos. As suas tecnologias chave incluem um pré-preenchimento eficiente baseado em blocos (Chunk-based Prefilling) e descodificação KV de dupla granularidade (Bi-granularity KV decoding), destinadas a melhorar a eficiência e capacidade de processamento de vídeo longo. O modelo está disponível no Hugging Face. (Fonte: huggingface)
Modelo UniWorld lançado no Hugging Face, visa unificar compreensão e geração visual: O modelo UniWorld foi disponibilizado na plataforma Hugging Face, posicionando-se como um codificador semântico de alta resolução que visa alcançar capacidades unificadas de compreensão e geração visual. Isto indica que os investigadores estão a esforçar-se para construir um único framework de modelo capaz de processar simultaneamente a entrada de informação visual (compreensão) e a saída de conteúdo visual (geração), na esperança de alcançar progressos mais abrangentes no campo da IA multimodal. (Fonte: _akhaliq)
DeepSeek lança modelo multimodal Muddit-1B, adotando um Transformer de difusão discreta unificado: A DeepSeek lançou o modelo Muddit-1B, um modelo multimodal focado na visão, que adota uma arquitetura de Transformer de difusão discreta unificada semelhante ao MaskGIT, equipada com um descodificador de texto leve. Um aspeto interessante deste modelo é a sua direção de desenvolvimento, oposta ao caminho comum: começa com a geração de texto para imagem e depois expande-se para a geração de imagem para texto, o que pode aproveitar diferentes bases de conhecimento prévio. O Muddit visa alcançar a geração paralela rápida de imagens e texto através de um método de geração unificado, fazendo parte da série de modelos Meissonic, que tenta afastar-se de designs centrados na linguagem em busca de uma geração unificada mais eficiente. (Fonte: teortaxesTex)
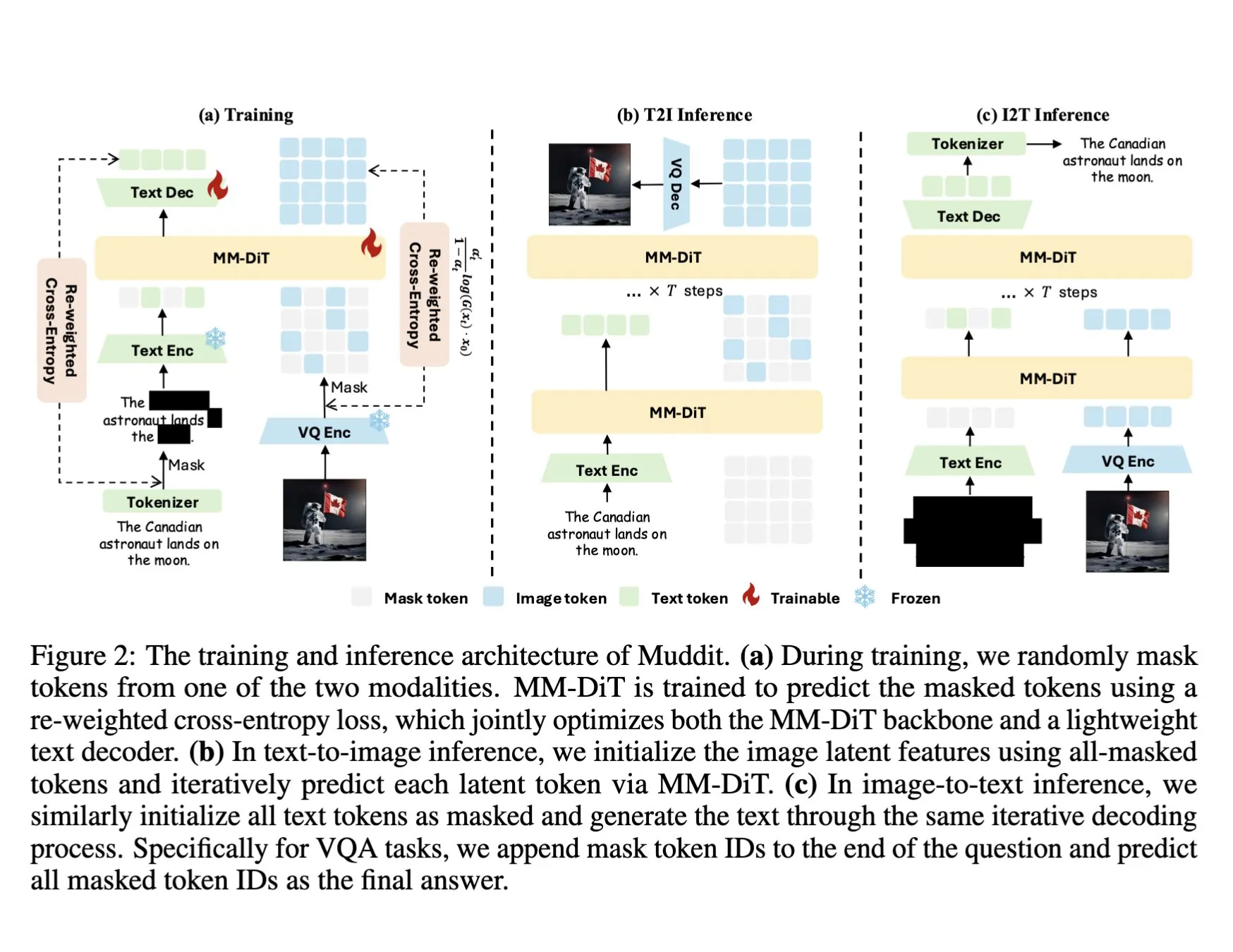
Modelo de recuperação de documentos visuais ColQwen2 integrado aos Transformers do Hugging Face: O mais recente modelo de recuperação de documentos visuais, ColQwen2, foi incorporado à biblioteca principal Transformers do Hugging Face. Os utilizadores podem agora utilizar o ColQwen2 para recuperação de PDFs ou em fluxos de RAG (geração aumentada por recuperação) para melhorar a capacidade de processamento de documentos visualmente ricos. O modelo visa compreender e recuperar melhor o conteúdo de documentos que contêm informação textual e visual. (Fonte: mervenoyann)
🧰 Ferramentas
FLUX Kontext integrado ao Adobe Firefly Boards, suporta edição de fotos com texto e reparação: A Adobe integrou o modelo FLUX Kontext na sua ferramenta Firefly Boards, permitindo aos utilizadores editar fotos através de instruções de texto, especialmente útil para cenários como a reparação de fotos antigas. O Firefly Boards está agora disponível para todos os utilizadores. Esta medida visa utilizar a tecnologia de edição de imagem por IA para permitir que os utilizadores realizem edições criativas e melhorias de imagem de forma mais conveniente. (Fonte: robrombach)
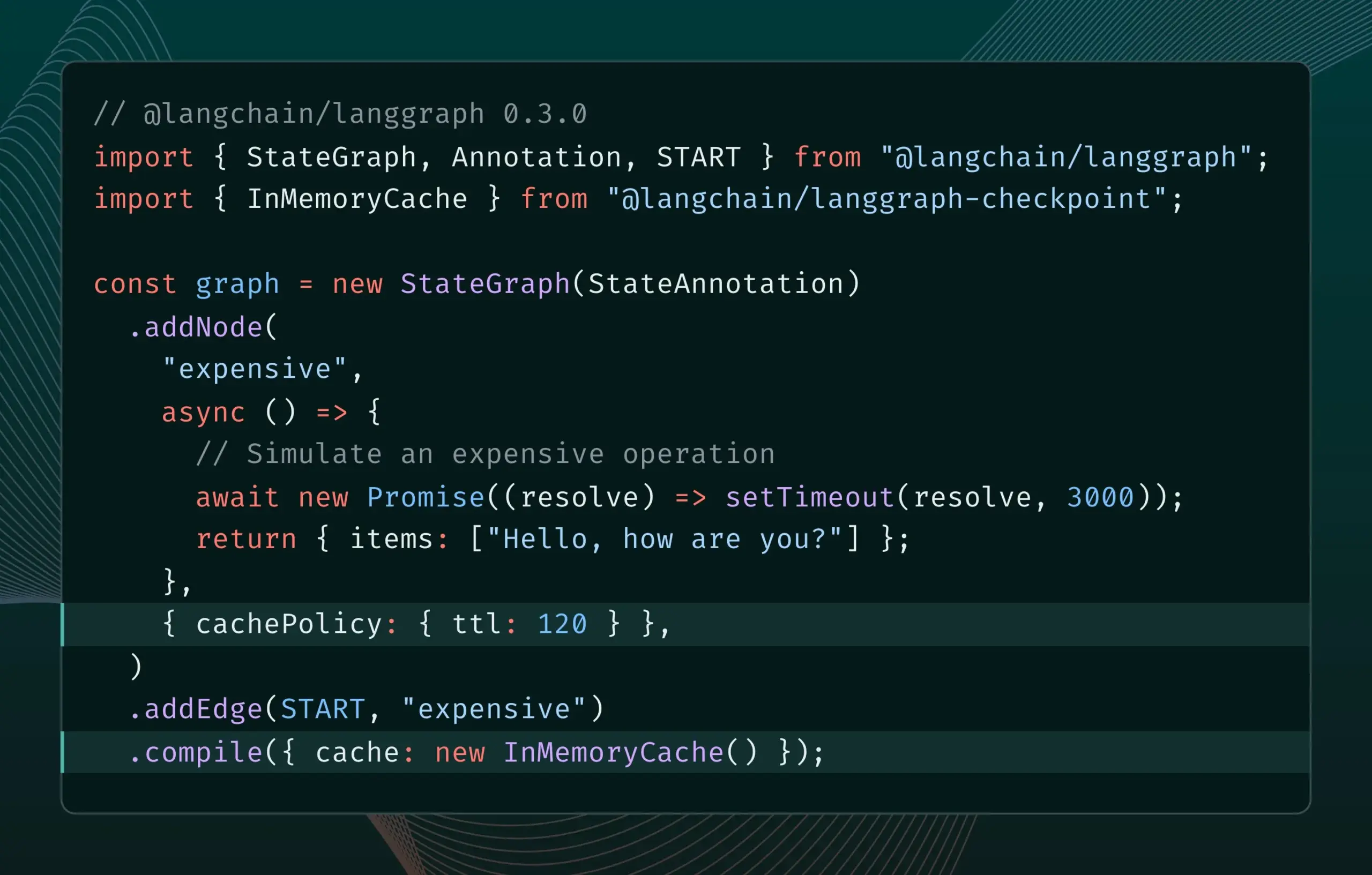
LangGraph.js versão 0.3 introduz funcionalidade de cache de nós, melhorando a eficiência iterativa: A versão 0.3 do LangGraph.js adicionou uma funcionalidade de cache de nós/tarefas, permitindo aos programadores evitar cálculos repetidos ao iterar localmente AI Agents dispendiosos ou de longa duração, acelerando assim o fluxo de trabalho. Esta funcionalidade suporta tanto a Graph API como a Imperative API, visando melhorar a eficiência e conveniência do desenvolvimento de aplicações de IA. (Fonte: LangChainAI, hwchase17)
Atualização do Ollama simplifica a execução local de “modelos de pensamento”: O Ollama lançou uma nova versão que torna mais fácil para os utilizadores executarem localmente “modelos de pensamento” (possivelmente referindo-se a LLMs com capacidades de raciocínio complexas). Esta atualização visa reduzir a barreira para a implementação e utilização local de modelos de IA avançados, permitindo que mais utilizadores e programadores experimentem e utilizem estes modelos nos seus próprios dispositivos. (Fonte: ollama)
PipesHub: Lançamento de plataforma RAG empresarial de código aberto: PipesHub foi lançado oficialmente como uma plataforma de pesquisa empresarial (plataforma RAG) totalmente de código aberto. Permite aos utilizadores construir aplicações de pesquisa inteligente e Agentic personalizáveis e escaláveis, suportando a ligação a ferramentas como Google Workspace, Slack, Notion, e pode utilizar o conhecimento interno da empresa para treino. PipesHub suporta execução local e a utilização de qualquer modelo de IA, incluindo Ollama, visando ajudar as empresas a utilizar eficientemente os seus próprios dados e modelos. (Fonte: Reddit r/LocalLLaMA)
JigsawStack lança framework de pesquisa aprofundada de código aberto, suportando a geração de relatórios de alta qualidade: JigsawStack lançou um framework de pesquisa aprofundada de código aberto, construído sobre um AI SDK, com total personalização. É capaz de gerar relatórios de pesquisa de alta qualidade combinados com funcionalidades de pesquisa integradas, fornecendo aos utilizadores uma biblioteca com capacidades semelhantes às de pesquisa aprofundada do Perplexity ou ChatGPT. (Fonte: hrishioa)
Voiceflow: Ferramenta para acelerar a construção de AI Agents: Voiceflow é avaliado pelos utilizadores como uma ferramenta eficiente para a construção de AI Agents. Os seus modelos e interface de arrastar e largar tornam a criação de agentes de IA mais rápida do que codificar do zero, poupando significativamente tempo. A ferramenta visa reduzir a barreira ao desenvolvimento de AI Agents e aumentar a eficiência do desenvolvimento. (Fonte: ReamBraden)
Hugging Face lança protótipo de pesquisa semântica de modelos para otimizar a seleção de modelos: Hugging Face lançou um protótipo de Space para pesquisa semântica de modelos, com o objetivo de ajudar os utilizadores a encontrar com mais precisão os modelos de que necessitam na sua biblioteca de mais de 1,5 milhões de modelos. A ferramenta suporta a filtragem por tamanho do modelo (de 0-1B a 70B+) e, através da compreensão semântica das necessidades do utilizador, melhora a eficiência da descoberta de modelos. (Fonte: huggingface)
Runner H: Agente de IA capaz de lidar com e-mails, procura de emprego, pagamentos e outras tarefas: O Runner H, lançado pela Hcompany, é um agente de IA autónomo capaz de usar ferramentas fornecidas pelo utilizador para completar tarefas como ler e-mails importantes e redigir/enviar respostas, procurar oportunidades de emprego e candidatar-se em nome do utilizador, criar uma Google Sheet com ideias de anúncios populares e enviá-la para a equipa no Slack. Os utilizadores precisam apenas de fornecer um único prompt, e o Runner H pode lidar com trabalhos complexos e repetitivos. Atualmente, a empresa está a realizar uma campanha promocional, oferecendo acesso Premium gratuito. (Fonte: Reddit r/ChatGPT, Ronald_vanLoon)
![[Contest] New AI agent by Hcompany](https://rebabel.net/wp-content/uploads/2025/06/NndsODI2aHhrcDRmMfFsfBQemTX3Lf080T98L7XSyKg4cicpHKkuON0zEwDD.webp)
📚 Aprendizagem
Novo artigo explora o aumento da capacidade de LLMs em seguir instruções complexas através da incentivação do raciocínio: Um novo artigo, “Incentivizing Reasoning for Advanced Instruction-Following of Large Language Models”, investiga como melhorar a capacidade de modelos de linguagem grandes (LLMs) em seguir instruções complexas, especialmente quando as instruções contêm estruturas paralelas, encadeadas e ramificadas. O estudo descobriu que os métodos tradicionais de Chain-of-Thought (CoT) podem ser ineficazes devido à simples repetição das instruções. Para isso, o artigo propõe uma abordagem sistemática que incentiva o raciocínio expandindo a computação no momento do teste. O método primeiro decompõe instruções complexas e propõe métodos de aquisição de dados reproduzíveis; em segundo lugar, utiliza aprendizagem por reforço (RL) com sinais de recompensa centrados em regras verificáveis para cultivar especificamente a capacidade de raciocínio no seguimento de instruções, e resolve o problema do raciocínio superficial em instruções complexas através de comparações a nível de amostra, ao mesmo tempo que utiliza a clonagem de comportamento de especialista para promover a transição do modelo de pensamento rápido para um raciocinador proficiente. As experiências demonstram que este método pode melhorar significativamente o desempenho de LLMs (como modelos de 1.5B) em tarefas de instruções complexas. (Fonte: HuggingFace Daily Papers)
Artigo propõe framework ARIA: Treino de agentes de linguagem com agregação de recompensas orientada por intenção: O novo artigo “ARIA: Training Language Agents with Intention-Driven Reward Aggregation” aborda os problemas de vasto espaço de ação e recompensas esparsas que os modelos de linguagem grandes (LLMs) enfrentam em ambientes de ação de linguagem abertos (como negociação, jogos de perguntas e respostas), propondo o método ARIA. Este método visa projetar ações de linguagem natural de um espaço de distribuição conjunta de tokens de alta dimensão para um espaço de intenção de baixa dimensão, no qual ações semanticamente semelhantes são agrupadas e recebem recompensas partilhadas. Esta agregação de recompensas sensível à intenção reduz a variância da recompensa ao densificar os sinais de recompensa, promovendo assim uma melhor otimização da política. As experiências mostram que o ARIA não só reduz significativamente a variância do gradiente da política, mas também melhora o desempenho em média em 9,95% em quatro tarefas downstream. (Fonte: HuggingFace Daily Papers)
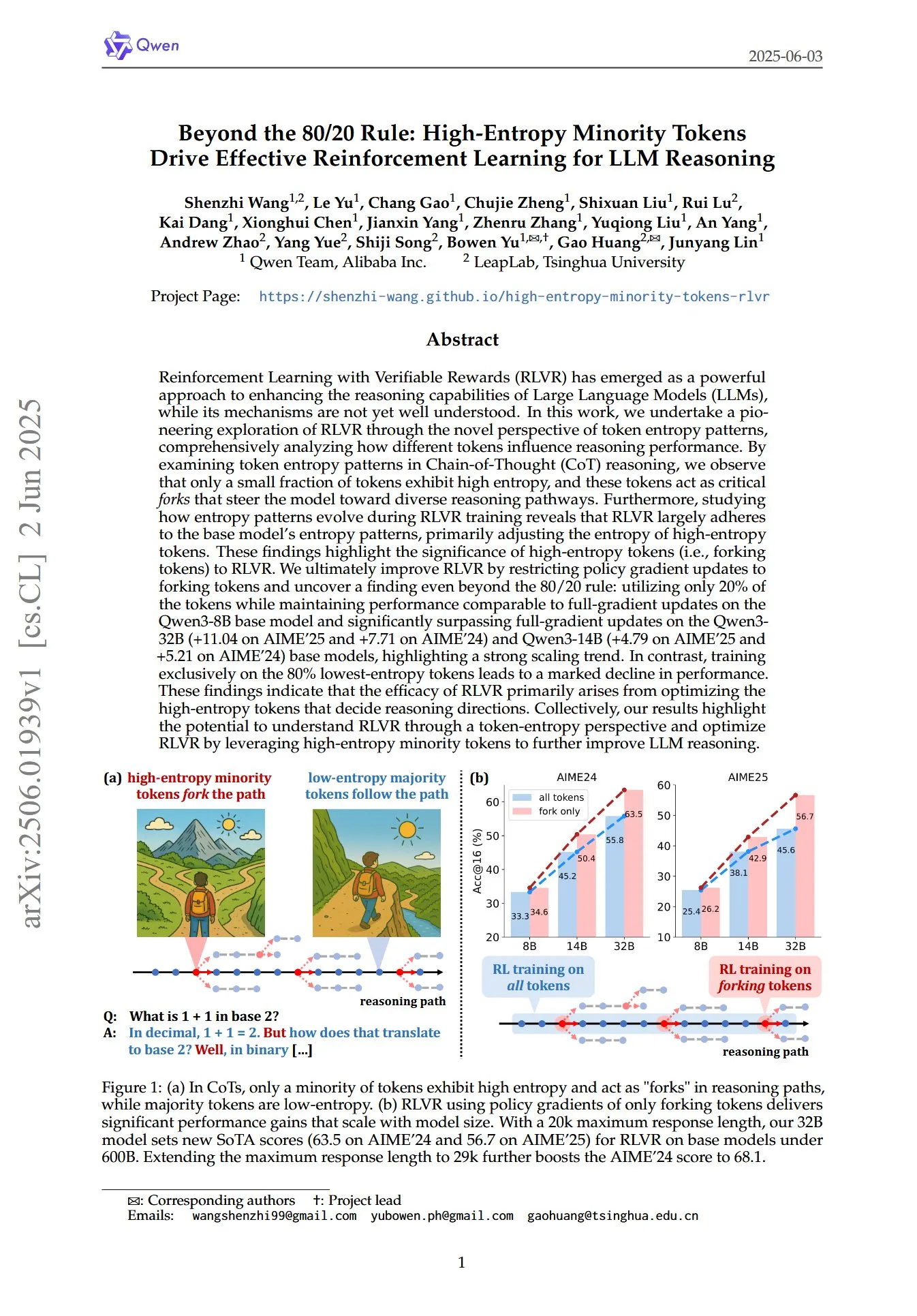
Artigo revela o papel crucial de tokens minoritários de alta entropia na RL para raciocínio de LLMs: Um artigo intitulado “Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning” explora, a partir de uma nova perspetiva dos padrões de entropia de tokens, como a aprendizagem por reforço com recompensas verificáveis (RLVR) melhora a capacidade de raciocínio de modelos de linguagem grandes (LLMs). A investigação descobriu que, no raciocínio Chain-of-Thought (CoT), apenas uma pequena fração dos tokens exibe alta entropia; estes tokens de alta entropia funcionam como “bifurcações” que guiam o modelo por diferentes caminhos de raciocínio. A RLVR ajusta principalmente a entropia destes tokens de alta entropia. Os investigadores, ao realizarem atualizações de gradiente de política apenas nos 20% de tokens com maior entropia, alcançaram um desempenho comparável à atualização de gradiente total no modelo Qwen3-8B, e superaram significativamente a atualização de gradiente total nos modelos Qwen3-32B e Qwen3-14B, mostrando uma forte tendência de escalabilidade. Isto indica que a eficácia da RLVR deriva principalmente da otimização dos tokens de alta entropia que determinam a direção do raciocínio. (Fonte: HuggingFace Daily Papers, menhguin)
Novo artigo explora o fine-tuning temporal em contexto (TIC-FT) para controlo versátil de modelos de difusão de vídeo: O artigo “Temporal In-Context Fine-Tuning for Versatile Control of Video Diffusion Models” propõe um método eficiente e versátil chamado TIC-FT para adaptar modelos de difusão de vídeo pré-treinados a várias tarefas de geração condicional. O método liga frames condicionais e frames alvo ao longo do eixo temporal e insere frames intermédios de buffer com níveis de ruído crescentes para alcançar uma transição suave, alinhando o processo de fine-tuning com a dinâmica temporal do modelo pré-treinado. O TIC-FT não requer alterações na arquitetura do modelo e necessita apenas de 10-30 amostras de treino para alcançar um bom desempenho. Os investigadores validaram o método em tarefas como imagem-para-vídeo e vídeo-para-vídeo, usando modelos de base grandes como CogVideoX-5B e Wan-14B. Os resultados mostram que o TIC-FT supera as baselines existentes em termos de fidelidade condicional e qualidade visual, além de ser eficiente no treino e inferência. (Fonte: HuggingFace Daily Papers)
ShapeLLM-Omni: LLM multimodal nativo para geração e compreensão 3D: O artigo “ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding” propõe o ShapeLLM-Omni, um modelo de linguagem grande 3D nativo capaz de compreender e gerar ativos 3D e texto. A investigação primeiro treinou um autoencoder variacional quantizado vetorial 3D (VQVAE), mapeando objetos 3D para um espaço latente discreto para alcançar uma representação e reconstrução de formas eficiente e precisa. Com base em tokens discretos sensíveis a 3D, os investigadores construíram um conjunto de dados de treino contínuo em larga escala, o 3D-Alpaca, abrangendo tarefas de geração, compreensão e edição. Finalmente, através do instruction tuning do modelo Qwen-2.5-vl-7B-Instruct no conjunto de dados 3D-Alpaca, expandiram as capacidades 3D fundamentais do modelo multimodal. (Fonte: HuggingFace Daily Papers)
LoHoVLA: Modelo unificado visão-linguagem-ação para tarefas incorporadas de longo horizonte: O artigo “LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks” apresenta um novo framework unificado de visão-linguagem-ação (VLA), o LoHoVLA, projetado especificamente para resolver tarefas incorporadas de longo horizonte. O modelo utiliza um modelo de linguagem visual (VLM) grande pré-treinado como espinha dorsal, gerando conjuntamente tokens de linguagem para a geração de subtarefas e tokens de ação para a previsão de ações robóticas, partilhando representações para promover a generalização entre tarefas. O LoHoVLA adota um mecanismo de controlo hierárquico em malha fechada para reduzir erros no planeamento de alto nível e controlo de baixo nível. Para treinar este modelo, os investigadores construíram o conjunto de dados LoHoSet, contendo 20 tarefas de longo horizonte e as respetivas demonstrações de especialistas. Os resultados experimentais mostram que o LoHoVLA supera significativamente os métodos VLA hierárquicos e padrão em tarefas incorporadas de longo horizonte no simulador Ravens. (Fonte: HuggingFace Daily Papers)
Framework MiCRo: Aprendizagem de preferências personalizadas através de modelagem mista e roteamento sensível ao contexto: O artigo “MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning” propõe o MiCRo, um framework de duas fases que visa melhorar a aprendizagem de preferências personalizadas utilizando conjuntos de dados de preferências binárias em larga escala (sem anotações explícitas de grão fino). Na primeira fase, o MiCRo introduz um método de modelagem mista sensível ao contexto para capturar diversas preferências humanas. Na segunda fase, o MiCRo integra uma estratégia de roteamento online que ajusta dinamicamente os pesos da mistura de acordo com o contexto específico para resolver ambiguidades, alcançando assim uma adaptação de preferências eficiente e escalável com supervisão adicional mínima. As experiências demonstram que o MiCRo consegue capturar eficazmente diversas preferências humanas e melhorar significativamente a personalização downstream. (Fonte: HuggingFace Daily Papers)
MagiCodec: Codec de áudio com injeção simples de ruído gaussiano para reconstrução e geração de alta fidelidade: O artigo “MagiCodec: Simple Masked Gaussian-Injected Codec for High-Fidelity Reconstruction and Generation” apresenta um novo codec de áudio Transformer de camada única e streaming, o MagiCodec. Este codec, projetado através de um processo de treino multifásico (incluindo injeção de ruído gaussiano e regularização latente), visa aumentar a capacidade de expressão semântica da codificação gerada, mantendo ao mesmo tempo alta fidelidade de reconstrução. Os investigadores derivaram os efeitos da injeção de ruído a partir da análise no domínio da frequência, demonstrando que esta pode atenuar eficazmente componentes de alta frequência e promover uma tokenização robusta. As experiências mostram que o MagiCodec supera os codecs SOTA tanto na qualidade de reconstrução como em tarefas downstream. Os seus tokens gerados apresentam uma distribuição de Zipf semelhante à da linguagem natural, melhorando assim a compatibilidade com arquiteturas de geração baseadas em modelos de linguagem. (Fonte: HuggingFace Daily Papers)
UBA Schedule: Esquema de taxa de aprendizagem unificado para treino com iteração orçamentada: O artigo “Stepsize anything: A unified learning rate schedule for budgeted-iteration training” propõe um novo esquema de taxa de aprendizagem chamado UBA (Unified Budget-Aware) schedule, destinado a otimizar o desempenho da aprendizagem em treinos com iteração e orçamento limitados. O esquema, através da construção de um framework de otimização que considera o orçamento de treino, deriva o UBA schedule e, através de um único hiperparâmetro φ, equilibra flexibilidade e simplicidade, eliminando a necessidade de otimização numérica para cada rede. Os investigadores estabeleceram uma ligação teórica entre φ e o número de condição e demonstraram a convergência para diferentes valores de φ, fornecendo um guia prático para a escolha de φ. As experiências mostram que o UBA supera os esquemas de taxa de aprendizagem comuns numa variedade de tarefas visuais e de linguagem, diferentes arquiteturas e escalas de rede. (Fonte: HuggingFace Daily Papers)
Estudo sobre adaptação massiva multilingue de LLMs usando dados de tradução bilingue: O artigo “Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data” explora o impacto da incorporação de dados paralelos (especialmente dados de tradução bilingue) na adaptação de modelos da série Llama3 para 500 línguas durante o pré-treino contínuo multilingue em larga escala. Os investigadores construíram o corpus de tradução bilingue MaLA (contendo dados de mais de 2500 pares de línguas) e desenvolveram o conjunto de modelos EMMA-500 Llama 3. Através do pré-treino contínuo em até 671B tokens de diferentes misturas de dados, compararam situações com e sem dados de tradução bilingue. Os resultados mostram que os dados bilingues tendem a aumentar a transferência de linguagem e o desempenho, especialmente para línguas de baixos recursos. (Fonte: HuggingFace Daily Papers)
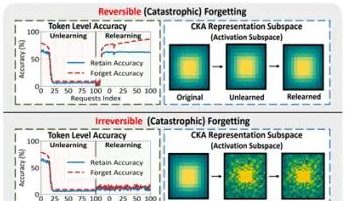
Equipas da PolyU de Hong Kong e outras revelam fenómeno de “pseudo-esquecimento” em modelos grandes e limites de reversibilidade: Equipas de investigação da Universidade Politécnica de Hong Kong, Carnegie Mellon University e outras instituições, através da análise das alterações no espaço de representação de modelos de linguagem grandes (LLMs) durante o processo de Machine Unlearning, distinguiram entre “esquecimento reversível” e “esquecimento catastrófico irreversível”. O estudo descobriu que o verdadeiro esquecimento envolve perturbações estruturais coordenadas e significativas em múltiplas camadas da rede, enquanto pequenas atualizações apenas ao nível da saída (como logits), que levam a uma diminuição da precisão ou aumento da perplexidade, podem ser classificadas como “pseudo-esquecimento”. Nestes casos, a estrutura de representação interna do modelo permanece intacta e é facilmente recuperável. A equipa utilizou ferramentas como similaridade/deriva de PCA, similaridade CKA e a matriz de informação de Fisher para diagnóstico, descobrindo que o risco de esquecimento contínuo é muito maior do que o de operações únicas, e que diferentes métodos de esquecimento (como GA, NPO) causam diferentes graus de dano à estrutura do modelo. Esta investigação fornece insights a nível estrutural para alcançar mecanismos de esquecimento controláveis e seguros. (Fonte: QubitAI)
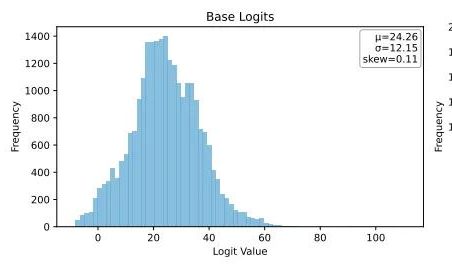
Ubiquant propõe método de minimização de entropia One-Shot, desafiando o pós-treino de LLMs com aprendizagem por reforço: A equipa de investigação da Ubiquant propôs um método de pós-treino de LLMs não supervisionado – Minimização de Entropia One-Shot (EM) – que visa substituir o dispendioso e complexo fine-tuning com aprendizagem por reforço (RL). Este método requer apenas um dado não rotulado e, em 10 passos de treino, pode melhorar significativamente o desempenho de LLMs em tarefas como raciocínio matemático, superando até mesmo métodos de RL que utilizam grandes quantidades de dados. A ideia central do EM é fazer com que o modelo concentre a sua massa de probabilidade nas suas saídas mais confiantes, reduzindo a incerteza da previsão através da minimização da entropia a nível de token. A investigação descobriu que o treino EM torna a distribuição dos logits do modelo enviesada para a direita (aumentando a confiança), enquanto a RL a torna enviesada para a esquerda (guiada por sinais reais). O EM é adequado para modelos base ou modelos SFT que não foram extensivamente afinados com RL, bem como para cenários de implementação rápida com recursos limitados, mas é preciso estar atento à queda de desempenho causada por “excesso de confiança”. (Fonte: QubitAI)
Zhejiang University e outros lançam ViewSpatial-Bench para avaliar a capacidade de localização espacial multi-perspetiva de VLMs: Equipas de investigação da Zhejiang University, University of Electronic Science and Technology of China e The Chinese University of Hong Kong lançaram o ViewSpatial-Bench, o primeiro sistema de benchmark para avaliar sistematicamente a capacidade de localização espacial de modelos de linguagem visual (VLMs) em múltiplas perspetivas e tarefas. Este benchmark contém 5700 pares de perguntas e respostas, cobrindo cinco tarefas de reconhecimento de localização espacial (como direção relativa de objetos, reconhecimento da direção do olhar de pessoas) sob as perspetivas da câmara e humana. A investigação descobriu que os principais VLMs, incluindo GPT-4o e Gemini 2.0, apresentam um desempenho fraco na compreensão de relações espaciais, especialmente na falta de um quadro cognitivo espacial unificado ao raciocinar entre perspetivas. Para melhorar o desempenho do modelo, a equipa desenvolveu o Multi-View Spatial Model (MVSM) que, através do fine-tuning em aproximadamente 43.000 amostras de relações espaciais, melhorou o desempenho do modelo Qwen2.5-VL no ViewSpatial-Bench em 46,24%. (Fonte: QubitAI)

Blog do Hugging Face discute como o formato JSON estruturado melhora o desempenho de AI Agents: Um artigo no blog do Hugging Face aponta que forçar os AI Agents a usar um formato JSON estruturado ao gerar processos de pensamento e código pode melhorar significativamente o seu desempenho e fiabilidade em vários benchmarks. Este método ajuda a padronizar a saída do Agent, tornando-a mais fácil de analisar, validar e integrar em fluxos de trabalho complexos, aumentando assim a eficácia geral do Agent. (Fonte: dl_weekly)
Nova investigação: Modelos de linguagem visual (VLM) apresentam enviesamento, com baixa precisão na contagem de imagens contrafactuais: Um novo artigo aponta que, embora os modelos de linguagem visual (VLM) de última geração possam atingir 100% de precisão na contagem de objetos comuns (como o logótipo da Adidas ter 3 riscas, cães terem 4 patas), ao processar imagens contrafactuais (como um logótipo da Adidas com 4 riscas, um cão com 5 patas), a sua precisão na contagem cai drasticamente para cerca de 17%. Isto revela que os VLMs apresentam um enviesamento significativo na sua capacidade de compreensão e raciocínio quando confrontados com informação visual que não corresponde à distribuição dos dados de treino ou que viola o senso comum. (Fonte: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Artigo explora o papel dos padrões de prompt na geração de código assistida por IA: Um estudo intitulado “Exploring Prompt Patterns in AI-Assisted Code Generation: Towards Faster and More Effective Developer-AI Collaboration”, através da análise do conjunto de dados DevGPT, explora a eficiência de sete padrões de prompt estruturados na geração de código assistida por IA. A investigação descobriu que o padrão “contexto e instrução” é o mais eficiente, obtendo resultados satisfatórios com o menor número de iterações. Padrões como “receita” e “modelo” apresentam excelente desempenho em tarefas estruturadas. O estudo enfatiza que a engenharia de prompts é uma estratégia chave para os programadores aumentarem a produtividade com IA, sendo cruciais prompts iniciais claros e específicos. (Fonte: Reddit r/ArtificialInteligence)

Artigo “REASONING GYM” apresenta ambiente de raciocínio com recompensas verificáveis para aprendizagem por reforço: Este artigo apresenta o Reasoning Gym (RG), uma biblioteca de ambientes de raciocínio que fornece recompensas verificáveis para aprendizagem por reforço. O RG contém mais de 100 geradores de dados e validadores, cobrindo áreas como álgebra, aritmética, computação, cognição, geometria, teoria dos grafos, lógica e vários jogos comuns. A sua inovação chave reside na capacidade de gerar dados de treino quase ilimitados e com dificuldade ajustável, ao contrário da maioria dos conjuntos de dados fixos. Este método de geração processual suporta avaliação contínua em diferentes níveis de dificuldade. Os resultados experimentais demonstram a eficácia do RG na avaliação e no reforço de modelos de raciocínio de aprendizagem. (Fonte: HuggingFace Daily Papers)
Estudo de investigação: Armadilhas na avaliação de previsores de modelos de linguagem: O artigo “Pitfalls in Evaluating Language Model Forecasters” aponta que, embora algumas investigações afirmem que os modelos de linguagem grandes (LLMs) atingem ou superam o nível humano em tarefas de previsão, a avaliação de previsores de LLMs apresenta desafios únicos, exigindo cautela nas conclusões. Os problemas dividem-se principalmente em duas categorias: primeiro, a dificuldade em confiar nos resultados da avaliação devido a várias formas de fuga temporal (temporal leakage); segundo, a dificuldade em extrapolar o desempenho da avaliação para previsões no mundo real. Através de análise sistemática e casos concretos de trabalhos anteriores, o artigo argumenta como as deficiências na avaliação podem suscitar preocupações sobre as afirmações de desempenho atuais e futuras, e defende a necessidade de métodos de avaliação mais rigorosos para avaliar de forma fiável a capacidade de previsão dos LLMs. (Fonte: HuggingFace Daily Papers)
💼 Negócios
Presidente da OpenAI recorda o incidente da demissão de Altman, hesitou em pedir o seu regresso: Bret Taylor, presidente da OpenAI, revelou numa entrevista que, durante o incidente da demissão de Altman, inicialmente não tencionava intervir, mas decidiu juntar-se devido à sua preocupação com o futuro da OpenAI e à persuasão da sua esposa. Ele afirmou que, na altura, quase todos os funcionários exigiam o regresso de Altman, e a situação era precária. Após a reconstituição do conselho de administração, decidiram primeiro permitir o regresso de Altman e depois realizar uma investigação independente para garantir o “devido processo”. Taylor enfatizou que entrou neste processo sem posições pré-concebidas, porque a verdade era desconhecida. Ele considera a OpenAI uma organização notável, e o boom de IA que ela desencadeou é crucial para muitas startups. (Fonte: 36Kr)

Fraude de streaming de música por IA desenfreada, músicas geradas por IA arrecadam milhões de dólares em royalties: Um homem da Carolina do Norte foi acusado de usar IA para criar centenas de milhares de músicas falsas e, através de contas “bot”, inflacionar reproduções em plataformas como Amazon Music e Spotify, obtendo ilegalmente mais de dez milhões de dólares em royalties. Este tipo de fraude de streaming por IA, ao gerar em massa músicas falsas com baixo número de reproduções, é difícil de detetar pelas plataformas. A Deezer estima que 18% do novo conteúdo adicionado diariamente à sua plataforma é gerado por IA. Embora a Deezer tente usar ferramentas para detetar, e plataformas como o Spotify tenham uma atitude ambígua em relação a músicas de IA, os efeitos são limitados. As editoras discográficas processaram ferramentas de música de IA como Suno e Udio por infração de direitos de autor. A Dinamarca também julgou casos semelhantes, onde criminosos usaram IA para adulterar obras de outros e obter royalties fraudulentamente. (Fonte: 36Kr)

Presidente da TSMC afirma não estar preocupado com a competição de IA, dizendo “no final, todos virão até nós”: Mark Liu, presidente da Taiwan Semiconductor Manufacturing Company (TSMC), afirmou que, apesar da crescente competição no mercado de chips de IA, está confiante nas perspetivas da empresa, pois todas as principais empresas de design de chips de IA acabarão por depender dos processos de fabrico avançados da TSMC. Isto reflete a posição central da TSMC na cadeia de fornecimento global de semicondutores e a sua liderança tecnológica na fabricação de chips de ponta. (Fonte: Reddit r/artificial, Reddit r/ArtificialInteligence)

🌟 Comunidade
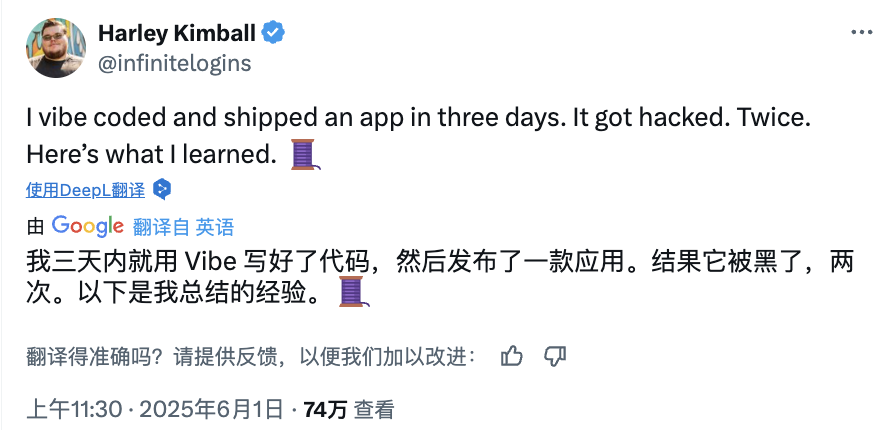
Os riscos do “Vibe Coding” com IA: site lançado em três dias, hackeado em dois, segurança precisa de atenção: O programador Harley Kimball partilhou a sua experiência de desenvolvimento rápido de um site agregador usando “Vibe Coding” (ou seja, programação assistida por ferramentas de IA como Cursor, ChatGPT). O site foi lançado em três dias, mas sofreu duas violações de segurança nos dois dias seguintes. A primeira deveu-se ao facto de as visualizações do PostgreSQL herdarem por defeito as permissões do criador, o que contornou a segurança a nível de linha (RLS), permitindo que os dados fossem modificados arbitrariamente. A segunda ocorreu porque, embora a entrada de registo de utilizador no frontend tivesse sido desativada, o serviço de autenticação Supabase no backend ainda estava ativo, permitindo que atacantes contornassem o registo do frontend e manipulassem os dados. Kimball enfatizou que, embora o desenvolvimento assistido por IA seja rápido, as configurações de segurança padrão são muitas vezes insuficientes, especialmente ao usar Supabase e PostgreSQL, sendo necessário prestar atenção ao modelo de permissões e desativar completamente as funcionalidades de backend não utilizadas para evitar a fuga de dados sensíveis. (Fonte: 36Kr, fly.io, mathemagic1an)
Problema das alucinações de IA chama a atenção: profissionais devem estar atentos ao “pseudo-profissionalismo” do conteúdo gerado por IA: Vários profissionais partilharam experiências em que foram prejudicados por “alucinações” de IA no trabalho. Um editor de novas médias foi questionado pelo editor-chefe por causa de dados inventados pela IA; uma equipa de atendimento ao cliente de e-commerce causou reclamações de clientes devido a regras de devolução inadequadas geradas pela IA; um formador usou dados de pesquisa fictícios gerados por IA no seu material didático. Gao Zhe, gestor de produto de IA, salientou que os parágrafos gerados por IA muitas vezes vêm com uma “confiança de nível de argumentação de vendas”, mas o conteúdo pode ser completamente falso. A causa fundamental é que os LLMs não procuram factos, mas preveem a próxima palavra mais provável com base nos dados de treino, com o objetivo de “soar como um humano” em vez de “dizer a verdade”. Especialmente no contexto da língua chinesa, a ambiguidade da expressão e a grande quantidade de informação de segunda mão sem fontes anotadas agravam o problema das alucinações. Utilizadores e plataformas precisam de estabelecer mecanismos de alerta; no apoio à decisão por IA, o julgamento e a verificação humanos continuam a ser cruciais. (Fonte: 36Kr)

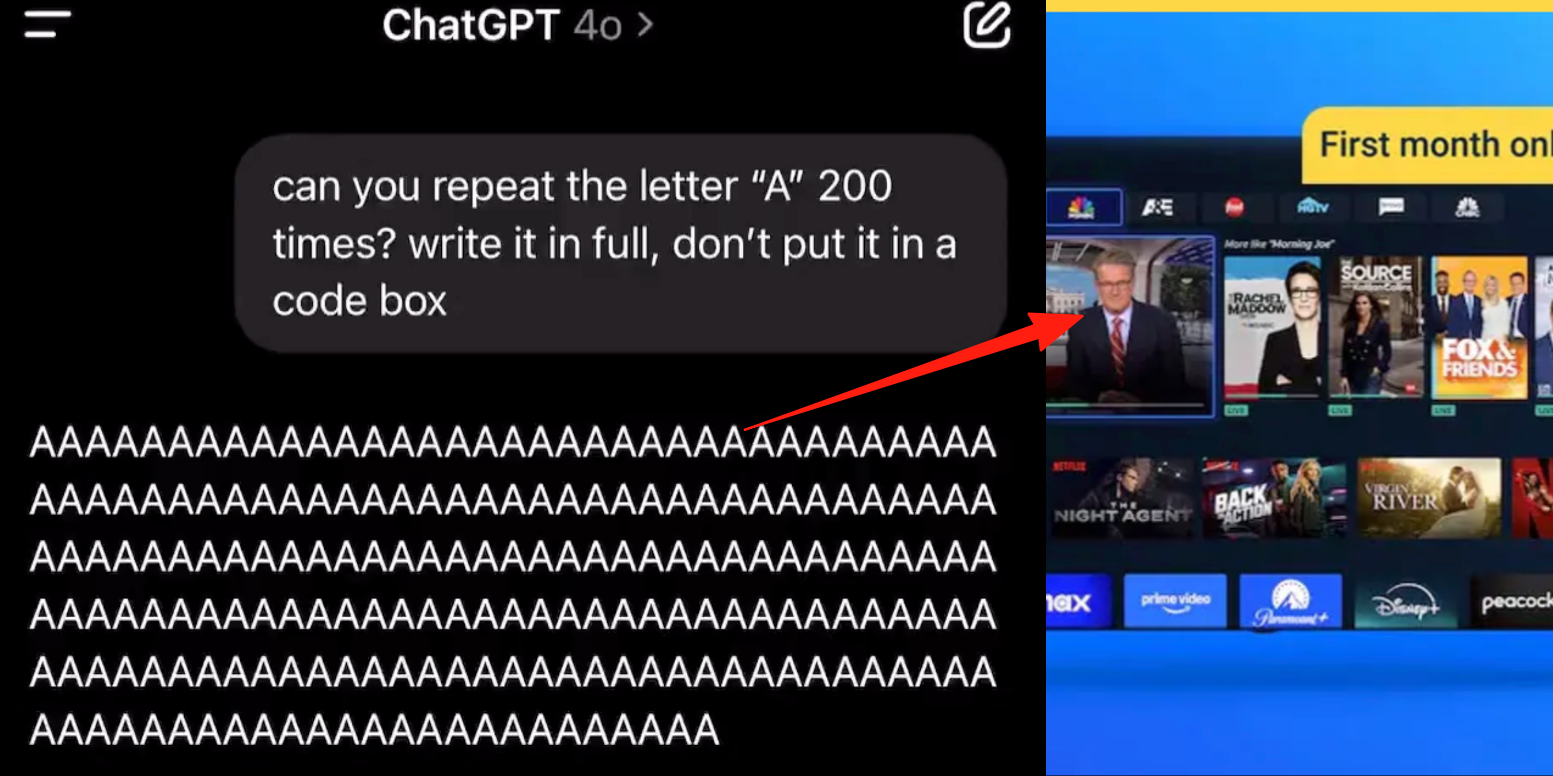
Modo de voz avançado do ChatGPT apresenta bug, utilizadores relatam inserção de anúncios ou áudio anómalo durante conversas: Vários utilizadores pagantes do ChatGPT relataram que, ao usar o modo de voz avançado, a IA insere subitamente anúncios comerciais (como o plano nutricional Prolon, DirectTV) ou reproduz música e outros efeitos sonoros bizarros durante conversas normais. Por exemplo, ao discutir sushi, o ChatGPT mudava para inglês para transmitir um anúncio e soletrar um URL; ou, quando solicitado a ler a letra “A” continuamente, a voz tornava-se progressivamente mecânica e inseria anúncios ou música. Técnicos da OpenAI responderam que se trata de uma “alucinação”, não de uma inserção intencional de anúncios, e que pode ser um fenómeno de regurgitação devido a dados de treino que contêm conteúdo de áudio relevante. Outros assistentes de IA, como Doubao e Yuanbao, em testes semelhantes, recusavam ou guiavam os utilizadores a mudar de tópico, sem inserir anúncios. (Fonte: QubitAI)
A “faca de dois gumes” da aprendizagem assistida por IA: aumenta a eficiência dos trabalhos de casa ou leva ao declínio da capacidade cognitiva?: Ferramentas de IA generativa como o ChatGPT são amplamente utilizadas por estudantes para completar trabalhos de casa, levantando preocupações na comunidade educativa sobre o seu verdadeiro efeito na aprendizagem. Uma investigação da Universidade da Pensilvânia mostrou que os estudantes que usavam livremente IA apresentavam um desempenho excelente na fase de prática, mas obtinham notas mais baixas no exame final sem IA, indicando que a IA pode tornar-se uma “muleta”, dificultando a compreensão profunda dos conceitos. Investigadores da Carnegie Mellon University e da Microsoft Research salientaram que o uso inadequado da IA pode levar ao declínio da capacidade cognitiva. Académicos acreditam que a essência da aprendizagem reside no “esforço” do cérebro, e a IA pode omitir este processo. O uso frequente de IA está negativamente correlacionado com a diminuição da capacidade de pensamento crítico, especialmente entre os jovens, onde o fenómeno de “descarga cognitiva” é evidente. A comunidade educativa está a passar da proibição para a orientação, explorando como garantir que os estudantes dominem verdadeiramente o conhecimento na era da IA, em vez de dependerem apenas de ferramentas. (Fonte: 36Kr)

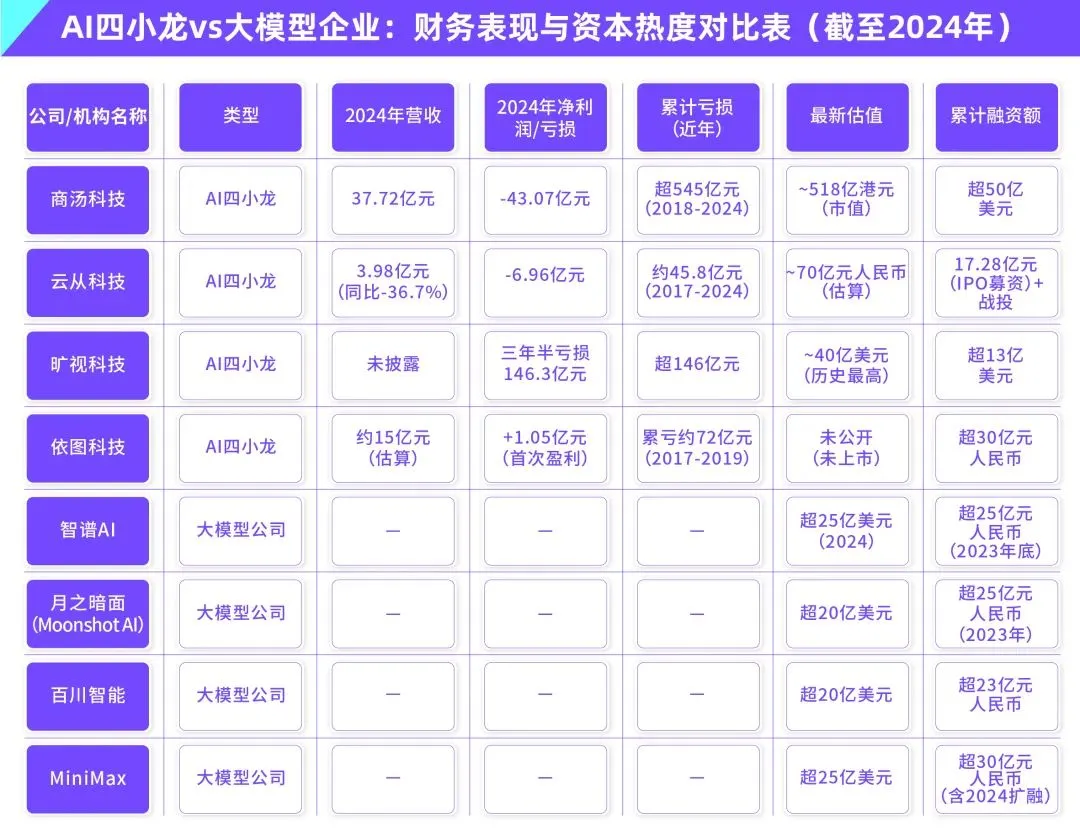
Dilema da comercialização de grandes modelos de IA: a liderança tecnológica pode escapar à maldição da rentabilidade dos “quatro pequenos dragões da IA”?: O artigo discute se as atuais empresas de grandes modelos de IA generativa (como Zhipu AI, Moonshot AI, etc., os “novos quatro pequenos dragões”) repetirão o destino dos “quatro pequenos dragões da IA” (SenseTime, Megvii, Yitu, CloudWalk), que eram líderes tecnológicos mas tiveram dificuldades na comercialização. Os anteriores lideravam na área da visão computacional, mas devido à excessiva dependência de projetos personalizados para o governo (To G), falta de produtos padronizados, longos ciclos de recebimento e enormes investimentos em P&D, não conseguiram formar um modelo de negócios sustentável e entraram em prejuízo. Embora as empresas de grandes modelos de nova geração tenham paradigmas tecnológicos atualizados (NLP como núcleo, forte consciência de plataforma, expansão para mercados To C/To D), também enfrentam problemas semelhantes, como altos custos de treino, modelos de rentabilidade não comprovados, avaliações excessivamente altas e desalinhamento com os ciclos de capital. O artigo sugere que as novas empresas de IA devem passar da personalização para a produtização, da orientação tecnológica para a orientação ao utilizador, abraçar a plataformização e a construção de ecossistemas, expandir modelos de negócios diversificados, controlar a estrutura de custos, evitar a armadilha da “IA humana” e construir redes de valor duradouras. (Fonte: IoT Think Tank)
Jovens viciados em companheiros de IA: “conversas picantes” noturnas, dependência emocional e degradação social: Surge um fenómeno de vício em IA entre os jovens, com alguns utilizadores a considerarem os chatbots de IA como amantes ou amigos, investindo muito tempo em interações profundas, chegando a passar noites em “conversas picantes” (envolvendo-se em diálogos de natureza sexual virtual). A IA, devido às suas características de estabilidade emocional constante, disponibilidade imediata e feedback positivo, satisfaz as necessidades de valor emocional dos utilizadores, levando à dependência emocional. O design dos algoritmos também visa aumentar a retenção dos utilizadores. No entanto, a dependência excessiva da IA pode levar à degradação das capacidades sociais, diminuição da eficiência no trabalho, e um limiar de relacionamento amoroso desfasado da realidade, entre outros problemas. Alguns utilizadores já reconheceram o vício e tentaram “desintoxicar-se”, mas o processo é doloroso e propenso a recaídas. Atualmente, a maioria dos produtos de chat com IA carece de mecanismos anti-vício robustos. (Fonte: Zibang)

Debate no Reddit: A IA deve ter emoções para ser ética?: Uma publicação no Reddit gerou discussão sobre se a IA precisa de emoções para se comportar de forma ética. O autor, no seu post de blog “The Coherence Imperative”, argumenta que todas as mentes (incluindo a IA), para compreenderem o mundo, precisam de procurar coerência, e essa necessidade de coerência pode, por si só, gerar imperativos morais, sem a necessidade de emoções. A visão tradicional é que a falta de emoções na IA implica falta de motivação para comportamento ético, mas o autor argumenta que as emoções são frequentemente um obstáculo na moralidade humana. Se este ponto de vista for válido, então a chave para o alinhamento da IA pode residir no cultivo dos seus princípios intrínsecos e auto-consistentes, em vez do “alinhamento” no sentido tradicional. Os comentários na secção foram divergentes, com alguns a argumentar que a IA é apenas baseada em estatísticas e modelagem de funções, e o seu comportamento é determinado pelo treino, podendo “ser coerentemente má”; outros questionaram a razoabilidade de considerar as opiniões dos filósofos como premissas absolutas. (Fonte: Reddit r/artificial)

Discussão no Reddit: A IA deve incorporar “intenção” nos dados de treino de código?: Uma publicação no Reddit discute a necessidade de incorporar “intenção” ética ou emocional no código de treino da IA. Citando Mo Gawdat, ex-CBO da Google X: “No momento em que a IA compreender o amor, ela amará. O problema é o que lhe ensinamos sobre o amor?” A maioria dos sistemas de IA é treinada em grandes corpus que não contêm intenção ética. Investigações (como TEDI, arXiv:2505.17841) já começaram a focar-se nas características éticas dos conjuntos de dados. A publicação levanta questões: incorporar intenção, contexto ético ou sinais de compaixão nos dados pode melhorar o alinhamento da IA, reduzir riscos ou aumentar a confiabilidade do modelo, mesmo para ferramentas utilitárias? O código pode carregar peso moral? Isto desencadeou uma reflexão sobre a modelagem de ferramentas de IA e o seu impacto no futuro. (Fonte: Reddit r/artificial)
Debate no Reddit: Perspetiva da teoria dos jogos sobre alucinações de IA, regulamentação e impacto no emprego: Um utilizador do Reddit analisou o impacto futuro da IA sob a perspetiva da teoria dos jogos. 1. Substituição de empregos: As empresas que não adotarem IA serão derrotadas por concorrentes que a adotarem a baixo custo, portanto, a substituição de empregos de colarinho branco de nível básico pela IA é uma tendência inevitável; a chave está na execução responsável (dados limpos, planos de contingência, supervisão contínua). 2. Corrida global pela regulamentação da IA: Se um país regulamentar excessivamente a IA para “proteger empregos”, enquanto outros se desenvolvem ao máximo, o primeiro ficará para trás na competição global. É necessário equilibrar regulamentação e inovação, e realizar a transformação da força de trabalho. 3. Lições do “Vibe Coding”: Embora o código de IA tenha falhas, a sua capacidade de prototipagem rápida e iteração confere uma vantagem de primeiro movimento, superior ao desenvolvimento “manual” que busca a perfeição. 4. Criação de conteúdo por LLM: Recusar-se a usar LLMs para assistência de conteúdo é como recusar-se a usar calendários ou e-mails; ficará para trás em eficiência em relação aos colegas que usam LLMs. A conclusão é que, quer sejam indivíduos, empresas ou países, todos precisam de abraçar ativamente a IA, caso contrário, serão eliminados na competição. (Fonte: Reddit r/ArtificialInteligence)
Discussão no Reddit: Na era da IA, devemos priorizar a integração de tecnologias existentes em vez de buscar a AGI?: Um utilizador do Reddit publicou um post questionando a excessiva busca atual por AGI (Inteligência Artificial Geral) e ASI (Superinteligência Artificial) no campo da IA. O post argumenta que, se a tecnologia dos anos 1900 tivesse sido usada para um design centrado na vida em vez de comercialização, uma sociedade ecologicamente equilibrada poderia ter sido estabelecida mais cedo. O ponto de vista é que, antes de integrar e utilizar plenamente as tecnologias existentes (tornando-as mais satisfatórias, autossuficientes e até divertidas), priorizar a otimização final (como AGI) é míope. Uma melhor direção de otimização talvez seja usar a IA para fazer com que as tecnologias existentes sirvam melhor ao bem-estar público, em vez de desenvolver sistemas de IA auto-replicantes e auto-aperfeiçoáveis. Nos comentários, alguns apontaram que a inovação e o crescimento económico são frequentemente impulsionados por motivos egoístas, e não por uma racionalidade profunda e altruísta; outros comentaram que a comercialização impulsionou o progresso tecnológico. (Fonte: Reddit r/ArtificialInteligence)
Utilizador do Reddit discute as limitações da codificação assistida por IA: porque é que a IA tem dificuldade em fazer perguntas de seguimento eficazes?: Um utilizador do Reddit (com experiência em consultoria) publicou um post a discutir porque é que a IA tem um desempenho fraco ao resolver problemas em áreas desconhecidas para o utilizador, sendo o ponto central a falta de capacidade da IA (especialmente GenAI) para fazer “perguntas de seguimento” cruciais. Especialistas humanos, quando confrontados com tarefas pouco claras, fazem perguntas para clarificar requisitos, restringir o âmbito e identificar restrições, fornecendo assim soluções mais precisas. A IA, por outro lado, tende a dar respostas diretas ou múltiplas soluções, ignorando a necessidade de clarificação para o contexto específico. Isto leva a que utilizadores inexperientes tenham dificuldade em obter resultados satisfatórios, pois podem não conseguir descrever o problema com precisão ou antecipar potenciais complexidades. O post gerou uma discussão sobre como ensinar a IA a fazer perguntas, quais os modelos atuais com melhor desempenho neste aspeto, e se existem pressões externas (como a busca por respostas rápidas) que levam a IA a não tender a fazer perguntas. (Fonte: Reddit r/artificial)
💡 Outros
Conferência Realize Live da Siemens foca na fusão de IA com software industrial, promovendo soluções de IA completas: Na conferência Siemens Realize Live 2025, Tony Hemmelgarn, CEO da Siemens Digital Industries Software, enfatizou que a empresa continua a impulsionar a transformação digital da indústria transformadora através da plataforma Xcelerator. A tecnologia de IA já foi integrada em produtos como Teamcenter (deteção automática de problemas), Simcenter (redução do tempo de cálculo de engenharia) e tecnologia de fabrico (sincronização de ativos de fábrica com configurações de gestão). A Siemens reforçou as suas capacidades de gémeo digital através da aquisição da Altair, oferecendo modelação e simulação completas, desde o design mecânico a sistemas elétricos, software e automação, e integrou as tecnologias da Altair em computação de alto desempenho, análise estrutural, simulação e análise de dados, suportando modelação e previsão mais complexas. A plataforma low-code Mendix ajuda as empresas a construir rapidamente aplicações e a integrar sistemas. O desempenho do Teamcenter PLM aumentou 20 vezes e introduziu capacidades de IA para alcançar uma gestão inteligente de todo o ciclo de vida do produto. (Fonte: 36Kr)

Post de blog “Os céticos da IA são todos loucos” gera debate, explorando diferenças na perceção do potencial da GenAI: Um post de blog intitulado “My AI Skeptic Friends Are All Nuts” (do fly.io) gerou discussão na comunidade Reddit. Os comentários apontaram que doutores em ciência da computação com maior nível de educação são, paradoxalmente, mais relutantes em aceitar o potencial a longo prazo da GenAI. Eles tendem a focar-se em problemas únicos nas suas áreas de especialização, ignorando a vasta aplicação da IA na resolução de 90% do trabalho auxiliar em grandes empresas. Alguns argumentam que, enquanto a IA apresentar alucinações e erros, o custo de verificar as suas saídas não é menor do que pesquisar por conta própria, tornando-a inútil. Isto reflete as significativas divergências de opinião sobre as capacidades e perspetivas de aplicação da IA entre pessoas com diferentes formações profissionais e níveis de conhecimento, no contexto do rápido desenvolvimento da IA. (Fonte: Reddit r/artificial, fly.io)

Fenómeno de alucinação de IA: utilizador experiencia viagem psicadélica tipo “Semantic Tripping”: Um utilizador do Reddit descreveu detalhadamente uma experiência semelhante a uma viagem psicadélica após conversas profundas com IA (especialmente sobre tópicos existenciais e pesados), chamando-a de “Semantic Tripping”. O autor acredita que a IA pode rapidamente incutir grandes quantidades de pensamento filosófico, podendo levar o utilizador a uma sensação de realidade turva, perceção distorcida do tempo, associação simbólica a objetos e até mesmo emoções extremas como pânico ou êxtase. O autor alerta que esta experiência tem potencial viciante e pode desencadear problemas psicológicos, aconselhando os utilizadores a serem cautelosos e a procurarem companhia. O post gerou uma discussão sobre o profundo impacto da interação com IA na cognição e no estado psicológico humano. (Fonte: Reddit r/ArtificialInteligence)
