
Palavras-chave:DeepMind AlphaEvolve, Sakana AI DGM, DeepSeek-R1, Aprendizagem por Reforço ProRL, NVIDIA Cosmos, Modelo Multimodal de Grande Escala, Framework de Agentes de IA, Otimização de Inferência LLM, Recorde Matemático AlphaEvolve, Máquina de Gödel Darwin de Autoaperfeiçoamento, Avaliação Médica MedHELM, Escalabilidade de Aprendizagem por Reforço ProRL, Simulação Física Cosmos Transfer
🔥 Foco
DeepMind AlphaEvolve quebra recorde matemático, colaboração homem-máquina impulsiona progresso científico: O AlphaEvolve da DeepMind quebrou duas vezes em uma semana o recorde matemático de 18 anos, atraindo ampla atenção. Terence Tao comentou que isso demonstra como diferentes métodos podem se complementar para impulsionar o progresso matemático, em vez de simples “vencedores” e “perdedores”. Este evento destaca o potencial da colaboração entre AI e humanos para criar novos paradigmas nas áreas de tecnologia e ciência, onde a AI não substitui simplesmente os humanos, mas sim abre novos caminhos para o progresso em conjunto (Fonte: shaneguML)

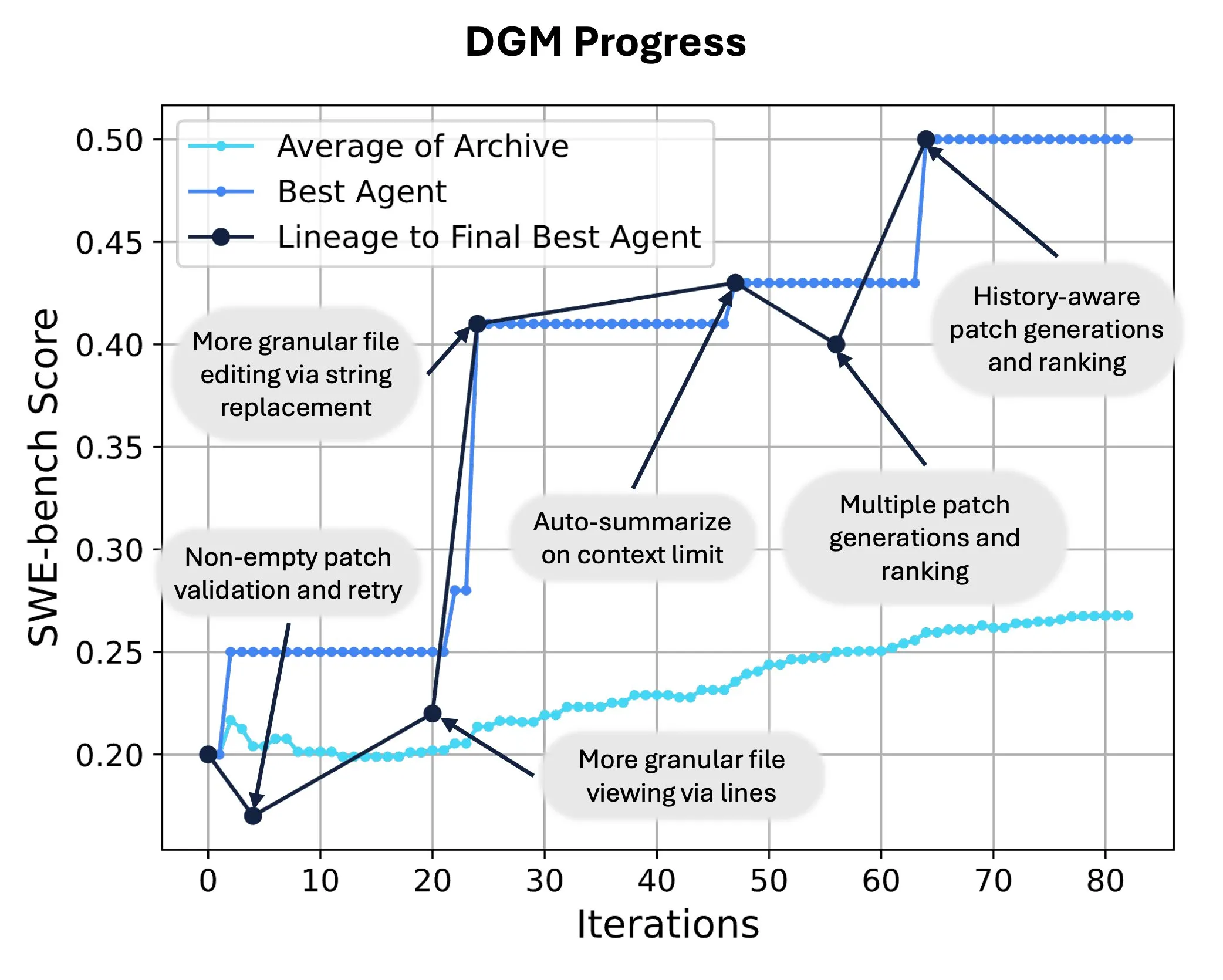
Sakana AI lança Darwin Gödel Machine (DGM), permitindo reescrita e evolução de código por AI: A Sakana AI apresentou a Darwin Gödel Machine (DGM), um agente autoaperfeiçoável capaz de melhorar seu desempenho modificando seu próprio código. Inspirado na teoria da evolução, o DGM mantém uma linhagem em constante expansão de variantes de agentes, permitindo uma exploração aberta do espaço de design de agentes “autoaperfeiçoáveis”. No SWE-bench, o DGM elevou o desempenho de 20,0% para 50,0%; no Polyglot, a taxa de sucesso aumentou de 14,2% para 30,7%, superando significativamente os agentes projetados por humanos. Essa tecnologia oferece um novo caminho para que os sistemas de AI alcancem aprendizado contínuo e evolução de capacidades (Fonte: SakanaAILabs, hardmaru)
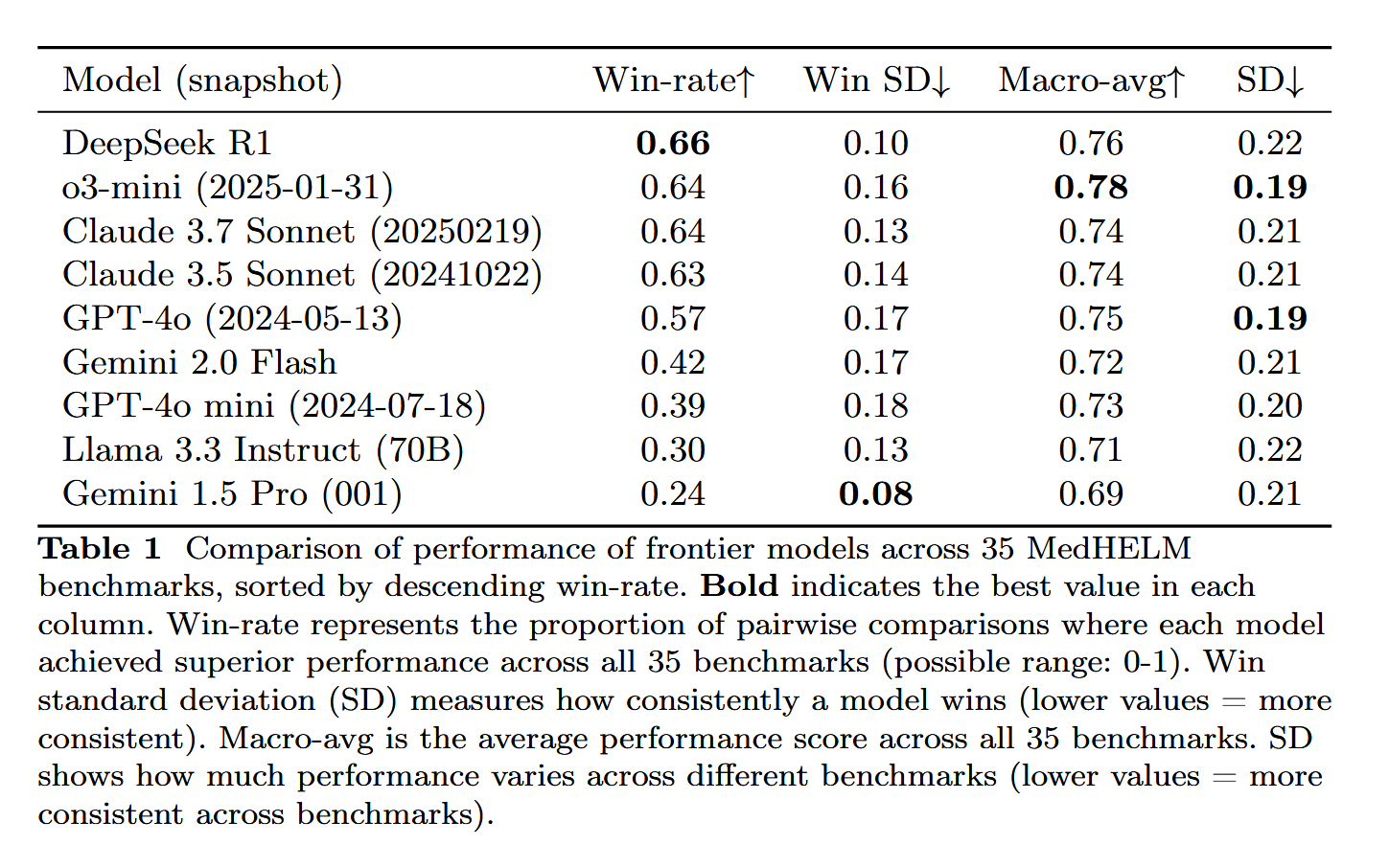
DeepSeek-R1 destaca-se na avaliação de tarefas médicas MedHELM: O Large Language Model DeepSeek-R1 obteve o melhor desempenho no benchmark MedHELM (Avaliação Holística de Tarefas Médicas para Large Language Models), que visa avaliar o desempenho de LLMs em tarefas clínicas mais realistas, em vez dos tradicionais exames de licenciamento médico. Este resultado é considerado significativo, demonstrando o potencial do DeepSeek-R1 em aplicações na área médica, especialmente na capacidade de lidar com cenários clínicos reais (Fonte: iScienceLuvr)
Novo avanço na pesquisa de escalabilidade do Reinforcement Learning: ProRL expande as fronteiras do raciocínio de LLM: Um novo artigo sobre a escalabilidade do Reinforcement Learning (RL) (arXiv:2505.24864) atraiu atenção, mostrando que o treinamento prolongado com Reinforcement Learning (ProRL) pode descobrir novas estratégias de raciocínio que os modelos base dificilmente obteriam por meio de amostragem extensiva. O ProRL combina controle de divergência KL, redefinição da política de referência e um conjunto diversificado de tarefas, permitindo que os modelos treinados com RL superem consistentemente os modelos base em várias avaliações pass@k. A pesquisa oferece novos insights sobre como o RL pode expandir substancialmente as fronteiras do raciocínio de modelos de linguagem e estabelece as bases para futuras pesquisas sobre raciocínio com RL de longa duração. A NVIDIA já disponibilizou os pesos dos modelos relacionados (Fonte: Teknium1, cognitivecompai, natolambert, scaling01)

🎯 Tendências
NVIDIA lança Cosmos Transfer e Cosmos Reason, impulsionando aplicações de AI no mundo físico: A NVIDIA apresentou o sistema Cosmos, onde o Cosmos Transfer pode converter simples cenas de motores de jogos, informações de profundidade ou até mesmo simulações robóticas rudimentares em vídeos de cenas realistas, fornecendo uma grande quantidade de dados de treinamento controláveis para AI em robótica e condução autônoma. O Cosmos Reason, por sua vez, permite que a AI compreenda essas cenas e tome decisões, como determinar como dirigir em testes de condução autônoma. Ambas as ferramentas são atualmente de código aberto e prometem acelerar o desenvolvimento da AI no mundo físico, resolvendo os desafios da escassez de dados de treinamento e do controle de cenários (Fonte: )
DeepSeek lança atualização R1, ecossistema de código aberto continua a prosperar: A DeepSeek lançou uma atualização para o modelo R1, incluindo o próprio R1 e uma versão menor destilada com 8 bilhões de parâmetros. Ao mesmo tempo, a ByteDance tem se mostrado ativa no campo do código aberto, lançando projetos como BAGEL, Dolphin, Seedcoder e Dream0. Esses avanços demonstram a atividade e a capacidade de inovação da China na área de AI de código aberto, especialmente no rápido desenvolvimento de modelos multimodais e especializados (Fonte: TheRundownAI, stablequan, reach_vb, clefourrier)
Google lança Edge AI Gallery, promovendo a aplicação de modelos de AI de código aberto em smartphones: O Google lançou a Edge AI Gallery, com o objetivo de levar modelos de AI de código aberto para smartphones, permitindo aplicações de AI localizadas e privadas. Os usuários podem executar LLMs do Hugging Face diretamente no dispositivo para realizar operações como geração de código e diálogo com imagens, suportando conversas multi-turno e permitindo a escolha de qualquer modelo. O aplicativo é baseado no LiteRT, atualmente suporta Android, e a versão para iOS será lançada em breve, o que impulsionará ainda mais o desenvolvimento e a popularização da AI na ponta (edge AI) (Fonte: TheRundownAI, huggingface, reach_vb, osanseviero)
Nova pesquisa explora o uso de trajetórias de inferência de destilação positiva e negativa para otimizar LLMs: Um novo artigo propõe o framework Refined Distillation (REDI), que visa aprimorar a capacidade de raciocínio de modelos estudantes menores utilizando trajetórias de inferência corretas e incorretas geradas por um modelo professor (como o DeepSeek-R1). O REDI é dividido em duas fases: primeiro, aprende-se com trajetórias corretas por meio de supervised fine-tuning (SFT); em seguida, utiliza-se a recém-proposta função objetivo REDI (uma função de perda sem referência) combinada com trajetórias positivas e negativas para otimizar ainda mais o modelo. Experimentos demonstram que, em tarefas de raciocínio matemático, o REDI supera os métodos de linha de base, com o modelo Qwen-REDI-1.5B alcançando uma pontuação alta de 83,1% no MATH-500 (Fonte: HuggingFace Daily Papers)
Framework LLMSynthor utiliza LLM para síntese de dados com reconhecimento de estrutura: LLMSynthor é um framework universal de síntese de dados que transforma Large Language Models (LLMs) em simuladores com reconhecimento de estrutura, guiados por feedback de distribuição. O framework trata os LLMs como simuladores de copula não paramétricos para modelar dependências de alta ordem e introduz a amostragem de propostas de LLM para aumentar a eficiência da amostragem. Ao minimizar a discrepância no espaço de estatísticas resumidas, um ciclo de síntese iterativo alinha os dados reais e sintéticos. Avaliações em conjuntos de dados heterogêneos de domínios sensíveis à privacidade, como comércio eletrônico, demografia e mobilidade, demonstram que os dados sintéticos gerados pelo LLMSynthor possuem alta fidelidade estatística e utilidade (Fonte: HuggingFace Daily Papers)
Framework v1 aprimora o raciocínio interativo multimodal por meio de revisitação visual seletiva: v1 é uma extensão leve que permite que Multimodal Large Language Models (MLLMs) realizem revisitação visual seletiva durante o processo de raciocínio. Diferentemente dos MLLMs atuais, que geralmente processam a entrada visual de uma só vez, o v1 introduz um mecanismo de “apontar e copiar”, permitindo que o modelo recupere dinamicamente regiões relevantes da imagem durante o raciocínio. Treinado no conjunto de dados v1g, que contém trajetórias de raciocínio multimodal com anotações de fundamentação visual, o v1 demonstra melhorias de desempenho em benchmarks como o MathVista, especialmente em tarefas que exigem referência visual detalhada e raciocínio em várias etapas (Fonte: HuggingFace Daily Papers)
MetaFaith aumenta a fidelidade da expressão de incerteza em linguagem natural por LLMs: Para resolver o problema de LLMs frequentemente exagerarem ao expressar incerteza, o MetaFaith propõe um novo método de calibração baseado em prompts. A pesquisa descobriu que os LLMs existentes têm um desempenho ruim em refletir fielmente sua incerteza intrínseca, os métodos de prompting padrão têm efeito limitado e as técnicas de calibração baseadas em factualidade podem até prejudicar a calibração fiel. Inspirado na metacognição humana, o MetaFaith pode aumentar significativamente a capacidade de calibração fiel de modelos em diferentes tarefas e modelos, com um aumento de até 61% na fidelidade e uma taxa de vitória de 83% em avaliações humanas (Fonte: HuggingFace Daily Papers)
CLaSp: Aceleração da decodificação auto-especulativa de LLM por meio de saltos de camada dentro do contexto: CLaSp é uma estratégia de decodificação auto-especulativa para Large Language Models (LLMs) que acelera o processo de decodificação construindo um modelo de rascunho comprimido por meio de saltos nas camadas intermediárias do modelo de verificação, sem necessidade de treinamento adicional ou modificação do modelo. O CLaSp utiliza um algoritmo de programação dinâmica para otimizar o processo de salto de camada e ajusta dinamicamente a estratégia com base no estado oculto completo da fase de verificação anterior. Experimentos mostram que o CLaSp alcança uma aceleração de 1,3 a 1,7 vezes em modelos da série LLaMA3, sem alterar a distribuição original do texto gerado (Fonte: HuggingFace Daily Papers)
HardTests sintetiza casos de teste de código de alta qualidade usando LLM: Para resolver o problema de que os LLMs, ao gerar código para problemas de programação complexos, têm dificuldade em serem validados eficazmente pelos casos de teste existentes, o HardTests propõe um fluxo de trabalho chamado HARDTESTGEN que utiliza LLMs para gerar casos de teste de alta qualidade. O conjunto de dados HardTests, construído com base nesse fluxo de trabalho, contém 47.000 problemas de programação e casos de teste sintéticos de alta qualidade. Em comparação com os testes existentes, os testes gerados pelo HARDTESTGEN aumentam a precisão em 11,3% e o recall em 17,5% ao avaliar o código gerado por LLM, com o aumento da precisão para problemas difíceis chegando a 40%. O conjunto de dados também demonstra melhores resultados no treinamento de modelos (Fonte: HuggingFace Daily Papers)
Pesquisa revela que Visual Language Models (VLMs) possuem vieses: Um estudo descobriu que Visual Language Models (VLMs) avançados, ao processar tarefas visuais relacionadas a tópicos populares (como contagem e reconhecimento), são fortemente influenciados pelo vasto conhecimento prévio que aprenderam na internet. Por exemplo, os VLMs têm dificuldade em reconhecer uma quarta listra adicionada ao logotipo da Adidas. Em tarefas de contagem abrangendo 7 domínios diferentes, como animais, logotipos e jogos de tabuleiro, a taxa de precisão média dos VLMs foi de apenas 17,05%. Mesmo instruindo o modelo a examinar cuidadosamente ou a confiar apenas nos detalhes da imagem, o aumento da precisão foi limitado. O estudo propõe um framework automatizado para testar vieses em VLMs (Fonte: HuggingFace Daily Papers)
Point-MoE: Utilizando Mixture-of-Experts para generalização interdomínio em segmentação semântica 3D: Para resolver o desafio de treinar um modelo unificado devido à diversidade de fontes de dados de nuvem de pontos 3D (como câmeras de profundidade, LiDAR) e à heterogeneidade de domínios (como interno, externo), o Point-MoE propõe uma arquitetura Mixture-of-Experts (MoE). Essa arquitetura, por meio de uma simples estratégia de roteamento top-k, especializa automaticamente as redes de especialistas, mesmo sem rótulos de domínio. Experimentos mostram que o Point-MoE não apenas supera modelos de linha de base multi-domínio robustos, mas também possui melhor capacidade de generalização em domínios não vistos, oferecendo um caminho escalável para percepção 3D em larga escala e interdomínio (Fonte: HuggingFace Daily Papers)
SpookyBench revela “pontos cegos temporais” em Video Language Models: Apesar dos avanços dos Video Language Models (VLMs) na compreensão de relações espaço-temporais, eles têm dificuldade em capturar padrões puramente temporais quando a informação espacial é ambígua. O benchmark SpookyBench, ao codificar informações (como formas, texto) em sequências de frames ruidosos, descobriu que os humanos conseguem identificar com mais de 98% de precisão, enquanto VLMs avançados têm precisão de 0%. Isso indica que os VLMs dependem excessivamente de características espaciais em nível de frame e não conseguem extrair significado de pistas temporais. A pesquisa enfatiza a necessidade de superar os “pontos cegos temporais” dos VLMs, possivelmente exigindo novas arquiteturas ou paradigmas de treinamento para desacoplar a dependência espacial do processamento temporal (Fonte: HuggingFace Daily Papers, _akhaliq)
Novo método e conjunto de dados para detecção de inovação científica usando LLMs: Identificar novas ideias em pesquisa científica é crucial, mas desafiador. Para abordar esse problema, pesquisadores propõem o uso de Large Language Models (LLMs) para detecção de inovação científica e construíram dois novos conjuntos de dados nas áreas de marketing e processamento de linguagem natural. O método constrói os conjuntos de dados extraindo o conjunto de fechamento de artigos e utilizando LLMs para resumir suas ideias principais. Para capturar conceitos de ideias, os pesquisadores propõem treinar um recuperador leve que alinha ideias com conceitos semelhantes, destilando conhecimento em nível de ideia de LLMs, permitindo assim uma recuperação de ideias eficiente e precisa. Experimentos demonstram que o método supera outras abordagens nos conjuntos de dados de benchmark propostos (Fonte: HuggingFace Daily Papers)
un^2CLIP melhora a capacidade de captura de detalhes visuais do CLIP invertendo o unCLIP: Para resolver as deficiências do modelo CLIP em distinguir diferenças de detalhes em imagens e lidar com tarefas como previsão densa, o un^2CLIP propõe melhorar o CLIP invertendo o modelo unCLIP. O próprio unCLIP treina um gerador de imagens usando embeddings de imagem do CLIP, aprendendo assim a distribuição de detalhes da imagem. O un^2CLIP utiliza essa característica para permitir que o codificador de imagem CLIP aprimorado obtenha a capacidade de captura de detalhes visuais do unCLIP, mantendo o alinhamento com o codificador de texto original. Experimentos mostram que o un^2CLIP supera significativamente o CLIP original e outros métodos de aprimoramento em várias tarefas (Fonte: HuggingFace Daily Papers)
ViStoryBench: Lançado conjunto abrangente de benchmarks para visualização de histórias: Para impulsionar o desenvolvimento da tecnologia de visualização de histórias (geração de sequências de imagens coerentes com base em narrativas e imagens de referência), o ViStoryBench oferece um benchmark de avaliação abrangente. Este benchmark inclui conjuntos de dados com vários tipos de histórias (comédia, terror, etc.) e estilos artísticos (anime, renderização 3D, etc.), e apresenta histórias com um único protagonista e múltiplos protagonistas para testar a consistência dos personagens, bem como enredos complexos e construção de mundo para desafiar a precisão da geração visual dos modelos. O ViStoryBench adota múltiplas métricas de avaliação, visando avaliar de forma abrangente o desempenho dos modelos em termos de estrutura narrativa e elementos visuais, ajudando os pesquisadores a identificar os pontos fortes e fracos dos modelos e a realizar melhorias direcionadas (Fonte: HuggingFace Daily Papers)
Decodificação Fork-Merge (FMD) melhora a compreensão multimodal equilibrada de grandes modelos de áudio e vídeo: Para resolver o problema de possível viés modal em Audio-Visual Large Language Models (AV-LLMs) (ou seja, o modelo depende excessivamente de uma modalidade ao tomar decisões), a Decodificação Fork-Merge (FMD) propõe uma estratégia em tempo de inferência que não requer treinamento adicional. A FMD primeiro processa entradas puramente de áudio e puramente de vídeo separadamente por meio de camadas de decodificação iniciais (fase de bifurcação) e, em seguida, mescla os estados ocultos resultantes para inferência conjunta (fase de mesclagem). O método visa promover uma contribuição modal equilibrada e utilizar informações complementares entre modalidades. Experimentos em modelos como VideoLLaMA2 e video-SALMONN mostram que a FMD pode melhorar o desempenho em tarefas de inferência de áudio, vídeo e áudio-vídeo combinadas (Fonte: HuggingFace Daily Papers)
LegalSearchLM: Reestruturando a recuperação de casos jurídicos como geração de elementos legais: Os métodos tradicionais de recuperação de casos jurídicos (LCR) dependem de correspondência de embedding ou lexical, enfrentando limitações em cenários reais. O LegalSearchLM propõe um novo método que trata a LCR como uma tarefa de geração de elementos legais. O modelo realiza inferência de elementos legais sobre o caso da consulta e gera diretamente conteúdo com base no caso alvo por meio de decodificação restrita. Ao mesmo tempo, os pesquisadores lançaram o LEGAR BENCH, um benchmark LCR em larga escala contendo 1,2 milhão de casos jurídicos coreanos. Experimentos mostram que o LegalSearchLM supera os modelos de linha de base em 6-20% no LEGAR BENCH e demonstra forte capacidade de generalização interdomínio (Fonte: HuggingFace Daily Papers)
RPEval: Novo benchmark para avaliar a capacidade de role-playing de Large Language Models: Para enfrentar os desafios da avaliação da capacidade de role-playing de Large Language Models (LLMs), o RPEval fornece um novo benchmark. Este benchmark avalia o desempenho de role-playing dos LLMs em quatro dimensões principais: compreensão emocional, tomada de decisão, inclinação moral e consistência do personagem. Visa resolver os problemas do alto consumo de recursos da avaliação manual e dos possíveis vieses da avaliação automatizada (Fonte: HuggingFace Daily Papers)
GATE: Modelo de embedding de texto universal para aprimorar o STS em árabe: Para resolver a escassez de conjuntos de dados de alta qualidade e modelos pré-treinados na pesquisa de similaridade textual semântica (STS) em árabe, surgiu o modelo GATE (General Arabic Text Embedding). O GATE utiliza aprendizado de representação Matryoshka e métodos de treinamento com perda híbrida, combinados com um conjunto de dados de trios de inferência de linguagem natural em árabe para treinamento. Os resultados experimentais mostram que o GATE alcançou desempenho SOTA em tarefas STS do benchmark MTEB, com melhoria de desempenho de 20-25% em comparação com modelos grandes, incluindo o OpenAI, capturando efetivamente as nuances semânticas únicas do árabe (Fonte: HuggingFace Daily Papers)
CoDA: Framework colaborativo de otimização de ruído de difusão para manipulação de corpo inteiro de objetos articulados: Para alcançar realismo e precisão na manipulação de corpo inteiro de objetos articulados (incluindo movimentos do corpo, mãos e objetos), o CoDA propõe um novo framework colaborativo de otimização de ruído de difusão. Este framework otimiza o espaço de ruído de três modelos de difusão especializados para o corpo, mão esquerda e mão direita, e alcança coordenação natural entre as mãos e o resto do corpo através do fluxo de gradiente na cadeia cinemática humana. Para melhorar a precisão da interação mão-objeto, o CoDA adota uma representação unificada baseada em Basis Point Set (BPS), codificando a posição do efetor final como a distância à geometria BPS do objeto, guiando assim a otimização do ruído de difusão para gerar movimentos de interação de alta precisão (Fonte: HuggingFace Daily Papers)
Nova interpretação do mecanismo de reflexão na inferência de LLM: Framework de Reinforcement Learning Adaptativo Bayesiano BARL: A Northwestern University, em colaboração com o Google DeepMind, propôs o framework de Reinforcement Learning Adaptativo Bayesiano (BARL), com o objetivo de explicar e otimizar o comportamento de “reflexão” de Large Language Models (LLMs) durante o processo de inferência. O Reinforcement Learning (RL) tradicional geralmente utiliza apenas a política aprendida durante o teste, enquanto o BARL, ao introduzir a modelagem da incerteza ambiental, permite que o modelo explore adaptativamente novas políticas durante a inferência. Experimentos mostram que o BARL pode alcançar maior precisão em tarefas como raciocínio matemático e reduzir significativamente o consumo de tokens. Esta pesquisa, pela primeira vez, explica da perspectiva bayesiana por que, como e quando os LLMs devem realizar exploração reflexiva (Fonte: 量子位)

Aplicação de LLMs em gramáticas formais de incerteza: Quando confiar em LLMs para raciocínio automático: Large Language Models (LLMs) demonstram potencial na geração de especificações formais, mas sua natureza probabilística entra em conflito com os requisitos determinísticos da verificação formal. Pesquisadores investigaram exaustivamente os modos de falha e a quantificação de incerteza (UQ) em artefatos formais gerados por LLMs. Os resultados mostram que o impacto da formalização automática baseada em SMT na precisão varia de acordo com o domínio, e as técnicas de UQ existentes têm dificuldade em identificar esses erros. O artigo introduz o framework de Gramáticas Livres de Contexto Probabilísticas (PCFG) para modelar a saída de LLMs e descobre que os sinais de incerteza são dependentes da tarefa. Ao fundir esses sinais, é possível realizar validação seletiva, reduzindo drasticamente os erros e tornando a formalização orientada por LLM mais confiável (Fonte: HuggingFace Daily Papers)
Comparação entre fine-tuning de Small Language Models (SLMs) e prompting de Large Language Models (LLMs) na geração de fluxos de trabalho low-code: Um estudo comparou os efeitos do fine-tuning de Small Language Models (SLMs) com o prompting de Large Language Models (LLMs) na tarefa de gerar fluxos de trabalho low-code em formato JSON. Os resultados indicam que, embora um bom prompt possa fazer com que os LLMs produzam resultados razoáveis, para tarefas específicas de domínio e saídas estruturadas, o fine-tuning de SLMs apresenta uma melhoria média de 10% na qualidade. Isso sugere que, em cenários específicos, os SLMs ainda têm vantagens, especialmente quando os requisitos de qualidade da saída são altos (Fonte: HuggingFace Daily Papers)
Avaliação e orientação da preferência modal em grandes modelos multimodais: Pesquisadores construíram o benchmark MC² para avaliar sistematicamente a preferência modal de Multimodal Large Language Models (MLLMs) (ou seja, a tendência de favorecer uma modalidade ao tomar decisões) em cenários controlados de conflito de evidências. O estudo descobriu que os 18 MLLMs testados exibiram vieses modais significativos, e a direção da preferência pode ser influenciada por intervenções externas. Com base nisso, os pesquisadores propuseram um método de sondagem e orientação baseado em engenharia de representação, que pode controlar explicitamente a preferência modal sem fine-tuning adicional ou prompts elaborados, e obteve resultados positivos em tarefas downstream, como mitigação de alucinações e tradução automática multimodal (Fonte: HuggingFace Daily Papers)
Estado atual da pesquisa sobre segurança de LLMs multilíngues: Da medição da lacuna linguística à sua superação: Uma revisão sistemática de quase 300 artigos de conferências de NLP entre 2020 e 2024 revela um problema significativo de centralização no inglês na pesquisa de segurança de LLMs. Mesmo idiomas não ingleses com muitos recursos raramente recebem atenção, e idiomas não ingleses raramente são objetos de estudo independentes. A pesquisa de segurança em inglês também geralmente carece de boas práticas de documentação linguística. Para promover a pesquisa de segurança multilíngue, o artigo propõe direções futuras, incluindo avaliação de segurança, geração de dados de treinamento e generalização de segurança entre idiomas, com o objetivo de desenvolver práticas de segurança de AI mais robustas e inclusivas para diferentes populações globais (Fonte: HuggingFace Daily Papers, sarahookr)

Revisitando a transição de estado bilinear em redes neurais recorrentes: A visão tradicional é que as unidades ocultas das redes neurais recorrentes (RNNs) são usadas principalmente para modelar a memória. Este estudo parte de outra perspectiva, considerando as unidades ocultas como participantes ativos na computação da rede. Os pesquisadores revisitaram as operações bilineares que envolvem interações multiplicativas entre unidades ocultas e embeddings de entrada, demonstrando teórica e empiricamente que elas são um viés indutivo natural para representar a evolução do estado oculto em tarefas de rastreamento de estado. O estudo também mostra que as atualizações de estado bilinear constituem uma hierarquia natural, correspondendo a tarefas de rastreamento de estado de complexidade crescente, enquanto RNNs lineares populares (como Mamba) estão localizadas no centro de menor complexidade dessa hierarquia (Fonte: HuggingFace Daily Papers)
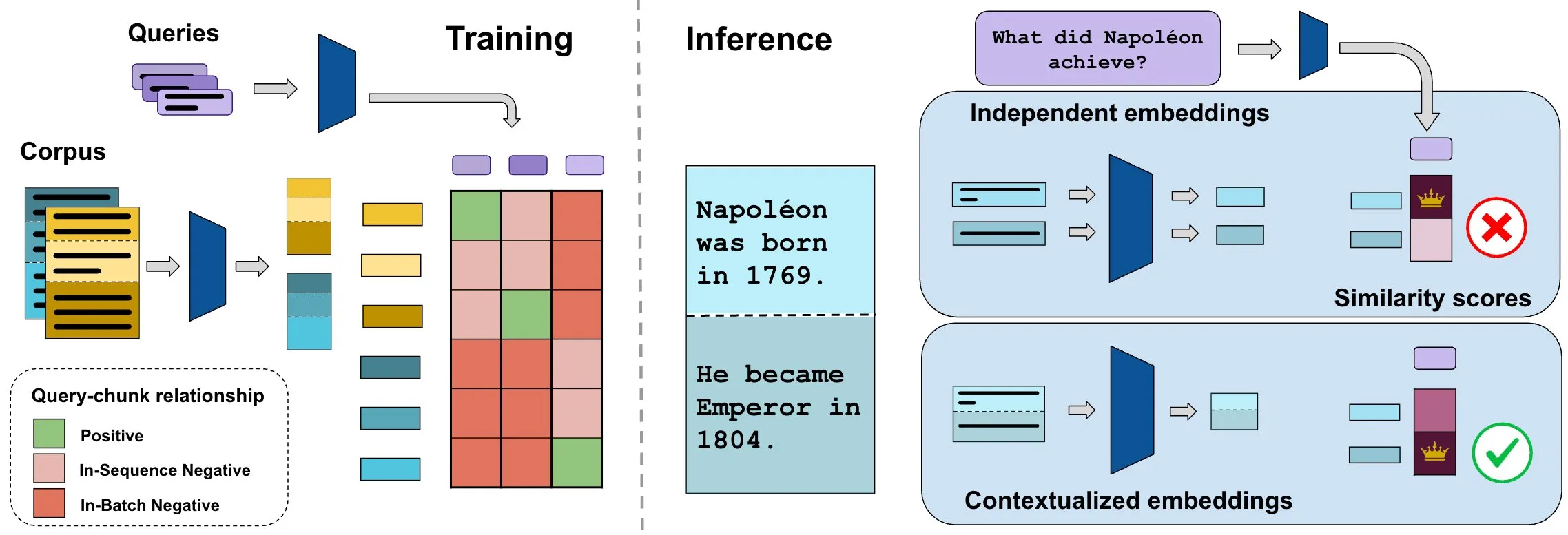
Benchmark ConTEB avalia embeddings de documentos contextuais, método InSeNT melhora a qualidade da recuperação: Os métodos atuais de embedding para recuperação de documentos geralmente codificam independentemente os vários fragmentos (chunks) do mesmo documento, ignorando as informações contextuais em nível de documento. Para resolver esse problema, os pesquisadores lançaram o benchmark ConTEB, que avalia especificamente a capacidade dos modelos de recuperação de utilizar o contexto do documento, e descobriram que os modelos SOTA têm um desempenho ruim nesse aspecto. Ao mesmo tempo, os pesquisadores propuseram o método de pós-treinamento de aprendizado contrastivo InSeNT (In-Sequence Negative Training), combinado com pooling de chunks tardio, para aprimorar o aprendizado de representação contextual, melhorando significativamente a qualidade da recuperação no ConTEB e sendo mais robusto a estratégias de chunking subótimas e a corpora de maior escala (Fonte: HuggingFace Daily Papers, tonywu_71)
🧰 Ferramentas
PraisonAI: Framework low-code de múltiplos agentes de AI: PraisonAI é um framework de múltiplos agentes de AI de nível de produção, projetado para simplificar a automação e a resolução de problemas, desde tarefas simples até desafios complexos, por meio de uma solução low-code. Ele integra PraisonAI Agents, AG2 (AutoGen) e CrewAI, enfatizando a simplicidade, personalização e colaboração eficaz homem-máquina. Suas funcionalidades incluem criação automática de agentes de AI, autorreflexão, multimodalidade, colaboração multiagente, adição de conhecimento, memória de curto e longo prazo, RAG, interpretador de código, mais de 100 ferramentas personalizadas e suporte a LLM, entre outros. Suporta Python e JavaScript, e oferece opções de configuração YAML sem código (Fonte: GitHub Trending)
TinyTroupe: Framework de simulação de papéis multiagente orientado por LLM de código aberto da Microsoft: TinyTroupe é uma biblioteca Python experimental que utiliza Large Language Models (LLMs, especialmente GPT-4) para simular personagens (TinyPerson) com personalidades, interesses e objetivos específicos, interagindo em um ambiente simulado (TinyWorld). O framework visa aprimorar a imaginação e fornecer insights de negócios por meio da simulação, podendo ser aplicado em avaliação de publicidade, teste de software, geração de dados sintéticos, feedback de produtos e brainstorming, entre outros cenários. Os usuários podem definir agentes e ambientes por meio de arquivos Python e JSON, realizando experimentos de simulação programáticos, analíticos e multiagente (Fonte: GitHub Trending)

FLUX Kontext alcança novo avanço em referência multi-imagem e edição de imagens: Usuários relatam que o FLUX Kontext tem um desempenho excelente em referência multi-imagem, funcionalidade que pode ser ativada através do nó de junção de imagens no ComfyUI. A ferramenta permite edição de imagens com alta consistência, por exemplo, ao criar imagens de exibição para caixas de presente, consegue restaurar bem detalhes como material e poeira. Além disso, usuários demonstraram o uso do FLUX Kontext para operações de retoque como emagrecimento com um clique, afinamento de rosto, aumento de músculos, com efeitos naturais e alta similaridade facial, oferecendo conveniência para cenários como e-commerce (Fonte: op7418, op7418, op7418)

Ichi: AI conversacional no dispositivo baseada em MLX Swift e MLX audio: Rudrank Riyam desenvolveu o Ichi, um projeto de AI conversacional no dispositivo que utiliza MLX Swift e MLX audio. Isso significa que o processamento da conversa pode ser feito localmente no dispositivo, ajudando a proteger a privacidade do usuário e reduzindo a dependência de serviços em nuvem. O código do projeto está disponível em código aberto no GitHub (Fonte: stablequan, awnihannun)
FedRAG introduz NoEncode RAG com abstração central MCP: O projeto FedRAG lançou uma nova abstração central – NoEncode RAG com MCP. O RAG tradicional inclui um recuperador, um gerador e uma base de conhecimento, onde o conhecimento na base de conhecimento precisa ser codificado pelo modelo recuperador. Já o NoEncode RAG pula completamente a etapa de codificação, sendo constituído diretamente por uma base de conhecimento NoEncode e um gerador, sem necessidade de recuperador/embedding. Isso abre caminho para a construção de sistemas RAG que utilizam servidores MCP (Model Component Provider) como fonte de conhecimento, permitindo que os usuários se conectem a múltiplas fontes MCP de terceiros e façam fine-tuning do RAG através do FedRAG para obter o melhor desempenho (Fonte: nerdai)

📚 Aprendizado
Curso CS224n da Universidade de Stanford (versão 2024) lançado, com adição de conteúdo sobre LLM e agentes: O clássico curso de processamento de linguagem natural da Universidade de Stanford, CS224n, lançou sua versão mais recente de 2024. O novo conteúdo do curso abrange temas de ponta relacionados a Large Language Models (LLMs), como pré-treinamento, pós-treinamento, benchmarks, inferência e agentes. Os vídeos do curso foram disponibilizados publicamente no YouTube, e também é oferecida uma experiência de curso síncrono paga (Fonte: stanfordnlp)
Guia para aprimorar a capacidade de arquitetura de sistemas: Prática e aprendizado na era da AI: Dotey compartilhou métodos detalhados sobre como aprimorar a capacidade individual de arquitetura de sistemas no contexto do crescente poder da programação assistida por AI. O artigo enfatiza que o design de sistemas é o processo de decompor sistemas complexos em módulos menores, fáceis de implementar e manter, e definir claramente a colaboração entre os módulos. Os métodos de aprimoramento incluem “observar muito” (estudar casos clássicos, projetos de código aberto), “praticar muito” (restauração de arquitetura, aprendizado comparativo, design先行, validação assistida por AI, refatoração, prática em Side Projects) e “revisar muito” (resumir a base das decisões, lições aprendidas). A AI pode ser usada como ferramenta auxiliar para ajudar na pesquisa de informações, validação de design, auxílio na comunicação e tomada de decisões, mas não pode substituir a prática e o pensamento (Fonte: dotey)

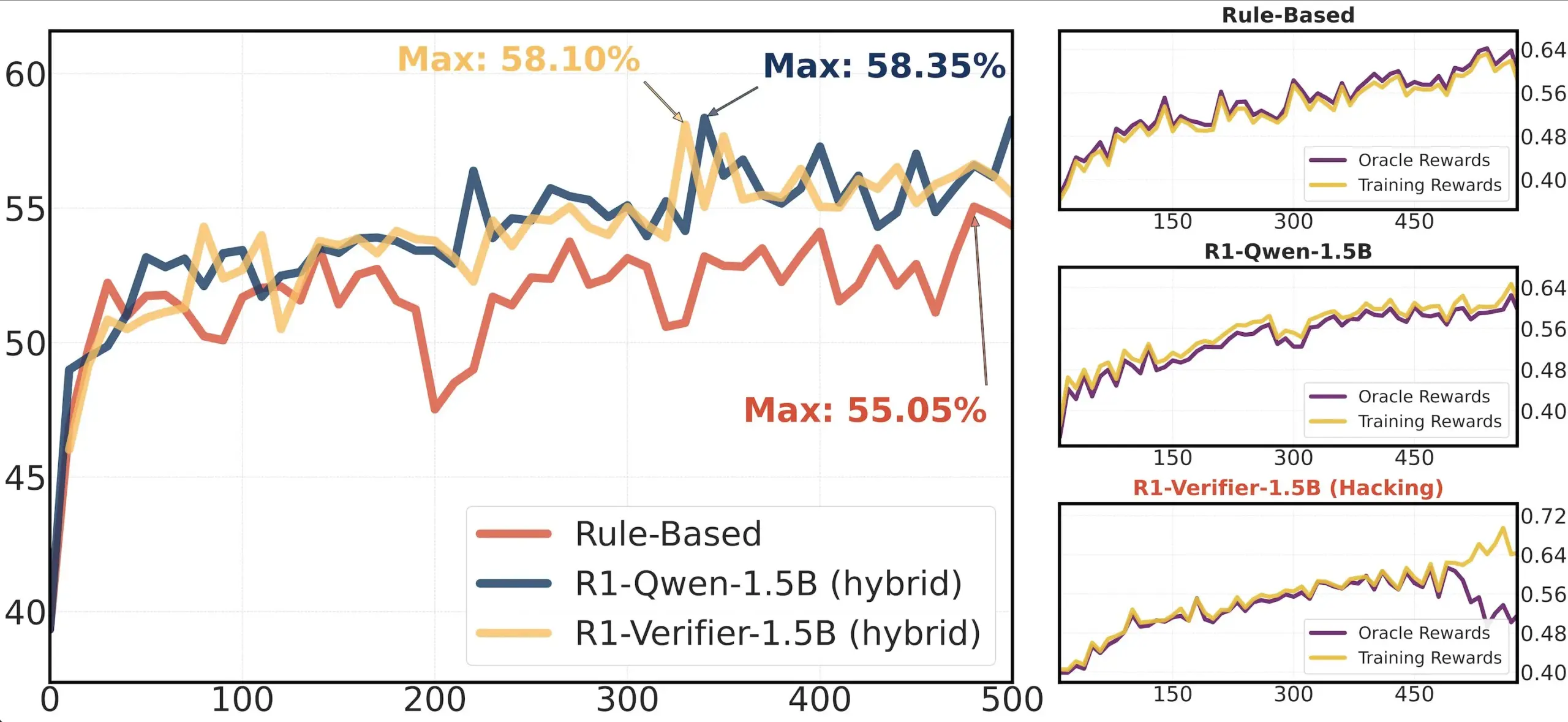
Compartilhamento de artigo: Estudo sobre a confiabilidade de validadores em RLHF: Um artigo intitulado “Pitfalls of Rule- and Model-based Verifiers” explora as deficiências de validadores baseados em regras e modelos na validação por Reinforcement Learning (RLVR). O estudo descobriu que validadores baseados em regras, mesmo no domínio da matemática, são frequentemente não confiáveis e indisponíveis em muitos domínios; enquanto validadores baseados em modelos são facilmente atacados, por exemplo, através da construção de padrões adversariais simples. Curiosamente, à medida que a comunidade se volta para validadores generativos, o estudo descobriu que eles são mais suscetíveis à manipulação de recompensa (reward hacking) do que validadores discriminativos, o que sugere que validadores discriminativos podem ser mais robustos em RLVR (Fonte: Francis_YAO_)
Recomendação de artigo: Teorema da equioscilação para a melhor aproximação polinomial: Um artigo apresenta o teorema da equioscilação para a melhor aproximação polinomial, bem como o problema de diferenciação da norma do supremo associado. Este teorema é um resultado clássico na teoria da aproximação de funções, com importante significado para a compreensão e o design de algoritmos numéricos (Fonte: eliebakouch)
Reasoning Gym: Ambientes de raciocínio para Reinforcement Learning com recompensas verificáveis: O novo artigo “Reasoning Gym: Reasoning Environments for Reinforcement Learning with Verifiable Rewards” (arXiv:2505.24760) propõe um conjunto de ambientes de raciocínio para Reinforcement Learning. A característica desses ambientes é que suas recompensas são verificáveis, fornecendo uma plataforma para pesquisar e desenvolver agentes de raciocínio por Reinforcement Learning mais confiáveis (Fonte: Ar_Douillard)

🌟 Comunidade
Discussão sobre “Mid-training”: A comunidade de AI iniciou uma discussão sobre o significado e a prática do termo “Mid-training”. Alguns expressaram confusão, conhecendo apenas o pré-treinamento e o pós-treinamento. Uma opinião sugere que o “Mid-training” pode se referir a uma fase específica de treinamento realizada entre o pré-treinamento e o fine-tuning final, como o pré-treinamento contínuo para conhecimento de domínio específico ou alinhamento precoce. Dorialexander compartilhou artigos de blog relevantes, explorando ainda mais o conceito, sugerindo que pode envolver a injeção de tarefas ou capacidades específicas sobre o modelo base, mas ainda não há uma definição e metodologia unificadas (Fonte: code_star, fabianstelzer, Dorialexander, iScienceLuvr, clefourrier)

Análise de engenharia reversa do Claude Code atrai atenção: Hrishi, por meio da engenharia reversa do código minimizado do Claude Code, gastando de 8 a 10 horas e utilizando múltiplos sub-agentes e modelos principais de grandes provedores, revelou a complexidade de sua estrutura interna. A análise indica que o Claude Code não é um simples loop do modelo Claude, mas contém um grande número de mecanismos dignos de estudo. Essa descoberta gerou discussão na comunidade, que acredita que se pode aprender muito sobre a construção de agentes e a aplicação de modelos a partir disso (Fonte: rishdotblog, imjaredz, hrishioa)
Discussão sobre o comprimento do prompt de sistema e o desempenho do modelo: A comunidade discutiu o impacto do comprimento do prompt de sistema no desempenho do LLM. Dotey acredita que prompts de sistema excessivamente longos nem sempre são bons, podendo diluir a atenção do modelo e aumentar os custos, e aponta que os prompts de sistema dos produtos da série ChatGPT são relativamente curtos, mas eficazes. Por outro lado, Tony出海号 mencionou que os prompts de sistema de produtos como Claude e Cursor chegam a dezenas de milhares de palavras, sugerindo a necessidade de expandir os sistemas de prompts. Um artigo da YC também revelou que as principais empresas de AI usam prompts longos, XML, meta-prompts e outros métodos para “domar” LLMs. Dorialexander, por sua vez, questionou a robustez dos métodos de prompts longos mencionados no artigo da YC no treinamento de RL/inferência e se preocupa em como mitigar o problema de “sycophancy” (bajulação) (Fonte: dotey, Dorialexander)

Problema de escalabilidade do Softpick gera elogios à transparência na pesquisa científica: O pesquisador Zed declarou publicamente que seu método Softpick, pesquisado anteriormente, ao ser dimensionado para modelos maiores (parâmetros de 1.8B), apresentou perdas de treinamento e resultados de benchmark inferiores ao Softmax, e já atualizou o preprint no arXiv. A comunidade elogiou veementemente essa partilha transparente de resultados negativos, considerando-a crucial para o progresso científico e uma qualidade de excelentes colegas de pesquisa (Fonte: gabriberton, vikhyatk, BlancheMinerva)
Usuários compartilham escolhas e experiências com modelos LLM executados localmente: Usuários da comunidade r/LocalLLaMA do Reddit discutem ativamente os Large Language Models locais que estão usando atualmente. Modelos como Qwen 3 (especialmente 32B Q4, 32B Q8, 30B A3B), Gemma 3 (especialmente 27B QAT Q8, 12B), Devstral, entre outros, foram amplamente mencionados por seu desempenho em código, criação, raciocínio geral, etc. Os usuários estão atentos ao comprimento do contexto dos modelos, velocidade de inferência, versões quantizadas (como IQ1_S_R4) e seu desempenho em diferentes hardwares (como VRAM de 8GB, celulares com chip Snapdragon 8 Elite). Modelos de código fechado como Claude Code, Gemini API, etc., também são usados simultaneamente devido às suas vantagens específicas (como processamento de contexto longo, capacidade de codificação) (Fonte: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
💡 Outros
Desenvolvimento de habilidades na era da AI: Questionamento, pensamento crítico e aprendizado contínuo são cruciais: A discussão enfatiza que, na era da AI, seis habilidades são cruciais: capacidade de questionar, pensamento crítico, manter um modo de aprendizado, capacidade de codificar ou dar instruções, proficiência no uso de ferramentas de AI e comunicação clara. A empresa Zapier chega a exigir que 100% dos novos funcionários sejam proficientes em AI, o que é interpretado como uma ênfase principal nas necessidades de comunicação e na capacidade de delegar tarefas corretamente, em vez de puro conhecimento técnico. A AI facilita a execução, portanto, a qualidade do design e do pensamento tem um impacto maior no resultado final (Fonte: TheTuringPost, zacharynado)

Ética da AI e impacto social: Preocupações e empoderamento coexistem: O ator Steve Carell expressou preocupação com a sociedade futura retratada em seu novo filme “Mountainhead”, acreditando que esta pode ser a sociedade em que viveremos em breve, insinuando preocupações sobre os potenciais impactos negativos da AI. Por outro lado, há quem acredite que a AI não causará necessariamente uma polarização extrema entre “camponeses e reis”, mas poderá, ao contrário, capacitar indivíduos, reduzindo a lacuna de capacidade entre indivíduos e grandes empresas, promovendo o aumento da produtividade, criatividade e influência individual. No entanto, quanto às perspectivas de democratização da AI, alguns mantêm uma atitude cautelosa, acreditando que as grandes empresas ainda manterão o domínio através do controle do treinamento e implantação de modelos (Fonte: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Plataforma de agregação de informações de recrutamento impulsionada por AI Hiring Cafe: Hamed N. utilizou a API do ChatGPT para extrair 4,1 milhões de informações de recrutamento publicadas diretamente nos sites das empresas, criando o site Hiring Cafe. A plataforma visa resolver o problema de “vagas fantasmas” e intermediários terceirizados que infestam plataformas como LinkedIn e Indeed, ajudando os candidatos a filtrar vagas de forma mais eficaz por meio de filtros poderosos (como cargo, função, setor, anos de experiência, função de gerenciamento/IC, etc.). Este é um projeto paralelo não comercial de um doutorando, que recebeu elogios e adesão da comunidade (Fonte: Reddit r/ChatGPT)
